
Методы кодирования данных
Содержание:

ВВЕДЕНИЕ
Важной составляющей процессов обработки, передачи и хранения информации является кодирование сообщений. Целью кодирования при отсутствии препятствий является представление сообщений в более компактном виде или сжатие, а при их наличии – выявление и исправление ошибок, возникающих в сообщениях под влиянием помех, то есть обеспечение достоверности информации.
Кодирование (coding, encode) и криптографическая (cryptographic) защита информации является частью более широкого понятия – теория информации (information theory). Основы этой науки заложены К. Шенноном, который в 1948-1949 годах опубликовал две основные свои работы – «Математическая теория связи» и «Теория связи в секретных системах». Эти работы не только дали толчок развитию методов кодирования, но и заложили основы современной научной криптологии (сriptologic, с греческого kryptos – тайный, logos – слово) – науки, занимающейся проблемой защиты информации путем ее преобразования.
Криптология разделяется на два направления:
- криптография – занимается поиском и исследованием математических методов преобразования информации с целью ее защиты;
- криптоанализ – исследование возможности расшифровки информации без знания ключей.
Кодирования можно определить, как процесс представления информации в виде некоторой последовательности символов (кодовых комбинаций). При этом такую последовательность, в свою очередь, можно представить (перекодировать) в виде совокупностей физических сигналов.
Современная теория информации и кодирования позволяет решать задачи сбора, преобразования, передачи, хранения и предоставления информации наиболее экономическими и эффективными способами.
Широкое применение компьютерной техники в различных сферах деятельности, бурное развитие компьютерных сетей делает все более актуальными вопросы защиты информации от несанкционированного доступа, поскольку последствия этого могут быть непредсказуемы.
Защита информации с помощью кодирования является одним из самых надежных путей решения проблемы ее безопасности, поскольку зашифрована информация становится доступной только для того, кто знает, как ее расшифровать, и абсолютно непригодной для стороннего пользователя.
Несмотря на то, что защита информации связана с целым рядом комплексных мер, как чисто технических, так и организационных, без кодирования информации невозможно построить надежную систему ее защиты.
Цель работы – изучить методы кодирования данных.
Исходя из цели можно поставить следующие задачи:
- раскрыть основные понятия;
- рассмотреть количественное оценивание информации;
- изучить основную теорему Шеннона для кодирования;
- рассмотреть типовую классификацию методов кодирования;
- изучить статистические методы сжатия данных без потерь;
- обозначить словарные методы оптимального кодирования;
- раскрыть арифметическое кодирование.
ГЛАВА 1. ИНФОРМАЦИЯ И ЕЕ КОЛИЧЕСТВЕННЫЕ ОЦЕНКИ
1.1 Основные понятия
Понятие информации является центральным моментом кибернетики (cybernetics). Под информацией в широком смысле слова понимают сведения об окружающем мире, которые мы получаем в результате взаимодействия с ним, приспособления к нему и изменения его в процессе приспособления.
Комитет по терминологии академии наук рекомендует следующее определение информации: информация – это сведения, которые являются объектом хранения, передачи и преобразования [5].
Необходимо различать понятия информации и сообщения (messages). Сообщение – это форма представления информации. Например, при телеграфической передачи сообщения есть текст телеграммы. Сообщение для его передачи по соответствующему адресу предварительно превращают в сигнал (signal). Под сигналом понимают физическую величину, которая изменяется и отражает содержание сообщения. Сигнал – это материальный носитель сообщения. В современной технике нашли применение электрические, электромагнитные, световые и другие сигналы. Все сообщения по характеру изменений по времени можно разделить на непрерывные (continuous) и дискретные (discrete). Непрерывные по времени сообщения отображаются непрерывной функцией времени. Дискретные по времени сообщения характеризуются тем, что поступают в определенные моменты времени и описываются дискретной функцией времени.
Поскольку сообщения обычно носят случайный характер, то непрерывные сообщения описываются случайной функцией времени, а дискретные как последовательность случайных событий. Сообщение также можно разделить на непрерывные и дискретные по множеству.
Непрерывные по множеству сообщение характеризуются тем, что функция, которая их описывает, может принимать непрерывное множество значений в некотором интервале. Дискретные по множеству сообщения описываются конечным набором цифр или дискретных значений некоторой функции.
Дискретность по множеству и временем не связана друг с другом. Поэтому возможны такие типы сообщений [13].
- Непрерывные по множеству и временем.
- Непрерывные по множеству и дискретные по времени.
- Дискретные по множеству и непрерывные по времени.
- Дискретные по множеству и времени.
Графически эти четыре типа сообщений представлен на рис. 1.1.
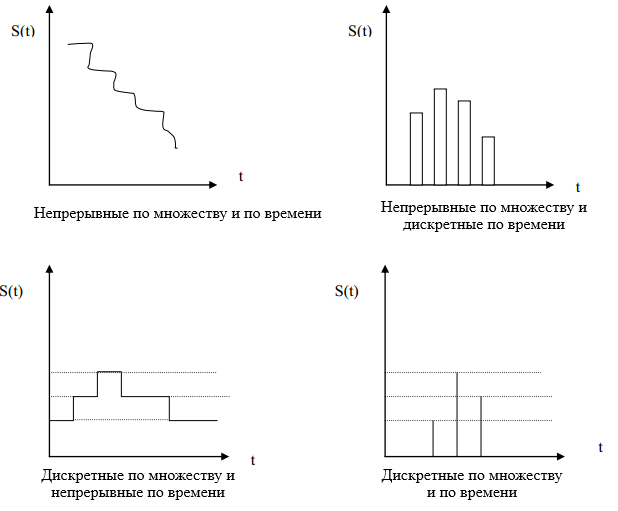
Рисунок 1.1 – Различные типы сообщений
В широком смысле преобразования сообщения в сигнал называют кодированием сообщения. В узком смысле – кодирование – это отображения дискретных сообщений сигналами в виде определенных сочетаний символов. Устройство, которое выполняет кодирование, называется кодером (coder), а декодирование – декодер (decoder). Кодер и декодер образуют кодек (codec) [8].
1.2 Количественное оценивание информации
Понятие энтропии, как меры исходной (априорной) неопределенности результатов опыта, был введен Шенноном по аналогии с термодинамической энтропией.
На основе этого количество информации, полученные в результате проведения опыта, определяется как
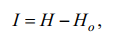
где H – априорноя энтропия, Ho – остаточная энтропия (неопределенность последствий) опыта.
В этом представлении количество информации, полученное в результате опыта, – это мера снятой неопределенности.
При передаче сообщений в каналах без помех Ho = 0 и I = H.
В приложении к системам связи термин «количество информации» ввел Ральф Хартли в 1928 году. Он предложил определять эту величину как
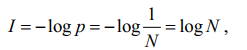
где p – вероятность появления одного из N возможных равновероятных последствий опыта.
Логарифмическая мера количества информации может быть обоснована такими соображениями:
1. Количество информации больше в опыте с большим числом равновероятных последствий:
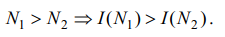
2. Если опыт имеет один результат, N =1, то
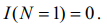
3. Количество информации в опыте, состоящий из отдельных этапов, в которых имеют место взаимозависимы последствия N1, N2 ...
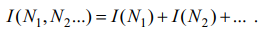
Тогда в общем случае количество информации определится как
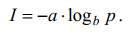
Постоянные a и b устанавливают масштаб величины I. По Хартли a = 1,
b = 2. В том случае, если
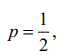
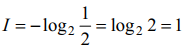
Эта единица количества информации используется, как правило, в системах связи. Известны также аналогичные единицы измерения нат (b = e ≈ 2,73 ...) и дит (b = 10). В дальнейшем, если значение основы b = 2, оно в функции логарифма не указывается.
Различные способы оценки количества информации представлены в [16]. Наиболее простым является комбинаторный (combinatory) подход. Согласно этому подходу, если дискретный источник информации U в каждый конкретный момент времени может принять случайным образом одно состояние с конечным множеством возможных состояний N, то энтропия (entropy) источника равна:
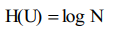
Эта мера информации была предложена Хартли в 1928 году. Основа логарифма не имеет принципиального значения и определяет только масштаб и единицу неопределенности. Поскольку современная информационная техника базируется на двоичной системе счисления, то конечно основу логарифма выбирают равной двум. При этом единица неопределенности называется двоичной единицей или битом (binary digit – bit). Если основу логарифма выбрать равной десяти, то неопределенность получим в десятичных единицах на одно состояние – дитах (dit). Основным недостатком комбинаторного подхода является его ориентированность на системы с равновероятны состояниями, хотя реальными системы не являются такими.
Вероятностный (probabilistic) подход учитывает этот недостаток. В общем случае источник характеризуется совокупностью состояний (states) с вероятностями (probabilities) их появления (ансамблем).
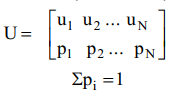
Для источников информации по неравновероятными состояниями мера неопределенности была предложена американским ученым К. Шенноном. Согласно Шенноном:
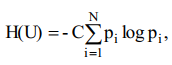
где С – произвольное положительное число. Если основание логарифма равна двум, то С = 1, и
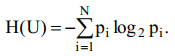
Предложенная мера названа Энтропией, поскольку совпадает с Энтропией физической системы, определенной ранее Больцманом.
Если воспользоваться условными вероятностями, то получим условную Энтропию, однако независимо от способа получения вероятностей характер зависимости остается неизменным.
Алгоритмический подход [11] находит применение, если данные характеризуются некоторыми закономерностями, т.е. могут быть описаны некоторыми формулами или порождающими (образующими) алгоритмами (algorithms). Тогда энтропия будет равна минимальному количеству информации для передачи этих формул или алгоритмов от источника к приемнику информации. Алгоритмический подход может применяться при уплотнении графической информации.
Взаимосвязь меры Шеннона и Хартли. Если в источнике может быть реализовано N равновероятных состояний, то вероятность каждого из них равна
1/N, тогда неопределенность по Хартли, приходящаяся на одно состояние источника определяется так [12]:
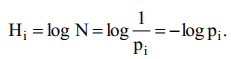
Будем считать вероятности состояний pi разными, а неопределенность, приходится на одно состояние источника, по аналогии, характеризуется величиной:
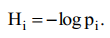
Усреднив по всему ансамблю U состояний источника найдем неопределенность, которая приходится в среднем на одно состояние источника:
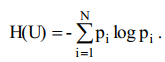
А это и есть мера Шеннона, то есть мера Шеннона является обобщением меры Хартли в случае источника с неравномерными состояниями. Она позволяет учесть статистические свойства источника информации [5].
Свойства энтропии
- Энтропия – действительно неотъемлемая величина.
- Энтропия – величина ограничена.
- Энтропия – равна нулю, если вероятность одного из состояний равна 1, то есть состояние источника полностью определено.
- Энтропия – максимальна, когда все состояния источника равно вероятны.
- Энтропия источника с двумя состояниями u1 и u2 меняется от 0 до 1, достигая максимума при равенстве их вероятностей.
- Энтропия – объединение нескольких статистически независимых источников информации равна сумме энтропии начальных источников. В объединении двух источников U и V понимают обобщенный источник информации, характеризующееся вероятностями p (ui, vj) всех возможных комбинаций состояний ui источника U и состояний vj источника V.
ГЛАВА 2. ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ИНФОРМАЦИИ
2.1 Основная теорема Шеннона для кодирования
Эффективное кодирование сообщений для передачи их в дискретном канале без помех основывается на теореме Шеннона, которую можно сформулировать так [7]:
– сообщение источника с энтропией H(z) всегда можно закодировать последовательностями символов с объемом алфавита m так, что среднее число символов в знак сообщение lср будет как угодно близким к величине 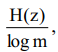 , но не меньше ее. При m = 2, lср ≥ H(z).
, но не меньше ее. При m = 2, lср ≥ H(z).
Теорема не указывает конкретного способа кодирования, но из нее видно, что каждый символ кодовой комбинации должен нести максимальную информацию, то есть каждый символ должен принимать значение либо 0, либо 1 по возможности с равными вероятностями и каждый выбор должен быть независимым от значения предыдущих символов. Для случая отсутствия взаимосвязей между знаками конструктивные методы построения эффективных кодов разработаны американскими учеными Шенноном и Фано. Поскольку их методики подобные, то соответствующий метод получил название Шеннона-Фано [3] .
Эффективное кодирование некоррелированной последовательности знаков методом Шеннона-Фано
Согласно методу Шеннона-Фано код строят следующим образом [3].
- Знаки алфавита сообщения вписывают в таблицу в порядке убывания их вероятностей.
- Затем их разделяют на 2 группы так, чтобы суммы вероятностей в обоих группах были по возможности одинаковы.
- Всем знакам одной группы приписывают как первый символ 0 (1), а знакам второй группы приписывают символ 1 (0).
- Каждую из полученных групп снова аналогично разбивают на 2 подгруппы.
- Процесс повторяется до тех пор, пока в каждой подгруппе не останется по одном знаке.
Пример. Выполнить эффективное кодирование ансамбля с 8 знаков, если известны их вероятности.
Решение. Используя методику Шеннона-Фано, получим совокупность кодовых комбинаций, приведенных в табл. 2.1.
Таблица 2.1 – Кодирование Шеннона-Фано
|
Знак |
p |
Кодовые комбинации |
Степень |
|
z1 |
1/2 |
1 |
I |
|
z2 |
1/4 |
01 |
II |
|
z3 |
1/8 |
001 |
II |
|
z4 |
1/16 |
0001 |
IV |
|
z5 |
1/32 |
00001 |
V |
|
z6 |
1/64 |
000001 |
VI |
|
z7 |
1/128 |
0000001 |
VII |
|
z8 |
1/128 |
0000000 |
VII |
Вычислим энтропию сообщения:
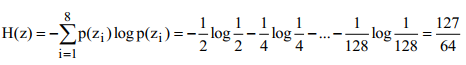
А среднее количество символов в знак после кодирования определяется так:
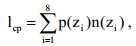
где n(zi) – количество символов (разрядов) в кодовой комбинации, соответствующей знаку zi .
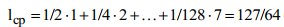
Поскольку вероятности знаков является целочисленные отрицательные значения двойки, то избыточность при кодировании изымается полностью, что и подтверждает равенство энтропии средним количеством символов в знак после кодирования.
Рассмотрена методика Шеннона-Фано не всегда приводит к однозначному построению кода. При разбиении на подгруппы можно сделать большею за вероятностями как одну, так и другую подгруппу. Этих недостатков не имеет методика Хаффмана.
2.2 Типовая классификация методов кодирования
Теория экономного или оптимального кодирования (optimal coding) объединяет в себе несколько различных направлений. В рамках данной теории методы принято разделять на методы экономного кодирования информации без потерь (lossless) и методы экономного кодирования информации с потерями (lossy) [9, 12-14]. Как следует из названий, обработка информации методами первой группы не ведет к информационным потерям, тогда как использование методов второй группы связано с такими потерями. Рассмотрим более подробно методы первой группы.
Среди алгоритмов уплотнения без потерь две схемы уплотнения – кодирования Хаффмана (Huffman) и LZW-кодирования (по начальным буквам фамилий Лэмпел (Lempel), Зив (Ziv) (его авторов) и Уэлч (Welch), который его существенно модифицировал), формируют основу для многих систем уплотнения [12].
Эти схемы подают два разных подхода к уплотнению данных. Отдельный класс образуют методы, которые известны как арифметическое кодирования. Таким образом алгоритмы сжатия данных без потерь можно разделить на следующие группы:
- статистические методы уплотнения;
- словарные (эвристические) методы уплотнения;
- арифметическое кодирование.
Статистические методы (Шеннона-Фано, Хаффмана, кодирование с степени новизны, вероятностное уплотнения и др.) требуют знания вероятностей появления символов в сообщении, оценкой которой является частота появления символов во входных данных [12].
Как правило, эти вероятности неизвестны. С учетом этого статистические алгоритмы можно разделить на три класса.
- Неадаптивные – используют фиксированные, заранее заданные вероятности символов. Таблица вероятностей символов не передается вместе с файлом, поскольку она известна заранее. Недостаток: полный список файлов, для которых достигается приемлемый коэффициент уплотнения.
- Полуадаптивный – для каждого файла строится таблица частот символов и с ее помощью уплотняют файл. Вместе с уплотненным файлом передается таблица символов. Такие алгоритмы достаточно неплохо уплотняют большинство файлов, но необходима дополнительная передача таблицы частот символов, а также два прохода начального файла для выполнения кодирования.
- Адаптивные – дело с фиксированной начальной таблицей частот символов (обычно все символы сначала равновероятны) и в процессе работы эта таблица меняется в зависимости от символов, встречающихся в файле. Преимущества: однопроходимость алгоритма, не требует передачи таблицы частот символов, достаточно эффективно сжимает широкий класс файлов.
Эвристические (словарные) алгоритмы уплотнения (типа LZ77, LZ78), как правило, ищут в файле строки, повторяющиеся и строят словарь фраз, которые уже встречались. Обычно такие алгоритмы имеют целый ряд специфических параметров (размер буфера, максимальная длина фразы и т.п.), подбор которых зависит от опыта автора работы, и эти параметры добираются таким образом, чтобы достичь оптимального соотношения времени работы алгоритма, коэффициента сжатия и перечень файлов, что хорошо сжимаются [12].
Арифметическое кодирование, подобно статистических методов, использует как основу технологии уплотнения, вероятность появления символа
в файле, однако сам процесс арифметического кодирования имеет принципиальные различия. В результате арифметического кодирования символьная последовательность (строка) заменяется действительным числом больше нуля и меньше единицы [10].
2.3 Статистические методы сжатия данных без потерь
Алгоритм RLE
Данный алгоритм очень прост в реализации. RLE (Run Length Encoding), или групповое кодирование, один из самых древних алгоритмов кодирования графики. Его суть заключается в замене повторяющихся символов, на один этот символ и счетчик повторений. Проблема заключается в том, чтобы архиватор при восстановлении мог отличить в результирующем потоке такую кодированную серию от других символов.
Решение очевидно – поместить во все цепочки некоторые заголовки (например, использовать первый бит как признак кодирования серии). Метод достаточно эффективен для графических изображений в формате «байт (byte) на пиксел» (например, формат РСХ использует кодирования RLE).
Однако недостатки алгоритма очевидны – это, в частности, было приспособленность ко многим типам файлов, часто встречающиеся, например, в текстовых. Поэтому его можно эффективно использовать только в сочетании с вторичным кодированием. Этот подход нашел свое отражение в алгоритме кодирования факсов: сначала изображение разбивается на черные и белые точки, превращаются алгоритмом RLE в поток длин серий, а потом эти длины серий кодируются методом Хаффмана со специально подобранным (экспериментально) деревом [7].
Кодирование Хаффмана
Хаффман предложил строить кодовое дерево не сверху вниз, как это неявно делается в алгоритме Шеннона-Фано – от корневого узла до листовых узлов, а снизу-вверх – от листовых узлов к корневому узлу. Такой подход оказался наиболее эффективным и получил весьма широкое распространение.
На начальном этапе работы алгоритма каждому символу информационного алфавита ставится в соответствие вес, равный вероятности (частоте) появления данного символа в сообщении. Символы помещаются в список, который сортируется по убыванию весов. На каждом шаге (итерации) два остальные элементы списка объединяются в новый элемент, который затем помещается в список вместо двух объединяемых элементов.
Новому элементу списка ставится в соответствие вес, равный сумме весов тех элементов, которые замещаются. Каждая итерация заканчивается упорядочиванием полученного нового списка, который всегда содержит в один элемент меньше, чем старый список.
Параллельно с работой указанной процедуры осуществляется последовательное построение кодового дерева. На каждом шаге алгоритма любому элементу списка соответствует корневой узел бинарного дерева, который состоит из вершин, соответствующих элементам, объединением которых был полученный данный элемент. При объединении двух элементов списка происходит объединение соответствующих деревьев в одно новое бинарное дерево, в котором корневой узел соответствует новому элементу, что помещается в список, а элементам списка что замещаются, соответствуют дочерние узлы этого корневого узла.
Алгоритм завершает работу, когда в списке остается один элемент, соответствующий корневом узлу построенного бинарного дерева. Это дерево называется деревом Хаффмана.
Система префиксных кодов может быть получена путем присвоения конкретных двоичных значений ребрам этого дерева. Пример построения дерева Хаффмана приведен на рис. 2.1.
Система кодов, полученная в результате построения дерева Хаффмана, является оптимальной системой префиксных кодов [13-14]. Отсюда, однако, в
некотором случае не следует вывод о том, что префиксные системы, полученные с использованием других алгоритмов, всегда менее эффективны.
Исходное сообщение
«Обороноспособность»
Статистика появления
букв в сообщении
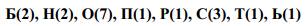
Построение системы префиксных кодов
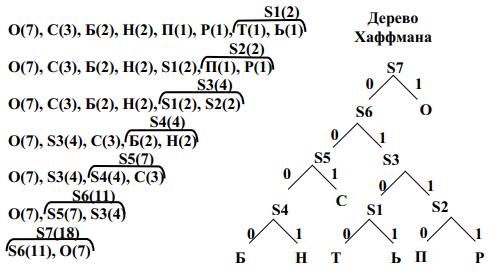
Система префиксных кодов
Рисунок 2.1 – Иллюстрация работы алгоритма Хаффмана
Недостатком такого кодирования является тот факт, что вместе с закодированным сообщением необходимо передавать также и построенную таблицу кодов (дерево), что снижает величину уплотнения. Однако существует динамический алгоритм построения дерева Хаффмана, в котором кодовая таблица обновляется самым кодировщиком и синхронно, и аналогично декодировщику в процессе работы после получения каждого очередного символа. Получаемые при этом коды оказываются квазиоптимальными, поэтому текст уплотняется немного хуже. Более того, растет сложность алгоритма и время работы программы (хотя она и становится однопроходных) [14].
Кодирование по степени новизны
Одним из вариантов адаптивного алгоритма Хаффмана алгоритм кодирования по степени новизны, известный также как MTF (Move To Front – двигай вверх), или кодирование с помощью кучки книг [12,15]. Идея метода такова: пусть алфавит источника состоит из N символов с номерами 1,2, ..., N. Кодер сохраняет список символов, которые представляют собой некоторую перестановку алфавита. Когда на вход поступает символ С, имеющий в список номер «и», кодер передает код номеру «и». Затем кодер переставляет символ С в начало списка, увеличивая на единицу номера всех символов, которые стоят перед С. Таким образом, более «популярные» символы будут тяготеть к началу списка и будут иметь более короткие коды.
Как код для кодирования по степени новизны можно использовать монотонный код – универсальный код источника, для которого известно лишь упорядоченность вероятностей символов. Монотонный код построен так, что более близкие к началу списка позиции, получают более короткие коды. В результате буквы, которые часто появляются и тяготеют к началу списка, будут иметь короткие кодовые обозначения. Рассмотрим уплотнения информации методом кодирования по степени новизны на примере.
Пусть необходимо передать слово w = 221312233 в алфавите А = {1,2,3}. Монотонным кодом позиции 1 является 0, позиции 2 – 10, позиции 3 – 11. Кучка книг при последовательном появлении букв слова w изменяется таким образом:
(1,2,3) - (2,1,3) - (2,1,3) - (1,2,3) - (3,1,2) и т.д.
Кодом слова будет
100101110110 ...
Кодирование по степени новизны ненамного хуже лучшего кодирования методом Хаффмана. Данный метод уступает кодированию Хаффмана при уплотнении текстовых файлов, однако, для файлов с малым начальным алфавитом, можно добиться хороших результатов. Кодирование по степени новизны не требует предварительного просмотра начального массива. Этот метод легко приспосабливается к возможным колебаниям частот, поэтому он назван еще – локально-адаптивным. Кроме-того, он идеально подходит к совместному использованию вместе с BWT-преобразованием, которое размещает одинаковые символы блока, превращается, один за другим.
Вероятностное кодирования
Очень интересный и самый быстрый из известных методов уплотнения информации, дает к тому же неплохие результаты. Вероятностное уплотнения во многом напоминает гадание на кофейной гуще или предсказания погоды, только более эффективно [16].
Работает алгоритм следующим образом: достаточно большая таблица предсказаний, которая довольно быстро обновляется, в которой для каждой возможной пары последовательных входных символов указывается предусмотрен следующий (третий) символ. Если символ предусмотрен правильно – генерируется код в виде однобитного префикса, равного 1. Если знак не угадано – выдается код в виде префикса, равного 0 и не угаданного символа. При этом не угадан символ заменяет в таблице символ, который был там до этого, обеспечивая постоянное обновление статистической информации [1].
Алгоритм является адаптивным и поэтому он однопроходной и не требует сохранение таблицы вместе с закодированным текстом.
Декомпрессор работает по аналогичной программе, поддерживая и обновляя таблицу синхронно с компрессором. Если поступил префикс 1, очередная исходная буква берется из таблицы по индексу, полученным из двух предыдущих букв, иначе просто копируется код из входного потока в выходной. Для небольшого повышения степени уплотнения рекомендуется инициализировать таблицу перед началом работы любыми сочетаниями, которые часто встречаются.
Похожий алгоритм используется в архиваторе PKZIP Ver.1.5 под именем Reducing. Он почти по всем параметрам хуже, чем вероятностный (двухпроходной, требует передачи таблицы вместе с текстом), однако заслуживает упоминания. Таблица программы Reducing содержит массив символов V [256] [32], то есть для каждой входной буквы на первом проходе находятся не более, чем 32 (но может быть и меньше) следующих букв, которые часто встречаются. На втором проходе подобно вероятностного, если очередной символ b, поступающей по символу a находится среди 32 ожидаемых, генерируется код <prefix, position>, prefix = 1, position равно положению символа b в массиве V [a] [ ] с 32 букв. Иначе выдается префикс 0 и сам символ b. Алгоритм статический, поэтому таблица не обновляется в процессе работы.
2.4 Словарные методы оптимального кодирования
Словарные алгоритмы предназначены для устранения избытка цепочек событий. Суть алгоритма заключается в том, что цепочки событий помещаются в словарь. Если в дальнейшем во входном потоке встречается цепочка событий, который присутствует в словаре, то вместо этой цепочки в выходной поток помещается ссылка на элемент словаря.
Идея словарных алгоритмов была предложена Я. Зивом и А. Лемпелем в 1977 [15]. Идея была воплощена в алгоритме LZ77, ставший основой целого семейства алгоритмов. Альтернативный подход, предложенный ими же в 1978, породил семейство алгоритмов LZ78.
Словарные алгоритмы имеют не самые высокие коэффициенты уплотнения, но допускают очень быструю реализацию, особенно при декодировании данных, что и обуславливает их широкое использование.
Под словарем в алгоритмах семейства LZ77 понимается некоторое количество предыдущих событий. Как ссылки на элементы словаря используются расстояние до цепочки событий, которые встречались раньше, и длина этой цепочки [2].
Естественно, не для всех цепочек событий входного потока можно найти соответствующие цепочки в словаре. Чтобы обеспечить различие между цепочками событий и литерально событиями (событиями, не вошедшие в цепочки из словаря), алгоритм LZ77 просто чередует ссылки на элементы словаря с литерально событиями.
В алгоритме LZSS ссылки на элементы словаря и литеральны события различаются флажком-битом.
Алгоритм LZH аналогичный LZSS, но использует для указателей кодирования Хаффмана.
В настоящее время алгоритмы семейства LZ77 широко используются в программах универсальных архиваторов. Это, как правило, модификации LZSS с использованием кодов Хаффмана (LHARC) Шеннона-Фано (PKZIP) или арифметического кодирования (HA).
В алгоритмах семейства LZ78 цепочки в словаре увеличиваются на один символ каждый раз, когда цепочка из словаря встречается в входном потоке. В алгоритме LZ78, так же, как и в LZ77, литеральные события и элементы словаря чередовались.
В 1984 году Т. Уэлч предложил алгоритм LZW в котором все литеральные события являются элементами словаря [9]. Таким образом, в выходной поток помещаются только ссылки на элементы словаря, что упрощает алгоритм. Уэлч показал, что алгоритм может быть легко реализован на аппаратном уровне. Программная реализация, как правило, выполняется на основе вектора двоичных деревьев. Корнями деревьев служат элементы входного алфавита.
LZC – модификация алгоритма LZW направлена на повышение коэффициента сжатия.
Во-первых, в нем используется переменная длина кодов. Например, при уплотнении изображений с 4 битами на пиксель использование 5-битных кодов при пустом словаре дает значительную экономию по сравнению с 12-битными. По мере заполнения словаря длина кодов увеличивается.
Во-вторых, отслеживается степень уплотнения алгоритма. Если она падает ниже определенного предела, словарь очищается. Этим достигается быстрая адаптация алгоритма к резкому изменению характера данных.
LZC используется в утилите COMPRESS операционной системы UNIX и графическом формате GIF.
Алгоритм LZFG в некотором смысле является гибридом LZ77 и LZ78. Как и LZ77 он допускает кодирование цепочек произвольной длины (в алгоритмах LZ78 длина цепочек, как правило, ограничено количеством предыдущих появлений цепочки во входном потоке). С другой стороны, адресация элементов словаря аналогична технике LZ78 с той разницей, что вместо двоичного дерева используется так называемое дерево Patricia. Его отличие заключается в том, что если дерево не содержит разветвлений, то последовательность вершин объединяется в одну.
Алгоритм RFGD является модификацией LZFG с высокой степенью сжатия [1]. Он помещает в выходной поток данные четырех типов: терминальные вершины дерева, нетерминальные вершины дерева, литералы, что встречались ранее во входном потоке и литералы, которые ранее не встречались.
Каждый из них кодируется по собственной схеме. Для определения того, какого именно типа данные помещаются в выходной поток, непосредственно перед ними в выходной поток помещается специальный префикс. Алгоритм реализован на аппаратном уровне.
Алгоритм LZW
Алгоритм очень прост. Если коротко, то LZW-сжатие заменяет строки символов некоторыми кодами. Это делается без какого-либо анализа входного текста. Вместо этого, при добавлении каждой новой строки просматривается таблица строк. Сжатие происходит, когда код заменяет строка символов. Коды, генерируемые LZW-алгоритмом, могут быть любой длины, но они должны содержать больше бит, чем единичный символ.
Первые 256 кодов (когда используются 8-битные символы) по умолчанию соответствуют стандартному набору символов. Остальные коды соответствуют строкам, которые обрабатываются алгоритмом.
При сжатии и восстановлении LZW манипулирует тремя объектами: потоком символов, потоком кодов и таблицей строк. При сжатии поток символов является входным и поток кодов – выходным. При восстановлении входным является поток кодов, а поток символов – выходным. Таблица строк порождается и при сжатии, и при восстановлении, однако она никогда не передается от сжатия к восстановлению и наоборот.
Поскольку мы не знаем заранее объем файла, то трудно определить, какая
разрядность кодов будет оптимальной. Поэтому целесообразно использовать коды разной длины.
Уплотнения информации. Приведем алгоритм в простой форме. Каждый раз, когда генерируется новый код, новая строка добавляется в таблицу строк. LZW постоянно проверяет, данная строка уже известен, и, если так, выводит код без генерирования нового. Процедура LZW-сжатия приведена на рис. 2.2.

Рисунок 2.2 – Алгоритм уплотнения методом LZW
2.5 Арифметическое кодирование
Арифметическое кодирование позволяет кодировать события с вероятностью p количеством бит, как угодно близкой к величине -log2 p [14].
Пусть необходимо закодировать последовательность событий, причем в каждый момент может наступить событие A, B или C. Отложим вероятность событий A, B и C на отрезке [0,1].
Работа алгоритма наглядно показана на рис. 2.3, где на 4 диаграммах схематически отображены первые 3 шага работы алгоритма для входного алфавита, состоящего из событий «А», «В» и «С» при поступлении на вход алгоритма потока событий «А», «В», «С». Первая диаграмма показывает разделение интервала (0,1) на начальные подинтервалы между символами входного алфавита до начала работы алгоритма. После поступления на вход алгоритма события «В» рабочий интервал (X, Y) аналогичным образом делится между символами входного алфавита (диаграмма 2) и т.д. Диаграмма 4 соответствует заштрихованной области диаграммы 1.
По мере кодирования событий из входного потока рабочий интервал (X, Y) (X', Y') (X', Y') ... сокращается. Насколько он сократится при кодировании одного события, зависит от ширины начального интервала, соответствующего события (вероятность события).
Теоретически исходными данными алгоритма может служить любое число, входит в рабочий интервал после обработки последнего события входного потока. На практике же при каждом сокращении интервала в выходной поток помещаются все совпадающие старшие биты верхней и нижней границы рабочего интервала. Очевидно, что при поступлении события с большей вероятностью и с более широким начальным интервалом рабочий интервал сократится меньше и меньше битов попадет в выходной поток. Таким
образом, события с большей вероятностью появления кодируются меньшим числом битов.
Недостатком арифметического кодера является его высокая вычислительная сложность. Для каждого бита исходного потока необходимо выполнять ряд операций сравнения и смещения. Кроме того, для каждого кодированной события необходимо выполнить ряд операций умножения и деления.
С целью повышения быстродействия был предложен ряд быстрых алгоритмов. Как наиболее быстрая альтернатива арифметическому кодированию может быть использовано квазиарифметические [16]. В нем операции умножения и деления заменены операциями выбора значения из таблицы.
Алгоритм организован в виде конечного цифрового автомата. Во время поступления на вход кодированного события алгоритма в зависимости от текущего состояния при необходимости помещает в выходной поток некоторые биты и переходит в некоторое новое состояние. Таблицы переходов и выходов составлены так, чтобы эмулировать работу арифметического кодера. К недостаткам квазиарифметического кодера можно отнести низкую точность (или чрезмерно большой объем таблиц), а также то, что он реализован только для случая с двумя событиями.
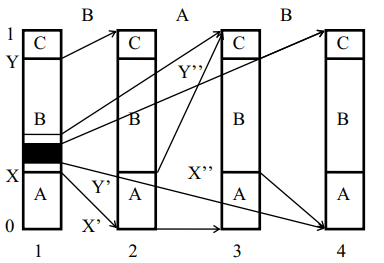
Рисунок 2.3 – Схема работы алгоритма арифметического кодирования
Удачной альтернативой арифметическому кодера, широко используемой в настоящее время, является Range-кодер [14]. Основным его отличием от арифметического кодера является не побитное, а побайтное сравнения верхней и нижней границы и побайтное размещения закодированного результата в выходной поток. Такой подход позволяет заметно повысить быстродействие кодера. При этом точность (качество кодирования) в отдельных реализациях Range-кодеров оказывается даже выше, чем у классического арифметического кодера (при использовании 32-битной целочисленной арифметики).
ЗАКЛЮЧЕНИЕ
В связи с возрастанием роли компьютерных технологий в повседневной жизни людей, интерес к теории информации и ее неотъемлемых составляющих кодирования и криптологии увеличивается. Причем, широкое применение находят равной степени три основные составляющие теории информации, которые имеют прикладной характер: экономное кодирование, помехоустойчивое кодирование и криптологии.
Методы теории информации, которые ранее были лишь предметом теоретических исследований, стали основой промышленных стандартов, используемых в сетях. Не в последнюю очередь это вызвано тем, что из сети передаются сообщения не только развлекательного характера, но и важные как с точки зрения отдельного человека, так и для общества в целом, в том числе и секретные. Повреждения или попадания в руки злоумышленников таких документов может привести к непредсказуемым последствиям.
О росте интереса к теории информации и ее составляющих свидетельствует появление в последние годы сайтов в Интернет, специализирующихся на распространении бесплатной учебной информации о методах теории информации.
Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Кодирование применяется во всех формах передачи, а также и хранении информации. И именно проблема кодирования приводит к недостаткам определенных систем.
СПИСОК ЛИТЕРАТУРЫ
- Akansu N. Multiresolution Signal Decomposition: Transforms, Subbands, and Wavelets (Second Edition) / N. Akansu, R.A. Haddad. – San Diego, USA: Academic Press, 2016. – 499 p.
- Torun M.U. An Efficient Method to Derive Explicit KLT Kernel for FirstOrder Autoregressive Discrete Process / M.U. Torun, A.N. Akansu // IEEE Trans. on Signal Processing. – Aug. 2015. – Vol. 61. – №. 15. – P. 3944–3953.
- Брассар Ж. Современная криптология: Пер. с англ. – М.: Издательско-полиграфическая фирма Полимед, 2014. – 176 с.
- Бовбель Е. И. Элементы теории информации / Е. И. Бовбель, И. К. Дайнеко, В. В. Изох. – Минск: БГУ, 2014. – 112 с.
- Вернер М. Основы кодирования. Учебник для ВУЗов. – М: Техносфера, 2014. – 288 с.
- Гнатив Л.А. Методы синтеза эффективных ортогональных преобразований высокой и низкой корреляции и их быстрых алгоритмов для кодирования и сжатия цифровых изображений / Л. А. Гнатив, Е. С. Шевчук // Кибернетика и системный анализ. – 2012. – № 6. – С. 104- 117.
- Дмитриев В. И. Прикладная теория информации. – М.: Высшая школа, 2015. – 420 с.
- Золотарев В. В., Овечкин Г. В. Помехоустойчивое кодирование. Методы и алгоритмы: Справочник / Под. ред. чл.-кор. РАН Ю. Б. Зубарева. – М.: Горячая линия-Телеком, 2014. – 126 с
- Касами Т., Токура Н, Ивадари Е., Инагаки Я. Теория кодирования: Пер. с японск. – М.: Мир, 2013. – 576 с.
- Кодирование информации (двоичные коды) / Н. Т. Березюк, А. Г. Андрущенко, С. С. Мощицкий и др. – М.: Высшая школа, 2015. – 252 с.
- Кузьмин И. В. Основы теории информации и кодирования / И. В. Кузьмин, В. А. Кедрус. – М.: Высшая школа, 2017. – 280 с.
- Орлов В. А. Теория информации в упражнениях и задачах / В. А. Орлов, Л. И. Филиппов. – М.: Высшая школа, 2016. – 136 с.
- Основы информационной безопасности. Учебное пособие для вузов / Е. Б. Белов, В. П. Лось, Р. В. Мещеряков, А. А. Шелупанов. – М.: Горячая линия – Телеком, 2016. – 544 с.
- Основы теории информации и кодирования / И. В. Кузьмин, В. А. Кедрус. – М: Высшая школа, 2016. – 238 с.
- Сэломон Д. Сжатие данных, изображений и звука / Д. Сэломон. – М.: Техносфера, 2014. – 368 с.
- Солодовников А.И. Основы теории и методы обработки информации / А. И. Солодовников, А. М. Спиваковский. – Л.: Изд-во Ленингр. ун-та, 1986. – 272 с.
- Хэмминг Р. В. Теория кодирования и теория информации. Пер. с англ. – М.: Радио и связь, 2013. – 176 с.

- Разработка регламента выполнения процесса «Учет реализации лекарственных препаратов через аптечную сеть» (Описание бизнес-процессов «AS-IS»)
- Возмещение морального вреда
- Проектирование реализации операций бизнес-процесса (Выбор комплекса задач автоматизации)
- Облачные сервисы
- Индивидуальное предпринимательство
- Статус нотариуса
- Развитие взглядов на управление человеческими ресурсами
- Общий порядок ведения кассовых операций в банке
- Формы и системы оплаты труда на предприятии
- Преимущества и недостатки инструментов интегрированных коммуникаций
- Организация маркетинга на предприятии
- Разработка регламента выполнения процесса «Учет реализации лекарственных препаратов через аптечную сеть» (Описание предметной области)