
Операции, производимые с данными (Единицы представления и хранения данных)
Содержание:

ВВЕДЕНИЕ
Данные – могут рассматриваться как признаки или записанные наблюдения, которые пока не используются, а только хранятся. Если есть возможность использовать их для уменьшения неопределённости чего-либо, данные становятся информацией. Компьютер работает с данными, а пользователь с информацией. Информация бывает: текстовая, звуковая, числовая, графическая, видео. Измерение данных основано на способе кодирования данных – при обработке их на компьютере в двоичной системе счисления.
Мир данных постоянно меняется и развивается каждую секунду. Это, в свою очередь, создало совершенно новое измерение роста и проблем для компаний по всему миру. Точно записывая данные, сохраняя, обновляя и отслеживая их на эффективной и регулярной основе, компании могут решать свои задачи, с одной стороны, и использовать огромные возможности, предлагаемые этим сектором, с другой стороны.
Собирая каждые малый или большой объём данных, компании используют указанную информацию для достижения своих целей на систематической основе, и наделяют свой бизнес стратегическим способом развития, который позволяет автоматизировать многие процессы, привлекать новых клиентов, а соответственно увеличить прибыль. В этом и заключается актуальность данной работы.
Объектом исследования являются данные. Предметом исследования операции, производимые над данными.
Целью данной работы является анализ операций, производимых над данными. Для выполнения поставленной цели требуется выполнить ряд задач:
- раскрыть понятие «данные»;
- изучить единицы представления и хранения данных;
- рассмотреть специфические операции, производимые над данными;
- проанализировать работу с данными на конкретном примере.
Методами проектного исследования данной работы являются теоретический анализ, изучение соответствующей литературы, сравнение.
Практическая значимость работы заключается в изучении вопросов использования операций над данными, поскольку любое взаимодействие с информацией, со сбором, хранением и другими видами, подразумевает под собой работу с данными.
В ходе работы использовался большой объем литературы, полный список которой представлен в конце этой работы.
1. ИССЛЕДОВАНИЕ ПРЕДМЕТНОЙ ОБЛАСТИ
1.1 Понятие «данные»
Над любыми структурами данных могут выполняться четыре общие операции: создание, уничтожение, выбор (доступ), обновление.
Операция создания заключается в выделении памяти для структуры данных. Память может выделяться в процессе выполнения программы или на этапе компиляции. В ряде языков (например, в С) для структурированных данных, конструируемых программистом, операция создания включает в себя также установку начальных значений параметров, создаваемой структуры.
Для структур данных, объявленных в программе, память выделяется автоматически средствами систем программирования либо на этапе компиляции, либо при активизации процедурного блока, в котором объявляются соответствующие переменные. Программист может и сам выделять память для структур данных, используя имеющиеся в системе программирования процедуры, функции выделения, освобождения памяти. В объектно-ориентированных языках программирования при разработке нового объекта для него должны быть определены процедуры создания и уничтожения [26].
Главное заключается в том, что независимо от используемого языка программирования, имеющиеся в программе структуры данных, не появляются «из ничего», а явно или неявно объявляются операторами создания структур. В результате этого всем экземплярам структур в программе выделяется память для их размещения.
Операция уничтожения структур данных противоположна по своему действию операции создания. Операция уничтожения помогает эффективно использовать память.
Операция выбора используется программистами для доступа к данным внутри самой структуры. Форма операции доступа зависит от типа структуры данных, к которой осуществляется обращение. Метод доступа — один из наиболее важных свойств структур, особенно в связи с тем, что это свойство имеет непосредственное отношение к выбору конкретной структуры данных.
Операция обновления позволяет изменить значения данных в структуре данных. Примером операции обновления является операция присваивания, или, более сложная форма — передача параметров [26].
Вышеуказанные четыре операции обязательны для всех структур и типов данных. Помимо этих общих операций для каждой структуры данных могут быть определены операции специфические, работающие только с данными данного типа (данной структуры). Специфические операции рассматриваются при рассмотрении каждой конкретной структуры данных.
1.2 Единицы представления и хранения данных
Данные — это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства. Единицы измерения информации.
В качестве единицы информации условились принять один бит. Бит– количество информации необходимое для различения двух равновероятных сообщений. Бит – слишком малая единица измерения. На практике чаще применяется более крупная единица – байт, равная восьми битам. Именно 8 битов требуется для того, чтобы закодировать любой из 256 символов алфавита клавиатуры компьютера [24].
Совокупность двоичных разрядов, выражающих числовые или иные данные, образует некий битовый рисунок. Практика показывает, что с битовым представлением удобнее работать, если этот рисунок имеет регулярную форму. В настоящее время в качестве таких форм используются группы из восьми битов, которые называются байтами. Группа из 16 взаимосвязанных бит (двух взаимосвязанных байтов) в информатике называется словом. Соответственно, группы из четырех взаимосвязанных байтов (32 разряда) называются удвоенным словом, а группы из восьми байтов (64 разряда) — учетверенным словом.
В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл — это последовательность произвольного числа байтов, обладающая уникальным собственным именем. Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла. Таким образом, файл – программа с именем на диске. Каталог – место, где регистрируются файлы.
Проще всего представить себе файл в виде безразмерного канцелярского досье, в которое можно по желанию добавлять содержимое или извлекать его оттуда.
Хранение файлов организуется в иерархической структуре, которая в данном случае называется файловой структурой. В качестве вершины структуры служит имя носителя, на котором сохраняются файлы. Далее файлы группируются в каталоги (папки), внутри которых могут быть созданы вложенные каталоги (папки). Путь доступа к файлу начинается с имени устройства и включает все имена каталогов (папок), через которые проходит.
Под файлом понимают логически связанную совокупность однотипных данных или программ, для размещения которой во внешней памяти выделяется именованная область [12, 22].
Файловая система обеспечивает возможность доступа к конкретному файлу и позволяет найти свободное место при записи нового файла. Она определяет схему записи информации, содержащейся в файлах, на физический диск.
Файлы на диске записываются в свободные кластеры, поэтому фрагменты одного и того же файла могут находиться в разных местах диска. Относительно производительности системы наиболее предпочтительным является такой вариант размещения файла, когда его фрагменты занимают подряд идущие кластеры. Windows9х использует файловые системы FAT16 и FAT32, WindowsNT – файловую систему NTFS. Каждый файл имеет имя и расширение. Расширение указывает на тип файла.
Имя файла в Windows (полное, с указанием директорий, его содержащих) может иметь до 255 символов. Расширение отделяется от имени точкой. В Windows каждому типу файла ставится в соответствие свой значок.
Система управления базами данных хранит, организует и управляет большим объемом информации в одном программном приложении. Использование этой системы повышает эффективность бизнес-операций и снижает общие затраты. База данных представляет собой набор информации, которая организована таким образом, что её можно легко извлечь, управлять ею и обновлять.
Данные упорядочены по строкам, столбцам и таблицам и индексируются для облегчения поиска релевантной информации. Данные обновляются, расширяются и удаляются по мере добавления новой информации. Базы данных обрабатывают рабочие нагрузки для создания и обновления самих себя, запроса данных, которые они содержат, и запуска приложений.
Компьютерные базы данных обычно содержат агрегирование записей или файлов данных, таких как транзакции продаж, каталоги продуктов и запасы, а также профили клиентов.
Как правило, диспетчер баз данных предоставляет пользователям возможность контролировать доступ для чтения и записи, определять создание отчетов и анализировать его использование. Некоторые базы данных обеспечивают соответствие “ACID” (атомарность, согласованность, изоляцию и долговечность), чтобы гарантировать совместимость данных и завершение транзакций [5, 8, 19].
Вот лишь некоторые из действий, которые можно выполнять благодаря базам данных, которые трудно, если не невозможно, выполнить в электронной таблице:
- извлечь все записи, соответствующие определенным критериям;
- обновлять все записи сразу;
- перекрестные ссылки в разных таблицах;
- выполнять сложные совокупные вычисления.
База данных состоит из нескольких таблиц. Также, как таблицы Excel, таблицы базы данных состоят из столбцов и строк. Каждый столбец соответствует атрибуту, и каждая строка соответствует одной записи. Каждая таблица должна иметь уникальное имя в базе данных.
Важным аспектом таблицы является то, что каждый должен иметь столбец первичного ключа, чтобы каждая строка (или запись) иметь уникальное поле для ее идентификации.
Базы данных распространены в крупных системах мейнфреймов, но также присутствуют в небольших распределенных рабочих станциях и системах среднего уровня, таких как AS и 400 IBM и персональные компьютеры.
Базы данных развивались с момента их создания в 1960-х годах, начинали с иерархических и сетевых баз данных, в 1980-х годах с объектно-ориентированных баз данных и развились до сегодняшних современных реляционных баз данных и NoSQL, а также до облачных баз данных [11].
В одном представлении базы данных можно классифицировать в соответствии с типом контента: библиографическим, текстовым, цифровым и так далее. При вычислении, базы данных иногда классифицируются в соответствии с их организационным подходом. Существует множество различных типов баз данных, начиная от наиболее распространенного подхода, реляционной базы данных до распределенной базы данных, облачной базы данных или базы данных NoSQL [14].
Система управления базами данных (СУБД) — это системное программное обеспечение для создания и управления базами данных. СУБД предоставляет пользователям и программистам систематический способ создания, извлечения, обновления и управления данными.
СУБД позволяет конечным пользователям создавать, считывать, обновлять и удалять данные в базе данных. СУБД по существу служит интерфейсом между базой данных и конечными пользователями или прикладными программами, гарантируя, что данные последовательно организованы и остаются легкодоступными.
СУБД управляет тремя важными вещами: данными, механизмом базы данных, который позволяет осуществлять доступ к данным, блокировкой и изменением, а также схемой базы данных, которая определяет логическую структуру базы данных. Эти три основных элемента помогают обеспечить параллелизм, безопасность, целостность данных и единообразные процедуры администрирования. Типичные задачи администрирования базы данных, поддерживаемые СУБД, включают управление изменениями, контроль и настройку производительности, а также резервное копирование и восстановление. Многие системы управления базами данных также несут ответственность за автоматические откаты, перезагрузки и восстановление, а также регистрацию и аудит деятельности [15, 17].
СУБД наиболее полезно для обеспечения централизованного представления данных, к которым могут обращаться несколько пользователей, из нескольких мест, контролируемым образом. СУБД может ограничить данные, которые видит конечный пользователь, а также то, как этот конечный пользователь может просматривать данные, предоставляя множество представлений о единой схеме базы данных. Конечным пользователям и программным программам не нужно понимать, где находятся данные физически, или на каком носителе данных он находится, поскольку СУБД обрабатывает все запросы.
СУБД может обеспечить как логическую, так и физическую независимость данных. Это означает, что он может защитить пользователей и приложения от необходимости знать, где хранятся данные или быть обеспокоенным изменениями в физической структуре данных (хранилище и оборудование). Пока программы используют интерфейс прикладного программирования (API) для базы данных, предоставляемой СУБД, разработчикам не придется изменять программы только потому, что были внесены изменения в базу данных [7, 13].
С реляционными СУБД (RDBMS) этот API — это SQL, стандартный язык программирования, используемый для определения, защиты и доступа к данным в РСУБД.
Популярные модели баз данных и их системы управления включают:
- Системы управления реляционными базами данных (RDMS), которые могут быть адаптированы под большинство случаев использования.
- СУБД NoSQL — хорошо подходит для слабо определенных структур данных, которые могут развиваться с течением времени.
- Система управления базами данных в памяти (IMDBMS) — обеспечивает более быстрое время отклика и лучшую производительность.
- Система управления базами данных Columnar (CDBMS) — хорошо подходит для хранилищ данных, которые имеют большое количество аналогичных элементов данных.
- Облачная система управления данными — поставщик облачных услуг отвечает за предоставление и обслуживание СУБД [1].
Использование СУБД для хранения и управления данными имеет свои преимущества, но также и накладные расходы. Одним из самых больших преимуществ использования СУБД является то, что она позволяет конечным пользователям и прикладным программистам получать доступ и использовать одни и те же данные при управлении целостностью данных. Данные лучше защищены и поддерживаются, когда их можно использовать с СУБД вместо создания новых итераций тех же данных, которые хранятся в новых файлах для каждого нового приложения. СУБД обеспечивает централизацию хранилищам данных, доступ к которым осуществляется несколькими пользователями контролируемым образом [8, 17].
Центральное хранение и управление данными в СУБД обеспечивает:
- абстракцию и независимость данных;
- безопасность данных;
- механизм блокировки для одновременного доступа;
- эффективный обработчик для сбалансирования потребностей нескольких приложений с использованием одних и тех же данных;
- возможность быстрого восстановления после сбоев и ошибок, включая перезапуск и возможность восстановления;
- надежные возможности целостности данных;
- регистрация и аудит деятельности;
- простой доступ с использованием стандартного интерфейса прикладного программирования (API);
- единообразные процедуры администрирования данных.
Другим преимуществом СУБД является то, что ее можно использовать для навязывания логической структурированной организации данных. СУБД обеспечивает экономию при обработке больших объемов данных, поскольку она оптимизирована для таких операций [19].
СУБД может также предоставлять множество представлений о единой схеме базы данных. Его вид определяет, какие данные пользователь видит и как этот пользователь видит данные. СУБД обеспечивает уровень абстракции между концептуальной схемой, которая определяет логическую структуру базы данных и физическую схему, которая описывает файлы, индексы и другие физические механизмы, используемые базой данных. Когда используется СУБД, системы могут быть изменены намного легче при изменении бизнес-требований. Новые категории данных могут быть добавлены в базу данных без нарушения существующей системы, и приложения могут быть изолированы от того, как данные структурируются и сохраняются [12, 17].
Разумеется, СУБД должна выполнять дополнительную работу для обеспечения этих преимуществ, тем самым принося с собой накладные расходы. СУБД будет использовать больше памяти и процессорной мощности, чем простая система хранения файлов. И, конечно, для разных типов СУБД потребуются разные типы и уровни системных ресурсов.
Таким образом, в рамках данной главы было раскрыто понятие «данные», рассмотрены вопросы хранения данных.
2. ОСОБЕННОСТИ РАБОТЫ С ДАННЫМИ
2.1 Специфические операции над данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов, обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
- сбор – накопление информации с целью обеспечения достаточной полноты для принятия решений;
- формализация – приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
- фильтрация – отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
- сортировка – упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
- архивация – организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
- защита – комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя - клиентом;
- преобразование данных – перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например, книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства – телефонные модемы.
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно. Сейчас важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление, наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой [26].
Технологии доступа при выполнении действий изменения элемента показана на рисунке 1.
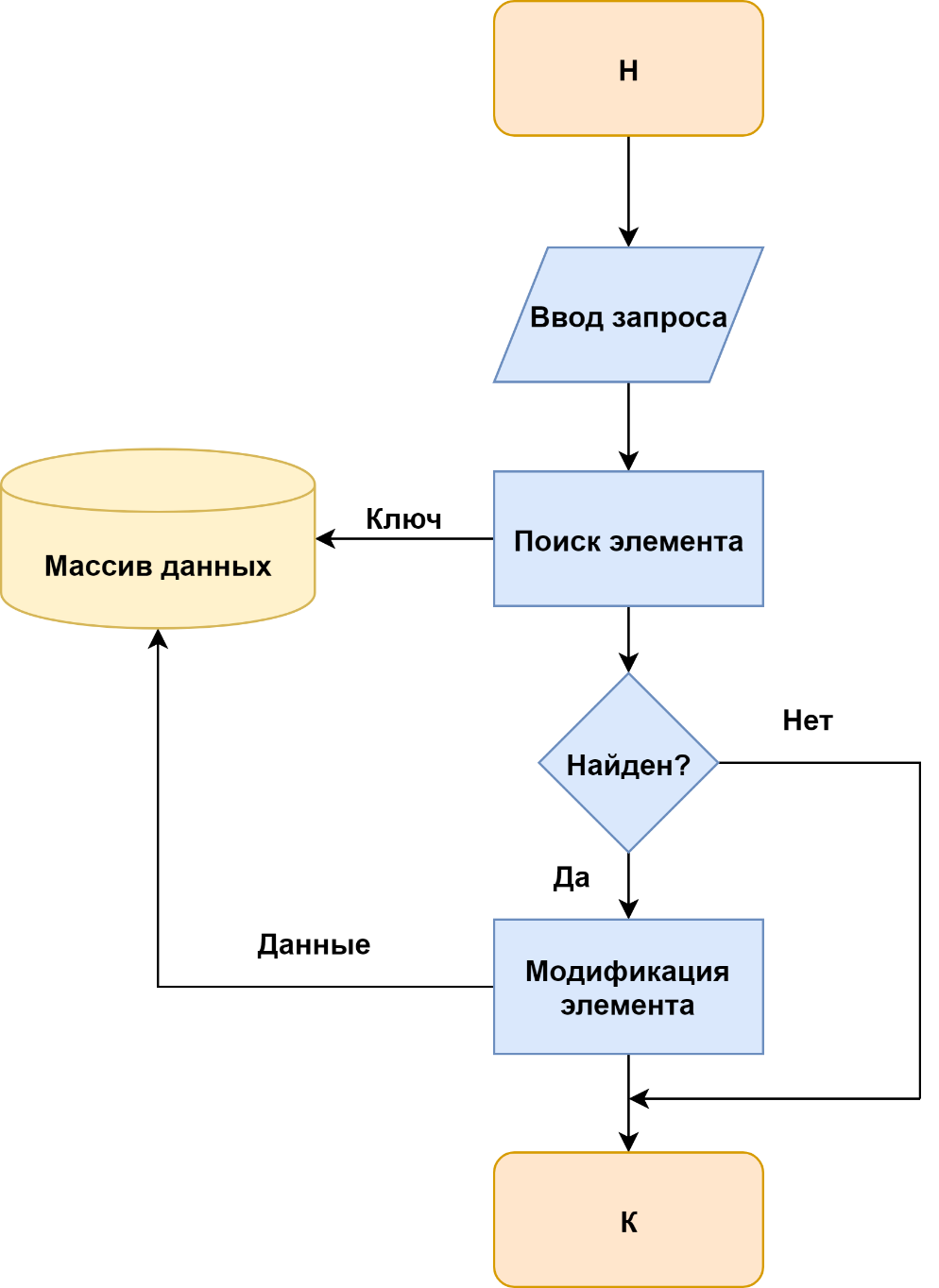
Рисунок 1 – Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рисунке 2.
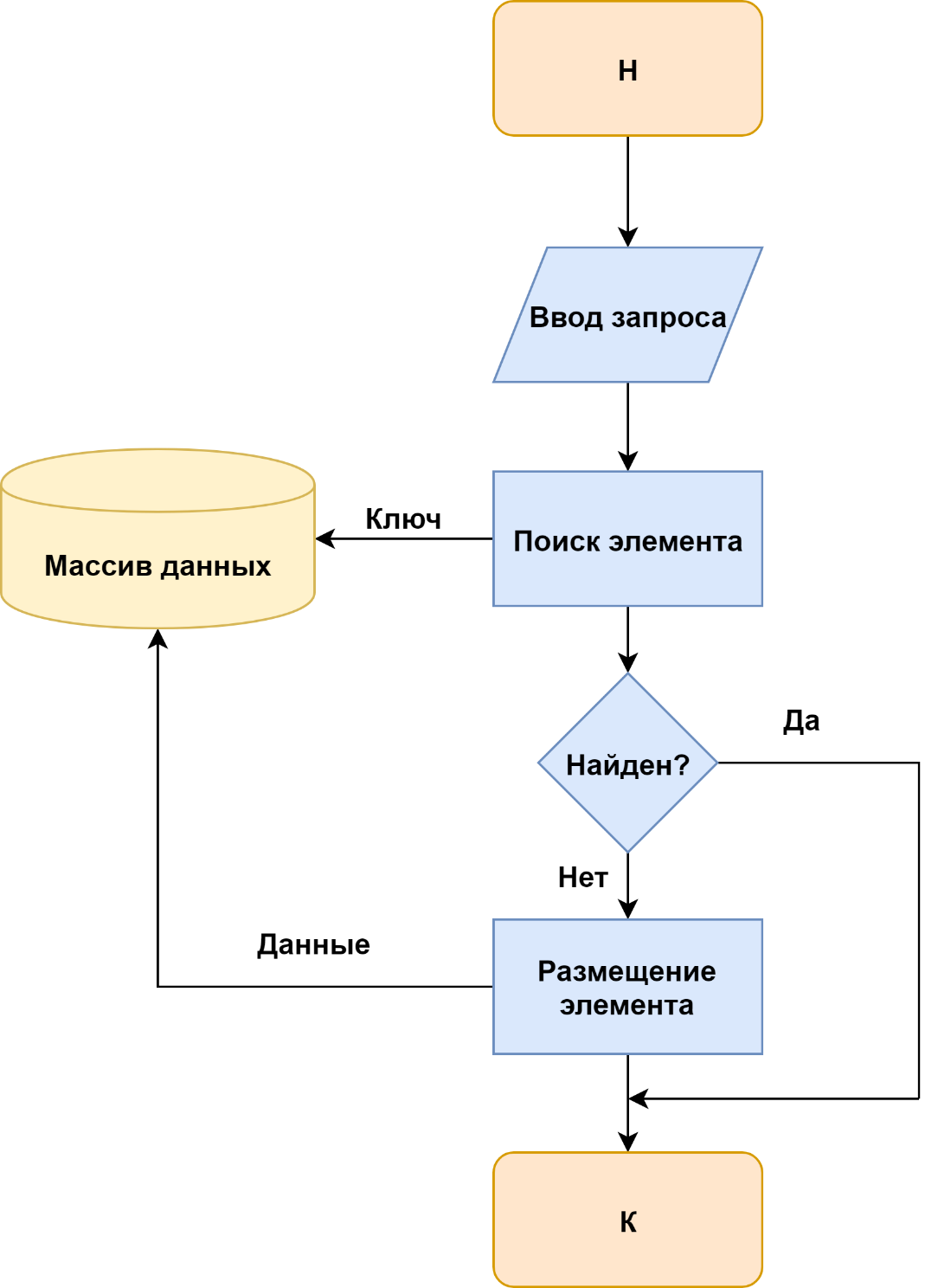
Рисунок 2 – Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рисунке 3.
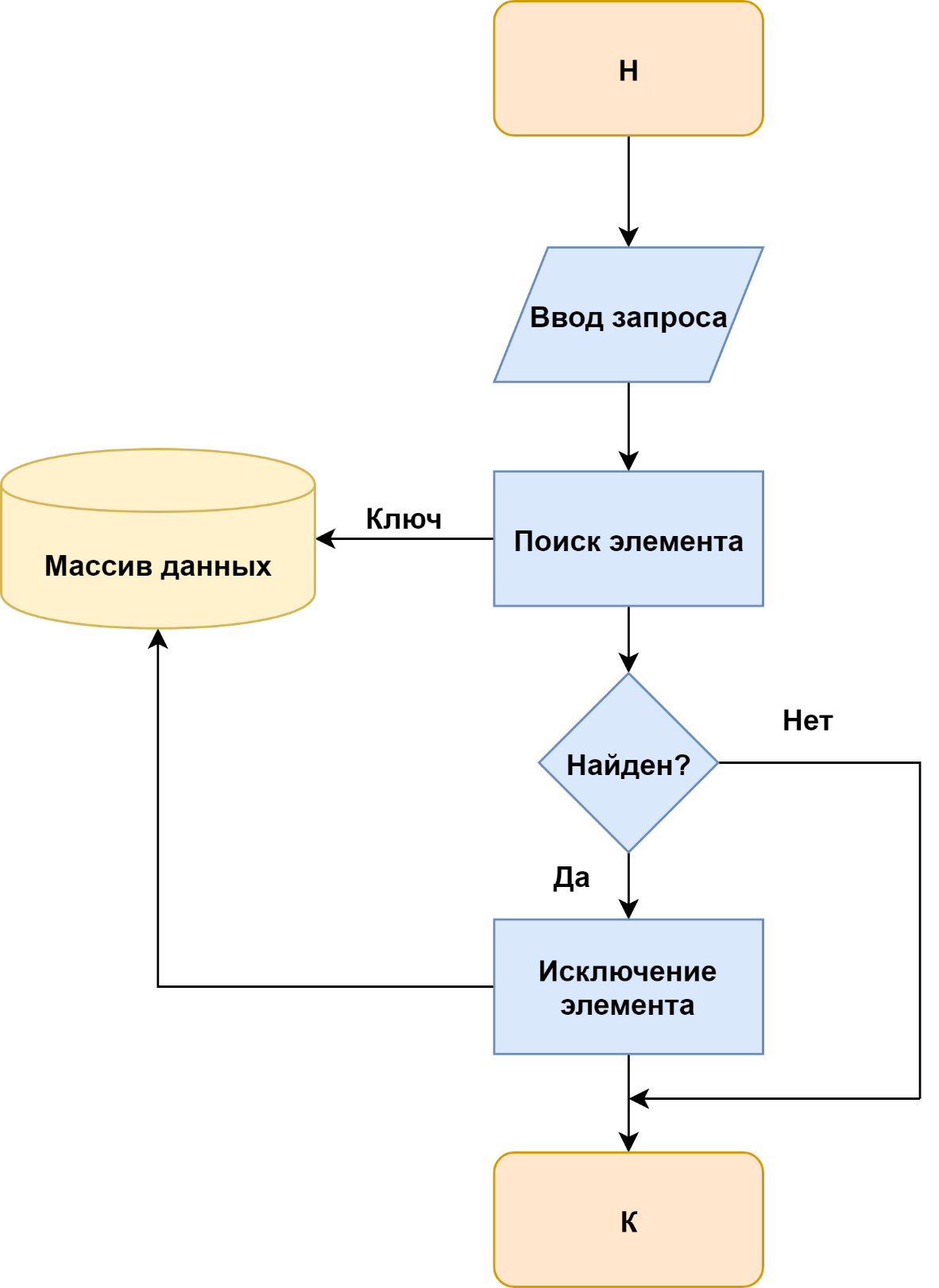
Рисунок 3 – Технология удаления элемента
Технология просмотра элемента приведена на рисунке 4. Различие в схемах состоит в том, что по технологии рисунках 1 и 2 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рисунке 3 воздействие не связано с передачей данных, а по схеме рисунка 4 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
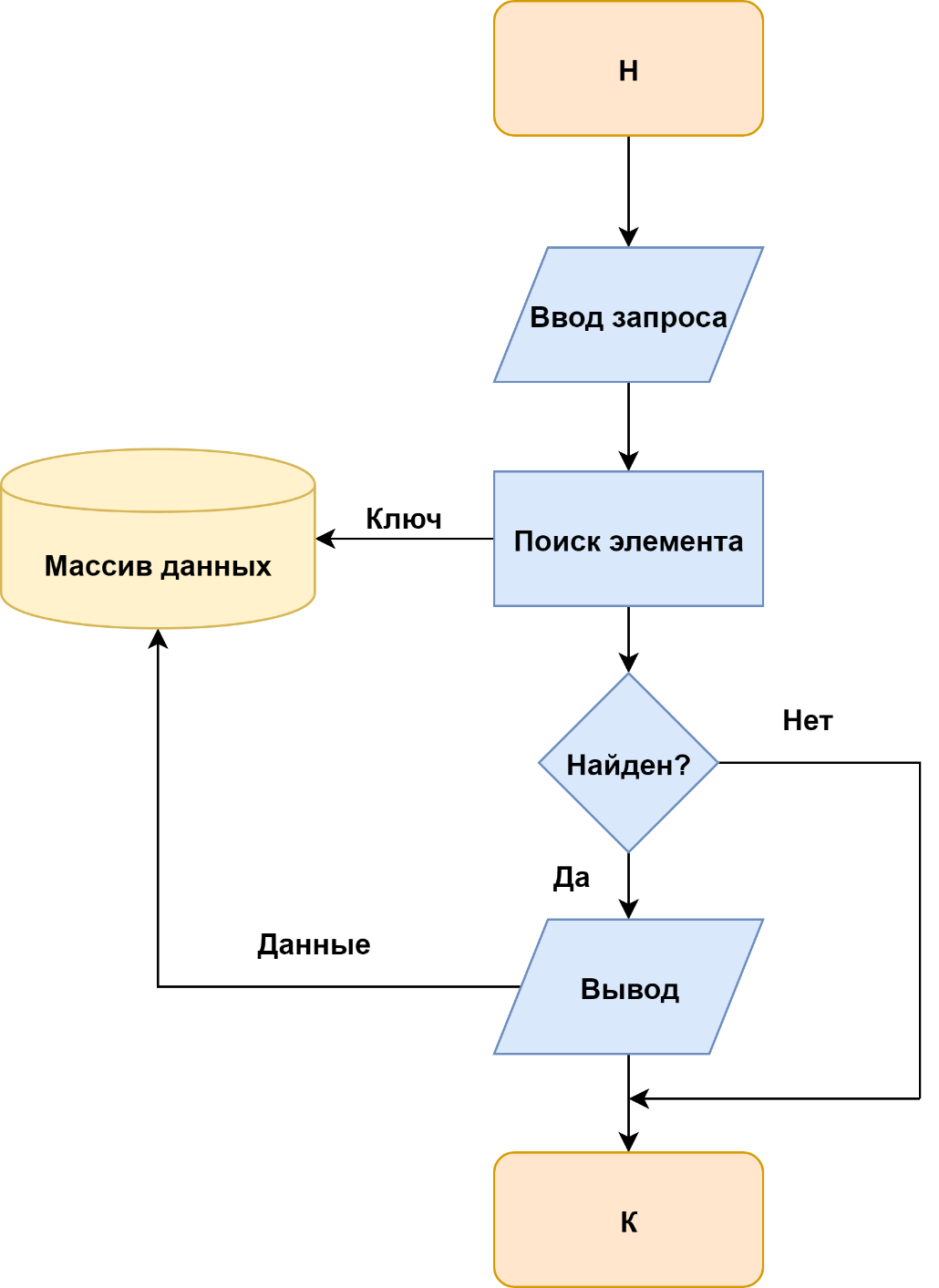
Рисунок 4 – Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения [26].
В силу вышесказанного, основное внимание в данном разделе уделено задачам организации хранения данных разных видов и поиска по ключам, входящим в запросы пользователей, поскольку поисковые операции и определяют, в основном, продолжительность различных действий над информационным массивом. Из приведенных типов действий в рассмотрение включены добавление и просмотр элементов данных, поскольку добавление связано с воздействием на информационный массив и изменением его объема (удаление является обратным действием по отношению к добавлению), а просмотр – это наиболее часто выполняемые действия на практике. При этом рассматриваются общие вопросы работы с текстовой и структурированной информацией, методы и модели, используемые при организации хранения, поиска и добавления данных.
Излагаемые модели данных и алгоритмы доступа к ним составляют «brainware» современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
2.2 Работа с данными на примере My SQL Server
Основной способ извлечения данных из базы данных SQL Server является запрос. Запрос выражается с использованием варианта SQL под названием T-SQL, диалект Microsoft SQL Server разделяет с Sybase SQL Server. Запрос декларативно указывает, что нужно извлечь. Он обрабатывается процессором запросов, который вычисляет последовательность шагов, которые необходимы для извлечения запрошенных данных. Последовательность действий, необходимых для выполнения запроса, называется планом запроса. Возможно, существует несколько способов обработки одного и того же запроса. Например, для запроса, который содержит оператор объединения и выбор оператора, выполняющий объединение в обеих таблицах. В таком случае SQL Server выбирает вариант, который, как ожидается, даст результаты в кратчайшие сроки. Это называется оптимизацией запросов и выполняется самим процессором запросов [7].
SQL Server включает оптимизатор запросов на основе затрат, который пытается оптимизировать стоимость с учетом ресурсов, необходимых для выполнения запроса. Учитывая запрос, оптимизатор запросов смотрит на схему базы данных, статистику базы данных и загрузку системы в это время. Затем он решает, какая последовательность для доступа к таблицам, указанным в запросе, какая последовательность для выполнения операций и какой метод доступа используется для доступа к таблицам. Например, если таблица имеет связанный индекс, должен ли использоваться индекс или нет: если индекс находится в столбце, который не является уникальным для большинства столбцов (низкая «избирательность»), может быть не стоит использовать индекс для доступа к данным. Наконец, он решает, будет ли выполняться запрос одновременно или нет. Хотя одновременное выполнение является более дорогостоящим с точки зрения общего времени процессора, поскольку выполнение фактически разделено на разные процессоры, это может означать, что он будет выполняться быстрее. После создания запроса он временно кэшируется. Для дальнейших вызовов одного и того же запроса используется кэшированный вариант. Неиспользованные варианты отбрасываются через некоторое время [4, 18].
SQL Server также позволяет определять хранимые процедуры. Хранимые процедуры — это параметризованные запросы T-SQL, которые хранятся на самом сервере (и не выдаются клиентским приложением, как в случае с общими запросами). Хранимые процедуры могут принимать значения, отправленные клиентом в качестве входных параметров, и отправлять результаты в виде выходных параметров. Они могут вызывать определенные функции и другие хранимые процедуры, включая одну и ту же хранимую процедуру (до определенного количества раз). Они могут быть выборочно обеспечены доступом. В отличие от других запросов, хранимые процедуры имеют связанное имя, которое используется во время выполнения для разрешения фактических запросов. Кроме того, поскольку код не нужно отправлять клиенту каждый раз (поскольку его можно получить по имени), он снижает сетевой трафик и несколько улучшает производительность. Варианты выполнения хранимых процедур также кэшируются по мере необходимости.
Команды SQL — это набор инструкций, которые используются для взаимодействия с базой данных, такой как Sql Server, MySql, Oracle и т. д. Команды SQL берут на себя всё взаимодействие с базой данных.
Разные команды sql для разных целей. Можно сгруппировать Sql-команды в пять основных категорий, которые разделены на группы по функциональности.
1. Язык определения данных (DDL)
- CREATE TABLE – создать таблицу;
- ALTER TABLE – изменить таблицу;
- DROP TABLE – удалить таблицу;
- CREATE INDEX – создать индекс;
- ALTER INDEX – изменить индекс;
- DROP INDEX – удалить индекс.
2. Язык манипулирования данными (DML)
- INSERT - добавление;
- UPDATE - обновление;
- DELETE - удаление.
3. Язык запросов данных (DQL)
В этой группе только одна команда SELECT. Она используется для извлечения информации.
4. Язык управления транзакциями (TCL)
- SET TRANSACTION – начинает транзакцию и устанавливает ее базовые характеристики;
- COMMIT – заканчивает текущую транзакцию сохранением изменений в базе данных и начинает новую транзакцию;
- ROLLBACK – заканчивает текущую транзакцию отменой изменений в базе данных и начинает новую транзакцию;
- SAVEPOINT – устанавливает контрольные точки (точки прерывания) для транзакции, разрешая неполный откат.
5. Язык управления данными (DCL)
Эти SQL-команды используются для обеспечения безопасности объектов базы данных, таких как таблица, представление, хранимая процедура и т. Д. В этой категории есть команды GRANT и REVOKE [21].
Соединения SQL используются для извлечения / извлечения данных из двух или более таблиц данных на основе условия соединения. Условие соединения - это отношение между некоторыми столбцами в таблицах данных, которые участвуют в объединении SQL. В основном таблицы базы данных связаны друг с другом ключами. Используются эти отношения ключей в SQL-соединениях [15].
На Sql Server у нас есть только три типа объединений. Используя эти объединения, мы извлекаем данные из нескольких таблиц на основе условия.
1. Внутреннее соединение
Он возвращает значения, которые есть в обеих таблица. Синтаксис для Inner Join представлен в листинге 1:
Листинг кода 1.
Select * from table_1 as t1Select * from table_1 as t1
inner join table_2 as t2
on t1.IDcol=t2.IDcol
2. Левая внешняя связь
Он возвращает значения из левой, которые согласованы с правой таблицей. Синтаксис для левой внешней связи представлен листингом 2.
Листинг кода 2.
Select * from table_1 as t1Select * from table_1 as t1
left outer join table_2 as t2
on t1.IDcol=t2.IDcol
3. Правостороннее соединение
Тоже самое, что и на предыдущем шаге, только наоборот. Синтаксис для правого внешнего соединения представлен листингом 3.
Листинг кода 3.
Select * from table_1 as t1Select * from table_1 as t1
right outer join table_2 as t2
on t1.IDcol=t2.IDcol
Основными преимуществами SQL Server являются повышенная надежность, повышенная производительность, снижение сетевого трафика и повышение масштабируемости. Недостатками являются увеличенная стоимость развертывания и более сложная среда поддержки. Для небольших рабочих групп до десятка пользователей в локальной сети со скромными требованиями к данным и без сверхвысоких требований к надежности, то доступ, вероятно, он не подойдет. Вне этих параметров лучшим решением будет именно клиент-серверный подход с SQL Server.
Он обладает многозадачные функциями, которые позволяют выполнять дополнительную логику, такую как объявление переменной, заполнение переменных таблицы и обновление значений внутри нее, циклическое перемещение записей и многое другое. Многозадачные функции — отличный способ переписать хранимую процедуру, если выполняются следующие условия:
- вывод хранимой процедуры может использоваться другими подпрограммами;
- хранимые процедуры не вносят никаких изменений данных в постоянные таблицы;
- единственная цель хранимой процедуры создать набор результатов, который, возможно, придется манипулировать до его возвращения пользователю;
- хранимые процедуры не выполняют никаких задач, запрещенных внутри UDF.
Таким образом, можно сделать следующие выводы касательно использования MS SQL Server:
- Он поставляется с множеством отличных инструментов, таких как Sql Server Profiler, SQL Server Management Studio, и все это сэкономит много времени на разработку и устранение неполадок.
- Это один из главных продуктов Microsoft, поэтому она хорошо поддерживается документацией.
- SQL-сервер быстро развивается в нескольких технологиях, в Sql Server 2012 ввели индексирование на основе столбцов, что в некотором роде представляет собой введение в NoSQL в sql-сервере.
- Сервер Sql 2017 поставляться с оптимизированной памятью
- T-SQL остается последовательным в новых версиях SQL-сервера.
- Версия SQL Express бесплатна и включает почти всю функциональность полнофункционального SQL-сервера с ограничением поддержки на 10 ГБ базы данных.
- Для подключения к нему есть практически все платформы подключения.
В рамках данной главы были рассмотрены примеры работы с данными на примере My SQL Server, а также специфические операции над данными.
ЗАКЛЮЧЕНИЕ
В данной работе были рассмотрены операции, производимые над данными. Они играют большую роль в современном мире, так как являются структурной составляющей любой области деятельности человека.
В ходе работы было выполнено ряд задач:
- раскрыто понятие «данные»;
- изучены единицы представления и хранения данных;
- рассмотрены специфические операции, производимые над данными;
- проанализирована работа с данными на конкретном примере.
Данными могут быть любые символы, текст, слова, цифры, картинки, звук или видео, и вне контекста они почти нечего не значат для человека. А вот информация полезна и как правило формируется таким образом, чтобы быть понятной людям.
Компьютеры считывают данные, но это не значит, что они их на самом деле понимают. С помощью формул, программных сценариев или приложений, компьютер может превратить данные в информацию понятную человеку.
Динамические свойства модели данных выражаются множеством операций, которые определяют допустимые действия над некоторой реализацией базы данных для перевода ее из одного состояния в другое. Это множество операций соотносят с языком манипулирования данными.
Реализация любой конкретной операции над данными включает в себя селекцию данных, т. е. выделение из всей совокупности именно тех данных, над которыми должна быть выполнена требуемая операция, и действие над выделенными данными, которое определяет характер операции.
Условие селекции специфицируется в виде некоторого критерия отбора данных, над которыми должно быть произведено требуемое действие. Селекция выполняется любым из способов с использованием: логической позиции данного; значений данных; связей между данными.
В работе были рассмотрены основные и специфические способы взаимодействия с данными такие как:
- сбор;
- формализация;
- фильтрация;
- сортировка;
- архивация;
- защита.
В рамках данной работы на примере базы данных My SQL Server были рассмотрены вопросы операции, производимые с данными на конкретных примерах. Данная работа может быть расширена изучением других операций над данными и более глубоким изучением специфических операций.
СПИСОК ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
- Баранникова И. В., Темкин И. О., Конов И. С. Аппаратные средства хранения и обработки данных. Технические средства хранения данных. – МИСиС, 2018. – 46 с.
- Браст, Э.Дж. Разработка приложений на основе Microsoft SQL Server 2008 / Э.Дж. Браст. - М.: Русская Редакция, 2010. - 751 c.
- Бен-Ган И. Microsoft SQL Server 2012. Основы T-SQL. — Эксмо, 2012. — 401 с.
- Бондарь А. Microsoft SQL Server 2012. — БХВ-Петербург, 2013. — 598 с.
- Вознесенский А. С. Средства передачи и обработки информации. – МИСиС, 2019. – 212 с.
- Гущин А.Н. Базы данных. 2-е изд., испр. и доп.: учебно-методическое пособие. М.-Берлин: Директ-Медиа, 2015. – 311 с.
- Диго С.М. Базы данных. Проектирование и создание. – УМК: ЕАОИ, 2011. – 171 с.
- Додонов М.В. Распределенная обработка данных в современных СУБД. – Самара, 2010. – 106 с.
- Дунаев В. Базы данных. Язык SQL для студента. — БХВ-Петербург, 2006. — 280 с.
- Кириллов В.В., Громов Г.Ю. Введение в реляционные базы данных. — БХВ-Петербург, 2008. — 451 с.
- Левчук Е. А. Технологии организации, хранения и обработки данных. – Вышэйшая школа, 2007. – 241 с.
- Михеев Р. MS SQL Server 2005 для администраторов. Специальный курс. — БХВ-Петербург, 2007. — 522 c.
- Майк, Хотек Microsoft SQL Server 2008. Реализация и обслуживание. Учебный курс Microsoft / Хотек Майк. - М.: Русская Редакция, 2012. - 961 c.
- Нестеров С.А. Базы данных: учеб. пособие. – СПб.: Изд-во Политех. ун-та, 2013. – 150 с.
- Саак А.Э. Информационные технологии управления: Учебник для вузов. 2-е изд. / А.Э. Саак, Е.В. Пахомов, В.Н. Тюшняков. – СПб.: Питер, 2012. – 320 с.
- Тарасов С. СУБД для программиста. Базы данных изнутри. — СОЛОН-Пресс, 2015. — 322 с.
- Тейлор, Аллен SQL для чайников / Аллен Тейлор. - М.: Вильямс, 2014. - 416 c.
- Уилсон Д., Редмонд Э. Семь баз данных за семь недель. Введение в современные базы данных и идеологию NoSQL. — ДМК Пресс, 2013. — 386 с.
- Хименко В. И. Случайные данные: структура и анализ. – Техносфера, 2017. – 425 с.
- Abraham Silberschatz Database System Concepts. — McGraw-Hill Education, 2010. — 1376 p.
- Jeffrey A. Hoffer Modern Database Management. — Pearson, 2015. — 601 p.
- Itzik, Ben–gan Microsoft SQL Server 2012 High–Performance T–SQL Using Windows Functions / Itzik Ben–gan. - Москва: Мир, 2012. - 244 c.
- Laine Campbell Database Reliability Engineering: Designing and Operating Resilient Database Systems. — O'Reilly Media, 2017. — 294 p.
- Dusan Petkovic Microsoft SQL Server 2016: A Beginner's Guide, Sixth Edition 6th Edition. — McGraw-Hill Education, 2016. — 896 p.
- Ramez Elmasri Fundamentals of Database Systems. — Pearson, 2015. — 1280 p.
- БК Автоматизированные системы управления и кибернетика [Электронный ресурс] Основные операции с данными. Режим доступа: http://automationlab.ru/index.php/2014-08-25-13-20-03/461-35---- Дата обращения (05.12.2019)

- Облачные сервисы ( Облачные сервисы: характеристики )
- Управление поведением в конфликтных ситуациях ( Теоретические основы конфликтов )
- Прибыль и рентабельность производственной организации на примере реально существующей организации
- Налоги с физических лиц и их экономическое значение(1. Теоретические основы налогообложения физических лиц и их экономическое значение)
- Критерии выбора средств разработки мобильных приложений (Предлагаемые мероприятия по улучшению БП)
- Критерии выбора средств разработки мобильных приложений (Android Studio)
- Жизненный цикл организации и управление организации
- Влияние кадровой стратегии на работу службы персонала ( ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ КАДРОВОЙ СТРАТЕГИИ УПРАВЛЕНИЯ ПЕРСОНАЛОМ )
- Влияние кадровой стратегии на работу службы персонала (Понятие и сущность оценки персонала)
- Теория менеджмента. Организационная культура и ее роль в современных организациях.
- Основы работы с операционной системой Windows 7 (Операционные системы корпорации MICROSOFT)
- Общие особенности кадровой стратегии организаций бюджетной сферы ( Сущность и понятие кадровой политики )