
Операции, производимые с данными (Основные структуры данных)
Содержание:

Введение
Важность обладания информацией сложно преувеличить.
Даже в животном мире общение играет важную роль. А общение есть ни что иное как обмен информацией. Так же с обменом информацией неразрывно связан прогресс человечества. Мало придумать новый способ добычи. Для развития человечества в целом, важно этому новому способу обучить других людей. То есть информацию нужно сохранить. С развитием общество начало ценить не только материальные плоды труда, но и интеллектуальные. И этот процесс обусловил появление таких понятий как обладание информацией и ее защита.
До настоящего времени не существует единого толкования слова «информация»: в различных источниках приводятся различные определения. Так же часто смешиваются и путаются слова «информация», «данные», «знания». Даже специалисты в области информационных технологий зачастую путаются в этих понятиях. Сегодня существует очень много определений данных терминов, зависящих от профессиональных интересов и целей.
Рассмотрим несколько определений из свободной энциклопедии «Википедия»:
Информа́ция (от лат. informātiō «разъяснение, представление, понятие о чём-либо», informare «придавать вид, форму, обучать; мыслить, воображать») — сведения независимо от формы их представления.
Да́нные — зарегистрированная информация; представление фактов, понятий или инструкций в форме, приемлемой для общения, интерпретации, или обработки человеком или с помощью автоматических средств.
– поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи или обработки.
– формы представления информации, с которыми имеют дело информационные системы и их пользователи.
– совокупность значений, сопоставленных основным или производным мерам и/или показателям.
В обоих статьях Википедии после определений приводится следующий абзац:
Хотя информация должна обрести некоторую форму представления (то есть превратиться в данные), чтобы ею можно было обмениваться, информация есть в первую очередь интерпретация (смысл) такого представления. Поэтому в строгом смысле информация отличается от данных, хотя в неформальном контексте эти два термина очень часто используют как синонимы.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
Однако, информация — это интерпретация данных, и, казалось бы, перефразируя Ротшильда, можно сказать: «Кто владеет данными, тот владеет миром». Но данные без интерпретации — это просто набор фактов. К примеру, пазлы (данные) — просто набор кусочков картона, но после сбора (интерпретации) мы можем увидеть картину (информацию).
Аналогично, обладать информацией мало — необходимо донести ее до других. А для этого ее необходимо превратить в данные.
Так же в различных источниках встречается мнение что «данные» — это различные состояния носителя. Носители могут быть самыми разными. От старинных: глиняные таблички, папирус, кожа, береста; до более современных: бумага, магнитные ленты и диски, оптические и электрические носители, а также экран, радио и телевизионный эфир и многие другие. Для того чтобы различать состояния носителей, человек использует свои органы чувств: зрение, слух и осязание (алфавит Л. Брайля). Можно представить себе передачу информации и с применением обоняния или вкуса.
У компьютера также есть свои «органы чувств», позволяющие состояния доступных ему носителей (магнитные, электрические и оптические).
Также необходимо подчеркнуть важность возможности интерпретировать имеющиеся данные. Если человек получит электронное письмо на китайском языке, то, чтобы суметь прочесть письмо, во-первых, на устройстве в качестве системного должен быть установлен шрифт, включающий китайские иероглифы, во-вторых, человек должен знать китайский язык. Таким образом, и компьютер, и человек могут обладать данными, но не иметь возможности извлечь из них информацию.
Вышесказанное можно обобщить следующим алгоритмом:

Получение данных
Получение данных можно рассматривать под разными углами.
1. Откуда.
Данные могут быть получены как из внешних источников, так и в результате обработки уже имеющихся данных.
При получении данных из внешних источников необходимо убедиться в их правдоподобности, адекватности. Например, при вводе с клавиатуры оператор может допустить опечатку. Желательно обеспечить некую автоматическую первичную проверку (контрольные суммы, подтверждение ввода).
При автоматическом получении данных может возникать погрешность или помехи (хорошим вариантом будет съем результатов нескольких тестов и усреднение показателей, а также накапливание информации о погрешностях).
При получении информации от постоянных поставщиков можно ввести индекс доверия.
При получении данных в результате обработки уже имеющихся, так же необходимо проводить операции по контролю правильности расчетов.
2. В каком виде.
Данные могут поступать в различных формах. Самым банальным примером может служить способ записи даты (30.11.1990, 30 ноября 1990, 11/30/90 и т.д.). Если все эти виды записи даты мы оставим в таком виде, это очень усложнит поиск. Поэтому желательно преобразовывать получаемые данные. Также необходимость преобразовывать возникает при изменении типа носи-
теля. Например, автор принес в издательство рукопись книги на бумаге. Для
того чтобы напечатать эту книгу, рукопись необходимо либо отдать наборщику, чтобы он набрал ее на компьютере, либо отсканировать и распознать.
Преобразование данных — перевод данных из одной формы в другую.
Очень часто данные поступают в виде пакетов и из разных источников порядок формирования этих пакетов может быть разным. Например:
AABBBCDDEFF
FFEDDCBBBAA
2A3B1C2D1E2F
1:C,E / 2:A,D,F / 3:B
…
И, несмотря на то, что все эти 4 строки содержат одни и те же данные, оперировать ими сложно. Поэтому желательно проводить формализацию
данных.
Формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме для того, чтобы сделать их сопоставимыми между собой.
Нередко пакеты данных содержат лишнюю информацию. Например, фирма занимается продажей игрушек. Раз в неделю принято проводить анализ цен на рынке. Для этого скачиваются прайсы нескольких конкурентов, которые продают не только игрушки, но и другие детские товары. Для анализа необходима фильтрация данных.
Фильтрация данных — отсеивание лишних данных, в которых нет необходимости для принятия решений; при этом достоверность и адекватность данных должны возрастать.
3. Когда.
Данные мы можем получить в один момент времени, а понадобиться они могут в другой. Таким образом, данные необходимо хранить.
Структурирование данных
Для удобства хранения и поиска полученные данные желательно структурировать.
Структурирование данных — размещение данных по определенному макету. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Структуры данных являются важнейшим компонентом программирования. Еще в 1976 году швейцарский ученый Никлаус Вирт написал книгу «Алгоритмы + структуры данных = программы». Формула актуальна и сейчас.
Структуры данных могут быть линейными и нелинейными.
Линейные: элементы образуют последовательность или линейный список, обход узлов линеен. Например: массив, связанный список, стек, очередь.
Нелинейные: данные не последовательны, обход узлов нелинейный. Например: граф, деревья.
Основные структуры данных
Массивы
Массив — это простейшая и наиболее распространенная структура данных. Другие структуры данных, например, стеки и очереди, производны от массивов. Любая таблица есть пример массива.
Здесь показан простой массив размером 4, содержащий элементы (1, 2, 3 и 4).
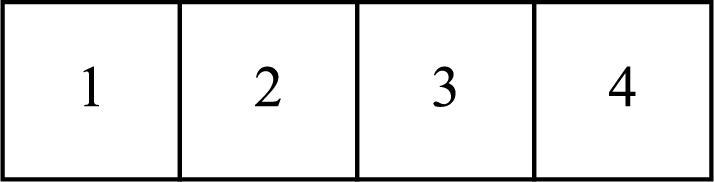
Каждому элементу данных присваивается положительное числовое значение, которое называется индекс и соответствует положению этого элемента в массиве. В большинстве языков программирования элементы в массиве нумеруются с 0.
Существуют массивы двух типов:
Одномерные (такие, как показанный выше).
Многомерные (массивы, в которые вложены другие массивы).
Стеки
Все привыкли пользоваться сочетанием клавиш «CTRL+Z». Оно предусмотрено практически во всех приложениях. Задумывались ли вы когда-нибудь, как это работает? Алгоритм выглядит так: в программе сохраняется история последних ваших действий (количество сохраняемых записей ограничено), причем, они располагаются в памяти в таком порядке, что последний сохраненный элемент идет первым. И, нажав «CTRL+Z» вы можете вернуться к предыдущему шагу. Массивами такую задачу решить проблематично. В подобной ситуации используется стек.
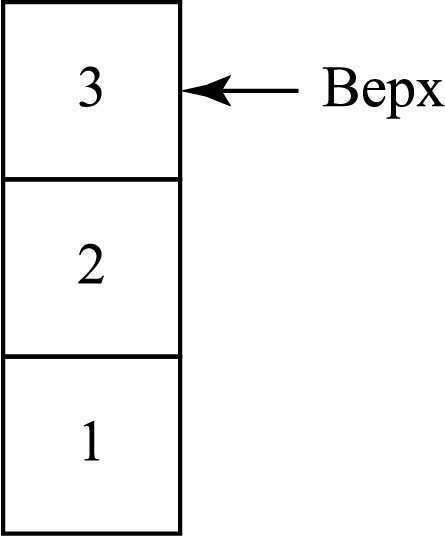
Стек можно сравнить со стопкой белья. Если вам нужна какая-то вещь, лежащая в конце стопки, вам сначала придется снять все белье, лежащее выше. Именно так работает принцип LIFO (Последним пришел — первым вышел).
Так выглядит стек, содержащий три элемента данных (1, 2 и 3), где 3 находится сверху — поэтому будет убран первым:
Очереди
Классический пример очереди — это и есть очередь покупателей. Новый покупатель становится в самый хвост очереди, а самый первый покупатель будет обслужен первым и первым покинет очередь.
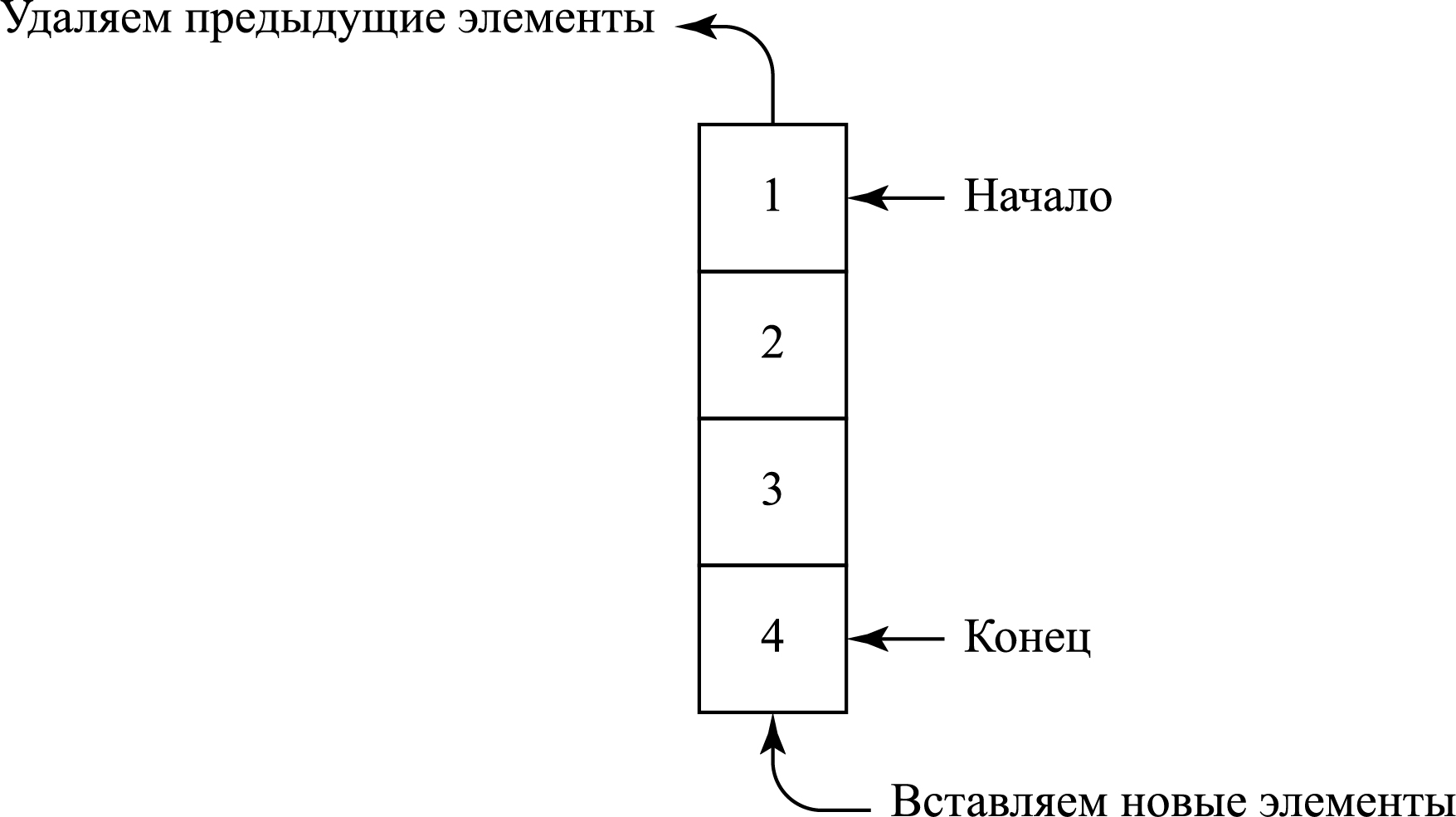
Очередь, как и стек — это линейная структура данных, элементы в которой хранятся в последовательном порядке. Единственная существенная разница между стеком и очередью заключается в том, что в очереди действует принцип FIFO (Первым пришел — первым вышел).
На рисунке изображена очередь с четырьмя элементами данных (1, 2, 3 и 4), где 1 идет первым и первым же покинет очередь:
Связные списки
В качестве примера связного списка можно рассматривать любой адрес. Будь то ссылка в адресной строке браузера или заполненные адресные графы на конверте.
|
Область |
Московская |
|
|
Город |
Электросталь |
|
|
Улица |
Ленина |
|
|
Дом |
17 |
|
|
Квартира |
34 |
Связный список — еще одна важная линейная структура данных, на первый взгляд напоминающая массив. Однако, связный список отличается от массива по выделению памяти, внутренней структуре и по тому, как в нем выполняются базовые операции вставки и удаления.
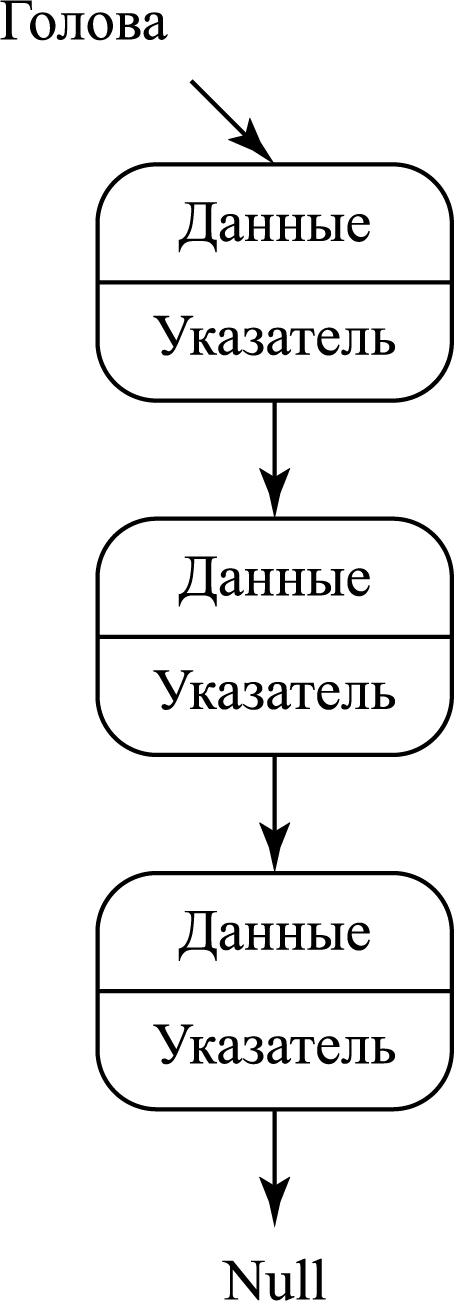
Связный список это цепочка узлов, содержащих данные и указатель на следующий узел в цепочке. Есть головной указатель, соответствующий первому элементу в связном списке, и, если список пуст, то он направлен просто на null (ничто).
Вот так можно наглядно изобразить внутреннюю структуру связного
списка:
При помощи связных списков реализуются файловые системы,
хеш-таблицы и списки смежности.
Существуют такие типы связных списков:
- Односвязный список (однонаправленный)
- Двусвязный список (двунаправленный)
Графы
Графы — это совокупности узлов (вершин) и связей между ними (рёбер). Также их называют сетями.
Примером графа может служить любое предприятие. В качестве вершин будут выступать отделы, в качестве рёбер — их взаимодействие.
Графы делятся на два основных типа: ориентированные и неориентированные. У ориентированных графов рёбра имеют направления, у неориентированных — нет.
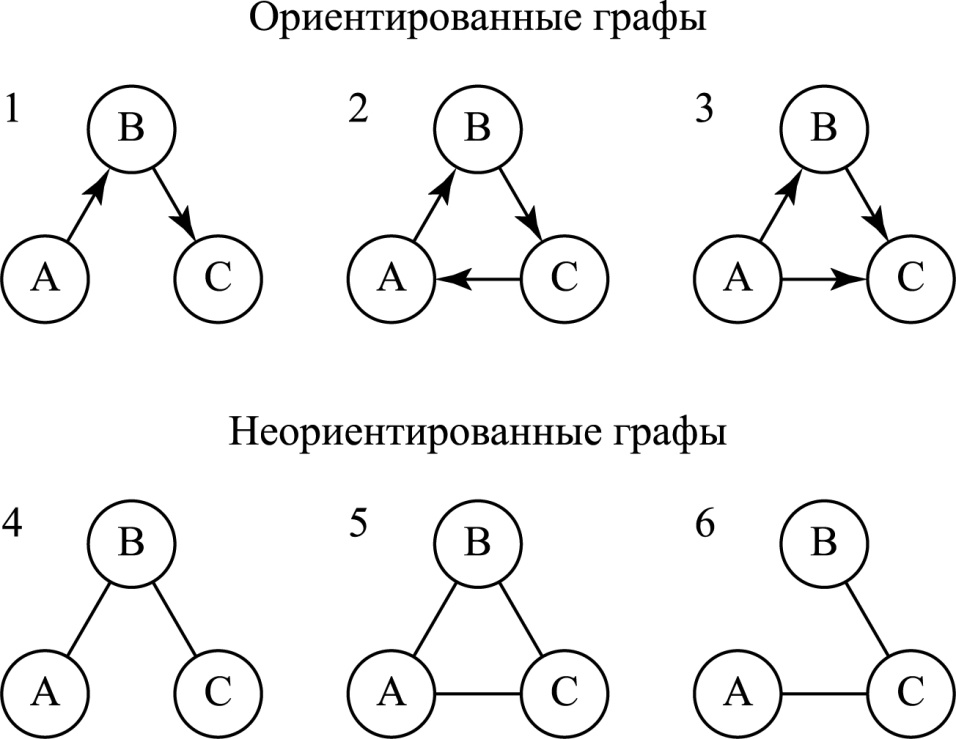
Чаще всего граф изображают в одном из двух видов: список смежности или матрица смежности.
Список смежности можно представить как перечень элементов, где слева находится один узел, а справа — все остальные узлы, с которыми он соеди-няется.
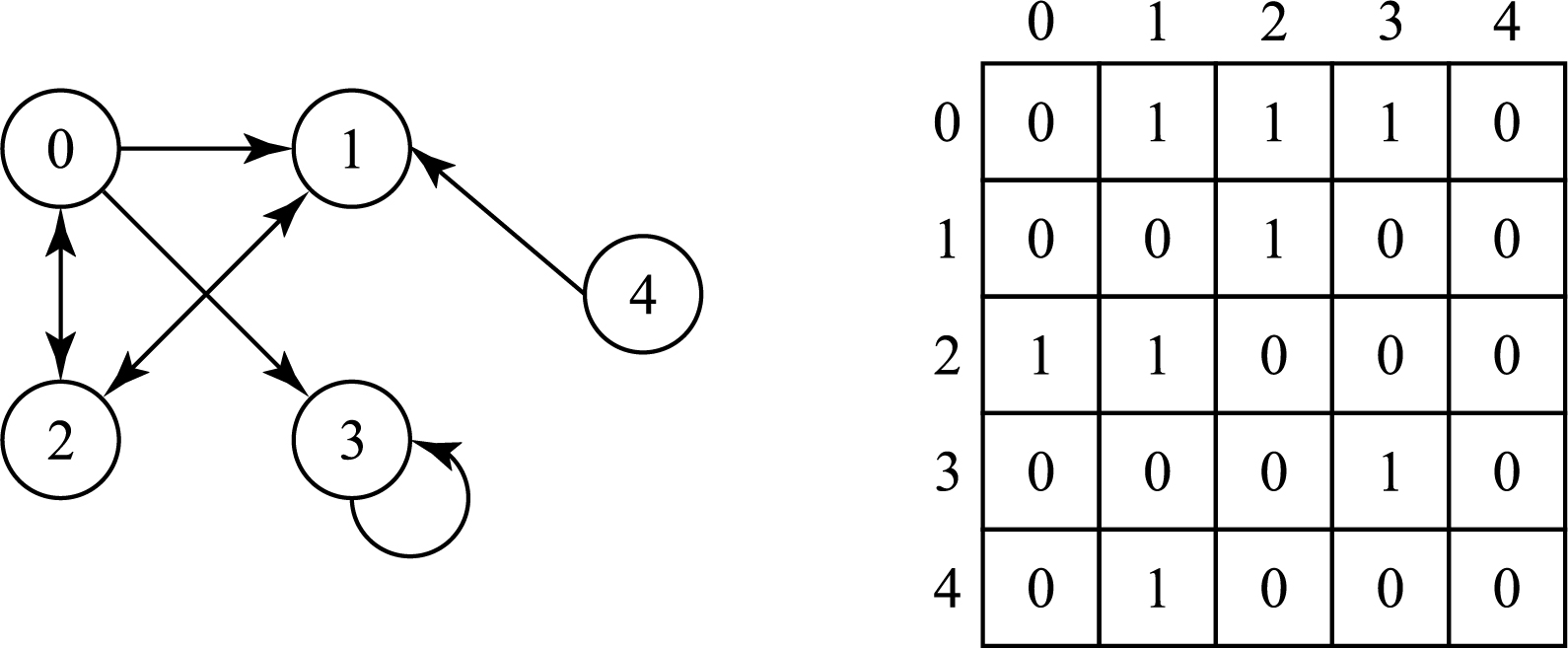
Граф в виде матрицы смежности
Матрица смежности — это таблица с числами, где каждый ряд или колонка соответствуют отдельному узлу графа. На пересечении колонки и ряда располагается число, которое указывает на наличие (1) или отсутствие (0) связи. Для обозначения веса связи используются числа больше единицы.
Существуют специальные алгоритмы для просмотра рёбер и вершин в графах — так называемые алгоритмы обхода. К их основным типам относят поиск в ширину (breadth-first search) и в глубину (depth-first search).
Деревья
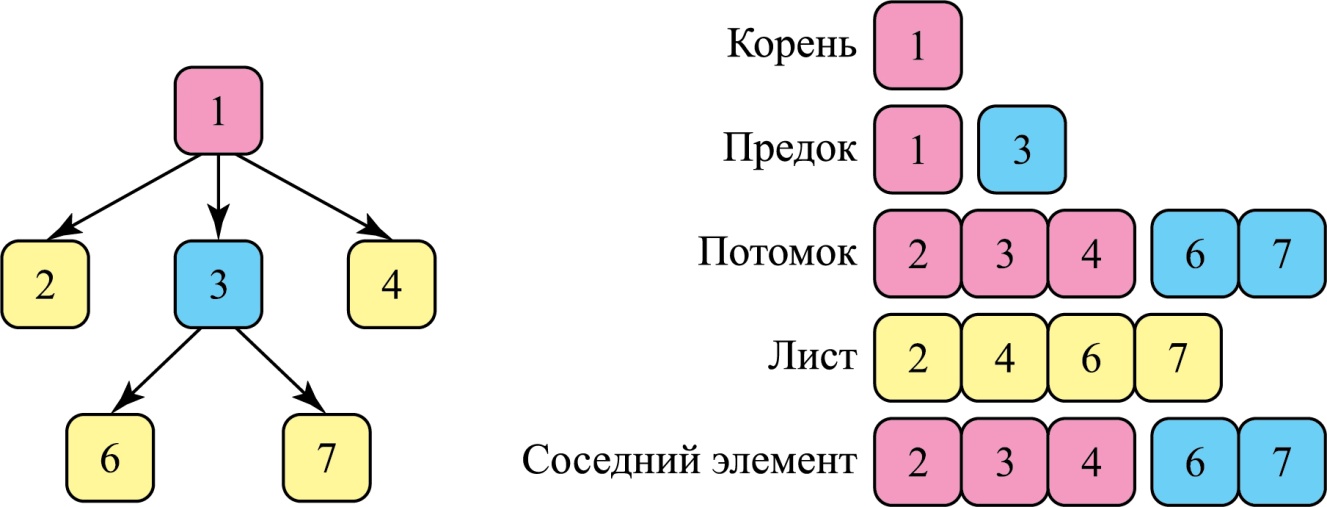
В качестве примера дерева может служить любая иерархическая струк-тура.
Дерево — это иерархическая структура данных, состоящая из вершин (узлов) и ребер, которые их соединяют. Деревья похожи на графы, главное отличие состоит в том, что в дереве не бывает циклов.
Деревья широко используются в области искусственного интеллекта и в сложных алгоритмах, выступая в качестве эффективного хранилища информации при решении задач.
На рисунке показана схема простого дерева и базовая терминология, связанная с этой структурой данных:
Существуют деревья следующих типов:
- N-арное дерево
- Сбалансированное дерево
- Двоичное дерево
- Двоичное дерево поиска
- АВЛ-дерево
- Красно-черное дерево
- 2–3 дерево
Из вышеперечисленных деревьев чаще всего используются двоичное дерево и двоичное дерево поиска.
Префиксные деревья
Такие структуры часто используют, чтобы хранить слова и выполнять быстрый поиск по ним. Например, так работает функция автозаполнения Т9 в любом сматрфоне.
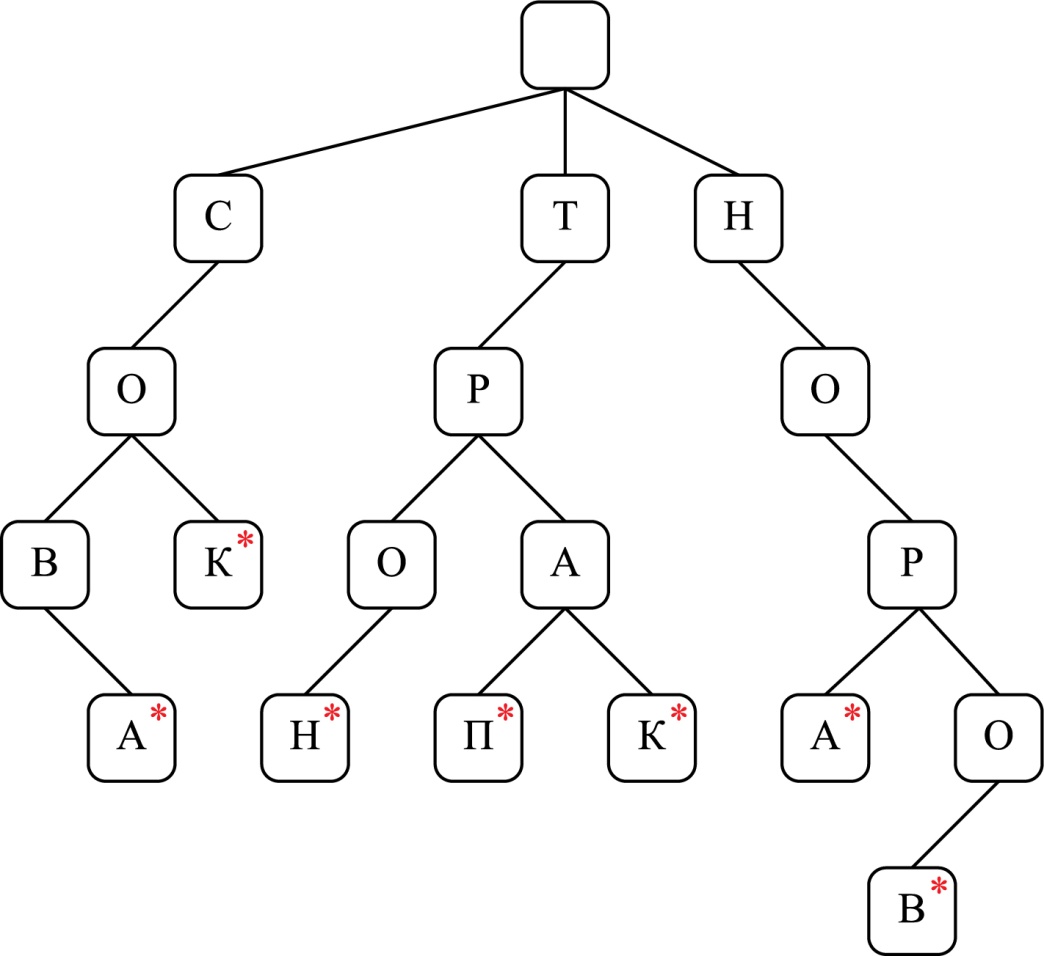
Пример префиксного дерева
Префиксное (нагруженное) дерево — это разновидность дерева поиска. Оно хранит данные в метках, каждая из которых представляет собой узел на дереве.
Каждый узел содержит букву (данные) и булево значение, которое указывает, является ли он последним. Чтобы составить слово, нужно следовать по ветвям дерева, проходя один узел за раз (получая одну букву).
Map
Map (англ. карта) — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных.
Хэш таблицы
Хэш-таблица — это похожая на Map структура, которая содержит пары ключ/значение. Она использует хэш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение.
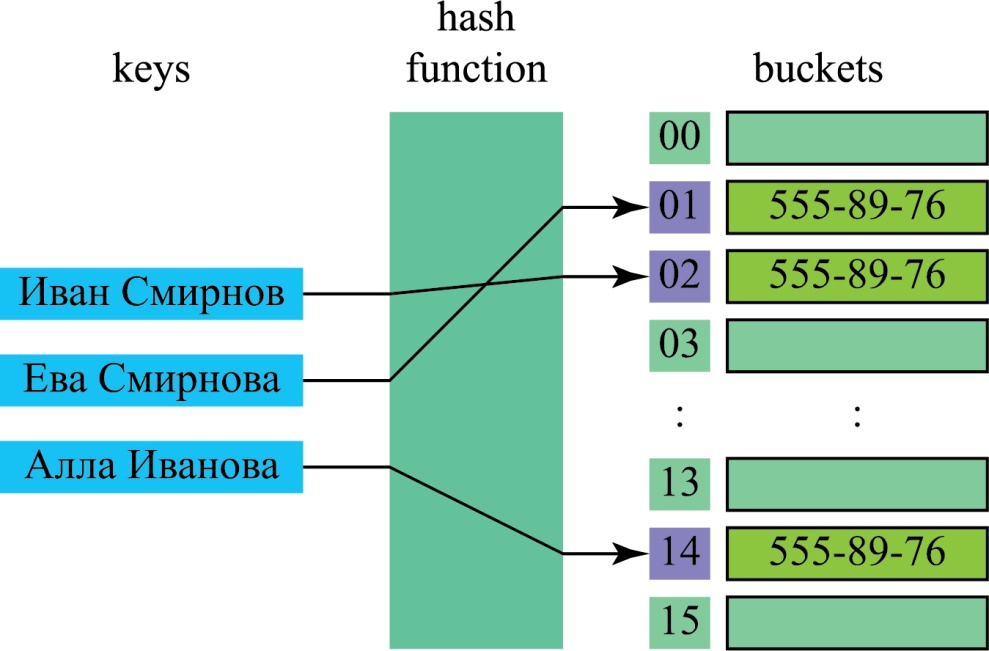
Так работают хэш-таблица и хэш-функция
Обычно хэш-функция принимает строку символов в качестве вводных данных и выводит числовое значение. Для одного и того же ввода хэш-функция должна возвращать одинаковое число. Если два разных ввода хэшируются с одним и тем же итогом, возникает коллизия. Цель в том, чтобы таких случаев было как можно меньше.
Таким образом, когда вы вводите пару ключ/значение в хэш-таблицу, ключ проходит через хэш-функцию и превращается в число. В дальнейшем это число используется как фактический ключ, который соответствует определенному значению. Когда вы снова введёте тот же ключ, хэш-функция обработает его и вернет такой же числовой результат. Затем этот результат будет использован для поиска связанного значения. Такой подход заметно сокращает среднее время поиска.
Множества
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ряд важных функций, которые можно применять к двум множествам сразу.
|
Функция |
Результат |
|
Объединение |
комбинирует все элементы из обоих исходных множеств (без дубликатов) |
|
Пересечение |
анализирует два множества и создает новое множество из тех элементов, которые присутствуют и в первом, и во втором изначальных множествах |
|
Разность |
возвращает список уникальных элементов, которые есть в одном множестве, но отсутствуют в другом |
|
Подмножество |
выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества |
Базы данных
Структурированные данные принято называть базами данных (БД).
База данных (в узком смысле слова) — поименованная совокупность структурированных данных относящихся к некоторой предметной области.
Для точности дадим определение базы данных, предлагаемое Глоссарий.ру
База данных — это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ. База данных является информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД). СУБД обеспечивает поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей.
В реальной деятельности в основном используют системы БД.
Система баз данных (СБД) — это компьютеризированная система хранения структурированных данных, основная цель которой — хранить информацию и предоставлять ее по требованию.
Системы БД существуют и на малых, менее мощных компьютерах, и на больших, более мощных. На больших применяют в основном многопользовательские системы, на малых — однопользовательские.
Однопользовательская система (single-user system) — это система, в которой в одно и то же время к БД может получить доступ не более одного пользователя.
Многопользовательская система (multi-user system) — это система, в которой в одно и то же время к БД может получить доступ несколько пользователей.
Основная задача большинства многопользовательских систем — позволить каждому отдельному пользователю работать с системой как с однопользовательской.
Различия однопользовательской и многопользовательской систем — в их внутренней структуре, конечному пользователю они практически не видны.
Система баз данных содержит четыре основных элемента: данные, аппаратное обеспечение, программное обеспечение и пользователи.
Способов хранения данных внутри БД существует множество (способы хранения называются моделями представления или хранения данных). Наиболее популярные — объектная и реляционная модели данных.
Автором реляционной модели считается Э. Кодд, который первым предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение.
Таким образом, реляционная база данных представляет собой набор таблиц, связанных между собой. Строка в таблице соответствует сущности реального мира.
Примеры реляционных СУБД: MySql, PostgreSql.
В основу объектной модели положена концепция объектно-ориен-тированного программирования, в которой данные представляются в виде набора объектов и классов, связанных между собой родственными отношениями, а работа с объектами осуществляется с помощью скрытых (инкапсулированных) в них методов.
Примеры объектных СУБД: Cache, GemStone, ONTOS.
В последнее время производители СУБД стремятся соединить два этих подхода и проповедуют объектно-реляционную модель представления данных. Примеры таких СУБД — IBM DB2 for Common Servers, Oracle8.
Сортировка данных
Объем данных, содержащийся в реальных БД, может быть огромным (количество может измеряться миллионами записей). При работе с подобными БД одним из ключевых предъявляемых требований является скорость отклика, (время от момента указания задачи управления данными, например, поиска или создания записи, до момента выполнения этой задачи). Операции управления данными выполняются существенно быстрей в отсортированных данных.
Сортировка данных — упорядочивание данных по заданному признаку с целью удобства их использования; сортировка данных повышает доступность информации.
Виды сортировок данных
Существует множество алгоритмов сортировок, со своими достоинствами и недостатками. Вот некоторые из них:
Сортировка пузырьком / Bubble sort
Шейкерная сортировка / Shaker sort
Сортировка вставками / Insertion sort
Сортировка Шелла / Shellsort
Гномья сортировка / Gnome sort
Сортировка выбором / Selection sort
Пирамидальная сортировка / Heapsort
Быстрая сортировка / Quicksort
Сортировка слиянием / Merge sort
Блочная сортировка / Bucket sort
Архивация данных
Как говорилось выше, количество записей в базе данных может измеряться миллионами. Соответственно, объем памяти необходимый для ее хранения — может быть существенен. Особенно критичным этот параметр может стать во время перемещения базы данных. Уменьшить объем памяти, выделенной для хранения БД, можно с помощью архивации данных.
Архивация данных — организация хранения данных в компактной сжатой форме; архивация данных повышает общую надежность информационного процесса и используется для снижения затрат по хранению данных.
Сжатие информации в файлах происходит за счет устранения избыточности различными способами. Например за счет упрощения кодов, исключения из них постоянных битов или представления повторяющихся символов или повторяющейся последовательности символов в виде коэффициента повторения и соответствующих символов. Применяют различные алгоритмы сжатия информации. Например, алгоритмы Хаффмана, Лемпеля-Зива.
Архивация (упаковка) — помещение (загрузка) исходных файлов в архивный файл в сжатом или не сжатом виде.
Разархивация (распаковка) — процесс восстановления файлов из архива точно в таком виде, какой он имел до загрузки в архив. При распаковке файлы извлекаются из архива и помещаются на диск или в оперативную память.
Программы, осуществляющие упаковку и распаковку файлов, называются программами архиваторами.
В настоящее время применяется несколько десятков программ–архиваторов, которые отличаются перечнем функций и параметрами работы. Из числа наиболее популярных программ можно выделить: WinZip, WinRar, 7z.
Защита данных
Развитие средств, методов и форм автоматизации процессов хранения и обработки данных, массовое применение персональных компьютеров, сетей и облачных хранилищ делают данные более уязвимыми. Данные могут быть незаконно изменены, похищены или уничтожены и поэтому так важна и актуальна защита данных.
Защита данных — комплекс мер, направленных на предотвращение утраты, воспроизведения и изменения данных.
Для обеспечения защиты хранимых данных используется несколько методов и механизмов их реализации. Рассмотрим основные способы защиты.
Физические способы защиты основаны на создании физических препятствий для злоумышленника, преграждающих ему путь к защищаемой информации (строгая система пропуска на территорию и в помещения с аппаратурой или с носителями информации).
Законодательные средства защиты составляют законодательные акты, которые регламентируют правила использования и обработки информации ограниченного доступа и устанавливают меры ответственности за нарушение этих правил.
Управление доступом представляет способ защиты информации путем регулирования доступа ко всем ресурсам системы (техническим, программным, элементам баз данных). В автоматизированных системах для информационного обеспечения должны быть регламентированы порядок работы пользователей и персонала, право доступа к отдельным файлам в базах данных и т. д. Управление доступом предусматривает следующие функции защиты:
Идентификация пользователей. Присвоение каждому объекту персонального идентификатора: имени, кода, пароля и т. п.
Аутентификация. Опознание (установление подлинности) объекта или субъекта по предъявляемому им идентификатору; Самым распространенным методом аутентификации является метод паролей. Парольная защита широко применяется в системах защиты информации. Ее основными достоинствами являются небольшая цена и простота реализации, малые затраты машинных ресурсов. Однако парольная защита часто не дает достаточного эффекта.
Авторизация. Проверка полномочий (проверку соответствия дня недели, времени суток, запрашиваемых ресурсов и процедур установленному регла-менту).
Разрешение и создание условий работы в пределах установленного регламента.
Регистрация. Протоколирование обращений к защищаемым ресурсам.
Реагирование. Сигнализация, отключение, задержка работ, отказ в запросе при попытках несанкционированных действий.
Криптографические методы защиты информации. Для реализации мер безопасности используются различные способы шифрования (криптографии), суть которых состоит в том, что данные зашифровываются и тем самым преобразуются в шифрограмму или закрытый текст. Санкционированный пользователь получает данные или сообщение, дешифрует их посредством обратного преобразования криптограммы, в результате чего получается исходный текст. Методу преобразования в криптографической системе соответствует использование специального алгоритма. Действие такого алгоритма запускается уникальным числом (или битовой последовательностью), обычно называемым шифрующим ключом.
Выдача данных
После прохождения процедуры верификации и подтверждения полномочий, пользователь получает доступ к некоему кластеру БД и хранящимся там данным. Для удобства взаимодействия пользователя с БД необходимо предусмотреть возможность поиска и вывода данных. Желательно обеспечить возможность получения не только всей записи целиком, но и определенных частей. Например, в базе данных содержится список сотрудников, их дни рождения, номера телефонов, адреса, стаж работы и т. д. Если пользователь хочет получить номер телефона определенного сотрудника, то не надо выдавать ему всю запись о данном сотруднике.
Данные могут выдаваться в виде списков, таблиц, диаграмм, изображений и т. д. в зависимости от содержимого БД и пожеланий пользователя.
Данные могут выводиться на экран, распечатываться, отправляться по электронной почте и т. д.
Вывод
В современном мире информационные системы занимают все более важную позицию. Операции над данными являются важнейшей составляющей частью информационных систем. И не смотря на то, что так и не существует окончательных определений основополагающих понятий, практически каждую операцию над данными можно выделить в отдельную дисциплину. Важен каждый пункт: и получение данных, и их оценка, и структуры, и сортировка, и архивация, и защита. С развитием информационных технологий, все эти понятия все более расширяются, накапливают все больше наработок и алгоритмов. Вполне возможно, что через некоторое время каждую из этих операций будут преподавать в учебных заведениях как отдельный предмет.
Список литературы
- Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. — М.: Издательский дом Вильямс, 2001. — 384 с.
- Вирт Н. Алгоритмы + структуры данных = программы. — М.: Мир, 1985. — 544 с.
- Вирт Н. Алгоритмы и структуры данных. — М.: Мир, 1989. — 360 с.
- Жоголев Е.А. Введение в технологию программирования. — М.: ДИАЛОГ-МГУ, 1994
- Исаев А. Л. Конспект лекций по информатике. Электронное учебное издание. — М.: МГТУ имени Н.Э. Баумана, 2016, 60 с.
- Кнут Д. Искусство программирования. Т. 3. Сортировка и поиск. — М.: Вильямс, 2002. — 720 с.
- Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. — М.: МЦНМО, 2000. — 960 с.
- Хусаинов Б. С. Структуры и алгоритмы обработки данных. Примеры на Си. М.: Финансы и статистика, 2004.
- Информатика : учебник для сред, проф, образования / Е. В. Михеева, О. И. Титова. — М.: Издательский центр Академия, 2007. — 352 с.
- Управление данными: учебник для студ. высших учеб. заведений / А. В. Кузовкин, А. А. Цыганов, Б. А. Щукин. М.: Издательский центр Академия, 2010. — 256 с.
- «Глоссарий.ру», ссылка доступа http://www.glossary.ru/
- «Википедия», ссылка доступа https://ru.wikipedia.org/
- «Студопедия», ссылка доступа https://studopedia.ru/

- Корпоративная культура в организации (Теоретические основы исследования)
- Менеджмент человеческих ресурсов (Анализ кадрового менеджмента на предприятии мебельная фабрика «Восток».)
- Проблемы коммуникаций в современных организациях (Понятие, цели, функции коммуникации)
- Место и роль Федерального собрания Российской Федерации в системе высших органов власти (Статус, вѐдение и полномочия Государственной Думы)
- Адаптация детей к школе (Теоретический анализ проблемы адаптации ребенка к школе)
- Политика мотивации персонала в системе стратегического управления кадровым направлением деятельности организации (Мотивация в системе управления персоналом предприятия)
- Жизненный цикл организации и управление организацией (Понятие и общая модель жизненного цикла организации)
- Оценка готовности детей к школе (Разработка программы по повышению психологической готовности к обучению в школе)
- Статус нотариуса (Теоретические основы нотариата в РФ)
- Социально-психологический климат организации (Социально – психологический климат организации)
- Социально-психологический климат организации (Роль и значение СПК для повышения эффективности деятельности организации)
- Дидактическая игра как метод обучения (Методика руководства дидактической игрой)