
Способы представления данных в информационных системах
Содержание:

Введение
В данной курсовой работе будет расмотрет вопрос по теме КР «Способы представления данных в информационных системах» и разработана программа для тестирования для примера.
Существуют разные способы представления данных. Наиболее распространенный из них - графический. Например, Panorama предоставляет следующие возможности (предполагается, что система использует в качестве механизма связи сообщения):
карта процессоров (процессоры и их соединения, а также текущие сообщения между ними);
окно отладки (состояния задач, данные, и.т.п.);
окно потока сообщений (все сообщения между процессорами во времени (и время приема, и время получения).
В дополнение к графическому способу можно использовать, например, звуковой, как это описано в [14]. Преимущество использования звука при отладке состоит в том, что при большом объеме собранных данных может быть сложно обнаружить ошибку визуально. Например, если в процессе работы затерялось какое-то сообщение от одного процессора к другому, то, анализируя графическое представление взаимодействия процессоров, трудно найти потерянное сообщение, так как оно может быть графически просто не представлено. Однако, если каждое сообщение (от посылки до получения) будет сопровождать некоторый звуковой сигнал, то потерянное сообщение будет сразу обнаруживаться.
Как видно, при отладке распределенных приложений необходимо учитывать связь между процессорами и, в основном, асинхронный ее характер, то есть на первое место выступает обнаружение ошибок, связанных со взаимодействием задач и усиленных тем, что задачи выполняются на разных процессорах.
Программа подразумевает выбор правильного варианта ответа из представленных посредствам переключателя. Каждый правильный ответ приносит пользователю один балл. По окончанию тестирования, когда пользователь ответит на все вопросы, программа подсчитывает количество баллов и отображает результат тестирования с оценкой. В программе предусмотрен вариант пробного тестирования, где правильные варианты ответа выделены другим цветом. Доступ к пробному тестированию предоставляется по паролю. Вопросы и варианты ответа к тесту хранятся в отдельном текстовом файле.
Цель курсовой работы – Способы представления данных в информационных системах.
1 Теоритические аспекты о представлениях данных в информационных системах
1.1 Понятие данных в ИС
Информация и данные. Восприятие окружающего мира связано с регистрацией различных, часто взаимосвязанных явлений, в результате чего мы получаем информацию о реальном мире. С давних времен человечество пыталось как-то описать эти явления вне зависимости от того, достигалось их полное понимание или нет. Элементы такого описания реального мира будем называть данными.
Слово «данные» происходит от латинского «datum», буквально означающего «факт». Тем не менее, данные не всегда соответствуют конкретным или действительным фактам. Иногда они неточны или описывают нечто, не имеющее место в реальной действительности, например идею или сновидение. Поэтому к данным будем относить описания любых явлений (в широком смысле слова), которые представляются ценными для того, чтобы их зафиксировать. Под информацией понимают любые сведения о каком-либо событии, сущности, процессе, явлении и т.п., являющиеся объектом некоторых операций: восприятия, передачи, преобразования, хранения или использования.
Иными словами информация – это знание о чем-либо. На современном этапе считается, что информация присуща всем видам и формам движения материи и связана с неотъемлемыми свойствами или атрибутами материи (отражением, разнообразием, структурой, распределением вещества и энергии в пространстве и времени и т.д.). Для того, чтобы соотнести между собой данные и информацию, представим следующую абстрактную ситуацию. Имеется некоторая система, ин формация о состоянии которой представляет интерес, и наблюдатель, способный воспринимать состояния системы и в определенной форме фиксировать их в своей памяти (никаких других действий он не выполняет). В этом случае говорят, что в памяти наблюдателя находятся данные, описывающие состояние системы.
В качестве такого «наблюдателя» в общем случае выступают СОД. Таким образом, данные можно определить также как информацию, фиксированную в определенной форме, пригодной для последующей обработки, хранения и передачи. Данные соответствуют зарегистрированным фактам об объектах и явлениях реального мира. Чтобы в дальнейшем использовать данные, требуется их смысловое содержание – семантика данных. Поэтому в СОД должны быть предусмотрены правила и средства интерпретации данных. Традиционно фиксация данных осуществляется с помощью конкретного средства общения (например, с помощью языка или изображений) на некотором носителе (например, бумаге, камне и т.п.). Основное и самое мощное средство представления семантики данных – естественный язык. Чаще всего данные описываются на естественном языке и фиксируются на бумаге.
Обычно данные (факты) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления и того и другого. Примером может служить утверждение «Рост Иванова – 173 см». Здесь «173» данное, а его семантика «рост Иванова в сантиметрах». Однако использование естественного языка в СОД вызывает известные трудности, поэтому в них широко используют формализованные языки, позволяющие эффективно организовать обработку данных и, с определенными ограничениями, – представлять семантику данных, удовлетворяющую практическим потребностям.
Данные и их интерпретация могут быть разделены. Например, расписание авиарейсов представляет собой таблицу данных, а их интерпретация приводится в начале (шапке) таблицы. Разделение данных и их интерпретации может затруднять работу с данными, что проявляется, в частности, и при пользовании расписанием авиарейсов. Широкое применение СОД привело к разделению данных и интерпретации. Компьютеры имеют дело главным образом с данными как таковыми. Большая часть интерпретирующей информации вообще не фиксируется в явной форме. Например, программа численного анализа, предназначенная для решения дифференциальных уравнений в частных производных, получает в качестве исходных данных некоторые числа и вырабатывает другие числа. Она не содержит информации о том, какие реальные явления описывают эти дифференциальные уравнения.
Ответственность за интерпретацию результатов в контексте их применения лежит на пользователе программы. Существуют, по крайней мере, две причины, по которым применение компьютеров привело к отделению данных от интерпретации. Во-первых, компьютеры не обладают достаточными возможностями для обработки текстов на естественном языке, который остается основным средством кодирования и интерпретации семантики данных. Во-вторых, стоимость компьютерной памяти была первоначально весьма велика, и память использовалась в основном для хранения самих данных, а интерпретация традиционно возлагалась на пользователя. По мере развития вычислительной техники возможность обеспечения автоматической интерпретации возрастает.
Программы, в которых заложена интерпретация используемых данных, имеют существенно большую значимость, так как без интерпретации данные не несут для потребителя никакой полезной информации и представляют собой не более чем совокупности битов. Однако в современных СОД, в условиях совместного использования данных, при множестве различных приложений такой подход можно применять только до определенного предела. За этим пределом написание программ, в каждую из которых встроены близкие, хотя и не идентичные механизмы интерпретации, становится весьма неэффективным.
В такой ситуации целесообразнее ассоциировать данные и механизмы интерпретации и обеспечить однократность представления интерпретирующей информации. В результате изменяется роль данных. Их уже нельзя рассматривать как совокупность битов, они приобретают определенную семантическую окраску. В таком качестве их можно расценивать уже как семантически значимое представление реального мира, как некоторое абстрактное знание. Интерпретация данных должна позволять наряду со стабильным базисом отображать множественность и эволюцию взглядов на данные. Такая гибкость достигается двумя способами. Во-первых, обеспечиваются разносторонние взгляды на одни и те же данные. Например, различные приложения могут накладывать на данные свои ограничения и конкретную интерпретацию. Так, человек может рассматриваться в приложениях, связанных с кадровыми вопросами – как служащий, в производственных приложениях – как исполнитель работ, при обработке данных выборных кампаний – как избиратель, в медицинских приложениях – как пациент и т.д. Вместе с тем, та часть интерпретации данных, которая осуществляется системой ведения данных, должна оставаться достаточно абстрактной для того, чтобы обеспечить множественность взглядов.
С другой стороны, должна существовать возможность единообразного представления различных данных. Например, администраторы, клерки, торговые агенты, секретари могут рассматриваться как служащие независимо от рода их деятельности. Это также требует значительной абстрактности интерпретации. Двум понятиям – «информация» и «данные» в СОД соответствуют два аспекта рассмотрения вопросов: инфологический и датологический. Инфологический аспект употребляется при рассмотрении вопросов, связанных со смысловым содержанием данных (семантика данных) независимо от способов их представления. Датологический аспект употребляется при рассмотрении вопросов представления данных в памяти СОД.
Моделирование данных. Очевидно, что наряду с абстрактностью интерпретации должны обеспечиваться развитые возможности представления соотношения данных. Интеллектуальное средство, позволяющее реализовать интерпретацию данных, находящихся между собой в определенных взаимоотношениях, называется моделью данных. Модель данных – это средство абстракции, которое дает возможность составить целостную картину отображения данных определенной предметной области, т.е. увидеть «лес» (информационное содержание данных), а не «отдельные деревья» (конкретные значения данных). Модели данных широко используются в различных дисциплинах, они помогают понять проблемы и абстрагироваться от деталей. Уровень абстрактности модели может меняться в зависимости от того, как она будет использоваться. Существует множество моделей, отражающих различные аспекты реального мира: физические, позволяющие понять его физические свойства, математические, представляющие собой абстрактное описание мира с помощью математических знаков, экономические, отображающие тенденции экономики и позволяющие получить прогноз ее развития. Модели данных дают возможность представить частичную семантику данных, что в свою очередь обеспечивает пользователей частичными знаниями о реальном мире. Привлекательной, на первый взгляд, может показаться мысль – найти универсальную модель данных, которая бы полностью отражала реальный мир.
Однако возможность создания такой модели весьма проблематична. Система наших знаний о мире – это открытая система. Даже, располагая самыми обширными знаниями в некоторой области, мы фактически никогда не достигнем исчерпывающего ее познания. Важно, чтобы объем знаний и семантика данных, представленные в модели, были адекватны желаемому использованию данных. Приступая к задаче моделирования данных, необходимо, прежде всего, определить элементарные объекты моделирования. Примем в качестве рабочего определения элементарной единицы данных кортеж .
Первый элемент кортежа – имя объекта – является, по существу, идентификатором объекта, явления (или идеи). Второй элемент – свойство объекта – дает определенную характеристику объекту, явлению и может принимать некоторое конкретное значение (значение свойства) в определенное время (время). Среди названных четырех характеристик данных наибольшие проблемы вызывает характеристика времени. Для множества данных требуется решить сложную задачу синхронизации времени их представления и изменения. Кроме того, часто представляет интерес не абсолютное, а относительное время наблюдения явления (т. е. последовательность, в которой возникают явления). В этом случае необходимый результат достигается временным упорядочением данных, а не фиксацией абсолютного времени. В разных аспектах использования данных может меняться информационная ценность новых и старых данных. Например, в расчетах заработной платы предприятия используется текущий размер заработной платы служащего и не требуется знания всех предыдущих изменений его заработка. В то же время, для других приложений, связанных, например, с динамикой роста заработной платы на предприятии, сведения об изменениях заработка служащего станут необходимыми.
Поэтому характеристика времени во многих моделях данных подменяется, либо некоторыми другими характеристиками, либо упорядочением объектов. Опуская временную характеристику, приходим к следующему представлению элементарной единицы данных: . Она может быть реализована множеством способов, что и привело к созданию множества моделей данных. Простым и естественным способом представления элементарных данных и связей между ними является сетевая структура, в которой вершины соответствуют элементам, а дуги – связям между ними. Другой мощный способ установления связей между данными состоит в распределении их по категориям. Данные одной категории предполагаются подобными.
В соответствии с уровнем требований к категоризации данных, модели данных разделяются на два класса: сильно типизированные и слабо типизированные. Сильно типизированные – это модели, в которых предполагается, что все данные должны быть отнесены к какой-либо категории. Если данные нельзя отнести ни к одной из них, то их следует с помощью искусственных приемов привести к той или иной категории. Слабо типизированные модели не связаны никакими предположениями относительно категорий. Категории используются в той степени, в какой это целесообразно в каждом конкретном случае. Отдельные данные могут существовать как сами по себе, так и в связи с другими данными. Сильно типизированные модели накладывают весьма жесткие ограничения на представление данных и на их применение, что затрудняет передачу тонких семантических различий.
Например, категория СЛУЖАЩИЙ в сильно типизированной модели данных должна быть гомогенной, т. е. все объекты, принадлежащие этой категории, должны иметь однотипные свойства, структуру и т. д. Между тем, женатые и неженатые, временные и постоянные, находящиеся на сдельной и повременной оплате служащие могут характеризоваться поразному. Вместе с тем, сильно типизированные модели данных обладают и большими достоинствами.
Они позволяют построить строгие абстракции свойств данных и исследовать их в терминах категорий. Иными словами, можно построить теорию, основывающуюся на категориях, которые фактически ин капсулируют (не требуют специального описания) свойства конкретных данных. Отдельные свойства категорий наследуются принадлежащими к ним данными. Кроме того, устраняется дублирование имен: имена подобных объектов и их свойств могут быть абстрагированы соответственно в имя категории и имя свойства категории.
Например, путем присвоения самой категории имени СЛУЖАЩИЙ, а свойству этой категории – имени ВОЗРАСТ, устраняется повторение имен в каждой тройке < СЛУЖАЩИЙ, ВОЗРАСТ, ЗНАЧЕНИЕ >.
Еще одно преимущество сильно типизированных моделей состоит в возможности устранять очевидную противоречивость данных, поскольку семантически близкие данные будут рассматриваться в рамках одной категории. Это не всегда имеет место в слабо типизированных моделях данных. Гибкость последних позволяет отводить факту различные места в общей структуре фактов. В слабо типизированных моделях обнаружить противоречивость далеких по представлению фактов очень трудно. В отличие от сильно типизированных моделей слабо типизированные модели данных обеспечивают интеграцию данных и категорий. Предельные возможности в этом плане обеспечиваются исчислением предикатов, в котором акцент делается на обеспечении универсальности средств описания, вне связи с искусственными ограничениями на типизацию и категоризацию данных. Во многих моделях данных исчисление предикатов используется для представления знаний, не реализуемого базовыми средствами модели.
Вместе с тем, исчисление предикатов не обеспечивает хорошего наглядного представления данных, поскольку предполагает работу с линейными текстами (или с конструкциями формального языка типа ПРОЛОГ), и поэтому не может служить универсальным средством моделирования. Основные причины, по которым в сильно типизированных моделях поддерживаются столь серьезные ограничения, связаны с тем, что число представляемых объектов обычно весьма велико, а возможности интеллекта человека ограничены.
Для облегчения понимания данных и работы с ними необходимо разбить множество объектов на подмножества. Элементы каждого подмножества должны подчиняться общим закономерностям. При небольшом числе объектов или высоком уровне интеллекта пользователей ограничения могут быть ослаблены, а значения представлены в естественной для них форме. Определение модели данных. Большинство моделей данных, используемых в СОД, относится к сильно типизированным.
Поэтому в данном курсе основное внимание будет уделено именно этим моделях. В модели данных конкретной предметной области совокупность именованных категорий (например, ЛИЧНОСТЬ, АВТОМОБИЛЬ), их свойств (ФИО, МАРКА АВТОМОБИЛЯ) и связей между ними (ВЛАДЕЕТ, ВОДИТ) называется схемой. Рассмотрим простую модель данных – т.н. «плоский файл», в которой категории называются типами сущностей, а свойства категорий – атрибутами.
Пусть эта модель применяется для представления данных о служащих. Тогда в схеме будет специфицирован тип сущности СЛУЖАЩИЙ (ФИО, Возраст, Адрес), где СЛУЖАЩИЙ – имя типа сущности, ФИО, Возраст, Адрес – имена атрибутов. Конкретные данные будут иметь форму, например, Иванов И.И._29_ Таганрог, ул. Греческая, 82 !
Модель данных определяет правила, в соответствии с которыми структурируются данные. Однако структурные спецификации не обеспечивают возможности полной интерпретации семантики данных и способа их использования. Должны быть также специфицированы операции над данными. Так, например, список объектов в зависимости от допустимых операций может приобрести свойства стека или очереди. Обычно операции соотносятся со структурами данных.
Совокупность данных, структура которых соответствует конкретной схеме, называется базой данных (БД). Этот термин применяется, как к определенной реализации указанной совокупности данных, так и к ряду связанных между собой реализаций. Дело в том, что операции, предусмотренные моделью данных, преобразуют одну БД в другую. Эти БД имеют одну и ту же структуру и соответствуют одной и той же схеме. Последовательность БД, получаемую в результате преобразований, обычно и называют БД.
Разнообразие моделей данных соответствует разнообразию областей применения и контингента пользователей. Тем не менее, существует ряд общих понятий и определений, относящихся ко всем моделям. Свойства, которые отображает модель реального мира в основном делятся на два класса: статические и динамические. К статическим относятся свойства, инвариантные во времени. Они всегда справедливы и неизменны. Динамические свойства соответствуют эволюционной природе мира. Любая модель данных должна некоторым образом представлять эти два класса свойств. Исходя из этого, модель данных М можно определить как множество правил порождения G и множество операций О. Множество правил порождения выражает статические свойства модели данных и соотносится с языком описания данных (ЯОД).
Множество операций выражает динамические свойства модели данных и соотносится с языком манипулирования данными (ЯМД). Средствами ЯОД определяются допустимые структуры данных объектов и связей, а также допустимые реализации данных. Определение структур данных реализуется посредством спецификаций, которые должны удовлетворять правилам порождения.
Например, спецификация типа сущности СЛУЖАЩИЙ производится в терминах атрибутов и типов значений каждого атрибута. Селекция допустимых реализаций объектов или связей задается путем указания для каждой категории ограничений целостности. Так, можно указать, что каждый номер по реестру социального страхования может быть присвоен не более чем одному служащему или что никакой служащий не может зарабатывать больше, чем его руководитель.
В некоторых моделях данных правила порождения G разделяют на две части: правила порождения структур GS и правила порождения ограничений GС. Соответственно этому схема S будет также состоять из двух частей: спецификации структуры SS и спецификации явных ограничений SС. Примером явного ограничения целостности служит указание на то, что атрибут Номер служащего типа сущности
СЛУЖАЩИЙ есть идентификатор (ключ). Это означает, что в каждый момент времени множество реализаций типа сущности
СЛУЖАЩИЙ не может содержать две или более реализаций с одинаковым значением атрибута Номер служащего. Наряду с явными ограничениями в модели данных могут поддерживаться также внутренние ограничения, отражаемые в структурной части SS.
Эти ограничения налагаются на объекты и связи по определению. Например, связи между объектами могут быть ограничены только древовидной структурой (т. е. более общие – сетевые структуры недопустимы). Правила G обеспечивают порождение множества схем S, каждая из которых определяет конкретную структуру данных и специфицирует ограничения целостности. Если под БД понимать реализацию совокупности данных, удовлетворяющую схеме, то можно сказать, что схеме соответствует множество D различных БД. Множество операций О, которые соотносятся с ЯМД, определяют допустимые действия над реализацией Di БД для преобразования ее в другую реализацию Dj. Не все операции приводят к изменению реализации БД.
Поэтому для отслеживания динамики БД вводят некоторые дополнительные объекты – индикаторы текущих и другие управляющие элементы. Эти объекты в строгом смысле не относятся к объектам БД, но они связаны с реализацией БД и могут изменяться в результате выполнения операций.
Совместно с конкретной реализацией D БД они определяют состояние БД – DBS. Рассмотрим, например, последовательную выборку из плоского файла с использованием команды «дать следующую (запись)». Текущее состояние БД определяется реализацией D, а также значением индикатора текущей. Выполнение операции «дать следующую» не приведет к изменению реализации D БД, но состояние БД изменится, так как изменится значение индикатора текущей.
Управление БД осуществляется системой управления БД (СУБД), которая поддерживает средства определения схем БД и обеспечивает выполнение операций над данными БД. Естественно, СУБД должна поддерживать модель данных. Иногда СУБД вообще создаются под определенную модель данных. В 14 других СУБД эволюционное изменение модели данных привело к независимым реализациям ее отдельных версий.
2 Способы представления данных в информационных системах
2.1 Назначение и область применения
Суть программы заключается в предоставлении пользователю выбора одного правильного ответа из нескольких предоставленных, осуществляемого посредством переключателя. За каждый правильный ответ пользователю начисляется один балл. Когда пользователь завершает процесс ответов на вопросы тестирование заканчивается, программа резюмирует количество баллов, определяет оценку и выдает результат тестирования. Программа содержит модуль пробного тестирования, в котором корректные варианты ответа отображаются другим цветом. Пройти пробное тестирование пользователь может, введя пароль. Вопросы и ответы на них по каждому тесту сохранены в отдельный текстовый файл.
Сфера использования: разрабатываемую программу планируется применять для оценивания знаний учащихся; образовательный процесс.
Условия задачи курсового проекта не предусматривают управление программы какой-либо конкретной операционной системой. Решено разрабатывать новую программу для работы в среде самого распространенного на данный момент семейства операционных систем Windows.
Программу необходимо создать в среде языка программирования Delphi. При выборе данной системы программирования пользователем берется на себя задача по написанию подпрограмм. После написания взаимосвязь между подпрограммами обеспечивается непосредственно самой средой визуального программирования Delphi. Работая в среде визуального программирования пользователь имеет в своем распоряжении внушительный комплект визуальных компонентов и средств для разработки качественной программной продукции.
2.2 Постановка задачи
Согласно условию задачи требуется разработать для тестирования программный продукт. Суть программы заключается в предоставлении пользователю выбора одного правильного ответа из нескольких предоставленных, осуществляемого посредством переключателя. За каждый правильный ответ пользователю начисляется один балл. Когда пользователь завершает процесс ответов на вопросы тестирование заканчивается, программа резюмирует количество баллов, определяет оценку и выдает результат тестирования. Программа содержит модуль пробного тестирования, в котором корректные варианты ответа отображаются другим цветом. Пройти пробное тестирование пользователь может, введя пароль. Вопросы и ответы на них по каждому тесту сохранены в отдельный текстовый файл.
2.3 Описание алгоритма
В реализовываемом программном продукте реализуются следующие задачи:
1. Операции с переключателями (Radio Button);
2. Операции с внешним файлом в формате txt;
3. Операции с паролем;
4. Суммирование набранных баллов и оформление итогов тестирования.
Во время запуска приложения пользователь выбирает один из двух вариантов тестирования – обычный либо тестовый режим. Выбор производится в главном меню приложения – MainMenu.
В том случае, если выбран обычный режим тестирования, происходит обработка процедуры N1Click. Так как вопросы и ответы на них записаны во внешний txt-файл, программа должна проверить наличие данного файла в каталоге, а также его читабельность. В случае если при этом возникает проблема, программе следует предупредить об этом пользователя и прекратить свою работу. В случае успешного обращения к txt-файлу, начинается обработка программой текстового файла.
В процессе загрузки файла с тестовой информацией, программа заполняет два рабочих массива, level и mes. В первом из них будут храниться критерии оценки, а во втором – комментарии к оценкам. До начала работы программой обнуляются результаты тестирования, и выводится первый вопрос.
Для вывода в окне программы вопросов тестирования предназначается процедура NextQw. Посредством данной процедуры обеспечивается вычитка тестовых данных из текстового файла и последовательный вывод на форму вопросов. На следующем этапе обрабатываются варианты ответа: из текстового файла выводятся варианты ответов к соответствующему вопросу и отображаются в окне программы. По завершению данного процесса считываются оценки согласно с вариантами ответов. Для этого процесса используется следующий механизм: в случае правильного варианта ответа свойство Tag определенного переключателя обозначается значением «1», а прочие переключатели обозначаются значением «0». Счетчик суммарного количества вопросов, предусмотренный в приложении, после каждого нового вопроса изменяется на единицу. Пока тестируемым не выбран один из вариантов ответа, кнопку «Далее» использовать будет невозможно.
Пользовательскую процедуру NextQw используем для отображения в окне программы вопросов тестирования. В данном случае ни один из вариантов ответа не будет выбран.
Второй из разрабатываемых вариантов тестирования является тренировочным. Чтобы перейти к нему пользователю необходимо выбрать в меню приложения соответствующий пункт. Ранее уже упоминалось, что для получения доступа к этому режиму работы пользователю необходимо ввести пароль. В данном случае применяется переменная Boolean – Flag. Когда переменная объявляется, ей присваивается значение False. В случае введения пользователем корректного пароля, ее значение меняется на True. Это необходимо для разделения тренировочного и обычного режимов, разница между которыми в том, что при тренировочном правильный ответ на вопрос подсвечивается красным цветом. Доступ к тренировочному режиму открывается при введении пароля «123».
2.4 Организация входных и выходных данных
В разрабатываемом приложении входными данными являются тестовые данные из внешнего текстового файла, а также ответы на вопросы тестирования. Выходными данными являются результаты тестирования, которые отображаются в форме количественного выражения суммы правильных и неправильных ответов.
2.5 Выбор состава технических и программных средств
Программу тестирования решено создавать на языке программирования Delphi (современной версии классического языка программирования Pascal). На выбор именно этого языка в качестве среды программирования повлияла его простота, низкие системные требования, а также широкий выбор русскоязычной справочной литературы.
Выдать сообщение
Выдать сообщение
Начало
Взять имя файла теста
Файл
существует?
Да
Нет
Ошибка
при считывании файла?
Да
Нет
Открыть файл
Добавить комментарии в массив
Добавить критерии оценок в массив
Обнулить результаты теста
Чтение файла
А
В
С
Рисунок 1 - Обработка и вывод вопросов
Продолжение Рисунка 1
В
А
Вывести вопросы
Вывести варианты ответа
Счетчика количества вопросов +1
Кнопка «Дальше» недоступна
Радиокнопки не доступны
Конец
С
Вывести вопрос
Вывести варианты ответа
В
Выполнить процедуру N1Click
Цвет правильного ответа - красный
Чтение файла
А
Начало
Ввод пароля
Пароль введен верно?
Нет
Да
Flag:=true
Выдать сообщение
Рисунок 2 – Алгоритм тренировочного тестирования
Продолжение Рисунка 2
Конец
Счетчик количества вопросов +1
Цвет правильного ответа - красный
Да
А
В
Свойство объекта Label Tag=1?
Нет
3 Разработка приложения
3.1 Выбор средства разработки
25 августа 2009-го года был выпущен релиз очередной версии Embarcadero RAD Studio. Как и предыдущая, новая RAD Studio 2010 включила в себя три полноценныхпродукта, предназначенных для разработки программного обеспечения — Delphi 2010, C++ Builder 2010 и Delphi Prism 2010.
Delphi 2010 может работать на одной из следующих ОС:
- Microsoft Windows 7;
- Microsoft Windows XP Home or Professional (SP3);
- Microsoft Windows VistaTM (SP1);
- Microsoft Windows Server 2003 (SP1) или 2008.
Наибольшее количество функциональных изменений в новой версии продукта касаются IDE. Здесь, прежде всего, следует упомянуть IDE Insight. Я бы это определил как навигатором IDE. Нажав F6 или Ctrl+ "." пользователь увидит на экране окно с древовидным списком, элементы которого соответствуют ключевым пунктом меню. Таким образом, по мнению разработчиков, пользователям не придется запоминать ни горячие клавиши, ни расположение искомого элемента в меню. Все на виду, грамотно расположено, работает фильтрация
Некоторые изменения претерпел и редактор кода. В частности, появилась возможность автоматически форматировать код. К сожалению, форматировать можно только модули, входящие в состав проекта. Что, опять же, на мой взгляд, не совсем логично. Зато, форматирование — полностью настраиваемое и количество опций – весьма внушительное. Фактически, пользователь может настроить автоформатирование под свой стиль написания кода.
В Delphi 2010 появились и принципиально новые возможности. Прежде всего, это новый механизм RTTI. Run Time Type Information - очень эффективное средство, позволяющее получать информацию о типах в режиме исполнения (Run Time). В Delphi 2010 в функциональность языка были добавлены атрибуты, подобно тому, как это работает в .Net. По сути, атрибуты хранят в себе некую мета-информацию о типах.
Помимо атрибутов, новый RTTI предоставляет разработчикам значительно больше возможностей.
В контексте RTTI. естественно, были внесены дополнения и в VCL. Модуль RTTI.pas включил в себя все необходимые для работы классы. Но это далеко не все изменения в библиотеке классов. Следует отметить поддержку Direct2D. Наконец-то в Delphi включена поддержка механизмов, встроенных в новую ОС (в данном случае Windows 7) еще до ее выхода.
Еще одной интересной особенностью новой VCL стала поддержка механизма естественного ввода — альтернативного механизма ввода данных, с помощью устройств основанных на прикосновениях (Gesturing) (классические примеры таких устройств -точпад, точскрин или световое перо). Почти все визуальные компоненты обзавелись свойством Touch и событием OnGesture. Соответственно, появился и новый набор компонентов, помогающий организовать работу с Gesturing.
Таким образо, в версии Delphi 2010 разработчики получили:
1. Более быструю, надежную и удобную IDE.
2. Радикально обновленный RTTI, со значительно более широкими возможностями, чем в предыдущих версиях.
3. Развитие технологий работы с БД; обновленный DataSnap.
4. Попытку охватить интересы не только кодеров, но и других участников процесса разработки ПО (UML, QA инструменты).
5. Новые возможности VCL, позволяющие использовать альтернативные устройства ввода данных.
3.2 Описание программы
Будет разработана программа, которая получила название «Тестирование». Для разработки указанного ПО было принято решение использовать среду разработку Delphi 10.
По условию задачи разработанное ПО будет работать только под управлением 32-х битных операционных систем Windows.
3.3 Разработка приложения
ПО разрабатывается посредством языка программирования Паскаль в среде разработки Delphi 10. На рисунке 3 представлен проект программы, который содержит одно окно программы – Form1.
7
8
9
3
4
1
2
5
6
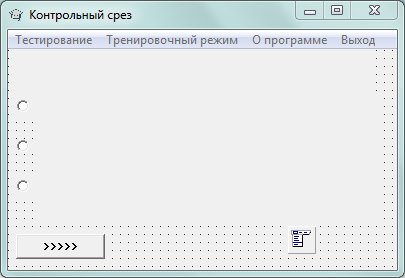
Рисунок 3 – Главное окно программы – Form1
Рассмотрим подробно компонентный состав окна Form1
1. Компонент Label1. Событие – нет. Измененные свойства – Caption:= «», Font.Name:= «MS Sans Serif»; Font.Size:= 10; Name:= Label1, Height:= 41, Left:= 8; Top:= 0, Width:= 353; Visible = False; . Назначение объекта – используется для вывода на экран тестового вопроса;
2. Компонент RadioButton1. Событие – Click. Измененные свойства –Name:= RadioButton1; Tag = 0; Checked = False; Visible = False; Height = 19; Left = 10; Top = 50; Width = 19. Назначение объекта – используется для выбора одного из вариантов ответа на тестовый вопрос;
3. Компонент RadioButton2. Событие – Click. Измененные свойства –Name:= RadioButton2; Tag = 0; Checked = False; Visible = False; Height = 17; Left = 10; Top = 92; Width = 19. Назначение объекта – используется для выбора одного из вариантов ответа на тестовый вопрос;
4. Компонент RadioButton3. Событие – Click. Измененные свойства –Name:= RadioButton3; Tag = 0; Checked = False; Visible = False; Height = 19; Left = 10; Top = 131; Width = 19. Назначение объекта – используется для выбора одного из вариантов ответа на тестовый вопрос;
5. Компонент Button1. Событие – Click. Измененные свойства – Caption = «>>>>>»; Name:= Button1; Enabled = «True»; Visible = False; Tag = 0; Height = 27; Left = 0; Top = 178; Width = 92. Назначение объекта – объект используется в качестве кнопки для перехода по тестовым заданиям, для окончания процедуру тестирования, для вывода результатов на экран;
6. Компонент MainMenu1. Назначение объекта – для создания главного меню программы;
7. Компонент MainMenu1.N1. Событие – Click. Измененные свойства – Caption = «Тестирование». Назначение объекта – начинает процесс тестирования;
8. Компонент MainMenu1.N2. Событие – Click. Измененные свойства – Caption = «Тренировочный режим». Назначение объекта – запускает тренировочный режим тестирования;
9. Компонент MainMenu1.N3. Событие – Click. Измененные свойства – Caption = «Выход». Назначение объекта – завершает работу программы.
Рассмотрим подробно обработку событий программы.
procedure TForm1.Button1Click(Sender: TObject);
Процедура загружает новый вопрос, завершает процедуру тестирования и выводит на экран результаты тестирования.
procedure TForm1.RadioButton1Click(Sender: TObject);
Компонент RadioButton1 содержит один из вариантов ответа к тесту. При активации компонента становится доступной компонент Button1.
При выборе компонента RadioButton1 становится доступной кнопка Button1 (Visible = True).
procedure TForm1.RadioButton2Click(Sender: TObject);
При выборе компонента RadioButton2 становится доступной кнопка Button1 (Visible = True).
procedure TForm1.RadioButton3Click(Sender: TObject);
При выборе компонента RadioButton3 становится доступной кнопка Button1 (Visible = True).
procedure TForm1.N1Click(Sender: TObject);
При выборе пункта «Тестирование» в меню будет запущена процедура тестирования.
procedure TForm1.N2Click(Sender: TObject);
При выборе пункта «Тренировочный режим» в меню будет запущена процедура тренировочного тестирования, которая предполагает предварительный ввод пароля.
Функции программы:
function NextQw : boolean;
Функция осуществляет работу с текстовым файлом, обеспечивает вывод на экран вопросов тестирования.
3.4 Спецификация программы
В таблице 1 приведен состав проекта.
Таблица 1 – состав проекта
|
Наименование |
Обозначение |
Примечание |
|
TEST.dof |
Файл параметров проекта |
Текущие установки проекта: настройки компилятора, имена служебных каталогов, условные директивы. |
Продолжение таблицы 1
|
Наименование |
Обозначение |
Примечание |
|
TEST.dpr |
|
Связывает все файлы, из которых состоит приложение. |
|
TEST01.PAS |
|
Определяет функциональность формы |
|
TEST01.dfm |
|
Содержит список свойств всех компонентов, включенных в форму |
|
TEST01.DCU |
|
Откомпилированная версия TEST01.PAS |
|
TEST.RES |
|
Содержит пиктограммы, графические изображения |
|
TEST01.ddp |
|
Страница Диаграммы обеспечивает визуальные инструментальные средства для установки логической связи среди визуальных и не визуальных компонентов |
|
TEST.cfg |
|
Файл содержит установки конфигурации проекта. |
|
Programm.TXT |
|
Файл содержит вопросы тестирования и варианты ответа к ним. |
3.5 Тестирование программы
В своей работе программа использует базу вопросов и ответов. В данном проекте база данных с вопросами и ответами храниться в текстовом файле Programm.TXT. Программа должна найти указанный файл. Для этого в параметре командной строки необходимо указать имя выше обозначенного файла (см. рисунок 4).
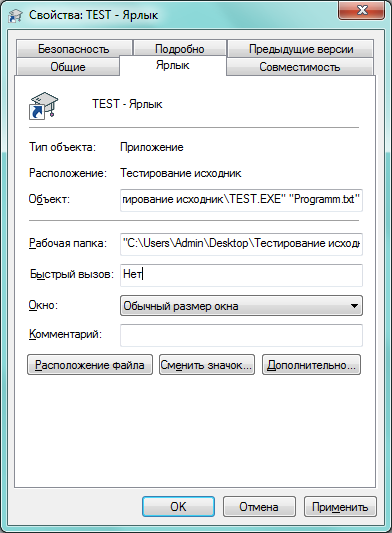
Рисунок 4 – Настройка программы
После запуска исполняемого файла перед пользователем откроется главное окно программы, представленное на рисунке 5.
Рисунок 5 – Главное окно программы
Главное окно программы содержит меню, которое включает в себя три пункта:
1. Тестирование;
2. Тренировочный режим;
3. Выход.
Первый режим предполагает запуск традиционной процедуры тестирование – в окне выводятся вопросы и варианты ответа на тестирование (см. рисунок 6).
Следующий режим – тренировочный (см. рисунок 7, 8). Для запуска тестирования в тренировочном режиме программа потребует ввод пароля. При выборе любого из доступных вариантов тестирования, другой режим становится недоступным.
На рисунке 9 скриншот окна с результатами тестирования.
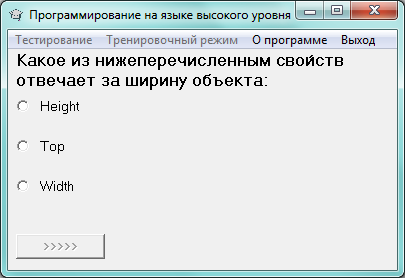
Рисунок 6 – Тестирование в обычном режиме
Рисунок 7 – Тестирование в тренировочном режиме, ввод пароля
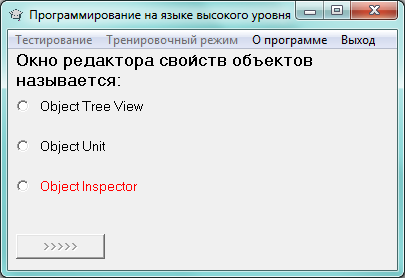
Рисунок 8 - Тестирование в тренировочном режиме
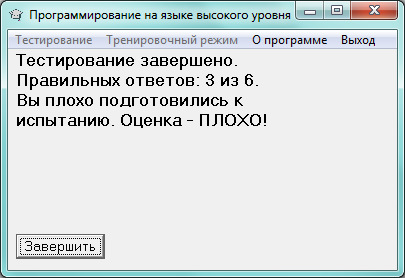
Рисунок 9 – Результаты тестирования
Рисунок 10 – Сведения о программе
Заключение
По условию задачи было расмотреть способы представления данных в информационных системах, как теоритические и практическое применение (разработать ИС). Программа подразумевает выбор правильного варианта ответа из представленных посредствам переключателя. Каждый правильный ответ приносит пользователю один балл. По окончанию тестирования, когда пользователь ответит на все вопросы, программа подсчитывает количество баллов и отображает результат тестирования с оценкой. В программе предусмотрен вариант пробного тестирования, где правильные варианты ответа выделены другим цветом. Доступ к пробному тестированию предоставляется по паролю. Вопросы и варианты ответа к тесту хранятся в отдельном текстовом файле.
Курсовая работа состоит из трех глав. В первой главе теоритические моменты по теме КР и во второй главе описание практическе применение, а также осуществлялась разработка эскизного и технического проектов программы. Для этого были произведены следующие действия: изучены назначение и область применения программы, изучены технические характеристики и постановка задачи; описан алгоритм работы создаваемой программы; описана организация входных и выходных данных; сделан и обоснован выбор состава технических и программных средств.
Во третьей главе курсовой работу осуществлялась непосредственно разработка приложения. Для этого были произведены следующие действия: сделано описание программы; описан процесс разработки приложения; дана спецификация программы; произведено тестирование программы.
Созданная программа представляет собой программу для тестирования, которая предназначена для использования в сфере образования.
Интерфейс программы представляет собой главное окно программы, в котором содержится строка меню. При выборе режима тестирования перед пользователям появляются переключатели и варианты ответа, а также кнопка для перехода к следующему вопросу/окончание тестирования.
Разработка программы осуществлялась в среде визуального программирования Delphi, которое отличается относительной простотой и богатым функционалом приобретая с каждым годом все больше и больше поклонников.
В процессе создания курсовой работы все поставленные цели были достигнуты, все поставленные задачи выполнены.
Список использованных источников
- Афонин В.Л., Моделирование систем: учебно-практическое пособие [Текст] / В.Л. Афонин - М.: Интернет-Университет Информационных Технологий (ИНТУИТ), 2016. – 232 с.
- Баженова И.Ю., Основы проектирования приложений баз данных [Текст] / И.Ю. Баженова - М.: Интернет-Университет Информационных Технологий (ИНТУИТ), 2016. – 261 с.
- Голицына О.Л., Базы данных. Учебное пособие. Гриф УМО вузов России [Текст] / О.Л. Голицына - М.: Форум, 2014. – 400 с.
- Голицына О.Л., Основы проектирования баз данных. [Текст]: Учебное пособие / О.Л. Голицына - М.: Форум, 2016. – 416 с.
- Дадян Э.Г., Методы, модели, средства хранения и обработки данных [Текст] / Э.Г. Дадян - М.: Инфра-М, 2017. – 268 с.
- Джесси Р., Проектирование баз данных [Текст] / Р. Джесси - М.: VSD, 2013. – 100 с.
- Долганова О.В., Моделирование бизнес-процессов. Учебник и практикум для академического бакалавриата [Текст] / О.В. Долганова - М.: Издательство: Юрайт, 2016. – 289 с.
- Иванова Г.С., Объектно-ориентированное программирование [Текст] / Г.С. Иванова - М.: Московский Государственный Технический Университет (МГТУ) имени Н.Э. Баумана, 2014. – 456 с.
- Илюшечкин В.М., Основы использования и проектирования баз данных. Учебник для СПО [Текст] / В.М. Илюшечкин - М.: Юрайт, 2016. – 213 с.
- Информатика для гуманитариев: учебник и практикум для академического бакалавриата [Текст] / Г.Е. Кедрова [и др.]; под ред. Г.Е. Кедровой. - М.: Издательство Юрайт, 2016. - 439 с.
- Казиев В.М., Введение в анализ, синтез и моделирование систем. Учебное пособие [Текст] / В.М. Казиев - М.: Интернет-Университет Информационных Технологий (ИНТУИТ), 2014. – 244 с.
- Кириллов В.В., Введение в реляционные базы данных. Учебник (+ CD-ROM) [Текст] / В.В. Кириллов - М.: БХВ-Петербург, 2017. – 464 с.
- Козлов В., Системный анализ, оптимизация и принятие решений. Учебное пособие [Текст] / В. Козлов - М.: Проспект, 2016. – 76 с.
- Кумскова И.А., Базы данных. Учебник. Гриф МО РФ [Текст] / И.А. Кумскова - М.: КноРус, 2016. – 400 с.
- Мовчан Д.А., InterBase и Delphi. Клиент-серверные базы данных [Текст] / Д.А. Мовчан - М.: ДМК-Пресс, 2015 г. – 536 с.
- Назаров С.В., Архитектура и проектирование программных систем [Текст] / С.В. Назаров - М.: Инфра-М, 2016. – 376 с.
- Новиков Б.В., Настройка приложений баз данных. Гриф УМО МО РФ [Текст] / Б.В. Новиков - М.: БХВ-Петербург, 2012.
- Озерова М.Е., Программирования в среде Delphi [Текст] / М.Е. Озерова - М.: Нобель Пресс, 2014. – 110 с.
- Туманов В., Основы проектирования реляционных баз данных [Текст] / В. Туманов - М.: Интернет-Университет Информационных Технологий (ИНТУИТ), 2014. – 420 с.
Приложение А
unit test01;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, Menus, ExtCtrls;
type
TForm1 = class(TForm)
Label1: TLabel;
RadioButton1: TRadioButton;
RadioButton2: TRadioButton;
RadioButton3: TRadioButton;
Label2: TLabel;
Label3: TLabel;
Label4: TLabel;
Button1: TButton;
MainMenu1: TMainMenu;
N1: TMenuItem;
N2: TMenuItem;
N4: TMenuItem;
procedure Button1Click(Sender: TObject);
procedure RadioButton1Click(Sender: TObject);
procedure RadioButton2Click(Sender: TObject);
procedure RadioButton3Click(Sender: TObject);
procedure N4Click(Sender: TObject);
procedure N1Click(Sender: TObject);
procedure N2Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
Flag: Boolean=false;
implementation
{$R *.dfm}
var
f: TextFile;
nq: integer;
right: integer;
level: array[1..4] of integer;
mes: array[1..4] of string;
buf: string;
function NextQw : boolean;
begin
if flag=true then
begin
Form1.Label2.font.color:=clblack;
Form1.Label3.font.color:=clblack;
Form1.Label4.font.color:=clblack;
end;
if not EOF(f) then
begin
Readln(f,buf);
Form1.Label1.Caption := buf;
Readln(f,buf);
Form1.Label2.Caption := buf;
Readln(f,buf);
Form1.RadioButton1.Tag := StrToInt(buf);
if (Form1.RadioButton1.Tag=1) and (flag=true) then
Form1.Label2.font.color:=clred;
Readln(f,buf);
Form1.Label3.Caption := buf;
Readln(f,buf);
Form1.RadioButton2.Tag := StrToInt(buf);
if (Form1.RadioButton2.Tag=1) and (flag=true) then
Form1.Label3.font.color:=clred;
Readln(f,buf);
Form1.Label4.Caption := buf;
Readln(f,buf);
Form1.RadioButton3.Tag := StrToInt(buf);
if (Form1.RadioButton3.Tag=1) and (flag=true) then
Form1.Label4.font.color:=clred;
nq:= nq + 1;
Form1.Button1.Enabled := False;
Form1.RadioButton1.Checked := False;
Form1.RadioButton2.Checked := False;
Form1.RadioButton3.Checked := False;
NextQw := TRUE;
end
else NextQw := FALSE;
end;
procedure TForm1.Button1Click(Sender: TObject);
var
buf: string;
i: integer;
begin
if Button1.Caption = 'Завершить' then Close;
if RadioButton1.Checked then
right := right + RadioButton1.Tag;
if RadioButton2.Checked then
right := right + RadioButton2.Tag;
if RadioButton3.Checked then
right := right + RadioButton3.Tag;
if not NextQW then
begin
Button1.Caption := 'Завершить';
RadioButton1.Visible := False;
RadioButton2.Visible := False;
RadioButton3.Visible := False;
Label2.Visible := False;
Label3.Visible := False;
Label4.Visible := False;
buf := 'Тестирование завершено.' + #13 +
'Правильных ответов: ' + IntToStr(right) +
' из ' + IntToStr(nq) + '.' + #13;
i:=1;
while (right < level[i]) and (i < 4) do
inc(i);
buf := buf + mes[i];
Label1.AutoSize := TRUE;
Label1.Caption := buf;
end;
end;
procedure TForm1.RadioButton1Click(Sender: TObject);
begin
Button1.Enabled := True;
end;
procedure TForm1.RadioButton2Click(Sender: TObject);
begin
Button1.Enabled := True;
end;
procedure TForm1.RadioButton3Click(Sender: TObject);
begin
Button1.Enabled := True;
end;
procedure TForm1.N4Click(Sender: TObject);
begin
Close;
end;
procedure TForm1.N1Click(Sender: TObject);
var
i: integer;
fname : string;
begin
{ Если программа запускается из Delphi,
то имя файла теста надо ввести в
поле Parameters диалогового окна
Run Parameters, которое становится
доступным в результате выбора в меню
Run команды Parameters.}
N1.Enabled:=false;
N2.Enabled:=false;
Label1.Visible:=true;
Label2.Visible:=true;
Label3.Visible:=true;
Label4.Visible:=true;
RadioButton1.Visible:=true;
RadioButton2.Visible:=true;
RadioButton3.Visible:=true;
Button1.Visible:=true;
fname := ParamStr(1); // взять имя файла теста
if fname = '' then
begin
ShowMessage('В командной строке запуска программы' +#13+
'надо указать имя файла теста.');
Application.Terminate; // завершить программу
end;
AssignFile(f,fname);
try
Reset(f); // эта инструкция может вызвать ошибку
except
on EInOutError do
begin
ShowMessage('Ошибка обращения к файлу теста: ' + fname);
Application.Terminate; // завершить программу
end;
end;
Readln(f,buf);
Form1.Caption := buf;
for i:=1 to 4 do
begin
Readln(f,buf);
mes[i] := buf;
Readln(f,buf);
level[i] := StrToInt(buf);
end;
right := 0;
nq := 0;
NextQW;
end;
procedure TForm1.N2Click(Sender: TObject);
var
MyPwd: string;
begin
MyPwd:=InputBox('Тест студент', 'Введите пароль','');
if MyPwd='123' then
begin
flag:=true;
N1Click(self);
end
else
showmessage('Вы ввели не правильный пароль!');
end;
end.

- Интегрированные среды разработки программ.
- Разработка регламента выполнения процесса «Управление запасами»
- Субъекты предпринимательского права
- Виндикационный и негаторный иски
- оль кадровой службы в формировании и реализации кадровой стратегии(Типы кадровой политики)
- Налоги и налоговая система: понятие и функции
- Процедуры несостоятельности (банкротства)(Теоретические и правовые аспекты понятия банкротства)
- Политика регулирования численности персонала в системе стратегического управления кадровым направлением деятельности организации.
- Корпоративная культура в организации
- Особенности политики мотивации персонала корпораций
- Ложные друзья переводчика.
- Американизмы в английском языке.