
Обзор языков программирования высокого уровня (Двусвязный список)
Содержание:

Введение
Прогресс не стоит на месте, появляются новые классы задач, возрастают требования к существующим решениям. В ответ на это совершенствуются имеющиеся языки программирования, появляются новые, нередко предназначенные для наиболее эффективного использования в определенной области. Встает вопрос о правильном выборе языка программирования для решения поставленных задач. И для этого необходимо понимать, чем отличаются языки программирования, каковы их сильные и слабые стороны, в каких областях они показывают себя с лучшей стороны.
Актуальность темы исследования заключается в том, что языки программирования в той или иной мере работают с данными, которые в большинстве случаев организованы в динамические структуры. В различных языках может по-разному решаться вопрос работы с ними. Где-то нужно самостоятельно выделять и освобождать память, оперировать указателями. В других случаях имеется автоматическое управление памятью, и эта обязанность возложена на сборщик мусора. Но даже в сценарных языках программирования нужно правильно выбирать структуры данных для решения тех или иных задач, исходя из их особенностей, используемых алгоритмов. А в высокопроизводительных программах помимо указанного необходимо учитывать и другие параметры, такие как скорость доступа к элементам, время удаления и добавление новых элементов, размер используемой памяти и так далее. Для этого требуются знания о внутреннем представлении динамических структур, достоинствах и недостатках различных подходов.
Также базовые динамические структуры являются основами для организации данных в более сложную иерархию. Как прочный дом не построить на шатком фундаменте, так и более-менее сложные программы не написать без понимания динамических структур.
Объект исследования – языки программирования высокого уровня.
Предмет исследования – динамические структуры данных, организация данных в списковые структуры.
Цель работы – провести анализ современных языков программирования высокого уровня, рассмотреть основные динамические структуры данных, продемонстрировать организацию данных в списковые структуры.
Задачи исследования:
- провести анализ литературы по выбранной теме;
- рассмотреть современные языки программирования высокого уровня;
- классифицировать и сравнить языки программирования по различным критериям;
- определить принципы построения динамических структур данных, выделить их достоинства и недостатки;
- рассмотреть основные динамические структуры данных;
- написать программу, демонстрирующую работу с данными в списковой структуре.
В работе использованы научные произведения таких авторов, как Седжвик Р., Прата С., Вирт Н., Страуструп Б., Поляков К.Ю. и другие.
Языки программирования высокого уровня
Согласно ГОСТ 19781-90, языком высокого уровня называется язык программирования, понятия и структура которого удобны для восприятия человеком. Из этого определения следует, что существуют языки и низкого уровня, которые не так удобны для восприятия. В чем тогда заключается удобство, можно ли его как-то охарактеризовать, какие возможности языка способствуют удобству восприятия?
Для ответа на эти вопросы следует определить критерии классификации и сравнить языки программирования.
Классификация языков программирования
Существуют различные классификации языков программирования, рассмотрим некоторые из них.
Одним из основных критериев является уровень языка программирования, то есть глубина абстракции, на которой позволяет работать язык. По этому критерию выделяют:
1. Языки низкого уровня. При программировании на них приходится непосредственно оперировать памятью и регистрами процессора. Они рассчитаны на определенный тип компьютера, на использование его особенностей. Первыми были машинные языки программирования, в которых регистры, данные, адресация памяти и команды представлены непосредственно в двоичных кодах. Естественно, программирование в таких условиях превращается в довольно сложную и трудоемкую задачу. Для ее упрощения стали разрабатываться языки ассемблера, позволяющие представлять двоичные коды в виде удобных для человека обозначений. Также появилась возможность использовать макросы, что положительно сказалось на переносимости программ и повторном использовании кода. Но по-прежнему сохранилась привязка к особенностям аппаратного обеспечения, поэтому перенос программ на другую архитектуру остался затруднителен.
В настоящее время чаще всего ассемблер используется для написания архитектурно-зависимого слоя, например, в операционных системах, или критичных участков программ, требующих максимального быстродействия, например в кодеке X264. Ассемблер также используется для программирования устройств с сильно ограниченными ресурсами.
2. Языки высокого уровня. Они позволяют абстрагироваться от аппаратного обеспечения, что дает возможность писать переносимый код и использовать более удобные для восприятия и работы понятия. Это способствует быстрой разработке программного обеспечения и уменьшению количества ошибок в нем. Часто ценой этих удобств являются более высокие требования к вычислительным ресурсам.
Подавляющее большинство кода сейчас пишется на языках программирования высокого уровня, их мы и будем рассматривать.
Существует огромное количество языков программирования [23]. Вполне закономерным будет вопрос, чем они отличаются, зачем создавать все новые и новые языки? Для ответа на этот вопрос необходимо рассмотреть другие критерии классификации.
Перед исполнением языки высокого уровня должны быть преобразованы в язык, понятный компьютеру. Для этого существует два основных подхода [17].
Компиляция — процесс преобразования исходного текста программы, написанного на языке высокого уровня в машинный язык, близкий к нему язык или в объектный модуль. Примерами современных компилируемых языков программирования являются C, C++, Objective-C, Go.
Интерпретация — поочередный анализ, обработка и выполнение команд высокоуровневого языка без предварительной компиляции. Часто интерпретируемыми языками программирования называют Python, Ruby, JavaScript, но это не всегда так и зависит от реализации языки программирования.
Таблица 1 – Сравнение компиляции и интерпретации
|
Критерий |
Компиляция |
Интерпретация |
|
Скорость работы |
Высокая |
Довольно низкая, так как происходит пооператорное выполнение |
|
Потребляемые ресурсы |
Минимальны |
Дополнительные расходы, особенно памяти |
|
Переносимость |
Высокая вероятность необходимости переписывания части кода для переноса на другую платформу |
Работает везде, где есть интерпретатор для данного языка |
|
Время компиляции |
Ощутимо для больших проектов |
Не требуется |
|
Наличие интерпретатора |
Не требуется |
Требуется предварительная установка |
|
Вероятность ошибок |
Ниже из-за анализа кода во время компиляции |
Даже самые простые ошибки (опечатки) могут нарушить работу во время выполнения очередной строки |
Как видно из таблицы 1, у каждого метода есть свои достоинства и недостатки. Указанные варианты трансляции являются диаметральными подходами, и в современных реализациях спецификаций языков программирования часто используются комбинированные подходы [17]. Примером промежуточного решения является байт-код, когда исходный код программы компилируется в машинно-независимый псевдокод виртуальной машины, а затем либо интерпретируется в машинный код (Python, Ruby), либо компилируется «на лету» в машинный код (Java). Такой подход позволяет добиться части важнейших преимуществ обоих методов, таких как высокая скорость выполнения и переносимость кода, но сохраняются и недостатки в виде высокого потребления ресурсов (особенно памяти) и необходимости установленной виртуальной машины.
По степени ориентации на решение определенного класса задач языки программирования разделяют на языки общего назначения и предметно-ориентированные (DSL – Domain Specific Language). Первые (C, C++, Java, Python…) являются универсальными и позволяют решать довольно широкий класс задач, вторые специализируются на определенной области применения, благодаря чему есть возможность оперировать терминами, наиболее приближенными к предметной области. В качестве примеров можно привести HTML, SQL, Postscript, PDF, Tex. Использование предметно-ориентированных языков дает ряд преимуществ, таких как высокая доступность для целевой аудитории, быстрота и эффективность разработки, легкость понимания и сопровождения [18]. Недостатком можно считать ограниченные возможности переноса в другие предметные области. Из существующих языков программирования именно предметно-ориентированные занимают значительную долю, и в будущем их количество будет только расти.
Также существует разделение языков на два класса: императивные (процедурные) и декларативные. В первых описывается сам процесс в виде инструкций, которые изменяют состояние программы и данных. Все ниже рассматриваемые языки программирования относятся к этой категории. Во вторых описывается логика вычислений, что должно быть выполнено, а не как. В качестве примера декларативных языков можно привести Ant, Prolog, SQL.
Современные языки программирования
Разобравшись в критериях классификации и причинах многообразия языков программирования, нужно определиться, какие из языков являются актуальными на сегодняшний день и почему. Для этого воспользуемся рейтингом TIOBE [24], в котором оценивается популярность языков программирования на основе подсчетов количества запросов по ним.
1.С (Си) — компилируемый язык программирования общего назначения. Характеризуется близостью к аппаратному обеспечению, высоким быстродействием и эффективным использованием ресурсов [13]. Его компиляторы существуют для самых различных платформ, что говорит о высокой переносимости. Но эта гибкость и мощь не дается даром — программисту приходится работать на довольно низком уровне: выделять и освобождать память, оперировать указателями, воспринимать строки как последовательность байт и так далее. Благодаря этому его в шутку называют универсальным ассемблером. Тем не менее язык Си оказал не только огромное влияние на последующие языки программирования, такие как Java, C++, C#, Objective-C, но и остается одним из самых популярных языков на данный момент, широко используется в разработке системного программного обеспечения, встраиваемых систем.
Стандартная библиотека Си практически не содержит динамических структур, но некоторые реализации (например, glib) предоставляют списки, деревья и другие структуры, также можно реализовать все это самостоятельно или воспользоваться сторонними библиотеками.
2. C++ создавался как Си с классами, в который были добавлены возможности для объектно-ориентированного программирования. Он не только сохраняет практически все преимущества языка Си, но и позволяет использовать более высокоуровневые абстракции, такие как классы и шаблоны, добавлена работа с исключениями, что положительно сказывается на читаемости и дальнейшей поддержке кода. Один из основных принципов – не нужно платить за то, что не используется [21]. К примеру, те же исключения отрицательно сказываются на быстродействии программы, но если они не используются, то никаких расходов на них не будет. Казалось бы, что имея всю эту мощь и гибкость, C++ должен быть идеальным языком программирования. Но есть и обратная сторона медали – для умелого использования языка требуется достаточно высокая квалификация разработчика, так как язык сложен, и имеется множество способов «выстрелить себе в ногу».
C++ пользуется популярностью в научной и финансовой среде, разработке игр и другого программного обеспечения, требующего максимальной производительности. В последнее время широко используется в разработке приложений для мобильных устройств, когда их нужно переносить на другие платформы с минимальными изменениями, например, с IOS на Android.
Стандартная библиотека С++ предоставляет различные динамические структуры, вопрос встает больше в том, как правильно выбрать динамическую структуру для конкретной задачи.
3. Java создавался под влиянием C++ и является полностью объектно-ориентированным языком программирования [1]. Основными целями при ее создании были кроссплатформенность, когда программа не зависит или почти не зависит от типа процессора, и возможность командной работы над большими и сложными проектами, где немаловажными факторами являются скорость разработки и надежность самих программ. Для этого была реализована виртуальная машина (JVM — Java Virtual Machine), которая работает с промежуточным байт-кодом. По сути это была первая реализация двухэтапной модели выполнения программ [9]. Язык не предоставляет низкоуровневые инструменты вроде указателей и адресной арифметики, ручного управления памятью, этим в Java занимается сборщик мусора. Для повышения надежности кода и избавления от потенциальных ошибок также было решено отказаться от множественного наследования и перегрузки операторов.
У Java имеются традиционно сильные позиции в корпоративном секторе. Также она является основным языком программирования в распределенной обработке большого количества данных Hadoop. Стоит упомянуть и мобильный сектор, в котором программы для лидирующей платформы (Android) пишутся на Java.
Библиотеки Java предоставляют различные динамические структуры, но при самостоятельной реализации динамических структур нужно учитывать сборщик мусора, который должен освободить память после удаления элемента, что может приводить к задержкам выполнения в самый неподходящий момент.
4. C# создавался с оглядкой на Java, это очень похожие языки. C# также использует концепцию промежуточного байт-кода, который затем интерпретируется в общеязыковой исполняющей среде (CLR — Common Language Runtime), имеется автоматическое управление памятью. Язык очень тесно связан с платформой .NET, которая предоставляет множество как коммерческих, так и бесплатных библиотек. Также есть возможность работать со старыми интерфейсами Win32 и COM [3]. С одной стороны такая интеграция технологий является весомым преимуществом, если проект рассчитан в основном на Windows, с другой стороны это сильно ограничивает переносимость на другие платформы. Стоит заметить, что существуют открытые реализации платформы .NET, включая компилятор для C# – Mono. Но помимо неполной поддержки возможностей .NET, а следовательно и работы C# программ, существуют юридические риски, связанные с патентами Microsoft. По указанным причинам многие сообщества разработчиков скептически относятся к Mono, что негативно сказывается на распространении этой платформы в отличной от Windows среде.
C# очень популярен в корпоративном секторе и закономерно является лидером в разработке приложений для Windows-платформ.
Ситуация с динамическими структурами для .NET (C#) аналогична таковой в Java, также имеется большой выбор структур.
5.Objective-C является подмножеством языка C, дополняя его объектно-ориентированными возможностями. Особенностью языка можно считать механизм обмена сообщениями, когда выполняемый код выбирается исполнительной средой динамически, а не во время компиляции, тип объекта определяется во время выполнения [4]. Также язык достаточно прост для изучения. Существует мнение, что своей популярности он добился только из-за того, что Apple выбрала его в качестве основного для своей платформы. Впрочем, этот язык действительно не столь популярен вне платформы Apple.
Для Objective-C ситуация с динамическими структурами данных похожа на таковую с языком Си, когда в стандартной библиотеке их нет, но можно воспользоваться сторонними источниками или написать самому.
6. JavaScript (JS) появился как дополнение к Java для программирования интерактивных веб-страниц [15], со временем став доминирующим языком программирования на клиентской части веба (в браузере). Сам язык является объектно-ориентированным (прототипо-ориентированным) с динамической типизацией и сборкой мусора. Первые реализации были основаны на интерпретации исходного кода, что сильно сказывалось на скорости выполнения. В дальнейшем были написаны различные JS движки, которые использовали как промежуточный байт-код, так и компиляцию сразу в машинный код. Отдельно стоит выделить движок от Google — V8. Благодаря его скорости, эффективности и открытой лицензии он получил широкое распространение не только в браузерах, но и на стороне сервера. К примеру, на его основе создана платформа Node.js, предоставляющая возможности асинхронного программирования с неблокирующим вводом/выводом и превращающая JavaScript из узкоспециализированного языка в язык общего назначения. JS часто ругают за непривычную реализацию объектно-ориентированного программирования через прототипы.
В JavaScript благодаря динамической типизации и автоматическому управлению памятью можно создавать динамические структуры, не заботясь о типе элементов и выделении памяти для них. Стоит рассмотреть две основные структуры, которые являются основами для остальных: массивы и ассоциативные массивы (словари). Не смотря на то, что они и называются массивами, их реализация в большинстве JS движках использует списковые структуры. С одной стороны мы получаем удобный инструмент, которым легко пользоваться, и который достаточно быстр, но с другой стороны из-за его универсальности, он может быть не самым оптимальным решением в случае, когда предъявляются повышенные требования к производительности и используемым ресурсам.
7. Python является высокоуровневым языком общего назначения и поддерживает различные парадигмы программирования. Особенностями языка являются минималистичный синтаксис и использование отступов в качестве выделения блоков, что делает код удобным для чтения, повышается производительность разработки [8]. Язык легок в обучении, имеет множество библиотек для решения задач из самых разных областей. Существуют реализации языка под различные платформы, что позволяет говорить о его высокой кроссплатформенности. В зависимости от реализации используются различные подходы к исполнению кода, начиная от простой интерпретации до компиляции в промежуточный байт-код и его последующего выполнения.
К недостаткам Python можно отнести не такую высокую производительность, как у компилируемых языков, но существуют и развиваются проекты по увеличению быстродействия, например, PyPy и Pyston. Также не всем нравятся принудительные отступы, но такое навязывание заставляет придерживаться стандартов форматирования кода, что является большим преимуществом языка.
Python нашел широкое применение в задачах автоматизации, системном администрировании, в веб-разработке, распределенных вычислениях и научных исследованиях.
Ситуация с динамическими структурами данных аналогична таковой с JavaScript. Также имеются удобные и универсальные инструменты (словари и списки), за которые приходится расплачиваться быстродействием и повышенными требованиями к ресурсам.
Сравнение языков программирования
Теперь выделим те качества в языках программирования, по которым их можно сравнивать между собой. Хотя этому процессу присуща определенная доля субъективизма и личных предпочтений, благодаря чему он нередко становится предметом священных войн, постараемся все же опираться на факты.
Рассмотрим основные критерии оценки языков программирования [19].
1. Скорость разработки. В современном мире это очень важный критерий, так как в условиях конкуренции зачастую успех продукта определяется тем, как быстро он может выйти на рынок, сколько времени потребуется для реализации дополнительных возможностей. Сюда же можно отнести доступность библиотек для различных задач, развитость среды разработки для того или иного языка. Явными лидерами здесь являются сценарные языки программирования, такие как Python, Ruby, Perl. Согласно проведенным экспериментам, они позволяют создавать программы в 2-3 раза быстрее, нежели компилируемые языки со строгой типизацией [11].
2. Читабельность и поддержка. Насколько легко понимать и сопровождать код (чаще чужой). Также сюда можно отнести количество специалистов по данному языку. Чем запутаннее код и меньше специалистов, тем дороже будет поддержка проектов на этом языке. К примеру, не без основания ходит шутка о том, что Perl является языком только для написания кода («write only»), но никак не для чтения. Так как сам язык позволяет (и даже поощряет) выражать одни и те же вещи различными способами, зачастую это приводит к плохо читаемому коду, особенно если он был написан не очень опытным разработчиком. Другим примером может служить Кобол. Сейчас его практически не преподают в университетах, но данный язык считался лидером по количеству кода, написанному на нем, поэтому специалистов будет найти все труднее и труднее, а стоить их работа будет дороже.
Также немаловажным фактором является типизация языка программирования. В больших и серьезных проектах предпочтительнее использовать статическую типизацию, так как это позволяет отслеживать ошибки еще на уровне компиляции.
Больше других современных языков этому критерию соответствуют Java и C#.
3. Надежность. В первую очередь надежность программ зависит от самого разработчика. В качестве разработчика может выступать группа людей. Существует множество факторов, которые влияют на конечный продукт. Например, квалификация разработчиков, временные рамки, сложность проекта, используемая методология и так далее. Тем не менее многие языки позволяют не допустить часть ошибок. К примеру, в C/C++ разработчику самостоятельно нужно заботиться о выделении/освобождении памяти, невыходе за границы массивы и так далее. Другие языки, такие как Java, C#, Python, JavaScript ограничивают использование этих возможностей, что положительно сказывается на надежности кода. Еще одним источником проблем является динамическая типизация, поэтому языки со статической типизацией являются более надежными, так как позволяют отследить эти ошибки еще на этапе компиляции. Суммируя выше сказанное, можно сделать вывод, что наиболее надежными из популярных языков программирования являются Java и C#.
4. Переносимость. Под этим критерием подразумевается возможность переноса программы на другую платформу, доступность и качество средств разработки, сред выполнения для различных платформ. Казалось бы, что в данной номинации должна безоговорочно победить Java, но не все платформы поддерживают JVM, очень часто из-за недостатка вычислительных ресурсов, например, во встраиваемых устройствах. В таких случаях хорошим выбором будут C и C++, где желательно низкоуровневое взаимодействие с операционной системой выносить на отдельный уровень или использовать кроссплатформенные
библиотеки (например, QT).
5. Быстродействие и потребляемые ресурсы. В современном мире труд программистов стоит дороже «железа», поэтому чаще выгоднее приобрести более мощное оборудование, нежели оптимизировать программное обеспечение, и тем более использовать другой язык, который будет потреблять меньше ресурсов. Но существуют области, где этот критерий играет одну из ключевых ролей. Например, встраиваемая техника, системное программное обеспечение.
Естественно, что многое зависит от квалификации разработчика, используемых алгоритмов и структур данных. Поэтому можно создать программу на C, которая будет работать медленнее таковой, написанной на Java или Python [11]. Но если считать, что квалификация разработчиков одинакова, то лидерами по этому критерию являются C и C++.
Выводом для вышесказанного должно стать понимание того, что, зная слабые и сильные стороны языков программирования, для каждого типа задач нужно выбирать наиболее подходящий язык. Не существует языков, которые справляются со всеми задачами лучших других. У каждого языка есть свои сильные и слабые стороны. Поэтому при выборе оного нужно исходить из потребностей и задач, для которых планируется его применение.
В данной курсовой работе для практической части был выбран язык C++, потому что он позволяет работать как на относительно низком уровне, так и использовать более высокоуровневые абстракции. Первая возможность отлично подходит для демонстрации принципов организации динамических данных, а используя инструменты объектно-ориентированного программирования, можно отделить внутреннюю реализацию от внешней, что является одним из принципов построения сложных и надежных систем.
Также в большей степени верно высказывание о том, что научившись решать вопросы на C++, вы сможете это делать на других языках программирования [20].
Динамические структуры данных
Обычно при изучении языков программировании первыми идут статические данные. Эти данные не меняют свои размеры и взаимное расположение во время своего существования. Но в реальных программах зачастую заранее неизвестно, каков будет объем данных, сколько памяти нужно выделить на их хранение. Можно, конечно, взять с запасом, но это будет неэффективное использование памяти, и в итоге все равно можно упереться в выделенный объем. В таких случаях стоит использовать динамические структуры данных.
Динамическими структурами данных называют данные, количество элементов в которых, их взаиморасположение и связи могут меняться во время выполнения программы. В отличие от динамических массивов, где выделяется непрерывный участок памяти, в динамических структурах элементы могут располагаться на несмежных участках памяти и связываются друг с другом с помощью указателей.
Элемент динамической структуры состоит из полей данных, в которых хранится необходимая информация, и полей связи [6]. Поля данных могут состоять в свою очередь из других структур, а в полях связи хранится один или несколько указателей в зависимости от типа динамических данных.
Так как память для элементов выделяется блоками по мере необходимости, и не требуется их физическая смежность, поэтому количество элементов ограничено лишь потребностями программы и объемом доступной памяти в системе. Также преимуществом такого подхода является то, что при изменении последовательности элементов не требуется их перемещение — достаточно поменять соответствующие указатели.
К недостаткам можно отнести менее эффективный доступ к элементам по сравнению с массивом, ведь для того, чтобы добраться до элемента, нужно пройти всю цепочку узлов. Также динамические структуры накладывают дополнительные расходы на память, которая выделяется для хранения указателей на другие элементы.
Из динамических структур в программах чаще всего используются различные линейные списки, стеки, очереди и бинарные деревья [12]. Они и будут рассматриваться.
Связный (связанный) список является динамической структурой данных, представляющую собой последовательность элементов (узлов). Каждый узел содержит как сами данные, так и одну или две ссылки на предыдущие и/или последующие элементы. Не смотря на свою простоту, связный список является основной для множества задач, относящихся к обработке динамических данных.
Связный список — это фундаментальная структура данных, без понимания которой нельзя переходить к рассмотрению более сложных структур. Существуют три основные разновидности связных списков: односвязный, двусвязный и кольцевой [10].
Односвязный список
Данный вид списка еще называют линейным однонаправленным списком. Визуально его можно представить следующим образом (рисунок 1):

Рисунок 1 – Односвязный список
На начало списка указывает head. Если список пустой, то значение head будет равно NULL, в противном случае — адрес первого элемента. Все элементы списка имеют одинаковый тип, а сами данные (DATA) могут быть представлены в произвольном формате. Указатель на следующий элемент находится в поле next. В последнем элементе списка поле next будет пустым (NULL).
Передвигаться по односвязному списку можно только в одну сторону, начиная с головы. Добавлять элементы можно в любую позицию списка. На рисунке 2 изображено добавление элемента в середину списка.
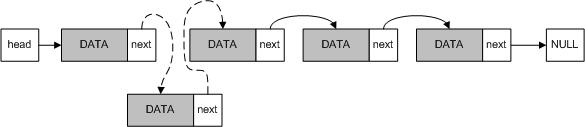
Рисунок 2 – Добавление элемента в список
При добавлении элемента необходимо динамически выделить для него память, присвоить полю next нового элемента значение next предыдущего элемента (или head, если вставляем в начало), а потом указателю next предыдущего элемента (если он имеется) присвоить адрес нового элемента. Если новый элемент добавляется в начало списка, указателю head присваиваем его адрес, если в конец списка, то поле next выставляем в NULL.
При удалении элемента (рисунок 3) сначала меняется значение указателя предыдущего элемента, а потом освобождается занимаемая память. Следует заметить, что для этой операции требуется указатель на предыдущий элемент.

Рисунок 3 – Удаление элемента из списка
При удалении первого элемента списка значение указателя head меняется на поле next удаляемого элемента, то есть на следующий элемент, который станет первым. В случае отсутствия других элементов в списке указатель head станет нулевым.
При перестановке элементов, которая требуется, например, для сортировки списка, не требуется менять местами сами данные, меняются лишь поля указателей. В общем случае перестановка двух соседних элементов представлена на рисунке 4.

Рисунок 4 – Перестановка соседних элементов
Если какой-нибудь элемент однонаправленного списка пройден, доступ к нему возможен только при повторном прохождении списка, начиная с головы (указатель head). Для устранения этого недостатка в последнем элементе линейного списка в поле next устанавливается указатель на первый элемент списка. Получается замкнутый список, который называется кольцевым или циклическим. В этом списке любой элемент можно достичь из любого другого элемента.
Визуально кольцевой список представлен на рисунке 5.

Рисунок 5 – Кольцевой список
В некоторых случаях указатель устанавливается на последний элемент, тогда появляется возможность эффективно добавлять элементы в конец и начало списка, так как есть быстрый доступ как к концу списка, так и к его началу (поле next последнего элемента).
Операции с элементами циклического списка аналогичны таковым односвязного списка, но есть и особенности. Если список состоит из единственного элемента, поле next будет указывать на него самого. Если необходимо проходить все элементы списка по одному разу (например, для поиска данных), то есть несколько вариантов:
- сравнивать каждый элемент с головным (head) или с тем элементом, откуда начинается проход;
- поместить в конец списка специальный узел, который легко может быть распознан;
- хранить общее количество элементов, а при проходе списка использовать счетчик.
Рассмотренные списки имеют недостаток, заключающийся в невозможности просмотра в обратном направлении. Например, имея указатель только на заданный элемент, его не получится так просто удалить или вставить на это место новый, так как для данных операций требуется модификация поля next предыдущего элемента [2]. Если нужно обойти указанные ограничения, используется двусвязный (двунаправленный) список. В этих списках добавляется еще одно поле, указывающее на предыдущий элемент (рисунок 6).

Рисунок 6 – Двусвязный список
В линейном двусвязном списке поля prev первого элемента и next последнего будут иметь нулевые указатели. Обычно поля next и prev находятся после данных, но для удобства восприятия было выбрано именно такое отображение. Строго говоря, в рисунке 6 есть неточность, заключающаяся в том, что указатели next и prev указывают на поля данных, на самом деле они должны указывать на сам элемент, а его началом является именно адрес поля prev. Но эта неточность также допущена лишь для удобства восприятия.
Операции удаления, добавления и перестановки элементов аналогичны таковым для односвязного списка, только нужно учитывать второе поле (prev).
Разобрав основные виды списков, продемонстрируем, как они применяются. Для этого рассмотрим реализацию на основе списков таких динамических структур как очередь, стек и дек.
Очередь
Очередь — это структура данных, организованная по принципу первым вошел, первым вышел (FIFO — first in, first out) [14]. То есть добавление элементов осуществляется в конец очередь, а извлечение с начала. Очереди широко используются в самых различных задачах, от низкоуровневых вещей вроде очередей событий в операционной системе до обычной очереди в магазине.
При работе с очередью удобно хранить два указателя – на ее начало и конец, а также переменную количества элементов в очереди. Эта концепция хорошо ложится на линейный односвязный список, операции с которым были рассмотрены ранее. В качестве интерфейсов для работы с очередью можно предоставить методы создания очереди, ее удаления, вывода количества элементов, добавления элемента (в конец) и извлечения элемента (удаление узла и возврата его значения).
Стек
Стек – это структура данных, организованная по принципу последним пришел, первым вышел (LIFO — last in, first out). В отличие от очереди извлечение и добавление элементов осуществляется с одного конца, который называется вершиной стека. Стек нашел широкое применение не только в компьютерной области вроде программного стека для размещения локальных переменных, параметров функций, адреса возврата, но и в повседневной жизни. Типичным примером является почта, когда и новые сообщения «заталкивают» в верхнюю часть списка при их поступлении, и просмотр писем мы тоже начинаем сверху, чтобы прочитать самые свежие поступления [14].
Стек, так же как и очередь, легко реализуется на основе линейного списка, в котором все операции производятся с одним концом.
Дек
Дек является своеобразной комбинацией очереди и стека, когда операции с элементами (добавление и удаление) возможны как с начала, так и с конца. Слово дек (deque) происходит из выражения double-ended queue (двусторонняя очередь), точно описывающего свой смысл [16]. Можно организовать дек на основе однонаправленного списка, но в этом случае для удаления элемента с конца списка придется проходить весь список, что явно неэффективно. Гораздо удобнее оперировать деком на основе двусвязного списка и хранить указатели как на начало, так и на конец списка.
Дерево
В зависимости от решаемых задач могут применяться нелинейные структуры, в которых у элементов может быть несколько связей, и переход от одного элемента к другому может зависеть от определенного условия.
Дерево является основным представителем нелинейных структур, являясь совокупностью узлов (вершин) и соединяющих их направленных ребер (дуг), причем в каждый узел за исключением корня ведет ровно одна дуга. Корнем называется начальный узел дерева, в который не ведет ни одна дуга [22]. Вершины, не имеющие последующих узлов, называют листьями. Как видно, линейные односвязные списки представляет собой вырожденный случай дерева, в котором каждая вершина имеет не более одного поддерева.
На практике часто используются двоичные (бинарные) деревья. В них каждый узел имеет не более двух потомков, которые образуют левое и правое поддерево. Типичным примером бинарного дерева является генеалогическое дерево. Если двоичное дерево упорядочить таким образом, чтобы корневой элемент имел большее значение, чем любой элемент в левом поддереве, но в то же время меньшее или равное значение, чем элементы в правом поддереве, то получится бинарное дерево поиска. Как следует из названия, оно широко применяется в алгоритмах поиска, используется для построения больших поисковых индексов.
Существует множество типов деревьев, применяемых в различных областях. По мнению экспертов, деревья являются наиболее важными нелинейными структурами, которые встречаются при работе с компьютерными алгоритмами [5].
Рассмотренные динамические структуры нередко часто служат базовыми элементами, комбинация которых позволяет решать самые сложные задачи. Но даже в простых задачах выбор правильной структуры оказывает ощутимое влияние на производительность решения [7]. Как показывают проведенные эксперименты [11], даже относительно медленные сценарные языки программирования при выборе наиболее подходящей структуры данных для конкретной задачи показывают более высокую производительность, чем компилируемые языки, использующие не самую оптимальную структуру.
Организация данных в списковые структуры
Разобравшись с теоретическими аспектами в динамических структурах, рассмотрим организацию данных в списковые структуры на практике. В качестве примера напишем программу, которая работает со списком из целых чисел – добавляет новые значения в указанную позицию, удаляет имеющиеся, производит поиск элемента с заданным значением.
В качестве основы взят односвязный список, так как он является простой базовой динамической структурой, на которой удобно демонстрировать основные операции работы со списками.
Как говорилось в конце первой главы, в качестве языка программирования был выбран C++, потому что он позволяет работать не только на относительно низком уровне, что необходимо для полноценной демонстрации внутренней организации списка, так и естественным образом представить список в виде класса, имеющего удобные публичные методы, предназначенные для взаимодействия с ним. Такой подход также повышает безопасность и надежность программы. Ведь при возможном расширении функциональности программы достаточно будет воспользоваться проверенными внутренними методами, обернув их в необходимый публичный метод.
Элементом списка является следующая структура:
struct Node {
int val;
Node *next;
};
Node *head;
int node_counter;
В ней поле val содержит полезные данные, ради которых и строится список. Поле next указывает на следующий элемент. Также нам понадобится указатель на первый элемент списка head и счетчик элементов в списке node_counter. Без последнего можно обойтись, но он дает весомые преимущества.
- Упрощение проверок перед выполнением операций. К примеру, если поступит запрос на удаление элемента 10, то без использования счетчика мы должны перебрать все элементы, пока не дойдем до нужного элемента. И тут может оказаться, что в списке всего 9 элементов. Использование счетчика позволяет сразу сказать об этом, без прохода по списку.
- Значительное ускорение части операций со списком. Например, в случае запроса на количество элементов в списке достаточно вернуть значение счетчика.
Но самих элементов и вспомогательных переменных недостаточно, нужны еще и методы, которые будут оперировать этими элементами и предоставлять доступ к ним. И здесь уже стоит задуматься об архитектуре приложения.
Архитектурно правильным решением будет выделение внутренних (приватных) и внешних (публичных) методов доступа к данным. Первые будут представлять низкоуровневую часть, непосредственно работать с элементами. Вторые будут являться так называемой оберткой к низкоуровневым методам и предоставлять интерфейс для работы со списком. Это позволит разграничить доступ, повысив надежность программы. Разумно будет возложить на внешние методы осуществление различных проверок, такие как выход за границы списка, удаление несуществующего элемента. Также они могут являться удобной комбинацией внутренних методов, например, pop – удаление последнего элемента и возврат его значения реализуется через последовательное выполнение внутренних методов get (получение значения) и remove (удаление значения).
Внутренние методы
Рассмотрим внутренние методы.
int insertNode(int index, int val) – этот метод вставляет элемент val в указанное место index. И, согласно принятой практике, возвращает 0 в случае успешного выполнения и код ошибки в противном случае. Как уже говорилось, проверка выхода за границы списка производится во внешних методах, поэтому здесь мы уверены, что index допустимый. Во время выделения памяти для нового элемента может произойти ошибка, поэтому соответствующее исключение ловится, и функция возвращает -1.
Следует выделять три разных ситуации: добавление в начало списка, середину и конец. В первом случае поле next нового элемента должно указывать на бывший первый элемент, а указатель начала head списка следует перенаправить на новый элемент.
new_node->next = head;
head = new_node;
Вставку в середину и конец списка можно объединить. Для этих случаев нужно начать с головы списка и продвигаться по нему до тех пор, пока не будет найден узел, после которого нужно вставить новый элемент.
node = head;
for (int i=0; i<index-1; i++)
node = node->next;
На выходе цикла node будет указывать на элемент, после которого будет производиться вставка. Для самой вставки полю next нового элемента присваивается указатель следующего элемента, на который указывает предыдущий элемент, а потом и полю next предыдущего элемента следует присвоить адрес нового элемента.
new_node->next = node->next;
node->next = new_node;
Также не стоит забывать и о том, что в случае вставки в конец списка поле next нового элемента должно иметь значение NULL, но этот шаг опускается, так как он уже был сделан при инициализации структуры нового элемента. В конце функции увеличивается счетчик количества элементов.
Метод int getNodeValue(int index) предназначен для поиска элемента по его индексу. Здесь поиск аналогичен описанному выше, только итерация идет не до index-1 (предыдущий элемент), а до index. Сам метод возвращает значение найденного элемента.
Метод void updateNodeValue(int index, int val) обновляет существующий элемент новым значением. Для этого нужно найти этот элемент по индексу и обновить ему поле val.
Метод int findValue(int value) ищет элемент по его значению.
Node *node = head;
// если элемент найден, возвращаем его индекс
for (int i=0; node; node=node->next, i++)
if (node->val == value)
return i;
// элемент не найден
return -1;
В данном случае цикл выполняется до тех пор, пока не будет найден элемент с нужным значением, или пока не будет достигнут конец списка. В этом цикле признаком конца списка является достижение элемента с нулевым полем next. Также в качестве признака конца списка можно использовать известное количество элементов в списке (node_counter). Если элемент находится, возвращается значение счетчика цикла – он будет равен индексу искомого узла. Если же элемент не найден (выход из цикла), то будет возращено значение -1, которое не может служить индексом узла, и поэтому является признаком отсутствия искомого элемента.
Метод void deleteNode(int index) предназначен для удаления элемента по его индексу. Как и в случае добавления элемента стоит выделить 3 ситуации: удаление с начала списка, с середины и с конца. В первом случае мы перенаправляем указатель головы списка на следующий элемент и удаляем первый узел:
node = head;
head = head->next;
delete node;
Для удаления с середины и конца списка нам также нужно найти предыдущий узел. Далее по его полю next находим удаляемый элемент, и полю next предыдущего элемента присваиваем указатель next удаляемого узла. После этого можно освобождать память удаляемого элемента.
node = head;
for (int i=0; i<index-1; i++)
node = node->next;
del_node = node->next;
node->next = del_node->next;
delete del_node;
Удаление с середины и конца списка также легко объединяется. При удалении последнего элемента указатель next предыдущего элемента должен быть обнулен, но это является частным случаем операции node->next = del_node->next, так как del_node->next уже равнялся NULL. В конце функции нужно уменьшить счетчик node_counter.
Метод void deleteAllNodes() удаляет все имеющиеся элементы. Для этого понадобится два указателя, ведь для удаления нужно знать адрес удаляемого элемента, а также адрес следующего элемента, который мы не узнаем, сначала удалив узел.
Node *node = head;
while (node) {
head = head->next;
delete node;
node = head;
}
Указанные приватные методы являются базой для работы со списком. На их основе можно создавать удобные интерфейсы, что и будет показано в публичных методах.
Публичные методы
Рассмотрим внешний интерфейс, который предоставляет класс LinkedList. В интерфейсе используется термин позиция – это порядковый номер элемента в списке. Людям привычнее начинать счет с единицы, а не с нуля, поэтому позиция автоматически преобразуется в индекс вычитанием единицы.
Методы void append(int value), voide prepend(int value) добавляют узел соответственно в конец и начало списка. Они являются частными случаями метода void insert(int pos, int value), который вставляет элемент на указанную позицию, и служат для удобства работы с классом. Все три метода вызывают приватный метод insertNode, только с разными параметрами. Количество элементов в списке нам известно благодаря счетчику, поэтому вычислить индекс при добавлении элемента в конец списка не составляет труда. Помимо этого метод insert сначала проверяет границы списка, и лишь потом вызывает insertNode. Стоит заметить, что эти три публичных метода намеренно никак не реагируют на ошибку выделения памяти для нового элемента (сообщение о проблеме выведет приватный метод), и программа продолжает работу. Можно завершить программу, но тогда данные в списке будут потеряны.
Метод void insert(int pos, int value) вставляет элемент в указанную позицию, void remove(int pos) удаляет элемент, void get(int pos) выводит значение элемента, а void update(int pos, int value) обновляет элемент по указанной позиции. Все они проверяют значение позиции, чтобы она была не меньше 1 (нумерация начинает с 1) и не выходила за края списка.
if (pos < 1 || pos > node_counter)
cout << "неверная позиция" << endl;
else
…
Метод void pop() является удобной комбинацией получения значения элемента и его последующим удалением:
void pop() {
if (!node_counter) {
cout << "список пуст" << endl;
} else {
cout << getNodeValue(node_counter-1) << endl;
deleteNode(node_counter-1);
}
}
Метод void length() выводит количество элементов в списке. Благодаря хранению счетчика узлов, достаточно вывести его значения, а не проходить весь список.
Метод void find(int val) ищет элемент с заданным значением val, используя для этого приватный метод int findValue(int value).
Метод void print() выводит поочередно все элемента списка.
Node* node;
if (!head) {
cout << "список пуст" << endl;
} else {
// проход по списку без использования знаний о количестве
// элементов (node_counter)
cout << "Список (" << node_counter << " элемент(а,ов)): ";
for (node=head; node; node=node->next)
cout << node->val << " ";
cout << endl;
}
Здесь отдельно обрабатывается ситуация, когда список пуст – в этом случае указатель на голову списка равен NULL. Следуя ранее заданной концепции, когда публичный метод обращается к приватному для доступа к элементу, стоило написать цикл, чтобы в нем вызывался getNodeValue от 0 до node_counter-1. Но решено был продемонстрировать проход по циклу без использования node_counter. В этом случае цикл выполняется, пока node не равен NULL, что укорочено можно записать как просто node.
Сама программа имеет консольный интерфейс. В нем за публичными методами закреплен свой номер. Эти значения имеются в меню, которое выводится в бесконечном цикле. Пользователь может самостоятельно работать со списком, выбирая необходимые операции по их номеру. У выхода из программы есть свой номер операции, также можно стандартно завершить программу по Ctrl+C.
Меню программы имеет следующий вид:
Операции:
1. Create list (создать список)
2. Append (добавить элемент в конец)
3. Prepend (добавить элемент в начало)
4. Insert (вставить элемент на указанную позицию)
5. Update (обновить элемент на указанной позиции)
6. Find (найти элемент по указанному значению)
7. Get (вывести элемент на указанной позиции)
8. Print (вывести все элементы)
9. Remove (удалить элемент на указанной позиции)
10. Pop (удалить последний элемент и вывести его значение)
11. Delete list (удалить список)
12. Exit (выход из программы)
Выберите номер операции:
Программа проверяет корректность введенных значений и в случае ошибки предлагает попробовать снова. Благодаря оператору switch удалось сгруппировать проверки по операциям и повысить читаемость кода.
Полный текст программы находится в Приложении.
Как видно, практическая часть организации данных в списковые структуры имеет свои тонкости, которые не всегда освещаются в теории. К сожалению, их нельзя освоить, просто прочитав необходимую литературу. Помимо этого необходим самостоятельный опыт работы, использование изученных методов на реальных примерах. Как говорил Александр Суворов, «Теория без практики — мертва, практика без теории — слепа».
Заключение
В данной работе были рассмотрены различные группы языков программирования. Как было показано, классификация не всегда носит строгий характер, но этого и не требовалось. Основная задача проведения классификации заключалась в выявлении характерных черт, присущих той или иной группе. А обладая этими знаниями, можно судить не только о знакомых языках, но и составить общее представление о возможностях неизвестных, возможно новых языках по их описанию. Также были рассмотрены самые популярные языки программирования на сегодняшний день, их сильные и слабые стороны.
Сравнивая языки между собой, было показано, что не существует лучшего языка программирования, каждый хорош в своей области, где важны определенные критерии, а при использовании в другой области с отличными критериями язык может оказаться в аутсайдерах. Даже у самых мощных языков имеются недостатки, заключающиеся как минимум в сложности программирования на них, что является весомым фактором не только для новичков, выбирающих свой первый язык для изучения, но и для корпораций, которые задумываются о поиске квалифицированного персонала, времени и затратах на разработку и дальнейшую поддержку своих продуктов.
Внутреннее устройство динамических структур в языках программирования имеет большое значение, ведь скорость работы алгоритмы и программы в целом сильно зависит от них. Сценарные языки часто скрывают их внутреннее представление, называя списки массивами. Это далеко не всегда является преимуществом. При повышенных требованиях к быстродействию и потребляемым ресурсам нередко приходится переходить на другой, не всегда такой же удобный язык, но позволяющий явно задавать необходимое внутреннее устройство динамических структур.
При рассмотрении динамических структур данных были определены принципы их построения, основные операции для работы с ними. Не смотря на имеющиеся недостатки, динамические структуры являются необходимой составляющей в программах, размер данных в которых заранее неизвестен. Благодаря своим особенностям они показывают отличные результаты в операциях, где необходимо интенсивное перемещение данных, например, в сортировке. Ведь для этого не требуют перемещение самих данных, как массивах, достаточно поменять указатели.
Особое внимание было уделено спискам, так как они являются основой для остальных динамических структур. Были рассмотрены широко используемые не только в компьютерной области, но и в повседневной жизни такие структуры, как очередь, стек и дек, особенности их построения на основе списков. Также затрагивались и более сложные нелинейные структуры на примере их характерного представителя – дерева, его частный случай бинарное дерево, которое позволяет добиться высокой эффективности не только в сортировке, но и в поиске.
В практической части была написана программа на языке программирования C++ для работы с линейным списком и описаны тонкости, на которые стоит обратить внимание при организации данных в списковые структуры. Благодаря выбору подходящего инструмента (C++) удалось не только продемонстрировать внутреннее устройство динамических данных и основных операций для работы с ними, но и изолировать эту внутреннюю реализацию, предоставив в качестве публичных методов удобные (хотя и избыточные) интерфейсы для работы со списком, что повышает надежность программы и безопасность данных.
Список использованной литературы
- Васильев А.Н. Java. Объектно-ориентированное программирование: Учебное пособие. - СПб.: Питер, 2013. – 400 с.
- Вирт Н. Алгоритмы и структуры данных. – М.: ДМК Пресс, 2010. - 272 с.
- Гриффитс И. Программирование на C# 5.0 – М.: Эксмо, 2014. - 1136 с.
- Гэлловей М. Сила Objective-C 2.0. Эффективное программирование для iOS и OS X. - СПб.: Питер, 2014. – 304 с.
- Кнут Д. Искусство программирования. – М.: Вильямс, 2013. - Т. 1 : 720 с.
- Конова Е.А., Поллак Г.А., Ткачев А.М. Структуры данных. Программирование на языке С и С++. Учебное пособие. - Челябинск: ЮУрГУ, 2004. – 106 с.
- Кормен Т.Х. Алгоритмы: вводный курс. – М.: Вильямс, 2014. – 208 с.
- Лутц М. Изучаем Python, 4-е издание. - СПб.: Символ-Плюс, 2011. – 1280 с.
- Молчанов А.В. Системное программное обеспечение. - СПб.: Питер, 2010. – 400 с.
- Монган Дж., Киндлер Н., Гижере Э. Работа мечты для программиста. Тестовые задачи и вопросы при собеседовании в ведущих IT-компаниях. - СПб.: Питер, 2014. – 368 с.
- Орам Э., Уилсон Г., Идеальная разработка ПО. Рецепты лучших программистов. - СПб.: Питер, 2012. – 592 с.
- Павловская Т. А., Щупак Ю. А. C/C++. Структурное и объектно-ориентированное программирование: Практикум. - СПб.: Питер, 2011. - 352 с.
- Прата С. Язык программирования С. Лекции и упражнения, 5-е издание. – М.: Вильямс, 2013. – 960 с.
- Седжвик Р., Уэйн К. Алгоритмы на Java, 4-е издание. – М.: Вильямс, 2013. – 848 с.
- Херман Д. Сила JavaScript. 68 способов эффективного использования JS. - СПб.: Питер, 2013. – 288 с.
- Хэзфилд Р., Кирби Л. Искусство программирования на C. Фундаментальные алгоритмы, структуры данных и примеры приложений. - Киев: ДиаСофт, 2001. – 736 с.
- Gabbrielli M. Martini S. Programming Languages: Principles and Paradigms. - London: Springer-Verlag, 2010. – 440 с.
- Mernik M. Formal and Practical Aspects of Domain-Specific Languages: Recent Developments. - Hershey: Information Science Reference, 2012. – 677 с.
- Parker K.R., Ottaway T.A. Criteria for the selection of a programming language for introductory courses. - Pocatello: International Journal of Knowledge and Learning, 2006.
- Spraul A. Think like a programmer. - San Francisco: No Starch Press, 2012. – 256 с.
- Stroustrup B. The C++ programming language, Fourth edition. - Ann Arbor: Addison-Wesley, 2013. – 1366 с.
- Поляков К.Ю. «Программирование на языке Си» 2009. [Электронный ресурс]
URL: http://kpolyakov.narod.ru/download/devcpp_4.pdf (дата обращения: 9.05.2017)
- List of programming languages // Wikipedia. [Электронный ресурс].
URL: http://en.wikipedia.org/wiki/List_of_programming_languages (дата обращения: 9.05.2017)
- TIOBE Index for February 2015 // TIOBE. [Электронный ресурс].
URL: http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html (дата обращения: 9.05.2017)
#include <iostream>
#include <cstdlib>
using std::cout;
using std::cin;
using std::endl;
class LinkedList {
private:
struct Node {
int val;
Node *next;
};
// начало списка
Node *head;
// количество элементов в списке
int node_counter;
/* внутренние методы, в них не производится проверка на выход за границы
количества элементов, этим занимаются публичные методы
*/
// создание и вставка элемента
int insertNode(int index, int val) {
Node *node, *new_node;
// проверка на успешное выделение памяти
try {
new_node = new Node();
} catch(std::bad_alloc&) {
cout << "memory allocation failed" << endl;
return -1;
}
// выставление значения нового элемента
new_node->val = val;
new_node->next = NULL;
if (!index) {
// вставка в начало списка
new_node->next = head;
head = new_node;
} else {
// вставка в середину или конец списка
// поиск нужного элемента
node = head;
for (int i=0; i<index-1; i++)
node = node->next;
new_node->next = node->next;
node->next = new_node;
}
// увеличиваем счетчик количества элементов в списке
++node_counter;
return 0;
}
int getNodeValue(int index) {
Node *node = head;
// поиск нужного элемента
for (int i=0; i<index; i++)
node = node->next;
return node->val;
}
void updateNodeValue(int index, int val) {
Node *node = head;
// поиск нужного элемента
for (int i=0; i<index; i++)
node = node->next;
// обновление значения
node->val = val;
}
// возвращает индекс первого элемента, чье значение совпадает с заданным
// возращает -1, если элемент не найден
int findValue(int value) {
Node *node = head;
// если элемент найден, возвращаем его индекс
for (int i=0; node; node=node->next, i++)
if (node->val == value)
return i;
// элемент не найден
return -1;
}
void deleteNode(int index) {
Node *node, *del_node;
if (!index) {
// удаление из начала списка
node = head;
head = head->next;
delete node;
} else {
// удаление из середины или конца списка
// поиск нужного элемента
node = head;
for (int i=0; i<index-1; i++)
node = node->next;
del_node = node->next;
node->next = del_node->next;
delete del_node;
}
// уменьшение счетчика количества элементов
--node_counter;
}
// удаление всех элементов в списке
void deleteAllNodes() {
Node *node = head;
while (node) {
head = head->next;
delete node;
node = head;
}
}
public:
// конструктор
LinkedList() {
head = NULL;
node_counter = 0;
}
// деструктор, удаляем элементы в списке
~LinkedList() {
deleteAllNodes();
}
// Публичные методы работы со списком. Нумерация начинается с 1
// добавление в начало списка
void prepend(int value) {
insertNode(0, value);
}
// добавление в конец списка
void append(int value) {
insertNode(node_counter, value);
}
// добавление в указанную позицию
void insert(int pos, int value) {
if (pos < 1 || pos > node_counter+1)
cout << "неверная позиция" << endl;
else
insertNode(pos-1, value);
}
// удаление элемента на указанной позиции
void remove(int pos) {
if (pos < 1 || pos > node_counter)
cout << "неверная позиция" << endl;
else
deleteNode(pos-1);
}
// удаление элемента из конца списка и вывод его значения
void pop() {
if (!node_counter) {
cout << "список пуст" << endl;
} else {
cout << getNodeValue(node_counter-1) << endl;
deleteNode(node_counter-1);
}
}
// вывод значения элемента на указанной позиции
void get(int pos) {
if (pos < 1 || pos > node_counter)
cout << "неверная позиция" << endl;
else
cout << getNodeValue(pos-1) << endl;
}
// обновление значения элемента на указанной позиции
void update(int pos, int value) {
if (pos < 1 || pos > node_counter)
cout << "неверная позиция" << endl;
else
updateNodeValue(pos-1, value);
}
// вывод количества элементов в списке
void length() {
cout << node_counter << endl;
}
// выводит позицию первого найденного элемента по его значению
void find(int val) {
int index;
if ((index = findValue(val)) == -1)
cout << "нет элемента с таким значением " << val << endl;
else
cout << index+1 << endl;
}
// вывод всего списка
void print() {
Node* node;
if (!head) {
cout << "список пуст" << endl;
} else {
// проход по списку без использования знаний о количестве
// элементов (node_counter)
cout << "Список (" << node_counter << " элемент(а,ов)): ";
for (node=head; node; node=node->next)
cout << node->val << " ";
cout << endl;
}
}
};
int main() {
int res, pos, val;
LinkedList *list = NULL;
const char *menu =
"Операции:\n"
"1. Create list (создать список)\n"
"2. Append (добавить элемент в конец)\n"
"3. Prepend (добавить элемент в начало)\n"
"4. Insert (вставить элемент на указанную позицию)\n"
"5. Update (обновить элемент на указанной позиции)\n"
"6. Find (найти элемент по указанному значению)\n"
"7. Get (вывести элемент на указанной позиции)\n"
"8. Print (вывести все элементы)\n"
"9. Remove (удалить элемент на указанной позиции)\n"
"10. Pop (удалить последний элемент и вывести его значение)\n"
"11. Delete list (удалить список)\n"
"12. Exit (выход из программы)\n"
"Выберите номер операции: ";
for (;;) {
cout << menu;
cin >> res;
if (!cin || res < 1 || res > 12) {
cout << "неверное значение" << endl << endl;
cin.clear();
cin.ignore();
continue;
}
switch(res) {
case 12:
std::exit(0);
case 1:
// проверка наличия списка
if (list) {
cout << "список уже существует" << endl;
} else {
try {
list = new LinkedList();
} catch(std::bad_alloc&) {
cout << "memory allocation failed" << endl;
std::exit(-1);
}
}
break;
default:
// проверка наличия списка
if (!list) {
cout << "сначала создайте список" << endl;
} else {
switch(res) {
case 2:
case 3:
case 6:
cout << "введите значение: ";
cin >> val;
break;
case 4:
case 5:
cout << "введите позицию и значение через пробел: ";
cin >> pos >> val;
break;
case 7:
case 9:
cout << "введите позицию: ";
cin >> pos;
break;
}
if (!cin) {
cout << "неверное значение" << endl << endl;
cin.clear();
cin.ignore();
continue;
}
switch(res) {
case(2): list->append(val); break;
case(3): list->prepend(val); break;
case(4): list->insert(pos, val); break;
case(5): list->update(pos, val); break;
case(6): list->find(val); break;
case(7): list->get(pos); break;
case(8): list->print(); break;
case(9): list->remove(pos); break;
case(10): list->pop(); break;
case(11): delete list; list=NULL; break;
default:
cout << "что-то пошло не так, "
"обратитесь к системному администратору:-)" << endl;
}
}
}
cout << endl;
cin.get();
}
return 0;
}

- Адаптация детей в условиях первого класса школы ( Понятие адаптации к школе и её характеристика)
- Особенности коммуникаций в организации ( оммуникационный процесс: понятие, основные факт элементы, этапы, их фаза характеристика )
- Затраты как объект управленческого учета (Понятие затрат предприятия)
- «Годовая бухгалтерская отчетность организации: состав, характеристика и взаимосвязь форм отчетности»
- Особенности коммуникаций в организации ( Теоретические опыт основы и характеристика быть коммуникаций указ в организации )
- Правовые основы организации нотариата (Конституционно-правовой статус нотариуса)
- Обзор языков программирования высокого уровня (Реализация цикла с предусловием)
- Менеджмент человеческих ресурсов (Анализ классификации работников предприятия УК «Новое Жегалово»)
- ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРОГРАММЫ ЛОЯЛЬНОСТИ К ГОСТЯМ (НА ПРИМЕРЕ ГОСТИНИЦЫ ООО «МОНАРХ - ЦЕНТР»)
- История развития менеджмента (История развития менеджмента).
- Юридическая ответственность ( Теоретико-правовые основы юридической ответственности )
- Выбор стиля руководства в организации (Виды стилей управления)