
Основы программирования на языке Pascal ( Машинный язык )
Содержание:

НЕГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ ЧАСТНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«МОСКОВСКИЙ ФИНАНСОВО-ПРОМЫШЛЕННЫЙ «УНИВЕРСИТЕТ УНИВЕРСИТЕТ»
Факультет электронного обучения
курсовая работа
по дисциплине
«Технологии программирования»
на тему
«Основы программирования на языке Pascal»
|
Работу выполнил (а) студент (ка) |
|
группы ОБМ-1706МБам |
|
Направление подготовки: Менеджмент |
|
Профиль: Управление человеческими ресурсами |
|
Байрамов Илгар |
|
Научный руководитель: |
МОСКВА
2018
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ………………………………………………………………………..3
Глава 1. Классификация языков программирования……………………...6
1.1. Машинный язык……………………………………………………………...6
1.2. Машинно-ориентированные языки…………………………………………8
1.3. Машинно-независимые языки……………………………………………….9
1.4. Языки символического кодирования……………………………………....10
1.5. Автокоды…………………………………………………………………….10
1.6. Макрос……………………………………………………………………….11
1.7.Диалоговые языки…………………………………………………………...12
1.8.Непроцедурные языки………………………………………………………13
1.9 Универсальные языки……………………………………………………….14
Глава 2. Линейные списочные структуры…………………………………15
2.1. Однонаправленный и двунаправленный список………………………….17
2.2. Очередь………………………………………………………………………18
2.3. Стек…………………………………………………………………………..19
2.4. Дек…………………………………………………………………………..21
Глава 3. Операции над списочными структурами………………………...23
3.1 Структуры памяти…………………………………………………………..23
3.2 Представления списков через списочные ячейки………………………...24
3.3 Представления списков через точечную пару……………………………..24
3.4 Списочная ячейка и базовые функции……………………………………..25
3.5 Переменные списки………………………………………………………….26
3.6 Использование разрушающих функций……………………………………26
Заключение……………………………………………………………………...28
Список использованной литературы………………………………………..30
Введение
Множество языков программирования, они предназначены, для написания программ. Программа – алгоритм, который представляет собой язык, который понимает система операционной системы для исполнения. В набор языков программирования входит лексический, синтаксический, семантический эти правила используются для создания компьютерной программы. Всё это помогает определить, то что будет срабатывать, каким образом будут сохраняться и передаваться данные, так же, будет обратить внимание на действия, что будет выполнять написанная программа.
С того дня когда была создана первая программируемая машина, программисты написали более 8,5 тысяч языков программирования, но на этом точку никто не ставит, число языков программирования только растёт. Существуют языки, которыми могут пользоваться исключительно люди которыми он был написан, но многие языки программирования становятся знаменитыми на весь мир. Профессионалы примерно используют от 2 до 5 языков программирования.
Сам язык программирования предназначен для – написания программ, они предназначены для передачи определённому компьютеру какой либо инструкции к выполнению какого либо процесса или для управления отдельным устройством или оборудованием.
Задачи для языков программирования бывают различными, язык программирования от естественного отличается лишь тем, что он предназначен для передачи какой либо команды вычислительной машине от человека, а естественные язык люди используют только для передачи какого либо сообщения или общения. То есть, язык программирования осуществляет передачу информации, команды, или какого либо действия от человека к ЭВМ, в то время как человеческий язык служит для того чтобы обменяться информацией.
Исполнение языков программирования использует специальные конструкции для манипулирования, определения структур данных, а так же управление процессом вычислительных действий.
Первые языки программирования, были очень примитивны, они ни чем не отличались от обычных единиц и нулей, которые может разобрать компьютер. Использование таких языков программирования, было крайне не удобно, так как программисту приходилось знать машинный код каждой ЭВМ и умело расставить команды, для того чтобы компьютер смог воспроизвести его. Первым языком, который помог облегчить работу программистам был Ассемблер. В этом языке, то что раньше отображалось цифрами, отображалось символами. То есть числа просто на просто, заменили на символы, их на много проще запомнить и работать с ними. Язык Фортран был одним из первых языков программирования, его написали в 50-х годах, и до сих пор он является одним из самых распространённых языков программирования. Этот язык, больше использовали люди работа которых сводилась, к инженерии, строительству, решение задач по физике и многих других наук, где работа велась с вычислением.
Так же для работы с экономическими проблемами был создан язык, под названием Кобол. Был объявлен конкурс в 1968 г. на лучший язык программирования. Язык программирования названый Алгол-68 победил в этом конкурсе, но большой популярностью так он и пользовался. После чего, Никлаус Вирт, это создатель языка Паскаль, создал более простой и быстрый язык программирования. В данное время этот язык является одним из самых распространённых языков программирования.
Для школ был создан ещё более простой язык, с которым можно было вести целый диалог его назвали Бэйсик, на текущее время, его используют для ознакомления с языками программирования. Когда человек вступил на новую ступень программирования, это потребовало написание более сложных программ, которые могли бы управлять работой ЭВМ, что привело к написанию языка программирования Си, он появился в начале 70-х годов. Этот язык является самым универсальным языком программирования. Про язык Си можно сказать одно – он самый простой и универсальный язык для написания программ, программы которые написаны на этом языке по скорости ни чем не уступают программ написанным на языке программирования Ассемблер.
Есть всего пару подходов для определения языка программирования.
Часто используемые языки программирования: Денудационного (математического), Деривационного (аксиоматического), Операционного.
Когда описывается операционный подход исполняется языки программирования с помощью которых интерпретация воображаемых ЭВМ.
Последствие Деривационной семантики можно описать как конструкцию языка с помощью логики. В то время как Денудационная семантика типична для математических исчислений
Актуальность темы исследования заключается в том, что для повышения эффективности программы ссылочный тип данных необходим при работе с данными различного размера и структуры.
Объект исследования – структуры данных языка программирования Паскаль. Предмет исследования – ссылочный тип данных языка программирования Паскаль.
Цель курсовой работы заключается в расширении и систематизации теоретических знаний по теме: «Создание ссылочных типов в языке программирования Паскаль».
Задач исследования:
- изучение классификацию языков программирования;
- рассмотреть линейные списочные структуры;
- исследовать операции над списочными структурами;
- рассмотреть использование разрушающих функций.
Глава 1. Классификация языков программирования
Представление языков программирования может быть в виде набора спецификаций которые определяет их по синтаксису и семантику.
Для языков программирования, которые пользуются большим спросом создаются стандарты. Эти организации проводят, проверки, обновления и публикации специальных и формальных видов языка. [2, с.27]
Сами языки программирования могут строиться только по той или иной модели вычислений программирования.
Множество языков программирования больше всего уделяют внимание на императивную модель вычислений, но так же существуют и множество других подходов. Существуют языки со стековой вычислительной моделью, а так же логические и функциональные языки программирования, которые ввёл ещё советский математик Марков А.А.
В данный момент развитие берёт проблемно – ориентированные и визуальные языки программирования.
В рамки эти организаций так же входят разработки и модернизации, поддержка языков программирования которые в этом нуждаются.
1.1. Машинный язык
У каждого компьютера имеется свой машинный язык, который является индивидуальным, машинные языки являются командными. Но бывают такие виды компьютеров такие как «IMB, 370, EC ЭВМ» имеют единый язык для компьютеров у которых мощность отличается друг от друга. [14, с.27]
Подразделение языков программирование может быть компилируемыми и интерпретируемыми.
На самом компилируемом языке специальная программа под названием «компилятор» преобразует действие под машинный код, после чего записывается в исполнимый модуль, так же он может быть запущен совершенно отдельно. Одним словом, компилятор осуществляет перевод с языка высокого уровня на язык который распознаёт двоичный процессор.
Если же программа написана на языке под названием «интерпретатор», то перевод осуществлён не будет, а сразу перейдёт к выполнению. Но при этом без запуска интерпретатора программу нельзя будет запустить. Сам процессор компьютера, по сути и есть интерпретатор машинного кода.
Говоря о компиляторе, то он по сути просто переводит исходный текс программы на машинный либо сразу, либо целиком, но при этом создаётся совершенно отдельная программа, а потом уже интерпретатор будет выполнять свою работу во время выполнения процесса.
Само разделение языков на «Компилируемые» и «Интерпретируемые» называется условным. Например для языка «Паскаль» будет возможно написать интерпретатор, так как язык считает традиционным в направлении программирования. Современные интерпретаторы например не посредственно не выполняют условия языка, происходит компиляция в промежуточное время. [1, с.7]
Язык который является интерпретируемым уже может быть скомпилирован, пример можно привести на языке «Лисп», с момента создания, он был интерпретируемым, и у него нет ограничений по компиляции.
При компиляции создаётся код, который во время исполнения может динамически меняться во время исполнения программного хода.
Обычно программы, которые прошли компилятор, работают на много лучше, нежели программы не прошедшие его. Такие программы не требуют дополнительных программ для улучшения работоспособности, так как они уже переведены на машинный язык.
Если при написании программы, будет изменена хоть одна буква, символ или знак, то программа будет нуждаться в повторной компиляции, это обычные трудности при создании программ. Скомпилированная программа может работать в той же системе, в который была скомпилирована, и под той же производительностью компьютера. Но для того чтобы создать новый код, придётся заново компилировать программу.
Некоторые интерпретируемые языки обладают хорошими возможностями, то есть программу которую вы пишите можно запустить, для просмотра ваших ошибок, что облегчает работу. Программа, которая прошла интерпретацию может быть запущена на любом компьютере и на любой операционной системе, без как либо дополнительных действий.
Интерпретируемые программы по работоспособности уступают программам прошедшим компилятор, да и без дополнительных программ они могут вообще не работать. [5, с.2]
Такие языки как: Java и С#, они стоят между интерпретируемым и компилируемым языком. То есть эти языки компилируются не в машинный язык, а в независимый машинный код низкого уровня (байт-код). После (байт-код ) чего он проходит виртуальную машину. Для того чтобы получить байт-код нужно пройти интерпретацию, хотя некоторые его части могут быть интерпретированы в машинный код сразу во время выполнения работы для её ускорения, это всё происходит по теории компиляции «на лету».
Такой подход помогает использовать плюсы как интерпретатора так и компилятора. Имеется язык под название «Форт» он имеет и интерпретатор и компилятор. Но вот уже компьютеры нового поколения, имеют на много больше способностей чтения языков программирования.
1.2. Машинно-ориентированные языки
Машинно-ориентированные языки – это язык у которого набор операторов будет работать в зависимости от того какова производительность компьютера.
Языки программирования, рассчитаны на использование всех символов ASCII, это необходимо для написания любого языка. Управляющие символы могут использоваться в ограниченном порядке, имеются исключения для следующих символов символ CR, для возврата «Каретки», горизонтальная табуляция HT, перевод строки CF.
Языка возникшие в эпоху 6-битных символов очень ограниченный набор символов. Так называемый алфавит Фортрана имеет всего 49 символов. Исключение имеет лишь язык APL, в нём имеется множество символов специализирующих какую либо функцию.
От реализации зависит использование кода на языках «Юникод», KOI8-R, это разрешается только в комментариях, строковых константах, символьных. Во время СССР был написан язык, в котором все символы состояли из русских букв, но особого признания такой язык не получил, единственное исключение для встроенного языка 1C:Предприятие.
Так как проекты по написанию языков сдерживаются международным стандартом, этим и задерживается число используемых символов. Если бы каждый писал свой код, на своём языке было бы очень сложно писать программы. [6, с.27]
Это самый лучший язык программирования, при котором задействуются все способности компьютера и его параметры:
Машинно-ориентированные языки подразделяются на классы.
1.3. Машинно-независимые языки
Машино-независимые языки – служит для описания алгоритмов, решение задач, которые подлежат обработке. Эти языки программирования не требуют особых знаний и навыков, то есть доступны для широкого круга пользователей.
Языки подобные этому получили название «Высокоуровневых языков» программирования. Программы написанные на этом языке выполняются последовательностью оператора, согласно написанным языком. Т о есть система будет выполнять те действия которые описаны в программе для трансляции.
Последовательность команд часто используется в машинных программах, которые используются операторами в «высокоуровневых языка». Тем самым программисты теперь могут не задерживаться и не расписывать по строчно процесс который он выполнял для машинных команд, а начать работу именно в особенности алгоритма.
1.4.Языки символического кодирования
Язык символического кодирования, так же относится к командным языкам. Коды представляют собой либо двоичную либо восьмеричную систему исчисления, эти коды используются для написания программ. Индикаторы заменены на коды, что помогает и облегчает написание программ, да и после легко запомнить смысл операции. [7, с.52]
Это уменьшает число ошибок при составлении программы. Первым шагом к созданию символических языков, является использование символических адресов. Вместо реальных адресов команды подаваемые ЭВМ содержат символические адреса. Количество ячеек, которое потребуется для хранения данных, будет видно по результатам составленной программы. Исполнение и назначение адресов, может выполнить программист который владеет минимальным набором знаний, порой это делается для того чтобы ускорить и снизить нагрузку на программиста.
1.5. Автокоды
Автокод – это язык, который включает в себя все возможности программирования «языка символического кодирования», это выполняется путём введения макрокоманд - это уже называется автокод.
В каждой программе встречаются последовательности которые упоминаются наиболее часто, которые способствуют преобразованию информации. Реализация таких макрокоманд помогает оформлять их в язык программирования, доступный только программисту. Есть два пути, которые переводят макрокоманду в машинные коды:
- Расстановка
- Генерирование.
Содержание «Остов» так называемые серии команд, исполняют функцию требуемую макрокомандой. Макрокоманды необходимы для передачи параметров, которые путём подстановки в «остов», преобразуют её в программу для ЭВМ.
Специальные программы помогают анализировать макрокоманду, эти программы выявляют последовательность команд и выполняют работу по их реализации. [22, с.27]
Две системы указанных выше используют тот же набор команд и являются операторами автокода.
Например язык программирования «Ассемблер» является автокодом. Программы в которых выполняются функции сервиса программируются на «Ассемблере».
1.6.Макрос
Этот язык используют для замены последовательности символов, для того чтобы описать очерёдность выполнения действий ЭВМ в более сжатую форму, это и называется «Макрос».
Главное преимущество «интерпретаторов» состоит лишь в том, что его режим работы выполняется в «непосредственном режиме». Суть «непосредственного режима, заключается в том, что с помощью него мы можем задать действия компьютеру, после чего мы получаем ответ, на наш запрос. Например обработку данных можно прервать в любой момент, для просмотра переменных, а уже после чего, можно продолжать работу.
Ещё один из больших плюсов работы интерпретатора, это то, что ответ можно получить в считанные секунды. Интерпретируемые программы не нуждаются в компиляции, потому как вмешательство в программу можно выполнить в любое время. При вводе команды «RUN» на экране отобразиться ваше последнее действие в данном разделе.
По мимо плюсов, так же имеются и минусы у интерпретируемых программ. Потому как для нормальное работы, нужно всегда иметь копию интерпретатора в памяти.
После обработки на интерпретаторе, плохо обрабатывается программа в других стилях программирования. Так как комментарии занимают много места в памяти компьютера, программисты предпочитают не пользоваться этим. Скорость работы интерпретатора очень низкая, он очень долго определяется в действиях.
При записи данных, интерпретатор сканирует каждый сектор программы после чего можно будет произвести чтение, и выполнение действий. [13, с.10]
Одно из предназначений «Макроса» это, то что он выполняет функцию сокращения исходной программы. Компонент отвечающий за работоспособность программы называется макропроцессором.
Макрос может работать как с программами так и с данными.
1.7. Диалоговые языки
С появлением новых как технических так и механических возможностей, программистам была поставлена задача создать программу которая обеспечила бы, оперативное взаимодействие между человеком и ЭВМ, позднее было дано название «Диалоговые языки».
Для этого были созданы специальные языки, работы велись в двух направлениях, для улучшения взаимодействия оперативного воздействия на прохождение задач, которые были составлены на языках написанными ранее.
Так же велись работы над языками, которые бы кроме управления могли бы обеспечивать решение алгоритмов, задач.
Для того чтобы произвести взаимодействие с пользователем, нужно было сохранение в памяти ЭМВ копии программы даже уже после того как была получена программа. После изменений в программе с помощью диалоговых окон и специальных таблиц, устанавливало взаимосвязь с объектом программы. Это и помогало выполнять изменения в корне программы. [17, с.27]
Допустим одним из диалоговых языков является «Бэйсик».
Бэйсик обозначает все данные подобно в математике, подставляя выражения и символы.
1.8. Непроцедурные языки
Такие языки помогают описывать организацию данных, где обработка происходит в фиксированных алгоритмах и операционных системах которые с ними связаны.
Всё это позволяет чётко описывать как задачу так и все действия по её решению, тем самым таблицы получают функцию определения, и после чего видно какие действия могут быть выполнены в первую очередь, перед тем как преступить к выполнению. [23, с.27]
Компилятором является код который переводит всё в машинный язык. Суть компилятора заключается в том, что он читает язык программирования и переводит его на понятный машине язык. Строение программы выполняет компилятор. Если программировать на языке Турбо Бэйсик,то нужно следить за периодом прогона и периодом компилирования. Чем интерпретируемые программы, компилируемые работают от 4 до 10 раз быстрее. А если вы хорошо постараетесь то работоспособность программ увеличится в 100 раз. А так как большинство программистов работают лишь над вознёй с файлами, то не могут продемонстрировать работоспособность программы.
Табличные методы могут осваиваться без всякого труда вне зависимости от того по какой профессии вы работаете. [12, с.27]
Написанные на этом языке программы хорошо могут описывать сложные ситуации в табличном языке.
1.9. Универсальные языки
Создание универсальных языков, было необходимо для того, чтобы ими могли пользоваться не только программисты, но и широкий круг пользователей, а конкретно для коммерческих, научных и т.д. Первый универсальный язык, был написано фирмой IBM, позднее он получил название Пл/1. После него был написан язык Алгол-68, он является вторым по мощности. Этот язык позволяет работать как с числами, так и с плавающей запятой. В языке Пл/1 более развитая система которая без труда управляет форматами, что позволяет работать с полями переменной длины, с данными структуры, а так же для использования каналов связи. [3, с.27]
Компилирование в Пл/1 происходит в автоматическом режиме. В этом языке собраны многие возможности, которые есть и в таких программах как Алгола, Кобола, Фортрана, но в отличии от них в Пл/1 можно выполнить статистическое распределение памяти.
Глава 2. Линейные списочные структуры
Динамическая память – это оперативная память компьютера, предоставляемая программе при ее работе. Размер динамической памяти может изменяться, потому как динамическая память может обрабатывать массивы данных больших размеров. Динамические, переменные вызываются по адресу. Чтобы вызвать ячейку, обращение идёт по имени. Переменные устанавливаются комприлятором в памяти и подставляют свои адреса ячеек и команды. С помощью указателя осуществляется обращение к динамическим переменным. Указатель – это переменная, которая в качестве своего значения содержит адрес байта памяти. [25, с.27]
Для того чтобы произвести работу с динамическими переменными нужно следующее:
• Выделить память под динамическую переменную;
• Инициализировать указатель;
• Освободить память после использования динамической переменной. (см. рис. 1).

Рис.1.Освобождение памяти
Линейные списки относятся к динамическим структурам данных. Объекты данных могут обладать динамической структурой, если его размер изменяется в процессе выполнения программы. [24, с.36]
Операции которые мы можем делать с линейными списками:
- Получение доступа к списку, для анализа и изменения.
- Для включения нового узла.
- Исключение какого либо узла.
- Возможность объединения списка.
- Разбиение линейных списков.
- Возможность копировать линейные списки.
- Определение узлов в списке.
- Сортировка узлов в каком либо порядке.
- Нахождение какого либо узла.
В линейных списках самое простое получить доступ к первому и последнему элементу, они особо выделяются. Выше перечисленные операции редко когда используются все, это зависит от класса операций, что нуждаются в более частом выполнении. Сложно выделить единственный метод для линейных списков. Сами типы линейных списков можно определять по главным операциям. [10, с.27]
Списком - называется структура данных, каждый элемент которой посредством указателя связывается со следующим элементом (односвязный или однонаправленный список) и, возможно, с предыдущим (двусвязный или двунаправленный список). Если последний элемент связать указателем с первым, получится кольцевой список.
Все элементы списка хранят:
- Хранит информацию любого вида.
- Указывает следующий элемент списка.
Каждый элемент списка хранит разные части, в одном хранится объект, а в другом указатель такая запись называется звеном, и уже структура будет называться список (см. рис. 2).
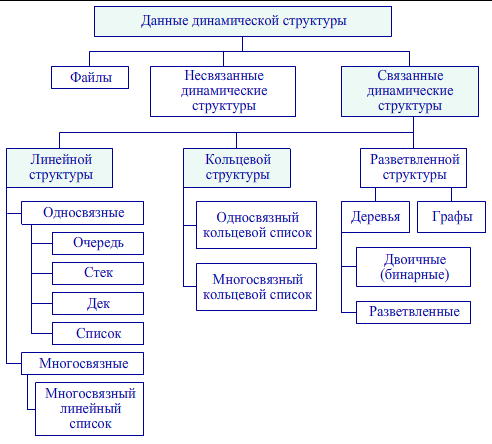
Рис.2.Данные динамической структуры
2.1. Однонаправленный и двунаправленный список
Этот метод заключается в том, что его изменение может проходит на любом промежутке списка. [20, с.27]
Направление однонаправленного списка отличает от двунаправленного в том, их различие только в связи. Получается, что в однонаправленном изменения в списке можно производить только в одном направлении, а уже в двунаправленном в любом порядке. [15, с.27]
Первый рисунок является однонаправленным, а второй двунаправленным (см. рис 3-4).
5
4
2
1
3
Рис.3. Двунаправленный список
Рис.4. Двунаправленный список
5
3
1
2
4
В двунаправленном списке, как ниже показано на рисунке, осуществляется удаление и добавление элемента. Когда добавляется новый элемент между 2 и 3 , связь которая была теряется в участке 3 и 4 (см. рис 5).
4
N
5
3
1
2
Рис.5.Связь между 3 и 4
Структура однонаправленных списков состоит в том, что их построение может быть только односторонняя.
2.2. Очередь
Существуют списки под названием «Очередь» - это так называемые линейные списки, где включение может происходить только одном конце списков, но исключения которые возможны производятся на другом конце. «Очередь» - это такой тип данных, где данные могут располагаться только в порядке поступления, а данные которые поступили в список первыми будут проходить обработку в первую очередь (см. рис. 6).
Рис.6.Очередеь
Начало
Второй
Третий
Конец
Исключить
Включить
Само правило этого списка, подобно живой очереди, первым стоял, первым будешь обслужен, а уже при добавлении будет увеличиться число в списке. У любой очереди имеется как голова, так и хвост. Те элементы, которые добавляются в список оказываются в хвосте, а объект удаляемый из этой очереди находится в голове списка. [18, с.27]
Новый элемент в очереди, может добавляться только с одной стороны, а удаление его будет происходить на другом конце. В подобных случаях может быть только 4 элемента (см. рис 7).
Рис.7.Новый элемент очереди
Начало
Второй
Третий
Конец
Новый
Эти 4 элемента показаны на рисунке выше. Очередь – это так называемый односторонний список, где добавление или исключение из него происходит в конце.
.Стек
Так называемый список под названием стек – это обычный линейный список, где все возможные исключения могут быть только в конце списка.
Стек – временная память, которая занимает часть ОЗУ, памяти компьютера, то что использует микропроцессор. При таком режиме работы, работает функция «запоминания байтов». Принцип этого списка, последним войдя, первым уйдёшь. Данные списки проще всего организовать, и быстрота операций на много лучше. Эти функции включаются при помощи «Регистра», если же на любой части этого стека, будет повреждение то это приведёт к неработоспособности списка (см. рис 8).
Возможно и такое что, элемент введённый в список элемент окажется на вершине списка. Исключается всегда элемент, который оказался младшим в его частности, или тот что включился позже всех.
Второй сверху
Включить или исключить
Верх
Низ
Третий сверху
Рис.8. Регистра
Для такой очереди имеется абсолютно противоположное правило, где может быть исключён из списка только старший, узлы которого покидают его в том же порядке в котором были в него добавлены (см. рис 9).
Сами стеки очень часто могут встречаться на практике, например когда мы стоим какой либо список состоящий из каких либо событий, и выстраиваем порядок их обработки, после обработки мы возвращаемся к следующей обработке данных. [8, с.27]
Тем самым мы подчищаем список, где уже видно нужные и не нужные объекты. Но это можно делать как в «стеке» так в «очереди». Допустим стек работает как мозг, в нём удобнее производить анализ, то есть когда решается какая либо проблема, мы просто её удаляем, то же самое и выполняет «стек».
Стеки очень удобны при обработке языка, к ним относятся языки программирования. Чаще всего «Стек» можно встретить при работе с алгоритмами.
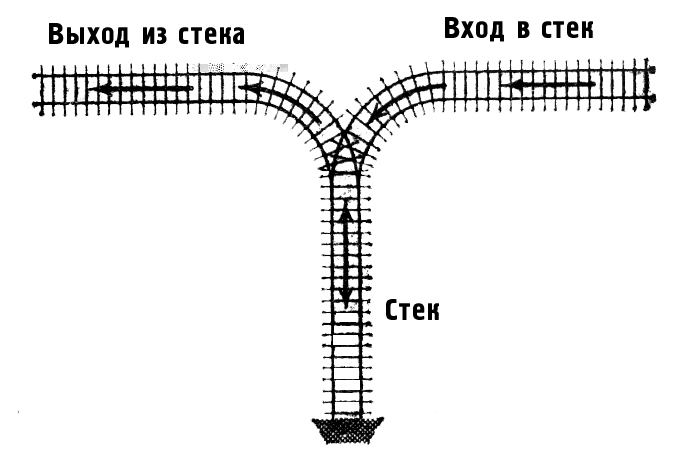
Рис.9. Стек, представленный в виде железнодорожного разъезда
2.4. Дек
Деком называется линейный список, где изменения делаются на обоих концах списка. Дек похож на колоду карт, чем стек, он имеет больше возможностей. Дек бывает с «ограниченным входом» или «ограниченным выходом», но в этих случаях исключения происходят только на одном конце(см. рис. 10).

Рис.10.Дек с «ограниченным входом»
Дек это так называемый двунаправленный список.
В связных списках порядок уже определяется не как в массиве, а элементами входящими в список. Списки применяются для хранения динамических множеств, где можно будет реализовывать какие либо операции. [19, с.27]
1
2
3
4
N
N
Если система обнаруживает беспорядок, то она выполнит операцию по установлению порядка. [16, с.27]
Элементы двустороннего списка это списки состоящие из 3 полей, кроме этого могут содержаться дополнительные данные.
Если же имеются элементы которые не были оговорены, то это уже будет двусторонний связной список (см. рис. 11).
Элемент 5
Элемент 4
Элемент 3
Элемент 2
Элемент 1
L0 + 5c:
L0 + 4c:
L0 + 3c:
L0 + 2c:
L0 + c:
Элемент 5
Элемент 4
Элемент 3
Элемент 2
Элемент 1
Л
E
D
C
B
Л:
E:
D:
C:
B:
Последовательное распределение
Адрес
Содержимое
Связанное распределение
Адрес
Содержимое
Рис.11. Двусторонний связной список
Чтобы использоваться гибкие схемы, достаточно будет создать связь с о следующим узлом списка. Программы в которых используются такие таблицы обычно имеют система последовательного распределения и у них имеется либо константа либо переменная которая их связывает.
Какую либо связь можно указать стрелкам, так как без разницы какую клетку наймёт клиент (см. рис. 12).
Рис.12. Элементы
Элемент 1
Элемент 2
Элемент 3
Элемент 4
Элемент 5
FIRST
Первый элемент является – это переменная связи, указывающая на то что он первый в списке.
Глава 3. Операции над списочными структурами
В машинной памяти списки представляются в виде комбинации каким
либо образом связанных между собой или с полями в которых есть два поля (см рис 13).
…
Рис.13.Комбинации
Количество элементов может ссылаться на другой какой либо элемент или произвольное. Имя может иметь значение как и списочный элемент. Все имена которые хранит программа, находятся в постоянной работе, которые строены в таблицу программы. Так же они могут и не иметь имён, но в этом случае они будут работать на ограниченном промежутке. [21, с.27]
3.1. Структуры памяти
Списки – это такая совокупность атомов, что позволяет связывать специальные элементы, то есть в информационной науке это называется cons-ячейки или списочные ячейки. [4, с.27]
Мир устроен так, что каждый атом, должен занимать свою ячейку. Так как каждая списочная ячейка состоит из двух частей и полей это приводит в действие работу ячеек. Поля содержащие списочные ячейки содержат другие указатели которые обрабатывают другие ячейки.

Рис.14.Ячейки указывают на атомы
Бывает, что обе ячейки указывают на атомы, это записывается как (см. рис 14).
3.2. Представления списков через списочные ячейки
Содержание одного атома, записывается следующим образом (см.рис 15):
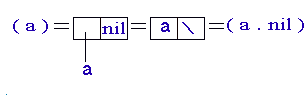
Рис.15. Содержание одного атома
На конце списка указывается NIL
Вместо nil пишут - \.
Список получается как операция (cons 'a nil)
Список из двух элементов (b a)

Правое поле указывается на cdr хвост списка.
Левое должно поле, на саr голову списка.
Соответствием списка занимается списочная ячейка.

Если в списке нет ни одного уровня (a (b c) d), тогда каждому элементу списка должна соответствовать списочная ячейка. Причем саr это поле второй списочной ячейки может указывать на вложенный список.
3.3 .Представления списков через точечную пару
Абсолютно любой список возможно записать в точечной нотации.
(a) <=> (a.nil)
(a b c) <=> (a.(b.(c.nil)))
Выражение которое представленно в точечной нотации нужно привести к списочной в том случае, если cdr поле является списком.
(a.(b c)) <=> (a b c)
(a.(b.c)) <=> (a b.c)
3.4. Списочная ячейка и базовые функции
Результатом какого либо действия функции car может быть значение левого поля первой списочных ячеек
* (сar '(a (b c) d)
a
Результатом любого действия функции cdr будет значение либо правого поля либо первой списочной ячейки.
* (сdr '(a (b c) d)
((b c) d)
CONS создает новые списочные ячейки, car поле которых указывает на первый элемент, а уже cdr на второй (cons 'x '(a b c))
или
LIST * (list 'a '(b c)) (a (b c))
Такие списки представляются в этом виде.
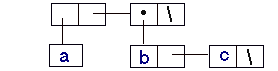
Это всё получается следующим образом:
1. Создается списочная ячейка где для каждого аргумента функции.
2. В car поле должен ставится указатель на соответствующий элемент.
3. В cdr поле должен ставится указатель на следующую списочную ячейку.
3.5.Переменные и списки
Рассмотрим данное выражение:
(setq y '(a b c))
Где переменная Y должна иметь значение '(a b c)
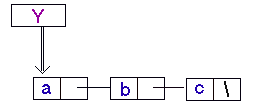
Использование данной переменной , в функции обеспечивает доступ к структуре.
(setq x (cons 'd y))
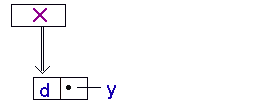
CONS не может изменять структуры, и увеличивает список.
Если в функции идёт присвоение списков задается явно, то под него должны отводится новые списочные ячейки т.е.
(setq z '(a b c))
Допустим переменная z будет иметь значение '(a b c).
3.6. Использование разрушающих функций
Разрушающую функцию необходимо использовать при работе с очень большими списками, чтобы не увеличивать расход памяти к примеру использовать nconc вместо append. [11, с.27]
Однако такое использование разрушающих функций приводит к побочным эффектам.
Так же можно получить бесконечные списки:
* (setq v1 '(a b c))
(a b c)
* (setq v2 v1)
(a b c)
* (setq v2 (nconc v1 v2))
(a b c a b c....)
Именно поэтому использование так называемых разрушающих функций требует осторожности.
Заключение
Выводы по главе 1 то что, общение с машиной нам позволило создание языков программирования высокого уровня, в данный момент, наше общение с машиной уже перешло с «ВЫ» на «ТЫ». Развитие языки программирования получили совсем недавно, так что мы не всё знаем о их возможностях. Но смотря на то, с какой скоростью растут темпы по созданию и развитию как ЭВМ так и языков программирования, то в скором будущем пределов в программировании точно не возникнет. Возможно, что в будущем будут созданы языки, которые мы сможем писать силой мысли, жестов или знаков.Всё абсолютно всё связанно между собой, как языки программирования, так и человек который управляет и маневрирует работой ЭВМ. Языки программирования появились в 50-х годах. Их развитие не стояло на месте. Всё начиналось с простых цифр, а дальше перетекло в целый поток информации который может обрабатывать как один так и сотни людей, для достижения какой либо цели.
Как показывает время, с момент создания жизни на земле, всё что человек не изобретал и о чём бы он не думал, всё доводиться до конца. Порой это имеет, может и не хорошие тенденции, допустим в плане программирования, бывают злоумышленники, которые хотят навредить чужим компьютерам, или взломать какую либо систему, что может поставить под угрозу работы, банков, больниц и многих организаций. Такие языки программирования как Паскаль, Бэйсик, Си, Ассемблер на сегодняшнее время являются самыми распространёнными, и ходовыми в промышленности программирования. Если бы люди создавшие эти языки, не написали их, то возможно, что человек так бы и не смог работать с ЭВМ. Написанная мною работа, рассказывает о том, как долго и упорно идёт развитие программирование языков. Языки программирования классифицируются на много подразделений, одни служат для создания архитектурных или математических программ. Другие же, для моделирования или создания 3-х мерной графики так называемой «3D». Создание 3D фильмов тоже вывело программирование на новый уровень, что позволило увеличить спросы на кинотеатры.
Говоря о 2-й главе списке, это очень тонкая вещь, которая так же как и программирование, не терпит ошибок. Всего лишь одна буква может изменить хоть действия. Как описывалось ранее, то существует множество видов списков таких как (Стек, дек, очередь, динамические списки, линейные списки, графы и т.д) их очень много. Каждый список отвечает за свою работу, выполнить чужую работу или не запрограммированную по смыслу он не сможет. Со времён их создания они играют важную роль в программировании. Жизненно важно научиться правильно работать с информацией, которую делает ЭВМ. Чтобы добиться хорошей работы, нужно правильно выстраивать списки, их поочередность и информацию касающуюся работы списка. Даже таблица выполненная в простейшей форме, может уже быть линейным списком. Допустим если усложнить процесс, то линейный список преобразуется в список с двухмерным массивом.
При обработке списков очень важно не допустить ошибки, что может привести к ограничениям работы. Существует несколько терминов которые необходимо запомнить. Так как в таблице всё указывается в виде узлов или элементов. Каждый элемент в памяти машины связан несколькими или одним узлом. Проще говорят, одно слово это один узел памяти ЭВМ, он может включать всё слово. Цель проведённой мною работой это изучение ЭВМ и языков программирования, где с помощью языков программирования, выстраиваются списки. Так же были изучены факты, касающие на прямую информационных структур. Смотря на списки, можно сказать какой узел или элемент будет первым рассчитан, доведён до конечного результата. Списки могут разрушать структура информации, но так же и создавать её.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Учебная литература
- Алексеев Е.Г., Богатырев С.Д. Информатика. Мультимедийный электронный учебник.2012
- Альфред Ахо, Джон Хопкрофт, Джеффри Ульман, «Структуры данных и алгоритмы» - Москва: Диалектика-Вильямс, 2013, С. 56-289
- Б.В. Керниган, Д. Ритчи, А. Фьюэр 1984г. «Язык программирования Си».
- Бабичев А. В., «Распознавание и спецификация структур данных» - Москва: Ленанд, 2013, С. 100-112
- Бакнелл Дж., «Фундаментальные алгоритмы и структуры данных в Delphi. Библиотека программиста» - Санкт Петербург: Питер, 2012, С. 313-332
- Брайан Керниган, Деннис Ритчи , «Язык программирования C» - Москва: Вильямс, 2012, С. 130-143
- Бьярн Страуструп, «Программирование. Принципы и практика использования C++» - Москва: Вильямс, 2014, С. 745-755
- Виноград Т. Программа, понимающая естественный язык. М.: №гр, IS76, 294 с.
- Джулиан Бакнелл, «Фундаментальные алгоритмы и структуры данных в Delphi» - Санкт Петербург: Питер, 2012, С. 443-460
- Костюкова Н. И., «Графы и их применение. Комбинаторные алгоритмы для программистов» - Санкт Петербург: СПб:Питер, 2013, С. 113-137
- Костюкова Н. И., «Графы и их применение. Комбинаторные алгоритмы для программистов» - Санкт Петербург: СПб:Питер, 2014, С. 44-67
- Костюкова Н. И., «Программирование на C++» - Санкт Петербург: СПб:Питер, 2013, С. 212-223
- Магда Ю. 2014г. Использование ассемблера для оптимизации программ на C++.
- Малютин Э.А., Малютина Л.В., «Языки программирования».
- Никлаус Вирт, «Алгоритмы и структуры данных» - Москва: ДМК Пресс, 2014, С. 146-221
- Никлаус Вирт, «Алгоритмы и структуры данных» - Москва: ДМК Пресс, 2014, С. 146-221
- Окулов С. М., «Графы и алгоритмы. Структуры данных. Модели вычислений» - Москва: ИНФРА-М ,2013,С. 10-135.
- П. Терренс; «Языки программирования: разработка и реализация».
- Павловская Т.А., «Программирование на языке высокого уровня» - Санкт Петербург: Питер, 2013, С. 134-149
- Роберт Лафоре «Структуры данных и алгоритмы в Java. Классика Computers Science. 2-е изд.» - Санкт Петербург: Питер, 2014, С. 80-112
- С. В. Глушаков, Т. В. Дуравкина, «Структуры и алгоритмы обработки данных: объектно-ориентированный подход и реализация на С++» - Санкт Петербург: АСТ, 2013, С. 200-286
- С. Окулов, «Основы программирования» - Москва: Бином. Лаборатория знаний, 2012, С. 174-185
- Т.А. Павловская 1982 г. «C/C++ Программирование на языке высокого уровня».
- Финогенов К., «Структуры данных и проектирование программ» - Москва: Бином. Лаборатория знаний, 2012, С. 600-739
- Янг С. 1986 «Алгоритмические языки реального времени».
Электронная литература
- Динамические структуры данных на C++ [Электронный ресурс].
- URL: http://khpi-iip.mipk.kharkiv.edu/library/datastr/book_sod/kgsu/oglav.html
(дата обращения:05.12.2014).
- Динамические структуры данных : Списки
- [Электронный ресурс].
- URL: http://comp-science.hut.ru/Progr_new/release_01/cpp8_1.html
- (дата обращения: 08.12.2014).
- Программирование на языке Си [Электронный ресурс].
- URL: http://wm-help.net/books-online/book/93964/93964.html
- (дата обращения: 15.12.2014).739

- «Разработка регламента выполнения процесса «Расчет заработной платы»( Теоретические основы финансового планирования операционной деятельности предприятия)
- Построение организационных структур(Общая характеристика организации)
- Построение организационных структур ( Понятие и принципы проектирования организационных структур )
- Корпоративная культура в организации (Сущность, функции, принципы)
- Человеческий фактор в управлении организацией (Оценка степени влияния человеческого фактора на результаты деятельности АО «РКС»)
- Построение организационных структур (Анализ организационной структуры предприятия ООО «КОНРАС»)
- Менеджмент как организационно-целевое управление ( Сущность и содержание понятия «менеджмент» )
- Организация и развитие коммерческой деятельности предприятий на рынке товаров и услуг ( Теоретические аспекты управления коммерческой деятельностью торгового предприятия )
- Налог на прибыль организаций ( Особенности формирования себестоимости продукции при определении налога на прибыль )
- Общее равновесие и общественное благосостояние»
- Человеческий фактор в управлении организации ( Роль человеческого фактора в менеджменте)
- Основы программирования на языке Pascal ( ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПАСКАЛЬ)