
Распределенные системы обработки информации (Типы серверов и информационных служб)
Содержание:

ВВЕДЕНИЕ
Реальное распространение архитектуры "клиент-сервер" стало возможным благодаря развитию и широкому внедрению в практику концепции открытых систем.
Основным смыслом подхода открытых систем является упрощение комплексирования вычислительных систем за счет международной и национальной стандартизации аппаратных и программных интерфейсов.
Главной побудительной причиной развития концепции открытых систем явились повсеместный переход к использованию локальных компьютерных сетей и те проблемы, которые вызвал этот переход.
В связи с бурным развитием технологий глобальных коммуникаций, открытые системы приобретают еще большее значение и масштабность.
Технологии и стандарты открытых систем обеспечивают реальную и проверенную практикой возможность производства системных и прикладных программных средств со свойствами мобильности (portability) и интероперабельности (interoperability).
Свойство мобильности означает сравнительную простоту переноса программной системы в широком спектре аппаратно-программных средств, соответствующих стандартам. Интероперабельность означает упрощение комплексирования новых программных систем на основе использования готовых компонентов со стандартными интерфейсами.
Преимуществом для пользователей является то, что они могут постепенно заменять компоненты системы на более совершенные, не утрачивая работоспособности системы.
В частности, в этом кроется решение проблемы постепенного наращивания вычислительных, информационных и других мощностей компьютерной системы.
При работе с файл-серверной версией вся ответственность за сохранность и целостность базы данных лежит на программе и сетевой операционной системе.
Обработка всех данных происходит на рабочих местах, а сервер используется только как разделяемый накопитель. Каждый пользователь непосредственно использует информацию и вносит изменения в файлы данных и в индексные файлы.
При больших объемах данных и работе в многопользовательском режиме существенно снижается быстродействие – ведь, чем больше пользователей, тем выше требования к разделению данных. Кроме того, может возникнуть повреждение баз данных.
Например, в момент записи в файл может возникнуть сбой сети или питания. В этом случае компьютер прерывает работу, база данных может оказаться поврежденной, а индексный файл – разрушенным.
Переиндексация, которую необходимо провести после подобных сбоев, может длиться несколько часов.
Клиент-серверная версия позволяет обойти эти проблемы, так как вся работа с базой данных происходит на сервере, не проходит по проводам и не зависит от сбоев на рабочих станциях. Все запросы на запись в файл перехватываются сервером.
Для написания курсовой работы были пользованы различные источники информации, такие как:
- Валерий Коржов «Многоуровневые системы клиент-сервер»
- Грофф Дж., Вайнберг П. «Энциклопедия SQL»
- Шкрыль, А. «Разработка клиент-серверных приложений в Delphi»
Актуальность работы заключается в том, что в современных вычислительных системах архитектура "клиент-сервер" обеспечивает простое и относительно дешевое решение проблемы коллективного доступа к базам данных в сети.
Цель курсовой работы – рассмотреть применение технологии «клиент-сервер».
Предмет исследования – история развития технологии «клиент-сервер», сферы и методы использования. Объект - технология «клиент-сервер».
Задачами курсовой работы являются:
- изучение основ технологии «клиент-сервер»;
- анализ практической реализации технологии «клиент-сервер»;
- изучение базовых принципов работы протоколов HTTP и HTTPS.
1. Теоретические основы технологии «клиент-сервер»
1.1 Типы серверов и информационных служб
Как правило, каждый сервер обслуживает один (или несколько схожих) протоколов и серверы можно классифицировать по типу услуг, которые они предоставляют.
Универсальные серверы — особый вид серверной программы, не предоставляющий никаких услуг самостоятельно. Вместо этого универсальные серверы предоставляют серверам услуг упрощенный интерфейс к ресурсам межпроцессного взаимодействия и/или унифицированный доступ клиентов к различным услугам. Существуют несколько видов таких серверов:
· inetd от англ. internet super-server daemon демон сервисов IP — стандартное средство UNIX-систем — программа, позволяющая писать серверы TCP/IP (и сетевых протоколов других семейств), работающие с клиентом через перенаправленные inetd потоки стандартного ввода и вывода (stdin и stdout). [3, c. 158]
· RPC от англ. Remote Procedure Call удаленный вызов процедур — система интеграции серверов в виде процедур доступных для вызова удаленным пользователем через унифицированный интерфейс. Интерфейс изобретенный Sun Microsystems для своей операционной системы (SunOS, Solaris; Unix-система), в настоящее время используется как в большинстве Unix-систем, так и в Windows.
· Прикладные клиент-серверные технологии Windows:
· (D-)COM (англ. (Distributed) Component Object Model — модель составных объектов) и др. — позволяет одним программам выполнять операции над объектами данных используя процедуры других программ. Изначально данная технология предназначена для их «внедрения и связывания объектов» (OLE англ. Object Linking and Embedding. COM работает только в пределах одного компьютера, DCOM доступна удаленно через RPC.
· Active-X — Расширение COM и DCOM для создания мультимедиа-приложений.
Универсальные серверы часто используются для написания всевозможных информационных серверов, серверов, которым не нужна какая-то специфическая работа с сетью, серверов, не имеющих никаких задач, кроме обслуживания клиентов. Например, в роли серверов для inetd могут выступать обычные консольные программы и скрипты.
Большинство внутренних и сетевых специфических серверов Windows работают через универсальные серверы (RPC, (D-)COM).
Сетевые службы обеспечивают функционирование сети, например серверы DHCP и BOOTP обеспечивают стартовую инициализацию серверов и рабочих станций, DNS — трансляцию имен в адреса и наоборот.
Серверы туннелирования (например, различные VPN-серверы) и прокси-серверы обеспечивают связь с сетью, недоступной роутингом.
Серверы AAA и Radius обеспечивают в сети единую аутентификацию, авторизацию и ведение логов доступа.
Информационные службы. К информационным службам можно отнести как простейшие серверы сообщающие информацию о хосте (time, daytime, motd), пользователях (finger, ident), так и серверы для мониторинга, например SNMP. Большинство информационных служб работают через универсальные серверы. [7, c. 57]
Особым видом информационных служб являются серверы синхронизации времени — NTP кроме информировании клиента о точном времени NTP-сервер периодически опрашивает несколько других серверов на предмет коррекции собственного времени.
Кроме коррекции времени анализируется и корректируется скорость хода системных часов. Коррекция времени осуществляется ускорением или замедлением хода системных часов (в зависимости от направления коррекции), чтобы избежать проблем возможных при простой перестановке времени.
Файл-серверы представляют собой серверы для обеспечения доступа к файлам на диске сервера.
Прежде всего, это серверы передачи файлов по заказу, по протоколам FTP, TFTP, SFTP и HTTP. Протокол HTTP ориентирован на передачу текстовых файлов, но серверы могут отдавать в качестве запрошенных файлов и произвольные данные, например, динамически созданные веб-страницы, картинки, музыку и т. п.
Другие серверы позволяют монтировать дисковые разделы сервера в дисковое пространство клиента и полноценно работать с файлами на них. Это позволяют серверы протоколов NFS и SMB. Серверы NFS и SMB работают через интерфейс RPC.
Недостатки файл-серверной системы:
• Очень большая нагрузка на сеть, повышенные требования к пропускной способности. На практике это делает практически невозможной одновременную работу большого числа пользователей с большими объемами данных.
• Обработка данных осуществляется на компьютере пользователей. Это влечет повышенные требования к аппаратному обеспечению каждого пользователя. Чем больше пользователей, тем больше денег придется потратить на оснащение их компьютеров.
• Блокировка данных при редактировании одним пользователем делает невозможной работу с этими данными других пользователей.
• Безопасность. Для обеспечения возможности работы с такой системой Вам будет необходимо дать каждому пользователю полный доступ к целому файлу, в котором его может интересовать только одно поле
Серверы доступа к данным обслуживают базу данных и отдают данные по запросам. Один из самых простых серверов подобного типа — LDAP (англ. Lightweight Directory Access Protocol — облегчённый протокол доступа к спискам).
Для доступа к серверам баз данных единого протокола не существует, однако все серверы баз данных объединяет использование единых правил формирования запросов — язык SQL (англ. Structured Query Language — язык структурированных запросов).
Службы обмена сообщениями позволяют пользователю передавать и получать сообщения (обычно — текстовые).
В первую очередь это серверы электронной почты, работающие по протоколу SMTP. SMTP-сервер принимает сообщение и доставляет его в локальный почтовый ящик пользователя или на другой SMTP-сервер (сервер назначения или промежуточный). На многопользовательских компьютерах, пользователи работают с почтой прямо на терминале (или веб-интерфейсе). Для работы с почтой на персональном компьютере, почта забирается из почтового ящика через серверы, работающие по протоколам POP3 или IMAP.
Для организации конференций существует серверы новостей, работающие по протоколу NNTP. [2, c. 117]
Для обмена сообщениями в реальном времени существуют серверы чатов, стандартный чат-сервер работает по протоколу IRC — распределенный чат для интернета. Существует большое количество других чат-протоколов, например ICQ или Jabber.
Серверы удаленного доступа, через соответствующую клиентскую программу, обеспечивают пользователя консольным доступом к удаленной системе.
Для обеспечения доступа к командной строке служат серверы telnet, RSH, SSH.
Графический интерфейс для Unix-систем — X Window System, имеет встроенный сервер удаленного доступа, так как с такой возможностью разрабатывался изначально. Иногда возможность удаленного доступа к интерфейсу Х-Window неправильно называют «X-Server» (этим термином в X-Window называется видеодрайвер).
Стандартный сервер удаленного доступа к графическому интерфейсу Microsoft Windows называется терминальный сервер.
Некоторую разновидность управления (точнее мониторинга и конфигурирования) также предоставляет протокол SNMP. Компьютер или аппаратное устройство для этого должно иметь SNMP-сервер. [5, c.92]
Игровые серверы служат для одновременной игры нескольких пользователей в единой игровой ситуации. Некоторые игры имеют сервер в основной поставке и позволяют запускать его в невыделенном режиме (то есть позволяют играть на машине, на которой запущен сервер).
Серверные решения — операционные системы и/или пакеты программ, оптимизированные под выполнение компьютером функций сервера и/или содержащие в своем составе комплект программ для реализации типичных сервисов.
Примером серверных решений можно привести Unix-системы, изначально предназначенные для реализации серверной инфраструктуры, или серверные модификации платформы Microsoft Windows.
Также необходимо выделить пакеты серверов и сопутствующих программ (например, комплект веб-сервер/PHP/MySQL для быстрой развертки хостинга) для установки под Windows (для Unix свойственна модульная или «пакетная» установка каждого компонента, поэтому такие решения редки).
В интегрированных серверных решениях установка всех компонентов выполняется единовременно, все компоненты в той или иной мере тесно интегрированы и предварительно настроены друг на друга. Однако в этом случае, замена одного из серверов или вторичных приложений (если их возможности не удовлетворяют потребностям) может представлять проблему.
Серверные решения служат для упрощения организации базовой ИТ-инфраструктуры компаний, то есть для оперативного построения полноценной сети в компании, в том числе и «с нуля».
Компоновка отдельных серверных приложений в решение подразумевает, что решение предназначено для выполнения большинства типовых задач; при этом значительно снижается сложность развертывания и общая стоимость владения ИТ-инфраструктурой, построенной на таких решениях.
Прокси-сервер (от англ. proxy — «представитель, уполномоченный») служба в компьютерных сетях, позволяющая клиентам выполнять косвенные запросы к другим сетевым службам.
Сначала клиент подключается к прокси-серверу и запрашивает какой-либо ресурс (например, e-mail), расположенный на другом сервере. Затем прокси-сервер либо подключается к указанному серверу и получает ресурс у него, либо возвращает ресурс из собственного кэша (в случаях, если прокси имеет свой кэш).
В некоторых случаях запрос клиента или ответ сервера может быть изменён прокси-сервером в определённых целях. Также прокси-сервер позволяет защищать клиентский компьютер от некоторых сетевых атак. [5, c.128]
Клиент и сервер это программы, расположенное на разных компьютерах, в разных контроллерах и других подобных устройствах. Между собой они взаимодействуют через вычислительную сеть с помощью сетевых протоколов.
Программы-серверы являются поставщиками услуг. Они постоянно ожидают запросы от программ-клиентов и предоставляют им свои услуги (передают данные, решают вычислительные задачи, управляют чем-либо и т.п.). Сервер должен быть постоянно включен и “прослушивать” сеть. Каждая программа-сервер, как правило, может выполнять запросы от нескольких программ-клиентов.
Программа-клиент является инициатором запроса, который она может произвести в любой момент. В отличие от сервера, клиент не должен быть постоянно включен. Достаточно подключиться в момент запроса.
Итак, в общих чертах система клиент-сервер выглядит так:
- Есть компьютеры, контроллеры, планшеты, сотовые телефоны и другие интеллектуальные устройства.
- Все они включены в общую вычислительную сеть. Проводную или беспроводную - неважно. Они могут быть подключены даже к разным сетям, связанным между собой через глобальную сеть, например через интернет.
- На некоторых устройствах установлены программы-серверы. Эти устройства называются серверами, должны быть постоянно включены, и их задача обрабатывать запросы от клиентов.
- На других устройствах работают программы-клиенты. Такие устройства называются клиентами, они инициируют запросы серверам. Их включают только в моменты, когда необходимо обратиться к серверам.
1.2 Пакетная передача данных
Технология клиент-сервер в общем случае предназначена для использования с объемными информационными сетями. От одного абонента до другого данные могут проходить сложный путь по разным физическим каналам и сетям.
Путь доставки данных может меняться в зависимости от состояния отдельных элементов сети. Какие-то компоненты сети могут не работать в этот момент, тогда данные пойдут другим путем. Может изменяться время доставки. Данные могут даже пропасть, не дойти до адресата. [7, c.198]
Поэтому простая передача данных в цикле, в сложных сетях совершенно невозможна. Информация передается ограниченными порциями – пакетами. На передающей стороне информация разбивается на пакеты, а на приемной “склеивается” из пакетов в цельные данные. Объем пакетов обычно не больше нескольких килобайт. Пакет это аналог обычного почтового письма. Он также, кроме информации, должен содержать адрес получателя и адрес отправителя.
Пакет состоит из заголовка и информационной части. Заголовок содержит адреса получателя и отправителя, а также служебную информацию, необходимую для “склейки” пакетов на приемной стороне. Сетевое оборудование использует заголовок для определения, куда передавать пакет.
Адресация пакетов.
В общем случае нам придется задавать следующие параметры:
- IP-адрес устройства;
- маску подсети;
- доменное имя;
- IP-адрес сетевого шлюза;
- MAC-адрес;
- порт.
IP-адреса.
Технология клиент-сервер предполагает, что все абоненты всех сетей мира подключены к единой глобальной сети. На самом деле во многих случаях это так и есть. Например, большинство компьютеров или мобильных устройств подключено к интернету. Поэтому используется формат адресации, рассчитанный на такое громадное количество абонентов. Но даже если технология клиент-сервер применяется в локальных сетях, все равно сохраняется принятый формат адресов, при явной избыточности.
Каждой точке подключения устройства к сети присваивается уникальный номер – IP-адрес (Internet Protocol Address). IP-адрес присваивается не устройству (компьютеру), а интерфейсу подключения. В принципе устройства могут иметь несколько точек подключения, а значит несколько различных IP-адресов. [3, c.210]
IP-адрес это 32х разрядное число или 4 байта. Для наглядности принято записывать его в виде 4 десятичных чисел от 0 до 255, разделенных точками. Например, IP-адрес сервера 31.31.196.216.
Для того чтобы сетевому оборудованию было проще выстраивать маршрут доставки пакетов в формат IP-адреса введена логическая адресация. IP-адрес разбит на 2 логических поля: номер сети и номер узла. Размеры этих полей зависят от значения первого (старшего) октета IP-адреса и разбиты на 5 групп – классов.
Таблица 1.
Метод классовой маршрутизации
|
Класс |
Старший октет |
Формат (С-сеть, |
Начальный адрес |
Конечный адрес |
Количество сетей |
Количество узлов |
|
A |
0 |
С.У.У.У |
0.0.0.0 |
127.255.255.255 |
128 |
16777216 |
|
B |
10 |
С.С.У.У |
128.0.0.0 |
191.255.255.255 |
16384 |
65534 |
|
C |
110 |
С.С.С.У |
192.0.0.0 |
223.255.255.255 |
2097152 |
254 |
|
D |
1110 |
Групповой адрес |
224.0.0.0 |
239.255.255.255 |
- |
228 |
|
E |
1111 |
Резерв |
240.0.0.0 |
255.255.255.255 |
- |
227 |
Класс A предназначен для применения в больших сетях. Класс B используется в сетях средних размеров. Класс C предназначен для сетей с небольшим числом узлов. Класс D используется для обращения к группам узлов, а адреса класса E зарезервированы.
Существуют ограничения на выбор IP-адресов. Я посчитал главными для нас следующие:
- Адрес 127.0.0.1 называется loopback и используется для тестирования программ в пределах одного устройства. Данные посланы по этому адресу не передаются по сети, а возвращаются программе верхнего уровня, как принятые.
- “Серые” адреса – это IP-адреса разрешенные только для устройств, работающих в локальных сетях без выхода в Интернет. Эти адреса никогда не обрабатываются маршрутизаторами. Их используют в локальных сетях.
- Класс A: 10.0.0.0 – 10.255.255.255
- Класс B: 172.16.0.0 – 172.31.255.255
- Класс C: 192.168.0.0 – 192.168.255.255
- Если поле номера сети содержит все 0, то это означает, что узел принадлежит той же самой сети, что и узел, который отправил пакет.
Маски подсетей.
При классовом методе маршрутизации число битов адресов сети и узла в IP-адресе задается типом класса. А классов всего 5, реально используется 3. Поэтому метод классовой маршрутизации в большинстве случаях не позволяет оптимально выбрать размер сети. Что приводит к неэкономному использованию пространства IP-адресов.
В 1993 году был введен бесклассовый способ маршрутизации, который в данный момент является основным. Он позволяет гибко, а значит и рационально, выбирать требуемое количество узлов сети. В этом методе адресации применяются маски подсети переменной длины.
Сетевому узлу присваивается не только IP-адрес, но и маска подсети. Она имеет такой же размер, как и IP-адрес, 32 бит. Маска подсети и определяет, какая часть IP-адреса относится к сети, а какая к узлу.
Каждый бит маски подсети соответствует биту IP-адреса в том же разряде. Единица в бите маски говорит о том, что соответствующий бит IP-адреса принадлежит сетевому адресу, а бит маски со значением 0 определяет принадлежность бита IP-адреса к узлу.
При передаче пакета, узел с помощью маски выделяет из своего IP-адреса сетевую часть, сравнивает ее с адресом назначения, и если они совпадают, то это означает, что передающий и приемный узлы находятся в одной сети. [7, c.298]
Тогда пакет доставляется локально. В противном случае пакет передается через сетевой интерфейс в другую сеть. Маска подсети не является частью пакета. Она влияет только на логику маршрутизации узла.
По сути, маска позволяет одну большую сеть разбить на несколько подсетей. Размер любой подсети (число IP-адресов) должен быть кратным степени числа 2. Т.е. 4, 8, 16 и т.д.
Это условие определяется тем, что биты полей адресов сети и узлов должны идти подряд. Нельзя задать, например, 5 битов - адрес сети, затем 8 битов – адрес узла, а затем опять биты адресации сети.
Пример формы записи сети с четырьмя узлами выглядит так:
Сеть 31.34.196.32, маска 255.255.255.252
Маска подсети всегда состоит из подряд идущих единиц (признаков адреса сети) и подряд идущих нулей (признаков адреса узла). Основываясь на этом принципе, существует другой способ записи той же адресной информации.
Сеть 31.34.196.32/30
Таблица 2
Пример формы записи
|
Размер сети (количество узлов) |
Длинная маска |
Короткая маска |
|
4 |
255.255.255.252 |
/30 |
|
8 |
255.255.255.248 |
/29 |
|
16 |
255.255.255.240 |
/28 |
|
32 |
255.255.255.224 |
/27 |
|
64 |
255.255.255.192 |
/26 |
|
128 |
255.255.255.128 |
/25 |
/30 это число единиц в маске подсети. В данном примере остается два нуля, что соответствует 2 разрядам адреса узла или четырем узлам.
- Последнее число первого адреса подсети должно делиться без остатка на размер сети.
- Первый и последний адреса подсети – служебные, их использовать нельзя.
Доменное имя.
Человеку неудобно работать с IP-адресами. Это наборы чисел, а человек привык читать буквы, еще лучше связно написанные буквы, т.е. слова.
Для того, чтобы людям было удобнее работать с сетями используется другая система идентификации сетевых устройств.
Любому IP-адресу может быть присвоен буквенный идентификатор, более понятный человеку. Идентификатор называется доменным именем или доменом.
Доменное имя это последовательность из двух или более слов, разделенных точками. Последнее слово это домен первого уровня, предпоследнее – домен второго уровня и т.д.
Связь между IP-адресами и доменными именами происходит через распределенную базу данных, с использованием DNS-серверов. DNS-сервер должен иметь каждый владелец домена второго уровня. DNS-серверы объединены в сложную иерархическую структуру и способны обмениваться между собой данными о соответствии IP-адресов и доменных имен.
Главное, что любой клиент или сервер может обратиться к DNS-серверу с DNS-запросом, т.е. с запросом о соответствии IP-адрес – доменное имя или наоборот доменное имя – IP-адрес.
Если DNS-сервер обладает информацией о соответствии IP-адреса и домена, то он отвечает.
Если не знает, то ищет информацию на других DNS-серверах и после этого сообщает клиенту.
1.3 Сетевые шлюзы.
Сетевой шлюз это аппаратный маршрутизатор или программа для сопряжения сетей с разными протоколами. В общем случае его задача конвертировать протоколы одного типа сети в протоколы другой сети. Как правило, сети имеют разные физические среды передачи данных.
Пример – локальная сеть из компьютеров, подключенная к Интернету. В пределах своей локальной сети (подсети) компьютеры связываются без необходимости в каком-либо промежуточном устройстве. Но как только компьютер должен связаться с другой сетью, например, выйти в Интернет, он использует маршрутизатор, который выполняет функции сетевого шлюза.
Роутеры, которые есть у каждого, кто подключен к проводному интернету, являются одним из примеров сетевого шлюза. Сетевой шлюз – это точка, через которую обеспечивается выход в Интернет.
В общем случае использование сетевого шлюза выглядит так:
- Допустим у нас система, подключенных через локальную сеть Ethernet к маршрутизатору, который в свою очередь подключен к Интернету.
- В локальной сети мы используем ”серые” IP-адреса, которые не допускают выхода в Интернет. У маршрутизатора два интерфейса: нашей локальной сети с “серым” IP-адресом и интерфейс для подключения к Интернету с ”белым” адресом.
- В конфигурации узла мы указываем адрес шлюза, т.е. “белый” IP-адрес интерфейса маршрутизатора, подключенного к Интернету.
- Теперь, если маршрутизатор получает от устройства с ”серым” адресом пакет с запросом на получение информации из Интернета, он заменяет в заголовке пакета ”серый” адрес на свой ”белый” и отправляет его в глобальную сеть. Получив из Интернета ответ, он заменяет ”белый” адрес на запомненный при запросе ”серый” и передает пакет локальному устройству.
MAC-адрес.
MAC-адрес это уникальный идентификатор устройств локальной сети. Как правило, он записывается на заводе-производителе оборудования в постоянную память устройства.
Адрес состоит из 6 байтов. Принято записывать его в шестнадцатеричной системе исчисления в следующих форматах: c4-0b-cb-8b-c3-3a или c4:0b:cb:8b:c3:3a. Первые три байта это уникальный идентификатор организации-производителя. Остальные байты называются ”Номер интерфейса” и их значение является уникальным для каждого конкретного устройства.
IP-адрес является логическим и устанавливается администратором. MAC-адрес – это физический, постоянный адрес. Именно он используется для адресации фреймов, например, в локальных сетях Ethernet. При передаче пакета по определенному IP-адресу компьютер определяет соответствующий MAC-адрес с помощью специальной ARP-таблицы. Если в таблице отсутствуют данные о MAC-адресе, то компьютер запрашивает его с помощью специального протокола. Если MAC-адрес определить не удается, то пакеты этому устройству посылаться не будут. [2, c. 107]
Порты.
С помощью IP-адреса сетевое оборудование определяет получателя данных. Но на устройстве, например сервере, могут работать несколько приложений. Для того чтобы определить какому приложению предназначены данные в заголовок добавлено еще одно число – номер порта.
Порт используется для определения процесса приемника пакета в пределах одного IP-адреса.
Под номер порта выделено 16 бит, что соответствует числам от 0 до 65535. Первые 1024 портов зарезервированы под стандартные процессы, такие как почта, веб-сайты и т.п. В своих приложениях их лучше не использовать.
Статические и динамические IP-адреса. Протокол DHCP.
IP-адреса могут назначаться вручную. Достаточно утомительная операция для администратора. А в случае, когда пользователь не обладает нужными знаниями, задача становится трудноразрешимой. К тому же не все пользователи находятся постоянно подключенными к сети, а выделенные им статические адреса другие абоненты использовать не могут.
Проблема решается применением динамических IP-адресов. Динамические адреса выдаются клиентам на ограниченное время, пока они непрерывно находятся в сети. Распределение динамических адресов происходит под управлением протокола DHCP.
DHCP – это сетевой протокол, позволяющий устройствам автоматически получать IP-адреса и другие параметры, необходимые для работы в сети.
На этапе конфигурации устройство-клиент обращается к серверу DHCP, и получает от него необходимые параметры. Может быть задан диапазон адресов, распределяемых среди сетевых устройств.
Просмотр параметров сетевых устройств с помощь командной строки.
Существует много способов, как узнать IP-адрес или MAC-адрес своей сетевой карты. Самый простой – это использовать CMD команды операционной системы. Покажем, как это делать на примере Windows 7.
В папке Windows\System32 находится файл cmd.exe. Это интерпретатор командной строки. С помощь него можно получать системную информацию и конфигурировать систему.
Открываем окно выполнить. Для этого выполняем меню Пуск -> Выполнить или нажимаем комбинацию клавиш Win + R.
Рисунок 1 Команда выполнения cmd
Набираем cmd и нажимаем OK или Enter. Появляется окно интерпретатора команд.
Рисунок 2 Окно интерпретатора команд
Теперь можно задавать любые из многочисленных команд. Пока нас интересуют команды для просмотра конфигурации сетевых устройств.
Прежде всего, это команда ipconfig, которая отображает настройки сетевых плат.
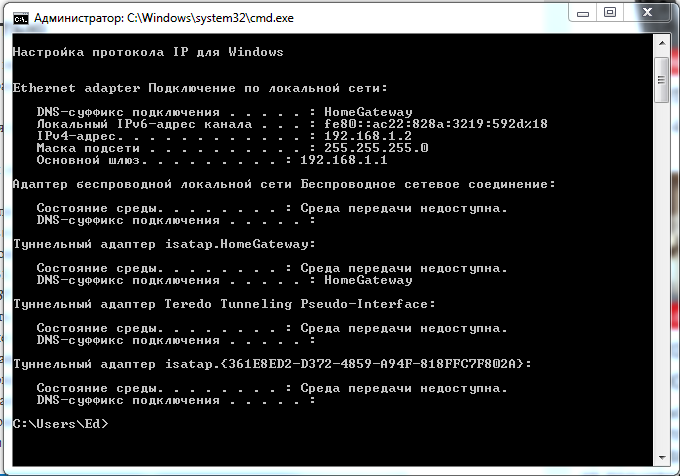
Рисунок 3 Команда ipconfig
Подробный вариант ipconfig/all.
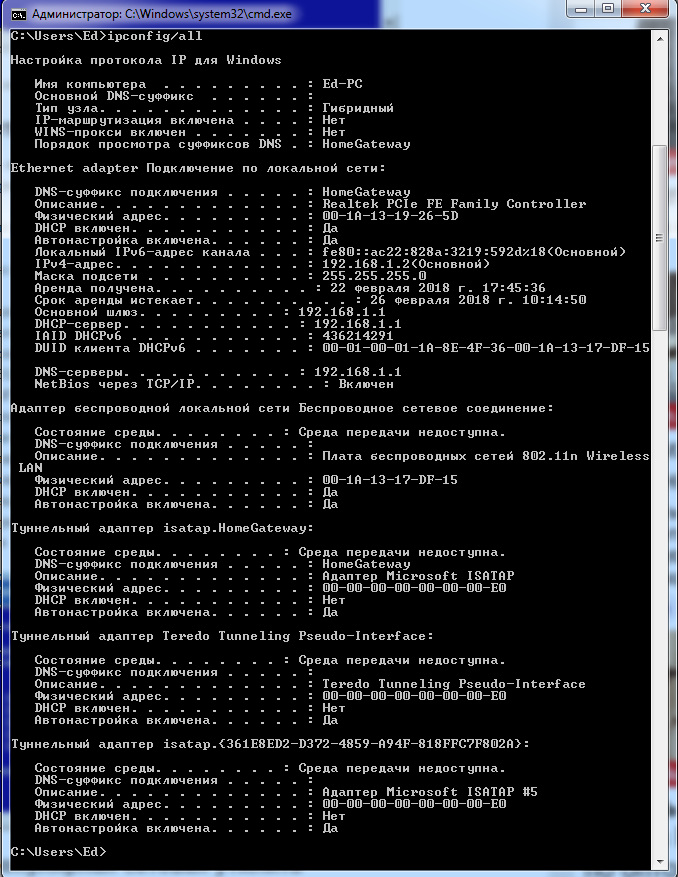
Рисунок 4 Подробный вариант ipconfig/all.
Только MAC-адреса показывает команда getmac.
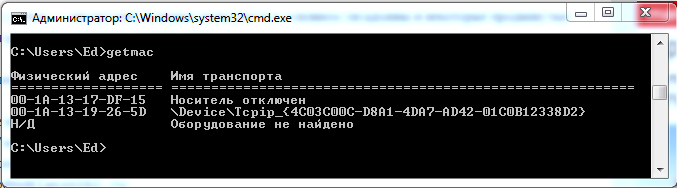
Рисунок 5 Команда getmac
Таблицу соответствия IP и MAC адресов (ARP таблицу) показывает команда arp –a.
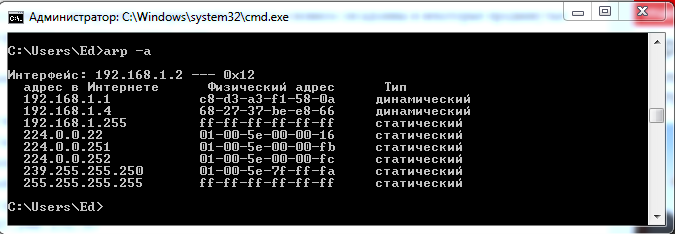
Рисунок 6 Команда arp –a
Проверить связь с сетевым устройством можно командой ping.
- ping доменное имя
- ping IP-адрес
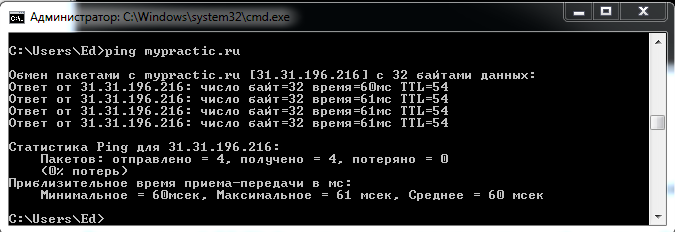
Рисунок 7 Команда ping
2. Практическое использование технологии клиент-сервер.
2.1 Базовые сетевые протоколы
Сетевой протокол это набор соглашений, правил, которые определяют обмен данными в сети. Мы не собираемся реализовывать эти протоколы на низком уровне. Мы намерены использовать готовые аппаратные и программные модули, которые реализуют сетевые протоколы. Поэтому нет необходимости подробно разбирать форматы заголовков, данных и т.п. Но, зачем нужен каждый протокол, чем он отличается от других, когда используется, знать надо.
Протокол IP.
Inernet Protocol (межсетевой протокол) доставляет пакеты данных от одного сетевого устройства к другому. IP протокол объединяет локальные сети в единую глобальную сеть, обеспечивая передачу пакетов информации между любыми устройствами сетей. Из представленных здесь протоколов IP находится на самом низком уровне. Все остальные протоколы используют его.
IP протокол работает без установления соединений. Он просто пытается доставить пакет по указанному IP-адресу.
IP обрабатывает каждый пакет данных, как отдельную независимую единицу, не связанную с другими пакетами. Невозможно используя только IP протокол, передать значительный объем связанных данных.
В протоколе IP нет механизмов, позволяющих контролировать достоверность конечных данных. Контрольные коды используются только для защиты целостности данных заголовка.
Т.е. IP не гарантирует, что данные в полученном пакете будут правильными. [3, c. 55]
Если во время доставки пакета произошла ошибка, и пакет был потерян, то IP не пытается заново послать пакет. Т.е. IP не гарантирует, что пакет будет доставлен.
Коротко о протоколе IP можно сказать, что:
- это протокол без установления соединений;
- он доставляет небольшие (не более 1500 байт) отдельные пакеты данных между IP-адресами;
- он не гарантирует, что доставленные данные будут правильными;
- он не гарантирует, что данные вообще будут доставлены;
- он не сообщит отправителю, были ли доставлены данные и не повторит передачу пакета;
- нет упорядоченности пакетов, порядок доставки сообщений не определен.
Протокол TCP.
Transmission Control Protocol (протокол управления передачей) основной протокол передачи данных Интернета. Он использует способность IP протокола доставлять информацию от одного узла другому. Но, в отличии, от IP он:
- Позволяет переносить большие объемы информации. Разделение данных на пакеты и “склеивание” данных на приемной стороне обеспечивает TCP.
- Данные передаются с предварительной установкой соединения.
- Производит контроль целостности данных.
- В случае потери данных инициирует повторные запросы потерянных пакетов, устраняет дублирование при получении копий одного пакета.
По сути, протокол TCP снимает все проблемы доставки данных. Если есть возможность, он их доставит. Не случайно это основной протокол передачи данных в сетях. Часто используют терминологию TCP/IP сети.
Протокол UDP.
User Datagram Protokol (протокол пользовательских датаграмм) простой протокол для передачи данных без установления соединения. Данные отправляются в одном направлении без проверки готовности приемника и без подтверждения доставки. Объем данных пакета может достигать 64 кБайт, но на практике многие сети поддерживают размер данных только 1500 байт.
Главное достоинство этого протокола – простата и высокая скорость передачи. Часто применяется в приложениях критичных к скорости доставки данных, таких как видеопотоки. В подобных задачах предпочтительнее потерять несколько пакетов, чем ждать отставшие.
Особенности работы UDP:
- протокол без установления соединений;
- доставляет небольшие отдельные пакеты данных между IP-адресами;
- не гарантирует, что данные вообще будут доставлены;
- не сообщит отправителю, были ли доставлены данные и не повторит передачу пакета;
- нет упорядоченности пакетов, порядок доставки сообщений не определен.
2.2 Протокол HTTP
Протокол HTTP – это протокол передачи гипертекста (Hyper Text Transfer Protocol).
Он используется для получения информации с веб-сайтов. При этом веб-браузер выступает в роли клиента, а сетевое устройство в качестве веб-сервера.
История HTTP
HyperText Transfer Protocol был создан в CERN в 1991 году Тимом Бернерсоном-Ли, во времена, когда призрак Интернета бродил по земному шарику. Как и многие великие изобретения, он создавался не ради каких-то абстрактных целей, а ради удобства автора и решал конкретную проблему: давал доступ к гигантскому количеству информационных ресурсов лаборатории.
Документацию и экспериментальные данные необходимо было не только хранить, но обеспечивать к ним доступ для сотен специалистов и институтов по всему миру. HTTP был придуман с целью упростить доступ к информации и оказался настолько удобен, что в 1993 году была опубликована спецификация HTTP/0.9, доступная каждому.
В ней описывался базовый синтаксис протокола, давались определения базовым понятиям и подготавливалась почва для дальнейшего расширения протокола. Также были опубликованы исходные коды браузера (программы для просмотра гипертекста, передаваемого через HTTP) под названием WorldWideWeb:
Рисунок 3 Скриншот работы WorldWideWeb
Так мировая сеть сделала свой первый шаг.
Первоначально HTTP использовался исключительно для передачи гипертекста (текста с перекрёстными ссылками) между компьютерами, но позже оказалось, что он прекрасно подходит и для того, чтобы посылать на ПК пользователя бинарные данные — например, изображения или музыку.
В мае 1996 года, всего через три года после первого релиза, была выпущена спецификация HTTP/1.0 (RFC1945), которая расширяла исходную версию протокола, закрепляла коды ответа и вводила новый тип данных для передачи — application/octet-stream, что фактически «легализовало» передачу нетекстовых данных.
В июне 1999 года была опубликована версия протокола 1.1, которая фактически оставалась неизменной на протяжении 16 лет. Более того, она послужила основой для многих других протоколов, в частности WebSocket и WebDav.
И, наконец, 11 февраля 2015 года вышла черновая версия протокола HTTP/2. В отличие от предыдущих двух релизов, он не является переработанным HTTP/0.9, имеет не текстовый, а бинарный формат представления данных, требует обязательного шифрования и имеет множество более мелких отличий от своих предков: сжатие заголовков, использование одного TCP соединения для серии запросов, а также даёт возможность послать серверу дополнительные данные в теле ответа, превентивно отдавая ресурсы в браузер.
Как работает HTTP/1.1
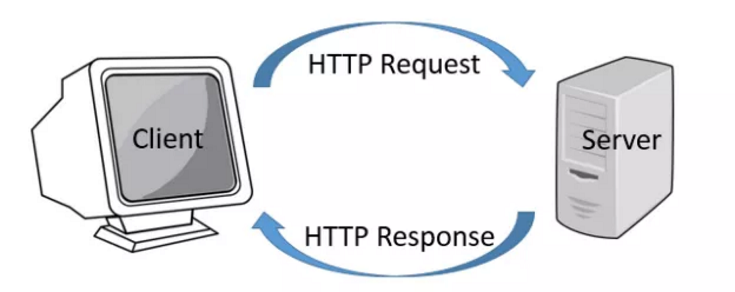
Рисунок 4 Схема работы HTTP/1.1
В основе протокола HTTP лежит концепция клиент-серверной архитектуры: клиент, чаще всего браузер, делает запрос на сервер. Существует множество видов запросов, самые распространённые — это GET и POST: первый означает, что клиент хочет получить данные, а второй — что клиент хочет послать данные на сервер.
Таким образом, общение между клиентом и сервером сводится к обмену сообщениями, причём всегда по принципу «клиент послал запрос — сервер прислал ответ».
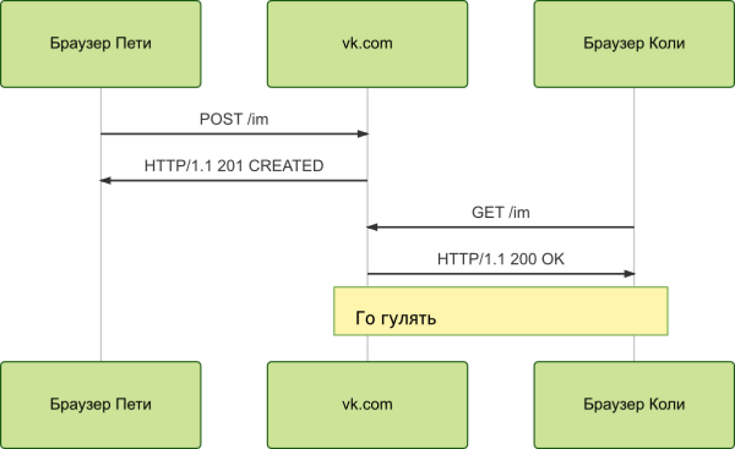
Рисунок 5 Схема работы между клиентом и сервером
Таким образом, любое взаимодействие между сервером и клиентом можно разбить на пары «вопрос-ответ», что очень упрощает взаимодействие с веб-сервисами.
Внутреннее устройство протокола
Как было замечено выше, протокол HTTP до версии 2.0 имеет текстовую природу. Фактически клиент посылает на сервер специальным образом составленное «письмо»:
------------------------------------------------------
GET /im HTTP/1.1
Host: vk.com
User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9b5) Gecko/2008050509 Firefox/3.0b5
Accept: text/html
Connection: close
------------------------------------------------------
Разберём его построчно.
Первая строка содержит в себе название метода (GET), URI — универсальный идентификатор ресурса (/im в данном случае), и версию используемого протокола - HTTP/1.1.
После этой обязательной строки, с которой начинается любое HTTP-сообщение, идут несколько пар значений, разделённых двоеточиями. Они называются заголовками (HTTP-headers).
Эти значения могут быть самыми разными, но наиболее распространенными являются Host (содержит имя сайта, наличие такого заголовка позволяет хостить несколько сайтов на одном IP адресе) и User-Agent, который по задумке должен обозначать вид используемого браузера, а на практике сложным образом описывает список поддерживаемых браузером технологий.
Поле Accept определяет формат данных в ответе, который нужен клиенту, а «Connection: close» означает, что клиент хочет закрыть TCP соединение сразу после получения ответа от сервера. [1, c. 127]
Если запрос сформирован правильно, и сервер функционирует нормально, и сеть в порядке, то в ответ на HTTP пакет от клиента придёт ответ, который выглядит примерно вот так:
------------------------------------------------------
HTTP/1.1 200 OK
Date: Wed, 27 Aug 2017 09:50:20 GMT
Server: Apache
X-Powered-By: PHP/5.2.4-2ubuntu5wm1
Content-Language: ru
Content-Type: text/html; charset=utf-8
Content-Length: 18
Connection: close
------------------------------------------------------
Здесь мы наблюдаем отсутствие названия метода в первой строке, и ряд новых заголовков, рекомендуется обратить внимание на поле «Content-Length: 18». Это число обозначает длину данных в байтах, которые передаются после пустой строки в конце пакета (так как в заголовке Content-Type указана кодировка utf-8, то каждая буква кириллицы в сообщении занимает два байта). Таким образом, мы рассмотрели простой пример работы протокола HTTP.
HTTP позволяет миллиардам людей получать доступ новостям, письмам друзей, спорам о самолёте на конвейерной ленте, смешным фотографиям котиков и данным о недавно открытом в БАКе гамма-резонансе (HTTP по-прежнему приносит пользу на своей малой родине, ЦЕРНе).
Мало какие изобретения обладают столь мощным влиянием на человечество в том объёме, как этот простенький протокол передачи структурированного текста. И, разумеется, такой протокол не мог остаться без расширений, и самым популярным из них стал HTTPS.
Все мы привыкли при вводе названия сайта видеть впереди HTTP – стандартный протокол передачи данных от сервера, на котором находится сайт, к пользователю. Однако, не смотря на всю его популярность, все больше сайтов предпочитают использовать более продвинутый протокол – HTTPS, так как он защищает передаваемые данные от перехвата злоумышленниками путем их шифрования.
Рассмотрим этот протокол более подробно: как он работает, кому рекомендуется использовать и что нужно, чтобы подключить HTTPS к сайту.
2.3 Протокол HTTPS
HTTPS (Hypertext Transport Protocol Secure) – это протокол, который обеспечивает конфиденциальность обмена данными между сайтом и пользовательским устройством. Безопасность информации обеспечивается за счет использования криптографических протоколов SSL/TLS, имеющих 3 уровня защиты:
- Шифрование данных. Позволяет избежать их перехвата.
- Сохранность данных. Любое изменение данных фиксируется.
- Аутентификация. Защищает от перенаправления пользователя.
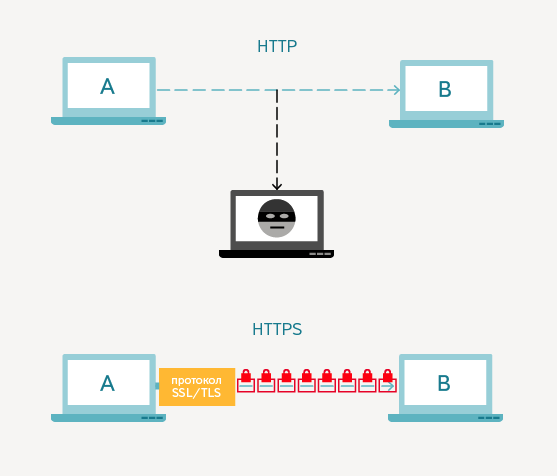
Рисунок 6 Схема работы HTTP и HTTPS
Обязательное использование защищенного протокола передачи данных требует вся информация, касающаяся проведения платежей в интернете: оплата товаров в интернет-магазинах любым способом (индивидуальная платежная карта, онлайн системы платежей и пр.), оплата услуг через интернет-банкинг, совершение платежей в онлайн сервисах (казино, online-курсы и т.п.) и многое другое.
Использовать протокол HTTPS рекомендуется также на сайтах, которые для доступа к определенному контенту запрашивают личные данные пользователей, например, номер паспорта – такие данные необходимо защищать от перехвата злоумышленниками.
Если на сайте используется что-либо похожее, то стоит серьезно задуматься над переходом на HTTPS. Поэтому далее мы рассмотрим, что для этого необходимо.
Что нужно для перехода сайта на HTTPS?
Работа протокола HTTPS основана на том, что компьютер пользователя и сервер выбирают общий секретный ключ, с помощью которого и происходит шифрование передаваемой информации.
Это ключ уникальный и генерируется для каждого сеанса. Считается, что его подделать невозможно, так как в нем содержится более 100 символов. Во избежание перехвата данных третьим лицом используется цифровой сертификат – это электронный документ, который идентифицирует сервер.
Каждый владелец сайта (сервера) для установки защищенного соединения с пользователем должен иметь такой сертификат.
В этом электронном документе указываются данные владельца и подпись. С помощью сертификата вы подтверждаете, что:
- Лицо, которому он выдан, действительно существует,
- Оно является владельцем сервера (сайта), который указан в сертификате.
Первое, что делает браузер при установке соединения по протоколу HTTPS, это проверку подлинности сертификата, и только в случае успешного ответа начинается обмен данными.
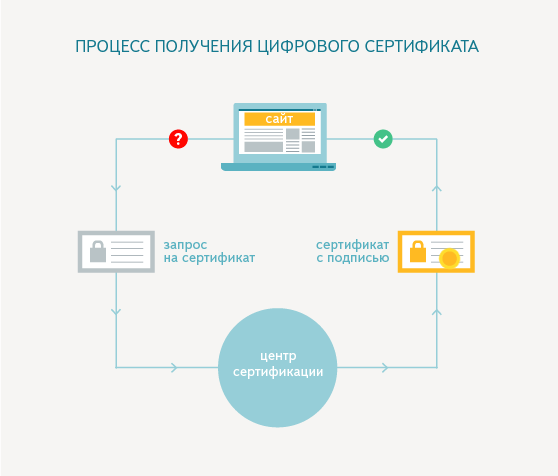
Рисунок 7 Схема работы HTTPS
Сертификатов существует несколько видов в зависимости от:
- того, какой уровень безопасности вам необходим,
- количества доменных имен и поддоменов,
- количества владельцев.
Выдают их специализированные центры сертификации на возмездной основе и на определенный период, поэтому важно не забывать продлевать действие сертификата, иначе вместо вашего сайта пользователь получит сообщение в браузере следующего содержания:
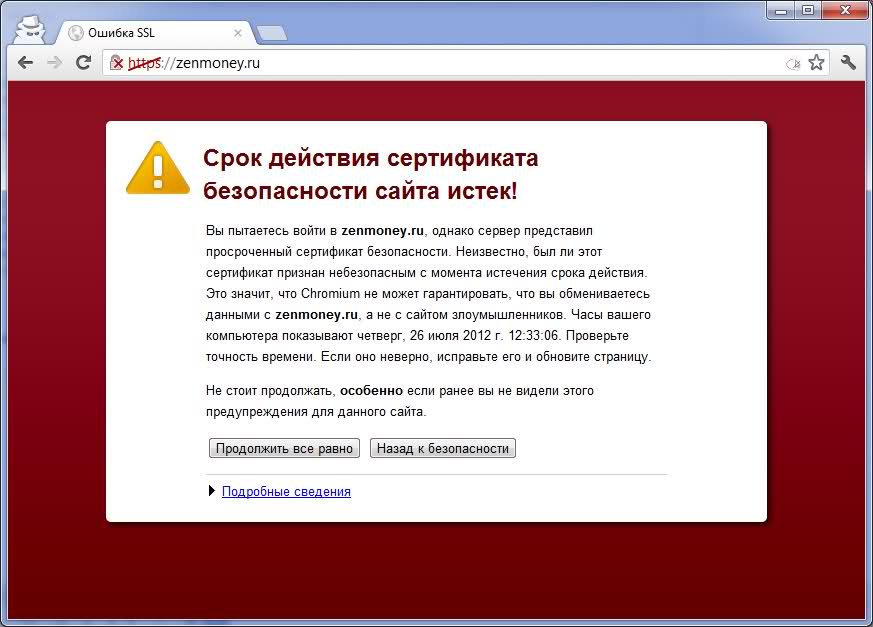
Рисунок 8 Неверный сертификат HTTPS
Не так давно поисковая система Google заявила о том, что для нее наличие протокола HTTPS является одним из важных факторов ранжирования сайта.
ЗАКЛЮЧЕНИЕ
Технология клиент-сервер – это способ соединения между клиентом (компьютером пользователя) и сервером (мощным компьютером или оборудованием, предоставляющем данные), при котором они взаимодействуют между собой напрямую.
Общие принципы передачи данных между компонентами вычислительной сети устанавливаются сетевой архитектурой.
Технология “клиент-сервер” представляет собой такую систему, в которой хранение информации и ее обработка осуществляются на серверной части, а формирование запроса и получение данных предоставляется клиентской стороне.
При этом, клиент-серверные технологии предусматривают наличие специального программного обеспечения – клиентского и серверного. Эти программы взаимодействуют с помощью специальных сетевых протоколов передачи данных.
Как правило, клиент и сервер установлены на разных компьютерах, но иногда могут быть установлены и на одну машину.
Серверное программное обеспечение настроено на получение и обработку запросов от пользователя, предоставляя ему результат в виде данных или функций (электронная почта, общение или просмотр страниц в интернете).
Подобная технология работает по такому же принципу, как и база данных: запрос – обработка – передача результата.
Сервер выполняет следующие функции:
- хранение данных;
- обработка запроса от клиента с помощью процедур и триггеров;
- отправка результата клиенту.
Функции, которые реализуются клиентской частью:
- формирование и отправка запроса к серверу;
- получение результатов и отправка дополнительных команд (запросов на добавление, удаление или обновление информации).
Достоинства и недостатки.
Клиент-серверная архитектура обладает следующими преимуществами:
- высокая скорость обработки данных;
- низкая нагрузка на сетевую инфраструктуру;
- возможность быстрой работы с большим количеством клиентов;
- разделение программного кода серверных и клиентских приложений.
Несколько пользователей могут одновременно работать с данными за счет транзакций (последовательность операций, представляемых в виде единого блока) и блокировок (изоляция данных от редактирования другими пользователями).
Недостатки клиент-серверной технологии:
- высокие требования к аппаратно-программным характеристикам серверного оборудования за счет того, что обработка данных происходит на стороне сервера;
- потребность в системном администраторе, контролирующем бесперебойность работы серверного оборудования.
Многоуровневая технология “клиент-сервер” предусматривает выделение отдельного серверного оборудования для обработки данных. Операции хранения, обработки и вывода данных производятся на разных серверах. Благодаря этому распределению обязанностей повышается эффективность работы сети.
Примером многоуровневой архитектуры является трехуровневая технология. В такой сети, помимо клиента и сервера приложений, есть дополнительный сервер базы данных.
Предусматриваются следующие три уровня:
- Нижний. Это звено включает клиентское программное обеспечение с пользовательским интерфейсом и системой взаимодействия со следующим уровнем обработки данных.
- Средний. Запросы от клиентских программ обрабатываются сервером приложений, на котором осуществляются операции по обработке и подготовке информации для передачи между сервером верхнего уровня и клиентом. Он позволяет разгрузить хранилище данных от лишней нагрузки и распределить запросы от разных пользователей.
- Верхний. Это независимый сервер базы данных, на котором хранится вся информация. Он получает подготовленный запрос от сервера приложений и предоставляет ему необходимую информацию без непосредственного взаимодействия с клиентскими приложениями.
Архитектура с выделенным сервером представляет собой такую локальную сеть, в которой все взаимодействующие устройства находятся под управлением одного или нескольких серверов.
При этом клиенты (рабочие станции) отправляют запрос к ресурсам через серверное программное обеспечение. Выделенный сервер не имеет клиентской части и функционирует только как сервер для обработки запросов от клиентов и защиты данных.
При наличии нескольких серверов, функции между ними могут распределяться с определением для каждого отдельных обязанностей.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Боуман Д., Эмерсон C., Дарновски М. Практическое руководство по SQL. - Киев: Диалектика, 2015.
2. Горев А., Макашарипов С., Владимиров Ю. SQL Server 6.5 для профессионалов. - СПб.: Питер, 2011.
3. Конноли Т., Бэгг К., Страчан А. Базы данных: проектирование, реализация и сопровождение. Теория и практика. 2-е изд М.: Издательский дом «Вильямс», 2000
4. Коржов В.В. Многоуровневые системы клиент-сервер. Издательство Открытые системы 2007.
5. Ланг К., Чоу Д. Публикация баз данных в Интернете. – СПб.: Символ-Плюс, 2014.
6. Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование - М.: «Вильямс», 2007
7. Шкрыль, А. Разработка клиент-серверных приложений в Delphi - Санкт-Петербург: БХВ-Петербург, 2006.

- Методы и средства проектирования информационных систем и технологий.Применение процессного подхода для оптимизации бизнес-процессов.
- Понятие и виды сделок
- Выбор стиля руководства в организации (Понятие управления)
- Логический подход к управлению запасами.
- Технология обслуживания клиентов в ресторане
- Понятие оперативно – розыскной деятельности.
- Аналитические регистры налогового учёта по налогу на прибыль
- Распределение и использование прибыли как источник экономического роста предприятий (на примере ОАО «ГОМЕЛЬКАРТ»)
- Построение организационных структур (основы построения)
- Проектирование организации (Миссия организации)
- Логистический менеджмент и задачи оптимизации которые он решает в фирме.
- Социальное страхование и его функции