
Технологии программирования (Теоретические аспекты кодирования информации)
Содержание:

ВВДЕНИЕ
Важнейшей частью информатики как науки является теория информации, которая занимается изучением информации, ее появлением, развитием и уничтожением. К этой науке близко примыкает теория кодирования, в задачу которой входит изучение форм представления информации при ее передаче по различным каналам связи, а также при хранении и обработке.
Рассматриваемая тема в курсовой является актуальной, так как кодирование данных - одна из первых тем, раскрываемых в информатике. Вычислительная техника первоначально возникла как средство автоматизации вычислений. Следующим видом обрабатываемой информации стала текстовая. Сначала тексты просто поясняли труднообозримые столбики цифр, но затем машины все более существенным образом стали преобразовывать текстовую информацию. Оформление текстов достаточно быстро вызвали у людей стремление дополнить их графиками и рисунками. Делались попытки частично решить эти проблемы в рамках символьного подхода: вводились специальные символы для рисования таблиц и диаграммам. Но практические потребности людей в графике делали ее появление среди видов компьютерной информации неизбежной. Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи.
Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Цель работы – рассмотреть форматы данных и их способы представления кодированием в компьютере.
Для достижения цели необходимо решить следующие задачи:
1) Рассмотреть основные понятия теоретической основы кодирования информации;
2) Рассмотреть представление различных типов, данных в компьютере;
3) Описать способы кодирования информации.
Объектом изучения, представленным в теоретической части являются данные в компьютере.
Предмет изучения - основные методы кодирования информации на данный момент. Методы исследования: • теоретический анализ научной и учебно-методической литературы; •методы презентации данных: схемы, рисунки. Курсовая работа состоит из введения, двух глав, заключения и списка литературы.
1.Теоретические аспекты кодирования информации
1.1. История возникновения и использования кодирования информации
Кодировка данных:
Прежде чем рассмотреть задачу кодирования, необходимо рассмотреть ряд определений, использующихся в теории кодирования:
Код – правило, описывающее соответствие знаков или их сочетаний одного алфавита знакам или их сочетаниям другого алфавита; - знаки вторичного алфавита, используемые для представления знаков или их сочетаний первичного алфавита.
Кодирование – это процесс использования различных комбинаций уровней напряжения или тока для представления единиц и нулей цифровых сигналов в линии передачи.
Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов.
Операции кодирования и декодирования - называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Информационная энтропия - в теории связи энтропия используется как мера неопределенности ожидаемого сообщения, т.е. энтропия источника информации с независимыми сообщениями есть среднее арифметическое количеств информации сообщений
Распространенными типами кодирования линий являются униполярный, полярный, биполярный и манчестерский.
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли.
Теория кодирования — это раздел теории информации, изучающий способы отображения дискретных сообщений сигналами в виде определенных сочетаний символов.
С глубокой древности люди искали эффективные способы передачи информации:
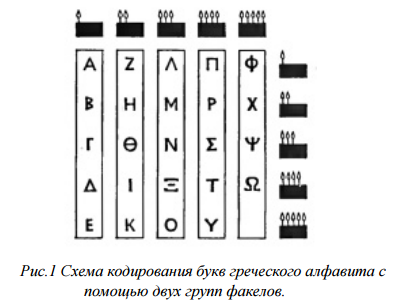
• Движение факелов использовал древнегреческий историк Полибий (II в. до н.э.};см. Рис. 1
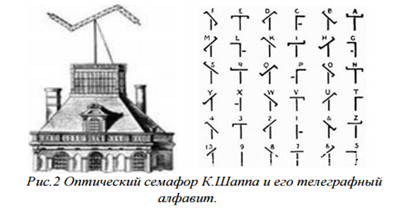
• Оптический телеграф – семафор – впервые использовал Клод Шапп в 1791 г.; см. Рис. 2
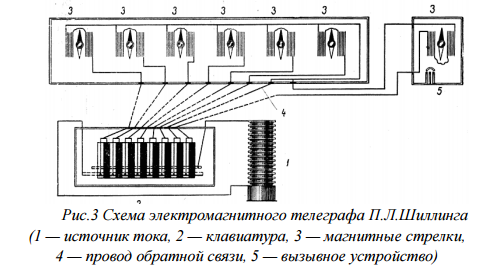
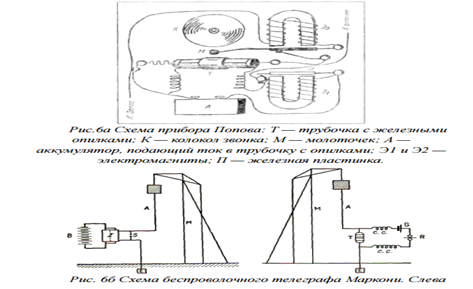
Движение электромагнитной стрелки в электромагнитных телеграфных аппаратах впервые применили русский физик П.Л.Шиллинг (1832г.) и профессора Геттингёнского университета Вебер и Гаусс (1833г.); см. Рис. 3
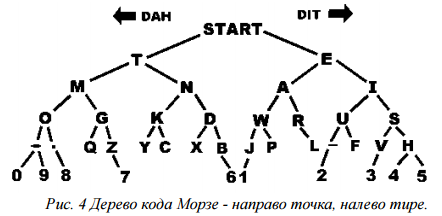
• Азбука и телеграфный аппарат Самюэла Морзе (1837); Рис.4
• Международный флажковый код для передачи информации оптическими сигналами впервые ввел капитан Фредерик Марьят в 1861г. На основе свода корабельных сигналов; Рис.5

Беспроволочный телеграф (радиопередатчик) был изобретен А.С.Поповым в 1895 г. И Маркони в 1897 г. независимо друг от друга; Рис.66
Беспроволочный телефон, телевидение (1935), затем и ЭВМ – новые средства связи, появившиеся в XX в., с которыми связана новая эпоха в информатизации общества.
Одновременно с потребностью передавать информацию люди искали способы скрыть смысл передаваемых сообщений от посторонних любопытных глаз. Императоры, торговцы, политики и шпионы искали способы шифрования своих посланий. Образцы тайнописи можно встретить еще у Геродота (V в. до н. э.). К тайнописи – криптографии прибегал Гай Юлий Цезарь, заменяя в своих тайных записях одни буквы другими. Использовали шифрование не только древнегреческие жрецы, но и ученые Средневековья: математики итальянец Джироламо Кардана и француз Франсуа Виет, нидерландский гуманист, историк, юрист Гроций, выдающийся английский философ Фрэнсис Бэкон. Отцом криптографии считается архитектор Леон Баттиста Альберти (1404-1472), который ввел шифрующие коды и многоалфавитные подстановки.
Сэр Фрэнсис Бэкон (1561 – 1626), автор двух литерного кода, доказал в 1580 г., что для передачи информации достаточно двух знаков. Также Ф.Бэкон сформулировал требования к шифру:
1. Шифр должен быть несложен, прост в работе;
2. Шифр должен быть надежен, труден для дешифровки 10 посторонним;
3. Шифр должен быть скрытен, по возможности не должен вызывать подозрений.
Шифры Бэкона – сочетание шифрованного текста с дезинформацией в виде нулей. Таким образом, двузначные коды и шифры использовались задолго до появления ЭВМ. Новый толчок развитию теории кодирования дало создание в 1948 году Клодом Эльвудом Шенноном (1916 — 2001) теории информации. Идеи, изложенные Шенноном в статье «Математическая теория связи», легли в основу современных теорий и техник обработки, передачи и хранения информации. Результаты его научных исследований способствовали развитию помехоустойчивого кодирования и простых методов декодирования сообщений.
1.2. Основные понятия кодирования данных, классификация кодов
Рассмотрим основные понятия, связанные с кодированием информации. Для передачи в канал связи сообщения преобразуются в сигналы. Символы, при помощи которых создаются сообщения, образуют первичный алфавит, при этом каждый символ характеризуется вероятностью его появления в сообщении. Каждому сообщению однозначно соответствует сигнал, представляющий определенную последовательность элементарных дискретных символов, называемых кодовыми комбинациями. Кодирование - это преобразование сообщений в сигнал, т.е. преобразование сообщений в кодовые комбинации. Код - система соответствия между элементами сообщений и кодовыми комбинациями. Кодер - устройство, осуществляющее кодирование
Декодер - устройство, осуществляющее обратную операцию, т.е. преобразование кодовой комбинации в сообщение. Алфавит - множество возможных элементов кода, т.е. элементарных символов (кодовых символов) X = {xi}, где i = 1, 2,..., m. Количество элементов кода - m называется его основанием. Для двоичного кода xi = {0, 1} и m = 2. Конечная последовательность символов данного алфавита называется кодовой комбинацией (кодовым словом). Число элементов в кодовой комбинации - n называется значностью (длиной комбинации). Число различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Если N0 - число сообщений источника, то N N0. Множество состояний кода должно покрывать множество состояний объекта. Полный равномерный n - значный код с основанием m содержит N = mn кодовых комбинаций. Такой код называется примитивным.
Классификация – это «разделение множества объектов на подмножества по их сходству или различию в соответствии с принятыми методами». Классификация фиксирует закономерные связи между классами объектов с целью определения места объекта в системе, которое указывает на его свойства. Под объектом понимается любой предмет, процесс, явление материального или нематериального свойства.
Система классификации позволяет сгруппировать объекты и выделить определенные классы, которые будут характеризоваться рядом общих свойств. Классификация объектов – та процедура группировки на качественном уровне, направленная на выделение однородных свойств.
Применительно к информации как к объекту классификации выделенные классы называют информационными объектами. С этой точки зрения классификация информации является важнейшим средством создания систем хранения и поиска информации, без которых сегодня невозможно эффективное функционирование информационного обеспечения управления.
Классификатор – систематизированный свод однородных наименований, т.е. классифицируемых объектов и их кодовых обозначений.
Классификатор (классификационная схема) – систематизированный перечень наименований объектов, каждому из которых в соответствии дан уникальный код.
Систематизация объектов производится согласно правилам распределения, заданного множества объектов на подмножества (классификационные группировки) в соответствии с установленными признаками их различия и сходства. Применяется в автоматизированных системах управления и обработки информации. Классификатор является стандартным кодовым языком документов, финансовых отчетов и автоматизированных систем.
Структура классификатора, как правило, должна иметь три блока: блок идентификации, включающий коды объектов классификации и классификационных группировок, блок наименований объектов и классификационных группировок на естественном языке и блоке дополнительных признаков объектов, включающий наименования и коды дополнительных признаков объектов классификации.
Коды можно классифицировать по различным признакам:
1. По основанию (количеству символов в алфавите): бинарные (двоичные m=2) и не бинарные (m ¹2).
2. По длине кодовых комбинаций (слов):
равномерные — если все кодовые комбинации имеют одинаковую длину;
неравномерные — если длина кодовой комбинации не постоянна.
3. По способу передачи:
последовательные и параллельные;
блочные — данные сначала помещаются в буфер, а потом передаются в канал и бинарные непрерывные.
4. По помехоустойчивости:
простые (примитивные, полные) — для передачи информации используют все возможные кодовые комбинации (без избыточности);
корректирующие (помехозащищенные) — для передачи сообщений используют не все, а только часть (разрешенных) кодовых комбинаций.
5. В зависимости от назначения и применения условно можно выделить следующие типы кодов:
Внутренние коды — это коды, используемые внутри устройств. Это машинные коды, а также коды, базирующиеся на использовании позиционных систем счисления (двоичный, десятичный, двоично-десятичный, восьмеричный, шестнадцатеричный и др.). Наиболее распространённым кодом в ЭВМ является двоичный код, который позволяет просто реализовать аппаратное устройство для хранения, обработки и передачи данных в двоичном коде. Он обеспечивает высокую надежность устройств и простоту выполнения операций над данными в двоичном коде. Двоичные данные, объединенные в группы по 4, образуют шестнадцатеричный код, который хорошо согласуется с архитектурой ЭВМ, работающей с данными кратными байту (8 бит).
Коды для обмена данными и их передачи по каналам связи. Широкое распространение в ПК получил код ASCII (American Standard Code for Information Interchange). ASCII- это 7-битный код буквенно-цифровых и других символов. Поскольку ЭВМ работают с байтами, то 8-й разряд используется для синхронизации или проверки нечётность, или расширения кода. В ЭВМ фирмы IBM используется расширенный двоично-десятичный код для обмена информацией EBCDIC (Extended Binary Coded Decimal InterchangeCode).
В каналах связи широко используется телетайпный код МККТТ (международный консультативный комитет по телефонии и телеграфии) и его модификации (МТК и др.).
При кодировании информации для передачи по каналам связи, в том числе внутри аппаратным трактам, используются коды, обеспечивающие максимальную скорость передачи информации, за счет ее сжатия и устранения избыточности (например: коды Хаффмана и Шеннона-Фано), и коды обеспечивающие достоверность передачи данных, за счет введения избыточности в передаваемые сообщения (например: групповые коды, Хэмминга, циклические и их разновидности).
Коды для специальных применений — это коды, предназначенные для решения специальных задач передачи и обработки данных. Примерами таких кодов является циклический код Грея, который широко используется в АЦП угловых и линейных перемещений. Коды Фибоначчи используются для построения быстродействующих и помехоустойчивых АЦП.
Основное внимание в курсе уделено кодам для обмена данными и их передачи по каналам связи.
ЦЕЛИ КОДИРОВАНИЯ:
1) Повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
2) Повышение помехоустойчивости при передаче данных.
В соответствии с этими целями теория кодирования развивается в двух основных направлениях:
1. Теория экономичного (эффективного, оптимального) кодирования занимается поиском кодов, позволяющих в каналах без помех повысить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи данных с пропускной способностью канала связи.
2. Теория помехоустойчивого кодирования занимается поиском кодов, повышающих достоверность передачи информации в каналах с помехами.
2. Структура и особенности способов кодирования данных в настоящее время
2.1. Основная характеристика методов кодирования
Кодирование - это процесс перевода информации, выраженной одной системой знаков, в другую систему, то есть перевод записи на естественном языке в запись с помощью кодов.
Методы кодирования технико-экономической и социальной информации тесно взаимосвязаны с методами классификации. Каждому методу классификации соответствует один или несколько методов кодирования.
В процессе кодирования объектам классификации и их группировкам по определенным правилам присваиваются цифровые, буквенные и буквенно-цифровые коды. Код характеризуется алфавитом, то есть знаками, используемыми для его образования, основанием кода - числом знаков в алфавите кода и длиной кода.
К методам кодирования ТЭСИ предъявляются определенные требования, соблюдение которых способствует повышению качества классификатора. Метод кодирования должен:
1. предусматривать использование в качестве алфавита кода десятичных цифр и букв;
2. обеспечивать по возможности минимальную длину кода и достаточный резерв незанятых позиций для кодирования новых объектов без нарушения структуры классификатора;
3. быть максимально ориентированным на автоматизированную обработку информации.
Методы кодирования могут носить самостоятельный характер - регистрационные методы кодирования, или быть основанными на предварительной классификации объектов - классификационные методы кодирования.
Регистрационные методы кодирования бывают двух видов: порядковый и серийно-порядковый.
Порядковый метод кодирования - это такой метод, при котором кодами служат числа натурального ряда. В этом случае каждый из объектов классифицируемого множества кодируется путем присвоения ему текущего порядкового номера. Данный метод кодирования обеспечивает довольно большую долговечность классификатора при незначительной избыточности кода. Этот метод обладает наибольшей простотой, использует наиболее короткие коды и лучше обеспечивает однозначность определения каждого объекта классификации. Кроме того, он обеспечивает наиболее простое присвоение кодов новым объектам, появляющимся в процессе ведения классификатора. Существенным недостатком порядкового метода кодирования является отсутствие в коде какой-либо конкретной информации о свойствах объекта, а также сложность машинной обработки информации при получении итогов по группе объектов классификации с одинаковыми признаками. Этот метод кодирования не обеспечивает возможности размещения вновь появившихся объектов классификации в необходимом месте классификатора, так как резервные коды располагаются в конце ряда. По этим причинам порядковый метод кодирования отдельно очень редко применяется при создании классификаторов ТЭСИ. Чаше всего он применяется в сочетании с другими методами кодирования.
Серийно-порядковый метод кодирования - это такой метод, при котором кодами служат числа натурального ряда с закреплением отдельных серий этих чисел (интервалов натурального ряда) за объектами классификации с одинаковыми признаками. В каждой серии, кроме кодов имеющихся объектов классификации, предусматривается определенное количество кодов для резерва. Резерв кодов располагается в середине или в конце серии. Это является большим преимуществом данного метола по сравнению с порядковым методом кодирования. Серийно-порядковый метод кодирования целесообразно применять для объектов, имеющих два соподчиненных признака. Данный метод кодирования обладает всеми преимуществами и недостатками порядкового метода кодирования. Несмотря на наличие в кодах, построенных по этому методу кодирования, определенных элементов классификации, они чаще всего используются для идентификации объектов в сочетании с классификационными методами кодирования.
Классификационные методы кодирования бывают двух видов: последовательный и параллельный.
1. Последовательный метод кодирования -это такой метод, при котором код классификационной группировки и (или) объекта классификации образуется с использованием кодов последовательно расположенных подчиненных группировок, полученных при иерархическом методе классификации. В этом случае код нижестоящей группировки образуется путем добавления, соответствующего количества разрядов к коду вышестоящей группировки. Последовательный метод кодирования чаше всего используется при иерархическом методе классификации.
Преимуществами последовательного метода кодирования являются логичность построения кода и большая емкость. Вместе с тем он обладает всеми недостатками, присущими иерархическому методу классификации, а также ограниченными возможностями идентификации объектов. Использование последовательного метода кодирования связано с определенными трудностями, обусловленными тем, что в результате зависимости значений последующих разрядов кода от предыдущих применять этот код по частям нельзя, группировать объекты по различным сочетаниям имеющихся признаков сложно, практически невозможно вносить новые признаки и производить изменения в коде без коренной перестройки классификатора. Поэтому применять последовательный метод кодирования целесообразно в тех случаях, когда набор признаков классификации и их последовательность стабильны в течение длительного времени.
Параллельный метод кодирования - это метод, при котором код классификационной группировки и (или) объекта классификации образуется с использованием кодов независимых группировок, полученных при фасетном методе классификации. При этом методе кодирования признаки объекта кодируются независимо друг от друга. Для параллельного метода кодирования возможны два варианта записи кодов объектов:
1. Каждый фасет и признак внутри фасета имеют свои коды, которые включаются в состав кода объекта. Такой способ записи удобно применять тогда, когда объекты характеризуются неодинаковым набором признаков и различным их числом. При формировании кода какого-либо объекта берутся только необходимые признаки;
2. Для определенных групп объектов выделяется фиксированный набор признаков и устанавливается стабильный порядок их следования, то есть устанавливается фасетная формула. В этом случае не надо каждый раз указывать, значение какого признака приведено в определенных разрядах кода объекта.
Параллельный метод кодирования имеет ряд преимуществ. К достоинствам рассматриваемого метода кодирования относится гибкость структуры кода, обусловленная независимостью признаков, из кодов которых строится код объекта классификации. Метод позволяет использовать при решении конкретных технико-экономических и социальных задач коды только тех признаков объектов, которые необходимы, что дает возможность работать в каждом отдельном случае с кодами небольшой длины. При этом методе кодирования можно осуществлять группировку объектов по любому сочетанию признаков. Параллельный метод кодирования хорошо приспособлен для машинной обработки информации. По конкретной кодовой комбинации легко указать, набором каких характеристик обладает рассматриваемый объект. При этом из небольшого числа признаков можно образовать большое число кодовых комбинаций. Набор признаков при необходимости может легко пополняться присоединением кода нового признака. Это свойство параллельного метода кодирования особенно важно при решении технико-экономических задач, состав которых часто меняется.
Параллельный метод кодирования целесообразно использовать для кодирования однородных объектов, так как в противном случае реальной становится лишь незначительная часть сочетаний признаков, и емкость классификатора будет использоваться не полностью. Это является недостатком данного метода кодирования. К недостаткам метода можно отнести также и другие недостатки, присущие фасетному методу классификации.
Перечисленные классификационные методы кодирования характеризуются тем, что даже при глубокой классификации объектов код несет информацию о классификационной группировке, но не всегда идентифицирует конкретный объект, а коды, полученные на основе идентификационных методов, хорошо выполняя функцию идентификации объектов, практически не несут информацию об их свойствах. Поэтому идентификационные и классификационные методы кодирования чаше всего применяются в классификаторах в сочетании друг с другом.
Одним из наиболее узких мест во всей технологии использования классификаторов информации является кодирование и ввод данных. С целью устранения этого проводятся исследования по автоматизации процесса кодирования информации. Однако для реализации автоматизированного процесса кодирования требуются большие объемы памяти, так как вначале вся информация вводится на естественном языке, и связанные с этим большие трудозатраты. Другим направлением снижения трудозатрат в процессе кодирования и ускорения этого процесса является использование штриховых (линейных) кодов.
Преимущества штриховых кодов состоят в следующем:
1. резкое снижение числа ошибок при вводе информации в виде штриховых кодов по сравнению с вводом информации с клавиатуры на естественном языке;
2. легкость считывания штриховых кодов электронными оптическими системами по сравнению с буквенно-цифровыми символами;
3. высокая экономическая эффективность применения систем на основе штриховых кодов вследствие резкого снижения стоимости ввода данных в систему.
Штриховой (линейный) код представляет собой комбинацию вертикальных полосок разной ширины и пробелов между ними. При этом за базу принимается ширина узкого элемента (полоски) кода. Широкие полоски должны быть кратными им по ширине или находиться с ними в определенных соотношениях. В основе штрихового кода лежит цифровой код.
В разных странах используются различные виды штриховых кодов. В каждом из них установлено определенное соотношение между широкими и узкими полосками и между полосками и интервалами между ними. Так, в "Коде 39" каждому знаку цифрового кода соответствует комбинация из девяти элементов (три широких полоски и шесть узких) и из них пять штрихов и четыре интервала между ними.
Разработка штриховых кодов осуществляется Международной ассоциацией по нумерации (ЕАН), коды которой являются наиболее распространенными в Европе. Наша страна с 1987 года также стала членом ЕАН. В 1988 году Госстандарт СССР утвердил РД 50-666-88 "Методические указания. Присвоение цифровых кодов товарам народного потребления". Этим документом устанавливались правила присвоения товарам народного потребления цифровых (торговых) кодов. Эти цифровые коды служат основой для штриховых кодов, наносимых на ярлыки, упаковку и этикетки товаров. Такой цифровой (торговый) код строится в полном соответствии с кодом ЕАН-13. Он состоит из тринадцати разрядов и имеет следующую структуру:
1. 2 знака - идентификатор страны-изготовителя товара;
2. 5 знаков - идентификатор фирмы-изготовителя товара;
3. 5 знаков - идентификатор товара;
4. 1 знак - контрольное число.
В этом коде, например, США и Канада имеют идентификаторы с 00 до 09, Франция - с 30 до 37, ФРГ - с 40 до 43, СНГ - 46, Япония - 49, Италия -с 80 до 83, Корея -88 и так далее.
В штриховом коде, построенном на основе ЕАН-13, каждому знаку цифрового кода соответствует комбинация из семи элементов - штрихов и пробелов между ними.
Штриховые коды могут использоваться кроме торговли также в таких областях, как медицина, банковское дело, промышленность и других. При этом в качестве цифровых кодов для них могут использоваться коды классификаторов ТЭСИ.
Использование кодов ТЭСИ требует обеспечения высокой степени достоверности кодированной информации. В классификаторах ТЭСИ для выявления ошибок в кодах используется метод контрольных чисел.
Контроль правильности записи кодов при обработке информация основан на принципе делимости чисел. Иначе его называют контролем по модулю. Суть метода заключается в том, что к коду добавляется ещё один проверочный знак - контрольное число, связанный с кодом определенной математической зависимостью. При вводе кодированной информации в базу данных, ее обработке или использовании в ЭВМ специальной программой контроля выполняется проверка этой зависимости по каждому коду. Если зависимость нарушается, машина выдает информацию о наличии ошибки в коде.
Контроль по модулю широко используется в классификаторах ТЭСИ как у нас в стране, так и за рубежом. В качестве модуля используют различные числа, но наибольшее распространение получил в настоящее время контроль по модулю 11. Для общероссийских классификаторов расчет контрольных чисел осуществляется в соответствии с методикой, разработанной ВНИИКИ". В соответствии с этой методикой контрольным числом является остаток от деления на 11 суммы произведений весов на значения разрядов кода. Весом (весовым коэффициентом) является порядковый номер разряда в коде слева направо.
Формула, по которой вычисляется контрольное число, имеет следующий вид:
КЧ=? aixi-11
где КЧ - контрольное число по модулю 11,
ai - вес i-го разряда кода,
xi - значение I -го разряда кода,
? aixi - модуль 11, т.е целая часть суммы произведений значений разрядов кода на их веса.
Методика ВНИИКИ предлагает использовать в качестве весов натуральный ряд чисел от 1 до 10. Если разрядность кода больше 10, то набор весов повторяется. При использовании данного метода остаток может получить значение от 0 до 10. Так как методика предусматривает использование одноразрядных контрольных чисел, то при получении остатка, равного 10, следует сделать повторный расчет контрольного числа со сдвигом строки весов. В этом случае весовой ряд начинается с 3 до 10, а если разрядность кода больше, то дальше веса идут с 1 до 10. В случае повторного получения контрольного числа, равного 10, в качестве контрольного числа используется 0. В случае, если сумма произведений весов на значения разрядов получается меньше 10, то эта сумма и является контрольным числом.
Использование контрольных чисел обеспечивает возможность обнаруживать и исправлять ошибки в кодированной документной информации, что повышает ее достоверность.
Как правило, при кодировании товаров используют в основном 10 –разрядный штриховой код, удобный для машинной обработки данных.
Для образования кода применяют регистрационный и классификационный порядок.
Регистрационное кодирование осуществляется порядковым номером. Это самый простой метод и кодовыми обозначениям в этом случае являются натуральные числа. Разновидностью этого метода является серийно-порядковый метод.
К классификационному методу относятся последовательный и параллельный метод кодирования. Последовательный метод применяют для объектов, разделенных по иерархическому методу. В его кодовом обозначении указываются признаки классификации. По этому методу образуются коды продукции в ОКП.
Параллельный метод применяется для объектов, разделенных по фасетному методу, при сочетании иерархического и фасетного методов. В этом случае значение каждой части кодового обозначения не зависят от других.
В современных условиях применяются много различных по типу стандартов ШК, которые можно разделить на две группы: товарные и технологические.
В данное время в мире используют несколько основных систем штрихового кодирования:
Западногерманская система BAN. Эта система введена в ФРГ в 1968 году и является усовершенствованной формой прежней идентификации. Символ кода состоит из 8 цифр: первая и вторая цифра содержат информацию о виде товара; третья – номер товарной группы; четвёртая – номер ассортиментной группы; пятая, шестая и седьмая – порядковый номер товара; восьмая – номер пробы.
ХХ Х Х ХХХ Х
Вид товара
Товарная группа
Ассортиментная группа
Порядковый номер
Номер пробы
В таком виде BAN применяется только для обозначения потребительских товаров.
Американская система UPC. Она введена в 1973 году в США и Канаде и была приспособлена к системе розничной торговли. Символ кода обозначается 12 цифрами, так как префикс стран в этой системе всегда состоит из 2-х цифр. Каждая позиция кода образуется двумя тёмными и двумя светлыми штрихами. Ширина и расстояние между этими знаками отмеряется с помощью фотоэлектронного устройства. Символ кода UPC состоит из 2-х частей – левой и правой. Каждая часть имеет форму прямоугольника. Элементы левой части представляют собой зеркальное отражение правой. Светлая полоса означает ноль, темная – единицу. Прочтение символа совершается посредством движения луча света фотоэлемента, который должен быть направлен под углом 180, чтобы охватить обе стороны символа.
Код UPC бывает 3-х видов:
- UPC – A – содержит 11 информационных и 1 контрольный знак. Предназначен для кодирования продовольственных и непродовольственных товаров, продаваемых через супермаркеты
- UPC – D – предназначен для кодирования непродовольственных товаров. Кодируется любая информация.
- UPC – E – имеет 6 знаков распространён и является половиной версией UPC – A. Применяется для кодирования товаров малыми геометрическими размерами.
Европейская система EAN. Эта система используется с 1977 года. Для её введения была основана международная европейская ассоциация кодирования товаров (JANA). Данная система представляет собой международный стандарт, в соответствии с которым осуществляется разработка технических средств для нанесения и считывания кодов обозначений. Символ кода состоит из цифровых обозначений и штрихов. Цифровые обозначения состоят из 8, либо из 13 цифр.
ХХХ ХХХХ ХХХХХ Х
Страна
Производитель
Товар
Контрольный
Индекс
Цифровое обозначение кода EAN – 13.
Последняя цифра – контрольный индекс, в коде EAN – 13.
Код EAN не классифицирует, а идентифицирует товары таким образом, что никакой другой товар не может иметь такого же кода. Его наличие позволяет потребителю определить страну-импортёра товара, его конкретный номер, предъявить при необходимости претензии к качеству товара и его безопасности.
Японская система CALRA-CODE. Эта новая система кодирования, введена в Японии в 1987 году и представляет собой графический год. Он состоит из 10 больших квадратов, каждый из которых разделён на меньшие одинаковые величины, им приписываются конкретные цифры – 1,2,4,8. Эта система более проста в применении. Она содержит большой объём информации, причем устройство для её расшифровки дешевле и эффективней при нечётном шрифте. Её можно прочитать при искажении квадрата до 1 мм. Данная система применяется только в Японии, так как не получила распространения в других странах.
Так же применяются ещё несколько систем кодирования, но они широко не используются.
2.2. Кодирование текстовой информации
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 28 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ. Все символы такого алфавита пронумерованы от 0 до 255, а каждому номеру соответствует 8-разрядный двоичный код от 00000000 до 11111111. Этот код является порядковым номером символа в двоичной системе счисления.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов.
Сейчас существует несколько различных кодовых таблиц для русских букв (КОИ-8, СР-1251, СР-866, Mac, ISO), причем тексты, созданные в одной кодировке, могут неправильно отображаться в другой. Решается такая проблема с помощью специальных программ перевода текста из одной кодировки в другую. В операционной системе Windows пришлось передвинуть русские буквы в таблице на место псевдографики, и получили кодировку Windows 1251 (Win-1251).
В течение долгого времени понятия «байт» и «символ» были почти синонимами. Однако, в конце концов, стало ясно, что 256 различных символов - это не так много. Математикам требуется использовать в формулах специальные математические знаки, переводчикам необходимо создавать тексты, где могут встретиться символы из различных алфавитов, экономистам необходимы символы валют ($, £, ¥). Для решения этой проблемы была разработана универсальная система кодирования текстовой информации - Unicode. В этой кодировке для каждого символа отводится не один, а два байта, т.е. шестнадцать бит. Таким образом, доступно 65536 (216) различных кодов. Этого хватит на латинский алфавит, кириллицу, иврит, африканские и азиатские языки, различные специализированные символы: математические, экономические, технические и многое другое. Главный недостаток Unicode состоит в том, что все тексты в этой кодировке становятся в два раза длиннее. В настоящее время стандарты ASCII и Unicode мирно сосуществуют.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Таким образом, человек различает символы по их начертанию, а компьютер - по их коду. Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице.
В настоящее время существует много различных кодовых таблиц (DOS, ISO, WINDOWS, KOI8-R, KOI8-U, UNICODE и др.), поэтому тексты, созданные в одной кодировке, могут не правильно отображаться в другой.
2.3. Кодирование числовой информации
Числовую информацию компьютер обрабатывает в двоичной системе счисления. Таким образом, числа в компьютере представлены последовательностью цифр 0 и 1, называемых битами (бит – один разряд двоичного числа). В начале 1980-х гг. процессоры для персональных компьютеров были 8-разрядными, и за один такт работы процессора компьютер мог обработать 8 бит, т.е. максимально обрабатываемое десятичное число не могло превышать 111111112 (или 25510). Последовательность из восьми бит называют байтом, т.е. 1 байт = 8 бит.
Затем разрядность процессоров росла, появились 16-, 32- и, наконец, 64-разрядные процессоры для персональных компьютеров, соответственно возросла и величина максимального числа, обрабатываемого за один такт.
Использование двоичной системы для кодирования целых и действительных чисел позволяет с помощью 8 разрядов кодировать целые числа от 0 до 255, 16 бит дает возможность закодировать более 65 тыс. значений.
В ЭВМ применяются две формы представления чисел:
• естественная форма, или форма с фиксированной запятой. В этой форме числа изображаются в виде последовательности цифр с постоянным для всех чисел положением запятой, отделяющей целую часть от дробной, например +00456,78800; +00000,00786; -0786,34287. Эта форма неудобна для вычислений и применяется только как вспомогательная для целых чисел;
• нормальная форма, или форма с плавающей точкой. В этой форме число выражается с помощью мантиссы и порядка как N = ±Μ • Р±r, где Μ – мантисса числа (|M| < 1), r – порядок числа (целое число), Р – основание системы счисления. Приведенные выше числа в нормальной форме будут представлены как +0,456788 • 103, +0,786 • 102, -0,3078634287 • 105.
Нормальная форма представления обеспечивает большой диапазон отображения чисел и является основной в современных ЭВМ. Все числа с плавающей запятой хранятся в ЭВМ в нормализованном виде. Нормализованным называют такое число, старший разряд мантиссы которого больше нуля.
В памяти ЭВМ для хранения чисел предусмотрены форматы: слово – длиной 4 байта, полуслово – 2 байта, двойное слово – 8 байт.
Разрядная сетка для чисел с плавающей запятой имеет следующую структуру: • нулевой разряд – это знак числа;
• с 1-го по 7-й разряд – записывается порядок в двоичном коде;
• с 8-го по 31-й – указывается мантисса.
2.4. Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек.
Давайте посмотрим на экран компьютера через увеличительное стекло. В зависимости от марки и модели техники мы увидим либо множество разноцветных прямоугольников, либо множество разноцветных кружочков.
И те, и другие группируются по три штуки, причем одного цвета, но разных оттенков. Они называются пикселями (от английского PICture's ELement).
Пиксели бывают только трех цветов - зеленого, синего и красного. Другие цвета образовываются при помощи смешения цветов. Рассмотрим самый простой случай - каждый кусочек пикселя может либо гореть , либо не гореть. Тогда мы получаем следующий набор цветов: Из трех цветов можно получить восемь комбинаций.
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцати цветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно. Число цветов, воспроизводимых на экране монитора (N), и число бит, отводимых в видеопамяти на каждый пиксель, связаны формулой:
Величину I называют битовой глубиной или глубиной цвета. Чем больше битов используется, тем больше оттенков цветов можно получить.
Итак, любое графическое изображение на экране можно закодировать c помощью чисел, сообщив, сколько в каждом пикселе долей красного, сколько - зеленого, а сколько - синего цветов. Также графическая информация может быть представлена в виде векторного изображения.
Векторное изображение представляет собой графический объект, состоящий из элементарных отрезков и дуг. Положение этих элементарных объектов определяется координатами точек и длиной радиуса. Для каждой линии указывается ее тип (сплошная, пунктирная, штрих-пунктирная), толщина и цвет.
Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами. Качество изображения определяется разрешающей способностью монитора, т.е. количеством точек, из которых оно складывается. Чем больше разрешающая способность, т.е. чем больше количество строк растра и точек в строке, тем выше качество изображение.
2.4. Кодирование звуковой информации
Из физики известно, что звук – это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), то видно плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой – аналоговый – сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел. Делается это, например, так – измеряется напряжение через равные промежутки времени и полученные значения записываются в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его – аналого-цифровым преобразователем (АЦП).
Чтобы воспроизвести закодированный таким образом звук, нужно сделать обратное преобразование (для этого служит цифро-аналоговый преобразователь – ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук, но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Важными параметрами дискретизации являются частота и разрядность.
Разрядность указывает, с какой точностью происходят изменения амплитуды аналогового сигнала. Точность, с которой при оцифровке передается значение амплитуды сигнала в каждый из моментов времени, определяет качество сигнала после цифро-аналогового преобразования. Именно от разрядности зависит достоверность восстановления формы волны.
Для кодирования значения амплитуды используют принцип двоичного кодирования. Звуковой сигнал должен быть представленным в виде последовательности электрических импульсов (двоичных нулей и единиц). Обычно используют 8, 16-битное или 20-битное представление значений амплитуды. При двоичном кодировании непрерывного звукового сигнала его заменяют последовательностью дискретных уровней сигнала.
Частота - количество измерений амплитуды аналогового сигнала в секунду.
В новом формате компакт-дисков Audio DVD за одну секунду сигнал измеряется 96 000 раз, т.е. применяют частоту дискретизации 96 кГц. Для экономии места на жестком диске в мультимедийных приложениях довольно часто применяют меньшие частоты: 11, 22, 32 кГц. Это приводит к уменьшению слышимого диапазона частот, а, значит, происходит сильное искажение того, что слышно.
От частоты дискретизации (количества измерений уровня сигнала в единицу времени) зависит качество кодирования. С увеличением частоты дискретизации увеличивается точность двоичного представления информации. При частоте 8 кГц (количество измерений в секунду 8000) качество оцифрованного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц (количество измерений в секунду 48000) - качеству звучания аудио- CD.
В современных преобразователях принято использовать 20-битное кодирование сигнала, что позволяет получать высококачественную оцифровку звука.
Вспомним формулу К = 2a . Здесь К - количество всевозможных звуков (количество различных уровней сигнала или состояний), которые можно получить при помощи кодирования звука а битами
Недостаточно для достоверного восстановления исходного сигнала, так как будут большие нелинейные искажения. Применяют в основном в мультимедийных приложениях, где не требуется высокое качество звука
Используется при записи компакт-дисков, так как нелинейные искажения сводятся к минимуму.
Где требуется высококачественная оцифровка звука.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Издавна используется довольно компактный способ представления музыки – нотная запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Есть и другие, чисто компьютерные, форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18–20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200.
Одна песня занимает, примерно, 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
2.5. Кодирование графической информации.
Графический формат — это способ записи графической информации. Графические форматы файлов предназначены для хранения изображений, таких как фотографии и рисунки.
Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части - растровую и векторную графику.
Для представления графической информации растровым способом используется так называемый точечный подход. На первом этапе вертикальными и горизонтальными линиями делят изображение. Чем больше при этом получилось элементов (пикселей), тем точнее будет передана информация об изображении.
Как известно из физики, любой цвет может быть представлен в виде суммы различной яркости красного, зеленого и синего цветов. Поэтому надо закодировать информацию о яркости каждого из трех цветов для отображения каждого пикселя. В видеопамяти находится двоичная информация об изображении, выводимом на экран.
Таким образом, растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. picture element), а код пикселя содержит информацию о его цвете.
Для черно-белого изображения (без полутонов) пиксель может принимать только два значения: белый и черный (светится - не светится), а для его кодирования достаточно одного бита памяти: 1 - белый, 0 - черный.
Пиксель на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксель недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 - черный, 10 - зеленый, 01 - красный, 11 - коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов: красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций (Таблица 1):
Основные комбинации цвета
|
Цвет |
R |
G |
B |
|
Черный |
0 |
0 |
0 |
|
Синий |
0 |
0 |
1 |
|
Зеленый |
0 |
1 |
0 |
|
Голубой |
0 |
1 |
1 |
|
Красный |
1 |
0 |
0 |
|
Пурпурный |
1 |
0 |
1 |
|
Желтый |
1 |
1 |
0 |
|
Белый |
1 |
1 |
1 |
Качество кодирования изображения зависит от двух параметров.
Во-первых, качество кодирования изображения тем выше, чем меньше размер точки и соответственно большее количество точек составляет изображение.
Во-вторых, чем большее количество цветов, то есть большее количество возможных состояний точки изображения, используется, тем более качественно кодируется изображение (каждая точка несет большее количество информации). Совокупность используемых в наборе цветов образует палитру цветов.
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые в свою очередь содержат определенное количество точек (пикселей). Качество изображения определяется разрешающей способностью монитора, т.е. количеством точек, из которых оно складывается. Чем больше разрешающая способность, тем выше качество изображения.
Цветные изображения формируются в соответствии с двоичным кодом цвета каждой точки, хранящимся в видеопамяти. Цветные изображения могут иметь различную глубину цвета, которая задается количеством битов, используемым для кодирования цвета точки.
В противоположность растровой графике векторное изображение состоит из геометрических примитивов: линия, прямоугольник, окружность и т.д. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов. Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
3. Способы представления кодов
В зависимости от применяемых методов кодирования, используют различные математические модели кодов, при этом наиболее часто применяется представление кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д.
3.1 Матричное представление кодов
Используется для представления равномерных n — значных кодов. Для примитивного (полного и равномерного) кода матрица содержит n — столбцов и 2n — строк, т.е. код использует все сочетания. Для помехоустойчивых (корректирующих, обнаруживающих и исправляющих ошибки) матрица содержит n — столбцов (n = k+m, где k-число информационных, а m — число проверочных разрядов) и 2k — строк (где 2k — число разрешенных кодовых комбинаций). При больших значениях n и k матрица будет слишком громоздкой, при этом код записывается в сокращенном виде. Матричное представление кодов используется, например, в линейных групповых кодах, кодах Хэмминга и т.д.
3.2 Представление кодов в виде кодовых деревьев
Кодовое дерево — связной граф, не содержащий циклов. Связной граф — граф, в котором для любой пары вершин существует путь, соединяющий эти вершины. Граф состоит из узлов (вершин) и ребер (ветвей), соединяющих узлы, расположенные на разных уровнях. Для построения дерева равномерного двоичного кода выбирают вершину называемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
Пример кодового дерева для полного кода приведен на рис.1.
/>
1 0
1 0 1 0
1 0 1 0 1 0 1 0
111 110 101 100 011 010 001 000
Рис.1. Дерево для полного двоичного кода при n = 3
Дерево помехоустойчивого кода строится на основе дерева полного кода путем вычеркивания запрещенных кодовых комбинаций. Для дерева неравномерного кода используется взвешенный граф, при этом на ребрах дерева указываются вероятность переходов. Представление кода в виде кодового дерева используется, например, в кодах Хаффмена.
3.3 Представление кодов в виде многочленов
Представление кодов в виде полиномов основано на подобии (изоморфизме)пространства двоичных n — последовательностей и пространства полиномов степени не выше n — 1.
Код для любой системы счисления с основанием Х может быть представлен в виде:
G (x) = an-1 xn-1+ an-2xn-2+… + a1 x+ a0 =/>,
где аi — цифры данной системы счисления (в двоичной 0 и 1);
х — символическая (фиктивная) переменная, показатель степени которой соответствует номерам разрядов двоичного числа-
Например,: Кодовая комбинация 1010110 может быть представлена в виде:
G (x) =1×x6+0×x5+1×x4+0×x3+1×x2+1×x1+0×x0=x6+x4+x2+x=10101
При этом операции над кодами эквивалентны операциям над многочленами. Представление кодов в виде полиномов используется, например, в циклических кодах.
3.4 Геометрическое представление кодов
Любая комбинация n — разрядного двоичного кода может быть представлена как вершина n — мерного единичного куба, т.е. куба с длиной ребра равной 1. Для двухэлементного кода (n = 2) кодовые комбинации располагаются в вершинах квадрата. Для трехэлементного кода
(n = 3) — в вершинах единичного куба (рис.2).
В общем случае n мерный куб имеет 2n вершин, что соответствует набору кодовых комбинаций 2n.
/>
n = 2 n = 3
Рис.2. Геометрическая модель двоичного кода
Геометрическая интерпретация кодового расстояния. Кодовое расстояние — минимальное число ребер, которое необходимо пройти, чтобы попасть из одной кодовой комбинации в другую. Кодовое расстояние характеризует помехоустойчивость кода.
ЗАКЛЮЧЕНИЕ
В данной работе рассмотрены основные моменты по «Методике изучения кодирования информации» и приведены некоторые методические особенности. Тема «Кодирование информации» в различных учебных пособиях освещена по-разному, но несмотря на это, в данной курсовой работе удалось представить необходимый минимум учебного материала, который подлежит обязательному рассмотрению.
Далее приведено подтверждение целесообразности такого выбора в соответствии с образовательным стандартом и требованиями к знаниям учащихся, заключенными в нем. Тема «Кодирование информации» обладает большим развивающим потенциалом, так как в ходе ее изучения происходит обобщение знаний, развитие целостной системы знаний за счет введения новых обобщающих понятий.
За недолгое время компьютер из вычислительного устройства превратился в устройство для обработки многих видов информации: текстовой, графической, звуковой. С помощью компьютера информация упаковывается и шифруется, путешествует по различным каналам связи и может быть доставлена в любой уголок мира. Современный человек уже не представляет свою деятельность без применения компьютера. Как информация может быть представлена в компьютере, как она передается по каналам связи - ответы на все эти вопросы мы получаем после изучения темы "Кодирование информации".
Сведения об информации, языках как способах представления информации, о кодировании информации без компьютера, о двоичном кодировании, о системах счисления, о кодировании информации в компьютере - все эти вопросы должны входить в содержание Федерального компонента образовательного стандарта школьного курса информатики.
Цель данной работы достигнута: я познакомилась со всеми кодировочными таблицами, которые существуют для русскоязычной раскладки клавиатуры. Выяснила, что текст, набранный в одной кодировке, не может быть прочитан с помощью другой кодировки. Узнала различные способы кодирования различных видов информации: текстовой, числовой, звуковой и т.д.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1)Агеев В.М. Теория информации и кодирования: дискретизация и
кодирование измерительной информации. — М.: МАИ, 1977.
2)Агальцов В.П., Титов В.М. Информатика для экономистов: Учебник. - М.: ИД «ФОРУМ»: ИНФРА-М, 2014. - 448 с.
3)Баричев С.Г., Гончаров В.В., Серов Р.Е. Основы современной криптографии. – М.: Горячая линия. Телеком, 2015. – 120с.
4)Баранова, Е.К. Основы информатики и защиты информации: Учебное пособие / Е.К. Баранова. - М.: Риор, 2016. - 199 c.
5)Березюк Н.Т., Андрущенко А.Г., Мощицкий С.С. и др. Кодирование информации (двоичные коды). / Под ред. Н.Т. Березюка. – Харьков: Вища школа, 1978. – 252 с.
6)Балдин, К.В. Информатика для ВУЗов: Учебник / К.В. Балдин, В.Б. Уткин. - М.: Дашков и К, 2016. - 395 c.
7)Балдин, К.В. Информатика и информационные системы в экономике: Учебное пособие / К.В. Балдин. - М.: НИЦ ИНФРА-М, 2016. - 218 c.
8)Васильев К.К. Методы обработки сигналов: Учебное пособие. – Ульяновск: УлГТУ, 2014. – 80с.
9)Давлетов, З.Х. Основы современной информатики: Учебное пособие / З.Х. Давлетов. - СПб.: Лань КПТ, 2016. - 256 c.
10)Жаров, М.В. Основы информатики: Учебное пособие / М.В. Жаров, А.Р. Палтиевич, А.В. Соколов. - М.: Форум, 2017. - 512 c.
11) Забуга, А.А. Теоретические основы информатики: Учебное пособие / А.А. Забуга. - СПб.: Питер, 2015. - 80 c
12)Рябко Б.Я., Фионов А.Н. Эффективный метод адаптивного арифметического кодирования для источников с большими алфавитами // Проблемы передачи информации. - 2009. - Т.35, Вып. - С.95 - 108.
13)Трусов, Б.Г. Информатика и программирование: Основы информатики: Учебник / Б.Г. Трусов. - М.: Academia, 2017. - 158 c.
14)Чепурнова, Н.М. Правовые основы информатики: Учебное пособие / Н.М. Чепурнова, Л.Л. Ефимова. - М.: Юнити, 2015. - 295 c.
15)Электронный источник «Кодирование информации», дата обращения 08.08.2019 год. http://sch10ptz.ru/projects/002/inf/1.7.htm
16)[Электронный ресурс]. Электрон. дан. Режим доступа: http://www.school.edu.ru/dok_edu.asp?ob_no=21917
17)[Электронный ресурс] Костомаров М.Н. Классификация и кодирование документов и документной информации // https://mykonspekts.ru/2-22893.html
18) )[Электронный ресурс]. Электрон. дан. Режим доступа: https://infourok.ru/kursovaya-rabota-na-temu-teoriya-grafov-v-reshenii-shkolnih-zadachproblemi-kodirovaniya-informacii-3369457.html
19) )[Электронный ресурс] Электрон. дан. Режим доступа: http://infoprotect.net/protect_network/kodirovanie_dannyih#2
20) )[Электронный ресурс] Электрон. дан. Режим доступа: https://allbest.ru/otherreferats/programming/00011629_0.html

- Основные функции в системе менеджмента ( Теоретические аспекты функций менеджмента)
- Понятие и признаки государства (место и роль государства в политической системе общества.)
- Аппарат государственной власти ( ТЕОРЕТИЧЕСКИЕ ОСНОВЫ АППАРАТА ОРГАНОВ ГОСУДАРСТВЕННОЙ ВЛАСТИ)
- Особенности управления мужчинами и женщинами (Женщина-руководитель)
- Теории интеллекта: подходы и современный взгляд
- Технологии программирования. Методы кодирования данных
- Карьера госслужащего
- Органы местного самоуправления (Содержание понятия «местное самоуправление» и сущность органов местного самоуправления)
- Интернет-маркетинговые решения по ведению туристического бизнеса.
- PR в системе Интегрированных коммуникации
- УСТРОЙСТВО ПЕРСОНАЛЬНОГО КОМПЬЮТЕРА ( Функционально-структурная организация)
- Финансовая политика и ее реализация в Российской Федерации(Сущность и содержание финансовой политики)