
Операции производимые с данными
Содержание:

Введение
Актуальность исследования.
Работа с динамическими данными имеет некоторое преимущество по сравнению с работой со статическими данными:
Подключая динамическую память, можно увеличивать объем обрабатываемых данных;
При необходимости память, занимаемую динамическими данными, можно освободить и записать туда другую информацию;
Можно создать динамические структуры данных переменного размера.
Для работы с динамическими данными используется ссылочный тип данных, т.е. указатель. Указатель — это переменная, которая содержит адрес объекта определенного типа. Память под данные может быть выделена во время компиляции или выполнения программы.
Способ организации данных, когда память для их хранения выделяется при необходимости небольшими блоками, которые с помощью указателей связаны друг с другом, называется динамическими структурами данных. К основным динамическим структурам относятся линейные списки, очереди, стеки и бинарные деревья, которые различаются способами связи между собой отдельных элементов и допустимыми к ним операциями.
Проблема данного исследования заключается в рассмотрении следующих вопросов: что представляют собой динамические структуры данных, в чем заключаются их основные функции и задачи, их значение для программирования.
Цель исследования заключается в изучении структур данных.
Задачи исследования формируются исходя из его цели и заключаются в следующем:
- Раскрыть понятие структур данных.
- Провести классификацию структур данных.
- Рассмотреть общую концепцию организации структур данных.
- Изучить операции, проводимые с данными.
Практическая значимость исследования заключается в его возможном использовании при изучении программирования в учебных заведениях разного уровня.
Глава 1. Динамические структуры данных.
1.1. Введение в динамические структуры данных.
Объект данных обладает динамической структурой, если его размер изменяется в процессе выполнения программы или он потенциально бесконечен.
Данные динамической структуры – это данные, внутреннее строение которых формируется по какому-либо закону, но количество элементов, их взаиморасположение и взаимосвязи могут динамически изменяться во время выполнения программы, согласно закону формирования.
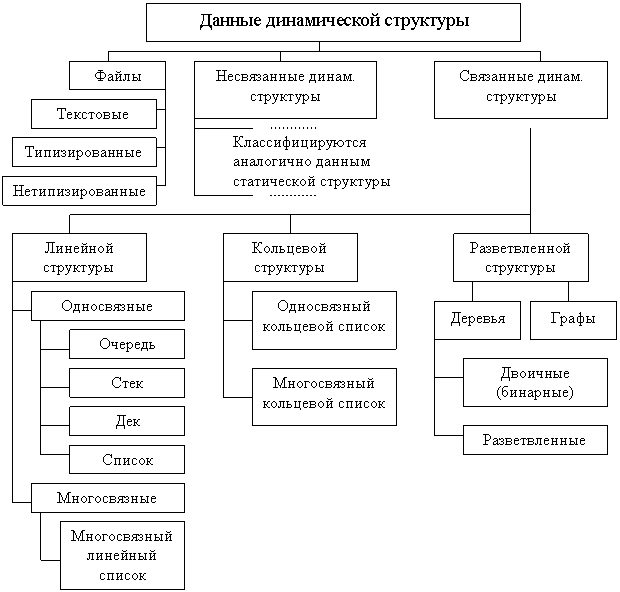
Рисунок 1 - Обобщенная классификация данных динамической структуры
К данным динамической структуры относят файлы, несвязанные и связанные динамические данные.
Заметим, что файлы в данной классификации отнесены к динамическим структурам данных. Это сделано исходя из вышеприведенного определения. Хотя удаление и вставка элементов в середину файла не допускается, зато длина файла в процессе работы программы может изменяться – увеличиваться или уменьшаться до нуля. А это уже динамическое свойство файла как структуры данных.
1.2. Статические и динамические переменные в Паскале.
В Паскале одной из задач описания типов является то, чтобы зафиксировать на время выполнения программы размер значений, а, следовательно, и размер выделяемой области памяти для них. Описанные таким образом переменные называются статическими.
Все переменные, объявленные в программе, размещаются в одной непрерывной области оперативной памяти – сегмент данных. Длина сегмента данных определяется архитектурой микропроцессора и составляет обычно 65536 байт.
Однако порой заранее не известны не только размеры значений, но и сам факт существования значения той или иной переменной. Для результата переменной приходится отводить память в расчете на самое большое значение, что приводит к нерациональному использованию памяти. Особенно это затруднительно при обработке больших массивов данных.
Предположим, например, что у вас есть программа, требующая массива в 400 строк по 100 символов каждая. Для этого массива требуется примерно 40К, что меньше максимума в 64К. Если остальные ваши переменные помещаются в оставшиеся 24К, массив такого объема проблемы не представляет. Но что если вам нужно два таких массива? Это потребовало бы 80К, и 64К сегмента данных не хватит. Другим общим примером является сортировка. Обычно когда вы сортируете большой объем данных, то делаете копию массива, сортируете копию, а затем записываете отсортированные данные обратно в исходный массив. Это сохраняет целостность ваших данных, но требует также наличия во время сортировки двух копий данных.
С другой стороны объем памяти компьютера достаточно велик для успешного решения задач с большой размерностью данных. Выходом из положения может служить использование так называемой динамической памяти.
Динамическая память (ДП) – это оперативная память ПК, предоставляемая программе при ее работе, за вычетом сегмента данных (64 Кб), стека (16 Кб) и собственно тела программы. Размер динамической памяти можно варьировать. По умолчанию ДП – вся доступная память ПК.
ДП – это фактически единственная возможность обработки массивов данных большой размерности. Многие практические задачи трудно или невозможно решить без использования ДП. Например, при разработке САПР статическое распределение памяти невозможно, т.к. размерность математических моделей в разных проектах может значительно различаться.
И статические и динамические переменные вызываются по их адресам. Без адреса не получить доступа к нужной ячейке памяти, но при использовании статических переменных, адрес непосредственно не указывается. Обращение осуществляется по имени. Компилятор размещает переменные в памяти и подставляет нужные адреса в коды команд.
Адресация динамических переменных осуществляется через Динамические структуры данных. Линейные списки. Их значения определяют адрес объекта.
Для работы с динамическими переменными в программе должны быть выполнены следующие действия:
- Выделение памяти под динамическую переменную;
- Инициализация указателя;
- Освобождение памяти после использования динамической переменной.
Программист должен сам резервировать место, определять значение указателей, освобождать ДП.
Вместо любой статической переменной можно использовать динамическую, но без реальной необходимости этого делать не стоит.
1.3. Динамические структуры данных. Линейные списки
Вся ДП рассматривается как сплошной массив байтов, который называется кучей.
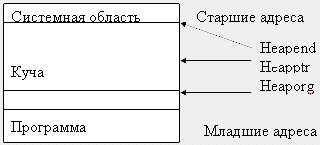
Рисунок 2 – Расположение кучи в памяти ПК.
Существуют стандартные переменные, в которых хранятся значения адресов начала, конца и текущей границы кучи:
- Heaporg – начало кучи;
- Heapend – конец кучи;
- Heapptr – текущая граница незанятой ДП.
Выделение памяти под динамическую переменную осуществляется процедурой:
New (переменная_типа_указатель)
В результате обращения к этой процедуре указатель получает значение, соответствующее адресу в динамической памяти, начиная с которого можно разместить данные.
Var i, j: ^integer;
r: ^real;
begin
new( i); {после этого указатель i приобретает значение адреса Heapptr, а Heapptr смещается на 2 байта}
……………
new( r) ; { r приобретает значение Heapptr, а Heapptr смещается на 6 байт}
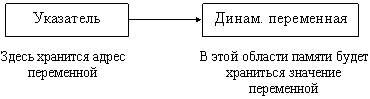
Рисунок 3 – Графически действие процедуры new
Вещественная переменная --->R^:= sqr( R) <---аргумент – адрес.
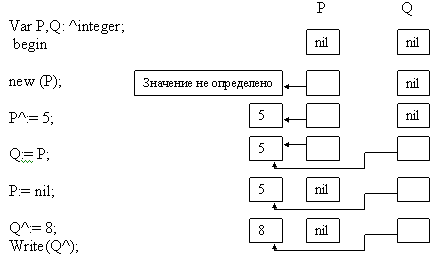
Рисунок 4 – Пример работы с указателями
Работа с динамическими данными имеет некоторое преимущество по сравнению с работой со статическими данными [1-4]:
Подключая динамическую память, можно увеличивать объем обрабатываемых данных;
При необходимости память, занимаемую динамическими данными, можно освободить и записать туда другую информацию;
Можно создать динамические структуры данных переменного размера.
Для работы с динамическими данными используется ссылочный тип данных, т.е. указатель. Указатель — это переменная, которая содержит адрес объекта определенного типа. Память под данные может быть выделена во время компиляции или выполнения программы.
Способ организации данных, когда память для их хранения выделяется при необходимости небольшими блоками, которые с помощью указателей связаны друг с другом, называется динамическими структурами данных. К основным динамическим структурам относятся линейные списки, очереди, стеки и бинарные деревья, которые различаются способами связи между собой отдельных элементов и допустимыми к ним операциями.
Рассмотрим способы работы с линейными списками в С++, создаваемые самим пользователем без применения готовых библиотек системы. Такие задачи часто возникают при выполнении студентами контрольных и лабораторных работ.
В С++ элемент линейного списка представляет собой структуру, которая содержит минимум два поля. Например, первое поле для хранения данных, а второе для хранения значения указателя:
struct <имя_типа_структуры> {
<имя_типа> <имя_поля_данных>;
<имя_типа_структуры> *<имя_поля_указателя>;};
Линейный список является самым простым способом связывания множества элементов. Когда каждый элемент списка содержит ссылку на следующий элемент, то такой список называется однонаправленным или односвязным. Если каждый элемент списка имеет одну ссылку на следующий элемент, а другую — на предыдущий, то список называется двунаправленным или двусвязным.
Над списками можно выполнять следующие операции:
начальное формирование списка (создание первого элемента);
добавление элемента в конец списка;
чтение элемента с заданным ключом;
вставка элемента в заданное место списка (до или после элемента с заданным ключом);
удаление элемента с заданным ключом;
упорядочивание списка по ключу.
Удаление элемента из списка зависит от того, где находится элемент в начале списка, в середине или в конце. Также вставка элемента в начало и в середину отличаются. Сортировка связанного списка по ключу заключается только в изменении связей между элементами.
Задача №1
Создать односвязный список, состоящий из списка студентов группы (ф.и.о., дата рождения (день, месяц, год)). Вывести список на экран.
Решение
#include
#include
#include
#include
struct spisok{ char fam[20];
int d,m,y;
spisok *p; };
void main () {
int n,j;
// Предполагаем, что в списке больше одного элемента
cout<<"Введите количество записей: \n";
cin>>n;
spisok *t;
/*указатель first всегда будет указывать на 1-й элемент списка */
spisok *first=new spisok;
/*Вводим данные первого элемента*/
cout<<"Введите фамилию \n"; gets(first->fam);
cout<<"Введите дату рождения в виде: 7 11 2006 \ (7-е ноября 2006 года)";
cin>>first->d>>first->m>>first->y;
first->p=0;
t=first;
/*Вводим данные для последующих элементов*/
for (j=2; j<=n; j++){
spisok *z=new spisok;
if(t!=0) t->p=z;
cout<<"Введите фамилию \n"; gets(z->fam);
cout<<"Введите дату рождения в виде: 7 11 2006";
cin>>z->d>>z->m>>z->y;
t=z; t->p=0;
}
cout <<"Исходный список\n";
t=first;
j=1;
while(t!=0){
cout
Задача №2
В списке, созданной в предыдущей задаче организовать поиск элемента по ключу. Ключом служит дата рождения.
Решение
/* подключение заголовочных файлов */
struct spisok{ char fam[20];
int d,m,y;
spisok *p; };
void main () {
int n,j;
cout<<"Введите количество записей: \n"; cin>>n;
spisok *t;
spisok *first=new spisok;
cout<<"Введите фамилию \n"; gets(first->fam);
cout<<"Введите дату рождения в виде: 7 11 2006 \ (7-е ноября 2006 года)";
cin>>first->d>>first->m>>first->y;
first->p=0;
t=first;
for (j=2; j<=n; j++){
spisok *z=new spisok;
if(t!=0) t->p=z;
cout<<"Введите фамилию \n"; gets(z->fam);
cout<<"Введите дату рождения в виде: 7 11 2006";
cin>>z->d>>z->m>>z->y;
t=z; t->p=0;
}
cout <<"Введенный список\n";
t=first;
j=1;
while(t!=0){
cout>d>>m>>y;
t=first;
while(t!=0){
if(d==t->d && m==t->m && y==t->y){
cout<<"\n найденный по ключу элемент списка \n";
cout
Задача №3
Список, созданной в задаче №1, отсортировать по алфавиту.
Решение
/* подключение заголовочных файлов */
struct spisok{ char fam[20];
int d,m,y;
spisok *p; };
void main () {
int n,j;
cout<<"Введите количество записей: \n"; cin>>n;
spisok *t;
spisok *first=new spisok;
cout<<"Введите фамилию \n"; gets(first->fam);
cout<<"Введите дату рождения в виде: 7 11 2006 \ (7-е ноября 2006 года)";
cin>>first->d>>first->m>>first->y;
first->p=0;
t=first;
for (j=2; j<=n; j++){
spisok *z=new spisok;
if(t!=0) t->p=z;
cout<<"Введите фамилию \n"; gets(z->fam);
cout<<"Введите дату рождения в виде: 7 11 2006";
cin>>z->d>>z->m>>z->y;
t=z; t->p=0;
}
cout <<"Введенный список\n";
t=first;
j=1;
while(t!=0){
coutp!=0){
q=g;w=g->p;
if (strcmp(q->fam,w->fam)>0) {
if(q==t){t=w;r=w;q->p=w->p;w->p=q;}
else {q->p=w->p;w->p=q;r->p=w;r=w;}
flag=0; }
else {g=g->p;r=q;}
}
}while (flag==0);
cout <<"\n Отсортированный по алфавиту список\n";
j=1;
while(t!=0){
cout
Глава 2. Списковые структуры данных
2.1. Линейные списки (однонаправленные цепочки).
Списком называется структура данных, каждый элемент которой посредством указателя связывается со следующим элементом.
Каждый элемент связанного списка, во-первых, хранит какую-либо информацию, во-вторых, указывает на следующий за ним элемент. Так как элемент списка хранит разнотипные части (хранимая информация и указатель), то его естественно представить записью, в которой в одном поле располагается объект, а в другом – указатель на следующую запись такого же типа. Такая запись называется звеном, а структура из таких записей называется списком или цепочкой.
Лишь на самый первый элемент списка (голову) имеется отдельный указатель. Последний элемент списка никуда не указывает.
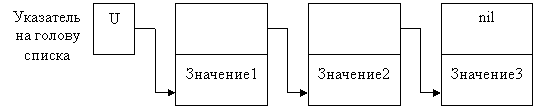
Рисунок 5 – Однонаправленный список
Type ukazat= ^ S;
S= record
Inf: integer;
Next: ukazat;
End;
В Паскале существует основное правило: перед использованием какого-либо объекта он должен быть описан. Исключение сделано лишь для указателей, которые могут ссылаться на еще не объявленный тип.
Чтобы список существовал, надо определить указатель на его начало.
Type ukazat= ^S;
S= record
Inf: integer;
Next: ukazat;
End;
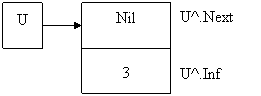
Рисунок 6 – Элемент списка
Создадим первый элемент списка:
New (u); {выделяем место в памяти}
u^. Next:= nil; {указатель пуст}
u^. Inf:=3;
Продолжим формирование списка. Для этого нужно добавить элемент либо в конец списка, либо в голову.
А) Добавим элемент в голову списка. Для этого необходимо выполнить последовательность действий:
- получить память для нового элемента;
- поместить туда информацию;
- присоединить элемент к голове списка.
New(x);
Readln(x^.Inf);
x^. Next:= u;
u:= x;
Б) Добавление элемента в конец списка. Для этого введем вспомогательную переменную, которая будет хранить адрес последнего элемента. Пусть это будет указатель с именем hv.
x:= hv;
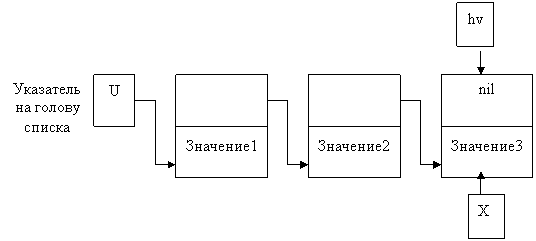
New( x^. next); {выделяем память для следующего элемента}
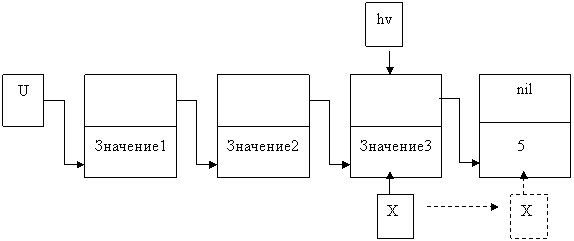
Рисунок 7 – Добавление элемента в конец списка.
x:= x^.next;
x^.next:= nil;
x^. inf:= 5;
hv:=x;
While u<> nil do
Begin
Writeln (u^.inf);
u:= u^.next;>
end;
Удаление элемента из списка
А) Удаление первого элемента. Для этого во вспомогательном указателе запомним первый элемент, указатель на голову списка переключим на следующий элемент списка и освободим область динамической памяти, на которую указывает вспомогательный указатель.
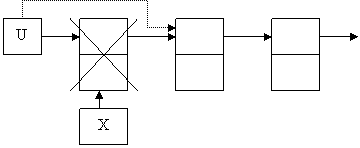
Рисунок 7 – Удаление первого элемента
x:= u;
u:= u^.next;
dispose(x);
Б) Удаление элемента из середины списка. Для этого нужно знать адреса удаляемого элемента и элемента, стоящего перед ним. Допустим, что digit – это значение удаляемого элемента.
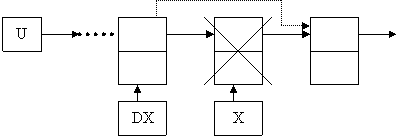
Рисунок 8 – Удаление элемента из середины списка
x:= u;
while ( x<> nil) and ( x^. inf<> digit) do
begin
dx:= x;
x:= x^.next;
end;
dx:= x^.next:
dispose(x);
В) Удаление из конца списка. Для этого нужно найти предпоследний элемент.
x:= u; dx:= u;
while x^.next<> nil do
begin
dx:= x; x:= x^.next;
end;
dx^.next:= nil;
dispose(x);
Прохождение списка. Важно уметь перебирать элементы списка, выполняя над ними какую-либо операцию. Пусть необходимо найти сумму элементов списка.
summa:= 0;
x:= u;
while x<> nil do
begin
summa:= summa+ x^.inf;
x:= x^.next;
end;
2.2. Динамические объекты сложной структуры
Использование однонаправленных списков при решении ряда задач может вызвать определенные трудности. Дело в том, что по однонаправленному списку можно двигаться только в одном направлении, от головы списка к последнему звену. Между тем нередко возникает необходимость произвести какую-либо операцию с элементом, предшествующим элементу с заданным свойством. Однако после нахождения элемента с данным свойством в однонаправленном списке у нас нет возможности получить удобный и быстрый способ доступа к предыдущему элементу.
Для устранения этого неудобства добавим в каждое звено списка еще одно поле, значением которого будет ссылка на предыдущее звено.
Type ukazat= ^S;
S= record
Inf: integer;
Next: ukazat;
Pred: ukazat;
End;
Динамическая структура, состоящая из звеньев такого типа, называется двунаправленным списком, который схематично можно изобразить так:

Рисунок 9 – Двунаправленный список
Наличие в каждом звене двунаправленного списка ссылки как на следующее, так и на предыдущее звено позволяет от каждого звена двигаться по списку в любом направлении. По аналогии с однонаправленным списком здесь есть заглавное звено. В поле Pred этого звена фигурирует пустая ссылка nil, свидетельствующая, что у заглавного звена нет предыдущего (так же, как у последнего нет следующего).
В программировании двунаправленные списки часто обобщают следующим образом: в качестве значения поля Next последнего звена принимают ссылку на заглавное звено, а в качестве значения поля Pred заглавного звена – ссылку на последнее звено:

Рисунок 10 – Кольцевой список
Как видно, здесь список замыкается в своеобразное «кольцо»: двигаясь по ссылкам, можно от последнего звена переходить к заглавному звену, а при движении в обратном направлении – от заглавного звена переходить к последнему. Списки подобного рода называют кольцевыми списками.
Существуют различные методы использования динамических списков:
- Стек – особый вид списка, обращение к которому идет только через указатель на первый элемент. Если в стек нужно добавить элемент, то он добавляется впереди первого элемента, при этом указатель на начало стека переключается на новый элемент. Алгоритм работы со стеком характеризуется правилом: «последним пришел – первым вышел».
- Очередь – это вид списка, имеющего два указателя на первый и последний элемент цепочки. Новые элементы записываются вслед за последним, а выборка элементов идет с первого. Этот алгоритм типа «первым пришел – первым вышел».
- Возможно организовать списки с произвольным доступом к элементам. В этом случае необходим дополнительный указатель на текущий элемент.
2.3. Примеры списковых структур на Паскале
Пример 1. Записать в стек 5 целых чисел. Затем изменить порядок следования элементов в стеке согласно варианту, совпадающему с последней цифрой учебного шифра, меняя только адресную часть записи стека. Считать, что адресная часть первого элемента указывает на отсутствие следующего элемента списка. После чего вывести на печать содержимое стека (в обратном порядке), освобождая занятую память.
Поменять местами 1-й с 5-м элементом в стеке, не изменяя расположение в динамической памяти информационной части всех элементов стека.
Решение
Представим исходное состояние стека в следующем виде :

Рисунок 11 – Исходное состояние стека
Затем, согласно варианту 5, порядок следования изменится следующим образом:
5
4
3
2
1
Рисунок 12 Изменение состояние стека
Пояснение
- Заполняем стек элементами от 1 до 5.
- Переменной UU присваиваем значение указателя на последний элемент в стеке – число 5.
- Переменной А2 присваиваем значение указателя на последний элемент в стеке – число 5.
- Двигаясь от последнего элемента стека до первого, запоминаем Динамические структуры данных. Линейные списки элементов: первого и пятого в переменных А1 и А5.
- Меняем значения указателей :
указатель 5-го элемента на А1;
указатель 1-го элемента на А5;
переменной UU присваиваем значение указателя 2-го элемента;
указатель 2-го элемента на А2.
- Далее, передвигаясь от последнего элемента стека числа 1 до первого – числа 5 выводим их значения.
Текст и результат работы программы представлены в приложении Б.
На рис. 13 изображено дерево с пятнадцатью вершинами. Корнем дерева служит точка 1. Кроме того, для каждой вершины указана целочисленная пометка, согласно следующей ниже таблицы.
Используя рекурсивные процедуры для перебора всех вершин дерева, пройти вершины дерева с помощью рекурсивной процедуры, дойти до вершины с пометкой 25 и вывести хотя бы один номер такой вершины.
3
1
2
4
5
7
61
8
9
10
11
12
13
14
15
Рисунок 13 – Дерево
|
Номер вершины |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
45 |
|
Число-пометка |
10 |
22 |
16 |
11 |
45 |
25 |
25 |
4 |
10 |
7 |
8 |
25 |
10 |
1 |
9 |
Решение
Задаем узел дерева записью, которая содержит метки: правая, левая, имя: номер узла и вес: число-пометка. Создаем три процедуры: поиск узла по содержимому-имени, вывод списка узлов и поиск узла с заданным весом.
Задаем начальные значения для корня дерева - текущего узла – его номер и вес. Значения правой и левой меток обнуляем.
Создаем цикл с постусловием, в котором будем формировать дерево и решать поставленную задачу.
Выводим имя текущего узла и его вес-пометку.
В зависимости от введенного значения переменной n: 1, 2,3 ,4 или 0 выполняются следующие задачи:
1: присваивается имя левому потомку и правому потомку;
2: вводится имя текущего узла;
3: выводит список всех созданных узлов дерева;
4: ищет номер узла с весом 25;
0: выход из цикла.
Текст и результат работы программы представлены в приложении А
Пример 3. В типизированном файле хранится некоторый текст, как последовательность слов, число слов  , длина слова
, длина слова  .
.
- сформировать линейный однонаправленный список из слов, хранимых в файле, используя структуру массива;
- модифицировать список, удалив все чётные по номеру слова, корректируя только связи, не удаляя элементы физически из массива;
- подсчитать в списке количество двухбуквенных слов;
- удалить из списка заданное слово, которое вводится с клавиатуры:
а) слово находится в начале списка;
б) слово находится в середине списка;
в) слово находится в конце списка;
г) слово находится в произвольном месте;
д) слово отсутствует в списке.
Текст и результат работы программы представлены в приложении В
Заключение
Хотя динамика и не является значительной особенностью языка Паскаль, все-таки существует возможность создавать динамические объекты и оперировать ими. Динамический объект представляет собой область памяти без идентификатора. Для обращения к этой области создается специальная переменная-ссылка, которая описывается в программе. Элементами множества значений типа ссылка на значение адреса оперативной памяти.
Чаще всего динамические структуры состоят из объектов, которые являются записями с нескольких полей, один или несколько из которых являются ссылками на такой же объект. Таким образом можно составлять цепочки или более сложные структуры объектов, которые ссылаются друг на друга. Размер таких структур ограничивается только объемом свободной памяти и может легко меняться при удалении и создании объектов, что и определило основную область их применения - моделирование нелинейных последовательных структур данных (например, деревьев). Однако, несмотря на почти полное отсутствие недостатков, динамические структуры все же имеют свои минусы. Главный из них - отсутствие наглядности программы, что вызывает значительные трудности при создании особо крупных структур.
Список использованной литературы
- Алексеев А., Евсеев Г., Мураховский В., Симонович С. Новейший самоучитель работы на компьютере. М.: ДЕСС КОМ, 2000. – 654 с.
- Белоусова Л.И., С.А.Веприк, А.С.Муравка. Сборник задач по курсу информатики. Учебно-методическое пособие.–Мю: Экзамен, 2007. – 412 с.
- Бен-Ари М. Языки программирования: Практический сравнительный анализ: Учебник для вузов. - М.: Мир, 2000. - 366 с.
- Вирт Н. Алгоритмы и структуры данных. – М.: Мир, 1989. – 562 с.
- Грызлов В.И., Грызлова Т.П. Турбо Паскаль 7.0. - М.: ДМК, 2000. - 416 с.
- Зуев Е. А. Программирование на языке Turbo Pascal 6.0, 7.0 – М.:Веста, Радио и связь, 1993 – 238 с.
- Информатика: Учебник/ под ред. Н.В.Макаровой. – М.: Финансы и статистика, 2007. – 768 с.
- Кассера В. Turbo Pascal 7.0. М.: Диасофт, 2003 – 356 с.
- Коффман Э. Б. Turbo Pascal = Turbo Pascal Web Update.– М.:Вильямс, 2005. – 308 с.
- Леонтьев В.П. Новейшая энциклопедия персонального компьютера. – М.: ОЛМА-ПРЕСС, 2008 – 626 с.
- Лилитко Е.П. Практикум по программированию. Начальный курс. - Переяславль-Залесский, 2007. – 156 с.
- Марченко А.И., Марченко Л.А. Программирование в среде Turbo Pascal 7.0 / Под ред. В. П.Тарасенко. — Киев: ВЕК+; М.: Бином Универсал, 2008. – 414 с.
- Моргун А. Н. Справочник по Turbo Pascal для студентов.– М.:Диалектика, 2006. – 162 с.
- Немнюгин С. А. Turbo Pascal – СПб: Питер, 2003. – 496 с.
- Себеста, Роберт У. Основные концепции языков программирования. - М.: Издательский дом «Вильямс», 2001. - 672 с.
- Симонович С.В. Информатика. Базовый курс. - Издательство Питер, 2003. – 640 с.
- Степанов А.Н. Информатика для студентов гуманитарных специальностей. - Издательство Питер, 2002. – 608 с.
- Терминологический словарь по основам информатики и вычислительной техники / А.П. Ершов, Н.М. Шанский, А.П. Окунева, Н.В. Баско. - М.: Просвещение, 2001.
- Фаронов В. Turbo Pascal в подлиннике. Полное руководство. – Автор: М.: Мир, 2004. – 1056 c.
- Фаронов В. В. Turbo Pascal – СПб.: BHV, 2007.– 268 с.
- Фаронов В.В. Turbo Pascal 7.0 Практика программирования М.:КноРус, 2011 – 414 с.
- Федоренко Ю. Алгоритмы и программы на Turbo Pascal. – М.: Финансы и статистика, 2001. – 240 с.
- Фёдоров М.А. Основы современных компьютерных технологий. – К.: МАУП, 2008. – 595 с.
- Фигурнов В.Э. IBM PC для пользователя. – М.: ИНФРА, 2007 – 458с.
- Шпак Ю.А. Название: Turbo Pascal 7.0 на примерах. – К.: ЮНИОР, 2003. – 496 с.
Приложение А
Листинг программы «Стек»
Program Prim5;
Const NN=5;
Type Uk=^Stek;
Stek = Record
I : Integer;
A : Uk
End;
Var
U1, U2: Uk;
I1, J, J1 : Integer ;
A1, A2, A5, UU : Uk;
Begin
U2 := Nil; I1 := 0;
Writeln;
for J:=1 to NN do begin
New(U1); Write('Введите число : '); Readln(I1);
U1^.I := I1; U1^.A := U2; U2 := U1; end;
A2:=u1;
{Переставим в стеке значения первого и пятого элементов}
{ Запомним значения указателей в соответств. элементах }
UU := U1; //сохраняет указатель на последний элемент стека – число 5
for J:=1 to NN do begin
U2:= U1^.A; J1:=NN-J+1; {Номер элемента}
If J1=1 then A5:=U2 else if J1=5 then A1:=U2; U1:=U2; end;
{Поменяем значения указателей должным образом}
U1:=UU;
For J:=1 to NN do
begin
U2:=U1^.A; J1:=NN-J+1;
if J1=1 then U1^.A := A1 else if J1=2 then begin UU:=U1^.A;U1^.A:=A2; end else if J1=5 then U1^.A:=A5;U1:=U2;
end;
Writeln;
U1:=UU; //после замены значения указывает на последний элемент стека– число 1
Repeat // Вывод элементов стека
Writeln('Элемент стека - ',U1^.I);
U2:=U1^.A;
Dispose(U1); //освобождает память, выделенную под адресацию элемента
U1:=U2;
Until U1=nil;
End.
Результат работы программы
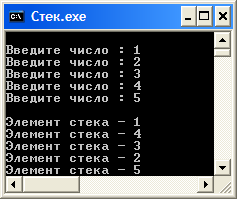
Приложение Б
Листинг программы «Дерево»
uses crt;
Const
{ данный массив-константа }
V : array [1..15] of integer = (10,22,16,11,45,25,25,4,10,7,8,25,10,1,9);
type node=record // запись, которая содержит имя узла, его вес-пометку и метки:правая-левая
name, ves: integer;
left, right: pointer;
end;
var
s,n:integer;
pnt_s,current_s,root: pointer;
pnt,current:^node;
procedure node_search (pnt_s:pointer; var current_s:pointer);
{Poisk uzla po soderzhimomu}
var
pnt_n:^node;
begin
pnt_n:=pnt_s; writeln(pnt_n^.name);
if not (pnt_n^.name=s) then
begin
if pnt_n^.left <> nil then
node_search (pnt_n^.left,current_s);
if pnt_n^.right <> nil then
node_search (pnt_n^.right,current_s);
end
else current_s:=pnt_n;
end;
procedure node_list (pnt_s:pointer);
{Vyvod spiska vseh uzlov dereva}
var
pnt_n:^node;
begin
pnt_n:=pnt_s; writeln(pnt_n^.name);
if pnt_n^.left <> nil then node_list (pnt_n^.left);
if pnt_n^.right <> nil then node_list (pnt_n^.right);
end;
procedure node_25 (pnt_s:pointer);
{Poisk uzla po весу-метке, равной 25}
var pnt_n,l,r:^node;
begin
pnt_n:=pnt_s;
if pnt_n^.left<>nil then
begin
l:=pnt_n^.left;
if l^.ves = 25 then write(' ',l^.name,' ');
if l^.left<>nil then node_25(l);
end;
if pnt_n^.right<>nil then
begin
r:=pnt_n^.right;
if r^.ves = 25 then write(' ',r^.name,' ');
if r^.right<>nil then node_25(r);
end;
end;
begin
clrscr;
new(current);root:=current;
current^.name:=1;
current^.ves:=10;
current^.left:=nil;
current^.right:=nil;
repeat
writeln('tekuwij uzel – ',current^.name,' ves=',current^.ves);
writeln('1-prisvoit imja levomu potomoku i prisvoit imja pravomu potomku');
writeln('2-sdelat uzel tekuwim');
writeln('3-vyvesti spisok vseh uzlov');
writeln('4-vivesti elenent, ravnye 25');
writeln('0-vihod');
read(n);
if n=1 then
begin {Sozdanie levogo potomka i Sozdanie pravigo potomka}
writeln('Sozdanie levogo potomka');
if current^.left= nil then new(pnt)
else pnt:= current^.left;
writeln('left ?');
readln;
read(s);
pnt^.name:=s;
pnt^.ves:=V[s];
pnt^.left:=nil;
pnt^.right:=nil;
current^.left:= pnt;
writeln('Sozdanie pravigo potomka');
if current^.right= nil then new(pnt)
else pnt:= current^.right;
writeln('right ?');
readln;
read(s);
pnt^.ves:=V[s];
pnt^.name:=s;
pnt^.left:=nil;
pnt^.right:=nil;
current^.right:= pnt;
end;
if n=2 then
begin {Poisk uzla}
writeln('name ?');
readln;
read(s);
current_s:=nil; pnt_s:=root;
node_search (pnt_s, current_s);
if current_s <> nil then current:=current_s;
end;
if n=3 then
begin {Vyvod spiska uzlov}
writeln;
writeln('spisok uzlov');
pnt_s:=root;
node_list(pnt_s);
writeln;
end;
if n=4 then
begin {poisk нужного uzlа = 25}
pnt_s:=current;
writeln('elementi, ravnye 25: ');
if current^.ves = 25 then writeln(' ',current^.name);
node_25(pnt_s);
writeln;
end;
until n=0;
end.
Результат работы программы
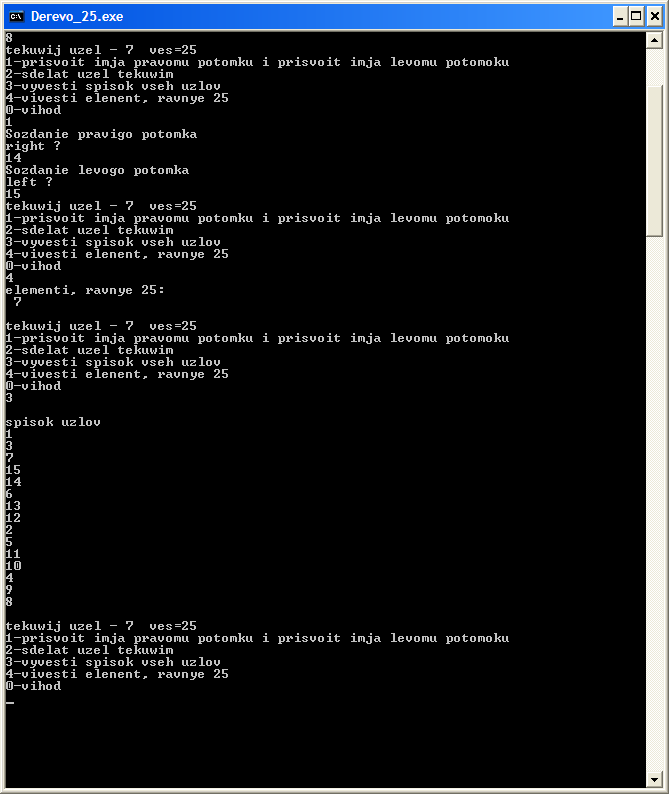
Приложение В
Листинг программы «Список»
program spisok;
type
link = ^linelink; {Формирование списка}
linelink = record
number : integer;
next : link
end;
var
start,last : link; {Начальный и конечный Динамические структуры данных. Линейные списки соответственно}
c : integer;
f1 : text;
procedure list ( var top, last : link; n1 : integer ); {Процедура формирования списка на основе входных данных в виде целого числа}
begin
if top=nil then {Если записываем первый элемент - записываем его в следующий за головой элемент, а в голове делаем буфер из нуля (его использовать не надо)}
begin
new(top);
top^.number:=0;
last:=start;
new(last^.next);
last:=last^.next;
last^.number:=n1;
last^.next:=nil
end
else {Если элемент не первый, то добавляем в конец}
begin
new(last^.next);
last:=last^.next;
last^.number:=n1;
last^.next:=nil
end
end;
procedure delete1 ( var top : link ); {Процедура удаления из списка отрицательных элементов}
var
last,uk : link;
begin
if top<>nil then {Если список не пуст}
begin
last:=top; {Указатель делаем на голову, в которой буфер, чтобы сравнивать последующие элементы}
while last^.next<>nil do {Пока не дойдем до последнего элемента, проверяем на отрицательность}
begin
if last^.next^.number < 0 then
begin
uk:=last^.next; {Запоминаем адрес удаляемого элемента}
last^.next:=last^.next^.next; {Связываем предыдущий и последующий элементы этого удаляемого элемента}
dispose (uk) {Очищаем память под удаляемый элемент}
end
else last:=last^.next {Если удаление не было произведено - мотаем список}
end
end
end;
procedure conclusion ( var top : link ); {Процедура вывода списка}
var
last : link;
begin
if top<>nil then {Если список не пуст}
begin
last:=top^.next; {Начинаем вывод с самого списка - буфер в голове нам не нужен}
while last<>nil do {Пока не достигнем конца списка - выводим содержимое и мотаем}
begin
writeln (last^.number);
last:=last^.next
end
end
end;
begin
start:=nil; {Динамические структуры данных. Линейные списки ни на что не указывают пока}
last:=nil;
writeln ('Удаление отрицательных чисел из списка');
writeln('Введите числа - окончание ввода - 0');
readln (c);
while c<>0 do {Ввод продолжать до первого нуля}
begin
list (start,last,c); {формирование}
readln (c)
end;
writeln ('------------');
delete1 (start); {удаление}
writeln('Икомый список чисел');
conclusion (start); {вывод}
readln
end.
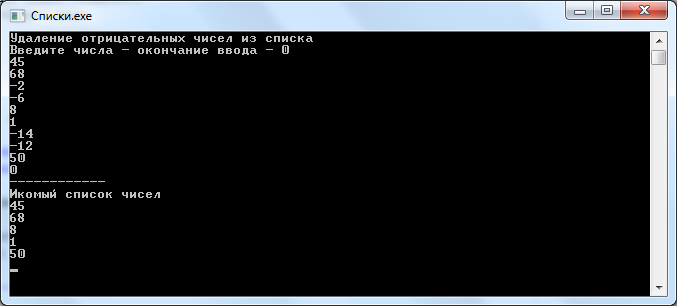
Результат работы программы

- Мотивации персонала и проектирование систем стимулирования труда
- История развития средств вычислительной техники ( Домеханический период)
- Разработка регламента выполнения процесса «Управление персоналом»
- Теории происхождения государства (Результаты исследования)
- Разработка сайта компании «ООО АрендЗем
- Автоматизация учета арендованных средств для компании ООО “АрендаЗем”
- Ценовые войны в теории и на практике»
- Основные нормативные документы, регулирующие ведение бухгалтерского учета в организациях. Международные стандарты бухгалтерского учета ( Национальная система нормативного регулирования бухгалтерского учета и ее структура )
- Организационная культура и ее роль в современных организациях ( ТФакторы, влияющие на организационную культуру )
- Стандарты управления проектами ( Управление проектами и его значение в деятельности современного предприятия )
- Развитие взглядов на управление человеческими ресурсами (новая теория и научные подходы)
- Корпоративная культура в организации