
Анализ и оценка средств реализации объектно-ориентированного подхода к проектированию экономической информационной системы (Сущность объектно-ориентированного подхода)
Содержание:

ВВЕДЕНИЕ
Активно развивающимся инструментом проектирования производственных систем является универсальный язык моделирования UML (universal modeling language), который обеспечивает единую среду общения, позволяющую связать и описать процессы в самых разнородных сферах производства от финансово-экономических, организационных и управленческих решений до производственных процессов, логистики, сопровождения жизненного цикла ПС [1].
Объектно-ориентированный подход обеспечивает структурирование системы и упрощение её программной реализации: производство представляется в виде совокупности объектов, взаимодействующих друг с другом. В объектно-ориентированном подходе используются несколько базовых принципов: абстракция (сосредоточение на важнейших аспектах приложения), инкапсуляция (отделение внешних аспектов объекта от деталей внутренней реализации), полиморфизм (объединение данных и поведения), наследование (совместное использование структур данных на самых разных уровнях), выделение сущности объекта.
Стремительное развитие компьютерных и информационных технологий изменило традиционный взгляд на возможности информационных систем, предназначенных для хранения, обработки, представления и поиска различного рода информации по требованию пользователя. Неуклонное расширение глобальной информационной сети Internet повлекло за собой практический неограниченный доступ к компьютерным хранилищам данных.
Благодаря реализации графических и гипертекстовых возможностей World Wide Web (WWW) Internet стала информационным феноменом десятилетия. Реализация гипертекста явилась огромным шагом в преодолении барьера между непрофессиональными пользователями и обширными информационными ресурсами сети Internet. Объем информации и услуг, предоставляемых в сети, непрерывно растет. В этих условиях обостряется проблема быстрого и эффективного поиска.
Эта проблема характеризуется отсутствием унифицированного интерфейса для получения информации из разнородных источников в сети, а также необходимостью просмотра большого объема текстов и ссылок, выдаваемых WWW сервером на запрос о поиске с целью уточнения запроса или сужения пространства ручного поиска.
Таким образом, актуальной является проблема разработки информационно-поисковых систем нового поколения, предназначенных для функционирования в сети Internet и обеспечивающих по возможности быстрый, смысловой поиск релевантной информации.
Поисковая система — веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet.
Как правило, основной частью поисковой системы является поисковая машина (поисковый движок) — комплекс программ, обеспечивающий функциональность поисковой системы. Основными критериями качества работы поисковой машины являются релевантность (степень соответствия запроса и найденного, то есть уместность результата), полнота базы, учёт морфологии языка. Индексация информации осуществляется специальными поисковыми роботами.
Цель курсовой работы – анализ и оценка средств реализации объектно-ориентированного подхода к проектированию экономической информационной системы.
Задачи курсовой работы:
-исследовать объектно-ориентированный подход при проектировании информационной системы;
- провести разработку поисковой системы на основе объектно-ориентированного подхода.
Объект курсовой работы – поисково-информационные системы в Интернет
Предмет курсовой работы - особенности объектно-ориентированного подхода при проектировании информационной системы.
ГЛАВА 1. ОБЪЕКТНО-ОРИЕНТИРОВАННЫЙ ПОДХОД ПРИ ПРОЕКТИРОВАНИИ ЭКОНОМИЧЕСКОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ
1.1 Сущность объектно-ориентированного подхода
При проектировании различных систем используются два принципиально разных подхода: структурный и объектно-ориентированный.
Структурный подход предполагает декомпозицию поставленной задачи на отдельные функции. В свою очередь, функции также разбиваются на подфункции, задачи, процедуры. В результате получается упорядоченная иерархия функций и передаваемой информации между функциями. Производственное оборудование для реализации цифровых технологий во многом являются программными устройствами, имеющими много общего с технологиями обработки изделий на станках с числовым программным управлением. Традиционная организация программного обеспечения (ПО) в виде библиотек подпрограмм соответствует технологии разработки, опирающейся на идеи процедурного программирования: выделение структурируемых и самостоятельно значимых подпрограмм, выполняющих некоторую последовательность операций над данными и решающих независимые подзадачи. К его недостаткам относятся: необходимость унификации внутренних форматов данных, которые используются импортируемыми библиотечными модулями, в связи с чем реализуется избыточная поддержка нескольких эквивалентных представлений данных; низкие наглядность и выразительность процедурных средств программирования, а также отсутствие внутренней структуризации программы, несмотря на процедурную завершенность отдельных подпрограмм) затрудняют модификацию программного кода. Развитие программного обеспечения осуществляется, в основном, не за счет замены имеющихся модулей на их более совершенные версии, а за счет расширения и включения в программу новых модулей, отражающих различные решения, принимаемые в ходе вычислительного эксперимента [2].
К отличительным чертам ООП относятся прозрачность и возможность доступа к деталям реализации конкретного метода и алгоритма для разработчика и пользователя, открытость и возможность дополнения библиотеки новыми процедурами.
Основные принципы объектно-ориентированного подхода, предлагаемые авторами, разработаны как на основе общесистемных понятий автоматизации научных исследований, так и в процессе совместной практической реализации систем автоматизации исследовательского проектирования (САИПР). Относительная простота и отсутствие формально-математического аппарата не есть следствие пренебрежения строгостью теоретических изысканий, но результат естественного стремления к быстрой практической реализации.
Современные системы исследовательского проектирования, как правило, не реализуют достаточно гибкой единой системо-образующей технологии и поэтому обладают рядом существенных недостатков.
Накопленный научно-методический потенциал не может быть эффективно использован в рамках существующих САИПР, поскольку в них отсутствуют удобные средства классификации, структуризации, накопления и поиска методов проектных исследований, алгоритмических и процедурных знаний.
Кроме того, отсутствие современных средств, позволяющих проектантам оперировать в традиционных для кораблестроения терминах и понятиях, существенно сдерживает расширение круга пользователей таких систем.
Классическая модель разработки программного обеспечения таких крупных и сложных систем, как системы автоматизированного проектирования кораблей, не предполагает информационной технологии, позволяющей практически реализовать принципы системного подхода.
Опыт разработки и эксплуатации САИПР показал, что программные системы на базе классической модели "программы+данные" могут в большинстве случаев эффективно эксплуатироваться только их разработчиками, что принципиально противоречит основополагающим целям разработки таких систем.
1.2 Преимущества объектно-ориентированного подхода
Системы автоматизации проектирования традиционного типа довольно жестко настроены на определенную модель конкретного предмета проектирования или в лучшем случае на определенный, достаточно узкий класс моделей. При исследовательском проектировании сама модель предмета исследования реально является динамически изменяемой, многовариантной, и жесткость структур данных и процедур становится препятствием для успешного и эффективного их использования [3].
По сравнению с традиционными методами объектно-ориентированная технология обладает следующими преимуществами:
-возможность оперативной сборки корректных прикладных программ из готовых модулей;
-наличие естественных средств создания привычной семантической среды для проектных исследований;
- возможность унификации форм представления информации для взаимодействия между различными категориями разработчиков и проектантов-исследователей;
- возможность управления специальной деятельностью проектантов-исследователей в рамках общей стратегии проектных исследований.
Вместе с тем использование объектно-ориентированной технологии требует:
- проведения значительных предварительных исследований по вопросам:
- разработка варианта(ов) классификации используемых объектов (корабля, его подсистем и элементов);
- структуризация понятий предметной области, методов и методик проектирования;
- разработки:
- программной поддержки для описания объектов и их функциональности в терминах предметной области;
- интегрированной среды разработки моделей и проведения вычислительных экспериментов.
Объектно-ориентированный подход к автоматизации проектирования и/или научных исследований - это естественный способ осмысления и структуризации процесса построения моделей реального мира. Термин "объектно-ориентированный" означает, что мы разрабатываем модель предмета проектирования/исследования как структуру данных, включающую набор объектов, каждый из которых объединяет конкретную информацию (совокупность данных) и определенное поведение (набор допустимых операций). В этом аспекте излагаемый подход может быть противопоставлен традиционному, при котором такое объединение не фиксируется.
Для объектно-ориентированного подхода характерно присутствие следующих четырех аспектов:
- идентификации,
- классификации,
- полиморфизма,
- наследования.
Идентификация означает, что вся совокупность рассматриваемой в рамках модели информации сгруппирована в отдельные, различаемые элементы, называемые объектами.
Классификация означает, что объекты с одинаковыми наборами атрибутов и поведением группируются в классы. Каждый объект относится к некоторому классу, и в качестве экземпляра этого класса имеет собственные значения для каждого из атрибутов, но разделяет имена атрибутов и операций с другими экземплярами этого класса.
Полиморфизм означает, что одна и та же операция может определять различное поведение для различных классов. Операция - это действие или преобразование, выполняющееся объектом, или выполняемое над ним. Реализацию операции в рамках определенного класса будем называть методом.
Можно сказать, что каждый объект "знает", как производить собственные операции -посредством методов своего класса. Поэтому исследователю не нужно думать о всей совокупности методов, существующих для реализации данной полиморфной операции. При этом новые классы могут быть добавлены без переработки существующей модели, поскольку они обеспечивают собственные методы, реализующие специфическое поведение этих классов.
Наследование - это разделение атрибутов и операций между классами, основанное на иерархических взаимосвязях. Сущность отношения наследования заключается в том, что каждый класс наследует все свойства своих предков и, как правило, добавляет еще и собственные, уникальные. Таким образом, объектно-ориентированные модели обладают свойством расширяемости, которое является естественным результатом наследования.
Последовательное применение объектно-ориентированного проектирования позволяет использовать существующие классы, модели и объекты в других исследованиях и проектах, обеспечивая реальную возможность накапливать знания в виде алгоритмов и методов исследования, в конечном итоге создавая библиотеки таких знаний.
В основе объектно-ориентированной технологии лежат также принципы абстракции и инкапсуляции. Хотя они присущи не только объектно-ориентированным системам, их последовательное проведение является характерным свойством объектно-ориентированного подхода.
Абстракция заключается в выделении существенных свойств предмета и игнорировании случайных свойств. Большинство современных языков программирования обеспечивают абстракцию данных, но возможность использовать наследование и полиморфизм придают этому принципу дополнительную мощность.
Инкапсуляция (сокрытие информации) заключается в отделении внешних аспектов объекта, которые доступны другим объектам, от внутренней реализации деталей объекта, которые скрыты от других объектов. При этом реализация объекта может быть изменена без какой-либо модификации модели, его использующей.
Технология объектно-ориентированного подхода в САИПР предназначена для выполнения следующих функций [4]:
- обеспечения единства подходов в рамках САИПР к структуризации и средствам обработки информации;
- концентрации интеллектуальных, алгоритмических и процедурных знаний для различных проектных задач;
- управления проведением проектных исследований и получения выходных документов установленных форм;
- создания и управления программными средствами семантики конечного пользователя;
- подготовки информационно-программной среды для автоматизации разработки новых моделей исследований.
Под моделью предмета исследовательского проектирования здесь будет пониматься совокупность объектов вместе с определенной структурой связей между ними, отражающей значимые для целей конкретной задачи исследовательского проектирования свойства и качества реального предмета проектирования и в силу этого позволяющей проведение определенного набора вычислительных экспериментов.
Модель предмета проектирования - совокупность объектов, являющихся частными моделями компонентов или аспектов предмета проектирования, связанных в одну или несколько древовидных структур. При этом для одного и того же объекта допускается вхождение в несколько древовидных структур одновременно. Древовидные структуры модели отражают декомпозицию предмета проектирования по различным критериям или различные аспекты рассмотрения предмета проектирования.
Концептуализация производственной системы - это изложение основных концепций производства. Существует несколько способов поиска концепций: придание новых функциональных возможностей создаваемой или существующей системе, модернизация производства с целью снятия ограничений и универсализации, упрощение системы, повышение уровня автоматизации производственных процессов, поиск аналогий в других предметных областях и исследование их на наличие полезных идей [5].
Одной из основных задач на этом этапе является формирование функциональных требований к производственной системе, определяющих её взаимодействие с пользователями (заказчик, аналитики, разработчики, конструкторы, технологи, материаловеды, наладчики, инженеры поддержки жизненного цикла и др.). Задание требований осуществляется с помощью моделирования прецедентов. Модель прецедентов описывает систему в терминах: пользователи системы и прецеденты. Прецеденты выражают внешние требования к системе, устанавливают последовательность взаимодействий между одним или несколькими пользователями и системой, описывают поведение некоторой части системы, не раскрывая её внутренней структуры.
Основными требованиями, предъявляемыми к информационным системам, являются [6]:
- интеллектуальность,
- автоматичность,
- дружественный интерфейс,
- кросс-платформенность,
- поддержка multimedia,
- высокая скорость обработки запросов.
К сожалению, на данный момент не разработаны системы, удовлетворяющие этим критериям в полном объеме.
Объектно-ориентированный подход использует объектную декомпозицию, при этом статическая структура описывается в терминах объектов и связей между ними, а поведение системы описывается в терминах обмена сообщениями между объектами. Целью методики является построение бизнес-модели организации, позволяющей перейти от модели сценариев использования к модели, определяющей отдельные объекты, участвующие в реализации бизнес-функций.
Существующие на сегодняшний день технологические решения не всегда позволяют достичь требуемый для промышленности уровень эксплуатационных и функциональных свойств материалов, обеспечивающий расчетную продолжительность эксплуатации ответственных технических объектов. В наибольшей степени это относится к авиационной, ракетно-космической, нефтехимической, энергетической отраслям промышленности, развитие которых невозможно без создания новых материалов. На этапе концептуализации оценивается необходимость проектирования перспективных технологических процессов; получения новых композиционных, функционально-градиентных и многофункциональных материалов, псевдосплавов, высокоэнтропийных сплавов, интерметаллидов; изделий сложной геометрической формы.
Создание производственных систем может основываться как на развитии существующих технологий, так и на разработке и освоении принципиально новых мультиаддитивных, гибридных и интеллектуальных технологий, сочетающих различные способы формирования готового изделия (сплавление, пайка, спекание, напыление, осаждение и др.) и источники энергетического воздействия разнородной физической природы (лазерный луч, электронный или ионный пучок, плазменная и электрическая дуга). Создание таких систем включает проектирование технологических процессов на базе семейства наукоёмких математических моделей, конструирование нового оборудования, разработку оригинальных алгоритмов управления, обучение персонала, создание средств контроля качества готового изделия и др.
К критериям организации нового производства для синтеза новых материалов и изделий относятся следующие показатели: технологические (пространственная ориентация, точность и шероховатость поверхности; механические и теплофизические свойства), экологические (возможность повторной переработки исходного сырья и изделия; минимизация отходов, энергетических и прочих затрат); экономические (стоимость разработки новой технологии и оборудования для её реализации, стоимость изготовления изделия, время изготовления изделия, объём выпуска, коэффициент использования исходного материала) и др.
Таким образом, на этапе концептуализации системы формируются основные задачи проекта и требования к конечному продукту, обосновывается экономическая целесообразность реализации производства.
Объектно-ориентированный подход обладает следующими преимуществами:
1. Объектная декомпозиция дает возможность создавать модели меньшего размера путем использования общих механизмов, обеспечивающих необходимую экономию выразительных средств. Использование объектного подхода существенно повышает уровень унификации разработки и пригодность для повторного использования, что ведет к созданию среды разработки и переходу к сборочному созданию моделей.
2. Объектная декомпозиция позволяет избежать создания сложных моделей, так как она предполагает эволюционный путь развития модели на базе относительно небольших подсистем.
3. Объектная модель естественна, поскольку ориентирована на человеческое восприятие мира.
К недостаткам объектно-ориентированного подхода относятся высокие начальные затраты. Этот подход не дает немедленной отдачи. Эффект от его применения сказывается после разработки двух–трех проектов и накопления повторно используемых компонентов. Диаграммы, отражающие специфику объектного подхода, менее наглядны.
Наиболее продвинутыми среди современных ИПС являются библиотечные системы, которые обеспечивают поиск среди больших массивов текстовой информации по различным критериям:
- авторскому (поиск по фамилии);
- с использованием УДК или тематический поиск (обычно занимает много времени и выделяет информационное поле слишком большого объема);
- поиск по ключевым словам (не всегда выделяет релевантную информацию).
Однако использование подобных систем для поиска текстовой информации на библиотечных WWW серверах может быть действительно эффективным лишь при условии реализации поисковых процедур на основе семантических представлений. Действительно, типичной является ситуация, когда поиск ведется среди огромных массивов информации, представленной в виде неструктурированных естественноязыковых текстов (статей, обзоров, рефератов, научных сборников и т.п.). При этом критичным является как время поиска, так и релевантность найденной информации.
Следует отметить, что в существующих поисковых системах оба эти показателя весьма далеки от совершенства. Причем, если время поиска может зависеть от качества связи и других технических характеристик, которые могут быть улучшены, то соответствие найденной информации запросу пользователя является на сегодняшний день большой проблемой.
Обычной является ситуация, когда в ответ на запрос пользователь в результате многих итераций и существенных временных затрат получает-таки солидные объемы текстовой информации, которая более или менее соответствует заданной теме, но, как правило, лишь косвенно. Тем не менее, эта информация сохраняется пользователем, которому жаль потраченного времени, а процесс поиска повторяется. В результате через некоторое время пользователь “накапливает” свою персональную библиотеку текстовой информации, которая вроде бы имеет какое-то отношение к исследуемой теме (что вообще говоря, не обязательно). Информацию эту весьма проблематично систематизировать и структурировать, в результате большая ее часть так и остается невостребованной. Решением этой неприятной проблемы может стать формирование так называемого “смыслового портрета” или “смыслового образа” для каждого неструктурированного текста. Под смысловым образом понимается логическая структура информационной базы (текста или множества текстов), которая для удобства работы может быть представлена в графическом виде, демонстрируя смысловые связи между фрагментами текста. При этом можно потребовать, чтобы смысловые связи устанавливались между двумя и более смысловыми образами в информационной базе. Такой подход в настоящее время представляется наиболее перспективным для аналитической работы с большими объемами неструктурированной информации.
1.3 Современные CASE-средства для разработки объектно-ориентированных поисковых информационных систем
Современные CASE-средства для разработки объектно-ориентированных поисковых информационных систем (ИС) прочно входят в практику программной инженерии. При этом они используются не только для производства программных систем, но и как инструмент решения исследовательских и проектных задач на начальных этапах разработки, таких, как анализ предметной области, разработка проектных спецификаций, подготовка проектной документации, планирование и контроль разработок, моделирование функционирования приложений и т.п. Все современные CASE-средства можно классифицировать по типам и категориям. Классификация по типам отражает функциональную ориентацию CASE-средств на те пли иные процессы жизненного цикла. Классификация по категориям определяет степень интегрированное™ по выполняемым функциям и включает отдельные локальные средства, решающие небольшие автономные задачи, набор частично интегрированных средств, охватывающих большинство этапов жизненного цикла информационных систем и полностью интегрированные средства, поддерживающие весь жизненный цикл информационных систем и связанные общим депозитарием. Помимо этого CASE-средства можно классифицировать по применяемым методологиям и моделям систем и БД; степени интегрированности с СУБД; доступным платформам .Классификация по типам в основном совпадает с компонентным составом CASE-средств и включает [7]:
- средства анализа (Upper CASE), предназначенные для построения и анализа моделей предметной области (Design/IDEF (Meta Software), BPwin (Logic Works));
- средства анализа и проектирования (Middle CASE), поддерживающие наиболее распространенные методологии проектирования и использующиеся для создания проектных спецификаций (Vantage Team Builder (Cayenne), Designer/2000 (ORACLE), Silverrun (CSA), PRO-IV (McDonnell Douglas), САвЕ;
- средства проектирования баз данных, обеспечивающие моделирование данных и генерацию схем баз данных (как правило, на языке SQL) для наиболее распространенных СУБД. К ним относятся ERwin (Logic Works), S-Designor (SDP) и DataBase Designer (ORACLE).;
- средства разработки приложений. К ним относятся средства 4GL (Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (ORACLE), New Era (Informix), SQL Windows (Gupta), Delphi (Borland) и др.) и генераторы кодов, входящие в состав Vantage Team Builder, PRO-IV и частично - в Silverrun;
- средства реинжиниринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций. Средства анализа схем БД и формирования ERD входят в состав Vantage Team Builder, PRO-IV, Silverrun, Designer/2000, ERwin и S-Designor.
На сегодняшний день российский рынок программного обеспечения располагает следующими наиболее развитыми CASE средствами [8]: Westmount I-CASE; Uniface; Designer/2000+Developer/2000 (ORACLE); SILVERRUN+JAM; ERwin ERX+PowerBuilder; Rational Rose. На рис. 1 приведены результаты сравнительного анализа перечисленных выше CASE средств.

Рисунок 1 – Сравнительный анализ CASE средств [13-14]
Анализ данных, приведенных на рис. 1, показывает, что из перечисленных CASE средств только комплекс Rational Rose наиболее полно удовлетворяет всем критериям, принятым в качестве основных. Так, например, в комплексе Rational Rose целостность базы проектных данных и единая технология сквозного проектирования ИС обеспечивается за счет использования интерфейса Rational Rose. Следует отметить, что каждый из двух продуктов сам по себе является одним из наиболее мощных в своем классе.
Таким образом, наиболее развитыми средствами разработки крупномасштабных ИС на сегодняшний день является, по мнению автора, комплекс Rational Rose. С другой стороны, его применение не исключает использования в том же самом проекте таких средств, как PowerBuilder, для разработки сравнительно небольших прикладных систем в среде MS Windows.
ГЛАВА 2. РАЗРАБОТКА ПОИСКОВОЙ ЭКОНОМИЧЕСКОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ НА ОСНОВЕ ОБЪЕКТНО-ОРИЕНТИРОВАННОГО ПОДХОДА
2.1 Описание среды разработки поисковой системы
Поиско́вая систе́ма (англ. search engine) — это компьютерная система, предназначенная для поиска информации.
Поисковая система — программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в интернете.
Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос. По запросу пользователя поисковая система генерирует страницу результатов поиска.
Такая поисковая выдача может сочетать различные типы файлов, например [9]:
- веб-страницы,
- изображения,
- аудиофайлы.
Некоторые поисковые системы также извлекают данные из баз данных и каталогов ресурсов в Интернете.
Требования к поисковой системе:
- Простой и удобный HTML интерфейс.
- Поиск по форумам
- Релевантность по датам
- Морфологический анализ (выделение корня искомого слова)
Система должна представляет из себя простую поисковую машину для форумов с базой данных и запросами пользователя. На данном этапе поиск планируется производить по начальному списку заданных сайтов.
2.2 Описание решения разработки поисковой системы
Построение Базы данных поисковика имеет структуру конвейера. Каждый модуль представляет из себя отдельную утилиту. Различные утилиты могут быть написаны на различных языках. Они передают друг другу управление работы с данными. В данном случае можно было бы передавать сами данные через стандартный ввод-вывод. Но по причинам быстродействия это было сделано через загрузку на диск.
Тем более это позволило повысить устойчивость всей системы к сбоям. В случае падения или зависания одной из утилит это слабо повлияет на работу остальных. При восстановлении работы мы можем начать с того момента, на котором обработка оборвалась. Для удобства использования утилит используется управляющая программа, которая запускает последовательно каждую утилиту и на стандартный вывод ошибок выводит лог работы всей системы. В окошко вывода управляющей программы выводится этап обработки конкретного сайта.
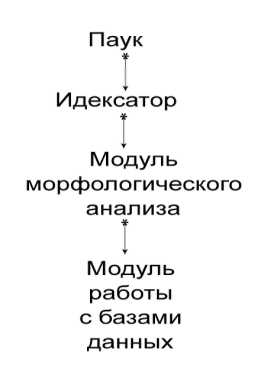
Рисунок 2 – Порядок обработки сайта
Паук загружает содержимое сайта на диск. Индексатор вычленяет нужные страницы из файлов сайта и создает индекс. Индекс представляет из себя текстовый файл в формате: СЛОВО РЕЛЕВАНТНОСТЬ.
Релевантность определяется по дате сообщения форума. Схема с полной загрузкой достаточно не экономична. Возможно, намного логичнее было бы предавать страницы сайта непосредственно индексатору, вернее той его части, которая отвечает за вычленение нужной информации. Но это значительно бы навредило быстродействию, и как было сказано выше уменьшило бы отказоустойчивость. Текстовый файл индекса берет модуль морфологического анализа. Он сам является частью утилиты, которая на выходе подает БД для поисковой системы. Сначала производится морфоанализ, а на основе его результатов создается база данных слов. Эту базу данных можно добавить к общей БД поисковой системы на сервере.
Взаимодействие базы данных на сервере и Web-интерфейса осуществляется по следующей схеме рис. 3.
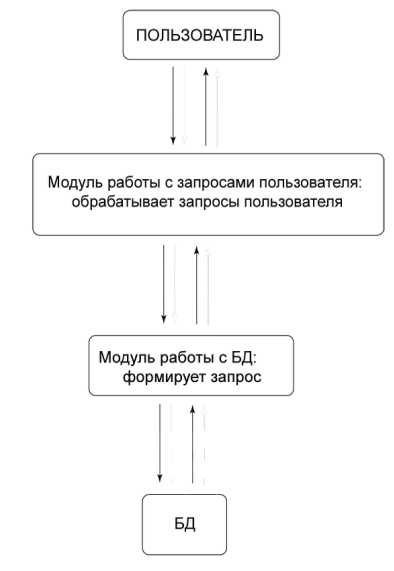
Рисунок 3 – Порядок взаимодействия базы данных на сервере и Web-интерфейса
Пользователь — человек, который пытается найти какое-то слово. Оператор — человек, который создаст базу данных по списку сайтов.
Таблица 1
Схема базы данных
|
Сторона |
Утилита |
Модуль |
|
Пользователь |
http://gt.m-team.ru/ |
finderData |
|
na.viga.torDa.ta. |
||
|
htmlDcsign |
finderData формирует результат запроса. Работает он следующим образом: на вход ему подаются слова, выход — таблица, содержащая поля: название страницы, дата последнего сообщения и найденные слова в последнем сообщении. Эти таблицы имеют имена типа а_1, а_2, а_3 и т. д. и сохраняются в нашей базе. Следующее имя для таблицы хранится в специальном файле captionTable. После того, как таблица сохранена под своим именем, finderData стирает текущее имя из captionTable и записывает туда имя для следующей таблицы, которое формируется следующим образом: из старого имени берётся числовая часть, она находится в конце после подчёркивания, и инкрементируется, после этого перед ней приписывается а_.
Для создания таблицы используются SQL запросы. Запросы формируются таким образом, чтобы было как можно меньше обращений к серверу БД. Эти запросы имеют следующий вид:
insert into table values (1, 2, 3), (4, 5, 6), (7, 8, 9).
За счёт того, что команда insert поддерживает такой синтаксис, мы можем за одно обращение к БД создать сразу всю таблицу результата.
navigatorData объекты этого класса позволяют отображать на экран какой-то кусок таблицы результатов. Получив имя таблицы, количество ссылок на страницы и количество записей в таблицы результатов, navigatorData выдаёт строки, которые потом можно как-либо отобразить, текущую страницу для подсветки, и количество страниц.
htmlDesign предназначен для оформления результата в виде html-страницы. Получив сведения от navigatorData, htmlDcsign генерит html код. Поскольку у страницы может быть лишь один дизайн, этот класс спроектирован таким образом, что можно создать лишь один экземпляр этого класса.
Взаимодействие объектов этих классов происходит следующем образом: слова, кото рыс ввёл пользователь для поиска сначала отдаются на обработку объекту, который сопоставляет слову определённую лексему (это нужно чтобы избавиться от проблемы окончаний, суффиксов и прочего). Затем эти лексемы идут к объекту flnderData, который создаёт таблицу результатов и возвращает её имя и количество записей. Эти данные идут к объекту navigatorData. Он по ним определяет возможное количество страниц и выдаёт строки, содержащие ссылку, дату, слова сообщения. Эти строки переходят на обработку объекту htmlDesign, который формирует страницу для браузера. Так работает скрипт, если нажать кнопку поиска. Если же происходит перемещение по страницам, то объект finderData нам не нужен и он не создаётся.
Основная база данных имеет простую схему с тремя таблицами. Достаточно очевидно, как связаны между собой – рис. 4.
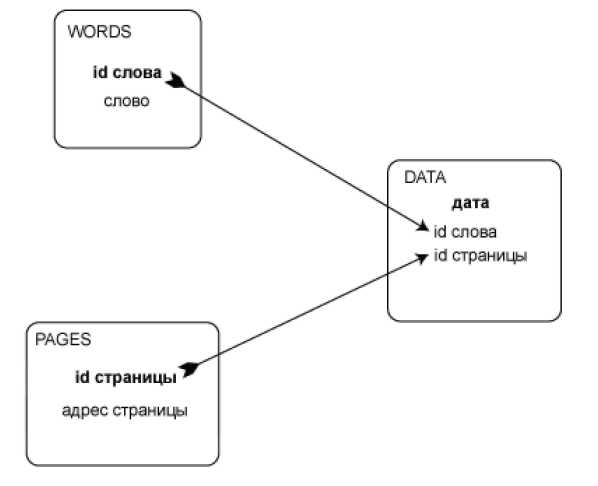
Рисунок 4 –Связь база данных
WORDS:
id слова (ключ) само слово
PAGES:
id страницы (ключ) адрес страницы
DATA:
календарная дата (юн id слова id страницы
Для того, чтобы не осуществлять повторный поиск для часто запрашиваемого слова, временно создается другая вспомогательная база данных.
ТАБЛИЦЫ РЕЗУЛЬТАТОВ ("а_+"): список слов (ключ) адрес страницы дата
CORRESPONDENCE:
список слов (ключ) название таблицы результатов
Таблица 2
Использованные шаблоны проектирования
|
Шаблон Что |
Где |
Зачем |
|
|
Singleton |
класс Config |
в модуле config в утилите indexer.py |
Конфигурация утилиты происходит один раз, на старте. Ее результаты могут быть использованы в любых модулях. |
|
класс htmlDcsign |
в Web-интерфейсе |
Поскольку у страницы может быть лишь один дизайн, этот класс спроектирован таким образом, что можно создать лишь один экземпляр этого класса. |
|
|
Адаптер |
класс Module |
в модуле Module в утилите main.py |
Класс Module использует уже существующий стандартный класс subproccss.Popcn. Но стандартный класс, не смотря на заявленную кросс-платформенность, не всегда работает на различных системах, это было исправлено в Module (в частности метод kill для ОС Windows). subprocess. |
Продолжение табл. 2.
|
Popen no-умолчанию запускает вызовы как консольное приложении, в Module это было заменено на «оконный старт». В результате у пользователя не возникает много лишних «черных окон». |
|||
|
Ленивая инициализация |
Леммы из таблиц загружаются только по требованию (см. описание crawler) |
в crawler, php |
Леммы загружаются только по требованию, то есть файл с леммами начинающимися на соответствующую букву, загружается только если в запросе есть слово начинающееся с данной буквы. Это значительно ускорило быстро действие программы. |
|
класс finderData |
в Web-интерфейсе |
Нам не нужен объект finderData если мы не выполняем поиск, а просто перемещаемся по таблицам. |
|
|
Фасад |
класс RcgExpr |
в модуле RcgExpr в утилите indexer.py |
Нужно было некоторым образом обернуть, стандартные функции для работы с регулярными выражениями. Таскать их в естественном виде было бы громоздко и нечитаемое. |
|
Состояние |
Core |
в модуле Core в утилите main.py |
Core меняет свое поведение (action F() ), в зависимости от состояния своего сайтов из свое словаря. По-хорошему поведение должен менять сам сайт, но во избегания перепроектирования мы не создавали отдельно такого класса. |
Можно описать шаблоны, которые использовались, при создании графической оболочки, но это уже не наши шаблоны а шаблоны QT.
Интерфейс программы
1 Web
Сам поисковик имеет Web-интерфейс. Он доступен по адресу http: //gt. m-team. ru/.
Рис. 5 - окошко браузера, на сайте gt-mteam.ru до ввода искомого слова

Рис. 6 - Окошко браузера на сайте gt-mtcam.ru после того как искомое слово было найдено
2 Интерфейс конвейра
Для удобства использования утилит используется управляющая программа, которая запускает последовательно каждую утилиту и на стандартный вывод ошибок выводит лог работы всей системы. В окошко вывода управляющей программы выводится этап обработки конкретного сайта. У сайта может есть 4 атрибута:
Скачан / Не скачан
Проиндексирован / Не проиндексирован
Создана БД / Не создана БД
БД послана на сервер / БД не послана на сервер
Последний параметр является фиктивным. Пока нами не реализована посылка БД на сервер и в ближайшее время вряд ли будет. Но сама идея полной автоматики весьма заманчива и потому мы решили оставить этот параметр до лучших времен. На данный момент сами БД приходится загружать вручную.
Для управляющей программы можно ввести, что она будет использовать в качестве утилит скачки, индексации, создания БД. При желании пользователь сможет написать свои и их использовать.
Имена утилит можно запомнить «Меню Файл / Загрузить параметры » или сохранить «Меню Файл / Сохранить параметры ». Утилиты при этом сохраняются в файл в расширении «programs.ini», который можно редактировать. При старте программы имена утилит исключительно берутся из него. Настройки интерфейса программы хранятся в файле «coring.ini» Галочки у кнопок «Открыть» означают блокировку этих кнопок. При быстрой и напряженной работе оператора это бывает удобно.
Чтобы начать индексацию некоторого списка сайтов достаточно создать текстовый файл с их именами. А потом воспользоваться «Меню Файл / Открыть список сайтов ». При этом, в папке с текущем списком сайтов создастся файл со словарем, который также можно просматривать и редактировать от запуска к запуску. Словарь содержит имя и атрибуты каждого сайта.
Для успокоения пользователя окно управляющей программы снабжено индикаторами процесса, которые показывают прогресс. Прогресс вычисляется на по атрибутам сайтов.
3 Управляющая программа во время работы. Снимки – рис. 7.
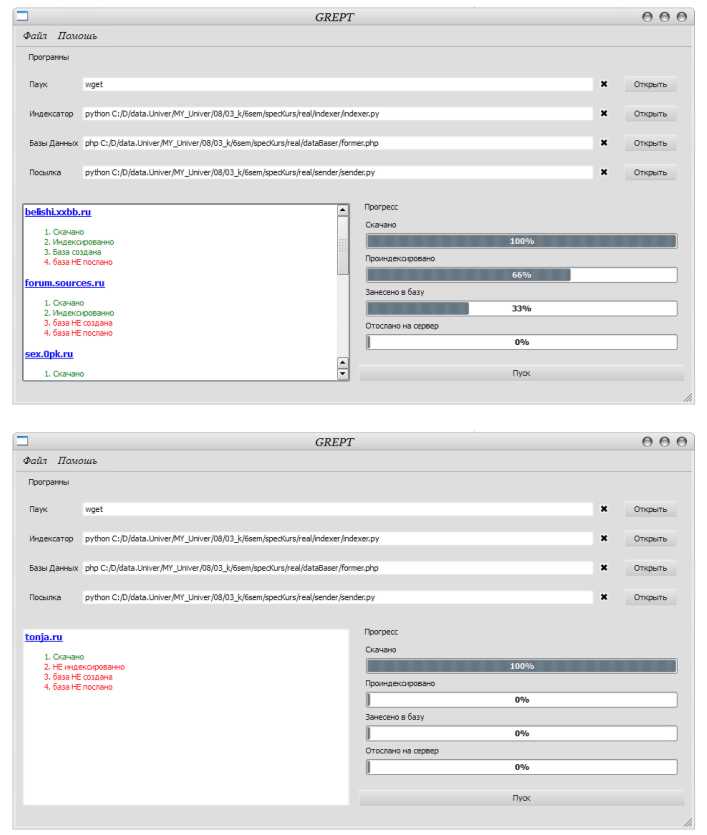
Рис. 7 – Снимки управляющей программы
Тестирование
1 Модульное тестирование
При отладке индексатора использовалось модульное тестирование, в частности тестировался класс DatcFindcr. Модульное тестирование позволяет проверить на корректность отдельные модули исходного кода программы. Идея состоит в том, чтобы писать тесты для каждой нетривиальной функции или метода. Это позволяет достаточно быстро проверить, не привело ли очередное изменение кода к регрессии, то есть к появлению ошибок в уже написанных и оттестированных местах программы, а также облегчает обнаружение и устранение таких ошибок. Опишем работу модульного теста на тривиальном примере с одним тестирующим методом:
from Date import DatcFindcr
import unittest
4 class TestDateFinder (unittest.TestCase):
5 def sctUp(sclf):
6 sclf.dateFinder = DateFindcr ()
7
8 def test Year (self):
9 is_year=self.dateFinder.is Year (2009)
10 self.assertEqual(is_ycar, True)
11
12 if name = " main ":
13 unittest .main ()
Модуль unittest входит в стандартную библиотеку Python и служит базовым инструментом для организации регрессионных unit-тестов. Для того чтобы использовать все возможности модульных тестов, тестирующий класс необходимо унаследовать от базового — unittest.Case. Метод setUpQ — служебный. Он вызывается перед запуском каждого теста и подготавливает среду выполнения. В нашем случае метод sctUpQ просто создает экземпляр класса DateFindcr. Имена остальных методов начинаются с «test» (необходимое условие для нахождения тестов в коде модуля). Если запустить наш тестирующий модуль получим следующее:
1 .
2
3 Ran I test in 0.016s
4
5 OK
Что означает, что все тесты выполнены успешно.
Как и любая технология тестирования, модульное тестирование не позволяет отловить все ошибки программы. В самом деле, это следует из практической невозможности трассировки всех возможных путей выполнения программы, за исключением простейших случаев. Кроме того, происходит тестирование каждого из модулей по отдельности. Это означает, что ошибки интеграции, системного уровня, функций, исполняемых в нескольких модулях, не будут определены. Кроме того, данная технология бесполезна для проведения тестов на производительность. Таким образом, модульное тестирование более эффективно при использовании в сочетании с другими методиками тестирования, например функциональным.
Функциональное тестирование — это тестирование ПО в целях проверки реализуемости функциональных требований, т.е. способности ПО в определенных условиях решать задачи, нужные пользователям. Функциональные требования определяют, что именно делает ПО, какие задачи оно решает. В нашем случае функциональным тестом являлся запуск индексатора на нескольких уже выкаченных сайтах и визуальная проверка результатов его работы, т. е. проверялось корректность выделения слов и правильность соответствующих дат путем сравнения с исходными html-страницами. Проверять автоматически в данном случае не актуально, так как, при этом подразумевается тестирование на каких-либо тривиальных примерах, с уже строго известным результатом. Но индексатор предназначен для работы с html-страницами, имеющими сложную структуру, что преобладает на практике, и тестировать нужно именно на реальных документах, кроме того он может допускать некий процент ошибок из-за слишком нестандартного оформления сайтов и т. п. [10]
При этом возникает сложность проверки корректности выполнения, так как вручную разбивать страницы на слова не реально, а автоматически это может сделать только сам индексатор.
2 Функциональное тестирование
Функциональное тестирование — это тестирование ПО в целях проверки реализуемости функциональных требований, т.е. способности ПО в определенных условиях решать задачи, нужные пользователям.
Протестировать функциональность поисковой системы может каждый и в любое время всего лишь пройдя по адресу http://gt.m-team.ru/.
А нормальная работа конвейера доказывается самим фактом существования нашей БД на сервере. Вообще функциональное тестирование каждой утилиты проводилось в процессе разработки и по се окончанию. В качестве тестовых примеров брались простенькие форумы к примеру (http://forum.zhtw.org.ru/) и не форумы вообще (http://tonja.ru/).
ЗАКЛЮЧЕНИЕ
Одним из подходов, обеспечивающих структурирование производственной системы и упрощение ее программной реализации, является объектно-ориентированный подход. Выделение совокупности объектов и отношений между ними позволяет построить объектную модель производственной системы и разработать на ее основе программные средства для исследования соответствующих свойств изделий и принятия решений. Использование средств UML является инструментом для моделирования производства. CASE-технологии обеспечивают единую информационную среду для проектирования, инженерного расчета, технологической подготовки производства.
Использование объектно-ориентированного подхода в первую очередь обусловлено объектной организацией мира. Каждый предмет, каждая сущность в этом мире представляют собой объект. Каждый объект обладает рядом свойств и характеристик – признаков данного объекта. Деление объектов на классы или множества по совокупности признаков можно представить в виде иерархической структуры, но для того чтобы представить все многообразие отношений между всеми объектами иерархической структуры уже не достаточно. Здесь на помощь приходят семантические сети как основа представления взаимоотношений и взаимозависимостей между объектами любой системы. Таким образом, объединение двух подходов дает возможность построить информационную модель представления знаний какой-либо области. Важным моментом является то, что сама по себе такая модель как информационная единица является независимой от конкретного естественного языка, поскольку базируется на семантически универсальных описаниях объектов, и по сути представляет собой знания о выбранной предметной области. Разумеется, ограничение такой модели рамками конкретной предметной области идет в ущерб ее универсальности, но авторам представляется что построение и применение универсальной системы семантической обработки любых текстов в конечном итоге будет сводиться к выделению предметной области (определению тематики) конкретного текста и затем анализе этого текста на основе модели его предметной области.
В результате выполнения курсовой работы нами разработана поисковая система для Интернета. Построение Базы данных поисковика имеет структуру конвейера. Каждый модуль представляет из себя отдельную утилиту. Различные утилиты могут быть написаны на различных языках. Они передают друг другу управление работы с данными. В данном случае можно было бы передавать сами данные через стандартный ввод-вывод.
Для удобства использования утилит используется управляющая программа, которая запускает последовательно каждую утилиту и на стандартный вывод ошибок выводит лог работы всей системы.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
- Анисимов, А. Е. Сборник заданий по основаниям программирования : учеб. пособие / А. Е. Анисимов, В. В. Пупышев. – М. : Интернет-Университет Информационных Технологий : БИНОМ. Лаборатория знаний, 2014. − 348 с.
- Баранова, Е. К. Моделирование системы защиты информации. Практикум : учеб. пособие / Е. К. Баранова, А. В. Бабаш. – М. : РИОР : Инфра-М, 2015. − 119 с.
- Боровская, Е. В. Основы искусственного интеллекта : учеб. пособие / Е. В. Боровская, Н. А. Давыдова. – М. : БИНОМ. Лаборатория знаний, 2014. − 127 с.
- Васильков, А. В. Информационные системы и их безопасность : учеб. пособие / А. В. Васильков, А. А. Васильков, И. А. Васильков. – М. : ФОРУМ, 2015. − 527 с.
- Волкова, В. Н. Теория информационных процессов и систем : учебник и практикум для академического бакалавриата : учебник для студ. / В. Н. Волкова ; Санкт-Петербургский политех. ун-т. – М. : Юрайт, 2014. − 502 с.
- Гвоздева, В. А. Основы построения автоматизированных информационных систем : учебник для студ. / В. А. Гвоздева, И. Ю. Лаврентьева. – М. : Форум : Инфра-М, 2015. − 317 с.
- Голицына, О. Л. Языки программирования : учеб. пособие для студ. / О. Л. Голицына, Т. Л. Партыка, И. И. Попов. – М. : Форум, 2015. − 398 с.
- Грекул, В. И. Управление внедрением информационных систем : учебник для студ. / В. И. Грекул, Г. Н. Денищенко, Н. Л. Коровкина. – М. : БИНОМ. Лаборатория знаний : Интернет-Университет Информационных Технологий, 2014. − 223 с.
- Гринчук, С. Н. Технология подготовки презентаций в Microsoft PowerPoint 2013 : учеб.-метод. пособие (с эл. приложением) / С. Н. Гринчук, И. А. Дзюба ; М-во образования Республики Беларусь, ГУО "Респ. ин-т высш. школы". − Минск : РИВШ, 2015. − 155 с.
- Емельянов, С. Г. Архитектура параллельных логических мультиконтроллеров / С. Г. Емельянов, И. В. Зотов, В. С. Титов . – М. : Высшая школа, 2009. − 232 с.
- Жадаев, А. Г. PHP для начинающих / А. Г. Жадаев. − Санкт-Петербург [и др.] : Питер, 2014. − 287 с.
- Заботина, Н. Н. Проектирование информационных систем : учеб. пособие для студ. / Н. Н. Заботина. – М. : Инфра-М, 2015. − 330 с.
- Задачи по программированию / [авт. : С. М. Окулов и др.] ; под ред. С. М. Окулова. – М. : БИНОМ. Лаборатория знаний, 2014. − 823 с.
- Зайдельман, Я. Н. Готовимся к ЕГЭ. Информатика. Диагностические работы в формате ЕГЭ 2014 / Я. Н. Зайдельман, М. А. Ройтберг . – М. : Изд-во МЦНМО, 2014. − 200 с.
- Затонский, А. В. Программирование и основы алгоритмизации: теоретические основы и примеры реализации численных методов : учеб. пособие для студ. / А. В. Затонский, Н. В. Бильфельд. – М. : РИОР : Инфра-М, 2014. − 166 с.
-
Зайдельман, Я. Н. Готовимся к ЕГЭ. Информатика. Диагностические работы в формате ЕГЭ 2014 / Я. Н. Зайдельман, М. А. Ройтберг . – М. : Изд-во МЦНМО, 2014. − 200 с. Затонский, А. В. Программирование и основы алгоритмизации: теоретические основы и примеры реализации численных методов : учеб. пособие для студ. / А. В. Затонский, Н. В. Бильфельд. – М. : РИОР : Инфра-М, 2014. − 166 с. ↑
-
Заботина, Н. Н. Проектирование информационных систем : учеб. пособие для студ. / Н. Н. Заботина. – М. : Инфра-М, 2015. − 330 с. Задачи по программированию / [авт. : С. М. Окулов и др.] ; под ред. С. М. Окулова. – М. : БИНОМ. Лаборатория знаний, 2014. − 823 с. ↑
-
Емельянов, С. Г. Архитектура параллельных логических мультиконтроллеров / С. Г. Емельянов, И. В. Зотов, В. С. Титов . – М. : Высшая школа, 2009. − 232 с. Жадаев, А. Г. PHP для начинающих / А. Г. Жадаев. − Санкт-Петербург [и др.] : Питер, 2014. − 287 с. ↑
-
Грекул, В. И. Управление внедрением информационных систем : учебник для студ. / В. И. Грекул, Г. Н. Денищенко, Н. Л. Коровкина. – М. : БИНОМ. Лаборатория знаний : Интернет-Университет Информационных Технологий, 2014. − 223 с. Гринчук, С. Н. Технология подготовки презентаций в Microsoft PowerPoint 2013 : учеб.-метод. пособие (с эл. приложением) / С. Н. Гринчук, И. А. Дзюба ; М-во образования Республики Беларусь, ГУО "Респ. ин-т высш. школы". − Минск : РИВШ, 2015. − 155 с. ↑
-
Гвоздева, В. А. Основы построения автоматизированных информационных систем : учебник для студ. / В. А. Гвоздева, И. Ю. Лаврентьева. – М. : Форум : Инфра-М, 2015. − 317 с. Голицына, О. Л. Языки программирования : учеб. пособие для студ. / О. Л. Голицына, Т. Л. Партыка, И. И. Попов. – М. : Форум, 2015. − 398 с. ↑
-
Васильков, А. В. Информационные системы и их безопасность : учеб. пособие / А. В. Васильков, А. А. Васильков, И. А. Васильков. – М. : ФОРУМ, 2015. − 527 с. Волкова, В. Н. Теория информационных процессов и систем : учебник и практикум для академического бакалавриата : учебник для студ. / В. Н. Волкова ; Санкт-Петербургский политех. ун-т. – М. : Юрайт, 2014. − 502 с. ↑
-
Баранова, Е. К. Моделирование системы защиты информации. Практикум : учеб. пособие / Е. К. Баранова, А. В. Бабаш. – М. : РИОР : Инфра-М, 2015. − 119 с. Боровская, Е. В. Основы искусственного интеллекта : учеб. пособие / Е. В. Боровская, Н. А. Давыдова. – М. : БИНОМ. Лаборатория знаний, 2014. − 127 с. ↑
-
Анисимов, А. Е. Сборник заданий по основаниям программирования : учеб. пособие / А. Е. Анисимов, В. В. Пупышев. – М. : Интернет-Университет Информационных Технологий : БИНОМ. Лаборатория знаний, 2014. − 348 с. ↑
-
Баранова, Е. К. Моделирование системы защиты информации. Практикум : учеб. пособие / Е. К. Баранова, А. В. Бабаш. – М. : РИОР : Инфра-М, 2015. − 119 с. Боровская, Е. В. Основы искусственного интеллекта : учеб. пособие / Е. В. Боровская, Н. А. Давыдова. – М. : БИНОМ. Лаборатория знаний, 2014. − 127 с. ↑
-
Васильков, А. В. Информационные системы и их безопасность : учеб. пособие / А. В. Васильков, А. А. Васильков, И. А. Васильков. – М. : ФОРУМ, 2015. − 527 с. Волкова, В. Н. Теория информационных процессов и систем : учебник и практикум для академического бакалавриата : учебник для студ. / В. Н. Волкова ; Санкт-Петербургский политех. ун-т. – М. : Юрайт, 2014. − 502 с. ↑

- История возникновения и развития языка программирования C++ и Java (Происхождение языка Java)
- Роль мотивации в поведении организации (Общая характеристика базы исследования акционерного общества «Петербургский социальный коммерческий банк»)
- Анализ управления конфликтами в ООО «ТД «Пищевые технологии»
- Международный опыт развития школьного и студенческого спорта (Мировая история зарождения школьного и студенческого спорта)
- Профессиональный стресс в управленческой деятельности ( Основные подходы к изучению профессионального стресса )
- Организационная культура и ее роль в современных организациях (Понятие, сущность и роль организационной культуры)
- Общие особенности кадровой стратегии организаций бюджетной сферы (Описание предметной области)
- Организационная культура и ее роль в современных организациях (Концептуальные подходы к изучению феномена организационной культуры)
- Система права: понятие, признаки, элементы (Структура системы права)
- Организационная культура и ее роль в современных организациях (Концептуальные подходы к изучению феномена)
- Система права: понятие, признаки, элементы
- История возникновения и развития языка программирования С++ и java