
Динамические структуры данных. Бинарные деревья (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ДИНАМИЧЕСКИХ СТРУКТУР ДАННЫХ: ДЕРЕВЬЯ)
Содержание:

ВВЕДЕНИЕ
В настоящее время существует большое количество языков программирования, которые включают в себя различные операции, направленные на решение определенных задач компьютерной системы. В рамках данной курсовой работы мы рассматриваем одну из структур выделения памяти под данные, которая называется динамическим способом. В первой части работы мы рассмотрим разновидности существующих динамических систем, однако более подробно остановимся на изучении бинарных деревьях.
В современном мире наблюдается процесс постоянного внедрения новейших информационных технологий, что обусловлено развитием общества и повышением качества жизни.
Системы, которые предназначены для хранения, поиска и обработки различного рода информации приобретают всё большее значение, повышается их роль и в технологической части построения эффективной организационной системы учреждений. Вместе с этим увеличивается конкуренция, появляется всё больше попыток взлома и несанкционированных проникновений к важной информации.
С каждым годом информации становится всё больше и больше, оптимизируются способы её хранения, быстрой передачи и различных видов использования.
Динамический способ позволяет отводить определенное количество памяти под выполнения той или иной операции. Выделяют два вида распределяемой памяти: статистической и динамической.
Применение динамических величин открывает перед программистами массу возможностей, что и характеризует актуальность выбранной темы:
- это позволяет увеличить объем памяти;
- позволяет освободить память для другой информации;
- создает структуры данных переменного размера.
Динамические структуры достаточно часто применяют для того, чтобы добиться более эффективной работы с различными данными, размер которых известен, особенно для решения задач сортировки, поскольку при упорядочивании динамических структур нет необходимости перестанавливать элементы, что сводится к изменению указателей на эти элементы.
В данной курсовой работе мы более подробно рассмотрели элемент динамической структуры данных, который называется бинарным деревом.
Объект данного исследования – бинарные деревья в динамических структурах данных.
Предмет исследования – динамические структуры данных в программировании.
Цель курсовой работы – изучить сущность и значение динамических структур данных, разобраться в таком виде динамических структур, как бинарные деревья.
Для достижения поставленной цели, необходимо решить следующие задачи:
- Определить понятие, сущность и необходимость построения динамических структур данных.
- Изучить существующую классификацию динамической структуры данных.
- Подробно рассмотреть структуру бинарных деревьев.
- Определить алгоритм реализации программ при работе с бинарными деревьями.
- Описать данные программы.
Работа состоит из двух разделов. Первый раздел включает теоретическое описание аспектов динамических структур данных и состоит из трех параграфов. Второй раздел содержит описание программ пи работе с бинарными деревьями и состоит из двух параграфов.
При написании данной курсовой работы мы использовали метод анализа научной литературы отечественных и, по большей части, зарубежных авторов, таких как: С.Н. Белоусова, Г.В. Ваныкина, В.П. Гергель, О.Л. Голицына, Р.С. Сикорд, В.И. Оседлов, А. Поляков, О.Е. Степаненко и другие.
При написании данной курсовой работы использовались следующие методы социологических исследований:
- теоретический анализ и синтез информации;
- аналогия и моделирование;
- изучение опыта программирования;
- анализ научной литературы.
1 ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ДИНАМИЧЕСКИХ СТРУКТУР ДАННЫХ: ДЕРЕВЬЯ
В современном мире наблюдается процесс постоянного внедрения новейших информационных технологий, что обусловлено развитием общества и повышением качества жизни.
Системы, которые предназначены для хранения, поиска и обработки различного рода информации приобретают всё большее значение, повышается их роль и в технологической части построения эффективной организационной системы учреждений. Вместе с этим увеличивается конкуренция, появляется всё больше попыток взлома и несанкционированных проникновений к важной информации.
С каждым годом информации становится всё больше и больше, оптимизируются способы её хранения, быстрой передачи и различных видов использования.
Многие организации имеют достаточно много конфиденциальной информации о сотрудниках, об организационных моментах предприятия, о продукции и так далее. Информацией владеет также и каждый человек, храня ее в своем смартфоне.
К сожалению, от угроз взлома не застрахован никто, так как каждый день появляются новые способы получения той или иной информации. Рассмотрим более подробно суть проблемы информационной безопасности и обозначим основные пути обеспечения её безопасности.
Любая сфера жизни может быть оцифрована информацией, изменение или потеря которой может привести к достаточно серьезным и зачастую неблагоприятным последствиям. Информация на сегодняшний день становится стратегическим ресурсом, в защите которой заинтересованы государство, бюджетные и частные компании, публичные личности и так далее. Риски, связанные с информационной безопасностью делятся на два вида, один из которых связан с внезапными стихийными бедствиями, сбоем в работе техники, устареванием программных обеспечений и так далее. Другой вид связан с человеческим фактором, связанным с умышленным намерением похитить или изменить информацию.
В силу технического прогресса, большие объемы информации на предприятии обрабатываются при помощи специальной вычислительной техники, а для более удобной и оперативной работы сотрудников организации, разрабатываются корпоративные сети.
Возникают проблемы защиты обрабатываемой информации, а также передаваемой в сети информации.
Для того чтобы предотвратить взлом или изменение информации, специалисты в области информационной безопасности должны постоянно мониторить и оценивать новости, касающиеся появлению новых способов атак на информационные системы. Они также должны уметь выделять новые угрозы, определять уровень их воздействия и находить способы минимизации или полного устранения проблемы.
Чтобы разработать политику безопасности предприятия, необходимо определить необходимые программные решения в области информационной безопасности.
Организация должны быть готова заранее к любым видам атак, обезопасив себя эффективными способами защиты.
В свою очередь, защита информации характеризует собой деятельность, направленную на устранение утечки защищаемой информации, несанкционированных и непреднамеренных попыток воздействия на защищаемую информацию.
Огромное количество задач, которые необходимо решить в системе программирования, требуют эффективной работы со статистическими переменными, которые создаются в момент определения и автоматически удаляются при выходе из программы, когда заканчивается область их действия.
Статистические переменные и структуры данных имеют определенный размер выделенной памяти.
Помимо этого, однако, существуют такие задачи, при которых использование структур данных фиксированного размера не допускаются, и требуют введения динамических структур, которые, в свою очередь, могут увеличиваться в размерах во время работы программы.
Об этом говорится в лекциях Стивена Прата, который подробно описывал особенности практического использования языка программирования[1].
Если до начала работы с данными невозможно понять, сколько именно памяти потребуется для их хранения, то память должна выделять по мере необходимости отдельными блоками, связанными друг с другом указателями. Динамическая структура может занимать несмежные участки оперативной памяти[2].
Язык С++ имеет средства, направленные на создание динамических структур данных, которые необходимы для образования во время работы объекты, выделять и освобождать в них память, когда это необходимо[3].
Итак, сформулируем определение динамических структур данных, которые представляют собой структурную организацию различной информации, при которой размер памяти, который был отведен под нее, не фиксируется.
Другими словами, объект данных обладает динамической структурой в том случае, когда его размер трансформируется в процессе реализации какой-либо программы или он потенциально бесконечен.
Динамические структуры данных в процессе существования в памяти могут изменять не только число составляющих их элементов, но и характер связей между этими элементами.
При этом, важно отметить, что не учитывается изменение содержимого самих элементов данных[4].
Такие особенности динамических структур, как непостоянство их размера и характера отношений между элементами, приводят к тому, что на этапе создания машинного кода программа-компилятор не может выделить для всей структуры в целом участок памяти фиксированного размера, а также не может сопоставить с отдельными компонентами структуры конкретные адреса.
Динамические структуры часто используются программистами для создания тех или иных программ, приложений и так далее, чтобы создать определенный объем памяти, необходимый для осуществления определенных функций.
В рамках данной курсовой работы мы рассматриваем динамические системы, как способы создания и управления памятью, так необходимой при работе с программами.
Несомненно, память является хоть и важнейшим компонентом создания программы. Для того, чтобы подробней разобраться в изучаемом объекте, определим ее основные характеристики. Каждой динамической структуре данных сопоставляется статическая переменная типа указатель (ее значение – адрес этого объекта), посредством которой осуществляется доступ к динамической структуре. Сами динамические величины не требуют описания в программе, поскольку во время компиляции память под них не выделяется. Во время компиляции память выделяется только под статические величины. Указатели – это статические величины, поэтому они требуют описания[5].
Выделим основные характеристики динамической структуры данных, которые мы изучили в процессе написания работы (рисунок 1):
Характеристики динамической структуры данных
Изменчивость взаимосвязи
Выделение памяти
Отсутствие имени
Размерность структуры может меняться
Возможность не фиксировать количество элементов структуры
Рисунок 1 - Характеристики динамической структуры данных
На рисунке 1, мы представили основные характеристики динамических структур данных, к которым можно отнести:
- отсутствие имени;
- выделение памяти в процессе осуществления программы;
- возможность не фиксировать количество элементов структуры;
- размерность структуры может меняться в процессе выполнения программы;
- может меняться характер взаимосвязи между элементами[6].
Рассмотрим ситуации, в которых необходимо использовать динамическую структуру данных (рисунок 2):
Ситуации использования динамической структуры данных
Когда размер данных, обрабатываемых в программе, превышает объем сегмента данных.
В процессе работы программы нужен массив, список или иная структура, размер которой изменяется в широких пределах и трудно предсказуем.
При использовании переменные, которые имеют довольно большой размер (например, массивы большой размерности), необходимые в одних частях программы и совершенно не нужные в других.
Рисунок 2 – Ситуации использования динамической структуры данных
На рисунке 2 данной курсовой работы представлены ситуации, при которых необходимо использовать динамические структуры данных.
Отметим, также, что они характеризуются еще тем, что в них отсутствует физическая смежность элементов структуры в памяти, непостоянство и непредсказуемость размера структуры в процессе ее обработки.
Поскольку элементы динамической структуры располагаются по непредсказуемым адресам памяти, адрес элемента такой структуры не может быть вычислен из адреса начального или предыдущего элемента.
Для установления связи между элементами динамической структуры используются указатели, через которые устанавливаются явные связи между элементами. Такое представление данных в памяти называется связным. Рассмотрим достоинства и недостатки работы связного представления данных, которые представлены в таблице 1.1[7].
Таблица 1.1. – Достоинства и недостатки работы связного представления данных
|
№ |
Связное представление данных |
|
|
Достоинства |
Недостатки |
|
|
1 |
Размер структуры ограничивается только доступным объемом машинной памяти |
Доступ к элементам связной структуры может быть менее эффективным по времени |
|
2 |
При изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей |
На поля, содержащие указатели для связывания элементов друг с другом, расходуется дополнительная память |
|
3 |
Большая гибкость структуры |
|
Анализируя таблицу 1.1, можно сделать вывод, что существуют минусы и плюсы при работе со связным представлением днных.
На наш взгляд, последний недостаток является наиболее серьезным и именно им ограничивается применимость связного представления данных.
Рассмотрим алгоритм работы с динамическими структурами данных[8]:
- Создать (отвести место в динамической памяти).
- Работать при помощи указателя.
- Удалить (освободить занятое структурой место).
Динамические структуры данных могут быть реализованы с помощью типа «указатель» и организованы линейно, в виде дерева и в виде сети. В данной курсовой работе мы более подробно рассмотрим второй вид.
Каждая динамическая структура характеризуется, во-первых, взаимосвязью элементов, и, во-вторых, набором типовых операций над этой структурой. В случае динамической структуры важно решить следующие вопросы:
- каким образом может расти и сокращаться данная структура;
- каким образом можно включить в структуру новый и удалить существующий элемент;
- как можно обратиться к конкретному элементу структуры для выполнения над ним определенной операции.
Из динамических структур в программах чаще всего используют линейные списки, их частные случае – стеки и очереди, а также бинарные деревья.
Таким образом, динамические структуры широко применяют для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки, поскольку упорядочивание динамических структур не требует перестановки элементов, а сводится к изменению указателей на эти элементы. Например, если в процессе выполнения программы требуется многократно упорядочивать большой массив данных, имеет смысл организовать его в виде динамической структуры.
Для того, чтобы более подробно изучить динамические структуры данных, рассмотрим их классификацию, которая представлена в следующем параграфе.
1.2 Классификация динамических структур данных
Все данные, которые используются в программировании, условно делятся на две большие группы, которые представлены на рисунке 3[9].
Данные
Данные динамической структуры
Данные статистической структуры
Рисунок 3 – Виды данных
На рисунке 3 представлены два вида данных, которые используются в программировании.
Важно отметить, что взаимосвязь этих двух видов всегда остается постоянной. В данной работе мы более подробно рассмотрим данные динамической структуры.
Как уже было сказано в предыдущем параграфе работы, для того чтобы в процессе выполнения программы произвольно добавлять и удалять данные, необходимо организовать данные не в массив, а в нечто другое. Если к элементу данных добавить ещё и указатель, в котором будет храниться адрес какого-то другого элемента, то это и будет кардинальным решением проблемы. Такая организация представления и хранения данных называется динамической структурой данных. Рассмотрим подробней данные динамической структуры, которые представлены на рисунке 4[10].
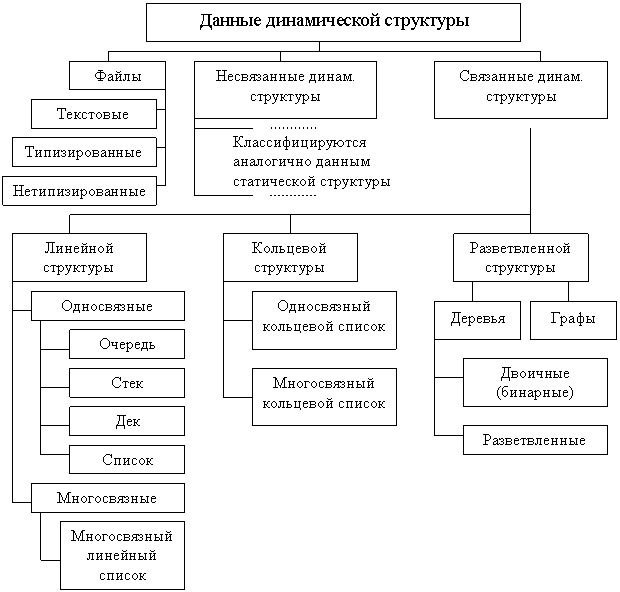
Рисунок 4 – Данные динамической структуры
Изучая рисунок 4, можно сделать вывод, что динамические структуры включают в себя файлы, а также несвязанные и связанные динамические данные.
Заметим, что файлы в данной классификации отнесены к динамическим структурам данных. Это происходит по той причине, что динамические структуры содержат файлы и данные. Отметим, что в данной структуре не допускается удаление и перемещение в середину элементов, и, не смотря на это, длина файла на протяжении всей работы может меняться.
Каждый элемент динамических структур данных состоит из собственно данных и одного или нескольких указателей, ссылающихся на аналогичные элементы.
Это позволяет добавлять в динамическую структуру новые данные или удалять какие-то из имеющихся, не затрагивая при этом другие элементы структуры[11].
Кроме того, динамические структуры позволяют нам организовать данные так, чтобы их представление в программе было максимально приближено к тому, как эти данные выглядят в реальности. Так, для моделирования обслуживания очереди к кассе в магазине лучше всего подойдет динамическая структура данных под названием «очередь», а не пресловутый массив, а для представления сети автомобильных дорог массив вообще неприемлем. Здесь нужна именно «сеть»[12].
Динамические структуры данных бывают двух видов, которые представлены на рисунке 5 данной курсовой работы.
Динамические структуры данных
Нелинейные
Линейные
Рисунок 5 – Виды динамических структур данных
Изучая рисунок 5, можно сделать вывод, что существует два вида динамических структур данных:
- линейные (списки, стеки, очереди);
- нелинейные.
К линейным структурам относятся списки (односвязные, двухсвязные, кольцевые), стеки, очереди (односторонние, двухсторонние, очереди с приоритетами).
Линейная динамическая структура представляет собой изменяемую последовательность элементов. Частными случаями таких структур являются:
- стеки, в которых разрешено добавлять элементы только в конец и удалять только последние элементы;
- очереди, в которых добавление элементов осуществляется в конец, а удаление – из начала;
- деки, которые допускают добавление и удаление элементов и с начала, и с конца[13].
Списком называют структуру, в которой помимо данных хранятся также адреса элементов. Элемент списка состоит из двух частей:
- информационной, которая содержит данные;
- адресной, в которой хранятся указатели на следующие элементы.
В зависимости от количества полей в адресной части и порядка связывания элементов различают несколько видов списков, которые представлены в таблице 1.2[14]..
Таблица 1.2 – Списки элементов связывания
|
№ |
Название |
Характеристика |
|
1 |
2 |
|
|
1 |
Линейные односвязные списки |
Единственное адресное поле содержит адрес следующего элемента, если следующий элемент отсутствует, то в адресное поле заносят константу nil |
|
2 |
Кольцевые односвязные списки |
Единственное адресное поле содержит адрес следующего элемента, а последний элемент ссылается на первый |
|
3 |
Линейные двусвязные списки |
Каждый элемент содержит адреса предыдущего и последующих элементов, соответственно, первый элемент в качестве адреса предыдущего, а последний — в качестве адреса следующего элемента содержат nil |
|
4 |
Кольцевые двусвязные списки |
Каждый элемент содержит адреса предыдущего и последующих элементов, причем первый элемент в качестве предыдущего содержит адрес последнего элемента, а последний элемент в качестве следующего – адрес первого элемента |
|
5 |
П-связные списки |
Каждый элемент включает несколько адресных полей, в которых записаны адреса других элементов или nil |
Организация нелинейных структур более сложная.
Нелинейные структуры представляются, как правило, в виде дерева (каждый элемент имеет некоторое количество связей, например, в бинарном дереве каждый элемент (узел) имеет ссылку на левый и правый элемент).
Во многих задачах требуется использовать данные, у которых конфигурация, размеры и состав могут меняться в процессе выполнения программы. Для их представления используют динамические информационные структуры. К таким структурам относят:
- однонаправленные (односвязные) списки;
- двунаправленные (двусвязные) списки;
- циклические списки;
- стек;
- дек;
- очередь;
- бинарные деревья.
Они отличаются способом связи отдельных элементов и/или допустимыми операциями.
Динамическая структура может занимать несмежные участки оперативной памяти.
Динамические структуры широко применяют и для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки.
Таким образом, мы рассмотрели классификацию динамических структур данных, которые широко применяются в тех случаях, когда необходимо увеличить объем памяти.
Подведем краткие итоги из данного параграфа курсовой работы:
- в программах возникает необходимость обрабатывать данные, размер которых заранее неизвестен;
- для данных с достаточно большим или переменным размером используются динамические структуры;
- динамические структуры не имеют имени, под них выделяется память в процессе выполнения программы, количество их элементов может не фиксироваться, в процессе выполнения программы может меняться характер взаимосвязи между элементами структуры;
- каждой динамической структуре ставится в соответствие статическая переменная – ее адрес;
- представление динамических структур в памяти определяется как связное;
- связное представление данных в программах имеет как достоинства, так и недостатки;
- существует классификация динамических структур данных в зависимости от связей между элементами и допустимых операций;
- элемент динамической структуры состоит как минимум из двух полей: адресного и информационного;
- адресное поле формируется из двух слов: адрес сегмента и смещение;
- доступ к данным в динамических структурах осуществляется с помощью операции косвенного выбора.
Рассмотрим в следующем параграфе работы конкретно один из видов динамических структур данных, который носит название бинарные деревья, который относится к разветвленной структуре.
1.3 Структуры данных: бинарные деревья
В предыдущих параграфах курсовой работы мы определили что такое динамические структуры, описали их необходимость и структуру, а также выделили классификацию структур данных. В этой классификации были определены разветвленные структуры, к которым и относят деревья. Именно данный вид динамической структуры мы рассмотрим более конкретно в данном параграфе работы. Для начала дадим определение «дерево» и рассмотрим основные его характеристики.
Дерево – это структура данных, представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов[15].
Каждый элемент дерева называется вершиной или узлом дерева. Вершины дерева соединены направленными дугами, которые называют ветвями дерева. Начальный узел дерева называют корнем дерева, ему соответствует нулевой уровень.
Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви[16].
Каждое дерево обладает следующими свойствами:
- существует узел, в который не входит ни одной дуги (корень);
- в каждую вершину, кроме корня, входит одна дуга.
Деревья особенно часто используют на практике, чтобы изобразить различные иерархии. Например, популярны генеалогические деревья, которые представлены на рисунке 6[17].
Рисунок 6 – Генеалогические деревья
На рисунке 6 представлено генеалогические деревья, все вершины, в которые входят ветви, исходящие из одной общей вершины, называются потомками, а сама вершина – предком. Для каждого предка может быть выделено несколько.
При этом листьями в дереве являются вершины, имеющие степень нуль. По величине степени дерева различают два типа деревьев, которые показаны на рисунке 7[18]
Типы деревьев
Сильноветвящиеся
Двоичные
Когда степень дерева произвольная
Когда степень дерева не более двух
Рисунок 7 – Типы деревьев
На рисунке 7 показаны два типа деревьев, которые различаются числом степени, в первом типе дерева степень может быть не более двух, а во втором типе произвольное число.
Деревья являются рекурсивными структурами, так как каждое поддерево также является деревом.
Таким образом, дерево можно определить как рекурсивную структуру, в которой каждый элемент является:
- либо пустой структурой;
- либо элементом, с которым связано конечное число поддеревьев.
Действия с рекурсивными структурами удобнее всего описываются с помощью рекурсивных алгоритмов.
Списочное представление деревьев основано на элементах, соответствующих вершинам дерева. Каждый элемент имеет поле данных и два поля указателей:
- указатель на начало списка потомков вершины;
- указатель на следующий элемент в списке потомков текущего уровня[19].
При таком способе представления дерева обязательно следует сохранять указатель на вершину, являющуюся корнем дерева.
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая вершина встречается только один раз.
При обходе все вершины дерева должны посещаться в определенном порядке. Существует несколько способов обхода всех вершин дерева. На рисунке 8 представлены наиболее часто используемые способы обхода дерева[20].
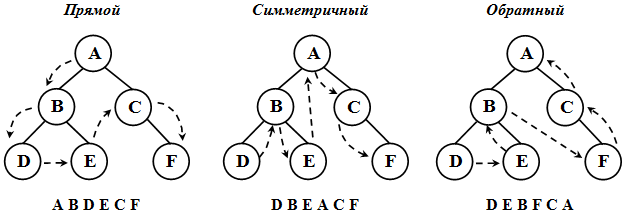
Рисунок 8 - Обходы деревьев
Итак, на рисунке 8 представлены три наиболее часто используемых обхода деревьев: прямой, симметричные и обратный, каждый из которых отличается направлениями движения путей.
Существует большое многообразие древовидных структур данных. Выделим самые распространенные из них: бинарные или двоичные деревья; красно-черные деревья; В-деревья; АВЛ-деревья; матричные деревья; смешанные деревья и другие[21].
Бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья. На каждый элемент дерева имеется ровно одна ссылка. На рисунке 9 представлено бинарное дерево и его организация[22].
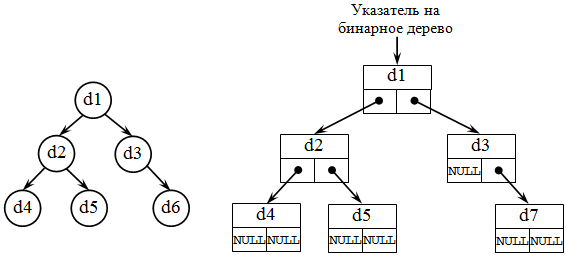
Рисунок 9 –Бинарное дерево и его организация
На рисунке 9 можно рассмотреть структуру бинарного дерева, а также его организацию. Важно отметить, что каждая вершина бинарного дерева является структурой, состоящей из четырех видов полей. Содержимым этих полей будут соответственно:
-информационное поле (ключ вершины);
-служебное поле (их может быть несколько или ни одного);
-указатель на левое поддерево;
-указатель на правое поддерево.
По степени вершин бинарные деревья делятся на несколько видов, схематически которые изображены на рисунке 10[23].
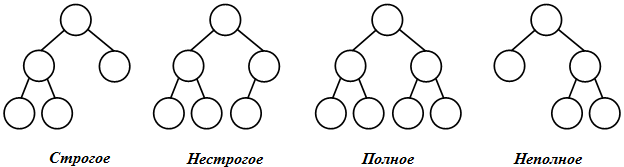
Рисунок 10 – Виды бинарных деревьев по степени вершин.
На рисунке 10 представлены разновидности бинарных деревьев, которые отличаются по степени вершин. Рассмотрим их более подробно:
- строгие – вершины дерева имеют степень ноль (у листьев) или два (у узлов);
- нестрогие – вершины дерева имеют степень ноль (у листьев), один или два (у узлов).
В общем случае у бинарного дерева на каждом уровне может быть до двух вершин. Бинарное дерево называется полным, если оно содержит только полностью заполненные уровни. В противном случае оно является неполным.
Бинарное дерево может представлять собой пустое множество, а также может выродиться в список, что представлено на рисунке 11[24].
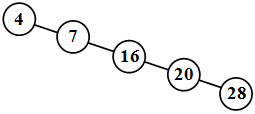
Рисунок 11 – Список как частный случай бинарного дерева
Структура дерева отражается во входном потоке данных так: каждой вводимой пустой связи соответствует условный символ, например, '*' (звездочка). Для структуры бинарного дерева, представленного на рисунке 12, входной поток имеет вид: ABD*G***CE**FH**J**.
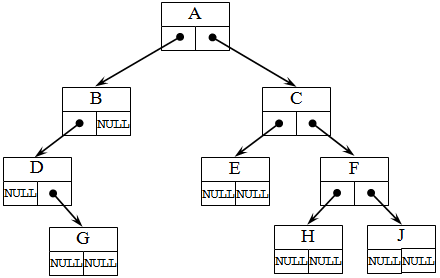
Рисунок 12 – Адресация в бинарном дереве
На рисунке 12 представлена адресация в бинарном дереве. Бинарные деревья могут применяться для поиска данных в специально построенных деревьях (базы данных), сортировки данных, вычислений арифметических выражений, кодирования (метод Хаффмана) и так далее.
Таким образом, в данной главе курсовой работы мы определили, что достаточно большое количество задач, которые встречаются в программировании, требуют применение статистических переменных. Такие переменные имеют определенный размер выделенной памяти, которой, при определенных задачах не хватает. В таком случае применяются динамические структуры данных, размер памяти на которые может меняться во время работы.
Во втором параграфе первой главы мы более подробно разобрали классификацию динамической структуры данных, выделили ее необходимость и преимущества, что позволило нам приблизиться к изучению такого вида динамической структуры данных, как дерево.
Далее, мы выделили, что дерево представляет собой структуру данных, характеризующаяся совокупностью элементов и отношений, которые образуют иерархическую структуру этих элементов.
Мы также определили, что бинарное дерево представляет собой динамическую структуру данных, представляющих собой дерево, в котором каждая вершина имеет не более двух потомков. Таким образом, бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья.
В следующей главе курсовой работы рассмотрим структуру реализации программ над бинарными деревьями.
2 РЕАЛИЗАЦИЯ ОПЕРАЦИЙ ПО РАБОТЕ С БИНАРНЫМИ ДЕРЕВЬЯМИ
2.1 Операции над бинарными деревьями
В предыдущей главе курсовой работы была определена сущность и характеристика динамической структуры данных.
Также мы разобрали классификацию структуры и выделили один вид для дальнейшего изучения, с двоичной степенью, который называется бинарное дерево.
Рассмотрим операции, которые используют для бинарных деревьев, которые представлены на рисунке 13[25].
Операции над бинарными деревьями
Операция добавления некоторого поддерева в дерево
Операция обхода узлов в определенном порядке
Другие примитивные операции над узлами дерева
Операция исключения некоторого поддерева из дерева
Рисунок 13 – Операции над бинарными деревьями
На рисунке 13 представлены основные операции, которые производят с бинарными деревьями. Рассмотрим более подробно каждую из них. Обход дерева необходим для систематического последовательного просмотра узлов дерева.
Данная операция используется для контроля информации, которая хранится в древовидной структуре и включает в себя следующие шаги:
- обработка или просмотр корня дерева или поддерева;
- обход левого поддерева обработанного корня;
- обход правого поддерева обработанного корня.
Различный порядок выполнения перечисленных выше шагов определяет три процедуры обхода бинарного дерева:
1) обход сверху вниз – сначала обрабатывается корень, затем обходится его левое, затем правое поддеревья (операция UpDownRevision);
2) обход слева направо – сначала обходится левое поддерево корня, затем обрабатывается корень, затем обходится его правое поддерево (операция LeftRightRevision);
3) обход снизу вверх – обходится левое поддерево корня, затем правое, затем обрабатывается корень (операция DownUpRevision)[26].
Примитивные операции над узлами бинарного дерева могут быть следующими. Addr(v) возвращает адрес узла со значении емv. Если p– указатель на узел Node бинарного дерева, то операция Value(p)возвращает значение узла Node. Операции Left(p), Right(p), Father(p), Brother(p) возвращают соответственно указатели на левого сына, правого сына, отца и брата узла Node. Операции IsLeft(p) и IsRight (p)возвращают значение «истина», если Node является соответственно левым или правым сыном некоторого узла дерева, и значение «ложь» – в противном случае.
Дополнительно могут быть определены следующие операции: Create– создание пустого дерева, Clear– удаление всех узлов дерева, WriteTo(f) – вывод дерева в файл f с помощью отступов, Nodes Quantity– определение числа узлов дерева.
Таким образом, для работы с деревьями имеется множество алгоритмов. К наиболее важным относятся задачи построения и обхода деревьев. Для примера, пусть в программе дано описание переменных: var t: ptr; s: integer; c: char; b: boolean.
Тогда двоичное дерево можно построить с помощью следующей рекурсивной процедуры[27]:
Procedure V (var t: ptr) var st: string begin readln (st) if st<>'. 'then begin new (t) t. info: =st V (t. Llink) V (t. Rlink) end else t: =nil end
Структура дерева отражается во входном потоке данных: каждой вводимой пустой связи соответствует условный символ (в данном случае точка).
Существует три основных способа обхода деревьев: в прямом порядке, обратном и концевом. Обход дерева может быть выполнен рекурсивной процедурой и процедурой без рекурсии, который по-другому называется стековым обходом. В приведенной ниже рекурсивной процедуре выполняется обход дерева в обратном порядке.
Нерекурсивный алгоритм обхода дерева в прямом порядке:
Пусть T – указатель на бинарное дерево; А – стек, в который заносятся адреса еще не пройденных вершин; TOP – вершина стека; P – рабочая переменная.
1. Начальная установка: TOP: =0; P: =T.
2. Если P=nil, то перейти на 4. {конец ветви}
3. Вывести P. info. Вершину заносим в стек: TOP: =TOP+1; A [TOP]: =P; шаг по левой ветви: P: =P. llink; перейти на 2.
4. Если TOP=0, то КОНЕЦ.
5. Достаем вершину из стека: P: =A [TOP]; TOP: =TOP-1;
Шаг по правой связи: P: =P. rlink; перейти на 2.
Итак, деревом поиска, или таблицей в виде дерева, называется двоичное дерево в котором слева от любой вершины находятся вершины с элементами, меньшими элемента из этой вершины, а справа - с большими элементами (предполагается, что все элементы дерева попарно различны и что их тип (ТЭД) допускает применение операций сравнения).
Таким образом, в данном параграфе курсовой работы были представлены основные операции, которые могут быть использованы при работе с бинарными деревьями.
Мы выделили четыре основные операции и подробно разобрали их характеристики.
Рассмотрим также описание программ, чтобы более точно конкретизировать сущность и особенности работы с бинарными деревьями, что представлено в следующем параграфе главы курсовой работы.
2.2 Описание программы
Деревья (как упорядоченные, так и нет) активно используются в программировании, что было уже определено в предыдущем параграфе курсовой работы. По этой причине мы сосредоточимся в основном на рассмотрении процедур работы с ними.
Для описания узла бинарного дерева в программе введем тип, имеющий вид следующей записи[28]:
type
PNode = ^TNode;
TNode = record
Info : string; {поле данных}
Left,Right : PNode; {указатели на левое и правое поддеревья}
end;
Процедура создания нового узла.
{ Создание нового узла со значением информационного поля X.
Возвращается указатель на новый узел}
function NewNode(X:string):PNode;
var
P : PNode;
begin
New(P);
P^.Info := X;
P^.Left := Nil;
P^.Roght := Nil;
NewNode := P;
end;
Процедура создания потомка (поддерева)
procedure SetLeft(P:PNode; X:string);
begin
P^.Left := NewNode(X);
end;
Правила создание бинарного дерева[29]:
- данные (целые числа) заносятся с клавиатуры;
- дубликаты не включаются (но выводятся на экран);
- признаком окончания ввода является ввод числа 0;
- результат - бинарное упорядоченное дерево.
При обработке динамических структур типа «дерево» чаще всего используются рекурсивные алгоритмы.
Рекурсия предполагает определение некоторого понятия с использованием самого этого понятия.
Примером рекурсивного определения является факториал неотрицательного числа:
n! = 1 при n=0
n! = n*(n-1)! при n >0
В Турбо-Паскале рекурсия разрешена: подпрограмма может вызывать сама себя:
program FactDemo;
var
k : integer;
function Factor(n:integer):integer;
begin
if n=0 then
Factor : 1
else
Factor := n * Factor(n-1);
{end if}
end;
begin
write('Введите целое число ');
readln(k);
if k>=0 then
writeln('Факториал ',n:1,' = ', Factor(k));
{end if}
end.
Первое значение Factor вычисляется, когда n=0, оно подставляется в соответствующий экземпляр памяти. Теперь на каждом очередном шаге значения всех членов выражения n*Factor(n-1) известны, и алгоритм подставляет в это выражение значение, полученное на предыдущем шаге. Это происходит в процессе свертывания рекурсии.
Сформулируем два важных свойства рекурсивных алгоритмов[30]:
1. Наличие тривиального случая.
Правильный рекурсивный алгоритм не должен создавать бесконечную последовательность вызовов самого себя.
Для этого он обязательно должен содержать нерекурсивный выход: т.е. при некоторых входных данных вычисления в алгоритме должны производиться без вызовов его самого.
Для функции «факториал» тривиальный случай: «0!=1».
2. Определение сложного случая в терминах более простого.
При любых входных данных нерекурсивный выход должен достигаться за конечное число рекурсивных вызовов.
Для этого каждый новый вызов рекурсивного алгоритма должен решать более простую задачу. Иными словами рекурсивный алгоритм должен содержать определение некоторого сложного случая в терминах более простого случая.
Для функции «факториал» вместо вычисления n! заменяется умножением n*(n-1)!, и при этом с каждым вызовом значение n уменьшается, стремясь к нулю и достигая его за конечное число вызовов.
Из определения структуры типа «дерево» видно, что она рекурсивна по определению, а в силу этого рекурсивными являются и практически все алгоритмы работы с деревьями. Для этого достаточно посмотреть на приведенный выше пример создания бинарного упорядоченного дерева.
В процедуре Add имеется тривиальный случай (когда дерево пустое) и
рекурсивные вызовы: добавить в левое и правое поддеревья - Add (NewData,Root^.left) и Add(NewData,Root^.right).
Алгоритмы работы с деревьями
В приведенных ниже алгоритмах предполагается, что узел (элемент) дерева декларирован следующей записью[31]:
Type
PNode = ^TNode;
TNode = record
Data : integer; {информационное поле}
left,right : PNode;
end.
Анализ приведенных алгоритмов показывает, что для получения ответа в них производится просмотр всех узлов дерева. Ниже будут приведены алгоритмы, в которых порядок обхода узлов дерева отличается. И в зависимости от порядка обхода узлов бинарного упорядоченного дерева, можно получить различные результаты, не меняя их размещения.
Просмотр используется не сам по себе, а для обработки элементов дерева, а просмотр сам по себе обеспечивает только некоторый порядок выбора элементов дерева для обработки. В приводимых ниже примерах обработка не определяется; показывается только место, в котором предлагается выполнить обработку текущего.
Алгоритмы просмотра дерева
Самой интересной особенностью обработки бинарных деревьев является та, что при изменении порядка просмотра дерева, не изменяя его структуры, можно обеспечить разные последовательности содержащейся в нем информации. В принципе возможны всего четыре варианта просмотра: слева-направо, справа-налева, сверху-вниз и снизу-вверх.
Прежде чем увидеть, к каким результатам это может привести, приведем
их[32]. Просмотр дерева слева - направо
procedure ViewLR(Root:PNode); {LR -> Left - Right }
begin
if Root<>Nil then
begin
ViewLR(Root^. left); {просмотр левого поддерева}
{Операция обработки корневого элемента - вывод на печать, в файл и др.}
ViewLR(Root^.right); { просмотр правого поддерева }
end;
end;
Таким образом, в данном разделе курсовой работы мы изучили виды операций, которые могут осуществляться при работе с бинарными деревьями. Мы выделили четыре вида операций:
- обход узлов в определенном порядке;
- добавление некоторого поддерева в дерево;
- исключение некоторого поддерева из дерева;
- примитивные операции над узлами дерева.
Далее, мы более подробно рассмотрели алгоритм операций, которые используются программистами.
В целом, можно сделать вывод, что данный вид динамической структуры данных достаточно актуален и довольно часто используется при создании различных программ. Описание алгоритма программ, который приведен в заключительной части курсовой работы позволит создать бинарное дерево на практике.
ЗАКЛЮЧЕНИЕ
Курсовая работа посвящена динамическим структурам данных, а именно – бинарным деревьям.
В первом разделе работы мы определили, что динамические структуры широко применяют для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки, поскольку упорядочивание динамических структур не требует перестановки элементов, а сводится к изменению указателей на эти элементы.
В современном мире наблюдается процесс постоянного внедрения новейших информационных технологий, что обусловлено развитием общества и повышением качества жизни.
Системы, которые предназначены для хранения, поиска и обработки различного рода информации приобретают всё большее значение, повышается их роль и в технологической части построения эффективной организационной системы учреждений. Вместе с этим увеличивается конкуренция, появляется всё больше попыток взлома и несанкционированных проникновений к важной информации.
С каждым годом информации становится всё больше и больше, оптимизируются способы её хранения, быстрой передачи и различных видов использования.
Также, мы подробно рассмотрели классификацию динамической структуры данных. К таким структурам относят:
- однонаправленные (односвязные) списки;
- двунаправленные (двусвязные) списки;
- циклические списки;
- стек;
- дек;
- очередь;
- бинарные деревья.
Третий параграф первой главы курсовой работы мы посвятили описанию структуры бинарных деревьев. Мы также определили, что бинарное дерево представляет собой динамическую структуру данных, представляющих собой дерево, в котором каждая вершина имеет не более двух потомков. Таким образом, бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья.
Второй раздел курсовой работы включает описание программ и алгоритма их выполнения при работе с бинарными деревьями.
Мы выделили четыре вида операций:
- обход узлов в определенном порядке;
- добавление некоторого поддерева в дерево;
- исключение некоторого поддерева из дерева;
- примитивные операции над узлами дерева.
Далее, мы более подробно рассмотрели алгоритм операций, которые используются программистами.
Для того чтобы информационная система была изначально выстроена достаточно безопасно и эффективно, мы выделили несколько рекомендаций, которых необходимо придерживаться при ее создании:
- средства защиты, которые используются в системе, должны быть доступны для персонала технического обслуживания, также они должны быть выражены в понятной для них форме и содержать инструкцию;
- довести систему защиты до автономности;
- при создании информационной системы учитывать тот факт, что сбои могут возникнуть в любое время, что непосредственно повлияет на выполнение работы, поэтому нужно выстроить стратегическую систему разрешения внезапных угроз;
- наличие, содержание и место хранение защитных способов должно быть конфиденциально.
Итак, можно сказать, что древовидная модель оказывается довольно эффективной для представления динамических данных с целью быстрого поиска информации. Деревья являются одними из наиболее широко распространенных структур данных в информатике и программировании, которые представляют собой иерархические структуры в виде набора связанных узлов.
Нами выявлено, что дерево является структурой данных, представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов. Каждый элемент дерева называется вершиной (узлом) дерева. Вершины дерева соединены направленными дугами, которые называют ветвями дерева. Начальный узел дерева называют корнем дерева, ему соответствует нулевой уровень. Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви.
Деревья особенно часто используют на практике при изображении различных иерархий.
Тексты приведенных алгоритмов очень компактны и просты в понимании. В заключение отметим, что рекурсивные алгоритмы широко используются в базах данных и при построении компиляторов, в частности для проверки правильности записи арифметических выражений, синтаксис которых задается с помощью синтаксических диаграмм.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Александреску А. Современное проектирование на C++. Обобщенное программирование и прикладные шаблоны проектирования. Перевод с английского – Издательский дом «Вильямс», 2016 г. 336 с.
- Ашарина, И.В. Основы программирования на языках С и С++: Курс лекций для высших учебных заведений / И.В. Ашарина. – М.: Гор. линия-Телеком, 2018. – 208 c.
- Баженова, И.Ю. Языки программирования: Учебник для студентов учреждений высш. проф. образования / И.Ю. Баженова; Под ред. В.А. Сухомлин. – М.: ИЦ Академия, 2018. – 368 c.
- Белоусова, С.Н. Основные принципы и концепции программирования на языке VBA в Excel: Учебное пособие / С.Н. Белоусова, И.А. Бессонова. – М.: БИНОМ. ЛЗ, 2017. – 200 c.
- Бьянкуцци, Ф. Пионеры программирования. Диалоги с создателями наиболее популярных языков программирования / Ф. Бьянкуцци, Ш. Уорден. – СПб.: Символ-плюс, 2018. – 608 c.
- Ваныкина Г.В. Структуры и алгоритмы компьютерной обработки данных / Г.В. Ваныкина, Т.О. Сундукова. – ИНТУИТ. URL: https://intuit.ru/studies/courses/648/504/lecture/11455 (Дата обращения: 03.11.2020)
- Васильев А.Н. Программирование на С++ в примерах и задачах / Васильев А.Н. – 2017г. – 369С. URL: https://t.me/technobooks/376 (Дата обращения 03.11.2020)
- Вершинов Ф.Н. Классификация структур данных. / Ф.Н. Вершинов. URL: https://pandia.ru/text/78/302/22759.php (Дата обращения: 04.11.2020)
- Гергель, В.П. Современные языки и технологии параллельного программирования: Учебник/ предисл.: В.А. Садовничий. / В.П. Гергель. – М.: Изд. МГУ, 2016. – 408 c.
- Голицына, О.Л. Основы алгоритмизации и программирования: Учебное пособие / О.Л. Голицына, И.И. Попов. –М.: Форум; Издание 2-е, 2015. – 432 c.
- Дмитриева М.В. Динамические структуры данных / М.В. Дмитриева. Школа современного программирования. – 2017г. URL: https://cyberleninka.ru/article/n/dinamicheskie-struktury-dannyh/viewer (Дата обращения: 03.11.2020)
- Девис, Т. OpenGL. Руководство по программированию / Т. Девис, Д. Шрайнер, Дж. Нейдер, и др.. – М.: СПб: Питер, 2016. – 624 c
- Дорогов, В.Г. Основы программирования на языке С: Учебное пособие / В.Г. Дорогов, Е.Г. Дорогова; Под общ. ред. проф. Л.Г. Гагарина. – М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2017. – 224 c.
- Керниган, Б.У. Язык программирования С / Б.У. Керниган, Д.М. Ритчи; Пер. с англ. В.Л. Бродовой. – М.: Вильямс, 2016. – 304 c.
- Кнут, Д.Э. Искусство программирования (Том 1. Основные алгоритмы) / Д.Э. Кнут. – М.: РИЦ, 2016. – 853 c.
- Литвиненко Н.А. Технология программирования на С++ / Н.А. Литвиненко – БХВ-Петербург.2015 – 281 С.
- Маслов, В.В. Основы программирования на языке Perl / В.В. Маслов. – М.: Радио и связь, 2016. – 144 c.
- Медведев В.И. Особенности объектно-ориентированного программирования С++/CLI, C# и Java. / В.И. Медведев .:РИЦ «Школа», Казань, 2-е изд. – 2010г. С. – 444.
- Монахов, В.В. Язык программирования Java и среда NetBeans. 3-е изд., пер. и доп. + DVD / В.В. Монахов. – СПб.: BHV, 2017. – 704 c.
- Роберт, С. Сикорд Безопасное программирование на C и C++ / Роберт С. Сикорд. – Москва: РГГУ, 2014. – 496 c.
- Оседлов В.И. Классификация динамической структуры данных. С++./ В.И. Оседлов URL: https://zen.yandex.ru/media/codeblog/dinamicheskie-struktury-dannyh-c-5b06f5e4256d5c1d650b7aa9 (Дата обращения: 04.11.2020)
- Поляков, А. Методы и алгоритмы компьютерной графики в примерах на Visual C++ / А. Поляков, В. Брусенцев. – М.: БХВ-Петербург, 2017. – 560 c.
- Понамарев, В. Программирование на C++/C# в Visual Studio .NET 2003 / В. Понамарев. – М.: БХВ-Петербург, 2015. – 917 c.
- Степаненко О.Е. Visual C++/ NET. Классика программирования / О.Е. Степаненко .:Изд-во: Букинист, Научная книга, 2016 , С. – 766.
- Стивен Прата. Язык программирования C++ (C++11). Лекции и упражнения, 6-е издание – М.: Вильямс, 2016. – 248 с.
- Страуструп Б. Язык программирования С++. Специальное издание. Пер. с англ. – М.: Издательство Бином, 2017 г. – 1136 с.
- Троелсен, Э. Язык программирования С# 5.0 и платформа .NET 4.5 / Э. Троелсен; Пер. с англ. Ю.Н. Артеменко. – М.: Вильямс, 2016. – 1312 c.
- Хейлсберг, А. Язык программирования C#. Классика Computers Science / А. Хейлсберг, М. Торгерсен, С. Вилтамут. – СПб.: Питер, 2016. – 784 c.
- Элджер Дж. C++. Библиотека программиста: Пер. с англ. – СПб.: Питер, 2018. – 320 с.
-
Стивен Прата. Язык программирования C++ (C++11). Лекции и упражнения, 6-е издание – М.: Вильямс, 2016. – 248 с. ↑
-
Страуструп Б. Язык программирования С++. Специальное издание. Пер. с англ. – М.: Издательство Бином, 2017 г. – 1136 с. ↑
-
Ваныкина Г.В. Структуры и алгоритмы компьютерной обработки данных / Г.В. Ваныкина, Т.О. Сундукова. – ИНТУИТ. URL: https://intuit.ru/studies/courses/648/504/lecture/11455 (Дата обращения: 03.11.2020) ↑
-
Дмитриева М.В. Динамические структуры данных / М.В. Дмитриева. Школа современного программирования. URL: https://cyberleninka.ru/article/n/dinamicheskie-struktury-dannyh/viewer (Дата обращения: 03.11.2020) ↑
-
Васильев А.Н. Программирование на С++ в примерах и задачах / Васильев А.Н. – 2017г. – 369С. URL: https://t.me/technobooks/376 (Дата обращения 03.11.2020) ↑
-
Литвиненко Н.А. Технология программирования на С++ / Н.А. Литвиненко – БХВ-Петербург.2015 – 281 С. ↑
-
Медведев В.И. Особенности объектно-ориентированного программирования С++/CLI, C# и Java. / В.И. Медведев .:РИЦ «Школа», Казань, 2-е изд. – 2010г. С. – 444. ↑
-
Степаненко О.Е. Visual C++/ NET. Классика программирования / О.Е. Степаненко .:Изд-во: Букинист, Научная книга, 2016 , С. – 766. ↑
-
Вершинов Ф.Н. Классификация структур данных. / Ф.Н. Вершинов. URL: https://pandia.ru/text/78/302/22759.php (Дата обращения: 04.11.2020) ↑
-
Оседлов В.И. Классификация динамической структуры данных. С++./ В.И. Оседлов URL: https://zen.yandex.ru/media/codeblog/dinamicheskie-struktury-dannyh-c-5b06f5e4256d5c1d650b7aa9 (Дата обращения: 04.11.2020) ↑
-
Александреску А. Современное проектирование на C++. Обобщенное программирование и прикладные шаблоны проектирования. Перевод с английского – Издательский дом «Вильямс», 2016 г. 336 с. ↑
-
Элджер Дж. C++. Библиотека программиста: Пер. с англ. – СПб.: Питер, 2018. – 320 с. ↑
-
Роберт, С. Сикорд Безопасное программирование на C и C++ / Роберт С. Сикорд. – Москва: РГГУ, 2014. – 496 c. ↑
-
Поляков, А. Методы и алгоритмы компьютерной графики в примерах на Visual C++ / А. Поляков, В. Брусенцев. – М.: БХВ-Петербург, 2017. – 560 c. ↑
-
Понамарев, В. Программирование на C++/C# в Visual Studio .NET 2003 / В. Понамарев. – М.: БХВ-Петербург, 2015. – 917 c. ↑
-
Кнут, Д.Э. Искусство программирования (Том 1. Основные алгоритмы) / Д.Э. Кнут. – М.: РИЦ, 2016. – 853 c. ↑
-
Девис, Т. OpenGL. Руководство по программированию / Т. Девис, Д. Шрайнер, Дж. Нейдер, и др.. – М.: СПб: Питер, 2016. – 624 c ↑
-
Голицына, О.Л. Основы алгоритмизации и программирования: Учебное пособие / О.Л. Голицына, И.И. Попов. –М.: Форум; Издание 2-е, 2015. – 432 c. ↑
-
Ашарина, И.В. Основы программирования на языках С и С++: Курс лекций для высших учебных заведений / И.В. Ашарина. – М.: Гор. линия-Телеком, 2018. – 208 c. ↑
-
Баженова, И.Ю. Языки программирования: Учебник для студентов учреждений высш. проф. образования / И.Ю. Баженова; Под ред. В.А. Сухомлин. – М.: ИЦ Академия, 2018. – 368 c. ↑
-
Белоусова, С.Н. Основные принципы и концепции программирования на языке VBA в Excel: Учебное пособие / С.Н. Белоусова, И.А. Бессонова. – М.: БИНОМ. ЛЗ, 2017. – 200 c. ↑
-
Хейлсберг, А. Язык программирования C#. Классика Computers Science / А. Хейлсберг, М. Торгерсен, С. Вилтамут. – СПб.: Питер, 2016. – 784 c. ↑
-
Страуступ, Б. Язык программирования С++. Специальное издание / Б. Страуступ. – М.: Бином, 2015. – 1136 c. (см. в библиографии источник 20) ↑
-
Керниган, Б.У. Язык программирования С / Б.У. Керниган, Д.М. Ритчи; Пер. с англ. В.Л. Бродовой. – М.: Вильямс, 2016. – 304 c. ↑
-
Дорогов, В.Г. Основы программирования на языке С: Учебное пособие / В.Г. Дорогов, Е.Г. Дорогова; Под общ. ред. проф. Л.Г. Гагарина. – М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2017. – 224 c. ↑
-
Гергель, В.П. Современные языки и технологии параллельного программирования: Учебник/ предисл.: В.А. Садовничий. / В.П. Гергель. – М.: Изд. МГУ, 2016. – 408 c. ↑
-
Гергель, В.П. Современные языки и технологии паралелльного программирования: Учебник / В.П. Гергель. – М.: МГУ, 2016. – 408 c. (см. источник 8) ↑
-
Бьянкуцци, Ф. Пионеры программирования. Диалоги с создателями наиболее популярных языков программирования / Ф. Бьянкуцци, Ш. Уорден. – СПб.: Символ-плюс, 2018. – 608 c. ↑
-
Баженова, И.Ю. Языки программирования: Учебник для студентов учреждений высш. проф. образования / И.Ю. Баженова; Под ред. В.А. Сухомлин. – М.: ИЦ Академия, 2018. – 368 c. ↑
-
Троелсен, Э. Язык программирования С# 5.0 и платформа .NET 4.5 / Э. Троелсен; Пер. с англ. Ю.Н. Артеменко. – М.: Вильямс, 2016. – 1312 c. ↑
-
Монахов, В.В. Язык программирования Java и среда NetBeans. 3-е изд., пер. и доп. + DVD / В.В. Монахов. – СПб.: BHV, 2017. – 704 c. ↑
-
Маслов, В.В. Основы программирования на языке Perl / В.В. Маслов. – М.: Радио и связь, 2016. – 144 c. ↑

- Проектирование БД клиентов магазина (Проектирование базы данных)
- Проектирование баз данных для домашней библиотеки (Архитектура базы данных: понятие, определение, уровни)
- Базы данных. Проектирование БД клиентов магазина
- ФОРМИРОВАНИЕ ЭФФЕКТИВНОЙ КОМАНДЫ ПРОЕКТА
- Пример проекта и команды для его реализации (ТЕОРЕТИЧЕСКИЕ ОСНОВЫ СОЗДАНИЯ И ФУНКЦИОНИРОВАНИЯ ПРОЕКТА)
- СТАДИЯ ФОРМИРОВАНИЯ КОМАНДЫ ПРОЕКТА (ПРОБЛЕМЫ ФОРМИРОВАНИЯ И ФУНКЦИОНИРОВАНИЯ КОМАНД УПРАВЛЕНИЯ ПРОЕКТАМИ)
- Управление оборотными средствами на предприятии (Аспекты анализа и управления денежными оборотами предприятия)
- Стратегический менеджмент: цели, задачи, функции (Теоретические основы стратегического менеджмента)
- Налог на доходы физических лиц (Теоретические основы налогообложения на доходы физических лиц)
- Налогообложение физических лиц (Сущность налогообложения физических лиц)
- Составные части управленческого учета (Теоретические основы управленческого учета)
- Динамические структуры данных. Бинарные деревья (Динамические структуры данных)