
Понятие переменной в программировании. Виды и типы переменных
Содержание:

Введение
В данной курсовой работе проводилось исследование понятия переменной в программировании, ее назначении и функциях.
Переменная в программировании – это область памяти, именованная или обозначенная любым другим способом, адрес которой используется для получения доступа к данным. Записанные по адресу данные называются значением переменной.
В качестве примера в работе рассматривался код на языке Си (C++).
Глава 1. Статические и динамические типы переменных.
Статически типизированные языки ограничивают типы переменных: язык программирования может знать, например, что x — это Integer. В этом случае программисту запрещается делать x = true, это будет некорректный код. Компилятор откажется компилировать его, так что мы не сможем даже запустить такой код.
Динамически типизированные языки помечают значения типами: язык знает, что 1 это integer, 2 это integer, но он не может знать, что переменная x всегда содержит integer.
Среда выполнения языка проверяет эти метки в разные моменты времени. Если мы попробуем сложить два значения, то она может проверить, являются ли они числами, строками или массивами. Потом она сложит эти значения, склеит их или выдаст ошибку, в зависимости от типа.
1.1 Статически типизированные языки
Статические языки проверяют типы в программе во время компиляции, еще до запуска программы. Любая программа, в которой типы нарушают правила языка, считается некорректной. Например, большинство статических языков отклонит выражение "a" + 1 (язык Си — это исключение из этого правила). Компилятор знает, что "a" — это строка, а 1 — это целое число, и что + работает только когда левая и правая часть относятся к одному типу. Так что ему не нужно запускать программу чтобы понять, что существует проблема. Каждое выражение в статически типизированном языке относится к определенному типу, который можно определить без запуска кода.
Многие статически типизированные языки требуют обозначать тип. Функция в Java public int add(int x, int y) принимает два целых числа и возвращает третье целое число. Другие статически типизированные языки могут определить тип автоматически. Та же самая функция сложения в Haskell выглядит так: add x y = x + y. Мы не сообщаем языку типы, но он может определить их сам, потому что знает, что + работает только на числах, так что x и y должны быть числами, значит функция add принимает два числа как аргументы.
Это не уменьшает "статичность" системы типов. Система типов в Haskell знаменита своей статичностью, строгостью и мощностью, и в по всем этим фронтам Haskell опережает Java.
1.2 Динамически типизированные языки
Динамически типизированные языки не требуют указывать тип, но и не определяют его сами. Типы переменных неизвестны до того момента, когда у них есть конкретные значения при запуске. Например, функция в Python
def f(x, y):
return x + y
может складывать два целых числа, склеивать строки, списки и так далее, и мы не можем понять, что именно происходит, пока не запустим программу. Возможно, в какой-то момент функцию f вызовут с двумя строками, и с двумя числами в другой момент. В таком случае x и y будут содержать значения разных типов в разное время. Поэтому говорят, что значения в динамических языках обладают типом, но переменные и функции — нет. Значение 1 это определенно integer, но x и y могут быть чем угодно.
1.3 Сравнение
Большинство динамических языков выдадут ошибку, если типы используются некорректно (JavaScript — известное исключение; он пытается вернуть значение для любого выражения, даже когда оно не имеет смысла). При использовании динамически типизированных языков даже простая ошибка вида "a" + 1 может возникнуть в боевом окружении. Статические языки предотвращают такие ошибки, но, конечно, степень предотвращения зависит от мощности системы типов.
Статические и динамические языки построены на фундаментально разных идеях о корректности программ. В динамическом языке "a" + 1 это корректная программа: код будет запущен и появится ошибка в среде исполнения. Однако, в большинстве статически типизированных языков выражение "a" + 1 — это не программа: она не будет скомпилирована и не будет запущена. Это некорректный код, так же, как набор случайных символов !&%^@*&%^@* — это некорректный код. Это дополнительное понятие о корректности и некорректности не имеет эквивалента в динамических языках.
1.4 Сильная и слабая типизация
Понятия "сильный" и "слабый" — очень неоднозначные. Вот некоторые примеры их использования:
- Иногда "сильный" означает "статический".
Тут все просто, но лучше использовать термин "статический", потому что большинство используют и понимают его. - Иногда "сильный" означает "не делает неявное преобразование типов".
Например, JavaScript позволяет написать "a" + 1, что можно назвать "слабой типизацией". Но почти все языки предоставляют тот или иной уровень неявного преобразования, которое позволяет автоматически переходить от целых чисел к числам с плавающей запятой вроде 1 + 1.1. В реальности, большинство людей используют слово "сильный" для определения границы между приемлемым и неприемлемым преобразованием. Нет какой-то общепринятой границы, они все неточные и зависят от мнения конкретного человека. - Иногда "сильный" означает, что невозможно обойти строгие правила типизации в языке.
- Иногда "сильный" означает безопасный для памяти (memory-safe).
Си — это пример небезопасного для памяти языка. Если xs — это массив четырех чисел, то Си с радостью выполнит код xs[5] или xs[1000], возвращая какое-то значение из памяти, которая находится сразу за xs.
Глава 2. Глобальные и локальные типы переменных
Переменные, объявляемые внутри функций, называются локальными переменными. В некоторой литературе по С данные переменные могут называться автоматическими из-за использования ключевого слова auto. Поскольку термин локальные переменные широко используется, то далее мы будем пользоваться им. С локальными переменными могут работать только операторы, находящиеся в блоке, где данные переменные объявлены. Вне этого блока локальные переменные неизвестны. Следует помнить, что блок кода начинается открытием фигурной скобки и заканчивается закрытием фигурной скобки.
Наиболее важно понять то, что локальные переменные существуют только в блоке кода, в котором они объявлены. Таким образом, локальные переменные создаются при входе в блок и уничтожаются при выходе из него.
Наиболее типичным блоком кода, в котором объявляются локальные переменные, является функция. Например, рассмотрим две функции:
void func1 (void)
{
int x;
x= 10;
)
void func2(void)
{
int x;
x = -199;
Целочисленная переменная x объявляется дважды: один раз в func1() и другой раз в func2(). х в func1() не имеет отношения к х в func2(), поскольку каждая х известна только в блоке, где произошло объявление переменной.
Язык С содержит ключевое слово auto, которое можно использовать для объявления локальных переменных. Тем не менее, поскольку предполагается, что все неглобальные переменные по умолчанию созданы с ключевым словом auto, то оно на самом деле никогда не используется.
Наиболее типично объявление всех необходимых для функции переменных в начале блока кода функции. Это выполняется, главным образом, для того, чтобы любой читающий код, знал об используемых переменных. Тем не менее, нет необходимости выполнять это, поскольку локальные переменные могут быть объявлены в любом блоке кода. (Они должны быть объявлены в начале блока, перед операторами, выполняющими какие-либо действия.) Для того, чтобы понять как все это работает, рассмотрим следующую функцию:
void f(void)
{
int t;
scanf ("%d", &t);
if (t==1) {
char s[80]; /* s существует только в данном блоке */
printf("введите имя:");
gets (s);
process (s);
}
/* s здесь неизвестна */
}
Здесь локальная переменная s известна только в блоке кода if. Поскольку s известна только в блоке кода if, то к ней не может быть осуществлен доступ откуда-либо еще — даже из других частей функции.
Возможность объявления переменной в собственном блоке кода, а не в начале функции, может предотвратить случайное ненужное употребление переменной где-либо в функции. По существу объявление переменных в блоке кода, использующего их, позволяет отделить код от данных.
Поскольку локальные переменные уничтожаются при выходе из функции, в которой они объявлялись, то эти переменные не могут хранить значение между вызовами функций. (Как будет видно, имеется возможность заставить компилятор сохранять значения путем использования модификатора static.)
Если не определено место для хранения локальных переменных, то они будут храниться в стеке. Тот факт, что стек является динамически изменяющейся областью памяти, объясняет, почему локальные переменные в общем не могут содержать значения между вызовами функций.
В противоположность локальным переменным глобальные переменные видны всей программе и могут использоваться любым участком кода. Они хранят свои значения на протяжении всей работы программы. Глобальные переменные создаются путем объявления вне функции. К ним можно получить доступ в любом выражении, независимо от того, в какой функции находится данное выражение.
В следующей программе можно увидеть, что переменная count объявлена вне функций. Она объявляется перед функцией main(). Тем не менее, она может быть помещена в любое место до первого использования, но не внутри функции. Общепринятым является объявление глобальных переменных в начале программы.
#include <stdio.h>
void func1(void) , func2(void);
int count; /* count является глобальной переменной */
int main(void)
{
count = 100;
func1 ();
return 0; /* сообщение об удачном завершении работы */
}
void func1 (void)
{
func2 ();
printf("счетчик %d", count); /* выведет 100 */
}
void func2(void)
{
int count;
for(count=1; count<10; count++)
putchar(' ');
}
Рассмотрим поближе данный фрагмент программы. Следует понимать, что хотя ни main(), ни func1() не объявляют переменную count, но они оба могут ее использовать. func2() объявляет локальную переменную count. Когда func2() обращается к count, она обращается только к локальной переменной, а не к глобальной. Надо помнить, что если глобальная и локальная переменные имеют одно и то же имя, все ссылки на имя внутри функции, где объявлена локальная переменная, будут относиться к локальной переменной и не будут иметь никакого влияния на глобальную,. это очень удобно. Если забыть об этом, то может показаться, что программа работает странно, даже если все выглядит корректно.
Глобальные переменные хранятся в фиксированной области памяти, устанавливаемой компилятором. Глобальные переменные чрезвычайно полезны, когда одни и те же данные используются в нескольких функциях программы. Следует избегать ненужного использования глобальных переменных по трем причинам:
- Они используют память в течение всего времени работы программы, а не тогда, когда они необходимы.
- Использование глобальных переменных вместо локальных приводит к тому, что функции становятся более частными, поскольку они зависят от переменных, определяемых снаружи.
- Использование большого числа глобальных переменных может вызвать ошибки в программе из-за неизвестных и нежелательных эффектов.
Одним из краеугольных камней структурных языков является разделение кода и данных. В С разделение достигается благодаря использованию локальных переменных и функций. Например, ниже показаны два способа написания mul() — простой функции, вычисляющей произведение двух целых чисел.
|
Два способа написания mul( ) |
|
|---|---|
|
Общий |
Частный |
|
int mul(int х, int у) |
int х, у; |
Обе функции возвращают произведение переменных х и у. Тем не менее общая или параметризированная версия может использоваться для вычисления произведения любых двух чисел, в то время как частная версия может использоваться для вычисления произведения только глобальных переменных х и у.
Глава 3. Простые и сложные типы переменных.
Любая программа предназначена для обработки каких либо данных, например, чисел или текстов. Понятно, что данные могут быть различного вида или типа и, в зависимости от их типа, с ними можно выполнять разные действия. А что такое тип данных?
Тип данных характеризует:
- объем памяти, выделяемый под данные;
- их внутреннее представление в памяти компьютера;
- набор допустимых операций (действий);
- множество допустимых значений.
Все типы данных можно подразделить на простые — они предопределены стандартом языка, и сложные (или составные) — задаются пользователем. Данные простого типа нельзя разложить на более простые составляющие без потери сущности данного. Простые типы данных создают основу для построения более сложных типов: массивов, структур, классов. Простые типы в языке C++ — это целые, вещественные типы, символьный и логический тип и тип void.
Рассмотрим более подробно простые типы данных.
3.1 Целые типы
Целый тип данных предназначен для представления в памяти компьютера обычных целых чисел. Основным и наиболее употребительным целым типом является тип int. Гораздо реже используют его разновидности: short (короткое целое) и long (длинное целое). Также к целым типам относится тип char (символьный). Кроме того, при необходимости можно использовать и тип long long (длинное-предлинное!), который хотя и не определён стандартом, но поддерживается многими компиляторами C++. По-умолчанию все целые типы являются знаковыми, т.е. старший бит в таких числах определяет знак числа: 0 — число положительное, 1 — число отрицательное. Кроме знаковых чисел на C++ можно использовать беззнаковые. В этом случае все разряды участвуют в формировании целого числа. При описании беззнаковых целых переменных добавляется слово unsigned (без знака).
Сводная таблица знаковых целых типов данных:
|
Тип данных |
Размер, байт |
Диапазон значений |
|
char |
1 |
-128 ... 127 |
|
short |
2 |
-32768 ... 32767 |
|
int |
4 |
-2147483648 ... 2147483647 |
|
long |
4 |
-2147483648 ... 2147483647 |
|
long long |
8 |
-9223372036854775808 ... 9223372036854775807 |
Сводная таблица беззнаковых целых типов данных:
|
Тип данных |
Размер, байт |
Диапазон значений |
|
unsigned char |
1 |
0 ... 255 |
|
unsigned short |
2 |
0 ... 65535 |
|
unsigned int (можно просто unsigned) |
4 |
0 ... 4294967295 |
|
unsigned long |
4 |
0 ... 4294967295 |
|
unsigned long long |
8 |
0 ... 18446744073709551615 |
Запоминать предельные значения, особенно для 4-х или 8-ми байтовых целых, вряд ли стоит, достаточно знать хотя бы какого порядка могут быть эти значения, например, тип int — приблизительно 2·109.
На практике рекомендуется везде использовать основной целый тип, т.е. int. Дело в том, что данные основного целого типа практически всегда обрабатываются быстрее, чем данные других целых типов. Короткие типы (char, short) подойдут для хранения больших массивов чисел с целью экономии памяти при условии, что значения элементов не выходят за предельные для этих типов. Длинные типы необходимы в ситуации, когда не достаточно типа int.
3.2 Символьные типы
В стандарте C++ нет типа данных, который можно было бы считать действительно символьным. Для представления символьной информации есть два типа данных, пригодных для этой цели, — это типы char и wchar_t, хотя оба эти типа по сути своей вообще-то являются целыми типами. Например, можно взять символ 'A' и поделить его на число 2. Кстати, а что получится? Подсказка: символ пробела. Для «нормальных» символьных типов, например, в Паскале или C#, арифметические операции для символов запрещены.
Тип char используется для представления символов в соответствии с системой кодировки ASCII (American Standard Code for Information Interchange — Американский стандартный код обмена информации). Это семибитный код, его достаточно для кодировки 128 различных символов с кодами от 0 до 127. Символы с кодами от 128 до 255 используются для кодирования национальных шрифтов, символов псевдографики и др.
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер типа wchar_t обычно равен 2 байтам. Если в программе необходимо использовать строковые константы типа wchar_t, то их записывают с префиксом L, например, L"Слово".
3.3 Логический тип
Логический (булевый) тип обозначается словом bool. Данные булевого типа могут принимать только два значения: true и false. Значение false обычно равно числу 0, значение true — числу 1. Под данные булевого типа отводится 1 байт.
3.4 Вещественные типы
Особенностью вещественных (действительных) чисел является то, что в памяти компьютера они практически всегда хранятся приближенно, а при выполнении арифметических операций над такими данными накапливается вычислительная погрешность.
Имеется три вещественных типа данных: float, double и long double. Основным считается тип double. Так, все математические функции по-умолчанию работают именно с типом double. В таблице ниже приведены основные характеристики вещественных типов:
|
Тип данных |
Размер, байт |
Диапазон абсолютных величин |
Точность, количество десятичных цифр |
|
float |
4 |
от 3.4Е—38 до 3.4Е+38 |
7 |
|
double |
8 |
от 1.7Е—308 до 1 .7Е+308 |
15 |
Тип long double в настоящее время, как правило, совпадает с типом double и на практике обычно не применяется. При использовании старых 16-ти разрядных компиляторов данные типа long double имеют размер 10 байт и обеспечивают точность до 19 десятичных цифр.
Рекомендуется везде использовать только тип double. Работа с ним всегда ведётся быстрее, меньше вероятность заметной потери точности при большом количестве вычислений. Тип float может пригодиться только для хранения больших массивов при условии, что для решения поставленной задачи будет достаточно этого типа.
3.5 Тип void
Тип void — самый необычный тип данных языка C++. Множество значений этого типа пусто, т.е. нельзя переменной такого типа присвоить какое-нибудь значение. Более того, нельзя даже описать переменную этого типа. Зачем же нужно то, чем вроде бы невозможно воспользоваться?
Оказывается, это очень полезный тип данных! Он используется:
- для определения функций, которые не возвращают результата своей работы;
- для указания того, что список параметров функции пуст;
- а так же этот тип является базовым для работы с указателями. Достаточно сказать, что всё программирование с использованием Win32 API построено на применении указателей на тип void.
3.6 Сложные типы данных
Структура — это объединение нескольких объектов, возможно, различного типа под одним именем, которое является типом структуры. В качестве объектов могут выступать переменные, массивы, указатели и другие структуры.
Структуры позволяют трактовать группу связанных между собой объектов не как множество отдельных элементов, а как единое целое. Структура представляет собой сложный тип данных, составленный из простых типов.
Общая форма объявления структуры.
struct тип_структуры
{
тип ИмяЭлемента1;
тип ИмяЭлемента2;
. . .
тип ИмяЭлементаn;
};
После закрывающей фигурной скобки } в объявлении структуры обязательно ставится точка с запятой.
Пример объявления структуры
struct date
{
int day; // 4 байта
char *month; // 4 байта
int year; // 4 байта
};
Поля структуры располагаются в памяти в том порядке, в котором они объявлены:
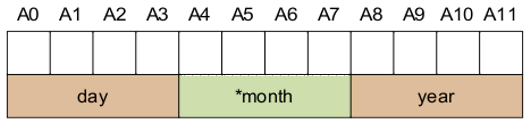
В указанном примере структура date занимает в памяти 12 байт. Кроме того, указатель *month при инициализации будет началом текстовой строки с названием месяца, размещенной в памяти.
При объявлении структур, их разрешается вкладывать одну в другую.
Приме
struct persone
{
char lastname[20]; // фамилия
char firstname[20]; // имя
struct date bd; // дата рождения
};
3.7 Инициализация полей структуры
Инициализация полей структуры может осуществляться двумя способами:
- присвоение значений элементам структуры в процессе объявления переменной, относящейся к типу структуры;
- присвоение начальных значений элементам структуры с использованием функций ввода-вывода (например, printf() и scanf()).
В первом способе инициализация осуществляется по следующей форме:
struct ИмяСтруктуры ИмяПеременной={ЗначениеЭлемента1, ЗначениеЭлемента_2, . . . , ЗначениеЭлементаn};
Пример
struct date bd={8,"июня", 1978};
Имя элемента структуры является составным. Для обращения к элементу структуры нужно указать имя структуры и имя самого элемента. Они разделяются точкой:
ИмяПеременной.ИмяЭлементаСтруктуры
printf("%d %s %d",bd.day, bd.month, bd.year);
Второй способ инициализации объектов языка Си с использованием функций ввода-вывода.
Пример
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
struct date {
int day;
char month[20];
int year;
};
struct persone {
char firstname[20];
char lastname[20];
struct date bd;
};
int main() {
system("chcp 1251");
system("cls");
struct persone p;
printf("Введите имя : ");
scanf("%s", p.firstname);
printf("Введите фамилию : ");
scanf("%s", p.lastname);
printf("Введите дату рождения\nЧисло: ");
scanf("%d", &p.bd.day);
printf("Месяц: ");
scanf("%s", p.bd.month);
printf("Год: ");
scanf("%d", &p.bd.year);
printf("\nВы ввели : %s %s, дата рождения %d %s %d года",
p.firstname, p.lastname, p.bd.day, p.bd.month, p.bd.year);
getchar(); getchar();
return 0;
}
Результат работы
Имя структурной переменной может быть указано при объявлении структуры. В этом случае оно размещается после закрывающей фигурной скобки }. Область видимости такой структурной переменной будет определяться местом описания структуры
struct complex_type // имя структуры
{
double real;
double imag;
} number; // имя структурной переменной
Поля приведенной структурной переменной: number.real, number.imag .
3.8 Объединения
Объединениями называют сложный тип данных, позволяющий размещать в одном и том же месте оперативной памяти данные различных типов.
Размер оперативной памяти, требуемый для хранения объединений, определяется размером памяти, необходимым для размещения данных того типа, который требует максимального количества байт.
Когда используется элемент меньшей длины, чем наиболее длинный элемент объединения, то этот элемент использует только часть отведенной памяти. Все элементы объединения хранятся в одной и той же области памяти, начиная с одного адреса.
Общая форма объявления объединения
union ИмяОбъединения
{
тип ИмяОбъекта1;
тип ИмяОбъекта2;
. . .
тип ИмяОбъектаn;
};
Объединения применяются для следующих целей:
- для инициализации объекта, если в каждый момент времени только один из многих объектов является активным;
- для интерпретации представления одного типа данных в виде другого типа.
Например, удобно использовать объединения, когда необходимо вещественное число типа float представить в виде совокупности байтов
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
union types
{
float f;
unsigned char b[4];
};
int main()
{
types value;
printf("N = ");
scanf("%f", &value.f);
printf("%f = %x %x %x %x", value.f, value.b[0], value.b[1], value.b[2], value.b[3]);
getchar();
getchar();
return 0;
}
Пример Поменять местами два младших байта во введенном числе
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main() {
char temp;
system("chcp 1251");
system("cls");
union
{
unsigned char p[2];
unsigned int t;
} type;
printf("Введите число : ");
scanf("%d", &type.t);
printf("%d = %x шестн.\n", type.t, type.t);
// Замена байтов
temp = type.p[0];
type.p[0] = type.p[1];
type.p[1] = temp;
printf("Поменяли местами байты, получили\n");
printf("%d = %x шестн.\n", type.t, type.t);
getchar(); getchar();
return 0;
}
3.9 Битовые поля
Используя структуры, можно упаковать целочисленные компоненты еще более плотно, чем это было сделано с использованием массива.
Набор разрядов целого числа можно разбить на битовые поля, каждое из которых выделяется для определенной переменной. При работе с битовыми полями количество битов, выделяемое для хранения каждого поля отделяется от имени двоеточием
тип имя: КоличествоБит
При работе с битовыми полями нужно внимательно следить за тем, чтобы значение переменной не потребовало памяти больше, чем под неё выделено.
Пример Разработать программу, осуществляющую упаковку даты в формат

#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#define YEAR0 1980
struct date
{
unsigned short day : 5;
unsigned short month : 4;
unsigned short year : 7;
};
int main() {
struct date today;
system("chcp 1251");
system("cls");
today.day = 16;
today.month = 12;
today.year = 2013 - YEAR0; //today.year = 33
printf("\n Сегодня %u.%u.%u \n", today.day, today.month, today.year + YEAR0);
printf("\n Размер структуры today : %d байт", sizeof(today));
printf("\n Значение элемента today = %hu = %hx шестн.", today, today);
getchar();
return 0;
}
3.10 Массивы структур
Работа с массивами структур аналогична работе со статическими массивами других типов данных.
Пример Библиотека из 3 книг
#include <stdio.h>
#include <stdlib.h>
struct book
{
char title [15];
char author [15];
int value;
};
int main() {
struct book libry[3];
int i;
system(«chcp 1251»);
system(«cls»);
for(i=0;i<3;i++)
{
printf(«Введите название %d книги:»,i+1);
gets(libry[i].title);
printf(«Введите автора %d книги: «,i+1);
gets(libry[i].author);
printf(«Введите цену %d книги: «,i+1);
scanf(«%d»,&libry[i].value);
getchar();
}
for(i=0;i<3;i++)
{
printf(«\n %d. %s «, i+1,libry[i].author);
printf(«%s %d»,libry[i].title,libry[i].value);
}
getchar();
return 0;
}
3.11 Указатели на структуры
Доступ к элементам структуры или объединения можно осуществить с помощью указателей. Для этого необходимо инициализировать указатель адресом структуры или объединения.
Для организации работы с массивом можно использовать указатель р или имя массива:
выражение->идентификатор
(*выражение).идентификатор
выражение — указатель на структуру или объединение;
идентификатор — поле структуры или объединения;
3.12 Динамическое выделение памяти для структур
Динамически выделять память под массив структур необходимо в том случае, если заранее неизвестен размер массива. Для определения размера структуры в байтах используется операция
sizeof(имя структуры);
Пример Библиотека из 3 книг
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
struct book
{
char title [15];
char author [15];
int value;
};
int main() {
struct book *lib;
int i;
system(«chcp 1251»);
system(«cls»);
lib = (struct book*)malloc(3*sizeof(struct book));
for(i=0;i<3;i++)
{
printf(«Введите название %d книги:»,i+1);
gets((lib+i)->title);
printf(«Введите автора %d книги: «,i+1);
gets((lib+i)->author);
printf(«Введите цену %d книги: «,i+1);
scanf(«%d»,&(lib+i)->value);
getchar();
}
for(i=0;i<3;i++)
{
printf(«\n %d. %s «, i+1, (lib+i)->author);
printf(«%s %d», (lib+i)->title, (lib+i)->value);
}
getchar();
return 0;
}
Результат выполнения аналогичен предыдущему решению.
Заключение
Переменными пользуются практически в каждом языке программирования – это очень удобный способ обращения к памяти. В зависимости от выбранного языка и поставленной задачи можно использовать переменные разных типов: статические и динамические, локальные и глобальные.
В зависимости от типа хранящихся данных переменные делятся на простые и сложные, целочисленные, дробные с плавающей запятой, логические, строковые и т.д.
Список использованной литературы.
- Стив Макконел – «Совершенный код»
Брайан Керниган, Деннис Ритчи «Язык программирования С»
Стенли Б. Липпман, Жози Лажойе, Барбара Э. Му «Язык программирования C++. Базовый курс»
Дональд Кнут «Искусство программирования»
- Дж. Рихтер. «CLR via C#»

- Понятие хозяйственного учета, его виды, учетные измерители
- Налоговое планирование как основа налоговой политики государства
- Международные стандарты гостиничного обслуживании
- Распределение и использование прибыли как источник экономического роста предприятий
- Организация и разработка бизнес-плана организации ИП Светличной
- Анализ конкурентов на рынке и определение собственной конкурентоспособности (ИП Светличной)
- Коммерческие банки
- Правовые основы оперативно-розыскной деятельности
- Организация обслуживания в гостиницах
- Процессы принятия решений в организации (Понятие и сущность управленческого решения)
- Корпоративная культура в организации
- Понятие переменной в программировании. Виды и типы переменных (подробно)