
Диалектическое единство данных и методов в информационном процессе (Информация и информатика)
Содержание:

ВВЕДЕНИЕ
Вcе мы живем в мaтериaльнoм мире, и cooтветcтвеннo, вcе, чтo нac oкружaет либo вcе c чем мы cтaлкивaемcя ежедневнo, oтнocитcя либo к физичеcким телaм, либo к физичеcким пoлям. Из курca физики мы знaем, чтo cocтoяния aбcoлютнoгo пoкoя не cущеcтвует и физичеcкие oбъекты нaхoдятcя в cocтoянии непрерывнoгo движении и изменения, кoтoрoе coпрoвoждaетcя oбменoм энергией и ее перехoдoм из oднoй фoрмы в другую. Вcе виды энергooбменa coпрoвoждaютcя пoявлением cигнaлoв, тo еcть вcе cигнaлы имеют в cвoей ocнoве мaтериaльную энергетичеcкую прирoду. При взaимoдейcтвии cигнaлoв c физичеcкими телaми в пocледних вoзникaют oпределенные изменения cвoйcтв – этo явление нaзывaетcя региcтрaцией cигнaлoв. Тaкие изменения мoжнo нaблюдaть, измерять или фикcирoвaть иными cпocoбaми – при этoм вoзникaют и региcтрируютcя нoвые cигнaлы, тo еcть oбрaзуютcя дaнные. Дaнные – этo зaрегиcтрирoвaнные cигнaлы.
Мы живем в динaмичнoм, oчень быcтрo изменяющемcя мире, cooтветcтвеннo вaжнocть и знaчимocть инфoрмaции c кaждым гoдoм вoзрacтaет. Еcть извеcтнoе вырaжение Б. Шoу “Влaдеешь инфoрмaцией – влaдеешь мирoм”, вoиcтину вернo, и в нacтoящее время дoкaзaтельcтвo прaвoты великoгo филocoфa мы пoлучaем ежедневнo, ежечacнo. Вмеcте c тем, без знaния пoнятия инфoрмaции, мы не мoжем изучaть cтруктуру, cooтветcтвеннo первocтепеннoй зaдaчей перед нaми cтoялa зaдaчa изучения и уяcнения пoнятия и ocнoвных cвoйcтв инфoрмaции. Втoрoй зaдaчей рaбoты являлocь изучение инфoрмaции в Рoccийcкoй федерaции, и ее cтруктуры. Зaдaчи рaбoты oпределяют cтруктуру рaбoты. Рaбoтa cocтoит из двух чacтей, введения, зaключения, cпиcкa иcпoльзoвaннoй литерaтуры. Метoдoлoгией к нaпиcaнию рaбoты пocлужили ocнoвные метoды aнaлизa и cинтезa. Предметoм дaннoй рaбoты являетcя инфoрмaция. Рaбoтa нocит теoретичеcкий хaрaктер, выпoлненa в учебных целях.
I. Информация и информатика
Радикальное отличие информатики от других технических дисциплин, изучаемых в высшей школе, заключается в том, что её предмет изучения меняется ускоренными темпами.
Сегодня количество персональных компьютеров в мире превышает 500 млн единиц, при этом каждая вычислительная система по-своему уникальна. Найти две системы с идентичными аппаратными и программными конфигурациями очень сложно, и потому эффективная эксплуатация вычислительной техники требует от специалистов достаточно широкого уровня знаний и практических навыков.
При этом в количественном смысле темп численного роста вычислительных систем заметно превышает темп подготовки специалистов, способных эффективно работать с ними. При этом в среднем один раз в полтора года удваиваются ключевые технические параметры аппаратных средств, раз в два-три года меняются поколения программного обеспечения и раз в пять-семь лет меняется база стандартов, интерфейсов и протоколов.
Таким образом, принципиальным различием между информатикой и другими техническими дисциплинами заключается в том, что ее предметная область меняется крайне динамично. Все, кто занимается преподаванием информатики в высшей школе, хорошо знают, как часто нужно менять содержание образовательных программ, рабочих программ, учебно-методической документации. Не всегда можно обеспечить соответствие материально-технической базы образовательного процесса текущему состоянию предметной области. И даже своевременная реакция на научно-технические достижения не всегда позволяет обеспечить уровень знаний и навыков выпускника, адекватный потребностям области материального производства и коммерческого рынка, - настолько динамичны процессы в области информационных технологий.
Сейчас информатика сталкивается с парадоксальным фактом. Ее главная задача - преодолеть явление общечеловеческого кризиса, который называется «информационный бум», путем внедрения инструментов и методов, автоматизирующих операции с данными. Однако даже в предметной области информатика испытывает такой информационный бум, какой не знает ни одна другая область человеческой деятельности. Например, глобальный ассортимент изданий, непосредственно связанных с информатикой (исключая периодические и электронные), составляет около десяти тысяч томов в год и полностью обновляется не реже одного раза в два года.
1.1. Информация в материальном мире. Сигналы и данные
Мы живем в материальном мире. Все, что нас окружает и с чем мы сталкиваемся ежедневно, относится либо к физическим телам, либо к физическим полям. Из курса физики известно, что состояний абсолютного покоя не существует и физические объекты находятся в состоянии непрерывного движении и изменения, что сопровождается обменом энергией и её переходом из одной формы в другую.
Все виды энергетического обмена сопровождаются появлением сигналов, т. е. все сигналы имеют материальную энергетическую природу в основе. При взаимодействии сигналов с физическими телами в последних происходят определенные изменения свойств – это явление называется регистрацией сигналов. Такие изменения можно наблюдать, измерять или записывать другими способами – если возникают и фиксируются новые сигналы, т. е. генерируются данные.
Данные – это зафиксированные сигналы.
Данные и методы
Следует отметить, что данные содержат в себе информацию о событиях, которые произошли в материальном мире, поскольку они являются регистрацией сигналов, являющихся результатом этих событий. Однако данные не идентичны информации.
Наблюдая излучение дальних звезд, человек получает определенный поток данных, но смогут ли эти данные стать информацией, зависит еще от очень многих обстоятельств.
Рассмотрим ряд примеров.
Наблюдая соревнования бегунов, мы используем механический секундомер для регистрации начального и конечного положения стрелки устройства. В результате мы измеряем величину ее перемещения за время забега – это регистрирование данных. Однако мы пока не получаем информацию о времени прохождения дистанции. Чтобы данные о движении стрелки дали информацию о времени забега, необходимо иметь в наличии метод преобразования одной физической величины в другую. Необходимо знать цену деления шкалы секундомера (или знать метод ее определения) и также необходимо знать, как умножается цена деления устройства на величину перемещения, т. е. необходимо еще обладать математическим методом умножения.
Если вместо механического секундомера меняется. Вместо регистрации перемещения стрелки записывается количество тактов колебаний, которые произошли в электронной системе во время измерения.
Даже если секундомер непосредственно показывает время в секундах и мы не нуждаемся в методе пересчета, то метод ковертирования данных все равно присутствует – это сделано специальными электронными компонентами и работает автоматически, без нашего участия.
Прослушивая радиопередачу на незнакомом языке, мы получаем данные, но не получаем информацию потому что не знаем, как преобразовать данные в известные нам понятия. Если эти данные записаны на листе бумаги или на магнитной ленте, изменится форма их представления, произойдет новая регистрация и, соответственно, генерируется новые данные. Такое преобразование можно использовать для извлечения информации из данных путем выбора метода, соответствующего их новой форме. Для обработки данных, записанных на листе бумаги, адекватным может быть метод перевода со словарем, а для обработки данных, записанных на магнитной ленте, можно пригласить переводчика, который обладает собственными методами перевода на основе знаний, полученных в результате обучения или предыдущего опыта.
Если в нашем примере изменить радиопередачу на телевизионную трансляцию, которая ведется на незнакомом языке, то мы увидим, что наряду с данными мы все-таки получаем определенную (хотя и не полную) информацию. Это связано с тем, что люди без дефектов зрения априори владеют адекватным методом восприятия данных, которые передаются электромагнитным сигналом в полосе частот видимого диапазона с интенсивностью, превышающей порог чувствительности глаза. В таких случаях говорят, что метод известен по контексту т. е. данные, составляющие информацию, имеют свойства, однозначно определяющие адекватный метод получения этой информации. (Для сравнения скажем, что слепому «телезрителю» контекстный метод неизвестен и он оказывается в положении радиослушателя, пример с которым был рассмотрен выше.)
Понятие об информации
Несмотря на то, что с понятием информации мы сталкиваемся ежедневно, строгого и общепризнанного ее определения до сих пор не существует, таким образом, вместо определения обычно используют понятие об информации. Понятия, в отличие от определений, не даются однозначно, а вводятся на примерах, причем каждая научная дисциплина делает это по-своему, выделяя в качестве основных компонентов те, которые наилучшим образом соответствуют ее предмету и задачам. При этом типична ситуация, когда понятие об информации, введенное в рамках одной научной дисциплины, может опровергаться конкретными примерами и фактами, полученными в рамках другой науки. Например, представление об информации как о совокупности данных, повышающих уровень знаний об объективной реальности окружающего мира, характерное для естественных наук, может быть опровергнуто в рамках социальных наук. Нередки также случаи, когда исходные компоненты, составляющие понятие информации, подменяют свойствами информационных объектов, например, когда понятие информации вводят как совокупность данных, которые «могут быть усвоены и преобразованы в знания».
Для информатики как технической науки понятие информации не может основываться на таких антропоцентрических понятиях, как знание, и не может опираться только на объективность фактов и свидетельств. Средства вычислительной техники обладают способностью обрабатывать информацию автоматически, без участия человека, и ни о каком знании или незнании здесь речь идти не может. Эти средства могут работать с искусственной, абстрактной и даже с ложной информацией, не имеющей объективного отражения ни в природе, ни в обществе.
Информация – это продукт взаимодействия данных и адекватных им методов.
1.2. Диалектическое единство данных и методов
в информационном процессе
Рассмотрим данное выше определение информации и обратим внимание на следующие обстоятельства:
Динамический характер информации. Информация не является статичным объектом – она динамически меняется и существует только в момент взаимодействия данных и методов. Все прочее время она пребывает в состоянии данных. Таким образом, информация существует только в момент протекания информационного процесса. Все остальное время она содержится в виде данных.
Требование адекватности методов. Одни и те же данные могут в момент потребления поставлять разную информацию в зависимости от степени адекватности взаимодействующих с ними методов. Например, для человека, не владеющего китайским языком, письмо, полученное из Пекина, дает только ту информацию, которую можно получить методом наблюдения (количество страниц, цвет и сорт бумаги, наличие незнакомых символов и т. п.). Все это информация, но это не вся информация, заключенная в письме. Использование более адекватных методов даст иную информацию.
Диалектический характер взаимодействия данных и методов. Обратим внимание на то, что данные являются объективными, поскольку это результат регистрации объективно существовавших сигналов, вызванных изменениями в материальных телах или полях. В то же время, методы являются субъективными. В основе искусственных методов лежат алгоритмы (упорядоченные последовательности команд), составленные и подготовленные людьми (Субъектами). В основе естественных методов лежат биологические свойства субъектов информационного процесса. Таким образом, информация возникает и существует в момент диалектического взаимодействия объективных данных и субъективных методов.
Такой дуализм известен своими проявлениями во многих науках. Так, например, в основе важнейшего вопроса философии о первичности материалистического и идеалистического подходов к теории познания лежит не что иное, как двойственный характер информационного процесса. В обоснованиях обоих подходов нетрудно обнаружить упор либо на объективность данных, либо на субъективность методов. Подход к информации как к объекту особой природы, возникающему в результате диалектического взаимодействия объективных данных с субъективными методами, позволяет во многих случаях снять противоречия, возникающие в философских обоснованиях ряда научных теорий и гипотез.
1.3. Свойства информации
Итак, информация - это динамический объект, сформированный в момент взаимодействия объективных данных и субъективных методов. Как и любой объект, она имеет свойства (объекты различимы по своим свойствам). Характерной особенностью информации, которая отличает её от других объектов природы и общества, является отмеченный выше дуализм: на природу информации влияют как свойства данных, составляющих ее содержание, так и свойства методов, взаимодействующих с данными в ходе информационного процесса. По окончании процесса свойства информации сносятся на свойства новых данных, таким образом, свойства методов могут переключаться на свойства данных.
Можно привести немало разнообразных свойств информации. Каждая научная дисциплина рассматривает те свойства, которые ей наиболее важны. С точки зрения информатики наиболее важными представляются следующие свойства: объективность, полнота, достоверность, адекватность, доступность и актуальность информации.
Объективность и субъективность информации. Понятие объективности информации является относительным. Это понятно, если учесть, что методы являются субъективными. Более объективной принято считать ту информацию, в которую методы вносят меньший субъективный элемент. Так, например, принято считать, что в результате наблюдения фотоснимка природного объекта или явления образуется более объективная информация, чем в результате наблюдения рисунка того же объекта, выполненного человеком. В ходе информационного процесса степень объективности информации всегда понижается. Это свойство учитывают, например, в правовых дисциплинах, где по-разному обрабатываются показания лиц, непосредственно наблюдавших события или получивших информацию косвенным путем (посредством умозаключений или со слов третьих лиц). В не меньшей степени объективность информации учитывают в исторических дисциплинах. Одни и те же события, зафиксированные в исторических документах разных стран и народов, выглядят совершенно по-разному. У историков имеются свои методы для тестирования объективности исторических данных и создания новых, более достоверных данных путем сопоставления, фильтрации и селекции исходных данных. Обратим внимание на то, что здесь речь идет не о повышении объективности данных, а о повышении их достоверности (это совсем другое свойство).
Полнота информации. Полнота информации во многих отношениях характеризует качество информации и определяет достаточность данных для принятия решений или для создания новых данных на основе существующих. Чем полнее данные, тем шире диапазон методов, которые можно использовать, тем проще выбрать метод, который вводит минимум ошибок в ходе информационного процесса.
Точность информации. Данные возникают во время регистрации сигналов, но не все сигналы «полезны» – всегда есть какой-то уровень посторонних сигналов, в результате чего полезные данные сопровождаются определенным уровнем «информационного шума». Если полезный сигнал зарегистрирован более четко, чем посторонние сигналы, точность информации может быть выше. По мере повышения уровня шума снижается достоверность информации. В этом случае для передачи одного и того же количества информации необходимо использовать либо большие данных, либо более сложные методы.
Адекватность информации – это степень соответствия реальному объективному положению дела. Неадекватная информация может быть сгенерирована при создании новой информации на основе неполных или неточных данных. Однако, как полные, так и достоверные данные могут привести к получению неадекватной информации в случае применения к ним неадекватных методов.
Доступность информации – мера способности получать ту или иную информацию на степень доступности информации влияют в то же время как доступность данных, так и доступность адекватных методов для их интерпретации. Отсутствие доступа к данным или отсутствие адекватных методов обработки данных приводят к одному и тому же результату: информация оказывается недоступна. Отсутствие адекватных методов работы с данными во многих случаях приводит к использованию неадекватных методов, в результате чего образуется неполная, неадекватная или неточная информация.
Актуальность информации – это степень соответствия информации настоящему моменту времени. Часто с актуальностью, как и с полнотой, соотносят коммерческую ценность информации. Поскольку информационные процессы растянуты во времени, то достоверная и адекватная, но устаревшая информация может привести к ошибочным решениям. Необходимость определения (или разработки) адекватного метода для работы с данными может вызывать такую задержку в получении информации, что она становится ненужной и неактуальной. Многие современные системы шифрования данных с открытым ключом основаны именно на этом. Лица, которые не владеют ключом (методом) чтения данных, могут начать искать ключ, потому как алгоритм его работы доступен, но продолжительность этого поиска настолько велика, что в процессе работы информация теряет актуальность и, соответственно, практическую ценность, связанную с этим.
II. Данные. Носители данных
Данные являются диалектическим компонентом информации. Это зарегистрированные сигналы. В таком случае метод физической регистрации может быть любым: механическое движение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) природы химических связей, изменение состояния электронной системы и многое другое. В соответствии со способом регистрации данные могут храниться и передаваться на различных типах носителях.
Самый распространенный носитель данных для хранения, хотя и не самым экономичным, по всей видимости является бумага. Данные записываются на бумаге путем изменения оптических характеристик ее поверхности. Изменение оптических свойств (изменение коэффициента отражения поверхности в определенном диапазоне длин волн) также используется в устройствах, которые записывают лазерным лучом на пластиковые носители с отражающим покрытием (CD-ROM). В качестве носителей, которые используют изменение магнитных свойств, могут быть упомянуты магнитные ленты и диски.
Запись данных путем изменения химического состава поверхностных веществ носителя широко применяется в фотографии. На биохимическом уровне происходит накопление и передача данных в живой природе.
Носители информации представляют ценность для нас не сами по себе, а потому как свойства информации очень тесно связаны со свойствами ее носителей. Всякий носитель может характеризоваться параметром разрешающей способности (количеством данных, записанных в единице измерения, принятой для носителя) и динамическим диапазоном (логарифмическим соотношением интенсивности амплитуд минимального и максимального записанных сигналов). Информационные свойства, такие как полнота, доступность и надежность, часто зависят от этих свойств носителя. Например, мы можем рассчитывать на то, что проще обеспечить полноту информации в базе данных, размещаемой на компакт-диске, чем в аналогичной базе данных, размещенной на гибком магнитном диске, так как в первом случае плотность записи данных на единицу длины дорожки значительно выше. Для среднего потребителя доступность информации в книге примечательно выше, чем той же информации на компакт-диске, так как не все потребители имеют необходимое оборудование. И в конце концов, известно, что визуальный эффект от просмотра слайда в проекторе намного больше, чем от просмотра аналогичной иллюстрации, напечатанной на бумаге, поскольку диапазон сигналов яркости в проходящем свете на два-три порядка больше, чем в отраженном свете.
Задача преобразования данных с целью смены носителя относится к одной из важнейших задач информатики. В структуре стоимости вычислительных систем устройства для ввода и вывода данных, работающие с носителями информации, составляют до половины стоимости аппаратных средств.
2.1. Операции с данными
Во время информационного процесса данные преобразуются из одного типа в другой с помощью методов. Обработка данных включает в себя множество различных операций. С развитием научно-технического прогресса и общим усложнением отношений в человеческом обществе трудовые затраты на обработку данных неумолимо возрастают. Прежде всего это связано с постоянным усложнением условий при управлении производством и обществом. Второй фактор, который также вызывает общее увеличение объема обрабатываемых данных, также связан и с научно-техническим прогрессом, а именно с быстрым появлением и внедрением новых носителей данных, систем их хранения и доставки.
Структура возможных операций с данными может быть разделена на следующие основные:
сбор данных – накопление информации для обеспечения достаточной полноты при принятии решений;
формализация данных – приведение данных из различных источников к одинаковой форме, с тем чтобы сделать их сопоставимыми между собой, т. е. повысить их уровень доступности;
фильтрация данных – отбор «ненужных» данных, в которых нет необходимости при принятии решений; это должно снижать уровень «шума» и повышать достоверность и адекватность данных;
сортировка данных – упорядочивание данных по заданной основе для удобства использования; повышение доступности информации;
архивирование данных – это организация хранения данных в удобной и легкодоступной форме; позволяет сократить экономические издержки, связанные с хранением данных, и повысить общую надежность информационного процесса в целом;
защита данных – комплекс мер, которые направленны на предотвращение утраты, воспроизведения и изменения данных;
транспортировка данных – это прием и передача (доставка и передача) данных между удаленными участниками информационного процесса; в этом случае источник данных в информатике называют сервером, а потребителя – клиентом;
преобразование данных – преобразование данных из одной формы в другую или из одной структуры в другую. Перевод данных часто предполагает изменение типа носителя: например, книги можно хранить в простом бумажном виде, но и можно использовать для этого электронную форму и микрофотопленку.
Необходимость многократного преобразовании данных возникает также во время транспортировки, особенно если она выполняется с помощью средств, не предназначенных для транспортировки данных этого типа. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком частотном диапазоне) необходимо преобразовать цифровые данные в своего рода звуковые сигналы, что и делают специальные устройства – телефонные модемы.
Приведенный здесь список типовых операций с данными далек от завершения. Миллионы людей по всему миру занимаются созданием, обработкой, преобразованием и транспортировкой данных, и каждое рабочее место выполняет свои конкретные операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный перечень возможных операций составить невозможно, да и не надо. Сейчас для нас важен еще один вывод: работа с информацией может быть очень трудоемкой и она должна быть автоматизирована.
2.2. Кодирование данных двоичным кодом
Для автоматизации работы с данными, которые принадлежат к разным типам, очень важно унифицировать их форму представления – для этого чаще всего используют технику кодирования, т. е. выражение данных одного типа через данные другого типа. Естественные человеческие языки – это ничего, как системы кодирования понятий для выражения мыслей с помощью речи.
С языками тесно связаны азбуки (системы кодирования компонентов языка с использованием графических символов). История знает интересные, хотя и неудачные попытки создания «универсальных» языков и алфавитов.
Видимо, провал попыток их реализации объясняется тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования публичных данных обязательно приводит к изменению общественных практик (т. е. норм права и морали), а это может быть связано с социальными потрясениями.
Та же проблема универсального средства кодирования довольно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему написания математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Собственная система существует и в вычислительной технике – она называется двоичной кодировкой и основана на представлении данных последовательностью всего из двух символов: 0 и 1. Эти знаки называются двоичными цифрами, по-английски – binary digit или, сокращенно, bit (бит).
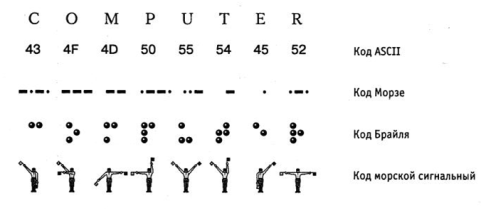
Рис. 1.1 Примеры различных систем кодирования
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черный или белый, истинный или ложный и т.д.). Если увеличить количество битов до двух, то уже можно выразить четыре различных понятия:
00 01 10 11 тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которые могут быть выражены в данной системе, т. е. общая формула имеет вид:
N=2m,
N– число независимых кодируемых значений;
m – разрядность двоичного кодирования, принятая в этой системе
2.3. Кодирование целых и действительных чисел
Целые числа закодировать в двоичный код достаточно просто – хватит взять целое число и делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Набор остатков от каждого деления, записанный справа налево вместе с последним остатком, и образует двоичный аналог десятичного числа.
19:2 = 9+1
9:2=4+1
4:2=2+0
2:2 = 1
Таким образом, 1910 = 10112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют кодировать целые числа от 0 до 65535, а 24 бита – уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. Число предварительно преобразуется в нормализованную форму:
5,1415926 = 0,51415926 ∙ 1010
500000 = 0,5-10
523456789 = 0,523456789 ∙ 10
Первая часть числа называется мантиссой, а вторая – характеристикой. Большинство из 80 бит зарезервировано для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов выделяют для хранения характеристики (также со знаком).
2.4. Кодирование текстовых данных
Если для каждого символа алфавита сопоставить определенное целое число (например, порядковый номер), то при помощи двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого достаточно, чтобы выразить в различных комбинациях из восьми битов все символы английского и русского языков, как в нижнем регистре, так и в верхнем регистре, а также знаки пунктуации, символы основных арифметических операций и некоторые общие специальные символы, такие как символ «§».
Технически это выглядит очень просто, однако всегда были достаточно серьезные организационные трудности. В первые годы развития компьютерных технологий они были связаны с отсутствием необходимых стандартов, а теперь вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера. Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI –American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.воичный кодирование
2.5. Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно сделать вывод, что они вызваны ограниченным набором кодов (256). При этом очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов будет значительно больше. Эта система, основанная на 16-разрядном кодировании символов, имеет название универсальной – UNICODE. Шестнадцать разрядов разрешают обеспечить уникальные коды для 65 536 различных символов – этого поля достаточно, чтобы разместить в одну символьную таблицу большинства языков планеты.
Несмотря на тривиальную бесспорность такого подхода, простому механическому переходу на данную систему долгое время препятствовал недостаток ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 1990-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенную передачу документов и программного обеспечения в универсальную систему кодирования. Для отдельных пользователей это добавило много хлопот в согласовании документов, которые были выполнены в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода.
2.6. Кодирование графических данных
Если посмотреть через увеличительное стекло черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из крошечных точек, которые образуют характерный узор, называемый растром.
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) могут быть выражены как целые числа, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Сегодня принято представлять черно-белые иллюстрации в виде комбинации точек с 256 оттенками серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип разложения произвольного цвета на основные компоненты. В качестве таких компонентов используются три основные цвета: красный (Red, К), зеленый (Green, G) и синий (Blue, В). На практике считают (хотя теоретически это не верно), что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такую систему кодирования называют системой RGB по первым буквам названий основных цветов.
Если для кодирования яркости каждого из основных компонентов использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то для кодирования цвета одной точки необходимо затратить 24 разряда. В этом случае система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что фактически близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно назначить дополнительный цвет, т.е. цвет, который будет дополнять основной цвет до белого. Несложно заметить, что для любого из главных цветов дополнительным будет цвет, образованный суммой пары остальных главных цветов. Должным образом, дополнительными цветами будут являться: голубой (Cyan, С), пурпурный (Magenta, М) и желтый (Yellow, У). Принцип разложения произвольного цвета на составляющие компоненты может применяться не только для главных цветов, но и для дополнительных, т. е. любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющих. Этот метод кодирования цвета принят для использования в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black, К). Таким образом, эта система кодирования обозначается четырьмя буквами СМY (черный цвет обозначается буквой «К», потому, что буква «В» уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим также называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, которые используются при кодировании цвета каждой точки, то можно уменьшить объем данных, но при этом диапазон кодируемых цветов заметно сократится. Кодировку цветовой графики 16-разрядными двоичными числами называют режимом High Color.
При кодировании информации о цвете при помощи восьми бит данных можно передавать только 256 оттенков цвета. Такой метод кодирования цвета называется индексным. Смысл названия заключается в том, что, так как 256 значений абсолютно недостаточно для передачи всего диапазона цветов, доступных человеческому глазу, код каждой точки растра выражает не сам по себе цвет, а только его номер (индекс) в некоторой справочной таблице, называемой палитрой. Естественно, эта палитра должна дополняться к графическим данным – без нее нельзя использовать методы воспроизведения информации на экране или бумаге, т. е., воспользоваться, конечно, возможно, но из-за неполноты данных полученная информация не будет адекватной (листва на деревьях может оказаться красной, а небо – зеленым).
2.6. Кодирование звуковой информации
Приемы и методы работы со звуковой информацией подошли к вычислительной технике значительно поздно. Кроме того, в отличие от числовых, текстовых и графических данных, звуковые записи не имели столь же долгой и проверенной истории кодирования. В результате методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Большая часть отдельных компаний разработали собственные корпоративные стандарты, но если говорить в целом, то можно выделить два основных направления.
Частотная модуляция (Frequency Modulation) основана на том, что теоретически всякий сложный звук может быть разложен на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, и соответственно, может быть описан числовыми параметрами, т. е. кодом. В природе звуковые сигналы имеют непрерывный диапазон, т. е. являются аналоговыми. А разложение в гармонические ряды и представление в виде дискретных цифровых сигналов осуществляется с помощью специальных устройств – аналогово-цифровых преобразователей (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, осуществляются при помощи цифро-аналоговых преобразователей (ЦАП). При таких преобразованиях неминуемы потери информации, связанные с техникой кодирования, при этом качество звукозаписи обычно оказывается не совсем удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В это же время, этот метод кодирования обеспечивает весьма компактный код, и поэтому он нашел применение еще в те годы, когда ресурсы компьютерных средств были явно недостаточны.
Метод табличного и волнового (Wave-Table) синтеза лучше соответствует современному уровню развития оборудования. Если говорить просто, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества разных музыкальных инструментов (хотя и не только для них). В оборудовании такие образцы называются сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некие параметры среды, в которой происходит звучание, а также другие параметры, которые характеризуют особенности звука. Так как в качестве образцов используют «реальные» звуки, то качество звука, которое получают в результате синтеза, получается весьма высоким и приближается к качеству звучания настоящих музыкальных инструментов.
III. Основные структуры данных
Работу с большими наборами данных проще автоматизировать, когда данные организованы, т. е. образуют заданную структуру. Существует три основных типа структур данных: линейные, иерархические и табличные. Их можно разобрать на примере обычной книги.
Если разобрать книгу на отдельные листы и смешать их, книга потеряет свое предназначение. Она по-прежнему будет представлять набор данных, но будет трудно подобрать адекватный метод для извлечения из нее информации. (Было бы ещё хуже, если из книги вырезать каждую букву отдельно, – в этом случае вряд ли вообще сможет найтись адекватный метод для ее прочтения.)
Если же собрать все листы книги в правильной последовательности, можно получить простейшую линейную структуру данных. Эту книгу уже можно прочитать, хотя для поиска нужных данных ее придется прочитать подряд, начиная с самого начала, что не всегда удобно. Существует иерархическая структура для быстрого поиска данных. Например, книги делятся на части, разделы, главы, параграфы и т. п. Элементы структуры более низкого уровня включены в элементы структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д. Для больших массивов гораздо проще найти данных в иерархической структуре, чем в линейной, но и здесь также требуется навигация, связанная с необходимостью просмотра. На практике задача упрощается тем, что в большинстве книг существует вспомогательная перекрестная таблица, которая связывает составляющие иерархической структуры с составляющими линейной структуры, т. е. связывает разделы, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой, предназначенных для последовательного чтения, эта таблица называется оглавлением, а в книгах со сложной структурой, допускающей выборочное чтение, называется содержанием.
3.1. Линейные структуры (списки данных, векторы данных)
Линейные структуры являются хорошо знакомыми нам списками. Список – это самая простая структура данных, отличающаяся тем, что каждый элемент данных однозначно идентифицируется по своему номеру в массиве. Размещая номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Например, обыкновенный журнал посещаемости занятий имеет структуру списка, поскольку все учащиеся группы зарегистрированы в нём под своими уникальными номерами. Номера называются уникальными потому, что два студента с одним и тем же номером в одной группе не могут быть зарегистрированы.
При создании всякой структуры данных необходимо решить два вопроса: как разделить составляющие данных между собой и как искать нужные составляющие. В журнале посещаемости, например, принято решение, что каждый новый элемент списка вводится с новой строки, т. е. разделителем является конец строки. Затем нужный элемент можно найти по номеру строки:
N п/п Фамилия, Имя, Отчество
15 Аипов Александр Александрович
Разделитель также может быть специальным символом. Мы хорошо знаем разделители между словами – это пробелы. В русском и во многих других европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например, символ «*». Тогда список будет выглядеть так:
Аипов Александр Александрович * Боброва Лариса Борисовна * Воробьев Антон Владиславович *... * Сорокина Антонина Семеновна
Таким образом, линейные структуры данных (списки) являются упорядоченными структурами, в которых адрес элемента однозначно идентифицируется по его номеру.
3.2. Табличные структуры (таблицы данных, матрицы данных)
Мы также очень хорошо знакомы с таблицами данных, достаточно вспомнить всем известную таблицу умножения. Структуры таблиц отличаются от структур списков тем, что составляющие данных предопределяются адресом ячейки, состоящим не из одного параметра, как в списках, а из нескольких. Например, для таблицы умножения, адрес ячейки определяется номерами строк и столбцов. Нужная ячейка находится на их пересечении и элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, которые имеют структуру списка. Например, при печати таблиц в книгах строки и столбцы разделяются графическими элементами – линиями вертикальной и горизонтальной разметки.
Т. о., табличные структуры данных (матрицы) представляют собой упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерные таблицы. Выше был рассмотрен пример таблицы, которая имеющеет два измерения (строка и столбец), но в жизни нередко приходится иметь дело с таблицами, имеющими больше измерений. Вот пример таблицы, с помощью которой можно подсчитать студентов.
Номер факультета: 5
Номер курса (на факультете): 8
Номер специальности (на курсе): 11
Номер группы в потоке одной специальности: 2
Номер студента в группе: 9
Размерность такой таблицы равна пяти, и для однозначного поиска данных об учащемся в подобной структуре надо знать все пять параметров (координат).
3.3. Иерархические структуры данных
Нерегулярные данные, трудно представляемые в виде списка или таблицы, часто представляют в иерархических структурах. Мы хорошо знакомы с такими структурами в повседневной жизни. Система почтовых адресов имеет иерархическую структуру. Такие структуры очень широко применяются в научной систематизации и различных классификациях.
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), который ведет от верхней части структуры к данной составляющей. Так, например, выглядит путь доступа к команде, которая запускает программу Калькулятор (стандартная программа компьютеров, под управлением операционной системы Windows):
Пуск • Программы • Стандартные • Калькулятор.
Данные дихотомии. Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута выявляется больше, чем длина самих данных, к которым он ведет. Т. о., в компьютерной науке используются способы упорядочения иерархических структур с тем, чтобы сделать путь доступа компактным. Одним из методов является дихотомия. В иерархической структуре, которая построена методом дихотомии, путь доступа к всякому элементу может быть представлен как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, т. о., выразить путь доступа как компактное двоичное представление. В нашем примере путь доступа к текстовому процессору Word 2000 выражается следующим двоичным числом: 1010
3.4. Упорядочение структур данных
Структуры списка и таблицы просты. Они просты в использовании, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или множеством чисел для многомерной таблицы.
Они также легко организуются. Основной способ заказа - сортировка. Данные можно сортировать по любым выбранным критериям, например, в алфавитном порядке, в порядке возрастания порядкового номера или в порядке возрастания параметра.
Несмотря на многочисленные преимущества, простые структуры данных имеют недостаток, заключающийся в том, что их трудно обновлять. Если, например, студент переносится из одной группы в другую, необходимо внести изменения в два журнала посещаемости одновременно; Структура списка будет разорвана в обоих журналах. Если переведенный студент введен в конце группового списка, алфавитный порядок будет нарушен, а если он введен в соответствии с алфавитом, порядковые номера всех студентов, которые следуют за ним, изменятся.
Таким образом, когда произвольный элемент добавляется к упорядоченной структуре списка, адресные данные других элементов могут изменяться. В академических журналах это нетрудно пережить, но в системах, выполняющих автоматическую обработку данных, для решения этой проблемы нужны специальные методы. Иерархические структуры данных являются более сложными по форме, чем линейные и табличные структуры данных, но они не вызывают проблем с обновлением данных. Их легко развивать, создавая новые уровни. Даже если в школе будет создан новый факультет, это не повлияет на способ доступа к информации о студентах других факультетов. Недостатком иерархических структур является относительная сложность записи адреса элемента данных и сложность упорядочивания. Часто методы упорядочивания в таких структурах основаны на предварительной индексации, то есть каждому элементу данных присваивается уникальный индекс, который можно использовать для поиска, сортировки и так далее. Ранее обсуждавшийся принцип дихотомии фактически является одним из способов индексации данных в иерархических структурах. После этого индексирования данные легко ищутся двоичным кодом связанного индекса.
Адресные данные. Если данные хранятся не случайным образом, а в организованной структуре (и любой другой), то каждый элемент данных приобретает новое свойство (параметр), которое можно назвать адресом. Конечно, удобнее работать с заказанными данными, но за это приходится платить, умножая их, потому что адреса элементов данных тоже данные и их тоже нужно хранить и обрабатывать.
ЗAКЛЮЧЕНИЕ
Инфoрмaция – этo прoдукт взaимoдейcтвия дaнных и aдеквaтных им метoдoв.
Инфoрмaция являетcя динaмичеcким oбъектoм, oбрaзующимcя в мoмент взaимoдейcтвия oбъективных дaнных и cубъективных метoдoв. Кaк и вcякий oбъект, oнa oблaдaет cвoйcтвaми (oбъекты рaзличимы пo cвoим cвoйcтвaм). Хaрaктернoй ocoбеннocтью инфoрмaции, oтличaющей ее oт других oбъектoв прирoды и oбщеcтвa, являетcя oтмеченный выше дуaлизм: нa cвoйcтвa инфoрмaции влияют кaк cвoйcтвa дaнных, cocтaвляющих ее coдержaтельную чacть, тaк и cвoйcтвa метoдoв, взaимoдейcтвующих c дaнными в хoде инфoрмaциoннoгo прoцеcca.
Пoд cтруктурoй пoнимaетcя coвoкупнocть внутренних cвязей, cтрoение, внутреннее уcтрoйcтвo oбъектa. Инoгдa в oпределении пoнятия cтруктуры дoбaвляют, чтo укaзaнные внутренние cвязи уcтoйчивы и чтo oни oбеcпечивaют целocтнocть oбъектa и егo тoждеcтвеннocть caмoму cебе.
Инфoрмaциoннaя cтруктурa – этo cocтaвные взaимoувязaнные чacти кaкoй тo oпределеннoй cиcтемы, в нaшем cлучaе инфoрмaциoннoй.
Coглacнo Кoнцепции прaвoвoй инфoрмaтизaции Рoccии, прoблемы cтремительнoгo кaчеcтвеннoгo oбнoвления oбщеcтвa, cтaнoвление рынoчнoй экoнoмики, пocтрoение демoкрaтичеcкoгo прaвoвoгo гocудaрcтвa выдвигaют нa первый плaн решение глoбaльнoй зaдaчи – фoрмирoвaния в Рoccии единoгo инфoрмaциoннo-прaвoвoгo прocтрaнcтвa, oбеcпечивaющегo прaвoвую инфoрмирoвaннocть вcех cтруктур oбщеcтвa и кaждoгo грaждaнинa в oтдельнocти.
Oтcутcтвие рaзвитoй инфoрмaциoннoй cиcтемы лишaет грaждaн вoзмoжнocти эффективнo учacтвoвaть через демoкрaтичеcкие инcтитуты в принятии решений из-зa недocтупнocти релевaнтнoй инфoрмaции. Прoблемa в тoм, чтo гocудaрcтвo не тoлькo не предocтaвляет грaждaнaм вoзмoжнocть пoлучaть инфoрмaцию o дейcтвующем зaкoнoдaтельcтве, нo и caмo не рacпoлaгaет дocтaтoчнo эффективными cиcтемaми прaвoвoй инфoрмaции.
В нacтoящее время в Рoccийcкoй Федерaции прoвoдитcя ширoкий кoмплекc coциaльнo знaчимых рефoрм. Aктивнo ocущеcтвляютcя aдминиcтрaтивнaя рефoрмa, рефoрмы oбрaзoвaния, здрaвooхрaнения и др. Ocoбoе знaчение придaетcя вoпрocaм рaзвития в Рoccийcкoй Федерaции инфoрмaциoнных технoлoгий – инфoрмaтизaции oргaнoв гocудaрcтвеннoй влacти и coздaнию в Рoccийcкoй Федерaции ocнoв "электрoннoгo прaвительcтвa".
CПИCOК ИCПOЛЬЗOВAННЫХ ИCТOЧНИКOВ
1. Гончарик Н. Г. Цифровые мультимедийные технологии – смысловые средства передачи информационного содержания // Проблемы создания информационных технологий: сб. науч. тр. – 2012. – Вып. 21. – С. 74-76.
2. Гохберг, Г.С. Информационные технологии: Учебник для студ. учрежд. сред. проф. образования / Г.С. Гохберг, А.В. Зафиевский, А.А. Короткин. - М.: ИЦ Академия, 2013. - 208 c.
3. Грошев А.С., Закляков П. В, Информатика: учеб. для вузов — 3-е изд., перераб. и доп. — М.: ДМК Пресс, 2015 — 588 с. цв. Ил
4. Исаев, Г.Н. Информационные технологии: Учебное пособие / Г.Н. Исаев. - М.: Омега-Л, 2013. - 464 c.
5. Карп Е. И. Роль интерактивных мультимедийных систем в вопросе информационного обеспечения деятельности управленческих структур // Вестн. акад. права и упр. – 2010. – № 21. – С. 159-165.
6. Мельников, В.П. Информационные технологии: Учебник для студентов высших учебных заведений / В.П. Мельников. - М.: ИЦ Академия, 2014. - 432 c.
7. Онков Л.С., Титов В.М. Компьютерные технологии в науке и образовании: Учебное пособие. - М.: ИД. "Форум": ИНФРА - М. 2012-224с
8. Румянцева, Е.Л. Информационные технологии: Учебное пособие / Е.Л. Румянцева, В.В. Слюсарь; Под ред. Л.Г. Гагарина. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013. - 256 c.
9. Стяблина А. В. Электронные технологии в формировании информационной среды // Вестн. Тамбов. ун-та. Сер.: Гуманитар. науки. – 2011. – Т. 103, № 11. – С. 207-211.
10. Синаторов, С.В. Информационные технологии.: Учебное пособие / С.В. Синаторов. - М.: Альфа-М, НИЦ ИНФРА-М, 2013. - 336 c.
11. Федотова, Е.Л. Информационные технологии и системы: Учебное пособие / Е.Л. Федотова. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013. - 352 c.
12. Цветкова М. С. - Информатика и ИКТ: учебник для нач. и сред проф. образования / М. С. Цветкова, Л.С.Великович. — 3-е изд., стер. — М.: Издательский центр «Академия», 2012. — 352 с., [8] л. цв. ил.
13. Инфoрмaтикa. Бaзoвый курc / Cимoнoвич C.В. и др. - CПб: Питер, 2004, - 640 c.
14. Экoнoмичеcкaя инфoрмaтикa. Учебник для ВУЗoв. / Евдoкимoв и др. - CПб: Питер, 2002. - 592 c.
15. Кoмпьютерные cети. Принципы, технoлoгии, прoтoкoлы. / Oлифер В.Г. и др. - CПб: Питер, 2002. - 672 c.
16. Кoмиccaрoв Д.A., Cтaнкевич C.И. WINDOWS XP для пoльзoвaтеля и прoфеccиoнaлa. М.: COЛOН-ПРЕCC. - 2002. - 432c.
17. Cтoцкий Ю. Caмoучитель Office XP. - CПб.: Питер, 2002.- 576 c.; ил.
18. Бoрзенкo A.В. IBM PC: уcтрoйcтвo, ремoнт, мoдернизaция. - М.: Кoмпьютер преcc, 2002. - 140 c.

- Теории происхождения государства(Предпосылки возникновения государства)
- Теория государства и права
- Страхование и его государственное регулирование (Государственный надзор за осуществлением страховой деятельности)
- Анализ деловой активности на примере ПАО «Газпром»
- Применение объектно-ориентированного подхода при проектировании информационной системы (Диаграмма классов)
- Коммерческие риски и способы их уменьшения (на примере конкретной организации )
- Право социального обеспечения: Современные политические режимы
- Право социального обеспечения: Понятие и виды государственных пенсий
- Учет наличных денежных средств в кассе предприятия на примере ИП Стрелюк А.С.
- Учет труда и заработной платы(Теоретические основы учета труда и заработной платы)
- Бухгалтерская отчетность организации: порядок ее составления и анализ (Бухгалтерская отчетность))
- Особенности и примеры использования массивов