
Операции, производимые с данными (Индексирование, формы представления данных, структуры данных)
Содержание:

введение
В мире накоплено много информации, характеризующей различные научные, образовательные, социальные и др. сферы деятельности человечества. Всемирная паутина радикально изменила то, как мы обмениваемся знаниями, за счет снижения помех для публикации и доступа к данным в рамках глобального информационного пространства.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно.
Актуальность темы работы заключается в том, что работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Как известно, в материальном мире все физические объекты, окружающие нас, есть или телами, или полями. Физические объекты, взаимодействуя друг с другом, порождают сигналы различных типов. В общем случае любой сигнал - это меняется во времени физический процесс. Такой процесс может иметь различные характеристики. Та из них, которая используется для представления данных, называется параметром сигнала. Если параметр сигнала принимает ряд последовательных, конечных во времени, значений, то сигнал называется дискретным. Если параметр сигнал - непрерывная во времени функция, то сигнал называется непрерывным.
Сигналы, в свою очередь, могут порождать в физических телах изменения свойств. Это явление называется регистрацией сигналов. Сигналы, зарегистрированные на материальном носителе, называются данными.
Данные относятся к способу представления, хранения и элементарным операциям обработки информации. Прежде всего, данные - это носитель информации. Образно говоря, данные - это текст в некоторой азбуке, а информация - это рассказ (сообщение), имеющий определенный семантический смысл [1, с.107].
Для определения понятия данных представим некоторую абстрактную ситуацию:
- есть некоторая система (событие, процесс), информация о которой представляет интерес;
- есть наблюдатель, способный воспринимать состояния системы и в определенной форме фиксировать их в своей памяти.
Тогда говорят, что в памяти наблюдателя находятся «данные», описывающих состояние системы. В общем случае таким наблюдателем является информационная система.
Данные — диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) характера химических связей, изменение состояния электронной системы и многое другое. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов.
Таким образом, «данные» можно определить как информацию, фиксированную в определенной форме, пригодной для дальнейшей обработки, хранения и передачи информационной системой.
формы представления данных, структуры данных
Работа с большими объемами информации автоматизируется гораздо проще, когда данные упорядочены, то есть образуют определенную структуру. Структура информации - это то, что отражает взаимосвязи между ее составляющими (элементами).
Если данные хранятся в организованной форме, то есть определенным образом упорядочены (структурированные), то каждый элемент данных приобретает новое свойство, которое можно назвать адресу, который определяет размещение, расположение, местонахождение этого элемента по отношению к другим.
Наиболее распространенными являются следующие три типа структур: линейные, иерархические, табличные.
Линейные структуры - это хорошо известные списки. Список - самая структура данных, в которой каждый элемент однозначно определяется своим номером. Например, журнал посещения студентами занятий имеет структуру списка, поскольку каждый студент группы зарегистрирован под своим уникальным номером. Итак, линейные структуры данных - это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
Табличные структуры отличаются от линейных тем, что элементы данных определяются адресом ячейки, которая состоит не из одного параметра, а из нескольких. В частности, для прямоугольных таблиц адрес ячейки определяется номером строки и номером столбца. Упоминавшийся уже журнал посещения можно рассматривать и как табличную структуру. Обобщением двумерных (прямоугольных) таблиц является многомерные таблицы.
Иерархические структуры. Данные, которые трудно представить в виде списков и таблиц, часто подают в виде иерархических структур. В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведет с вершины структуры к каждому элементу.
Структуры в виде списков и таблиц простые. Ими легко пользоваться, а к тому же их нетрудно упорядочивать. Основным методом упорядочения является сортировка. Данные можно отсортировывать по произвольно выбранному критерию, например, по алфавиту, по возрастанию порядкового номера и тому подобное.
Но простые структуры, несмотря на всю их удобство, имеют определенные недостатки. Прежде всего их трудно восстанавливать, поскольку с добавлением в таких упорядоченных структур произвольного элемента могут меняться адреса других элементов. Поэтому в системах автоматической обработки информации необходимы специальные средства для решения этой проблемы.
Иерархические структуры по форме сложнее, но у них не возникает проблем с обновлением данных. Их легко развивать, создавая новые уровни. Недостатком иерархических структур является трудоемкость записи адреса элемента, обусловленная ростом пути доступа, а также сложность их упорядочения [2, с.225].
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление, наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой.
Технологии доступа при выполнении действий изменения элемента показана на рис. 1.
Здесь и далее сплошные линии означают управляющие связи, пунктирные - информационные связи.
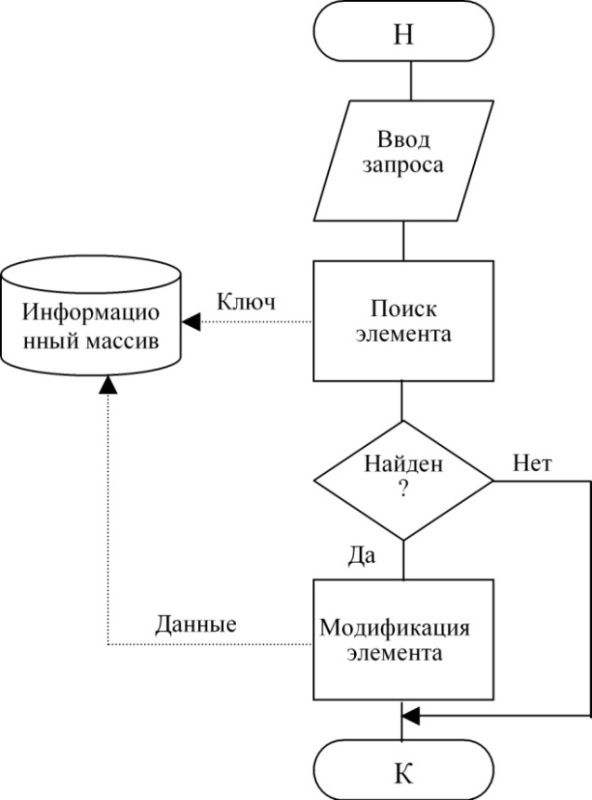
Рисунок 1 - Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рис. 2:
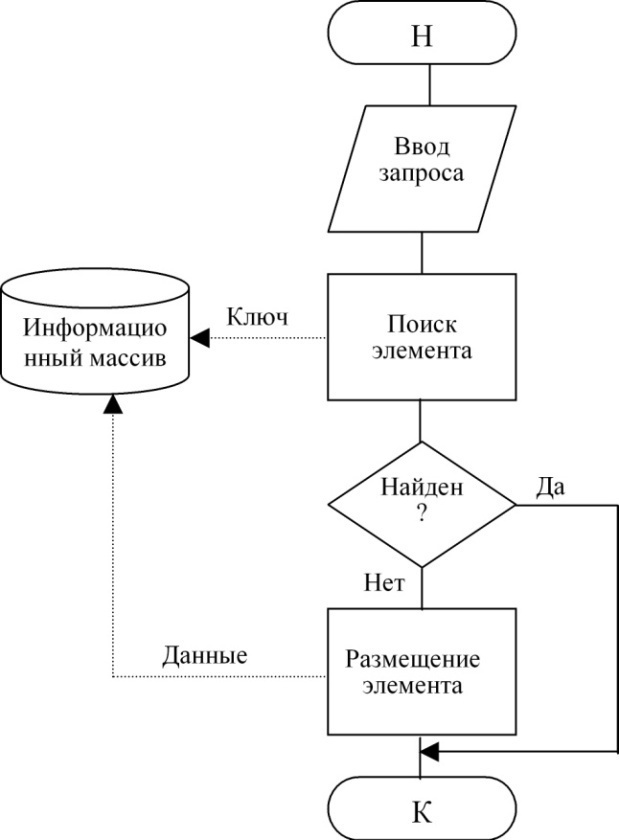
Рисунок 2 – Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 3.
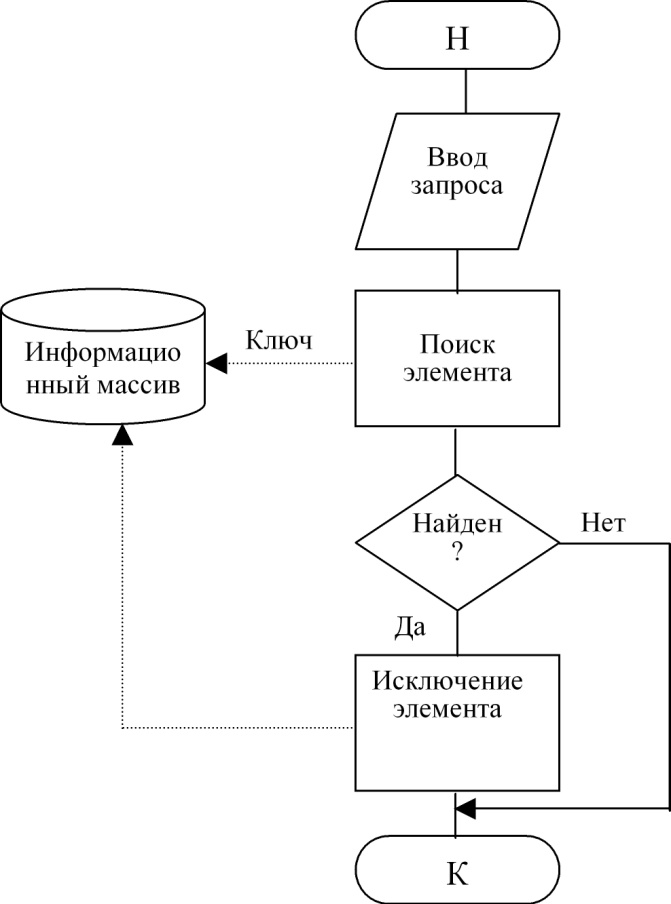
Рисунок 3 – Технология удаления элемента
Технология просмотра элемента приведена на рис. 4. Различие в схемах состоит в том, что по технологии рис. 1 и 2 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 3 воздействие не связано с передачей данных, а по схеме рис. 4 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
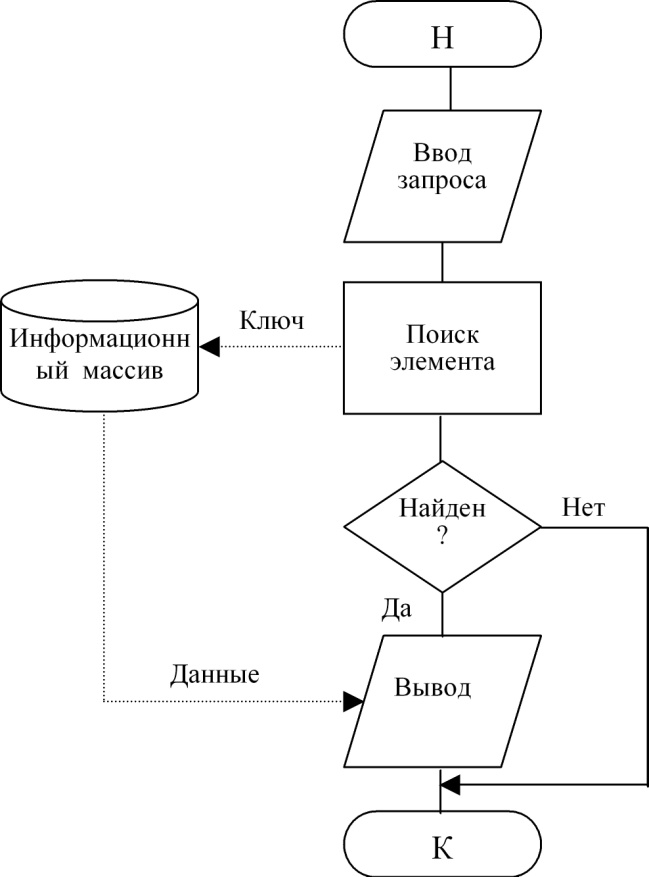
Рисунок 4 – Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
В силу вышесказанного, основное внимание уделяется задачам организации хранения данных разных видов и поиска по ключам, входящим в запросы пользователей, поскольку поисковые операции и определяют, в основном, продолжительность различных действий над информационным массивом. Из приведенных типов действий в рассмотрение включены добавление и просмотр элементов данных, поскольку добавление связано с воздействием на информационный массив и изменением его объема (напомним, что удаление является обратным действием по отношению к добавлению), а просмотр - это наиболее часто выполняемые действия на практике. При этом рассматриваются общие вопросы работы с текстовой и структурированной информацией, методы и модели, используемые при организации хранения, поиска и добавления данных.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
Индексирование
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно короткое время и с достаточно большой точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше объем таблицы, тем выше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то база данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения.
Сегодня наиболее острые проблемы управления информацией возникают у организаций (например, гостиниц, баз отдыха, оздоровительных учреждений, туристических агентств), работа которых заключается в обработке большого количества разнотипных, взаимонезависимых источников данных. Такой тип системы получил название пространство данных. В отличие от систем интеграции данных, что также предлагают общепринятый доступ к разнородным источникам данных, пространства данных не предполагают, что вcе семантические взаимосвязи между источниками известны и указаны. Многие пользователи, работающие с пространствами данных, проводят исследования данных, и нет единой схемы, по которой они могут создавать запросы.
В структуре возможных операций с данными можно выделить следующие:
• сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
Чем больше будет данных для анализа, тем лучше, отбросить их можно на следующих этапах работ - это легче, чем собрать новые сведения.
Однако сбор данных не самоцель. Если информация получить легко, то, естественно, следует ее собрать. Если данные получить сложно, то необходимо посчитать затраты на ее сбор и систематизацию с ожидаемыми результатами.
Есть несколько методов сбора, необходимых для анализа данных:
1. Получение из учетных систем. Конечно, в учетных системах есть различные механизмы построения отчетов и экспорта данных, поэтому извлечение нужной информации, чаще всего, относительно несложная операция.
2. Получение сведений из косвенных данных. На многие показатели можно судить по косвенным признакам и этим нужно воспользоваться. Например, можно оценить реальное финансовое положение жителей определенного региона следующим образом. В большинстве случаев несколько товаров, предназначенных для выполнения одной и той же функции, но отличающихся по цене: товары для бедных, средних и богатых. Если получить отчет о продажах товара в регион, интересует, и проанализировать пропорции, в которых продаются товары для бедных, средних и богатых, то можно предположить, что чем больше доля дорогих изделий из одной товарной группы, тем более способны в среднем жители данного региона [4, с.317].
3. Использование открытых источников. Большое количество данных присутствует в открытых источниках, таких как статистические сборники, отчеты корпораций, опубликованные результаты марке-тингов исследований и др.
4. Проведение собственных маркетинговых исследований и аналогичных мероприятий по сбору данных. Это может быть достаточно дорогостоящим мероприятием, но, в любом случае, такой вариант сбора данных возможен.
5. Ввод данных "вручную", когда данные заносятся по различного рода экспертным оценкам сотрудниками организации. Этот трудоемкий метод.
Стоимость сбора информации различными методами существенно отличается по цене и необходимым для этого время, поэтому нужно просчитать расходы результатам. Возможно, от сбора некоторых данных придется отказаться, но факторы, которые эксперты оценили как наиболее значительные следует собрать обязательно, несмотря на стоимость этих работ, или вообще отказаться от анализа. Модель, не учитывает значимые факторы, не представляет практической ценности.
Собранные данные необходимо преобразовать к единому формату, например, Excel, текстовый файл с разделителями, или любая СУБД. Данные обязательно должны быть унифицированы, одна и та же информация везде должна описываться одинаково. Конечно проблемы с унификацией возникают при сборе информации из разнородных источников.
Очень часто в аналитических приложениях направляют усилия на механизмы анализа данных, не оказывая должного внимания задачам обработки и очистки данных. Хотя именно плохое качество исходных данных является одной из самых серьезных и распространенных проблем. Очевидно, что некорректные исходные данные приводят к некорректным выводам. Поскольку в связи с тем, что в большинстве случаев источником информации для аналитических систем является хранилище данных, в котором аккумулируются сведения из множества разнородных источников, острота проблемы существенно возрастает.
Для анализируемых процессов различной природы данные должны быть подготовлены специальным образом.
• формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
При сборе данных нужно придерживаться следующих принципов.
1. Абстрагироваться от существующих информационных систем и имеющихся данных. Большие объемы накопленных данных совершенно не говорят о том, что их достаточно для анализа в конкретной компании.
Необходимо отталкиваться от задачи и подбирать данные для ее решения, а не брать имеющуюся информацию.
Например, при построении моделей прогноза продаж опрос экспертов показал, что на спрос влияет цветовая характеристика товара. Анализ имеющихся данных показал, что информация о цвете товарной позиции отсутствует в учетной системе. Значит, нужно каким-то образом добавить эти данные, иначе не стоит рассчитывать на хороший результат использования моделей.
2. Описать все факторы, потенциально влияющие на рассматриваемый процесс / объект. Основным инструментом здесь становится опроса экспертов и людей, непосредственно владеют проблемной ситуацией. Необходимо максимально использовать знания экспертов о предметной области и, полагаясь на здравый смысл, постараться собрать и систематизировать максимум возможных предположений и гипотез.
3. Экспертно оценить значимость каждого фактора. Эта оценка не является окончательной, она будет отправной точкой. В процессе анализа вполне может выясниться, что фактор, который эксперты посчитали очень важным, таковым не является, и наоборот, незначительный, с их точки зрения, фактор может оказать значительное влияние на результат.
4. Определить способ представления информации - число, дата, да / нет, категория (то есть тип данных). Определить способ представления, то есть формализовать некоторые данные, просто. Например, объем продаж в рублях - это определенное число. но довольно часто бывает непонятно, как представить фактор.Найчастише такие проблемы возникают с качественными характеристиками
Например, на объемы продаж влияет качество товара. Качество - сложное понятие, но если этот показатель действительно важен, то нужно придумать способ его формализации. Скажем, качество можно определять по количеству брака на тысячу единиц продукции или оценивать экспертно, разбив на несколько категорий - отлично / хорошо / удовлетворительно / плохо.
5. Собрать все легкодоступные факторы. Они содержатся в первую очередь в источниках структурированной информации - учетных системах, базах данных и т. П
6. Обязательно собрать наиболее значимые, с точки зрения экспертов, факторы. Вполне возможно, что без них не удастся построить качественную модель.
7. Оценить сложность и стоимость сбора средних и наименее важных по значимости факторов. Некоторые данные легкодоступны, их можно извлечь из существующих информационных систем. Но есть информация, которую непросто собрать, например сведения о конкурентах, поэтому необходимо оценить, во что обойдется сбор данных. Сбор данных не является самоцелью. Если информация получить легко, то, естественно, нужно ее собрать. Если сложно, то необходимо сравнить затраты на ее сбор и систематизацию с ожидаемыми результатами [4, с.335].
• фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
Для поиска данных можно использовать фильтрацию. Фильтрация - это процесс поиска и выбора записей в соответствии с установленными критериями. Фильтры также упрощают процесс ввода и удаления записей из списка. При фильтрации записи, не соответствующие указанным критериям, скрываются, но их порядок размещения в таблице остается неизменным и они не изымаются из таблицы.
Фильтрация данных - это достаточно быстрый и простой способ найти отдельную подмножество данных и начать работу с ней в диапазоне ячеек или в столбце таблицы. В результате данных фильтрации отображаются только те строки, соответствующие определенным условиям, и скрываются строки, не отображаются. Также еще можно выполнять фильтрации одновременно по нескольким столбцам. Фильтры могут быть составными - каждый следующий фильтр базируется на текущем фильтре и дальше уменьшается диапазон данных. Можно создать два набора фильтров: по списку значений по критериям Что такое фильтрация? Фильтрация -это процесс выбора из таблицы строк, удовлетворяются определенными условиями. Если говорить о фильтрации данных, то различают простые и составные условия:
Простые - уце языка, созданных с использованием операторов сравнения, таких как <,>, =
Составленные - это условия, которые построены из простых с помощью логических операций, таких как not ( Не), and (и), or (или)
• сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
Сортировка - это изменение положения данных в списке в соответствии со значением или типа данных. Если возникает необходимость расположить в алфавитном порядке данные, поставить в порядке возрастания, то для этого на панели инструментов есть кнопки, обозначающие сортировки от А до R, или от R до A.Також можно использовать команду меню Данные → Сортировка. Диалоговое окно Сортировка диапазона предназначено для выбора поля, на котором происходит сортировка (выделяем ячейки).
Правила сортировки:
1) пустые ячейки всегда помещаются в конец отсортированного списка;
2) числовые типы данных сортируются от наименьшего отрицательного до наибольшего положительного;
3) текстовые типы данных сортируются познаково слева направо;
4) текстовые данные сортируются в следующем порядке: сначала цифры, затем пробел и символы цифровых клавиш верхнего регистра, и только после этого буквы в алфавитном порядке;
5) при сортировке логических значений значение ЛОЖЬ ставится перед значением ИСТИНА.
• архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
Архивация данных
Несмотря на повышение надежности компьютеров и носителей данных, все же полной гарантии сохранности данных они не дают.
Потеря данных может привести к очень серьезным последствиям. Так, уничтожение данных о вкладах и перечисления средств клиентов приведет к краху банка, потеря данных о продаже билетов повлечет перебои в перевозке пассажиров, потеря результатов опытов может свести на нет многолетние научные исследования. Даже потеря записной книжки с телефонами друзей принесет вам значительные проблемы. Поэтому возникает потребность в создании копий данных. Важнейшие данные дублируют, записывая на другие жесткие диски, на магнитную пленку стримера, на оптические диски и тому подобное.
Размеры файлов, которые нужно хранить, большие и требуют дополнительных затрат. Чтобы уменьшить эти размеры в копиях и соответственно уменьшить расходы, используют сжатие данных. При этом используются методы, обеспечивающие сжатие без потерь данных.
Результатом работы этих программ является архивный файл, или просто архив, который содержит в сжатом либо не сжатом состоянии файлы и папки. В процессе архивации могут быть использованы дополнительные меры по защите данных от несанкционированного доступа, например установки пароля на доступ к данным в архиве.
В зависимости от алгоритмов, по которым осуществляется архивирование данных, различают следующие форматы архивных файлов: ZIP, RAR, ARJ, CAB, LZH, ACE, ISO и др. Чаще всего, особенно в сети Интернет, используют архивные файлы формата ZIP.
При выборе формата архивного файла следует учитывать, что по данным тестов, проведенных авторами учебника, формат RAR обеспечивает эффективное сжатие. Однако на процесс архивации в этом формате затрачивается больше времени.
Примерами архиваторов являются программы WinZIP, WinRAR, 7? Zip, Winace, PowerArchiver, ArjFolder, BitZipper, Gnochive, bzip2 и др.
Одним из архиваторов является программа WinRAR российского программиста Александра Рошаля, которая использует высокоэффективные алгоритмы сжатия данных.
Основные функции этой программы следующие:
• создание архивов файлов и папок с возможным сжатием данных;
• добавление файлов и папок в уже существующих архивов;
• просмотр содержимого архивов;
• замена и обновление файлов и папок в архивах;
• извлечения из архива всех или только избранных файлов и папок;
• создание многотомных архивов (архив разбивается на несколько отдельных файлов - томов) размер томов устанавливает пользователь;
• создание обычных и многотомных архивов, содержащих программу самостоятельного извлечения файлов и папок, без участия программы архиватора - так называемых SFX? Архивов (англ. SelF eXtracting - самовидобування)
• проверка целостности данных в архивах;
• шифрование данных и имён файлов в архивах и др.
• защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
Большое значение приобретают информационные процессы, влияющие на развитие новых информационных и технических средств передачи информации, ее обработки, использования и внедрения в науку и производство. Первостепенное значение приобретают информационные ресурсы и документирования информации с точки зрения ее безопасности, по субъектов и объектов в которых создаются определенные массивы последних. Поэтому чрезвычайно важное значение имеет защита информации.
Целью защиты информации должно быть:
- предотвращение утечки, хищения, утраты, искажения, подделки информации;
- предотвращение угроз безопасности личности, общества в целом;
- предотвращение несанкционированных действий по уничтожению, модификации, копированию, блокированию информации; предотвращения других форм незаконного вмешательства в информационные ресурсы и информационные базы данных и системы, обеспечение правового режима документированной информации как объекта собственности;
- защита конституционных прав граждан на сохранение личной тайны и конфиденциальности персональных данных, имеющихся в информационных системах и ресурсах субъектов и объектов различных форм собственности;
- сохранение государственной тайны, конфиденциальности документированной информации в соответствии с действующим законодательством;
- обеспечение прав субъектов в информационных процессах и при разработке, производстве и применении информационных систем, технологий и средств их обеспечения.
• транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя - клиентом;
Транспортировка данных
При доставлении пакетов на узел, необходимо чтобы эти данные попали в конкретной прикладной сущности (процессы, приложения). Когда на узле выполняется только одна прикладная программа (например, в контроллере) данные передаются ей, или системе. Однако современные ПТС могут поддерживать одновременное выполнение нескольких Процессов. Поэтому необходимо реализовать доступ к конкретному Процесса. Для этого выделим следующие типы сервисов:
- доступ к операционной системе;
- доступ к прикладного сервиса;
- доступ к программе пользователя;
- доступ к отдельной программной составляющей;
Рассмотрим пример. Допустим в сети есть два узла, которые представлены двумя компьютерами (рис. 5).
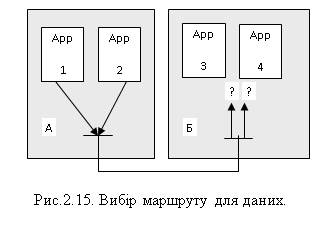
Рисунок 5 – Выбор маршрута для данных
Клиентский Процесс App1 хочет передать определенные данные Процесса App3, а App2 - App4. Если данные будут вставляться непосредственно в пакеты / кадры и передаваться из узла А на узел Б, то сетевая / канальная сущность не сможет определить котором с Процессов предназначены данные в пакете / кадре. Ведь на канальном и сетевом уровне решается вопрос доставки данных узлу, а не конкретной прикладной сущности. Эта задача возлагается на сущность транспортного уровня. Как и на предыдущих двух уровнях она решается с помощью адресации. В данном случае адресуются НЕ узлы и не сообщение, а прикладные сущности, то есть Процессы-получатели и процессы-отправители. Эти адреса (точки доступа TPDU) принято называть TSAP (Transport Service Access Point - точки доступа транспортного сервиса), а в ряде протоколов портами (port). В дальнейшем в данном пособии будет использоваться термин "порт".
Каждой прикладной сущности назначается свой порт, с помощью которого к ней можно обратиться (серверный порт). В нашем примере App3 и App4 можно было назначить серверные порты соответственно 3 и 4. Таблица соответствия портов прикладным сущностям должна храниться как на узле А, так и на узле Б. Клиентам тоже должны быть назначены порты. В протоколах UDP и TCP клиентские порты назначаются динамично, поскольку сервер будет соответствовать тому клиенту, который к нему обратился.
Транспортные протоколы, как и сетевые, могут предоставлять несколько типов сервисов: с установкой или без установки соединения с подтверждением или без подтверждения. Эти типы сервисов будут прокомментированы при рассмотрении протоколов TCP и UDP (см. 10).
В различных областях науки наблюдается экспоненциальный рост объемов экспериментальных данных. Сложность использования таких данных возникает вследствие их естественной разнородности (хранение в разных системах, назначения для различных задач, различные методы обработки и хранения и т.д.). Разрыв, который увеличивается между источниками данных и сервисами, приводит к необходимости поиска новых путей организации решения задач над множественными распределенными коллекциями данных и программ, которые концентрируются в специализированных центрах данных и вычислительных ресурсах.
Традиционно при решении определенных задач специалисты используют привычные для них источники информации и формулируют задачи с учетом только на такие источники. Очевидна неполнота информации, которую удается охватить при таком подходе. Множество источников данных и сервисов, существующих в Интернете, их разнообразие вызывают потребность в радикальном изменении такого традиционного подхода. Сущность этого изменения заключается в том, что задачи должны формулироваться независимо от существующих источников информации, и только после такой формулировки должна осуществляться идентификация релевантных задаче источников, приведения их к виду, необходимому для решения задачи, интеграция, идентификация сервисов, которые позволяют реализовать отдельные части абстрактного процесса решения за- дания.
Для принятия адекватных решений в определенной отрасли необходимо, чтобы данные, которые поступают из разных источников и используются для принятия управленческих решений, удовлетворяли следующим требованиям:
- были полными, непротиворечивыми и поступали вовремя;
- были информативными, поскольку они будут применяться для принятия решений;
- были одинаковой структуры, чтобы иметь возможность загрузить их в единое хранилище данных и проанализировать;
- хранились в одинаковых моделях данных и были независимыми от платформы разработки, чтобы иметь возможность использования этих данных другими средствами.
Сегодня наиболее острые проблемы управления информацией возникают у организаций (например, гостиниц, баз отдыха, оздоровительных учреждений, туристических агентств), работа которых заключается в обработке большого количества разнотипных, взаимонезависимых источников данных. Такой тип системы получил название пространство да- них. В отличие от систем интеграции данных, также предлагают общепринятый доступ к разнородным источникам данных, пространства данных не предполагают, что вcе семантические взаимосвязи между источниками известны и указаны. Многие пользователи, работающие с пространствами данных, проводят исследования данных, е нет единой схемы, по которой они могут создавать запросы [8, с.97].
• преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства - телефонные модемы.
Заключение
Составной частью информации являются данные, которые во время информационного процесса превращаются из одного вида в другой с помощью методов.
Для принятия адекватных решений в определенной области необходимо, чтобы данные, которые поступают из разных источников и используются для принятия управленческих решений, удовлетворяли следующим требованиям:
- были полными, непротиворечивыми и поступали вовремя;
- были информативными, поскольку они будут применяться для принятия решений;
- были одинаковой структуры, чтобы иметь возможность
загрузить их в единое хранилище данных и проанализировать;
- хранились в одинаковых моделях данных и были независимыми от платформы разработки, чтобы была возможность использования этих данных другими средствами.
Основные операции над данными:
• Сбор данных. Накопление информации с целью обеспечения достаточной полноты для принятия решений.
• Формализация данных. Приведение данных, поступающих из разных источников, к одинаковой формы, чтобы сделать их соизмеримыми и повысить уровень доступности.
• Фильтрация данных. Отсеивания «лишних» данных, которые не являются важными для принятия решений. После фильтрации достоверность и адекватность данных должны возрастать.
• Сортировка данных. Упорядочение данных по заданному признаку с целью удобства использования и повышения доступности информации.
• Архивирование данных. Организация хранения данных в удобной и легкодоступной форме. Это нужно для снижения экономических затрат на хранение данных и повышает общую надежность информационного процесса в целом.
• Защита данных. Комплекс мероприятий, направленных на предотвращение потерь, воспроизведения и модификации данных.
• Транспортировка данных. Прием и передача данных между удаленными участниками информационного процесса.
• Преобразование данных. Перевод данных из одной формы в другую или из одной структуры в другую.
Работа с информацией довольно вместительная, поэтому ее стремятся автоматизировать.
Список использованной литературы
- Акулов, О. А. Информатика. Базовый курс : учеб. для студентов вузов, бакалавров, магистров, обучающихся по специальности Информатика и вычислительная техника, а также студентов, изучающих естественные науки / О. А. Акулов, Н. В. Медведев. - 5-е изд., стер. - М. : Омега-Л, 2009. - 574 с.
- Безручко, В. Т. Информатика (курс лекций) : учеб. пособие / В. Т Безручко. - М. : Инфра-М : Форум, 2009. - 432 с.
- Высшая математика для экономистов: Учебник для вузов /Н.Ш. Кремер, Б.А. Путко, И.М. Тришин, М.Н. Фридман; Под ред. проф. Н.Ш. Кремера. – 2-е изд., перераб. и доп. – М.: ЮНИТИ, 2003. – 471 с.
- Информатика : учеб. для экон. специальностей вузов / под ред. Н. В. Макаровой. - 3-е изд., перераб. - М. : Финансы и статистика, 2009. - 768 с.
- Интеграция данных и хранилища [Електронний ресурс] : за данными InterSoft Lab. – 2006. – Режим доступа: http://citcity.ru/12101/
- Интеграция корпоративной информации: новое направление [Електронний ресурс] : за данными InterSoft Lab. – 2006. – Режим доступа: http://citcity.ru/11155/
- Могилев, А. В. Информатика : учеб. пособие для студентов высш. пед. учеб. заведений / А. В. Могилев, Е. К. Хеннер, Н. И. Пак. - 5-е изд., стер. - М. : Академия, 2007. - 848 с.
- Острейковский, В. А. Информатика : учеб. для студентов техн. и экон. специальностей вузов / В. А. Острейковский. - 5-е изд, стер. - М. : Высшая школа, 2009. - 511 с.
- Симонович, С. В. Информатика для юристов и экономистов : учеб. для вузов / С. В. Симонович. - СПб. : Питер, 2008. - 688 с.
- Симонович, С. В. Информатика. Базовый курс : учеб. для техн. вузов / С. В. Симонович. - 2-е изд. - СПб. : Питер, 2009. - 640 с.
- Соболь, Б. В. Информатика : учеб. / Б. В. Соболь |и др.| - 4-е изд., перераб. и доп. - Ростов н/Д : Феникс, 2009. - 446 с.
- Степанов, А. Н. Информатика : учеб. для вузов / А. Н. Степанов. - 5-е изд., испр. и доп. - СПб. : Питер, 2008. - 768 с.
- Трофимов, В. В. Информатика в 2 т. Том 1 : учебник для среднего профессионального образования / В. В. Трофимов ; под редакцией В. В. Трофимова. — 3-е изд., перераб. и доп. — Москва : Издательство Юрайт, 2019. — 553 с.
- Трофимов, В. В. Информатика в 2 т. Том 2 : учебник для академического бакалавриата / В. В. Трофимов ; ответственный редактор В. В. Трофимов. — 3-е изд., перераб. и доп. — Москва : Издательство Юрайт, 2019. — 406 с.
- Федотова, Е.Л. Информационные технологии в науке и образовании: Учебное пособие / Е.Л. Федотова, А.А. Федотов. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013. - 336 c.

- Корпоративная культура в организации (Сущность корпоративной культуры и ее функции)
- Особенности политики мотивации персонала малых предприятий (Сущность мотивации персонала на предприятии и ее механизм)
- Принципы формирования портфеля проектов организации (на примере ООО «ПИК «Техпроектбезопасность»)»
- Организационная культура и ее роль в современных организациях(ОРГАНИЗАЦИОННАЯ КУЛЬТУРА, ЕЁ ФУНКЦИИ И ПЕРСПЕКТИВЫ)
- «Организационная культура и ее роль в современных организациях»
- Формирования корпоративной культуры
- Адаптация детей в условиях первого класса обучения (Адаптация детей в условиях первого класса обучения )
- Налоговая система РФ (Структура налогообложения РФ)
- Информационная база анализа финансово-хозяйственной деятельности предприятия (организации, фирмы) и ее совершенствование
- Корпоративная культура в организации (Определение и суть корпоративной культуры)
- Внутренняя и внешняя среда организаций (Принципы и методы анализа среды организации)
- Обзор языков программирования высокого уровня (ОСНОВЫ ТЕОРИИ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ)