
Модель клиент-сервер (Основные требования модели «клиент-сервер»)
Содержание:

ВВЕДЕНИЕ
Создание современных электронно-вычислительных машин позволило автоматизировать обработку данных во многих сферах человеческой деятельности. Без современных систем обработки данных трудно представить сегодня передовые производственные технологии, управление экономикой на всех ее уровнях, научные исследования, образование, издательское дело, функционирование средств массовой информации и многое другое.
Одним из наиболее распространенных классов систем обработки данных являются информационные системы.
Информационные системы используют ресурсы нескольких категорий — средства вычислительной техники, системное и прикладное программное обеспечение, информационные, лингвистические и человеческие ресурсы.
К категории информационных систем часто относят многие системы обработки данных, которые не только поддерживают информационную модель предметной области, но и позволяют решать на ее основе некоторые классы задач управленческого, исследовательского, конструкторского или иного характера. На сегодняшний день, постоянно находясь в развитии, тенденции современных информационных технологий приводят к постоянному возрастанию сложности информационных систем (ИС), создаваемых в различных областях экономики [4].
Современные крупные проекты ИС характеризуются следующими особенностями:
• сложность описания (достаточно большое количество функций, процессов, элементов данных и сложные взаимосвязи между ними);
• наличие совокупности тесно взаимодействующих компонентов (подсистем), имеющих свои локальные задачи и цели функционирования; отсутствие прямых аналогов, ограничивающее возможность использования каких-либо типовых проектных решений и прикладных систем;
• необходимость интеграции существующих и вновь разрабатываемых приложений;
• функционирование в неоднородной среде на нескольких аппаратных платформах.
Целью работы является рассмотрение технологии проектирования «клиент-сервер».
Для достижения поставленной цели необходимо решить следующие задачи:
- Раскрыть теоретические основы архитектуры «клиент-сервер»;
- Провести оценку архитектуры распределения данных;
- Представить практический пример разработки базы данных по модели «клиент-сервер».
Объектом исследования в данной работе является модель «клиент-сервер».
Предметом исследования являются методы описания модели «клиент-сервер».
1. Теоретические основы модели «клиент-сервер»
1.1. Основные требования модели «клиент-сервер»
Цель любой информационной системы — обработка данных об объектах реального мира. В широком смысле слова база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области.
Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например предприятие, организация, фирма, вуз и т. д. Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать выборку с произвольным сочетанием признаков [6].
Сделать это возможно, только если данные структурированы. Структурирование — это введение соглашений о способах представления данных. Неструктурированными называют данные, записанные, например, в текстовом файле. Чтобы автоматизировать поиск и систематизировать эти данные, необходимо выработать определенные соглашения о способах представления данных, например, дату рождения нужно записывать одинаково для каждого студента, она должна иметь одинаковую длину и определенное место среди остальной информации. Эти же замечания справедливы и для остальных данных (номер личного дела, фамилия, имя, отчество).
Пользователями базы данных могут быть различные прикладные программы, программные комплексы, а также специалисты предметной области, выступающие в роли потребителей или источников данных, называемые конечными пользователями. В современной технологии баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария — системы управления базами данных.
База данных (БД) — это поименованная совокупность структурированные данных, относящихся к определенной предметной области.
Система управления базами данных (СУБД) — это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации. Централизованный характер управления данными в базе данных предполагает необходимость существования некоторого лица (группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе [10].
Классификация баз данных. По технологии обработки данных базы данных подразделяются на централизованные и распределенные.
Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования баз данных часто применяют в локальных сетях ПК. Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети.
Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД). Такая отличительная особенность БД, как многоцелевое параллельное использование данных, предопределяет наличие средств, обеспечивающих практически одновременный и независимый доступ к одним и тем же данным.
Причем сама база может быть размещена на одном или нескольких компьютерах [9].
В этой части приводятся следующие, сформулированные ведущими поставщиками СУБД свойства «идеальной» системы управления распределенными базами данных:
• прозрачность относительно расположения данных — СУБД должна представлять все данные так, как если бы они были локальными;
• гетерогенность системы — СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью (независимость от СУБД);
• прозрачность относительно сети — СУБД должна одинаково работать в условиях разнородных сетей;
• поддержка распределенных запросов — пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах;
• поддержка распределенных изменений — пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в разных системах;
• поддержка распределенных транзакций — СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов как в отдельных системах, так и в сети;
• безопасность — СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа;
• универсальность доступа — СУБД должна обеспечивать единую методику доступа ко всем данным.
Однако ни одна из существующих СУБД не достигает этого идеала вследствие следующих практических проблем [12]:
• низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки;
• обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего» и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных;
• необходимо обеспечить совместимость данных стандартного типа, для хранения которых в разных системах используются разные физические форматы и кодировки;
• выбор схемы размещения системных каталогов. Если каталог будет храниться в одной системе, то удаленный доступ будет замедлен. Если будет размножен — изменения придется распространять и синхронизировать;
• необходимо обеспечить совместимость СУБД разных типов и поставщиков;
• увеличение потребностей в ресурсах для координации работы приложений с целью обнаружения и устранения тупиковых ситуаций в распределенных транзакциях.
Следует отметить, что общая тенденция развития технологий обработки данных вполне соответствует этапам развития средств вычислительной техники и информационных технологий, и в первую очередь сетевых. В этом смысле следует выделить два класса: системы распределенной обработки данных и системы распределенных баз данных.
Системы распределенной обработки данных в основном отражают структуру и свойства многопользовательских операционных систем с базой данных, размещенной на большом центральном компьютере (мэйнфрейме). Еще до недавнего времени это был единственно возможный вариант вычислительной среды для реализации больших баз данных. Клиентские места в этом случае реализовались в виде терминалов или мини-ЭВМ, обеспечивающих в основном ввод-вывод данных и не имеющих собственных вычислительных ресурсов для функционально ориентированной обработки получаемых данных [13].
Развитие сетевых технологий в сочетании с широким распространением персональных ЭВМ и внедрением стандартов открытых систем привело к появлению систем баз данных, размещенных в сети разнотипных компьютеров. Такие системы распределенных баз данных обеспечивают обработку распределенных запросов, когда при обработке одного запроса используются ресурсы базы, размещенные на различных ЭВМ сети.
Система распределенных баз данных состоит из узлов, каждый из которых является СУБД, а узлы взаимодействуют между собой так, что база данных любого узла будет доступна пользователю, как если бы она была локальной.
Соответственно, программы, обеспечивающие целевую (функциональную) обработку данных, могут быть организованы таким образом, чтобы обеспечить более эффективное использование совокупных вычислительных ресурсов за счет специализированного разделения функций обработки между центральным процессом СУБД и клиентскими функционально ориентированными процедурами.
Для «типового» приложения обработки данных можно выделить следующие группы (уровни) функций [6]:
• ввод и отображение данных: внешний (пользовательский) уровень реализации целевой функциональной обработки и представления (Presentation logic);
• функциональная обработка, реализующая алгоритм решения задач пользователя. Соответствующие «бизнес-правила» реализуются обычно средствами высокоуровневого языка программирования или расширенного языка манипулирования данными типа ADABAS Natural или 4-GL (Business logic);
• манипулирование данными БД в рамках приложения, которое обычно реализуется средствами SQL (Database logic);
• управление данными и другими ресурсами БД, реализуемое специализированными (внутренними) средствами конкретной СУБД обычно в рамках файловой системы ОС.
1.2. Архитектура распределенной обработки данных
Почти все модели организации взаимодействия пользователя с базой данных построены на основе модели «клиент — сервер».
Т.е. предполагается, что каждое такое приложение отличается способом распределения функций ранее приведенных групп обработки данных между как минимум двумя частями [3]:
• клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
• серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты).
Сервер — это программа, реализующая функции собственно СУБД: определение данных, запись — чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных.
Клиент — это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня.
Разделение процесса выполнения запроса на «клиентскую» и «серверную» компоненту позволяет:
• различным прикладным (клиентским) программам одновременно использовать общую базу данных;
• централизовать функции управления, такие как защита информации, обеспечение целостности данных, управление совместным использованием ресурсов;
• обеспечивать параллельную обработку запроса в случае распределенных БД;
• высвобождать ресурсы рабочих станций и сети;
• повышать эффективность управления данными за счет использования ЭВМ, специально разработанных для работы СУБД (серверы баз данных и машины баз данных).
Проблема выбора между централизованной и распределенной моделями предоставления вычислительных ресурсов является одной из центральных проблем организации вычислительных систем. Примером данной борьбы может являться статья Джона Лесли Кинга «Централизованные и децентрализованные вычислительные системы: организационные соображения и варианты управления» 1983 г. До середины 70-х годов прошлого века по причине высокой стоимости телекоммуникационного оборудования и относительно слабой мощности вычислительных систем доминировала централизованная модель. В конце 70-х годов появление систем разделения времени и удаленных терминалов, явилось предпосылкой возникновения клиент-серверной архитектуры, обеспечивающей предоставление ресурсов мейнфреймов конечным пользователям посредством удаленного соединения. Дальнейшее развитие телекоммуникационных систем и появление персональных компьютеров дало толчок развитию клиент-серверной парадигме обработки данных [11].
Согласно парадигме клиент-серверной архитектуры один или несколько клиентов и один или несколько серверов совместно с базовой операционной системой и средой взаимодействия образуют единую систему, обеспечивающую распределенные вычисления, анализ и представление данных. Использование клиент-серверного подхода позволило пользователю персонального компьютера получить доступ к различным ресурсам удаленных серверов, таких как базы данных, файлы, принтеры, процессорное время и др.
В базовой модели клиент-сервер все процессы в распределенных системах делятся на две возможно перекрывающиеся группы. Процессы, реализующие некоторую службу, например службу файловой системы или базы данных, называются серверами. Процессы, запрашивающие службы у серверов путем посылки запроса и последующего ожидания ответа от сервера, называются клиентами.
Если базовая сеть так же надежна, как локальные сети, взаимодействие между клиентом и сервером может быть реализовано посредством простого протокола, не требующего установления соединения. В этом случае клиент, запрашивая службу, облекает свой запрос в форму сообщения с указанием в нем службы, которой он желает воспользоваться, и необходимых для этого исходных данных. Затем сообщение посылается серверу. Последний, в свою очередь, постоянно ожидает входящего сообщения, получив его, обрабатывает, упаковывает результат обработки в ответное сообщение и отправляет его клиенту.
Использование не требующего соединения протокола дает существенный выигрыш в эффективности. До тех пор пока сообщения не начнут пропадать или повреждаться, можно вполне успешно применять протокол типа запрос-ответ. К сожалению, создать протокол, устойчивый к случайным сбоям связи, – нетривиальная задача. Все, что мы можем сделать, – это дать клиенту возможность повторно послать запрос, на который не был получен ответ. Проблема, однако, состоит в том, что клиент не может определить, действительно ли первоначальное сообщение с запросом было потеряно или ошибка произошла при передаче ответа. Если потерялся ответ, повторная посылка запроса может привести к повторному выполнению операции. Если операция представляла собой что-то вроде «снять 10 000 долларов с моего банковского счета», понятно, что было бы гораздо лучше, если бы вместо повторного выполнения операции вас просто уведомили о произошедшей ошибке. С другой стороны, если операция была «сообщите мне, сколько денег у меня осталось», запрос прекрасно можно было бы послать повторно. Нетрудно заметить, что у этой проблемы нет единого решения. В качестве альтернативы во многих системах клиент-сервер используется надежный протокол с установкой соединения [4].
Хотя это решение в связи с его относительно низкой производительностью не слишком хорошо подходит для локальных сетей, оно великолепно работает в глобальных системах, для которых ненадежность является «врожденным» свойством соединений. Так, практически все прикладные протоколы Интернета основаны на надежных соединениях по протоколу TCP/IP. В этих случаях всякий раз, когда клиент запрашивает службу, до посылки запроса серверу он должен установить с ним соединение. Сервер обычно использует для посылки ответного сообщения то же самое соединение, после чего оно разрывается. Проблема состоит в том, что установка и разрыв соединения в смысле затрачиваемого времени и ресурсов относительно дороги, особенно если сообщения с запросом и ответом невелики.
1.3. Базовая архитектура модели «клиент-сервер»
Учитывая, что одним из основных показателей эффективности сетевой обработки данных является время обслуживания запроса, рассмотрим различные модели архитектуры распределенной обработки на примере, когда прикладная программа работы с базой данных, расположенной на сервере, загружена на рабочую станцию, и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям [3].
Архитектура «файл-сервер». В архитектуре «файл — сервер», схема которой представлена на рис. 1, средства организации и управления базой данных (в том числе и СУБД) целиком располагаются на машине клиента, а база данных, представляющая собой обычно набор специализированных структурированных файлов, — на машине-сервере.
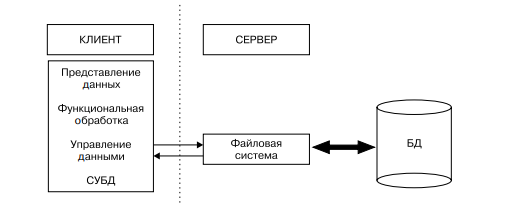
Рис. 1 – Строение модели
В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удаленный разделяемый доступ к файлам. Таким образом, «файл-сервер» представляет собой вырожденный случай клиент-серверной архитектуры.
Взаимодействие между клиентом и сервером происходит на уровне команд ввода-вывода файловой системы, которая возвращает запись или блок данных.
Запрос к базе, сформулированный на языке манипулирования данными, преобразуется самой СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
Достоинство — возможность обслуживания запросов нескольких клиентов.
Недостатки:
• высокая загрузка сети и машин-клиентов, так как обмен идет на уровне единиц информации файловой системы — физических записей, блоков или даже файлов, из которых на машине клиента будут выбраны и представлены необходимые для приложения элементы данных;
• низкий уровень защиты данных, так как доступ к файлам БД управляется общими средствами ОС-сервера;
• низкий уровень управления целостностью и непротиворечивостью информации, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми и несинхронизированными.
В среде файлового сервера программа управления данными, которая выполняется на машине-клиенте, должна осуществить запрос каждой записи базы, после чего она может определить, удовлетворяет ли запись поисковым условиям, лишь после этого передать запись для функциональной обработки. Архитектура «выделенный сервер базы данных».
В архитектуре сервера базы данных, схема которой представлена на рис. 2, средства управления базой данных и база данных размещены на машине-сервере.
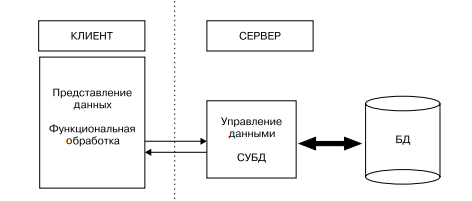
Рис. 2 - Архитектура с выделенным сервером БД
Взаимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере, и после того как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи, удовлетворяющие условиям.
Достоинства:
• возможность обслуживания запросов нескольких клиентов;
• снижение нагрузки на сеть и машины сервера и клиентов;
• защита данных осуществляется средствами СУБД, что позволяет блокировать не разрешенные пользователю действия;
• сервер реализует управление транзакциями и может блокировать попытки одновременного изменения одних и тех же записей.
Недостатки:
• бизнес-логика функциональной обработки и представление данных могут быть одинаковыми для нескольких клиентских приложений, и это увеличит совокупные потребности в ресурсах при исполнении вследствие повторения части кода программ и запросов;
• низкий уровень управления непротиворечивостью информации, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми.
Данная технология позволяет снизить сетевой трафик и повысить общую эффективность обработки за счет оптимизации и буферизации ввода-вывода. Таким образом, сервер может осуществлять поиск и обрабатывать запросы даже быстрее, чем если бы они обрабатывались на рабочей станции.
Архитектура «активный сервер баз данных». Для того чтобы устранить недостатки, свойственные архитектуре сервера базы данных, необходимо, чтобы непротиворечивость бизнес-логики и изменения базы данных контролировались на стороне сервера, причем некоторые заранее специфицированные состояния могли бы изменять последовательность взаимодействия приложения с базой данных [7].
Для этого функции бизнес-логики разделяются между клиентской и серверной частями. Общие или критически значимые функции оформляются в виде хранимых процедур, включаемых в состав базы данных. Кроме этого вводится механизм отслеживания событий БД — триггеров, также включаемых в состав базы. При возникновении соответствующего события (обычно изменения данных), СУБД вызывает для выполнения хранимую процедуру, связанную с триггером, что позволяет эффективно контролировать изменение базы данных.
Хранимые процедуры и триггеры могут быть использованы любыми клиентскими приложениями, работающими с базой данных. Это снижает дублирование программных кодов и исключает необходимость компиляции каждого запроса (рис. 3).
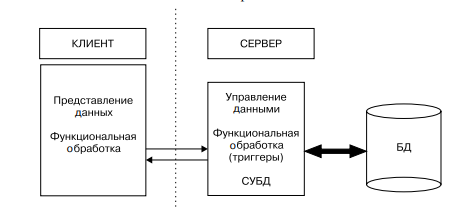
Рис. 3 - Архитектура «активный сервер БД»
Недостатком такой архитектуры становится существенно возрастающая загрузка сервера за счет необходимости отслеживания событий и выполнения части бизнес-правил.
Такую архитектуру организации взаимодействия (а также рассматриваемый далее сервер приложений) иногда называют моделью с «тонким клиентом», в отличие от предыдущих архитектур, называемых моделью с «толстым клиентом», где на стороне клиента выполняется большинство функций.
Архитектура «сервер приложений». Рассмотренные выше архитектуры являются двухзвенными: здесь все функции доступа и обработки распределены между программой клиента и сервером БД. Дальнейшее снижение уровня требований к ресурсам клиента достигается за счет введения промежуточного звена — сервера приложений, на который переносится значительная часть программных компонентов управления данными и большая часть бизнес-логики.
При этом серверы баз данных обеспечивают исключительно функции СУБД по ведению и обслуживанию базы данных. Схема трехзвенной архитектуры сервера приложений приведена на рис. 4.
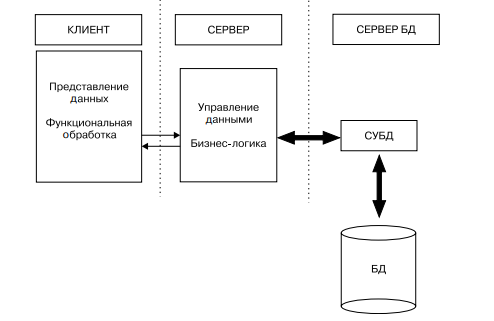
Рис. 4 - Архитектура сервера приложений
К другим (организационно-технологическим) достоинствам трехзвенной архитектуры можно отнести:
• централизованное ведение бизнес-логики и в случае внесения изменения отсутствие необходимости их тиражирования в клиентских приложениях;
• отсутствие необходимости устанавливать на клиентских машинах компоненту программного обеспечения управления доступом к данным;
• возможность отложенного обновления БД в случае изменения данных, запрошенных с сервера, в автономном режиме. Данные будут обновлены в базе после следующего соединения клиентской программы с сервером приложений.
Архитектура «один к одному». В этом случае (рис. 15) для обслуживания каждого запроса запускается отдельный серверный процесс.
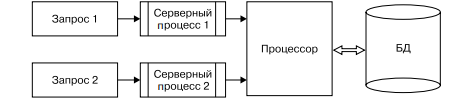
Рис. 5 - Архитектура сервера «один к одному»
Таким образом, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будут запущены отдельные процессы, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы.
Многопотоковая односерверная архитектура. Обработку всех клиентских запросов выполняет один серверный процесс (использующий один процессор), взаимодействующий со всеми клиентами.
Такой тип распараллеливания называют моделью вертикального параллелизма. Использование моделей параллельной обработки позволяет существенно сократить общее время обслуживания запроса, что особенно важно в случае работы с большими базами данных и аналитической обработки (OLAP-приложений).
2. Анализ современных тенденция развития модели «клиент-сервер»
2.1. Анализ современных моделей и направлений
Экономическая информационная система (ЭИС) представляет собой совокупность внутренних и внешних потоков информации экономического объекта, методов, средств, специалистов, участвующих в процессах сбора, хранения, обработки, поиска и выдачи необходимой информации, предназначенной для выполнения функций управления.
Информационные системы в свою очередь делят на информационно-справочные, которые выполняют задачу обеспечения руководства необходимыми справочными данными по запросам, и информационно-советующие, в которых кроме сбора, передачи и обработки информации подготавливаются рекомендации, используемые при принятии решений.
Управляющие системы делят на информационно-управляющие (например, система управления проектами), управляющие системы с запрограммированными командами, в которых решаются задачи регулирования (например, АСУТП), самонастраивающиеся и самообучающиеся системы, функционирование которых меняется в зависимости от воздействия внешней среды.
По степени централизации обработки информации выделяют системы, имеющие несколько уровней обработки информации (характерны для крупных объектов), системы с централизованной обработкой информации (характерны для средних объектов), системы коллективного пользования (характерны для малых объектов).
По уровню управления различают системы, относящиеся к низшему уровню управления (АСУП - для уровня предприятий и организаций, АСОУ, АСУТП и т.д.), среднему уровню управления (ОАСУ - отраслевые АСУ, РАСУ - республиканские и региональные АСУ территориальных органов и др.) и высшему уровню управления (ОГАС - общегосударственная автоматизированная система).
Системы нормативно-методического обеспечения управления предприятием (организацией) как документально-фактографические ИПС. При переходе к правовому государству, а также в процессе развития рыночной экономики возрастает роль еще одного важного вида информации - нормативно-правовой и нормативно-методической, регламентирующей деятельность предприятий при предоставлении им самостоятельности и сокращении организационно-распорядительной документации (стандартов, приказов и распоряжений).
Системы нормативно-методического обеспечения управления (СНМОУ) предприятием регламентируют деятельность подразделений и всех исполнителей управленческих функций. В числе нормативной документации предприятий нормативно-правовые, нормативно-методические, нормативно-технические и организационно-распорядительные документы (НПД, НМД, НТД и ОРД), которые обеспечивают реализацию принятых проектных и управленческих решений при создании и в процессе функционирования предприятия (организации).
На сегодняшний день «уровень информатизации государственных структур традиционно ниже, чем в бизнесе - как с точки зрения используемых средств компьютерной техники, программного обеспечения, так и доступа сотрудников к интернету». Кроме того, уровень развития информационно-коммуникационных технологий в деятельность органов власти в РФ значительно отстает от ведущих западных государств. Чтобы проанализировать уровен развития информационно-коммуникационных технологий и «электронного правительства» в РФ и сопоставить его с ведущими Западными государствами обратимся к методологии ООН. В соответствии с ней выделяется четыре ступени развития предоставления электронных услуг:
1) Развивающееся электронное правительство, в котором государственные сайты представлены в виде простых визиток и официальных веб-страниц. На данном этапе возможно электронное взаимодействие министерств и ведомств центрального правительства, а также между центральными и местными органами власти. Некоторая официальная информация может быть представлена в онлайновом режиме.
2) Расширенное присутствие электронного правительства, в котором государство предоставляет больший объем информации через Интернет - законы и нормативные документы, отчеты, новости, скачиваемые базы данных. Пользователь может использовать поисковую систему для ознакомления с имеющимися на сайте документами.
3) Транзакционное присутствие, предполагающее интерактивное взаимодействие между гражданином и правительством.
4) Сетевое электронное правительство, являющееся наиболее развитым уровнем работы государства в Интернете. Сервисы G2G (государство-государство), G2C (государство-гражданин) и C2G (гражданин-государство) интегрированы между собой. Правительство вовлекает граждан в процессы подготовки и принятия решений и общественные дискуссии».
Россия еще не прошла весь путь развития электронных услуг. Однако, большое количество нормативно-правовых актов по данному вопросу, заинтересованность ведущих политиков, наличие постоянного прогресса как в организации и предоставлении самих электронных государственных услуг, так и в совершенствовании информационных ресурсов (сайтов) органов государственной власти, а также рост числа граждан, зарегистрированных на едином портале предоставления государственных услуг - все это говорит о том, что процесс организации и предоставления электронных услуг развивается и совершенствуется.
В чем же заключаются причины замедления такого глобального и важного в современных условиях для Российской Федерации процесса внедрения информационно-коммуникационных технологий? Частично на данный вопрос отвечает Концепция развития механизмов предоставления государственных и муниципальных услуг в электронном виде от 25 декабря 2013, подводя итоги реализации прошлых нормативно-правовых актов, в Концепции выделяется ряд проблем, которые снижают эффективность деятельности по переходу на предоставление услуг в электронном виде:
Медленный процесс внедрения электронных государственных услуг. По состоянию на ноябрь 2013 г. более 4,5 % граждан страны зарегистрированы на Едином портале, в 2010 году - 0,15 %, в 2012 году - 1,8 %. Установленные показатели, в частности повышение к 2018 году до 70 процентов доли граждан, использующих механизм получения услуг в электронном виде, недостижимы при сохранении текущей динамики.
Низкая доля опубликованной корректной информации. Доля корректной и актуальной информации о предоставлении услуг на федеральном уровне и формах заявлений, опубликованной на Едином портале составляет 53 % (в 2010 году - 66 %, в 2012 году - 43,5 %).
Отсутствие проработанных механизмов перевода документов из бумажного в электронный вид. Не созданы удобные и доступные механизмы перевода документов из бумажной формы в электронную, а правовая база предоставления услуг часто не предусматривает электронной формы взаимодействия. Использование электронной формы получения услуг в редких случаях уменьшает для заявителя число посещений органа, предоставляющего услуги, или устраняет необходимость подачи бумажных документов.
Разница поколений и социального статуса. Не все граждане могут в равной степени воспользоваться электронными государственными услугами. Некоторые просто из-за отсутствия доступа к Интернету, некоторые из-за неумения работать в сети (пожилые люди). Конечно, распространение Интернета и обучение людей это вопрос времени. Однако в предоставлении государственных электронных услуг необходимо учитывать данный фактор и искать альтернативы для таких групп населения. Так, например, во Франции для поддержания бедных слоев населения созданы специальные центры юридической помощи. Этот положительный опыт можно применить и в процессе оказания государственных услуг.
Недостаточное информирование граждан о возможности получения электронных государственных услуг. Многие люди просто не знают о такой возможности. Рекламу целесообразно было бы размещать в многофункциональных центрах.
Консервативность государственных служащих. Во многом процессы развития электронных государственных услуг тормозят сами государственные служащие, привыкшие работать определенным образом: с бумагами и с оригиналами.
Для освоения новых информационных технологий необходимы учебные пособия, в которых была бы отражена методика изучения этих изменений.
Слияние применяется в тех случаях, когда необходимо создать набор однотипных документов, каждый из которых содержит уникальные элементы.
Слияние используется при массовой рассылке документов и сообщений по факсу или электронной почте, а также для создания почтовых наклеек, конвертов, каталогов.
Анализируя реформы, которые связаны с трансформацией механизма применения информационных услуг в современной России представляет собой три взаимодополняемых теоретических подходов:
- правительство в поисках пути освобождения от своих обязательств по услугам населению, переводя их в третичный сектор с ресурсом приватизации;
- правительство в поисках возможностей осуществлять «политику рационализации», которая должна привести к росту эффективности общественной бюрократической администрации (в большей или меньшей степени);
- правительство основывается на инновациях, варианты для исполнения новых методов руководства общественными делами, рост качества и объема общественных услуг.
Трансформация инструментов по общественному управлению связано с созданием, в первую очередь, концепции достижения цели на основе действующих приемов познания. Под концепцией, как правило имеется в виду «основной» замысел, который и определяет стратегию для дальнейших действий субъекта общественного управления при осуществлении трансформации организационно-экономического механизма общественного управления, реформы общественного управления в целом и государственной политики развития страны.
2.2. Современные информационные технологии представленные в данной архитектуре
Функциональные подсистемы обеспечивают обработку, преобразование данных для выработки и принятия управленческих решений по определенному направлению деятельности корпорации (производственной, маркетинговой, сбытовой, финансовой, бухгалтерской, кадровой).
ERP-система представляет собой идеологию планирования и управления крупными корпорациями с помощью автоматизации и оптимизации бизнес-процессов. Посредством применения ERP-систем автоматизируют все основные корпоративные бизнес-процессы в единой информационной среде и на основе единой базы данных.
ERP-системы предоставляют возможность решения задач интеграции при осуществлении практически всех функций управления корпорацией. При этом под понятием “интеграция” подразумевается комплексное использование однократно вводимых в систему данных, обеспечивающее решение многочисленных взаимосвязанных управленческих задач с использованием единого стандарта информационных процессов (формирование единых требований к формам и методам хранения, передачи и представления информации) [2].
Информация в современных условиях стала для компаний одним из самых ценных слагаемых в их рыночном успехе. Информационные потоки, циркулирующие как внутри организаций, так и поступающие извне, являются необходимой составляющей их повседневной деятельности. Для обеспечения управления этими потоками необходима интегрированная корпоративная информационно-аналитическая система, функционирующая на предприятии. От совершенства ее организации напрямую зависит судьба всего бизнеса [4].
С ростом и развитием предприятия система управления становится все более сложной. С одной стороны, существенно возрастает объем информации, которую приходится обрабатывать руководителям компании. С другой стороны, бизнес диверсифицируется — появляются новые направления, зачастую существенно отличающиеся от первоначального. Поэтому на определенном этапе развитие предприятия достигает такого этапа («зрелости»), когда необходимы новые методы управления. С чем это связано? Прежде всего, в системе управления явно выделяются специализированные подсистемы — финансовая, логистическая, производственная, сбытовая. Между ними необходимо обеспечивать эффективную информационную связь, т.е. выстраивать горизонтальные и вертикальные информационные потоки (особенно важно обеспечивать получение достоверной информации о деятельности компании подсистемой финансового управления). Кроме того, существенно усложняются процедуры планирования [1].
Особенно это важно на производственных предприятиях, когда информация по прогнозам продаж, производства и закупок должна быть согласована с финансовой точки зрения на разных временных горизонтах планирования. Финансовый «верхний» слой управления нуждается в подкреплении своевременными достоверными данными «снизу» — от других подразделений компании. Финансовым директором должен быть обеспечен такой график поступления платежей (кредитов, прочих поступлений), который позволит финансировать не только текущую деятельность компании (оперативный уровень планирования), но и инвестиционные проекты (средне- и долгосрочная перспектива).
Именно на данном этапе, когда существенно возрастает сложность системы управления, возникает потребность в сложных интегрированных ERP-системах, которые адекватны потребностям бизнеса и могут обеспечить полноту, достоверность, единый формат необходимой управленческой информации, единство методик и быстроту ее обработки. Тем самым ERP-система может обеспечить предприятию необходимые конкурентные преимущества
ERP-системы (Enterprise Resource Planning — управление ресурса- ми предприятия) — набор интегрированных приложений, которые комплексно, в едином информационном пространстве поддерживают все основные аспекты управленческой деятельности предприятий — планирование ресурсов (финансовых, человеческих, материальных) для производства товаров (услуг), оперативное управление выполнением планов (включая снабжение, сбыт, ведение договоров), все виды учета, анализ результатов хозяйственной деятельности. Среди требований, предъявляемым к ERP-системам: централизация данных в единой базе, близкий к реальному времени режим работы, сохранение общей модели управления для предприятий любых отраслей, поддержка территориально-распределенных структур, работа на широком круге аппаратно-программных платформ и СУБД.
Концепция ERP предложена аналитической фирмой Gartner Group не так давно, в начале 1990-х гг., и уже подтвердила свою жизнеспособность. Системы ERP предназначены для управления финансовой и хозяйственной деятельностью предприятий. Это «верхний уровень» в иерархии систем управления предприятием, затрагивающий ключевые аспекты его производственной и коммерческой деятельности, такие как производство, планирование, финансы и бухгалтерия, материально-техническое снабжение и управление кадрами, сбыт, управление запасами, ведение заказов на изготовление (поставку) продукции и предоставление услуг. Такие системы создаются для предоставления руководству информации для принятия управленческих решений, а также для создания инфраструктуры электронного обмена данными предприятия с поставщиками и потребителями [7].
Основное преимущество ERP-систем состоит в том, что они позволяют осуществлять управление полным операционным циклом компании, охватывающим все фазы бизнес-процессов: планирование, исполнение, контроль и анализ деятельности. Это позволяет получать фактические данные о деятельности компании с высокой степенью достоверности. При этом, однако, нужно иметь в виду, что ERP-система реализует методы управления, заложенные разработчиками, поэтому, используя ее, пользователь вынужден в известной степени менять систему управления компанией.
Призванные оптимизировать все многообразие внутренних и внешних процессов предприятия ERP-системы позволяют снизить операционные, управленческие и коммерческие затраты, сократить цикл реализации, увеличить оборачиваемость материальных запасов, улучшить утилизацию основных фондов и т.д. Глобальная интеграция всех информационных потоков в рамках единой системы обеспечивает оптимальное использование информации, напрямую влияя на оперативность принятия управленческих решений и быстроту реакции на рыночные изменения.
Вопрос интеграции составных частей ERP-системы оказывается во многих случаях отнюдь не простым. Одно дело — частный случай использования общих данных модулями «Учет персонала» и «Расчет заработной платы», что реализовано практически везде. Совсем другое — адекватная взаимосвязь всех модулей с точки зрения бизнес-процедур. Например, если рассмотреть процедуру «Увольнение сотрудника», проводимую в модуле «Учет персонала», то этап «Проверка отсутствия закрепленных за сотрудником материальных ценностей» должен, по идее, проводиться с обращением к подсистеме «Бухгалтерский учет». Однако на практике возможность такой проверки реализована далеко не во всех программах.
3. Разработка модели «клиент-сервер»
3.1. Проектирование модели «клиент-сервер»
После открытия СУБД, создания БД нужно на ленте «Создание» выбрать пункт «Конструктор таблиц» (рисунок 6.)
Рис. 6. Выбор конструктора.
Далее будет открыто окно, где надо указать имя поля, его тип, описание, задать свойства полей, установить ключевое поле.
Интерфейс окна конструктора на примере таблицы Клиенты показан ниже на рисунке 7:
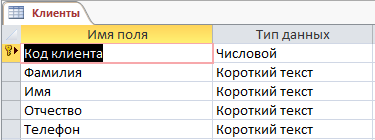
Рис. 7. Структура таблицы Клиенты
Аналогично созданы остальные структуры таблицы.
Рассмотрим процесс создания связей для таблиц. Для этого надо нажать Данные – Схема данных, а потом добавить все таблицы. После этого перетащим надобные поля одно на другое – в результате этого откроется окно, показанное на рисунке 8:
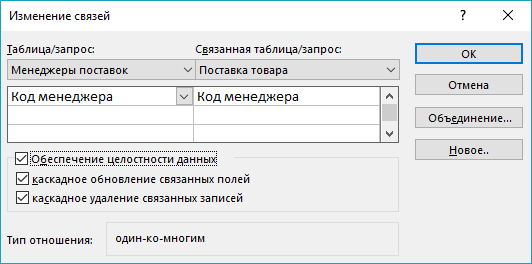
Рис. 8. Изменение связей
Выполнив такую процедуру для всех таблиц, получим такую схему (рисунок 9):
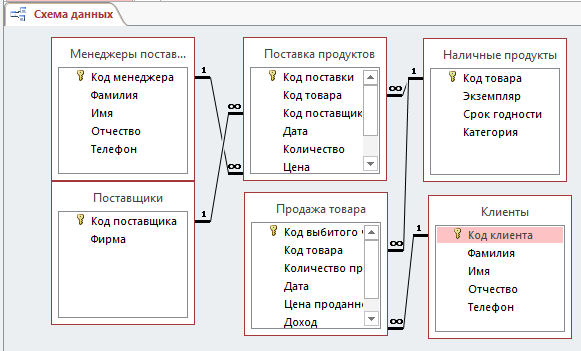
Рис.9. Схема данных
3.2. Представление результатов разработки
Рассмотрим созданные запросы для работы склада:
– Запрос Товары, что показывает данные о проданных товарах (рисунок 10):
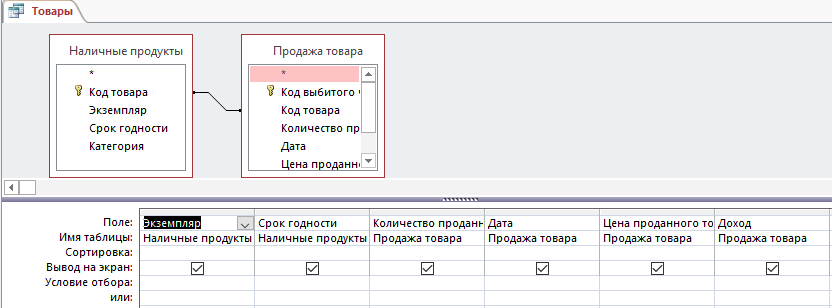
Рис. 11. Конструктор запроса
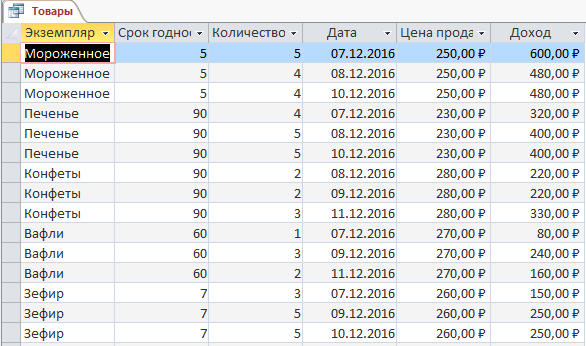
Рис. 12. Выполненный запрос Товары
– Минимальное количество товаров, которые поставляются рассматриваются в запросе на рисунках 13, 14:
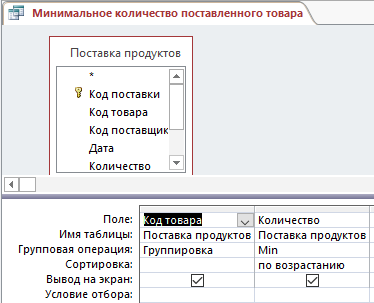
Рис. 13. Конструктор запроса
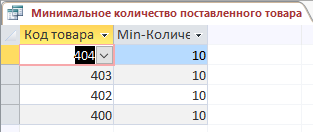
Рис. 14. Выполненный запрос Минимальное количество поставленных товаров
– Запрос, выводящий наименование товара по алфавиту (рисунок 15, 16):
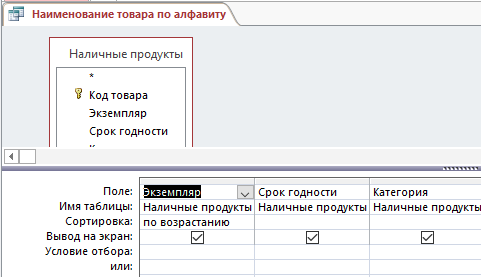
Рис. 15. Конструктор запроса
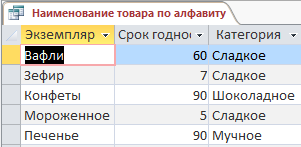
Рис.16. Выполненный запрос Наименование товара
– запрос Менеджеры поставок (рисунок 17, 18):
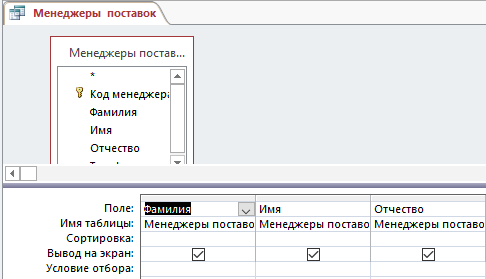
Рис.17. Конструктор запроса
Рис.18. Выполненный запрос Менеджеры поставок
– Запрос Товар с истекшим сроком (рисунок 19):
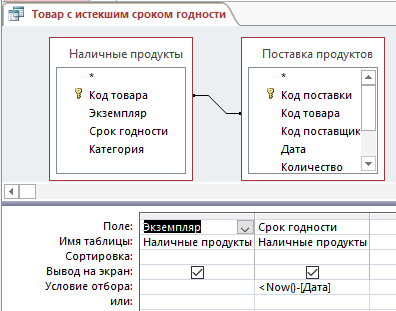
Рис. 19. Конструктор запроса
Рис.20. Запрос Товар с истекшим сроком годности
В базе разработаны составные и простые формы по заполнению таблиц. На рисунках 21, 22 показаны несколько форм для ввода данных:
Рис. 21. Форма Продажа продуктов
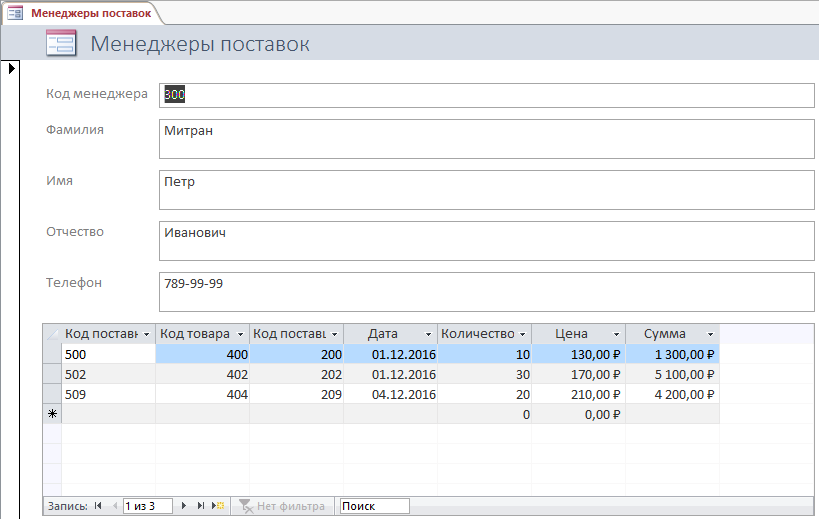
Рис.22. Форма Менеджеры поставок
В БД часто создают отчеты – элементы БД для вывода информации на экран или печать.
Для примера рассмотрим отчет Менеджер поставок (рисунок 23):
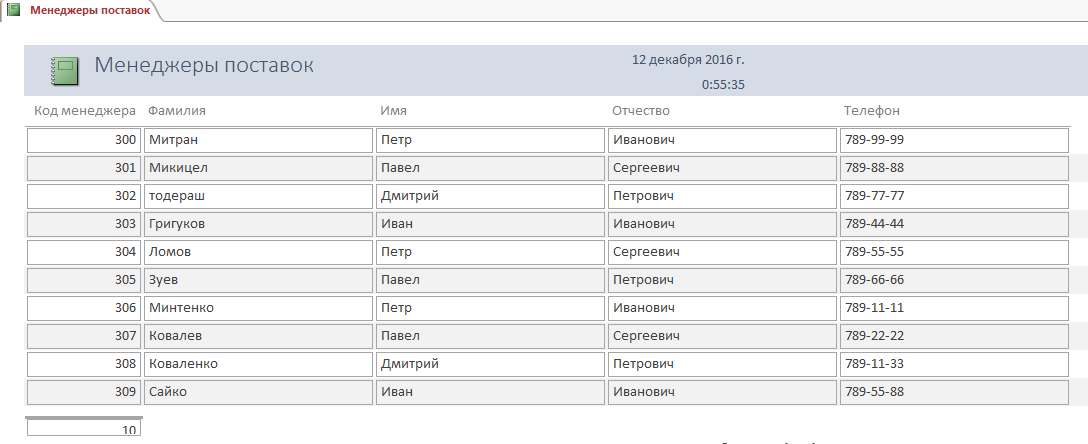
Рис.23. Отчет Менеджер поставок
Одним из самых распространенных элементов по администрированию БД является установка пароля на вход в БД. Для этого нужно выполнить последовательность действий Файл – Зашифровать с использованием пароля (пароль 1111):
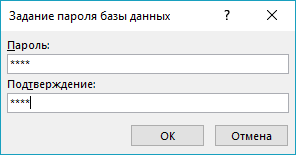
Рис.24. Установка и подтверждение пароля
Далее появится окно вида при открытии БД:
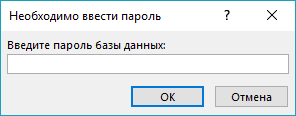
Рис. 24. Ввод пароля
ЗАКЛЮЧЕНИЕ
Нынешние программные системы постоянно усовершенствуются для того чтобы обеспечивать возможности по выполнению глобальных задач, к примеру, создание единой системы функционирования предприятия, обработки многоуровневой базы данных и прочее.
При разработке таких систем важно хорошо представлять современные подходы по хранению данных, что существуют в рассматриваемой области, основные сложности этого процесса.
Основной целью данной работы было изучение задач, целей для создания современной БД, которая может с легкостью использоваться в различных информационных систем (ИС).
Также описывались основные понятия БД, области их применения, главные модели данных, на основании которых и разрабатываются СУБД.
Рассматриваемый материал может быть отправной точкой для изучения основ построения ИС с помощью СУБД MS Access.
При выполнении работы также были рассмотрены все основные механизмы СУБД Access, одним с которых является инструмент создания запросов.
С его применением можно анализировать таблицы, имеющие огромное количество обрабатываемой информации. Освоение запросов упрощается наличием программ-мастеров.
База данных MS Access – это совокупность различных отношений, которые могут содержать всю информацию, которая должна быть сохранена в БД. Все пользователи ее воспринимают базу данных как совокупность таблиц, которые между собой связаны.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Агафонов, В.Н. Логическое программирование / В.Н. Агафонов. - М.: [не указано], 2016. - 471 c.
- Алгоритмизация и программирование (+ CD-ROM) / И.Н. Фалина и др. - М.: КУДИЦ-Пресс, 2012. - 280 c.
- Ашманов, С.А. Линейное программирование / С.А. Ашманов. - М.: [не указано], 2015. - 537 c.
- Бартеньев, О. 1С: Предприятие. Программирование для всех / О. Бартеньев. - М.: Диалог МИФИ, 2012. - 464 c.
- Валеева-Сулейманова, Г.Ф. Декоративно-прикладное искусство казанских татар / Г.Ф. Валеева-Сулейманова, Р.Г. Шагеева. - М.: Советский художник, 2016. - 216 c.
- Голуб, А.И. Веревка достаточной длины, чтобы... выстрелить себе в ногу. Правила программирования на Си и Си++ / А.И. Голуб. - М.: [не указано], 2017. - 309 c.
- Де Моран История декоративно-прикладного искусства / Де Моран, Анри. - М.: Искусство, 2016. - 578 c.
- Долгов, А. И. Алгоритмизация прикладных задач / А.И. Долгов. - М.: Флинта, 2013. - 136 c.
- Заковряшин, А. И. Алгоритмизация и программирование вычислительных задач / А.И. Заковряшин. - М.: Science Press, 2013. - 164 c.
- Кнут, Д.Э. Искусство программирования (Том 1. Основные алгоритмы) / Д.Э. Кнут. - М.: [не указано], 2017. - 855 c.
- Кнут, Д.Э. Искусство программирования (Том 2. Получисленные алгоритмы) / Д.Э. Кнут. - М.: [не указано], 2016. - 147 c.
- Кнут, Д.Э. Искусство программирования (том 3) / Д.Э. Кнут. - М.: [не указано], 2013. - 407 c.
- Кофман, А. Методы и модели исследования операций. (том 3) Целочисленное программирование. / А. Кофман, А. Анри-Лабордер. - М.: [не указано], 2015. - 369 c.
- Левенталь, Л. Введение в микропроцессоры: Программное обеспечение, аппаратные средства, программирование / Л. Левенталь. - М.: Энергоатомиздат, 2012. - 464 c.
- Мартынов, Н. Н. Алгоритмизация и основы объектно-ориентированного программирования на JavaScript. Информатика и ИКТ. Профильный уровень. 10 класс / Н.Н. Мартынов. - Москва: ИЛ, 2013. - 272 c.
- Бриллинджер, Д. Временные ряды. Обработка данных и теория / Д. Бриллинджер. - М.: [не указано], 2012. - 158 c.
- Еремеев, В.В. Современные технологии обработки данных дистанционного зондирования Земли / В.В. Еремеев. - М.: ФИЗМАТЛИТ, 2015. - 194 c.
- Калинин, С.И. Компьютерная обработка данных для психологов / С.И. Калинин. - М.: СПб: Речь, 2012. - 118 c.
- Калинин, С.И. Компьютерная обработка данных для психологов / С.И. Калинин. - М.: СПб: Речь, 2015. - 134 c.
- Мартин, Дж. Вычислительные сети и распределенная обработка данных: программное обеспечение, методы и архитектура / Дж. Мартин. - М.: Финансы и статистика, 2017. - 525 c.
- Плющ, О. Б. Информационные технологии анализа и обработки данных. Практикум / О.Б. Плющ, Г.М. Северин, Т.В. Безъязычная. - М.: Академия управления при Президенте Республики Беларусь, 2014. - 134 c.
- Репин, В.М. Вычислительные методы и системы обработки данных на ЭВМ / ред. В.А. Морозов, В.М. Репин. - М.: МГУ, 2017. - 186 c.
- Хаслак, П. Основные инструменты и технологии обработки дерева / П. Хаслак. - М.: АСТ, 2017. - 758 c.
- Розенталь, Р. История прикладного искусства нового времени / Р. Розенталь, Х. Ратцка. - М.: Искусство, 2017. - 240 c.
- Романенко, А. Музей прикладного искусства и быта XVII века. 22 открытки / А. Романенко. - М.: Изобразительное искусство, 2016. - 668 c.
- Сигал, И. Х. Введение в прикладное дискретное программирование / И.Х. Сигал, А.П. Иванова. - М.: ФИЗМАТЛИТ, 2016. - 304 c.
- Трояновский, В.М. Информационно-управляющие системы и прикладная теория случайных процессов / В.М. Трояновский. - М.: Гелиос АРВ, 2014. - 304 c.

- Характеристики и его особенности в проектировании.
- Менеджмент человеческих ресурсов (Характеристика менеджмента человеческих ресурсов)
- Корпоративная культура в организации (на примере ОАО «Наш Отель)
- Проблема личности в социальной психологии (личность и ее особенности в социальной психологии)
- Комплект мебели для гостиной в стиле конструктивизма
- Колористическая, цветовая и тональная организация живописного произведения Винсента Ван Гога «Звёздная ночь»
- Разработка конфигурации «Планирование закупок и размещение заказов поставщикам» в среде 1С: Предприятие 8.3
- Методы и средства проектирования информационных систем и технологий (разработка мероприятий по повышению качества информационной системы ФССП)
- Функции операционных систем персональных компьютеров (общая характеристика операционных систем)
- Разработка регламента выполнения процесса «Управление персоналом» (информационная система Федеральной Службы судебных приставов)
- Анализ кадрового потенциала ООО «Мечта»
- Методы психофизиологического исследования: возможности и ограничения в практике управления персоналом (на примере ООО «Соланж»)