
Операции, производимые с данными (Операции над данными в общем смысле)
Содержание:

Введение
Понятие «информация» является достаточно широким и неразрывно связано с понятием данные. Данные — это поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи или обработки.
В современном мире сбор, обработка и анализ данных идет постоянно и непрерывно, а уровень техники и технологии настолько высок, что имеет смысл рассматривать возможные операции с разных уровней, начиная от непосредственного сбора и заканчивая их обработкой на программном уровне, архивацией и защитой. Список операций, которые могут быть выполнены над данными довольно большой и включает в себя операции, производимые над данными на разных уровнях технологического процесса и абстракции.
В данном предмете «Технологии программирования» очень важно дать определения возможным операциям над данными, так как именно технологии определяют эти операции. Тема данной работы является очень широкой, поэтому в силу ограниченности объема в качестве основной цели был установлен обзор существующих решений и процессов. В данной работе будут рассмотрены только основные операции, а связанные с этими операциями основные понятия и определения будут даны в краткой форме и с небольшим количеством примеров.
Основным источником информации для этой работы являются работы известных авторов, таких как Таненбаум Э., Хелд Д., написавших достаточное количество книг и монографий и получивших мировое признание. Также в качестве источников были взяты работы и учебники высших технических заведений, написанные преподавателями и научными работниками и рекомендованные министерством образования.
Операции над данными в общем смысле
Данные — «зарегистрированная информация; представление фактов, понятий или инструкций в форме, приемлемой для общения, интерпретации, или обработки человеком или с помощью автоматических средств» [17]. Данные в общем случае представляют собой зарегистрированные сигналы о материальном мире. Можно говорить, что данные несут информацию о произошедших событиях, однако они не тождественны информации. Понятие «информация» является очень широким, поэтому в каждой дисциплине говорят о «понятии информации». В общем смысле информацию следует понимать, как – «сведения об окружающем мире и протекающих в нем процессах, воспринимаемые человеком или специальным устройством» [8]. Если говорить о связи информации и данных, то стоит отметить, что в таком случае информацию можно понимать, как продукт взаимодействия данных и адекватных им методов [10, с. 18]. Именно так и следует понимать информацию в данном предмете «Технологии программирования».
Данные — это диалектическая составная информации, они представляют собой зарегистрированные сигналы. При этом метод регистрации этих сигналов может быть любым. Это может быть механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) характера химических связей, изменение состояния электронной системы и многое другое. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов [10, с. 21]. Бумага является самым простым носителем. Изменяя ее оптические характеристики, например, с помощью карандаша, становится возможно зарегистрировать на ее поверхности некоторые данные. Это самый простой способ регистрации, но сходный же способ используется для регистрации информации на оптических и лазерных дисках CD, DVD, Blue-ray disc. Например, если рассмотреть диск стандарта CD-R (CD-Recordable — записываемый компакт-диск), имеющий поликарбонатную основу и слой золота, между которыми располагается краситель, то регистрация или запись данных на нем осуществляется путем изменения оптических характеристик этого красителя. На начальной стадии слой красителя прозрачен, что дает возможность свету лазера проходить сквозь него и отражаться от слоя золота. При записи информации мощность лазера увеличивается, краситель нагревается, и в результате разрушается химическая связь. Такое изменение молекулярной структуры создает темное пятно. При чтении фотодетектор улавливает разницу между темными пятнами, где краситель был поврежден, и прозрачными областями, где краситель остался нетронутым [12, с. 126]. Также в качестве носителей, использующих изменение магнитных свойств, можно назвать магнитные диски и ленты. Регистрация данных путем изменения химического состава поверхностных веществ носителя широко используется в фотографии. На биохимическом уровне происходит накопление и передача данных в живой природе.
Любой носитель можно характеризовать параметром разрешающей способности (количеством данных, записанных в принятой для носителя единице измерения) и динамическим диапазоном (логарифмическим отношением интенсивности амплитуд максимального и минимального регистрируемых сигналов) [10, с. 22]. Эти свойства носителей определяют другие свойства данных и информации — полноту, доступность и достоверность. Например, если разместить какую-либо объемную базу данных на компакт-диске, то полноту информации будет обеспечить гораздо проще, чем размещая эту же самую базу данных на магнитном диске. Плотность записи на компакт-диске гораздо выше, что позволяет разместить гораздо больший объем информации. Однако, если говорить о доступности информации, то она будет гораздо выше, например, если информация будет размещена в книге, так как далеко не все потребители обладают необходимым оборудованием для чтения компакт-дисков.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя большое количество операций [11, с. 6]:
- Сбор данных — накопление информации с целью обеспечения достаточной полноты для принятия решений;
- Формализация данных — повышение доступности и понятности данных путем приведения данных, поступающих из разных из разных источников, к одинаковой форме, сделав их сопоставимыми между собой;
- Фильтрация данных — отсеивание лишних данных. Под лишними данными в данном случае подразумеваются данные, в которых нет необходимости для принятия решений. При этом достоверность информации должна возрастать;
- Сортировка данных — упорядочивание данных по определенному заданному признаку с целью повышения доступности информации;
- Архивация данных — организация хранения данных в любой доступной форме с целью снижения затрат на хранение и повышение общей надежности;
- Преобразование данных — перевод данных из одной формы в другую или из одной структуры в другую;
- Защита данных — комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
- Транспортировка данных — прием и передача данных между удаленными участниками информационного процесса.
В последующих главах будут рассмотрены основные операции, однако важно понимать, что список операций над данными, приведенный выше является далеко не полным, в то время как задача составления полного списка является очень трудоёмкой или даже невозможной. В окружающем мире над данными постоянно совершается бесчисленное множество операций, каждая из которых имеет свою специфику. Также важно понимать, что основные операции над данными осуществляет в современном мире ЭВМ, однако инструкции для вычислительной машины пишутся программистами, с точки зрения которых операции над данными тоже выглядят особым образом.
Системы счисления
Перед тем как рассматривать дальнейшую обработку данных с помощью различных операций необходимо рассмотреть такое понятие как системы счисления. «Система счисления — это совокупность правил и приемов записи чисел с помощью набора цифровых знаков. Количество цифр, необходимых для записи числа в системе, называют основанием системы счисления» [1].
Любая система исчисления должна позволять человеку и техническому устройству записывать числа, используя минимум места, а также выполнять действия с этими числами, придерживаясь максимально простого набора правил. Системы исчисления обладают следующими свойствами [9, с. 356]:
- позиционные — непосредственный вес единицы разряда числа зависит от позиции этого разряда;
- с постоянным основанием — для любого разряда числа количество различных цифр одинаково;
- с естественным порядком следования весов — система счисления, при которой вес единицы следующего разряда на 1 больше максимального числа, представимого всеми предыдущими разрядами;
- с естественным представлением цифр в разрядах (не кодированным) — для каждого разряда используется количество цифр, равное основанию системы счисления.
Если система счисления обладает вышеуказанным набором свойств, то арифметические действия, выполняемые в такой системе, будут достаточно просты. Например, m-разрядное число (где di — это обозначение цифры в записи числа) в любой системе счисления связано количеством N, изображаемым этим числом следующей формулой (1) [9, с. 356]:
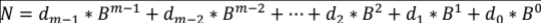 (1),
(1),
Где:
- B — основание системы исчисления;
- dm-1, dm-2… d0 — цифры в записи числа.
Так как все операции выполняются на ЭВМ, которая может оперировать числами, точность которых конечна и фиксирована. Любая ЭВМ обладает ограниченным объемом памяти, поэтому может оперирует только теми числами, которые можно представить в фиксированном количестве разрядов. Такие числа называются числами конечной точности [12, c. 708]. В ходе развития ЭВМ наиболее эффективным и выгодным представлением чисел оказалось представление в двоичной системе счисления.
Двоичные числа строятся только из цифр 1 и 0. Двоичный разряд обычно называют битом.
С точки зрения разработчика видов данных много: есть простые и очевидные (например, целые и плавающие для представления чисел), а также данные, предназначенные для представления символов и строк. В зависимости от поставленной задачи программист может комбинировать простые данные, создавая таким образом бесконечное число специфических пользовательских видов данных. [9, с. 49]
А с точки зрения процессора все объекты в памяти представляются совокупностью битов, содержащих 0 и 1, но:
- разным объектам может соответствовать разное количество битов;
- даже если количество битов одинаково, эти 0 и 1 для каждого вида данных по замыслу программиста имеют совершенно разный смысл (например, форматы хранения коротких плавающих и целых принципиально разные), поэтому действия процессора должны быть разными.
Возможности процессора по работе с данными разного типа ограничены. Обычно в системе команд процессора имеются низкоуровневые команды для работы с одно-, двух- и четырёхбайтовыми целыми, а также специальные низкоуровневые команды для работы с данными в плавающем формате и команды, которые позволяют обращаться к отдельным разрядам. Поэтому, естественно, существуют правила, позволяющие устанавливать взаимосвязь между двоичным представлением данных и их сущностью [9, с. 49]:
- для некоторых видов данных эти правила просты (например, для целых);
- для некоторых правила достаточно сложны, но всю работу по отображению берет на себя компилятор (например, для плавающих);
- для некоторых (пользовательских типов) соответствие должен установить программист.
Сбор и формализация данных
Сбор данных — «процесс получения данных от источников их регистрации, т.е. их фиксирование на носителях данных (документах, машинных носителях и т. п.)» [6]. В данной дисциплине процесс сбора данных уместно рассматривать с точки зрения определенной системы сбора данных. В общем случае система сбора данных — это система, осуществляющая функцию преобразования первичных входных сигналов от одного или нескольких измерительных преобразователей в эквивалентные цифровые сигналы, пригодные для дальнейшей обработки. [3, с. 34]. Применение таких систем очень широко. Их можно использовать для контроля какого-то одного процесса или величины, и в то же время для контроля сотни параметров большой и сложной системы или систем.
Системы сбора данных бывают одноканальные и многоканальные. В составе простейшей одноканальной измерительной системы всегда присутствует измерительный преобразователь, устройство выборки хранения (УВХ) и аналогово-цифровой преобразователь (АЦП). Измерительный преобразователь — это техническое устройство, построенное на определенном физическом принципе действия, выполняющее одно измерительное преобразование [16, с. 14]. УВХ — специальное устройство, предназначенное для уменьшения погрешности в выходном сигнале преобразователя, связанной с возможным быстрым изменением входного сигнала [3, с. 34]. АЦП — устройство, преобразующее входной аналоговый сигнал в дискретный код. По сути, аналогово-цифровое преобразование — это операция, устанавливающая соотношение двух величин [3, с. 19]. Видов АЦП большое множество, однако наиболее распространённые — это АЦП последовательного приближения, обладающие средним и высоким быстродействием [3, с. 29].
Многоканальные системы сбора данных необходимы тогда, когда существует более одного источника входного сигнала. В таком случае более всего распространены 2 подхода: аналоговое мультиплексирование и параллельное преобразование. При аналоговом мультиплексировании специальное устройство мультиплексор по очереди коммутирует сигналы с разных УВХ со входом АЦП. При параллельном способе сбора данных каждый источник данных имеет собственный АЦП для преобразования [3, с. 37-38].
Говоря о формализации данных, имеет смысл ввести понятие модели. Модель — это объект, который отражает существенные особенности и характеристики изучаемого объекта, явления или процесса. При накоплении достаточного количества данных становится возможным составление модели данных при помощи их формализации. В данном случае под формализацией имеет смысл понимать процесс построения моделей при помощи формальных языков. Это могут быть языки программирования, дифференциальное и интегральное исчисление, теория множеств и др. Таким образом, становится возможным описать данные единообразно и привести к одному виду для дальнейшей обработки [4, с. 96].
Операции над формализованными данными
В данной работе имеет смысл рассматривать данные, формализованные с помощью определенного языка программирования. При работе с формализованными данными на уровне программиста обычно средства языков программирования позволяют выделять и использовать два типа данных:
- константы — данные, которые программист точно знает и которые не будут меняться во время выполнения программного кода. Такие значение программист может сообщить компилятору заранее;
- переменные — основный тип данных. Такие данные меняются в процессе выполнения программы, а программист может задать только начальные значения. Хотя вполне возможна ситуация, при которой программист задает значения переменных в ходе выполнения программы.
И те, и другие могут быть следующего вида [9, с. 50]:
- числа: целые или с плавающей точкой — элементы данных, выражающие количества. Эти числа имеют различные форматы хранения и размеры. Важно отметить, что переменные целого типа могут быть знаковыми и беззнаковыми;
- символы — целочисленные элементы, предназначенные для хранения кодов отдельных символов, и строки — совокупности символов;
- логические — для хранения результата логических операций — одного из двух значений: истина и ложь;
- адреса — специальный тип данных, содержащий в себе физический адрес ячейки памяти, в которой находится адресуемая переменная.
Операции с переменными и константами с точки зрения программиста зависят от возможностей выбранного языка, однако большинство языков программирования поддерживают ряд стандартных операций. Все операции над данными осуществляются посредством операторов. С операторами связаны следующие понятия [9, с. 31]:
- количество операторов. Оператор может совершать действия над:
- одним операндом (унарный оператор);
- двумя операндами (бинарный оператор);
- тремя операндами (тернарный оператор).
- приоритет операторов. Зачастую возможны случаи, когда программистом в одном выражении указаны несколько операторов. В таком случае говорят о приоритете, который разрешается средствами используемого языка;
- ассоциативность операторов — если в выражении содержатся операторы с одинаковы приоритетом, тогда порядок выполнения вычисляется с учетом ассоциативности операторов: справа-налево или слева-направо;
- порядок синтаксического разбора — правила, по которым действует компилятор языка при разборе выражения.
Большинство языков программирования поддерживает стандартный набор арифметических операторов [10, с. 593]:
- Сложение;
- Вычитание;
- Умножение;
- Деление.
В языках высокого уровня также имеют место быть следующие арифметические операции [9, с. 36]:
- Остаток от целочисленного деления;
- Инкремента (увеличение на единицу);
- Декремента (уменьшение на единицу).
При написании любой программы возникает необходимость в написании логических выражений, то есть тех выражений, результат которых может быть равен только «истина» (true) или «ложь» (false). Чаще всего «истина» ассоциируется с 1, ложь с 0. [10, с. 594] Логические операции соответствуют операциям над высказываниями в алгебре логики (табл. 1).
Таблица 1
|
Оператор |
Операнд 1 |
Операнд 2 |
Результат |
|
Логическое «НЕ» |
true |
false |
|
|
false |
true |
||
|
Логическое «И» |
true |
true |
true |
|
Все остальные комбинации |
false |
||
|
Логическое «ИЛИ» |
false |
false |
false |
|
Все остальные комбинации |
true |
||
Операторы отношения сравнивают значение выражений слева и справа от оператора и формируют значения «истина» или «ложь» в зависимости от соотношения выражения, т.е. результатом сравнения является true, если оно удачно, и false в противном случае [10, с. 594].
Побитовые операторы позволяют производить действия непосредственно с битами операндов. Используются эти операторы в языках программирования для [9, с. 39]:
- Установки битов;
- Сброса битов;
- Инверсии отдельных битов.
В таблице 2 приведены правила истинности для основных логических операций: И (AND), ИЛИ (OR) и Исключающее ИЛИ (XOR).
Также в числе побитовых операций существуют операции побитового сдвига и отрицания. Операция сдвига влево и сдвига вправо эквиваленты умножению и делению на 2.
Таблица 2
|
Операнд 1 |
Операнд 2 |
Результат |
||
|
И (AND) |
ИЛИ (OR) |
Исключающее ИЛИ (XOR) |
||
|
0 |
0 |
0 |
0 |
0 |
|
0 |
1 |
0 |
1 |
1 |
|
1 |
0 |
0 |
1 |
1 |
|
1 |
1 |
1 |
1 |
0 |
Ниже приведена таблица основных операторов с соответствующими обозначениями в большинстве современных языков программирования по порядку убывания приоритета выполнения (табл. 3):
Таблица 3
|
Оператор |
Название |
|
++ |
Инкремент |
|
-- |
Декремент |
|
+ |
Сложение |
|
- |
Вычитание |
|
! |
Логическое отрицание |
|
~ |
Поразрядная инверсия |
|
* |
Умножение |
|
/ |
Деление |
|
% |
Остаток от деления |
|
<< |
Сдвиг влево |
|
>> |
Сдвиг вправо |
|
< |
Меньше |
|
> |
Больше |
Продолжение таблицы 3
|
<= |
Меньше или равно |
|
>= |
Больше или равно |
|
== |
Равно |
|
!= |
Не равно |
|
& |
Побитовое И |
|
^ |
Побитовое исключающее ИЛИ |
|
| |
Побитовое ИЛИ |
|
&& |
Логическое И |
|
|| |
Логическое ИЛИ |
|
= |
Присваивание |
В таблице 3 также указан оператор присваивания. Для компиляторов высокоуровневых языков программирования его использование означает, что значение, полученное в результате вычисления выражения справа от знака равенства, нужно скопировать в область памяти, на которую ссылается выражение слева от знака равенства [9, 38].
Все рассмотренные выше данные и операции над ними являются базовыми. Однако в реальности работать с простыми данными представляется трудоемкой задачей, которая способна произвести большое количество ошибок. Для большей производительности программиста и повышения качества и удобства его работы современные языки программирования поддерживают объявление и использование данных в таком виде, при котором они будут максимально приближены к их реальным аналогам [10, с. 596]. Ключ к эффективному использованию современных языков программирования — это использование типов, определяемых пользователем или программистом [18, с. 201].
Одним из таких сложных типов данных являются массивы. Массивы существуют и поддерживаются в большинстве современных языков программирования. Массив — это совокупность упорядоченных, расположенных в памяти последовательно элементов данных. Все элементы массива имеют один тип, а сам массив занимает в памяти непрерывную линейную область. Каждый элемент массива пронумерован и имеет индекс. Доступ к каждому элементу массива является одинаково эффективным для любого элемента [9, с. 196]. Массивы — это мощный инструмент для работы с одинаковыми типами данных. С помощью массивов разумно организовывать обработку больших объемов данных с постоянным временем доступа к любому элементу. Также стоит отметить, что в современных языках программирования организована поддержка создания и использования многомерных массивов, что позволят работать с различными представлениями данных как с математическими моделями и производить над ними соответствующие математические операции.
При выполнении некоторых задач удобно использовать и управлять данными как некой совокупностью, объединяющей какое-то количество различных разнотипных данных. В современных языках программирования были представлен сложный тип данных — структура. Структура позволяет объединить данные, относящиеся к одному объекту так, чтобы [9, с. 314]:
- хранить совокупность характеристик как единое целое;
- манипулировать этой совокупностью как единым целым;
- иметь возможность обращаться к характеристикам по отдельности.
Структуры строятся на основании базовых или определенных ранее сложных типов данных, в результате чего программист может организовать и построить структуры данных любой сложности, в том числе списки, деревья и графы.
Стоит отметить, что также для эффективной работы с видами данных используются указатели. Указатель — это такая конструкция языка для хранения и использования адресов и ссылок [18, с. 171]. При выполнении программы фрагменты программного кода и элементы данных располагаются в различных участках оперативной памяти, каждый из которых имеет свой уникальный адрес. Обращение к любому элементу программы в современных языках программирования можно осуществить по этому адресу. Для предоставления адреса и существует специальный тип данных — указатель [9, с. 173].
В этой главе были рассмотрены особенности и основные понятия, связанные с операциями, производимыми над данными, с точки зрения разработчика программного обеспечения. Были изложены основы представления данных в ЭВМ и принципы работы с ними с точки зрения разработчика программного обеспечения. Также были рассмотрены основные возможные операции над данными, которые доступны программисту посредствам высокоуровневых языков программирования.
Фильтрация, преобразование и сортировка данных
Сбор данных всегда сопряжен с выборкой большого количества лишних, «сырых» и неупорядоченных данных. Для повышения полезности информации и удобства ее дальнейшего использования целесообразно ее отфильтровать, таким образом понизив уровень шума, преобразовать в структуры с которыми в последствие будет удобно работать и отсортировать для эффективной дальнейшей обработки и быстроты доступа.
Задача фильтрации неразрывно связана с задачей поиска, так как, по сути, при фильтрации производится поиск данных, которые удовлетворяют какому-либо условию, а остальные данные отсеиваются. Алгоритмов поиска существует великое множество, начиная с самого тривиального и медленного — последовательного поиска, при котором сравнение элементов данных происходит последовательно и упорядоченно [2, с. 426] и заканчивая более сложными алгоритмами, например, бинарным поиском и поиском Фибоначчи.
Важно понимать, что методы поиска и фильтрации напрямую зависят от структуры данных, поэтому «сырые» данные необходимо представить в какой-либо удобной форме. Это могут быть простые массивы, понятие которым давалось в предыдущей главе, и списки или более сложные типы, например, деревья и хеш-таблицы.
Список является одной из самых основных структур данных. Он может использоваться в качестве альтернативной массиву структуры для хранения упорядоченных данных, а также быть основой для более сложных структур [5, с. 180]. В связанном списке каждый элемент данных встраивается в специальный объект, называемый элементом списка. Каждый элемент содержит ссылку на следующий элемент списка, тогда такой список называется односвязным. Также каждый элемент списка может содержать ссылку на предыдущий элемент, тогда такой список называется двусвязным. Таким образом конкретный элемент можно найти только одним способом: отследив его по цепочке элементов от начала списка [5, с. 182-183]. Важное преимущество связанных списков перед массивами заключается в том, что связанный список всегда использует ровно столько памяти, сколько необходимо, и может расширяться вплоть до всей доступной памяти [5, с. 200].
Деревья — это структуры данных, состоящие из узлов, соединенных ребрами. Обычно на верхнем уровне дерева располагается один узел, который соединяется с другими узлами на втором уровне; те, в свою очередь, соединяются с еще большим количеством узлов на третьем уровне и т.д. Таким образом, деревья постепенно расширяются сверху вниз. Существует несколько разновидностей деревьев такие как: бинарные, красно-чёрные, деревья 2-3-4 и другие [5, с. 347]. В данной работе в силу ограниченности объема имеет смысл рассмотреть один из самых популярных видов деревьев — бинарное дерево.
Если каждый узел дерева имеет не более двух потомков, такое дерево называется двоичным или бинарным. Два потомка каждого узла двоичного дерева называются левым потомком и правым потомком в зависимости от позиции на изображении дерева [5, с. 350]. Говоря о бинарном дереве, обычно говорят о его частном случае — бинарном дереве поиска. Бинарное дерево поиска — это бинарное дерево, у которого ключ левого потомка узла всегда должен быть меньше, чем у родителя, а ключ правого потомка — больше либо равен ключу родителя. Такие деревья хорошо подходят для представления данных в случае, когда необходимо выполнять поиск нужного элемента в неупорядоченном наборе данных, используя алгоритм бинарного поиска, однако добавление и удаление элементов представляется не самой простой задачей.
Еще одной популярной структурой данных является хеш-таблица — структура данных, обеспечивающая очень быструю вставку и поиск. Для пользователя хеш-таблицы обращение к данным происходит практически мгновенно. Все делается настолько быстро, что компьютерные программы часто используют хеш-таблицы при необходимости сделать выборку из десятков тысяч элементов менее чем за секунду [5, с. 487]. По сути, хеш-таблица реализует интерфейс ассоциативного массива, у которого ключи представляют собой результат работы некоторой выбранной хеш-функции. Таким образом, имея возможность вычислить хеш-функцию заданного ключа, можно обеспечить доступ к необходимым данным практически мгновенно.
Говоря о сортировке данных, имеет смысл отметить, что термин «сортировка» определяется как процесс разделения объектов по виду и сорту [2, с. 12], однако в данной дисциплине его имеет смысл рассматривать как упорядочивание. Наиболее важными областями применения сортировки являются [2, с. 12]:
- Решение задачи группирования, когда нужно собрать вместе все элементы с одинаковыми значениями некоторого признака;
- Поиск элементов в двух или более массивах. Если два или более массивов рассортировать в одном и том же порядке, то можно отыскать в них общие элементы за один последовательный просмотр;
- Поиск информации по значениям ключей. Сортировка активно используется при поиске, с ее помощью можно сделать результаты обработки более удобными для восприятия человеком.
Методов сортировки существует огромное количество, рассмотреть их все не представляется возможным в рамках этой работы, однако имеет смысл перечислить самые популярные из них: сортировка вставками, сортировка Шелла, быстрая сортировка, пузырьковая сортировка и другие.
Архивация данных. Базы данных
Необходимость архивировать и хранить данные в технологическом процессе возникает очень часто. Физически данные возможно хранить на различных носителях информации. Это могут быть [4, с. 50-53]:
- Накопитель на гибких магнитных дисках. Это устройство, позволяющее записывать и читать магнитные диски. Магнитный диск вращается с помощью привода, для записи и считывания информации используются магнитные головки. Сюда относятся, как и обыкновенные 3,5 дюймовые диски емкостью 1,4 Мб, так и специализированные диски формата ZIP, способные хранить в себе до 700 Мб информации [10, с. 99].
- Накопитель на жестких магнитных дисках. Это устройство для чтения и записи жестких магнитных дисков, находящихся внутри накопителя. В таком накопителе несколько жестких магнитных пластин нанизано на стержень с блоком магнитных считывающих головок. Емкость современных жестких дисков достигает внушительных размеров от сотен гигабайт до нескольких десятков терабайт.
- Накопитель на магнитной ленте. Это устройство, позволяющее записать и хранить информацию на магнитной ленте. Характеризуется последовательным доступом, а емкость достигает нескольких десятков гигабайт [10, с. 99].
- Магнитооптический накопитель. Представляет собой то же, что и накопитель на гибких магнитных дисках, однако запись и чтение производится с помощью лазера. Последнее поколение носителей формата 5,25 дюйма достигает емкости 5,2 Гб. Емкость носителей 3,5 дюйма несколько ниже, от 640 Мб до 2,3 Гб [10, с. 100].
- Оптические устройства хранения данных. Это устройство, использующее в качестве носителя информации оптические компакт-диски. Такие диски представляют собой круглые поликарбонатные пластины, на которые информация записывается и считывается с помощью лазера. Существующие стандарты компакт дисков CD, DVD, Blue-ray позволяют записывать и хранить информацию объемом от 700 Мб до нескольких сотен гигабайт.
- Flash-память. Наиболее перспективный и широко распространенный современный носитель информации. Носитель основан на электронных схемах и относится к статической энергонезависимой памяти. Современная Flash-память способна хранить объем информации от нескольких десятков гигабайт до десятков терабайт.
Архивировать и хранить большие объемы информации может оказаться трудоемкой задачей, в случае, когда к этой информации необходимо предъявлять определенные правила доступа, хранения, организации и выборки. В таком случае целесообразно использовать системы, предоставляющие услуги по обработке данных. Такие системы называются СУБД (Системы Управления Базами данных), а совокупность данных, хранимых под управлением СУБД, называется базой данных. [7, с. 11-12].
Основные требования к СУБД [7, с. 13-14]:
- Разделение программ и данных;
- Высокоуровневый язык запросов;
- Целостность;
- Согласованность;
- Отказоустойчивость;
- Защита и разграничение доступа.
СУБД предоставляют операции над данными сложной структуры. Необходимо, чтобы описание этой структуры было доступно СУБД и было бы общим для всех программ, использующих эти данные. Это приводит к идее отделения описания структуры данных от программ [7, с. 15].
Любая СУБД включает в себя описания структур данных и зависимостей между ними, а также дополнительные условия, которым хранимые данные должны удовлетворять. Система управления базами данных проверяет ограничения целостности при выполнении любых изменений хранимых данных и не допускает выполнения операций, нарушающих эти ограничения. Поддержка ограничений целостности на уровне СУБД позволяет существенно упростить разработку приложений и одновременно улучшить их качество, так как исключает необходимость обработки некорректных данных [7, с. 19].
Современные СУБД обладают сложными логическими структурами и для эффективной работы с ними необходимо наличие высокоуровневого языка. Такой язык называется язык запросов (SQL) [7, с. 18].
Современные СУБД спроектированы таким образом, чтобы обеспечить полную сохранность данных и восстановление после отказов оборудования. СУБД способны обеспечить значительно более высокую надежность и доступность данных, чем надежность или доступность оборудования, на котором эти данные хранятся и на котором работают эти системы [7, с. 20].
Большинство современных СУБД содержат средства как для предотвращения доступа к базе данных, так и для разграничения доступа к данным. Допускается чтение или модификация только тех данных, для которых соответствующие операции разрешены [7, с. 21].
Подобные средства защиты реализуются не только на уровне СУБД: защитой приходится заниматься практически на всех уровнях и во всех компонентах информационной системы. Различные способы защиты данных будут рассмотрены с следующей главе.
Защита данных
Современные методы хранения и обработки информации способствуют появлению угроз данным. Угрозы могут быть связаны с раскрытием, искажением и потерей критичных данных пользователи или предприятия. Поэтому защита данных или информационная безопасность являются сейчас одними из ведущих направлений развития информационных технологий [15, с. 25].
Угроза данным может существовать на различных уровнях информационной системы [15, с. 38]:
- На уровне носителей информации. Параметры носителя могут быть определены, и сам носитель может быть похищен или уничтожен.
- На уровне взаимодействия с носителем. Может быть получена информация о программно-аппаратном составе системы, о функциях и методах защиты. Существует угроза несанкционированного доступа к ресурсам, несанкционированных действий и даже перехват данных, передаваемых по каналу связи.
- На уровне представления и содержания информации. Если информация не зашифрована и не имеет цифровой подписи, то ее содержание может быть раскрыто и искажено.
Информационная безопасность состоит в предотвращении этих угроз. Защита данных или информации — это деятельность по предотвращению утечки защищаемой информации, несанкционированных и непреднамеренных воздействий на защищаемую информацию [15, с. 26].
На различных уровнях применяются различные методы обеспечения информационной безопасности. На уровне носителей информации существуют особые механизмы, предотвращающие доступ к информации при использовании их в не доверенном окружении, такие как аппаратное шифрование и трудоемкость физического извлечения информации из носителя. На промышленном уровне банки данных на носителях могут помещены в защищенный периметр и иметь охрану.
Для обеспечения безопасности на уровне взаимодействия с носителем в настоящее время применяется достаточное количество мер для обеспечения информационной безопасности. Это могут быть комплексные модули доверенной загрузки системы, контролирующие ее работу на протяжении всего рабочего цикла. А также важным средством является резервное копирование наиболее ценных данных. Наличие резервной копии позволяет восстановить данные в случае их утраты [10, с. 236]. Также в числе мер на уровне взаимодействия с носителем могут быть [10, с. 234]:
- Защита от удаленного администрирования. Под несанкционированным удаленным администрированием понимается получение незаконного доступа к охраняемой информации программными средствами. Для предотвращения удаленного администрирования использует большое количество программных средств и решений, а также организационными средствами.
- Защита от компьютерных вирусов. Компьютерный вирус — это программный или сценарный код, встроенный в программу, сообщение, документ или в определенную область носителя данных и предназначенный для выполнения несанкционированных действий на несущей системе. Решениями для предотвращения заражения системы вирусами являются использование специальных средств противовирусной защиты, а также организационными средствами.
Самым важным уровнем, на котором следует производить защиту данных — это уровень представления и содержания информации. Обычно вопрос о защите данных на уровне содержания и представления встает тогда, когда данные необходимо передать от некоторого отправителя к некоторому получателю. Зачастую данные передаются по открытым каналам, которые доступны для прослушивания кем-то еще помимо отправителя и получателя. Чтобы защитить данные от искажения и раскрытия используется криптография. Криптография представляет собой совокупность методов преобразования данных, направленных на то, чтобы защитить эти данные, сделав их бесполезными для незаконных пользователей [15, с. 113]. Основой большинства криптографических систем защиты служит шифрование данных. Под шифром понимается совокупность процедур и правил криптографических преобразований, используемых для шифрования и расшифровывания информации по ключу шифрования. Ключ шифрования — это секретная информация, использующаяся алгоритмом шифрования для варьирования результата шифрования [15, с. 114].
Преобразование шифрования может быть симметричным и ассиметричным. При симметричном шифровании один и тот же ключ используется для шифрования и расшифровывания. При ассиметричном шифровании используются разные ключи для этих процессов — открытый для зашифровывания и закрытый для расшифровывания [15, с. 114].
Электронная цифровая подпись (ЭЦП) используется для подтверждения целостности и авторства данных. Как и в случае асимметричного шифрования, в данном методе применяются алгоритмы с простым вычислением открытого ключа из секретного и практической невозможностью обратного вычисления. Однако назначение ключей ЭЦП совершенно иное. Секретный (закрытый) ключ применяется для вычисления ЭЦП, открытый ключ необходим для ее проверки. При соблюдении правил безопасного хранения секретного ключа никто, кроме его владельца, не в состоянии вычислить верную ЭЦП какого-либо электронного документа [15, с. 114].
Транспортировка данных
Транспортировку или передачу данных в данной работе имеет смысл рассматривать как процесс обмена информацией в двоичной форме между двумя и более точками. Передача данных может быть осуществлена между различными устройствами: персональными и промышленными компьютерами, мобильными телефонами, терминалами и различными периферийными устройствами [14, с. 20]. Передача данных является очень сложным и многоуровневым процессом, поэтому для описания требований международной организацией по стандартизации была создана модель взаимодействия открытых систем OSI – ISO Model for Open System Interconnection (рис. 1).
Прикладной уровень
Уровень представления
Сеансовый уровень
Транспортный уровень
Сетевой уровень
Канальный уровень
Физический уровень
Прикладной уровень
Уровень представления
Сеансовый уровень
Транспортный уровень
Сетевой уровень
Канальный уровень
Физический уровень
Рис. 1
Модель состоит из семи уровней: Физический уровень, Канальный уровень, Сетевой уровень, Транспортный уровень, Сеансовый уровень, Уровень представления и Прикладной уровень. Осветить подробно в данной работе каждый уровень не представляется возможным в силу ограниченности объема, однако краткое определение каждого уровня дать необходимо. Стоит отметить, что наличие абсолютно всех уровней модели в системе совсем необязательно и зависит от архитектуры и реализации конкретной системы.
Физический уровень модель OSI занимается реальной передачей необработанных данных по выбранному каналу связи. На данном уровне определяются самые низкоуровневые и технические детали передачи данных по каналу связи. Эти детали включают в себя, но не ограничены уровнями напряжениями, которые будут использоваться для определения единицы и нуля, направлением связи, способами определения начала и конца передачи, физическими аспектами канала связи, т. е. типами и количеством проводов или частотами передатчиков [13, с. 58]. Например, на физическом уровне всемирно известный стандарт Ethernet имеет определенный интерфейс. В качестве среды передачи используется тонкий коаксиальный кабель, различные виды витых пар и волоконно-оптических кабелей. Передача данных возможна со скоростью 10, 100, 1000 Мбит/с. Кодировка данных в случае, например, 10 Мбит/с происходит с помощью Манчестерского кодирования [14, с. 471]. А очень популярный интерфейс RS-232, использующийся в промышленности повсеместно имеет на физическом уровне ограниченную длину кабеля в 50 футов [14, с. 169].
|
8 байт |
6 байт |
6 байт |
2 байта |
46-1500 байт |
4 байта |
|
Преамбула |
Адрес получателя |
Адрес источника |
Тип протокола |
Данные |
Контрольная последовательность кадра |
На канальном уровне модели OSI происходит передача сырых данных физического уровня по надежной линии связи. Такая линия связи должна обеспечивать непрерывный контроль и исправление ошибок, чтобы на следующем (сетевом) уровне такие ошибки были не видны. Обычно эта задача решается разбиением данных на кадры, которые передаются в соответствии с кадрами подтверждения, которые отсылает получатель [13, с. 59]. Например, интерфейс Ethernet на канальном уровне имеет определенный и стандартизированный формат кадра (рис. 2) [14, с. 475].
Рис. 2
Сетевой уровень ответственен за управление операциями подсети. Здесь происходит маршрутизация пакетов от источника к получателю по специальным таблицам, которые могут быть статическими или перестраиваться автоматически от различных условий [13, с. 59]. Классическим примером протокола сетевого уровня является протокол IPv4. Его дейтаграмма (рис. 3) состоит из заголовка и полезной части. Заголовок состоит из служебной информации и включает в себя поля: Версия протокола, IHL (длина заголовка), тип службы, полная длина и другие [13, с. 471].
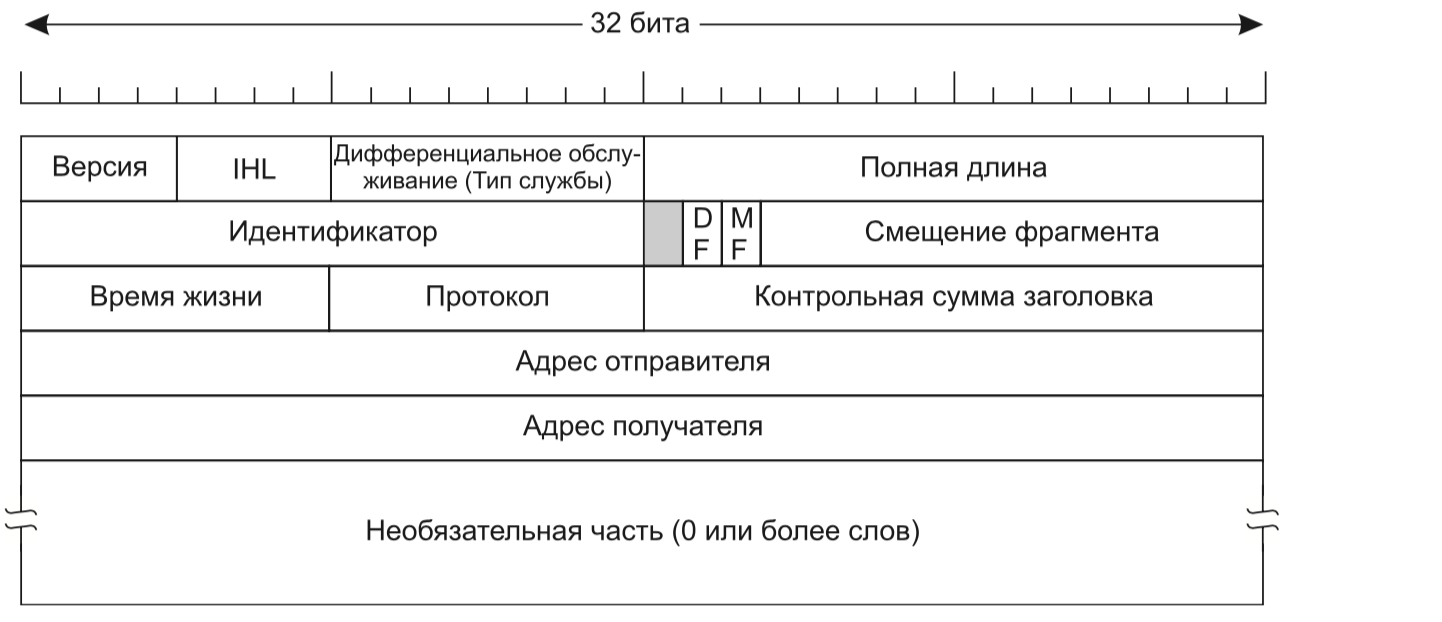
Рис. 3
Основной задачей транспортного уровня является прием данных от сеансового уровня, разбиение при необходимости их на более мелкие части и передача сетевому уровню, гарантируя при этом, что эти мелкие части будут получены на другом конце в неизменном виде [13, с. 59-60]. Например, протокол UDP (User Datagram Protocol — протокол передачи дейтаграмм пользователя) является протоколом транспортного уровня. С помощью протокола UDP передаются сегменты, состоящие из 8-байтного заголовка (рис. 4), за которым следует поле полезной нагрузки. Два номера портов служат для идентификации сокетов внутри отправляющей и принимающей машин [13, с. 575].
Сеансовый уровень позволяет устройствам или пользователям устанавливать сеансы связи друг с другом, предоставляя при этом различные виды сервисов: управление диалогом, управление маркерами и синхронизацию [13, с. 60].

Рис. 4
Уровень представления занимается в основном синтаксисом и семантикой передаваемой по каналу связи информации. Чтобы передача данных между устройствами или системами, использующими различное внутреннее представление данных, была возможной на этом уровне происходит преобразование данных в стандартизированный вид [13, с. 60].
На прикладном уровне происходит работа с непосредственными протоколами, которыми пользуется операционная система или программа, написанная программистом. На этом уровне пользователи и системы полностью абстрагированы от конкретной технологии передачи данных [13, с. 61]. Количество протоколов прикладного уровня великое множество. Фактически любая программа, которой необходимо передать данных с одного устройства на другой может использовать свой собственный уникальный разработанных протокол сетевого взаимодействия со своими собственными управляющими командами и логикой обработки ошибок.
Заключение
В данной работе были рассмотрены основные операции, которые могут быть произведены с данными на разных уровнях технологического процесса: на уровне сбора и формализации, на уровне обработки, на уровне хранения, защиты и транспортировки. Рассмотренные операции являются абсолютно базовыми и дают только общее представление о сложности практически любого технологического процесса. Так как данные по своей сути могут быть абсолютно любыми, а технологии в современном мире не стоят на месте, то и методов их обработки становится все больше и больше. С развитием техники и методов обработки возрастает сложность любых манипуляций с данными, однако основные операции всегда останутся теми же.
Библиография
- Алексеев Е.Г., Богатырев С.Д. Информатика: учебник — Саранск: Морд. гос. ун-т, 2009. URL: http://inf.e-alekseev.ru/text/Schisl_pon.html. (Дата обращения: 17.03.2019)
- Кнут Д., Искусство программирования. Том 3, Сортировка и поиск. 2-е изд. — М.: Вильямс, 2001. — 800 с.
- Крюков В. В., Информационно-измерительные системы. Учебное пособие. — Владивосток: ВГУЭС, 2000. — 102 с.
- Кудинов Ю. И., Пащенко Ф. Ф. Основы современной информатики: Учебное пособие. 2-е изд., испр. — СПб.: Издательство «Лань», 2011. — 256 с.
- Лафоре Р., Структуры данных и алгоритмы в JAVA. Классика Computers Science. 2-е изд. — СПб.: Питер, 2013. — 704 с.
- Лопатников Л. И. Экономико-математический словарь: Словарь современной экономической науки. — М.: Дело, 2003. URL: https://economic_mathematics.academic.ru/4010/Сбор_данных (Дата обращения: 12.03.2019)
- Новиков Б. А., Горшкова Е. А. Основы технологий баз данных: учеб. Пособие; под ред. Рогова Е. В. — М.: ДМК Пресс, 2019. — 240 с.
- Ожегов С. И. Толковый словарь Ожегова, URL: https://slovarozhegova.ru/word.php?wordid=10048. (Дата обращения: 09.03.2019)
- Полубенцева М. И. C/C++ Процедурное программирование. — СПб.: БХВ-Петербург, 2008. — 448 с.
- Симонович С. В. Информатика. Базовый курс: Учебник для вузов. 3-е изд. Стандарт третьего поколения. — СПб.: Питер, 2011. — 640 с
- Таганов Л. С., Пимонов А. Г. Информатика: учеб. Пособие. Кузбас. гос. техн. ун-т. — Кемерово, 2010. — 330 с.
- Таненбаум Э., Остин Т. Архитектура компьютера. 6-е изд. — СПб.: Питер, 2013. — 816 с.
- Таненбаум Э., Уэзэрол Д. Компьютерные сети. 5-е изд. — СПб.: Питер, 2012. — 960 с.
- Хелд Г., Технологии передачи данных. 7-е изд. — СПб.: Питер, 2003. — 720 с.
- Шаньгин В. Ф. Защита компьютерной информации. Эффективные методы и средства — М. ДМК Пресс, 2010. — 544 с.
- Шарапов В. М., Полищук Е. С. Датчики: Справочное пособие Москва: Техносфера, 2012. — 624 с.
- ISO/IEC/IEEE 24765-2010 Systems and software engineering — Vocabulary, URL: https://www.iso.org/obp/ui/#iso:std:iso-iec-ieee:24765:ed-1:v1:en. (Дата обращения: 09.03.2019)
- Stroustrup, Bjarne. The C++ Programming language. — Fourth edition. Addison-Wesley, 2013 — 1376 с.

- Применение объектно-ориентированного подхода при проектировании информационной системы
- Понятие и структура правовой основы оперативно-розыскной деятельности(Понятие и основания осуществления)
- Основания приобретения и прекращения право собственности (Понятие собственности и понятие права собственности)
- Физические и юридические лица. Общее понятие.
- Организация маркетинга на предприятии (теоретические аспекты)
- Определение, основные задачи, функции бухгалтерского учета (Теоретические аспекты понятия бухгалтерского учета, становление и метод)
- Рынок ценных бумаг (Теоретические основы понятия рынка ценных бумаг)
- Виды договоров
- Понятие и виды наследования (Понятие наследования. Круг наследников по закону)
- Классификация, структура и основные характеристики современных микропроцессоров ПК
- Проектирование реализации операций бизнес-процесса Управление персоналом (среда программирования Microsoft Visual Studio на платформе .Net, язык программирования C#)
- Построение модели угроз малого предприятия розничной торговли продуктами питания