
Методы кодирования данных (Функциональные модели)
Содержание:

Введение
Испокон веков не было ценности большей, чем информация. ХХ век – век информатики и информатизации. Технология дает возможность передавать и хранить все большие объемы информации. Это благо имеет и оборотную сторону. Информация становится все более уязвимой по разным причинам:
• возрастающие объемы хранимых и передаваемых данных;
• расширение круга пользователей, имеющих доступ к ресурсам ЭВМ, программам и данным;
• усложнение режимов эксплуатации вычислительных систем.
Поэтому все большую важность приобретает проблема защиты информации от несанкционированного доступа (НСД) при передаче и хранении. Сущность этой проблемы – постоянная борьба специалистов по защите информации со своими «оппонентами».
Для того чтобы ваша информация, пройдя шифрование, превратилась в «информационный мусор», бессмысленный набор символов для постороннего, используются специально разработанные методы – алгоритмы шифрования. Такие алгоритмы разрабатываются учеными математиками или целыми коллективами сотрудников компаний или научных центров.
Алгоритмы шифрования делятся на два больших класса: симметричные (AES, ГОСТ, Blowfish, CAST, DES) и асимметричные (RSA, El-Gamal). Симметричное шифрование
Для работы применяется всего один пароль. Происходит всё следующим образом:
1. Существует некий математический алгоритм шифрования.
2. На его вход подаётся текст и пароль.
3. На выходе получаем зашифрованный текст.
4. Если хотим получить исходный текст, применяется тот же самый пароль, но с алгоритмом дешифрования.
Говоря простым языком, если кто-то узнает наш пароль, безопасность криптосистемы тут же нарушится. Именно поэтому, используя подходы симметричного шифрования, мы должны особое внимание уделять вопросам создания и сохранения конфиденциальности пароля. Он должен быть сложным, что исключит подбор программным перебором значений. И не должен передаваться кому-нибудь в открытом виде как в сети, так и на физических носителях информации. Очевидно, что листочек, прикреплённый к монитору — явно не лучший вариант)). Тем не менее если наша секретная комбинация используется командой, нужно обеспечить безопасность её распространения. Пригодится и система оповещения, которая сработает, если шифр узнают, произойдёт утечка данных.
Несмотря на свои ограничения и угрозу безопасности, подход до сих пор широко распространён в криптографии. Дело в том, что он очень прост в работе и понимании. И техническая нагрузка на железо невелика (как правило, всё работает очень быстро).
Ассиметричное шифрование
Здесь применяют 2 пароля — публичный (открытый) и секретный (закрытый). Первый отсылается всем людям, второй остаётся на стороне сервера. Эти названия достаточно условные, а зашифрованное одним из ключей сообщение можно расшифровать лишь с помощью другого. По сути и значимости они равноценны.
Данные алгоритмы шифрования дают возможность без проблем распространять пароли по сети, ведь не имея 2-го ключа, любое исходное сообщение останется для вас непонятным шифром. Кстати, на этом принципе работает и протокол SSL, позволяющий устанавливать безопасные соединения с пользователями, т. к. закрытый ключ есть только на стороне сервера. Для ассиметричного шифрования хранение паролей проще, ведь секретный ключ не нужно передавать кому-либо. А в случае взлома сервер сменит пару ключей и разошлёт всем новые комбинации.
Считается, что ассиметричное шифрование «тяжелее» симметричного. Всё потому, что оно требует больше компьютерных ресурсов. Есть ограничения и на процесс генерации ключей.
Как правило, возможности ассиметричного шифрования используют для выполнения идентификации пользователей (например, при входе на сайт). Или с его помощью создают сессионный ключ для симметричного шифрования (речь идёт о временном пароле для обмена данными между сервером и пользователем). Или формируют зашифрованные цифровые подписи. В последнем случае проверить такую подпись может каждый, используя публичный ключ, находящийся в открытом доступе.
Что важно знать
Давайте перечислим основные моменты и сравним оба вида шифрования:
1. Симметричный алгоритм прекрасно подходит при передаче больших объёмов зашифрованных данных. Ассиметричный в этом случае будет работать медленнее. Кроме того, при организации обмена информацией по ассиметричному алгоритму оба ключа должны быть известны обеим сторонам либо пар должно быть две (по одной на каждую сторону).
2. Ассиметричное шифрование позволяет дать старт безопасному соединению без каких-либо усилий со стороны пользователя. Если говорить о симметричном шифровании, то пользователю нужно знать пароль. Однако не стоит думать, что ассиметричный подход безопасен на 100 %. К примеру, он подвержен атакам «человек посередине». Это когда между сервером и вами размещается компьютер, который вам отсылает свой открытый ключ, а при передаче информации с вашей стороны, использует открытый ключ сервера. В итоге происходит перехват конфиденциальных данных.
3. Продолжая тему взлома и компрометации пароля, давайте ещё раз отметим, что в случае с симметричным шифрованием возникает проблема конфиденциально передать следующий пароль. В этом плане ассиметричный алгоритм «легче». Серверу достаточно сменить пару и разослать вновь созданный публичный ключ. Однако и тут есть своя Ахиллесова пята. Дело в том, что генерация ключей постоянно происходит по одному и тому же алгоритму, стало быть, если его узнают, безопасность окажется под угрозой.
4. Симметричный шифр обычно строится на основании ряда блоков с математическими функциями преобразования, ассиметричный — на математических задачах. Тот же RSA создан на задаче возведения в степень с последующим вычислением модуля. В результате алгоритмы симметричного шифрования модифицировать просто, а ассиметричного — практически невозможно.
5. Лучший эффект достигается при комбинации обоих видов шифрования. Происходит это так:
— посредством ассиметричного алгоритма серверу отсылается сессионный ключ для симметричного шифрования;
— происходит обмен информацией по симметричному алгоритму.
Тут возможны варианты, но общий смысл обычно не меняется.
6. В симметричном шифровании пароли генерируются по специальным правилам с учётом цифр, букв, регистра и т. д., создаются комбинации повышенной сложности. В ассиметричном пароли не так безопасны, однако их секретность обеспечивается тем, что их знает только сервер.
7. Вне зависимости от выбранного вида шифрования ни один из них не является гарантом стопроцентной безопасности. Помните, что любой подход нужно комбинировать с другими средствами информационной защиты.
Алгоритм RSA стоит у истоков асимметричной криптографии. В 1982 году была создана RSA Data Security Inc. тремя парнями – математиками Рональдом Ривестом (R. Rivest), Ади Шамиром (A. Shamir) и Леонардом Адльманом (L. Adleman), которые в 1977 году опубликовали свою идею алгоритма. В результате обороты продаж этой компании составили $900 миллионов, принеся создателям и огромные деньги, и признание мировой общественности. Но были и другие люди... Шифр RSA (под другим названием), однако с точностью до совпадения всех обозначений, был открыт в 1969 году. В штаб-квартиру правительственой связи в Великобритании был предложен шифр, авторами которого были Клиффорд Кокс, Малькольм Вильямсон и Джеймс Эллис, сотрудники этой организации.
Из-за математической сложности, руководство шифровальной службы Великобритании не приняло этот шифр в качестве рабочего инструмента. В чём же заключалась разница? Ривест, Шамир и Адлерман опубликовали алгоритм в открытой печати, и он стал всем известен, а эти люди, как сотрудники секретной службы, написали разработанный ими шифр своему начальству. Убедить начальство в 69 году в Англии у них не получилось, ведь тогда никакого понятия односторонних функций не существовало. Да, они использовались, но на доводы о сложности разложения произведения двух простых больших чисел им возражали в духе «ну мало ли математических задач, пройдёт 3 года и может какой-нибудь студент вам всё разложит. И что вы будете делать?». И шифр был отклонён. Описание положили «в стол», а т.к. они были сотрудниками секретной службы, наложили гриф Top Secret, соответственно ни о какой публикации и не могло идти речи. Его сняли лишь в 1983 году, это уже через 6 лет после открытой публикации RSA. Забавность в том, что они обозначали p и q — простые числа, n — произведение, d от слова decription, e — encryption, и вообще алгоритм был идентичен…
Таким образом, 3 человека, которые могли занять место Ривеста, Шамира и Адлермана, могли только следить за распространением полной копии своего алгоритма, который им публиковать не разрешили. Известно, что Агентство национальной безопасности (США) пыталось бороться с распространением алгоритма RSA уже после того, как его начали использовать всё больше и больше людей, однако попытки оказались безуспешны. Асимметричное шифрование прочно вошло в наш мир…
Это, конечно, далеко не единственный случай. Зачастую засекреченные теоремы (например, из теории решёток, теории групп, булевой алгебры и пр.) имеющие стратегическое значение, рассекречивались уже не при жизни автора, таким образом написанная дата создания теоремы была позже смерти самого автора.
1. Постановка задачи
Разработать и отладить программу на языке Лисп реализующую криптографический алгоритм кодирования информации с открытым ключом – RSA.
Шифрование:
Входные данные: M – сообщение, состоящее из целых чисел.
Выходные данные: T – Зашифрованное сообщение.
Дешифрование:
Входные данные: T – Результат шифрования.
Выходные данные: M – изначальное сообщение.
-
- Язык программирования Лисп
LISP (от англ. LISt Processing - "обработка списков") - семейство языков программирования, основанных на представлении программы системой линейных списков символов, которые притом являются основной структурой данных языка. Лисп считается вторым после Фортрана старейшим высокоуровневым языком программирования. В 1950-х годах специалисты по искусственному интеллекту начали поиски языка программирования, который бы позволял манипулировать понятиями, выраженными словами и фразами на естественном языке. Первый результат был получен в виде семейства языков под названием ИПЛ (IPL, от Information Processing Languages - языки обработки информации), созданного одним из пионеров в области искусственного интеллекта Алленом Ньюэллом и его сотрудниками. Центральным для ИПЛ являлось понятие списка. Представляя данные в виде списка слов и символов, программист мог связать понятия в памяти компьютера приблизительно таким же образом, как, по мнению специалистов по искусственному интеллекту, они связываются в памяти человека. Понятием списка заинтересовался и Джон Маккарти, разносторонний математик, один из ведущих исследователей в области искусственного интеллекта (причем сам термин искусственный интеллект был предложен именно им в 1956 году).
Язык Лисп был предложен Джоном Маккарти в работе в 1960 году и ориентирован на разработку программ для решения задач не численного характера. Английское название этого языка - LISP является аббревиатурой выражения LISt Processing (обработка списков) и хорошо подчеркивает основную область его применения. Понятие "список" оказалось очень емким. В виде списков удобно представлять алгебраические выражения, графы, элементы конечных групп, множества, правила вывода и многие другие сложные объекты. Списки являются наиболее гибкой формой представления информации в памяти компьютеров. Неудивительно поэтому, что удобный язык, специально предназначенный для обработки списков, быстро завоевал популярность. После появления LISP различными авторами был предложен целый ряд других алгоритмических языков ориентированных на решение задач в области искусственного интеллекта. Однако это не помешало LISP остаться наиболее популярным языком для решения таких задач. На протяжении почти сорокалетней истории его существования появился ряд диалектов этого языка: Common LISP, Mac LISP, InterLISP, Standard LISP и др. [3] Различия между ними не носят принципиального характера и в основном сводятся к несколько отличающемуся набору встроенных функций и некоторой разнице в форме записи программ. Поэтому, программист, научившийся работать на одном из них, без труда сможет освоить и любой другой. Большим достоинством LISP является его функциональная направленность, т. е. программирование ведется с помощью функций. Причем функция понимается как правило, сопоставляющее элементам некоторого класса соответствующие элементы другого класса. Сам процесс сопоставления не оказывает никакого влияния на работу программы, важен только его результат - значение функции. Это позволяет относительно легко писать и отлаживать большие программные комплексы. Ясность программ, четкое разграничение их функций, отсутствие каверзных побочных эффектов при их выполнении является обязательными требованиями к программированию таких логически сложных задач, каковыми являются задачи искусственного интеллекта. Дисциплина в программировании становится особенно важной, когда над программой работает не один человек, а целая группа программистов.
Основные функции языка Лисп
К числу основных особенностей языка Лисп относится то, что программой является несколько определенных пользователем функций. С точки зрения синтаксиса Лисп-функция, как и обрабатываемые ею данные, представляет собой так называемое S-выражение. В простейшем случае S-выражением является атом (идентификатор или число), в более сложном - список, т.е. последовательность элементов, разделенных обычно пробелом и заключенных в круглые скобки. Списки языка Лисп имеют рекурсивную структуру: элементом списка может быть произвольное S-выражение - как атом, так и список, например: (1() (a b (c)) class). Некоторые S-выражения можно вычислять, получая в результате значения (тоже S-выражения); такие выражения называются формами. Формой может быть переменная, т.е. атом-идентификатор, которому было присвоено значение одной из функций Лиспа (значением такой формы является текущее значение переменной). Формой является также список-обращение к функции вида(f a1, a2 ... an), где f - имя функции, а ai - ее аргументы (n≥0). Программа на Лиспе представляет собой последовательность таких форм, и ее выполнение заключается в их вычислении. В большинстве версий языка Лисп имеется много встроенных (стандартных) функций, на основе которых составляется программа. Все они есть в наиболее известных версиях Лиспа, таких как Common Lisp и MuLisp. Для определения новых функций используется встроенная функция defun, к которой возможны следующие (равноценные) обращения: (defun f (lambda (v1 v2 ... vn) e)) или (defun f (v1 v2 ... vn) e). Вычисление функции defun в качестве побочного эффекта приводит к появлению в программе новой функции с именем f ; vi - формальные параметры новой функции (n≥0), а e - форма, зависящая от vi. Таким образом, определяется обычная ЛИСП-функция, т.е. функция с фиксированным количеством аргументов, которые всегда вычисляются при обращении к ней. При последующем обращении к этой уже определенной функции (f a1 a2 ... an) сначала вычисляются аргументы (фактические параметры) ai, затем вводятся локальные переменные vi, которым присваиваются значения соответствующих аргументов ai, и далее вычисляется форма e при этих значениях переменных vi, после чего эти переменные уничтожаются. Значением данной формы становится значение функции f при аргументах ai. Операции над списками (car l) - значением аргумента l должен быть непустой список, тогда значением функции является первый элемент (верхнего уровня) этого списка (cdr l) и значением функции является "хвост" этого списка, т.е. список, полученный отбрасыванием первого элемента. Кроме этих двух функций-селекторов элементов списка часто используются функции, являющиеся их суперпозициями. Имена всех таких функций начинаются на букву c, а заканчиваются на букву r, между ними же может стоять произвольная комбинация из не более чем 5 букв a и d, например, (cadar l)≡(car(cdr(car l))) . Предполагается, что список-аргумент l всех этих функций, так же как и следующей функции nth, содержит необходимое число элементов (в противном случае вычисления прерываются). (nth n l) - значением аргумента n должно быть положительное целое число (обозначим его N), а значением аргумента l - список. Значением функции является N-й от начала элемент этого списка. (last l) - функция выбирает последний (от начала) элемент списка, являющегося значением ее аргумента. программирование диалект язык лисп (cons e l) - в отличие от предыдущих функций эта функция является конструктором, т.е. строит новый список, который и выдает в качестве своего результата. Первым элементом этого списка будет значение аргумента e, а хвостом списка - значение аргумента l . Например, (append l1 l2). Эта функция осуществляет слияние (конкатенацию) двух списков, являющихся значением двух ее аргументов. (list e1 e2 ... en ) - еще одна функция конструктор, она имеет произвольное количество аргументов, из их значений она строит список (количество элементов результирующего списка равно количеству аргументов). Арифметические функции
(add1 n) - значением аргумента этой функции должно быть число, функция прибавляет к этому числу 1 и выдает результат в качестве своего значения. (sub1 n) - значением аргумента должно быть число, функция вычитает из него 1 и выдает результат в качестве своего значения. (+ n1 n2) - значениями обоих аргументов функции должны быть числа, результат вычисления функции - их сумма. (- n1 n2) - значениями аргументов должны быть числа, значение функции - их разность. (length l) - значением аргумента l должен быть список, значением функции является количество элементов (верхнего уровня) этого списка, например: (mod n1 n2) - значениями обоих аргументов функции должны быть целые числа. Функция выполняет деление нацело первого числа на второе, и результат выдает в качестве своего значения. (rem n1 n2) - значениями аргументов функции должны быть целые числа, результат вычисления функции - остаток от деления первого числа на второе. Предикатом обычно называется форма, значение которой рассматривается как логическое значение "истина" или "ложь".
Особенностью языка Лисп является то, что "ложью" считается пустой список, записываемый как () или nil, а "истиной" - любое другое выражение (часто в этой роли выступает атом T). (null e) - эта функция проверяет, является ли значение ее аргумента пустым списком: если да, то значение функции равно T, иначе - (). (eq e1 e2) - функция сравнивает значения своих аргументов, которые должны быть атомами-идентификаторами. В случае их совпадения (идентичности) значение функции равно T, иначе - (). (eql e1 e2) - в отличие от предыдущей функции eql сравнивает значения своих аргументов, которыми могут быть не только атомы-идентификаторы, но и атомы-числа. Если они равны, то значение функции равно T, иначе - (). (equal e1 e2) - пункция производит сравнение двух произвольных S-выражений - значений своих аргументов. Если они равны (имеют одинаковую структуру и состоят из одинаковых атомов), то значение функции равно T, иначе - (). (neq e1 e2) - аналог, но значения аргументов сравниваются на "не равно". Функция (member a l) производит поиск атома, являющегося значением первого ее аргумента, в списке (на верхнем его уровне), являющемся вторым аргументом. В случае успеха поиска значение функции равно T, иначе - (). Значениями аргументов функции (gt n1 n2) или (> n1 n2) должны быть числа. Если первое из них больше второго, то значение функции равно T, иначе - (). (lt n1 n2) или (< n1 n2) - аналог, но числа сравниваются на "меньше". Логическими функциями называются три функции, реализующие основные логические операции. Функция (not e), реализующая "отрицание", является дубликатом функции null: если значение аргумента равно () ("ложь"), то функция выдает результат T ("истина"), а при любом другом значении аргумента выдает результат (). (and e1 e2 ... ek) (k≥1) - конъюнкция. Функция по очереди вычисляет свои аргументы. Если значение очередного из них равно () ("ложь"), то функция, не вычисляя оставшиеся аргументы, заканчивает свою работу со значением (), а иначе переходит к вычислению следующего аргумента. Если функция дошла до вычисления последнего аргумента, то с его значением она и заканчивает свою работу. (or e1 e2 ... ek) (k≥1) - дизъюнкция. Функция по очереди вычисляет свои аргументы. Если значение очередного из них не равно () ("ложь"), то функция, не вычисляя оставшиеся аргументы, заканчивает свою работу со значением этого аргумента, в противном случае она переходит к вычислению следующего аргумента. Если функция дошла до вычисления последнего аргумента, то с его значением она и заканчивает свою работу. К числу логических функций можно отнести и условное выражение: [cond (p1 e1,1 e1,2 ... e1,k1) ... (pn en,1 en,2 ... en,kn)] (n≥1, ki≥1) Функция cond последовательно вычисляет первые элементы своих аргументов - обращения к предикатам pi. Если все они имеют значение () ("ложь"), тогда функция заканчивает свою работу с этим же значением. Но если был обнаружен предикат pi, значение которого отлично от (), т.е. он имеет значение "истина", тогда функция cond уже не будет рассматривать остальные предикаты, а последовательно вычислит формы ei,j из этого i-го аргумента и со значением последнего из них закончит свою работу. Следует отметить, что поскольку значения предыдущих форм из этого аргумента нигде не запоминаются, то в качестве этих форм имеет смысл использовать только такие, у которых есть побочный эффект, например, обращение к функции присвоения значения.
Специальные функции
Функция блокировки вычислений (quote e) или 'e, выдает в качестве значения свой аргумент, не вычисляя его. Функция (gensym) генерации уникальных атомов, при каждом обращении к ней вычисляет (образует) новый атом-идентификатор. Этот идентификатор получается склеиванием специального префикса и очередного целого числа. Префикс и целое число, от которого начинается нумерация генерируемых атомов, могут быть установлены заранее, как например, в языке MuLisp: (setq *gensym-prefix* 'S) (setq *gensym-count* 2) [10]. После этого функция gensym будет последовательно выдавать атомы S2, S3, S4, ... . (prog (v1 v2 ... vn) e1 e2 ... ek) (n≥0, k≥1) - Блочная и связанные с ней функции. Эту функцию называют "блочной", поскольку ее вычисление напоминает выполнение блоков в других языках программирования. Вычисление функции начинается с того, что вводятся локальные переменные vi, перечисленные в ее первом аргументе, и всем им присваивается в качестве начального значения пустой список (). После этого функция последовательно вычисляет остальные свои аргументы - формы ei. Вычислив последнюю из них, функция prog заканчивает работу со значением этой формы, уничтожив при этом свои локальные переменные. Вычисленные значения всех форм ei, кроме последней, нигде не запоминаются, поэтому имеет смысл использовать в качестве них только функции с побочным эффектом. Некоторые из этих функций перечислены ниже. В качестве ei может быть записан и атом-идентификатор, в этом случае он не вычисляется, и трактуется как метка, на которую будет производиться переход внутри этого блока (функцией go). (setq v e) - аналог оператора присваивания. В качестве аргумента v должно быть задано имя переменной, существующей в данный момент. Функция присваивает этой переменной новое значение - значение аргумента е. Это же значение является значением и самой функции setq, хотя оно, как правило, не используется. В функции (pop v1 v2) обоими аргументами должны быть имена переменных, существующих в данный момент, причем переменная v2 должна иметь значение и им должен быть непустой список. Функция разделяет этот список на две части - на его первый элемент, который присваивается переменной v1, и на его оставшуюся часть (без первого элемента), которая становится новым значением переменной v2. В качестве второго аргумента функции (push е v) должно быть задано имя переменной, в качестве первого - произвольная форма. Функция вычисляет эту форму и строит новый список, первый элемент которого - вычисленное значение, а хвост - список, являющийся значением переменной v. Результирующий список присваивается в качестве нового значения переменной v (он также является значением самой функции push). (return e) - функция досрочного выхода из блока, она может использоваться только внутри блочной функции prog, поскольку завершает вычисление ближайшей объемлющей блочной функции, объявляя ее значением значение аргумента e. (go e) - функция перехода по метке. В качестве аргумента функции go должен быть задан идентификатор - одна из меток ближайшей объемлющей блочной функции. Функция go полностью завершает вычисление той формы этой блочной функции, в которую она входит (на любом уровне), и осуществляет переход для вычисления формы, следующей за этой меткой.
Особенности диалектов языка Лисп
1 MacLISP
Помимо символьной обработки MacLISP широко использовался в традиционных числовых вычислениях, применяемых, например, в обработке речи и изображений. Кроме исследователей ИИ и разработчиков алгебраической системы Максима на Маклисп оказали влияние и работы групп в МИТ по робототехнике, обработке речи и изображений. Исходя из требований, предъявляемых этими областями, в Маклисп были включены новые математические типы данных, такие как матричная и битовая обработка, а также широкий набор арифметических функций и средств. Быть может, важнейшая из них - возможность вычислений с неограниченной точностью, основывающаяся на созданных Кнутом в 1969 году алгоритмах. MacLISP был также первой LISP-системой для которой создан хороший транслятор. Транслятор генерирует машинную программу в форме списков. Машинный код в виде списка легко обрабатывать и результирующий код для числовых задач получался эффективнее, чем у лучших трансляторов фортрана. Однако большую часть своих свойств MacLISP приобрел под влиянием стоящих перед исследователями ИИ проблем и накопленного опыта. Так в язык попали макросы чтения и таблицы чтения, позволяющие легко изменять и расширять структуру языка. Таким же образом из требований к программам и окружению возникли управляющие структуры, механизмы обработки прерываний и ошибок, а также использование управляющих символов, создан и интегрирован в систему экранный редактор, появились управление и взаимодействие параллельных процессов. Основное внимание разработчики MacLISP сосредоточили на эффективности. Этому служат указания, уточняющие способы обработки аргументов функций, а также экранирование от вмешательства программиста внутренних механизмов системы. За счет этих мер скорость работы Маклиспа в 1,5 - 2,5 раза выше, чем Интерлисп. Всего в Маклиспе используется около 400 функций. Самым большим недостатком системы является то, что ее никогда не документировали должным образом. Документация по этой системе разбросана по различным отчетам и руководствам. MacLISP был исследовательской системой и не предназначался для обучения и промышленного использования.
2 MuLISP
Интерпретатор MuLISP-85, разработанный для ПЭВМ серии IBM PC -удачный вариант реализации диалекта языка, включающий сравнительно ограниченный набор базовых функций (около 260) и оказавшийся вследствие этого более простым для изучения. По сравнению с CommonLISP диалект MuLISP не имеет такого широкого спектра доступных типов данных. В нем обеспечивается работа только с двумя типами числовой информации: целыми числами с любым основанием и рациональными. В диалекте отсутствуют средства работы со структурами, массивами, потоками и другими типами данных, указанная реализация языка LISP имеет одно существенное преимущество - возможность пополнения базового набора функций путем подключения подпрограмм, написанных на языке ассемблера, что позволило повысить гибкость использования интерпретатора и ффективность прикладного программного обеспечения, создаваемого на его основе. Возможность такого пополнения отсутствует в большинстве других Лисп - систем, являющихся в этом смысле замкнутыми программными продуктами. Среди других, вероятно, менее существенных, особенностей системы можно указать на реализацию специального механизма, позволяющего не заботиться о присваивании начальных значений литеральным атомам, получающих изначальное значение, равное "печатному" имени самого атома. Еще одной особенностью диалекта является возможность использования новой синтаксической конструкции "встроенный COND", существенно сокращающей тексты описаний функций пользователя и применяемой при записи тел функций и лямбда-выражений. Набор базовых функций MuLISP-интерпретатора включает ряд функций, обеспечивающих доступ практически ко всем функциям ОС ЭВМ через соответствующие прерывания. Наконец, указанная Лисп-сис-тема обеспечивается библиотеками Лисп-функций, дополняющими базовый набор функциями, имеющимися в диалектах CommonLISP и InterLISP, что облегчает решение проблемы переносимости исходных текстов программных модулей, а также библиотеками, позволяющими выполнять манипулирование окнами на экране дисплея и обрабатывать управляющие воздействия через устройство типа "мышь". В комплект дополнительного программного обеспечения к интерпретатору входят интерактивный редактор текстов и простая обучающая система, написанные на диалекте языка MuLISP.
3 InterLISP
InterLISP появился в 1972 году из ББН-Лиспа. К 1978 году, когда вышло описание InterLISP, язык и система уже достаточно стабилизировались. Интерлисп уже не был языком в том же смысле, что и MacLISP или другие LISP-системы или обычные традиционные системы программирования. Он представлял собой интегрированную среду программирования, в которую вошло множество различных вспомогательных средств. InterLISP стал классическим примером хорошо развитых программных средств и средств в системах разделения времени. Этот диалект наряду с CommonLISP один из наиболее распространенных, имеет достаточно развитый аппарат представления и манипулирования различными структурами данных, включая массивы. Среди общих особенностей данного варианта языка следует отметить использование для обозначения встроенных функций нетрадиционных имен, что порой затрудняет перенос готовых программных продуктов на другие диалекты и другие ЭВМ [8]. В 1974 году Xerox начала разработку для InterLISP персональной лисповской рабочей станции под названием Alto. В реализации LISP для Alto впервые применили спроектированную специально для языка LISP и программируемую систему команд и мини-ЭВМ, способную с более высокой производительностью, чем универсальные ЭВМ, интерпретировать программы LISP. Из этой машины Alto впоследствии развились LISP-машины серии 1100 фирмы Xerox.
На основе версии Интерлиспа, работавшей в системе разделения времени, была создана совместимая снизу вверх версия LISP InterLISP-де, используемая на LISP - машинах серии 1100. В ее пользовательский интерфейс входили многооконное взаимодействие, графика с высокой разрешающей способностью, средства выбора из меню и мышь, а также ориентированный на использование экрана инспектор структур данных. Идея разделения экрана на многие независимые окна родилась в XLG. Алан Кэй уже в конце 60-х годов предложил такую идею подхода к компьютерам будущего и интерфейсу между человеком и машиной. Работа XLG привела к созданию в 70-х годах разработки языка программирования Smolltalk и объектного программирования . При создании InterLISP работа велась весьма тщательно. Система хорошо документирована и более новые версии совместимы с более ранними. Так преимуществом системы стало непрерывно пополняющееся большое количество переносимого программного обеспечения. С другой стороны, ограничение системы старым, зафиксированным уже в конце 70-х годов, диалектом сделало систему отчасти устаревшей и трудно расширяемой. В InterLISP среди прочего отсутствуют иерархические типы данных, объекты и замыкания. К тому же он базируется на динамическом связывании, тогда как новые версии LISP - статические. Однако из InterLISP берет начало новая версия - CommonLISP. Для программирования на более высоком уровне в InterLISP разработаны такие средства, в которых уже присутствовали объекты. InterLISP - столь замкнутая система, что доступна только ее оттранслированная версия в машинных кодах.
В некоторых других системах, таких как, например Зеталисп, поддерживается версия LISP на исходном языке, которая доступна пользователю и может модифицироваться им. Развитие закрытых систем, похожих на InterLISP, связано с ресурсами, имеющимся у создавших их лабораторий. InterLISP использует свыше 500 функций и большое количество системных имен и флажков, с помощью которых можно настроить и подогнать систему. InterLISP реализован в системе разделения времени на многих больших ЭВМ. В Интерлиспе основное внимание было уделено удобству системы для пользователя. Главный принцип разработчиков этого диалекта: все, что может иметь место в системе, должно естественно выражаться в терминах ее входного языка. Поэтому в Интерлисп программисту доступно все. Он может переопределять любые, в том числе и встроенные, функции; задавать и переопределять реакции на ошибки; работать непосредственно с уровня входного языка с внутренними структурами интерпретатора и т. д. При этом система поддерживает свою целостность и работоспособность.
4 CommonLISP
Этот диалект отличается наиболее широким представлением различных структур данных и включает около 800 встроенных функций. В нем обеспечиваются средства обработки основных классов числовой информации: целых, вещественных и комплексных. Символьные данные (литеры, литеральные атомы, строки) в CommonLISP соответствуют основным возможностям других LISP - систем. Дополнительно имеются средства обработки непечатных литер в символьных именах. Одним из существенных преимуществ диалекта CommonLISP является наличие средств обработки массивов и структур, по своим возможностям не уступающих соответствующим средствам традиционных языков программирования (Фортран, Паскаль). Массивы в CommonLISP могут иметь любое неотрицательное число измерений и индексируются последовательностью целых чисел. Тип компонентов массива может быть произвольным. Выделяется подкласс векторов - одномерных массивов, среди которых отдельно рассматриваются строки и битовые массивы. Структуры CommonLISP являются типом многокомпонентных записей, определяемых пользователем и имеющих именованные компоненты. Встроенное макроопределение DEFSTRUCT используется для определения структур новых типов. Для создания данных нового типа в виде структуры предусмотрены средства автоматической генерации набора функций, обеспечивающих средства манипулирования объектами этого класса. Удобным средством контроля доступа к различным переменным и функциям LISP -программ в CommonLISP являются пакеты. Пакет - множество имен объектов, определенных и доступных в нем. Внутри пакета имена объектов подразделяются на внутренние и внешние. Первые предназначены для использования только внутри данного пакета, а вторые - для обеспечения связи с другими пакетами. LISP - интерпретатор представляет широкий спектр средств манипулирования пакетами. Как правило, LISP - система имеет в своем составе четыре стандартных пакета:
• Lisp - содержит примитивы системы .
• User - умалчиваемый пакет прикладных программ и данных пользователя .
• Keyword - содержит ключевые слова всех встроенных функций и функций, определяемых пользователем .
• System - зарезервированный пакет для системных целей.
Значительной переработке и расширению в CommonLISP подверглись средства ввода-вывода и передачи информации. Для эффективной организации различных обменов с внешней средой введена концепция потоков, позволяющих осуществлять одно- и (или) двухстороннюю передачу информации. Для потоков предусмотрен набор базовых функций. В диалекте различают символьные и двоичные потоки. В первом случае передача осуществляется по байтам, а во втором - целыми числами. Кроме стандартных потоков пользователь имеет возможность создавать и использовать собственные потоки. В дополнение к указанным типам данных CommonLISP имеет ряд специфических классов объектов:
⁕ Хэш-таблицы, обеспечивающие эффективный способ доступа к данным по ключу;
⁕ READ-таблицы, обеспечивающие управление обработкой информации поступающей из входного потока Лисп-системы, и некоторые другие.
Такое множество имеющихся в диалекте различных типов данных, с одной стороны, развеивает существующее ошибочное представление о языке LISP как о средстве обработки только символьной информации, а с другой - наличие мощных средств манипулирования типами данных существенно усложняет его. Этот диалект оставлен открытым: принципиальным является то, что осталась возможность в будущем, когда подойдет время и будет достигнуто согласие, добавить новые средства и методы. CommonLISP не является готовой программной системой в том же смысле, что и Интерлисп, поскольку вопросы среды в основном оставлены открытыми. В стандарте не определено, каким должен быть редактор или другие вспомогательные средства. Сказано лишь в самом общем виде, каким образом они вызываются. Для того чтобы обеспечить быстрое развитие, среда и инструментальные средства еще не затронуты стандартизацией, и поэтому есть возможность создавать различные среды для различных целей. CommonLISP не определяет также и интерфейс пользователя.
В CommonLISP на современном этапе не включены даже средства объектного программирования, хотя и определены необходимые для этого базовые механизмы (замыкание и др.). Таким образом, объекты можно реализовать на Лиспе. Но уже ведется работа по стандартизации средств и форм объектного программирования. В CommonLISP много внимания уделено практическим требованиям, и, вероятно, поэтому не все его черты эстетичны и чисты. Несомненно, что и другие LISP -системы будут использоваться в дальнейшем, и их также необходимо развивать. CommonLISP предназначен не только для работы со списками или символьной обработки. Он является универсальным языком программирования, включающим в себя особенно хорошие средства для численных вычислений, управления данными и связи. На CommonLISP можно с одинаковым успехом писать программы в традиционных операторном, процедурном, фразовом стиле, а также и в свойственных LISP стилях. В языке содержатся предпосылки для использования различных способов и стилей программирования, таких как операторное, функциональное, макропрограммирование, программирование, управляемое данными, и продукционное программирование, а также средства, необходимые для логического и объектного программирования и реализации других средств более высокого уровня. Можно смело сказать, что CommonLISP содержит почти все, что на сегодняшний день могут дать другие известные языки программирования, и, кроме того, он предусматривает средства для расширения языка.
Пример 1.
- Выбираем два простых числа: p = 3557, q = 2579.
- Вычисляем их произведение: n = p · q = 3557 · 2579 = 9173503.
- Вычисляем функцию Эйлера: φ(n) = (p-1) (q-1) = 9167368.
- Выбираем открытый показатель: e = 3.
- Вычисляем секретный показатель: d = 6111579.
- Публикуем открытый ключ: (e, n) = (3, 9173503).
- Сохраняем секретный ключ: (d, n) = (6111579, 9173503).
- Выбираем открытый текст: M = 127.
- Вычисляем шифротекст: P(M) = Me mod n = 10223mod 9173503 = 116.
- Вычислить исходное сообщение: S(C) = Cd mod n = 1166111579mod 9173503 = 1022.
Пример 2.
- Выбираем два простых числа: p = 79, q = 71.
- Вычисляем их произведение: n = p · q = 79 · 71 = 5609.
- Вычисляем функцию Эйлера: φ(n) = (p-1) (q-1) = 5460.
- Выбираем открытый показатель: e = 5363.
- Вычисляем секретный показатель: d = 2927.
- Публикуем открытый ключ: (e, n) = (5363, 5609).
- Сохраняем секретный ключ: (d, n) = (2927, 5609).
- Выбираем открытый текст: M = 23.
- Вычисляем шифротекст: P(M) = Me mod n = 235363mod 5609 = 5348.
- Вычислить исходное сообщение: S(C) = Cd mod n = 53482927mod 5609 = 23.
2. Математические и алгоритмические основы решения задачи
Первым этапом любого асимметричного алгоритма является создание пары ключей: открытого и закрытого и распространение открытого ключа «по всему миру». Для алгоритма RSA этап создания ключей состоит из следующих операций:
1). Выбираются два простых числа p и q
2). Вычисляется их произведение n (=p*q)
3). Выбирается произвольное число e (e<n), такое, что
НОД (e, (p-1) (q-1))=1,
то есть e должно быть взаимно простым с числом (p-1) (q-1).
4). Методом Евклида решается в целых числах уравнение
e*d+(p-1) (q-1)*y=1.
Здесь неизвестными являются переменные d и y – метод Евклида как раз и находит множество пар (d, y), каждая из которых является решением уравнения в целых числах.
5). Два числа (e, n) – публикуются как открытый ключ.
6). Число d хранится в строжайшем секрете – это и есть закрытый ключ, который позволит читать все послания, зашифрованные с помощью пары чисел (e, n).
Как же производится собственно шифрование с помощью этих чисел:
Отправитель разбивает свое сообщение на блоки, равные k=[log2(n)] бит, где квадратные скобки обозначают взятие целой части от дробного числа.
Подобный блок может быть интерпретирован как число из диапазона (0; 2k-1). Для каждого такого числа (назовем его mi) вычисляется выражение
ci=((mi)e) mod n.
Блоки ci и есть зашифрованное сообщение Их можно спокойно передавать по открытому каналу, поскольку операция возведения в степень по модулю простого числа, является необратимой математической задачей. Обратная ей задача носит название «логарифмирование в конечном поле» и является на несколько порядков более сложной задачей. То есть даже если злоумышленник знает числа e и n, то по ci прочесть исходные сообщения mi он не может никак, кроме как полным перебором mi.
А вот на приемной стороне процесс дешифрования все же возможен, и поможет нам в этом хранимое в секрете число d. Достаточно давно была доказана теорема Эйлера, частный случай которой утвержает, что если число n представимо в виде двух простых чисел p и q, то для любого x имеет место равенство
(x(p-1)(q-1)) mod n = 1.
Для дешифрования RSA-сообщений воспользуемся этой формулой. Возведем обе ее части в степень
(-y): (x(-y)(p-1)(q-1)) mod n = 1(-y) = 1.
Теперь умножим обе ее части на x:
(x(-y)(p-1)(q-1)+1) mod n = 1*x = x.
А теперь вспомним как мы создавали открытый и закрытый ключи. Мы подбирали с помощью алгоритма Евклида d такое, что
e*d+(p-1) (q-1)*y=1,
то есть
e*d=(-y) (p-1) (q-1)+1.
Следовательно, в последнем выражении предыдущего абзаца мы можем заменить показатель степени на число (e*d). Получаем
(xe*d) mod n = x.
То есть для того чтобы прочесть сообщение ci=((mi)e) mod n достаточно возвести его в степень d по модулю m:
((ci)d) mod n = ((mi)e*d) mod n = mi.
На самом деле операции возведения в степень больших чисел достаточно трудоемки для современных процессоров, даже если они производятся по оптимизированным по времени алгоритмам. Поэтому обычно весь текст сообщения кодируется обычным блочным шифром (намного более быстрым), но с использованием ключа сеанса, а вот сам ключ сеанса шифруется как раз асимметричным алгоритмом с помощью открытого ключа получателя и помещается в начало файла.
Скорость работы алгоритма RSA
Как при шифровании и расшифровке, так и при создании и проверке подписи алгоритм RSA по существу состоит из возведения в степень, которое выполняется как ряд умножений.
В практических приложениях для открытого (public) ключа обычно выбирается относительно небольшой показатель, а зачастую группы пользователей используют один и тот же открытый (public) показатель, но каждый с различным модулем. (Если открытый (public) показатель неизменен, вводятся некоторые ограничения на главные делители (факторы) модуля.) При этом шифрование данных идет быстрее чем расшифровка, а проверка подписи – быстрее чем подписание.
Если k – количество битов в модуле, то в обычно используемых для RSA алгоритмах количество шагов необходимых для выполнения операции с открытым (public) ключом пропорционально второй степени k, количество шагов для операций частного (private) ключа – третьей степени k, количество шагов для операции создания ключей – четвертой степени k.
Методы «быстрого умножения» – например, методы основанные на Быстром Преобразовании Фурье (FFT – Fast Fourier Transform) – выполняются меньшим количеством шагов; тем не менее они не получили широкого распространения из-за сложности программного обеспечения, а также потому, что с типичными размерами ключей они фактически работают медленнее. Однако производительность и эффективность приложений и оборудования реализующих алгоритм RSA быстро увеличиваются.
Алгоритм RSA намного медленнее чем DES и другие алгоритмы блокового шифрования. Программная реализация DES работает быстрее по крайней мере в 100 раз и от 1,000 до 10,000 – в аппаратной реализации (в зависимости от конкретного устройства). Благдаря ведущимся разработкам, работа алгоритма RSA, вероятно, ускорится, но аналогично ускорится и работа алгоритмов блокового шифрования.
Функциональные модели и блок-схемы решения задачи
Функциональные модели и блок-схемы решения задачи представлены на рисунках 1 – 6.
Условные обозначения:
- P и Q – случайные простые числа;
- N – произведение простых чисел P и Q;
- PHI – значение функции Эйлера;
- E – взаимно простое число с PHI;
- PRIVATE_KEY – секретный ключ;
- LST – список простых чисел;
- NUM – число для шифрования / дешифрования;
- I, IO, I1, J, JO, R, L – рабочие переменные.

Рисунок 1 – Функциональная модель решения задачи для функции SIMPLE_NUMBER

Рисунок 2 – Функциональная модель решения задачи для функции ENCRYPT

Рисунок 3 – Функциональная модель решения задачи для функции DECODING

Рисунок 4 – Функциональная модель решения задачи для функции RSA

Рисунок 5 – Блок-схема решения задачи для функции DISTINCT_SIMPLE_NUM

Рисунок 6 – Блок-схема решения задачи для функции ALG_ EUCLID
Программная реализация решения задачи
; ПОИСК ВЗАИМНО ПРОСТОГО ЧИСЛА
(DEFUN DISTINCT_SIMPLE_NUM (NUM PH)
(DO
()
((< NUM PH) NUM)
; TRUNCATE – ЦЕЛОЧИСЛЕННОЕ ДЕЛЕНИЕ
(SETQ NUM (TRUNCATE NUM 2))
)
(DO
()
; GCD – НАИБОЛЬШИЙ ОБЩИЙ ДЕЛИТЕЛЬ
((EQL (GCD NUM PH) 1) NUM)
; REM – ОСТАТОК ОТ ДЕЛЕНИЯ
(IF (EQL (REM NUM 2) 0) (SETQ NUM (+ NUM 1)))
(SETQ NUM (+ NUM 2))
)
)
; ГЕНЕРИРУЕМ СЛУЧАЙНОЕ ПРОСТОЕ ЧИСЛО
(DEFUN SIMPLE_NUMBER ()
; ОБЪЯВЛЕНИЕ ПЕРЕМЕННОЙ
(DECLARE (SPECIAL LST))
; СПИСОК ПРОСТЫХ ЧИСЕЛ
(SETQ LST ' (2 3 5 7 11 13 17 19 23 31 37 41 43 47 53 61 67 71 73 79 83 89 97 101))
; ВЫБИРАЕМ СЛУЧАЙНОЕ ЧИСЛО ИЗ СПСКА
(NTH (RANDOM (– (LENGTH LST) 1)) LST)
)
; РАСШИРЕННЫЙ АЛГОРИТМ ЕВКЛИДА
(DEFUN ALG_EUCLID (X Y)
; – ОБЪЯВЛЕНИЕ ПЕРЕМЕННЫХ–
(DECLARE (SPECIAL I))
(DECLARE (SPECIAL I0))
(DECLARE (SPECIAL I1))
(DECLARE (SPECIAL J0))
(DECLARE (SPECIAL J1))
(DECLARE (SPECIAL R))
(DECLARE (SPECIAL L))
;–
(IF (EQL X 1) (SETQ X (+ X Y))
; ИНАЧЕ
(PROGN
(SETQ I0 0)
(SETQ I1 1)
(SETQ L Y)
(SETQ R (REM L X))
(SETQ J0 (TRUNCATE L X))
(SETQ L X)
(SETQ X R)
(SETQ R (REM L X))
(SETQ J1 (TRUNCATE L X))
(SETQ L X)
(SETQ X R)
(DO
(())
((<= R 0) R)
(SETQ R (REM L X))
(SETQ I (– I0 (* I1 J0)))
(IF (< I 0) (SETQ I (- Y (REM (* -1 I) Y))) (SETQ I (REM I Y)))
(SETQ I0 I1)
(SETQ I1 I)
(SETQ J0 J1)
(SETQ J1 (TRUNCATE L X))
(SETQ L X)
(SETQ X R)
)
(SETQ I (– I0 (* I1 J0)))
(IF (< I 0) (SETQ I (FLOOR (- Y (REM (* -1 I) Y)))) (SETQ I (FLOOR (REM I Y))))
I
)
)
)
; РЕАЛИЗАЦИЯ АЛГОРИТМА RSA
(DEFUN RSA ()
; – ОБЪЯВЛЕНИЕ ПЕРЕМЕННЫХ–
(DECLARE (SPECIAL N))
(DECLARE (SPECIAL E))
(DECLARE (SPECIAL PHI))
(DECLARE (SPECIAL PRIVATE_KEY))
(DECLARE (SPECIAL P))
(DECLARE (SPECIAL Q))
;–
; ВЫБИРАЮТСЯ ДВА ПРОСТЫХ ЧИСЛА
(SETQ P (SIMPLE_NUMBER))
(SETQ Q (SIMPLE_NUMBER))
; ВЫЧИСЛЯЕМ ИХ ПРОИЗВЕДЕНИЕ
(SETQ N (* P Q))
; НАХОДИМ PHI = (P-1) (Q-1)
(SETQ PHI (* (- P 1) (- Q 1)))
; ВЫБИРАЕМ ПРОИЗВОЛЬНОЕ ЧИСЛО
(SETQ E (RANDOM 10000000000000000))
; НАХОДИМ ВЗАИМНОЕ ПРОСТОЕ E С PHI
(SETQ E (DISTINCT_SIMPLE_NUM E PHI))
; НАХОДИМ ЗАКРЫТЫЙ КЛЮЧ PRIVATE_KEY
(SETQ PRIVATE_KEY (ALG_EUCLID E PHI))
(LIST E N PRIVATE_KEY)
)
; ПОЛУЧАЕМ КЛЮЧИ
(SETQ LIST_KEY (RSA))
(SETQ E (CAR LIST_KEY))
(SETQ N (CADR LIST_KEY))
(SETQ D (CADDR LIST_KEY))
; ШИФРОВАНИЕ ЧИСЛА
(DEFUN CODING (NUM)
(MOD (EXPT NUM E) N)
)
; ДЕШИФРОВАНИЕ ЧИСЛА
(DEFUN DECODING (NUM)
(MOD (EXPT NUM D) N)
)
; ПОЛУЧАЕМ СООБЩЕНИЕ
(SETQ TEXT 0)
(SETQ INPUT (OPEN «D:\MESSAGE.TXT»:DIRECTION:INPUT))
(SETQ TEXT (READ INPUT))
(CLOSE INPUT)
; ШИФРУЕМ СООБЩЕНИЕ
(SETQ OUTPUT (OPEN «D:\CODING.TXT»:DIRECTION:OUTPUT))
(SETQ CODING_TEXT (MAPCAR 'CODING TEXT))
(PRINT (LIST 'CODING_TEXT CODING_TEXT) OUTPUT)
(PRINT (LIST 'PUBLIC_KEY (LIST E N)) OUTPUT)
(TERPRI OUTPUT)
(CLOSE OUTPUT)
; ДЕШИФРУЕМ СООБЩЕНИЕ
(SETQ OUTPUT (OPEN «D:\DECODING.TXT»:DIRECTION:OUTPUT))
(SETQ DECODING_TEXT (MAPCAR 'DECODING CODING_TEXT))
(PRINT (LIST 'DECODING_TEXT DECODING_TEXT) OUTPUT)
(TERPRI OUTPUT)
(CLOSE OUTPUT)
5. Пример выполнения программы
Пример 1
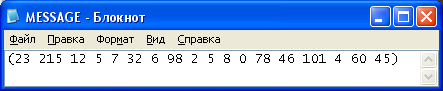
Рисунок 7. Переданное сообщение

Рисунок 8. Зашифрованное сообщение

Рисунок 9. Расшифрованное сообщение
Пример 2
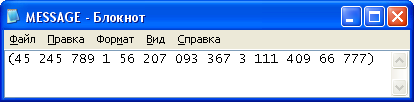
Рисунок 10. Переданное сообщение

Рисунок 11. Зашифрованное сообщение
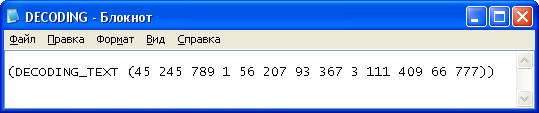
Рисунок 12. Расшифрованное сообщение
Пример 3

Рисунок 13. Переданное сообщение
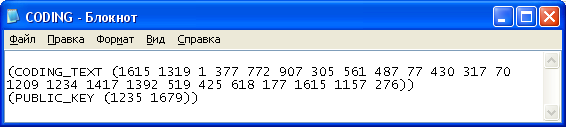
Рисунок 14. Зашифрованное сообщение
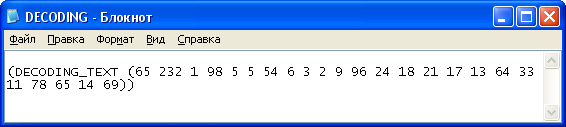
Рисунок 15. Расшифрованное сообщение
Заключение
Криптосистема RSA используется в самых различных продуктах, на различных платформах и во многих отраслях. В настоящее время криптосистема RSA встраивается во многие коммерческие продукты, число которых постоянно увеличивается. Также ее используют операционные системы Microsoft, Apple, Sun и Novell. В аппаратном исполнении RSA алгоритм применяется в защищенных телефонах, на сетевых платах Ethernet, на смарт-картах, широко используется в криптографическом оборудовании THALES (Racal). Кроме того, алгоритм входит в состав всех основных протоколов для защищенных коммуникаций Internet, в том числе S/MIME, SSL и S/WAN, а также используется во многих учреждениях, например, в правительственных службах, в большинстве корпораций, в государственных лабораториях и университетах. На осень 2000 года технологии с применением алгоритма RSA были лицензированы более чем 700 компаниями.
Итогом работы можно считать созданную функциональную модель алгоритма кодирования информации RSA. Данная модель применима к положительным целым числам.
Созданная функциональная модель и ее программная реализация могут служить органической частью решения более сложных задач.
Список использованных источников и литературы
- Венбо Мао. Современная криптография: теория и практика. [Электронный ресурс] / Венбо Мао. – М.: Вильямс, 2005. С. 768.
- Кландер, Л. Hacker Prof: полное руководство по безопасности компьютера. [Электронный ресурс] / Л. Кландер – М.: Попурри, 2002. С. 642.
- Фергюсон, Н. Практическая криптография. [Текст] / Н. Фергюсон, Б. Шнайер. – М.: Диалектика, 2004. С. 432.
- Шнайер, Б. Прикладная криптография. Протоколы, алгоритмы. [Текст] / Б. Шнайер. – М.: Триумф, 2002. С. 816

- Основы программирования на языке HTML (Что такое HTML)
- Обучение персонала организации (Управление человеческими ресурсами)
- Разработка сайта интернет-магазина «Барахолка»
- Автоматизация учета выполнения заказов ООО "Ripair"
- Роль мотивации в поведении организации ( Современные технологии мотивации персонала и их использование в практике управления сотрудниками)
- Игра как метод воспитания (Общая характеристика младшего школьника, его учебной игровой деятельности)
- Использование наглядного метода в начальной школе (Психолого-педагогические особенности младшего школьного возраста)
- Взгляды В. А. Сухомлинского на обучение и воспитание детей
- Взгляды В.А. Сухомлинского на обучение и развитие детей (Методы воспитания в системе В.А. Сухомлинского)
- Эффективность менеджмента организации (Финансовый менеджмент в системе эффективного управления компании)
- Понятие и признаки государства (Подходы к определению понятия государства)
- Определение стоимости недвижимого имущества