
Динамические структуры данных. Списки ( Структуры данных: понятие, типы и форматы)
Содержание:

ВВЕДЕНИЕ
Создание очень сложных программных продуктов, к примеру, разного рода информационных систем (ИС), требует подготовки квалифицированных разработчиков, которые в совершенстве могут владеть современными методами для построения систем по обработке данных.
Для решения разных задач, с одной стороны, крайне необходимо выбрать подходящий уровень абстрагирования, а также определить множество данных, представляющих реальную ситуацию и относящуюся к конкретно поставленному заданию.
С иной стороны, необходимо выбирать способ представления обработанных данных с учетом всех возможностей языка программирования (ЯП) и персонального компьютера (ПК).
Стоит отметить, что в разных языках программирования применяются специальные способы для выделения объемов памяти для хранимой информации, который часто называют динамическим.
В настоящее время инструментарий обработки и сохранения любой информации значительно упростился, поскольку появились новые программные средства, которые могут с легкостью обрабатывать большие массивы данных.
В таких случаях почти всегда используется динамическое распределение применяемой памяти.
Актуальностью проводимого исследования является изучение динамических структур в программировании, ведь очень важно уметь разрабатывать программные продукты, которые могут корректно использовать имеющуюся память, так как во время реализации программных продуктов память необходима практически во всех основных элементах программ.
Объект курсовой работы – современные динамические структуры данных.
Предметом исследования являются списочные динамические структуры.
Цель исследования – рассмотреть главные понятия и операции с динамическими списочными структурами.
Согласно указанной цели, выделим основные задачи, которые выдвигаются в рассматриваемой работе:
- рассмотреть основные определения о структурировании данных с точки зрения программирования;
- выполнить анализ принципов обработки динамических структур;
- дать характеристику нелинейным динамическим структурам;
- рассмотреть односвязные динамические списки в С++;
- выполнить реализацию основных алгоритмов по работе со списками на практике.
Структурно работа состоит из введения, трех глав, заключения и списка использованных источников.
ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ
СТРУКТУРИРОВАНИЯ ДАННЫХ
Структуры данных: понятие, типы и форматы
Необходимым условием для хранения информации непосредственно в памяти ПК является возможность преобразования ее в подходящую для обработки компьютером форму.
В таком случае, если данное условие выполняется, то следует определить структуру, которая является пригодной именно для наличествующих данных, ту, которая предоставит весь требующийся набор возможностей для их обработки.
В программировании под структурой понимается метод представления информации, с помощью которого совокупность отдельно определенных элементов образует единое, обусловленное их практической взаимосвязью друг с другом.
Все скомпонованные по каким-то правилам и связанные логически между собой данные могут эффективно обрабатываться, поскольку общая структура для них предоставляет весь набор возможностей для управления ими. В результате этого достигаются высокие результаты при решении тех или других задач[1].
Стоит отметить, что не каждый объект может быть представлен в произвольной форме, может быть такой случай, что для него имеется только один единственный способ интерпретации, следовательно, при этом несомненным плюсом для разработчика будет знание практически всех существующих структур информации.
По данной причине, часто приходиться выполнять выбор между самыми различными методами хранения данных, и от этого выбора зависит практическая работоспособность программы.
Можно показать много случаев, где у информации видно явную структуру[2].
Наглядным примером этого служат книги, которые имеют разное содержания. Они разбиваются на страницы, главы и параграфы, имеют, как правило, свое оглавление, другими словами, интерфейс пользования.
В широком смысле рассматриваемого понятия, структуру имеет всякое живое существо.
Методы хранения информации, которые называют «простыми», то есть, неделимыми на разные составные части, предпочтительнее выучить вместе с определенным языком программирования (ЯП), либо же углубляться непосредственно в суть их работы.
Структуры данных можно применять в качестве информационных массивов, что предназначаются для непосредственного проектирования программного обеспечения[3]. Стоит отметить, что структурированные данные имеют свою специфическую форму текстов, чисел и могут в себе содержать более сложные структуры (рисунок 1):
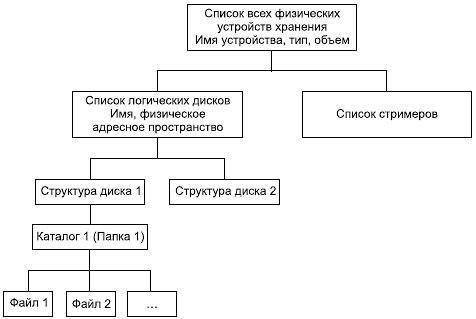
Рисунок 1 – Пример древоподобной структуры
Стоит отметить, что с понятием структуры данных в программировании тесно связан термин «тип данных». Виды применяемых данных при написании программ показаны на рисунке 2[4]:
Данные
Элементарные
(простые)
Составные
(структуры)
Символ
Целое
Статические
Динамические
Запись
Массив
Множество
Дерево
Список
Рисунок 2 – Типы данных
Для точного описания самых разных абстрактных структур, алгоритмов для их обработки применяются системы для выполнения формализованного обозначения, называющиеся языками программирования.
Стоит отметить, что много средств, для описания почти всех ЯП, есть возможность ссылаться в поэлементном варианте, пользуясь только названием[5].
Выбор конкретного представления информации служит также ключом к самому оптимальному программированию, и в большей степени может выполнять влияние на производительности программ, нежели обычные детали алгоритма.
Под структурой информации понимается множество составных элементов информации, а также перечень связей между ними[6].
Такое определение описывает полностью все подходы и реализации структуризации, где по каждому определенному заданию будут отведены аспекты для его решения.
Рассмотрим типы структур данных, которые используются в программировании.
Физическая структура данных имеет возможность отражать методологию физического и логического описания их в постоянной памяти ПК. Она называется структурой хранения (другими словами, внутренней) структурой предоставления данных.
Рассмотрение с такой точки зрения структур данных не обращая внимание на учет представлений их в машинном коде, называют их абстрактной структурой.
Заметим, что между логическими структурами данных и физическими есть некоторое различие, уровень которого напрямую зависит непосредственно от структуры, а также особенностей выбранной среды написания программ.
Вследствие ранее приведенного различия можно разделить программные процедуры, которые осуществляют повсеместное и полное отображение структурированных моделей данных (МД).
Другой важнейший признак, по которому можно структурировать данных – характер упорядоченности для её элементов[7] (рисунок 3).
В зависимости от указанной выше характеристики для взаимного расположения всех структуры в оперативной памяти, все современные структуры данных, которые называются линейными, еще можно разделить на несколько категорий:
- векторы;
- массивы;
- стеки;
- строки;
- очереди.
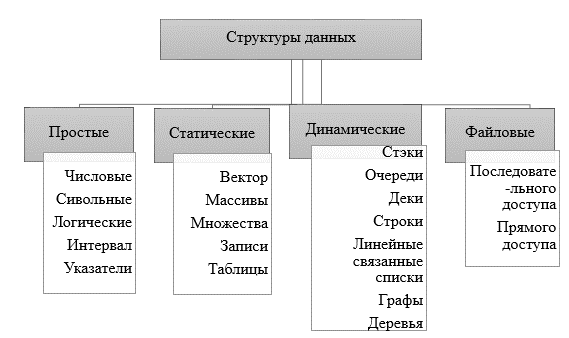
Рисунок 3 – Категории структур
По качестве и характеру связей между элементами структур их можно разделять на следующие типы (рисунок 4):
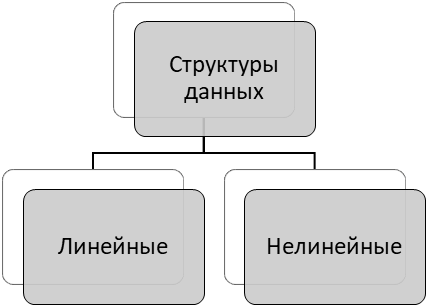
Рисунок 4 – Классификация структур по характеру связей
Типичным примером нелинейной структуры являются многофайловые списки, графы, деревья[8].
В современных ЯП очень тесно связывается определение «структуры» с термином «формат данных».
Простые структурные типы данных называют еще примитивами или же базовыми МД. Они являются так называемой отправной точкой для непосредственного применения структур в программных проектах.
В ЯП иногда применяются простые структуры, описывающиеся с применением таких базовых типов[9].
К таким типам можно отнести (рисунок 5):
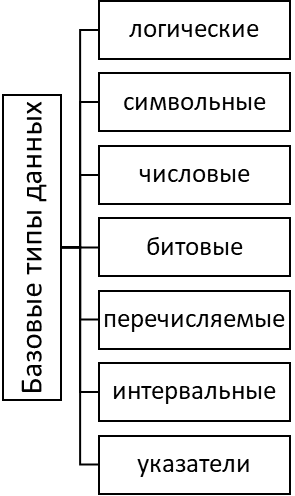
Рисунок 5 – Простые структуры данных
Все современные статические структуры можно отнести в категории непримитивных, представляющих собой некоторый перечень примитивных структур данных.
Выделение памяти после (или одновременно с) процесса компиляции обладает очень показательным свойством для статических структур данных, что в некоторых классических задачах программистами применяется в результате представлении самых разных объектов, которые обладают определенной степенью изменчивости.
Когда при объявлении массива заранее неизвестен его полный размер, то под его компоненты резервируется сразу максимальный возможный объем памяти.
Стоит отметить, что статические структуры данных в современной теории программирования связаны с процессами структурирования типов –средствами интеграции, позволяющие строить разные прикладные структуры информации любой сложности.
К ним можно отнести:
- массивы;
- структуры;
- множества.
Рассмотрим некоторые с перечисленных структур.
Вектор (или одномерный массив) – это структура данных, которая располагает конкретной численностью элементов базового формата данных[10].
Каждый такой компонент вектора может имеет уникальный свой номер в рамках применения заданного вектора.
Такой номер называют индексом.
Обращение к элементу можно реализовать по имени, номеру элемента массива.
Под массивом понимается специальная структура данных, характеризующаяся[11]:
- фиксированным перечнем элементов;
- каждый из компонентов имеет уникальный набор значений индексов;
- общее количество всех рассмотренных индексов описывает размерность массива;
В первом разделе курсовой работы рассмотрено определение структуры данных, приведена их базовая классификация, описаны все типы структур, а также особенности их использования.
1.2 Динамические структуры данных
Часто в больших программных проектах надо применять данные, в которых размер и структура должны меняться непосредственно при процессе работы.
Все динамические массивы выделяют память под свои компоненты только в процессе их обработки.
К примеру, надо проанализировать текст, определить, какие слова и сколько их встречаются, причем слова нужно упорядочить по алфавиту. В этих случаях применяют структуры, которые представляют собой элементы, связанные при использовании ссылок. Каждый такой компонент (или узел) состоит с двух областей памяти:
– ссылок;
– поля данных.
Ссылка (или указатель) – это адрес других узлов такого же типа, с которыми этот узел логически связан[12].
В языке программирования С++ для организации ссылок применяется переменная-указатели.
При добавлении узла в указанную структуру формируется новый блок памяти, а потом посредством ссылок устанавливаются связи нового элемента с существующими.
Для обозначения самого последнего элемента в цепи применяются нулевые ссылки (обозначаются NULL).
Достоинство применения ссылок состоит в следующем:
- возможность обеспечения изменчивости информации;
- размер структур ограничен только доступным объёмом оперативной ПК;
- при рассмотрении иных логических последовательностей для компонентов динамической структуры не нужно переместить всю информацию в оперативной памяти, а возможно только выполнить перенаправление указателей на нее[13].
Также, вместе с рассмотренным фактом, ссылки имеют также некоторые недостатки:
- работа с указателями выполняется разработчиками, которые имеют более высокую квалификацию;
- на поля ссылок будет расходоваться также некоторый объем дополнительной памяти;
- выполнение непосредственного доступа к элементам структур во времени может быть не эффективным.
Динамический список – упорядоченная совокупность, которая состоит из некоторого количества элементов (не обязательно постоянного), с которыми применяются операции по добавлению и удалению узлов в список (рисунок 6).
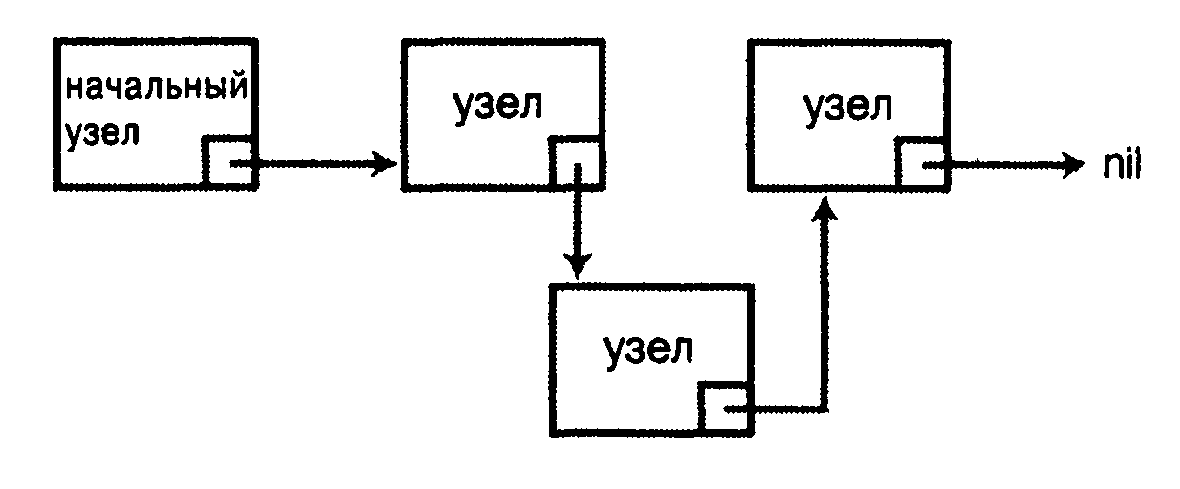
Рисунок 6 – Схема динамического списка
Каждый элемент списка содержит ссылку на следующий элемент за ним. У последнего элемента списка поле ссылки содержит указатель NULL.
Чтоб не потерять список, надо где-то (в основном, в переменной) хранить адрес первого его узла – его называют «головой» списка.
Стоит отметить, что в программе надо объявлять 2 новых формата данных, к примеру, узел Node и указатель PNode.
Узел представляется структурой, которая содержит сразу три поля:
- строку;
- целое число;
- указатель на аналогичный узел.
Ниже, на рисунке 7 приведена классическая структура односвязного списка. В структуре, которая рассмотрена ниже, поле inf реализуется как информационное поле или данные, а next – это указатель на следующий узел структуры.
Каждый список использует специальный компонент, что является указателем на первый элемент динамического списка.
Непосредственно в поле с указателем последнего элемента списка используется специальный признак, свидетельствующий об окончании линейного списка.

Рисунок 7 – Структура линейного односвязного списка
Многие проблемы при обработке односвязных списков вызваны тем, что невозможно в них перейти к прошедшему элементу.
Возникает естественная задача: как хранить в памяти ссылки не лишь на следующий, а и на предыдущий компонент списка.
Для выполнения доступа к списку применяется не одна переменная-указатель, а сразу две – ссылка на первый элемент списка (к примеру, Head) и на последний элемент – Tail.
Стоит заметить, что эту возможность может обеспечить только 2-связный список, в котором использованы 2 указателя[14]:
- на предыдущий элемент;
- на следующий элемент.
В крайних элементах расмотренных списков соответствующие указатели могут содержать значения nil (рисунок 8).
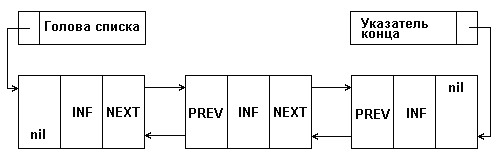
Рисунок 8 – Схема 2-связного списка
При обработке некоторых линейных списков можно добавить особенный элемент, который называется указателем для конец списка.
Указанное применение 2-х указателей для узлов значительно усложняет архитектуру списка, приводит также к разным дополнительным объемам памяти, обеспечивает выполнение всех команд, операций с обрабатываемой списочной структурой[15].
Разновидностью этой категории линейных списков считают циклический список, который организовывается при использовании разного рода динамических списков.
При непосредственной работе с списочной структурой односвязного типа указатели последнего элемента часто указывают на первый элемент списка (рисунок 9)[16].
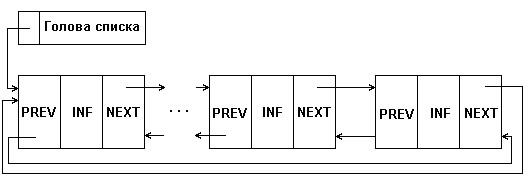
Рисунок 9 – Описание циклических списков
Линейные списки применяются широко в разного рода приложениях, где все требования непредсказуемы с точки зрения размера памяти, который применяется, также есть нужный для корректного хранения информации; при этом большое число сложнейших команд и операций для имеющихся данных, исключений элементов и включений их.
Нелинейным разветвляющимся списком называют такой динамический список, узлами у которого являются уже созданные ранее списки (рисунок 10)[17].
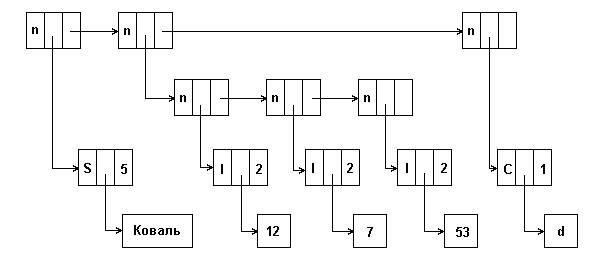
Рисунок 10 – Схема нелинейного разветвленного списка
В случае, если для всех элементов какой-то один указатель списка будет задавать определенный порядок следования компонентов обратный к которому был установлен другим указателем, то данный 2-связный список является линейным.
Граф – совокупность узлов (или вершин) и соединяющих их дуг (ребер).
Если дуги являются направленными, то такой граф называют ориентированным или направленным графом (орграфом) (рисунок 11)[18]
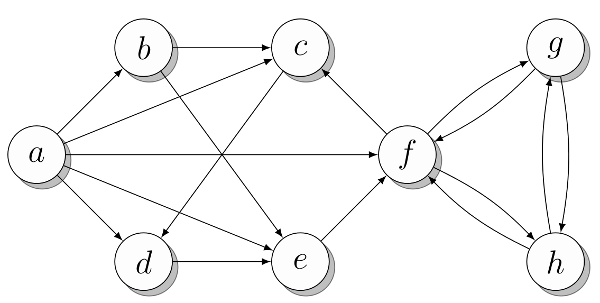
Рисунок 11 – Пример графа
На рисунке 12, показаны несколько примеров самых простейших графов:
Рисунок 12 – Примеры графов
При определении структуры ориентированного графа общее количество его ребер, входящих практически в любой с узлов, называют входной полустепенью, выходящих – выходной полустепенью[19].
Цепью называется определенная последовательность ребер, которые соединяют (возможно даже не соседние) вершины динамической структуры. В направленном графе рассмотренная последовательность ребер называется путем.
Граф является связным, если в нем существует цепь между всеми парами вершин.
Если же граф не связный, его можно разбивать на k связных элементов – в таком случае называется k-связным.
В разных практических задачах рассматриваются часто взвешенные графы, где каждому ребру приписывается определенный вес (длина).
Такой граф является сетью.
Циклом называют цепь с какой-нибудь вершины в нее саму.
Стоит отметить, что дерево – это граф, характеризующийся такими свойствами:
- Существует один единственный узел, на который не ссылаются иные элементы – корень (рисунок 13).
Рисунок 13 – Дерево
- Начиная с корневого элемента, следуя по определенной последовательности, можно качественно осуществлять доступ практически к всем элементам.
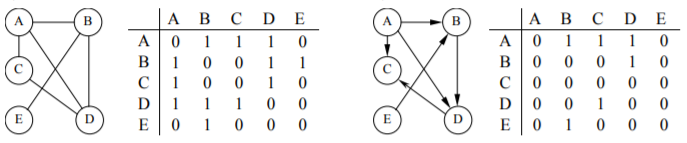
а) б)
Рисунок 14 – Примеры матриц смежности
Во второй главе исследования рассмотрены понятия и виды динамических структур данных, приведены отличительные их свойства, определения нелинейных структур.
ГЛАВА 2. РЕАЛИЗАЦИЯ ДИНАМИЧЕСКИХ СПИСКОВ
В С++
2.1 Односвязные списки в С++
Рассмотрим далее списковые динамические структуры и их обработку в С++.
Как было ранее указано, список – динамическая структура данных, где несколько полей являются адресом (ссылкой, указателем) на иные структуры аналогичного типа[20].
Такие списочные структуры могут применяться вместо обычных числовых, символьных массивов для выполнения процесса обработки данных какого-то типа, но количество узлов ложно быть заранее неизвестно, при этом может изменяться размерность при выполнении программы.
В указанных списках выполнять удаление элементов даже легче, нежели в классических массивах Аналогично можно сказать и об операциях добавления данных в массив.
В памяти все используемые одномерные массивы, к примеру, с целочисленными параметрами, размещаются последовательно в памяти, то есть, по соседству.
При этом, все такие узлы расположены только в направлении друг за другом, при этом используются возможности для непосредственной их нумерации с помощью индекса.
Элементы динамических списков часто располагаются в памяти несколько хаотично.
Указанный факт предоставляет хорошую возможность для беспрепятственного выполнения манипуляции практически с любым числом узлов списка.
Список, который имеет разные числовые значения в памяти можно расположить так (рисунок 15):
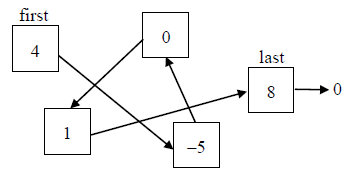
Рисунок 15 – Размещение узлов списка
Стрелки на рисунке 15 указывают последовательность размещения элементов.
Для выполнения работы с узлами списка так, как и в любой связной структуре данных, надо выполнить определение места нахождения требуемого элемента[21].
В этом случае часто хранят только адреса (указатели) первого элемента (first).
Далее для всех элементов есть необходимость «знать», именно где будет размещен узел, который за ним расположен
Заметим, что к всем элементам можно легко добраться, начиная с самого первого и т.д.
В приведенном выше рисунке 15 элемент, имеющий значение 1 может «направить» нас на место, где размещен узел со значением 8 и т.д.
Чтобы «найти» элемент, который имеет значение 1, надо обратится к первому элементу (4), узнать адрес следующего (-5), потом узнать остальные адреса.
Наглядно списки изображены таким образом (рисунок 16):
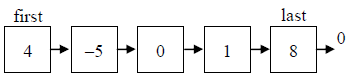
Рисунок 16 – Пример списка
2.2 Операции с элементами списка в С++
Рассмотрим пример с описанием основных операций и функции для обработки линейного односвязного списка.
//заголовочные файлы
#include <conio.h>
#include <iostream>
//объявление пространства имен
using namespace std;
//оглашение структуры ls
struct ls
{
int dat;
ls *next;
};
//описание указателей
ls * last, *first;
//функция, выполняющая просмотр списка
void print_ls()
{
ls *s=first;
cout<<"List: ";
while(s!=0)
{
cout<<s->dat<<"_";
s=s->next;
}
cout<<endl;
}
// добавления узлов в конец динамического списка
void a_end(int y)
{
ls *s=new ls;
s->dat=y;
c->next=NULL;
//проверка наличия первого элемента
if(first==0)
first=s;
else
last->next = s;
last = s;
}
//функция для добавления узлов в начало
void a_beg(int y)
{
ls *s=new ls;
s->dat=x;
s->next=0;
//наличние первого элемента
if(first==0)
{
first=s;
last=s;
}
else
s->next = first;
first = s;
}
// добавление узлов в середину линейного списка
void a_mid(int u, int y)
{
ls *s=new ls;
ls *s1;
s->dat=y;
s->next=0;
if(first==0)
first=s;
else
{
s1=first;
while(s1!=0)
{
if (s1->dat==u)
{
s->next=s1->next;
s1->next=s;
}
s1=s1->next;
}
}
}
// удаление элементов в начале списка
void d_beg()
{
ls *s=first;
first=first->next;
delete s;
}
// удаление элементов с конца
void d_end()
{
ls *s=first;
ls *s1;
while (s->next!=last)
s=s->next;
last=s;
s1=last->next;
delete s1;
s->next=0;
}
//
int main()
{
int y,N;
cout<<"N = ";
cin>>N;
cout<<"List: ";
for(int j=0;j<N;j++)
{
cin>>y;
a_beg(y);
}
//Вызов пользовательских функций
// добавление элементов в середину линейного списка
a_mid(3,11);
//печать
print_list();
// удаление элементов в начале списка
d_beg();
//печать
print_list();
// удаление элементов с конца
d_end();
{
//печать
getch();
print_list();
return 0;
}
}
Получим (рисунок 16):
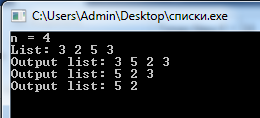
Рисунок 17 – Результат
При написании данной части курсовой работы на практике было рассмотрено все операции для выполнения обработки односвязного списка. Также рассмотрены главные функции для обработки классических динамических структур, разработана программа для демонстрации их.
ГЛАВА 3. ПЕРСПЕКТИВЫ РАЗВИТИЯ ОБЪЕКТНО-
ОРИЕНТИРОВАННОГО ПРОГРАММИРОВАНИЯ
Говоря о тенденциях развития языков программирования, для начала стоит обозначить те движущие силы, которые способствовали их эволюции и продолжают оказывать существенное влияние на их дальнейшее развитие.
- Стремление к совершенству;
ЯП является тем незаменимым инструментом, который служит программисту для создания ПО – это прописная истина, с которой сложно не согласиться. Чем лучше язык программирования, тем более совершенную программу удается написать.
- Нацеленность на эффективность;
Создание ПО во многом можно сравнить с производством, где среди прочих важнейших факторов, определяющими являются: производительность труда команды разработчиков, издержки и качество конечного продукта. Все разрабатываемые технологии создания программ должны поддерживаться языками программирования.
- Повышение сложности задач;
С каждым днем задачи, решаемые с использованием компьютеров, становятся все сложнее и разнообразней. Это приводит к тому, что лучшие умы планеты в лице талантливых разработчиков, стремятся к созданию новых, более мощных, ориентированных на проблемную область, языков программирования.
- Продление жизненного цикла ПО;
Языки программирования должны помогать разработчикам в нелегкой борьбе за продление жизненного цикла программ. Ведь не актуальный, морально и технически устаревший продукт мало кому интересен.
Выделить общую тенденцию развития языков программирования не так просто. При этом можно предположить, что этот процесс в ближайшее время будет двигаться в направлении все большей абстракции. Основные программы программирования будут стремиться к изменению уровня детализации, наибольшему упрощению. Это приведет к повышению надежности процесса создания ПО как такового и уменьшению количества допускаемых разработчиками ошибок.
Одним из первых ЯП является Фортран (FormulaTranslation). Созданный в 50-х годах прошлого века, он по-прежнему остается актуальным. Столь завидное долголетие языку во многом обеспечили простота и накопление значительного объема данных.
Сегодня Fortran используется в различных областях наук, в том числе для решения математических и физических задач, для разного рода научных и инженерных расчетов, для моделирования погоды и климата и т.д. Это жестко-стандартизированный язык, который без проблем переносится на различные платформы.
Изначально выразительные средства Фортран были довольно ограниченны. Однако на пути своего развития он дополнялся разноплановыми лексическими конструкциями. Причем многие из них характеризуют функциональное, структурное и даже объектно-ориентированное программирование.
К появлению, без преувеличения, наиболее используемого и востребованного ЯП современности, привело стремление разработчиков создавать программы, которые не зависели бы от типа компьютера и операционной системы. Java не только отвечает за выполнение программ, которые распространяются посредством Web-страниц, но и поддерживает все средства новых ИТ.
Сочетая в себе языки С и С++, Java объективно является наиболее мощным инструментом для создания кроссплатформенных приложений. Можно сказать, что принцип его работы заключен в выражении: «Write Once, Run Anywhere».Согласно данным TIOBE ЯП Java стал самым популярным в 2015 году.
Несмотря на все отличия и субъективные особенности языков Fortran и Java, оба они являются результатом эволюционных процессов, сотрясающих мир программирования. Эти языки продолжают решать сложнейшие задачи, остаются востребованными и продолжают развиваться. Что будет дальше посмотрим, ведь эволюция – естественный процесс, предотвратить который невозможно.
ЗАКЛЮЧЕНИЕ
Итак, в данной работе были изучены самые основоположные факты, касающиеся информационных структур, а именно, статические, динамические свойства хранимых данных; средства распределения объемов памяти и представления данных; эффективные алгоритмы при разрушении, создании, изменении структурной информации.
В курсовой работе решены следующие задачи:
- рассмотрены основные определения о структурировании данных с точки зрения программирования;
- выполнен анализ принципов обработки динамических структур;
- дана характеристика нелинейным динамическим структурам;
- рассмотрены односвязные динамические списки в С++;
- выполнена реализация основных алгоритмов по работе со списками на практике.
Также было применено графическое изображение компонентов динамических списочных структур, а также их связей, что значительно способствует наглядности выше описанного материала.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Аммерааль Л. STL для программистов на С++: Пер. с англ. – М.: ДМК, 2017. – 240 с.
- Бочков С. О., Субботин Д. М. Язык программирования Си для персонального компьютера. – М.: Радио и связь, 2016. – 384 с.
- Бобровский С. Самоучитель програмирования на языке C++ в среде Borland C++ Builder М.: ИНФРА-М, 2015.–251 c.
- Бруно Бабэ. Просто и ясно о Borland C++: Пер. с англ. - Москва: БИНОМ, 2014. – 400с.
- Джосьютис Н. М. C++. Стандартная библиотека. Для профессионалов: Пер. с англ. – СПб.: Питер, 2014. – 730 с.
- Керниган Б. В., Ритчи Д. М. Язык программирования Си: Пер. с англ. – 3-е изд. – СПб.: Невский Диалект, 2014. – 352 с.
- Липпман С. Б. Основы программирования на C++: Пер. с англ. – М.: Вильямс, 2013. – 256 с.
- Липпман С. Б., Лажойе Ж. Язык программирования С++. Вводный курс: Пер. с англ. – 3-е изд. – М.: ДМК, 2016. – 1104 с.
- Лишнер Р. STL. Карманный справочник: Пер. с англ. – СПб.: Питер, 2015. – 187 с.
- Мейерс С. Эффективное использование STL: Пер. с англ. – СПб.: Питер, 2013. – 224 с.
- Оллисон Ч. Философия С++. Практическое программирование. С.Петербург 2014. – 608 с.:ил.
- Послед Б.С. Borland C++ Builder 6. Разработка приложений баз. М.: 2013г. -360 г.
- Стенли Б. Липпман. C++ для начинающих: Пер. с англ. 2тт. - Москва: Унитех; Рязань: Гэлион, 2013. – 345с.
- Страуструп Б. Язык программирования C++: Пер. с англ. – 3-е спец. изд. – М.: Бином, 2013. – 1104 с.
- Страуструп Б. Дизайн и эволюция языка C++. Объектно- ориентированный язык программирования: Пер. с англ. – М.: ДМК пресс, Питер, 2013. – 448 с.
- Холингворт Д. Учебник по программированию в среде С++ Builder 5. – Наука.–М.: 2015. –865 с.
- Юпашников A.M. Программирование в среде C++ Builder. – М.: МИФИ, 2014. – 360 c.
- Эккель Б. Философия C++. Введение в стандартный C++: Пер. с англ. – 2-е изд. – СПб.: Питер, 2014. – 572 с.
- Эккель Б., Эллисон Ч. Философия C++. Практическое программирование: Пер. с англ. – СПб.: Питер, 2014. – 608 с. с. 1 (из 2)
- STL – стандартная библиотека шаблонов C++: Пер. с англ. / П. Плаугер, А. Степанов, М. Ли, Д. Массер. – СПб.: БХВ-Петербург, 2014. – 656 с.
-
Джосьютис Н. М. C++. Стандартная библиотека. Для профессионалов: Пер. с англ. – СПб.: Питер, 2014 ↑
-
STL – стандартная библиотека шаблонов C++: Пер. с англ. / П. Плаугер, А. Степанов, М. Ли, Д. Массер. – СПб.: БХВ-Петербург, 2014 ↑
-
Страуструп Б. Дизайн и эволюция языка C++. Объектно- ориентированный язык программирования: Пер. с англ. – М.: ДМК пресс, Питер, 2013 ↑
-
Мейерс С. Эффективное использование STL: Пер. с англ. – СПб.: Питер, 2013 ↑
-
Бруно Бабэ. Просто и ясно о Borland C++: Пер. с англ. - Москва: БИНОМ, 2014 ↑
-
Липпман С. Б., Лажойе Ж. Язык программирования С++. Вводный курс: Пер. с англ. – 3-е изд. – М.: ДМК, 2016 ↑
-
Послед Б.С. Borland C++ Builder 6. Разработка приложений баз. – М.: 2013 ↑
-
Бобровский С. Самоучитель програмирования на языке C++ в среде Borland C++ Builder М.: ИНФРА-М, 2015 ↑
-
Керниган Б. В., Ритчи Д. М. Язык программирования Си: Пер. с англ. – 3-е изд. – СПб.: Невский Диалект, 2014 ↑
-
Бобровский С. Самоучитель програмирования на языке C++ в среде Borland C++ Builder М.: ИНФРА-М, 2015 ↑
-
Керниган Б. В., Ритчи Д. М. Язык программирования Си: Пер. с англ. – 3-е изд. – СПб.: Невский Диалект, 2014 ↑
-
Лишнер Р. STL. Карманный справочник: Пер. с англ. – СПб.: Питер, 2015 ↑
-
Эккель Б. Философия C++. Введение в стандартный C++: Пер. с англ. – 2-е изд. – СПб.: Питер, 2014 ↑
-
Страуструп Б. Язык программирования C++: Пер. с англ. – 3-е спец. изд. – М.: Бином, 2013 ↑
-
Липпман С. Б. Основы программирования на C++: Пер. с англ. – М.: Вильямс, 2013 ↑
-
Оллисон Ч. Философия С++. Практическое программирование. – С.Петербург 2014 ↑
-
Стенли Б. Липпман. C++ для начинающих: Пер. с англ. 2тт. - Москва: Унитех; Рязань: Гэлион, 2013 ↑
-
Бочков С. О., Субботин Д. М. Язык программирования Си для персонального компьютера. – М.: Радио и связь, 2016 ↑
-
Юпашников A.M. Программирование в среде C++ Builder. — М.: МИФИ, 2014 ↑
-
Эккель Б., Эллисон Ч. Философия C++. Практическое программирование: Пер. с англ. — СПб.: Питер, 2014 ↑
-
Аммерааль Л. STL для программистов на С++: Пер. с англ. — М.: ДМК, 2017 ↑

- Логистический подход к управлению запасами?
- Основные современные подходы к истолкованию природы права (Правопонимание: понятие, объект, субъект, значение)
- Влияние информационных сетей на становление современного общества ( Примеры практического применения информационных сетей в обществе)
- Управление конфликтами в проектной среде (Понятие, субъекты, классификация конфликтов)
- Проектный офис (Понятие и назначение проектного офиса)
- Анализ внешней и внутренней среды организации (АНАЛИЗ ВНЕШНЕЙ И ВНУТРЕННЕЙ СРЕДЫ ООО «ДИАГНОСТИКА-2»)
- Проектирование баз данных для домашней библиотеки (Архитектура базы данных: понятие, определение, уровни)
- Базы данных. Проектирование БД клиентов магазина
- ФОРМИРОВАНИЕ ЭФФЕКТИВНОЙ КОМАНДЫ ПРОЕКТА
- Пример проекта и команды для его реализации (ТЕОРЕТИЧЕСКИЕ ОСНОВЫ СОЗДАНИЯ И ФУНКЦИОНИРОВАНИЯ ПРОЕКТА)
- СТАДИЯ ФОРМИРОВАНИЯ КОМАНДЫ ПРОЕКТА (ПРОБЛЕМЫ ФОРМИРОВАНИЯ И ФУНКЦИОНИРОВАНИЯ КОМАНД УПРАВЛЕНИЯ ПРОЕКТАМИ)
- Управление конфликтом в проектной среде (Понятие конфликта в организации)