
Анализ работы Российских и зарубежных поисковых систем на примере Яндекс и Google
Содержание:

Введение
В данной курсовой работе, коснемся чрезвычайно актуальной и важной темы – поисковых систем. Умение правильно работать с ними, знание основных понятий и принципов работы смогут помочь начинающим пользователям научиться быстро и оперативно искать различную информацию в сети, получать нужные данные и быстро развивать свой интернет бизнес.
В данной работе будет рассмотрена история создания систем поиска, принципах их работе и структуре. Помимо этого, остановлюсь на очень важных фишках, которые необходимо обязательно знать при работе с поисковыми системами. Ресурсы Интернета уже давно не просто игрушка, превратившаяся в незаменимый инструмент для каждодневной работы людей различных профессий. Количество данных в сети стремительно растет, и пропорционально им растет и объем. Ученые утверждают, что объем информации, передаваемой по Интернету, увеличивается в два раза каждые шесть месяцев.
В сети каждый день появляются множество новых документов, и, конечно же, в большинстве случаев они оставались бы не востребованными, ни кем не найдены, и все это огромное количество информации оказалось бы никому не доступным и не нужным. Появилась необходимость создавать такие средства, которые позволили бы просто и понятно ориентироваться в информационных ресурсах всемирных сетей, мгновенно и качественно находить нужную информацию.
Наиболее популярным и используемым способом поиска в Интернете является использование поисковых систем. Что же такое поисковая система? Поисковая система – портал, осуществляющий поиск, сбор и сортировку информации в сети Интернет. Поисковые системы — это инструмент, позволяющий пользователю глобальной сети в кратчайшие сроки найти интересующую его информацию.
- Целью данной работы является изучение анализа систем в сети интернет.
- Для реализации поставленной цели необходимо выполнить ряд задач:
- Изучить понятие поисковой системы;
- Рассмотреть задачи поисковых систем;
- Изучить состав и принципы работы поисковой системы;
- Рассмотреть поисковые системы в настоящее время и т.д.
При написании данной работы были использованы современные научные и учебные источники литературы.
Глава 1 Теоретические основы поисковой системы
1.1 Понятие и история создания поисковых систем
Поисковая система, данное понятие возникло еще в конце 80 – х, начале 90 – х годов прошлого века. Именно тогда и возникли их первые прототипы, как в России, так и за рубежом. Согласно определению – это система, которая позволяет искать, обрабатывать, отбирать требуемые данные запроса в своей особой базе, где находятся описания различных источников информации, а также правила пользования ими.[1]
Основной ее задачей является поиск нужной пользователю информации. Для того, чтобы он был более эффективным, используется понятие релевантности, то есть то, насколько сами результаты поиска точно подходят тому или иному запросу.
Самые первые ИПС появились в середине 90 – х годов 20 века. Они весьма напоминали обычные указатели, которые находятся в любых книгах, некие справочники. В их базе данных содержались специальные ключевики (слова), которые различными способами собирались с многочисленных сайтов. Так, как интернет – технологии были не совершенными, то и сам поиск выполнялся только по ключевым словам.
Значительно позднее был разработан специальный полнотекстовый поиск, облегчающий нахождение необходимой пользователю информации. Система производила фиксацию ключевых слов. Благодаря ей, пользователи могли производить нужные запросы по тем или иным словам и различным словосочетаниям.
Одной из первых, была «Wandex». Ее разработкой занимался очень известный программист Мэтью Греэм в 1993 году. Также, в этом же году возникла и новая «поисковка» «Aliweb» (кстати, и по сей день успешно работает). Однако все они имели достаточно сложную структуру и не обладали современными технологиями.
Одной из наиболее удачных явилась «WebCrawler», которая впервые была запущена в 1994 году. Отличительной особенностью и главным преимуществом, выгодно выделяющим ее среди других систем поиска, явилось то, что она могла находить любые ключевики на той или иной странице. После этого, это стало своего рода эталоном и для всех остальным ИПС, которые разрабатывались позднее.[2]
Значительно позже возникли и другие поисковики, которые иногда конкурировали между собой. Это были – «Excite», «AltaVista», «InfoSeek», «Inktomi» и многие другие. Начиная с 96 года, российские пользователи сети начали работать с «Рамблером» и «Апортом». Но, настоящим триумфом для российского интернета, стал созданный в 1997 году «Яндекс».
Этот российский аналог «Google» стал настоящей гордостью российских программистов. Сегодня, он уверенно теснит конкурента в рунете и также является одним из лидеров по поисковым запросам среди ИПС в России. На сегодняшний день, имеются многочисленные специальные «поисковики», которые созданы для решения определенных задач. Так, например, информационно – поисковая система «Патрон», разработана для того, чтобы хранить и искать данные по патронам для различного оружия и сейчас применяется, как в органах Министерства Внутренних Дел и спецслужб, так и для охотников – профессионалов и любителей.
Имеются и другие, разработанные для нотариусов, врачей, инженеров, военных, автолюбителей и т д
К основным типам ИПС относятся следующие понятия:
Каталог, который представляет собой специально созданную структуру. Он имеет свою четкую классификацию по различным темам. Каталоги также включают особые аннотации с многочисленными ссылками на различные ресурсы в сети интернет. Это могут быть сайты, порталы, веб-страницы и т д.
Разработка каталогов той или иной ИПС явилось очень удобной благодаря тому, что они могут поддерживать оперативный поиск той или иной категории различных ресурсов по особым ключевикам (словам) с использованием специальных роботов – пауков.
Индексация каталога может производиться, как вручную, так и автоматически с обновлением индекса. В свою очередь сам результат работы системы включает в себя особый список. В него входят гиперссылка на требуемые ресурсы и описание того или иного документа в интернете.
Из наиболее популярных каталогов можно выделить: Yahoo, Magellan (зарубежные) и Weblist, Улитка и @Rus из отечественных.
Поисковая машина представляет собой особую структуру поиска, которая для формирования базы данных применяет специальных роботов. Она содержит различные данные об интернет – ресурсах. Самым главным ее преимуществом является то, что ее основные функции автоматизированы, а ее база создается поисковым роботом.[3]
Для того чтобы произвести поиск в данной системе, пользователь вводит запрос, который включает в себя набор доступных ключевиков, либо фразу в «кавычках». В свою очередь индекс создают роботы – индексировщики. Само описание документа содержит: начальные предложения статьи, кусочек текста, где выделены «ключевики». В документе также есть дата, когда обновляли документ, его размер в Кб или Мб, а также кодировка.
К наиболее распространенным зарубежным ИПС относят – Google, Altavista, Excite. Русские – «Яндекс» и «Рамблер».
В мире существует огромное количество различных видов ИПС, которые содержат множество источников информации. Разумеется, что даже наличие самого современного и мощного сервера не может удовлетворить запросы миллионов пользователей. Именно поэтому, появились специальные метапоисковые системы. Они могут одновременно пересылать запросы пользователей различным поисковым серверам, а на основе своего обобщения имеют возможность предоставить пользователю документ, содержащий ссылки на требуемый ресурс. К их числу можно отнести – MetaCrawler или SavvySearch.
1.2 Принцип работы поисковых систем
Работа информационно – поисковой системы является очень сложной. Однако при желании можно разобраться в ее структуре. Первое, что необходимо отметить, что существует особая программа – она называется поисковым роботом (пауком).[4] Данная программа систематически мониторит различные страницы и индексирует их.
Веб сервер создает запрос пользователя на получение той или иной информации, а затем предоставляет данный запрос машине поиска. Поисковик исследует требуемую базу данных, потом составляет полный список страниц, а затем передает веб-серверу. Он в свою очередь окончательно формирует все результаты запроса в «читаемый» вид, затем передает их на «комп» пользователя.
ИПС предназначена для следующих целей:
- Хранить значительные объемы данных;
- Производить оперативный поиск нужной информации;
- Добавлять, а также удалять различные данные;
- Выводить информацию в простом и удобном виде.
Существуют несколько основных типов ИПС:
- Автоматизированные
- Библиографические
- Диалоговые
- Документальные.
Поисковые машины классифицируются по области поиска информации:
1. Локальный поиск. Он предназначен, чтобы осуществлять поиск информации по всемирной сети какой-либо ее части, например, по локальной сети, либо по одному или нескольким сайтам. Таким примером являются внутренние серверы крупных компаний или поисковый скрипт на сайте.
2. Глобальный поиск. Он предназначен для того, чтобы искать информацию по региональной части, по группе сайтов, либо в сети Интернет и т.д. Именно глобальным поиском пользуются такие крупные поисковые системы как Яндекс, Google, Yahoo и т.д.
Поисковые машины по сети интернет осуществляют различный поиск информации. Например, музыка, картинки, личная информация, географическое положение и т.д. Поисковая машина может работать с файлами различных форматов (например. html,.htm,.txt,.doc,.rtf, …), мультимедийного (видео, звука и другой информации) или графического (.gif, .png, .svg,) типа. Но самым распространенным поиском является поиск текстовых документов (документы в формате doc, rtf, txt, web-страницы и др.).[5] Но с технологической точки зрения поиск по звукам, видео, изображениям является более сложным, поэтому он не реализован массово. Например, такие системы как Яндекс.Картинки ищут картинки по альтернативным текстам, соответствующим этим изображениям, а не по самим изображениям. А в компании Google каталог поиска картинок составляется вручную, это тормозит обновление баз изображений, но значительно увеличивает релевантность запроса.
Работает поисковый сервер следующим образом:
- Запрос, который получен от пользователя подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (как раз оно и будет отображено в виде сниппета, т. е. текстовой информации соответствует запросу на странице выдачи результатов поиска).
- Все полученные данные передаются специальному модулю ранжирования в качестве входных параметров. После чего по всем документам происходит обработка данных, далее подсчитывается собственный рейтинг для каждого документа, который характеризует релевантность разных составляющих данного документа, хранящихся в индексе поисковой системы запроса, введенного пользователем.[6]
- Этот рейтинг может быть составлен в зависимости от выбора пользователя дополнительными условиями (например, «расширенный поиск»).
- Далее генерируется сниппет, т. е., из таблицы документов извлекаются краткая аннотация, наиболее соответствующая запросу, заголовок и ссылка на сам документ для каждого найденного документа, и еще подсвечиваются все найденные слова.
- Пользователю результаты поиска, которые мы получили, передаются в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Все эти компоненты работают во взаимодействии и тесно связаны друг с другом, именно они образовывают тот самый довольно сложный механизм работы поисковой системы, который требует огромных затрат ресурсов.
1.3 Популярные поисковые системы в настоящее время
На первом месте, без всякого сомнения, находиться неотъемлемый лидер – «Google». На сегодняшний день, к нему адресуется около 80 процентов различных мировых запросов по самым различным сферам. Что касается второго места, то его, также заслуженно, занимает американский «eBay».[7]
На третьем месте, наш, отечественный, российский «Яндекс». На четвертом – «Yahoo» и на пятом – MSN. Еще одним отечественным браузером, но занимающим только 10 место в рейтинге Европы – это российский «Rambler».
Этот поисковик знают огромное количество пользователей. На сегодняшний день это первая по популярности система в мире! Ежемесячно она обрабатывает более 41 млрд запросов и проводит индексацию 25 миллиардов страниц.
Что касается истории создания компании «Google», то еще в 1996 году, пара студентов университета Стэнфорда – Ларри Пейдж и Сергей Брин разработали браузер, созданный на новых методах поиска. Назвали они ее просто и лаконично, как собственно и дизайн поисковой системы «Google». Собственно, название google – это искаженный googol (число десять в сотой степени).
googol
В основе нее специальный поисковый робот, который называется «Googlebot». Он производит сканирование страниц и их индексацию. В качестве алгоритма авторитетности, эта ПС PageRank. Собственно, именно он обеспечивает то, как будут выдаваться страницы посетителю в поисковых результатах.
Одним из первых, эта фирма разработала и голосовой поиск на различных языках, который значительно облегчает введение данных в систему. Ну, и наконец, именно этот браузер и послужил основой для слова «гуглить», которое все чаще встречается в сленге молодых тинейджеров.
«Yahoo» – вторая по популярности в США. Ее организовали в 1994 году два аспиранта Стэнфорда – Дэвид Фило и Джерри Янг. В конце 90 –х ими был приобретен портал RocketMail и на основе него создан бесплатный почтовый сервер «Yahoo». Сегодня на ее серверах можно хранить любое количество писем. В 2010 году появляется и русскоязычный ресурс почты – Yahoo! Почта.[8]
Яндекс
Одним из лучших российских поисковиков, вне всякого сомнения, является «Яндекс». На сегодняшний день он стоит на четвертом месте по общему количеству запросов. В то же самое время, по популярности «Яндекс» занимает сегодня первое место в Российской Федерации. Общее количество произведенных запросов превышает 250 миллионов каждый день
Он был представлен в сентябре 1997 года, а уже в мае 2011, произведя размещение своих акций на IPO, эта фирма смогла заработать наибольшее количество акций среди других интернет – компаний.
Сервисы Яндекс
Сегодня, «Yandex» имеет 50 сервисов, из которых некоторые уникальные – Яндекс.Поиск, Яндекс.Карты, Яндекс.Маркет. Помимо этого, российских пользователей очень интересуют такие сервисы, как «Поиск по блогам», «Яндекс Пробки». Основные запросы для пользователей в основном из следующих стран ближнего зарубежья: Россия, Белоруссия, Турция и Казахстан.
Исторически фирму основал бизнесмен – программист Аркадий Волож в 1989 году. Само название компании было придумано Ильей Сегаловичем, директором «Яндекса». Благодаря сотрудничеству с институтом проблем передачи информации был создан справочный словарь с поиском.
В отличие от других браузеров, Яндекс браузер учитывает и морфологию русского языка. Таким образом, сама система предназначена именно для работы в русскоязычном сегменте интернета.
Начиная с 2010 года, помимо браузера «Yandex.ru» появился еще один поисковик «Yandex.com». Данный интернет – ресурс используется для поиска по зарубежным порталам.
Поисковая система «Ebay»
Ebay представляет собой интернет – компанию из США, которая специализируется на проведении интернет – аукционов. Она производит управление портала eBay.com, а также версиями в других странах мира. Помимо этого, в собственности фирмы есть еще одна eBay Enterprise.
Поисковик ebay
Основателем фирмы является американский программист Пьер Омидьяр, который в середине 90 – х годов разработал интернет – аукцион для своего личного портала. В то же время, eBay – это своего рода посредник при купле продаже. Чтобы использовать его продавцы вносят определенный взнос, а покупатели получают возможность бесплатного использования сайта.[9]
Общие принципы его работы следующие:
В основном все люди добропорядочны
Каждый может внести свой вклад
В открытом общении люди проявляют свои лучшие качества
Уже в 1995 году на тысячах онлайн аукционов продавались миллионы различных предметов. Сегодня, это мощная платформа для купли продажи, как физлицами, так и юрлицами.
С 2010 года возникла и русскоязычная версия популярного ресурса и стала называться «Международный торговый центр eBay». Оплата на аукционе производится через платежную систему «PayPal».
Для того, чтобы продать предметы на данном портале необходимо написать сколько он стоит, его стартовая цена, когда начнутся торги, а также сколько будут длиться торги. Как и в обычном аукционе, выбранный товар получает заплативший самую высокую цену.[10]
Из плюсов подобного аукциона стоит отметить то, что продавец и покупатель могут находиться в любом месте земного шара, а наличие локальных филиалов и временных рамок предоставляют возможность участвовать в аукционах огромному количеству продавцов и покупателей.
MSN
MSN - поисковая система
Данная поисковая система является ведущим интернет – браузером, разработанным компанией «Microsoft». Он появился одновременно с выпуском первой операционной системы Windows 95. Далее этим названием стал пользоваться и сервис электронной почты Hotmail, а также различные веб-узлы Майкрософт. В начале 2002 года он являлся одним из самых крупных интернет – провайдеров в США и имел 9 миллионов подписчиков.
Поисковая система Rambler
Вторым крупным российским поисковиком, является интернет – портал «Rambler». По своей сути, вместе с «Яндекс» он является родоначальником рунета, а также главным игроком на рынке медиа услуг.
Основателем его является Сергей Лысаков, который в 1994 году разработала поисковую систему, а в 1996 году был зарегистрирован и домен www.rambler.ru. Начиная с 2012 года, «Рамблер» стал работать, как новостной портал.
Сегодня он имеет 11 место по популярности среди других сайтов РФ. Также, был разработан и специальный классификатор Rambler Top-100. По своей сути он был первый и в России. Сегодня – это удобный каталог объектов недвижимости «Rambler – недвижимость».
Поисковик mail
Одной из самых крупных почтовых служб явилась, созданная в 1998 году, Mail.ru. Сегодня она представляет собой службу электронной почты, каталог интернет – ресурсов и информационные разделы. Помимо очень удобной почты, она имеет ряд специальных проектов, которые весьма популярны и нужны подписчикам: «Авто Mail.ru», Афиша «Mail.ru», «Дети mail.ru», «Здоровье mail.ru», «Леди mail.ru», «Новости mail.ru» и «Недвижимость mail.ru».
Глава 2 Анализ работы Российских и зарубежных поисковых систем на примере Яндекс и Google
2.1 Принцип работы Российской поисковой системы на примере Яндекса
Для начала необходимо рассмотреть алгоритмы, которые являются основополагающими для любой поисковой системы:
— Алгоритм прямого поиска.
Что это такое – вы помните, что читали замечательную историю в одной из книг. И вы начинаете по очереди искать. Взяли одну книгу – полистали – не нашли, взяли другую. Принцип понятен, но этот способ чрезвычайно долгий. Это тоже понятно.
— Алгоритм обратного поиска.
Для этого алгоритма создается из каждой страницы твоего блога – создается текстовый файл. В этом файле перечисляются в алфавитном порядке ВСЕ слова, которые ты использовал. Даже позиция этого слова в тексте указывается (координаты в тексте).
Это достаточно быстрый способ, но уже поиск происходит с какой-то погрешностью. Здесь главное понимать, что алгоритм этот ищет не в интернете, не поиском по блогу. А в отдельно взятом текстовом файле, который создан был когда-то давно. Когда робот заходил к тебе. И эти файлы (обратные индексы) хранятся на серверах Яндекса.[11]
Так, это были базовые алгоритмы поиска. Т.е. как Яндекс просто находит нужные документы. С этим вроде бы проблем не должно быть.
Но ведь документов Яндекс знает не один и даже не 100, а по последним данным из моих источников – Яндекс знает порядка 11 млрд. документов (10 727 736 489 страниц ) .
И среди всего этого количества нужно выбрать документы, подходящие под запрос. И что еще важнее – нужно как-то ранжировать их.
Математические модели поиска
Для решения этого вопроса на помощь приходят математические модели.
Булевская мат.модель – Если слово встречается в документе – документ считается найденным. Просто на совпадение и ничего сложного.
Векторная мат.модель – эта модель определяет «вес» документа. Уже не только совпадение встречается, но и это слово должно встречаться несколько раз. Причем чем больше слово встречается – тем выше релевантность (соответствие).[12]
Именно векторную модель используют ВСЕ поисковики.
Вероятностная модель – более сложная. Принцип такой: поисковик нашел сам эталон страницы. Например, вы ищете информацию об истории Яндекса.
И все остальные документы он будет сравнивать с этой статьёй. И логика здесь такая: чем более страница твоего блога похож на мою статью – тем ВЕРОЯТНЕЕ тот факт, что твоя страница блога тоже будет полезна читателю и тоже рассказывает об истории Яндекса.
Чтобы сократить количество документов, которые нужно показывать пользователю – было введено понятие релевантности, т.е. соответствия.
Релевантность поиска
Насколько страница твоего блога действительно соответствует теме. Это важная тема, которая касается качества поиска.
Асессоры — кто это и за что отвечают
Нужна эта релевантность еще и для оценки качества работы алгоритмов.
Для этого есть штаб спецназа – их называют Асессоры. Это специальные люди, которые руками просматривают поисковую выдачу. У них есть инструкция, как проверять сайты, как оценивать и т.п. И они руками определяют по порядку подходят твои страницы поисковым запросам или не подходит.
И вот от мнения асессоров зависит качество поисковых алгоритмов. Если все асессоры скажут, что поисковая выдача не соответствует запросам – значит неправильный алгоритм ранжирования и здесь вина только Яндекса.[13]
Кто такие асессоры?
Если асессоры говорят о том, что только один сайт не соответствует запросу – значит, сайт улетает куда-то далеко и понижается в выдаче. Точнее не весь сайт, а только одна статья, но это «не суть».
И на помощь приходят другие параметры, по которым проходит ранжирование страниц.
Их очень много, ну например:
- вес страницы (вИЦ, PageRank, пузомерки в общем);
- авторитетность домена;
- релевантность текста запросу;
- релевантность текстов внешних ссылок запросу;
- а также множество других факторов ранжирования.
Асессоры вносят замечания, а люди, которые отвечают за за настройку математической модели ранжирования уже, в свою очередь, редактируют формулу, в результате чего поисковик работает более качественно.
Основные критерии оценки работы формулы:
1. Точность выдачи поисковой системы — процент документов, соответствующих запросу (релевантных). Т.е. чем меньше страниц, не соответствующих запросу присутствует — тем лучше.
2. Полнота выдачи поисковой системы — это отношение релевантных веб-страниц по данному запросу к общему количеству релевантных документов, находящихся в коллекции (совокупности страниц, находящихся в поисковой системе).
Например, если во всей коллекции релевантных страниц больше, чем в поисковой выдаче, то это означает неполноту выдачи. Это произошло из-за того, что некоторая часть релевантных веб-страниц попала под фильтр.
3. Актуальность выдачи поисковой системы — это соответствие веб-страницы тому, что написано в сниппете. Например, документ может сильно отличаться или вовсе не существовать, но в выдаче присутствовать.
Актуальность выдачи напрямую зависит от того, как часто сканирует поисковый робот документы из своей коллекции.
Сбор коллекции (индексация страниц сайта) осуществляется специальной программой — поисковым роботом.
Поисковый робот
Поисковый робот получает список адресов для индексации, копирует их, далее содержимое скопированных веб-страниц отдаёт на обработку алгоритму, который преобразует их в обратные индексы.
Ну, вот «в двух словах», если можно так сказать, мы обсудили принципы работы поисковика.
Поисковая система большое значение придает показателю последнего изменения информации (Last-Modified). Если сервер не будет передавать эту информацию, то процесс индексации данного ресурса будет происходить намного реже.
Пока что остается нерешенной проблема страниц, использующих фреймовые структуры, но она может быть обойдена с помощью скриптов, отправляющих пользователей поисковой системы в нужное место сайта.
Если у сайта существуют «зеркала» (например, http://www.site.ru, http://site.ru, https://www.site.ru, https://www.site.ru), необходимо принять соответствующие действия для исключения их из процесса индексации. Если индексацию «зеркал» избежать не удалось, можно «склеить» их путем внесения необходимой информации в robots.txt.
В случае попадания сайтов в Яндекс.Каталог система будет идентифицировать их как заслуживающих отдельного внимания, что может повлиять на продвижение сайтов. Также это способствует упрощению процедуры определения тематики сайта, что в свою очередь означает получение сайтом значимой внешней ссылки.
Команда поисковой системы Яндекс держит в секрете IP-адреса своих роботов. Но в лог-файлах отдельных сайтов можно встретить текстовые пометки, оставленные поисковыми роботами Яндекс.
Одними из самых интересных роботов-сканеров поисковой системы Яндекс можно назвать:
- Yandex/1.01.001 (compatible; Win16; I) – основной робот, занимающийся непосредственно индексацией сайтов;
- Yandex/1.01.001 (compatible; Win16; P) – робот-индексатор изображений;
- Yandex/1.01.001 (compatible; Win16; H) – робот, который выявляет «зеркала» индексируемых сайтов;
- Yandex/1.02.000 (compatible; Win16; F) – робот-индексатор пиктограмм ресурсов (favicons);
- Yandex/1.03.003 (compatible; Win16; D) – робот, который обращается к страницам, добавленным с помощью формы «Добавить URL»;
- Yandex/1.03.000 (compatible; Win16; M) – задействуется при переходе на страницу посредством ссылки «Найденные слова»;
- YaDirectBot/1.0 (compatible; Win16; I) – этот робот отвечает за индексацию страниц ресурсов, принимающих участие в рекламной сети Яндекс.
Из всех поисковых роботов самый важный так и называется – основной поисковый робот. От того, как он проиндексирует страницы сайта, будет зависеть значимость ресурса для поисковой системы.
Работа всех роботов происходит по индивидуальному расписанию, и если сайт проиндексирован одним из них, то это не значит, что скоро будет произведена индексация и другим.
В помощь основным созданы и роботы, которые периодически посещают сайты и устанавливают, насколько те доступны. К таким можно отнести роботов «Яндекс.Каталога» и рекламной сети Яндекс.
Для поисковой системы Яндекс характерны следующие основные показатели внешней оптимизации:
- тИЦ – это общедоступный тематический индекс цитирования, он не оказывает прямого влияния на ранжирование и используется для определения позиций в тематической категории Яндекс.Каталога; применяется, когда необходима раскрутка сайта, тИЦ показывает, какое количество ссылок, в среднем, обращается к сайту.
- вИЦ, или взвешенный Индекс Цитирования, представляет собой алгоритм для подсчета количества внешних ссылок; значение его не разглашается и используется поисковой системой как определяющее при ранжировании сайтов в поисковой системе.
- Присутствие сайта в «Яндекс.Каталоге».
- Общее число страниц сайта, принявших участие в индексации.
- Частота, с которой индексируется содержимое сайта.
- Наличие и отсутствие ссылок с сайта, присутствие сайта в поисковых фильтрах.
Индекс цитирования создает основу для тематического и взвешенного индекса цитирования, которые влияют на ранжирование сайта.
Индекс цитирования (ИЦ) — это указатель цитирований (количества ссылок на источник) между публикациями, позволяющий узнать, какие из более поздних документов ссылаются на более ранние работы, при этом, ИЦ может рассматриваться как для отдельных статей, так и для авторов (ученных).
В поисковой системе Яндекс, а также в других поисковых системах, под индексом цитирования подразумевается количество обратных ссылок, без учета ссылок со следующих ресурсов: немодерируемых каталогов, досок объявлений, сетевых конференций, страниц серверной статистики, XSS ссылки и другие, которые могут добавляться без контроля со стороны владельца ресурса.
Стоит отметить, что в каталоге Апорт под ИЦ понимается взвешенный индекс цитируемости.
Рассчитывается этот индекс из ссылочного графа: если рассматривать ресурсы сети как вершины графа, а цитирование других ресурсов (ссылочные связи между сайтами) как связи вершин графа (ребра), тогда ссылочный граф можно представить в виде диаграммы, как показано на рисунке 1.
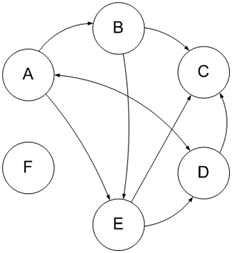
Рисунок 1 – Ссылочный граф
На рисунке буквами А, B, …, F обозначены определенные сайты в индексе поисковой системы, стрелки изображают направление связей — односторонние либо двусторонние.
ИЦ используется как один из факторов для ранжирования документов в поисковой выдаче, но не является главным.
Не стоит путать обычный индекс цитирования с взвешенным и тематическим, о которых будет написано позже. Индекс цитируемости всегда целое число и не зависит от тематик ссылающихся документов. Индекс цитируемости обычно рассматривается в качестве параметра значимости статьи, однако он не отражает структуру ссылок в каждой дисциплине (тематике), а также слабозначимые работы и труды с большой значимостью могут иметь одинаковый индекс цитируемости.
Поэтому был введен взвешенный индекс цитирования, который определяется не только количеством, но и качеством ссылающихся источников.
Введение ссылочного поиска и статической ссылочной популярности помогает поисковым системам справляться с примитивным текстовым спамом, который полностью разрушает традиционные статистические алгоритмы информационного поиска, полученные в свое время для контролируемых коллекций. ВИЦ является аналогом PageRank от Google.
Взвешенный индекс цитирования, как и другие ссылочные факторы ранжирования, рассчитывается из ссылочного графа.
Узнать вИЦ для своих страниц вы можете приблизительно, проверив их PageRank любым онлайн-сервисом проверки, однако, следует учесть, что в индексе Яндекса присутствуют только русскоязычные документы, а из зарубежных лишь некоторые популярные, таким образом, урезая ссылочный граф по сравнению с Google.[14]
Тематический индекс цитирования введен для отражения авторитетности сайта в своей тематике.
При определении тематики сайта сначала строится описание рассматриваемого ресурса (из названия категорий сайта, заголовков, структуры URL его страниц).
Далее вычисляется оценка близости между описаниями заранее подготовленных тематик (каталог) и описаниями ресурсов с выбором наиболее близких тематик для них.
Тематическая близость двух документов отражает вероятность принадлежности их обоих одной и той же тематике. Этот показатель может влиять на значение передаваемого ссылкой веса.
Расчет тИЦ основан на формуле:
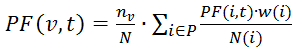
где PF(v,t) – тИЦ ресурса v;
P – количество ресурсов, которые ссылаются на сайт v и имеют ту же тематику;
nv– количество страниц на рассматриваемом сайте v;
N – общее число страниц в индексе Яндекса (при этом, nv/N — вероятность того, что пользователь читает сайт v);
w(i) – частота цитируемости ресурсом i сайта v;
N(i) – общее число ссылок на i-ом сайте.
При этом, PF(v,t) является нормализованной величиной.
Изначально тематический индекс цитирования отражал ситуацию в Рунете, но со временем индекс Яндекса расширился на такие географические сегменты, как Беларусь, Украина и другие. В Яндексе появились новые версии каталога для дополнительных регионов. [8]
Соответственно, чтобы ранжировать сайты в каждом из региональных Яндекс.Каталогов, потребовалось ввести региональный тИЦ, который учитывает, помимо тематической, географическую близость ссылок.
Таким образом, тИЦ обладает следующими свойствами:
1. тИЦ зависит от количества уникальных страниц на сайте и чем их больше, тем больше результирующий показатель.
2. Чем меньше исходящих ссылок на сайте-доноре, тем больше с него передается тИЦ.
3. тИЦ никак не зависит от перелинковки.
4. Анкоры ссылок не участвуют в определении тематической близости двух ресурсов.
При наличии у сайта нескольких зеркал (копий), при их склейке результирующий тИЦ суммируется.
2.2 Основные принцип работы поисковой системы Google
Алгоритм ранжирования Google сложнее, чем алгоритм Яндекса. Продвигать сайты в Google, особенно на начальном этапе, немного сложнее. Раскрутка молодого сайта в Google затруднительна, так как на новые веб-ресурсы накладывается фильтр (так называемая «песочница»). Google при ранжировании использует порядка 200 факторов, оптимизатор может повлиять лишь на некоторые.[15]
С другой стороны, поисковая система Google выглядит стабильнее своих конкурентов в плане смены алгоритма и апдейтов. Информация, только что размещенная на сайте, может в считанные минуты попасть в основную выдачу. Поисковые роботы Google в три раза быстрее, чем роботы других поисковых систем. Фильтры (критерии «нормальности» сайта) почти не меняются с момента начала их внедрения.
Контент и ссылки – вот два фактора, на которые может повлиять оптимизатор при продвижении сайта в поисковой системе Google.
Релевантность контента относительно поискового запроса повышается следующим образом: простановка ключевых слов в заголовках (тегах title и h1 – h6). В title прописывается единственная ключевая фраза без лишних слов. Ключевые слова в начале html-кода страницы сайта так же увеличивает релевантность текста.
Внешние ссылки Google учитывает по нескольким параметрам: количество, авторитетность сайта-донора (т.е. насколько поисковая система доверяет сайту), тематичность. Сквозные ссылки (ссылки, ведущие со всех страниц сайта-донора, устанавливаются, например, в шаблоне сайта) в глазах Google обладают большим весом, нежели 10 ссылок (с этого же сайта-донора).
Сайт-акцептором называют сайт А, на который стоит ссылка с сайта B, а сайтом-донором – сайт B, который размещает ссылку на сайт A.
Перед продвижением сайта в Google следует:
- В случае нового сайта сообщить поисковой системе по адресу: https://www.google.com/webmasters/tools/submit-url/
- С помощью страницы «инструменты для веб-мастеров» https://www.google.com/webmasters/tools/home?hl=ru подтвердить права на сайт, создать файл sitemap.xml и добавить ссылку на карту сайта вида http://www.site.ru/sitemap.xml.
- Проверить код на валидность
- Проверить работоспособность всех ссылок на сайте, при необходимости исправить ошибки.
Это позволит поисковому роботу Google полнее и точнее проиндексировать сайт и выделить заслуженное место на страницах своей выдачи.
Понятие Google PageRank является одним из ключевых моментов в работе поисковой машины Google. Наряду с другими параметрами, влияющими на выдачу (сортировку) сайтов в результатах поиска, знание модели PageRank необходимо как для понимания процесса поиска, так и для использования оптимизаторами при продвижении своих сайтов в поисковой системе.
PageRank (далее просто PR) это числовая величина — мера “важности” страницы в поисковой системе Google. Зависит от числа внешних ссылок на данную страницу и от их веса (важности). Другими словами от количества и качества ссылающихся страниц. А если говорить математическим языком, то PR – это алгоритм расчёта авторитетности страницы, используемый поисковой системой Google. PR не является основным, но является одним из вспомогательных факторов при ранжировании сайтов в результатах поиска.
Следует отметить, что при расчете PR Google учитывает не все ссылки, а отфильтровывает ссылки с сайтов, специально предназначенных для скопления ссылок. Некоторые ссылки могут не только не учитываться, но и отрицательно сказаться на ранжировании ссылающегося сайта (такой эффект называется поисковой пессимизацией). [9]
Основной формулой для расчета PR является формула:
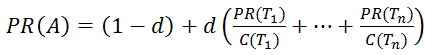
где PR(Ti ) – значение PageRank для страницы;
d – демпфирующий коэффициент, отражающий какую долю веса может передать страница-донор на страницу-акцептор. Обычно его принимают равным 0.85, что означает, что страница может передать 85% веса (распределяется между всеми акцепторами, на которые ссылается донор).
В других источниках d является вероятностью, с которой пользователь перейдет на один из акцепторов, а не закроет браузер, что, в принципе, то же самое. Какое числовое значение у этого параметра знают только в Google, остальные из экспериментальных данных принимают его равным 0,85;
n – количество страниц, ссылающихся на страницу-акцептор (на которые не наложен фильтр);
Ti – i-ая ссылающаяся страница;
C(Ti) – количество ссылок на странице-доноре Ti .
Поскольку ссылающихся страниц может быть много, и общее количество страниц в поисковой системе Google достаточно велико (около десятка биллионов штук), а также их количество постоянно растет, то представлять вес страницы в абсолютных значениях для вебмастеров было бы весьма неправильно. Для этого ввели понятие TLPR — ToolBar PageRank – значение PR, который имеет значение от нуля до 10 (шкала в Google Toolbar).
Для того, чтобы уложить все веса страниц между значениями от нуля до 10 используют логарифмическую шкалу. Определяется ToolBar PageRank по формуле:
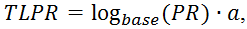
где base – основание логарифма, которое зависит от количества страниц в поисковой машине (возможно и от ряда других факторов). Некоторые принимают его равным 7;
a – некий коэффициент приведения, который удовлетворяет неравенству 0<a≤1
Из вышесказанного неверно делать выводы, что нулевой TLPR означает нулевой реальный PageRank. По формуле PR видно, что даже при n=0 , мы получим минимальный PRmin =(1-d)=0,15. Это значение соответствует TLPR≈-1.
При таких (отрицательных) значениях тулбарного PR считается что PR=N/A (или еще не определен), однако он также оказывает влияние на распределение веса между ссылками-акцепторами. Также следует заметить, что тулбарное значение предназначено только для отображения вебмастерам в Google Toolbar и никак не влияет на позицию в выдаче. На позицию в выдаче влияние оказывает реальный PR страницы. [10]
Исходя из принципов расчета Google PageRank, можно теперь легко рассчитать, с каких ссылок нужно ссылаться и сколько нужно ссылок, чтобы получить тот или иной PR.
Также можно прогнозировать PR. Один из важных выводов заключается в следующем: если у нового сайта более 10000 страниц (число страниц зависит от количества ссылок с них на другие страницы), они правильно перелинкованы и каждая ссылается на главную страницу, то главная страница получит хороший вес от этих ссылок. Учитывая, что минимальный PR равен 0,15 и в среднем на одной странице 10 ссылок, для такого сайта вычисляется по формуле PR:
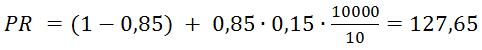
А ToolBar PageRank по формуле TBPR:
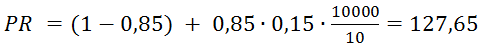
Это пример хорошего PR без единой внешней ссылки с других сайтов.
Таким образом, существует множество способов повышения веса своих страниц, но главная идея — это качественные ссылки с других сайтов. Для этого можно использовать каталоги, социальные закладки, статьи, форумы, блоги и другие типы сайтов. Однако не следует глупо расставлять множество ссылок на других сайтах, так как помимо PageRank существует множество других ранков, влияющих на выдачу страницы в результатах поиска (например TrustRunk).
Отрицательного PR не бывает. Реальный PR минимум равен 0,15, минимальный тулбарный PR равен нулю.
Ссылки на своем сайте на другие сайты ставить необходимо, так как своими ссылками вы увеличиваете PR страниц-акцепторов и тем самым, по первой формуле, к вам возвращается еще больший вес из огромной системы ссылок. На значение PageRank влияет только количество и качество ссылающихся ресурсов.
С картинок PageRank “перетекает”, только если они являются ссылками, по которым пользователь может перейти на другой ресурс.
2.3 Общее в работе всех поисковых машин
Удивительно, но эта невероятно популярная система, обслуживающая миллионы запросов ежедневно, зародилась как простая коллекция закладок, которую пополняли всего 2 человека - Дэвид Фило и Джерри Янг. На сегодняшний день Yahoo!, это уже не просто каталог, это целая группа разнообразных сервисов, среди которых такие как каталог Yahooligans - Yahoo! для детей, система персо-нальых каналов My Yahoo!, бесплатный E-mail сервис, система "Shop with Yahoo!" (покупайте с Yahoo!), совместный с MTV проект MTV unfURLed и многое другое.
Среди всех рассмотренных систем, Yahoo! – единственная чисто каталоговая, на Yahoo! нет собственной поисковой машины. Зато список категорий на Yahoo! является наиболее полным и простым - в отличие от других каталогов, на Yahoo! всегда легко определить, в каком разделе находится нужная информация. Заглав-ная страничка Yahoo! грузится очень быстро - хотя на ней очень много ссылок, но все они текстовые.
Центральная часть страницы, конечно, занята окном поиска и списком категорий. Ссылки вверху страницы (графические) обеспечивают доступ к такой информации, как "что нового", "что хорошего", "More Yahoos". Последнюю ссылку рекомендуется посетить - она приводит на страницу с огромным количеством ссылок на разнообразные Yahoo! - каталоги и сервисы. В нижней части основной страницы Yahoo! расположено большое количество ссылок на наиболее популярные разделы Yahoo!.
При вводе ключевых слов с основной страницы Yahoo, запрос обрабатывается по методу "Intelligent default", то есть Yahoo! ищет наиболее подходящие результаты в таких областях: в категориях Yahoo; в Web-сайтах, зарегистрированных на Yahoo; на Altavista (запрос передается при отсутствии результатов); в новостях. Такой интеллектуальный поиск занимает довольно много времени.
При задании критериев поиска для Yahoo! нужно помнить, что Yahoo! ищет эти слова только в названии и описании страницы, поскольку полнотекстового индекса на Yahoo! нет. Поэтому не следует указывать при поиске слишком много терминов или синонимов - количество результатов с Yahoo! снизится или даже будет нулевым. При вводе ключевых слов со страницы каталога, нужно выбрать область поиска - весь каталог Yahoo! или только его текущий раздел. Это делается с помощью радио кнопок под полем ввода. На странице с результатами поиска выводятся сначала удовлетворяющие критерию поиска категории, а потом сайты. Возле каждой категории в скобках стоит число - это количество сайтов в данной категории.
В случае если на Yahoo! нет результатов, сразу выводятся результаты с Altavista. Вверху и внизу страницы выводится маленькая табличка, с помощью которой можно одним нажатием кнопки мыши произвести поиск в категориях Yahoo!, на Altavista, в новостях и событиях. Количество результатов поиска на Yahoo!, естественно, невелико, зато большинство из них являются релевантными. [16]
Возможна проблема с отсутствующими страницами, поскольку вебмастера обычно забывают удалить свои сайты с поисковых систем, а на Yahoo! нет механизма автоматического обновления. Для расширенного поиска Yahoo! предлагает не очень большой, но очень полезный набор инструментов. Чтобы попасть на страничку расширенного поиска, надо перейти по ссылке "options" с основной страницы Yahoo!.
Среди средств расширенного поиска - ограничение результатов по дате, поиск в Yahoo!, Usenet и среди E-mail адресов, использование логических операций над терминами и поиск конкретной фразы. Также присутствует возможность искать слова с произвольными окончаниями, указывать слова, которые должны или НЕ должны присутствовать в документе, и т.д. Чисто русские ресурсы в Yahoo! не добавляются, потому что в Yahoo! Inc. просто некому смотреть и оценивать их содержимое. Но те запросы, которые не дали результатов на Yahoo! передаются на Altavista, а там есть хороший индекс русских ресурсов.
Как осуществлять поиск.
Как пишут сами разработчики Yahoo!, их страница с результатами поиска предназначена для того, чтобы помочь пользователям находить то, что они ищут, в дружественном и удобном для работы интерфейсе.
Рассмотрим более подробно различные разделы на странице с результатами поиска.
Inside Yahoo! (Внутренний Yahoo!) Это продукты или услуги Yahoo!, что соответствует пользовательскому критерию поиска. К примеру, если человек задал в запросе "лягушка" ("frogs"), Inside Yahoo! покажет результаты поиска областями, где пользователь сможет найти различные типы информации, такие как изображения из Картинной галереи Yahoo!, элементы для продажи в Yahoo! Аукцион, факты о лягушках от Yahooligans!
Directory Category Matches (Категории директивных сделок): Эта область подсвечивает категории в Yahoo! Каталог, которые соответствуют пользовательскому запросу поиска. Если человек хочет увидеть совокупность сайтов по специфической теме, ему следует щелкнуть по самой необходимой категории, после чего пользователю представится наглядный список сайтов, который был собран редактором Yahoo! по заданной теме.[17]
Если категорий больше, чем может отображаться, то справа вверху появится ссылка "Next". Щелчок по данной ссылке позволит пользователю видеть и коммерческие и некоммерческие категории в Yahoo! Каталог, которые соответствуют запросу поиска.
Sponsor Matches (Спонсорские сделки): Спонсорские сделки – релевантные результаты поиска, за которые платят предпринимателями или организациями и обеспечивается сторонним средством доступа поискового сервера.
Web Matches (Сетевые сделки): Эти результаты показывают комбинации релевантных web-страниц и сайтов, обеспеченных сторонними средствами доступа поискового сервера и Yahoo! Каталог. Это заданный по умолчанию стиль, в котором появляются результаты.
Когда сайт, перечисленный в результатах поиска, также перечислен в Yahoo! Каталог, листинг результата поиска покажет заголовок и описание, обеспеченному Yahoo! Каталог. Кроме того, пользователь будете видеть ссылку " More sites about", которая находится внизу. Кликая на эту ссылку, пользователь сможет просмотреть совокупность сайтов по той же самой теме в Yahoo! Каталог.
В списки каталога включают сайты, прошедшие через специальную программу Yahoo!. Эти сайты заплатили Yahoo! рассматривать и считать их для включения в Yahoo! Каталог.
Расширенный поиск – это особенность, которая помогает вам совершенствовать ваши результаты поиска.
В поисковой системе Yahoo! возможен прямой поиск (то есть поиск осуществляется только по заданным словам) и расширенный поиск.
Расширенный поиск помогает увеличить точность результатов поиска, используя дополнительный синтаксис, чтобы сосредоточить поиск. Пользователь может ввести большинство следующих параметров поиска непосредственно в блок поиска, или же выбрать их на странице Расширенного поиска, на которую можно перейти по ссылке advanced search, находящейся справа от строки поиска.
Страница расширенного поиска представлена ниже.
Advanced Search
Find web pages
include all of the words:
include this exact phrase:
include at least one of these words:
exclude these words:
Search:
the Web Yahoo! Directory listings
<< Fewer options
More options
Language:
only show pages in
Country:
only show pages from
Date:
only show pages updated in the
Keyword Locations:
show pages where the keyword is
Domain:
show pages from the site or domain
e.g., yahoo.com, .org, .gov
Search by URL (Web Address)
Find web pages similar to
Find web pages that link to
Рассмотрим данную страницу более подробно.
Include all of the words (Включите все слова) – Эта опция позволяет найти результаты поиска, которые включают все слова, которые пользователь напечатали в блоке поиска. Это подобно вставке "AND" между словами или символом "+" перед словом.
Include this exact phrase (Включите эту точную фразу) – Эта опция позволяет исследовать результаты, которые точно соответствуют словам, которые пользователи ввели. Это подобно помещению цитат (" ") вокруг набора слов. (Пример: Вы ищете известное высказывание или цитату: "Я хочу домой").
Include at least one of these words (Включите по крайней мере одно из этих слов) – Эта опция для поиска результатов по нескольким показателям, которые соответствуют или одному или большему количеству слов, которых задаются для поиска. Это соответствует вставке "OR" между словами. (Например, если пользователь хочет найти информацию или относительно каноэ или относительно лодок.) Exclude these words (Исключите эти слова) – Эта опция исключает заданные слова из поиска. В обычном поиске это соответствует вставке "NOT" между словами или символом " " перед словом. (Например, вы ищете информацию о цветах, но не хотите, чтобы выдавалась информация о розах. Для этого введите "цветы" во "All of the words", а в "Exclude these words" введите "розы").
Search (Поиск) – Здесь пользователю требуется выбрать, где он хочет искать информацию: в Сети или только в Yahoo-каталоге.
More options (Больше Вариантов) – Пользуясь дополнительными опциями, которые появляются при нажатии этой кнопки. Дадим им краткое описание:
Language (Язык) – Позволяет выбрать, на каком языке будут отображаться сайты на странице с результатами.
Country (Страна) – Данная функция позволяет показывать результаты в зависимости от выбранной страны.
Date (Дата) – Ограничивает результаты поиска теми сайтами, которые были модифицированы в пределах прошедших 3, 6, или 12 месяцев.
Keyword Location (Местоположение ключевых слов) – Позволяет пользователю самому выбрать условия поиска – на странице, где-нибудь, в заголовке, в тексте, в URL или в ссылках на другие страницы.
Domain (Домен, область поиска) – Запрашивает, на каких доменах должен (или не должен) происходить поиск (например, с com, org, gov, net, biz, info, name). Search by URL (Поиск URL) – Пользователь может попробовать найти web-страницы, являющиеся подобными или принадлежащими к специфическому узлу.
Заключение
В наше время информация играет огромную роль во всех сферах жизнедеятельности. Людям, имеющим дело с большими объемами текстов - это и новости, и подшивки газет в электронном виде, и электронная почта, и Web-страницы, важно быстро находить в этом море информации действительно нужную. Без помощи поисковой системы это было бы нереально. Благодаря удобству в обращении и хорошим техническим характеристикам, различные поисковые системы могут помочь в этом и новичку, и опытному пользователю.
Поисковые системы и существующие к ним приложения, способны облегчить работу представителей многих профессий: Web-мастера, аналитика, руководителя, лингвиста. Информационный бум продолжается, происходит дальнейшее развитие электронно-компьютерных технологий, а следовательно и в будущем без поисковых систем обойтись будет крайне сложно.
Итак, первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
Как показывает статистика, пользователи русскоязычной части Интернета предпочитают несколько поисковых машин. Прежде всего, это мультиязычная платформа Google, являющаяся своеобразным эталонов универсального поискового механизма.
Чуть менее популярный поисковик — Yahoo! - объединяет не одну, а целых 3 поисковых машины (Inktomi, AltaVista, Alltheweb).
Лидер среди русскоязычных поисковых систем — Яндекс — индексирует документы форматов pdf, rtf, doc, txt, swf, rss и так далее. С помощью Яндекса можно искать информацию на русском, английском, украинском, белорусском, румынском, немецком и французском языках.
Rambler — оценивает преимущественно посещаемость Интернет-страниц. Соответственно, чтобы оказаться в верхних строчка рейтинга Rambler, необходимо обеспечить своему сайту постоянный приток посетителей.
В настоящее время, практически каждая поисковая система имеет свои механизмы расчета рейтинга Интернет-страниц, и алгоритмы эти постоянно изменяются, совершенствуются. Однако в целом можно сказать, что наибольшее внимание современные поисковики уделяют внешним критериям оценки релевантности.
Список использованной литературы
- Балдин, К.В. Информационные системы в экономике: Учебник / К.В. Балдин, В.Б. Уткин. - М.: Дашков и К, 2016. - 395 c.
- Балдин, К.В. Информационные системы в экономике: Учебное пособие / К.В. Балдин. - М.: НИЦ ИНФРА-М, 2016. - 218 c.
- Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2016. - 112 c.
- Бодров, О.А. Предметно-ориентированные экономические информационные системы: Учебник для вузов / О.А. Бодров. - М.: Гор. линия-Телеком, 2017. - 244 c.
- Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2017. - 283 c.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2017. - 528 c.
- Вдовин, В.М. Предметно-ориентированные экономические информационные системы: Учебное пособие / В.М. Вдовин. - М.: Дашков и К, 2013. - 388 c.
- Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: БИНОМ. ЛЗ, 2016. - 292 c.
- Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2016. - 176 c.
- Золотова, Е.В. Основы кадастра: Территориальные информационные системы: Учебник для вузов / Е.В. Золотова. - М.: Фонд «Мир», Акад. Проект, 2016. - 416 c.
- Исаев, Г.Н. Информационные системы в экономике: Учебник для студентов вузов / Г.Н. Исаев. - М.: Омега-Л, 2017. - 462 c.
- Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2017. - 176 c.
- Олейник, П.П. Корпоративные информационные системы: Учебник для вузов. Стандарт третьего поколения / П.П. Олейник. - СПб.: Питер, 2016. - 176 c.
- Патрушина, С.М. Информационные системы в экономике: Учебное пособие / С.М. Патрушина, Н.А. Аручиди. - М.: Мини Тайп, 2016. - 144 c.
- Уткин, В.Б. Информационные системы в экономике: Учебник для студентов высших учебных заведений / В.Б. Уткин, К.В. Балдин. - М.: ИЦ Академия, 2016. - 288 c.
- Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2016. - 208 c.
- Ясенев, В.Н. Информационные системы и технологии в экономике: Учебное пособие для студентов вузов / В.Н. Ясенев. - М.: ЮНИТИ-ДАНА, 2016. - 560 c.
-
Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2016. - 112 c. ↑
-
Ясенев, В.Н. Информационные системы и технологии в экономике: Учебное пособие для студентов вузов / В.Н. Ясенев. - М.: ЮНИТИ-ДАНА, 2016. - 560 c. ↑
-
Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: БИНОМ. ЛЗ, 2016. - 292 c. ↑
-
Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2016. - 176 c. ↑
-
Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2016. - 208 c. ↑
-
Бодров, О.А. Предметно-ориентированные экономические информационные системы: Учебник для вузов / О.А. Бодров. - М.: Гор. линия-Телеком, 2017. - 244 c. ↑
-
Вдовин, В.М. Предметно-ориентированные экономические информационные системы: Учебное пособие / В.М. Вдовин. - М.: Дашков и К, 2013. - 388 c. ↑
-
Уткин, В.Б. Информационные системы в экономике: Учебник для студентов высших учебных заведений / В.Б. Уткин, К.В. Балдин. - М.: ИЦ Академия, 2016. - 288 c. ↑
-
Балдин, К.В. Информационные системы в экономике: Учебное пособие / К.В. Балдин. - М.: НИЦ ИНФРА-М, 2016. - 218 c. ↑
-
Балдин, К.В. Информационные системы в экономике: Учебник / К.В. Балдин, В.Б. Уткин. - М.: Дашков и К, 2016. - 395 c. ↑
-
Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2017. - 283 c. ↑
-
Золотова, Е.В. Основы кадастра: Территориальные информационные системы: Учебник для вузов / Е.В. Золотова. - М.: Фонд «Мир», Акад. Проект, 2016. - 416 c. ↑
-
Патрушина, С.М. Информационные системы в экономике: Учебное пособие / С.М. Патрушина, Н.А. Аручиди. - М.: Мини Тайп, 2016. - 144 c. ↑
-
Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2017. - 528 c. ↑
-
Исаев, Г.Н. Информационные системы в экономике: Учебник для студентов вузов / Г.Н. Исаев. - М.: Омега-Л, 2017. - 462 c. ↑
-
Олейник, П.П. Корпоративные информационные системы: Учебник для вузов. Стандарт третьего поколения / П.П. Олейник. - СПб.: Питер, 2016. - 176 c. ↑
-
Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2017. - 176 c. ↑

- Проектирование реализации операций бизнес-процесса "Складской учет" (Предметная область)
- Организационная культура и ее роль в современных организациях(Организационная культура предприятия: понятие, сущность и методики исследования)
- Обеспечение мотивации обучения в начальных классах (Теоретические аспекты мотивации учения в младшем школьном возрасте)
- Анализ внешней и внутренней среды организации (КОМПЛЕКСНЫЙ АНАЛИЗ ВНЕШНЕЙ И ВНУТРЕННЕЙ СРЕДЫ ОРГАНИЗАЦИИ))
- Применение объектно-ориентированного подхода при проектировании информационной системы (общая характеристика)
- Организационная культура и ее роль в современных организациях (менеджмент)
- Баланс как историческая категория (Этапы развития бухгалтерского баланса в России)
- Анализ корпоративной культуры на примере организации Лига Танцев Санкт- Петербурга»
- Управление поведением в конфликтных ситуациях (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ УРЕГУЛИРОВАНИЯ КОНФЛИКТОВ В ПЕДАГОГИЧЕСКОМ КОЛЛЕКТИВЕ))
- История развития менеджмента. Особенности менеджмента в России
- Распределение и использование прибыли как источник экономического роста предприятий (Теоретические основы формирования и использования прибыли организации))
- Корпоративная культура в организации(Понятие и сущность корпоративной культуры)