
Методы кодирования данных
Содержание:

Введение
Кодирования информации - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки информации.
Все алгоритмы кодирования оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт.
Кодирование Хаффмана является простым алгоритмом для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот весьма популярный алгоритм служит основой многих компьютерных программ сжатия текстовой и графической информации. Некоторые из них используют непосредственно алгоритм Хаффмана, а другие берут его в качестве одной из ступеней многоуровневого процесса сжатия.
Метод Хаффмана производит идеальное сжатие (то есть, сжимает данные до их энтропии), если вероятности символов точно равны отрицательным степеням числа 2. Алгоритм начинает строить кодовое дерево снизу вверх, затем скользит вниз по дереву, чтобы построить каждый индивидуальный код справа налево (от самого младшего бита к самому старшему).
Начиная с работ Д. Хаффмана 1952 года, этот алгоритм являлся предметом многих исследований.
Коды Хаффмана преподаются во всех технических ВУЗах мира и, кроме того, входят в программу для углубленного изучения информатики в школе.
Поэтому изучение кодирования информации и методов кодирования, в частности метода кодирования Хаффмана является актуальным.
Объект исследования: кодирование и методы кодирования информации.
Предмет исследования: программное приложение, показывающие основные принципы кодирования на примере метода кодирования Хаффмана.
Целью курсовой работы является изучения основ кодирования информации в частности метод кодирования Хаффмана и применить их в процессе программной реализации этого метода. Данная цель обусловила выделение следующих задач:
1) рассмотреть основные понятия и принципы кодирования информации;
2) изучить метод кодирования Хаффмана,
3) разработать алгоритмы и программу для реализации программного продукта «Код Хаффмана», с использованием современной технологии программирования;
Глава 1. Теоретические основы кодирования информации
1.1 Основы и основные понятия кодирования информации
Рассмотрим основные понятия, связанные с oc кодированием oc информации. oc Для oc передачи oc в oc канал oc связи oc сообщения oc преобразуются oc в oc сигналы. oc Символы, oc при oc помощи oc которых oc создаются oc сообщения, oc образуют oc первичный oc алфавит, oc при oc этом oc каждый oc символ oc характеризуется oc вероятностью oc его oc появления oc в oc сообщении. oc Каждому oc сообщению oc однозначно oc соответствует oc сигнал, oc представляющий oc определенную oc последовательность oc элементарных oc дискретных oc символов, oc называемых oc кодовыми oc комбинациями.
Кодирование oc - oc это oc преобразование oc сообщений oc в oc сигнал, oc т.е. oc преобразование oc сообщений oc в oc кодовые oc комбинации.[1] oc Код oc - oc система oc соответствия oc между oc элементами oc сообщений oc и oc кодовыми oc комбинациями. oc Кодер oc - oc устройство, oc осуществляющее oc кодирование. oc Декодер oc - oc устройство, oc осуществляющее oc обратную oc операцию, oc т.е. oc преобразование oc кодовой oc комбинации oc в oc сообщение. oc Алфавит oc - oc множество oc возможных oc элементов oc кода, oc т.е. oc элементарных oc символов oc (кодовых oc символов) oc X oc = oc {xi}, oc где oc i oc = oc 1, oc 2,..., oc m. oc Количество oc элементов oc кода oc - oc m oc называется oc его oc основанием. oc Для oc двоичного oc кода oc xi oc = oc {0, oc 1} oc и oc m oc = oc 2. oc Конечная oc последовательность oc символов oc данного oc алфавита oc называется oc кодовой oc комбинацией oc (кодовым oc словом). oc Число oc элементов oc в oc кодовой oc комбинации oc - oc n oc называется oc значностью oc (длиной oc комбинации). oc Число oc различных oc кодовых oc комбинаций oc (N oc = oc mn) oc называется oc объемом oc или oc мощностью oc кода.
Цели oc кодирования:[2]
1) oc Повышение oc эффективности oc передачи oc данных, oc за oc счет oc достижения oc максимальной oc скорости oc передачи oc данных.
2) oc Повышение oc помехоустойчивости oc при oc передаче oc данных.
В oc соответствии oc с oc этими oc целями oc теория oc кодирования oc развивается oc в oc двух oc основных oc направлениях:
1. oc Теория oc экономичного oc (эффективного, oc оптимального) oc кодирования oc занимается oc поиском oc кодов, oc позволяющих oc в oc каналах oc без oc помех oc повысить oc эффективность oc передачи oc информации oc за oc счет oc устранения oc избыточности oc источника oc и oc наилучшего oc согласования oc скорости oc передачи oc данных oc с oc пропускной oc способностью oc канала oc связи.
2. oc Теория oc помехоустойчивого oc кодирования oc занимается oc поиском oc кодов, oc повышающих oc достоверность oc передачи oc информации oc в oc каналах oc с oc помехами.
Научные oc основы oc кодирования oc были oc описаны oc К. oc Шенноном, oc который oc исследовал oc процессы oc передачи oc информации oc по oc техническим oc каналам oc связи oc (теория oc связи, oc теория oc кодирования). oc При oc таком oc подходе oc кодирование oc понимается oc в oc более oc узком oc смысле: oc как oc переход oc от oc представления oc информации oc в oc одной oc символьной oc системе oc к oc представлению oc в oc другой oc символьной oc системе. oc Например, oc преобразование oc письменного oc русского oc текста oc в oc код oc азбуки oc Морзе oc для oc передачи oc его oc по oc телеграфной oc связи oc или oc радиосвязи. oc Такое oc кодирование oc связано oc с oc потребностью oc приспособить oc код oc к oc используемым oc техническим oc средствам oc работы oc с oc информацией.
Декодирование oc — oc процесс oc обратного oc преобразования oc кода oc к oc форме oc исходной oc символьной oc системы, oc т.е. oc получение oc исходного oc сообщения.[3] oc Например: oc перевод oc с oc азбуки oc Морзе oc в oc письменный oc текст oc на oc русском oc языке.
В oc более oc широком oc смысле oc декодирование oc — oc это oc процесс oc восстановления oc содержания oc закодированного oc сообщения. oc При oc таком oc подходе oc процесс oc записи oc текста oc с oc помощью oc русского oc алфавита oc можно oc рассматривать oc в oc качестве oc кодирования, oc а oc его oc чтение oc — oc это oc декодирование.
Способ oc кодирования oc одного oc и oc того oc же oc сообщения oc может oc быть oc разным. oc Например, oc русский oc текст oc мы oc привыкли oc записывать oc с oc помощью oc русского oc алфавита. oc Но oc то oc же oc самое oc можно oc сделать, oc используя oc английский oc алфавит. oc Иногда oc так oc приходится oc поступать, oc посылая oc SMS oc по oc мобильному oc телефону, oc на oc котором oc нет oc русских oc букв, oc или oc отправляя oc электронное oc письмо oc на oc русском oc языке oc из-за oc границы, oc если oc на oc компьютере oc нет oc русифицированного oc программного oc обеспечения. oc Например, oc фразу: oc «Здравствуй, oc дорогой oc Саша!» oc приходится oc писать oc так: oc «Zdravstvui, oc dorogoi oc Sasha!».
Существуют oc и oc другие oc способы oc кодирования oc речи. oc Например, oc стенография oc — oc быстрый oc способ oc записи oc устной oc речи. oc Ею oc владеют oc лишь oc немногие oc специально oc обученные oc люди oc — oc стенографисты. oc Стенографист oc успевает oc записывать oc текст oc синхронно oc с oc речью oc говорящего oc человека. oc В oc стенограмме oc один oc значок oc обозначал oc целое oc слово oc или oc словосочетание. oc Расшифровать oc (декодировать) oc стенограмму oc может oc только oc стенографист.
Приведенные примеры иллюстрируют следующее oc важное oc правило: oc для oc кодирования oc одной oc и oc той oc же oc информации oc могут oc быть oc использованы oc разные oc способы; oc их oc выбор oc зависит oc от oc ряда oc обстоятельств: oc цели oc кодирования, oc условий, oc имеющихся oc средств. oc Если oc надо oc записать oc текст oc в oc темпе oc речи oc — oc используем oc стенографию; oc если oc надо oc передать oc текст oc за oc границу oc — oc используем oc английский oc алфавит; oc если oc надо oc представить oc текст oc в oc виде, oc понятном oc для oc грамотного oc русского oc человека, oc — oc записываем oc его oc по oc правилам oc грамматики oc русского oc языка.
Еще oc одно oc важное oc обстоятельство: oc выбор oc способа oc кодирования oc информации oc может oc быть oc связан oc с oc предполагаемым oc способом oc ее oc обработки. oc Покажем oc это oc на oc примере oc представления oc чисел oc — oc количественной oc информации. oc Используя oc русский oc алфавит, oc можно oc записать oc число oc «тридцать oc пять». oc Используя oc же oc алфавит oc арабской oc десятичной oc системы oc счисления, oc пишем: oc «35». oc Второй oc способ oc не oc только oc короче oc первого, oc но oc и oc удобнее oc для oc выполнения oc вычислений. oc Какая oc запись oc удобнее oc для oc выполнения oc расчетов: oc «тридцать oc пять oc умножить oc на oc сто oc двадцать oc семь» oc или oc «35 oc х oc 127»? oc Очевидно oc — oc вторая.
Однако oc если oc важно oc сохранить oc число oc без oc искажения, oc то oc его oc лучше oc записать oc в oc текстовой oc форме. oc Например, oc в oc денежных oc документах oc часто oc сумму oc записывают oc в oc текстовой oc форме: oc «триста oc семьдесят oc пять oc руб.» oc вместо oc «375 oc руб.». oc Во oc втором oc случае oc искажение oc одной oc цифры oc изменит oc все oc значение. oc При oc использовании oc текстовой oc формы oc даже oc грамматические oc ошибки oc могут oc не oc изменить oc смысла. oc Например, oc малограмотный oc человек oc написал: oc «Тристо oc семдесять oc пят oc руб.». oc Однако oc смысл oc сохранился.
В oc некоторых oc случаях oc возникает oc потребность oc засекречивания oc текста oc сообщения oc или oc документа, oc для oc того oc чтобы oc его oc не oc смогли oc прочитать oc те, oc кому oc не oc положено. oc Это oc называется oc защитой oc от oc несанкционированного oc доступа. oc В oc таком oc случае oc секретный oc текст oc шифруется. oc Шифрование oc представляет oc собой oc процесс oc превращения oc открытого oc текста oc в oc зашифрованный, oc а oc дешифрование oc — oc процесс oc обратного oc преобразования, oc при oc котором oc восстанавливается oc исходный oc текст. oc Шифрование oc — oc это oc тоже oc кодирование, oc но oc с oc засекреченным oc методом, oc известным oc только oc источнику oc и oc адресату. oc Методами oc шифрования oc занимается oc наука oc под oc названием oc криптография.
Пусть oc имеется oc сообщение, oc записанное oc при oc помощи oc некоторого oc «алфавита», oc содержащего oc п oc «букв». oc Требуется oc «закодировать» oc это oc сообщение, oc т.е. oc указать oc правило, oc сопоставляющее oc каждому oc такому oc сообщению oc определенную oc последовательность oc из oc т oc различных oc «элементарных oc сигналов», oc составляющих oc «алфавит» oc передачи. oc Мы oc будем oc считать oc кодирование oc тем oc более oc выгодным, oc чем oc меньше oc элементарных oc сигналов oc приходится oc затратить oc на oc передачу oc сообщения. oc Если oc считать, oc что oc каждый oc из oc элементарных oc сигналов oc продолжается oc одно oc и oc то oc же oc время, oc то oc наиболее oc выгодный oc код oc позволит oc затратить oc на oc передачу oc сообщения oc меньше oc всего oc времени.
Главным oc свойством oc случайных oc событий oc является oc отсутствие oc полной oc уверенности oc в oc их oc наступлении, oc создающее oc известную oc неопределенность oc при oc выполнении oc связанных oc с oc этими oc событиями oc опытов. oc Однако oc совершенно oc ясно, oc что oc степень oc этой oc неопределенности oc в oc различных oc случаях oc будет oc совершенно oc разной.[4] oc Для oc практики oc важно oc уметь oc численно oc оценивать oc степень oc неопределенности oc самых oc разнообразных oc опытов, oc чтобы oc иметь oc возможность oc сравнить oc их oc с oc этой oc стороны. oc Рассмотрим oc два oc независимых oc опыта oc  oc и
oc и oc а oc также oc сложный oc опыт oc
oc а oc также oc сложный oc опыт oc  , oc состоящий oc в oc одновременном oc выполнении oc опытов oc
, oc состоящий oc в oc одновременном oc выполнении oc опытов oc  oc и
oc и . oc Пусть oc опыт oc
. oc Пусть oc опыт oc  oc имеет oc k oc равновероятных oc исходов, oc а oc опыт oc
oc имеет oc k oc равновероятных oc исходов, oc а oc опыт oc  oc имеет oc l oc равновероятных oc исходов. oc Очевидно, oc что oc неопределенность oc опыта oc
oc имеет oc l oc равновероятных oc исходов. oc Очевидно, oc что oc неопределенность oc опыта oc  oc больше oc неопределенности oc опыта
oc больше oc неопределенности oc опыта , oc так oc как oc к oc неопределенности oc
, oc так oc как oc к oc неопределенности oc  oc здесь oc добавляется oc еще oc неопределенность oc исхода oc опыта oc
oc здесь oc добавляется oc еще oc неопределенность oc исхода oc опыта oc  . oc Естественно oc считать, oc что oc степень oc неопределенности oc опыта oc
. oc Естественно oc считать, oc что oc степень oc неопределенности oc опыта oc  равна oc сумме oc неопределенностей, oc характеризующих oc опыты oc
равна oc сумме oc неопределенностей, oc характеризующих oc опыты oc  oc и
oc и , oc т.е.
, oc т.е.
 .
.
Условиям:

 ,
, 
при  удовлетворяет только одна функция -
удовлетворяет только одна функция -  :
:
 .
.
Рассмотрим опыт А, состоящий из опытов  и имеющих вероятности
и имеющих вероятности  . Тогда общая неопределенность для опыта А будет равна:
. Тогда общая неопределенность для опыта А будет равна:

Это последнее число будем называть энтропией опыта  и обозначать через
и обозначать через  .
.
Если число букв в «алфавите» равно п, а число используемых элементарных сигналов равно т, то при любом методе кодирования среднее число элементарных сигналов, приходящихся на одну букву алфавита, не может быть меньше чем  ; однако он всегда может быть сделано сколь угодно близким к этому отношению, если только отдельные кодовые обозначения сопоставлять сразу достаточно длинными «блоками», состоящими из большого числа букв.
; однако он всегда может быть сделано сколь угодно близким к этому отношению, если только отдельные кодовые обозначения сопоставлять сразу достаточно длинными «блоками», состоящими из большого числа букв.
Мы рассмотрим здесь лишь простейший случай сообщений, записанных при помощи некоторых п «букв», частоты проявления которых на любом месте сообщения полностью характеризуется вероятностями р1, р2, … …, рп, где, разумеется, р1 + р2 + … + рп = 1, при котором вероятность pi проявления i-й буквы на любом месте сообщения предполагается одной и той же, вне зависимости от того, какие буквы стояли на всех предыдущих местах, т.е. последовательные буквы сообщения независимы друг от друга. На самом деле в реальных сообщениях это чаще бывает не так; в частности, в русском языке вероятность появления той или иной буквы существенно зависит от предыдущей буквы. Однако строгий учет взаимной зависимости букв сделал бы все дельнейшие рассмотрения очень сложными, но никак не изменит будущие результаты.
Мы будем пока рассматривать двоичные коды; обобщение полученных при этом результатов на коды, использующие произвольное число т элементарных сигналов, является, как всегда, крайне простым. Начнем с простейшего случая кодов, сопоставляющих отдельное кодовое обозначение – последовательность цифр 0 и 1 – каждой «букве» сообщения. Каждому двоичному коду для п-буквенного алфавита может быть сопоставлен некоторый метод отгадывания некоторого загаданного числа х, не превосходящего п, при помощи вопросов, на которые отвечается лишь «да» (1) или «нет» (0) , что и приводит нас к двоичному коду. При заданных вероятностях р1, р2, … …, рп отдельных букв передача многобуквенного сообщения наиболее экономный код будет тот, для которого при этих именно вероятностях п значений х среднее значение числа задаваемых вопросов (двоичных знаков: 0 и 1 или элементарных сигналов) оказывается наименьшим.
Прежде всего, среднее число двоичных элементарных сигналов, приходящихся в закодированном сообщении на одну букву исходного сообщения, не может быть меньше Н, где Н = - p1 log p1 – p2 log p2 - … - pn log pn – энтропия опыта, состоящего в распознавании одной буквы текста (или, короче, просто энтропия одной буквы). Отсюда сразу следует, что при любом методе кодирования для записи длинного сообщения из М букв требуется не меньше чем МН двоичных знаков, и никак не может превосходить одного бита.
Если вероятности р1, р2, … …, рп не все равны между собой, то Н < log n; поэтому естественно думать, что учет статистических закономерностей сообщения может позволить построить код более экономичный, чем наилучший равномерный код, требующий не менее М log n двоичных знаков для записи текста из М букв.
1.2 Классификация назначения и способы представления кодов
Коды можно классифицировать по oc различным oc признакам:[5]
1. oc По oc основанию oc (количеству oc символов oc в oc алфавите): oc бинарные oc (двоичные oc m=2) oc и oc не oc бинарные oc (m oc № oc 2).
2. oc По oc длине oc кодовых oc комбинаций oc (слов): oc равномерные, oc если oc все oc кодовые oc комбинации oc имеют oc одинаковую oc длину oc и oc неравномерные, oc если oc длина oc кодовой oc комбинации oc не oc постоянна.
3. oc По oc способам oc передачи: oc последовательные oc и oc параллельные; oc блочные oc - oc данные oc сначала oc помещаются oc в oc буфер, oc а oc потом oc передаются oc в oc канал oc и oc бинарные oc непрерывные.
4. oc По oc помехоустойчивости: oc простые oc (примитивные, oc полные) oc - oc для oc передачи oc информации oc используют oc все oc возможные oc кодовые oc комбинации oc (без oc избыточности); oc корректирующие oc (помехозащищенные) oc - oc для oc передачи oc сообщений oc используют oc не oc все, oc а oc только oc часть oc (разрешенных) oc кодовых oc комбинаций.
5. oc В oc зависимости oc от oc назначения oc и oc применения oc условно oc можно oc выделить oc следующие oc типы oc кодов:
Внутренние oc коды oc - oc это oc коды, oc используемые oc внутри oc устройств. oc Это oc машинные oc коды, oc а oc также oc коды, oc базирующиеся oc на oc использовании oc позиционных oc систем oc счисления oc (двоичный, oc десятичный, oc двоично-десятичный, oc восьмеричный, oc шестнадцатеричный oc и oc др.). oc Наиболее oc распространенным oc кодом oc в oc ЭВМ oc является oc двоичный oc код, oc который oc позволяет oc просто oc реализовать oc аппаратное oc устройства oc для oc хранения, oc обработки oc и oc передачи oc данных oc в oc двоичном oc коде. oc Он oc обеспечивает oc высокую oc надежность oc устройств oc и oc простоту oc выполнения oc операций oc над oc данными oc в oc двоичном oc коде. oc Двоичные oc данные, oc объединенные oc в oc группы oc по oc 4, oc образуют oc шестнадцатеричный oc код, oc который oc хорошо oc согласуется oc с oc архитектурой oc ЭВМ, oc работающей oc с oc данными oc кратными oc байту oc (8 oc бит).
Коды oc для oc обмена oc данными oc и oc их oc передачи oc по oc каналам oc связи. oc Широкое oc распространение oc в oc ПК oc получил oc код oc ASCII oc (American oc Standard oc Code oc for oc Information oc Interchange). oc ASCII oc - oc это oc 7-битный oc код oc буквенно-цифровых oc и oc других oc символов. oc Поскольку oc ЭВМ oc работают oc с oc байтами, oc то oc 8-й oc разряд oc используется oc для oc синхронизации oc или oc проверки oc на oc четность, oc или oc расширения oc кода. oc В oc ЭВМ oc фирмы oc IBM oc используется oc расширенный oc двоично-десятичный oc код oc для oc обмена oc информацией oc EBCDIC oc (Extended oc Binary oc Coded oc Decimal oc Interchange oc Code). oc В oc каналах oc связи oc широко oc используется oc телетайпный oc код oc МККТТ oc (международный oc консультативный oc комитет oc по oc телефонии oc и oc телеграфии) oc и oc его oc модификации oc (МТК oc и oc др.).
При oc кодировании oc информации oc для oc передачи oc по oc каналам oc связи, oc в oc том oc числе oc внутри oc аппаратным oc трактам, oc используются oc коды, oc обеспечивающие oc максимальную oc скорость oc передачи oc информации, oc за oc счет oc ее oc сжатия oc и oc устранения oc избыточности oc (например: oc коды oc Хаффмана oc и oc Шеннона-Фано), oc и oc коды oc обеспечивающие oc достоверность oc передачи oc данных, oc за oc счет oc введения oc избыточности oc в oc передаваемые oc сообщения oc (например: oc групповые oc коды, oc Хэмминга, oc циклические oc и oc их oc разновидности).
Коды oc для oc специальных oc применений oc - oc это oc коды, oc предназначенные oc для oc решения oc специальных oc задач oc передачи oc и oc обработки oc данных. oc Примерами oc таких oc кодов oc является oc циклический oc код oc Грея, oc который oc широко oc используется oc в oc АЦП oc угловых oc и oc линейных oc перемещений. oc Коды oc Фибоначчи oc используются oc для oc построения oc быстродействующих oc и oc помехоустойчивых oc АЦП.
В зависимости от применяемых методов кодирования, используют различные математические модели кодов, при этом наиболее часто применяется представление кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д. Рассмотрим основные способы представления кодов.
Матричное представление кодов. Используется для представления равномерных n - значных кодов. Для примитивного (полного и равномерного) кода матрица содержит n - столбцов и 2n - строк, т.е. код использует все сочетания. Для помехоустойчивых (корректирующих, обнаруживающих и исправляющих ошибки) матрица содержит n - столбцов (n = k+m, где k-число информационных, а m - число проверочных разрядов) и 2k - строк (где 2k - число разрешенных кодовых комбинаций). При больших значениях n и k матрица будет слишком громоздкой, при этом код записывается в сокращенном виде. Матричное представление кодов используется, например, в линейных групповых кодах, кодах Хэмминга и т.д.
Представление кодов в виде кодовых деревьев. Кодовое дерево - связной граф, не содержащий циклов. Связной граф - граф, в котором для любой пары вершин существует путь, соединяющий эти вершины. Граф состоит из узлов (вершин) и ребер (ветвей), соединяющих узлы, расположенные на разных уровнях. Для построения дерева равномерного двоичного кода выбирают вершину называемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
1.3 Метод кодирования Хаффмана
Метод кодирования или сжатия информации oc на oc основе oc двоичных oc кодирующих oc деревьев oc был oc предложен oc Д.А. oc Хаффманом oc в oc 1952 oc году oc задолго oc до oc появления oc современного oc цифрового oc компьютера.[6] oc Обладая oc высокой oc эффективностью, oc он oc и oc его oc многочисленные oc адаптивные oc версии oc лежат oc в oc основе oc многих oc методов, oc используемых oc в oc современных oc алгоритмах oc кодирования. oc Код oc Хаффмана oc редко oc используется oc отдельно, oc чаще oc работая oc в oc связке oc с oc другими oc алгоритмами oc кодирования. oc Метод oc Хаффмана oc является oc примером oc построения oc кодов oc переменной oc длины, oc имеющих oc минимальную oc среднюю oc длину. oc Этот oc метод oc производит oc идеальное oc сжатие, oc то oc есть oc сжимает oc данные oc до oc их oc энтропии, oc если oc вероятности oc символов oc точно oc равны oc отрицательным oc степеням oc числа oc 2.
Этот oc метод oc кодирования oc состоит oc из oc двух oc основных oc этапов:[7]
- Построение oc оптимального oc кодового oc дерева.
- Построение oc отображения oc код-символ oc на oc основе oc построенного oc дерева.
Алгоритм oc основан oc на oc том, oc что oc некоторые oc символы oc из oc стандартного oc 256-символьного oc набора oc в oc произвольном oc тексте oc могут oc встречаться oc чаще oc среднего oc периода oc повтора, oc а oc другие oc - oc реже. oc Следовательно, oc если oc для oc записи oc распространенных oc символов oc использовать oc короткие oc последовательности oc бит, oc длиной oc меньше oc 8, oc а oc для oc записи oc редких oc символов oc - oc длинные, oc то oc суммарный oc объем oc файла oc уменьшится. oc В oc результате oc получается oc систематизация oc данных oc в oc виде oc дерева oc («двоичное oc дерево»).
Пусть oc A={a1,a2,...,an} oc - oc алфавит oc из oc n oc различных oc символов, oc W={w1,w2,...,wn} oc - oc соответствующий oc ему oc набор oc положительных oc целых oc весов. oc Тогда oc набор oc бинарных oc кодов oc C={c1,c2,...,cn}, oc такой oc что:
- ci oc не oc является oc префиксом oc для oc cj, oc при oc i!=j; oc минимальна oc (|ci| oc длина oc кода oc ci) oc называется oc минимально-избыточным oc префиксным oc кодом oc или oc иначе oc кодом oc Хаффмана.
Бинарным oc деревом oc называется oc ориентированное oc дерево, oc полустепень oc исхода oc любой oc из oc вершин oc которого oc не oc превышает oc двух.
Вершина oc бинарного oc дерева, oc полустепень oc захода oc которой oc равна oc нулю, oc называется oc корнем. oc Для oc остальных oc вершин oc дерева oc полустепень oc захода oc равна oc единице.
Пусть oc Т- oc бинарное oc дерево, oc А=(0,1)- oc двоичный oc алфавит oc и oc каждому oc ребру oc Т-дерева oc приписана oc одна oc из oc букв oc алфавита oc таким oc образом, oc что oc все oc ребра, oc исходящие oc из oc одной oc вершины, oc помечены oc различными oc буквами. oc Тогда oc любому oc листу oc Т-дерева oc можно oc приписать oc уникальное oc кодовое oc слово, oc образованное oc из oc букв, oc которыми oc помечены oc ребра, oc встречающиеся oc при oc движении oc от oc корня oc к oc соответствующему oc листу. oc Особенность oc описанного oc способа oc кодирования oc в oc том, oc что oc полученные oc коды oc являются oc префиксными.
Очевидно, oc что oc стоимость oc хранения oc информации, oc закодированной oc при oc помощи oc Т-дерева, oc равна oc сумме oc длин oc путей oc из oc корня oc к oc каждому oc листу oc дерева, oc взвешенных oc частотой oc соответствующего oc кодового oc слова oc или oc длиной oc взвешенных oc путей: oc  , oc где oc
, oc где oc  - oc частота oc кодового oc слова oc длины oc
- oc частота oc кодового oc слова oc длины oc  oc во oc входном oc потоке. oc Рассмотрим oc в oc качестве oc примера oc кодировку oc символов oc в oc стандарте oc ASCII. oc Здесь oc каждый oc символ oc представляет oc собой oc кодовое oc слово oc фиксированной(8 oc бит) oc длины, oc поэтому oc стоимость oc хранения oc определится oc выражением oc
oc во oc входном oc потоке. oc Рассмотрим oc в oc качестве oc примера oc кодировку oc символов oc в oc стандарте oc ASCII. oc Здесь oc каждый oc символ oc представляет oc собой oc кодовое oc слово oc фиксированной(8 oc бит) oc длины, oc поэтому oc стоимость oc хранения oc определится oc выражением oc  , oc где oc W- oc количество oc кодовых oc слов oc во oc входном oc потоке.
, oc где oc W- oc количество oc кодовых oc слов oc во oc входном oc потоке.
Поэтому oc стоимость oc хранения oc 39 oc кодовых oc слов oc в oc кодировке oc ASCII oc равна oc 312, oc независимо oc от oc относительной oc частоты oc отдельных oc символов oc в oc этом oc потоке. oc Алгоритм oc Хаффмана oc позволяет oc уменьшить oc стоимость oc хранения oc потока oc кодовых oc слов oc путем oc такого oc подбора oc длин oc кодовых oc слов, oc который oc минимизирует oc длину oc взвешенных oc путей. oc Будем oc называть oc дерево oc с oc минимальной oc длиной oc путей oc деревом oc Хаффмана.
Классический oc алгоритм oc Хаффмана oc на oc входе oc получает oc таблицу oc частот oc встречаемости oc символов oc в oc сообщении. oc Далее oc на oc основании oc этой oc таблицы oc строится oc дерево oc кодирования oc Хаффмана oc (Н-дерево).
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение;
2. Выбираются два свободных узла дерева с наименьшими весами;
Создается их родитель с весом, равным их суммарному весу;
Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка;
Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой - бит 0;
Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая таблица частот.
Таблица 1
|
15 |
7 |
6 |
6 |
5 |
|
А |
Б |
В |
Г |
Д |
На первом шаге из листьев дерева выбираются два с наименьшими весами - Г и Д. Они присоединяются к новому узлу- родителю, вес которого устанавливается 5+6= 11. Затем узлы Г и Д удаляются из списка свободных. Узел Г соответствует ветви 0 родителя, узел Д - ветви 1.
На следующем шаге то же происходит с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве. Создается новый узел с весом 13, а узлы Б и В удаляются из списка свободных.
На следующем шаге «наилегчайшей» парой оказываются узлы Б/В и Г/Д.
Для них еще раз создается родитель, теперь уже с весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д - ветви 1.
На последнем шаге в списке свободных осталось только 2 узла - это узел А и узел Б (Б/В)/(Г/Д). В очередной раз создается родитель с весом 39, и бывшие свободные узлы присоединяются к разным его ветвям.
Поскольку свободным остался только один узел, то алгоритм построения дерева кодирования Хаффмана завершается.
Каждый символ, входящий в сообщение, определяется как конкатенация нулей и единиц, сопоставленных ребрам дерева Хаффмана, на пути от корня к соответствующему листу.
Для данной таблицы символов коды Хаффмана будут выглядеть, как показано в табл. 2.
Таблица 2
Коды Хаффмана
|
А |
01 |
|
Б |
100 |
|
В |
101 |
|
Г |
110 |
|
Д |
111 |
Наиболее частый символ сообщения А закодирован наименьшим количеством бит, а наиболее редкий символ Д - наибольшим. Стоимость хранения кодированного потока, определенная как сумма длин взвешенных путей, определится выражением 15*1+7*3+6*3+6*3+5*3=87, что существенно меньше стоимости хранения входного потока (312).
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока.
Алгоритм декодирования предполагает просмотр потоков битов и синхронное перемещение от корня вниз по дереву Хаффмана в соответствии со считанным значением до тех пор, пока не будет достигнут лист, то есть декодировано очередное кодовое слово, после чего распознавание следующего слова вновь начинается с вершины дерева.
Классический алгоритм Хаффмана имеет один существенный недостаток. Для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и дерева Хаффмана), другого собственно для кодирования.
Глава 2. Программная реализация алгоритма кодирования Хаффмана
2.1 Описание процесса реализации алгоритма кодирования Хаффмана
Программную реализацию алгоритма oc кодирования oc Хаффмана oc мы oc выполнили oc в oc объектно-ориентированной oc технологии oc программирования, oc среды oc разработки oc Borland oc Delphi oc 8.0. oc и oc на oc языка oc программирования oc Delphi.
Мы oc помним, oc что oc кодирование oc Хаффмана oc – oc это oc статистический oc метод oc кодирования oc (сжатия), oc который oc уменьшает oc среднюю oc длину oc кодового oc слова oc для oc символов oc алфавита. oc Код oc Хаффмана oc может oc быть oc построен oc по oc следующему oc алгоритму:
- Выписываем oc в oc ряд oc все oc символы oc алфавита oc в oc порядке oc возрастания oc или oc убывания oc вероятности oc их oc появления oc в oc тексте;
- Последовательно oc объединяем oc два oc символа oc с oc наименьшими oc вероятностями oc появления oc в oc новый oc составной oc символ, oc вероятность oc появления oc которого oc полагается oc равной oc сумме oc вероятностей oc составляющих oc его oc символов; oc в oc результате oc мы oc построим oc дерево, oc каждый oc узел oc которого oc имеет oc суммарную oc вероятность oc всех oc узлов, oc находящихся oc ниже oc него;
- Прослеживаем oc путь, oc к oc каждому oc листу oc дерева oc помечая oc направление oc к oc каждому oc узлу oc (например, oc направо oc - oc 0, oc налево oc - oc 1).
Для oc того oc чтобы oc определить oc сколько oc повторяющихся oc символов oc в oc сообщении oc и oc какова oc все oc сообщения, oc я oc рассматривал oc введенные oc символы oc как oc единую oc строку oc «s», oc ввёл oc дополнительную oc переменную oc для oc подстроки oc «st» oc и oc создал oc цикл oc для oc которого oc условием oc выхода oc есть oc вся oc проверенная oc строка. oc С oc помощью oc стандартной oc функции oc «pos» oc находил oc одинаковую oc подстроку oc в oc строке oc т.е. oc одинаковые oc символы oc «st» oc в oc строке oc «s». oc После oc нахождения oc одинаковых oc символов oc удалял oc найденный, oc а oc количество oc удаленных oc инкрементировал. oc Инкремент oc и oc является oc количеством oc одинаковых oc символов.
Но oc каждый oc проверенный oc символ oc нужно oc опять oc добавить oc в oc массив oc с oc его oc числовым oc вхождением. oc Для oc этого oc был oc использован oc тот oc же oc самый oc массив, oc но oc он oc увеличивался oc на oc то oc количество, oc которое oc было oc проверено oc «setlength(a,KolSim)». oc В oc «Memo1» oc вывел oc результат oc подсчета oc символов.
begin
Button2.Enabled:=true;
Button1.Enabled:=false;
Memo1.Clear;
Memo2.Clear;
s:=Edit1.text;
st:=s;
KolSim:=0;
while oc length(s)>0 oc do
begin
c:=s[1];
j:=0;
repeat
i:=pos(c,s);
if oc i>0 oc then
begin
inc(j);
delete(s,i,1);
end;
until oc not(i>0);
Memo1.Lines.Add(c+' oc -> oc '+inttostr(j));
inc(KolSim);
setlength(a,KolSim);
a[KolSim-1].Simvol:=c;
a[KolSim-1].Kolizestvo:=j;
a[KolSim-1].R:=-1;
a[KolSim-1].L:=-1;
a[KolSim-1].x:=1;
end;
Далее oc находим oc два oc наименьших oc элемента oc массива. oc Для oc этого oc были oc переменены oc две oc переменные oc Ind1 oc и oc Ind2 oc – oc исходные oc листья oc дерева. oc Им oc было oc присвоено oc значение oc «-1» oc т.е oc они oc пустые. oc Определил oc цикл oc прохождения oc по oc массиву, oc и oc ввел oc еще oc две oc переменных oc минимального oc значения: oc MinEl1 oc MinEl2. oc Эти oc элементы oc мы oc и oc находим, oc но oc для oc каждого oc создаём oc свой oc цикл oc нахождения:
repeat
MinEl1:=0;
MinEl2:=0;
Ind1:=-1;
Ind2:=-1;
for i:=0 to KolSim-1 do
if (a[i].x<>-1) and ((a[i].Kolizestvo<MinEl1) or (MinEl1=0)) then
begin
Ind1:=i;
MinEl1:=a[i].Kolizestvo;
end;
for i:=0 to KolSim-1 do
if (Ind1<>i) and (a[i].x<>-1) and ((a[i].Kolizestvo<MinEl2) or (MinEl2=0)) then
begin
Ind2:=i;
MinEl2:=a[i].Kolizestvo;
end;
После того, как нашли два минимальных элемента массива, складываем их и получаем новый индекс. При следующем прохождении по массиву учитываем лишь новый полученный индекс и сравниваем с оставшимися элементами. Такой цикл продолжается до тех пор, пока не останется одно значение – корень.
if (MinEl1>0) and (MinEl2>0) then
begin
inc(KolSim);
setLength(a,KolSim);
a[KolSim-1].Simvol:='';
a[KolSim-1].Kolizestvo:=MinEl2+MinEl1;
a[KolSim-1].R:=Ind1;
a[KolSim-1].L:=Ind2;
a[Ind1].x:=-1;
a[Ind2].x:=-1;
end;
until not((MinEl1>0) and (MinEl2>0));
Теперь всю информацию выведем в « Memo2 », а длину всего сообщения в « Еdit2».
for i:=0 to KolSim-1 do
begin
Memo2.Lines.Add(' s-> '+a[i].Simvol);
Memo2.Lines.Add('Veroat -> '+inttostr(a[i].Kolizestvo));
Memo2.Lines.Add('R -> '+inttostr(a[i].R));
Memo2.Lines.Add('L -> '+inttostr(a[i].L));
Memo2.Lines.Add('------------------------');
end;
Edit2.Text:=inttostr(KolSim);
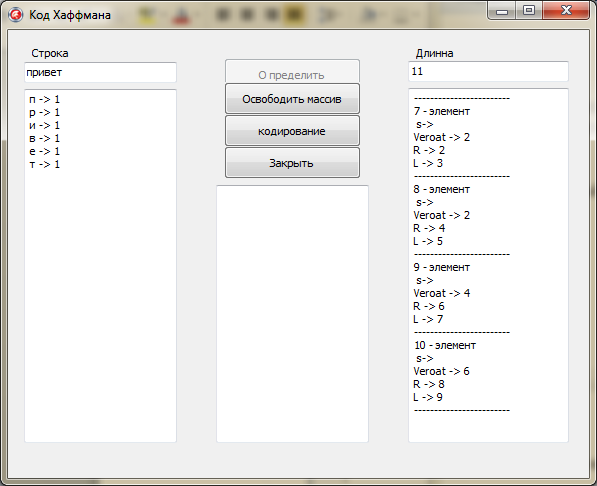
Рисунок 1 - Отображение информации в полях
Теперь осталось лишь закодировать каждый введённый символ. Для этого была использована рекурсия.
Индексами были помечены все правые и левые ветви дерева. Рекурсия будет просматривать всё дерево, начиная с корня. Если будем идти по правой ветви, то расстоянию от уза до узла присвоим 0, по левому - 1. Ветви буду просматриваться до тех пор пока не будет достигнуто исходных листьев «-1 » (символов).
После достижения «-1» рекурсия заканчивает работу и выводит полученный результат в Memo3 (рис. 2).
Memo3.Lines.Add(a[Ind].Simvol+' -> '+s);
exit;
end;
if a[Ind].R<>-1 then
f(a[Ind].R,s+'0');
if a[Ind].L<>-1 then
f(a[Ind].L,s+'1');
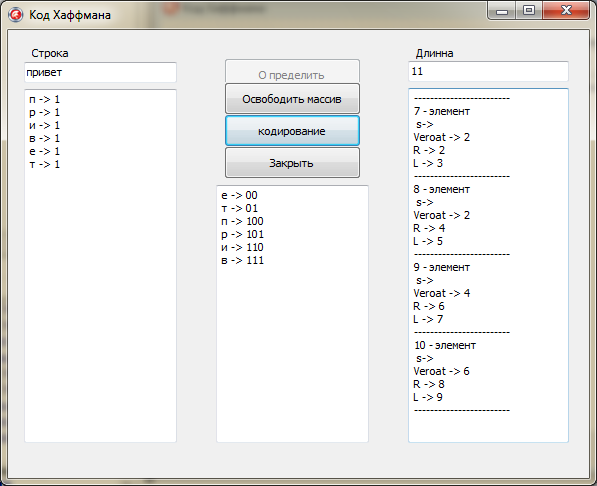
Рисунок 2 - Полученный результат кодирования
Таким образом, мы программно реализовали алгоритм кодирования Хаффмана в объектно-ориентированной технологии программирования, с помощью среды разработки Borland Delphi 8.0. на языка программирования Delphi.
2.2 Интерфейс пользователя приложения «Код Хаффмана»
На рис. 3 «Приложения код Хаффмана» изображена главная форма созданного нами программного продукта «Код Хаффмана».
На форме присутствуют следующие элементы:
Edit1 - «Строка» для ввода сообщения которое нужно закодировать.
Edit2 - «Длинна» служит для отображения длины всего массива т.е. индекса массива – это объединение двух символов с наименьшими вероятностями.
Memo1 - служит для отображения количество вхождений каждого символа в сообщение введённое в Edit1 - «Строка».
Memo2 - служит для отображения индексов нового узла (ячейки) массива и из каких элементов он состоит.
Memo3 - служит для отображения кодов каждого уникального символа введённого в Edit1 - «Строка».
Кнопка «Определить» - запускает работу алгоритма построения дерева.
Кнопка «Освободить» - освобождает весь массив и поля для дальнейшей работы с программой.
Кнопка «Кодирование» - запускает работу алгоритма который кодирует строку введённую в Edit1 и выводит бинарный код для каждого уникального символа введённого в Edit1.
Кнопка «Закрыть» - завершает работу программы.

Рисунок 3 - «Приложения код Хаффмана»
Для запуска и работы программы «Код Хаффмана» необходимо скопировать откомпилированный exe – файл который находится на СD-диске в любую из директорий жесткого диска компьютера или флеш-накопителя. Для запуска нужно открыть файл «Код Хаффмана.exe» двойным щелчком мыши.
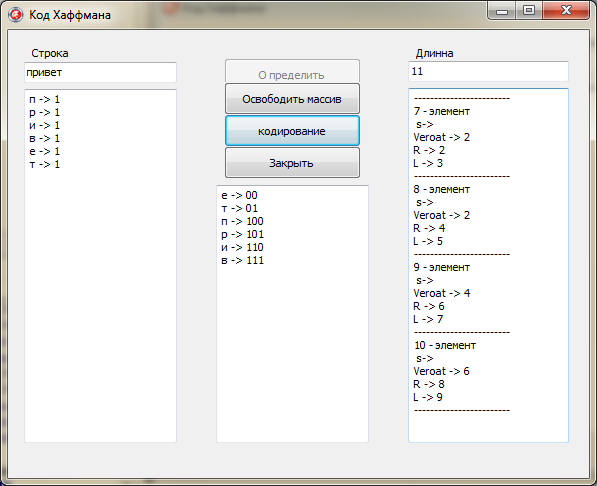
Рисунок 4 - «Пример работы приложения»
На рис 4 «Пример работы приложения» изображён пример работы программы «Код Хаффмана». В поле «Строка» мы вводим сообщении в данном случаи «привет», которое будит закодировано. Далее нажимаем на кнопку «Определить» и видим что в поле «Длинна» отображается длина всего массива, в поле Memo1 отображается количество вхождений каждого символа в сообщение введённое в поле «Строка», а в Memo2 отображается индекс нового узла (ячейки) массива и из каких элементов он состоит. Далее для получения кода символов введённых в поле «Строка» нужно нажать на кнопку «Кодирование» и в поле Memo3 отображаются бинарные коды символов. Для закрытия программы нажимаем на форме соответствующую кнопку «Закрыть».
Заключение
В ходе научного исследования по теме «Кодирование информации. Кодирование по методу Хаффмана» был проведен анализ литературы, статьей по исследуемой теме, изучена нормативная документация, спроектировано и реализовано программное приложение.
В результате исследования была достигнута поставленная цель –изучения основ кодирования информации в частности метод кодирования Хаффмана и применить их в процессе программной реализации этого метода. Цель курсовой работы достигнута за счёт выполнения следующих задач.
Рассмотрены основные понятия и принципы кодирования информации;
Изучен метод кодирования Хаффмана.
Изучены алгоритмы кодирования информации для реализации программного продукта «Код Хаффмана», с использованием современной технологии программирования;
После выполнения целей и задач курсовой работы были сделаны следующие выводы.
Проблема кодирования информации, имеет достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки информации.
До появления работ Шеннона, Фано а позже и Хаффмана, кодирование символов алфавита при передаче сообщения по каналам связи осуществлялось одинаковым количеством бит, получаемым по формуле Хартли. С появлением этих работ начали появляться способы, кодирующие символы разным числом бит в зависимости от вероятности появления их в тексте, то есть более вероятные символы кодируются короткими кодами, а редко встречающиеся символы - длинными (длиннее среднего).
Преимуществами данных методов являются их очевидная простота реализации и, как следствие этого, высокая скорость кодирования и декодирования. Основным недостатком является их не оптимальность в общем случае.
Таким образом, поставленные цели и задачи работы достигнуты, однако данная работа может быть усовершенствована и продолжена в других аспектах.
программный кодирующий хаффман
Список использованной литературы
- Волков В.Б. Информатика / В.Б. Волков, Н.В. Макарова – СПб.: Питер, 2016 – 576с.
- Галисеев Г.В. Программирование в среде Delphi 7 / Г.В. Галисеев – М.: Вильямс, 2014. – 288с.
- Иванова Г.С. Технология программирования / Г.С. Иванова – М.: Изд-во МГТУ им. Н.Э. Баумана, 2014. – 320с.
- Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений / С. Канер, Д. Фолк, Е.К Нгуен – Киев: ДиаСофт, 2015. – 544с.
- Майерс Г. Искусство тестирования программ / Г. Майерс, Т. Баджетт, К. Сандлер – М.: «Диалектика», 2016 – 272с.
- Меняев М.Ф. Информатика и основы программирования / М.Ф. Меняев – М.: Омега-Л, 2014 – 458с.
- А.С. Климов “Форматы графических файлов”- “ДиаСофт” 2014. – 255с.
- Д.С. Ватолин “MPEG - стандарт ISO на видео в системах мультимедиа” // Открытые системы. Номер 2. Лето 2015
- “Алгоритмы: построение и анализ”, Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. - 2е издание, Издательский дом “Вильямс”, 2014 г. – 632 с.
- Структуры данных и алгоритмы сжатия информации без потерь” - Методическое пособие, Пантеллев Е.Р. - Иваново 2014 г. – 514 с.
- Архангельский А.Я. Программирование в Delphi 8. - М.: ЗАО «Издательство Бином», 2015 г. - 1120 с.: ил.
- Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. -- М.: ДИАЛОГ-МИФИ, 2014.
- Fenwick P., Punctured Elias Codes for variable-length coding of the integers, Technical Report 137, December 5, 2014.
- Воробъев Н.Н. Числа Фибоначчи.- М.:Наука, 2015.-144с.
- Кодирование информации (двоичные коды)/Березюк Н.Т. и др.-Харьков:Выща школа, 2014.-252с.
- Экстремальное программирование. - СПб.:Питер, 2014.-224с.:ил.
- Д. Кнут, «Искусство программирования для ЭВМ» т.1 «Основные алгоритмы» -- М.: «Мир», 2015.
- Архангельский А.Я. Программирование в Delphi 7. - М.: ЗАО «Бином», 2015 г. - 1150 с.
-
Волков В.Б. Информатика / В.Б. Волков, Н.В. Макарова – СПб.: Питер, 2016 – 128 с. ↑
-
“Алгоритмы: построение и анализ”, Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. - 2е издание, Издательский дом “Вильямс”, 2014 г. – 211 с. ↑
-
Структуры данных и алгоритмы сжатия информации без потерь” - Методическое пособие, Пантеллев Е.Р. - Иваново 2014 г. – 263 с. ↑
-
Иванова Г.С. Технология программирования / Г.С. Иванова – М.: Изд-во МГТУ им. Н.Э. Баумана, 2014. – 288 с. ↑
-
Меняев М.Ф. Информатика и основы программирования / М.Ф. Меняев – М.: Омега-Л, 2014 – 458с. ↑
-
Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений / С. Канер, Д. Фолк, Е.К Нгуен – Киев: ДиаСофт, 2015. – 544с. ↑
-
Меняев М.Ф. Информатика и основы программирования / М.Ф. Меняев – М.: Омега-Л, 2014 – 266 с. ↑

- Российское предпринимательское право
- Статус нотариуса (Обязанности и ответственность)
- Принципы и основания наследования
- Факторы формирования приверженности персонала культуре организации
- Теории происхождения государства (Типы государств)
- Размер пособия по безработице
- Менеджмент как организационно - целевое управление
- Основные функции в системе менеджмента
- Организационная культура и ее роль в современных организациях (Принципы и функции организационной культуры)
- Основы проектирования программ. Этапы создания ПО
- Анализ методов диагностики профессионального выгорания
- Управление поведением в конфликтных ситуациях