
Проектирование и реализация операций бизнес-процесса «Ежедневный складской учет»
Содержание:

ВВЕДЕНИЕ
Тенденции развития современных информационных технологий приводят к постоянному возрастанию сложности информационных систем (ИС), создаваемых в различных областях экономики. Современные крупные проекты ИС характеризуются, как правило, следующими особенностями:
- сложность описания (достаточно большое количество функций, процессов, элементов данных и сложные взаимосвязи между ними), требующая тщательного моделирования и анализа данных и процессов;
- наличие совокупности тесно взаимодействующих компонентов (подсистем), имеющих свои локальные задачи и цели функционирования (например, традиционных приложений, связанных с обработкой транзакций и решением регламентных задач, и приложений аналитической обработки (поддержки принятия решений), использующих нерегламентированные запросы к данным большого объема);
- отсутствие прямых аналогов, ограничивающее возможность использования каких-либо типовых проектных решений и прикладных систем;
- необходимость интеграции существующих и вновь разрабатываемых приложений;
- функционирование в неоднородной среде на нескольких аппаратных платформах;
- разобщенность и разнородность отдельных групп разработчиков по уровню квалификации и сложившимся традициям использования тех или иных инструментальных средств;
- существенная временная протяженность проекта, обусловленная, с одной стороны, ограниченными возможностями коллектива разработчиков, и, с другой стороны, масштабами организации-заказчика и различной степенью готовности отдельных ее подразделений к внедрению ИС.
Для успешной реализации проекта объект проектирования (ИС) должен быть прежде всего адекватно описан, должны быть построены полные и непротиворечивые функциональные и информационные модели ИС. Накопленный к настоящему времени опыт проектирования ИС показывает, что это логически сложная, трудоемкая и длительная по времени работа, требующая высокой квалификации участвующих в ней специалистов. Однако до недавнего времени проектирование ИС выполнялось в основном на интуитивном уровне с применением неформализованных методов, основанных на искусстве, практическом опыте, экспертных оценках и дорогостоящих экспериментальных проверках качества функционирования ИС. Кроме того, в процессе создания и функционирования ИС информационные потребности пользователей могут изменяться или уточняться, что еще более усложняет разработку и сопровождение таких систем.
В 70-х и 80-х годах при разработке ИС достаточно широко применялась структурная методология, предоставляющая в распоряжение разработчиков строгие формализованные методы описания ИС и принимаемых технических решений. Она основана на наглядной графической технике: для описания различного рода моделей ИС используются схемы и диаграммы. Ручная разработка обычно порождала следующие проблемы:
- неадекватная спецификация требований;
- неспособность обнаруживать ошибки в проектных решениях;
- низкое качество документации, снижающее эксплуатационные качества;
- затяжной цикл и неудовлетворительные результаты тестирования.
Перечисленные факторы способствовали появлению программно-технологических средств специального класса - CASE-средств, реализующих CASE-технологию создания и сопровождения ИС. Термин CASE (Computer Aided Software Engineering) используется в настоящее время в весьма широком смысле. Под термином CASE-средства понимаются программные средства, поддерживающие процессы создания и сопровождения ИС, включая анализ и формулировку требований, проектирование прикладного ПО (приложений) и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом, а также другие процессы. CASE-средства вместе с системным ПО и техническими средствами образуют полную среду разработки ИС.
1.ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1.1 Методы и средства проектирования информационных систем.
В информационных системах методы реализуются через конкретные информационные технологии и поддерживающие их стандарты, инструкции и инструментальные средства, которые обеспечивают выполнение процессов жизненного цикла ИС.
Методы проектирования ИС подразумевают использование определённых программных и аппаратных средств, составляющих инструментальные средства программирования ИС.
Метод проектирования включает совокупность трёх составляющих:
- пошаговой процедуры, определяющей последовательность технологических операций проектирования (рис.1);
- критериев и правил, используемых для оценки результатов выполнения технологических операций;
- нотаций (графических и текстовых средств), используемых для описания проектируемой системы.
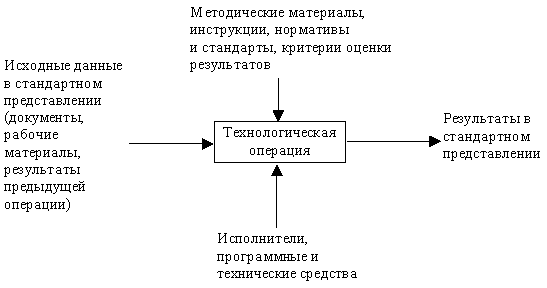
Рис.1 - . Представление технологической операции проектирования
Одним из базовых понятий методологии проектирования ИС является понятие жизненного цикла ее программного обеспечения (ЖЦ ПО). ЖЦ ПО - это непрерывный процесс, который начинается с момента принятия решения о необходимости его создания и заканчивается в момент его полного изъятия из эксплуатации.
Основным нормативным документом, регламентирующим ЖЦ ПО, является международный стандарт ISO/IEC 12207 Он определяет структуру ЖЦ, содержащую процессы, действия и задачи, которые должны быть выполнены во время создания ПО.
Структура ЖЦ ПО по стандарту ISO/IEC 12207 базируется на трех группах процессов:
- основные процессы ЖЦ ПО (приобретение, поставка, разработка, эксплуатация, сопровождение);
- вспомогательные процессы, обеспечивающие выполнение основных процессов (документирование, управление конфигурацией, обеспечение качества, верификация, аттестация, оценка, аудит, решение проблем);
- организационные процессы (управление проектами, создание инфраструктуры проекта, определение, оценка и улучшение самого ЖЦ, обучение).
Разработка включает в себя все работы по созданию ПО и его компонент в соответствии с заданными требованиями, включая оформление проектной и эксплуатационной документации, подготовку материалов, необходимых для проверки работоспособности и соответствующего качества программных продуктов, материалов, необходимых для организации обучения персонала и т.д. Разработка ПО включает в себя, как правило, анализ, проектирование и реализацию (программирование).
Эксплуатация включает в себя работы по внедрению компонентов ПО в эксплуатацию, в том числе конфигурирование базы данных и рабочих мест пользователей, обеспечение эксплуатационной документацией, проведение обучения персонала и т.д., и непосредственно эксплуатацию, в том числе локализацию проблем и устранение причин их возникновения, модификацию ПО в рамках установленного регламента, подготовку предложений по совершенствованию, развитию и модернизации системы.
Управление проектом связано с вопросами планирования и организации работ, создания коллективов разработчиков и контроля за сроками и качеством выполняемых работ. Техническое и организационное обеспечение проекта включает выбор методов и инструментальных средств для реализации проекта, определение методов описания промежуточных состояний разработки, разработку методов и средств испытаний ПО, обучение персонала и т.п. Обеспечение качества проекта связано с проблемами верификации, проверки и тестирования ПО. Верификация - это процесс определения того, отвечает ли текущее состояние разработки, достигнутое на данном этапе, требованиям этого этапа. Проверка позволяет оценить соответствие параметров разработки с исходными требованиями. Проверка частично совпадает с тестированием, которое связано с идентификацией различий между действительными и ожидаемыми результатами и оценкой соответствия характеристик ПО исходным требованиям. В процессе реализации проекта важное место занимают вопросы идентификации, описания и контроля конфигурации отдельных компонентов и всей системы в целом.
Управление конфигурацией является одним из вспомогательных процессов, поддерживающих основные процессы жизненного цикла ПО, прежде всего процессы разработки и сопровождения ПО. При создании проектов сложных ИС, состоящих из многих компонентов, каждый из которых может иметь разновидности или версии, возникает проблема учета их связей и функций, создания унифицированной структуры и обеспечения развития всей системы. Управление конфигурацией позволяет организовать, систематически учитывать и контролировать внесение изменений в ПО на всех стадиях ЖЦ. Общие принципы и рекомендации конфигурационного учета, планирования и управления конфигурациями ПО отражены в проекте стандарта ISO 12207-2.
Каждый процесс характеризуется определенными задачами и методами их решения, исходными данными, полученными на предыдущем этапе, и результатами. Результатами анализа, в частности, являются функциональные модели, информационные модели и соответствующие им диаграммы. ЖЦ ПО носит итерационный характер: результаты очередного этапа часто вызывают изменения в проектных решениях, выработанных на более ранних этапах.
Под средствами проектирования информационных систем (СП ИС) будем понимать комплекс инструментальных средств, обеспечивающих в рамках выбранной методологии проектирования поддержку полного жизненного цикла (ЖЦ) ИС, который включает в себя, как правило, стратегическое планирование, анализ, проектирование, реализацию, внедрение и эксплуатацию. При анализе СП их следует рассматривать не локально, а в комплексе, что позволяет реально охарактеризовать их достоинства, недостатки и место в общем технологическом цикле создания ИС.
В общем случае стратегия выбора СП для конкретного применения зависит от следующих факторов:
- характеристик моделируемой предметной области;
- целей, потребностей и ограничений будущего проекта ИС, включая квалификацию участвующих в процессе проектирования специалистов;
- используемой методологии проектирования.
К средствам проектирования ИС относятся:
- программные средства, поддерживающие процессы создания и сопровождения ИС, включая анализ и формулировку требований;
- проектирование прикладного ПО (приложений) и баз данных выполнение;
- генерация кода;
- документирование;
- обеспечение качества;
- конфигурационное управление и управление проектом.
На выбор СП могут существенно повлиять следующие особенности методологии проектирования:
- ориентация на создание уникального или типового проекта;
- итерационный характер процесса проектирования;
- возможность декомпозиции проекта на составные части, разрабатываемые группами исполнителей ограниченной численности с последующей интеграцией составных частей;
- жесткая дисциплина проектирования и разработки при их коллективном характере;
- необходимость отчуждения проекта от разработчиков и его последующего централизованного сопровождения.
Правильный выбор метода создания информационной системы и подбора средств проектирования – залог успешного завершения проекта по созданию жизнедеятельной ИС.
1.2 Методы и средства проектирования баз данных для ИС.
Процесс создания современных информационных систем (ИС) предполагает разработку базы данных (БД) и программных приложений. Причем и базы данных, и приложения информационной системы могут работать либо в конкретной имеющейся среде (с заданной конфигурацией аппаратных средств, топологией сети, используемой архитектурой и т. д.), либо в среде специально создаваемой для конкретной ИС. Проектируя базу данных для информационной системы и соответствующие приложения работы с ней, необходимо, во-первых, предусмотреть определенную гибкость реализуемой системы (должна обладать способностью не просто давать ответы на запросы, которые пользователь задает сегодня, но также в ней должна быть заложена возможность предвидения той информаций, которую он захочет получить завтра). Во-вторых, обеспечить требуемые пропускную способность и время реакции системы. А, учитывая среду функционирования ИС, следует заботиться о безотказности, безопасности работы системы, простоте ее эксплуатации и поддержке.
Сегодня при разработке информационных систем в целом, и баз данных в частности, используются различные известные методы, такие как:
- каскадная модель;
- поэтапная модель с промежуточным контролем;
- спиральная модель;
- модель эволюционной разработки (метод приращений).
Каждый из них имеет свои области применения, достоинства и недостатки. В этом случае эффективным решением могла бы быть определенная технология, которая:
- имела бы комплексное и общее решение, позволяющее разрабатывать основные составные элементы ИС (базы данных и программные приложения с ней работающие);
- способствовала бы использованию уже существующих компонентов, с целью отказа от экстенсивного ручного программистского труда в пользу интенсивных методов сборки, а не разработки их каждый раз уникальным способом под конкретное задание;
- позволяла бы прозрачно и в сжатые сроки разрабатывать любого уровня сложности новые БД и программные приложения с ней работающие;
- позволяла бы проводить реинжиниринг существующих баз данных, построенных на различных принципах, платформах и содержащих значительный объем разнообразных данных;
- упрощала и удешевляла бы процесс дальнейшей эксплуатации баз данных и ИС в целом.
В результате проведенного анализа развития информационных технологий была разработана такая технология. Она, как совокупность предлагаемых методов не привязана к конкретным программным решениям и платформам, хотя сегодняшняя ее реализация связана с определенными системами и платформами.
Рассмотрим ее методы.
1) Метод разработки баз данных информационной системы на основе использования схемы базы данных с универсальной моделью данных.
При создании данного метода была использована классическая технологии проектирования баз данных. За основу были взяты базовые ее этапы, которые и получили дальнейшую конкретизацию и уточнения с учетом особенностей и возможностей семантической модели данных «объект-событие» универсальной модели данных.
Основные этапы метода разработки базы данных информационной системы для любой ПрО, основывающегося на использовании схемы базы данных с универсальной моделью данных. Необходимо:
- изучение ПрО;
- анализ собранных сведений о ПрО;
- составление КО о ПрО ;
- составление логической модели ПрО;
- формализация модели ПрО ;
- инсталляция схемы БД с УМД;
- загрузка схемы БД с УМД ;
- просмотр загруженных данных;
- тестирование БД с УМД.
Этап 1. Изучение (сбор сведений) предметной области и выделение ее основных значимых элементов. На естественном языке формулируется описание предметной области и ограничения, накладываемые на выбранные элементы ПрО.
Этап 2. Анализ собранных сведений о ПрО и их фиксация. Конкретизируются и формализуются множества значимых элементов ПрО путем отнесения их к одной из методологий семантической модели «объект-событие» (раздел, класс объектов, класс событий, их экземпляры, характеристики и т. п.). Выясняется иерархия классов, экземпляров объектов ПрО, динамика событий с ними происходящими, их параметры и т. д. Определяются и формализуются ограничения целостности элементов ПрО.
Этап 3. Составление концептуального описания (КО) ПрО с помощью модели данных «объект-событие». В соответствии с правилами составляется концептуальные описания метаданных и данных ПрО.
Этап 4. Составление логической модели ПрО с помощью универсальной модели данных. В соответствии с правилами составляется логическая модель ПрО.
Этап 5. Формализация модели предметной области с помощью ЯМД. На данном этапе с помощью языка модели данных (ЯМД) осуществляется формализованное представление модели ПрО, составленной на предыдущих двух этапах. При составлении приложений, имеющих доступ к данным схемы БД с УМД, прикладным программистам необходимо знать язык модели данных и структуру интерфейса доступа к серверным (хранимым) процедурам интерпретатора ЯМД. Конечные пользователи также, понимая несложные операторы ЯМД, могут исполнять и составлять строки ЯМД самостоятельно, не прибегая к помощи программистов.
Этап 6. Инсталляция схемы БД с УМД. Данный этап может быть выполнен и в самом начале процесса разработки БД (для облегчения процесса инсталляции схемы БД с УМД разработан специальный скрипт и инструкция по его использованию). То есть процесс разработки физической структуры БД любой ИС сводится не к разработке каждый раз новых объектов базы данных, а к инсталляции стандартной схемы БД со структурой УМД, которая в дальнейшем наполняется элементами конкретной предметной области. Это позволяет разработчикам, больше сосредоточиться на ПрО, а, следовательно, лучше продумать состав необходимых данных в соответствии с реализуемыми бизнес- процессами.
Этап 7. Загрузка схемы БД с УМД реальными данными. Загрузка данными БД с УМД может осуществляться как с помощью специально разработанного (в рамках предлагаемой технологии) программного инструментария проектировщика БД, так и с помощью программных приложений, разработанных самостоятельно заказчиком или по его просьбе разработчиком индивидуально для конкретного пользователя.
Этап 8. Просмотр загруженных данных. Просмотр осуществляется с целью проверки их соответствия представлениям экспертов ПрО с помощью специальной программы из состава разработанного в рамках новой технологии программного инструментария разработчика БД с УМД, в которой данные представлены в виде связанного иерархического дерева. Анализируя такие представления, можно выявить несоответствия, отсутствующие или ошибочные связи между реальным данными ПрО и данными, занесенными в БД с УМД. После чего с помощью, опять же, предоставляемого программного инструментария легко провести проектирование заново, повторить загрузку реальных данных и получить новый вариант базы данных для анализа на адекватность предметной области. В результате нескольких итераций проектируется БД, адекватная представлениям о ПрО. При этом следует учесть, что итерационный характер носит не проектирование схемы БД и ее элементов, а заполнение сформированной уже схемы БД с ее элементами. Что позволяет существенно экономить временной и финансовый ресурс, соответственно выделяемый (затрачиваемый) на разработку базы данных.
Этап 9. Тестирование БД с УМД. Тестирование может проводиться как с помощью имеющегося программного инструментария разработчика БД с УМД, так и с помощью программного обеспечения ПО, разработанного пользователем самостоятельно или сторонним разработчиком. Данный этап является очень важным не только в плане правильности функционирования последней, но и в плане адекватного моделирования ПрО в базе данных, обеспечения необходимой безопасности информации, хранящейся в БД с УМД, а также развития и улучшения ее концептуальной структуры в соответствии с новыми возможными изменениями в представлении предметной области.
Итерационное исполнение всех перечисленных этапов создает достаточно подробную и понятную всем участникам проекта (специалистам различного профиля и квалификации) документацию, описывающую различные уровни представления данных разрабатываемой БД.
Большинство организаций уже имеет некоторые информационные системы, которые со временем становятся бременем компании и начинают требовать реинжиниринга. Занятие реорганизацией информационных систем не является сегодня для разработчика БД чем-то необычным. Это объясняется тем, что специалистам любой крупной и давно существующей компании, которая обладает несколькими базами данных, относящимися к разным видам деятельности, данные в которых могут иметь разные представления и быть даже несогласованными, становится очень трудно связывать и анализировать содержащуюся в них информацию. К тому же многие БД, составляющие основу таких ИС, как правило, построены на уже устаревших «платформах» (например, Dbase, FoxPro и т. д.). При этом данные, в них хранящиеся, имеют большую практическую ценность. Как результат, имея самые разнообразные изолированные друг от друга источники данных, найти необходимые для деятельности компании данные становится невозможным. Поэтому чтобы упростить и ускорить доступ к такой информации, дать возможность прослеживать связи между разными источниками данных и обеспечить использование для управления на всех уровнях, в том числе унаследованных настольных баз данных, необходимо каким-то образом интегрировать эти данные. На сегодняшний день в мире существует большое количество подходов, методов и технологических решений, напрямую или косвенно соотносимых с деятельностью по реинжинирингу ИС. Однако они не интегрированы на уровне методологий (процессов разработки). Поэтому ниже предлагается метод, с помощью которого можно решить эту проблему.
Характеристика основных этапов метода разработки баз данных Предлагаемый метод разработки базы данных основывается на использовании схемы БД с УМД и специально определенных типовых процессах реинжиниринга существующих баз данных в схему базы данных с универсальной моделью.
Этапы метода разработки новой базы данных путем реинжиниринга.
Этап 1. Экспорт данных во временные таблицы. Данные базы данных, подвергающейся реинжинирингу, экспортируются в одну из СУБД: Oracle, PostgreSQL или Access.
Этап 2. Создание таблицы-шаблона. В той СУБД, куда были экспортированы данные, создается, так называемая, таблица-шаблон.
Этап 3. Заполнение (формирование) таблицы-шаблона. С использованием различных конструкций и операторов языка модели данных заполняется таблица- шаблон.
Этап 4. Реинжиниринг исходной базы данных. На основании содержания таблицы-шаблона (данных ее строк и столбцов) и определенных строк (не всех сразу) определенных таблиц исходной БД, подвергающейся реинжинирингу, специально разработанное в рамках предлагаемой технологии приложение автоматически формирует корректные строки ЯМД, которые затем и исполняет. В результате таких действий данные, ранее хранящихся в исходной БД, помещаются в схему БД с УМД в виде определенных метаданных.
Этап 5. Проверка реинжиниринга. С помощью специально разработанной в рамках предлагаемой технологии программы просмотра проверяется правильность преобразования БД. В случае обнаружения несоответствий между описанием предметной области и занесенными в БД данными, последние с помощью различных приложений (предусмотренных технологией) удаляются. После чего вносятся требуемые изменения, помещаемые в таблицу-шаблон в виде соответствующих строк метаописаний ЯМД, и процесс преобразования (этапы 3…5) повторяется. Такое повторение осуществляется до тех пор, пока не будет найдено адекватное отображение ПрО в схеме БД с УМД, способствующее, в том числе, и улучшению функциональности получаемой новой БД.
Выводы:
1. Предлагаемый метод разработки баз данных информационных систем, основывающийся на использовании схемы базы данных с универсальной моделью, позволяет:
- оперативно создавать базы данных отвечающие функциональным потребностям заказчика, для любой предметной области;
- создавать достаточно подробную документацию, описывающую различные уровни представления данных разрабатываемой БД и понятную специалистам различного профиля и квалификации;
- развивать и улучшать концептуальную структуру базы данных для конкретной информационной системы, рассматриваемой предметной области, без изменения физической структуры схемы базы данных.
2) Созданный в рамках новой технологии проектирования баз данных метод разработки базы данных, основывающийся на специальных типовых процессах реинжиниринга существующих баз данных в схему базы данных с универсальной моделью, в отличие от традиционных методов имеет комплексное, целостное решение задач реинжиниринга ИС на уровне методологии, основывающейся на универсальной модели данных. Благодаря разработанному методу стало возможным использование данных «устаревших» информационных систем в системе, основанной на новой технологии с последующим возможным упрощением. Использование данного метода способствует расширению функциональности вновь создаваемой базы данных и улучшению других количественных и качественных ее характеристик, в том числе снижается стоимость сопровождения, вероятность возникновения значимых для заказчика рисков, уменьшаются сроки работ по ее сопровождению.
1.3 Примеры информационных систем.
Современные методы и средства проектирования информационных систем, основанные на использовании CASE-технологии. Они могут способствовать успешному внедрению CASE-средств и уменьшить риск неправильных инвестиций.
Несмотря на высокие потенциальные возможности CASE-технологии (увеличение производительности труда, улучшение качества программных продуктов, поддержка унифицированного и согласованного стиля работы) далеко не все разработчики информационных систем, использующие CASE-средства, достигают ожидаемых результатов.
Приведем три разные технологии создания информационных систем:
1) структурная;
2) объектно-ориентированная;
3) ориентированная на бизнес.
1) Структурный подход
Сущность структурного подхода к разработке ИС заключается в ее декомпозиции (разбиении) на автоматизируемые функции: система разбивается на функциональные подсистемы, которые в свою очередь делятся на подфункции, подразделяемые на задачи и так далее. Процесс разбиения продолжается вплоть до конкретных процедур. При этом автоматизируемая система сохраняет целостное представление, в котором все составляющие компоненты взаимоувязаны. При разработке системы "снизу-вверх" от отдельных задач ко всей системе целостность теряется, возникают проблемы при информационной стыковке отдельных компонентов.
Все наиболее распространенные методологии структурного подхода базируются на ряде общих принципов. В качестве двух базовых принципов используются следующие:
- принцип "разделяй и властвуй";
- принцип решения сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения;
- принцип иерархического упорядочивания;
- принцип организации составных частей проблемы в иерархические древовидные структуры с добавлением новых деталей на каждом уровне.
Основными из этих принципов являются следующие:
-принцип абстрагирования - заключается в выделении существенных аспектов системы и отвлечения от несущественных;
-принцип формализации - заключается в необходимости строгого методического подхода к решению проблемы;
- принцип непротиворечивости - заключается в обоснованности и согласованности элементов;
- принцип структурирования данных - заключается в том, что данные должны быть структурированы и иерархически организованы.
В структурном анализе используются в основном две группы средств, иллюстрирующих функции, выполняемые системой и отношения между данными. Каждой группе средств соответствуют определенные виды моделей (диаграмм), наиболее распространенными среди которых являются следующие:
- SADT (Structured Analysis and Design Technique) модели и соответствующие функциональные диаграммы;
- DFD (Data Flow Diagrams) диаграммы потоков данных;
- ERD (Entity-Relationship Diagrams) диаграммы "сущность-связь";
- STD;
- FDD;
- IDEF. :
На стадии проектирования ИС модели расширяются, уточняются и дополняются диаграммами, отражающими структуру программного обеспечения: архитектуру ПО, структурные схемы программ и диаграммы экранных форм.
Перечисленные модели в совокупности дают полное описание ИС независимо от того, является ли она существующей или вновь разрабатываемой. Состав диаграмм в каждом конкретном случае зависит от необходимой полноты описания системы.
2) Объективно-ориентированный подход
Методология RUP и диаграммы UML
Rational Unified Process (RUP) – одна из лучших методологий разработки программного обеспечения Основываясь на опыте многих успешных программных проектов, Унифицированный процесс позволяет создавать сложные программные системы, основываясь на индустриальных методах разработки. Одним из основных столпов, на которые опирается RUP, является процесс создания моделей при помощи унифицированного языка моделирования (UML).
Создание программного обеспечения – это сложный процесс, который, с одной стороны, имеет много общего с творчеством, а с другой, – хотя и высокодоходный, но и высоко затратный бизнес. Жестокая конкуренция на рынке вынуждает разработчиков к поиску более эффективных методов работы. Путей создания программных систем в еще более короткие сроки, с меньшими затратами и лучшим качеством. Будущее за индустриальным подходом к созданию ПО. Командная разработка требует совсем другого подхода и другой методологии, которая рано или поздно должна была быть создана.
Вся разработка ПО рассматривается в RUP как процесс создания артефактов. Любой результат работы проекта, будь то исходные тексты, объектные модули, документы, передаваемые пользователю, модели – это подклассы всех артефактов проекта. Каждый член проектной группы создает свои артефакты и несет за них ответственность. Программист создает программу, руководитель — проектный план, а аналитик — модели системы. RUP позволяет определить когда, кому и какой артефакт необходимо создать, доработать или использовать.
Одним из интереснейших классов артефактов проекта являются модели, которые позволяют разработчикам определять, визуализировать, конструировать и документировать артефакты программных систем. Модели позволяют рассмотреть будущую систему, ее объекты и их взаимодействие еще до вкладывания значительных средств в разработку, позволяют увидеть ее глазами будущих пользователей снаружи и разработчиков изнутри еще до создания первой строки исходного кода. Большинство моделей представляются UML диаграммами.
Бездумное применение UML, просто потому что это модно, не только не приведет разработку к успеху, но и может вызвать недовольство сотрудников, которым необходимо изучать большое количество дополнительной литературы и руководителей проекта, когда окажется, что трудозатраты на проекте возрастают, а отдача не повышается. Нужно четко представлять себе, что вы хотите получить от внедрения этой технологии и следовать этой цели. Применение UML экономит ресурсы разработки.
Основные процессы методологии RUP:
- определение требований;
- анализ;
- проектирование;
- реализация;
- тестирование;
- заключение.
Применение UML вместе с унифицированным процессом позволит получить предсказуемый результат, уложиться в отведенный бюджет, повысить отдачу от участников проекта и качество создаваемого программного продукта.
3) Ориентированная на бизнес (ARIS, eERS, VACD, PCDs, jCOM1)
Бизнес-процесс – это логичный, последовательный, взаимосвязанный набор мероприятий, который потребляет ресурсы, создаёт ценность и выдаёт результат. Моделирование бизнес-процессов – это эффективное средство поиска путей оптимизации деятельности компании, позволяющее определить, как компания работает в целом и как организована деятельность на каждом рабочем месте.
Описание бизнес-процессов проводится с целью их дальнейшего анализа и реорганизации. Целью реорганизации может быть внедрение информационной системы. Бизнес-инжиниринг состоит из моделирования бизнес-процессов (разработка модели "как есть", её анализ, разработка модели "как надо") и разработки и реализации плана перехода к состоянию "как надо".
Бизнес-модель - это формализованное (графическое, табличное, текстовое, символьное) описание бизнес-процессов. Основная область применения бизнес-моделей - это реинжиниринг бизнес-процессов.
Этапы описания бизнес-процессов:
- определение целей описания;
- описание окружения, определение входов и выходов бизнес-процесса, построение диаграмм;
- описание функциональной структуры (действия процесса), построение диаграмм;
- описание потоков (материальных, информационных, финансовых) процесса, построение DFD-диаграмм;
- построение организационной структуры процесса (отделы, участники, ответственные).
Используемые методологии:
- ARIS — любая организация в методологии ARIS рассматривается с пяти точек зрения: организационной, функциональной, обрабатываемых данных, структуры бизнес-процессов, продуктов и услуг. При этом каждая из этих точек зрения разделяется ещё на три подуровня: описание требований, описание спецификации, описание внедрения;
- eEPC — метод описания процессов;
- ERM — модель «сущность-связь» для описания структуры данных;
- UML — унифицированный объектно-ориентированный язык моделирования.
Технология ARIS Script позволяет в автоматическом режиме производить:
- формирование нормативных документов на основании моделей ARIS (например, паспорт процесса, регламент процесса);
- формирование аналитических отчётов на основании моделей ARIS;
- интеграцию ARIS Toolset с другими приложениями и базами данных;
- формирование базы моделей ARIS на основании готовых спецификаций.
2. ПРОЕКТНАЯ ЧАСТЬ
Во многих случаях эффективную информационную систему не удается построить вручную. Это объясняется следующими причинами:
- не обеспечивается достаточно глубокий анализ требований к данным;
- большая длительность процесса структурирования;
- трудность учета и согласования изменений, сделанных в системе несколькими разработчиками;
- ограничения сроков на разработку системы.
Выбираем структурный подход к разработке ИС.
Для преодоления сложностей начальных этапов разработки предназначен структурный анализ - метод исследования, которое начинается с общего обзора системы и затем детализуется, приобретая иерархическую структуру с все большим числом уровней. На каждом уровне рассматривается ограниченное число элементов (обычно от 3 до 6-8), каждый из которых в свою очередь может быть декомпозирован на составляющие детали на следующем уровне. При этом соблюдаются строгие формальные правила записи информации (обычно используются диаграммы различных типов).
Такая технология получила название CASE (Computer Aided Software Engeneering - создание программного обеспечения с помощью компьютера). Основные черты CASE - технологии:
- использование методологии структурного проектирования "сверху-вниз";
- разработка прикладной системы этапов проектирования..
Как правило, CASE-системы поддерживают следующие этапы процесса разработки:
- моделирование и анализ деятельности пользователей в рамках предметной области. Здесь осуществляется функциональная декомпозиция, определение иерархий (вложенности) функций, построение диаграмм потоков данных. Передается на следующий этап проектирования;
- концептуальное моделирование - создание модели "сущность-связь" на основе перечня объектов, полученного на предыдущем этапе. Здесь уточняются характеристики каждого объекта (атрибуты), устанавливаются связи между объектами;
- реляционное моделирование - преобразование модели "сущность-связь" в соответствии с требованиями реляционной модели (реляционная модель допускает только бинарные связи);
- генерация схемы базы данных. Результатом выполнения данного этапа является набор SQL-операторов, описывающих создание схемы базы данных (CREATE TABLE, CREATE INDEX,...), с учетом особенностей целевой СУБД;
- генерация прототипов программных модулей по иерархии функций и потокам данных. Для каждого модуля автоматически подготавливается описание используемых им фрагментов данных (таблицы, атрибуты, индексы), а также создаются заготовки экранных форм или отчетов.
2.1 Описание предметной области (с построением диаграммы потоков данных с декомпозицией)
На первом этапе моделирования и анализе предметной области выбираем DFD-диаграмму с декомпозицией.
Предположим, что перед нами стоит задача разработать информационную систему по заказу оптовой торговой фирмы для ежедневного складского учета. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия:
- хранить информацию о покупателях;
- печатать накладные на отпущенные товары;
- следить за наличием товаров на складе.
Следовательно на диаграмме должны присутствовать такие объекты как:
- покупатель;
- накладная;
- склад;
- товар.
Для построения DFD-диаграммы потоков данных выбираем нотацию Йордана (рис.2).
Товар
Покупатель
Накладная
Склад
Рис.2 – DFD диаграмма потоков данных
2.2 Жизненный цикл информационной системы
На следующем этапе моделируем жизненный цикл информационной системы.
Под моделью ЖЦ понимается структура, определяющая последовательность выполнения и взаимосвязи процессов, действий и задач, выполняемых на протяжении ЖЦ. Модель ЖЦ зависит от специфики ИС и специфики условий, в которых последняя создается и функционирует. Его регламенты являются общими для любых моделей ЖЦ, методологий и технологий разработки. Стандарт ISO/IEC 12207 описывает структуру процессов ЖЦ ПО, но не конкретизирует в деталях, как реализовать или выполнить действия и задачи, включенные в эти процессы.
К настоящему времени наибольшее распространение получили следующие две основные модели ЖЦ:
- каскадная модель (70-85 г.г.);
- спиральная модель (86-90 г.г.).
В изначально существовавших однородных ИС каждое приложение представляло собой единое целое. Для разработки такого типа приложений применялся каскадный способ. Его основной характеристикой является разбиение всей разработки на этапы, причем переход с одного этапа на следующий происходит только после того, как будет полностью завершена работа на текущем этапе. Каждый этап завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой разработчиков.
Положительные стороны применения каскадного подхода заключаются в следующем:
- на каждом этапе формируется законченный набор проектной документации, отвечающий критериям полноты и согласованности;
- выполняемые в логичной последовательности этапы работ позволяют планировать сроки завершения всех работ и соответствующие затраты (рис.3).
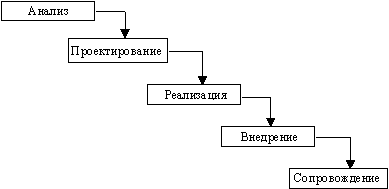
Рис. - 3. Каскадная схема разработки
Каскадный подход хорошо зарекомендовал себя при построении ИС, для которых в самом начале разработки можно достаточно точно и полно сформулировать все требования, с тем чтобы предоставить разработчикам свободу реализовать их как можно лучше с технической точки зрения. В эту категорию попадают сложные расчетные системы, системы реального времени и другие подобные задачи. Однако, в процессе использования этого подхода обнаружился ряд его недостатков, вызванных прежде всего тем, что реальный процесс создания ИС никогда полностью не укладывался в такую жесткую схему. В процессе создания ИС постоянно возникала потребность в возврате к предыдущим этапам и уточнении или пересмотре ранее принятых решений. В результате реальный процесс создания ИС принял следующий вид (рис. 4):
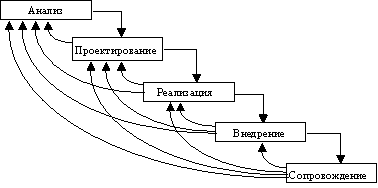
Рис. 4 - Реальный процесс разработки ПО по каскадной схеме
Основным недостатком каскадного подхода является существенное запаздывание с получением результатов. Согласование результатов с пользователями производится только в точках, планируемых после завершения каждого этапа работ, требования к ИС "заморожены" в виде технического задания на все время ее создания. Таким образом, пользователи могут внести свои замечания только после того, как работа над системой будет полностью завершена. В случае неточного изложения требований или их изменения в течение длительного периода создания ИС, пользователи получают систему, не удовлетворяющую их потребностям. Модели (как функциональные, так и информационные) автоматизируемого объекта могут устареть одновременно с их утверждением.
Для преодоления перечисленных проблем была предложена спиральная модель ЖЦ (рис. 5), делающая упор на начальные этапы ЖЦ: анализ и проектирование. На этих этапах реализуемость технических решений проверяется путем создания прототипов. Каждый виток спирали соответствует созданию фрагмента или версии ИС, на нем уточняются цели и характеристики проекта, определяется его качество и планируются работы следующего витка спирали. Таким образом углубляются и последовательно конкретизируются детали проекта и в результате выбирается обоснованный вариант, который доводится до реализации.
Разработка итерациями отражает объективно существующий спиральный цикл создания системы. Неполное завершение работ на каждом этапе позволяет переходить на следующий этап, не дожидаясь полного завершения работы на текущем. При итеративном способе разработки недостающую работу можно будет выполнить на следующей итерации. Главная же задача - как можно быстрее показать пользователям системы работоспособный продукт, тем самым активизируя процесс уточнения и дополнения требований.
Основная проблема спирального цикла - определение момента перехода на следующий этап. Для ее решения необходимо ввести временные ограничения на каждый из этапов жизненного цикла. Переход осуществляется в соответствии с планом, даже если не вся запланированная работа закончена. План составляется на основе статистических данных, полученных в предыдущих проектах, и личного опыта разработчиков.
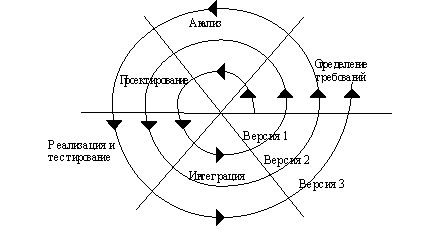
Рис 5 - Спиральная модель ЖЦ
Выбираем каскадную модель перехода событий. Информационная модель предполагается несложная и запаздывания с получением результатов не ожидается.
2.3 База данных информационной системы
На этапе концептуального моделирования базы данных используем полученные на предыдущем этапе перечень объектов. Уточняем характеристики каждого объекта (атрибуты) и устанавливаем связь между объектами. Строим ERD - диаграмму.
При разработке ER-моделей мы должны получить следующую информацию о предметной области:
- список сущностей предметной области.
- список атрибутов сущностей.
- описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Возьмем из предыдущего раздела (2.1) необходимые данные - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их.
Покупатель, Накладная, Товар - явные кандидаты на сущность.
Склад- под вопросом. Выясняем сколько складов имеет фирма. Если несколько, то это будет кандидатом на новую сущность.
Наличие товара– это атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями - "покупатели могут покупать много товаров" и "товары могут продаваться многим покупателям". Первый вариант диаграммы выглядит так на рис.6:
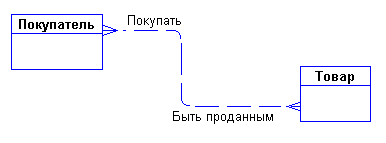
Рис. 6 - Первый вариант диаграммы
Задав дополнительные вопросы менеджеру, выясняем, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада.
Как связаны эти сущности между собой и с сущностями "Покупатель" и "Товар"? Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма будет выглядеть следующим образом на рис. 7:
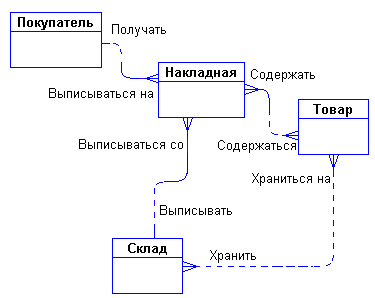
Рис. 7 – Уточненная диаграмма
Беседуя с сотрудниками фирмы, выясняем следующее:
- каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты;
- каждый товар имеет наименование, цену, а также характеризуется единицами измерения;
- каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного покупателя.
- каждый склад имеет свое наименование.
Снова выписываем все существительные, которые будут потенциальными атрибутами, и проанализируем их:
- юридическое лицо – мы работаем только с юридическими лицами.
- наименование покупателя - явная характеристика покупателя.
- адрес - явная характеристика покупателя.
- банковские реквизиты - явная характеристика покупателя.
- наименование товара - явная характеристика товара.
- цена товара - характеристика товара. Отличается ли эта характеристика от цены в накладной?
- единица измерения - явная характеристика товара.
- номер накладной - явная уникальная характеристика накладной.
- дата накладной - явная характеристика накладной.
- список товаров в накладной - список не может быть атрибутом. Вероятно, нужно выделить этот список в отдельную сущность.
- количество товара в накладной - это явная характеристика не просто "товара", а "товара в накладной".
- цена товара в накладной - характеристика товара в накладной. Но цена товара уже встречалась выше - это одно и то же?
- сумма накладной - явная характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров, входящих в накладную.
- наименование склада - явная характеристика склада.
В ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось, что каждый товар имеет некоторую текущую цену. Эта цена, по которой товар продается в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С возникающим понятием "Список товаров в накладной" все довольно ясно. Сущности "Накладная" и "Товар" связаны друг с другом отношением типа много-ко-многим. Такая связь, должна быть расщеплена на две связи типа один-ко-многим. Для этого требуется дополнительная сущность. Этой сущностью и будет сущность "Список товаров в накладной". Связь ее с сущностями "Накладная" и "Товар" характеризуется следующими фразами - "каждая накладная обязана иметь несколько записей из списка товаров в накладной", "каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную", "каждый товар может включаться в несколько записей из списка товаров в накладной", " каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром". Атрибуты "Количество товара в накладной" и "Цена товара в накладной" являются атрибутами сущности " Список товаров в накладной".
Точно также поступим со связью, соединяющей сущности "Склад" и "Товар". Введем дополнительную сущность "Товар на складе". Атрибутом этой сущности будет "Количество товара на складе". Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в окончательную диаграмму рис.8:
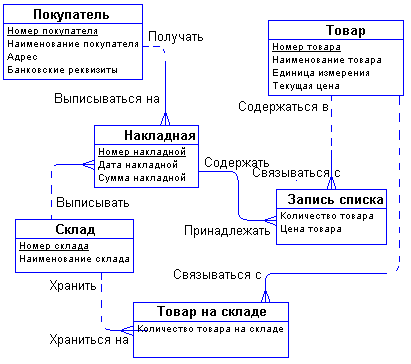
Рис. 8 – Окончательная диаграмма
Для получения физической ERD – модели (полученная диаграмма не учитывает особенности конкретной СУБД). По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД, как допустимые типы и наименования полей и таблиц, ограничения целостности и т.п. Физический вариант диаграммы, приведен на рис.9.
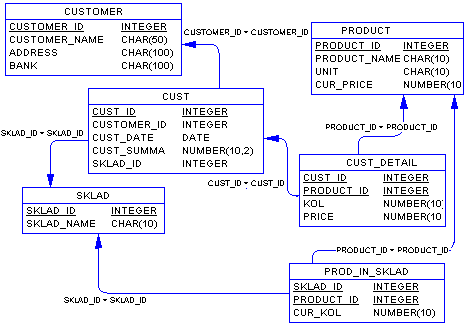
Рис. 9 – ERD-диаграмма с описанием типов данных
На данной диаграмме каждая сущность представляет собой таблицу базы данных, каждый атрибут становится колонкой соответствующей таблицы. Обращаем внимание на то, что во многих таблицах, например, "CUST_DETAIL" и "PROD_IN_SKLAD", соответствующих сущностям "Запись списка накладной" и "Товар на складе", появились новые атрибуты, которых не было в концептуальной модели - это ключевые атрибуты родительских таблиц, перешедшие в дочерние таблицы для того, чтобы обеспечить связь между таблицами посредством внешних ключей.
2.4 Функциональные возможности
Определяем функциональные возможности и строим SAD-диаграмму с декомпозицией. Методология SADT представляет собой совокупность методов, правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области.
Функциональная модель SADT отображает функциональную структуру объекта, т.е. производимые им действия и связи между этими действиями.
Управляющая информация входит в блок сверху, в то время как информация, которая подвергается обработке, показана с левой стороны блока, а результаты выхода показаны с правой стороны. Механизм (человек или автоматизированная система), который осуществляет операцию, представляется дугой, входящей в блок снизу. На рис.10 SADT-диаграмма с декомпозицией.
Магазин
А-0
Покупатель
Накладная
Склад
Товар
1
2
3
4
А-1
Товар на складе
Выписка с
Запись списка
41
42
43
А-2
Рис.10 – SADT-диаграмма с декомпозицией.
2.5 Категории пользователи
Прежде всего, к числу пользователей информационных систем относятся специалисты в предметной области системы, для удовлетворения информационных потребностей которых система создается. Пользователей этой категории называют конечными пользователями.
В некоторых информационных системах контингент пользователей не зафиксирован. Информационные ресурсы таких систем свободно предоставляются любому пользователю. В других системах для того, чтобы стать пользователем, необходимо получить от системного администратора требуемые полномочия доступа к системе, а иногда и к некоторым ее информационным ресурсам.
Вопросами ограничения прав пользователей при развертывании информационной системы, как правило, занимаются IT-специалисты. Со временем всегда имеется возможность внести изменения определенных на этапе развертывания системы настроек.
Условно говоря, доступ пользователей к информации ограничивается двумя базовыми механизмами платформы:
- ролями пользователей,
- интерфейсами.
В первом случае с ролями пользователей, говориться о реальной защите, когда к какой-нибудь информации доступ конкретных пользователей или групп пользователей ограничивается очевидным образом. В случае с защитой использования информации механизма интерфейсов, говориться о неявной защите - пользователь не видит некоторых справочников или документов в своем интерфейсе, а к другим интерфейсам у него доступа нет. В типовом решении последняя возможность не применяется - всякий пользователь может включить любой интерфейс, так как заранее неизвестно какие функции будет выполнять конкретный пользователь на конкретном предприятии. Если же ролевая структура фирмы определена, та этот вариант является наиболее "дешевым" с точки зрения реализации и понятным с позиции использования.
Пользователи являются краеугольным элементом всякой информационной системы. В том случае, если они эффективно используют функциональность прикладного решения и заложенные в нем возможности - можно сказать об успешности внедрения и эффективности информационной системы.
Список пользователей
Формирование списка пользователей (рис.16) информационной системы можно осуществлять двумя способами. Рассмотрим "традиционный", который осуществляется в два этапа:
- вначале в режиме "Конфигуратор" (меню " Администрирование - Пользователи").
- затем в режиме программы" описываются параметры определенных на предыдущем этапе записей. На рис.11 пользователи.
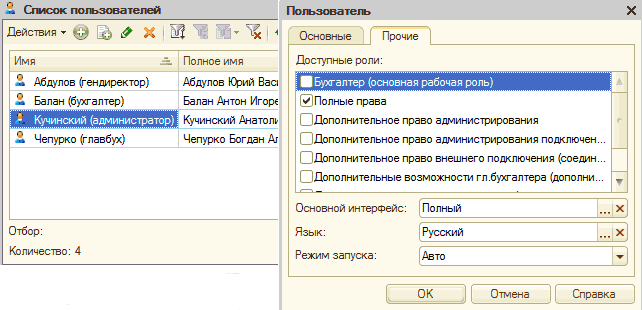
Рис.11.- Пользователи
Такое разделение процесса определения пользователя в информационной системе объясняется тем, что:
- доступ в информационную базу обязан иметь только явно определенные администратором системы пользователи,
- настройку части параметров можно описать лишь значениями самой информационной базы (например, все значения по умолчанию ).
Для удобства администрирования предусмотрен дополнительный механизм редактирования учетных записей пользователей (рис.12). Благодаря ему можно описать все параметры пользователя в одном месте.
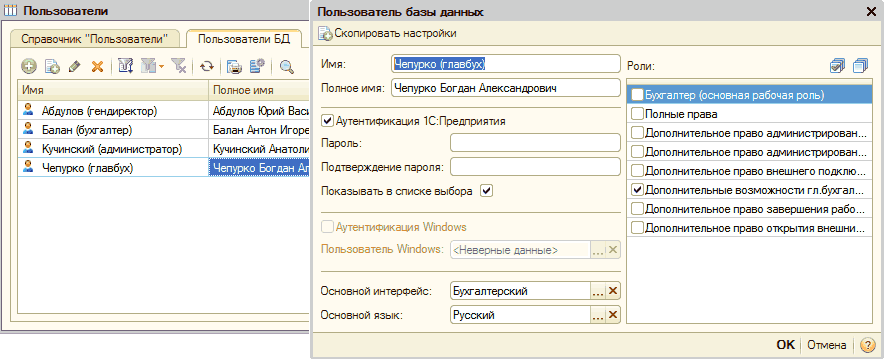
Рис.12 - Параметры пользователя
Пользователю, возможно, назначить одновременно несколько ролей. Кроме назначения ролей тут определяется:
- полное имя пользователя;
- пароль, который используется для получения доступа к информационной системе;
- основной интерфейс, какой будет использоваться для данного пользователя, когда он будет запускать систему,
- язык конфигурации.
После того как создаться новый пользователь в режиме "Конфигуратор" и запуститься система от имени этого пользователя, информация о пользователе автоматически будет занесена в справочник "Пользователи" информационной базы, про что будет сформировано соответствующее сообщение. Список пользователей можно соединять в группы, так как анализируемый справочник поддерживает иерархию. К примеру, можно создать такие группы пользователей: кассиры, бухгалтеры , администратор. Правда, права на подобные действия имеют только те пользователи, какие выполняют административные функции. Доступ к списку выполняется через меню "Сервис - Пользователи - Список пользователей", а к настройке параметров текущего пользователя осуществляется через меню "Сервис - Настройки пользователя".
Код элементов справочника "Пользователи" является текстовым. В качестве смысла кода вносится "Имя пользователя", какое назначено данному пользователю в Конфигураторе в списке пользователей системы. Когда вы входите в систему, конфигурация устанавливает пользователя, какой работает с системой, по совпадению имени этого пользователя в Конфигураторе и его имени в справочнике "Пользователи" (таблица 1).
Таблица 1 - Категории пользователей
|
Пользователи |
Пользователи посещают библиотеки и работают через библиотекаря. Все запросы таких посетителей к информационной системе обрабатываются библиотекарем. |
|
Прикладные администраторы |
Прикладные администраторы являются корпоративными пользователями и обладают правами на модификацию справочников, условно-постоянной информации, списков пользователей системы. Прикладные администраторы осуществляют назначение прав пользователям информационной системы. |
|
Системные администраторы |
Системные администраторы обеспечивают нормальное функционирование информационной системы, выполняют резервное копирование и восстановление данных, выполняют регламентные работы по обслуживанию системы, контролируют системные журналы безопасности, выполняют мониторинг системных ресурсов. |
2.6 Интерфейс пользователя
Интерфейс, обеспечивающий передачу информации между пользователем-человеком и программно-аппаратными компонентами компьютерной системы.
Под совокупностью средств и методов интерфейса пользователя подразумеваются:
Средства:
- вывода информации из устройства к пользователю - весь доступный диапазон воздействий на организм человека (зрительных, слуховых, тактильных, обонятельных) - экраны (дисплеи, проекторы) и лампочки, динамики, зуммеры и сирены;
- ввода информации/команд пользователем в устройство - множество всевозможных устройств для контроля состояния человека - кнопки, переключатели, потенциометры, датчики положения и движения, сервоприводы, жесты лицом и руками.
По наличию тех или иных средств ввода, интерфейсы разделяются на типы - жестовый, голосовой, брэйн, возможны смешанные варианты. Методы - набор правил, заложенных разработчиком устройства, согласно которым совокупность действий пользователя должна привести к необходимой реакции устройства и выполнения требуемой задачи - т. н. логический интерфейс. Правила эти должны быть достаточно ясны для понимания, естественны и легки для запоминания.
Интерфейс пользователя компьютерного приложения включает:
- средства отображения информации, отображаемую информацию, форматы и коды;
- командные режимы, язык «пользователь - интерфейс»;
- устройства и технологии ввода данных;
- диалоги, взаимодействие и транзакции между пользователем и компьютером, обратную связь с пользователем;
- поддержку принятия решений в конкретной предметной области;
- порядок использования программы и документацию на неё.
Пользовательский интерфейс объединяет в себе все элементы и компоненты программы, которые способны оказывать влияние на взаимодействие пользователя с программным обеспечением (ПО), это не только экран, который видит пользователь.
К этим элементам относятся:
- набор задач пользователя, которые он решает при помощи системы;
- используемая системой метафора (например, рабочий стол в MS Windows®);
- элементы управления системой;
- навигация между блоками системы;
- визуальный дизайн экранов программы;
- средства отображения информации, отображаемая информация и форматы;
- устройства и технологии ввода данных;
- диалоги, взаимодействие и транзакции между пользователем и компьютером;
- обратная связь с пользователем;
- поддержка принятия решений в конкретной предметной области;
- порядок использования программы и документация на неё.
Диаграмма классов является ключевым элементом в объектно-ориентированном моделировании (Язык UML). На диаграмме классы представлены в рамках, содержащих три компонента:
- в верхней части написано имя класса. Имя класса выравнивается по центру и пишется полужирным шрифтом. Имена классов начинаются с заглавной буквы. Если класс абстрактный - то его имя пишется полужирным курсивом;
- посередине располагаются поля (атрибуты) класса. Они выровнены по левому краю и начинаются с маленькой буквы;
- нижняя часть содержит методы класса. Они также выровнены по левому краю и пишутся с маленькой буквы.
Язык UML предоставляет механизмы для представления членов класса, например атрибутов и методов, а также дополнительной информации о них.
Для задания видимости членов класса (то есть любой атрибут или метод), эти обозначения должны быть размещены перед именем участника:
|
+ |
Публичный (Public) |
|
- |
Приватный (Private) |
|
# |
Защищённый (Protected) |
|
/ |
Производный (Derived) (может быть совмещён с другими) |
|
~ |
Пакет (Package) |
Чтобы показать принадлежность к классификатору, имя подчёркивается, в противном случае область действия полагается областью действия по умолчанию

Нотация UML для отображения взаимосвязи между классами на диаграммах
Диаграмма классов UML позволяет обозначать отношения между классами и их экземплярами. Они нужны для моделирования прикладной области. Проясним, как относятся друг к другу отношения между классами.
На рис.13 отражены отношения между классами.
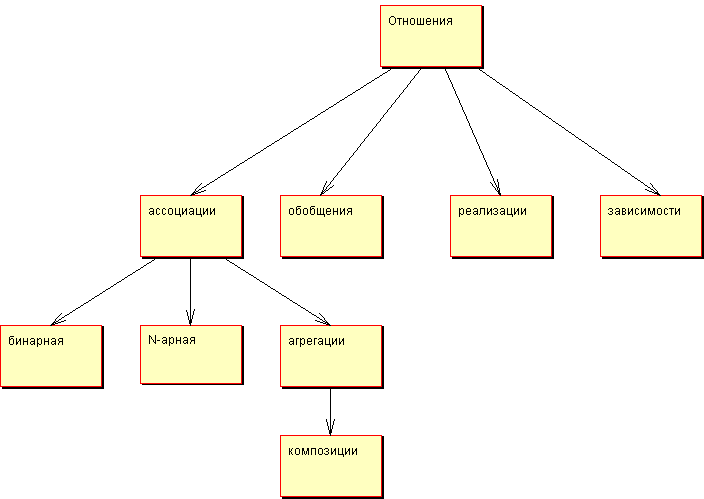
Рис. 13 — Отношения между классами
Мощность отношения (мультипликатор) означает число связей между каждым экземпляром класса (объектом) в начале линии с экземпляром класса в её конце. Различают следующие типичные случаи (таблица 2):
Таблица 2 – Мощность отношений
|
нотация |
объяснение |
|
0..1 |
Ноль или один экземпляр |
|
1 |
Обязательно один экземпляр |
|
0..* или * |
Ноль или более экземпляров |
|
1..* |
Один или более экземпляров |
Наша цель - построить UML-диаграмму классов (Class Model), а затем отразить ее в объектно-ориентированном коде.
У нас наблюдается наследование в класс Накладная из классов Запись списка и Склад, в класс Склад из класса Товар на складе, из класса Накладная в класс Покупатель. Агрегация из класса Товар на складе в класс Товар. На рис.14 диаграмма классов.
получать
0..1
Товар
Покупатель
номер товара
наименование товара
ед.измерения
текущая цена
номер покупателя
наименование покуп.
адрес
банковские реквизит.
выписываться на
содержать
1..*
0..*
0..*
Накладная
содержать
1..*
1..*
номер накладной
дата накладной
сумма накладной
выписывать
принадлежать
1..*
1..*
Запись списка
Склад
количество товара
цена товара
номер склада
наименование склада
1..*
Товар на складе
количество товара на складе
связываться с
храниться на
1..*
1..*
1..*
хранить
Рис.14 - Диаграмма классов
2.7 Программа реализации информационной системы
Для написания программного кода используем язык Java. Язык моделирования UML имеет набор отношений для построения модели классов, но даже такой развитой ООП язык, как Java имеет только две явные конструкции для отражения связей: extends(расширение) и interface/implements(реализация) рис.15.
+Gustomer
Для модуля класса Покупатель и модуля класса Накладная на языке Java напишем программный код используя наследование.
public class Customer{
public Integer customer_ID;
public Customer(String n){
customer_name=n;}
private Customer(string a, string b){
address=a;
bank=b;}
public void setCustomer_name (String newGustomer_name){
name=newGustomer_name;}
public String getGustomer_name(){
return customer_name;}
private void setAdress (String newAdress){
address=newAdress;}
private String getAdress(){
return address;}
private void setBank (String newBank){
bank=newBank;}
private String getBank(){
return bank;}
}
//наследуем класс Customer
public class Cust extendes Customer{
public Int cust_ID;
public cust (Int id, String n, String d, Float s, Int skl){
customer_name =n;
cust_ID=id;
custDate=d;
custSumma=s;
sklad_ID=skl;}
public void setCust_ID (Integer newCust_ID){
cust_ID=newCust_ID;}
public Integer getCust_ID(){
return cust_ID;}
public void setCust_date(Date newCust_date){
cust_date=newCust_date;}
public Date getCust_date(){
return cust_date;}
+ customer_ID:Integer
+ customer_name: String
- address: String
- bank: String
+Cust
+ cust_ID: Integer
+ customer_name: String
+ cust_date: Date
+ cust_summa: Number
+ sklad_ID: Integer
Рис. 15
public void setCust_summa (Float newCust_summa){
cust_summa=newCust_summa;}
public Float getCust_summa(){
return cust_summa;}
public void setSklad_ID (
Int newSklad_ID){
Sklad_ID=newSklad_ID;}
public Int getSklad_ID(){
return Sklad_ID;}
}
ЗАКЛЮЧЕНИЕ
Цель курсового проекта заключалась в ознакомлении с методами и средствами проектирования ИС, методами и средствами проектирования БД ИС. Проведен анализ предметной области и выбран метод создания ИС. На внедряемом объекте опрошены лица, которые будут обслуживать ИС. Учтены все их пожелания. Проверены функциональные возможности, созданы БД, категорий пользователей и выбран им интерфейс. Программно описан код участка диаграммы классов. Все необходимые диаграммы построены.
Задача по построению информационной модели выполнена в полном объеме.
СПИСОК ЛИТЕРАТУРЫ
1. Г. Буч, Д. Рамбо, А. Джекобсон. Язык UML Руководство пользователя.
А.В. Леоненков. Самоучитель UML
2. Эккель Б. Философия Java. Библиотека программиста. — СПб: Питер, 2001. — 880 с.
3. Орлов С. Технологии разработки программного обеспечения: Учебник. — СПб: Питер, 2002. — 464 с.
4. Мухортов В.В., Рылов В.Ю.Объектно-ориентированное программирование, анализ и дизайн. Методическое пособие. — Новосибирск, 2002.
5. Anand Ganesan. Modeling Class Relationships in UML
6. Хаф Л. Проектирование информационных систем [Электронный ресурс] /
Л. Хаф. – Режим доступа : http://www.inf
7. Вендров А.М. CASE-технологии. Современные методы и средства проектирования информационных систем.
8. Калянов Г.Н. CASE: структурный системный анализ (автоматизация и применение). М.: ЛОРИ. 1996.
9. Трофимов С. CASE-технологии: Практическая работа в Rational Rose.
Изд. 2-е.- М.: Бином-Пресс, 2002 г. - 288 с.
10. ГОСТ 24.602-86. Автоматизированные системы управления. Состав и содержание работ по стадиям создания. (Введён с 01.01.89.–М.: Изд-во стандартов, 1986.–12 с.).
11. ГОСТ 34.601-90. Информационная технология. Комплекс стандартов на автоматизированные системы. Автоматизированные системы. Стадии создания ( Введён с 29.12.90, 24.601-86. 24.602-86. 1997 г.).
12. РД 50-640-87. Системы автоматизированного проектирования. Порядок выполнения работ при создании систем: Инструкция.–М.: Изд-во стандартов,

- Современная законодательно-нормативная база защиты государственной тайны (Понятие и формы государственной измены)
- Основные функции в системе менеджмента (на примере компании ООО «Макдоналдс»)
- Выбор стиля руководства в организации (Сущность стиля руководства)
- Предпринимательское право. Субъекты малого предпринимательства
- Общее понятие о гражданском праве (Функции гражданского права )
- Контроль доступа к данным
- Авторитет и лидерство в системе менеджмента (Факторы формирования)
- Классификация систем защиты программного обеспечения (Обзор стандартов защиты)
- Основы работы с операционной системой Windows 7.
- Формирование группового поведения в организации (Понятие и виды групп)
- Отдельные способы защиты гражданских прав: самозащита; возмещение убытков; признание недействительным акта государственного органа
- Исследование проблем защиты информации компании