
Методы кодирования данных
Содержание:

Введение
Актуальность темы исследования состоит в том, что кодирование данных - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки данных.
Все алгоритмы кодирования оперируют входным потоком данных, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт.
Основателем теории данных принято считать Клода Шеннона, который, начав с углубленного изучения математической статистики, предоставил инженерам полное определение ёмкости коммуникационного канала. Его теория не рассматривает содержание передаваемого сообщения и не обращает особого внимания на процессы передачи данных, но старается оптимизировать процессы сжатия сообщения с небольшими потерями, что требует применения критерия точности.
Необходимость кодирования данных возникла задолго до появления компьютеров. Речь, азбука и цифры – есть не что иное, как система моделирования мыслей, речевых звуков и числовых данных. В технике потребность кодирования возникла сразу после создания телеграфа, но особенно важной она стала с изобретением компьютеров.
Область действия теории кодирования распространяется на передачу данных по реальным (или зашумленным) каналам, а предметом является обеспечение корректности переданной информации. Иными словами, она изучает, как лучше упаковать данные, чтобы после передачи сигнала из данных можно было надежно и просто выделить полезную информацию.
Поэтому изучение кодирования данных и методов кодирования данных является актуальным.
Объектом исследования курсовой работы является кодирование и методы кодирования данных.
Предметом исследования являются программные приложения, показывающие основные принципы кодирования данных.
Целью курсовой работы является изучения основных методов кодирования данных. Данная цель обусловила выделение следующих задач:
- раскрыть основные понятия кодирования данных;
- рассмотреть классификацию назначения и способы представления кодов;
- изучить метод кодирования данных Шеннона-Фано;
- изучить метод кодирования данных Хаффмена;
- рассмотреть конкретные методы кодирования данных.
Глава 1 Теоретические основы кодирования данных
1.1 Основные понятия кодирования данных
Кодирование данных - процесс преображения сигнала из вида, подходящего для конкретного применения данных, в форму, благоприятную для передачи, сохранения или автоматической обработки (цифровое кодирование, аналоговое кодирование, таблично-символьное кодирование, числовое кодирование). Процесс преобразования сообщения в комбинацию знаков в согласовании с кодом называется кодированием, процесс воссоздания сообщения из комбинации символов называется декодированием [10, c.17].
Данные следует отображать в каком-либо виде, т.е. кодировать.
Для отображения дискретных данных применяется отдельный алфавит. Хотя однозначного соотношения среди данных и алфавитом не имеется. Иными словами, одни и те же данные могут быть изображены с помощью разнообразных алфавитов. Такие возможности зарождают проблему перехода от одного алфавита к иному, притом, подобное изменение не должно вести к утрате данных.
Алфавит, с помощью которого представляются данные до преображения называется первичным; алфавит окончательного отображения – вторичным.
Код является правилом, описывающем соотношение знаков или их синтезирования одного алфавита знакам или их сочетаниям иного алфавита; или же знаки вторичного алфавита, применяемые для отображения знаков или их синтезов первичного алфавита.
Код – комплекс знаков (символов) и система поставленных правил, с использованием которых данные могут быть представлены (закодированы) в форме набора из таких символов для передачи, обрабатывания и сохранения. Окончательная последовательность кодовых знаков называется словом. Зачастую для кодирования данных применяют буквы, цифры, числа, знаки и их сочетания [10, c. 18].
Код отображается в виде набора символов к которому определённое значение (смысл). Код считается знаковой системой, содержащей итоговое число символов: буквы алфавита, цифры, знаки препинания, знаки препинания, знаки математических операций и т.д.
Кодирование является операцией сравнения знаков или групп знаков одного кода с знаками или группами знаков иного кода.
Кодирование – перевод данных, отображенных в виде первичного алфавита, в последовательность кодов [16, c. 29].
Кодирование данных является процессом формирования определенного представления данных. Более узко под словом «кодирование» понимают перевод от одной формы отображения данных к иной, наиболее подходящей для сохранения, передачи или обработки.
Кодирование данных – процесс преображения сигналов или знаков одной знаковой системы в знаки иной знаковой системы, для применения, сохранения, передачи или обработки.
Декодирование - действие, противоположное кодированию, т.е. восстановление данных из закодированной формы (возобновление в первичном алфавите по полученной очередности кодов) [16, c. 30].
Процессы кодирования и декодирования являются обратимыми тогда, когда поочередное использование гарантирует возвращение к исходным данным без каких-нибудь их утрат.
Примером обратимого кодирования представляется отображение знаков в телеграфном коде и их возобновление после передачи. Примером кодирования необратимого считается перевод с одного естественного языка на иной – обратный перевод, в принципе не воспроизводит начального текста. Бесспорно, на практике в задачах, сопряженных со знаковым отображением информации, вероятность воссоздания информации по ее коду считается важным условием использования кода, вследствие этого в последующем исследовании рассмотрим только обратимое кодирование.
Таким образом, кодирование предшествует передаче и хранению данных. При этом сохранение связано с фиксацией отдельного состояния носителя данных, а передача – с переменой состояния с ходом времени (т.е. процессом). Данные состояния или сигналы называются простыми сигналами – собственно их комплекс и является вторичным алфавитом.
Каждый код должен гарантировать единственное чтение сообщения (достоверность), так и, предпочтительно, быть экономным (применять в среднем минимальное число знаков на сообщение).
Вероятность воссоздать текст обозначает, что в языке присутствует некая избыточность, за счет которой восстанавливаются отсутствующие элементы по оставшимся. Избыточность обнаруживается в возможностях букв и их комбинациях, их понимание дает возможность выбрать максимально возможный ответ.
Компьютер может подвергать обработке только данные, представленные в числовой форме. Все другие данные для обработки на компьютере должны быть преобразованы в числовую форму. С использованием компьютерных программ можно трансформировать полученные данные, в том числе - текстовые. При введение в компьютер буква шифруется некоторым числом, а при отображении на внешние приборы (экран или печать) для восприятия людьми по данным числам отображаются изображения букв. Соотношение между набором букв и числами называется кодировкой символов. Обычно, все числа в компьютере отображаются с применением нулей и единиц, т.е. словами, компьютеры функционируют в двоичной системе счисления, потому что при этом приборы для их обработки выходят существенно более простыми [7, c. 61].
В ходе преображения данных из одной формы знаков представления (знаковой системы) в иную исполняется кодирование. Орудием кодирования является таблица соотношения, которая определяет взаимно единственное соответствие среди знаков или группами знаков двух разных знаковых систем. В ходе обмена данными зачастую случается совершать процедуры кодирования и декодирования данных. При вводе знака алфавита в компьютер, в процессе нажатия соответственной клавиши на клавиатуре производится его кодирование, т. е. преобразование в компьютерный код. При выводе знака на экран монитора или принтер происходит обратный процесс - декодирование, из компьютерного кода знак отображается в изображение.
Кодирование данных делится на этапы:
1) Установление объёма данных, подлежащих кодированию.
2) Систематизация и группировка данных.
3) Подбор системы кодирования и построение кодовых обозначений.
4) Непосредственное кодирование [10, c. 20].
Таким образом, кодирование данных – это процесс преображения сигнала из вида, удобного для конкретного применения данных, в вид, подходящий для передачи, сохранения или автоматической переработки.
1.2 Классификация назначения и способы представления кодов
Коды классифицируют по разным признакам:
1. По основанию (числу знаков в алфавите): бинарные (двоичные m=2) и не бинарные (m № 2).
2. По длине кодовых комбинаций (слов): равные, когда все кодовые комбинации обладают равной длиной и неравные, когда протяженность кодовой комбинации не стабильна.
3. По способам передачи: поочередные и параллельные; блочные - данные сначала помещаются в буфер, а потом подаются в канал и бинарные непрерывные.
4. По помехоустойчивости: простые (примитивные, полные) - для передачи информации применяют все вероятные кодовые комбинации (без избыточности); корректирующие (помехозащищенные) - для передачи информации применяют не все, а лишь часть (допустимых) кодовых комбинаций.
5. В связи с предназначением и применением [1, c. 36].
Условно выделяют следующие типы кодов:
1. Внутренние коды - коды, применяемые внутри устройств. К ним относятся машинные коды, а также коды, основывающиеся на применении позиционных систем счисления (двоичный, десятичный, двоично-десятичный, восьмеричный, шестнадцатеричный и др.). Известным кодом считается двоичный код, который дает возможность просто осуществить аппаратное устройство для хранения, обработки и передачи информации в двоичном коде. Он гарантирует большую надежность устройств и простоту исполнения операций над данными в двоичном коде. Двоичные данные, сведенные в группы по 4, формируют шестнадцатеричный код, который превосходно соответствует архитектуре ЭВМ, функционирующей с данными кратными байту (8 бит).
2. Коды для обмена данными и их передачи по каналам связи. Обширную популяризацию в ПК приобрел код ASCII (American Standard Code for Information Interchange). ASCII является 7-битным кодом буквенно-цифровых и иных символов. Так как ЭВМ функционируют с байтами, то 8-й разряд применяется для синхронизации или апробации на четность, или углубления кода. В ЭВМ фирмы IBM применяется раздвинутый двоично-десятичный код для обмена информацией EBCDIC (Extended Binary Coded Decimal Interchange Code). В каналах связи часто применяется телетайпный код МККТТ (международный консультативный комитет по телефонии и телеграфии) и его модели (МТК и др.) [6, c. 49].
При кодировании данных для передачи по каналам связи, в том числе внутри аппаратных трактов, применяются коды, позволяющие развить максимальную скорость передачи данных, за счет их сжатия и ликвидации избыточности (например: коды Хаффмана и Шеннона-Фано), и коды обеспечивающие точность передачи данных, за счет установления избыточности в передаваемые сообщения (к примеру: групповые коды, Хэмминга, повторяющиеся и их вариации).
Коды для особых применений - это коды, определенные для решения особенных задач передачи и обрабатывания данных. Образцами подобных кодов считается циклический код Грея, часто применяемый в АЦП угловых и линейных перемещений. Коды Фибоначчи употребляются для возведения быстродействующих и помехоустойчивых АЦП.
В связи с используемыми методами кодирования, применяют разнообразные математические модели кодов, при этом максимально часто используется отображение кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д. Рассмотрим ключевые способы отображения кодов.
Матричное отображение кодов. Применяется для отображения размеренных n - значных кодов. Для простого (полного и равномерного) кода матрица имеет n - столбцов и 2n - строк, т.е. код применяет все совокупности. Для помехоустойчивых (корректирующих, обнаруживающих и выправляющих ошибки) матрица охватывает n - столбцов (n = k+m, где k-число информативных, а m - число проверочных разрядов) и 2k - строк (где 2k - число разрешенных кодовых комбинаций). При крупных значениях n и k матрица станет чрезмерно массивной, при этом код вписывается в сокращенном виде. Матричное отображение кодов применяется, например, в линейных групповых кодах, кодах Хэмминга и т.д. [6, c. 51].
Отображение кодов в виде кодовых деревьев. Кодовое дерево - связной граф, не имеющий циклов. Связной граф - граф, в котором для любой пары вершин присутствует путь, объединяющий данные вершины. Граф складывается из узлов (вершин) и ребер (ветвей), объединяющих узлы, находящиеся на различных уровнях. Для возведения дерева размеренного двоичного кода находят вершину, именуемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
В зависимости от целей кодирования, различают следующие его виды:
- кодирование по образцу - используется всякий раз при вводе данных в компьютер для их внутреннего представления;
- криптографическое кодирование, или шифрование, – используется, когда нужно защитить данные от несанкционированного доступа;
- эффективное, или оптимальное, кодирование – используется для устранения избыточности данных, т.е. снижения их объема, например, в архиваторах;
- помехозащитное, или помехоустойчивое, кодирование – используется для обеспечения заданной достоверности в случае, когда на сигнал накладывается помеха, например, при передаче данных по каналам связи [4, c. 94].
Рассмотрим способы кодирования/декодирования данных.
1. Коды по образцу. Данный вид кодирования применяется для представления дискретного сигнала на том или ином машинном носителе. Большинство кодов, используемых в информатике для кодирования по образцу, имеют равную длину и используют двоичную систему для представления кода (и, возможно, шестнадцатеричную как средство промежуточного представления).
2. Криптографические коды. Криптографические коды используются для защиты сообщений от несанкционированного доступа, потому называются также шифрованными. В качестве символов кодирования могут использоваться как символы произвольного алфавита, так и двоичные коды.
3. Эффективное кодирование. Этот вид кодирования используется для уменьшения объемов информации на носителе - сигнале. Для кодирования символов исходного алфавита используют двоичные коды переменной длины: чем больше частота символа, тем короче его код [2, c. 117].
Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмена. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды.
Таким образом, коды классифицируют по разным признакам: по основанию, по длине кодовых комбинаций, по способам передачи, по помехоустойчивости, в зависимости от назначения и применения. В зависимости от используемых методов кодирования, применяют разнообразные математические модели кодов, при этом зачастую используется отображение кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д.
Глава 2 Обзор методов кодирования данных
2.1 Метод Шеннона-Фано
Метод Шеннона-Фано просит упорядочения начального множества знаков по не возрастанию их частот. Далее исполняются последующие шаги:
а) список символов разделяется на две части так, чтобы суммы частот двух частей (обозначим их Σ1 и Σ2) были точно или приблизительно равны. В том случае, когда четкого равенства добиться не получается, разность между суммами должна быть минимальной;
б) кодовым комбинациям первой части дописывается 1, кодовым комбинациям второй части дописывается 0;
в) оценивают первую часть: если она включает только один знак, работа с ней завершается, – считается, что код для ее знаков выстроен, и производится переход к шагу г) для построения кода второй части. Когда символов более одного, переключаются к шагу а) и действие повторяют с первой частью как с независимым упорядоченным списком;
г) оценивают вторую часть: в случае если она имеет только один знак, работа с ней завершается и производится обращение к оставшемуся списку (шаг д). Если знаков более одного, переключаются к шагу а) и действие повторяется со второй частью как с самостоятельным списком;
д) разбирается остальной список: если он пуст – код выстроен, работа завершается. Если нет, – исполняется шаг а) [10, c. 64].
Рассмотрим метод Шеннона-Фано на примере. Даны символы a, b, c, d с частотами fa = 0,5; fb = 0,25; fc = 0,125; fd = 0,125. Построим эффективный код методом Шеннона-Фано. Объединим начальные данные в таблицу, упорядочив их по не возрастанию частот:
|
Исходные символы |
Частоты символов |
|
a |
0,5 |
|
b |
0,25 |
|
c |
0,125 |
|
d |
0,125 |
Первая линия деления протекает под символом a: отвечающие суммы Σ1 и Σ2 одинаковы между собой и равны 0,5. Тогда создаваемым кодовым композициям дописывается 1 для верхней (первой) части и 0 для нижней (второй) части. Так как это первый шаг формирования кода, двоичные цифры не дописываются, а только принимаются формировать код:
|
Исходные символы |
Частоты символов |
Формируемый код |
|
a |
0,5 |
1 |
|
b |
0,25 |
0 |
|
c |
0,125 |
0 |
|
d |
0,125 |
0 |
В силу того, что верхняя часть списка содержит только один элемент (символ а), работа с ней заканчивается, а эффективный код для этого символа считается сформированным (в таблице, приведенной выше, эта часть списка частот символов выделена заливкой). Второе деление выполняется под символом b: суммы частот Σ1 и Σ2 вновь равны между собой и равны 0,25. Тогда кодовой комбинации символов верхней части дописывается 1, а нижней части – 0. Таким образом, к полученным на первом шаге фрагментам кода, равным 0, добавляются новые символы:
|
Исходные символы |
Частоты символов |
Формируемый код |
|
a |
0,5 |
1 |
|
b |
0,25 |
01 |
|
c |
0,125 |
00 |
|
d |
0,125 |
00 |
Поскольку верхняя часть нового списка содержит только один символ (b), формирование кода для него закончено (соответствующая строка таблицы вновь выделена заливкой). Третье деление проходит между символами c и d: к кодовой комбинации символа c приписывается 1, коду символа d приписывается 0:
|
Исходные символы |
Частоты символов |
Формируемый код |
|
a |
0,5 |
1 |
|
b |
0,25 |
01 |
|
c |
0,125 |
001 |
|
d |
0,125 |
000 |
Поскольку обе оставшиеся половины исходного списка содержат по одному элементу, работа со списком в целом заканчивается.
Таким образом, получили коды: а - 1, b - 01, c - 001, d - 000.
Определим эффективность построенного кода по формуле:
Icp = 0,5*1 + 0,25*01 + 0,125*3 + 0,125*3 = 1,75.
Поскольку при кодировании четырех символов кодом постоянной длины требуется два двоичных разряда, сэкономлено 0,25 двоичного разряда в среднем на один символ.
2.2 Метод Хаффмена
Метод Хаффмена имеет два преимущества по сравнению с методом Шеннона-Фано: он устраняет неоднозначность кодирования, возникающую из-за примерного равенства сумм частот при разделении списка на две части (линия деления проводится неоднозначно), и имеет, в общем случае, большую эффективность кода. Исходное множество символов упорядочивается по не возрастанию частоты и выполняются следующие шаги:
1) объединение частот:
- две последние частоты списка складываются, а соответствующие символы исключаются из списка;
- оставшийся после исключения символов список пополняется суммой частот и вновь упорядочивается;
- предыдущие шаги повторяются до тех пор, пока ни получится единица в результате суммирования и список ни уменьшится до одного символа;
2) построение кодового дерева:
- строится двоичное кодовое дерево: корнем его является вершина, полученная в результате объединения частот, равная 1; листьями – исходные вершины; остальные вершины соответствуют либо суммарным, либо исходным частотам, причем для каждой вершины левая подчиненная вершина соответствует большему слагаемому, а правая – меньшему; ребра дерева связывают вершины-суммы с вершинами-слагаемыми. Структура дерева показывает, как происходило объединение частот;
- ребра дерева кодируются: каждое левое кодируется единицей, каждое правое – нулём;
3) формирование кода: для получения кодов листьев (исходных кодируемых символов) продвигаются от корня к нужной вершине и «собирают» веса проходимых рёбер [10, c. 68].
Рассмотрим метод Хаффмена на примере. Даны символы a, b, c, d с частотами fa = 0,5; fb = 0,25; fc = 0,125; fd= 0,125. Построим эффективный код методом Хаффмена.
1) Объединение частот (результат объединения двух последних частот в списке выделен в правом соседнем столбце заливкой):
|
Исходные символы |
Частоты fs |
Этапы объединения |
||
|
первый |
второй |
третий |
||
|
a |
0,5 |
0,5 |
0,5 |
1 |
|
b |
0,25 |
0,25 |
0,5 |
|
|
c |
0,125 |
0,25 |
||
|
d |
0,125 |
|||
2) Построение кодового дерева:
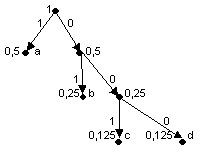
3) Формирование кода: a - 1; b - 01; c - 001; d -000.
Как видно, полученные коды совпадают с теми, что были сформированы методом Шеннона-Фано, следовательно, они имеют одинаковую эффективность.
Повысить эффективность кодирования можно, строя код не для символа, а для блоков из n символов, причем частота блока рассчитывается как произведение частот символов, входящих в блок. Рассмотрим этот тезис на примере.
Даны символы a и b с частотами, соответственно, 0,9 и 0,1. Построим эффективный код методом Шеннона-Фано для блоков из двух символов (n = 2).
Сформируем список возможных блоков и их частот. При этом частоту блока будем рассчитывать, как произведение частот символов, входящих в блок. Построение кода сведём в таблицу:
|
Блоки исходных символов |
Частоты блоков |
Этапы построения кода |
||
|
первый |
второй |
третий |
||
|
aa |
0,81 |
1 |
код построен |
|
|
ab |
0,09 |
0 |
1 |
код построен |
|
ba |
0,09 |
0 |
0 |
1 |
|
bb |
0,01 |
0 |
0 |
0 |
Таким образом, получены коды: aa – 1; ab - 01; ba - 001; bb - 000.
Определим эффективность построенного кода. Для этого рассчитаем сначала показатель эффективности для блока символов:
Iсрблока = 0,81⋅1 + 0,09⋅2 + 0,09⋅3 + 0,01⋅3 = 1,28.
Поскольку в блоке 2 символа (n=2), для одного символа
Iср=Iсрблока/2 = 1,28/2 = 0,64.
При посимвольном кодировании для эффективного кода потребуется по одному двоичному разряду. В самом деле, применение метода Шеннона-Фано даёт результат, представленный в таблице:
|
Исходные символы |
Частоты символов |
Построение кода |
|
a |
0,9 |
1 |
|
b |
0,1 |
0 |
Таким образом, при блочном кодировании выигрыш составил 1 - 0,64 = 0,36 двоичных разрядов на один кодируемый символ в среднем.
Эффективность блочного кодирования тем выше, чем больше символов включается в блок.
Особенностью эффективных кодов является переменное число двоичных разрядов в получаемых кодовых комбинациях. Это затрудняет процесс декодирования [15, c. 109].
Помимо рассмотренных универсальных методов эффективного кодирования на практике часто применяются методы, ориентированные на конкретные виды сообщений. В зависимости от типа исходного сообщения они делятся на методы эффективного кодирования (сжатия) числовых последовательностей, словарей, естественно-языковых текстов.
2.3 Конкретные методы кодирования
1. Алфавитное неравномерное двоичное кодирование
Данный случай относится к варианту (2) табл. 1. При этом как следует из названия, символы некоторого первичного алфавита кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться. Длительности элементарных сигналов при этом одинаковы (  ).
).
Очевидно, суммарная длительность сообщения будет меньше, если применить следующий подход: тем буквам первичного алфавита, которые встречаются чаще, присвоить более короткие по длительности коды, а тем, относительная частота которых меньше – коды более длинные. Но длительность кода – величина дискретная, она кратна длительности сигнала передающего один символ двоичного алфавита. Следовательно, коды букв, вероятность появления которых в сообщении выше, следует строить из возможно меньшего числа элементарных сигналов. Построим кодовую таблицу для букв русского алфавита, основываясь на приведенных ранее вероятностях появления отдельных букв [15, c. 114].






Очевидно, возможны различные варианты двоичного кодирования, однако, не все они будут пригодны для практического использования – важно, чтобы закодированное сообщение могло быть однозначно декодировано, т.е. чтобы в последовательности 0 и 1, которая представляет собой многобуквенное кодированное сообщение, всегда можно было бы различить обозначения отдельных букв. Проще всего этого достичь, если коды будут разграничены разделителем – некоторой постоянной комбинацией двоичных знаков. Условимся, что разделителем отдельных кодов букв будет последовательность 00 (признак конца знака), а разделителем слов – 000 (признак конца слова – пробел). Довольно очевидными оказываются следующие правила построения кодов:
- код признака конца знака может быть включен в код буквы, поскольку не существует отдельно (т.е. кода всех букв будут заканчиваться 00);
- коды букв не должны содержать двух и более нулей подряд в середине (иначе они будут восприниматься как конец знака);
- код буквы (кроме пробела) всегда должен начинаться с 1;
- разделителю слов (000) всегда предшествует признак конца знака; при этом реализуется последовательность 00000 (т.е. если в конце кода встречается комбинация …000 или …0000, они не воспринимаются как разделитель слов); следовательно, коды букв могут оканчиваться на 0 или 00 (до признака конца знака).
Длительность передачи каждого отдельного кода ti, очевидно, может быть найдена следующим образом:

где ki – количество элементарных сигналов (бит) в коде символа i.
В соответствии с приведенными выше правилами получаем следующую таблицу кодов (таблица 1).
Таблица 1 - Таблица кодов [15, c. 116]
|
Буква |
Код |
pi·103 |
ki |
Буква |
Код |
pi·103 |
ki |
|
пробел |
000 |
174 |
3 |
я |
1011000 |
18 |
7 |
|
о |
100 |
90 |
3 |
ы |
1011100 |
16 |
7 |
|
е |
1000 |
72 |
4 |
з |
1101000 |
16 |
7 |
|
а |
1100 |
62 |
4 |
ь,ъ |
1101100 |
14 |
7 |
|
и |
10000 |
62 |
5 |
б |
1110000 |
14 |
7 |
|
т |
10100 |
53 |
5 |
г |
1110100 |
13 |
7 |
|
н |
11000 |
53 |
5 |
ч |
1111000 |
12 |
7 |
|
с |
11100 |
45 |
5 |
й |
1111100 |
10 |
7 |
|
р |
101000 |
40 |
6 |
х |
10101000 |
9 |
8 |
|
в |
101100 |
38 |
6 |
ж |
10101100 |
7 |
8 |
|
л |
110000 |
35 |
6 |
ю |
10110000 |
6 |
8 |
|
к |
110100 |
28 |
6 |
ш |
10110100 |
6 |
8 |
|
м |
111000 |
26 |
6 |
ц |
10111000 |
4 |
8 |
|
д |
111100 |
25 |
6 |
щ |
10111100 |
3 |
8 |
|
п |
1010000 |
23 |
7 |
э |
11010000 |
3 |
8 |
|
у |
1010100 |
21 |
7 |
ф |
11010100 |
2 |
8 |
Теперь по формуле можно найти среднюю длину кода K(2) для данного способа кодирования:

Поскольку для русского языка, I1(r)=4,356 бит, избыточность данного кода составляет:
 ;
;
это означает, что при данном способе кодирования будет передаваться приблизительно на 12% больше информации, чем содержит исходное сообщение. Аналогичные вычисления для английского языка дают значение K(2) = 4,716, что при I1(e) = 4,036 бит приводят к избыточности кода Q(e) = 0,144.
Рассмотрев один из вариантов двоичного неравномерного кодирования, попробуем найти ответы на следующие вопросы: возможно ли такое кодирование без использования разделителя знаков? Существует ли наиболее оптимальный способ неравномерного двоичного кодирования?
Суть первой проблемы состоит в нахождении такого варианта кодирования сообщения, при котором последующее выделение из него каждого отдельного знака (т.е. декодирование) оказывается однозначным без специальных указателей разделения знаков. Наиболее простыми и употребимыми кодами такого типа являются так называемые префиксные коды, которые удовлетворяют следующему условию (условию Фано).
Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом (префиксом) какого-либо иного более длинного кода. Например, если имеется код 110, то уже не могут использоваться коды 1, 11, 1101, 110101 и пр. Если условие Фано выполняется, то при прочтении (расшифровке) закодированного сообщения путем сопоставления со списком кодов всегда можно точно указать, где заканчивается один код и начинается другой.
Использование префиксного кодирования позволяет делать сообщение более коротким, поскольку нет необходимости передавать разделители знаков. Однако условие Фано не устанавливает способа формирования префиксного кода и, в частности, наилучшего из возможных [15, c. 117].
Способ оптимального префиксного двоичного кодирования был предложен Д. Хаффманом. Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является самым экономичным из всех возможных, т.е. ни для какого метода алфавитного кодирования длина кода не может оказаться меньше, чем код Хаффмана.
Применение описанного метода для букв русского алфавита дает следующие коды (таблица 2).
Таблица 2 - Таблица кодов русских букв
|
Буква |
Код |
pi·103 |
ki |
Буква |
Код |
pi·103 |
ki |
|
пробел |
000 |
174 |
3 |
я |
0011001 |
18 |
6 |
|
о |
111 |
90 |
3 |
ы |
0101100 |
16 |
6 |
|
е |
0100 |
72 |
4 |
з |
010111 |
16 |
6 |
|
а |
0110 |
62 |
4 |
ь, ъ |
100001 |
14 |
6 |
|
и |
0111 |
62 |
4 |
б |
101100 |
14 |
6 |
|
т |
1001 |
53 |
4 |
г |
101101 |
13 |
6 |
|
н |
1010 |
53 |
5 |
ч |
110011 |
12 |
6 |
|
с |
1101 |
45 |
4 |
й |
0011001 |
10 |
7 |
|
р |
00101 |
40 |
5 |
х |
1000000 |
9 |
7 |
|
в |
00111 |
38 |
5 |
ж |
1000001 |
7 |
7 |
|
л |
01010 |
35 |
5 |
ю |
1100101 |
6 |
7 |
|
к |
10001 |
28 |
5 |
ш |
00110000 |
6 |
8 |
|
м |
10111 |
26 |
5 |
ц |
11001000 |
4 |
8 |
|
д |
11000 |
25 |
5 |
щ |
11001001 |
3 |
8 |
|
п |
001000 |
23 |
6 |
э |
001100010 |
3 |
9 |
|
у |
001001 |
21 |
6 |
ф |
001100011 |
2 |
9 |
Средняя длина кода оказывается равной K(2) = 4,395; избыточность кода Q(r) = 0,00887, т.е. менее 1%.
Таким образом, можно заключить, что существует метод построения оптимального неравномерного алфавитного кода. Не следует думать, что он представляет число теоретический интерес. Метод Хаффмана и его модификация – метод адаптивного кодирования (динамическое кодирование Хаффмана) – нашли широчайшее применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах.
Кодирование энтропии - кодирования словами (кодами) переменной длины, при которой длина кода символа имеет обратную зависимость от вероятности появления символа в передаваемом сообщении. Обычно энтропийные кодировщики используют для сжатия данных коды, длины которых пропорциональны отрицательному логарифму вероятности символа. Таким образом, наиболее вероятные символы используют наиболее короткие коды [13, c. 73].
2. Равномерное алфавитное двоичное кодирование.
В этом случае двоичный код первичного алфавита строится цепочками равной длины, т.е. со всеми знаками связано одинаковое количество информации равное I0. Передавать признак конца знака не требуется, поэтому для определения длины кодовой цепочки можно воспользоваться формулой: K(2) log2N. Приемное устройство просто отсчитывает оговоренное заранее количество элементарных сигналов и интерпретирует цепочку (устанавливает, какому знаку она соответствует). При этом недопустимы сбои, например, пропуск (непрочтение) одного элементарного сигнала приведет к сдвигу всей кодовой последовательности и неправильной ее интерпретации; решается проблема путем синхронизации передачи или иными способами. С другой стороны, применение равномерного кода оказывается одним из средств контроля правильности передачи, поскольку факт поступления лишнего элементарного сигнала или, наоборот, поступление неполного кода сразу интерпретируется как ошибка.










Примером равномерного алфавитного кодирования является телеграфный код Бодо, пришедший на смену азбуке Морзе. Исходный алфавит должен содержать не более 32-х символов; тогда K(2) = log2 32 = 5, т.е. каждый знак содержит 5 бит информации. Условие N≤32, очевидно, выполняется для языков, основанных на латинском алфавите (N = 27 = 26+ «пробел»), однако в русском алфавите 34 буквы (с пробелом) – именно по этой причине пришлось «сжать» алфавит (как в коде Хаффмана) и объединить в один знак «е» и «ё», а также «ь» и «ъ». После такого сжатия N = 32, однако, не остается свободных кодов для знаков препинания, поэтому в телеграммах они отсутствуют или заменяются буквенными аббревиатурами; это не является заметным ограничением, поскольку, как указывалось выше, избыточность языка позволяет легко восстановить информационное содержание сообщения. Избыточность кода Бодо для русского языка Q(r) = 0,129, для английского Q(e) = 0,193 [13, c. 75].
Другим важным для нас примером использования равномерного алфавитного кодирования является представление символьной информации в компьютере. Чтобы определить длину кода, необходимо начать с установления количество знаков в первичном алфавите. Компьютерный алфавит должен включать:
26*2=52 букв латинского алфавита (с учетом прописных и строчных);
33*2=66 букв русского алфавита;
цифры 0...9 – всего 10;
знаки математических операций, знаки препинания, спецсимволы = 20.
Получаем, что общее число символов N=148. Теперь можно оценить длину кодовой цепочки: K(2)≥log2148≥7,21. Поскольку K(2) должно быть целым, очевидно, K(2)= 8. Именно такой способ кодирования принят в компьютерных системах: любому символу ставится в соответствие цепочка из 8 двоичных разрядов (8 бит). Такая цепочка получила название байт, а представление таким образом символов – байтовым кодированием.
Байт наряду с битом может использоваться как единица измерения количества информации в сообщении. Один байт соответствует количеству информации в одном символе алфавита при их равновероятном распределении. Этот способ измерения количества информации называется также объёмным. Пусть имеется некоторое сообщение (последовательность знаков); оценка количества содержащейся в нём информации согласно рассмотренному ранее вероятностному подходу (с помощью формулы Шеннона) даёт Iвер, а объемная мера пусть равна Iоб; соотношение между этими величинами: Iвер ≤ Iоб.
Собственно, байт установлен как единица измерения количества информации в интернациональной системе единиц СИ. 1 байт = 8 бит. Применение 8-битных цепочек дает возможность зашифровать 28=256 символов, что превосходит оцененное выше N и, следственно, дает возможность применить остальную часть кодовой таблицы для изображения дополнительных символов [13, c. 76].
Однако слишком мало только условиться об некоторой длине кода. Понятно, что методов кодирования, т.е. вариантов сравнения знакам первичного алфавита восьмибитных цепочек, множество. По данной причине для сопоставимости технических устройств и предоставления потенциала обмена информацией между многочисленными пользователями требуется состыковка кодов. Подобная состыковка исполняется в форме типизации кодовых таблиц. Начальным таким интернациональным стандартом, который использовался на и телекоммуникационных системах используется международный байтовый код огромных вычислительных машинах, был EBCDIC> (Extended Binary Coded Decimal Interchange Code) – «расширенная двоичная кодировка десятичного кода обмена». В персональных компьютерах ASCII (American Standard Code for Information Interchange – «американский стандартный код обмена информацией»). Он регулирует коды первой половины кодовой таблицы (номера кодов от 0 до 127, т.е. первый бит всех кодов 0). В данную часть определяются коды прописных и строчных английских букв, цифры, знаки препинания и математических операций, а также определенные заправляющие коды (номера от 0 до 31). Ниже представлены некоторые ASCII-коды (таблица 3).
Таблица 3 - Некоторые ASCII-коды
|
Знак, клавиша |
Код двоичный |
Код десятичный |
|
пробел |
00100000 |
32 |
|
A (лат) |
01000001 |
65 |
|
B (лат) |
01000010 |
66 |
|
Z |
01011010 |
90 |
|
0 |
00110000 |
48 |
|
1 |
00110001 |
49 |
|
9 |
00111001 |
57 |
|
Клавиша ESC |
00011011 |
27 |
|
Клавиша Enter |
00001101 |
13 |
Вторая часть кодовой таблицы – она считается расширением основной – охватывает коды в интервале от 128 до 255 (первый бит всех кодов 1). Она используется для представления символов национальных алфавитов (например, русского или греческого), а также символов псевдографики. Для этой части также имеются стандарты, например, для символов русского языка это КОИ–8, КОИ–7 и др [15, c. 126].
Как в основной таблице, так и в её расширении коды букв и цифр соответствуют их лексикографическому порядку (т.е. порядку следования в алфавите) – это обеспечивает возможность автоматизации обработки текстов и ускоряет ее.
В настоящее время появился и находит все более широкое применение еще один международный стандарт кодировки – Unicode. Его особенность в том, что в нем использовано 16-битное кодирование, т.е. для представления каждого символа отводится 2 байта. Такая длина кода обеспечивает включения в первичный алфавит 65536 знаков. Это, в свою очередь, позволяет создать и использовать единую для всех распространенных алфавитов кодовую таблицу.
3. Азбука Морзе.
В качестве примера использования кодирования с неравной длительностью элементарных сигналов рассмотрим телеграфный код Морзе («азбука Морзе»). В нём каждой букве или цифре сопоставляется некоторая последовательность кратковременных импульсов – точек и тире, разделяемых паузами. Длительности импульсов и пауз различны: если продолжительность импульса, соответствующего точке, обозначить , то длительность импульса тире составляет 3, длительность паузы между точкой и тире , пауза между буквами слова 3, пауза между словами (пробел) – 6. Таким образом, под знаками кода Морзе следует понимать: « » – «короткий импульс + короткая пауза», «-» – «длинный импульс + короткая пауза», «0» – «длинная пауза», т.е. код оказывается троичным.



























Собственный код Морзе создал в 1838 г., т.е. за длительное время до изучений относительной частоты возникновения разных букв в текстах. Вместе с тем им был конкретно выбран закон кодирования – буквы, которые попадаются чаще, должны обладать более непродолжительными кодами, чтобы свести к минимуму совокупное время передачи. Условные частоты букв английского алфавита он расценил обычным подсчетом литер в ячейках типографской наборной машины. В связи с этим самая популярная английская буква «Е» приобрела код «точка». При синтезировании кодов Морзе для букв русского алфавита учёт условной частоты букв не выполнялся, что, естественно, нарастило его избыточность. Как и в разобранных ранее вариантах кодирования, осуществим анализ избыточности. По-прежнему для комфорта сравнения данные изобразим в приведенном ниже формате. Признак конца буквы («0») в их кодах не отражается, но учтён в величине ki – длине кода буквы I [15, c. 128].
Среднее значение длины кода K(3) = 3,361. Полагая появление знаков вторичного алфавита равновероятным, получаем среднюю информацию на знак равной I(2) = log23 = 1,585 бит. Так как для русского алфавита I1(1)= 4,356 бит, то:
Q(r) = 1 – 4,356/(3,361 – 1,585)≈ 0,182
т.е. избыточность составляет около 18% (для английского языка ≈15%). Код Морзе обладал в недальнем прошлом очень обширным распространении в обстановках, когда источником и приемником сигналов считался человек (не техническое устройство) и на первый план выходила не экономичность кода, а практичность его оценки человеком.
Таблица 4 - Таблица кодов Морзе
|
Буква |
Код |
pi·103 |
ki |
Буква |
Код |
pi·103 |
ki |
|
пробел |
00 |
174 |
2 |
я |
·-·- |
18 |
5 |
|
о |
--- |
90 |
4 |
ы |
-·-- |
16 |
5 |
|
е |
· |
72 |
2 |
з |
--· |
16 |
4 |
|
а |
·- |
62 |
3 |
ь, ъ |
-··- |
14 |
5 |
|
и |
·· |
62 |
3 |
б |
-··· |
14 |
5 |
|
т |
- |
53 |
2 |
г |
--· |
13 |
4 |
|
н |
-· |
53 |
3 |
ч |
---· |
12 |
5 |
|
с |
··· |
45 |
4 |
й |
·--- |
10 |
5 |
|
р |
·-· |
40 |
4 |
х |
···· |
9 |
5 |
|
в |
·-- |
38 |
4 |
ж |
···- |
7 |
5 |
|
л |
·-·· |
35 |
5 |
ю |
··-- |
6 |
5 |
|
к |
-·- |
28 |
4 |
ш |
---- |
6 |
5 |
|
м |
-- |
26 |
2 |
ц |
-·-· |
4 |
5 |
|
д |
-·· |
25 |
4 |
щ |
--·- |
3 |
5 |
|
п |
·-- |
23 |
4 |
э |
··-·· |
3 |
6 |
|
у |
··- |
21 |
4 |
ф |
··-· |
2 |
5 |
4. Блочное двоичное кодирование.
Рассмотрим проблему рационального кодирования. Пока что оптимальный итог (минимальная избыточность) был получен при кодировании по методу Хаффмана – для русского алфавита избыточность оказалась меньше 1%. При этом указывалось, что код Хаффмана выправить нельзя. По началу данное возражает первой теореме Шеннона, заявляющей, что всякий раз можно рекомендовать метод кодирования, при котором избыточность будет сколь угодно маленькой величиной. На самом деле данное опровержение появилось из-за того, что рассматривалось алфавитное кодирование. При алфавитном кодировании передаваемое сообщение выступать в роли очередности кодов самостоятельных знаков первичного алфавита. Тем не менее вероятны варианты кодирования, при которых кодовый знак принадлежит сразу к многим буквам изначального алфавита (блок) или даже к целостному слову первичного языка. Кодирование блоков убавляет избыточность. В данном можно удостовериться на примере [15, c. 129].
Пусть имеется в наличии словарь определенного языка, охватывающий n = 16000 слов. Назначим в соответствие каждому слову размеренный двоичный код. Разумеется, длина кода может быть определена из соответствия K(2)≥log2n≥13,97=14. Следовательно, каждому слову будет поставлена в соответствие комбинация из 14 нулей и единиц – получатся своего рода двоичные иероглифы.
Нетрудно выяснить, что при средней длине русского слова K(r) = 6,3 буквы (5,3 буквы + пробел между словами) средняя информация на знак первичного алфавита оказывается равной I(2)=K(2)/K(r) = 14/6,3 = 2,222 бит, что почти в 2 раза меньше, чем 4,395 бит при алфавитном кодировании. Для английского языка подобный способ кодирования дает 2,545 бит на знак. Таким образом, кодирование слов оказывается более выгодным, чем алфавитное.
Ещё более действенным станет кодирование в том случае, если первоначально ввести условную частоту явления разнообразных слов в текстах и затем применять код Хаффмана. По условным частотам 8727 более применимых в английском языке слов Шеннон, что средняя информация на знак первичного алфавита оказывается равной 2,15 бит. Вместо слов можно кодировать совокупности букв – блоки. В принципе блоки можно расценивать словами одинаковой длиной, не обладающими, однако, смыслового содержания. Удлиняя блоки и используя код Хаффмана можно достигнуть того, что средняя информация на знак кода будет сколь угодно близиться к I∞. Однако, применение блочного и словесного метода кодирования имеет свои недостатки.
1) Необходимо хранить огромную кодовую таблицу и постоянно к ней обращаться при кодировании и декодировании, что замедлит работу и потребует значительных ресурсов памяти.
2) Помимо основных слов разговорный язык содержит много производных от них, например, падежи существительных в русском языке или глагольные формы в английском; в данном способе кодирования им всем нужно присвоить свои коды, что приведет к увеличению кодовой таблицы еще в несколько раз.
3) Возникает проблема согласования (стандартизации) этих громадных таблиц, что непросто.
4) Алфавитное кодирование имеет то преимущество, что буквами можно закодировать любое слово, а при кодировании слов – использовать только имеющийся словарный запас.
По указанным причинам блочное и словесное кодирование представляет лишь теоретический интерес, на практике же применяется кодирование алфавитное.
Заключение
Кодирование данных - процесс преображения сигнала из вида, подходящего для конкретного применения данных, в форму, благоприятную для передачи, сохранения или автоматической обработки (цифровое кодирование, аналоговое кодирование, таблично-символьное кодирование, числовое кодирование). Процесс преобразования сообщения в комбинацию знаков в согласовании с кодом называется кодированием, процесс воссоздания сообщения из комбинации символов называется декодированием.
Коды классифицируют по разным признакам: по основанию, по длине кодовых комбинаций, по способам передачи, по помехоустойчивости, в зависимости от назначения и применения. В зависимости от используемых методов кодирования, применяют разнообразные математические модели кодов, при этом зачастую используется отображение кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д.
Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмена. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды.
Метод Хаффмена имеет два преимущества по сравнению с методом Шеннона-Фано: он устраняет неоднозначность кодирования, возникающую из-за примерного равенства сумм частот при разделении списка на две части (линия деления проводится неоднозначно), и имеет, в общем случае, большую эффективность кода.
Помимо рассмотренных универсальных методов эффективного кодирования на практике часто применяются методы, ориентированные на конкретные виды сообщений. В зависимости от типа исходного сообщения они делятся на методы эффективного кодирования (сжатия) числовых последовательностей, словарей, естественно-языковых текстов.
Ещё более действенным станет кодирование в том случае, если первоначально ввести условную частоту явления разнообразных слов в текстах и затем применять код Хаффмана.
Применение блочного и словесного метода кодирования имеет свои недостатки.
1) Необходимо хранить огромную кодовую таблицу и постоянно к ней обращаться при кодировании и декодировании, что замедлит работу и потребует значительных ресурсов памяти.
2) Помимо основных слов разговорный язык содержит много производных от них, например, падежи существительных в русском языке или глагольные формы в английском; в данном способе кодирования им всем нужно присвоить свои коды, что приведет к увеличению кодовой таблицы еще в несколько раз.
3) Возникает проблема согласования (стандартизации) этих громадных таблиц, что непросто.
4) Алфавитное кодирование имеет то преимущество, что буквами можно закодировать любое слово, а при кодировании слов – использовать только имеющийся словарный запас.
По указанным причинам блочное и словесное кодирование представляет лишь теоретический интерес, на практике же применяется кодирование алфавитное.
Список использованной литературы
- Агеев В.М. Теория информации и кодирования: дискретизация и кодирование измерительной информации / В.М. Агеев. - М.: МАИ, 2014. – 316 с.
- Березнюк Н.Т. Кодирование информации. Двоичные коды: Справочник / Н. Т. Березнюк. – М.: Проспект, 2013. – 252 с.
- Гладких А.А. Основы теории мягкого декодирования избыточных кодов в стирающем канале связи / А. А. Гладких. – Ульяновск: УлГТУ, 2010. – 379 с.
- Заренин Ю. Г. Корректирующие коды для передачи и обработки информации. – М.: Академия, 2015. – 170 с.
- Златопольский Д.М. Простейшие методы шифрования текста / Д.М. Златопольский. – М.: Чистые пруды, 2017 – 32 с.
- Иванова Г.С. Технология программирования / Г.С. Иванова - М.: Изд-во МГТУ им. Н.Э. Баумана, 2014. – 320 с.
- Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений / С. Канер, Д. Фолк, Е.К. Нгуен - Киев: ДиаСофт, 2015. – 544 с.
- Костомаров М.Н. Информационное обеспечение управления / М.Н. Костомаров, А.В. Соколов. - М.: МГИАИ,2015. – 364 с.
- Котов П.А. Повышение достоверности передачи цифровой информации / П.А. Котов. – СПб.: Питер, 2016. – 184 с.
- Кузьмин И.В. Основы теории информации и кодирования / И.В. Кузьмин, В.А. Кедрус. – М.: Академия, 2015. – 264 с.
- Кузьмин И.В. Теоретические основы информационной техники / И.В. Кузьмин. – М.: Сфера, 2016. – 162 с.
- Майерс Г. Искусство тестирования программ / Г. Майерс, Т. Баджетт, К. Сандлер - М.: Диалектика, 2016. – 272 с.
- Мартынов Ю.М. Обработка информации в системах передачи данных / Ю.М. Мартынов. – М.: Связь, 2012. – 263 с.
- Меняев М.Ф. Информатика и основы программирования / М.Ф. Меняев. - М.: Омега-Л, 2014. – 458 с.
- Удалов А.П. Избыточное кодирование при передаче информации двоичными кодами / А.П. Удалов, Б.А. Супругин. – М.: Связь, 2014. – 270 с.
- Шастова Г.А. Кодирование и помехоустойчивость передачи телемеханической информации / Г.А. Шастова. – М.: Энергия, 2016. – 454 с.
- Элиас П. Безошибочное кодирование. Коды с обнаружением и исправлением ошибок / П. Элиас. - М.: Академия, 2014. – 182 с.

- Отладка и тестирование программ: основные подходы и ограничения
- Управление поведением в конфликтных ситуациях
- Налоги как цена услуг государства
- Коммерческие банки
- Правовые основы оперативно-розыскной деятельности
- Организация обслуживания в гостиницах
- Семейное воспитание
- Нотариальные действия (Виды нотариальных действий)
- Автоматизация расчетов с клиентами
- Технология обслуживания клиентов в гостинице
- Основные функции менеджмента
- Американская модель менеджмента