
Методы сортировки данных: эволюция и сравнительный анализ. Примеры использования(Понятие данных и массивов данных)
Содержание:

ВВЕДЕНИЕ
Ещё десятилетие назад объёмы массивов данных не достигали таких размеров, которые сейчас являются фактически не мыслимыми. Актуальной становится задача оптимизации алгоритмов, а в нашем случае их сортировка, так как размеры перерабатываемых данных увеличиваются с каждым разом. Задачи на увеличение скорости работы алгоритмов по-прежнему остаются актуальными. К примеру, первостепенной образовательной задачей нередко является их простота. Важной и актуальной задачей сравнительного анализа сортировки алгоритмов является расширение круга задач, для которых они применяются, и в особенности рост требований к скорости алгоритмов сортировки.
Алгоритмы устойчивой сортировки; алгоритмы неустойчивой сортировки; непрактичные алгоритмы сортировки; алгоритмы, не основанные на сравнениях и алгоритмы топологической сортировки – это наиболее популярные алгоритмы, которые мы решили рассмотреть. Составляющие, с наличием комплекта нескольких равных данных, в отсортированном наборе сохраняются в том же порядке, как и в исходном наборе при помощи алгоритмов устойчивой (стабильной) сортировки. Таким образом, имея одинаковые ключи, сравнительный порядок сортируемых составляющих не меняется сравнительной сортировкой. К числу алгоритмов устойчивой сортировки относятся сортировка пузырьком, сортировка смешиванием (шейкерная, гномья сортировка, сортировка вставками, сортировка слиянием, сортировка с использованием двоичного дерева, метод сортировки Тима Петерса, сортировка подсчётом, блочная сортировка (корзинная сортировка) и ряд других. При сортировке по одному полю данных, которые состоят из нескольких полей, сохранение их взаимного месторасположения равных элементов принципиально – это одно из совокупных преимуществ алгоритмов устойчивой сортировки. [4]
Поэтому было принято решение, решая задачи, применив методы сортировки данных, разработать программу.
Объект: возможности различных методов сортировки данных.
Предмет: программирование с использованием методов сортировки данных.
Цель курсовой работы – разработать программу, реализующую основные методы сортировки данных.
Для достижения указанной цели потребуется решить ряд задач:
- Изучить данные, виды данных и методы их сортировки.
- Рассмотреть возможности среды Lazarus для реализации программы сортировки.
- Разработать программу, реализующую сортировку массивов при решении задач в среде разработки Lazarus.
Глава 1. Общая характеристика методов сортировки данных
1.1. Понятие данных и массивов данных
В условиях современного мира и бурного развития информационных технологий. Все больше проникает во все сферы, а все данные и информация хранятся на серверах. Для бизнеса и любой другой отрясли поиск информации и обработка данных становится проблемой, а скорость решающим фактором. В условиях рыночной экономики потребность ускорения обработки данных привела к созданию алгоритмов и методов сортировки.
После этого было предложено множество различных алгоритмов сортировки: например, вычисление адреса в 1956 году; слияние с вставкой, обменная поразрядная сортировка, каскадное слияние и метод Шелла в 1959 году, многофазное слияние и вставки в дерево в 1960 году, осциллирующая сортировка и быстрая сортировка Хоара в 1962 году, пирамидальная сортировка Уильямса и обменная сортировка со слиянием Бэтчера в 1964 году. В конце 60-х годов произошло и интенсивное развитие теории сортировки.
Появившиеся позже алгоритмы во многом являлись вариациями уже известных методов. Получили распространение адаптивные методы сортировки, ориентированные на более быстрое выполнение в случаях, когда входная последовательность удовлетворяет заранее установленным критериям.
Образ данных с прямым доступом к элементам, являющийся одновременно однородным, упорядоченным, структурированным будет называться массивом. Элементы массива в компьютере занимают конкретную конечную область памяти и объединяются общим именем. Указав имя массива и индекс элемента в нём, говорит о том, что таким образом можно обратиться ко всякому элементу этого массива.
Массив — упорядоченный набор данных, используемый для хранения данных одного типа, идентифицируемых с помощью одного или нескольких индексов. В простейшем случае массив имеет постоянную длину и хранит единицы данных одного и того же типа.
Массивы делятся на два типа, а именно одномерные и двумерные. Массив называется линейным, либо одномерным, в том случае, если в нём для обращения к элементам применяется лишь один порядковый номер. Таблица, в которой есть единственная строка, может быть представлен одномерный массив.
Размерностью элементов массива является количество составляющих индексов.
Массивы называются двумерными, индекс которых равен двум. Где номер строки соответствует первому индексу, а номер ячейки в строке (номер столбца) - второму индексу, именно в виде такой таблицы оформляются двумерные массивы.
Одномерные массивы и двумерные массивы в программировании используются чаще всего.
Значения соответствующих элементов массива, которые будут храниться в выделенной нами памяти, а так же при помощи ключевого слова МАССИВ [20] указываем размерность и его имя – все это необходимо нам, чтобы объявить массив.
Пример 1:
массив В [20]
В данном примере будет объявлен одномерный массив В, состоящий из 20 соответствующих элементов.
Пример 2:
массив Р [8,6]
В данном примере будет объявлен двумерный массив Р, который возможно представить в виде таблицы, состоящей из 8-х строк по 6 ячеек в каждой строке.
Ограничение на размер одномерного массива - 1000 элементов, для двумерных - 1000х1000. Чтобы время обработки не затягивалось, преследуя учебные цели, массивы более чем из 500 элементов лучше не применять. Все массивы в Game Logo имеют числовой тип (действительные числа).
Работа с массивами. После того, как мы объявили массив, каждый его элемент можно обработать, указав личный номер (имя) массива и индекс элемента в квадратных скобках. К примеру, запись Т [2] позволяет адресоваться ко второму элементу массива Т.
При работе с двумерным массивом указываются два индекса. К примеру, запись M [3,4] делает доступным для обработки значение элемента, оказавшегося в третьей строке четвертого столбца массива M.
Индексированные переменные применяются так же, как и обычные переменные, так как они именуются индексированными элементами массива. К примеру, они могут применяться в качестве аргументов в командах или находиться в выражениях в качестве операндов.
Присваивание значений элементам массива.
А[5] = 13
Пятому элементу массива А будет присвоено значение 13.
М[2,4] = 25
Элементу массива М, находящемуся во второй строке четвертого столбца, будет присвоено значение 25.
При помощи команды СПРОСИ можно ввести в элемент массива.
спроси А[5]
Загрузка данных в массив. Команда ЗАГРУЗИ вводит данные в массив.
Примеры для одномерного массива А.
загрузи в A
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
конец загрузки
загрузи в A
|
1 |
2 |
3 |
4 |
5 |
|
6 |
7 |
8 |
9 |
10 |
|
11 |
12 |
13 |
14 |
15 |
конец загрузки
Часть элементов может остаться незаполненной, если данных будет мало, или же отсекутся, если данных будет много.
Пример для двумерного массива В.
загрузи в В
|
15 |
17 |
25 |
36 |
24 |
56 |
78 |
56 |
36 |
24 |
|
56 |
78 |
56 |
36 |
24 |
15 |
17 |
25 |
36 |
25 |
|
15 |
17 |
25 |
36 |
24 |
56 |
78 |
56 |
36 |
24 |
|
78 |
56 |
36 |
24 |
15 |
17 |
17 |
25 |
36 |
25 |
|
36 |
24 |
56 |
78 |
24 |
56 |
78 |
56 |
36 |
24 |
|
39 |
78 |
56 |
36 |
24 |
25 |
15 |
15 |
89 |
71 |
|
15 |
17 |
25 |
36 |
24 |
56 |
78 |
56 |
36 |
24 |
|
78 |
56 |
36 |
24 |
15 |
17 |
17 |
25 |
36 |
25 |
|
36 |
24 |
56 |
78 |
24 |
56 |
78 |
56 |
36 |
24 |
|
39 |
78 |
56 |
36 |
24 |
25 |
15 |
15 |
89 |
71 |
конец загрузки
Заполнение массива случайными числами. Используя цикл, можно заполнить массив случайными числами.
Пример заполнения элементов массива А псевдослучайными целыми числами в диапазоне от 10 до 99:
массив А[100]
переменная х
повторить для х = 1 до 100 {А[х] = Int(случайное * 89) + 10}
Вывод значений элементов массива
ПИШИ A[3]
Значение третьего элемента одномерного массива А будет выводиться на экран.
ПИШИ# A
Будут выведены значения всех элементов массива А.
Знак # в команде ПИШИ выводит массив полностью. Для одномерных массивов вывод осуществляется с переносом строк. Для двумерных - как есть в виде таблицы, вследствие этого вероятен выход за пределы поля.
Вывод массива в графическом виде. Массив может быть выведен в виде ряда точек (или для двумерных массивов таблицы из точек), цвет которых соответствует значению элемента массива (диапазон от 0 до 15, черным цветом будут показываться все числа меньше 0, белым - больше 15). Во многих случаях, требующих зрительного восприятия происходящего в массиве для моделирования клеточных автоматов, для визуализации сортировки удобен метод вывода массива в графическом виде.
ТОЧКА# <имя массива> [, <координата х>, <координата у>]
В скобки взяты необязательные параметры <координата х> и <координата у>. Они обеспечивают отступ от начала координат (верхнего левого угла).
Пример:
точка# M, 150, 50
Замена и копирование значений в массивах. Команда для замены во всем массиве одного значения на другое.
заменить в <имя массива> <число1> на <число2>
Команда для копирования всех значений одного массива в иной массив. Численность составляющих и размерность массивов должны совпадать.
копировать <имя массива> в <имя массива> [1]
Далее рассмотрим методы сортировки массивов.
Расположением элементов по возрастанию (или убыванию) называется сортировкой или же упорядочением массива. Говорят о неубывающем (или невозрастающем) порядке в том случае, если не все элементы различны.
1.2. Общая характеристика методов сортировки данных
Количество используемых индексов массива может быть различным: массивы с одним индексом называют одномерными, с двумя — двумерными, и т. д. Одномерный массив — нестрого соответствует вектору в математике; двумерный («строка», «столбец»)— матрице. Чаще всего применяются массивы с одним или двумя индексами; реже — с тремя; ещё большее количество индексов — встречается крайне редко.
Алгоритмы сортировки разделяются по свойствам и классификации:
- Устойчивость — устойчивая сортировка не меняет взаимного расположения элементов с одинаковыми ключами.
- Естественность поведения — эффективность метода при обработке уже упорядоченных или частично упорядоченных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
- Использование операции сравнения. Алгоритмы, использующие для сортировки сравнение элементов между собой, называются основанными на сравнениях. Минимальная трудоемкость худшего случая для этих алгоритмов составляет O( n • log n), но они отличаются гибкостью применения. Для специальных случаев (типов данных) существуют более эффективные алгоритмы.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов упорядочения два:
- Внутренняя сортировка оперирует массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно упорядочиваются на том же месте без дополнительных затрат.
В современных архитектурах персональных компьютеров широко применяется подкачка и кэширование памяти. Алгоритм сортировки должен хорошо сочетаться с применяемыми алгоритмами кэширования и подкачки.
- Внешняя сортировка оперирует запоминающими устройствами большого объёма, но не с произвольным доступом, а последовательным (упорядочение файлов), то есть в данный момент «виден» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам упорядочения, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным во внешней памяти производится намного медленнее, чем операции с оперативной памятью.
Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим.
Объём данных не позволяет им разместиться в ОЗУ.
Также алгоритмы классифицируются по:
- потребности в дополнительной памяти или её отсутствию
- потребности в знаниях о структуре данных, выходящих за рамки операции сравнения, или отсутствию таковой.
Для моделирования сортировки были выбраны 3 алгоритма из разных классификаций и с разными свойствами , для более точногой оценки.
Говоря в общем, это большая и сложная содержательная тема, в которой известно большое количество всевозможных алгоритмов. Критерии оценки эффективности этих алгоритмов могут включать следующие характеристики:


|
количество шагов алгоритма, необходимых для упорядочения |
количество сравнений элементов |
количество перестановок, производимых при сортировке |
Мы рассмотрим только три простейшие схемы сортировки. [8]
Метод «пузырька» является наиболее простым методом сортировки. Если представить, что массив (таблица) располагается вертикально, то легко можно понять его идею. Подобно большим пузырькам всплывают вверх элементы с большим значением. При первом проходе вдоль массива, берется первый элемент, начиная проход «снизу», и поочередно сравнивается с последующими. При этом:
- если встречается с наименьшим значением (более «легкий») элемент, то они меняются местами;
- если встречается с более «тяжелым» элементом, конечный становится «эталоном» для сравнения, и все следующие сравниваются с ним.
В итоге в самом верху будет наибольший элемент массива.
Во время второго прохода вдоль массива располагается второй по величине элемент, который помещается под элементом, отысканным при первом проходе, т.е. на вторую сверху позицию, и т.д.
Хочется заметить, что надобности рассматривать ранее «всплывшие» элементы при втором и дальнейших проходах нет, так как уже известно, что они больше оставшихся. Говоря иначе, элементы, стоящие на позициях выше j не нужно проверять во время j-го прохода.
Теперь приведём текст программы упорядочения массива M[1..N]:
Для перестановки элементов местами во всех алгоритмах сортировки станет стандартная процедура swap:
Заметим, что в случае если массив M — глобальный, то процедура имеет возможность содержать лишь аргументы (а не результаты). Не считая того, что учитывая во внимание специфику ее использования в данном алгоритме, можно свести число параметров к одному, а не двум.
Второй метод называется метод вставок, т.к. на j-ом этапе мы «вставляем» j-ый элемент M[j] в нужную позицию среди элементов M[1], M[2],. . ., M[j-1], которые уже упорядочены. После этой вставки первые j элементов массива M станут упорядоченными.
Сказанное можно записать следующим образом:
Если воспользоваться барьером, а именно установить так называемый «фиктивный» элемент M[0], значение которого должно быть заведомо меньше значения любого из «реальных» элементов массива, то такой процесс перемещения элемента M[j] будет самым простым. И обозначим это значение через — оо.
Если барьер не применить, то перед вставкой M[j], в позицию i-1 надо выяснить, не будет ли i=1. В случае если нет, тогда сравнить M[j] (который в данный момент будет находиться в позиции i) с элементом M[i-1].
Описанный алгоритм имеет следующий вид:
Идея сортировки с помощью выбора не считается сложнее двух предыдущих. На j-ом этапе выбирается элемент минимальный среди M[j], M[j+1],. . ., M[N] и меняется местами с элементом M[j]. В результате после j-го этапа все элементы M[j], M[j+1],. . ., M[N]будут упорядочены.
Сказанное можно описать следующим образом:
Более точно:
В программе, применяется процедура , вычисляющая индекс элемента, меньшего среди элементов массива с индексами не меньше, чем :
При демонстрации сортировки выбором нужно учитывать то, что пошаговое выполнение этой процедуры отсутствует, что ухудшает эффективность во время использования. [6]
При разработке моделей следует избегать изначальной привязки функций исследуемой системы к существующей организационной структуре моделированию алгоритма сортировки. Это помогает избежать субъектной точки зрения, навязанной организацией и ее руководством. Организационная структура должна являться результатом использования модели. Сравнение результата с существующей структурой позволяет:
1. Оценить адекватность модели.
2. Предложить решение, направленные на совершенствование этой структуры.
Семантика определяет содержание синтаксических компонентов языка и способствует правильности их интерпретации. Интерпретация устанавливает соответствие между блоками и стрелками с одной стороны и функциями и их интерфейсами с другой.
Чтобы гарантировать точность модели, следует использовать стандартную терминологию. Блоки именуется глаголом или глагольными оборотами, и эти имена сохраняются при декомпозиции. Стрелки и сегменты помечаются существительными или оборотами существительного.
Каждая сторона функционального блока имеет стандартное назначение с точки зрения блок/стрелки. В свою очередь, сторона блока, к которому присоединена стрелка, однозначно определяет ее роль. Стрелка, входящая в левую сторону блока, - вход. Входы преобразуются или расходуются функцией, чтобы создавать то, что появиться на ее выходе. Стрелка, входящая в блок сверху - управление. Управление определяют условия, необходимые функции, чтобы произвести правильный выход. Стрелка, покидающая блок справа - выход, т.е. данные или материальные объекты, производственные функцией.
Стрелки, подключенные к нижней стороне блока, представляют механизмы, т.е. все то, с помощью чего осуществляется преобразование входов в выходы. Стрелки, направленные вверх, идентифицируют средства, поддерживающие выполнение функций. Другие средства могут наследоваться из родительского блока. Стрелки механизма, направленные вниз, являются стрелками вызова. Стрелки вызова обозначают обращение из данной модели к блоку, входящему в состав другой модели, обеспечивая их связь, т.е. разные модели могут совместно использовать один и тот же элемент (блок). Таким образом, можно построить алгоритмы сортировки в массиве с учетом того, что разные клиенты фактически порождают и определяют скорость и сохраность данных в процессе сортировки.
Память — ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. Как правило, эти алгоритмы требуют O(log n) памяти. При оценке не учитывается место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы (так как всё это потребляет O(1)). Алгоритмы сортировки, не потребляющие дополнительной памяти, относят к сортировкам на месте.
Итак, в данном параграфе мы рассмотрели понятие «массив», виды массивов. Изучили какая осуществляется работа над элементами массива. Так же были выявлены простейшие методы сортировки массива, а именно метод «пузырька», сортировка вставками, сортировка посредством выбора.
Глава 2. Особенности сортировки данных с учетом возможностей среды программирования.
2.1. Возможности среды Lazarus для реализации программы сортировки
Lazarus - это среда визуального программирования. В Lazarus есть возможность не только создавать программный код, но и, в особенности, наглядно (визуально) показывать в системе то, что мы хотели бы создать. [3]
Благодаря интерфейсу программы мы можем не только построить визуально программу, через специальные компоненты, но и реализовать все необходимые свойства. Количество данных компонент достаточно велико. Программист имеет готовый программный код и все необходимые для работы данные, что позволяет не создавать того, что уже было создано ранее. Время написания программы, уменьшается много раз, что повышает эффективность работы программиста. Кроме того, хочется заметить, что большая часть текста формируется автоматически, что увеличивает скорость создания программного кода в Lazarus.
Среда визуального программирования Lazarus облегчает и ускоряет создание программы, так как объединяет в себе компилятор, объектно-ориентированные средства визуального программирования и всевозможные технологии.
В среде Lazarus для ввода массивов не предусмотрены практически никакие особые компоненты, поэтому можно использовать компоненты или же любые другие, предназначенные для ввода данных. [9]
Элементы в окне можно вводить по одному. В обработчике событий при однократном нажатии кнопки ввода должны выполниться следующие операторы:
Нажатие кнопки приводит к добавлению одного элемента из окна в массив. Смысл переменной i обусловит количество элементов массива при выполнении последующих действий по обработке массива. В разделе описания типизированных констант, а так же в методе для формы можно задать начальное значение i=0, и каждый раз при вводе нового массива его сбрасывать. В этот массив запишется столько элементов, сколько раз будет нажата кнопка ввода. Ввод элементов в массив можно будет продолжить вносить даже после обработки массива, если значение i не будет сброшено.
На рисунке 1 представлена форма для ввода элементов массива.
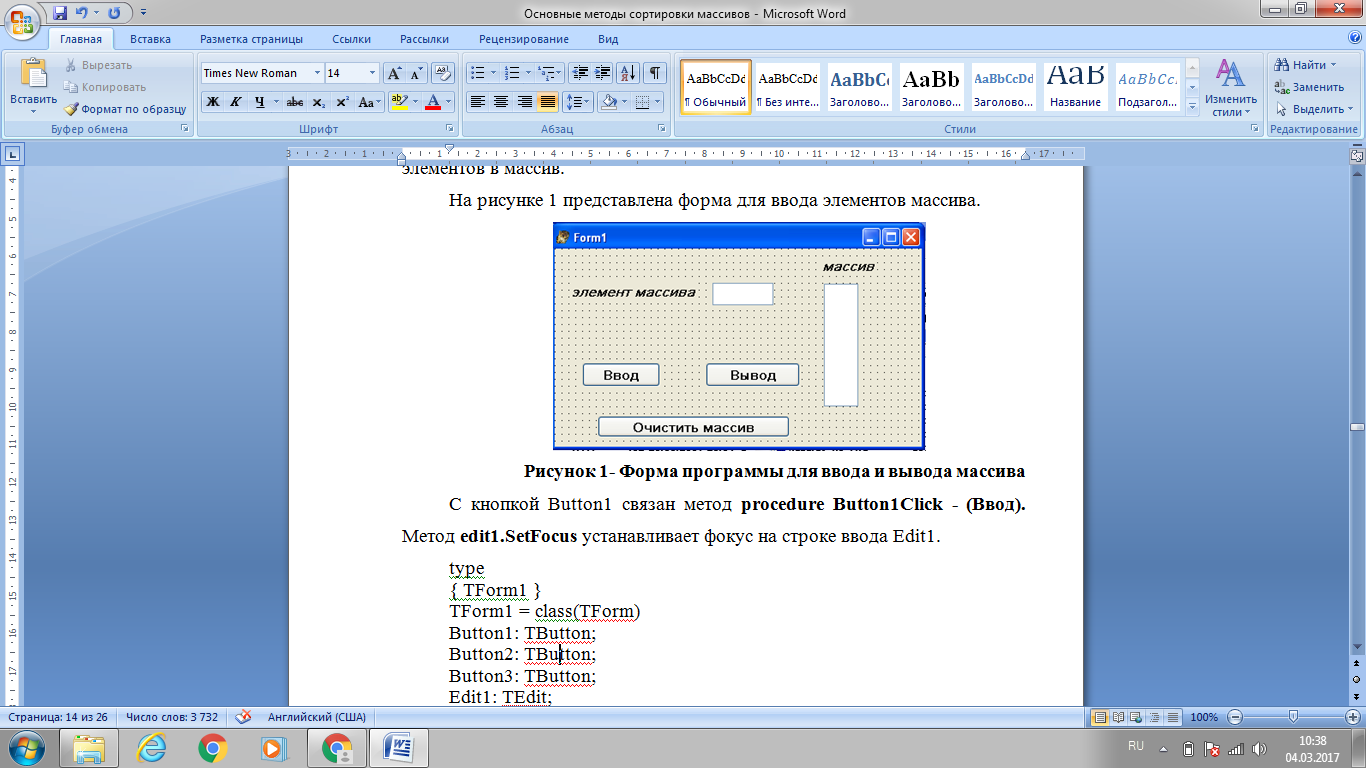
Рисунок 1. Форма программы для ввода и вывода массива
С кнопкой связан метод . Метод устанавливает фокус на строке ввода . [2]
На рисунке 2 представлен результат работы программы.
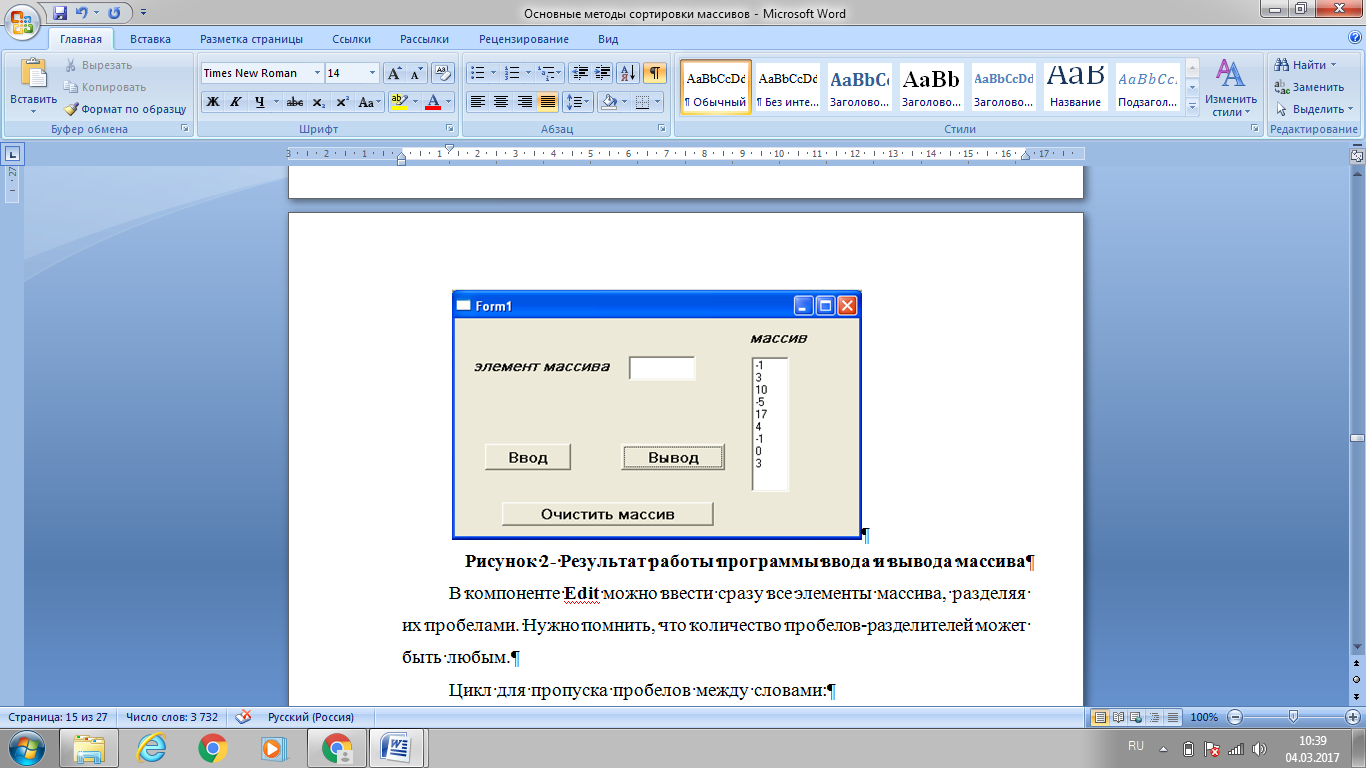
Рисунок 2. Результат работы программы ввода и вывода массива
Если разделить пробелами элементы массива в компоненте , то можно ввести сразу все элементы массива. Число пробелов-разделителей может быть любым.
Цикл для пропуска пробелов между словами:
Слова можно пропустить аналогичным циклом:
Эти два цикла должны быть включены во внешний цикл, который завершится тогда, когда закончится строка.
Текстовый редактор может содержать любое количество строк, это является отличием от строки ввода. Его свойство представляет собой строку, состоящую из находящихся в поле строк, разделенных последовательностью символов с кодами 13 и 10 (конец строки и переход на новую строку). При нажатии клавиши эти символы добавляются в поле . Для выделения подстроки, содержащей элемент массива, нужно отыскать символ с кодом 13 (#13), скопировать в новую подстроку, а затем удалить ее вместе с кодами 13 и 10 и продолжить поиск конца строки.
В приведенном ниже фрагменте программы вначале в строку записывается содержимое всего окна . Затем отыскивается позиция конца первой строки (n) и эта строка копируется в и удаляется из . На рисунке 3 приведен результат работы программы. [5]
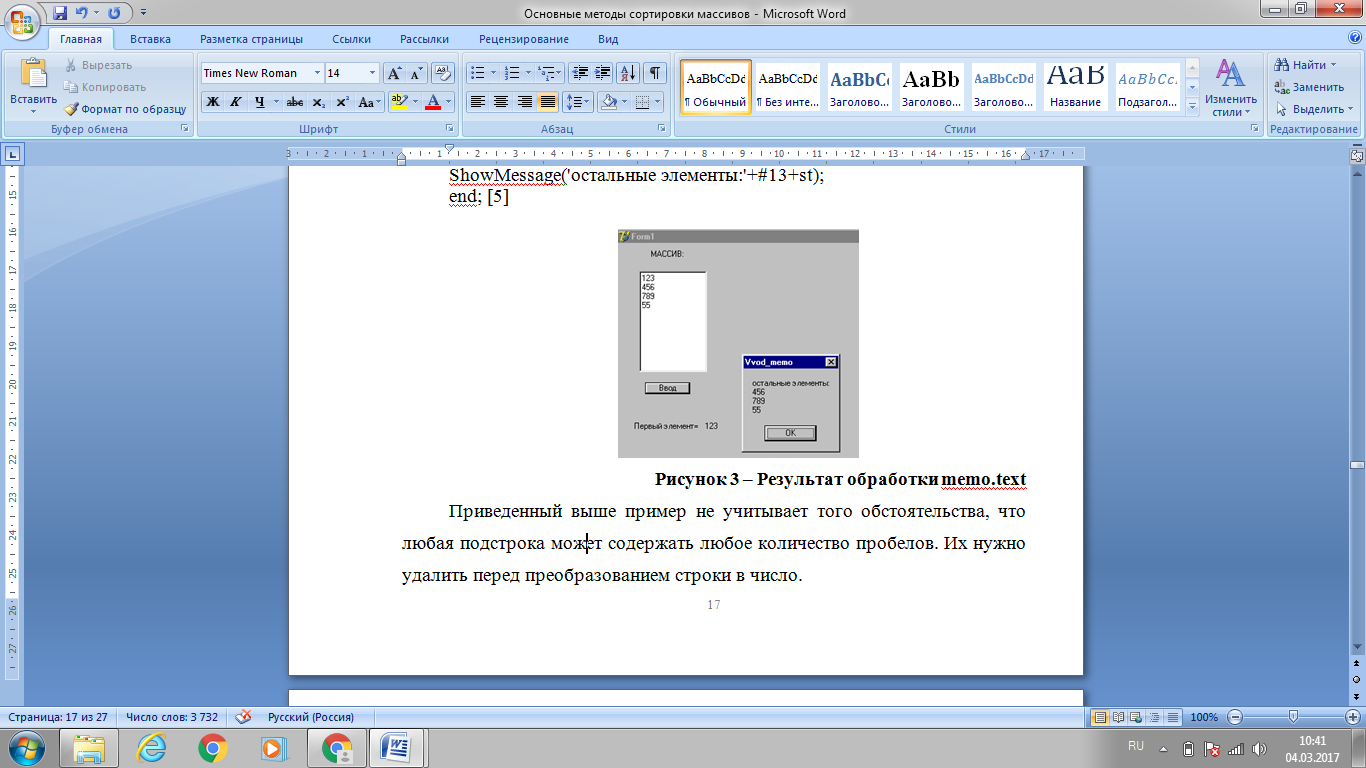
Рисунок 3. Результат обработки
Приведенный выше пример не предусматривает такого условия, что любая подстрока может содержать любое количество пробелов. Строки перед преобразованием в число нужно удалить.
Чтобы вернуть подстроку с номером n из строки мы воспользуемся функцией .
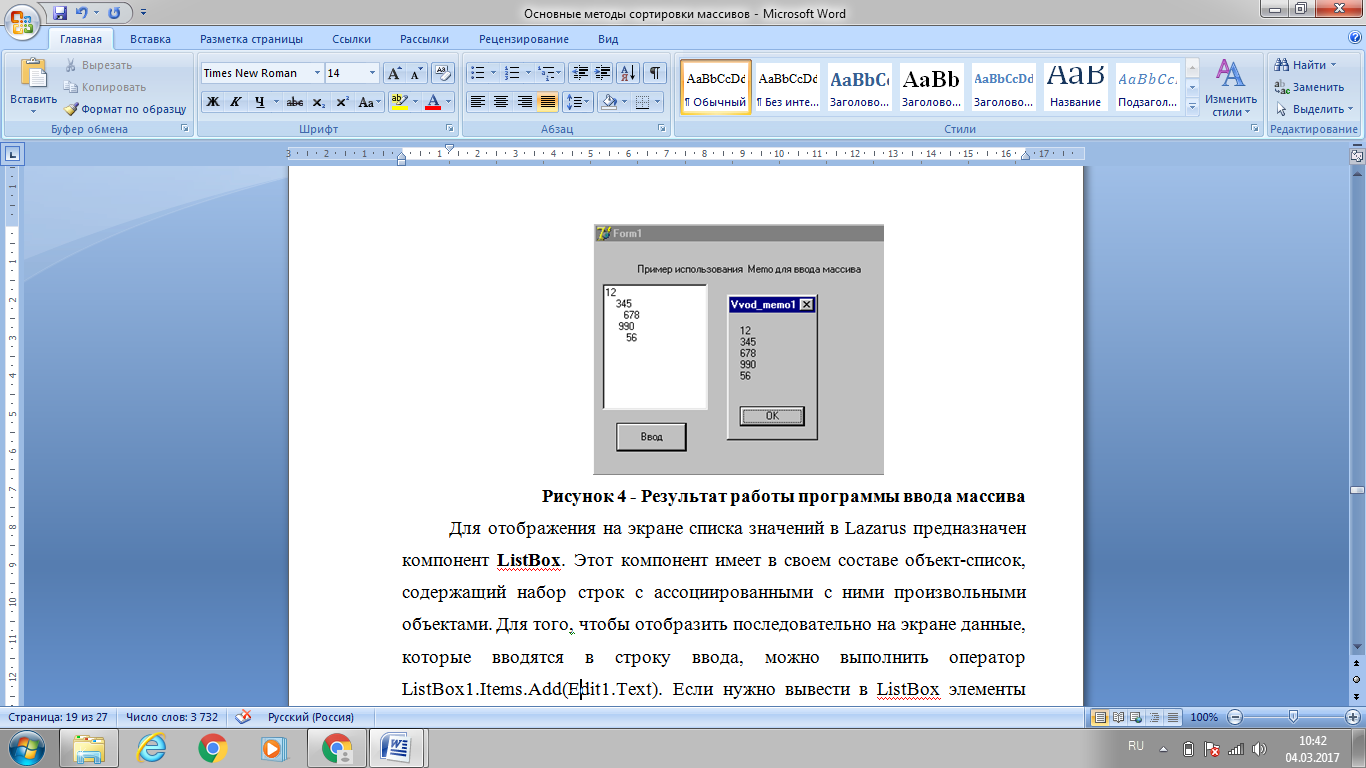
Рисунок 4. Результат работы программы ввода массива
Для отображения списка значений в Lazarus на экране воспользуемся компонентом . Этот компонент содержит в своем составе объект-список, имеющий набор строк с ассоциированными с ними случайными объектами. Для того чтобы отобразить последовательно на экране данные, которые вводятся в строку ввода, может исполнить оператор . Если нужно вывести в элементы массива, то используют оператор .
Возможности строк ввода и списка объединяет комбинированная строка ввода (поле со списком) . Чтобы добавить элемент в список вызовем оператор . Свойство логического типа указывает указывает отображается ли раскрывающийся список в данный момент. Свойство доступно только на этапе выполнения программы. [7]
В обработчике действия для формы можно задать установку исходных значений. Это событие появляется в момент создания формы. Размещение операторов в данном обработчике во множестве случаях эквивалентно размещению операторов в секции инициализации модуля. При выполнении двойного щелчка по форме появится заготовка обработчика этого действия. Методы , , и дают возможность очистить соответствующие компоненты.
Таким образом, в данном параграфе были исследованы наиболее популярные в настоящее время возможности среды Lazarus для реализации программы сортировки, выявлены их главные достоинства и недостатки.
2.2. Использование методов сортировки массивов при решении задач в языке программирования Lazarus
Для решения третьей задачи нам нужно на примере задачи разработать программу реализующую сортировку массива.
Задача. Выполнить сортировку несколькими способами одномерного массива 10 целых чисел, находящихся в диапазоне от 0 до 100.
Для начала, для лучшего понимания задачи, нам необходимо построить блок-схему.
Блок-схема.
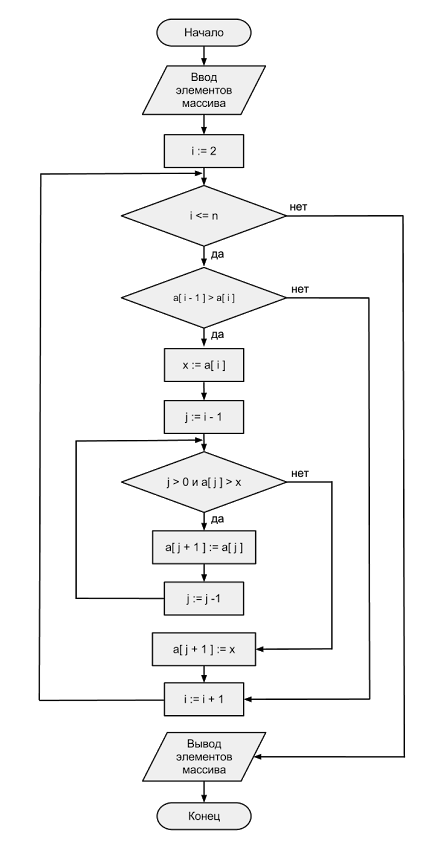
Теперь мы разработаем исходного кода (листинг программы) — для описания нашей программы.
Исходный код нам необходим, так как его можно использовать в качестве повторного кода, для создания другого проекта.
Исходный код — важнейший компонент для процесса портирования программного обеспечения на другие платформы. Без исходного кода какой-либо части ПО, портирование либо слишком сложно, либо вообще невозможно.
Программа
unit Unit1;
{$mode objfpc}{$H+}
interface
uses
Classes, SysUtils, FileUtil, Forms, Controls, Graphics, Dialogs, Grids, StdCtrls;
type
{ TForm1 }
TForm1 = class(TForm)
Button1: TButton;
Button2: TButton;
StringGrid1: TStringGrid;
StringGrid2: TStringGrid;
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
private
{ private declarations }
procedure ArrayCreate;
public
{ public declarations }
end;
var
Form1: TForm1;
i, j: Integer;
a: array [1..10] of Integer;
implementation
{$R *.lfm}
{ TForm1 }
{ Создание исходного массива }
procedure TForm1.ArrayCreate;
begin
Randomize;
for i := 0 to 9 do
begin
a[i + 1] := Random(100);
StringGrid1.Cells[i, 0] := FloatToStrF(i + 1, ffFixed, 2, 0);
StringGrid1.Cells[i, 1] := FloatToStrF(a[i + 1], ffFixed, 2, 0);
StringGrid2.Cells[i, 0] := FloatToStrF(i + 1, ffFixed, 2, 0);
StringGrid2.Cells[i, 1] := FloatToStrF(a[i + 1], ffFixed, 2, 0);
end;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
ArrayCreate;
end;
procedure TForm1.Button1Click(Sender: TObject);
begin
ArrayCreate;
end;
1) Разработаем программу сортировки простыми вставками.
{ Сортировка простыми вставками }
procedure TForm1.Button2Click(Sender: TObject);
var x: Integer;
begin
for i := 2 to 10 do
if a[i - 1] > a[i] then
begin
x := a[i];
j := i - 1;
while (j > 0) and (a[j] > x) do
begin
a[j + 1] := a[j];
j := j - 1;
end;
a[j + 1] := x;
end;
x := 0;
for i := 0 to 9 do
begin
StringGrid2.Cells[i, 1] := FloatToStrF(a[i + 1], ffFixed, 2, 0);
for j := 0 to 9 do
if (StringGrid2.Cells[i, 1] = StringGrid1.Cells[j, 1]) and (j <> x) then
begin
StringGrid2.Cells[i, 0] := FloatToStrF(j + 1, ffFixed, 2, 0);
x := j;
Break;
end;
end;
end;
end.
2) Разработаем программу сортировки простыми вставками с барьером.
{ Сортировка простыми вставками с барьером }
procedure TForm1.Button2Click(Sender: TObject);
begin
for i := 2 to 10 do
if a[i - 1] > a[i] then
begin
a[0] := a[i];
j := i - 1;
while a[j] > a[0] do
begin
a[j + 1] := a[j];
j := j - 1;
end;
a[j + 1] := a[0];
end;
a[0] := 0;
for i := 0 to 9 do
begin
StringGrid2.Cells[i, 1] := FloatToStrF(a[i + 1], ffFixed, 2, 0);
for j := 0 to 9 do
if (StringGrid2.Cells[i, 1] = StringGrid1.Cells[j, 1]) and (j <> a[0]) then
begin
StringGrid2.Cells[i, 0] := FloatToStrF(j + 1, ffFixed, 2, 0);
a[0] := j;
Break;
end;
end;
end;
end.
3)Разработаем программу сортировки простым выбором.
{ Сортировка простым выбором }
procedure TForm1.Button2Click(Sender: TObject);
var x, iMin: Integer;
begin
for i := 1 to 9 do
begin
iMin := i;
for j := i + 1 to 10 do
if a[j] <= a[iMin] then iMin := j;
if iMin <> i then
begin
x := a[i];
a[i] := a[iMin];
a[iMin] := x;
end;
end;
x := 0;
for i := 0 to 9 do
begin
StringGrid2.Cells[i, 1] := FloatToStrF(a[i + 1], ffFixed, 2, 0);
for j := 0 to 9 do
if (StringGrid2.Cells[i, 1] = StringGrid1.Cells[j, 1]) and (j <> x) then
begin
StringGrid2.Cells[i, 0] := FloatToStrF(j + 1, ffFixed, 2, 0);
x := j;
Break;
end;
end;
end;
4) Разработаем программу сортировки методом «пузырька».
{ Сортировка пузырьковым методом }
procedure TForm1.Button2Click(Sender: TObject);
var x: Integer;
begin
for i := 1 to 9 do
for j := 1 to 10 - i do
if a[j] > a[j + 1] then
begin
x := a[j];
a[j] := a[j + 1];
a[j + 1] := x;
end;
x := 0;
for i := 0 to 9 do
begin
StringGrid2.Cells[i, 1] := FloatToStrF(a[i + 1], ffFixed, 2, 0);
for j := 0 to 9 do
if (StringGrid2.Cells[i, 1] = StringGrid1.Cells[j, 1]) and (j <> x) then
begin
StringGrid2.Cells[i, 0] := FloatToStrF(j + 1, ffFixed, 2, 0);
x := j;
Break;
end;
end;
end;
Таким образом, на примере обычной задачи нами была разработана программа, реализующая сортировку массива, работа которой осуществлялась через следующую последовательность: написание блок-схемы → далее мы разработали исходный код (листинг программы) — для описания нашей основной программы → создаем программу исходного массива → разработали программу сортировки простыми вставками → разработали программу сортировки простыми вставками с барьером → разработаем программу сортировки простым выбором → разработали программу сортировки методом «пузырька».
ЗАКЛЮЧЕНИЕ
В ходе написания курсового проекта мы рассмотрели понятие «массив», виды массивов. Изучили какая осуществляется работа над элементами массива. Так же были выявлены простейшие методы сортировки массива, а именно метод «пузырька», сортировка вставками, сортировка посредством выбора.
Для успешной реализации проекта были исследованы наиболее популярные в настоящее время возможности среды Lazarus для реализации программы сортировки, выявлены их главные достоинства и недостатки.
В результате на примере обычной задачи нами была разработана программа, реализующая сортировку массива, работа которой осуществлялась через следующую последовательность: написание блок-схемы → далее мы разработали исходный код (листинг программы) — для описания нашей основной программы → создаем программу исходного массива → разработали программу сортировки простыми вставками → разработали программу сортировки простыми вставками с барьером → разработаем программу сортировки простым выбором → разработали программу сортировки методом «пузырька».
Таким образом, задачи данной работы выполнены, цель достигнута.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Алексеев, Е.Р., Чеснокова, О.В., Кучер, Т.В. Самоучитель по программированию на Free Pascal и Lazarus. [Текст] / Е.Р. Алексеев, О.В. Чеснокова, Т.В. Кучер. – М.: ALT Linux: Издательский дом ДМК-пресс, 2011. – 503 с.
- Алексеев Е.Р., Чеснокова О.В., Кучер Т.В. Free Pascal и Lazarus. Учебник по программированию. [Текст] / Е.Р. Алексеев, О.В. Чеснокова, Т.В. Кучер.– М.: ALT Linux: Издательский дом ДМК-пресс, 2010. – 440 с.
- Диканев, Т. В. Принципы и алгоритмы прикладного программирования [Текст] : учебное пособие для студентов, обучающихся на факультете нано- и биоме- дицинских технологий / Т. В. Диканев, С. Б. Вениг, И. В. Сысоев. – Саратов: Изд-во Сарат. ун-та, 2012. – 140 с. : ил.
- Довек, Ж. Введение в теорию языков программирования [Текст] / Ж. Довек, Ж.-Ж. Леви. - М.: ДМК, 2016. - 134 c.
- Лесневский, А. С. Объектно-ориентированное программирование для начинающих: Бином. Лаб. знаний [Текст] / Лесневский А. С. — М.: Бином. Лаб. знаний, 2010. — 232с.
- Мансуров, К.Т. Основы программирования в среде Lazarus [Текст]. - 2010. – 772 с.: ил.
- Могилёв, А. В., Пак, Н. И., Хеннер, Е. К. Информатика: учеб. пособие для студ. пед. вузов [Текст] / под ред. Е. К. Хеннера. – 5-е изд., стер. – М.: Издательский центр «Академия», 2007. – 848 с.
- Окулов, С.М. Основы программирования. [Текст] Москва, БИНОМ. Лаборатория знаний, 2010.
- Онков, Л.С., Титов, В.М. Компьютерные технологии в науке и образовании: [Текст] Учебное пособие. - М.: ИД. "Форум" : ИНФРА - М. 2012-224с.
- Lazarus [Электронный ресурс] // Официальный сайт. – Режим доступа: http://www.lazarus-ide.org/

- Менеджмент человеческих ресурсов, общее понятие технологии
- Теоретические основы разделения властей
- Теоретический анализ понятия правовой нормы в юридической науке
- ОБЩАЯ ХАРАКТЕРИСТИКА ПЕНСИЙ ПО ИНВАЛИДНОСТИ
- Автоматизация продажи театральных билетов для ООО TICLAND
- Политика мотивации персонала в системе стратегического управления кадровым направлением деятельности организации, Сущность политики мотивации персонала организации
- Коммерческая деятельность розничного торгового предприятия и ее совершенствование» на примере ООО «Вкусняшка
- Моделирование предметной области «Покупка сырья и материалов»
- Разработка конфигурации транспортная доставка заказов в среде предприятие
- Отладка и тестирование программ: основные подходы и ограничения
- Деньги, кредит, банки (Центральный Банк в банковской системе Российской Федерации)
- Разработка конфигурации «Складской учет» в среде 1С:Предприятие 8.3 (Организационная структура предприятия)