
Операции, производимые с данными (Основное понятие)
Содержание:

Введение
Специфической чертой цивилизации является рост производства, потребления и накопления информации по всем направлениям человеческой деятельности. Для текущего столетия характерен интенсивный прогресс науки, техники и компьютерных технологий. Установлено, что сейчас специалист должен тратить примерно 80% своего времени на то, чтобы уследить за всеми новинками печатных работ в той или иной области деятельности [2].
Рост объемов информации, а также увеличивающийся спрос на нее аргументировали возникновение отрасли, связанной с автоматизацией обработки информации, - информатики.
Но для перехода непосредственно к науке информатике, необходимо сказать о самой информации. Мы живём в материальном мире. Всё, что нас окружает, и с чем мы сталкиваемся, относится либо к физическим телам, либо физическим полям. Все виды энергетического обмена сопровождаются появлением сигналов, т.е. все сигналы имеют в своей основе материальную энергетическую природу. При взаимодействии сигналов с физическими телами, в них возникают определённые изменения свойств – это явление называется регистрацией сигналов. В результате образуются данные – зарегистрированные сигналы.
Актуальность данной курсовой работы заключается том, что одной из ключевых проблем человечества является лавинообразный поток информации в любой сфере его жизнедеятельности.
Предметом исследования данной курсовой работы является технология программирования.
Объектом исследования данной курсовой работы являются данные.
Целью курсовой работы является изучений операций, производимых с данными.
Для реализации поставленной цели необходимо выполнить ряд задач, а именно:
- изучить основные понятия касательно данных;
- проанализировать существующие носители данных;
- рассмотреть операции, осуществляющиеся с данными;
- изучить процесс кодирования данных.
Структура курсовой работы состоит из введения, двух глав, заключения и списка использованных источников.
1. Данные
1.1 Основное понятие
Информация – это отражение действительности при помощи разнообразных сведений [1]. Вместе с этим термином в информатике применяется понятие «данные», предполагающее отрывочные, не связанные каким-либо образом между собой сведения.
В технологическом процессе обработки данных имеют место четыре этапа, а именно:
- формирование первичных данных – первичные сообщения о хозяйственных операциях, документы, включающие нормативные и юридические акты, результаты экспериментов, например, характеристики новой модели дирижабля и пр.;
- накопление и систематизация данных – организация такого размещения данных, которое реализует оперативный поиск и фильтрацию необходимых сведений, методические обновление данных, защиту от искажения и пр.;
- обработка данных – процессы, итогом которых на базе ранее накопленных данных являются новые их виды – обобщающие, аналитические, прогнозные и пр. Такие данные вторичной обработки могут быть обработаны еще раз для того, чтобы выдать более целостные и осмысленные обобщения;
- отображение данных – представление данных в удобной форме для человека. Это может быть и вывод на печать, и звук, и графики [3].
Сообщение, создаваемые на этапе формирования данных, может быть различного вида (бумажный документ, звук, анимация и т.д.). Чаще всего носители первичной информации – бумага, кассеты, виниловые диски и т.д. – крайне недолговечны [1].
Компьютерные технологии являются совершенно прогрессивным подходом – они записывают информацию в цифровом виде на магнитных и лазерных носителях.
При помощи технических и программных средств ЭВМ первичные данные трансформируются в машинный код.
Одной из ключевых проблем касательно документации данных в компьютере является точность и корректность четырех различных видов данных.
Точность – это реализация задачи без каких-либо погрешностей или ошибок. Также точность можно определить и как степень соответствия меры к установленному стандарту [5].
Корректность – это мера частоты возникновения ошибок в данных. Ошибки способы появиться в процессе сбора данных, наблюдений или же измерениях.
Точность находится в зависимости от степени детализации, например, от числа десятичных знаков при измерении какой-либо величины. Вес тела, определенный как 56,23 кг более точен, чем вес, определенный как 56,2 кг.
Данные – это диалектический компонент информации, являющийся зарегистрированными сигналами [7]. Вместе с тем, физический метод регистрации может быть разным:
- механическое перемещение физических тел;
- изменение формы физических тел или характеристик качества поверхности;
- изменение электрических, магнитных, оптических характеристик;
- изменение химического состава или связей;
- изменение состояния электронной системы и т.д.
В соответствии с методом регистрации данные способны храниться и перемещаться на носителях разных видов.
1.2 Носители данных
Самым известным носителем данных является бумага. На ней данные фиксируются при помощи изменения оптических характеристик ее поверхности. Данное изменение (изменение коэффициента отражения поверхности в установленном диапазоне длин волн) применяется и в устройствах, реализующих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD-ROM). Носителями, использующими изменение магнитных свойств, являются магнитные ленты и диски. Регистрация данных при помощи изменения химического состава поверхностных веществ носителя повсеместно применяется в фотографии. На биохимическом уровне осуществляется накопление и трансляция данных в живой природе [9].

Рисунок 1 – Простейший компакт-диск
Носители данных представляют интерес по той причине, что свойства информации прямым образом связаны с характеристиками ее носителей. Всякий носитель можно определить параметром разрешающей способности (объемом данных, записанных в установленной для носителя единице измерения) и динамическим диапазоном (логарифмическим отношением интенсивности амплитуд наибольшего и наименьшего регистрируемого сигнала). От данных свойств носителя находятся в тесной зависимости определенные свойства информации – полнота, доступность и достоверность [11]. Так, вполне можно рассчитывать на то, что в базе данных, находящейся на компакт-диске, легче реализовать полноту информации, чем в схожей по назначению базе данных, находящейся на гибком магнитном диске, т.е. в первом случае плотность записи данных на единице длины дорожки существенно выше. Для рядового пользователя доступность информации в книге существенно выше, чем на диске, т.к. не все пользователи имеют нужное оборудование. Также логично, что визуальный эффект от просмотра слайдов на проекторе существенно больше, чем от просмотра бумажных иллюстраций.

Рисунок 2 – Книга в бумажной и в электронной форме
Задача преобразования данных для смены носителя является одной из ключевых задач информатики. В структуре стоимости ЭВМ устройства ввода-вывода данных, взаимодействующие с носителями информации, составляют до 50% от стоимости аппаратных средств.
Отличным запоминающим устройством и носителем данных является мозг человек, имеющий примерно 10-15*109 нейронов – ячеек, обладающих функциями памяти и логической обработки информации [13].
Примерный объем мозга – 1,5 м3, масса – 1,2 кг, потребляемая мощность – 2,5 кВт. Самые современные электронные запоминающие устройства при аналогичной емкости имеют объем в несколько кубических метров, массу в десятки и сотни килограммов и мощность в диапазоне нескольких десятков киловатт.
Научно обоснованные прогнозы позволяют сделать вывод о том, что развитие электронной техники и использование новых высокоэффективных аккумулирующих сред в комплексе с повсеместным применением методов бионики при реализации задач синтеза запоминающих устройств дает возможность производить запоминающие устройства, схожие по характеристикам с памятью человека [15].
1.3 Операции с данными
Данные определяются своим типом и разнообразием действий над ними. Данные в компьютере можно разделить на простые и сложные [2].
В таблице 1 приведены примеры простых данных, которые могут быть подвергнуты компьютерной обработке.
Таблица 1
Типы данных, обрабатываемых компьютером
|
№ |
Типы данных |
Операции |
|
1 |
Числа (числовые данные) |
Все арифметические действия |
|
2 |
Тексты (символьные данные) |
Замещение, вставка, удаление символов, сопоставление, конкатенация строк |
|
3 |
Логические (бинарные данные) |
Все логические действия |
|
4 |
Изображения: рисунки, графика, анимация (графические данные) |
Операции над пикселями, из которых состоит изображение: яркость, цвет, контрастность |
|
5 |
Видео данные |
Удаление фрагмента, вставка фрагмента, работа с кадрами |
|
6 |
Аудио данные |
Усиление, уменьшение, удаление, вставка фрагмента |
К сложным данным принадлежат:
- массивы и списки (однотипные);
- структуры;
- записи;
- таблицы (разнотипные) [2].
С течением информационного процесса данные трансформируются из одного вида в другой благодаря различным методам. Обработка данных состоит из разнообразия операций. В ходе научно-технической революции и всеобщего усложнения связей в социуме трудовые затраты на обработку данных стабильно растут. В первую очередь это происходит ввиду непрерывного усложнения условий управления производством и общество. Во вторую очередь это вызвано интенсивностью возникновения и интеграции носителей данных, средств их хранения и перемещения.
В структуре вероятных операций с данными имеют место быть такие, как:
- сбор – накопление информации для реализации достаточной полноты для вынесения того или иного решения;
- формализация – приведение данных из различных источников к одинаковой форме для того, чтобы сделать их сравнимыми друг с другом, т.е. повысить их уровень доступности;
- фильтрация – устранение лишних данных, которые не нужны для принятий решения; в данном случае должен снижаться уровень «шума», а достоверность и адекватность данных должны расти;
- сортировка – упорядочение данных по определенному признаку для удобства применения; это повышает доступность информации;
- архивация – организация хранения данных в доступной форме; необходима для сокращения денежных затрат по хранению данных, также повышает общую надежность информационного процесса;
- защита – совокупность мероприятий, ориентированных на предупреждение утраты, воспроизведения и изменения данных;
- транспортировка – прием и передача данных между удаленными участниками информационного процесса; вместе с тем источник данных является сервером, а потребитель – клиентом;
- преобразование – перевод данных из одной формы (структуры) в другую. Данная операция зачастую связана с изменением типа носителя – так, книги можно хранить и в бумажной, и в электронной форме [4].
Потребность в многократном преобразовании данных появляется и при их транспортировке, тем более есть она реализуется средствами, которые не предназначены для транспортировки такого вида данных. В роли примера можно привести факт того, что для транспортировки цифровых потоков данных по телефонному каналу (в первую очередь направленных лишь на трансляцию аналоговых сигналов в узком диапазоне частот) нужно преобразование цифровых данных в определенное подобие звуковых сигналов, что реализуют специальные устройства – телефонные модемы [6].
2. Кодирование данных
2.1 Кодирование данных двоичным кодом
Для того, чтобы автоматизировать работу с данными, которые принадлежат к разнообразным типам, крайне важно унифицировать их форму отображения. Для этого нередко применяется прием кодирования, т.е. выражение данных одного типа через данные другого типа. Естественные человеческие языки – это системы кодирования понятий для выражения мыслей при помощи речи [8]. К языкам близко примыкают азбуки (системы кодирования языковых элементов графическими символами). В ходе истории было немало интересных, но безуспешных попыток создания универсальных языков и азбук. Скорее всего, такая тщетность их интеграции обусловлена тем, что национальные и социальные образования естественным образом понимают, что трансформация системы кодирования общественных данных однозначно ведет к трансформации общественных методов (т.е. норм права и морали), а это может быть связано с социальными потрясениями. Аналогичная проблема универсального средства кодирования эффективно реализуется в различных отраслях техники, науки и культуры [10]. В роли примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку и т.д. Своя система есть и в вычислительной технике – это двоичное кодирование, базирующееся на отображении данных последовательностью всего двух знаков: нуля и единицы. Такие знаки именуются двоичными цифрами и по-английски называются сокращенно bit (бит). Примеры разнообразных систем кодирования отражены на рис. 3.
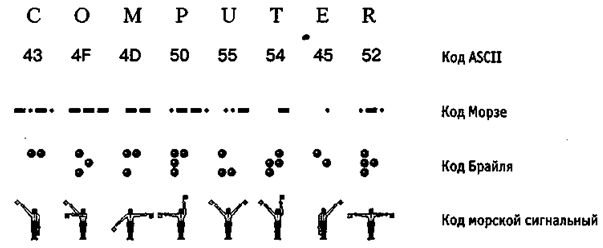
Рисунок 3 - Примеры различных систем кодирования
Одним битом способны быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и пр.). В том случае, если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11 данные обработка носитель кодирование
Тремя битами можно закодировать 8 различных значений: 000 001 010 011 100 101 ПО 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, вдвое увеличивается значений, которое может быть выражено в такой системе, т.е. общая формула имеет вид:
N=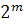
где N— количество независимых кодируемых значений;
m — разрядность двоичного кодирования, принятая в установленной системе.
2.2 Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом несложно — необходимо взять целое число и делить его надвое до тех пор, пока частное не будет равно единице [12]. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
19:2 = 9 + 1
9:2=4+1
4:2 = 2 +-0
2:2=1+0
Следовательно, 1910= 100112.
Для кодирования целых чисел от 0 до 255 нужно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит дают возможность закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 млн различных значений.
Для кодирования действительных чисел применяют 80-разрядное кодирование. В данном случае число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 • 101 300 000 = 0,3 • 106
123 456 789 - 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и определенное фиксированное количество разрядов отводят для хранения характеристики (также со знаком).
2.3 Кодирование текстовых данных
Если каждому символу алфавита сопоставить некоторое целое число (например, порядковый номер), то благодаря двоичному коду можно кодировать и текстовую информацию [14]. Восьми двоичных разрядов хватит для кодирования 256 разных символов. Этого достаточно, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и определенные общепринятые специальные символы, например, символ «§».
Технически это выглядит несложно, но в любом случае есть существенные организационные трудности. В первые годы эволюции вычислительной техники они были связаны с отсутствием нужных стандартов, а сейчас же вызваны, напротив, избытком одновременно действующих и противоречивых стандартов [16]. Для того, чтобы повсеместно кодировались текстовые данные, необходимые единые таблицы кодирования, а это пока невозможно ввиду противоречий между символами национальных алфавитов, а также противоречий корпоративной направленности.
Для английского языка противоречий нет. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США) [10]. В данной системе существуют две таблицы кодирования — базовая и расширенная. Базовая таблица фиксируют значения кодов от 0 до 127, а расширенная от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (прежде всего, производителям компьютеров и печатающих устройств). В данной области расположены управляющие коды, которым не соответствуют никакие символы языков, и, следовательно, такие коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как осуществляется вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и определенных вспомогательных символов [5]. Базовая таблица кодировки ASCII показана на рисунке 4. Подобные системы кодирования текстовых данных были созданы и в других странах. Поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальные системы кодирования вынуждены были отойти во вторую, расширенную часть системы кодирования, устанавливающую значения кодов со 128 по 255 [12]. Отсутствие единого стандарта в данной области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
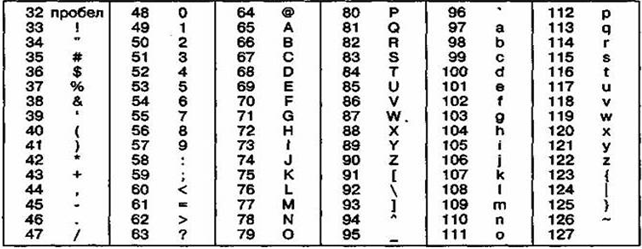
Рисунок 4 - Кодировка ASCII
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была интегрирована «извне» — компанией Microsoft, но, принимая во внимание широкое распространение операционных систем и иных продуктов данной компании в России, она глубоко закрепилась и нашла широкое распространение (рисунок 5). Такая кодировка применяется на большинстве локальных компьютеров, функционирующих на платформе Windows [11].
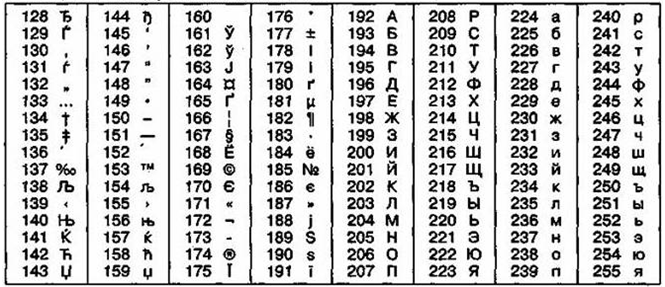
Рисунок 5 – Кодировка Windows 1251
Другая распространенная кодировка называется КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (рисунок 6) [1]. В настоящее время данная кодировка интенсивно применяется в компьютерных сетях на территории России и в российском секторе Интернет.
Международный стандарт, в котором есть кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации) [4]. На практике такая кодировка применяется нечасто (рисунок 7).
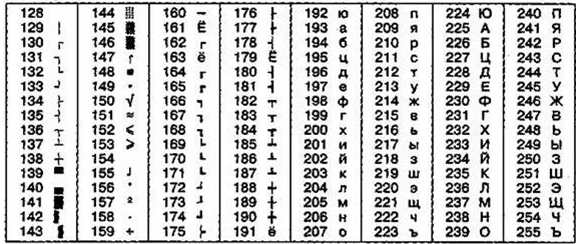
Рисунок 6 –Кодировка КОИ-8
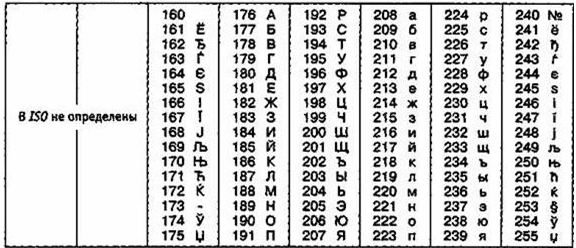
Рисунок 7 –Кодировка ISO
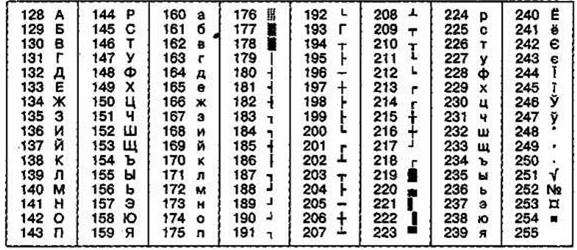
Рисунок 8 – ГОСТ-альтернативная кодировка
На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая применяется и в настоящее время (рисунок 8).
Ввиду большого количества систем кодирования текстовых данных, функционирующих в России, появляется задача межсистемного преобразования данных — это одна из ключевых задач информатики [1].
2.4 Универсальная система кодирования текстовых данных
Если провести анализ организационных сложностей, связанных с созданием единой системы кодирования текстовых данных, то можно сделать вывод о том, что они вызваны ограниченным набором кодов (256). Вместе с тем очевидно, что если, к примеру, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон вероятных значений кодов будет существенно больше. Данная система, базирующаяся на 16-разрядном кодировании символов, получила название универсальной — UNICODE [9]. Unicode — стандарт кодирования символов, дающий возможность представить знаки почти всех письменных языков. Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но ввиду несовместимости с ASCII она не получила распространения и не включена в стандарт. В Microsoft чаще всего применяется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X установлена форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium), объединяющей мощнейшие IT-корпорации. Использование данного стандарта дает возможность закодировать множество символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы [8].
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы, — а эта работа осуществляется непрерывно, т.к. изначально система Юникод включала только Plane 0 — двухбайтные коды, — выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
- 1.1 (соответствует стандарту ISO/IEC 10646—1:1993),
- 2.0, 2.1 (тот же стандарт ISO/IEC 10646—1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2),
- 3.0 (стандарт ISO/IEC 10646—1:2000).
- 3.2 (стандарт 2002 года)
- 4.0 (стандарт 2003)
- 4.01 (стандарт 2004)
- 4.1 (стандарт 2005)
-5.0 (стандарт 2006) и т.д.
Хотя формы записи UTF-8 и UTF-32 дают возможность кодировать до 231 (2 147 483 648) кодовых позиций, было принято решение применять только 220+216 (1 114 112) для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — в настоящее время применяется немногим больше 99 000 кодовых позиций [3].
Кодовое пространство разделено на 17 плоскостей по 216 (65536) символов [6]. Нулевая плоскость называется базовой, в ней находятся символы наиболее употребительных письменностей. Первая плоскость применяется чаще всего для исторических письменностей. Плоскости 16 и 17 выделены для частного использования.
Для обозначения символов Unicode применяется запись вида «U+xxxx» (для кодов 0…FFFF) или «U+xxxxx» (для кодов 10000…FFFFF) или «U+xxxxxx» (для кодов 100000…10FFFF), где xxx — шестнадцатеричные цифры. Так, символ «я» (U+044F) имеет код 044F16 = 110310.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы содержат такие группы, как:
- буквы, имеющиеся хотя бы в одном из обслуживаемых алфавитов;
- цифры;
- знаки пунктуации;
- специальные знаки (математические, технические, идеограммы и т.д.);
- разделители [11].
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character) [7].
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (base characters), а непротяжённые - модифицирующими (combining characters); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа «?» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов — селекторы варианта начертания (variation selectors) [6]. Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов письма Phags-Pa.
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
- Форма нормализации D (NFD) — каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
- Форма нормализации C (NFC) — каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция — текст обрабатывается от начала к концу и выполняются следующие правила:
Символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода.
В любой последовательности символов, стартующей с начального символа S символ C блокируется от S, если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки прошедшие каноническую декомпозицию.
Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода [2].
Символ X может быть первично совмещен с символом Y если и только если существует первичный композит Z, канонически эквивалентный последовательности <X, Y>.
Если очередной символ C не блокируется последним встреченным начальным базовым символом L, и он может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется.
- Форма нормализации KD (NFKD) — совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
- Форма нормализации KC (NFKC) — совместимая декомпозиция с последующей канонической композицией [16].
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены коды от U+0400 до U+052F. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать, как трудности переходного периода [2,4].
2.5 Кодирование графических данных
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. Растровое изображение представлено на рисунке 9.
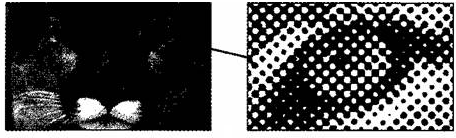
Рисунок 9 - Растровое изображение
Растр - это метод кодирования графической информации (точечная структура графического изображения) [4].
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа [8].
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основных цвета:
- красный (Red, R);
- зеленый (Green, G);
- синий (Blue, В).
На практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такая система кодирования называется системой RGB (по первым буквам названий основных цветов) [8].
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн. различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color) [5].
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно, дополнительными цветами являются:
-
- голубой (Cyan, С);
- пурпурный (Magenta., М);
- желтый (yellow, Y) [3].
Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска — черная (Black, К). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 цветовых оттенков [6]. Такой метод кодирования цвета называется индексным. Смысл названия в том, что, поскольку 256 значений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некоей справочной таблице, называемой палитрой. Разумеется, эта палитра должна прикладываться к графическим данным — без нее нельзя воспользоваться методами воспроизведения информации на экране или бумаге (то есть, воспользоваться, конечно, можно, но из-за неполноты данных полученная информация может быть неправильной: листва на деревьях может оказаться красной, а небо — зеленым).
2.6 Кодирование звуковой информации
Приемы и методы работы со звуковой информацией пришли в вычислительную технику позднее. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации [3]. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
- Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а, следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП) [1]. Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
- Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука [15].
Заключение
Таким образом, на основании проведенного исследования можно сделать вывод о том, что объем информации постоянно увеличивается, а принятие по-настоящему правильного решения зависит, прежде всего, от полноты, достоверности, оперативности предоставления необходимых информационных ресурсов и вместе с этим их доступности для максимально широкого круга заинтересованных лиц. Сегодня информацию рассматривают как один из основных ресурсов развития общества, а информационные системы и технологии как средство повышения производительности и эффективности работы современного специалиста.
Одной из ключевых проблем человечества является лавинообразный поток информации в любой сфере его жизнедеятельности, ввиду чего крайне актуальным является изучение множества операций, производимых с данными.
Таким образом, была выполнена цель курсовой работы – изучены операции, производимые с данными.
Цель была выполнена благодаря реализации следующих задач:
- изучена основные понятия касательно данных;
- проанализированы существующие носители данных;
- рассмотрены операции, осуществляющиеся с данными;
- изучен процесс кодирования данных.
Список использованных источников
1. Анашкина, Н.В. Технологии и методы программирования: Учебное пособие для студентов учреждений высшего профессионального образования / Н.В. Анашкина, Н.Н. Петухова, В.Ю. Смольянинов. - М.: ИЦ Академия, 2012. - 384 c.
2. Богачев, К.Ю. Основы параллельного программирования / К.Ю. Богачев. - М.: Бином, 2015. - 342 c.
3. Воскобойников, Ю.Е. Основы вычислений и программирования: Учебное пособие / Ю.Е. Воскобойников и др. - СПб.: Лань, 2016. - 224 c.
4. Гергель, В.П. Современные языки и технологии паралелльного программирования: Учебник / В.П. Гергель. - М.: МГУ, 2012. - 408 c.
5. Зыков, С.В. Основы современного программирования. Разработка гетерогенных систем в Интернет-ориентированной среде: Учебное пособие / С.В. Зыков. - М.: ГЛТ, 2012. - 444 c.
6. Камаев, В.А. Технологии программирования / В.А. Камаев, В.В. Костерин. - М.: Высшая школа, 2016. - 454 c.
7. Карпов, Ю. Теория и технология программирования. Основы построения трансляторов / Ю. Карпов. - СПб.: BHV, 2012. - 272 c.
8. Колдаев, В.Д. Основы алгоритмизации и программирования: Учебное пособие / В.Д. Колдаев; Под ред. Л.Г. Гагарина. - М.: ИД ФОРУМ, ИНФРА-М, 2012. - 416 c.
9. Кулямин, В.В. Технологии программирования. Компонентный подход / В.В. Кулямин. - М.: Интуит, 2014. - 463 c.
10. Кундиус, В.А. Теоретические основы разработки и реализации языков программирования / В.А. Кундиус. - М.: КноРус, 2013. - 184 c.
11. Линев, А.В. Технологии параллельного программирования для процессоров новых архитектур: Учебник / А.В. Линев, Д.К. Бастраков С.И. Боголепов. - М.: Моск.университета, 2014. - 160 c.
12. Лупин, С.А. Технологии параллельного программирования / С.А. Лупин, М.А. Посыпкин. - М.: ИД ФОРУМ, ИНФРА-М, 2013. - 208 c.
13. Окулов, С.М. Основы программирования, перераб / С.М. Окулов. - М.: Бином, 2015. - 336 c.
14. Семакин, И.Г. Основы алгоритмизации и программирования: Учебник для студ. учреждений сред. проф. образования / И.Г. Семакин, А.П. Шестаков. - М.: ИЦ Академия, 2012. - 400 c.
15. Фридман, А. Основы объектно-ориентированного программирования на языке СИ++ / А. Фридман. - М.: Горячая линия -Телеком, 2012. - 234 c.
16. Черпаков, И.В. Основы программирования: Учебник и практикум для прикладного бакалавриата / И.В. Черпаков. - Люберцы: Юрайт, 2016. - 219 c.

- Разработка регламента выполнения процесса "Управление документооборотом" (Описание предметной области. Постановка задачи)
- Реорганизация юридических лиц (Юридическое лицо как субъект реорганизации)
- Методики прогнозирования банкротства
- Патент в системе российского законодательства (Патент: понятие, сущность, виды)
- Анализ чистых активов
- Развитие воображения в дошкольном возрасте (Психологическая сущность воображения и основные аспекты его изучения в психологии)
- Транспортный налог
- Понятие гражданского права (Понятие гражданского права)
- Сроки в гражданском праве
- Институт наследования в древности
- Предмет, метод предпринимательского права и принципы предпринимательского права
- Понятие и виды наследования (Институт наследования в древности)