
Отладка и тестирование программ: основные подходы и ограничения (Понятия тестирования и отладки и их классификация )
Содержание:

ВВЕДЕНИЕ
История тестирования программного обеспечения отражает эволюцию разработки самого программного обеспечения. В течение длительного времени разработка программного обеспечения уделяла основное внимание крупномасштабным научным программам, а также программам министерства обороны, связанным с системами корпоративных баз данных, которые проектировались на базе универсальной ЭВМ или миникомпьютера. Тестовые сценарии записывались на бумагу. С их помощью проверялись целевые потоки управления, вычисления сложных алгоритмов и манипулирование данными. Окончательный набор тестовых процедур мог эффективно протестировать всю систему полностью. Тестирование обычно начиналось лишь после завершения плана-графика проекта и выполнялось тем же персоналом.[6]
Появление персональных компьютеров способствовало стандартизации этой отрасли, поскольку приложения стали изначально создаваться для работы с общей операционной системой.[8] Внедрение персональных компьютеров открыло новую эру и привело к быстрому и бурному росту коммерческих разработок. Коммерческие приложения жестко боролись за первенство и выживание. Пользователи компьютеров принимали выжившее программное обеспечение как стандарты defacto.[1] Пакетная обработка заменялась системами, работающими в реальном времени.
Таким образом, тема курсовой работы «Отладка и тестирование программ: основные подходы и ограничения» является актуальной.
Объектом курсовой работы является программное обеспечение. Предметом курсовой работы является изучение и анализ подходов к отладке и тестированию программного обеспечения.
Задачами курсовой работы является:
- Изучение теоретических основ тестирования и отладки программного обеспечения;
- Изучение стратегий тестирования и отладки программного обеспечения.
Изучению вопросов тестирования и отладки программ посвятили многие известные ученые и программисты. Куликов С. C. имеет многолетний опыт проведения тренингов для тестировщиков, позволивший обобщить типичные для многих начинающих специалистов вопросы, проблемы и сложности. Плаксин М.А. – автор более полутора сотен научных и методических публикаций в области информационных технологий и в том числе отладки и тестирования программ.
Тестирование систем реального времени потребовало другого подхода к проектированию тестирования из-за того, что рабочие потоки могли вызываться в любом порядке.[9] Эта особенность привела к появлению огромного количества процедур тестирования, способных поддержать бесконечное число перестановок и сочетаний.
Причиной многих несчастий разработчиков являются программные ошибки, из-за которых на их многострадальные головы сваливаются и давно просроченные проекты, и бессонные ночи. Ошибки могут сделать жизнь разработчиков действительно несчастной, потому что, достаточно нескольким ошибкам вкрасться в их программы, как заказчики прекращают этими программами пользоваться, а сами они могут потерять работу.[12]
Долгое время ошибки рассматривали как простые неприятности. Ничто не может быть дальше от истины. Всем программистам известны компании, которые закрылись только потому, что выпускали программные продукты, совершенно непригодные к использованию из-за обилия ошибок.[13] В связи со всеобщей компьютеризацией, все шире и шире захватывающей такие важные области, как управление системами жизнеобеспечения, медицинские приборы и сверхдорогую компьютерную аппаратуру, над ошибками больше нельзя просто посмеиваться или рассматривать их как нечто имеющее значение только на этапах разработки.
1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ТЕСТИРОВАНИЯ И ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
1.1. Понятия тестирования и отладки и их классификация
Тестирование программного обеспечения (software testing) – это процесс анализа или эксплуатации программного обеспечения с целью выявления дефектов.[13]
Несмотря на всю простоту этого определения, в нем содержатся пункты, которые требуют дальнейших пояснений. Слово процесс (process) используется для того, чтобы подчеркнуть, что тестирование суть плановая, упорядоченная деятельность.[1] Этот момент очень важен, если выражена заинтересованность в быстрой разработке, ибо хорошо продуманный, систематический подход быстрее приводит к обнаружению программных ошибок, чем плохо спланированное тестирование, к тому же проводимое в спешке.
Тестирование – это выполнение программы с целью обнаружения факта наличия в программе ошибки.[3]
Отладка – определение места ошибки и внесение исправлений в программу.[12]
В русском языке словосочетание «обнаружить ошибку» может иметь, по крайней мере, два смысла: «обнаружить факт наличия ошибки» и «обнаружить место, где допущена ошибка».
Под тестированием понимается обнаружение ошибки в первом смысле, под отладкой – во втором.
Как правило, эти два процесса тесно взаимосвязаны, но могут быть и разделены. Например, в процессе приемки системы заказчик занимается только тестированием – поиском несоответствий между заданием на разработку программы (спецификацией программы) и разработанной программой.[10] Если его поиски увенчаются успехом, программисту придется заниматься отладкой (определением места допущенных ошибок и исправлением программы).
Цель тестирования – обнаружение ошибок в программе.
Отметим важный психологический момент: цель тестирования – не доказать правильность программы, а обнаружить в ней ошибки. Если вы ставите себе задачей показать, что программа правильная и ошибок не содержит, то (на подсознательном уровне) и тесты будете подбирать такие, которые ошибок в программе не обнаружат.[7]
Отсюда следующее неожиданное рассуждение. Какой тест считать удачным? Если цель тестирования – найти в программе ошибку, то удачным должен считаться тест, который обнаруживает наличие в ней ошибки.[11] Это положение противоречит интуитивному представлению о тестировании и требует сознательного психологического настроя.
Тестирование можно классифицировать по очень большому количеству признаков, и практически в каждой серьёзной книге о тестировании автор показывает свой (безусловно имеющий право на существование) взгляд на этот вопрос.[7]
Тестирование можно классифицировать:
- По запуску кода на исполнение:
- Статическое тестирование – без запуска.
- Динамическое тестирование – с запуском.
- По доступу к коду и архитектуре приложения:
- Метод белого ящика – доступ к коду есть.
- Метод чёрного ящика – доступа к коду нет.
- Метод серого ящика – к части кода доступ есть, к части – нет.
- По степени автоматизации:
- Ручное тестирование – тест-кейсы выполняет человек.
- Автоматизированное тестирование – тест-кейсы частично или полностью выполняет специальное инструментальное средство.
- По уровню детализации приложения (по уровню тестирования):
- Модульное (компонентное) тестирование – проверяются отдельные небольшие части приложения.
- Интеграционное тестирование – проверяется взаимодействие между несколькими частями приложения.
- Системное тестирование – приложение проверяется как единое целое.
- По (убыванию) степени важности тестируемых функций (по уровню функционального тестирования):
- Дымовое тестирование – проверка самой важной, самой ключевой функциональности, неработоспособность которой делает бессмысленной саму идею использования приложения.[14]
- Тестирование критического пути – проверка функциональности, используемой типичными пользователями в типичной повседневной деятельности.
- Расширенное тестирование – проверка всей (остальной) функциональности, заявленной в требованиях.
- По принципам работы с приложением:
- Позитивное тестирование – все действия с приложением выполняются строго по инструкции без никаких недопустимых действий, некорректных данных и т. д. Можно образно сказать, что приложение исследуется в «тепличных условиях».
- Негативное тестирование – в работе с приложением выполняются (некорректные) операции и используются данные, потенциально приводящие к ошибкам (классика жанра – деление на ноль).[5]
Негативные тесты не предполагают возникновения в приложении ошибки. Напротив – они предполагают, что верно работающее приложение даже в критической ситуации поведёт себя правильным образом (в примере с делением на ноль, например, отобразит сообщение «Делить на ноль запрещено»).[13]
Часто возникает вопрос о том, чем различаются «тип тестирования», «вид тестирования», «способ тестирования», «подход к тестированию» и т.д. и т.п. Если вас интересует строгий формальный ответ, посмотрите в направлении таких вещей как «таксономия110» и «таксон111», т. к. сам вопрос выходит за рамки тестирования как такового и относится уже к области науки.
Но исторически так сложилось, что как минимум «тип тестирования» (testing type) и «вид тестирования» (testing kind) давно стали синонимами.[15]
Процесс разработки программного обеспечения является сложным и многоэтапным. Методы разработки ПО с каждым годом совершенствуются и усложняются. Часто этапы разработки похожи друг на друга и выполняются одними и теми же людьми, поэтому их границы размыты и существует несколько точек зрения на них.
Этапы часто переплетаются, но все же разделены – отладка не занимается проверкой на существование ошибок, а в процессе тестирования не следует искать их точное месторасположение и причину.[16]
С развитием программного обеспечения и методов его разработки было создано несколько довольно эффективных методов локализации, устранения и предупреждения ошибки. Дадим краткий обзор основных методов отладки.
Приведем классификацию видов отладки.
Под непосредственной отладкой понимается такой процесс отладки, когда отлаживаемое приложение запущено на машине разработчика. Это самый распространенный вид отладки.
Под удаленной отладкой понимается такой процесс отладки, когда отлаживаемое приложение запущено на машине пользователя, а отладочный инструмент – на машине разработчика.[4]
Удаленная отладка используется:
• при отладке приложения в условиях работы, которые нельзя воспроизвести на компьютере разработчика;
• при отладке ПО для отдельных устройств;
• при отладке кроссплатформенных приложений;
• при отладке распределенных систем.[2]
Очевидно, что нет препятствий к тому, чтобы использовать методы удаленной отладки при непосредственной отладке, но обычно они менее эффективны и связаны с большими временными затратами. Также методы отладки можно сгруппировать по признаку использования дополнительных технических средств:
• не требуют дополнительных средств (визуальный просмотр кода);
• требуют только сравнительно небольших дополнений в исходном коде программного продукта (протоколирование, диагностика в процессе исполнения);
• требуют отдельных самостоятельных программных продуктов-инструментов (интерактивный отладчик, графические средства).[2]
Отладчики, реализованные в виде отдельных программных продуктов, могут обладать следующими свойствами и возможностями:
• возможность просмотра текущих значений переменных;
• возможность изменения текущих значений переменных;
• возможность устанавливать (удалять) контрольные точки и условия остановки программы;
• кроссплатформенность;
• рефлексивность (возможность отладить отладчик им же самим);
• возможность удаленной работы;
• поддержка контекстно-зависимого графического вывода.[14]
Если первые две возможности реализует большинство отладчиков, то остальные свойства встречаются у отладчиков гораздо реже.
1.2. Принципы и ограничения тестирования и отладки
Тестирование предусматривает «анализ» или «эксплуатацию» программного продукта. Тестовая деятельность, связанная с анализом результатов разработки программного обеспечения, называется статическим тестированием (static testing). Статическое тестирование предусматривает проверку программных кодов, сквозной контроль и проверку программы без запуска па машине, т.е. проверку за столом (desk checks).[11] В отличие от этого, тестовая деятельность, предусматривающая эксплуатацию программного продукта, носит название динамического тестирования (dynamic testing). Статическое и динамическое тестирование дополняют друг друга, и каждый из этих типов тестирования реализует собственный подход к выявлению ошибок.
Для повышения качества тестирования рекомендуется соблюдать следующие основные принципы:
1. Ошибки в программе есть. Необходимо исходить из того, что ошибки в программе есть. Иначе тестирование не будет иметь для вас никакого смысла, и отношение к нему будет соответственное.[6]
2. Тест – это совокупность исходных данных и ожидаемых результатов. Очень частая ошибка заключается в том, что на вход программе подаются данные, для которых заранее не известны правильные результаты.[8] Здесь в дело опять вступает психология. Человеческая психика устроена так, что наши глаза очень часто видят не то, что есть на самом деле, а то, что нам хочется видеть. Если заранее не зафиксировать ожидаемый результат, то всегда возникает искус объявить, что полученные результаты – это и есть то, что должно было получиться.
3. Тестовые данные должны быть достаточно просты для проверки. Прямое следствие предыдущего принципа.
4. Тесты готовятся заранее, до выхода на машину. Это касается как исходных данных, так и ожидаемых результатов.[8] Реально в подавляющем большинстве случаев тесты придумываются на ходу, причем только исходные данные.
5. Первые тесты разрабатываются после получения задания на разработку программы до написания программного кода. Самые первые тесты следует продумать сразу же после постановки задачи до того, как начали писать программный код. Ранняя разработка тестов позволяет правильно понять поставленную задачу.[9] Даже в самых простых и, на первый взгляд, очевидных заданиях часто встречаются тонкости, которые сразу не видны, но становятся заметны, когда вы пытаетесь определить результат, соответствующий конкретным входным данным. Цель ранней разработки тестов – уточнить постановку задачи, выявить тонкие места.[15] Без этого есть риск написать программу, которая будет решать какую-то иную задачу, а не ту, которая была поставлена.
6. Перед началом тестирования следует сформулировать цели, которые должны быть достигнуты в ходе тестирования. В частности, набор тестов должен быть полон с точки зрения выбранных критериев полноты тестирования.[15] Независимо от применяемых критериев разработка тестов должна вестись систематически, по определенной методике.
7. В процессе тестирования необходимо фиксировать выполненные тесты и реально полученные результаты. К сожалению, обычной является ситуация, когда студент, получив задание, сразу же садится за компьютер, вводит некоторый программный текст, после нескольких перетрансляций избавляется от синтаксических ошибок, после чего запускает полученную программу, на ходу придумывает и подает на вход программы некие исходные данные, получает результаты, вводит новые данные, опять получает результаты и т. д.[16] Тестовые данные и результаты нигде не фиксируются. Для любых нетривиальных программ подобное тестирование почти бесполезно, поскольку не позволяет отделить проверенные участки от непроверенных, не позволяет оценить количество ошибок в программе, не дает информации для принятия решения об окончании тестирования.
8. Тесты должны быть одинаково тщательны как для правильных, так и для неправильных входных данных. На практике часто ограничиваются тестированием правильных входных данных, забывая о неправильных.
9. Необходимо проверить два момента: программа делает то, что должна делать; программа не делает того, чего делать не должна.[8] Особенно это важно для изменений в глобальной среде. Если программа выдает правильные результаты, но при этом затирает половину винчестера, то едва ли ее можно признать правильной.
10. Результаты теста необходимо изучать досконально и объяснять полностью.
11. Недопустимо ради упрощения тестирования изменять программу. Тестировать после этого пользователь будет уже другую программу.
12. После исправления программы необходимо повторное тестирование.
Для того чтобы исправить обнаруженную ошибку, мы вносим изменения в программу. Но кто может гарантировать, что, исправив одну ошибку, мы не внесем другую. Вероятность внесения новой ошибки при исправлении старой оценивается в 20–50%.[13] Для особо сложных систем эта вероятность может быть значительно выше. Так, в знаменитой в свое время ОС IBM/360 количество ошибок считалось постоянным и оценивалось примерно в 1000.[9] Система была настолько сложна и запутанна, что считалось невозможным «починить» ее в одном месте и при этом не «сломать» в другом. Итог: после внесения изменений в программу необходимо заново прогнать весь пакет ранее выполненных тестов.
13. Ошибки кучкуются. Чем больше ошибок обнаружено в модуле, тем больше вероятность, что там есть еще. Так, в одной из версий системы 370 (преемника IBM/360) 47% обнаруженных ошибок пришлось на 4% модулей [1].
Это утверждение противоречит здравому смыслу. «Здравый смысл» неявно исходит из предположения о равномерном распределении ошибок по всему тексту программы. На чем основано такое предположение. На взгляде на программу как на некую однородную сущность, все части которой обладают примерно одинаковыми свойствами. Реально программа устроена гораздо более сложно. В ней есть фрагменты простые и фрагменты сложные. Есть функции, которые были хорошо специфицированы, и функции, для которых спецификации были сформулированы нечетко. Есть модули, которые были спроектированы добротно, и модули, которые были спроектированы небрежно. Есть части, которые писали опытные программисты, и части, которые писали новички. Естественно, что большая часть ошибок окажется в тех частях, которые более сложны, хуже специфицированы, хуже спроектированы, написаны новичками. С учетом этих условий кучкование ошибок уже не выглядит странным.[6]
Данный принцип имеет одно неприятное последствие. Если следовать ему строго, то количество ошибок в программе должно возрастать до бесконечности. Ведь нахождение каждой следующей ошибки увеличивает вероятность существования других еще ненайденных ошибок. К счастью, это не так.
14. Окончательное тестирование программы лучше проводить не ее автору, а другому человеку.
Тестирование программы – процесс разрушительный. Цель его – выявление дефектов в программе. Психологически любой создатель всегда склонен в большей или меньшей степени отождествлять себя со своим созданием, «вкладывать в него душу».[8] И чем больше усилий потрачено на работу, тем больше степень отождествления. Программа начинает восприниматься программистом как продолжение его самого. В восприятии автора обнаружение ошибок в программе приобретает трагический оттенок: «Программа – это продолжение меня. Программа – дефектна. Следовательно, я дефектен!». Если вы не склонны к мазохизму, такая ситуация вам вряд ли понравится.
Необходимо либо передать окончательное тестирование вашей программы другому человеку. Либо четко отделить себя от программы, перестать воспринимать ее как часть себя (не «моя программа», а «программа, написанная мной»). Это, может быть, проще сделать в программистском коллективе, в котором все программы являются результатом коллективной работы и коллективной собственностью.[10] Но то же самое необходимо и при одиночной работе. Не отделив себя от своего детища, вы не сможете объективно оценить его достоинства и недостатки.
Естественно, что человек, проверяющий вашу программу, должен быть достаточно подготовлен, готов потратить на эту нужное количество времени и усилий. Это не сможет сделать первый встречный. Это нельзя сделать мимоходом.
1.3. Жизненный цикл тестирования программного обеспечения
Жизненный цикл тестирования выражается замкнутой последовательностью действий (рисунок 1).[5]
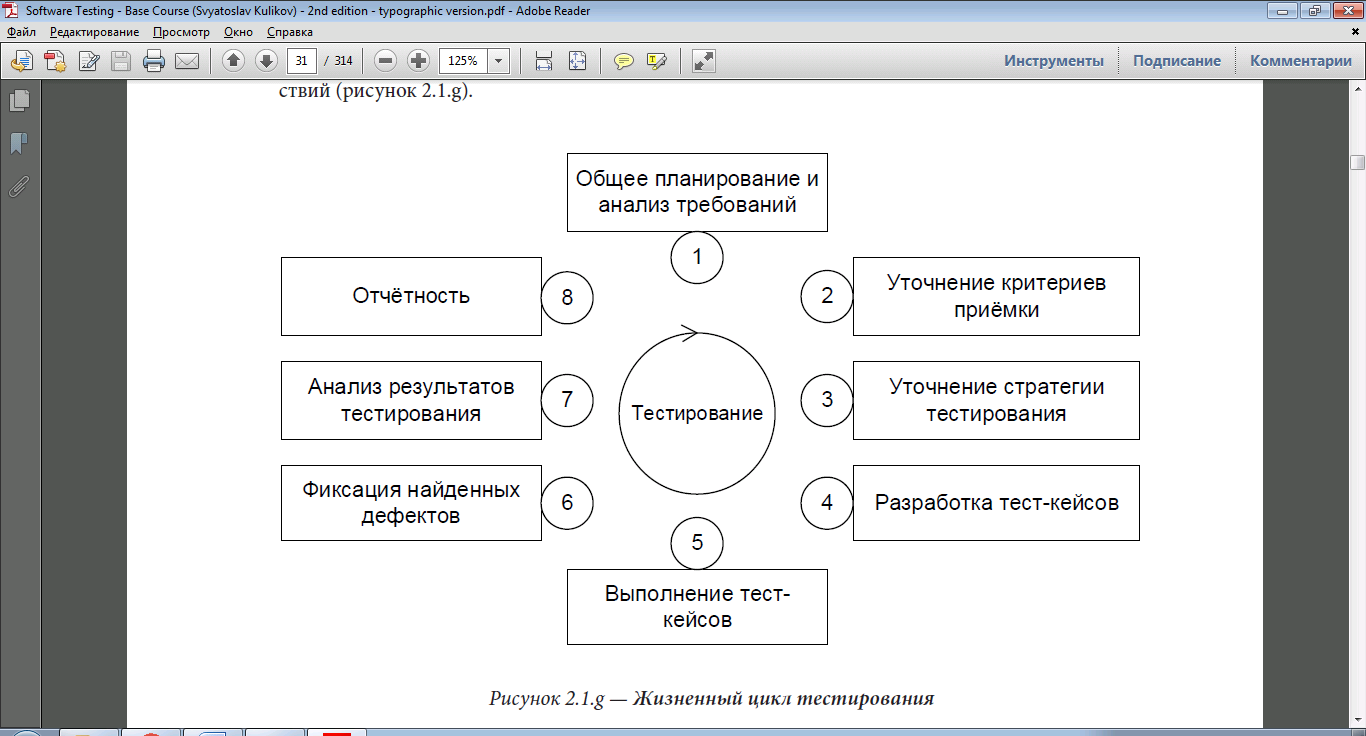
Рисунок 1 – Жизненный цикл тестирования
Важно понимать, что длина такой итерации (и, соответственно, степень подробности каждой стадии) может варьироваться в широчайшем диапазоне – от единиц часов до десятков месяцев. Как правило, если речь идёт о длительном промежутке времени, он разбивается на множество относительно коротких итераций, но сам при этом «тяготеет» к той или иной стадии в каждый момент времени (например, в начале проекта больше планирования, в конце – больше отчётности).[3]
Приведённая схема – не догма, и вы легко можете найти альтернативы, но общая суть и ключевые принципы остаются неизменными.
Стадия 1 (общее планирование и анализ требований) объективно необходима как минимум для того, чтобы иметь ответ на такие вопросы, как: что нам предстоит тестировать; как много будет работы; какие есть сложности; всё ли необходимое у нас есть и т.п. Как правило, получить ответы на эти вопросы невозможно без анализа требований, т.к. именно требования являются первичным источником ответов.
Стадия 2 (уточнение критериев приёмки) позволяет сформулировать или уточнить метрики и признаки возможности или необходимости начала тестирования, приостановки и возобновления тестирования, завершения или прекращения тестирования.[5]
Стадия 3 (уточнение стратегии тестирования) представляет собой ещё одно обращение к планированию, но уже на локальном уровне: рассматриваются и уточняются те части стратегии тестирования, которые актуальны для текущей итерации.
Стадия 4 (разработка тест-кейсов) посвящена разработке, пересмотру, уточнению, доработке, переработке и прочим действиям с тест-кейсами, наборами тест-кейсов, тестовыми сценариями и иными артефактами, которые будут использоваться при непосредственном выполнении тестирования.
Стадия 5 (выполнение тест-кейсов) и стадия 6 (фиксация найденных дефектов) тесно связаны между собой и фактически выполняются параллельно: дефекты фиксируются сразу по факту их обнаружения в процессе выполнения тест-кейсов.[5] Однако зачастую после выполнения всех тест-кейсов и написания всех отчётов о найденных дефектах проводится явно выделенная стадия уточнения, на которой все отчёты о дефектах рассматриваются повторно с целью формирования единого понимания проблемы и уточнения таких характеристик дефекта, как важность и срочность.
Стадия 7 (анализ результатов тестирования) и стадия 8 (отчётность) также тесно связаны между собой и выполняются практически параллельно. Формулируемые на стадии анализа результатов выводы напрямую зависят от плана тестирования, критериев приёмки и уточнённой стратегии[3], полученных на стадиях 1, 2 и 3. Полученные выводы оформляются на стадии 8 и служат основой для стадий 1, 2 и 3 следующей итерации тестирования. Таким образом, цикл замыкается.
1.4. Цели и задачи тестирования программного обеспечения
Цели тестирования заключаются в следующем:
- Повысить вероятность того, что приложение, предназначенное для тестирования, будет работать правильно при любых обстоятельствах.
- Повысить вероятность того, что приложение, предназначенное для тестирования, будет соответствовать всем описанным требованиям.
- Провести полное тестирование приложения за короткий срок.[5]
Задачи тестирования состоят в том, чтобы:
- Проверить, что система работает в соответствии с определенными временами отклика клиента и сервера.
- Проверить, что наиболее критические последовательности действий с системой конечного пользователя выполняются верно.
- Проверить работу пользовательских интерфейсов
- Проверить, что изменения в базах данных не оказывают неблагоприятного влияния на существующие программные модули.
- При проектировании тестов свести к минимуму переработку тестов при возможных изменениях приложения.
- Использовать инструменты автоматизированного тестирования там, где это целесообразно.
- Проводить тестирование таким образом, чтобы не только обнаруживать, но и предупреждать дефекты.
- При проектировании автоматизированных тестов использовать стандарты разработки таким образом, чтобы создать многократно используемые и сопровождаемые скрипты.[8]
2. СТРАТЕГИЯ ТЕСТИРОВАНИЯ И ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
2.1. Методы тестирования программного обеспечения
Для того чтобы процесс тестирования имел оправданную с экономической точки зрения трудоемкость, необходимо заранее выработать ряд стратегий.
Долгое время основным способом тестирования было тестирование методом «черного ящика» - программе подавались некоторые данные на вход и проверялись результаты в надежде найти несоответствия.[5] При этом, как именно работает программа, считается несущественным. Следует ответить, что даже при таком подходе необходимо иметь спецификацию программы для того, чтобы было с чем сравнивать результаты.
Этот подход до сих пор является самым распространенным в повседневной практике, но у него есть целый ряд недостатков. Во-первых, таким способом невозможно найти взаимоуничтожающихся ошибок, во-вторых, некоторые ошибки возникают достаточно редко (ошибки работы с памятью) и потому их трудно найти и воспроизвести и т.д.[8]
В связи с этим появились методы тестирования, которые изучают не только внешнее поведение программы, но и ее внутреннее устройство (исходные тексты). Такие методики обобщенно называют тестированием «белого ящика». К ним относятся: обзоры кода, инспекции, аудит, критический анализ и т.д.[9] Основной трудностью подобных методов является сложность отслеживания вычислений времени выполнения.
Внимательное изучение этих методов тестирования показывает, что они дополняют друг друга, то есть различные методы находят разные ошибки. Поэтому наиболее эффективные процессы разработки ПО используют некоторую комбинацию методик «черного ящика» и «белого ящика».
Метод белого ящика (white box testing, open box testing, clear box testing, glass box testing) – у тестировщика есть доступ к внутренней структуре и коду приложения, а также есть достаточно знаний для понимания увиденного. Выделяют даже сопутствующую тестированию по методу белого ящика глобальную технику – тестирование на основе дизайна (design-based testing).[15] Для более глубокого изучения сути метода белого ящика рекомендуется ознакомиться с техниками исследования потока управления или потока данных, использования диаграмм состояний. Некоторые авторы склонны жёстко связывать этот метод со статическим тестированием, но ничто не мешает тестировщику запустить код на выполнение и при этом периодически обращаться к самому коду (а модульное тестирование и вовсе предполагает запуск кода на исполнение и при этом работу именно с кодом, а не с «приложением целиком»).
Пример. Тестировщик, который, как правило, является программистом, изучает реализацию кода поля ввода на веб-странице, определяет все предусмотренные (как правильные, так и неправильные) и не предусмотренные пользовательские вводы, и сравнивает фактический результат выполнения программы с ожидаемым. При этом ожидаемый результат определяется именно тем, как должен работать код программы.
Тестирование методом белого ящика похоже на работу механика, который изучает двигатель машины, чтобы понять, почему она не заводится.
Техника белого ящика применима на разных уровнях тестирования – от модульного до системного, но главным образом применяется именно для реализации модульного тестирования компонента его автором.[13]
Метод чёрного ящика (black box testing, closed box testing, specifi cation-based testing) – у тестировщика либо нет доступа к внутренней структуре и коду приложения, либо недостаточно знаний для их понимания, либо он сознательно не обращается к ним в процессе тестирования.[14] При этом абсолютное большинство видов тестирования работают по методу чёрного ящика, идею которого в альтернативном определении можно сформулировать так: тестировщик оказывает на приложение воздействия (и проверяет реакцию) тем же способом, каким при реальной эксплуатации приложения на него воздействовали бы пользователи или другие приложения. В рамках тестирования по методу чёрного ящика основной информацией для создания тест-кейсов выступает документация (особенно – требования) и общий здравый смысл (для случаев, когда поведение приложения в некоторой ситуации не регламентировано явно; иногда это называют «тестированием на основе неявных требований», но канонического определения у этого подхода нет).
Пример. Тестировщик проводит тестирование веб-сайта, не зная особенностей его реализации, используя только предусмотренные разработчиком поля ввода и кнопки. Источник ожидаемого результата – спецификация.
Поскольку это тип тестирования, по определению он может включать другие его виды. Тестирование черного ящика может быть как функциональным, так и нефункциональным. Функциональное тестирование предполагает проверку работы функций системы, а нефункциональное – соответственно, общие характеристики нашей программы.[13]
Техника черного ящика применима на всех уровнях тестирования (от модульного до приемочного), для которых существует спецификация. Например, при осуществлении системного или интеграционного тестирования, требования или функциональная спецификация будут основой для написания тест-кейсов.[5]
Техники тест-дизайна, основанные на использования черного ящика, включают:
– классы эквивалентности;
– анализ граничных значений;
– таблицы решений;
– диаграммы изменения состояния;
– тестирование всех пар.[6]
Метод серого ящика (gray box testing) – комбинация методов белого ящика и чёрного ящика, состоящая в том, что к части кода и архитектуры у тестировщика доступ есть, а к части – нет.[7] Его явное упоминание – крайне редкий случай: обычно говорят о методах белого или чёрного ящика в применении к тем или иным частям приложения, при этом понимая, что «приложение целиком» тестируется по методу серого ящика.
Пример. Тестировщик изучает код программы с тем, чтобы лучше понимать принципы ее работы и изучить возможные пути ее выполнения. Такое знание поможет написать тест-кейс, который наверняка будет проверять определенную функциональность.
Техника серого ящика применима на разных уровнях тестирования – от модульного до системного, но главным образом применяется на интеграционном уровне для проверки взаимодействия разных модулей программы.
Если сравнить основные преимущества и недостатки перечисленных методов, получается следующая картина (см. таблицу 1 и 2).[7]
Таблица 1 – Преимущества методов
|
Метод белого ящика |
Метод чёрного ящика |
|
• Показывает скрытые проблемы и упрощает их диагностику. • Допускает достаточно простую автоматизацию тест-кейсов и их выполнение на самых ранних стадиях развития проекта. • Обладает развитой системой метрик, сбор и анализ которых легко автоматизируется. • Стимулирует разработчиков к написанию качественного кода. • Многие техники этого метода являются проверенными, хорошо себя зарекомендовавшими решениями, базирующимися на строгом техническом подходе. |
• Тестировщик не обязан обладать (глубокими) знаниями в области программирования. • Поведение приложения исследуется в контексте реальной среды выполнения и учитывает её влияние. • Поведение приложения исследуется в контексте реальных пользовательских сценариев. • Тест-кейсы можно создавать уже на стадии появления стабильных требований. • Процесс создания тест-кейсов позволяет выявить дефекты в требованиях. • Допускает создание тест-кейсов, которые можно многократно использовать на разных проектах. |
Таблица 2 – Недостатки методов
|
Метод белого ящика |
Метод чёрного ящика |
|
• Не может выполняться тестировщиками, не обладающими достаточными знаниями в области программирования. • Тестирование сфокусировано на реализованной функциональности, что повышает вероятность пропуска нереализованных требований. • Поведение приложения исследуется в отрыве от реальной среды выполнения и не учитывает её влияние. • Поведение приложения исследуется в отрыве от реальных пользовательских сценариев. |
• Возможно повторение части тест-кейсов, уже выполненных разработчиками. • Высока вероятность того, что часть возможных вариантов поведения приложения останется непротестированной. • Для разработки высокоэффективных тест-кейсов необходима качественная документация. • Диагностика обнаруженных дефектов более сложна в сравнении с техниками метода белого ящика. • В связи с широким выбором техник и подходов затрудняется планирование и оценка трудозатрат. • В случае автоматизации могут потребоваться сложные дорогостоящие инструментальные средства. |
Метод серого ящика сочетает преимущества и недостатки методов белого и чёрного ящика.[7]
Методы белого и чёрного ящика не являются конкурирующими или взаимоисключающими – напротив, они гармонично дополняют друг друга, компенсируя таким образом имеющиеся недостатки.
2.2. Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке.[4]
Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
- ручного тестирования;
- индукции;
- дедукции;
- обратного прослеживания.[4]
Метод ручного тестирования – самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.[4]
Данный метод часто используют как составную часть других методов отладки.
Пример фрагмента процедуры:
- Подать на вход три разных целых числа;
- Запустить тестовое исполнение;
- Проверить, соответствует ли полученный результат таблице [ссылка на документ1] с учетом поправок [ссылка на документ2];
- Убедиться в понятности и корректности выдаваемой сопроводительной информации.[12]
В этой процедуре тестировщик использует дополнительные документы и собственное понимание того, какую сопроводительную информацию считать «понятной и корректной». Успех от использования процедурного подхода достигается в случае однозначного понимания тестировщиком всех пунктов процедуры. Например, в п.1 приведенной процедуры не уточняется, из какого диапазона должны быть заданы три целых числа, и не описывается дополнительно, какие числа считаются «разными».
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя.[12]
Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе - выдвигают другую гипотезу.
Самый ответственный этап - выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется.[13]
Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента.[12]
В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе - проверяют следующую причину.
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.[14]
Отладка программы, так или иначе, принимает рассмотрение и логическое решение доступной информации об ошибках. Большая часть ошибок может быть узнана к косвенным знакам посредством тщательного анализа текстов программ и результатов тестирования, не получая дополнительной информации.
Отладка – это комплексный процесс по выявлению и исправлению дефектов в программном обеспечении. Сами же дефекты, обычно, обнаруживается в процессе тестирования ПО. Часто под термином «отладка» подразумевают «тестирование» + «непосредственно отладка».[4]
Отладка состоит из следующих этапов:
- воспроизведение дефекта (любым из доступных способов);
- анализ дефекта (поиск причины возникновения дефекта – root-cause);
- дизайн исправления дефекта (и возможно ревью, если есть альтернативы);
- кодирование исправления дефекта (и какие-либо активности связанные с кодированием);
- валидация исправления;
- интеграция исправления в кодовую базу или целевую систему;
- дополнительные валидации после интеграции (если необходимости).[9]
Пункты 1 и 2 – самые длительные этапы. Они могут объединяться, например, если сложность отладки именно в воспроизведение проблемы и имеется достаточно assert-ов в коде, то тогда после воспроизведение дефекта root-cause будет автоматически выявлен за счёт детального сообщения об ошибке в assert-е.
Но бывает и по-другому, когда дефект воспроизводится легко, но root-cause абсолютно не ясен.
Если root-cause дефекта найден, то разработать исправление не составляет большого труда (конечно, в зависимости от требований к качеству ПО). Поэтому с этапами 1 и 2 в большинстве случаев ассоциируется термин «отладка». Более того, отладка – это рекурсивный процесс.[4]
На любом этапе отладки могут возникнуть новые дефекты, которые придётся отлаживать. Например, какая-то часть исправления в коде работает не так как ожидается и соответственно придётся отлаживать эту часть в изоляции и снова основное время уходит на пункты 1 и 2 и т.д. Таким образом, под методами отладки дефектов понимаются методики и подходы выполнения пунктов 1 и 2.[4]
Методы отладки ПО, используемые на данный момент в индустрии:
Запуск программы из-под отладчика (софтварного, железячного или удалённого дебагера) с пошаговой отладкой, просмотром состояний (переменных, стека, памяти, регистров, тредов и т.п.) в требуемых точках исполнения программы.
Логирования кода – вывод в файл (или консоль и т.п.) входных, выходных аргументов функций, промежуточных состояний (переменных, стека, памяти, передаваемых или получаемых каким-либо образом данных и т.п.) в процессе исполнения программы. [4]
Детальный лог является историческим описанием исполнения программы. При сложностях с воспроизведением сценария дефекта, логирование становится основной методикой отладки.
Анализ кода без исполнения программы – поиск причин возникновения дефекта с помощью анализа исходного кода программы, проблемного контента, конфигурации, состояния базы данных и т.п.
Анализ поведения системы или её части (в т.ч. в более простых use-case-ах) – изолирование проблемы, путём упрощения сценария (используя ручное или автоматическое тестирование).[13]
Аксиома звучит так: чем проще сценарий, тем проще отладить проблему. Если найти более простой сценарий, то отладка может упроститься.
Unit тестирование – выполнение автоматических unit test-ов в основном изолировано (т.е. в более простых сценариях) для функций (модулей, компонентов и т.п.), и таким образом автоматическое выявление проблемных участков кода. Unit тестирование в каком-то смысле одна из разновидностей отладки путём «анализа поведения системы».
Прототипирование – проверка функций (модулей, библиотек, и т.п.) в изоляции с помощью небольших примеров кода (прототипов). Прототип легче отлаживать, чем целевую систему.[12]
Если проблема воспроизводиться с помощью прототипа, отладка упрощается. Unit тестирование в этом смысле более эффективный метод отладки, поскольку unit test-ы выполняются автоматически и «накапливаются» для будущего реюза, а прототипы редко становятся частью системы.
Отладка с помощью memory-dump-ов или crash-дампов (применимо в основном для анализа паник) – разновидность логирования кода, только здесь логируется не просто некая структура памяти, а целиком вся память процесса и состояния регистров, когда возникает exception.[4]
По такому дампу памяти, имея дебажные символы, можно «раскрутить» состояние программы (стеков, очередей, переменных и т.п.), в котором она находилась во время паники. Достаточно много существует инструментальных средств для выполнения этой операции.
Отладка с помощью перехватов (hook-ов, spy-ев) – в основном используется в случаях утечки ресурсов, разновидность логирования кода.[4]
Основная идея перехват и логирование вызова функций выделения и освобождения ресурса, а также анализ состояния ресурсов (например, памяти) в требуемый момент времени или в нужной точке исполнения программы.
Профилирование кода (если необходима оптимизация производительности) – разновидность логирования кода, хотя часто выполняется с использованием специализированных инструментальных средств (профилировщиков).
Этот метод отладки позволяет получить профиль исполнения программы – сколько и какая функция, строчка кода, модуль, и т.п. отнимают процессорного времени, и таким образом найти узкие места.
Выполнения программы (или её части) в другой среде (операционной системе, эмуляторе, симуляторе) – основная идея в том, что если нет инструментальных средств на целевой платформе, то можно спортировать код на другую платформу, где они есть.[12]
Также можно изначально писать кросс-платформенный код системы или какой-то её части, и таким образом, при необходимости практически без портирования отлаживать код на другой платформе.
Отладка методом RPC (remote procedure call) – применимо в основном для встроенного программирования.[13]
Суть метода в возможности вызвать любую функцию (модуль и т.п.) передавая аргументы и получая результаты исполнения удалённо с одного хоста на другом вместо того, чтобы тратить время на компиляцию или обновление софта на удалённом хосте (или железке).
Существуют множество готовых фреймворков (правда в основном платных), которые инструментируют код и позволяют вызывать любые функции кода через USB или IP соединения.
Отладка путём анализа документации, дизайна, требований или ограничений модулей (программных или аппаратных) – применимо в основном для сложных и крупных проектов.
Основная идея понять по имеющейся документации допустимо ли поведение, происходящее в дефекте. Например, поддерживается ли сложная комбинация одновременно работающих фич. Если поведение не поддерживается, то необходимо просто программно закрыть use-case, вместо того, чтобы пытаться глубоко анализировать код или пытаться найти root-cause в third-party компонентах.[14]
Отладка трансляцией кода – сложный алгоритм пишется или прототипируется на одном языке программирования (возможно медленном или интерпретируемом) с наличием всех доступных инструментальных средств (дебагера и т.п.), а потом исходный код отлаженного алгоритма транслируется в ручную или автоматически в другой язык программирования (целевой системы), для которого отсутствуют необходимые инструментальный средства.
При таком подходе отладится можно на практически любом удобном для себя языке программирования, а потом заново странслировать программу на целевой язык программирования. Возможны и другие варианты, например, дисассемблерование с целью более низкоуровневого понимания, что происходит при выполнении программы. Т.е. анализируется некий промежуточный вариант кода, который в некоторых ситуациях легче отладить или понять.[13]
Отладка разработкой интерпретатора - это не только метод отладки, но и паттерн проектирования.
Этот метод используется, когда модуль требует частых изменений (из-за плавающих требований или поддержки большого количества фич, железок и т.п.), а время построения приложения очень большое. Для ускорения процесса и гибкости пишется небольшой интерпретатор кода с наличием управляющих конструкций if, циклов, goto.[4]
При наличии такого интерпретатора разработчик сравнительно не сложно создаёт скрипты, которые можно быстрее исправить и отладить. Как упрощённый вариант такого способа отладки, например, использование дебажных флагов в коде, которые конфигурируют код и позволяют проверить разные варианты исполнения кода сделав лишь один build.
2.3. Процесс локализации ошибки на примере
Рассмотрим процесс локализации ошибки на конкретном примере.
Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(<strong>a</strong>>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',<strong>b</strong>:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая - из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=list>Наибольшим оказалось третье число 8.00
Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен.
1. Трассировка и промежуточная печать
Добавляем промежуточную печать:
- вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
writeln('Вы ввели число ',a:8:2); {отл.печать}
write('Введите второе число '); readln(b);
writeln('Вы ввели число ',b:8:2); {отл.печать}
write('Введите третье число '); readln(c);
writeln('Вы ввели число ',c:8:2); {отл.печать}
writeln('a>b=',a>b,', a>c=',a>c,', (a>b)and(a>c)=',(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else begin
writeln('b>a=',b>a,', b>c=',b>c,', (b>a)and(b>c)=',(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end;
end.
В принципе, еще при наборе есть неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко. Будем считать, что найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяется текст и обнаруживается, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число - второе или третье (если максимальное - первое, то определяется оно правильно, для доказательства можно проиграть еще два-три теста).
Просматриваются все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода - то быстро натыкаемся на замену b на с. Исправляем. Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- вводе данных;
- расчетном блоке;
- собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then... где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с - максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
ЗАКЛЮЧЕНИЕ
Программ без ошибок не существуют. Ошибки, соединенные с неправильным вводом команд в монтажере, неправильной записи идентификаторов почти всегда, это возможно узнать простое исследование начального текста, и фиксируется компилятором платформы, на котором пишется программа. Обычно по традиции компании-производители телевизионных программ применяют попытку метода - попытка, будет ли программа работать в этом или том изменении, обычно это называет устранение неисправностей.
Некоторые устройства участвовали в программировании, тестируя и устранение неисправностей зацепляются, более дешево. Поэтому необходимо обратиться к различным получениям компании-производителя телевизионных программ, позволяя повышать производительность программного обеспечения и открывать Ошибки как можно скорее как начало, и профессиональные компании-производители телевизионных программ совершают большинство различных ошибок, и в этапе проекта, и в коде программы. Довольно часто ошибка приводит к лавинным следствиям, усложняя работу компании-производителя телевизионных программ, приводя к пересмотру всего кода в начальной стадии. С этой целью сама компания-производитель телевизионных программ создает программу, тестирующую матобеспечение, или уже использует доступные пакеты программного обеспечения тестирования.
Главная роль в тестировании однако принадлежит компании-производителю телевизионных программ, отслеживающей производительность кода программы и появления точек прерывания. Компания-производитель телевизионных программ должна дефекты записи независимо, только она требуется, что отлаженная программа была запущена. Только затем среда разработки может контролировать блюдо производительности программы и изменения значений различных переменных. Раньше большие компьютеры, из-за чрезвычайно твердых необходимых условий к оперативной памяти и слабым компаниям-производителям телевизионных программ вычислительных ресурсов использовали технику устранения неисправностей основанного только на вводной части протоколов.
Происхождение этого, компания-производитель телевизионных программ может определить ошибка, чтобы узнать это быстро, это не возможно, зная подпрограмму, которая вызвала ошибка. В старых языках программирования были четные специальные действующие компании для вывода законной информации. Однако просто просматривая начальный текст наиболее эффективно поиском ошибок. В определенных случаях разработчики программ зацепляются в выпуске сырых программ, так называемых программ не выдержанное испытание. Потребитель или устройство полученный такие программы используют их в собственном риске. Сообщения на серьезных ошибках, в котором наличии, объектный код, созданный компилятором, является, конечно, неправильным также свое дальнейшее использование, это невозможно.
Каждая компания-производитель телевизионных программ знает, что является временем и шпигует листы при устранении неисправностей и тестировании программ. На этом этапе это - необходимые приблизительно 50 % общей стоимости программирования. Не каждый из разработчиков матобеспечения может истинно определить цель тестирования. Довольно часто возможно услышать, что тестирование - процесс производительности программы с целью укладки текста в этом ошибок. Но эта цель недосягаема: что самое тщательное тестирование не дает гарантии, что программа не содержит Ошибки.
На исследовании результатов каждого теста необходимо проверить, делает ли программа это, это не должно сделать. Тестируя не должен быть планированным происхождением успения, которое в ошибках в программе (в частности необходимо выбрать достаточное височное и имущество для того, чтобы протестировать) не будет узнано. Необходимо избежать когда бы ни было возможно тестирования программы своим автором как кроме уже указанной объективной сложности тестирования на компании-производителей телевизионных программ здесь есть также, что фактор, что укладка текста отсутствий действия противоречит человеческой психологии (однако отладка программы наиболее эффективно выполняется автором программы). Необходимо помнить всегда что, тестируя - творческий процесс вместо коснуться этого относительно стандартного размещения.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Вигерс К. Разработка требований к программному обеспечению / К. Вигерс, Д. Битти. – М.: БХВ-Петербург, 2014. – 736 c.
- Касперски К. Техника отладки программ без исходных текстов / Крис Касперски. – М.: БХВ-Петербург, 2005. – 832 c.
- Кирейцева А. Н. Азбука тестирования. Практическое руководство для преподавателей РКИ. – М.: Златоуст, 2013. – 184 с.
- Кодубец А. IT – блог. Обзор методов отладки программного обеспечения. – М.: Литрес, 2014. – 24 с.
- Коликова Т. В. Основы тестирования программного обеспечения. Учебное пособие / Т. В. Коликова, В.П. Котляров. – М.: Интуит, 2014. – 285 с.
- Криспин Л, Грегори Д. Гибкое тестирование. Практическое руководство для тестировщиков ПО и гибких команд. – М.: Вильямс, 2016. – 464 с.
- Куликов С. C. Тестирование программного обеспечения. Базовый курс / С. С. Куликов. – Минск: Четыре четверти, 2017. – 312 с.
- Курочкин М. А. Тестирование ПО. Психологические аспекты тестирования ПО, стратегии тестирования, принцип тестирования. – СПб.: СПГПТУ, 2014. – 107 с.
- Лаврищева Е.М. Технология разработки и моделирования вариантов программных систем. – М.: Юрайт, 2017. – 434 с.
- Непейвода Н. Н. Стили и методы программирования. Курс лекций. Учебное пособие. – М.: ИНТУИТ, 2012. – 320 с.
- Ошероув Р. Искусство автономного тестирования с примерами. – М.: ДМК Пресс, 2016. – 360 с.
- Плаксин М. А. Тестирование и отладка программ для профессионалов будущих и настоящих / М. А. Плаксин.–3-е изд. – М. : БИНОМ. Лаборатория знаний, 2015. – 167 с.
- Попова Ю. Б. Тестирование и отладка программного обеспечения. – Минск.: БНТУ, 2016. – 35 с.
- Рудаков А.В. Технология разработки программных продуктов. – М.: Академия, 2014. – 208 с.
- Черников Б.В. Управление качеством программного обеспечения. – М.: Форум, 2015. – 240 с.
- Черников Б.В., Поклонов Б.Е. Оценка качества программного обеспечения. – М.: Инфра-М, 2013. – 400 с.

- Организационные структуры.
- Базовые понятия теорий лидерств
- Ликвидность и платежеспособность банка и основы управления ими (на примере…)
- Организационная культура и ее роль в современных организациях (Характеристика и функции организационной культуры)
- Организация кассовой работы в банке(Теоретические основы кассовых операций)
- Прибыль и рентабельность производственной организации (Теоретические аспекты прибыли и рентабельности производственной организации)
- Налоги с физических лиц и их экономическое значение (Налоговая политика в системе государственного регулирования в РФ)
- Гарантии прав и свобод человека и гражданина (КОНСТИТУЦИОННЫЕ ПРАВА СВОБОДЫ ЧЕЛОВЕКА И ГРАЖДАНИНА)
- Юридическая ответственность (Понятие, сущность и принципы)
- Анализ деятельности спортивной организации на примере футбольного клуба «Ливерпуль»
- Оценка эффективности управления предприятием (Теоретические аспекты организационной структуры предприятия )
- Оценка эффективности менеджмента организации