
Определение и задачи распределённой системы
Содержание:

ВВЕДЕНИЕ
В современной индустрии нашего времени, практически, а точнее все большие программные системы являются распределёнными.
Для пользователей распределённая система является единой системой, которая представлена технически набором независимых компьютеров.
Распределенные системы с лёгкостью могут соединять пользователей с ресурсами и при этом успешно скрывать тот факт, что ресурсы разбросаны по сети, и могут быть открытыми и масштабируемыми.
Решающей целью распределенной обработки информации является оптимизация использования ресурсов и упрощение работы пользователя.
В построение распределённых систем необходимым условием является выполнение и решение следующих основных задач:
• Прозрачность;
• Открытость;
• Гибкость;
• Масштабируемость;
• Безопасность.
В современном мире использование возможностей распределённой системы играет значительную роль для бывалого пользователя.
Их использование представлено в разных сферах:в науке, на производстве, в энергетике, в военном деле, в корпоративном программном обеспечении и во множестве других областей. C развитием интернетаобласть использования распределённых систем значительно расширилась. Но есть и свои минусы,в силу высокой сложности распределённых систем практически невозможно спроектировать и разработать надежную систему, не содержащую ошибок. Вероятность возникновения программного или аппаратного сбоя при работе с распределённой системой довольно высока и может иметь достаточно серьезные негативные последствия. Таким образом, актуальной является задача повышения надежности эксплуатирования данной системы или задача построения отказоустойчивых распределённых систем, которые в свою очередь могут самостоятельно устранять последствия сбоев без прекращения работы системы.
Взвесив все за и против распространения распределённой обработки информации можно обозначить несколько обусловленностей: с одной стороны, ускоренным развитием микроэлектроники, снижением стоимости вычислительных средств, увеличением их производительности при уменьшении габаритов, а с другой стороны имеет место повысить требования к производительности, надежности и эффективности рабочих систем, предъявляемых сферами их применения.
Цель курсовой работы рассмотреть определение и задачи распределённой системы.
Объект исследования курсовой работы - распределённая система обработки информации.
Предмет исследования - определение и задачи распределённой системы обработки информации.
Для раскрытия донной темы в курсовой работе необходимо рассмотреть следующие вопросы:
- Определение распределённой системы;
- Вводное понятие распределённой системы;
- История создания распределённой системы;
- Задачи распределённой системы.
1. Определение распределённой системы
В литературе используются различные трактовки дающие представление определению распределённых систем, однако ни одно из них не согласуется с другими и является не достаточно развёрнутым и удовлетворительным определением. Основываясь только на вольной характеристике авторовприведём несколько определений распределённой системе:
- Распределённая система – это набор независимых компьютеров, представляющийся их пользователям как единая объединённая система.[5]
- Распределённая система – это совокупность взаимодействующих друг с другом программных компонентов.[6]
1.1. Вводное понятие распределённой системы
В самом определениираспределённой системы можно выделить два ключевых момента. Первый относится к аппаратуре: все машины автономны. Второй момент касается программного обеспечения: пользователи уверены, что имеют дело с единой системой. Оба момента важны и не могут быть взаимоисключающими.
Известно, что распределённая информационная система состоит изсовокупности взаимодействующих друг с другом программных компонент (включений).Каждый из таких включений может рассматриваться как программный модуль (оно же приложение), исполняемый в рамках отдельно взятого процесса.Пользователи и приложения в едином тандеме работают в распределённой системе независимо от того, где и когда происходит их взаимодействие.Для их взаимодействия распределённые системы должны иметь характерные признаки, как сокрытие от самого пользователя различий между компьютерами и способа связи между ними.[2] В работе распределённой системы не маловажной характеристикой является способ, при помощи которого обеспечивается комплексная и единая работа пользователей (или приложений) в указанной системе.Она достаточно легко должна поддаваться расширению (масштабированию), а выход из строя рабочей системы или в худшем случае некоторой части распределённой системы не должен приводить к отказу всей системы в целом и пользователи не должны даже об этом знать или уведомляться.
На примере рассмотрим некоторые из основных, так называемых базовых вопросов, касающиеся аппаратного и программного обеспечения системы.
Всё внимание сосредоточим на важных основополагающих характеристиках распределённых систем:
- от пользователей должны быть скрыты различия между компьютерами и способы их связи между ними.
- независимо где и когда происходит взаимодействие пользователей и приложения, они рационально и единообразно работают в распределённых системах.
- распределенные системы должны с относительной легкостью поддаваться расширению, или масштабированию. [7]
Распределённые системы относительно существуют постоянно, однако некоторые их части имеют свойства временно выходить из строя. Пользователи и приложения не должны уведомляться о том, что эти части заменены или починены, или о том, что добавлены новые части для поддержки дополнительных пользователей или приложений.
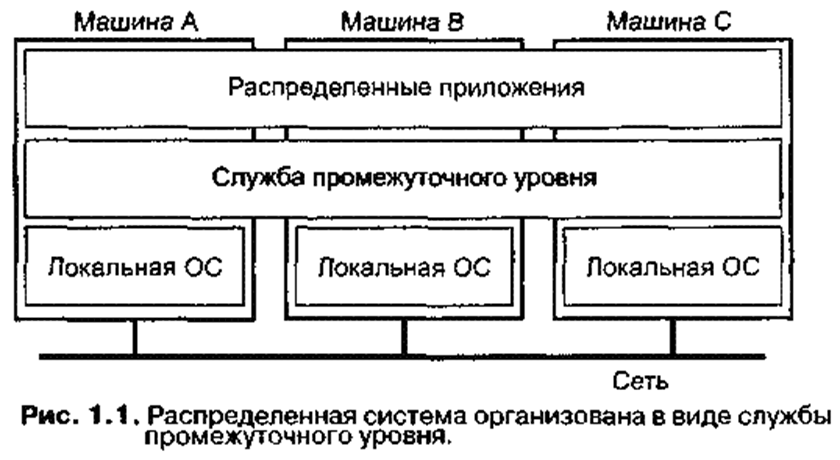
Для того чтобы поддержать представление различных компьютеров и сетей в виде единой и целостной системы, использование и организация распределенных систем часто включает в себя дополнительный уровень программного обеспечения, находящийся между верхним уровнем, на котором находятся пользователи и приложения, и нижним уровнем, состоящим из операционных систем, как представлено на рис. 1.
Исходя из данных, такая распределённая система обычно называется системой промежуточного уровня (middleware).
Рис. 1.
Распределённая система организована в виде службы промежуточного уровня
Теперь взглянем на некоторые примеры распределённых систем. В качестве главного и показательного примера рассмотрим сеть рабочих станций в университете или отделе производственной компании. Вдобавок к персональной рабочей станции каждого из пользователей имеется пул процессоров машинного зала, не назначенных заранее ни одному из пользователей, но динамически выделяемых им при желании в данной необходимости. Эта распределенная система может обладать единой файловой системой, в которой все файлы одинаково доступны со всех машин с использованием постоянного пути доступа. Кроме этого, когда пользователь набирает команду, система может найти наилучшее место для исполнения запрашиваемого действия, возможно, на собственной рабочей станции пользователя, возможно, на простаивающей иной рабочей станции, принадлежащей кому-то другому, а может быть, и на одном из свободных процессоров машинного зала. Если именуемая система в целом выглядит и ведет себя как классическая однопроцессорная система с разделением времени (то есть многопользовательская), она считается распределённой системой. В качестве иного, но значимого и рационального примера рассмотрим работу информационной системы, которая поддерживает автоматическую обработку заказов. По использованию подобнойсистемы,как правило, используются сотрудниками нескольких отделов, возможно даже в разных местах. Так, сотрудники отдела продаж могут быть разбросаны по обширному региону или даже по всей стране в целом. Заказы будут передаваться с переносных компьютеров, соединяемых с системой при помощи телефонной сети, а возможно, и при помощи мобильных телефонов. Поступающие заказы автоматически передаются в отдел распределения и планирования, превращаясь там во внутренние заказы на поставку, которые поступают в отдел доставки, и далее в заявки на оплату, поступающие в бухгалтерию. В свою очередь система автоматически даёт команду пересылать эти документы работающим на месте сотрудникам, отвечающим за их обработку. Пользователи остаются в полном неведении о том, как заказы на самом деле курсируют внутри самой системы, для них все это представляется так, будто вся поставленная работа происходит в единой централизованной базе данных.
В качестве последнего из примеров рассмотрим WorldWideWeb. Web предоставляет собой простую, целостную и единообразную модель распределённых документов. Чтобы просмотреть желаемый документ, пользователю достаточно лишь активизировать ссылку. После этого выбранный документ появляется на экране. В теории (но определенно не в ныне текущей практике) нет необходимости знать, с какого сервера изымается и доставляется документ, достаточно лишь информации о том, где был расположен данный документ. Публикация документа очень проста: вы должны только задать ему уникальное имя в форме унифицированного указателя ресурса (UniformResourceLocator, URL), которое ссылается на локальный файл с содержимым этого документа. Если бы ныне существующая Всемирная паутина представлялась своим пользователям гигантской централизованной системой документооборота, она также могла бы называться распределённой системой. К сожалению, но это таковым в данное время не является. Таким образом, пользователи сознают, что документы находятся в различных местах и распределены по различным серверам.
К причинам, по которым создаются распределенные системы, можно отнести следующие:
1. Естественная территориальная распределённость. Современный бизнес динамично развивается и укрупняется: открываются новые филиалы, идёт поглощение и объединение предприятий в холдинги. Как следствие, у предприятий возникает потребность в единой информационной платформе, связывающей территориально распределённые информационные системы и предоставляющей инструмент для их эффективного эксплуатирования.
2. Возможность достичь высоких показателей производительности.Можно достичь высокой производительности путем объединения микропроцессоров,котораяне может быть достигнута в централизованном компьютере. Решение таких задач являются актуальными при обработке графической информации.
3. Совместное использование ресурсов. Распределённые системы допускают совместное использование как аппаратных (жёстких дисков, принтеров), так и программных (файлов, компиляторов) ресурсов.[8]
Исследования в области распределённых систем решают проблемы синхронизации объектов, одновременного доступа к общим ресурсам, определения отказавших узлов и т.п. Известными исследователями в этой области являются:
- Лесли Лампорт;
- ЭнрдюТаненбаум;
- Нэнси Линч;
- KanianthraManiChandy.
Распределённость работы в системе можно рассматривать на разных уровнях иерархии программно-аппаратного обеспечения системы или её составных частей. В свою очередь распределёнными могут быть:
- Распределённые файловые системы;
- распределённые операционные системы;
- распределённые приложения;
- распределённые базы данных;
С точки зрения размеров систем и способов администрирования распределённые системы можно классифицировать иначе:
- Распределённая система корпоративного уровня – десятки и даже сотни компьютеров, при работе которых необходимо устанавливать правила совместного использования ресурсов.
- Глобальная система (грид-система) – огромное количество компьютеров, число которых может достигать несколькихмиллионов, распределённых по миру и объединённых единой глобальной сетью.
- Административное программное обеспечение, встроено в промежуточное программное обеспечение.[3]
Кластер - это несколько десятков компьютеров, объединенных с помощью локальной сети. Администрирование осуществляется вручную. Задачи, которые пытаются решать с применением технологии кластеризации, - две. Первая из них связана с резервированием некоторых критических сервисов. Для этого применяются кластеры, настроенные таким образом, что при сбое одного из узлов, входящих в кластер, сервисы, обслуживаемые этим узлом, автоматически загружаются на другом узле кластера. Такой подход позволяет существенно минимизировать время простоя системы, а для некоторых видов сервисов к тому же абсолютно прозрачен для клиентов. Кластеры, построенные по такому принципу, называются отказоустойчивыми кластерами. Вторая задача, которую решают путём кластеризации, состоит в увеличении производительности системы. При таком подходе, один сервис запускается на нескольких узлах кластера (реализация этого может быть различной - на каждом из узлов запускается копия сервиса, сервис запускается на одном узле, а часть его процедур размещается на других узлах и т.д.), при этом количество одновременно обрабатываемых заданий увеличивается (если не рассматривать тривиальные сервисы, то для обеспечения такой возможности сервис должен быть специальным образом спроектирован).Кластеры, решающие такого вида задачи, называются высокопроизводительными.
1.2. Экскурс в историю создания распределённой системы
С 1945 года, когда зарождалась эпоха современных компьютеров, до приблизительно 1985 года, тогдашние компьютеры были большими и довольно дорогими. Даже имеющиеся мини-компьютеры стоили сотни тысяч долларов. В результате имеющихся возможностей большинство организаций имели лишь несколько компьютеров. Способы соединить компьютеры воедино в то время отсутствовали, поэтому они работали независимо друг от друга.
В скором времени, в середине восьмидесятых, под воздействием двух технологических новинок ситуация коренным образом изменилась. Первой из представленных новинок была разработка мощных микропроцессоров. Вторая представляла собой изобретение высокоскоростных компьютерных сетей. Локальные сети (Local - AreaNetworks, LAN), которые имели возможностьсоединить сотни компьютеров, находящихся в одном здании, таким способом, что машины в состоянии были обмениваться небольшими порциями информационных сведений всего за несколько микросекунд. Большие массивы информации передаются с машины на машину со скоростью от 10 до 1000 Мбит/с. Глобальные сети (Wide - AreaNetworks , WAN) позволяли миллионам компьютеров во всём мире обмениваться данными со скоростями, варьирующимися от 64 кбит/с (килобит в секунду) до гигабит в секунду.[1]
Изначально развитие вычислительной техники и её использование делилось на два ключевых направления.
К первому относилось: использование вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Это направление поспособствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второму направлению была отведена другая роль: использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно объёмны и велики, а сама информация имеет достаточно узкую и сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность полученной информации.
Но поскольку информационные системы требуют сложных структурных данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной для создания различных систем управления.
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей более сложные методы хранения данных на стандартной базовой файловой системе. Например, было неэффективно хранить информационные данные в нескольких файлах.
Фактически, если информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись одной лишь библиотекой функций: такая система должна иметь некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных [4].
В одной из своих статей в 2001 году Дж. Бэкус отметил, что компьютерная революция испытала три волны.
Первая волна началась с коммерциализацией кремниевых чипов и продолжалась 10-15 лет.
Вторая волна связана с развитием технологий программного обеспечения и началась приблизительно в середине 80-х годов XX века.
Третья волна началась в конце 90-х годов XX века и связана с развитием сетей и использованием их для коммуникаций компьютеров. Эта волна послужила источником последующего бума информационных технологий.
Рост технологических возможностей привел к тому, что компьютерные устройства стали значительно меньше в размерах и быстрее в работе. [2]
В нашем современном мире существует огромное количество уже готовых к использованию информационно-вычислительных ресурсов. Однако они в свою очередь создавались в разное время и для их разработки использовались разные методы и подходы, но почти всегда при разработке новой информационной системы можно найти подходящие посвоим функциям уже существующие и хорошо выполняющие свою работу готовые компоненты.
В результате развития информационных технологий сегодня не просто возможно, но и достаточно легко можно собрать компьютерную систему, состоящую из множества компьютеров, соединенных высокоскоростной сетью. Она обычно называется компьютерной сетью, или распределённой системой (distributedsystem), в отличие от предшествовавших ей централизованных (centralizedsystems), или одно процессорных (single - processorsystems), систем, состоявших из одного компьютера, его периферии и, возможно, нескольких удаленных терминалов.
Вывод. Согласно рассмотренным определениям, можно привести следующие свойства присущие распределённой системе:
- автономность (но соединённые средой передачи);
- взаимодействие машин посредством передачи;
- много положительных примеров использования данной системы;
- система существует, но её нужно уметь развивать и поддерживать.
2. Задачи распределённой системы
Имея возможность построения распределённых систем, ещё не означает полезность этого. Ныне существующая современная технология имеет возможность подключить к персональному компьютеру до четырёх дисководов. В данной главе обсудим четыре основных и важных задач, решение которых позволяет сделать построение распределённых систем осмысленным решением. Распределённые системы могут с лёгкостью соединять пользователей с любыми ресурсами и успешно скрывать тот факт, что ресурсы разбросаны по сети и могут быть открытыми и масштабируемыми.
В итоге решается одна из основных задач системы соединение пользователей с ресурсами. Что коренным образом облегчает пользователям доступ к удаленным ресурсам и обеспечивает их совместное использование, при этом регулируя этот процесс.В свою очередь ресурсы могут быть виртуальными, однако традиционно они включают в себя принтеры, компьютеры, устройства хранения данных, файлы и имеющиеся данные. Web-страницы и сети также входят в этот перечисленный список. В быту существует множество причин для совместного использования ресурсов. Одна из очевидных — это экономичность. К примеру, гораздо дешевле разрешить совместную работу с принтером нескольких пользователей, чем покупать и обслуживать отдельный принтер для каждого из имеющегося пользователя. Аналогично имеет смысл в совместном использовании дорогих ресурсов, такие как суперкомпьютеры или высокопроизводительные хранилища информационных данных.
В данной работе соединения пользователей и ресурсов также облегчает кооперацию и обмен информацией, что лучше всего иллюстрируется успехом Интернета с его простыми протоколами для обмена файлами, почтой, документами, аудио- и видео-информацией. Имея связь через Интернет в настоящее время приводит к появлению многочисленных виртуальных организаций, в которых географически удаленные друг от друга группы сотрудников работают вместе при помощи систем групповой работы (groupware)— куда входят программы для совместного редактирования документов, проведения телеконференций и т. п. Подобным же образом подключение к Интернету вызвало в жизни электронную коммерцию, позволяющую нам покупать и продавать любые видытоваров, обходясь без посещения магазина в реальности.
Однако по мере роста числа подключений и степени совместного использования ресурсов все более и более важными становятся вопросы реализации безопасности. В современной практике системы имеют недочёты, которые характеризуют слабую защиту от подслушивания или вторжения по линиям информационной связи. Пароли и другая особо важная информация частенько пересылаются по сетям в открытомдоступе (то есть незашифрованными) или хранятся на серверах, надежность которых вызывает сомнения и не подтверждена ничем, кроме нашей убеждённости веры. Здесь имеется еще достаточно много возможностей для улучшения работы системы. К примеру, в настоящее время для заказа товаров необходимо просто сообщить номер личной кредитной карты. В редких случаях требуется подтверждение того, что покупатель действительно является владельцем данной карты. В будущем заказ товара таким аналогичным образом будет возможен только в том случае, если вы сможете физически, то есть непосредственно подтвердить факт обладания этой платёжной карты при помощи считывателя карт.
Иная проблема безопасности состоит в том, что прослеживание коммуникаций позволяет построить профиль предпочтений конкретного в данном случае пользователя. Подобное отслеживание в системе серьезно нарушает права личности, особенно если производится без уведомления самого пользователя. Связанная с этим проблема состоит в том, что непосредственно рост подключений ведет к росту нежелательного общения, такого как получаемые по электронной почте бессмысленные письма, так называемый спам. Единственное, что мы можем предпринять в этом случае, это защитить себя, используя специальные информационные фильтры, которые выполняют некую роль сортировщика входящих сообщений на основании их содержимого.
2.1. Прозрачность
Одной из важных задач распределённых систем является прозрачность. Распределённые системы, которые представляются пользователям и приложениям в виде единой компьютерной системы, называются прозрачными (transparent).
Под прозрачностью (transparency) понимают «незаметность» для пользователя внутренней работы самой системы. Это достигается путем сокрытия от пользователя аспектов организации и реализации распределённой обработки информации. Пользователи распределённой системы должны обладать доступом к ресурсам, не задаваясь вопросами о взаимодействии между процессами, о физическом месте размещения ресурсов и о том, какой именно процесс обслуживает тот или иной запрос пользователя.
В «Эталонной модели распределённой обработки информации в открытой системе» Международной организации по стандартизации ISO (InternationalStandardizationOrganization) определены следующие восемь ключевых «типов прозрачности», обеспечиваемых в работе распределённой системы, а именно:
1. Прозрачность доступа (accesstransparency) имеет возможность скрывать от пользователя детали реализации сетевых протоколов, обеспечивающих связь между удалёнными компьютерами. Кроме того, она также предоставляет универсальные средства доступа к данным, хранимым в различных форматах по всей системе;
2. Прозрачность местоположения (locationtransparency) берёт своё основание на прозрачности доступа и предназначена для сокрытия физического местоположения ресурсов в распределённой системе от клиента, желающего воспользоваться этими ресурсами. Распределённая система, в которой уже реализована прозрачность местоположения, предоставляет доступ к удалённым файлам так, как если бы они являлись локальными;
3. Прозрачность сбоев (failuretransparency) представляет собой некий метод обеспечения отказоустойчивости в распределённых системах. В случае выхода из строя любого ресурса, либо компьютера рабочей сети, пользователи сети имеют возможность заметить лишь некое снижение выполнения действий. Прозрачность сбоев обычно реализуется путем репликации (replication) ресурсов, либо создания контрольных точек восстановления. При применении репликации система обеспечивает работу дублирования ресурсов, выполняющих одни и те же функциональные задачи. Даже если представить, что из строя выйдут все копии, кроме одной, распределённая система всё же продолжит свою функциональную жизнедеятельность. Система, в которой обозначены и используются контрольные точки, имеют свойства периодически выполнять сохранение информации о состоянии имеющихся объектов (к примеру, процессов), по которым они могут быть восстановлены, если сбой в распределённой системе приведёт к повреждению или к утрате этих объектов;
4. Прозрачность репликации (replicationtransparency) позволяет скрыть от пользователя фактические существования нескольких копий, того или иного ресурса, доступного в системе. В такой системе доступ к группе реплицированных ресурсов будет осуществляться по пути аналогичен тому, как если бы доступным являлся лишь один-единственный ресурс;
5. Прозрачность постоянства (persistencetransparency) скрывает от пользователя информацию о пути и месте хранения ресурса (будь то ОЗУ или обычный дисковый накопитель);
6. Прозрачность транзакций (transactiontransparency) даёт возможность позволить системе добиваться непротиворечивости, при этом легко скрывая выполнение согласования в группе ресурсов. В последующем, транзакции включают запросы к службам (к примеру, доступ к файлам и вызов функций), позволяющие изменять имеющееся состояние системы. Следовательно, можно сделать вывод, что транзакции часто требуют создания контрольных точек, либо выполнения репликации в целях обеспечения реализации иных задач в распределённых системах. Прозрачность транзакций весьма удачно позволяет скрывать от пользователя детальные моментыэксплуатации этих служб;
- Прозрачность миграции (migrationtransparency);
- Прозрачность изменения местоположения (relocationtranspa-rency).
Прозрачность миграции и прозрачность изменения местоположения,в совокупности, скрывают от пользователя все действующие перемещения компонентов системы. Прозрачность миграции отлично исполняет роль маскировщика перемещения одного или нескольких объектов с одного места в другое в распределённой системе. Приведём имеющийся пример, перемещения выборочного файла с одного сервера на другой. Прозрачность изменения местоположения маскирует перемещения одного объекта по отношению к другим объектам, с которыми он ныне поддерживает связь.
Концепция прозрачности, как видно из табл. 1., применима к различным показательным аспектам распределённых систем.
Таблица 1.
Различные формы прозрачности в распределённых системах
|
Прозрачность |
Описание |
|
Доступ |
Скрывается разница в представлении данных и доступе к ресурсам |
|
Местоположение |
Скрывается местоположение ресурса |
|
Перенос |
Скрывается факт перемещения ресурса в другое место |
|
Смена местоположения |
Скрывается факт перемещения ресурса в процессе обработки в другое место |
|
Репликация |
Скрывается факт репликации ресурса |
|
Параллельный доступ |
Скрывается факт возможного совместного использования ресурса несколькими конкурирующими пользователями |
|
Отказ |
Скрывается отказ и восстановление ресурса |
|
Сохранность |
Скрывается, хранится ресурс (программный) на диске или находится в оперативной памяти |
Хотя прозрачность распределения в общем смысле желательна для всякой распределённой системы, однако существуют иные ситуации, когда попытки полностью скрыть от пользователя всякую распределённостьне является разумным решением. Приведём пример, к требованию присылать вам свежую электронную газету до семи утра по местному времени, особенно если вы в данный момент находитесь на другом конце света и живете в совершенно другом часовом поясе. Иначе говоря,ваша утренняя газета окажется совсем не той утренней газетой, которую вы так хотели получить.
Основываясь на данном примере, это же происходит и в глобальной распределённой системе, которая соединяет процесс в Сан-Франциско с процессомк примеру в Амстердаме, будьте уверены, вам не удастся скрыть тот факт, что мать-природа супротив иной логике не позволяет пересылать сообщения от одного процесса к другому быстрее чем за 35 мс. Руководствуясь практикой,данные показывают, что при использовании компьютерных сетей на это реально требуется несколько сотен миллисекунд. А сама скорость передачи сигнала ограничивается не столько скоростью света, сколько скоростью самой работы промежуточных переключателей.
В иных случаях, существует равновесие между высокой степенью прозрачности и производительностью системы. К примеру,многие приложения, предназначенные для Интернета, многократно пытаются установить контакт с сервером, пока, наконец, не откажутся от этой затеи. Иначе предпринятые попытки замаскировать сбой на промежуточном сервере, вместо того чтобы попытаться работать через другой сервер, замедляют всю систему в целом. Советом в данном случае было бы эффективнее как можно быстрее прекратить эти попытки или, по крайней мере,дать возможность позволить пользователю прервать попытки установления контакта.
Хочется привести ещё один не маловажный пример: мы нуждаемся в том, чтобы реплики, находящиеся на разных континентах, были в любой момент гарантированно идентичны. Иначе говоря, другими словами, если одна копия изменилась, изменения должны распространиться на все системы до того, как они выполнят какую-либо операцию. Известно, что одиночная операция обновления может в этом случае занимать до нескольких секунд и вряд ли удастся возможность проделать ее незаметно для пользователей.
Рассуждая здраво, можно сделать следующий вывод: достижение прозрачности распределения — это на самом деле разумная цель при проектировании и разработке распределённых систем, но она не должна рассматриваться в отрыве от других характеристик названной системы, например производительности.
2.2. Открытость
Другая важная задача в работе распределённых систем — это открытость. Под открытостью понимают использование синтаксических и семантических вводных правил, основанных на единых стандартах. Правильный интерфейс обеспечивает возможность исполнения совместной работы одного произвольного процесса, нуждающегося в интерфейсе, с другим произвольным процессом, представляющим так же интерфейс.
В распределённых системах службы повсеместно определяются через интерфейсы (interfaces),которые часто описываются при помощи языка определения интерфейсов (InterfaceDefinitionLanguage , IDL).Описание интерфейса на IDL почти исключительно касается синтаксиса служб. Излагая простым языком,оно точным образом отражает имена доступных функций, типы параметров, возвращаемых значений, исключительные ситуации, которые могут быть возбуждены службой и т. п. Сложнеевсего описать то, какие действия выполняет эта служба, то есть, семантику интерфейсов. На практике подобные спецификации задаются неформально, то есть посредством естественного языка команды.
Будучи правильно обозначенным, определение интерфейса допускает возможность совместной работы произвольного процесса, нуждающегося в таком интерфейсе, с другим произвольным процессом, предоставляющим этот интерфейс. Определение интерфейса также позволяет двум независимым группам создать абсолютно разные реализации этого интерфейса для двух различных распределённых систем, которые будут работать абсолютно идентично. Правильное определение самодостаточно и нейтрально. «Самодостаточно» означает то, что в нём имеется всё необходимое для реализации интерфейса. Однако, многие определения интерфейсов сделаны самодостаточными не до конца, поскольку разработчикам необходимо включать в них специфические детали реализации. Важно отметить, что спецификация не определяет внешний вид реализации, она должна быть нейтральной. Самодостаточность и нейтральность являются особой необходимостью для обеспечения переносимости и способности к взаимодействию. Способность к взаимодействию (interoperability)характеризует, насколько две реализации систем или компонентов от разных производителей в состоянии совместно работать, полагаясь только на то, что службы каждой из них, соответствуют общему стандарту. Переносимость (portability)характеризует то, насколько приложение, разработанное для распределённой системы 1, может без изменений выполняться в распределённой системе 2, реализуя по возможности те же, что и в 1 интерфейсы.
2.3. Гибкость
Следующая важная характеристика открытых распределённых систем — это гибкость.
Гибкостьв свою очередь характеризует некую легкость конфигурирования данной системы при замене и изменении состава компонентов.
Недолжны вызывать затруднений добавления к системе новых компонентов или замена уже существующих, при этом прочие компоненты, с которыми не производилось никаких действий, должны оставаться неизменными. Другими словами, открытая распределённая система должна удовлетворять возможность быть расширяемой. Например, к гибкой системе должно быть относительно несложным действия добавления частей, работающих под действием управления другой операционной системы, илик примеру даже, замена всей файловой системе целиком. Насколько всем нам знакома сегодняшняя реальность, говорить о гибкости куда проще, чем её осуществить.
В построении гибких открытых распределённых систем, решающим фактором оказывается организация этих систем в виде наборов, относительно небольших и легко заменяемых, или адаптируемых компонентов. Это предполагает необходимость определения не только интерфейсов верхнего уровня, с которыми работают пользователи и приложения, но также и интерфейсов внутренних модулей системы и описания взаимодействия этих модулей. Этот подход был применим совсем недавно и в использовании он относительно молод. Множество старых и современных систем создавались цельными, а компоненты одной гигантской программы разделялись только логически. В случае использования этого подхода, независимая замена или адаптация компонентов, не затрагивающая систему в целом, была почти невозможна. Так как монолитные системы стремятся скорее к закрытости, чем к открытости.
Необходимость изменений в распределённых системах часто связана с тем, что компонент не оптимальным образом соответствует нуждам конкретного пользователя или приложения. На данном примере, рассмотрим кэширование в WorldWideWeb. Браузеры обычно позволяют пользователям адаптировать правила кэширования под их нужды путем определения размера кэша, а также того, должен ли кэшируемый документ проверяться на соответствие постоянно или только один раз за сеанс. Однако пользователь лишён возможности воздействовать на другие параметры кэширования, такие как длительность сохранения документа в кэше или очередность удаления документов из кэша при его переполнении данных. Также невозможно создавать правила кэширования на основе содержимогодокумента. Приведём имеющийся пример: пользователь может пожелать кэшировать железнодорожные расписания, которые редко изменяются, но никогда — информациюпоступившую о пробках на улицах города.
Необходимым условием является отделить правила от механизма. В случае кэширования в Web, браузер в идеале должен предоставлять только возможности для сохранения документов в кэше и одновременно давать пользователям возможность решать, какие документы и на какой период будет там храниться. На практике это может быть реализовано предоставлением большого списка параметров, значения которых пользователь самостоятельно сможет (динамически) задавать. Но кудавыгоднее, если пользователь получит возможность сам устанавливать правила в виде подключаемых к браузеру компонентов. Разумеется, браузер должен понимать интерфейс этих компонентов, поскольку ему нужно будет, используя этот интерфейс, вызывать удовлетворяемые процедуры, содержащиеся в компонентах системы.
2.4. Масштабируемость
Масштабируемость - это одна из наиболее значимых задач при проектировании распределённых систем.
Масштабируемость,оно жерасширяемость (scalability), указывает на способность распределённой системы увеличиваться в масштабах (данная возможность подключения к системе дополнительных компонентов) без возможности влиять на саму работу уже существующих ныне приложений и пользователей.Масштабируемость функционально рассматривается по отношению к размеру (подключение возможных дополнительных пользователей и иных ресурсов), по отношению к географическому положению (пространственное расположение пользователей и ресурсов), а так же к административному устройству (управление в административно независимых организациях). Возникающие проблемы масштабируемости обычно связаны с «узкими» местами по обслуживанию (иными словами это один сервер для множества клиентов), далее по данным (один файл с общей информацией), и по алгоритмам (централизованный алгоритм и перегрузка в коммуникационной сети).
Применение в работе децентрализованных алгоритмов придаёт распределённой системе следующие характерные черты:
- никто не обладает полной информацией о системе;
- решения принимаются на основе локальной информации;
- сбой в одном месте не вызывает нарушения работы алгоритма;
- существования единого времени в использовании системы не требуется.
К сожалению, система, обладающая масштабируемостью по одному или нескольким из этих параметров, при масштабировании часто выдаёт потерю производительности.
Сначала рассмотрим масштабирование по размеру. Если возникает необходимость увеличить данное число пользователей или ресурсов, мы нередко сталкиваемся с ограничениями, связанными с централизацией служб, данных и алгоритмов (табл. 2). В итоге, многие службы централизуются потому, что при их реализации, предполагалось наличие в распределённой системе только одного сервера, запущенного на конкретной машине. Проблемы такой схемы очевидны: при увеличении числа пользователей, сервер легко может стать узким местом системы. Даже если мы обладаем фактически неограниченным запасом по мощности обработки и хранения данных, ресурсы связи с этим сервером, в конце концов будут исчерпаны и не позволят нам расти в дальнейшем.
Таблица 2.
Примеры ограничений масштабируемости
|
Концепция |
Пример |
|
Централизованные службы |
Один сервер на всех пользователей |
|
Централизованные данные |
Единый телефонный справочник, доступный в режиме подключения |
|
Централизованные алгоритмы |
Организация маршрутизации на основе полной информации |
К сожалению, использование единственного сервера, время от времени неизбежно. На примере это выглядит так: представьте себе службу управления особо конфиденциальной информацией, такой как истории болезни, банковские счета, кредиты и т. п. В подобных случаях, необходимо реализовывать службы на одном сервере в отдельной хорошо защищенной комнате и отделять их от других частей распределённой системы посредством специальных сетевых устройств. Копирование информации, содержащейся на сервере, в другие места, для повышения производительности, даже не обсуждается, поскольку это сделает службу менее жизнестойкой к атакам злоумышленников.
Централизация данных так же вредна, как и централизация служб. Как выбудете отслеживать телефонные номера и адреса 50 миллионов человек? Предположим, что каждая запись укладывается в 50 символов. Необходимой емкостью обладает один 2,5-гигабайтный диск. Но и в этом случае, наличие единой базы данных, очевидно, вызовет перегрузку входящих и исходящих линий связи. Так, представим себе, как работал бы Интернет, если бы служба доменных имён (DNS) была бы реализована в виде одной таблицы. DNS обрабатывает информацию с миллионов компьютеров во всём мире и предоставляет службу, необходимую для определения местоположения web -серверов. Если бы каждый запрос на интерпретацию URL передавался бы на этот единственный DNS -сервер, воспользоваться Web не смог бы никто (кстати, предполагается, что эти проблемы придется решать заново).
И, наконец, централизация алгоритмов — это тоже плохо. В больших распределённых системах гигантское число сообщений необходимо направлять по множеству каналов. Теоретически, для вычисления оптимального пути необходимо получить полную информацию о загруженности всех машин и линий и по алгоритмам из теории графов вычислить все оптимальны выгодные маршруты. Эта информация затем должна быть роздана по системе для оптимального улучшения маршрутизации.
Проблема состоит в том, что сбор и транспортировка всей информации туда-сюда — не слишком хорошая идея, поскольку сообщения, несущие эту информацию, могут перегрузить часть сети. Фактически в последующем, следует избегать любого алгоритма, который требует передачи информации, собираемой со всей сети, на одну из её машин для обработки, с последующей раздачей полученных результатов. Использовать следует только децентрализованные алгоритмы. Эти алгоритмы, обычно, обладают следующими свойствами, отличающими их от централизованных алгоритмов:
- ни одна из машин не обладает полной информацией о состоянии применимой системы;
- машины принимают решения на основе локально информационных данных;
- возникший сбой на одной машине не вызывает нарушения рабочего алгоритма;
- не требуется предположения о существовании единого времени.
Первые из указанных три свойства поясняют то, о чём велось выше. Последнее, вероятно, менее очевидно, но не менее значимо. Любой алгоритм, начинающийся со слов: «Ровно в 12:00:00 все машины должны определить размер своих входных очередей», работать не будет, поскольку в реальности невозможно синхронизировать все часы на свете. Алгоритмы должны принимать во внимание отсутствие полной синхронизации таймеров. Чем больше система, тем большим будет и рассогласование. В одной локальной сети, путём определённых усилий, можно добиться, чтобы рассинхронизация всех часов не превышала нескольких миллисекунд, но сделать это в масштабе страны или множества стран, звучит не реально и глупо.
У географической масштабируемости имеются свои сложности. Одна из основных причин сложности масштабирования существующих распределённых систем, разработанных для локальных сетей, состоит в том, что в их основе лежит принцип синхронной связи (synchronouscommunication).В этом виде, связи запрашивающий службу агент, которого принято называть клиентом (client), блокируется до получения ответа. Этот подход, обычно, успешно работает в локальных сетях, когда связь между двумя машинами продолжается по максимуму сотни микросекунд. Однако, в глобальных системах, мы должны принять во внимание тот факт, что связь между процессами может продолжаться сотни миллисекунд, то есть, на три порядка дольше. Построение интерактивных приложений с использованием синхронной связи в глобальных системах, требует большой осторожности и немалого терпения.
Другая проблема, препятствующая географическому масштабированию, состоит в том, что связь в глобальных сетях фактически всегда организуется от точки к точке, и потому ненадёжна. В противоположность глобальным, локальные сети, обычно, дают высоконадёжную связь, основанную на широковещательной рассылке, что делает разработку распределённых системдля них, значительно упрощённой. Для примера рассмотрим проблему локализации службы. В локальней сети система просто рассылает сообщение всем машинам, предварительно опрашивая их на предмет предоставления нужной службы. Машины, предоставляющие службу, отвечают на это сообщение, указывая в ответном сообщении свои сетевые адреса. Невозможно представить себе подобную схему определения местоположения в глобальной сети. Вместо этого необходимо обеспечить специальные места для расположения служб,которые может потребоваться масштабировать на весь мир и обеспечить их мощностью для обслуживания миллионов пользователей.
Географическая масштабируемость тесным образом завязана на проблемах централизованных решений, которые мешают масштабированию по размеру. Если у нас имеется система с множеством централизованных компонентов, то понятно, что географическая масштабируемость будет ограничиваться проблемами производительности и надёжности, связанными с глобальной связью. Кроме того, централизованные компоненты в настоящее время, легко способны вызвать перегрузку сети. Представьте себе, что в каждой стране существует всего одно почтовое отделение. Это будет означать, что для того, чтобы отправить письма родственникам, вам необходимо отправиться на центральный почтамт, расположенный, возможно, в сотнях миль от вашего дома. Ясно, что это не тот путь, которым следует идти.
И, наконец, нелегкий и во многих случаях остаётся открытый вопрос, как обеспечить масштабирование распределённой системы на множество административно независимых областей. Основная проблема, которую нужно при этом решить, состоит в конфликтах правил, относящихся к использованию ресурсов (и плате за них), эксплуатации в управлении и безопасности.
Так, множество компонентов распределённых систем, находящихся в одной области, обычно, может быть доверено пользователям, работающим в этой области. В этом случае, системный администратор может тестировать и сертифицировать приложения, используя специальные инструменты для проверки того факта, что эти компоненты не могут ничего изменить и повлиять на работу системы. Проще говоря, пользователи полностью доверяют своему системному администратору. Однако, это доверие не распространяется, естественным образом, за границы области.
Если распределённые системы распространяются на другую область, могут потребоваться два типа проверок безопасности. Во-первых, распределённая система должна противостоять злонамеренным атакам из новой области. Так, например, пользователи новой области могут получить ограниченные права доступа к файловой службе системы в исходной области, скажем, доступность только на чтение. Точно так же может быть закрыт доступ чужих пользователей и к аппаратуре, такой как, дорогостоящие полноцветные устройства печати или высокопроизводительные компьютеры. Во-вторых, новая область сама должна быть защищена от злонамеренных атак из распределённой системы. Типичным примером, является, загрузка по сети программ, таких как апплеты в web -браузерах. Изначально, новая область не знает чего ожидать от чужого кода, и потому, строго ограничивает ему права доступа. Проблема состоит в том, как обеспечить соблюдение и исполнение этих ограничений.
Обсуждение некоторых проблем масштабирования приводит нас к вопросу о том, а как же обычно решаются эти проблемы на практике. Поскольку проблемы масштабируемости в распределённых системах, такие как, проблемы производительности, вызываются ограниченной мощностью серверов и сетей. Существуют три основные технологии масштабирования: сокрытие времени ожидания связи, распределение и репликация.
Сокрытие времени ожидания связи применяется в том случае,если используется метод географического масштабирования. Основная идея проста: постараться по возможности избежать ожидания ответа на запрос от удалённого сервера. Например, если была запрошена служба удалённой машины, альтернативой ожиданию ответа от сервера будет осуществление на запрашивающей стороне других возможных действий. В сущности, это означает разработку запрашивающего приложения в расчёте на использование исключительно асинхронной связи(asynchronouscommunication).Когда будет получен ответ, приложение прервёт свою работу и вызовет специальный обработчик для завершения отправленного ранее запроса. Асинхронная связь часто используется в системах пакетной обработки и параллельных приложениях, в которых во время ожидания одной задачей завершения связи предполагается выполнение других более или менее независящих между собой исполнимых задач. Для осуществления запроса, может быть, запущен новый управляющий поток выполнения. Хотя он неминуемо будет блокирован на время ожидания ответа, однако другие потоки процесса продолжат свою исполнительную деятельность.
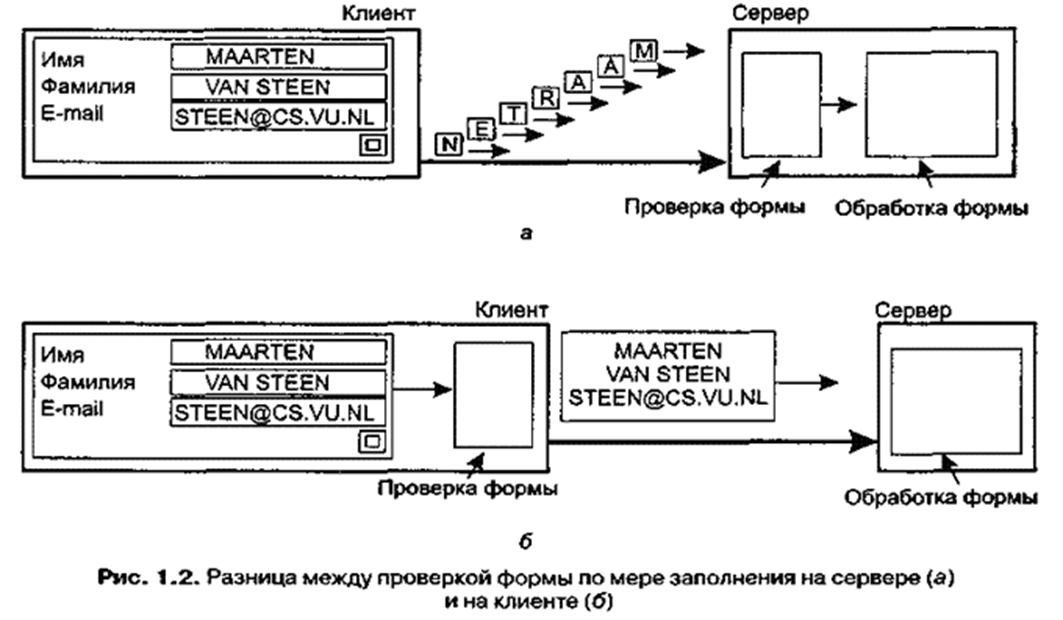
К сожалению многие приложения не в состоянии эффективно использовать асинхронную связь. Например, когда в интерактивном приложении пользователь посылает запрос, он обычно не в состоянии делать ничего более умного, чем просто ожидать ответа. В этих случаях наилучшим решением будет сократить необходимый объём взаимодействия, например, переместив часть вычислений, по обычаю выполняемых на сервере, на клиента, процесс которого запрашивает службу. Стандартный случай применения этого подхода — доступ к базам данных с использованием искомых форм. Обычно заполнение формы сопровождается посылом отдельного сообщения на каждое поле и ожиданием подтверждения приёма от сервера, как показано на рис. 2, а. Сервер, например, может перед приёмом введенного значения проверить его на синтаксические ошибки. Более успешное решение состоит в том, чтобы перенести код для заполнения формы и, возможно, проверки введённых данных на клиента, чтобы он мог послать серверу всецело заполненную форму (рис. 2, б). Такой подход — перенос кода на клиента — в настоящее время широко поддерживается в Web посредством Java -апплетов.
Рис 2.
Разница между проверкой формы по мере заполнения на сервере (а) и на клиента (б)
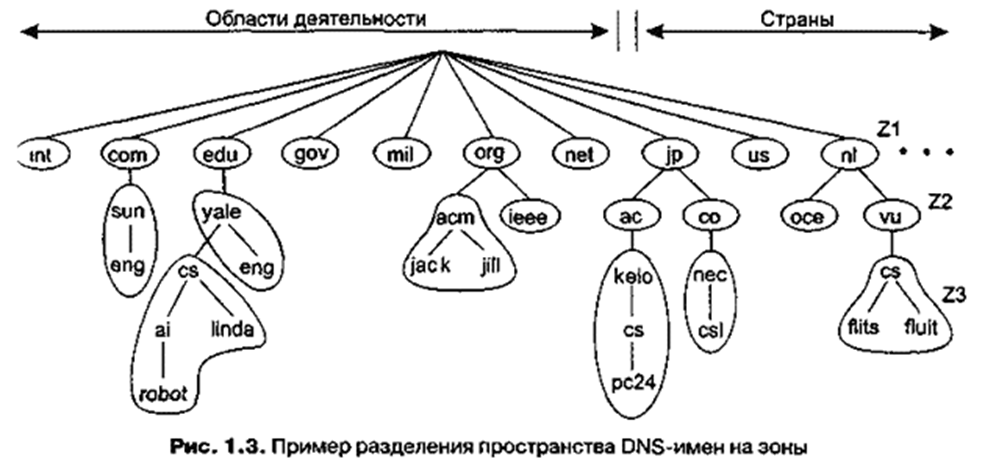
Следующая важная технология масштабирования — распределение (distribution). Распределение предполагает уже заранее разбиение компонентов на мелкие и отдельные части с последующим разнесением этих частей по системе. Хорошим примером распределения является система доменных имён Интернета (DNS). Пространство DNS имён организовано иерархически, в виде дерева доменов (domains), которые разбиты на неперекрывающиеся зоны (zones),как показано на рис. 3. Имена каждой зоны обрабатываются одним сервером имён. Не углубляясь чересчур в детали, можно рассчитывать на то, что каждое доменное имя является именем хоста в Интернете и ассоциируется с сетевым адресом этого хоста. В основном интерпретация имени означает получение сетевого адреса соответствующего хоста. Рассмотрим, к примеру, имяnl . vu . cs . flits. Для интерпретации этого имени оно изначально передаётся на сервер зоны Z 1 (рис. 3), который возвращает адрес сервера зоны Z 2, который, вероятнее всего, сможет обработать остаток имени, vu . cs . flits . Сервер зоны Z 2 вернёт адрес сервера зоны Z 3 , который способен обработать последнюю из частей имени и вернуть адрес соответствующего хоста.
Рис. 3.
Пример разделения пространства DNS – имён на зоны
Эти примеры показательно демонстрируют, как служба именования, предоставляемая DNS, распределена по нескольким машинам и как это позволяет избежать обработки всех именуемых запросов на интерпретацию имён одним сервером.
В качестве иного примера рассмотрим WorldWideWeb . Для большинства из пользователей, Web представляется гигантской информационной системой документооборота, в которой каждый документ имеет свое уникальное имя — URL .
Концептуально можно предположить даже, что все имеющиеся документы размещаются на одном сервере. Однако среда Web физически разнесена по множеству серверов, каждый из которых содержит некоторое количество документов. Имя сервера, содержащего конкретный документ, определяется по URL адресу документа. Только благодаря подобному распределению документов Всемирная паутина могла вырасти до её современных размеров.
При рассмотрении проблем масштабирования, часто проявляющихся в виде падения производительности, нередко хорошей идеей является репликация (replication)компонентов распределённой системы. Репликация не только повышает доступность, но и значительно помогает выровнять загрузку компонентов, что автоматически ведёт к повышению производительности. Кроме того, в сильно географически рассредоточенных системах наличие близко лежащей копии позволяет снизить остроту большей части ранее указанных проблем ожидания завершения связи.
Кэширование (caching)представляет собой особую форму репликации, причем различия между ними нередко малозаметны или вообще, искусственны. Как и в случае репликации, результатом кэширования является создание копии ресурса, обычно в непосредственной близости от клиента, использующего этот ресурс. Однако в противоположность репликации, кэширование — это действие, предпринимаемое потребителем ресурса, а не его именуемым владельцем.
На масштабируемость может плохо повлиять один лишь существенный недостаток кэширования и репликации. Поскольку мы получаем множество копий ресурса, модификация одной копии делает её отличимой от остальных. Соответственно, кэширование и репликация вызывают проблемынепротиворечивости (consistency).
Допустимая степень противоречивости зависит от степени загрузки ресурсов. Так, множество пользователей Web считают допустимым работу с кэшированным документом через несколько минут после его помещения в кэш без дополнительной на то проверки. Однако, существует множество случаев, когда необходимо гарантировать строгую непротиворечивость. Представим, к примеру, при игре на электронной бирже. Проблема строгой непротиворечивости состоит в том, что изменение в одной из копий должно незамедлительно распространяться на все остальные. Кроме того, если два изменения происходят одновременно, часто бывает необходимо, чтобы эти изменения вносились в одном и том же порядке во все копии. Для обработки ситуаций такого типа обычно требуется механизм глобальной синхронизации. К сожалению, реализовать масштабирование подобных механизмов крайне трудно, а может быть и невозможно. Это указывает на то, что масштабирование путем репликации может включать в себя отдельные немасштабируемые решения.
1.5. Безопасность
Концентрация информации в компьютерах - аналогично концентрации наличных денег в банках - заставляет все более усиливать контроль в целях защиты информации. Юридические вопросы, частная тайна, национальная безопасность - все эти соображения требуют усиления внутреннего контроля в коммерческих и правительственных организациях. Работы в этом направлении привели к появлению новой дисциплины: безопасность информации. Специалист в области безопасности информации отвечает за разработку, реализацию и эксплуатацию системы обеспечения информационной безопасности, направленной на поддержание целостности, пригодности и конфиденциальности накопленной в организации информации. В его функции входит обеспечение физической (технические средства, линии связи и удаленные компьютеры) и логической (данные, прикладные программы, операционная система) защиты информационных ресурсов.
Сложность создания системы защиты информации определяется тем, что данные могут быть похищены из компьютера и одновременно оставаться на месте; ценность некоторых данных заключается в обладании ими, а не в уничтожении или изменении.
Безопасность распределенных систем направлена на обеспечение защиты ресурсов от атак со стороны враждебно настроенных пользователей. С целью повышения безопасности данной распределённой системы должны использоваться защищенные каналы передачи информационных данных, далее разрешать доступ к ресурсам только для авторизованных пользователей и предоставлять допуск к чтению передаваемых по сети данных только относящиеся к получателям.
Вывод. Отметим, что в построении распределённых систем основополагающим условием является решение следующихзадач:
• Прозрачность;
• Открытость;
• Гибкость;
• Масштабируемость;
• Безопасность.
Сегодняшниереалии таковы, что использование возможностей распределённой системы играет значительную роль для пользователя. Как следствие вызванная заинтересованность к этим системам выражается в построении и внедрении возможностей распределения и оптимизации использования ресурсов, расширение функциональности и повышение эффективности решения определённых задач, гибкость построенияраспределённых систем, повышение степени их доступности для любого из пользователей.
ЗАКЛЮЧЕНИЕ
В работе проведен анализ определения и задачам распределённой системы.
Распределенные системы обработки информации подразумевают перспективные направления в различных областях и широко используются при проведении научных исследований, проектировании и разработке информационно-управляющих систем и процессов и во многих других сферах научной и практической деятельности. Постоянное развитие и совершенствование информационных технологий оказывает существенное влияние на все научные и технологические направления, связанные с использованием распределённых систем. Эволюция распределённых систем все в большей степени определяется их надежностью и устойчивостью, которые обеспечивают, во-первых, расширение круга задач, решаемых с помощью компьютеров, и, во-вторых, повышают уровень обработки информации.
Ключевая характеристика к которой можно отнести следующие свойства присущие распределённой системе, следующие:
- автономность (но соединённые средой передачи);
- взаимодействие посредством передачи;
- много положительных примеров использования данной системы;
- система существует, но её нужно уметь развивать и поддерживать.
Здесь следует отметить, что к решению задач предъявленных в построении распределённой системы рассматриваются различные аспекты эксплуатирования. Вполне естественно, что внимание к такой системе до сих пор не угасает, а становится всё популярнее и значимее.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Бобровский, С. Учебный курс - СПб.: Питер, 2004.
- Бэкон, Д. Операционные системы. Параллельные и распределённые системы / Д. Бэкон, Т. Харрис. – СПб. : Питер, 2004. – 800 с.
- Дейтел, Х.М. Операционные системы. Распределённые системы, сети, безопасность / Х.М. Дейтел, П.Дж. Дейтел, Д.Р. Чофнес. – М. : «Бином-Пресс», 2006. – 704 с.
- Петров, В.Н. Информационные системы – СПб.: Питер, 2003Санкт-Петербург: «Питер» 2003.
- Таненбаум, Э. «Распределённые системы. Принципы и парадигмы» - СПб: Питер 2003.
- Храпский, С.Ф. Вычислительные системы, сети и телекоммуникации: учебное пособие / С.Ф. Храпский. – Омск : ОГИС, 2005. – 372 с.
- Цимбал, А.А. Технологии создания распределённых систем / А. А. Цимбал, М.Л. Аншина – СПб. : Питер, 2003. – 732 с.
- Эндрюс, Г. Основы многопоточного, параллельного и распределённого программирования / Г. Эндрюс. – М. : «Вильямс», 2003. – 512 с.

- Разработка регламента выполнения процесса «Расчет заработной платы» (понятия регламента)
- Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы(Каноническая технологическая сеть проектирования экономической информационной системы)
- Роль мотивации в поведении организации (Наемные работники)
- Роль кадровой службы в формировании и реализации кадровой стратегии (Структура и формы организации кадровой службы)
- История развития средств вычислительной техники (Появление электронных вычислительных средств)
- Финансовая политика и ее реализация в РФ (характеристика финансовой политики РФ)
- Счета и двойная запись (понятие)
- Понятия «затраты», «расходы», «издержки» (понятие «себестоимость продукции»)
- Опека и попечительство. Патронаж над дееспособными гражданами (опека и попечительство, патронаж над дееспособными гражданами)
- Человеческий фактор в управлении организацией (влияния человеческого фактора на качество управления персоналом и эффективность деятельности предприятия)
- Анализ внешней и внутренней среды организации (ООО «СтройКомплект»)
- Реклама в сети Интернет (на примере компании ПАО «Банк ВТБ»)