
Основы алгоритмизации и программирования (Особенности описания операторов управления в различных языках программирования:достоинства и недостатки)
Содержание:

ВВЕДЕНИЕ
Основы алгоритмизации и программирование являются фундаментальными основами теоретической информатики, но по учебному плану дисциплины имеют весьма ограниченное время для изучения. Поэтому некоторые важные вопросы не рассматриваются на лекциях вообще, или рассматриваются недостаточно глубоко (например, решение задач на составление алгоритмов, основы программирования, запись выражений на языке программирования и др.). Предлагаемое пособие является учебным средством, предусматривающим ориентацию иностранных студентов на самостоятельную работу и самообразование.
Большая часть работы программистов связана с написанием исходного кода, тестированием и отладкой программ на одном из языков программирования. Исходные тексты и исполняемые файлы программ являются объектами авторского права и являются интеллектуальной собственностью их авторов и правообладателей
Единственный язык, напрямую выполняемый ЭВМ — это машинный язык (также называемый машинным кодом и языком машинных команд). Изначально все программы писались в машинном коде, но сейчас этого практически уже не делается. Вместо этого программисты пишут исходный код на том или ином языке программирования, затем, используя компилятор, транслируют его в один или несколько этапов в машинный код, готовый к исполнению на целевом процессоре, или в промежуточное представление, которое может быть исполнено специальным интерпретатором — виртуальной машиной. Но это справедливо только для языков высокого уровня.
В некоторых языках вместо машинного кода генерируется интерпретируемый двоичный код «виртуальной машины», также называемый байт-кодом (byte-code). Такой подход применяется в Forth, некоторых реализациях Lisp, Java, Perl, Python, языках для .NET Framework.
Тема 1. Основные структуры алгоритмов: сравнительный анализ и примеры их использования.
1.1. Понятие алгоритма
Алгоритмом называется строго определенная последовательность действий, определяющих процесс перехода от исходных данных к искомому результату. Само слово «алгоритм» возникло из названия латинского перевода книги арабского математика IX века Аль-Хорезми «Algoritmi de numero Indoru», что можно перевести как «Трактат Аль-Хорезми об арифметическом искусстве индусов». Составление алгоритмов и вопросы их существования являются предметом серьёзных математических исследований. Под алгоритмом понимают набор правил, определяющих процесс преобразования исходных данных задачи в искомый результат.
Одним из фундаментальных понятий в информатике является понятие алгоритма. Происхождение самого термина «алгоритм» связано с математикой. Это слово происходит от Algorithmi – латинского написания имени Мухаммеда аль-Хорезми (787 – 850) выдающегося математика средневекового Востока. В своей книге "Об индийском счете" он сформулировал правила записи натуральных чисел с помощью арабских цифр и правила действий над ними столбиком. В дальнейшем алгоритмом стали называть точное предписание, определяющее последовательность действий, обеспечивающую получение требуемого результата из исходных данных. Алгоритм может быть предназначен для выполнения его человеком или автоматическим устройством. Создание алгоритма, пусть даже самого простого, - процесс творческий. Он доступен исключительно живым существам, а долгое время считалось, что только человеку. В XII в. был выполнен латинский перевод его математического трактата, из которого европейцы узнали о десятичной позиционной системе счисления и правилах арифметики многозначных чисел. Именно эти правила в то время называли алгоритмами. Данное выше определение алгоритма нельзя считать строгим – не вполне ясно, что такое «точное предписание» или «последовательность действий, обеспечивающая получение требуемого результата».
1.2. Цели и задачи теории алгоритмов
Обобщая результаты различных разделов теории алгоритмов можно выделить следующие цели и соотнесенные с ними задачи, решаемые в теории алгоритмов:
- формализация понятия «алгоритм» и исследование формальных алгоритмических систем;
- формальное доказательство алгоритмической неразрешимости ряда задач;
- классификация задач, определение и исследование сложностных классов;
- асимптотический анализ сложности алгоритмов;
- исследование и анализ рекурсивных алгоритмов;
- получение явных функций трудоемкости в целях сравнительного анализа алгоритмов;
- разработка критериев сравнительной оценки качества алгоритмов.
1.3. Различные подходы к понятию "Алгоритм"
Алгоритмы являются объектом систематического исследования пограничной между математикой и информатикой научной дисциплины, примыкающей к математической логике - теории алгоритмов.
Особенность положения состоит в том, что при решении практических задач, предполагающих разработку алгоритмов для реализации на ЭВМ, и тем более при использовании на практике информационных технологий, можно, как правило, не опираться на высокую формализацию данного понятия. Поэтому представляется целесообразным познакомиться с алгоритмами и алгоритмизацией на основе содержательного толкования сущности понятия алгоритма и рассмотрения основных его свойств. При таком подходе алгоритмизация более выступает как набор определенных практических приемов, особых специфических навыков рационального мышления в рамках заданных языковых средств. Можно провести аналогию между этим обстоятельством и рассмотренным выше подходом к измерению информации: тонкие математические построения при «кибернетическом» подходе не очень нужны при использовании гораздо более простого «объемного» подхода при практической работе с компьютером. Само слово «алгоритм» происходит от algorithmi - латинской формы написания имени великого математика IX века аль-Хорезми, который сформулировал правила выполнения арифметических действий. Первоначально под алгоритмами и понимали только правила выполнения четырех арифметических действий над многозначными числами. Понятие алгоритма - одно из фундаментальных понятий информатики. Алгоритмизация наряду с моделированием выступает в качестве общего метода информатики. К реализации определенных алгоритмов сводятся процессы управления в различных системах, что делает понятие алгоритма близким и кибернетике.
Примеры их использования
Даны длины сторон треугольника A, B, C. Найти площадь треугольника S. Составьте блок-схему алгоритма решения поставленной задачи(рис.1).
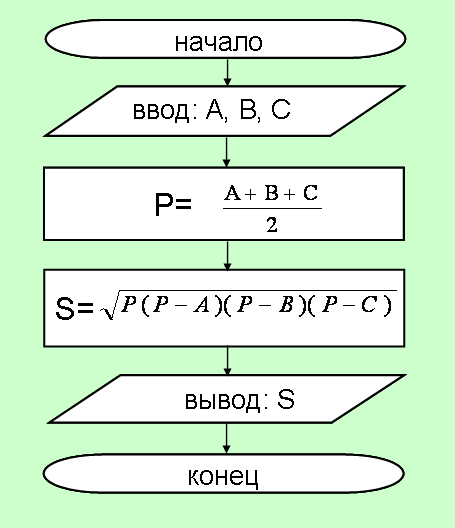
Тема 2. Особенности описания операторов управления в различных языках программирования:достоинства и недостатки.
2.1. Язык программирования
Язык программи́рования — формальный язык, предназначенный для записи компьютерных программ[1][2]. Язык программирования определяет набор лексических, синтаксических и семантических правил, определяющих внешний вид программы и действия, которые выполнит исполнитель (обычно — ЭВМ) под её управлением.
Язык программирования предназначен для написания компьютерных программ, которые представляют собой набор правил, позволяющих компьютеру выполнить тот или иной вычислительный процесс, организовать управление различными объектами, и т. п. Язык программирования отличается от естественных языков тем, что предназначен для управления
ЭВМ, в то время как естественные языки используются, прежде всего, для общения людей между собой. Большинство языков программирования использует специальные конструкции для определения и манипулирования структурами данных и управления процессом вычислений.
С течением времени одни языки развивались, приобретали новые черты и остались востребованы, другие утратили свою актуальность и сегодня представляют в лучшем случае чисто теоретический интерес
научные вычисления (языки C++, FORTRAN, Java);
системное программирование (языки C++, Java);
обработка информации (языки C++, COBOL, Java);
искусственный интеллект (LISP, Prolog);
издательская деятельность (Postscript, TeX);
удаленная обработка информации (Perl, PHP, Java, C++);
описание документов (HTML, XML).
2.2. Язык программирования QBASIC
QBasic был создан в качестве замены для GW-BASIC и поставлялся вместе с MS-DOS 5.0 и выше, вплоть до Windows 95. QBasic основан на более раннем QuickBASIC 4.5, но, в отличие от него, не содержит компилятора и компоновщика.
Microsoft прекратила поставку QBasic с более поздними версиями Windows. Однако обладатели лицензий Windows 98 могут найти его на установочном компакт-диске в папке \TOOLS\OLDMSDOS. Ранее QBasic можно было загрузить с сайта Microsoft.[1]
QBasic предоставлял удобную среду разработки (для своего времени), включающую расширенные возможности отладки и возможность работы в командном режиме.
С 2007 года существует версия QBasic для 64-битных систем, работающая в операционных системах Windows 7, 8, 10
Язык программирования Qbasic (как и любой другой язык) образуют три его составляющие: алфавит, синтаксис и семантика. Алфавит – это фиксированный для данного языка набор основных символов, т. е. «букв», из которых должен состоять любой текст на этом языке – никакие другие символы в тексте не допускаются. Синтаксис – это правила построения фраз, позволяющие определить, правильно или неправильно написана та или иная фраза. Семантика определяет смысловое значение предложений языка. Основными понятиями в языках программирования обычно являются алфавит языка, константы, переменные, встроенные функции, логические и арифметические выражения. Алфавит языка включает: • буквы латинского алфавита от A до Z (строчные и прописные) • арабские цифры: 0 1 2 … 9 • знаки арифметических операций: + – * / ^ \ • специальные символы объявления типа: % # ! $ & • круглые скобки ( ) кавычки “ ” апостроф ’ , подчеркивание _ • знаки отношений: < > = < > < = > = • буквы русского алфавита используются только для записи текстовых констант и комментариев к программе.
2.3. Язык программирования C++ и его достоинства и недостатки
C++ — компилируемый, статически типизированный язык программирования общего назначения.
Поддерживает такие парадигмы программирования, как процедурное программирование, объектно-ориентированное программирование, обобщённое программирование. Язык имеет богатую стандартную библиотеку, которая включает в себя распространённые контейнеры и алгоритмы, ввод-вывод, регулярные выражения, поддержку многопоточности и другие возможности. C++ сочетает свойства как высокоуровневых, так и низкоуровневых языков.В сравнении с его предшественником — языком C, — наибольшее внимание уделено поддержке объектно-ориентированного и обобщённого программирования.
Синтаксис C++ унаследован от языка C. Одним из принципов разработки было сохранение совместимости с C. Тем не менее, C++ не является в строгом смысле надмножеством C; множество программ, которые могут одинаково успешно транслироваться как компиляторами C, так и компиляторами C++, довольно велико, но не включает все возможные программы на C.
С одной стороны, C++ является потомком Симулы, которую Алан Кэй определил[21] как «Алгол с классами», и потому будет актуальной оценка C++ в сравнении с другими языками из семейства потомков Алгола (Pascal, Java, C#, Visual Basic, Delphi, D, Oberon и пр.). С другой стороны, C++ претендует на мультипарадигменность и универсальную применимость (в отличие от Си, ориентированного на очень узкий круг задач), и используется в промышленности намного шире других потомков Алгола, и потому будет актуальной оценка C++ в сравнении со всем многообразием применяемых языков, включая и Си. Во избежание повторений, оценки обычно совмещаются.
C++ — язык, складывающийся эволюционно. В отличие от языков с формальным определением семантики, каждый элемент C++ заимствовался из других языков отдельно и независимо от остальных элементов (ничто из предложенного C++ за всю историю его развития не было новшеством в Computer Science), что сделало язык чрезвычайно сложным, со множеством дублирующихся и взаимно противоречивых элементов, блоки которых основаны на разных формальных базах. В этом отношении C++ повторяет путь PL/1, но, в отличие от последнего, длительное повсеместное использование C++ обеспечил выбор языка Си в качестве отправной точки.
C++ содержит средства разработки программ контролируемой эффективности для широкого спектра задач, от низкоуровневых утилит и драйверов до весьма сложных программных комплексов. В частности:
- Высокая совместимость с языком Си : код на Си может быть с минимальными переделками скомпилирован компилятором C++.
- Внешнеязыковой интерфейс является прозрачным, так что библиотеки на Си могут вызываться из C++ без дополнительных затрат, и более того — при определённых ограничениях код на C++ может экспортироваться внешне не отличимо от кода на Си (конструкция extern "C").
- Как следствие предыдущего пункта — вычислительная производительность. Язык спроектирован так, чтобы дать программисту максимальный контроль над всеми аспектами структуры и порядка исполнения программы. Один из базовых принципов C++ — «не платишь за то, что не используешь» (см. Философия C++) — то есть ни одна из языковых возможностей, приводящая к дополнительным накладным расходам, не является обязательной для использования. Имеется возможность работы с памятью на низком уровне.
- Шаблоны C++ дают возможность построения обобщённых контейнеров и алгоритмов для разных типов данных. Попутно шаблоны дают возможность производить вычисления на этапе компиляции.
- Доступность. Для C++ существует огромное количество учебной литературы, переведённой на всевозможные языки. Язык имеет высокий порог вхождения, но среди всех языков такого рода обладает наиболее широкими возможностями.
К числу недостатков можно отнести:
- Отсутствие системы модулей. C++ использует заголовочные файлы, которые полны недостатков:
- Вынуждает дважды писать одну и ту же функцию (определение в файле с исходным кодом и объявление в заголовочном файле).
- Увеличивает время компиляции. Можно оптимизировать, используя Предкомпилированные заголовки.
- Сложный синтаксис и сложная спецификация языка.
Тема 3. Основные правила работы с функциями: примеры и ограничения использования функций в различных языках программирования.
3.1. Структура программы на языке С++
Структуру программы на языке С++ рассмотрим на примере простой программы, печатающей строку текста. Листинг, характеризующий структуру построения простейшей программы на языке С++, приведен на рис. 4.1.
// Моя первая программа
# include < iostream .h >
main ( )
{
cout << “ Это моя первая программа на языке С++”;
return 0;
}
Первая строка данной программы начинается с символа //, показывающего, что следующий за ним текст является комментарием, который игнорируется компилятором. Комментарии вставляются для документирования программы и облегчения ее чтения. Они помогают другим людям читать и понимать вашу программу. Комментарий, начинающийся с символа //, называется однострочным, потому что он должен заканчиваться в конце текущей строки. При использовании многострочных комментариев целесообразно применять символы /* и */. Все, что помещено между ними, игнорируется компилятором. Строка # include является директивой препроцессора.
Препроцессор − это специальная программа, которая обрабатывает строки программы, начинающиеся со знака #. Данная строка дает указание препроцессору перед компиляцией программы включить в нее информацию, содержащуюся в файле iostream.h. Следом идет обязательная функция main (), а круглые скобки прямо указывают на то, что main – имя функции. Открывающая фигурная скобка отмечает начало последовательности операторов, образующих тело функции. Строка cout << “……… ”; – оператор вывода, с помощью которого выводится на экран дисплея фраза, заключенная в кавычки. Функция может возвращать значение в программу с помощью оператора возврата (return). Этот оператор также означает выход из функции. Если же указанный оператор отсутствует, то функция автоматически возвращает значение типа void (пустой). Закрывающая фигурная скобка отмечает конец последовательности операторов, образующих тело функции. На этой скобке выполнение функции и программы завершается . Программа на С++ состоит из одной или более функций, причем ровно одна из них обязательно должна называться main().
Функция – это блок программы, который выполняет одно или несколько действий. Описание функции состоит из заголовка и тела .Круглые скобки являются частью имени функции, и ставить их надо обязательно, так как именно они указывают компилятору, что имеется в виду функция, а не просто английское слово main. Фактически каждая функция включает в свое имя круглые скобки, но в большинстве случаев в них содержится некая информация, передаваемая функции. Если же информация не передается, то в фигурных скобках можно указать ключевое слово void (пустой). Перед именем функции указывается ключевое слово, соответствующее типу возвращаемого функцией значения. Если значение не возвращается, то также можно указать ключевое слово void.
Заголовок функции состоит из имени функции, а тело функции заключено в фигурные скобки и представляет собой набор операторов, каждый из которых оканчивается символом;. Оператор описания int num определяет num как переменную целого типа (integer). Любая переменная в языке С++ должна быть описана раньше, чем она будет использована. В С++ используются правила, регулирующие употребление прописных и строчных букв [2]. Команды и стандартные имена функций (т.е. имена функций языка С++) всегда пишутся строчными буквами. Заглавные буквы в языке С++ обычно используются для задания имен констант. В именах своих функций и переменных Вы можете использовать как заглавные, так и строчные буквы. Однако следует помнить, что язык С++ различает использование прописных и строчных букв. Например, если Вы определите в своей программе переменные name, Name, NAME, то для компилятора это три различные переменные. В работе [3] даются следующие рекомендации относительно использования прописных и строчных букв в идентификаторах. Так, в именах переменных целесообразно использовать строчные буквы (нижний регистр), а прописные буквы (верхний регистр) использовать для обозначения констант, макросов и т.д. После того как компьютер заканчивает выполнение инструкций, заданных в вашей программе, программа завершается, и компьютер возвращается в исходное состояние (в то состояние, которое было перед запуском программы). Возврат в исходную среду в случаях, когда функция не возвращает значения, как правило, осуществляется автоматически. Исключение составляют отдельные компиляторы языка С++, которые требуют, чтобы Вы явно указали возврат.
Для таких компиляторов вводится инструкция return 0;, которую помещают непосредственно перед фигурной скобкой, завершающей тело функции main(). Если функция возвращает значение, то тело функции должно содержать как минимум один оператор return следующего формата: return выражение ; , где выражение определяет значение, возвращаемое данной функцией.
3.2. Описание функции
Самый распространенный способ задания в С++ каких-то действий –это вызов функции, которая выполняет такие действия. Функция – это именованная часть программы (блок кода, не входящий в основную программу), к которой можно обращаться из других частей программы столько раз, сколько потребуется. Основная форма описания функции имеет вид [4] Тип < Имя функции> (Список параметров) { Операторы тела функции } Tип определяет тип значения, которое возвращает функция с помощью оператора return. Если тип не указан, то по умолчанию предполагается, что функция возвращает целое значение (типа int). Список параметров состоит из перечня типов и имен параметров, разделенных запятыми. Функция может не иметь параметров, но круглые скобки необходимы в любом случае. Первая строка описания функции, содержащая тип возвращаемого значения, имя функции и список параметров, называется заголовком функции. Параметры, перечисленные в заголовке описания функции, называются формальными, а записанные в операторе вызова функции – фактическими. Тип возвращаемого значения может быть любым, кроме массива и функции. В приведенном ниже фрагменте программы функция перемножает два числа и возвращает результат в основную программу с помощью оператора return через переменную z. int multiply(int x, int y) // заголовок функции { int z = (x * y ); // тело функции return z ; } До использования функции ее необходимо объявить. Объявление функции осуществляется с помощью прототипа, который сообщает компилятору, сколько аргументов принимает функция, тип каждого аргумента и тип возвращаемого значения
// Вычисление произведения двух чисел
#include <iostream.h>
#include <conio.h>
#include <stdlib.h>
int multiply(int x, int y); // объявление прототипа функции
main( )
{
clrscr();
int x, y, result;
cout <<”\nВведите первое число:”;
cin >> x;
cout <<”\nВведите второе число:”;
cin>>y
result = multiply(x, y); // вызов функции
cout << “\nРезультат =” << result;
cout<<"\nНажмите любую клавишу ...";
getch();
return 0 ;
}
int multiply(int x, int y) //заголовок функции
{
return x * y ; // тело функции
Введите первое число: 3
Введите второе число: 2
Результат = 6
3.3. Правила работы с функциями
- Функция может принимать любое количество аргументов или не иметь их вообще.
- Функция может возвращать значение, но это не является обяза- тельным.
– Если для возвращаемого значения указан тип void, функция не возвращает никакого значения. При этом функция не должна содержать оператора return, однако при желании его можно оставить.
- Если в объявлении функции указано, что она возвращает значение, в теле функции должен содержаться оператор return, возвращающий это значение. В противном случае компилятор выдаст предупреж- дение.
- Функции могут иметь любое количество аргументов, но возвращаемое значение всегда одно.
- Аргументы могут передаваться функции по значению, через указатели или по ссылке.
Основные преимущества построения программ на основе функций сводятся к следующему:
- Программирование с использованием функций делает разработку программ более управляемой.
- Повторное использование программных кодов, т.е. использование существующих функций как стандартных блоков для создания новых программ.
- Возможность избежать в программе повторения каких-либо фраг- ментов.
Тема 4. Особенности и примеры использования массивов при разработке программ.
4.1. Массивы
Кроме базовых типов данных, в большинстве алгоритмических языков присутствует конструкция массив. Иногда массив называют также таблицей или вектором. Массив позволяет объединить множество элементов одного типа в единую переменную.
Массив переменных или объектов состоит из определенного числа однотипных данных, называемых элементами массива. Все элементы массива индексируются последовательно, начиная с нуля.
Размещение элементов массива в памяти выполняется последовательно.
Количество элементов в массиве определяет размер массива и является константным выражением.
Имя массива определяет адрес первого элемента массива.
Все элементы массива имеют один и тот же тип. Элементы массива обычно нумеруются индексами от 0 до n-1, где n - число элементов массива. В некоторых языках можно задавать границы изменения индексов, в других нижняя граница значения индекса равна единице, а не нулю. Мы, тем не менее, будем придерживаться языка Си (а также C++, Java, C#), в котором нижней границей индекса всегда является ноль. Это очень удобно, т.к. индекс элемента массива в этом случае равен его смещению относительно начала массива. Длина массива задается при его описании и не может быть изменена в процессе работы программы.
При описании массива указывается тип и число его элементов. Тип записывается перед именем массива, размер массива указывается в квадратных скобках после его имени. Примеры:
целый a[100]; описан массив целых чисел размера 100 (индекс меняется от 0 до 99)
вещественный r[1000]; описан вещ-й массив из 1000 элементов.
В языке Си соответствующие описания выглядят следующим образом:
int a[100];
double r[1000];
Для доступа к элементу массива указывается его имя и в квадратных скобках - индекс нужного элемента. С элементом массива можно работать как с обычной переменной, т.е. можно прочитать его значение или записать в него новое значение. Примеры:
a[3] = 0; элементу массива a с индексом 3 присваивается значение 0;
a[10] = a[10]*2; элемент массива a с индексом 10 удваивается.
Массив - это самая важная конструкция алгоритмического языка. Важность массива определяется тем, что память компьютера логически представляет собой массив (его можно рассматривать как массив байтов или как массив четырехбайтовых машинных слов). Индекс в этом массиве обычно называют адресом. Элементы массива читаются и записываются исключительно быстро, за одно действие, независимо от размера массива и величины индекса. Для программиста конструкция массива как бы дана свыше. Большинство других структур данных, используемых в программировании, моделируются на базе массива.
При создании массива память под все его элементы выделяется последовательно для каждого элемента в зависимости от типа массива. Для многомерных массивов в первую очередь изменяются значения самого правого индекса.
Например, для массива char a[2][4] будет выделено восемь байтов памяти, в которых в следующем порядке будут размещены элементы массива:
элемент a [0][0] a[0][1] a[0][2] a[0][3] a[1][0] a[1][1] a[1][2] a[1][3]
N байта 1 2 3 4 5 6 7 8
Двухмерные массивы можно рассматривать как матрицу, в которой первый индекс определяет строку, а второй индекс - столбец. Порядок расположения элементов матрицы в памяти - по строкам.
4.2. Описание массива в Паскале
Рассмотренные выше простые типы данных – логический (boolean), целый (integer , word , byte , longint), вещественный (real), символьный (char) позволяют работать с одиночными объектами. В языке Паскаль могут использоваться также объекты, содержащие множество однотипных элементов. Массив – это упорядоченная последовательность однотипных данных, рассматриваемых как одно целое. Упорядоченность данных в массиве позволяет обращаться к любому элементу массива по его порядковому номеру (индексу). Элементы массива расположены последовательно в непрерывной области памяти.
Нужно четко понимать, что индекс ячейки массива не является ее содержимым. Содержимым являются хранимые в ячейках данные, а индексы только указывают на них. Индексы элементов массива обычно целые числа, однако могут быть и символами, а также описываться другими порядковыми типами. Зачастую для задания количества элементов массива используется тип-диапазон. Типдиапазон задается левой и правой границами изменения индекса массива.
Перед использованием массив, как и любая переменная, должна быть объявлена (описана).
Описание типа массива задается следующим образом:
type
имя типа = array[ список индексов ] of тип;
Здесь имя типа – правильный идентификатор; список индексов – список одного или нескольких индексных типов, разделенных запятыми; тип – любой тип данных.
Пример.
const
n = 5;
type
mas = array[1..n] of integer;
var
a: mas;
Определить переменную как массив можно и непосредственно при ее описании в разделе var, без предварительного описания типа массива, например:
var
a,b,c: array[1..10] of integer;
Обращение к определенному элементу массива осуществляется путем указания имени переменной массива и в квадратных скобках индекса элемента, например a[3] – обращение к третьему элементу массива a, a[i] – обращение к i-му элементу массива a.
Простой массив является одномерным. Он представляет собой линейную структуру
Единственное действие, которое можно выполнять над массивами целиком, причем только при условии, что массивы 82 однотипны, – это присваивание. Если в программе описаны две переменные одного типа, например,
Var
a , b : array [1..10] of real;
то можно переменной a присвоить значение переменной b (a:=b). При этом каждому элементу массива a будет присвоено соответствующее значение из массива b. Все остальные действия над массивами Паскаля производятся поэлементно (это важно!)
4.3. Ввод массива
Для того чтобы ввести значения элементов массива, необходимо последовательно изменять значение индекса, начиная с первого до последнего, и вводить соответствующий элемент. Для реализации этих действий удобно использовать цикл с заданным числом повторений, где параметром цикла будет выступать переменная – индекс массива. Значения элементов могут быть введены с клавиатуры или определены с помощью оператора присваивания.
Пример фрагмента программы ввода массива с клавиатуры:
Var
A : array [1..10] of integer;
i : byte; {переменная i как индекс массива}
Begin
For i:=1 to 10 do
Read (a[i]); { ввод i- го элемента производится с клавиатуры }
Рассмотрим теперь случай, когда массив заполняется автоматически случайными числами. Для этого будем использовать генератор случайных чисел – random ( N ).
Пример фрагмента программы заполнения массива случайными числами:
Var
A: array [1..10] of integer;
i : byte ;
Begin
For i :=1 to 10 do
A [ i ]:= random (50)-25;
4.4. Вывод массива
Вывод массива в Паскале осуществляется также поэлементно, в цикле, где параметром выступает индекс массива, принимая последовательно все значения от первого до последнего. Пример фрагмента программы вывода массива:
Var
A: array [1..10] of integer;
i : byte ; {переменная i как индекс массива}
Begin
Writeln(‘Массив А’);
For i :=1 to 10 do
Write ( a [ i ]:5);
Writeln; (Для перевода курсора на следующую строку)
На экране мы увидим, к примеру, следующие значения:
Массив А
_ _ _ _ 5_ _ _ - 2_ _ 1 1 5 и т.д.
Вывод можно осуществить и в столбик (использовать оператор Writeln). Но в таком случае нужно учитывать, что при большой размерности массива все элементы могут не поместиться на экране и будет происходить скроллинг, т.е. при заполнении всех строк экрана будет печататься очередной элемент, а верхний смещаться за пределы экрана.
Пример программы вывода массива в столбик:
Var
A: array [1..10] of integer;
i : byte ;
Begin
For i:=1 to 10 do
Writeln (‘a[‘, i,’]=’, a[i]); {вывод элементов массива в столбик} .
На экране мы увидим, к примеру, следующие значения:
a [1]=2
a [2]=4
a [3]=1 и т.д.
Тема 5. Классификация языков программирования. Критерии выбора среды и языка разработки программ.
5.1. Классификация языков программирования
В настоящее время в мире существует несколько сотен реально используемых языков программирования. Для каждого есть своя область применения.
Любой алгоритм, есть последовательность предписаний, выполнив которые можно за конечное число шагов перейти от исходных данных к результату. В зависимости от степени детализации предписаний обычно определяется уровень языка программирования – чем меньше детализация, тем выше уровень языка.
По этому критерию можно выделить следующие уровни языков программирования:
• машинные;
• машинно-оpиентиpованные (ассемблеры);
• машинно-независимые (языки высокого уровня).
Машинные языки и машинно-ориентированные языки – это языки низкого уровня, требующие указания мелких деталей процесса обработки данных. Языки же высокого уровня имитируют естественные языки, используя некоторые слова разговорного языка и общепринятые математические символы. Эти языки более удобны для человека.
На заре компьютерной эры машинный код был единственным средством общения человека с компьютером. Огромным достижением создателей языков программирования было то, что они сумели заставить сам компьютер работать переводчиком с этих языков на машинный код.
Существующие языки программирования можно разделить на две группы: процедурные и непроцедурные (рис.2)
Процедурные (или алгоритмические) языки позволяют создавать программы, представляющие собой систему предписаний для решения конкретной задачи (выполнение команд программы определяется их последовательностью, командами перехода, цикла или обращениями к процедурам). Роль компьютера сводится к механическому выполнению этих предписаний.

Рис. 2. Общая классификация языков программирования
5.2. Процедурные языки
Процедурные языки разделяют на языки низкого и высокого уровня.
Разные типы процессоров имеют разные наборы команд. Если язык программирования ориентирован на конкретный тип процессора и учитывает его особенности, то он называется языком программирования низкого уровня. Имеется в виду, что операторы языка близки к машинному коду и ориентированы на конкретные команды процессора.
С помощью языков низкого уровня создаются очень эффективные (работают быстрее) и компактные программы (занимают меньше места в памяти), так как разработчик получает доступ ко всем возможностям процессора. С помощью этих языков Языки программирования Непроцедурные Высокого уровня (машиннонезависимые) Объектноориентированные Декларативные Процедурные Низкого уровня (машиннозависимые) Ассемблер Фортран, Бейсик, Паскаль, Си (машинноориентированный) Си++, Visual Basic, Delphi, Java Логические Функциональные Лисп Пролог 16 удобнее разрабатывать системные программы, драйверы (программы для управления устройствами компьютера), некоторые другие виды программ.
Языком низкого уровня (машинно-ориентированным) является Ассемблер, который просто представляет каждую команду машинного кода, но не в виде чисел, а с помощью условных символьных обозначений, называемых мнемониками.
Языки программирования высокого уровня значительно ближе и понятнее человеку, нежели компьютеру. Особенности конкретных компьютерных архитектур в них не учитываются, поэтому создаваемые программы на уровне исходных текстов легко переносимы на другие платформы, для которых создан транслятор этого языка. Разрабатывать программы на языках высокого уровня с помощью понятных и мощных команд значительно проще, а ошибок при создании программ допускается гораздо меньше. Для перевода исходных программ с языка высокого уровня на машинный язык используются специальные программы – трансляторы.
5.3. Интерпретация и компиляция.
Интерпретация подразумевает пооператорную трансляцию и последующее выполнение оттранслированного оператора исходной программы. В связи с этим можно отметить два недостатка метода интерпретации: во-первых, интерпретирующая программа должна находиться в памяти ЭВМ в течение всего процесса выполнения исходной программы, т. е. занимать определенный объем памяти; вовторых, процесс трансляции одного и того же оператора повторяется столько раз, сколько раз должна исполняться эта команда в программе, что резко снижает производительность работы программы.
Несмотря на указанные недостатки, трансляторы-интерпретаторы получили достаточное распространение, так как они удобны при разработке и отладке исходных программ.
При компиляции процессы трансляции и выполнения разделены во времени: сначала исходная программа полностью переводится на машинный язык (после чего наличие транслятора в оперативной памяти становится ненужным), а затем оттранслированная программа может многократно исполняться. Следовательно, для одной и той же программы трансляция методом компиляции обеспечивает более высокую производительность вычислительной системы при сокращении требуемой оперативной памяти.
Компиляция программы включает два действия: анализ, т. е. определение правильности записи исходной программы в соответствии с правилами построения языковых конструкций входного языка, и синтез – генерирование эквивалентной программы в машинных кодах.
Тема 6. История и развитие методологии объектно-ориентированного программирования. Сферы применения.
6.1. Объектно-ориентированный язык
Объектно-ориентированный язык создает окружение в виде множества независимых объектов. Каждый объект ведет себя подобно отдельному компьютеру, их можно использовать для решения задач как «черные ящики», не вникая во внутренние механизмы их функционирования. Из языков объектного программирования, популярных среди профессионалов, следует назвать прежде всего Си++, для более широкого круга программистов предпочтительны среды типа Delphi и Visual Basic.
При использовании декларативного языка программист указывает исходные информационные структуры, взаимосвязи между ними и то, какими свойствами должен обладать результат. При этом процедуру его получения («алгоритм») программист не строит (по крайней мере, в идеале). В этих языках отсутствует понятие «оператор» («команда»). Декларативные языки можно 18 подразделить на два семейства – логические (типичный представитель – Пролог) и функциональные (Лисп).
С развитием глобальной сети было создано много языков программирования, адаптированных специально для Интернета. Характерные особенности: языки являются интерпретируемыми, интерпретаторы для них распространяются бесплатно, сами программы – в исходных текстах. Такие языки называются скриптязыками.
Языки веб-программирования – это языки, которые в основном предназначены для работы с веб-технологиями. Языки вебпрограммирования можно условно разделить на две пересекающиеся группы: клиентские и серверные.
Как следует из названия, программы на клиентских языках обрабатываются на стороне пользователя, как правило их выполняет браузер. Это и создает главную проблему клиентских языков – результат выполнения программы (скрипта) зависит от браузера пользователя. То есть если пользователь запретил выполнять клиентские программы, то они исполняться не будут, как бы ни желал этого программист. Кроме того, может произойти такое, что в разных браузерах или в разных версиях одного и того же браузера один и тот же скрипт будет выполняться по-разному. С другой стороны, если программист возлагает надежды на серверные программы, то он может упростить их работу и снизить нагрузку на сервер за счет программ, исполняемых на стороне клиента, поскольку они не всегда требуют перезагрузку (генерацию) страницы. Самыми распространенными клиентскими языками программирования являются:
• HTML
•CSS
• JavaScript 19
• VBScript
• ActionScript
• Java
6.2. Серверные языки
Когда пользователь дает запрос на какуюлибо страницу (переходит на неё по ссылке или вводит адрес в адресной строке своего браузера), то вызванная страница сначала обрабатывается на сервере, то есть выполняются все программы, связанные со страницей, и только потом возвращается к посетителю по сети в виде файла. Этот файл может иметь расширения: HTML, PHP, ASP, ASPX, Perl, SSI, XML, DHTML, XHTML.
Работа программ уже полностью зависима от сервера, на котором расположен сайт, и от того, какая версия того или иного языка поддерживается.
К серверным языкам программирования можно отнести:
• PHP
• Perl
• Python
• Ruby
• любой .NET язык программирования (технология ASP.NET)
• Java
• Groovy
6.3. Языки программирования.
Охарактеризуем наиболее известные языки программирования.
1. Фортран (FORmula TRANslating system – система трансляции формул); старейший и сегодня активно используемый в решении задач математической ориентации язык. Является классическим языком для программирования на ЭВМ математических и инженерных задач.
2. Бейсик (Beginner's All-purpose Symbolic Instruction Code – универсальный символический код инструкций для начинающих); несмотря на многие недостатки и изобилие плохо совместимых 20 версий – самый популярный по числу пользователей. Широко употребляется при написании простых программ.
3. Паскаль (Pascal – назван в честь ученого Блеза Паскаля); чрезвычайно популярен как при изучении программирования, так и среди профессионалов. Создан в начале 70-х годов швейцарским ученым Никлаусом Виртом. Язык Паскаль первоначально разрабатывался как учебный, и, действительно, сейчас он является одним из основных языков обучения программированию в школах и вузах. Однако качества его в совокупности оказались столь высоки, что им охотно пользуются и профессиональные программисты. Не менее впечатляющей, в том числе и финансовой, удачи добился Филип Кан, француз, разработавший систему Турбо-Паскаль. Суть его идеи состояла в объединении последовательных этапов обработки программы – компиляции, редактирования связей, отладки и диагностики ошибок – в едином интерфейсе. Версии Турбо-Паскаля заполонили практически все образовательные учреждения, программистские центры и частные фирмы. На базе языка Паскаль созданы несколько более мощных языков (Модула, Ада, Дельфи).
4. АДА; является языком, победившим (май 1979 г.) в конкурсе по разработке универсального языка, проводимым Пентагоном с 1975 году. Разработчики – группа ученых во главе с Жаном Ихбиа. Победивший язык окрестили АДА, в честь Огасты Ады Лавлейс. Язык АДА – прямой наследник языка Паскаль. Этот язык предназначен для создания и длительного (многолетнего) сопровождения больших программных систем, допускает возможность параллельной обработки, управления процессами в реальном времени и многое другое, чего трудно или невозможно достичь средствами более простых языков.
5. Си (С – «си»); широ 21 на современное программирование (первая версия – 1972 г.), является очень популярным в среде разработчиков систем программного обеспечения (включая операционные системы). Си сочетает в себе черты как языка высокого уровня, так и машинно-ориентированного языка, допуская программиста ко всем машинным ресурсам, чего не обеспечивают такие языки, как Бейсик и Паскаль.
6. Си++ (С++); объектно-ориентированное расширение языка Си, созданное Бьярном Страуструпом в 1980 году. Множество новых мощных возможностей, позволивших резко повысить производительность программистов, наложилось на унаследованную от языка Си определенную низкоуровневость.
7. Дельфи (Delphi); язык объектно-ориентированного «визуального» программирования; в данный момент чрезвычайно популярен. Созданный на базе языка Паскаль специалистами фирмы Borland язык Delphi, обладая мощностью и гибкостью языков Си и Си++, превосходит их по удобству и простоте интерфейса при разработке приложений, обеспечивающих взаимодействие с базами данных и поддержку различного рода работ в рамках корпоративных сетей и сети Интернет.
8. Ява (Java); платформенно-независимый язык объектноориентированного программирования, чрезвычайно эффективен для создания интерактивных веб-страниц. Этот язык был создан компанией Sun в начале 90-х годов на основе Си++. Он призван упростить разработку приложений на основе Си++ путем исключения из него всех низкоуровневых возможностей.
9. C# (произносится си шарп) – объектно-ориентированный язык программирования. Разработан в 1998–2001 годах группой инженеров под руководством Андерса Хейлсберга в компании Microsoft как язык разработки приложений для платформы Microsoft .NET Framework и впоследствии был стандартизирован как ECMA- 22 334 и ISO/IEC 23270. C# относится к семье языков с C-подобным синтаксисом, из них его синтаксис наиболее близок к C++ и Java.
С тех пор язык сильно вырос в плане популярности и стал чуть ли не самым предпочитаемым языком среди разработчиков Windowsи Web-приложений, которые используют .NET Framework. Отчасти привлекательность языка С# связана с его понятным синтаксисом, который происходит от синтаксиса C/C++, но упрощает некоторые вещи. Несмотря на это упрощение, язык С# обладает той же мощью, что и C++.
10. Оберон (Oberon) – язык общего назначения, созданный автором Pascal и Modula-2 Никлаусом Виртом (Niklaus Wirth) и его коллегами из Швейцарского федерального технического института г. Цюрих (ETH Zurich) в ходе разработки одноименной операционной системы для однопользовательской рабочей станции Ceres. Язык и операционная система названы именем одного из спутников планеты Уран – Оберона. Имеет долгую историю создания, является наследником Algol 60 (1960), Pascal (1970) и Modula (1979). Oberon синтезировал более четверти века исследований Н.Вирта по методологии и языкам программирования. Ему с учениками удалось добиться точного синтеза «старых» достижений структурного и модульного программирования с «новыми» объектными методами. Вот, что говорил сам Вирт о своем «детище»: «Он (Оberon) включает в себя средства, необходимые для объектно-ориентированного программирования, сохраняя стиль Паскаля, и является результатом моего стремления к простоте без потери выразительности. В этом должна состоять сущность языка, равно пригодного как для учебной аудитории, так и для профессиональной деятельности. » Неслучайно, что в качестве эпиграфа к сообщению о языке Oberon Н. Вирт выбрал высказывание А.Эйнштейна: «Сделай так просто, как возможно, но не проще того». Наращивание мощи языка без его усложнения – 23 принцип, которому неуклонно следует Н. Вирт. В 1992 году сотрудничество Н.Вирта с Ханспетером Мёссенбёком (Hanspeter Mössenböck) привело к добавлению в язык ряда новых средств. Новая версия получила название Оberon-2. Оберон-2 представляет собой почти правильное расширение Оберона и является фактическим стандартом языка, который поддерживается большинством современных Оберон-систем.
11. Лисп (Lisp) – функциональный язык программирования. Ориентирован на структуру данных в форме списка и позволяет организовать эффективную обработку больших объемов текстовой информации.
12. Пролог (PROgramming in LOGic – логическое программирование). Главное назначение языка – разработка интеллектуальных программ и систем. Пролог – это язык программирования, созданный специально для работы с базами знаний, основанными на фактах и правилах (одного из элементов систем искусственного интеллекта). В языке реализован механизм возврата для выполнения обратной цепочки рассуждений, при котором предполагается, что некоторые выводы или заключения истинны, а затем эти предположения проверяются в базе знаний, содержащей факты и правила логического вывода. Если предположение не подтверждается, выполняется возврат и выдвигается новое предположение. В основу языка положена математическая модель теории исчисления предикатов.
13. HTML (HyperText Markup Language). Общеизвестный язык для оформления документов. Не является алгоритмическим языком программирования, а язык разметки гипертекста. Очень прост, содержит элементарные команды форматирования текста, добавления рисунков, задания шрифтов и цветов, организации ссылок 24 и таблиц. Все Web-страницы написаны на языке HTML или используют его расширения.
14. PHP – скриптовый язык программирования, применяющийся для создания сайтов. Важное его достоинство языка php – это создания динамических веб-сайтов, работа с базами данных (mysql).
6.4. Методологии программирования
Большая часть работы программистов связана с написанием исходного кода, тестированием и отладкой программ на одном из языков программирования. Исходные тексты и исполняемые файлы программ являются объектами авторского права и являются интеллектуальной собственностью их авторов и правообладателей.
Различные языки программирования поддерживают различные стили программирования (методологии или парадигмы программирования). Отчасти искусство программирования состоит в том, чтобы выбрать один из языков, наиболее полно подходящий для решения имеющейся задачи.
Разные языки требуют от программиста различного уровня внимания к деталям при реализации алгоритма, результатом чего часто бывает компромисс между простотой и производительностью (или между временем программиста и временем пользователя).
Тема 7. Отладка и тестирование программ: основные подходы и ограничения.
7.1. Отладка
Отладка программы – это процесс обнаружения и исправления ошибок. Программные ошибки можно разделить на два класса: синтаксические (синтаксис языка программирования) и алгоритмические (логические). Синтаксические ошибки выявляются в процессе компилирования программы – это наиболее простые с точки зрения исправления ошибки. Алгоритмические ошибки программы выявить гораздо труднее: программа работает, а результат выдает неправильный. Для обнаружения ошибок этого класса требуется этап тестирования программы.
Этот этап может быть весьма трудоемким, особенно для начинающих программистов. При отладке больших программ целесообразно использовать специальные программные 41 средства, облегчающие процесс нахождения ошибок
Отладка программ обычно осуществляется с использованием специальных программных средств. Последние используются для исследования внутреннего поведения программы. Типичный отладчик позволяет вводить в программу точки останова для оценки промежуточных результатов и производить проверку и модификацию значений переменных в этих точках.
7.2. Тестирование программ
Тестирование – это процесс исполнения программ с целью выявления (обнаружения) ошибок. Существуют различные способы тестирования программ
Тестирование программы (program testing) - проверка, которая проводится в ходе прогона программы с целью убедиться, работает ли она так, как требуется. Это осуществляется при выполнении одного или нескольких тестовых прогонов, при которых в программную систему подаются входные (тестовые данные), а реакция системы фиксируется для последующего анализа. Может осуществляться как с ЭВМ, так и без ЭВМ. Один из главных законов тестирования гласит: «Тестирование программы или ее отдельных модулей не должен осуществлять программист (группа программистов), создавший эту программу или модуль».
Тестирование программы как «черного ящика» (стратегия «черного ящика» определяет тестирование с анализом входных данных и результатов работы программы). Критерием исчерпывающего входного тестирования является использование всех возможных наборов входных данных.
Тестирование программы как «белого ящика» заключается в стратегии управления логикой программы, позволяет использовать ее внутреннюю структуру. Критерием выступает исчерпывающее тестирование всех маршрутов и управляющих структур программы.
Разумная и реальная стратегия тестирования – сочетание моделей «черного» и «белого ящиков».
Тема 8. Методы сортировки данных: эволюция и сравнительный анализ. Примеры использования.
8.1. Алгоритм сортировки.
Алгоритм сортировки — это алгоритм для упорядочивания элементов в списке. В случае, когда элемент списка имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
- Устойчивость (англ. stability) — устойчивая сортировка не меняет взаимного расположения элементов с одинаковыми ключами.
- Естественность поведения — эффективность метода при обработке уже упорядоченных или частично упорядоченных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
- Использование операции сравнения. Алгоритмы, использующие для сортировки сравнение элементов между собой, называются основанными на сравнениях. Минимальная трудоемкость худшего случая для этих алгоритмов составляет О ({\displaystyle n\cdot \log n}n*logn), но они отличаются гибкостью применения. Для специальных случаев (типов данных) существуют более эффективные алгоритмы.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов упорядочения два:
- Внутренняя сортировка оперирует массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно упорядочиваются на том же месте без дополнительных затрат.
- В современных архитектурах персональных компьютеров широко применяется подкачка и кэширование памяти. Алгоритм сортировки должен хорошо сочетаться с применяемыми алгоритмами кэширования и подкачки.
- Внешняя сортировка оперирует запоминающими устройствами большого объёма, но не с произвольным доступом, а последовательным (упорядочение файлов), то есть в данный момент «виден» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам упорядочения, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным во внешней памяти производится намного медленнее, чем операции с оперативной памятью.
- Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим.
- Объём данных не позволяет им разместиться в ОЗУ.
Также алгоритмы классифицируются по:
- потребности в дополнительной памяти или её отсутствию
- потребности в знаниях о структуре данных, выходящих за рамки операции сравнения, или отсутствию таковой
8.2. сортировки данных в массивах
Используемые в настоящее время объемы массивов данных достигают размеров, которые еще десятилетие назад казались почти невероятными. Чем большими становятся объемы перерабатываемых данных, тем актуальнее становится задача оптимизации используемых алгоритмов, в том числе и сортировки. В то же время по-прежнему важными остаются задачи, не требующие повышения скорости алгоритмов. Например, для образовательных целей часто более важной является их простота.
Рост требований к скорости алгоритмов сортировки и расширение круга задач, для которых они используются, приводит к тому, что по-прежнему важной и актуальной остается задача сравнительного анализа алгоритмов сортировки.
Целью проведенного исследования было сопоставление преимуществ и недостатков наиболее распространенных алгоритмов сортировки данных в массивах.
Для достижения поставленной цели были поставлены и решены следующие задачи:
1.Определить наиболее распространенные алгоритмы сортировки данных;
2.Выявить достоинства и недостатки данных алгоритмов;
3.Сопоставить достоинства и недостатки алгоритмов сортировки.
При определении наиболее распространенных алгоритмов мы пользовались следующей классификаций: алгоритмы устойчивой сортировки; алгоритмы неустойчивой сортировки; непрактичные алгоритмы сортировки; алгоритмы, не основанные на сравнениях и алгоритмы топологической сортировки.
При использовании алгоритмов неустойчивой сортировки могут меняться местами данные с одинаковыми значениями. Это является недостатком в том случае, когда при сортировке по одному полю данных, состоящих из нескольких полей, важно сохранение взаимного расположения равных элементов важно при сортировке по одному полю данных. В то же время большинство алгоритмов неустойчивой сортировки требуют меньшей памяти и времени, чем алгоритмы устойчивой сортировки. Наиболее известными алгоритмами неустойчивой сортировки являются сортировка Шелла (Shell sort), сортировка расчёской (Comb sort), пирамидальная сортировка (сортировка кучи, Heapsort), плавная сортировка (Smoothsort), быстрая сортировка (Quicksort), интроспективная сортировка (Introsort), терпеливая сортировка (Patience sorting), сортировка по частям (блуждающая сортировка, Stooge sort) и поразрядная сортировка (цифровая сортировка, Radix sort).
Тема 9. Методы поиска данных: эволюция и сравнительный анализ. Примеры использования.
9.1. Поиск
Поиск — обработка некоторого множества данных с целью выявления подмножества данных, соответствующего критериям поиска.
Все алгоритмы поиска делятся на
- поиск в неупорядоченном множестве данных;
- поиск в упорядоченном множестве данных.
Упорядоченность – наличие отсортированного ключевого поля.
Тема 10. Функциональное тестирование программного обеспечения на примере мобильных приложений.
10.1. Функциональное тестирование
Функциональное тестирование мобильных приложений обычно охватывает тестирование взаимодействия с пользователем, а также тестирование транзакций. Важные для этого вида тестирования факторы:
- Тип приложения, определяемый его бизнес-функциональностью (банкинг, игровая индустрия, социальные сети, образование).
- Целевая аудитория (пользователь, компания, образовательная среда).
- Канал, по которому распространяется приложение (например, App Store, Google Play или раздача напрямую).
Основные сценарии функциональных тестов:
- Проверить корректность работы обязательных полей.
- Убедиться, что обязательные поля отображаются на экране не так, как необязательные.
- Убедиться, что работа приложения во время запуска/выхода удовлетворяет основным требованиям.
- Убедиться, что приложение переходит в фоновый режим в случае входящего звонка. Для этого вам понадобится еще один телефон.
- Проверить, может ли телефон хранить, принимать и отправлять SMS-сообщения во время работы приложения. Для этого вам понадобится другой телефон, с которого можно отправить сообщение на тестируемое устройство с уже запущенным приложением.
- Убедиться, что устройство работает в многозадачном режиме, когда это необходимо.
- Проверить, как функционируют необходимые опции для работы с социальными сетями — Поделиться, Публикация, Навигация.
- Убедиться, что приложение поддерживает платежные операции через системы оплаты Visa, Mastercard, Paypal и др.
- Проверить адекватность работы сценариев прокрутки страницы.
- Проверить, присутствует ли надлежащая навигация между важными модулями приложения.
- Убедиться, что количество ошибок округления минимально.
- Проверить наличие сообщений об ошибках, например, сообщения «Ошибка сети. Пожалуйста, попробуйте позже» в случае некорректной работы сети.
- Убедиться, что установленное приложение не препятствует нормальной работе других приложений и не съедает их память.
- Проверить, способно ли приложение вернуться в то состояние, в котором оно находилось перед приостановкой (например, жесткая перезагрузка или системный сбой).
- Установка приложения должна проходить без значительных ошибок при условии, что устройство соответствует системным требованиям.
- Убедиться, что автоматический запуск приложения работает корректно.
- Проверить, как приложение работает на всех устройствах поколений 2G, 3G и 4G.
- Выполнить регрессивное тестирование для выявления новых программных ошибок в существующих и уже модифицированных областях системы. Дополнительное проведение всех предыдущих тестов для проверки поведения программы после изменений.
- Убедиться, что существует доступное руководство пользователя.
10.2. Тестирование производительности;
Основная цель этого вида тестирования — убедиться в том, что приложение работает приемлемо при определенных требованиях производительности: доступ большому числу пользователей, устранение важного элемента инфраструктуры, как, например, сервера базы данных, и др.
Основные сценарии тестирования производительности мобильных приложений:
- Определить, работает ли приложение одинаково в разных условиях загрузки сети.
- Выяснить, способно ли текущее покрытие сети обеспечить работу приложения на различных уровнях пользовательской нагрузки.
- Выяснить, обеспечивает ли существующая клиент-серверная конфигурация оптимальную производительность.
- Найти различные узкие места приложения и инфраструктуры, которые снижают производительность приложения.
- Проверить, соответствует ли требованиям время реакции приложения.
- Оценить способность продукта и/или аппаратного обеспечения справляться с планируемыми объемами нагрузки.
- Оценить время, в течение которого аккумулятор может поддерживать работу приложения в условиях планируемых объемов нагрузки.
- Проверить работу приложения в случаях перехода из Wi-Fi-сети в мобильную 2G/3G-сеть и наоборот.
- Проверить, что каждый из уровней памяти процессора работает оптимально.
- Убедиться в том, что потребление батареи и утечка памяти не выходят за пределы нормы, а работа различных ресурсов и сервисов, таких как GPS-навигация или камера, соответствует требованиям.
- Проверить стойкость приложения в условиях жесткой пользовательской нагрузки.
- Проверить эффективность сети в условиях, когда устройство находится в движении.
- Проверить производительность приложения, если оно работает в условиях непостоянного подключения к интернету.
10.3. Тестирование безопасности;
Основная цель этого типа тестирования — обеспечить безопасность сети и данных приложения.
Ниже приведены ключевые действия для проверки безопасности мобильного приложения.
- Убедиться в том, что данные пользователей приложения — логины, пароли, номера банковских карт — защищены от сетевых атак автоматизированных систем и не могут быть найдены путем подбора.
- Удостовериться в том, что приложение не дает доступ к секретному контенту или функциональности без надлежащей аутентификации.
- Убедиться в том, что система безопасности приложения требует надежного пароля и не позволяет взломщику завладеть паролями других пользователей.
- Убедиться в том, что время таймаута сессии адекватно для приложения.
- Найти динамические зависимости и принять меры для защиты этих уязвимых участков от взломщиков.
- Защитить приложение от атак типа SQL-injection.
- Найти случаи неуправляемого кода и устранить его последствия.
- Удостовериться в том, что срок действия сертификатов не истек, вне зависимости от того, использует приложение Certificate Pinnig или нет.
- Защитить приложение и сеть от DoS-аттак.
- Проанализировать требования хранения и проверки данных.
- Обеспечить управление сеансами для защиты информации от неавторизованных пользователей.
- Проверить все криптографические коды и, если необходимо, исправить ошибки.
- Удостовериться в том, что бизнес-логика приложения защищена и не подвержена атакам извне.
- Проанализировать взаимодействие файлов системы, выявить и скорректировать уязвимые места.
- Проверить обработчики протокола (например, не пытаются ли перенастроить целевую страницу по умолчанию, используя вредоносные плавающие фреймы).
- Защитить приложение от вредоносных атак на клиентов.
- Защитить систему от вредоносных внедрений в момент работы программы.
- Предотвратить возможные вредоносные последствия кэширования файлов.
- Предотвратить ненадежное хранение данных в кэш-памяти клавиатуры устройства.
- Предотвратить возможные вредоносные действия файлов cookie.
- Обеспечить регулярный контроль безопасности данных.
- Изучить пользовательские файлы и предотвратить их возможное вредоносное влияние.
- Обезопасить систему от случаев переполнения буфера или нарушения целостности информации в памяти.
- Сделать анализ различных потоков данных и защитить систему от их возможного вредоносного влияния.
10.4. Тестирование удобства пользования (юзабилити-тестирование);
Тестирование удобства использования — это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий
Тестирование удобства пользования дает оценку уровня удобства использования приложения по следующим пунктам:
Производительность, эффективность (efficiency) — сколько времени и шагов понадобится пользователю для завершения основных задач приложения, например, размещения новости, регистрации, покупки (чем меньше времени и шагов понадобится пользователю, тем лучше).
Правильность (accuracy) — сколько ошибок сделал пользователь во время работы с приложением?
Активизация в памяти (recall) — как долго пользователь помнит о том, как пользоваться приложением, после приостановки работы с ним на длительный период времени? (Повторное выполнение операций после перерыва должно проходить быстрее, чем у нового пользователя).
Эмоциональная реакция (emotional response) — Как пользователь себя чувствует после завершения задачи: растерян, испытал стресс или, наоборот, ему все понравилось? Порекомендует ли пользователь систему своим друзьям?
Для улучшения удобства использования полезно следовать двум принципам:
«Защита от дурака». Если поле предполагает ввод номера телефона, то стоит ограничить диапазон ввода только цифрами и соответствующим образом сформировать клавиатуру. Аналогично для e-mail и остальных элементов, которые предполагают пользовательский ввод данных.
Использовать цикл Демминга (планирование-действие-проверка- корректировка), то есть собирать информацию о дизайне и удобстве использования у существующих пользователей, и на основе их мнений планировать изменения в приложении.
10.5. Тестирование совместимости;
Конфигурационное тестирование проводится для того чтобы обеспечить оптимальную работу приложения на разных устройствах — с учетом их размера, разрешения экрана, версии, аппаратного обеспечения и пр.
Важнейшие сценарии конфигурационного тестирования:
- Убедиться в том, что интерфейс приложения соответствует размеру экрана устройства, текст не выходит за рамки дисплея.
- Убедиться в том, что текст легко читается на любом устройстве.
- Убедиться в том, что функция вызова/будильника доступна при запущенном приложении, приложение сворачивается или переходит в режим ожидания в случае входящего звонка, а по его завершении возобновляется.
"Это тип тестирования, предназначенный для проверки работоспособности приложения на различных конфигурациях системы. Имеет смысл рассмотреть клиентский уровень конфигурационного тестирования. Сервер у мобильных приложений часто единственный, а клиент устанавливается на большое количество самых разнообразных устройств. Но нужно учесть, что если приложение специфичное — например, игра, для которой выделено несколько серверов, то серверный уровень также становится приоритетным.
На клиентском уровне можно выделить:
Тип устройства: смартфон, планшет и т.д.
Конфигурация устройства: количество оперативной памяти, тип процессора, разрешение экрана, емкость аккумулятора и т.д.
Тип и версия операционной системы. iOS 6, 7; Android 4.2.2 и т.д.
Тип сети: Wi-Fi, GSM.
Перед проведением конфигурационного тестирования рекомендуется
Создавать матрицу покрытия (матрица покрытия — это таблица, в которую заносят все возможные конфигурации).
Проводить приоритезацию конфигураций (на практике, скорее всего, все желаемые конфигурации проверить не получится).
Шаг за шагом, в соответствии с расставленными приоритетами, проверяют каждую конфигурацию.
Уже на начальном этапе становится очевидно: чем больше требований к работе приложения при различных конфигурациях рабочих станций, тем больше тестов нам необходимо будет провести. В связи с этим рекомендуем по возможности автоматизировать этот процесс, так как именно при конфигурационном тестировании автоматизация реально помогает сэкономить время и ресурсы. Конечно же, автоматизированное тестирование не является панацеей, но в данном случае оно окажется очень эффективным помощником.
10.6. Тестирование на восстановление.
Тестирование на восстановление проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи. Применяется чаще всего в приложениях, которые должны работать 24x7, где каждая минута простоя стоит очень дорого.
Проверка восстановления после сбоя системы и сбоя транзакций.
Проверка эффективного восстановления приложения после непредвиденных сценариев сбоя.
Проверка способности приложения обрабатывать транзакции в условиях сбоя питания (разряженная батарея / некорректное завершение работы приложения).
Проверка процесса восстановления данных после перерыва в соединении.
Другие важные области проверки:
Тестирование установки (быстрая, соответствующая требованиям установка приложения).
Тестирование удаления (быстрое, соответствующее требованиям удаление приложения).
Сетевые тест-кейсы (проверка адекватной работы сети в разных условиях загрузки, а также способности сети обеспечить функционирование всех приложений, используемых в ходе тестирования).
Проверка наличия нефункциональных клавиш.
Проверка экрана загрузки приложения.
Проверка возможности ввода с клавиатуры во время сбоев сети.
Проверка методов запуска приложения.
Проверка наличия эффекта зарядки в случае, если приложение находится в фоновом режиме.
Проверка функционирования экономичного режима и режима высокой производительности.
Выявление последствий извлечения аккумулятора во время работы приложения.
Проверка уровня потребления энергии приложением.
Проверка побочных эффектов приложения.
Тема 11. Особенности алгоритмизации при разработке WEB-приложений.
11.1. Web-приложений в C#
C# (произносится си шарп) – объектно-ориентированный язык программирования. Разработан в 1998–2001 годах группой инженеров под руководством Андерса Хейлсберга в компании Microsoft как язык разработки приложений для платформы Microsoft .NET Framework и впоследствии был стандартизирован как ECMA- 22 334 и ISO/IEC 23270. C# относится к семье языков с C-подобным синтаксисом, из них его синтаксис наиболее близок к C++ и Java.
С тех пор язык сильно вырос в плане популярности и стал чуть ли не самым предпочитаемым языком среди разработчиков Windows и Web-приложений, которые используют .NET Framework. Отчасти привлекательность языка С# связана с его понятным синтаксисом, который происходит от синтаксиса C/C++, но упрощает некоторые вещи. Несмотря на это упрощение, язык С# обладает той же мощью, что и C++
11.2 . Задачи Web-приложений
Формулирование критериев качества веб-приложений, и проведение критического анализа существующих методов разработки, хранения и взаимодействия веб-приложений.
2. Постановка и решение задачи оптимизации процесса разработки веб-приложений.
3. Синтез эффективной архитектуры и алгоритмов функционирования веб-приложений. Определение уровней абстракции в ВП, их взаимодействия и жизненного цикла.
4. Разработка метода взаимного объектно-реляционного преобразования (ОРП) для организации взаимодействия ВП с БД и хранения данных, а также шаблона проектирования на его основе.
5. Решения практических задач разработки ВП на базе предлагаемых методов, в том числе методов взаимодействия ВП друг с другом и пользователями. Определение конкретных путей повышения эффективности разработки, хранения и взаимодействия веб-приложений. Реализация новой архитектуры, алгоритмов функционирования и ОРП-метода в конкретном веб-приложении.
Объектом исследований являются ВП на платформе LAMP.
Предметом исследований являются методы разработки ВП. Методы исследований. Результаты диссертационной работы получены на основе теории множеств, теории реляционных баз данных, имитационного моделирования, экспериментальных и теоретических методов информационных технологий. Научная новизна:
1. Проведён критический анализ существующих методов разработки, хранения и взаимодействия веб-приложений.
2. С помощью применения СКР-функции (среднестатистические колебания работоспособности) к определению дневного фокус-фактора (КПД) разработчика автор вычислил значение фокус-фактора (FFD) для новых команд, равное 0.72640625. Это значение может использоваться при планировании итерации новой команды, или индивидуальном планировании для нового члена команды разработки. Автором поставлена и решена оптимизационная задача по определению такого распределения задач по программистам, которое приведёт к максимизации показателя производительности (Рразр) всей команды.
3. Разработаны новая архитектура и алгоритмы функционирования ВП. Определены уровни абстракции ВП и их жизненный цикл. Метрический анализ разработанного ВП показал, что значение целевой функции метрик на 13% превосходит максимальное значение этой функции для других ВП. Применение предлагаемых методов позволяет увеличить количество повторно используемого кода на 16%. Как следствие, могут быть сокращены объем работ, бюджет, а также увеличена скорость разработки ВП. Качественные характеристики ВП (по ISO/IEC 9126) по данным экспертного анализа увеличиваются на 19% по сравнению с максимальным значением среди других ВП.
4. Создан новый метод объектно-реляционного преобразования «Активная модель», позволяющий взаимно преобразовывать объекты ЯП PHP в таблицы сервера баз данных. По результатам проведённых тестов можно заключить, что скорость работы на тестовой выборке увеличилась на 19 -27% для объектовозвращающего преобразования и на 16 - 25% для векторовозвращающего преобразования. Объем занимаемой памяти сократился на 16 - 24% для объектовозвращающего преобразования, и на 18 - 32% для векторовозвращающего преобразования по сравнению с системой Doctrine.
5. Разработаны методы решения практических задач синтеза ВП: методы загрузки ВП, методика работы со сторонними библиотеками, метод разграничения доступа к ВП, интернационализации данных и интерфейса, методика организации кэширования, методика аутентификации пользователя и взаимодействия со сторонними ВП. В результате тестирования было определено, что применение предлагаемых методов позволяет увеличить скорость обработки запросов ВП от 7% (при X = 15 и 35) до 35% (при X = 5).
6. Предлагаемая архитектура, алгоритмы функционирования ВП и ОРП-метод реализованы при создании нескольких ВП: системы публикации контента в сфере образования, визуального конструктора сайтов, системы управления сайтом, а также ВП, реализующего информационные процессы и структуры модели взаимодействия потребителя и производителя товаров и услуг (модель customer-supplier).
Тема 12. Критерии выбора средств разработки WEB-приложений.
12.1. Критерии выбора
Критерии выбора (в порядке важности):
0. Ориентация на stateless.
1. Качество.
2. Перспективность. Надеюсь что выбранный стэк технологий не умрет, пока я его учу.
3. Популярность. Важно, чтобы на эту тему было много вакансий (с убер большой З. П. разумеется).
4. Развитость. Не хочется ковыряться в багах инструментов. Было бы просто отлично, если бы я мог использовать уже готовые модули, а не делать свои для каждой задачи.
5. Быстродействие.
6. Грамотное сообщество, хорошие документации. Правда я верю, что для всех фрейворков в этом плане все хорошо, но мало-ли.
7. Отсутствие проблем с хостингом.
Тема 13. Критерии выбора средств разработки мобильных приложений.
13.1. Критерии выбора
Как правило, мобильные игры содержат большое количество элементов графики (картинки, анимация). Поэтому для сравнения Unity3D и ADT были выбраны уже готовые анимированные игры на Android Market, созданные с помощью этих пакетов. Игры оценивались по следующим критериям:
- время загрузки приложения (сек);
- размер памяти приложения (MB);
- средняя загрузка кэш памяти (MB);
- максимальная загрузка центрального процессора устройства (%);
- среднее время отклика приложения по запросу пользователя (мс);
- оценка использования анимации (мах 10);
- оценка управления (мах 10);
- оценка звуковых сопровождений (мах 10);
Тема 14. Этапы разработки, тестирования и ввода в эксплуатацию мобильных приложений
14.1. Тестирование
Тестирование – очень важный этап разработки мобильных приложений.
Стоимость ошибки в релизе мобильного приложения высока. Приложения попадают в Google Play в течении нескольких часов, в Appstore несколько недель. Неизвестно сколько времени будут обновляться пользователи. Ошибки вызывают бурную негативную реакцию, пользователи оставляют низкие оценки и истерические отзывы. Новые пользователи, видя это, не устанавливают приложение.
Мобильное тестирование сложный процесс: десятки различных разрешений экрана, аппаратные отличия, несколько версий операционных систем, разные типы подключения к интернету, внезапные обрывы связи.
Поэтому в отделе тестирования у нас работает 8 человек (0,5 тестировщика на программиста), за его развитием и процессами следит выделенный тест-лид.
Тестирование начинается до разработки. Отдел дизайна передает тестировщикам навигационную схему и макеты экранов, менеджер проекта – требования невидимые на дизайне. Если дизайн предоставляет заказчик, макеты до передачи в отдел тестирования проверяются нашими дизайнерами.
Быстрое тестирование проводится после завершения итерации разработки, если сборка не пойдет в релиз.
Для начала проводятся smoke-тесты, чтобы понять имеет ли смысл тестировать сборку.
Затем берутся все выполненные задачи и пофикшенные баги за итерацию из Jira и скурпулезно проверяется соответствие результата описанию таска. Если задача включала в себя новые элементы интерфейса, она отправляется дизайнерам для сверки с макетами.
Некорректно выполненные задачи переоткрываются. Баги заносятся в Jira. К не UI багам обязательно прикладываются логи со смартфона. К UI багам скриншоты с пометками что не так.
После этого выполняются функциональные тесты этой итерации. Если были найдены баги не покрытые тест-кейсами, создается новый тест-кейс.
Полное тестирование проводится перед релизом. Включает себя в себя быстрое тестирование, регресионное тестирование, monkey-тестирование на 100 устройствах и тестирование обновлений.
Регрессионное тестирование подразумевает прогон ВСЕХ тест-кейсов по проекту. Тест-кейсов не только за последнюю итерацию, но и за все предыдущие и общие тест кейсы по требованиям. Это занимает день-три на одно устройство в зависимости от проекта.
Очень важный шаг — тестирование обновлений. Почти все приложения хранят данные локально (даже если это кука логина) и важно удостовериться, что после обновления приложения все данные пользователя сохранятся. Тестировщик скачивает билд из маркета, создает сохраняемые данные (логин, плейлисты, транзации учета финансов), обновляет приложение на тестовую сборку и проверяет, что все на месте. Затем прогоняет smoke-тест. Процесс повторяется на 2-3 устройствах.
Разработчики часто забывают о миграции данных со старых версий и тестирование обновлений позволило нам выявить множество критических ошибок с падениями, удалением пользовательских данных о покупках. Это спасло не одно приложение от гневных отзывов и потери аудитории.
14.2. Тестирование внешних сервисов
Тестировать интеграцию с Google Analytics, Flurry или системой статистики заказчика непросто. Бывало, что в релиз уходили сборки с нерабочим Google Analytics и никто не обращал на это внимания.
Поэтому в обязательно порядке для внешних сервисов создается тестовый аккаунт и он проверяется при полном тестировании. Кроме того отправка статистики фиксируется в логах, которые проверяются тестировщиками. При релизе тестовый аккаунт подменяется боевым.
Тема 15. Тестирование производительности программ: подходы в зависимости от категорий приложений.
15.1. Тестирование производительности в инженерии программного обеспечения
Тестирование производительности в инженерии программного обеспечения — тестирование, которое проводится с целью определения, как быстро работает вычислительная система или её часть под определённой нагрузкой. Также может служить для проверки и подтверждения других атрибутов качества системы, таких как масштабируемость, надёжность и потребление ресурсов.
Тестирование производительности — это одна из сфер деятельности развивающейся в области информатики инженерии производительности, которая стремится учитывать производительность на стадии моделирования и проектирования системы, перед началом основной стадии кодирования.
В тестировании производительности различают следующие направления:
- нагрузочное (load)
- стресс (stress)
- тестирование стабильности (endurance or soak or stability)
- конфигурационное (configuration)
Возможны два подхода к тестированию производительности программного обеспечения[1]:
- в терминах рабочей нагрузки: программное обеспечение подвергается тестированию в ситуациях, соответствующих различным сценариям использования;
- в рамках бета-тестирования, когда система испытывается реальными конечными пользователями.
15.2. Требования к производительности
Очень важно детализировать требования к производительности и документировать их в каком-либо плане тестирования производительности. В идеальном случае это делается на стадии разработки требований при разработке системы, до проработки деталей её дизайна. См. Инженерия производительности.
Однако тестирование производительности часто не проводится согласно спецификации, так как нет зафиксированного понимания о максимальном времени ответа для заданного числа пользователей. Тестирование производительности часто используется как часть процесса профайлинга производительности. Его идея заключается в том, чтобы найти «слабое звено» — такую часть системы, соптимизировав время реакции которой, можно улучшить общую производительность системы. Определение конкретной части системы, стоящей на этом критическом пути, иногда очень непростая задача, поэтому некоторые приложения для тестирования включают в себя (или могут быть добавлены с помощью add-on’ов) инструменты, запущенные на сервере (агенты) и наблюдающие за временем выполнения транзакций, временем доступа к базе данных, оверхедами сети и другими показателями серверной части системы, которые могут быть проанализированы вместе с остальной статистикой по производительности.
Тестирование производительности может проводиться с использованием глобальной сети и даже в географически удаленных местах, если учитывать тот факт, что скорость работы сети Интернет зависит от местоположения. Оно также может проводиться и локально, но в этом случае необходимо настроить сетевые маршрутизаторы таким образом, чтобы появилась задержка, присутствующая во всех публичных сетях. Нагрузка, прилагаемая к системе, должна совпадать с реальным положением дел. Так например, если 50 % пользователей системы для доступа к системе используют сетевой канал шириной 56К, а другая половина использует оптический канал, то компьютеры, создающие тестовую нагрузку на систему должны использовать те же соединения (идеальный вариант) или эмулировать задержки вышеуказанных сетевых соединений, следуя заданным профайлам пользователей.
Тема 16. Варианты построения интерфейса программ: особенности и эволюция.
16.1. Эволюция дизайна интерфейсов операционных систем Windows
Windows 1.0x (1985)
В этом году Microsoft наконец-то подхватила всеобщую интерфейсоманию и выпустила Windows 1.0 — свою первую операционную систему основанную на GUI. Система имела 32x32 пиксельные иконки цветную графику. Однако самое интересное нововведение (правда позже исчезнувшее) была иконкаанимированных аналоговых часов (со стрелками :)).
Windows 2.0x (1987)
В этой версии было значительно улучшено управление окнами. Теперь стало возможным перекрывать, изменять размеры, разворачивать, увеличивать и уменьшать окна. 
Windows 3.0 (1990)
К этой версии разработчики из Microsoft поняли все реальные преимущества GUI и стали значительно его улучшать.
Сама операционная система стала поддерживать стандарты, и расширенный режим для 386 архитектуры, который стал требовать памяти больше чем, 640 килобайт, и больше пространства жесткого диска, в результате стали возможными разрешения, такие как Super VGA 800×600 и XGA 1024×768.
В тоже время, Microsoft пригласили художника и графического дизайнера Сьюзан Каре для разработки дизайна иконок Windows 3.0 и создания уникального образа своего GUI.
Windows 3.1 (1992)
Эта версия Windows включала в себя предустановленные TrueType шрифты. На тот момент это фактически определило использование Windows в качестве издательской платформы.
Такая функциональность была доступна ранее только в Windows 3.0 с использованием Adobe Type Manager (ATM) — системы работы со шрифтами от компании Adobe. Так же эта версия содержала цветовую схему под названием «Hotdog Stand», содержащую яркие оттенки красного, желтого и черного цветов.
Эта схема была создана для облегчения восприятия текстовой и графической информации людьми с нарушениями цветового зрения.
Windows 95 (1995)
В Windows 95 был полностью переработан пользовательский интерфейс. Это была первая версия Windows в которой в углу каждого окошка появилась кнопка с крестиком закрывающая его.
Были добавлены различные состояния иконок и элементов управления (такие как: доступно, недоступно, выбрано, отмечено и т. д.). Так же впервые появилась знаменитая кнопка «Пуск».
Для Microsoft это был огромный шаг вперед и для операционной системы, и для унификации GUI.
Windows 98 (1998)
Стиль иконок напоминал Windows 95, но система использовала уже больше 256 цветов для отображения графического интерфейса. Почти полностью изменился Windows Explorer и впервые появился «Active Desktop» 
Windows XP (2001)
Microsoft старалась полностью изменять пользовательский интерфейс с каждой новой платформой, Windows XP не стал исключением. Стало возможным менять стили для GUI, пользователи могли полностью изменить внешний вид и поведение интерфейса. По умолчанию иконки были размером 48x48 пикселей, и использовали миллионы цветовых оттенков.
Windows Vista (2007)
Это стало ответом Microsoft своим конкурентам. Также было добавлено много 3D и анимации. Начиная с Windows 98, Microsoft всегда пыталась улучшить рабочий стол. В Windows Vista появились виджеты и несколько улучшений вместе с отказом от «Active Desktop».
Windows 7
Операционная система семейства Windows, сейчас в стадии бета-тестирования. Из появившихся изменений стоит отметить поддержку мультитач дисплеев и появления нового таскбара. Подробнее например у турбомилк.
Windows 8
Операционная система Windows 8 получила полностью переработанный «плиточный» интерфейс Metro, задачей которого было привести мобильные устройства с сенсорным экраном и компьютеры к схожему пользовательскому опыту. Для удобства работы с ПК без сенсорного экрана в систему был встроен и «классический» рабочий стол. Кнопку «Пуск» убрали, заменив ее «активным углом», нажатие на который открывало стартовый экран с «плитками». Плитки на стартовом экране можно перемещать и группировать, давать группам имена и изменять размер плиток.
Windows 8 — это типичный продукт своего времени. Здесь есть магазин приложений с интерфейсом Metro, поддержка единой учетной записи Microsoft для синхронизации разных устройств между собой, интеграция облачного сервиса OneDrive и социальных сетей Facebook и Twitter.
Сегодня подавляющая часть компьютеров все еще работает под Windows XP и Windows 7, и многие еще не успели (или на захотели в силу своего консерватизма) попробовать на вкус «плиточную» Windows 8, однако уже скоро появится Windows 10.
Windows 10
Компания Microsoft была вынуждена признать, что ее попытки сделать интерфейс Metro основным пришлись не по вкусу консервативным пользователям ПК, и ей не оставалось ничего, кроме как вернуть кнопку «Пуск». Также система получит несколько рабочих столов, возможность запуска Metro-приложений в оконном режиме, а также центр уведомлений.
Тема 17. Способы организации данных: пользовательский тип данных – структура.
17.1. Тип данных
Тип данных определяет множество значений, допустимых для переменной, операции выполняемые на этих значениях, количество выделяемой памяти. То есть переменная может принимать только значения, определяемые ее типом и участвовать только в тех операциях, которые допустимы для этого типа.
В языке Паскаль тип величины задают заранее. Все переменные, используемые в программе, должны быть объявлены в разделе описания с указанием их типа. Обязательное описание типа приводит к избыточности в тексте программ, но такая избыточность является важным вспомогательным средством разработки программ и 40 рассматривается как необходимое свойство современных алгоритмических языков высокого уровня
В языке Паскаль существует пять простых типов данных:
Integer Целочисленные данные, во внутреннем представлении занимают 2 байта
Real Вещественные данные, занимают 6 байтов
Char Символ, занимает 1 байт
String Строка символов, занимает МАХ+1 байт, где МАХ – максимальное число символов в строке
Boolean Логический тип, занимает 1 байт и имеет два значения: false (ложь) и true (истина)
Целый и вещественный тип имеют подтипы. В таблице приведем подтипы целого типа:
|
Название |
Кол-во памяти (байт) |
Диапазон значений |
|
Byte |
1 |
0 … 255 |
|
ShortInt |
1 |
-128… +127 |
|
Word |
2 |
0 … 65535 |
|
Integer |
2 |
-32768 … +32767 |
|
LongInt |
4 |
-2147483648 … +2147483647 |
Над данными целого типа определены следующие арифметические операции
|
Знак операции |
Назначение |
Приоритет |
|
+ |
Сложение |
2 |
|
- |
Вычитание |
2 |
|
* |
Умножение |
1 |
|
/ |
Деление |
1 |
|
divmod |
Целая часть от деления |
1 |
|
mod |
Остаток от деления |
1 |
Результат выполнения этих операций над целыми операндами получается также целого типа (исключение составляет операция / – результат всегда вещественное число).
Над данными целого типа определены следующие операции отношения: =, <>, , <=, >=. Результат выполнения этих операций – логический тип.
Приоритет – это последовательность выполнения действий в строке операций. Если приоритет = 1, то эти действия выполняются в первую очередь, если приоритет = 2, то эти действия выполняются во вторую очередь. Для изменения приоритета используются круглые скобки.
Пример выполнения операций div и mod:
7 div 2 = 3
3 div 5 = 0
7 mod 2 = 1
3 mod 5=3
Список стандартных функции, дающие целый результат:
|
Функция |
Тип аргумента |
Назначение |
|
Abs(x) |
Х – целое |
Абсолютная величина X |
|
Sqr (x) |
Х – целое |
Возведение X в квадрат |
|
Trunc (x) |
Х – веществ |
Выделение целой части числа X |
|
Round (x) |
Х – веществ |
Округление X до целого числа |
|
Succ (x) |
Х – целое |
Следующее за X число |
|
Pred (x) |
Х – целое |
Предыдущее перед X число |
|
Random (x) |
Х – целое |
Случайное число от 0 до х-1 .Если функция не содержит аргумента, то генерируется случайное число от 0 до 1. |
|
Randomize |
Оператор, позволяющий генерировать новую последовательность случайных чисел при новом запуске программы |
Вещественные числа могут быть представлены в форме с фиксированной точкой и в форме с плавающей точкой:
|
С фиксированной точкой |
С плавающей точкой |
|
|
5600 -0.023 570 0.26 -0.003 |
Математическая. запись |
Запись на языке Паскаль |
|
0.56 * 104 -23 *10- 3 0.57 *103 26 * 10-2 -3 *10-3 |
0.56Е+04 23Е-03 0.57Е+03 26Е-02 -3Е-03 |
|
Над данными вещественного типа определены следующие арифметические операции:
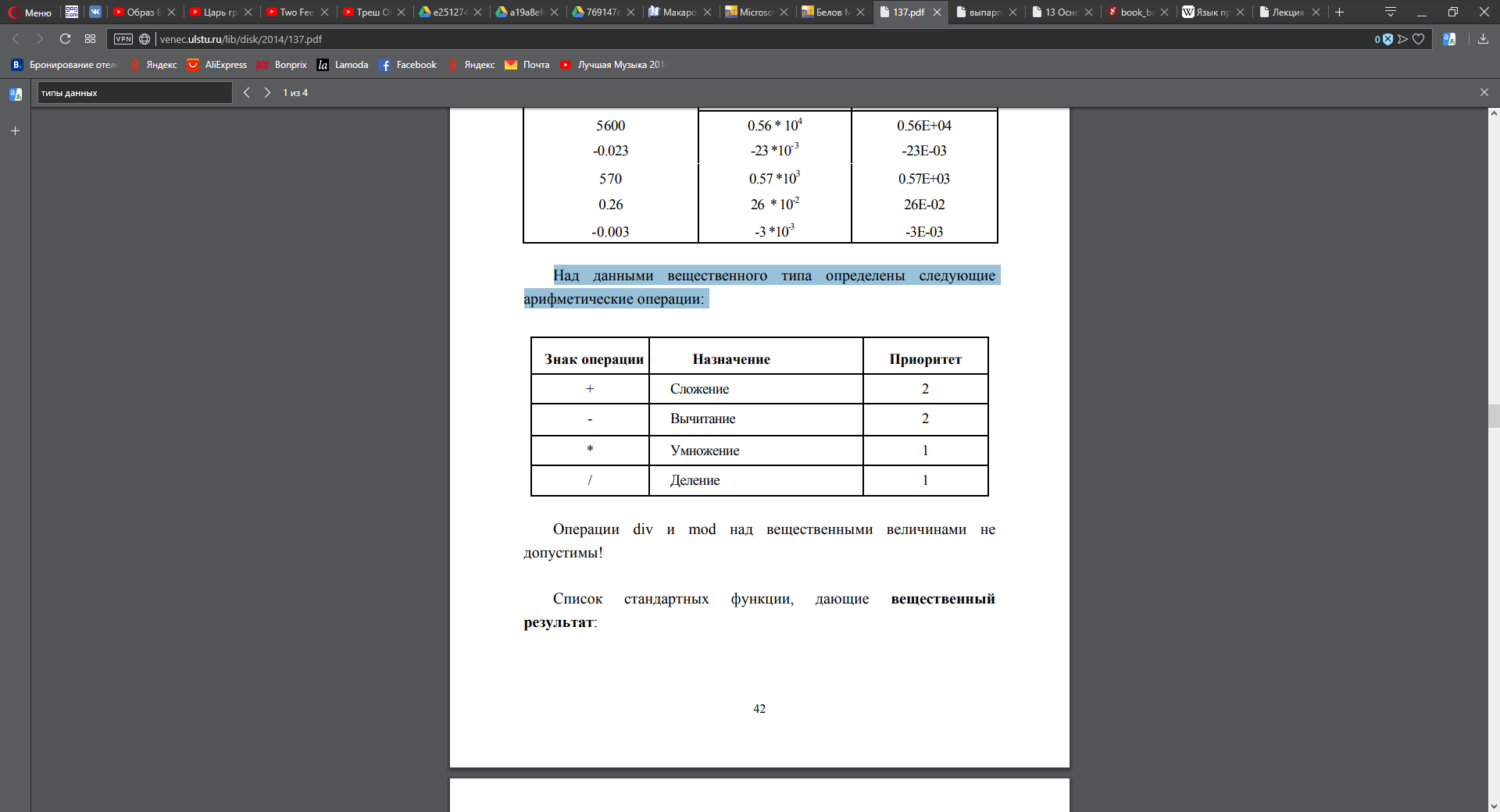
Операции div и mod над вещественными величинами не допустимы!
Список стандартных функции, дающие вещественный результат:

Функция ln (x) и exp (x) используются для возведения в степень по правилу: xn=enln(x) . Например, выражение x 9 вычисляется по формуле exp(9*ln(x)).
17.2. Логический тип данных
Логический тип данных имеет всего два значения True (истина), False (ложь) и является упорядоченным типом True > False.
В программе логический тип переменной задается служебным словом Boolean.
Существуют следующие логические операции:
1. Операции сравнения:
> – больше;
< – меньше;
= – равно;
<> – не равно;
>= – больше либо равно;
<= – меньше либо равно
2. or (или) – логическое сложение (дизъюнкция).
В физическом смысле логическое сложение – это объединение двух областей.
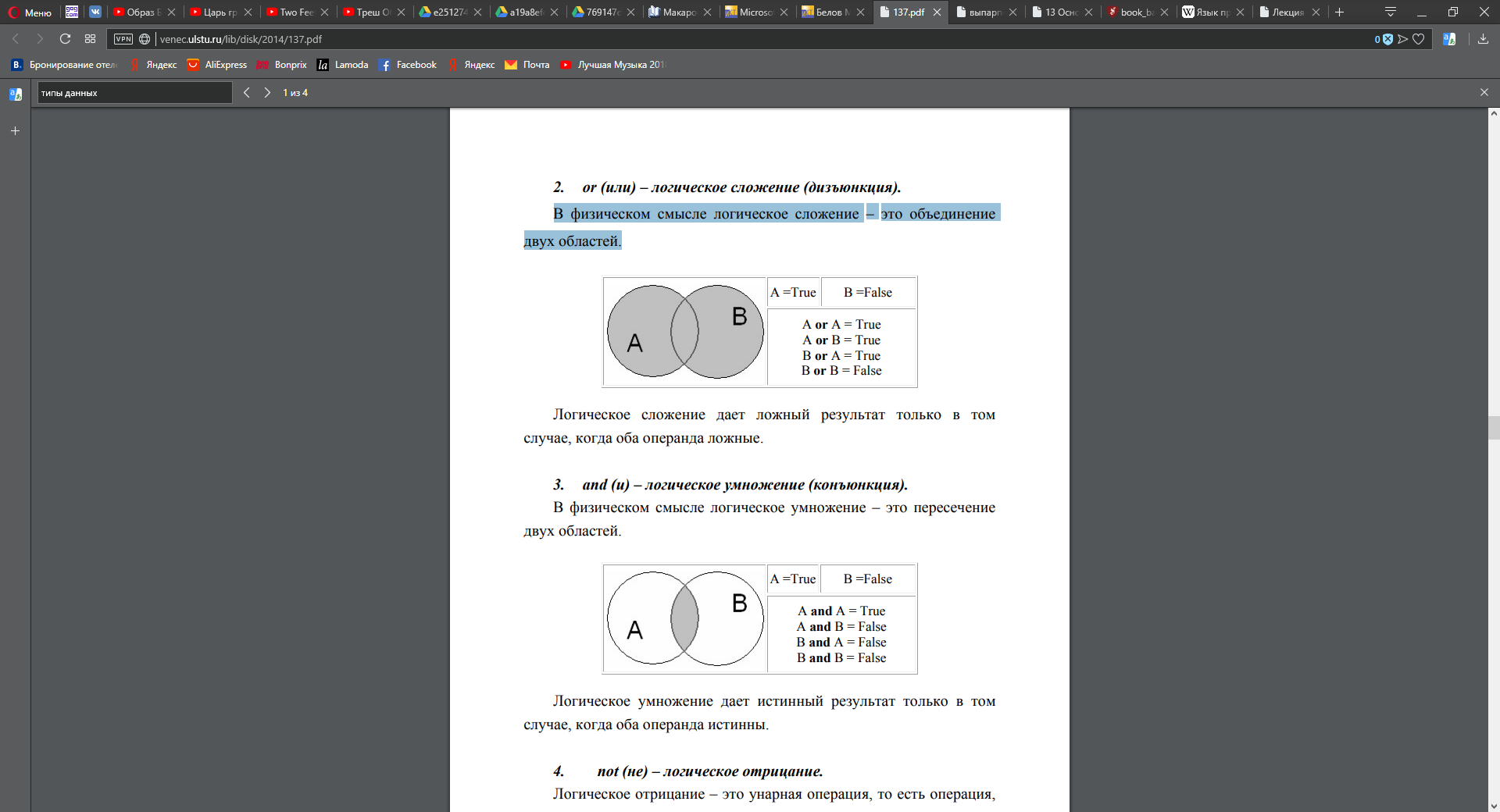
Логическое сложение дает ложный результат только в том случае, когда оба операнда ложные.
3. and (и) – логическое умножение (конъюнкция).
В физическом смысле логическое умножение – это пересечение двух областей.
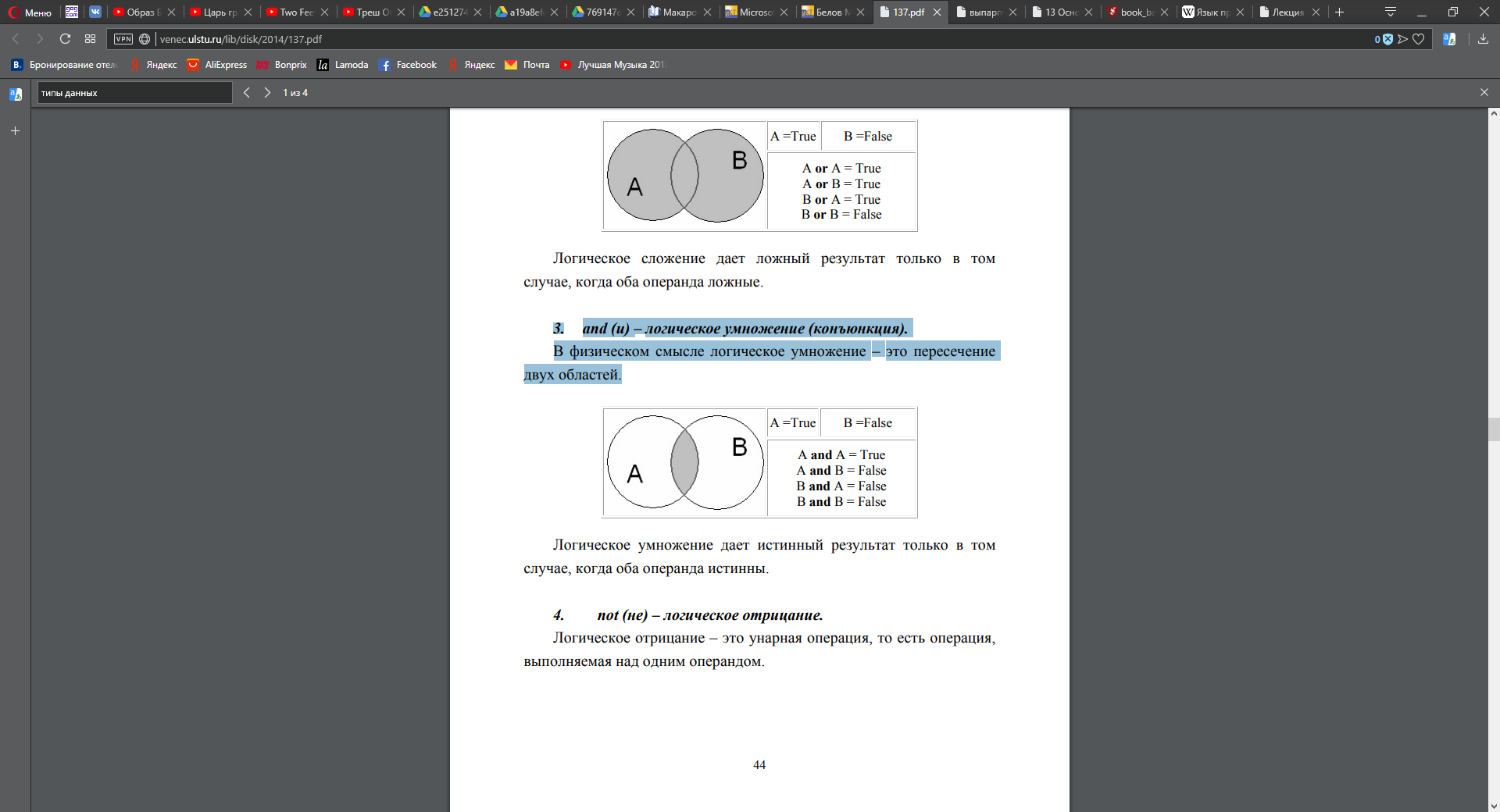
Логическое умножение дает истинный результат только в том случае, когда оба операнда истинны.
4. not (не) – логическое отрицание.
Логическое отрицание – это унарная операция, то есть операция, выполняемая над одним операндом.
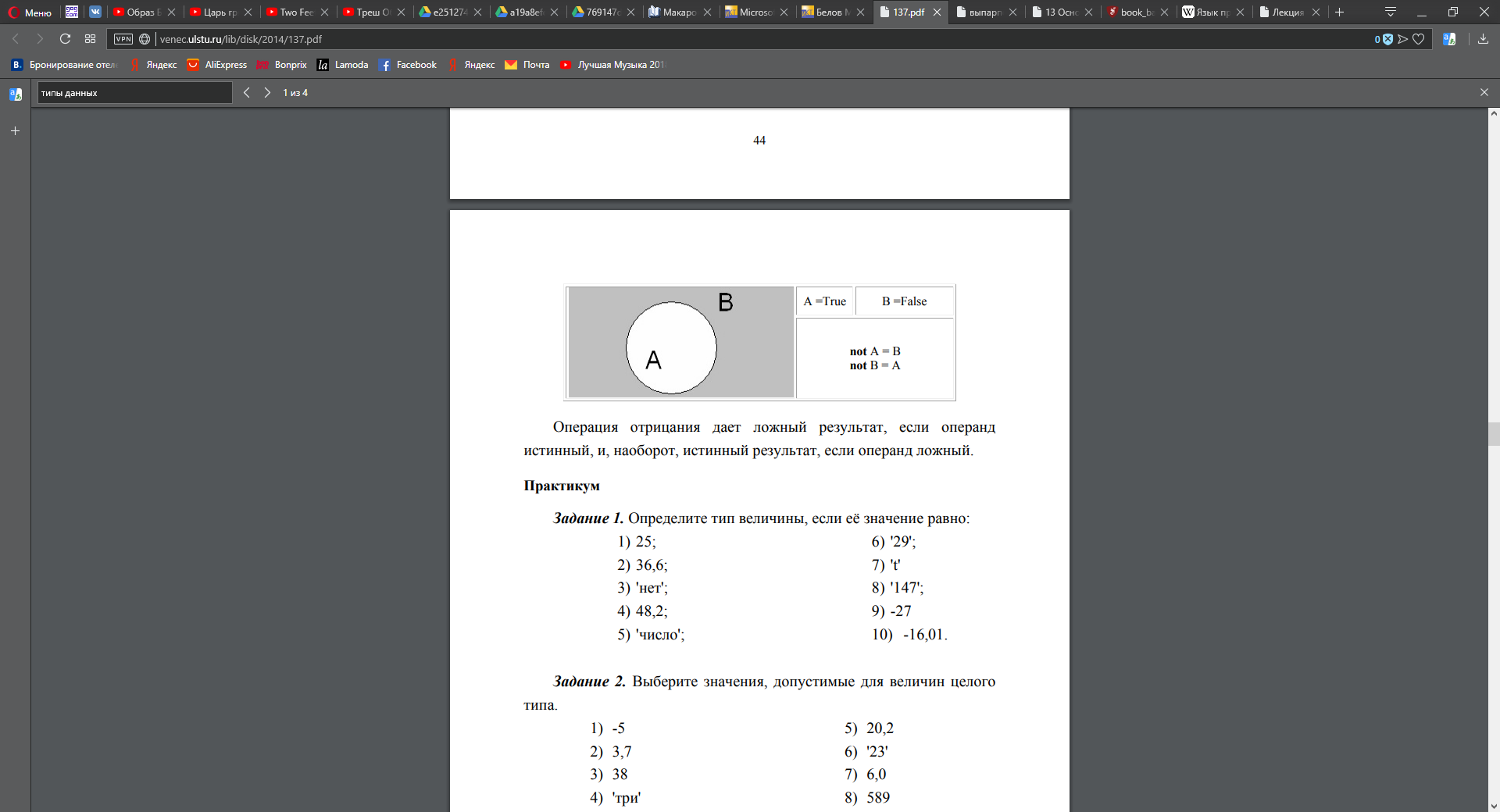
Операция отрицания дает ложный результат, если операнд истинный, и, наоборот, истинный результат, если операнд ложный.
Тема 18. Рекурсивные и итерационные алгоритмы: особенности и примеры использования
18.1. Рекурсивные алгоритмы
Рекурсия – фундаментальное понятие в математике и компьютерных науках. В языках программирования рекурсивной программой называется программа, которая обращается сама к себе (подобно тому, как в математике рекурсивная функция определяется через понятия самой этой функции). Рекурсивная программа не может вызывать себя до бесконечности, следовательно, вторая важная особенность рекурсивной программы – наличие условия завершения, позволяющее программе прекратить вызывать себя.
Таким образом рекурсия в программировании может быть определена как сведение задачи к такой же задаче, но манипулирующей более простыми данными.
Как следствие, рекурсивная программа должна иметь как минимум два пути выполнения, один из которых предполагает рекурсивный вызов (случай «сложных» данных), а второй – без рекурсивного вызова (случай «простых» данных).
Примеры рекурсивных программ. В ряде случаев рекурсивную подпрограмму можно построить непосредственно из формального математического описания задачи.
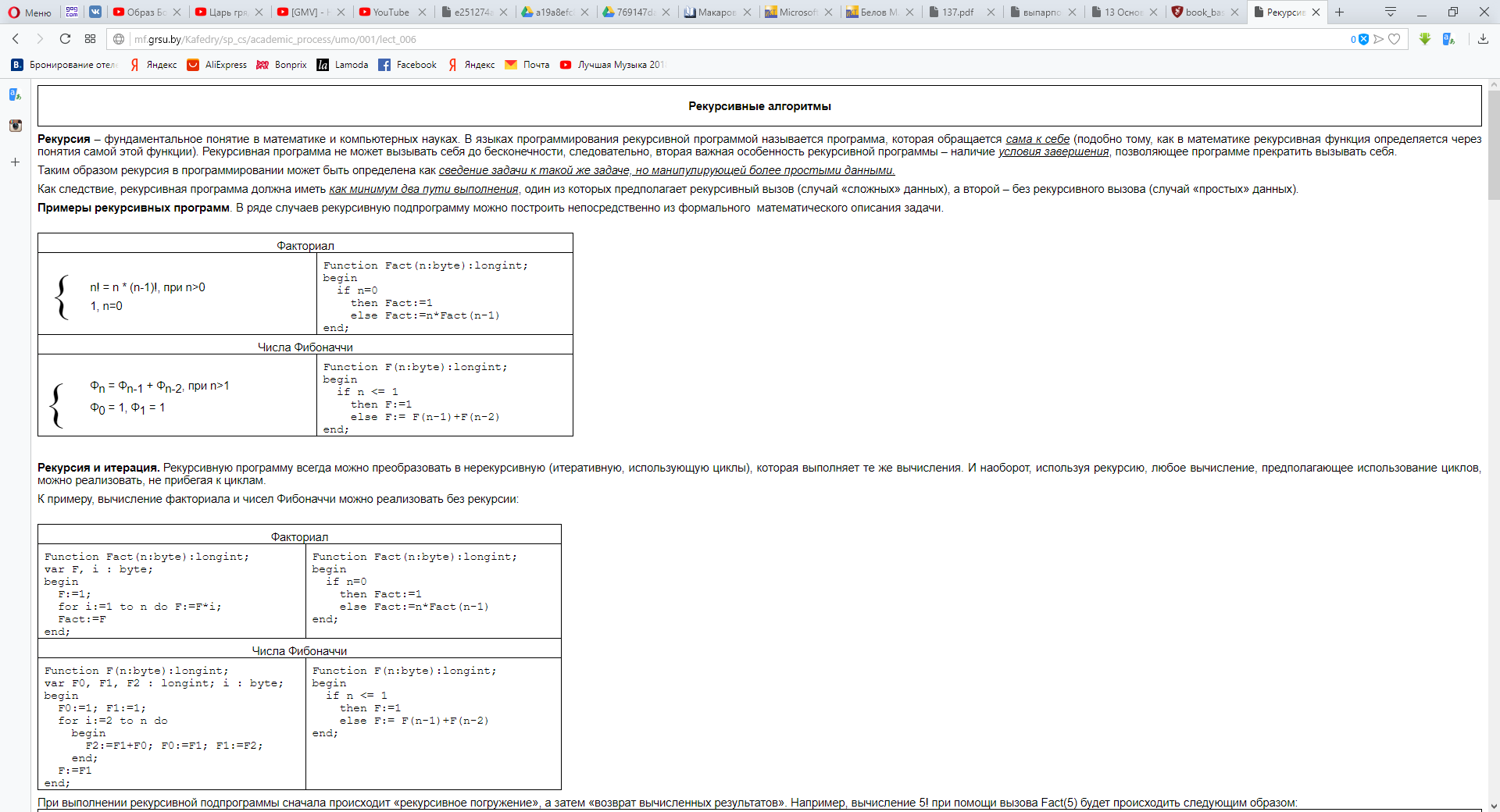
18.2. Рекурсия и итерация
Рекурсивную программу всегда можно преобразовать в нерекурсивную (итер ативную, использующую циклы), которая выполняет те же вычисления. И наоборот, используя рекурсию, любое вычисление, предполагающее использование циклов, можно реализовать, не прибегая к циклам.
К примеру, вычисление факториала и чисел Фибоначчи можно реализовать без рекурсии:
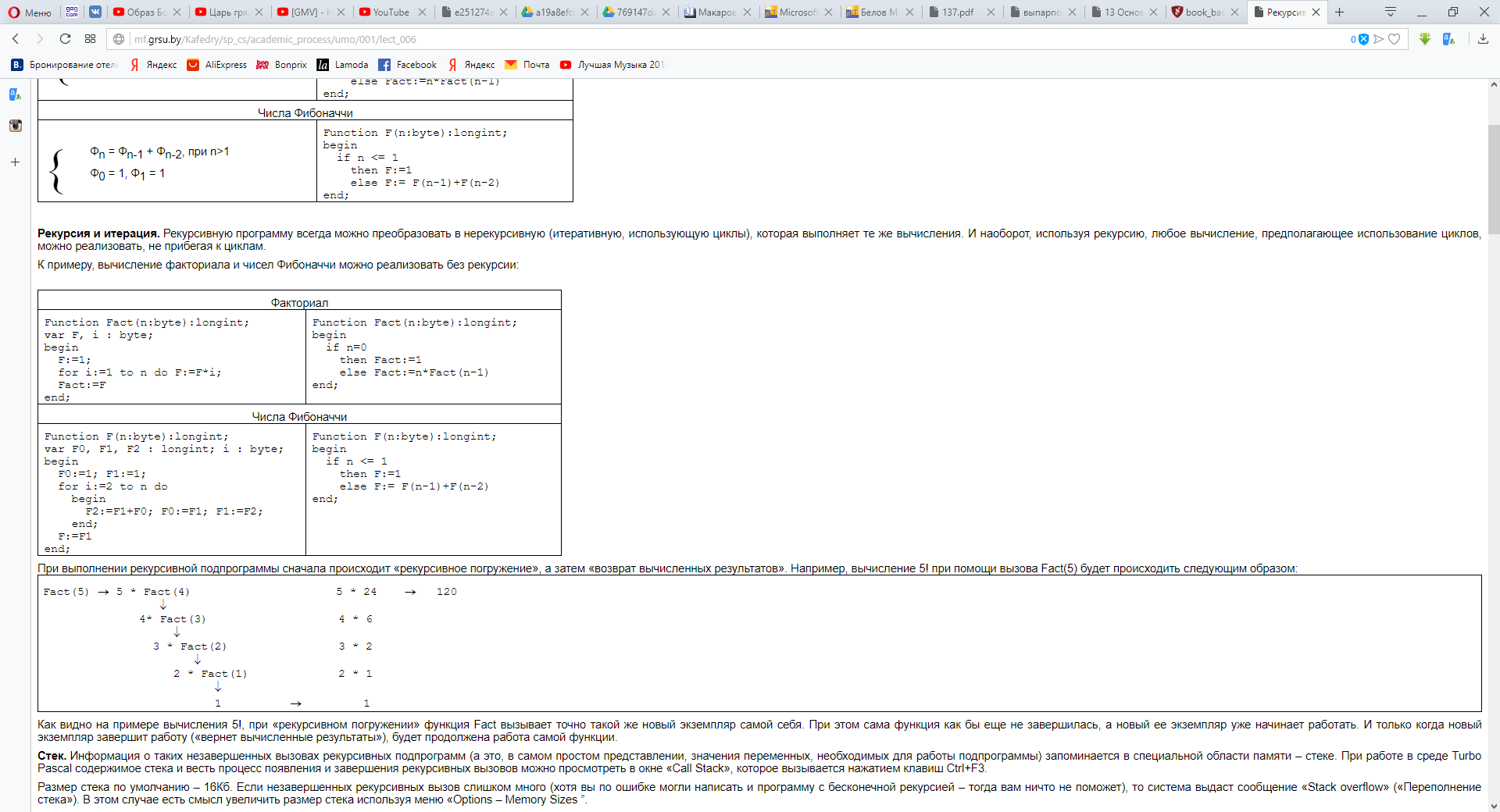
При выполнении рекурсивной подпрограммы сначала происходит «рекурсивное погружение», а затем «возврат вычисленных результатов». Например, вычисление 5! при помощи вызова Fact(5) будет происходить следующим образом:
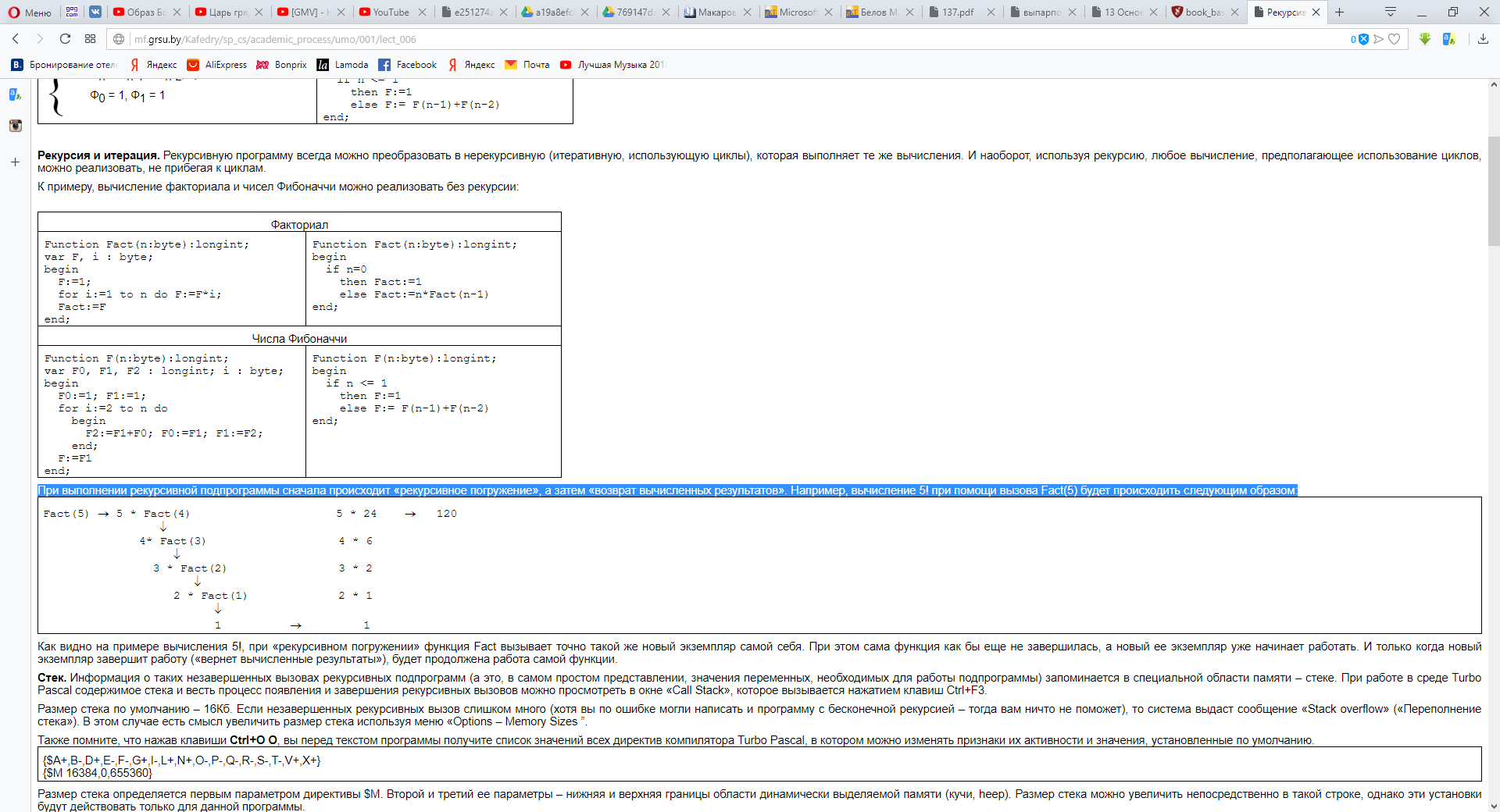
Как видно на примере вычисления 5!, при «рекурсивном погружении» функция Fact вызывает точно такой же новый экземпляр самой себя. При этом сама функция как бы еще не завершилась, а новый ее экземпляр уже начинает работать. И только когда новый экземпляр завершит работу («вернет вычисленные результаты»), будет продолжена работа самой функции.
Тема 19. Классификация языков программирования высокого уровня.
19.1. Примеры языков высокого уровня
Fortran. Первый компилируемый язык созданный Джимом Бэкусом в 50-е годы. Для этого языка было создано огромное количество библиотек, начиная от статических комплексов и кончая пакетами управления спутниками, поэтому Fortran продолжает активно использоваться во многих организациях, а сейчас ведутся работы над очередным стандартом Фортрана F2k, который появился в 2000 году. Имеется стандартная версия Фортрана HPF (High Perfomance Fortran) для параллельных супер компьютеров со множеством процессоров.
Cobol. Это компилируемый язык для применения в экономической области и решения бизнес-задач, разработанный в начале 60-х г. Он отличается большой "многословностью" – его операторы выглядят как обычные английские фразы. В Коболе были реализованы очень мощные средства работы с большими объемами данных, хранящимися на различных внешних носителях. На этом языке создано много различных приложений, которые активно эксплуатируются и сегодня. Достаточно сказать, что наибольшую зарплату в США получают программисты на Коболе.
Algol. Компилируемый язык, созданный в 1960 году. Он был призван заменить Фортран, но из-за более сложной структуры не получил широкого распространения. В 1968 году была создана версия Алгол68,по своим возможностям опережающая и сегодня многие языки программирования, однако из-за отсутствия достаточно эффективных компьютеров для нее не удалось своевременно создать хорошие компиляторы.
Pascal. Язык Паскаль, созданный в конце 70-х годов основоположником множества идей современного программирования Николаусом Виртом, во многом напоминает Алгол, но в нем ужесточен ряд требований к структуре программы и имеются возможности, позволяющие успешно применять его при создании крупных проектов.
Basic. Для этого языка имеются и компиляторы, и интерпретаторы, а по популярности он занимает первое место в мире. Он создавался в конце 60-х годов в качестве учебного пособия и очень прост в изучении.
C. Данный язык был создан в лаборатории Bell и первоначально не рассматривался как массовый. Он планировался для замены ассемблера, чтобы иметь возможность создавать столь же эффективные и компактные программы, и в то же время не зависеть от конкретного вида процессора.
C++. Это объектно-ориентированное расширения языка Си, созданное Бьярном Страуструпом в 1980 году. Множество новых мощных возможностей, позволивших резко увеличить производительность программистов, наложилось на унаследованную от языка Си определенную низкоуровневость, в результате чего создание сложных и надежных программ потребовало от разработчиков высокого уровня профессиональной подготовки.
Java. Этот язык был создан компанией Sun в начале 60-х годов на основе Си++. Он призван упростить разработку приложений на основе Си++ путем исключения из него всех низкоуровневых возможностей. Но главная особенность этого языка – компиляция не в машинный код, а в платформо-независимый байт-код. Этот байт-код может выполнятся с помощью интерпритатора-виртуальной машины Javа-машины JVM (Java Virtyal Machine), версии которой созданы сегодня для любых платформ. Благодаря наличию Java-машин программы на Java можно переносить не только на уровне исходных текстов, но и на уровне обычного байткода, поэтому по популярности язык Ява сегодня занимает второе место в мире после Бейсика.
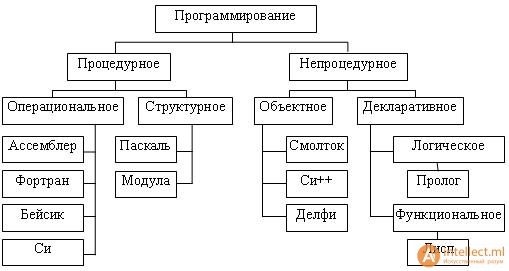
Рис.3. Классификация языков программирования
Тема 20. Сравнительный анализ операторов для различных языков программирования.
20.1. Сравнение языков программирования
Следует отличать язык программирования (Basic, Pascal) от его реализации, которая обычно представлена в составе среды программирования (Quick Basic, Virtual Pascal) − набора средств для редактирования исходных текстов, генерации исполняемого кода, отладки, управления проектами и т.д. Синтаксис и семантика языка программирования фиксируется в стандарте языка. Каждая среда программирования предоставляет свой интерпретатор или компилятор с этого языка, который зачастую допускает использование конструкций, не фиксированных в стандарте.
Существенна цель, для реализации которой выбирается язык – либо для обучения программированию, либо для решения конкретной прикладной задачи. В первом случае язык должен быть простым для понимания, строгим и по возможности лишенным "подводных камней". Во втором − пусть сложным, но эффективным и выразительным инструментом для профессионала.
Конечно, на практике обучение не может быть отделимо от реальных задач. Так называемые учебные задачи чаще всего страдают излишней абстрактностью и неприменимостью в жизни. Освоение языка (или среды программирования) само по себе не может считаться задачей, точнее − это очень непродуктивный подход. Эффективное освоение языка возможно только на реальных примерах. С другой стороны, программирование решения полноценной проблемы «из жизни» на начальном этапе освоения языка оказывается непосильной ношей, которая может отпугнуть, а не заинтересовать.
При решении конкретной прикладной задачи в большинстве случаев язык и среда программирования не выбираются, а задаются извне − заказчиком, руководителем и т.п. В том же редком случае, когда возможен выбор, исходить, на мой взгляд, следует из следующих условий (в порядке приоритета):
а) характера самой задачи и технических требований;
б) наработанного инструментария и имеющихся для данной среды библиотек;
в) имеющихся в языке и среде программирования инструментальных средств.
Зачастую при подобном выборе поступают строго наоборот: сначала решают, что программировать будут на объектах, затем − что использоваться будет конкретная библиотека, а потом подгоняют под это технические требования, объясняя все это тем, что заказчик «не знает чего хочет».
Применимость языка для той или иной задачи зависит от того, каким набором понятий профессионал оперирует, в рамках каких концепций (парадигм) он позволяет работать, какие имеются стандартные и распространенные пользовательские библиотеки и т.д.
По набору понятий языки подразделяются на высоко− и низкоуровневые. Первые предоставляют высокий уровень абстракции от оборудования, вторые − низкий, приближенный к машинному.
С точки зрения того, внесены ли в набор понятий особые, специфичные для предметной области объекты, языки делятся на универсальные (процедурные) и специализированные. К последним можно отнести Prolog, Lisp. Универсальные языки позволяют реализовать любой алгоритм, пользуясь стандартным набором конструкций. Благодаря этому, код на таком языке может быть достаточно легко перенесен из одного процедурного языка в другой при помощи консервативных изменений.
Приведем основные концепции, внесенные в те или иные общеупотребительные языки и связанные с ними понятия: типизации и структуры данных. Любой язык характеризуется набором базовых типов, возможностями по пополнению этого набора при помощи ряда конструкторов: массив, запись (структура), объединение. В некоторых языках имеется универсальный тип (Variant в Delphi и Visual Basic), свободно используемый как любой из базовых типов. Степень контроля типов может быть очень разной − от полного отсутствия до крайне жесткого. Важно наличие (возможно, в виде библиотеки) структур данных переменной длины, например, динамических массивов.
Тема 21. Сравнительный анализ процедур для различных языков программирования.
21.1. Процедурные языки
С точки зрения того, внесены ли в набор понятий особые, специфичные для предметной области объекты, языки делятся на универсальные (процедурные) и специализированные. К последним можно отнести Prolog, Lisp. Универсальные языки позволяют реализовать любой алгоритм, пользуясь стандартным набором конструкций. Благодаря этому, код на таком языке может быть достаточно легко перенесен из одного процедурного языка в другой при помощи консервативных изменений.
Приведем основные концепции, внесенные в те или иные общеупотребительные языки и связанные с ними понятия: типизации и структуры данных. Любой язык характеризуется набором базовых типов, возможностями по пополнению этого набора при помощи ряда конструкторов: массив, запись (структура), объединение. В некоторых языках имеется универсальный тип (Variant в Delphi и Visual Basic), свободно используемый как любой из базовых типов. Степень контроля типов может быть очень разной − от полного отсутствия до крайне жесткого. Важно наличие (возможно, в виде библиотеки) структур данных переменной длины, например, динамических массивов.
Различия в языках сводятся к способам определения процедур и функций, вариантам передачи параметров, возможностям определения рекурсивных процедур и наличию процедурного типа данных.
Наличие и широкая классификация типов памяти дает возможность эффективно управлять ее распределением, но и вносит сложность, требующую от программиста более внимательного отношения. Обычно выделяют (максимальный спектр): регистры, глобальные, локальные и динамические переменные.
Наличие средств логического объединения группы процедур, функций, переменных позволяет работать с большими проектами, упрощая их структуру. Важное свойство − возможность описания процедур инициации и завершения модуля.
Объединение структур и методов их обработки (инкапсуляция) создает значительные удобства при программировании. Возможность наследования позволяет привести в систему набор структур. Автоматически вызываемые конструкторы и деструкторы упрощают отслеживание взаимосвязей. Все это составляет удобный инструмент для описания понятий и действий прикладной программы.
Независимость от аппаратуры, реализуемая при помощи семантики, не зависящей от конкретной машины и внесением в язык ряда специфичных понятий – таких, как базовый тип с нефиксированным размером (int в C)
Тема 22. Сравнительный анализ описания данных для различных языков программирования.
22.1. Анализ
В основе языка C − требования системного программиста: полный и эффективный доступ ко всем ресурсам компьютера, средства программирования высокого уровня, переносимость программ между различными платформами и операционными системами. С++, сохраняя совместимость с C, вносит возможности объектно−ориентированного программирования, выражая идею класса (объекта) как определяемого пользователем типа. Благодаря перечисленным качествам, C/C++ занял позицию универсального языка для любых задач. Но его применение может стать неэффективным там, где требуется получить готовый к употреблению результат в кратчайшие сроки, либо там, где невыгодным становится сам процедурный подход.
Для реализации проекта построения нейросетевой модели для прогнозирования временных рядов финансовых данных на базе многослой ного персептрона, обученного по алгоритму обратного распространения ошибки (а также формализации полной схемы применения данной модели для анализа и прогнозирования временных рядов на примере котировок ак ций российских эмитентов на ММВБ) выбрана среда разработки С++ Builder 2010, так как она сочетает в себе функциональность и хорошую скорость работы программ сделанных на С++, а также позволяют в кратчайшие сроки создать рабочую программу из готовых компонентов, не растрачивая массу усилий на мелочи.
Список литературы для написания курсовой работы по дисциплине
«Основы алгоритмизации и программирования»
1. Основы алгоритмизации и программирования: учеб. пособие / Т.А.Жданова, Ю.С. Бузыкова. – Хабаровск : Изд-во Тихоокеан. гос.ун-та, 2011. –56 с. Режим доступа:
http://pnu.edu.ru/media/filer_public/2013/02/25/book_basics.pdf.
2. Программирование и основы алгоритмизации: Для инженерных
специальностей технических университетов и вузов. /А.Г. Аузяк, Ю.А.Богомолов, А.И. Маликов, Б.А. Старостин. Казань: Изд-во Казанского национального исследовательского технического ун-та - КАИ, 2013, 153 с. Режим доступа: http://au.kai.ru/documents/Auzyak_Progr_osn_alg_C_2013.pdf.
3. Основы алгоритмизации и программирования : учебное пособие / Г.Р. Кадырова. – Ульяновск : УлГТУ, 2014. – 95 с. . Режим доступа:
http://venec.ulstu.ru/lib/disk/2014/137.pdf
4. Основы алгоритмизации и программирования. Курс лекций. Режим доступа:
http://lib.ssga.ru/fulltext/UMK/исходные%20для%20Кацко/заменить%20полностью/Информатика/лекции/13%20Основы%20алгоритмизации%20и%20программирования.pdf
5. Белов П.М. Основы алгоритмизации в информационных системах: Учебн. Пособие.- Спб.: СЗТУ, 2003. – 85с. Режим доступа:
http://www.ict.edu.ru/ft/005406/nwpi225.pdf
6. Основы алгоритмизации и программирования: Метод. указ. / Сост.: И.П. Рак, А.В. Терехов, А.В. Селезнев. Тамбов: Изд-во Тамб. гос. техн. ун-та. Режим доступа: http://www.ict.edu.ru/ft/004758/terehov.pdf.
7. Макаров В.Л. Программирование и основы алгоритмизации.: учебн. пособие.-Спб., СЗТУ, 2003, - 110с. Режим доступа:
http://window.edu.ru/resource/126/25126/files/nwpi223.pdf

- Организационная культура и ее роль в современных организациях (АО "Феррум")
- Основные факторы формирования конструктивного взаимодействия родителей и детей раннего возраста (Условия развития взаимодействия родителей и ребенка раннего возраста)
- ЭФФЕКТИВНОСТЬ МЕНЕДЖМЕНТА ОРГАНИЗАЦИИ (ООО «Монолит-ПСК-7»)
- Типографика журнала «Esquire»
- Обзорная характеристика теорий происхождения государства
- «Государственное социальное страхование»(Функции, место и роль социального страхования в системе современной социальной защиты населения )
- Правовая культура. Правовой нигилизм и правовой фетишизм(Понятие правовой культуры)
- РАСПРЕДЕЛЕНИЕ И ИСПОЛЬЗОВАНИЕ ПРИБЫЛИ КАК ИСТОЧНИК ЭКОНОМИЧЕСКОГО РОСТА ФИРМ
- Менеджмент человеческих ресурсов в РФ
- Законность и правопорядок( Законность и правопорядок как правовые категории)
- Понятие социального обслуживания (МБУ «Комплексный центр социального обслуживания населения» г. Заречного Пензенской области)
- Правовые отношения особый вид общественных отношений