
Методы кодирования данных (Технологии программирования)
Содержание:

Введение
Кодирование – это представление сигнала в определенной форме, удобной или пригодной для последующего использования сигнала. Говоря строже, это правило, описывающее отображение одного набора знаков в другой набор знаков. Тогда отображаемый набор знаков называется исходным алфавитом, а набор знаков, который используется для отображения, – кодовым алфавитом, или алфавитом для кодирования. При этом кодированию подлежат как отдельные символы исходного алфавита, так и их комбинации.
Совокупность символов кодового алфавита, применяемых для кодирования одного символа или одной комбинации символов исходного алфавита, называется кодовой комбинацией или кодом символа. При этом кодовая комбинация может содержать один символ кодового алфавита.
Символ или комбинация символов исходного алфавита, которому соответствует кодовая комбинация называется исходным символом.
Совокупность кодовых комбинаций называется кодом.
Взаимосвязь символов или комбинаций символов исходного алфавита с их кодовыми комбинациями составляет таблицу соответствия (таблицу кодов).
Код – является очень обширным понятием, ведь звуки, которые мы произносим и складываем в слов, - код который понятен любому, кто слышит наш голос и понимает язык, на котором мы говорим. Этот код называется речью. Существуют коды для записи слов на бумаге, такой код – это рукописные и печатные символы, которые мы видим в книгах, журналах, газетах и экранах. Для нас это письменная речь или текст. Для глухих и немых был разработан другой код, облегчающий общение, - язык жестов, который состоит из движений рук, в которых могут быть зашифрованы не только буквы или слова, но и целые концепции. Для слепых письменный текст был заменен азбукой Брайля – системой выпуклых точек, соответствующих буквам, буквосочетаниям или целым словам.
При общении мы пользуемся различными кодами, поскольку одна кодировка удобнее других. Например, устную речь невозможно хранить на бумаге, и ее заменяет текст. Тихо передавать информацию на расстоянии невозможно ни речью, ни текстом. Однако раньше для этого хорошо подходила азбука Морзе.
В настоящее время с помощью кода можно предавать не только текстовые сообщения, но также видео, аудио, графическую информацию.
1. От простого к сложному
В основе современных методов кодирования данных лежит простой принцип, состоящий из всего двух чисел, 0 и 1. Проще всего объяснить его с помощью двух довольно старых методов, а именно с азбуки Морзе и шрифта Брайля.
1.1 Азбука Морзе
Азбука Морзе представляет собой набор «точек» и «тире», которые могут быть наглядным примером 0 и 1. В ней присутствуют два вида бликов или звуковых сигналов: короткие и длинные. В азбуке Морзе каждой букве алфавита, цифре и некоторым символам соответствует краткая серия точек и тире приведенная в рисунке 1.
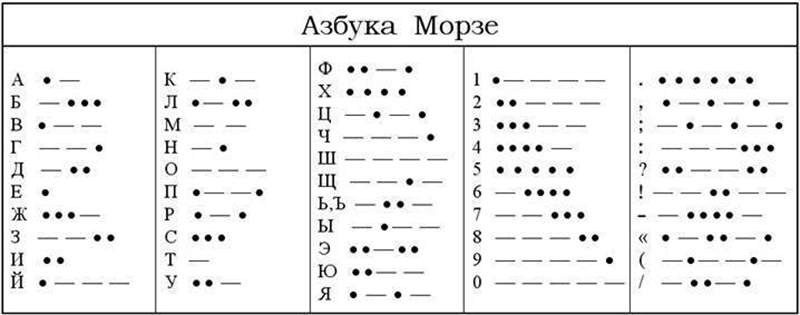
Рисунок 1
Допустим, у нас есть фонарик, и мы хотим передать букву «А», для этого мы быстро прищёлкиваем фонарик, а потом включаем и выключаем его более медленно. Перед отправкой следующего символа делаем небольшую паузу. Принято, что тире должно быть примерно втрое длиннее точки. Так, если точка длится одну секунду, то тире три.
Паузы между точками и тире в азбуке Морзе критически важны. Так при передаче «А» фонарик должен быть выключен между точкой и тире в течении периода, по длительности примерно равного одной точке. Между буквами в слове выдерживаются более долгие паузы, сравнимые по длительности с тире. Между словами выдерживается период примерно в два тире.
•−•− •−−• •• −−−− ••− −•− ••− •−• ••• −−− •−− ••− ••−− ••• •− −−
Например, данный код означает: «я пишу курсовую сам».
Код Морзе называется двоичным. Двоичные коды всегда можно описать в виде степени двойки:
количество кодов = 2количество точек и тире
1.2 Код Брайля
Код Брайля был разработан для помощи незрячим детям в обучении, в то время как он был создан, в ходу была другая система письма для слепых, она заключалась в тактильном отображении каждой буквы, но такой метод был очень дорог в производстве и почти не было возможности производить подобные книги в массовое пользование.
В шрифте Брайля символы письменного языка – буквы и знаки препинания – кодируются комбинациями от одной до шести выпуклых точек, расположенных в ячейке размерами 2 х 3. Точки в ячейке нумеруются с 1 по 6 (рисунок 2):
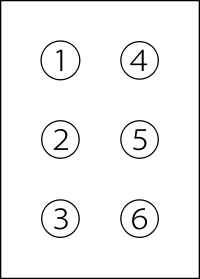
Рисунок 2
Для выдавливания точек используются специальные пишущие машинки и станки.
Самое важное что в шрифте Брайля используется двоичная система. Любая точка может пребывать в двух состояниях: плоская и выпуклая. Значит к нему можно применить систему комбинаторики, то есть общее число комбинаций шести точек, каждая из которых может быть плоской или выпуклой, равно 2 х 2 х 2 х 2 х 2 х 2 = 26 = 64.
Следовательно, система Брайля содержит 64 различных кода. При этом для обозначения цифр, букв и символов нужно меньше 64 комбинаций (рисунок 3):

Рисунок 3
⠫ ⠺⠎⠑ ⠑⠭⠑ ⠙⠑⠇⠁⠳ ⠑⠑ ⠎⠁⠍
На коде Брайля это означает «я все еще делаю ее сам»
Эти примеры подводят к одному простому факту, для передачи информации достаточно лишь бита.
2. Бит
Если нужно сказать «да» или «нет», обозначить «открыто» или «закрыто», «включено» или «выключено» и вообще отметить любое действие, имеющее два отличных друг от друга состояния можно использовать всего один бит, то есть 0 или 1.
Бит является основой самой простой системы счисления – двоичной. В ней всего две цифры: 0 и 1. Системой счисления называют совокупность правил и приемов наименования и записи чисел, а также получения значений чисел из изображающих их символов. Количество знаков в алфавите системы счисления обычно отражается в ее названии: двоичная, троичная, восьмеричная, десятичная, шестнадцатеричная и т.д. Если нужно что-то проще двоичной системы, придется избавится от 1, и останется только 0. Имея всего лишь 0, ничего не сделаешь.
Слово «бит» - сокращение от английского выражения binary digit («двоичная цифра»). В английском языке у слова bit есть и общеупотребительное значение – «кусочек, небольшая часть», и это описание отлично подходит, ведь бит – двоичная цифра, мельчайший фрагмент информации. Суть бита заключается в том, что он передает очень мало информации. Меньше бита – отсутствие информации.
3. Системы счисления в компьютере
Для хранения двоичных чисел в компьютере служит устройство, которое принято называть ячейкой памяти. Ячейки образуются их нескольких битов, так же как двоичные числа образуются из двоичных разрядов (разрядность двоичной системы счисления похожа на десятичную, есть разряды единиц, десятков, сотен и т.д., так как и для изображения двоичных чисел и двоичных машинных кодов используется несколько двоичных разрядов, несколько бит). Ячейки различных компьютеров могут состоять их различного количества бит. Однако это создает значительные сложности для организации обмена данными между разными моделями компьютеров. Поэтому, начиная с машин третьего поколения, стандартными являются ячейки, которые состоят из восьми битов.
Элемент памяти компьютера, состоящий из 8 битов, называется байтом.
Слово «байт» произошло от английского термина byte, представляющего собой сокращение словосочетания Binary term – двоичный терм, выражение. Байт сохраняет все свойства бита, то есть он может сколь угодно долго хранить записанный в него двоичный код, этот код, можно прочитать, можно также записать в байт любой новый код.
Условно бит изображают в виде небольшого прямоугольника, содержащего либо цифру «0», либо цифру «1», а байт рисуют в виде расположенных рядом восьми одинаковых прямоугольников, каждый из которых содержит какую-либо двоичную цифру. Каждый из восьми битов байта может содержать любую из двоичных цифр независимо от остальных. Следовательно, байт может содержать произвольную комбинацию, последовательность из восьми нулей или единиц, например последовательность 10110011. Такую последовательность также называют двоичным числом, двоичным кодом или просто кодом.
Запись двоичного кода легко спутать с аналогичным по записи десятичным числом. Например, двоичный код 10110011 можно рассматривать и как «обычное число» (десять миллионов сто десять тысяч одиннадцать). В таких случаях справа от числа записывают индекс 2, если число в двоичной системе или индекс 10, если число в десятичной системе. Таким образом: 101100112 – двоичное число, а 1011001110 – десятичное. Так же для удобства восприятия десятичные числа в текстах на русском языке принято делить на группы по три цифры в каждой и отделять эти группы друг от друга пробелом – 10 110 01110. По аналогии с этим двоичные числа иногда также группируют, но по четыре цифры в группе – 1011 00112.
Так как байт состоит из восьми двоичных разрядов, то количество различных кодов, различных комбинаций из восьми нулей и единиц, записываемых в один байт равно 28 = 256.
Стоит также упомянуть шестнадцатеричную систему счисления. Шестнадцатеричная система счисления – это позиционная система счисления по целочисленному основанию 16. В качестве цифр этой система счисления обычно используются цифры от 0 до 9 и латинские буквы от А до F. Буквы A, B, C, D, E, F имеют значения 1010, 1110, 1210, 1310, 1410, 1510 соответственно. Для перевода шестнадцатеричного числа в десятичное необходимо это число представить в виде суммы произведений степеней основания шестнадцатеричной системы счисления на соответствующие цифры в разрядах шестнадцатеричного числа. Например, требуется перевести шестнадцатеричное число 8С4ВВ в десятичное. В этом числе 3 цифры. В соответствии с вышеуказанным правилом представим его в виде суммы степеней с основанием 16:
8С4ВВ = 8 × 164 + 12 × 163 + 4 × 162 + 11 × 161 + 11 × 160 = 524 288 + 49 152 + 1024 + 176 + 11 = 574 651
Для перевода многозначного двоичного числа в шестнадцатеричную систему нужно разбить его на тетрады справа налево и заменить каждую тетраду соответствующей шестнадцатеричной цифрой. Для перевода числа из шестнадцатеричной системы в двоичную нужно заменить каждую его цифру на соответствующую тетраду из нижеприведённой таблицы перевода:
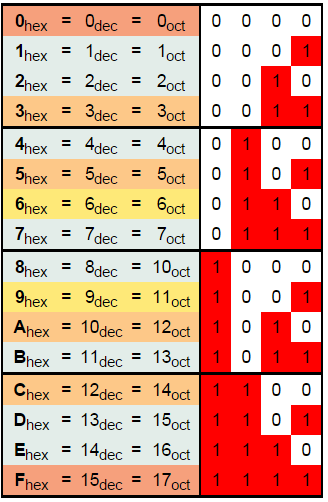
Всю память компьютера можно образно представить себе, как автоматическую камеру хранения, состоящую из большого количества пронумерованных байтов, в каждый из которых можно записать некоторый двоичный машинный код. Затем по известному номеру можно найти байт и прочитать записанный в нем код.
При компьютерной обработке данных приходится иметь дело с текстовой, графической, числовой, звуковой и некоторыми другими видами информации. Для хранения данных различной природы применяются разные способы кодирования. Кроме того, для одной и той же разновидности информации также могут использоваться различные способы кодирования, которые отличаются друг от друга эффективностью, а также различными требованиями к ресурсам компьютера.
Конкретный способ кодирования той или иной разновидности информации в компьютере принято называть форматом данных. В общем случае термин «формат» понимается как строго определенный, исчерпывающе полный набор правил. Следовательно, в приведенном выше определении речь идет об исчерпывающем наборе правил кодирования той или иной разновидности данных.
4. Кодирование данных
4.1 Текстовая информация
При вводе текстовой информации в компьютер символы (буквы, цифры, знаки) кодируются с помощью различных кодовых систем, которые состоят из набора кодовых таблиц, размещенных на соответствующих страницах стандартов для кодирования текстовой информации. В таких таблицах каждому символу присваивается определенный числовой код в шестнадцатеричной или десятичной системе счисления, т.е. кодовые таблицы отражают соответствие между изображениями символов и числовыми кодами и предназначены для кодирования и декодирования текстовой информации. При вводе текстовой информации с помощью клавиатуры компьютера каждый вводимый символ подвергается кодированию, т.е. преобразуется в числовой код, при выводе текстовой информации на устройство вывода компьютера (дисплей, принтер) по числовому коду символа строится его изображение. Присвоение символу определенного числового кода является результатом соглашения между соответствующими организациями разных стран. В настоящее время нет единой универсальной кодовой таблицы, удовлетворяющей буквам национальных алфавитов разных стран.
Современные кодовые таблицы включают в себя международную и национальную части, т.е. содержат буквы как латинского, так и национального алфавитов, цифры, знаки арифметических операций и препинания, математические и управляющие символы, символы псевдографики ( Псевдографические символы – это совокупность символов, включённых в набор символов компьютерного шрифта, отображающих графические примитивы: линии, прямоугольники, треугольники, кресты, различная заливка и тому подобное).
Международная часть кодовой таблицы, базирующаяся на стандарте ASCII (American Standard Code for Information Interchange), кодирует первую половину символов кодовой таблицы с числовыми кодами от 0 до 7F16 или в десятичной системе от 0 до 127.
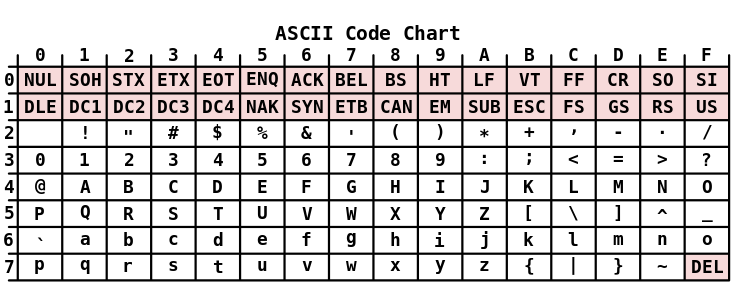
Выше находится международная часть кодовой таблицы символов (Первые два ряда и DEL, являются управляющими символами и не печатаются)
Национальная часть кодовых таблиц содержит коды национальных алфавитов, которую называют также таблицей наборов символов (charset).
В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев приводит к проблемам, связанным с операциями декодирования числовых значений символов.
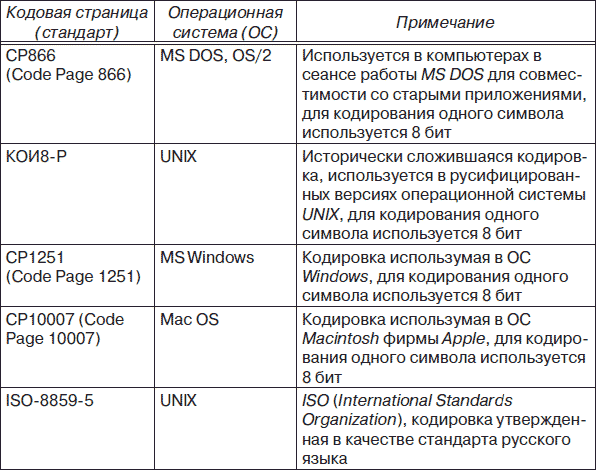
В приведенной выше таблице указаны названия кодовых стандартов, на которых размещены кодовые таблицы (кодировки) кириллицы.
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 216 = 65536 различных символов. На рисунке 4 отображается кодовая таблица 0400 (русский алфавит) стандарта Unicode.
Для преобразования русскоязычных текстов из одного стандарта кодирования текстовой информации в другой используются специальные программы – конверторы. Конверторы обычно встраивают в другие программы (как пример браузеры).
4.2 Графическая информация
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную.
Рассмотрим принципы кодирования графической информации на примере изображения на экране телевизора. Это изображение состоит из горизонтальных линий – строк, каждая из которых в свою очередь состоит из элементарных мельчайших частиц изображения – точек, которые принято называть пикселями (picsel – picture element – элемент картинки).
Степень четкости изображения зависит от количества строк на весь экран и количества точек в строке, которые представляют разрешающую способность экрана, или просто разрешение. Чем больше строк и точек, тем четче и лучше изображение.
Если мы посмотрим на показатели разрешения современных плазменных и жидкокристаллических телевизоров, то обнаружим, что наиболее распространенное разрешение – 1920 × 1080 (Full HD), так же можно встретить разрешения: 640 × 480 (ЖК-телевизоры с соотношением сторон 4:3), 852 × 480 (плазменные панели с соотношением сторон 16:9), 1366 × 786 (HD Ready), 3840 × 2160 (Ultra HD/4K), 7680 × 4320 (Ultra HD/8K).
Обозначение разрешения, например 1920 × 1080, означает, что используется 1080 горизонтальных строк по 1920 пикселей в каждой. Таким образом, изображение на экране представляет собой последовательность из 1920×1080 = 2 073 600 пикселей. Изображения могут быть монохромными и цветными.
Монохромное изображение состоит из любых двух контрастных цветов – черного и белого, зеленого и белого, коричневого и белого и т.д. Для простоты будем считать, что один из цветов белый, а второй черный. Поставив в соответствие белому цвету значение бита равное «0», а черному «1» (либо наоборот), мы сможем закодировать в 1 бите состояние 1 пикселя монохромного изображения. Однако полученное таким образом изображение будет чрезмерно контрастным.
Общепринятым сейчас считается кодирование состояния 1 пикселя с помощью 1 байта, которое позволяет предавать 256 различных оттенков серого цвета от полностью белого, до полностью черного. В этом случае для передачи всего растра из 1920 × 1080 потребуется 2 073 600 байт.
Цветное изображение может формироваться на основе различных моделей. Наиболее распространенные цветовые модели:
RGB чаще всего используются в информатике;
СMYK основная модель в полиграфии;
XYZ эталонная модель основанная на замерах характеристик человеческого глаза;
4.2.1 Модель RGB:
Модель RGB (от слов red, green, blue) наиболее точно подходит к принципам вывода изображения на экран монитора – три числа задают яркость свечения зерен красного, зеленого, и синего люминофора в заданной точке экрана. Поэтому данная модель получила наиболее широкое распространение в области компьютерной графики, ориентированной на просмотр изображений на экране монитора.
Модель RGB опирается на то, что глаз человека воспринимает все цвета как сумму трех основных цветов – красного, зеленого и синего. Так как цвет формируется в результате сложения трех цветов, эту модель часто называют аддитивной (суммирующей).
Например, для задания белого цвета необходимо указать для всех трех компонентов максимальные значения яркости, а для задания черного – полностью погасить все источники (например, точки люминофора), задающие цвет в нужной точке изображения, – указать для них нулевую яркость.
Если каждый из цветов кодировать с помощью 1 байта (яркость каждого компонента задается числом от 0 до 255), как это принято для реалистичного монохромного изображения, появится возможность передавать по 256 оттенков каждого из основных цветов. А всего в этом случае обеспечивается передача 256 х 256 х 256 = 16 777 216 различных цветов, что достаточно близко к реальной чувствительности человеческого глаза. Таким образом, при данной схеме кодирования цвета на изображение 1 пикселя потребуется 3 байта или 24 бита памяти. Этот способ представления цветовой графики принято называть режимом True Color (истинный цвет) или полноцветным режимом.
Существуют профессиональные устройства, позволяющие получать изображения, в которых каждый пиксел описывается не тремя, а шестью (48 битами на каждую цветовую составляющую) или даже восемью байтами. Подобные режимы используются для наилучшей передачи оттенков и, что самое главное, яркости точек изображения. Это позволяет наиболее достоверно воспроизводить изображения таких сложных с технической точки зрения сюжетов, как, например, вечерние или рассветные пейзажи. На рисунке 5 изображена RGB-цветовая модель, представленная в виде куба.
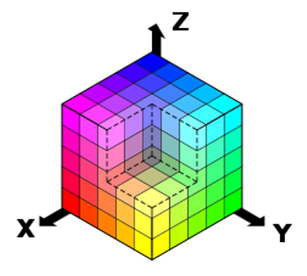
Рисунок 5
Например, в Win32 стандартный тип для представления цветов – COLORREF. Для определения цвета в RGB-спектре используется 4 байта в виде:
0×00BBGGRR
BB, GG, RR – значение интенсивности соответственно синей, зеленой и красной составляющих цвета. Максимальное их значение - 0×FF.
Тогда определить переменную типа COLORREF можно следующим образом:
COLORREF C = (b, g, r);
b, g, r – интенсивность (в диапазоне от 0 до 255) соответственной синей, зеленой и красной составляющих определенного цвета C. То есть ярко-красный цвет может быть определен как (255, 0, 0), ярко-фиолетовый – (255, 0, 255), черный – (0, 0, 0), а белый – (255, 255, 255).
Полноцветный режим требует много памяти. Поэтому памяти разрабатываются различные режимы и графические форматы, которые немного хуже передают цвет, но требуют гораздо меньше памяти. В частности, можно упомянуть режим High Color (богатый цвет), в котором для передачи цвета 1 пикселя используется 16 бит, и, следовательно, можно передать 65 535 цветовых оттенков, а также индексный режим, который базируется на заранее созданной для данного рисунка таблице используемых в нем цветовых оттенков. Затем нужный цвет пикселя выбирается из этой таблицы с помощью номера — индекса, который занимает всего 1 байт памяти. При записи изображения в память компьютера, кроме цвета отдельных точек, необходимо фиксировать много дополнительной информации — размеры рисунка, разрешение, яркость точек и т. д. Конкретный способ кодирования всей требуемой при записи изображения в память компьютера информации образует графический формат. Форматы кодирования графической информации, основанные на передаче цвета каждого отдельного пикселя, из которого состоит изображение, относят к группе растровых, или BMP (bit map— битовая карта), форматов.
4.2.2 Модель CMYK:
Модель CMYK (Cyan, Magenta, Yellow, blacK) субтрактивная схема формирования цвета, используемая прежде всего в полиграфии для стандартной триадной печати. Схема CMYK как правило, обладает сравнительно небольшим цветовым охватом. На рисунке 6 отображена цветовая модель CMYK.
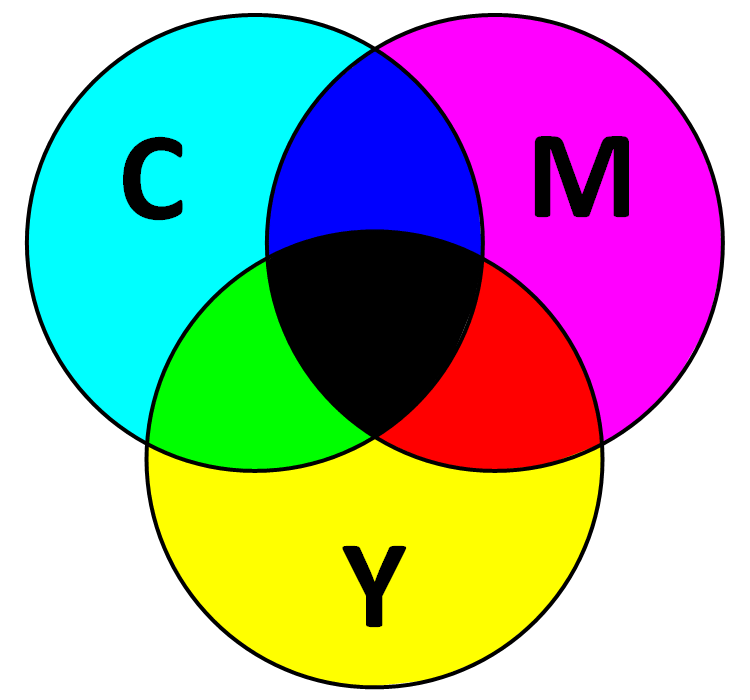
Рисунок 6
По-русски эти цвета часто называют: голубой, пурпурный, желтый. Цвет в такой схеме зависит не только от спектральных характеристик красителей и от способа их нанесения, но и их количества, характеристик бумаги и других факторов. Например, есть американский, европейский и японский стандарты для мелованной и немелованной бумаг.
Хотя теоретически черный цвет можно получать смешением в равной пропорции пурпурного, голубого и желтого, на практике смешение реальных пурпурного, голубого и желтого цветов дает скорее грязно-коричневый или грязно-серый цвет. Так как чистота и насыщенность черного цвета чрезвычайно важны в печатном процессе, в модель был введен ещё один цвет – черный.
Объяснение первых трех букв в аббревиатуре CMYK дано выше, а по поводу четвертой одна из версий утверждает, что K – сокращение от англ. blacK (если бы взяли B, то возникла бы путаница с моделью RGB, где B – это синий цвет). Согласно этой версии, при выводе полиграфических пленок на них одной буквой указывался цвет, которому они принадлежат. Согласно другому варианту, буква K появилась от сокращения англ. слова key: в англоязычных странах термином key plate обозначается печатная форма для черной краски.
CMYK называют субтрактивной моделью, потому что эту модель применяют в основном в полиграфии при цветной печати, а бумага и прочие печатные материалы служат поверхностями, отражающими свет: удобнее считать, какое количество света (и цвета) отразилось от той или иной поверхности, нежели – сколько поглотилось. Таким образом, если вычесть из белого три первичных цвета, RGB, мы получим тройку дополнительных цветов CMY. «Субтрактивный» означает «вычитаемый» – мы вычитаем первичные цвета из белого.
Каждое из чисел, определяющее цвет в CMYK, представляет собой процент краски данного цвета, составляющей цветовую комбинацию, например, для получения темно-оранжевого цвета следует смешать 30 % голубой краски, 45 пурпурной, 80 желтой и 5 % черной краски. Это можно обозначить следующим образом: (30,45,80,5). Иногда пользуются таким обозначением: C30M45Y80K5.
4.3 Кодирование аудио информации:
Звуковой сигнал – это непрерывная волна с изменяющейся амплитудой и частотой. Чем больше амплитуда сигнала, тем он громче для человека, чем больше частота сигнала, тем выше тон. Для того чтобы компьютер мог обрабатывать непрерывный звуковой сигнал, он должен быть дистретизирован (оцифрован), т.е. превращен в последовательность электрических импульсов (двоичных нулей и единиц).
Преобразование аналогового звукового сигнала в цифровой вид называется аналогово-цифровым преобразованием или оцифровкой. Процесс такого преобразования заключается в осуществлении замеров величины амплитуды аналогового сигнала с некоторым временным шагом – дискретизация и последующей записью полученных значений амплитуды в численном виде – квантовании.
Процесс дискретизации по времени — это процесс получения
мгновенных значений преобразуемого аналогового сигнала с определенным
временным шагом, называемым шагом дискретизации.
Чем выше частота дискретизации т.е. количество отсчетов за секунду
и чем больше разрядов отводится для каждого отсчета, тем точнее будет
представлен звук. Но при этом увеличивается и размер звукового файла.
Поэтому в зависимости от характера звука, требований, предъявляемых к его
качеству и объему занимаемой памяти, выбирают некоторые компромиссные
значения.
Количество осуществляемых в одну секунду замеров величины сигнала
называют частотой дискретизации или частотой выборки, или частотой
сэмплирования (от англ. «sampling» – «выборка»). Очевидно, что чем
меньше шаг дискретизации, тем выше частота дискретизации (то есть, тем
чаще регистрируются значения амплитуды), и, значит, тем более точное
представление о сигнале мы получаем.
Теперь, для записи каждого отдельного значения амплитуды, его
необходимо округлить до ближайшего уровня квантования. Этот процесс
называется квантованием по амплитуде. Говоря более формальным языком,
квантование по амплитуде – это процесс замены реальных (измеренных) значений амплитуды сигнала значениями, приближенными с некоторой
точностью. Каждый из 2 N возможных уровней называется уровнем
квантования, а расстояние между двумя ближайшими уровнями
квантования называется шагом квантования. Квантование значений
сигнала привносит в спектр сигнала дополнительную помеху, называемую
шумом квантования или шумом дробления. Шумом (ошибкой)
квантования называют сигнал, составляющий разницу между
восстановленным цифровым и исходным аудио сигналами. Эта разница
образуется в результате округления измеренных значений сигнала. При этом
выполняется следующая закономерность: чем выше разрядность
квантования, тем ниже уровень шума квантования (поскольку тем на
меньшее значение требуется округлять каждое измеренное значение
сигнала). Природа шума квантования такова, что ширина спектральной
области, в которой он простирается, пропорциональна значению частоты
дискретизации. На рисунке 7 изображен процесс оцифровки звукового сигнала:
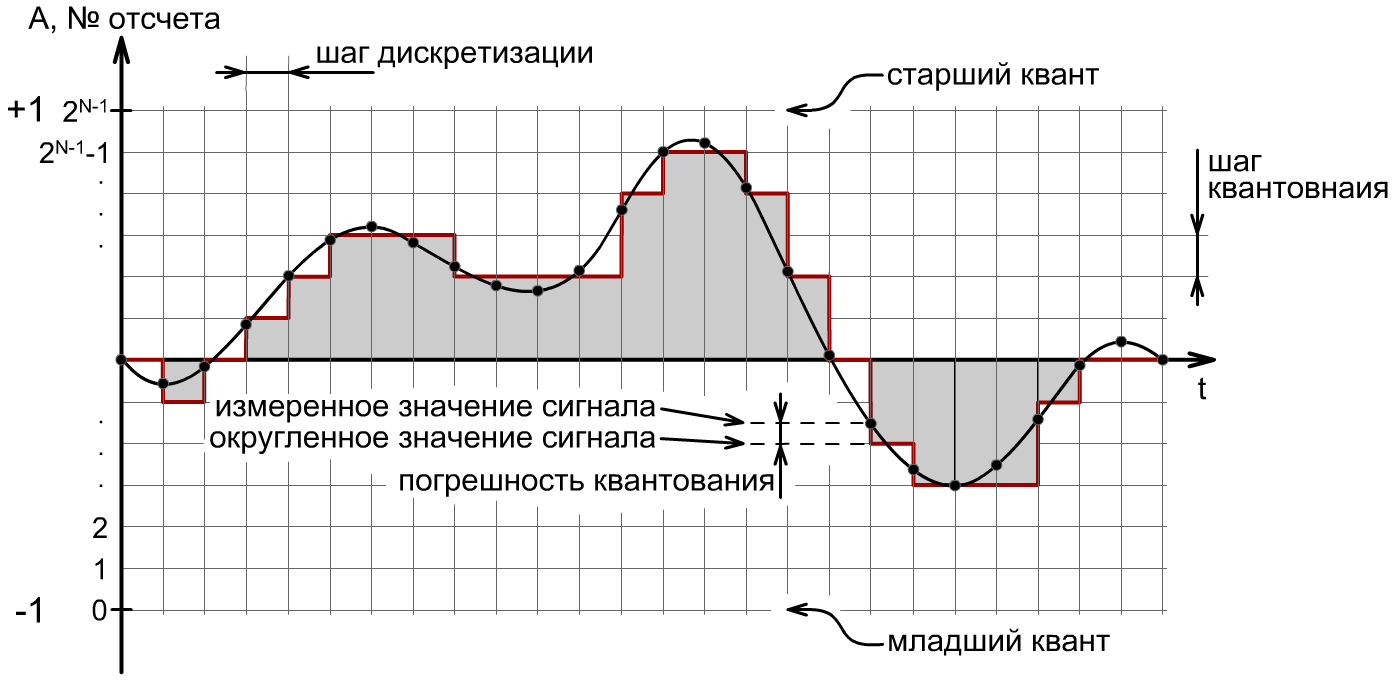
Рисунок 7
Устройство, выполняющее оцифровку, называют аналого-цифровым преобразователем. Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование для которого служит цифро-аналоговый преобразователь, а затем сгладить получившийся ступенчатый сигнал.
В настоящее время все упирается в вычислительную мощность современной цифровой техники. С возрастанием точности оцифровки одновременно возрастает скорость потока цифровых данных, увеличивается вычислительная нагрузка на процессор и требуется повышенный объем памяти для хранения цифровых отчетов. Имеются и серьезные схемотехнические трудности. Вместе со стремительным простом компьютерных технологий становится возможным применять более высокие частоты дискретизации и разрядность. Цифровой звук широко применяется в современной звукозаписывающей индустрии благодаря хорошему качеству звучания, высокой помехозащищенности и удобству хранения и архивирования материала.
В настоящее время при записи звука в мультимедийных технологиях применяются частоты 8, 11, 22, 44 кГц. Так, частота дискретизации 44 килогерца означает, что одна секунда непрерывного звучания заменяется набором из сорока четырех тысяч отдельных отсчетов сигнала. Чем выше частота дискретизации, тем лучше качество оцифрованного звука.
Как отмечалось выше, каждый отдельный отсчет можно описать некоторой совокупностью чисел, которые затем можно представить в виде некоторого двоичного кода. Качество преобразования звука в цифровую форму определяется не только частотой дискретизации, но и количеством битов памяти, отводимых на запись кода одного отсчета. Этот параметр принято называть разрядностью преобразования.
Методов сжатия (форматов), а также программ, реализующих эти
методы, существует много. Наиболее известными являются MPEG-1 Layer
I, II, III (последним является всем известный MP3), MPEG-2 AAC (advanced
audio coding), Ogg Vorbis, Windows Media Audio (WMA), TwinVQ (VQF),
MPEGPlus, TAC, и прочие. В настоящее время обычно используется разрядность 8, 16 и 24 бита.
На описанных выше принципах основывается формат WAV (от
WAVeform-audio – волновая форма аудио) кодирования звука. Получить
запись звука в этом формате можно от подключаемых к компьютеру
микрофона, проигрывателя, магнитофона, телевизора и других стандартно
используемых устройств работы со звуком. Однако формат WAV требует
очень много памяти. Так, при записи стереофонического звука с частотой
дискретизации 44 килогерца и разрядностью 16 бит – параметрами, дающими
хорошее качество звучания, – на одну минуту записи требуется около десяти
миллионов байтов памяти.
Кроме волнового формата WAV, для записи звука широко применяется формат с названием MIDI (Musical Instruments Digital Interface – цифровой интерфейс музыкальных инструментов). Фактически этот формат представляет собой набор инструкций, команд так называемого музыкального синтезатора – устройства, которые имитируют звучание реальных музыкальных инструментов. Команды синтезатора фактически являются указаниями на высоту ноты, длительность ее звучания, тип имитируемого музыкального инструмента и т.д. Таким образом, последовательность команд синтезатора представляет собой нечто вроде нотной записи музыкальной мелодии. Получить запись звука в формате MIDI можно только от специальных электромузыкальных инструментов, которые поддерживают интерфейс MIDI. Формат MIDI обеспечивает высокое качество звука и требует значительно меньше памяти, чем формат WAV.
Наиболее распространенный формат – MPEG-1 Layer III (всем известный формат MP3). Формат завоевал свою популярность совершенно заслуженно – это был первый распространенный кодек, который достиг столь высокого уровня компрессии при отличном качестве звучания. Сегодня этому кодеку имеется много альтернатив, но выбор остается за пользователем. Преимущества MP3 – широкая распространенность и высокое качество кодирования, которое улучшается благодаря разработчикам различных кодеров.
4.4 Кодирование видео информации:
Чтобы хранить и обрабатывать видео на компьютере, необходимо закодировать его особым образом. При этом кодирование звукового сопровождения видеоинформации ничем не отличается от кодирования звука, описанного в выше. Изображение в видео состоит из отдельных кадров, которые меняются с определенной частотой. Кадр кодируется как обычное растровое изображение, то есть разбивается на множество пикселей. Закодировав отдельные кадры и собрав их вместе, можно описать все видео.
Видеоданные характеризуются частотой кадров и экранным разрешением. Скорость воспроизведения видеосигнала составляет 30 или 25 кадров в секунду, в зависимости от телевизионного стандарта. Наиболее известными из таких стандартов являются: SECAM, принятый в России и Франции, PAL, используемый в Европе, и NTSC, распространенный в Северной Америке и Японии.
В основе кодирования цветного видео лежит известная модель RGB. В телевидении же используется другая модель представления цвета изображения, а именно модель YUV. В такой модели цвет кодируется с помощью яркости Y и двух цветоразностных компонент U и V, определяющих цветность. Цветоразностная компонента образуется путем вычитания из яркостной компоненты красного и зеленого цвета. Обычно используется один байт для каждой компоненты цвета, то есть всего для обозначения цвета используется три байта информации. При этом яркость и сигналы цветности имеют равное число независимых значений. Такая модель имеет обозначение 4:4:4. Опытным путем было установлено, что человеческий глаз менее чувствителен к цветовым изменениям, чем к яркостным. Без видимой потери качества изображения можно уменьшить количество цветовых оттенков в два раза. Такая модель обозначается как 4:2:2 и принята в телевидении. Для бытового видео допускается еще большее уменьшении размерности цветовых составляющих, до 4:2:0.
Если представить каждый кадр изображения как отдельный рисунок определенного размера, то видеоизображение будет занимать очень большой объем, например, одна секунда записи в системе PAL будет занимать 25 Мбайт, а одна минута – уже 1,5 Гбайт. Поэтому на практике используются различные алгоритмы сжатия для уменьшения скорости и объема потока видеоинформации. Если использовать сжатие без потерь, то самые эффективные алгоритмы позволяют уменьшить поток информации не более чем в два раза. Для более существенного снижения объемов видеоинформации используют сжатие с потерями.
Среди алгоритмов с потерями одним из наиболее известных является MotionJPEG или MJPEG. Приставка Motion говорит, что алгоритм JPEG используется для сжатия не одного, а нескольких кадров. При кодировании видео принято, что качеству VHS соответствует кодирование MJPEG с потоком около 2 Мбит/с, S-VHS – 4 Мбит/с. Свое развитие алгоритм MJPEG получил в алгоритме DV, который обеспечивает лучшее качество при таком же потоке данных. Это объясняется тем, что алгоритм DV использует более гибкую схему компрессии, основанную на адаптивном подборе коэффициента сжатия для различных кадров видео и различных частей одного кадра. Для малоинформативных частей кадра, например, краев изображения, сжатие увеличивается, а для блоков с большим количеством мелких деталей уменьшается. Еще одним методом сжатия видеосигнала является MPEG. Поскольку видеосигнал транслируется в реальном времени, то нет возможности обработать все кадры одновременно. В алгоритме MPEG запоминается несколько кадров.
Основной принцип состоит в предположении того, что соседние кадры мало отличаются друг от друга. Поэтому можно сохранить один кадр, который называют исходным, а затем сохраняются только изменения от исходного кадра, называемые предсказуемыми кадрами. Считается, что за 10-15 кадров картинка изменится настолько, что необходим новый исходный кадр. В результате при использовании MPEG можно добиться уменьшения объема информации более чем в двести раз, хотя это и приводит к некоторой потере качества.
Заключение
В заключении хотелось бы отметить, что на данный момент мы имеем очень большое количество возможностей для совершенствования способов передачи и кодирования информации. В двадцать первый век, человечеству доступны огромные объёмы информации, а также есть возможность подкреплять практическими способами ранее созданные теории. Уже сейчас существуют технологии дополненной реальности, которые позволяют не только воспринимать те объекты, которые она проецирует, но и взаимодействовать с ними.
Сейчас особое внимание уделяется скорости передачи данных и бесперебойному потоку информации. Помимо обычных способов передачи с помощью физических накопителей, появились сети Wi-Fi и поколения передачи сотовых данных, такие как 4G и 5G, что позволяет иметь доступ к информации из любой точки мира.
Пусть, возможно, мы и не успеем сделать что-то, что сейчас можно увидеть лишь в фантастических фильмах, однако попытаться приблизится к этому и продолжить строить путь для будущих поколений, как в свое время ученые и исследователи делали для нас, вполне в наших силах.
Список литературы
Малинина Л.А. – Основы информатики: Учебник для вузов / Л.А. Малинина. – М.: Феникс, 2006. – 352 с.
Петцольд Ч. – Код: Тайный язык информатики / Ч. Петцольд. – М.: МИФ, 2020. – 448 с.
Р.В. Хемминг – Теория кодирования и теория информации / Р.В. Хемминг. – М.: Радио и связь, 1983. – 168 с.
Степанов А. Н. – Информатика: Учебник для вузов / А.Н. Степанов. – СПб.: Питер, 2015. – 720 с.
Воронина И.В. – Информатика. Шпаргалка / И.В. Воронина. – М.: Научная книга, 2009. – 130 с.
Яшин В.Н. – Информатика: Аппаратные средства персонального компьютера / В.Н. Яшин. – М.: Инфра-М, 2010. – 256 с.
Таненбаум Э. – Архитектура компьютера. 6-е изд. / Э. Таненбаум. – СПб.: Питер, 2012. – 811 с.
Степанов А.Н. – Курс информатики для студентов информационно-математических специальностей / А.Н. Степанов. – СПб.: Питер, 2018. – 1088 с.
Грошев А.С. – Информатика: Учебник для вузов / А.С. Грошев. – Архангельск, Арханг. гос. тех. ун-т, 2010. – 470 с.
Шестнадцатеричная система счисления: сайт. – URL: https://ru.wikipedia.org/wiki/ (дата обращения 15.10.2019). – Текст: электронный.
Веселов А.И. – Обработка видеоинформации в системах сжатия, основанных на принципах кодирования зависимых источников: монография / А.И. Веселов. – М.: ГУАП, 2014. – 71 с.
Тропченко А.Ю. – Методы сжатия изображений, аудиосигналов и видео. Учебное пособие по дисциплине «Теоретическая информатика» / А.Ю. Тропченко, А.А. Тропченко // СПб.: Санкт-Петербург, 2009. – 108 с.

- Анализ конкурентов на рынке и определение собственной конкурентоспособности (на примере ООО «Агентика Тревэл»)
- История развития менеджмента (Современные подходы к менеджменту)
- Понятие и основные признаки правовой нормы (Структура нормы права )
- Теории происхождения государства ( Разнообразие теорий происхождения государства )
- Архитектура клиент-сервер
- Применение процессного подхода для оптимизации бизнес-процессов ( Процессный подход )
- Бухгалтерская (финансовая) отчетность
- Правовая культура. Правовой нигилизм и правовой фетишизм ( ПРАВОВАЯ КУЛЬТУРА: ПОНЯТИЕ, ФУНКЦИИ, ОСНОВНЫЕ РАЗНОВИДНОСТИ )
- Теория права и государства
- Распределение и использование прибыли как источник экономического роста предприятий ( Подходы к формированию и направлениям использования прибыли корпорации )
- Сущность, функции, задачи и организация аукционов
- выявление наиболее подходящей системы мотивации для сетевых предприятий.