
Операции, производимые с данными (Операции, производимые с данными)
Содержание:

Введение
Современное человечество существует буквально внутри огромного информационного потока. Сейчас не осталось практически ни одной сферы деятельности человека, где бы огромную роль не играли данные. Во многих направлениях, таких как банковская сфера, образование, торговля и промышленность, работа с информацией занимает решающую роль.
В связи с этим появились и проблемы, о которых нельзя забывать:
- огромный объем данных, циркулирующих в обществе, постоянно увеличивается, что ставит на первый план необходимость в их оптимизации и структуризации;
- необходимость запоминания человеком информации уступает умению управлять ею, используя персональный компьютер или смартфон;
- поддержка актуальности данных так же является решающим фактором в жизни людей.
Из этого следует вывод, что современный человек должен понимать, каким образом данные обрабатываются и как ими управлять в информационной среде, и какие вообще операции над данными можно совершать.
Понятие данных и структур данных
Что же такое «Данные»?
Данные — поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи, или обработки [1]. Говоря простым языком – это совокупность информации, сохраненной на том или ином носителе, с которой можно работать и производить различные операции.
На самом деле, хоть информацию и данные зачастую используют как синонимы, нужно понимать их различие. Информация – это результат преобразования определенных данных.
Данные хранятся в компьютере в двоичном формате, а зачастую они еще и закодированы или зашифрованы, поэтому для того, чтобы их получить, они должны быть обработаны при помощи программ. В качестве выходных данных мы получим информацию, из которой, проанализировав, мы получим знания.
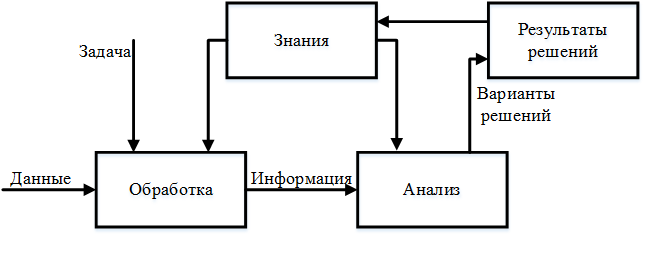
Рис. 1 - Взаимосвязь данных, информации и знаний
Хранение данных в двоичном формате обусловлено составляющими компьютера и способом обмена информацией внутри него. Данные передаются за счет электрических сигналов между комплектующими. Эти сигналы отправляются с определенной частотой и с определенной последовательностью. Наличие сигнала принято обозначать цифрой 1, его отсутствие – 0. С помощью этих цифр можно зашифровать и передать абсолютно любые данные. Такой поток единиц и нулей называют двоичным кодом.
 Операции с данными производятся при помощи информационных технологий. Их цель – производство информации в требуемом пользователю формате в результате переработки входных данных.
Операции с данными производятся при помощи информационных технологий. Их цель – производство информации в требуемом пользователю формате в результате переработки входных данных.
Рис. 2 - взаимодействие данных с информационными технологиями
Конечно же информация не может храниться в неупорядоченной куче. Для ее хранения и упорядочивания используется такое понятие, как структура данных.
Под структурой данных в общем случае понимают множество элементов данных, множество связей между ними, а также характер их организованности [2]. В качестве примера можно привести такую простейшую структуру данных, как массив – упорядоченная линейная совокупность однородных данных.
Различные виды структур подходят для различных программных решений. Например, такая структура, как «бинарное дерево», больше всего подходит для баз данных, а использование «словаря» (ключ-значение), которое является одной из самых популярных структур, можно использовать для создания адресной книги.
Правильный выбор структуры для разрабатываемого программного обеспечения крайне важен, так как от этого будет напрямую зависеть качество и эффективность приложения, поэтому важно понимать, какие операции над данными можно производить.
Рис. 3 - бинарное дерево

Операции, производимые с данными
Основные операции
Над любыми данными можно произвести пять основных операций:
- создание;
- удаление;
- выбор (доступ, отображение);
- изменение;
- копирование.
Операция создания подразумевает выделение памяти под требуемые данные. При данной операции информационный массив пополняется файлом или структурой данных. С точки зрения программирования память может выделяться при объявлении переменной или при компиляции программы. После создания данных объем информационного массива, а как следствие занятой памяти, увеличивается.
Операция удаления (уничтожения) высвобождает память, очищая хранящиеся данные. Объем информационного массива и занятой памяти уменьшается.
При разработке программ большинство языков программирования подразумевают установку начальных данных и создание указателей к ячейке памяти для возможности обращения к информации. Такой процесс называется инициализацией. При удалении же, уничтожаются не только данные, но и указатели к ним. Раньше данный процесс (выделить память, установить указатель) управлялся разработчиком вручную, что порождало ряд проблем. В лучшем случае в программе оставался указатель на ранее использовавшуюся ячейку памяти, но уже очищенную, что, при обращении к данным, не давало программе далее выполняться и приводило к сбоям. В худшем случае была обратная ситуация: указатель был удален, и программа считала, что таких данных уже нет, но память все так же была занята. Это производило лавинообразный эффект и утечку памяти, что отслеживается довольно сложно. В большинстве современных сред разработки данный процесс автоматизирован и анализируется без участия разработчика, помогая эффективно использовать память.
Операция выбора (доступа, отображения) связан с предоставлением данных пользователю или программе. В первом случае, информация будет доступна на устройстве вывода (например мониторе). В случае обращения к данным программой форма операции доступа будет зависеть от структуры, в которой эти данные будут храниться, но в любом случае при использовании операции выбора в приложении опять используются указатели.
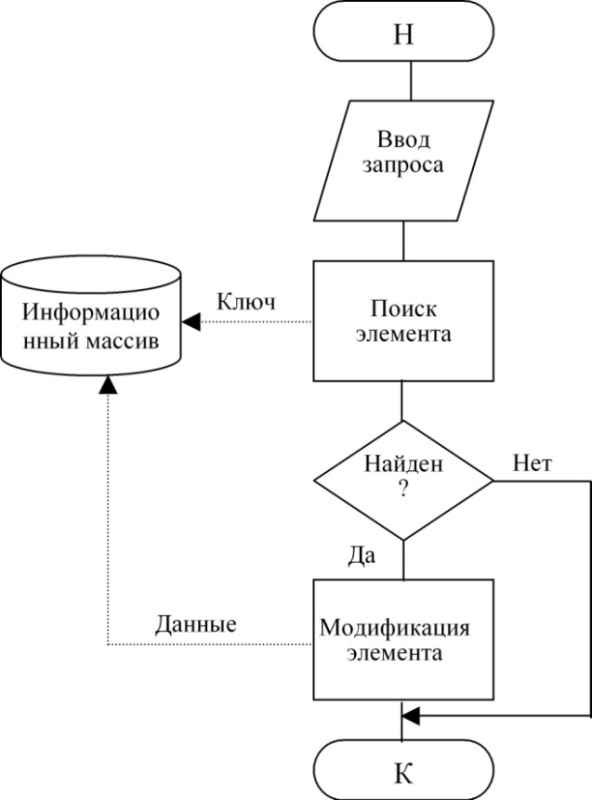 Операция изменения позволяет изменить значение данных в структуре данных. То есть данная операция относится не ко всему элементу в целом (напр. файлу), а к его составляющим (напр. строкам). В качестве примера можно привести изменение ячейки в файле таблицы, а в программировании операцию присваивания переменной. Технология доступа при выполнении операции изменения представлена на рис. 4.
Операция изменения позволяет изменить значение данных в структуре данных. То есть данная операция относится не ко всему элементу в целом (напр. файлу), а к его составляющим (напр. строкам). В качестве примера можно привести изменение ячейки в файле таблицы, а в программировании операцию присваивания переменной. Технология доступа при выполнении операции изменения представлена на рис. 4.
Операция копирования выделяет тот же объем памяти, что и у исходной структуры, и создает копию исходных данных в этой выделенной ячейке.
Эти операции являются обязательными для каждой структуры данных. Помимо них в зависимости от типа структуры могут использоваться и более специфические операции.
Рис. 4 - Технологии доступа при выполнении действий изменения элемента
Специфические операции
В ходе развития научно-технического прогресса данные меняют свой формат, переходят от одного вида к другому с помощью большого количества различных методов. Обработка таких, порой сложных, структур ведет к увеличению трудозатрат и поиску других операций, упрощающих работу с информацией. Причинами этого являются повышение сложности управления различными процессами и возрастающим количеством вариантов носителей информации и способов передачи данных между ними.
Одной из основных операций в современном мире является сбор информации – ее накопление с целью избыточности для принятия решений. Сбор – это аккумулирование различных данных для того, чтобы иметь возможность получить наиболее точные результаты.
В качестве примера можно привести любую научную работу. В начале идет сбор экспериментальных данных, и попытка провести зависимости. Далее, опираясь на ранее полученные знания, выводятся формулы или алгоритмы и сравниваются с собранной ранее информацией. В результате, если погрешность расчетов не удовлетворяет, производится анализ и делается вывод – либо данные не избыточны и требуется дополнительный сбор, либо имеет место ошибка в расчетах. Так или иначе требуется следующая итерация «Сбор-Анализ-Вывод».
Эту же логику можно переложить и на программу. Приложение собирает данные и хранит их в базе данных, потом производит расчеты, далее сравнивает результат и делает следующую итерацию в зависимости от заложенной в него логики.
Но что, если данные требуется с нескольких источников, а приходят они в различном формате? На помощь приходит следующая операция – формализация. Формализация – это процесс приведения данных, полученных из разных источников, к одному формату, чтобы иметь возможность их сопоставить и сделать более доступными.
На самом деле, человек постоянно прибегает к процессу формализации в жизни. Один из самых знакомых способов – приведение физических или, например, химических процессов к общедоступным и общепонятным формулам, что позволяет обмениваться информацией о различных явлениях на одном языке и структурировать и развивать научные знания.
В программировании операции формализации так же играют большую роль. Они постоянно встречаются при приведении значений к определенному типу (целочисленный, вещественный, строчный и т.п.) как просто в коде программы при создании и изменении переменных и констант, так и в собранной информации с различных источников в базе данных.
Зачастую, при работе с большим количеством источников, количество данных не просто избыточно, но и содержит в себе много лишней информации. В такой ситуации применяется операция фильтрации, которая позволяет отсеять лишнее, уменьшив «информационный шум», повысив ценность, достоверность и адекватность данных. Такая операция может быть как заметна пользователю, например вывод информации в таблице по его запросу с требуемыми параметрами, так и происходить внутри программы, например выборка из базы данных значений по определенным критериям и помещение их в массив для дальнейшего анализа.
Процесс фильтрации только лишь отсеивает данные, но не помогает их каким-либо образом систематизировать или упорядочить. За это уже отвечает сортировка – процесс упорядочивания данных по определенному признаку с целью удобства использования и повышения доступности информации.
Знакомый с детства результат сортировки – библиотека, где книги в стеллажах сгруппированы не только по категориям и тематике, но и в каждой категории они рассортированы по подгруппам и, далее, в алфавитном порядке. Это не только упрощает поиск нужной книги, но и значительно ускоряет его, что повышает доступность книг для использования.
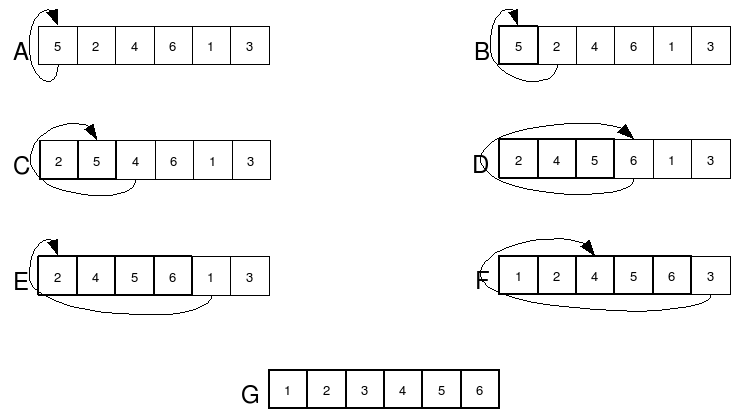
В программировании сортировка используется повсеместно. Любые данные для отображения или для удобства использования, как правило, сортируются. Существует масса алгоритмов для операции сортировки: пузырьковая сортировка, сортировка перемешиванием, слиянием, с помощью двоичного дерева и т.д.
Основными критериями оценки для данной операции являются время (или вычислительная сложность), характеризующее быстродействие алгоритма, и память, занимаемая в некоторых алгоритмах для хранения временных значений.
Рис. 5 - Пример сортировки вставками
Что касается оптимизации памяти для хранения данных – тут на помощь выступает операция архивации. Архивация – преобразование данных в другой формат при уменьшении занимаемого объема памяти, но без потери информации.
Сейчас существует множество алгоритмов для архивации, но они все используют в своей основе два решения: метод Хаффмана и метод RLE.
Метод Хаффмана анализирует и учитывает частоту использования символов: чем чаще встречается символ, тем короче последовательность битов, требуемая для его записи. К каждому архиву создается таблица, отображающая соответствия между символами и их кодами [3].
Метод RLE (Run Length Encoding) основан на выделении повторяющихся блоков данных, повторяющихся наборов байтов. Если говорить простым языком, то при архивировании мы получаем команду «повторить этот набор символов n раз». К примеру, из набора символов:
WWWWWWWWWWWWBWWWWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW
можно получить:
12W1B12W3B24W1B14W
что занимает гораздо меньше места.
Высокую актуальность сейчас имеет защита данных. Защита данных - организационные, программные и технические методы и средства, направленные на удовлетворение ограничений, установленных для типов данных или экземпляров типов данных в системе обработки данных [4].
Рис. 6 - Классификация методов защиты данных в компьютерных системах
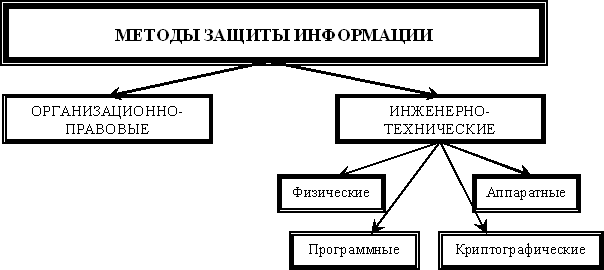
Другими словами, защитой данных называют комплекс операций, направленных на предотвращение незапланированного и несанкционированного удаления, изменения и воспроизведения данных. Такие меры, как правило, направлены на конфиденциальные и персональные данные.
Защита информации включает в себя:
- обеспечение целостности данных, исключая искажения или уничтожение информации. Тут речь идет, к примеру, о данных, представляющих материальную ценность;
- исключение возможности подмены данных, элементов структуры данных, при их сохранении. Например, злоумышленник может подменить сертификаты или ключи доступа, применяемые для авторизации на сервер с «узкими» данными, для несанкционированного доступа;
- ограничение (разграничение) полномочий на проведении операций с данными. С разграничением доступа мы сталкиваемся повседневно – это, например, стандартная система доступа на компьютере «администратор – пользователь – гость» с разными правами;
- ограничение возможностей применения полученных данных в строго оговоренных условиях. Тут имеется ввиду рассмотрение персональных и конфиденциальных данных с юридической точки зрения и закрепление условий посредством расписки/договора/т.п.
Данные нужно не только хранить и защищать, но и передавать. Для этих целей выступает операция маршрутизация. Маршрутизация – прием и передача данных между удаленными друг от друга участниками процесса. Между двумя пользователями в качестве средства транспортировки данных можно привести P2P-мессенджеры, либо более сложные клиент-серверные структуры.
Каждый компьютер в сети имеет свой IP-адрес, используемый для точной доставки пакета данных. Маршруты доставки пакетов данных могут быть разными, поэтому скорость доставки информации зависит не от физического расстояния между компьютером-отправителем и компьютером получателем, а от количества промежуточных серверов и качества линии связи.
Рис. 7 - различные маршруты передачи данных
Транспортировка данных производится путем разбиения файлов на Интернет-пакеты на компьютере-отправителе, индивидуальной маршрутизации каждого пакета и сборки файлов из пакетов в первоначальном порядке на компьютере-получателе [5].
Из формализации и транспортировки вытекает следующая операция над данными – преобразование. Под ним понимается перевод данных из одного формата в другой или из одной структуры в другую. Зачастую преобразование связано не только с формализацией, но и с более банальными вещами, например смена носителя. В качестве примера можно привести книгу – ее можно хранить как в физическом варианте, на бумаге, так и как отсканированную копию, в виде изображений, и, что чаще всего, в электронном виде, набором текста.
Так же преобразование крайне важно при транспортировке. Данные преобразуются в IP-пакеты и отправляются в данном формате, где собираются на компьютере-получателе в исходное состояние. Ранее, когда интернет был тесно связан с аналоговой телефонией и для подключения к нему требовались телефонные модемы, данные преобразовывались в некое подобие звуковых сигналов, а потом обратно в двоичный код.
Приведенный список операций далеко не полон и здесь выделены только основные из них. На каждом рабочем месте этот список дополняется своими специфическими операциями, необходимыми именно в требуемой предметной области. Из всего этого можно сделать вывод, что работа с информацией имеет огромную трудоемкость и в современном мире набор операций с данными в первую очередь направлен на автоматизацию процессов.
Модель представления данных (модель данных) - множество допустимых типов данных и отношений между ними, ограничений и действий над этими типами данных и отношений. Множество допустимых типов данных и отношений называют структурой данных. Модель данных является ядром базы данных [6].
Самыми распространенными являются три модели данных:
- иерархическая модель;
- сетевая модель;
- реляционная модель.
Иерархическая модель данных
Связи иерархической модели данных можно представить в виде дерева – связанный упорядоченный граф, не содержащий циклов. Обычно, при работе с иерархической моделью, у дерева определяют какую-либо конкретную вершину и определяют ее корнем дерева. В эту вершину не заходит ни одно ребро. Конечные вершины, из которых не выходит ни одной связи, называют листьями дерева.
В иерархической модели данных принята ориентация от корня к листьям, а графическое представление называют деревом определения.
Рис. 8 - Иерархическая модель структуры предприятия
Иерархическая модель является наиболее простой, по сравнению с остальными, поэтому она и старше других моделей.
Ее достоинствами являются:
- эффективное использование памяти;
- высокая скорость производимых операций над данными;
- удобство работы с иерархически упорядоченной структурой.
Не лишена она и недостатков:
- в случае сложных логических связей такая модель становится громоздкой;
- сложность включения новых объектов в заранее заданное дерево;
- трудности с восприятием такой модели обыкновенными пользователями.
3.2 Сетевая модель данных
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Активным пропагандистом этой модели был Чарльз Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS [7].
Рис. 9 - Пример сетевой модели данных
Основным отличием сетевой модели данных от иерархической является то, что любой узел данных может быть связан с любым другим узлом. Если говорить точнее, то различием этих моделей является то, что в сетевой запись может быть членом более, чем одного группового отношения.
Достоинства такой модели:
- высокоэффективное использование памяти;
- очень высокая скорость производимых операций над данными;
- широкие возможности образования произвольных связей.
Недостатки:
- высокая сложность базы данных, лежащей в основе модели, и ее жесткость;
- трудность понимания и выполнения пользователем операций над данными;
- сложность разработки и требование высокого уровня внимательности.
3.3 Реляционная модель данных
Реляционная модель данных была предложена математиком Э.Ф. Коддом в 1970 г. Она является наиболее широко распространенной моделью данных и единственной из трех основных моделей данных, для которой разработан теоретический базис с использованием теории множеств [8].
Реляционное представление дает возможность более четко оценить область действия и логические ограничения существующих систем форматированных данных, а также сравнить достоинства (с логической точки зрения) разных представлений данных в одной системе [9].
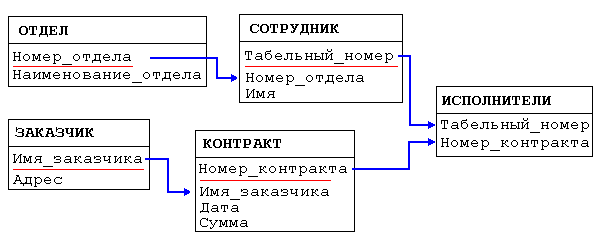
Реляционная модель данных представляет собой совокупность данных, состоящую из набора двумерных таблиц (отношений). Данные о строго типизированных объектах хранится в таблице. Ее поля (столбец таблицы) содержат значения характеристики объектов, а запись (строка таблицы) представляет собой описание этих соответствующих объектов.
Группу таких связанных таблиц называют схемой базы данных, а информацию о таблицах, полях, связях и иных объектах, метаданными.
Рис. 10 - Пример схемы реляционной модели данных
Достоинства реляционной модели данных:
- наличие математической теории ее построения;
- простота и удобство ее представления и реализации;
- минимальная избыточность и полнота данных;
- легкость модернизации.
Недостатки:
- высокие временные и трудозатраты на разработку базы данных;
- низкая производительность при обработке очень больших объемов данных;
- высокие требования к использованию памяти.
3.4 Роль данных в построении модели. Адекватность
На самом деле, как и с операциями над данными, моделей гораздо больше, чем описано, но все современные модели так или иначе в своей основе имеют одну из этих трех моделей. Стоит отметить, что наибольшую популярность в современном мире имеет реляционная модель и унаследованные от нее.
Строящаяся модель во многом определяется самими данными, которые в ней будут участвовать. Как следствие, от их качества и избыточности будет зависеть и качество разрабатываемой модели.
Адекватность модели – соответствие, т.е. совпадение свойств, функций, параметров, модели моделируемому объекту. Нужно понимать, что модель не может идеально совпадать с объектом, поэтому речь идет скорее о процентном соотношении совпадающих свойств между моделью и объектом.
Проверку соответствия модели реальной системе, называют оценкой адекватности. Она оценивается по близости результатов расчетов к экспериментальным данным.
Так же, немаловажную роль играет устойчивость модели. Устойчивость модели — это ее способность сохранять адекватность при исследовании эффективности системы на всем возможном диапазоне рабочей нагрузки, а также при внесении изменений в конфигурацию системы [10].
Говоря простым языком – результаты расчетов должны быть адекватными при любых объемах данных и любой нагрузке. К сожалению, универсальной проверки на устойчивость не существует, поэтому разработчик вынужден прибегать к большому количеству тестов, проводя различные операции с данными, руководствуясь частными случаями и здравому смыслу.
Очевидно, что устойчивость является положительным свойством модели. Однако если изменение входных воздействий или параметров модели (в некотором заданном диапазоне) не отражается на значениях выходных параметров, то польза от такой модели невелика. В связи с этим возникает задача оценивания чувствительности модели к изменению параметров рабочей нагрузки и внутренних параметров самой системы [11].
4.1 Физическая организация файлов, операции с файлами данных
Файл – упорядоченный набор данных на носителе, именованная область данных в памяти.
Работа с файлами осуществляется средствами операционных систем. Обычно выделяются следующие операции:
- связь полного имени файла с его указателем;
- открытие файла (для записи, чтения);
- закрытие файла;
- изменение его атрибутов;
- обеспечение целостности файлов: гарантия того, что файл содержит только те данные, которые и требовались;
- управление памятью: распределение внешней памяти для хранения данных.
Стоит отметить, что закрытие файла действительно является важной операцией. При ее выполнении, так как при ее совершении данные перезаписываются из оперативной памяти системы в физическую и занятые ресурсы операционной системы высвобождаются.
Основными критериями эффективности физической организации данных являются:
- скорость доступа к данным;
- объем адресной информации;
- степень фрагментированности общего пространства памяти;
- максимально возможный размер файла.
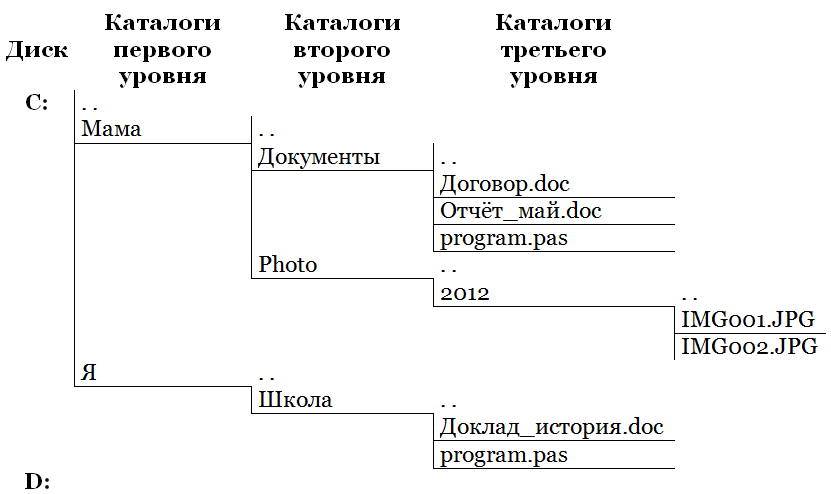
В современном мире у каждого пользователя хранится несколько тысяч различных файлов и структур данных. Если группировать все файлы и данные в одном месте, то организация работы с ними будет неэффективной, неудобной и долгой. Для этого используют многоуровневые каталоги файлов, вследствие чего, системное имя файла формируется из имени пути от корневой папки и расширения файла.
Рис. 11 - Пример многоуровневых каталогов
4.2 Логическая организация файлов
Данные, содержащиеся в файле, имеют какую-либо логическую структуру. Такая структура является базой при разработке программы, связанной с работой с файлами данных.
Сейчас известно пять видов организации файла:
- смешанный файл;
- последовательный файл;
- индексно-последовательный файл;
- индексируемый файл;
- файл прямого доступа.
При выборе организации файла, нужно учитывать такие критерии, как быстрота доступа, легкость обновления, экономность хранения, простота обслуживания и надежность.
Смешанный файл – наиболее простая форма организации файла. Данные в таком файле накапливаются по мере их поступления, образуя записи. Записи могут иметь различную длину и различные поля, расположенные в хаотичном порядке. Длинна каждого поля должна быть строго описана в данной записи.
Так как такой файл не имеет какой-либо структуры, то доступ к данным осуществляется обыкновенным перебором всех существующих в нем записей. Смешанные файлы используются только в том случае, если данные и структуры данных неудобно хранить в какой-либо другой форме организации файла. В таком виде память расходуется эффективно, но изменение данных и, например, вставка записи, довольно ресурсоемко.
Рис. 12 - Смешанный файл

В последовательном файле для записи используется фиксированный формат, все записи имеют одинаковую длину и состоят из одинаковых полей, расположенных в одинаковом порядке. Так как вся информация о записях есть, то для добавления записи в файл не требуется описание каждого поля записи, так как эти атрибуты являются постоянными.
Рис. 13 - Последовательный файл
Такой формат файлов в основном используют пакетные приложения при условии, что для работы требуются все записи, так как опять же, для доступа к ним требуется перебор всех записей. В отличии от смешанного файла, он занимает меньше дискового пространства и отличается более оперативной обработкой данных в нем.
Примером таких файлов являются простые текстовые с расширением *.txt.
Одним из способов исключения недостатков последовательного файла является переход к индексно-последовательной организации файла. В такой организации файл состоит из трех блоков – главный файл, содержащий записи с ключами, индексный файл с индексными полями и файл переполнения.
Рис. 14 - Индексно-последовательный файл
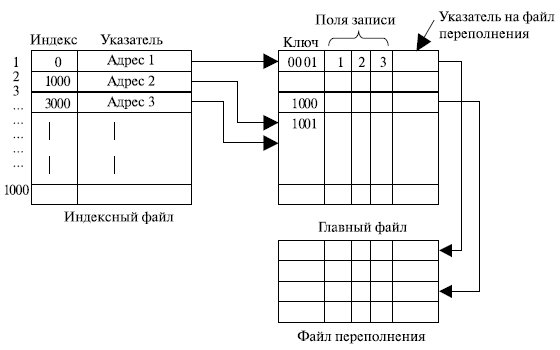
Для поиска нужной записи в первую очередь осуществляется поиск по индексному полю максимально точного ключа, не превышающего требуемого значения, после чего осуществляется поиск уже в самом файле.
Для дополнения записи в файл используется файл переполнения. Для этого в главном файле заводится поле-указатель на файл переполнения. Если в файл производится вставка, то запись добавляется в файл переполнения, где и индексируется. Время от времени производится слияние главного файла и файла переполнения, что помогает поддерживать его актуальность и устойчивость.
Индексированный файл применяется в тех приложениях, где время доступа к файлу является критичной величиной и редко требуется обработка сразу всех записей файла.
Предыдущие описанные организации файла сохраняют один минус: организация к записям ограничена работой с ключевым полем. Если появляется необходимость поиска записи по какой-либо другой характеристике, то даже индексно-последовательный файл уже будет непригоден. Для достижения такой гибкости требуется индексирование каждого поля, которое может потребоваться при поиске. Еще одним достоинством такого файла является реализация записей разной длины.
Файл прямого доступа (кэш – файл) использует возможность доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в таком случае тоже имеется ключевое поле, при этом концепция последовательного размещения не используется.
Рис. 15 - Индексированный файл
Файлы прямого доступа применяются тогда, когда необходим быстрый доступ при записях фиксированной длины, а также когда доступ необходим сразу же ко всем записям одновременно. Такая организация применяется, в частности, при организации каталогов.
Заключение
При написании курсовой работы были проанализированы современные тенденции работы с данными, были представлены основные и специфические операции с данными. Так же были рассмотрены частные случаи использования операций в различных моделях данных и различных типах файлов.
Были сделаны следующие выводы:
- правильный выбор структуры данных для разрабатываемого программного обеспечения крайне важен, так как от этого будет напрямую зависеть качество и эффективность приложения;
- работа с информацией имеет огромную трудоемкость и в современном мире набор операций с данными крайне широк и в первую очередь направлен на автоматизацию процессов;
- построение модели во многом определяется самими данными, которые в ней будут участвовать, и возможными операциями с ними. Как следствие, от их качества и избыточности будет зависеть и качество разрабатываемой модели;
- для выбора организации файлов нужно так же определить виды используемых данных, а так обратить внимание на такие критерии, как быстрота доступа, легкость обновления, экономность хранения, простота обслуживания и надежность.
СПИСОК ЛИТЕРАТУРЫ
- ISO/IEC 2382-1:1993. Информационные технологии. Словарь. Часть 1. Основные термины, 1993
- Камаев В.А., Костерин В.В. Технологии программирования. Учебник. — 2-е изд., перераб. и доп. — М.: Высш. шк. , 2006. - 454 с
- Левитин, А. В. Глава 9. Жадные методы: Алгоритм Хаффмана // Алгоритмы. Введение в разработку и анализ — М.: Вильямс, 2006. — С. 392–398. — 576 с. — ISBN 978-5-8459-0987-9
- ГОСТ 20886-85. Организация данных в системах обработки данных. Термины и определения. – Введ. 1986-06-30 – М.: Изд-во стандартов, 1986. – 8с.
- Угринович, Н.Д. Информатика и ИКТ: учебник для 8 класса / Н.Д. Угринович. - М.: Бином. Лаборатория знаний, 2009.
- Карпова, Т.С. Базы данных: модели, разработка, реализация: учеб. для вузов / Т.С. Карпова. — СПб.: Питер, 2001.
- С. Кузнецов. Базы данных. Вводный курс [Электронный ресурс] // Основы современных баз данных. URL: http://citforum.ru/database/osbd/glava_12.shtml (дата обращения: 08.11.2018)
- Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. -М: "Финансы и статистика", 1989.
- Е.Ф. Кодд (Edgar Frank Codd) Реляционная модель данных для больших совместно используемых банков данных / пер. с англ. М.Р. Когаловский // Журнал Системы Управления Базами Данных # 1 - М.: Изд. «Открытые системы», 1995
- К. К. Васильев, М. Н. Служивый. Математическое моделирование систем связи: учебное пособие – Ульяновск : УлГТУ, 2008. – 170 с.
- Гультяев, А. В. Визуальное моделирование в среде MATLAB : учебный курс / А. В. Гультяев. – СПб. : Питер, 2000. – 432 с.
- Буч, Г. Объектно-ориентированное проектирование с примерами применения / Г. Буч; Пер. с англ. — М.: Конкорд, 1992, — 519 с.

- Применение процессного подхода для оптимизации бизнес-процессов (Совершенствование бизнес-процессов финансового отдела ГТК «Телеканал «Россия»)
- Влияние процесса коммуникаций на эффективность управления организацией (Понятие, основные элементы и этапы коммуникации)
- Правовые отношения
- Понятие социального обеспечения ( Понятие социального обеспечения)
- Корпоративная культура в организации ( Содержание понятия и факторов формирования корпоративной культуры )
- История возникновения и развития будущего времени в английском языке
- анализ существующих теорий происхождения права.
- Функции менеджмента (Финансовый менеджмент)
- Налоговые отношения (Понятие налоговых отношений)
- Роль мотивации в поведении организации (Теоретические основы роли мотивации)
- Менеджмент человеческих ресурсов (Управление человеческими ресурсами)
- Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы (Характеристика предприятия)