
Операции, производимые с данными (Понятия информации, данных и сообщения в современной науке, технике и теории информации)
Содержание:

Введение
Компьютеры используются повсеместно: невозможно найти предприятие или учреждение, которые не использовали бы их для решения производственных или управленческих задач. Подобные высказывания не слишком заметны в средствах массовой информации потому, что они уже давно не являются новостью.
Профессионалы, однако, понимают, что на самом деле важны не компьютеры, а информационные системы, которые на них работают, а в центре любой информационной системы находятся данные.
Объектом исследования данной работы являются данные, базы данных (БД) и системы управления базами данных (СУБД).
Предмет исследования – методы и средства управления данными, администрирования баз данных.
Целью данного исследования является рассмотрение и изучение управления данными, деятельности администратора баз данных (АБД) по установке и администрированию СУБД и БД.
Для достижения поставленной цели необходимо выполнить задачи:
- Рассмотреть понятия данных, БД и СУБД;
- Изучить требования, предъявляемые к данным и базам данных;
- Ознакомиться с архитектурой «клиент-сервер»;
- Ознакомиться с деятельностью АБД;
- Рассмотреть установку и администрирование базы данных на примере СУБД Oracle 12c.
1. Обзор литературных источников по теме исследования
1.1 Понятия информации, данных и сообщения в современной науке, технике и теории информации
Информация (от лат. informatio - разъяснение, изложение) является основным понятием информатики. Несмотря на значительные достижения этой науки, ее составных частей, до настоящего времени нет четкого, однозначного и всеми принятого определения информации, отсутствует методология определения значений ее характеристик, что затрудняет решение задач информатики. Это одно из первичных неопределенных понятий науки, что подтверждается большим множеством дефиниций понятия информации, которые рассматриваются в приведенной литературе: от наиболее общего, философского (информация - есть отражение реального мира) до узкого практического (информация есть сведения, являющиеся объектом хранения, передачи и преобразования), в том числе и определенного нормативными правовыми актами.
Понимание информации как передачи сведений сохранялось на протяжении более двух тысячелетий. В связи с прогрессом технических средств массовых коммуникаций (телеграф, телефон, радио, телевидение и т.д.), в особенности с ростом объема передаваемых сведений, появилась необходимость их измерения. В 20-х годах XX века делались попытки измерения информации и высказывались идеи, которые затем были использованы в вероятностно-статистической теории информации (Фишер, 1921 г., Найквист, 1924 г.. Хартли, 1928 г., Сциллард, 1929 г.). Однако только в 1948 г., в статье К.Э. Шеннона «Математическая теория связи» было дано вероятностно-статистическое определение понятия количества информации, предложена абстрактная схема связи, сформулированы теоремы о пропускной способности, помехоустойчивости, кодировании и т.д., что позволило сформировать вероятностно-статистическую теорию информации - одну из наиболее развитых среди других математических теорий информации.
Математические теории информации выступают как совокупность количественных (и, в первую очередь, статистических) методов исследования передачи, хранения, восприятия, преобразования и использования информации. Используемые методы преследуют цель измерения информации. Проблема количества информации как первоочередного вопроса теории информации, неразрывно связана и с ее качественно-содержательным аспектом, т.е. выявлением содержания понимания информации, к которому применяются количественные методы исследования.
Существует, в частности, направление теории информации, основанное на использовании положений топологии - раздела математики, изучающего свойства пространства, которые сохраняются при взаимно однозначных непрерывных преобразованиях (растяжении, деформации и т.п.). Одним из топологических объектов является граф. Топологическое пространство информации определяется в зависимости от различия вершин графов, количества ребер, выходящих из них, ориентации этих ребер.
Развитие социального прогресса, науки, техники, объемов информации обусловили необходимость дальнейшего уточнения понятия «информация» и количественной оценки передаваемых сообщений, выявления наиболее характерных свойств информации, что привело к принципиальным изменениям и в трактовке самого понятия «информация».
Информация - сведения, сообщения, которые снимают существовавшую до их получения неопределенность полностью или частично. Это представление об информации как снимаемой неопределенности является наиболее распространенной трактовкой понятия информации.
Одними из признаков, характеризующих информацию, являются различие и разнообразие. Если в статистической теории понятие информации определяется как уничтоженная неопределенность, то в самом общем случае можно сказать, что информация есть уничтожение тождества, однообразия. Переход от трактовки информации как противоположности неопределенности к трактовке ее как противоположности тождеству диктуется всем ходом развития наших знаний, развитием кибернетики (где информация выступает как синоним разнообразия, которое получает и использует кибернетическая система), а также психологии, биологии, химии, экономики и многих других наук. Согласно данной концепции, информация существует там, где имеется разнообразие и различие.
Рассмотрим ряд определений понятий информации, используемых в известных источниках, приведенных в библиографии.
Информация - сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний.
Нетрудно увидеть, что по определению информация есть отражение или представление реального мира (чего-нибудь) с помощью сведений (сообщений).
Сообщение — это форма представления информации в виде речи, текста, изображения, цифровых данных, графиков, таблиц и т.п.
Тогда в широком смысле можно привести еще одно определение информации.
Информация — это общенаучное понятие, включающее в себя обмен сведениями между людьми, обмен сигналами между живой и неживой природой, людьми и устройствами.
Обобщенное понятие и классификация сообщений приводятся в словарях по информатике, указанных в библиографии.
Сообщение (message) - упорядоченная последовательность символов, предназначенная для передачи информации. Классификация сообщений может осуществляться по ряду показателей.
Классификация сообщений может осуществляться по ряду показателей.
По видам информационных коммуникаций (каналов передачи сообщений):
- формальные (созданные для организаций, учреждений и т.п.);
- неформальные (формируемые при личных встречах, беседах, телефонных разговорах и др.).
По форме представления сообщения делятся на виды:
- недокументальные: личные беседы, конференции, совещания, реализованные жестами, звуками, знаками, речью и др.);
- документальные:
1) кодированные: текстовые (опубликованные, неопубликованные), идеографические, аудиальные (запись речи), машиночитаемые;
2) некодированные: иконические, документы трех измерений, аудиальные (кроме записи речи).
- формализованные (formalized message) - сообщения, представленные в формализованном виде, требуемом для передачи по линиям связи или для ввода в ЭВМ.
По адресам рассылки:
- групповое сообщение (group message) - сообщение, адресуемое более чем одному абоненту или множество (пакет) сообщений, объединенных в одно сообщение, передаваемое по линиям связи;
- одноадресное (single-address message) - сообщение, передаваемое только в один пункт назначения;
- входное (incoming message) - сообщение, поступающее на вход ЭВМ от терминала или абонентского пункта.
По функциональному предназначению:
- диагностическое (сообщение об ошибке) (diagnostic (error) message) - сообщение, выдаваемое управляющей, обрабатывающей, или обслуживающей программой и содержащее сведения о месте, типе и характере ошибки в программе;
- квитирующее - сообщение системы, предназначенное пользователю и содержащее информацию о результатах выполнения запроса, но не сами результаты;
- контрольное (fox message) - стандартное сообщение, включающее полный набор допустимых знаков и используемое для проверки линий связи;
- наводящее (prompting message) - подсказка пользователю.
Информатика рассматривает информацию как концептуально связанные между собой сведения (сообщения), данные, изменяющие наши представления о явлении или объекте окружающего мира. Наряду с понятием «информация» в информатике часто употребляется понятие «данные». В чем же их общность и различия?
В учебнике Макаровой Н.В. приводятся следующие аргументы в пользу их различия. «Данные могут рассматриваться как признаки или записанные наблюдения, которые по каким-то причинам не используются, а только хранятся. В том случае, если появляется возможность использовать эти данные для уменьшения неопределенности о чем-либо, данные превращаются в информацию. Поэтому можно утверждать, что информацией являются используемые данные».
Насколько неоднозначны такие определения данных, сведений и информации, можно судить исходя из следующих известных определений этих понятий.
Данные:
1) сведения, необходимые для какого-нибудь вывода, решения;
2) факты, идеи, выраженные в формальном виде, обеспечивающем возможность их хранения, обработки, передачи;
3) факты, идеи, представленные в формальном виде, позволяющем передавать или обрабатывать их при помощи некоторого процесса и соответствующих технических средств;
4) информация, представленная в формализованном виде, пригодном для автоматической обработки при возможном участии человека;
5) обобщенное имя информационных продуктов, являющихся предметов труда в информационном производстве.
Представляют интерес содержание понятий информации и данных, изложенных известными авторами Преснухиным Л.Н. и Нестеровым В.П.
Данные - представление фактов и идей в формализованном виде, пригодном и удобном для фиксации, передачи и переработки в процессе их использования.
Анализируя определения данных и информации, можно отметить, что первичным (базисным) определением является понятие информации, с помощью которого последовательно и логично выводятся другие понятия: информация - данные - сообщение. Этот, далеко не полный, анализ понятий информации дает основание утверждать о большом разнообразии и неоднозначности их содержания, а также о разнообразии содержания информатики.
При работе с информацией всегда имеется ее источник, среда передачи и потребитель (получатель). Пути и процессы, обеспечивающие передачу сообщений от источника информации к ее потребителю, называются информационными коммуникациями.
1.2 Сбор, передача, обработка и накопление информации
Сбор информации является одним из важнейших этапов информационного процесса и в широком смысле означает процесс комплектования системы информационного обеспечения массивами первичных и вторичных документированных источников информации.
Необходимо напомнить, что к первичным документированным источникам информации относятся опубликованные, неопубликованные и непубликуемые документы, содержащие исходную информацию, к вторичным - документы, полученные в результате аналитико-синтетической переработки одного или нескольких первичных источников, например информационные издания (библиографические, реферативные, обзорные).
Применительно к информационным системам, созданным с применением ЭВМ, используется понятие сбора данных.
Сбор данных (data collection) - процесс идентификации и получения данных от различных источников, группирования полученных данных и представления их в форме, необходимой для ввода в ЭВМ.
Сбор информации связывает систему информационного обеспечения с внешней средой. Эффективность процесса сбора информации (информационного массива) оценивается показателями полноты, точности, оперативности, релевантности, стоимости, трудоемкости.
Полнота - количественная мера содержания в массиве всех пертинентных документов (информации), существующих на данный момент времени с точки зрения всех пользователей системы.
Пертинентность - соответствие содержания документа (информации) информационным потребностям пользователей.
Точность - количественная мера содержания в информационном массиве (системе) только пертинентных документов (информации). Этот показатель характеризует внутреннее состояние процесса сбора, его способность удовлетворять информационные запросы независимо от времени на поиски информации.
Оперативность - способность процесса сбора выполнить задачу в минимально возможное время.
Стоимость - способность процесса сбора минимизировать затраты ресурса на единицу массива информации.
Трудоемкость - способность процесса сбора минимизировать трудозатраты на единицу массива информации.
В рамках процесса сбора осуществляется структуризация информации, информационных потребностей объекта (пользователя) и выбор источника информации. Задача структуризации информации представляет системную классификацию информации по показателям удобства ее использования человеком в процессе решения практических задач и удобства обработки и хранения с использованием современных средств и методов. Такая классификация была рассмотрена при исследовании видов информации. Решение задачи структуризации информационных потребностей субъекта (пользователя) связано с формированием информационного кадастра, представляющего организованную совокупность всех данных, необходимых и достаточных для целенаправленного информационного обеспечения деятельности современного объекта.
Передача информации в широком смысле рассматривается как процесс и методы формирования и циркуляции информационного потока, который в общем, виде представляет движение структурированной информации в некоторой среде данных. Вопросы структурирования и представления информации рассмотрены в предыдущих параграфах, поэтому рассмотрим вопросы формирования среды циркуляции информационных потоков. Информационные потоки на объекте делятся на входные, внутренние и выходные. В канале телекоммуникации они могут быть разделены на односторонние и двухсторонние. Циркуляцией информационных потоков называется факт регулярного их движения между различными объектами или между различными элементами одного и того же объекта.
В существующих информационных системах различных классов в зависимости от видов используемых носителей информации и средств обработки можно выделить: устную передачу при непосредственном общении; передачу бумажных носителей с помощью фельдъегерско-почтовой связи; передачу машиночитаемых носителей (магнитных карт, перфокарт, перфолент, магнитных дисков и лент); передачу в виде различных электрических сигналов по каналам телекоммуникаций, в том числе по автоматизированным каналам связи.
Хранение информации (information storage) это ее запись во вспомогательные запоминающие устройства на различных носителях для последующего использования. Хранение является одной из основных операций, осуществляемых над информацией, и главным способом обеспечения ее доступности в течение определенного промежутка времени. Основное содержание процесса хранения (holding storage) и накопления информации состоит в создании, записи, пополнении и поддержании информационных массивов и баз данных.
В результате реализации такого алгоритма, документ, независимо от формы представления, поступивший в информационную систему, подвергается обработке и после этого отправляется в хранилище (базу данных), где он помещается на соответствующую «полку» в зависимости от принятой системы хранения. Результаты обработки передаются в каталог. Этап хранения информации может быть представлен на следующих уровнях: внешнем, концептуальном, (логическом), внутреннем, физическом.
Внешний уровень отражает содержательность информации и предлагает способы (виды) представления данных пользователю входе реализации их хранения.
Концептуальный уровень определяет порядок организации информационных массивов и способы хранения информации (файлы, массивы, распределенное хранение, сосредоточенное и др.).
Внутренний уровень представляет организацию хранения информационных массивов в системе ее обработки и определяется разработчиком.
Физический уровень хранения означает реализацию хранения информации на конкретных физических носителях.
Хранение и поиск информации являются не только операциями над ней, но и предполагают использование методов осуществления этих операций. Информация запоминается так, чтобы ее можно было отыскать для дальнейшего использования. Возможность поиска закладывается во время организации процесса запоминания. Дня этого используют методы маркирования запоминаемой информации, обеспечивающие поиск и последующий доступ к ней. Эти методы применяются для работы с файлами, графическими базами данных и т.д.
Важным этапом автоматизированного этапа хранения является организация информационных массивов.
Массив (англ. array) — упорядоченное множество данных.
Информационный массив — система хранения информации, включающая представление данных и связей между ними, т.е. принципы их организации.
С учетом этого рассматриваются линейные и многомерные структуры организации информационных массивов. В свою очередь линейная структура данных может быть представлена в виде: строк, одномерных массивов; стеков, очередей, деков и др.
Строка - представление данных в виде элементов, располагающихся по признаку непосредственного следования, т.е. по мере поступления данных в ЭВМ.
Одномерный массив - представление данных, отдельные элементы которых имеют индексы, т.е. поставленные им в соответствие целые числа, рассматриваемые как номер элемента массива.
Индекс обеспечивает поиск и идентификацию элементов, а, следовательно, и доступ к заданному элементу, что облегчает его поиск по сравнению с поиском в строке.
Идентификация - процесс отождествления объекта с одним из известных.
Стек - структура данных, учитывающая динамику процесса ввода и вывода информации, использующая линейный принцип организации, реализующий процедуру обслуживания «последним пришел - первым ушел». В стеке первым удаляется последний поступивший элемент.
Очередь - структура организации данных, при которой для обработки информации выбирается элемент, поступивший ранее всех других.
Дека - структура организации данных, одновременно сочетающая рассмотренные виды.
Нелинейные структуры хранения данных – структуры, использующие многомерные конструкции (многомерные массивы) следующих видов: деревья, графы, сети.
На физическом уровне любые записи информационного поля представляются в виде двоичных символов. Обращение к памяти большого объема требует и большой длины адреса. Если память имеет емкость 2n слов, то требуются для поиска этих слов n-разрядные адреса.
Хранение информации осуществляется на специальных носителях. Исторически наиболее распространенным носителем информации была бумага, которая, однако, непригодна в обычных (не специальных) условиях для длительного хранения информации. На бумагу оказывают вредное воздействие температурные условия: либо разбухает, либо ломается, способна к возгоранию.
2. Базы данных. Основные понятия и определения
2.1 Понятие баз данных. СУБД
Появление и относительно широкое распространение в начале 60-х годов XX века запоминающих устройств достаточно большой емкости с возможностью доступа к произвольным участкам памяти - магнитных дисков, - открыло широкие возможности для создания сложных структур долговременно хранимых данных. Высокая скорость обновления небольших объемов данных (доли секунды) создала условия для создания приложений, способных функционировать в режиме оперативной работы (on-line). В отличие от систем предшествующих поколений, время ответа стало измеряться не сутками, а секундами или долями секунды.
Эти возможности, однако, привели к существенному усложнению кода приложений и, как следствие, к удорожанию их разработки и снижению надежности. В связи с этим появилась идея централизации функций управления данными, которая привела к появлению систем, предоставляющих приложениям услуги по обработке данных. Такие системы получили название систем управления базами данных (СУБД).
Совокупность данных, хранимых под управлением СУБД, называется базой данных. В оригинальном английском варианте словосочетание data base означает «основание, состоящее из данных». Этот смысл несколько искажается в русском словосочетании «база данных». На самом деле это — фундамент, на котором строятся приложения и который состоит из данных. Действительно, данные (а, следовательно, база данных) являются очень существенной частью практически любой информационной системы.
Система управления базами данных (СУБД) — это программный комплекс, обеспечивающий централизованное хранение данных и предоставляющий приложениям услуги по обработке данных.
Система управления базами данных, находящаяся в фазе выполнения, связанная с некоторой конкретной базой данных и готовая выполнять запросы на обработку этой базы данных, называется экземпляром (instance) или сервером базы данных.
Основные требования к системам управления базами данных были сформулированы в документе, опубликованном в 1971 году комитетом по системам и языкам обработки данных (CODASYL)[1], русский перевод которого издан в 1975 году[2]. Основой для этих требований послужил анализ систем, применявшихся в период подготовки отчета, и особенностей прикладных областей, в которых эти системы использовались.
В дальнейшем круг областей применения СУБД непрерывно расширялся, появлялись новые системы и уходили старые, однако многие из этих требований остались актуальными и сегодня, и большинство современных СУБД в той или иной форме реализует значительную часть этих требований. Однако далеко не все классы приложений, в которых используются современные системы, предъявляют те же требования к обработке данных, поэтому и системы реализуются иначе.
Приложения, относящиеся к классу оперативной обработки (OLTP), характеризуются тем, что:
- каждое выполнение приложения занимает мало времени (в идеале — не больше долей секунды);
- данные используются совместно многими приложениями;
- при каждом выполнении приложение использует ничтожную долю общего объема хранимых данных, и обычно количество используемых данных не зависит от общего объема базы.
Важно также отметить, что процессы обработки данных и структуры данных в тех областях, в которых использовались ранние СУБД, фактически были формализованы задолго до появления электронных вычислительных систем. Так, правила бухгалтерского учета в основном сложились в XIV веке и мало изменились в последующем. Возможно, это привело к тому, что СУБД, как правило, ориентированы на обработку структурированных данных.
Перечислим основные требования к системам управления базами данных.
- Разделение программ и данных. Описание структуры данных должно быть отделено от кода приложений, и система должна допускать независимое изменение структуры данных и кода приложения.
- Высокоуровневый язык запросов. Система должна предоставлять средства для обработки данных, не включенные в какое-либо приложение.
- Целостность. Система должна предотвращать запись данных, нарушающих заранее специфицированные ограничения.
- Согласованность. Система должна предотвращать появление некорректностей в данных вследствие параллельной или псевдопараллельной работы нескольких приложений.
- Отказоустойчивость. СУБД не должна допускать потери данных даже в случае отказов оборудования.
- Защита и разграничение доступа. Система должна предотвращать несанкционированный доступ к данным и предоставлять каждому пользователю (или приложению) доступ только к части данных в соответствии с правами этого пользователя.
2.2 Архитектура «клиент-сервер»
Путь от однопользовательских централизованных до многопользовательских распределенных с параллельным доступом СУБД прошли еще на больших ЭВМ. Так, в 1970-е гг. на IBM 370 эксплуатировалось семейство многозадачных операционных систем MVT и MVS, позволявших запускать с удаленных терминалов одновременно несколько приложений, получавших свой независимый виртуальный ресурс. Распространение персональных ЭВМ ненадолго вернуло однопользовательскую централизованную архитектуру баз данных. Многие информационные системы 80-х - начала 90-х гг. создавались для персональной работы одного пользователя. Однако с ростом масштабов систем (от локальных персональных до интегрированных на уровне предприятия) потребовалось обеспечить единое информационное пространство, т.е. единую базу данных для всех пользователей системы.
Архитектура, обеспечивающая параллельный доступ удаленных пользователей к единому ресурсу, получила название клиент- серверной. Термин «клиент-сервер» с 1990-х гг. применяется для обозначения архитектуры программного обеспечения, состоящего из клиентского и серверного процессов. Клиентский процесс запрашивает некоторые услуги, а серверный обеспечивает их выполнение. Применительно к базам данных модель «клиент-сервер» воплощается в виде широкого спектр архитектур, допускающих различное распределение функций между клиентом и сервером.
Наиболее простым вариантом является архитектура, основанная на модели удаленного управления данными (рис. 2.1а). При такой архитектуре на файловом сервере (как правило, специальном выделенном компьютере) централизованно хранятся файлы базы данных предприятия. Эти файлы могут через сеть передаваться на другие компьютеры. На каждом из этих компьютеров установлена СУБД, поддерживающая свою базу данных и обеспечивающая решение определенных прикладных задач. Запрос, поступающий от приложения, СУБД преобразует с языка манипулирования данными (на сегодняшний день это SQL) в команду на получение соответствующего файла базы данных и отправляет эту команду серверу. Получая от сервера файл или его часть, СУБД вместе с приложением выполняет обработку и изменение данных, после чего возвращает файл на сервер для поддержания центральной базы данных в актуальном состоянии. Очевидный недостаток такой архитектуры - большие объемы передаваемой по сети информации.
Развитием модели удаленного управления данными стала модель удаленного доступа к данным (RDA, Remote Data Access) (рис. 2.16). При такой архитектуре на сервере хранится база данных и установлено ядро СУБД. Языком взаимодействия клиента и сервера является SQL. Приложение генерирует SQL-запросы, в ответ на которые СУБД отправляет приложению требуемые данные.
Особенностью данной архитектуры является то, что все функции обработки данных сосредоточены на клиенте, в то время как сервер осуществляет только хранение данных и управление транзакциями. Дальнейшая эволюция клиент-серверной архитектуры пошла в сторону переноса части функций обработки данных на сервер. Новая модель получила название модели сервера базы данных (DBS, Database Server) (рис. 2.1в). В этой архитектуре на сервере наряду с данными стали храниться и другие объекты - процедуры и триггеры.
Процедуры или. точнее, хранимые процедуры (stored procedure, англ.) представляют собой набор инструкций, написанных на языке СУБД (чаще всего на SQL) или на языке программирования (например, Java или С). Хранимые процедуры предназначены для выполнения определенных действий над данными. При такой архитектуре клиентское приложение обращается к серверу с командой запуска соответствующей процедуры, а сервер возвращает требуемые данные или результаты их обработки.
Одним из видов хранимых процедур являются триггеры (trigger, англ.), предназначенные, как правило, для обеспечения целостности данных. Исполнение триггеров активируется при наступлении определенного события, например, при попытке удалить или модифицировать данные. Триггеры могут также контролировать семантическую целостность и непротиворечивость данных.
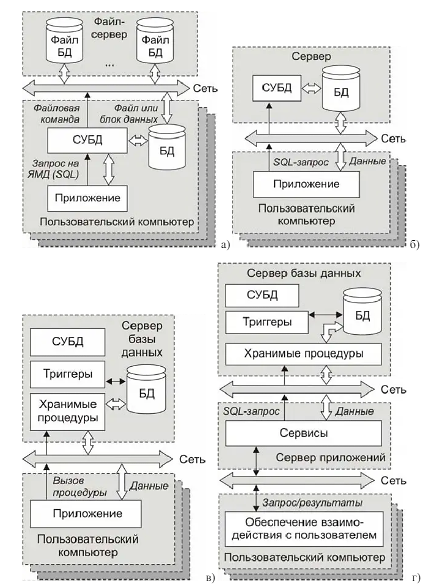
Рисунок 2.1 – Модели удаленного управления данными – FS (а), удаленного доступа к данным – RDA (б), сервера базы данных – DBS (в), сервера приложений – AS (г)
В реляционных базах данных триггеры привязываются к определенным таблицам или представлениям и контролируют операции, затрагивающие именно эти таблицы.
Архитектура DBS обеспечивает полностью централизованный контроль над базой данных и централизованное выполнение основных функций обработки данных. Однако в условиях большого числа клиентов существенно повышается нагрузка на сервер базы данных. Для разгрузки сервера базы данных было предложено ввести в архитектуру дополнительный компонент, получивший название «сервер приложений». Этот сервер предназначен для решения прикладных задач пользователей. Для получения необходимых данных он взаимодействует с сервером базы тайных в соответствии с моделью RDA или DBS. Соответственно новая архитектура стала называться моделью сервера приложений (AS, Application Server) (рис. 2.1г).
2.3 Управление базами данных (Администрирование)
Большинство организаций используют приложения для управления бизнес-процессами и действиями, а эти приложения обычно хранят данные в базе данных (БД). Организации все более и более зависят от приложений и данных, которые они хранят. В такой ситуации базы данных являются критически важным компонентом бизнеса в области инфраструктуры информационных технологий.
Роль администратора базы данных (database administrator, DBA) включает широкий круг обязанностей и задач, которые гарантируют, что эти базы данных оптимально хранятся, постоянно поддерживаются в согласованном состоянии и используются с высокой производительностью.
Основные требования, предъявляемые к администраторам баз данных.
- Технологические знания и навыки. Администрирование баз данных требует не только глубокого знания платформы, используемой для размещения баз данных, но также знаний в области конфигураций операционной системы, устройств хранения данных и сетей.
- Бизнес-осведомленность. Администратор баз данных должен понимать бизнес-контекст, в котором функционирует база данных, и ее роль в поддержке бизнеса.
- Организационные навыки. Системы баз данных могут быть сложными, с большим количеством компонентов и подсистем. Некоторые задачи должны выполняться в определенное время. Хороший администратор должен отслеживать эти задачи, а также оперативно реагировать на неожиданные проблемы в случае их возникновения.
- Умение выстраивать приоритеты. Когда возникают неожиданные проблемы, которые могут негативно повлиять на работу с базой данных, администратор должен грамотно расположить их решение по приоритетам, основываясь на таких факторах, как соглашения об уровне обслуживания (service level agreement, SLA), число пользователей и затронутых систем, а также степень влияния возникшей проблемы на текущие операции.
Общие задачи администрирования баз данных
- Подготовка баз данных и серверов баз данных. Это может включать установку и настройку экземпляров баз данных на физических или виртуальных серверах, или создание новых виртуальных машин на основе шаблонов изображений, а также создание баз данных и распределение их данных и файлов журналов на устройствах хранения.
- Сохранение файлов баз данных и объектов. После того, как база данных создана и заполняется данными, для оптимальной работы требуется ее постоянное обслуживание и оптимизация. Это предполагает уменьшение фрагментации, которая появляется по мере того, как записи добавляются и удаляются, сохранение файлов данных соответствующего размера и обеспечение последовательной структуры логических и физических данных.
- Управление восстановления в случае сбоя базы данных. Базы данных часто имеют решающее значение для деловых операций, поэтому главной задачей DBA является планирование соответствующей стратегии резервного копирования и восстановления для каждой базы данных, что позволило бы осуществить восстановление базы данных в случае сбоя.
- Импорт и экспорт данных. Данные часто передаются между системами, поэтому администраторам баз данных необходимо выполнять экспорт или импорт данных.
- Применение безопасности к данным. Серверы баз данных организации содержат данные, которые позволяют бизнесу работать. Нарушение безопасности может быть дорогостоящим и трудоемким для восстановления, приводить к потере доверия клиентов. Администратор баз данных должен реализовывать такие политики безопасности, которые обеспечивают пользователям доступ к необходимым данным, но при этом соблюдают правовые нормы бизнеса по защите своих активов, а также снижают риски, связанные с нарушением безопасности.
- Мониторинг и устранение неполадок систем баз данных. Многие операции по администрированию баз данных являются реактивными, то есть они предполагают принятие мер для устранения неполадок и возникающих проблем. Грамотные администраторы БД осуществляют упреждающий подход, чтобы попытаться обнаружить потенциальные проблемы до того, как они начнут влиять на операции с данными.
Большинство администраторов баз данных знакомы с системами, которыми они управляют, и знают задачи, которые должны выполняться ежедневно. Однако даже опытные DBA не полагаются исключительно на свою память.
Администраторы БД обычно составляют и ведут документацию («run book»), которая включает в себя такие сведения, как:
-
- параметры конфигурации и расположения файлов,
- контактная информация персонала,
- стандартные правила и графики технического обслуживания,
- процедуры аварийного восстановления.
Ведение документации является важной частью администрирования баз данных. Подробная книга может иметь неоценимое значение, особенно в случае, когда новый администратор должен взять на себя ответственность за управление базой данных, или при возникновении неожиданной чрезвычайной ситуации в отсутствии администратора. При сбое сервера четко задокументированные шаги восстановления базы данных уменьшают чувство паники и обеспечивают быстрое решение проблемы.
3. Практическая часть. Установка и администрирование базы данных на примере СУБД Oracle 12c
Для создания базы данных необходимо установить и настроить сервер СУБД Oracle 12c на локальной машине или облачной инфраструктуре.
1. Установка и настройка сервера СУБД Oracle 12c
Процесс установки начинается с установок обновлений (рисунок 3.1).
Рисунок 3.1 - Установка обновлений Oracle
Далее собираются необходимые сведения для установки. Первый шаг – следует выбрать, производится ли только установка программного обеспечения или еще и конфигурация базы данных (рисунок 3.2). Затем необходимо указать конфигурацию Server Class сервера Oracle (рисунок 3.3).
Рисунок 3.2 - Создание базы данных Oracle
Рисунок – 3.3 - Выбор конфигурации сервера Oracle
Следует определить, будет ли устанавливаемый сервер отдельным сервером или частью кластера (набора узлов, между которыми распределяется нагрузка) (рисунок 3.4). Необходимо указать, какой будет выбран режим установки: более или менее подробный (рисунок 3.5).

Рисунок 3.4 - Выбор кластерной конфигурации сервера Oracle
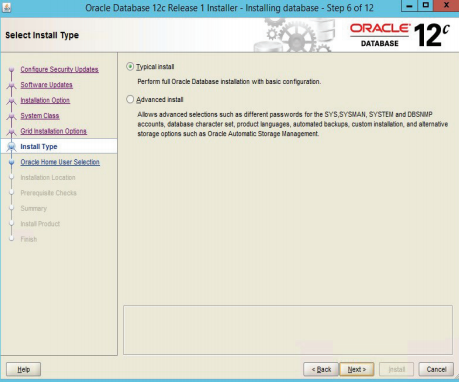
Рисунок 3.5 - Выбор режима установки сервера Oracle
Следует ввести для ОС Windows имя и пароль пользователя, под которым будет запускаться сервер Oracle (рисунок 3.6). Необходимо задать основные параметры сервера: место хранения данных, глобальное имя базы данных, тип установки сервера (рисунок 3.7).
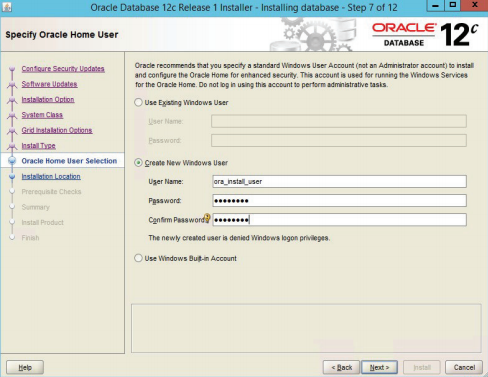
Рисунок 3.6 – Создание пользователя для запуска сервера Oracle
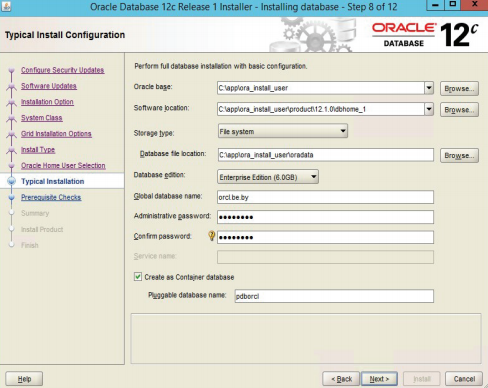
Рисунок 3.7 – Основные параметры сервера Oracle
После сбора всех сведений о параметрах сервера выводится итоговое окно установки (рисунок 3.8).
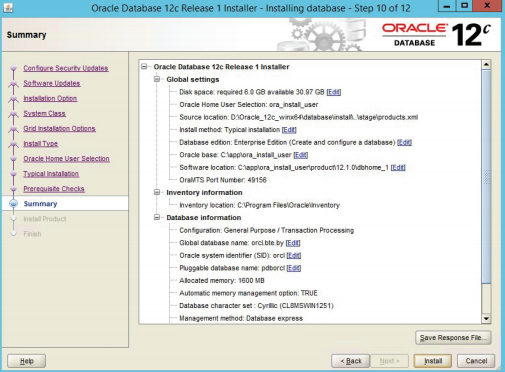
Рисунок 3.8 – Итоговое окно мастера установки сервера Oracle
В процессе установки требуется установить пароли для администраторов. При появлении следующего окна необходимо нажать кнопку Password Management (рисунок 3.9) и установить пароли для администраторов (рисунок 3.10).
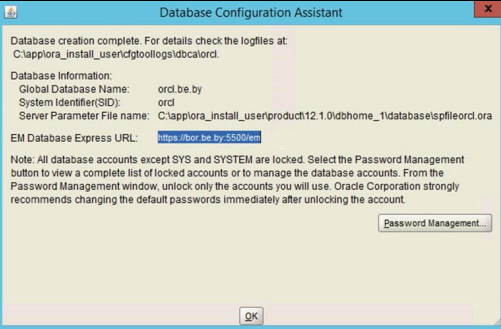
Рисунок 3.9 – Окно конфигурации сервера Oracle
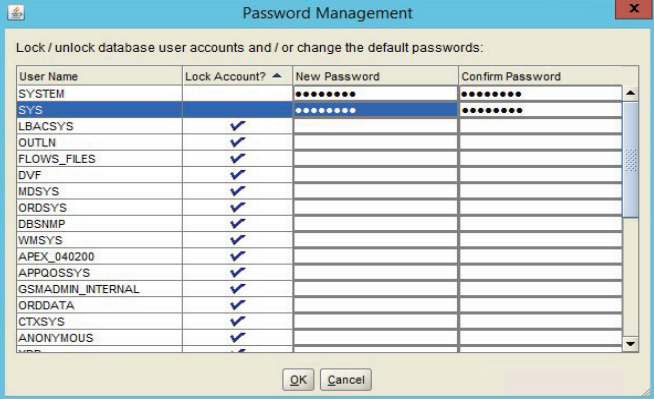
Рисунок 3.10 – Установка паролей администраторов сервера Oracle
После окончания установки следует проверить работу установленного сервера. Проверка осуществляется по следующему плану:
− проверить запущенные сервисы;
− проверить реестр;
− проверить пользователи и группы;
− установить соединение с базой данных.
Проверить запущенные сервисы можно в утилите Службы, сервисы Oracle должны быть запущены (рисунок 3.11).

Рисунок 3.11 – Проверка запущенных сервисов сервера Oracle
В реестре можно проверить, куда установлен сервер Oracle и его основные параметры (рисунок 3.12).
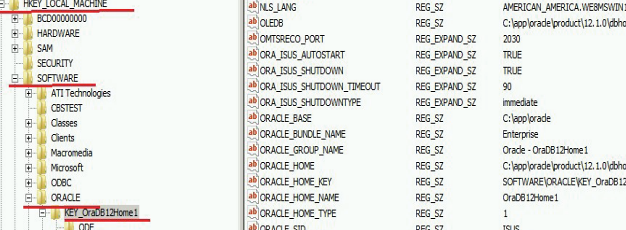
Рисунок 3.12 – Параметры сервера Oracle в редакторе реестра
В настройках локальных пользователей и групп следует убедиться, что созданы все необходимые группы сервера Oracle. Для выполнения административных работ под текущим пользователем Windows необходимо добавить его в группу ora_dba (рисунок 3.13).
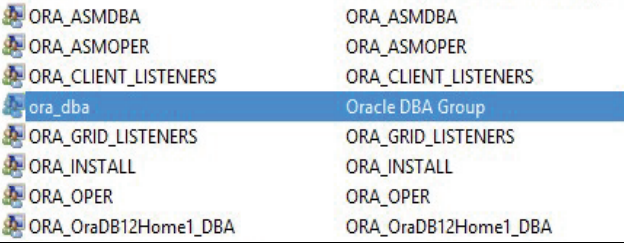
Рисунок 3.13 – Пользователи сервера Oracle
В заключение следует установить соединение с сервером из клиентского приложения. В качестве клиентских приложений будем использовать Oracle SQL Developer – интегрированную среду разработки на языках SQL и PL/SQL и администрирования баз данных, и утилиту командной строки SQLPlus. Продемонстрируем соединение из SQL Developer и SQLPlus.
В SQL Developer необходимо указать имя соединения, имя пользователя, пароль, тип соединения, имя компьютера, на котором установлен сервер Oracle, или его IP-адрес и нажать кнопку Test. При успешном соединении с сервером статус соединения изменится на Success (рисунок 3.14).
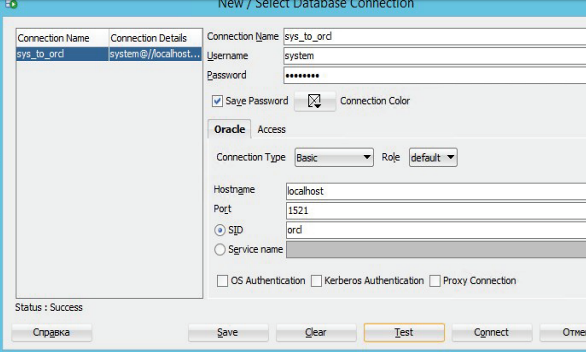
Рисунок 3.14 – Установка соединения с сервером Oracle
Далее следует установить соединение с сервером из утилиты командной строки SQLPlus. Можно установить соединение без указания имени пользователя и пароля, тогда соединение будет установлено от имени текущего пользователя Windows (рисунок 3.15).
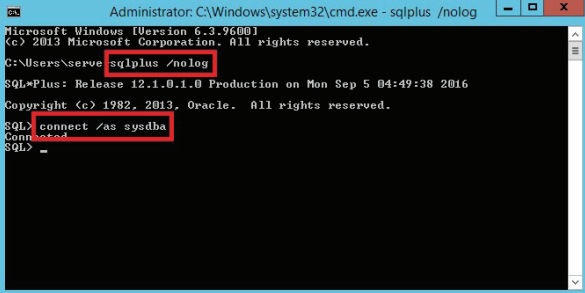
Рисунок 3.15 – Установка соединения с сервером Oracle без указания имени пользователя и пароля
Также можно установить соединение с указанием имени пользователя и пароля, тогда соединение будет установлено от имени данного пользователя (рисунок 3.16).
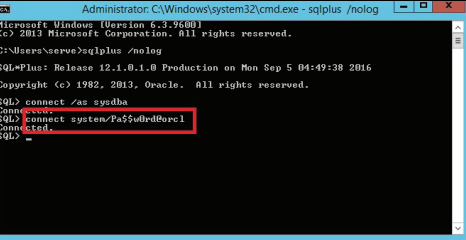
Рисунок 3.16 – Установка соединения с сервером Oracle с указанием имени пользователя и пароля
2. Установка и настройка мультиарендной архитектуры сервера СУБД Oracle 12c
Oracle Multitenant – технология, позволяющая запустить несколько независимых подключаемых баз данных в рамках одного экземпляра. Каждая подключаемая база данных имеет свой набор объектов, но при этом у них общая SGA и один набор серверных процессов. Базы данных изолированы друг от друга и не конфликтуют между собой. Для выполнения курсовой работы необходимо создать подключаемую базу данных. Продемонстрируем создание подключаемой базы данных. Для этого необходимо запустить утилиту Database Configuration Assistant (рисунок 3.17).
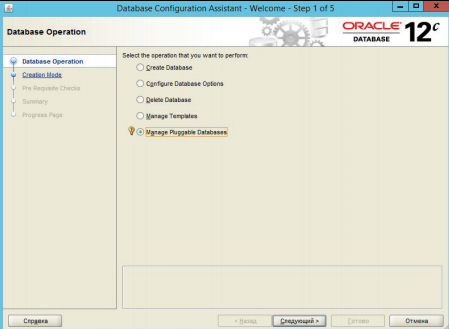
Рисунок 3.17 – Запуск утилиты Database Configuration Assistant
После чего следует указать, что будет создаваться подключаемая база данных (рисунок 3.18). Затем необходимо выбрать экземпляр, на котором будут создаваться подключаемые базы данных (рисунок 3.19).

Рисунок 2.18 – Создание подключаемой базы данных
Рисунок 3.19 – Выбор экземпляра
Следует указать способ создания подключаемой базы данных – из архива или из набора файлов (рисунок 3.20).

Рисунок 3.20 – Выбор источника для подключаемой базы данных
Необходимо выбрать месторасположение файлов базы данных и наделить пользователя административными полномочиями (рисунок 3.21).
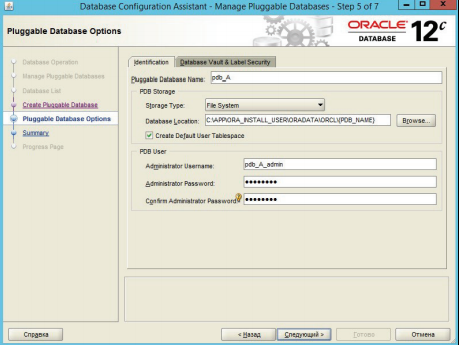
Рисунок 3.21 – Выбор свойств базы данных и администратора
В результате выполнения мастера база данных создана (рисунок 3.22).
Рисунок 3.22 – Итоговое окно создания базы данных
Чтобы запустить сервер, используется набор служебных файлов Oracle:
1) файл параметров;
2) управляющие файлы;
3) файл паролей;
4) файлы журналов работы.
Файлы параметров предназначены для конфигурирования действий Oracle при старте.
Файл параметров сервера (SPFILE) – двоичный файл, который может быть записан и считан сервером базы данных и не должен редактироваться вручную. Он находится на сервере, на котором выполняется экземпляр Oracle. Этот файл не изменяется при завершении работы экземпляра и его запуске. Именем по умолчанию для этого файла является spfile.ora. Текстовый файл параметров инициализации может быть прочитан сервером базы данных, но сервер не может записывать в него. Именем по умолчанию для этого файла является init.ora. Изменения в файле параметров могут быть произведены командой ALTER SYSTEM … SCOPE=SPFILE, тогда изменение параметров сохраняется в SPFILE и будет применяться при следующем старте Oracle.
Просмотреть значения параметров можно при помощи следующего динамического представления словаря (рисунок 3.23).
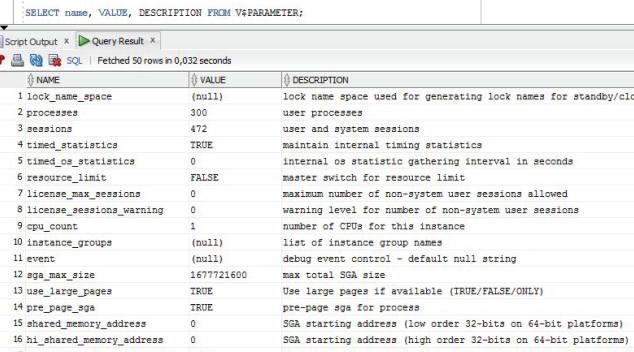
Рисунок 3.23 – Просмотр параметров экземпляра
Управляющие файлы – это файлы, содержащие имена и местоположение основных физических файлов базы данных и некоторых параметров. Управляющие файлы содержат данные о физической структуре базы данных. Эти файлы являются критическими по отношению к базе данных. Без них невозможно открыть файлы данных, чтобы получить доступ к данным в базе данных. Они могут также содержать метаданные, связанные с резервными копиями.
По умолчанию для надежности создается два управляющих файла, хотя сервер может стартовать и с одним. Обычно для надежности их размещают на разных дисковых носителях.
Файл паролей используется для аутентификации администраторов в задачах создания базы данных или запуска и остановки сервера. Аутентификация всех остальных пользователей выполняется внутри самой базы данных, но, поскольку база данных может быть выключена или не смонтирована, для этих случаев требуется иная форма аутентификации администратора. В связи со слишком большими привилегиями, предоставляемыми посредством этого файла, он должен храниться в защищенном каталоге, который недоступен ни для кого, за исключением администраторов базы данных и администраторов операционной системы.
Список пользователей, которым предоставлен административный доступ, можно получить из представления (рисунок 3.24).
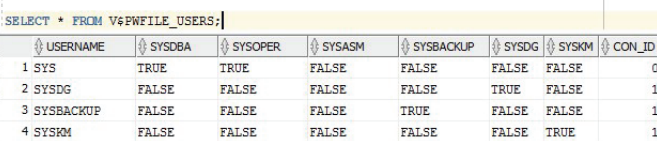
Рисунок 3.24 – Список привилегированных пользователей базы данных
Файл предупреждений базы данных является хронологическим журналом сообщений об ошибках или отклонениях в работе сервера, таких как:
- использование при запуске каких-либо параметров инициализации не по умолчанию;
- все внутренние ошибки, которые возникли в процессе работы;
- все административные операции, такие как создание, изменение, удаление объектов и старт или остановка сервера;
- возникновение ошибок автоматического обновления материализованных представлений.
База данных Oracle использует журнал предупреждений, чтобы вести учет таких событий. Если административная операция успешна, сообщение отмечается в журнале предупреждений как «завершено» с меткого времени. Следует просматривать журнал, чтобы изучить некритические ошибки и информационные сообщения. Поскольку файл может вырасти до очень большого размера, необходимо периодически делать резервную копию файла предупреждений и удалять текущий файл. Журнал предупреждений ведется в xml-формате и может быть просмотрен в браузере, текстовом редакторе или специализированном программном обеспечении для анализа файлов журналов.
Все данные в Oracle сохраняются в файлах данных. Все таблицы, представления, индексы, триггеры, последовательности, программы на PL/SQL находятся в файлах данных. В каждой базе данных Oracle имеется по крайней мере один файл данных и файл журнала повторного выполнения. Каждый файл данных может быть связан только с одной базой данных. Файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных содержит идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла и пр.
Оперативные файлы журналов повтора предназначены для записи всех изменений, выполненных над данными. Используются для хранения на диске информации для повторного выполнения операций. Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, и после его заполнения сервер переходит к записи в следующий файл. Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Как только оперативный файл журнала повтора заполнен, экземпляр сервера Oracle начинает запись в следующий файл. Эта операция повторяется, и информация в оперативных файлах журнала многократно перезаписывается. Если необходимо сохранить историю изменений, нужно, чтобы их копия после переключения журналов сохранялась. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повторного выполнения жизненно важны при восстановлении. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут быть использованы. Резервные копии базы данных следует делать по установленному плану резервного копирования и восстановления.
Заключение
В данной курсовой работе рассмотрены вопросы связанные с понятиями информация и данные, управление данными, базами данных и их администрирование. В ходе проведения исследования выполнены следующие задачи:
- Рассмотрены понятия БД и СУБД.
- Изучены требования, предъявляемые к СУБД.
- Рассмотрена архитектура «клиент-сервер».
- Рассмотрена и изучена деятельность АБД;
- Выполнена установка и администрирование базы данных на примере СУБД Oracle 12c.
Список использованных источников
- Грюнвальд, Р. Oracle. Справочник / Р. Грюнвальд, Д. Крейнс. – СПб.: Символ-Плюс, 2005. – 976 с.
- Каучмен, Д. Oracle Certified Professional. Подготовка администратора баз данных / Д. Каучмен, У. Швинн. – М.: Лори, 2009. – 868 с.
- Кайт, Т. Oracle для профессионалов. В 2 кн. Кн. 1. Архитектура и основные особенности / Т. Кайт. – СПб.: ДиаСофтЮП, 2005. – 656 с.
- Кайт, Т. Oracle для профессионалов. В 2 кн. Кн. 2. Расширение возможностей и защита / Т. Кайт. – СПб.: ДиаСофтЮП, 2005. – 816 с.
- Генник, Дж. Oracle SQL*Plus. Карманный справочник / Дж. Генник. – СПб.: Питер, 2004. – 188 с.
- Oracle [Электронный ресурс] / Oracle Corporation. – Redwood Shores, 2012. – Режим доступа: http://www.oracle.com. – Дата доступа: 18.11.2019.
- Oracle DBA Forum [Электронный ресурс] / Jelsoft Enterprises Ltd. – М., 2012. – Режим доступа: http://odba.ru. – Дата доступа: 18.11.2019.
-
Feature Analysis of Generalized Data Base Management Systems: CODASYL Systems Committee, May 1971 / B. K. Bhargava [et al.]. — ACM, 1971. ↑
-
Информационные системы общего назначения: аналитический обзор систем управления базами данных / под ред. Е. Ющенко. — М.: Статистика, 1975. — С. 472. ↑

- Особенности коммуникаций в организации (Особенности внутренних коммуникаций в организации)
- Программные средства создания клиентских программ (Операционная система клиента)
- Применение процессного подхода для оптимизации бизнес-процессов ( Характеристика и анализ бизнес-процессов финансового отдела ГТК «Телеканал «Россия» )
- «Основные понятия объектно-ориентированного программирования»
- Основы программирования на языке Pascal ( Основные элементы )
- Разработка комплекса маркетинговой службы предприятия (для любого реально существующего предприятия) ( Основные категории маркетинга. Концепции управления маркетингом)
- Мотивации персонала и проектирование систем стимулирования труда (Теоретико-методологические аспекты по теме исследования)
- Финансовая политика ( Теоретические аспекты функционирования финансовой политики Российской Федерации))
- Формы и виды кредита в современной экономике. Свойства кредита
- Финансовые ресурсы (Динамика и структура финансовых ресурсов организации)
- Возникновение, сущность и функции коммерческих банков
- Подходы к управлению человеческими ресурсами (Основные подходы к управлению человеческими ресурсами)