
Методы кодирования данных ( КОДИРОВАНИЕ И МЕТОДЫ КОДИРОВАНИЯ )
Содержание:

ВВЕДЕНИЕ
Актуальность. В современном информационном мире одной из самых актуальных задач является сжатие фото и видео. Главная цель сжатия – уменьшение избыточности данных, то есть передача только основной, самой значимой части, по которой можно восстановить целиком исходную информацию. Для сжатия графической информации существуют алгоритмы сжатия без потери и с потерей информации. Алгоритмы кодирования без потери информации предоставляют максимально качественное изображение, но сжатие максимум в 2-3 раза. Алгоритмы с потерей информации дают пользо- вателю выбрать степень компрессии и позволяют достигнуть сжатия в сотни раз.
Объект исследования: графическая информация (фото- и видеоизображения)
Предмет исследования: методы их кодирования
Цель работы: изучить методы кодирования данных на примере кодирования изображений.
Задачи:
Рассмотреть существующие виды кодирования изображений и видеоданных;
Исследование искажений при кодировании.
В работе представлен обзор существующих методов сжатия графической информации, сравнение основных алгоритмов. Для исследования искажений кодирования статических изображений были взяты тестовое изображение «метла» и три сюжетных закодированных в формате без потери данных BMP, для видеоизображений – три файла в формате YUV422. Файлы были закодированы различными алгоритмами и сравнивались с оригиналом.
ГЛАВА 1. КОДИРОВАНИЕ И МЕТОДЫ КОДИРОВАНИЯ
Кодирование - это процесс перевода информации, выраженной одной системой знаков, в другую систему, то есть перевод записи на естественном языке в запись с помощью кодов.
Методы кодирования технико-экономической и социальной информации тесно взаимосвязаны с методами классификации. Каждому методу классификации соответствует один или несколько методов кодирования.
В процессе кодирования объектам классификации и их группировкам по определенным правилам присваиваются цифровые, буквенные и буквенно-цифровые коды. Код характеризуется алфавитом, то есть знаками, используемыми для его образования, основанием кода - числом знаков в алфавите кода и длиной кода. [19][1]
К методам кодирования ТЭСИ предъявляются определенные требования, соблюдение которых способствует повышению качества классификатора. Метод кодирования должен:
1. предусматривать использование в качестве алфавита кода десятичных цифр и букв;
2. обеспечивать по возможности минимальную длину кода и достаточный резерв незанятых позиций для кодирования новых объектов без нарушения структуры классификатора;
3. быть максимально ориентированным на автоматизированную обработку информации.
Методы кодирования могут носить самостоятельный характер - регистрационные методы кодирования, или быть основанными на предварительной классификации объектов - классификационные методы кодирования.
Регистрационные методы кодирования бывают двух видов: порядковый и серийно-порядковый.
Порядковый метод кодирования - это такой метод, при котором кодами служат числа натурального ряда. В этом случае каждый из объектов классифицируемого множества кодируется путем присвоения ему текущего порядкового номера. Данный метод кодирования обеспечивает довольно большую долговечность классификатора при незначительной избыточности кода. Этот метод обладает наибольшей простотой, использует наиболее короткие коды и лучше обеспечивает однозначность определения каждого объекта классификации. Кроме того, он обеспечивает наиболее простое присвоение кодов новым объектам, появляющимся в процессе ведения классификатора. Существенным недостатком порядкового метода кодирования является отсутствие в коде какой-либо конкретной информации о свойствах объекта, а также сложность машинной обработки информации при получении итогов по группе объектов классификации с одинаковыми признаками. Этот метод кодирования не обеспечивает возможности размещения вновь появившихся объектов классификации в необходимом месте классификатора, так как резервные коды располагаются в конце ряда. По этим причинам порядковый метод кодирования отдельно очень редко применяется при создании классификаторов ТЭСИ. Чаше всего он применяется в сочетании с другими методами кодирования. [12][2]
Серийно-порядковый метод кодирования - это такой метод, при котором кодами служат числа натурального ряда с закреплением отдельных серий этих чисел (интервалов натурального ряда) за объектами классификации с одинаковыми признаками. В каждой серии, кроме кодов имеющихся объектов классификации, предусматривается определенное количество кодов для резерва. Резерв кодов располагается в середине или в конце серии. Это является большим преимуществом данного метола по сравнению с порядковым методом кодирования. Серийно-порядковый метод кодирования целесообразно применять для объектов, имеющих два соподчиненных признака. Данный метод кодирования обладает всеми преимуществами и недостатками порядкового метода кодирования. Несмотря на наличие в кодах, построенных по этому методу кодирования, определенных элементов классификации, они чаще всего используются для идентификации объектов в сочетании с классификационными методами кодирования.
Классификационные методы кодирования бывают двух видов: последовательный и параллельный. [3][3]
1. Последовательный метод кодирования -это такой метод, при котором код классификационной группировки и (или) объекта классификации образуется с использованием кодов последовательно расположенных подчиненных группировок, полученных при иерархическом методе классификации. В этом случае код нижестоящей группировки образуется путем добавления соответствующего количества разрядов к коду вышестоящей группировки. Последовательный метод кодирования чаше всего используется при иерархическом методе классификации.
Преимуществами последовательного метода кодирования являются логичность построения кода и большая емкость. Вместе с тем он обладает всеми недостатками, присущими иерархическому методу классификации, а также ограниченными возможностями идентификации объектов. Использование последовательного метода кодирования связано с определенными трудностями, обусловленными тем, что в результате зависимости значений последующих разрядов кода от предыдущих применять этот код по частям нельзя, группировать объекты по различным сочетаниям имеющихся признаков сложно, практически невозможно вносить новые признаки и производить изменения в коде без коренной перестройки классификатора. Поэтому применять последовательный метод кодирования целесообразно в тех случаях, когда набор признаков классификации и их последовательность стабильны в течение длительного времени. [5][4]
2. Параллельный метод кодирования - это метод, при котором код классификационной группировки и (или) объекта классификации образуется с использованием кодов независимых группировок, полученных при фасетном методе классификации. При этом методе кодирования признаки объекта кодируются независимо друг от друга. Для параллельного метода кодирования возможны два варианта записи кодов объектов:
1. Каждый фасет и признак внутри фасета имеют свои коды, которые включаются в состав кода объекта. Такой способ записи удобно применять тогда, когда объекты характеризуются неодинаковым набором признаков и различным их числом. При формировании кода какого-либо объекта берутся только необходимые признаки;
2. Для определенных групп объектов выделяется фиксированный набор признаков и устанавливается стабильный порядок их следования, то есть устанавливается фасетная формула. В этом случае не надо каждый раз указывать, значение какого признака приведено в определенных разрядах кода объекта.
Параллельный метод кодирования имеет ряд преимуществ. К достоинствам рассматриваемого метода кодирования относится гибкость структуры кода, обусловленная независимостью признаков, из кодов которых строится код объекта классификации. Метод позволяет использовать при решении конкретных технико-экономических и социальных задач коды только тех признаков объектов, которые необходимы, что дает возможность работать в каждом отдельном случае с кодами небольшой длины. При этом методе кодирования можно осуществлять группировку объектов по любому сочетанию признаков. Параллельный метод кодирования хорошо приспособлен для машинной обработки информации. По конкретной кодовой комбинации легко указать, набором каких характеристик обладает рассматриваемый объект. При этом из небольшого числа признаков можно образовать большое число кодовых комбинаций. Набор признаков при необходимости может легко пополняться присоединением кода нового признака. Это свойство параллельного метода кодирования особенно важно при решении технико-экономических задач, состав которых часто меняется. [3][5]
Параллельный метод кодирования целесообразно использовать для кодирования однородных объектов, так как в противном случае реальной становится лишь незначительная часть сочетаний признаков, и емкость классификатора будет использоваться не полностью. Это является недостатком данного метода кодирования. К недостаткам метода можно отнести также и другие недостатки, присущие фасетному методу классификации.
Перечисленные классификационные методы кодирования характеризуются тем, что даже при глубокой классификации объектов код несет информацию о классификационной группировке, но не всегда идентифицирует конкретный объект, а коды, полученные на основе идентификационных методов, хорошо выполняя функцию идентификации объектов, практически не несут информацию об их свойствах. Поэтому идентификационные и классификационные методы кодирования чаше всего применяются в классификаторах в сочетании друг с другом.
Одним из наиболее узких мест во всей технологии использования классификаторов информации является кодирование и ввод данных. С целью устранения этого проводятся исследования по автоматизации процесса кодирования информации. Однако для реализации автоматизированного процесса кодирования требуются большие объемы памяти, так как вначале вся информация вводится на естественном языке, и связанные с этим большие трудозатраты. Другим направлением снижения трудозатрат в процессе кодирования и ускорения этого процесса является использование штриховых (линейных) кодов.
Преимущества штриховых кодов состоят в следующем:
1. резкое снижение числа ошибок при вводе информации в виде штриховых кодов по сравнению с вводом информации с клавиатуры на естественном языке;
2. легкость считывания штриховых кодов электронными оптическими системами по сравнению с буквенно-цифровыми символами;
3. высокая экономическая эффективность применения систем на основе штриховых кодов вследствие резкого снижения стоимости ввода данных в систему.
Штриховой (линейный) код представляет собой комбинацию вертикальных полосок разной ширины и пробелов между ними. При этом за базу принимается ширина узкого элемента (полоски) кода. Широкие полоски должны быть кратными им по ширине или находиться с ними в определенных соотношениях. В основе штрихового кода лежит цифровой код.
В разных странах используются различные виды штриховых кодов. В каждом из них установлено определенное соотношение между широкими и узкими полосками и между полосками и интервалами между ними. Так, в "Коде 39" каждому знаку цифрового кода соответствует комбинация из девяти элементов (три широких полоски и шесть узких) и из них пять штрихов и четыре интервала между ними.
Разработка штриховых кодов осуществляется Международной ассоциацией по нумерации (ЕАН), коды которой являются наиболее распространенными в Европе. Наша страна с 1987 года также стала членом ЕАН. В 1988 году Госстандарт СССР утвердил РД 50-666-88 "Методические указания. Присвоение цифровых кодов товарам народного потребления". Этим документом устанавливались правила присвоения товарам народного потребления цифровых (торговых) кодов. Эти цифровые коды служат основой для штриховых кодов, наносимых на ярлыки, упаковку и этикетки товаров. Такой цифровой (торговый) код строится в полном соответствии с кодом ЕАН-13. Он состоит из тринадцати разрядов и имеет следующую структуру:
1. 2 знака - идентификатор страны-изготовителя товара;
2. 5 знаков - идентификатор фирмы-изготовителя товара;
3. 5 знаков - идентификатор товара;
4. 1 знак - контрольное число.
В этом коде, например, США и Канада имеют идентификаторы с 00 до 09, Франция - с 30 до 37, ФРГ - с 40 до 43, СНГ - 46, Япония - 49, Италия -с 80 до 83, Корея -88 и так далее.
В штриховом коде, построенном на основе ЕАН-13, каждому знаку цифрового кода соответствует комбинация из семи элементов - штрихов и пробелов между ними.
Штриховые коды могут использоваться кроме торговли также в таких областях, как медицина, банковское дело, промышленность и других. При этом в качестве цифровых кодов для них могут использоваться коды классификаторов ТЭСИ. [10][6]
Использование кодов ТЭСИ требует обеспечения высокой степени достоверности кодированной информации. В классификаторах ТЭСИ для выявления ошибок в кодах используется метод контрольных чисел.
Контроль правильности записи кодов при обработке информация основан на принципе делимости чисел. Иначе его называют контролем по модулю. Суть метода заключается в том, что к коду добавляется ещё один проверочный знак --контрольное число, связанный с кодом определенной математической зависимостью. При вводе кодированной информации в базу данных, ее обработке или использовании в ЭВМ специальной программой контроля выполняется проверка этой зависимости по каждому коду. Если зависимость нарушается, машина выдает информацию о наличии ошибки в коде.
Контроль по модулю широко используется в классификаторах ТЭСИ как у нас в стране, так и за рубежом. В качестве модуля используют различные числа, но наибольшее распространение получил в настоящее время контроль по модулю 11. Для общероссийских классификаторов расчет контрольных чисел осуществляется в соответствии с методикой, разработанной ВНИИКИ". В соответствии с этой методикой контрольным числом является остаток от деления на 11 суммы произведений весов на значения разрядов кода. Весом (весовым коэффициентом) является порядковый номер разряда в коде слева направо. [13][7]
Формула, по которой вычисляется контрольное число, имеет следующий вид:
КЧ=? aixi-11
где КЧ - контрольное число по модулю 11,
ai - вес i-го разряда кода,
xi - значение I -го разряда кода,
? aixi - модуль 11, т.е целая часть суммы произведений значений разрядов кода на их веса.
Методика ВНИИКИ предлагает использовать в качестве весов натуральный ряд чисел от 1 до 10. Если разрядность кода больше 10, то набор весов повторяется. При использовании данного метода остаток может получить значение от 0 до 10. Так как методика предусматривает использование одноразрядных контрольных чисел, то при получении остатка, равного 10, следует сделать повторный расчет контрольного числа со сдвигом строки весов. В этом случае весовой ряд начинается с 3 до 10, а если разрядность кода больше, то дальше веса идут с 1 до 10. В случае повторного получения контрольного числа, равного 10, в качестве контрольного числа используется 0. В случае, если сумма произведений весов на значения разрядов получается меньше 10, то эта сумма и является контрольным числом.
ГЛАВА 2. СУЩЕСТВУЮЩИЕ МЕТОДЫ КОДИРОВАНИЯ ИЗОБРАЖЕНИЙ И ВИДЕО ДАННЫХ
2.1.КОДИРОВАНИЕ ИЗОБРАЖЕНИЙ
2.1.1. АЛГОРИТМЫ БЕЗ ПОТЕРИ ДАННЫХ
Алгоритмы сжатия информации без потери данных – это метод компрессии, при котором можно восстановить сжатье изображение с точностью до бита. Сжатие основано на статистической избыточности [1][8] - соседние пикселы имеют одинаковое или близкое друг другу значения цветового тона и яркости. Например изображение серых гор на фоне голубого неба с белыми облаками.
Но у этих алгоритмов есть недостаток. Если в изображении значения цвета и яркости пикселов никак не совпадают, то есть отсутствует статистическая избыточность, то сжатия статистическими методами не добиться.
2.1.2. КОДИРОВАНИЕ ДЛИН СЕРИЙ RLE
RLE (Run-Length Encoding) – один из самых старых и самых простых методов кодирования. Он основан на замене последовательности одинаковых элементов парами кодовых элементов – количество одинаковых значений и само значение [2][9]. Если встречается последовательность не из одинаковых значений, то первое значение пары устанавливается 0, а второе является счетчиком, который показывает количество неповторяющихся элементов.
Коэффициент сжатия, которое обеспечивает данный алгоритм можно рассчитать по формуле (1)
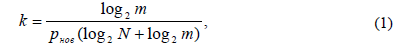
где k – коэффициент сжатия; m – число уровней квантования яркости в кодируемом изображении; нов - вероятность появления новой последовательности; N – максимальная протяженность последовательности
Для записи числа повторений одинаковых отсчетов в последовательности необходимо затратить log2N двоичных единиц, а также необходимо затратить log2m двоичных единиц для записи значения самой величины [2][10].
Формула показывает, что коэффициент сжатия зависит от вероятности появления новой последовательности. При 265 уровнях квантования эта вероятность, по статистике, приближается к единице. Тогда коэффициент сжатия окажется равен меньше единицы – «сжатое» изображение окажется объёмней исходного. Объясняется это тем, что добавляется информация о длительности последовательности, хотя эта длительность почти всегда равна единице.
К достоинствам данного алгоритма можно отнести простоту и быстродействие [7].[11]
Данный метод предназначен для узкоспециализированной графики, такой как чертежи, плакаты и т.п., так как такие графические изображения содержат однородные участки, большие последовательности одинаковых пикселов. Применяется в графических форматах BMP, TIFF, GIF, TGA, PCX.
2.1.3. КОДИРОВАНИЕ МЕТОДОМ LZW
Алгоритм назван по первым буквам фамилий разработчиков - Лемпель-Зив-Велч (Lempel-Ziv-Welch, LZW). Предком LZW является алгоритм LZ78, созданный Абрахамом Лемпелем (Abraham Lempel) и Якобом Зивом (Jacob Ziv) в 1978г. Однако в то время алгоритм воспринимался как математическая абстракция. В 1984 году был доработан Терри Уэлчем (Terry Welch). Опубликование алгоритма произвело большое впечатление на всех специалистов по сжатию информации [2].[12]
Сжатие происходит следующим образом. Создается таблица, в которую записываются все символы исходного алфавита. В общем случае 8-битного алфавита, первые 256 записей (отдельные символы с номерами от 0 до 255) заносятся в словарь до поступления сжимаемых файлов [8]. Далее в таблицу записываются коды очистки 256 и конца записи 257. Алгоритм накапливает поступающие символы в строке. После добавления нового символа кодер ищет строку в таблице. Если строка присутствует в таблице, то добавляется следующий символ. Когда строка не обнаруживается в таблице, полученная последовательность символов записывается в таблице, а на вывод поступает код предыдущего «опознанного» кода. Во входной строке остаётся только что поступивший символ. Код очистки используется, чтобы не допустить переполнения таблицы, которая по принятому соглашению ограничена 12 двоичными единицами (максимум 4095 значений). При использовании кода очистки стираются значения, записанные в таблицу, начиная с кода 258. Тем самым освобождается место для следующих встречающихся в изображении комбинаций. Код конца записи говорит о том, что кодируемая последовательность закончилась.
Таким образом, алгоритм кодирования можно описать следующими шагами:
Создать первоначальную таблицу кодов;
Во входную строку занести первый символ из сообщения «Х»;
Считать следующий символ «Y»;
Если «Y» - код конца записи, то на выход отправить код, соответствующий символу «Х», иначе:
а) Если фразы «XY» нет в таблице, на выход отправить код символа
«Х», а фразу «XY» записать в таблицу. Во входной строке остается символ
«Y»;
б) Если фраза «XY» есть в таблице, перейти к считыванию следующего символа входной последовательности (шаг 3).
Декодирование построено так, что для получения исходного файла не нужно передавать таблицу кодов последовательностей. Она создаётся в процессе декодирования тем же методом, что и при кодировании.
В начале создается таблица с кодами символов исходного алфавита. Во входную строку поступают коды символов, которые используются как указатели для таблицы. Когда во входной строке появляется отсутствующая в таблице последовательность, она записывается. Так как таблица кодов декодирования заполняется «синхронно» или шаг в шаг с таблицей кодирования, не может оказаться неопознанных значений на входе декодера.
Алгоритм LZW ориентирован на 8-битные изображения, построенные на компьютере, применяется в графических форматах TIFF, PDF, GIF, PCD, PNG [15][13]. Может быть достигнут коэффициент сжатия до 1000 раз.
Но метод сжатия может быть применен не только для компрессии данных, каждая единица которых имеет размер в один байт (например отсчеты яркости полутонового черно-белого изображения), но так же для сжатия данных произвольного размера.
2.1.4. МЕТОД КОДИРОВАНИЯ ХАФФМАНА
Дэвид Хаффман в 1952 году будучи аспирантом Массачусетского технологического института разработал алгоритм сжатия данных при написании курсовой работы.
Алгоритм заключается в создании так называемого бинарного дерева или кодовой таблицы. Для каждого символа определяется частота его появления в потоке, при этом часто встречающимся символам сопоставляют короткие кодовые слова, а для редких символов – длинные.
Построение таблицы начитается с того, что два символа с наименьшей частотой появления объединяются в узел кодового дерева, которому приписывается их суммарная частота [19][14]. Этот процесс продолжается до тех пор, пока ветви не сойдутся к одному единственному узлу. Далее ветви, в зависимости от их расположения, обозначаются нулями или единицами (например ветви, идущие влево от узла, обозначим нулями, вправо - единицами или наоборот). Чтобы определить значение кодового слова, кото- рое приписано к определенному символу, нужно пройти от вершины дерева к данному символу, записывая нули или единицы пройденных ветвей.
Алгоритма Хаффмана в чистом виде не применяется для сжатия изображений, а используется как один из этапов. Модификация CCITT Group 3 – алгоритм, предложенный третьей группой по стандартизации Международного консультационного Комитета по Телеграфии и Телефонии (Consultative Committee International Telegraph and Telephone), используется для сжатия черно-белых изображений [17].[15]
В алгоритме последовательности подряд идущих черных и белых точек заменяются числом, равным их количеству. А этот ряд уже сжимается алгоритмом Хаффмана с фиксированной таблицей, полученной с помощью анализа частоты появления большого количества изображений.
В изображении каждая строка сжимается независимо. Считается, что на изображении преобладает белый цвет и каждая строка начинается с белой точки. Если строка начинается с черной точки, то считаем, что строка начинается с последовательности белых точек длинной нуль. Так например последовательность 0,5,362,6… значит, что в начале строки пять черных точек, далее 362 белые, далее 6 черных точек и так далее. Когда в изображении преобладает черный цвет, то перед сжатием изображение инвертируется и информация об этом записывается в заголовок файла.
В среднем, алгоритм CCITT Group 3 имеет коэффициент сжатия в 2 раза, но при применении к файлу с часто чередующимися черных и белых точек размер файла может увеличиться до пяти раз. Используется в формате TIF.
2.1.5. АРИФМЕТИЧЕСКОЕ КОДИРОВАНИЕ
Идея данного алгоритма состоит в том, чтобы присваивать коды не отдельным символам, а их последовательностям. Алгоритм состоит из не- скольких этапов: декорреляция, определение вероятностей каждого символа и чтение всего входного файла символ за символом с добавлением битов к сжатому файлу [11].[16] При этом задаётся «текущий интервал» [0,1), который далее делится на зоны пропорционально вероятностям кодируемых символов. Информация о вероятности и зоны каждого символа составляются в таблицу, которую должен знать как кодер так и декодер.
Шаги кодирования:
Задаётся «текущий интервал» [0,1);
Действия, повторяющиеся для каждого символа входного файла:
«Текущий интервал» делится на части пропорционально вероятностям каждого символа;
Сместить «текущий интервал» в зону кодируемого символа;
На выходе алгоритма объявляется любая точка, однозначно определяющая «текущий интервал», то есть любая точка внутри интервала.
«Текущий интервал» становится меньше с каждым новым кодированным символом, и требуется все больше бит, чтобы выразить его, однако на выходе получаем единственное число [6][17].
Декодирование происходит с помощью кода и таблицы вероятности и зоны символов. При этом код однозначно определяет символ: значение кода попадает в вероятностную зону символа.
Алгоритм требует большого количества вычислительной силы и предоставляет сжатие до теоретически возможной границы без потери информации, но это только в теории. Проблемы возникают при наличии символов с очень маленькой вероятностью появления: «текущий интервал» оказывается очень маленьким.
2.1.6. МЕТОД JPEG-LS
Алгоритм JPEG-LS основан на формате LOCO-I (Low Complexity Lossless Compression for Images), который был разработан компанией Hewlett-Packard для сжатия непрерывно-тоновых изображений. Официально этот метод известен как рекомендация ISO/IEC CD 14495.
JPEG-LS кодирование состоит из следующих шагов:
изучает несколько предыдущих соседей текущего пиксела и рас- сматривает их как контекст этого пиксела;
использует контекст для прогнозирования пиксела и для выбора распределения пиксела и для выбора распределения вероятностей из нескольких имеющихся;
применяет полученное распределение вероятностей для кодирования ошибки прогноза с помощью специального кода Голомба.
Если большое количество пикселов в строке одинаковы, то используется кодирование длин серий. Сжатый файл состоит из сегментов данных (содержащих коды Голомба и длины серий), сегментов маркеров (в качестве которых используются некоторые зарезервированное маркеры JPEG).
Формат разрабатывался для хранения изображений в медицинских целях, то есть в тех случаях, когда необходимо иметь большие изображения без потери информации.
2.1.7. АЛГОРИТМЫ С ПОТЕРЕЙ ДАННЫХ
Изображения крайне важны для современного человека, но они требуют большого объема памяти. Алгоритмы сжатия изображений с потерей данных сжимают психофизическую избыточность [9][18]. Этот вид избыточности обусловлен особенностями зрительной системы человека. Например, объекты малого размера с малой контрастностью не заметны для глаза на изображении, поэтому их можно не передавать.
Как правило, в таких алгоритмах можно задавать степень потери качества, создавая компромисс между качеством и объемом изображения. Существует множество критериев оценки потерь качества (например, среднеквадратичное отклонение, пиковое отношение сигнал-шум), но часто оценка этими критериями расходится с визуальной оценкой человеком. Лучше всего потерю качества оценивают наши глаза. Отличным считается сжатие, при котором исходное и сжатое изображение не различить. Хорошим – когда можно отличить сжатое изображение только в сравнении с оригинальным. При дальнейшем сжатии, как правило, становятся заметны артефакты, характерные для данного алгоритма.
2.1.8. АЛГОРИТМ СЖАТИЯ JPEG
JPEG назван по первым буквам организации, разработавшей этот алгоритм – Joint Photographic Experts Group (Объединенная группа экспертов по фотографии). Метод позволяет сжимать любые изображения: как полутоновые черно-белые, так и цветные. Далее будем рассматривать алгоритм сжатия цветных изображений.
В цветном изображении каждый пиксел описан тремя байтами, по байту на цвета красный (R), зеленый(G) и синий(B). Сжатие начинается с разбиения изображения на блоки 16x16 отсчетов, затем сжимаются независимо друг от друга. Если число строк или столбцов изображения не кратно 8, то самая нижняя строка или самый правый столбец повторяются нужное число раз[8][19].
Далее в каждом блоке переводим изображение в другую цветовую систему: из RGB в YCrCb по формуле (2).
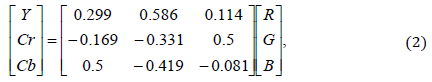
где Y-яркостная компонента; Cr-цветоразностная красная компонента; Cb-цветоразностная синяя компонента; R, G, B – значения красной, зеленой и синей компоненты цвета соответственно.
Переход к системе YCrCb выгоден, так как глаз лучше замечает переходы яркости, чем цвета, поэтому компоненты Cr и Cb можно сильнее сжимать.
Далее блок 16х16 яркостной компоненты делится на 4 блока 8х8 отсчетов каждая, а цветоразностные матрицы Cr и Cb с помощью прореживания преобразуются в матрицы 8х8 отсчетов. При прореживании этих матриц удаляются каждая вторая строка и каждый второй столбец. При декодировании недостающие элементы восстанавливаются интерполированием. Такое преобразование допустимо, так как глаз имеет пониженную остроту при наблюдении чисто хроматических изображений и не замечает подобных погрешностей [16][20].
На данном этапе у нас 4 матрицы яркостной компоненты Y и 2 цветоразностных матрицы Cr и Cb. К каждой матрице применяется дискретное косинус преобразование (ДКП), в результате получаем матрицу частотных коэффициентов. Особенность матриц состоит в том, что полученные коэффициенты расположены в определенном порядке: коэффициенты низкой частоты – в левом верхнем углу, высокой частоты – в правом нижнем. Крупные объекты на изображении соответствуют низкочастотным составляющим, а мелкие – высокочастотным. Коэффициенты низкой частоты оказываются больше коэффициентов высокой частоты. На данном этапе происходит некоторые необратимые изменения в информации из-за ограниченности точности машинных вычислений. Несмотря на то, что пока не произошло сжатия, происходит очень слабое искажение изображения.
Далее каждый коэффициент делится на матрицу квантования и округляется до целого числа. При этом частотные коэффициенты с большими индексами (коэффициенты низких частот), на долю которых приходится малая доля энергии изображения, квантуются на малое число уровней. Все коэффициенты матрицы квантования пользователь, в принципе, может задавать самостоятельно, но подавляющее число приложений используют значения коэффициентов, рекомендованных стандартом JPEG. В результате получаем матрицу проквантованных частотных коэффициентов, в которой множество нулевых и единичных коэффициентов, расположенных преимущественно в правом нижнем углу (высокочастотных составляющих изображения).
Следующим шагом матрица 8х8 преобразуется в вектор из 64 элементов. Для того, чтобы нулевые и единичные коэффициенты оказались сгруппированы в одном месте, используется специальный метод, называемый зиг-заг сканированием, пример на рисунке 1.
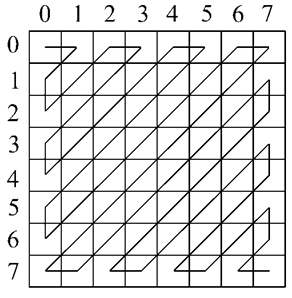
Рисунок 1 – Зиг-заг сканирование
Зиг-заг сканирование начинается с точки (0,0). В начале считываются коэффициенты с большими значениями, в конце – с малыми. В результате получаем последовательность из 64 значений, в начале которого большие числа, а ближе к концу - последовательность из нулей и единиц. Этот код сжимается с помощью метода Хаффмана с фиксированной таблицей CCITT Group 3.
При декодировании повторяются все шаги кодирования в обратном порядке. Переход из системы YCrCb в RGB выполняется по формуле (3).
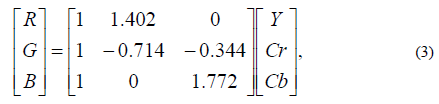
где Y-яркостная компонента; Cr-цветоразностная красная компонента; Cb- цветоразностная синяя компонента; R, G, B – значения яркости красной, зеленой и синей компоненты соответственно.
Этот алгоритм широко распространен в нынешнее время. Коэффициент сжатия цветных изображений при отличном сжатии может достигать 6-10. В большинстве графических редакторов можно изменять степень сжатия в обмен на качество. Это реализовано с помощью изменения коэффициентов матрицы квантования. Но чем больше степень сжатия, тем больше будет заметны артефакты на восстановленном изображении. В случае JPEG это будет блочность – выделение границ блоков 8х8, с которыми производятся преобразования.
2.1.9. ВЕЙВЛЕТ-ПРЕОБРАЗОВАНИЕ
Вейвлет (Wavelet) переводят как «короткая волна» или «всплеск». В алгоритме к исходному изображению применяются так называемые вейвлет- и скейлинг-функции [3][21]. В результате вейвлет-преобразования спектр исходного сигнала делится на низкочастотную и высокочастотную компоненты, причем, в случае сжатия изображения.
Рассмотрим алгоритм на примере черно-белого изображения. Изображение разбивается на группы 2х2 пиксела, обозначим яркость пикселов L(2k, 2n), L(2k + 1,2n ), L(2k , 2n + 1), L(2k + 1,2n + 1) , где k – номер строки, n – номер столбца. Яркость используется для вычисления последовательностей v(1) (k,n), v(2) (k,n), v(3) (k,n), v(4) (k,n), которые представляют собой полусуммы и полуразности яркостей, см. формулу (4).
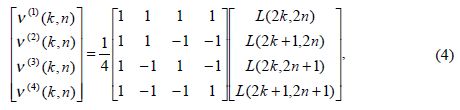
Эти компоненты объединяются в четыре матрицы и размещаются рядом, как показано на рисунке 2. Так же на рисунке 2 обозначена ориентация контуров, представляемых матрицами v(2) (k,n), v(3) (k,n), v(4) (k,n).

v(1) (k,n)v(2) (k,n)
v(3) (k,n)v(4) (k,n)
а б
Рисунок 2– а – матрица отсчетов; б – матрицы компонентов вейвлет-преобразования
Матрица v(1) (k,n) содержит уменьшенное исходное изображение и называется «аппроксимация». Компоненты v(2) (k,n), v(3) (k,n), v(4) (k,n) называются «деталями» и представляют собой резкие границы, расположенные вертикально, горизонтально и по диагонали.
Полученные таким образом компоненты квантуются, причем идея квантования совпадает с квантованием в алгоритме JPEG: высокочастотные компоненты квантуются на меньшее число уровней, низкочастотные – на большее. Принцип все тот же: если наш глаз хуже различает объекты малого контраста и малого размера, то можно передавать их менее качественно. Отличие от JPEG состоит в том, что квантование применяется ко всему изображению, а не к блоку 8х8, что исключает образование блочности при большом коэффициенте сжатия. Полученные отсчеты подвергаются энтропийному кодированию аналогичному тому, что применяется в JPEG.
Декодирование происходит в обратном порядке: вначале отсутствующие отсчеты в матрицах восстанавливаются интерполяцией, а затем все компоненты суммируются.
В результате вейвлет-преобразования можно достигнуть коэффициента сжатия в 30-50 раз. Так же как и в JPEG коэффициент сжатия можно регулировать с помощью изменения коэффициентов матрицы квантования. Однако вейвлет-преобразование не лишено артефактов: характерные искажения – это окантовки и посторонние узоры.
2.1.10. АЛГОРИТМ JPEG2000
Алгоритм JPEG2000 был разработан в 2000 году той же группой экспертов, что и JPEG. JPEG2000 очень похож на своего предшественника, однако использует более ресурсозатратные операции. Основное различие в том, что вместо дискретного косинус-преобразования в нем используется вейвлет-преобразование.
Первым шагом осуществляется сдвиг по интенсивности каждого компонента RGB изображения, это делается для симметрирования динамического диапазона сигнала относительно нуля, что приводит к увеличению степени сжатия. Преобразование выполняется по формуле (5). При декомпрессии выполняется обратное преобразование.
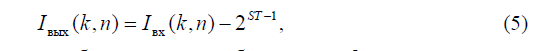
где Iвых - интенсивность бита после преобразования; Iвх - интенсивность бита до преобразования; k – номер строки; n – номер столбца; ST – значение степени для каждого компонента R, G, B определяется кодером при сжатии и сообщается декодеру.
Следующим шагом изображение переводится из цветовой системы RGB в YUV по формуле (6). При декодировании используется обратное преобразование.
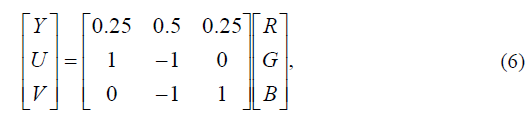
где R, G, B – значения красной, зеленой и синей компоненты цвета соот- ветственно; Y – яркостная компонента; U и V – цветоразностные состав- ляющие красная и синяя соответственно.
Далее применяется дискретное вейвлет-преобразование ко всем трем матрицам, причем для лучшего сжатия эта операция применяется трижды: вначале ко всему изображению, далее к получившимся аппроксимациям. В этом случае получаем до v(10) (k, n) компоненты для каждой матрицы. В отличие от алгоритма JPEG в JPEG2000 не применяется прореживание матриц U и V, однако для этих компонент просто не сохраняют составляющие вейвлет-преобразования v(8) (k, n), v(9) (k, n), v(10) (k, n). [13][22]
Следующая операция над матрицами – квантование всех компонентов. Высокочастотные составляющие квантуются на меньшее число уровней, низкочастотные – на большее.
К результирующим отсчетам применяется энтропийное кодирование посредством так называемого MQ-кодера. В кодере производится де- корреляция отсчетов и арифметическое кодирование.
Так как алгоритм использует вейвлет-преобразование он достаточно ресурсозатратный, однако по сравнению с JPEG при одинаковом качестве размер файла отказывается меньшим.
2.1.11. ФРАКТАЛЬНОЕ КОДИРОВАНИЕ
Начало разработке данного метода положила работа Майкла Барнсли, открывшим новый класс теорем, которые можно использоваться для сжатия изображений. По сути, сжимается не само изображение, а алгоритм его построения [18][23]. Метод основывается на особенности природных объектов, который заключается в том, что эти объекты состоят из множества вариаций самоподобных элементов. То есть изображение состоит из некоторого количества основных элементов и их вариаций, например, окна в доме, чешуя на рыбе, границы между градациями цвета. Вариации создаются из основных элементов с помощью преобразований, называемых аффинные – преобразование координат X и Y и яркости.
Фактически фрактальная компрессия – это поиск самоподобных элементов и определение для них параметров аффинных преобразований. В файле сжатого изображения содержится самоподобные элементы и ин- формация о том, как из этих элементов составить исходное изображение.
Потеря информации состоит в том, что реальные изображения не могут состоять из идентичных элементов, и непременно некоторые уникальные элементы будут потеряны при сжатии. Параметр ошибки можно задать до сжатия. Несмотря на то, что в идеальной ситуации, когда изображение состоит из одного самоподобного элемента и его вариаций, можно достигнуть коэффициента сжатия до 500 раз, данный алгоритм используется в редких случаях, почти не используется. Проблема состоит в необходимости чрезмерной вычислительной мощи для перебора групп элементов во всем изображении. Однако существует много настраиваемых параметров, с помощью которых можно уменьшить вычисления, например, ограничить количество аффинных преобразований, ограничить минимальных размер самоподобного элемента. Закодированные файлы имеют расширение fif.
ГЛАВА 3. КОДИРОВАНИЕ ВИДЕОСЮЖЕТОВ
Одно изображение занимает достаточно большой объём, что уж говорить о видео изображении? Если говорить о сжатии видео, алгоритмы компрессии без потерь неприемлемы.
Так же как и для статических изображений, алгоритмы сжатия видео удаляют избыточность. В видеосюжетах существует два вида избыточности: пространственная и временная. Пространственная избыточность идентична избыточности статического изображения. Временная избыточность заключается в том, что значительную часть времени последующий кадр похож на предыдущий. Основной выигрыш в сжатии видеосюжетов получается, благодаря удалению именно временной избыточности.
В следующих подразделах будут описаны только основные кодеки, которые являлись или являются стандартом. Существуют несколько аль- тернативных и коммерчески бесплатных кодеков, таких как Theora, однако они проигрывают основной ветке по соотношению качество-битрейт.
3.1. H.262
Видеокодек H.262 входит в группу стандартов цифрового кодирования видео- и аудиосигналов MPEG-2 часть 2. Первоначально этот кодек мог кодировать видео с разрешением 720*480 точек при 30 кадрах в секунду, при дальнейшем усовершенствовании достигалось сжатие разрешения 1920*1080 точек при 30 кадрах в секунду.
Сжатие основано на устранении пространственной и временной избыточностей. Пространственную избыточность можно убрать сжимая кадры с помощью алгоритма компрессии статического изображения. С временной избыточностью посложнее: так как в большинстве случаев последующие кадры не слишком сильно отличаются от предыдущего, то для лучшей компрессии потока хочется передавать только перемещение объектов в кадре, а неизменные области брать из первого карда в последовательности. Для решения обеих этих задач в кодеке вводится понятие группа кадров (group of pictures - GOP), и кадры в группе делятся на три вида: основные I- (intrapictures), предсказанные P- (predicted) и двунаправленные B- (bidirectional) кадры. I-кадры – это входная точна для декодера, они кодируются независимо в соответствии с методом, используемым в стандарте JPEG. P-кадры кодируются на основе предсказания, путем ссылок на блоки предыдущих I- или P-кадров. B-кадры используют ссылки на два кадра, находящихся впереди и позади них. Группа кадров всегда должна начинаться с I-кадра, по нему предсказываются Р- и В-кадры. Количество P- и B- кадров может варьироваться в зависимости от желаемой степени сжатия: чем больше P- и B-кадров, тем больше сжатие, однако если I-кадр будет закодирован ошибочно, либо произойдет потеря информации в I- кадре, то ошибка будет тянуться на всю группу кадров.
Сжатие видеоизображения происходит следующим образом. Последовательность кадров разбивается на макроблоки 16х16 отсчетов как в алгоритме JPEG и разделяются на три типа кадров: I-, P- и B-кадры. I-кадры сжимаются с помощью алгоритма JPEG: в каждом макроблоке 16х16 отсчетов производится переход к цветовой системе YCrCb, компоненты Cr и Cb прореживаются до матриц 8х8 (удаляется каждая вторая строка и каждый второй столбец), производится ДКП матриц и их квантование, в заключении зиг-заг сканирование и сжатие получившейся последовательности отсчетов методом Хаффмана.
P-кадры передают уже не полностью закодированное изображение, а ошибку предсказания с учетом компенсации движения – разницу между предыдущим и последующим кадром с векторами движения. Вектора движения рассчитываются следующим образом: каждый блок из предыдущего кадра сравнивается с блоком из следующего. Если они идентичны, то ни- какого движения не произошло, вектор движения отсутствует. Если нет, то блок перемещается в некоторой области поиска основного изображения, чтобы найти такое его положение, при котором среднеквадратическая разность блока и фрагмента основного изображения принимает минимальное значение. За вектор движения принимается это смещение блока по вертикали и горизонтали относительно исходного положения.
B-кадры при кодировании ссылаются на два кадра: впереди и позади них. То есть в них передаётся информация о том, как «собрать» кадр из двух окружающих. Благодаря тому, что передаётся не каждый кадр по отдельности, а ссылки на основные кадры. Стандарт MPEG2 хорошо подходит для хранения фильмов, однако из-за структуры группы кадров совершенно не годится для видеомонтажа. Так же возникают проблемы со сжатием видеосюжетов с быстродвижущимися объектами или с часто меняющимися планами. Объект будет размазан, а если I-кадр окажется не на моменте смены плана, то вся информация будет записана в P-кадр, что приведет к увеличению объема файла.
3.2. H.264
Видеокодек входит в группу стандартов MPEG4 часть 10. Эта рекомендация в настоящее время (2016 год) является стандартом сжатия видеоизображения. Используется для записи видео высокой четкости на Blu- ray и HD DVD, является стандартом для онлайн-видеохостингов, таких как сайт Youtube, а так же стандарт в системах цифрового телевещания [10][24]. По сравнению с H.262 данный кодек обеспечивает сжатие в два раза больше при неизменном качестве видеоизображения [11][25]. Достигается это благодаря существенному усложнению кодека.
В данном кодеке реализовано разбиение кадра не только на макроблоки 16x16, а так же 16x8, 8x16, 8x8, 8x4, 4x8, 4x4, в зависимости от наличия мелких деталей. При этом увеличивается четкость передачи мелких объектов и качество компенсация движения: обеспечивается большая точность представления векторов движения. При этом точность поиска вектора движения составляет 1/4 или 1/8 макроблока, чего не было в кодеке H.262. Изменено внутреннее кодирование I-кадра. Кодирование так же основано на алгоритме JPEG, но с некоторыми дополнениями. Перед операцией ДКП над макроблоком производится его пространственное предсказание (intra-prediction) по уже закодированным соседним макроблокам. Затем яр- костные и цветоразностные отсчеты предсказанного макроблока вычитаются из соответствующих отсчетов кодируемого макроблока, и над матрицей с разностными компонентами производится ДКП. В кодере предусмотрено 9 направлений внутреннего предсказания.
Так же изменены методы устранения временной избыточности. P- и B-кадры, при их формировании, могут ссылаться на несколько кадров (более двух).
Энтропийное кодирование Хаффмана заменено более сложным и ресурсозатратным контекстным адаптивным двоичным арифметическим кодером (Context Adaptive Binary Arithmetic Coder, CABAC).
Каждый новый кодек и каждое нововведение основываются на увеличении мощности компьютеров. Кодек H.264 обязан своим появлением вы- ходу в продажу двухъядерного процессора от компании Intel. Все перечисленные выше улучшения усложняют алгоритм, и увеличивают время сжатия, по сравнению с MPEG-2. Но в настоящее время сложностей с кодированием видео с помощью H.264 не возникает даже на домашнем персональном компьютере. Кодер позволяет обрабатывать видео с разрешением до 4096х2304 точки при скорости 26,7 кадров в секунду.
3.3. H.265/HEVC
H.265/HEVC (High Efficiency Video Coding) – следующий разрабатываемый стандарт сжатия видеосюжетов. Создается в связи с необходимостью увеличить коэффициент сжатия видеопотока и для передачи видео d aормате UHDTV. Заявлено, что данный кодек позволит сжимать информацию в 50% эффективнее, чем H.264.
В данном алгоритме реализована поддержка большого диапазона размера блоков, от 64х64 до 8х8, а для увеличения точности компенсации движения мелких деталей используется блоки 4х4.
На начальном этапе кодирования изображение делится на одинаковые по размеру блоки – элементы кодового дерева (Coding Tree Unit - CTU) – это логический элемент, состоящий из трех блоков (Coding Tree Block - CTB). CTB содержит в себе блок яркостной и цветоразностных компонент. В зависимости от изображения для внутрикадрового или межкадрового предсказаний CTB может делиться на меньшее число отсчетов. Кодек поддерживает 35 направлений внутрикадрового предсказания.
Использование кодека H.265/HEVC даёт выигрыш в снижении битрейта порядка 51-74% в зависимости от характера видео. В настоящее время разработка кодека продолжается, однако уже сейчас существуют свободные библиотеки кодирования видео, основанные на существующих наработках, такие как OpenHEVC FFmpeg, DivX HEVC и др.
ЗАКЛЮЧЕНИЕ
Проблема кодирования информации, имеет достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки информации.
Преимуществами рассмотренных методов являются их очевидная простота реализации и, как следствие этого, высокая скорость кодирования и декодирования. Основным недостатком является их не оптимальность в общем случае.
В данной работе были рассмотрены методы сжатия графической ин- формации: приведено описание алгоритмов сжатия статических изображений с потерей и без потери данных и видеоизображений.
В исследовательской части произведено сравнение алгоритмов коди- рования на различных сюжетах. Для исследования искажений кодирования алгоритмов с потерей данных были взяты JPEG и JPEG2000 для статических изображений.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Сэломон Д. Сжатие данных, изображений и звука. М.: Техносфера, 2004. 368 с.
- Красильников Н.Н. Цифровая обработка 2D- и 3D-изображений: учебное пособие. СПб.: БХВ-Петербург, 2011. 608 с.
- Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео / Ватолин Д., Ратушняк А., Смирнов М., Юркин В. М.: ДИАЛОГ- МИФИ, 2002. 384 с.
- Особенности графических форматов. // URL: courses.narod.ru/graphics.html (Дата обращения 14.04.2018)
- HP Labs LOCO-I/JPEG-LS Home Page // URL: http://www.labs.hp.com/research/info_theory/loco/ (Дата обращения 14.04.2018)
- Рубаков Г., Суслов А. JPEG, JPEG2000, JPEG-LS. Сжатие изображений с потерями и без // URL: http://rain.ifmo.ru/cat/view.php/theory/data- compression/jpeg-2006 (Дата обращения 13.04.2018)
- Воробьев В.И., Грибунов В.Г. Теория и практика вейвлет- преобразования. СПб.: ВУС, 1999. 204 с.
- H.262/MPEG-2 Part 2 // URL: https://en.wikipedia.org/wiki/H.262/MPEG- 2_Part_2 (Дата обращения 13.04.2018)
- Гьен Д. Семейство форматов MPEG. Часть вторая - MPEG-2 // URL: http://www.3dnews.ru/170047
- Таналин М. H.264 // URL: http://tanalin.com/articles/h264/
- Гук И. Особенности сжатия видеоданных по рекомендации H.264 / MPEG 4 Part 10 // URL: http://www.kit-e.ru/articles/dsp/2006_2_20.php
- История развития форматов видеосжатия // URL: https://habrahabr.ru/company/intel/blog/133198/
- Орлов В.Г., Пушкарев А.В.; Современные и перспективные технологии телевидения высокой четкости // INTERMATIC. 2014. Ч. 5. М.: МИРЭА, 2014. С. 233-238.
- CCD Binning // URL: http://www.andor.com/learning-academy/ccd- binning-what-does-binning-mean
- Xiaodan Jin, Keigo Hirakawa Analysis and processing of pixel binning for color image sensor // URL: http://asp.eurasipjournals.springeropen.com/articles/10.1186/1687-6180-2012- 125
- Bosoon P., Renfu Lu Hyperspectral Imaging Technology in Food and Agri- culture. New York: Springer, 2015. 403 с.
- Интерполяция цифрового изображения // URL: http://www.cambridgeincolour.com/ru/tutorials-ru/image-interpolation.htm
- YUV – Кодированный файл изображения YUV (YUV Encoded Image File) // URL: http://fileext.ru/yuv СанПин 2.2.2/2.4.1340-03 «Гигиенические требования к персональным электронно-вычислительным машинам и организации работы» // URL: http://www.rosteplo.ru/Npb_files/npb_shablon.php?id=707
-
СанПин 2.2.2/2.4.1340-03 «Гигиенические требования к персональным электронно-вычислительным машинам и организации работы» // URL: http://www.rosteplo.ru/Npb_files/npb_shablon.php?id=707 ↑
-
Рубаков Г., Суслов А. JPEG, JPEG2000, JPEG-LS. Сжатие изображений с потерями и без // URL: http://rain.ifmo.ru/cat/view.php/theory/data- compression/jpeg-2006 ↑
-
Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео / Ватолин Д., Ратушняк А., Смирнов М., Юркин В. М.: ДИАЛОГ- МИФИ, 2002. 384 с. ↑
-
HP Labs LOCO-I/JPEG-LS Home Page // URL: http://www.labs.hp.com/research/info_theory/loco/ ↑
-
Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео / Ватолин Д., Ратушняк А., Смирнов М., Юркин В. М.: ДИАЛОГ- МИФИ, 2002. 384 с. ↑
-
Таналин М. H.264 // URL: http://tanalin.com/articles/h264/ ↑
-
Орлов В.Г., Пушкарев А.В.; Современные и перспективные технологии телевидения высокой четкости // INTERMATIC. 2014. Ч. 5. М.: МИРЭА, 2014. С. 233-238. ↑
-
Сэломон Д. Сжатие данных, изображений и звука. М.: Техносфера, 2004. 368 с. ↑
-
Красильников Н.Н. Цифровая обработка 2D- и 3D-изображений: учебное пособие. СПб.: БХВ-Петербург, 2011. 608 с. ↑
-
Красильников Н.Н. Цифровая обработка 2D- и 3D-изображений: учебное пособие. СПб.: БХВ-Петербург, 2011. 608 с. ↑
-
Воробьев В.И., Грибунов В.Г. Теория и практика вейвлет- преобразования. СПб.: ВУС, 1999. 204 с. ↑
-
Красильников Н.Н. Цифровая обработка 2D- и 3D-изображений: учебное пособие. СПб.: БХВ-Петербург, 2011. 608 с. ↑
-
Xiaodan Jin, Keigo Hirakawa Analysis and processing of pixel binning for color image sensor // URL: http://asp.eurasipjournals.springeropen.com/articles/10.1186/1687-6180-2012- 125 ↑
-
СанПин 2.2.2/2.4.1340-03 «Гигиенические требования к персональным электронно-вычислительным машинам и организации работы» // URL: http://www.rosteplo.ru/Npb_files/npb_shablon.php?id=707 ↑
-
Интерполяция цифрового изображения // URL: http://www.cambridgeincolour.com/ru/tutorials-ru/image-interpolation.htm ↑
-
Гук И. Особенности сжатия видеоданных по рекомендации H.264 / MPEG 4 Part 10 // URL: http://www.kit-e.ru/articles/dsp/2006_2_20.php (Дата обращения 20.05.2016) ↑
-
Рубаков Г., Суслов А. JPEG, JPEG2000, JPEG-LS. Сжатие изображений с потерями и без // URL: http://rain.ifmo.ru/cat/view.php/theory/data- compression/jpeg-2006 ↑
-
Гьен Д. Семейство форматов MPEG. Часть вторая - MPEG-2 // URL: http://www.3dnews.ru/170047 ↑
-
H.262/MPEG-2 Part 2 // URL: https://en.wikipedia.org/wiki/H.262/MPEG- 2_Part_2 ↑
-
Bosoon P., Renfu Lu Hyperspectral Imaging Technology in Food and Agri- culture. New York: Springer, 2015. 403 с. ↑
-
Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео / Ватолин Д., Ратушняк А., Смирнов М., Юркин В. М.: ДИАЛОГ- МИФИ, 2002. 384 с. ↑
-
Орлов В.Г., Пушкарев А.В.; Современные и перспективные технологии телевидения высокой четкости // INTERMATIC. 2014. Ч. 5. М.: МИРЭА, 2014. С. 233-238. ↑
-
YUV – Кодированный файл изображения YUV (YUV Encoded Image File) // URL: http://fileext.ru/yuv ↑
-
Таналин М. H.264 // URL: http://tanalin.com/articles/h264/ ↑
-
Гук И. Особенности сжатия видеоданных по рекомендации H.264 / MPEG 4 Part 10 // URL: http://www.kit-e.ru/articles/dsp/2006_2_20.php ↑

- Методы и средства проектирования информационных систем и технологий. Применение процессного подхода для оптимизации бизнес-процессов.
- Сравнительный анализ стандартов, видов и особенностей систем контроля в российских и зарубежных компаниях (Виды управленческого контроля)
- Роль мотивации в поведении организации (Процессуальные и содержательные теории мотивации)
- Роль мотивации в поведении организации (Процессуальные и содержательные теории)
- Проектный контроллинг (Факторы, влияющие на достижение целей проекта)
- Налоги как цена услуг государства (Виды налоговых проверок и их особенности)
- Цели создания запасов и их классификация
- Основные этапы формирования налогового учета в России ( Сущность налогового учета )
- Стандартные и социальные налоговые вычеты по налогу на доходы физических лиц
- Страхование ответственности и проблемы его развития в РФ ( Виды страхования, относящиеся к страхованию ответственности на территории РФ )
- Основные этапы формирования налогового учета в России ( Система налогового учета )
- ПОНЯТИЕ, ЦЕЛИ И ЗАДАЧИ НАЛОГОВОГО УЧЕТА