
Технология клиент-сервер
Содержание:

ВВЕДЕНИЕ
Распределенные операционные системы используются для управления аппаратным обеспечением взаимосвязанных компьютерных систем, к которым относятся мультипроцессорные и мультикомпьютерные системы.
Распределенные системы представляют множество автономных компьютеров, которые работают совместно в виде единой масштабируемой системы. Размер распределенной системы ограничивается размером базовой сети. Подобная организация взаимодействующих компьютеров упрощает интеграцию разных работающих приложений.
Сетевые операционные системы успешно объединяют компьютеры, работающие под управлением своих операционных систем, что позволяет пользователям получать доступ к общим сетевым службам. Однако сетевые операционные системы не создают ощущения работы с единой системой, в отличие от распределенных систем.
Распределенные системы обычно поверх сетевой операционной системы предлагают дополнительный промежуточный уровень программного обеспечения, который скрывает распределенную природу отдельных компьютеров. Распределенные системы обычно требуют специфическую модель распределения и связи, которая может основываться на удаленном вызове процедур, а также на распределенных файлах или объектах.
Для распределенной системы крайне важна схема внутренней организации. Распространена модель, в которой процессы клиента запрашивают службы сервера. Клиент посылает сообщение серверу и ждет его ответ. Службы в такой модели реализуются в виде процедур отдельных модулей, обеспечивающих уровень интерфейса пользователя, уровень обработки данных и уровень данных. Серверная часть обычно отвечает за уровень данных. Клиентская часть обычно отвечает за уровень графического пользовательского интерфейса. Уровень обработки может быть реализован как на клиенте, так и на сервере, либо поделен между клиентом и сервером. В крупномасштабных распределенных системах вертикальной организации приложений по модели клиент-сервер недостаточно. Требуется распределение по горизонтали, т.е. клиенты и серверы физически распределены и реплицируются на несколько компьютеров. Примером успешного горизонтального распределения является всемирная паутина (www, world wide web).
Объект: распределенные системы обработки данных.
Предмет: клиент-сервер.
Цель: выполнить построение и анализ программной модели клиент-серверного приложения общего назначения.
Задачи:
1. Анализ аппаратных и программных компонентов распределенных систем, взаимодействия процессов клиента и сервера.
2. Сравнение сетевой модели OSI с уровнями стека протоколов TCP/IP.
3. Рассмотрение вариантов организации архитектуры клиент-сервер
4. Составление программной модели клиента и сервера.
1. Распределенные системы обработки информации
1.1 Аппаратно-программные компоненты системы
Использование технологий распределенной обработки данных стало актуально для высокотехнологичных географически удаленных компаний. Идея распределенной обработки в том, что пользователь получает возможность работать с данными и программами, расположенными в нескольких взаимосвязанных оконечных системах.
Современная распределенная вычислительная система основывается на комплексе аппаратных и программных компонентов, который может быть описан многослойной архитектурой: сервера и рабочие станции, сетевое оборудование, сетевые операционные системы, сетевые приложения.
1. Компьютеры. В основе сети лежит аппаратный слой стандартизированных компьютерных платформ, серверов, рабочих станций и персональных компьютеров от персональных до супер-ЭВМ и кластерных систем. Термин «сервер» может трактоваться в двух значениях: «выделенный» или приспособленный для тех или иных сетевых сервисных функций компьютер, либо специализированное программное обеспечение, которое принимает и обрабатывает задачи пользователей. Особенностью обоих вариантов является то, что и аппаратное устройство, и программное обеспечение адаптированы для решения определенных сетевых запросов без прямого вмешательства человека. Это свойство отличает физический сервер от, например, рабочей станции, которая подразумевает присутствие оператора. Другими словами, рабочая станция – это «невыделенным сервером», когда некоторые сервисные задачи могут выполняться на ней параллельно с работой пользователя. Серверы находят самые нестандартные применения, их можно встретить в центрах управления полетами, магазинах, на автозаправках, электрических подстанциях и в офисах телефонных компаний, при этом также используются и сетевые устройства других типов, такие как сетевые хранилища данных и т.д. [10].
2. Коммуникационное оборудование. Второй слой модели сети как основы распределенной системы – коммуникационное оборудование: кабельные системы, повторители, коммутаторы, маршрутизаторы и т.д. При любом типе соединения, как только компьютеров становится больше двух, возникает проблема выбора конфигурации физических связей или топологии сети [9].
Рабочая станция
Рабочая станция
Рабочая станция
Рисунок 1 – Топология «звезда» вычислительной (компьютерной) сети
Коммутатор уровня ядра
Рабочая станция
Коммутатор
Сервер
Рабочая станция
Рабочая станция
Коммутатор
Сервер
Рабочая станция
Рисунок 2 – Топология «дерево» вычислительной (компьютерной) сети
Число конфигураций возрастает при увеличении числа связываемых устройств. Под топологией сети понимается способ соединения ее отдельных компонентов (компьютеров, серверов, принтеров и т.д.). При использовании топологии типа звезда информация между клиентами сети передается через единый центральный узел (сервер, концентратор или хаб), коммутатор или свитч).
Основание дерева вычислительной сети (корень) располагается в точке, в которой собираются коммуникационные линии информации (ветви дерева). Вычислительные сети с древовидной структурой применяются там, где невозможно непосредственное применение базовых сетевых структур в чистом виде. Для подключения большого числа рабочих станций соответственно адаптерным платам применяют коммутаторы.
На практике зачастую применяется комбинированная древовидная структура, которая образуется в виде комбинаций других топологий.
3. Операционные системы. Третьим слоем, образующим платформу сети, являются сложные программы – операционные системы. При проектировании сети важно учитывать то, как выбранная операционная система может взаимодействовать с другими сетевыми системами, какой уровень информационной безопасности она обеспечивает, как масштабируется число пользователей. На сервер устанавливается серверная операционная система, которая, в отличие от обычной операционной системы, обладает некоторыми преимуществами, например поддержкой нескольких процессоров, большего объема оперативной памяти, инструментами администрирования сети и т.д. К серверным операционным системам относятся Windows Server 2008, Windows Server 2016, Windows Server Small Business, Linux Server OpenSuSe и т.д. [9].
4. Сетевые приложения. Верхний, четвертый слой вычислительной системы образуют сетевые приложения – базы данных, средства передачи данных, системы коллективной работы и т.д. Важно представлять их функциональные возможности для различных областей и степень совместимости друг с другом и операционными системами. [1].
Многослойная архитектура в виде аппаратно-программных компонентов распределенной системы дает общее представление о ее устройстве.
1.2 Сетевая модель OSI и стек протоколов TCP/IP
В соответствии с эталонной семиуровневой моделью взаимодействия открытых систем OSI ISO (Open System Interconnection) в сетях коммутации пакетов для передачи данных между несмежными компьютерными системами создается сетевая платформа, образуемая физическими средствами соединения, физическим, канальным и сетевым уровнями.
Уровни модели OSI и соответствующие ее уровням уровни стека протоколов TCP/IP представлены на рисунке. Протокол TCP разбивает поток данных на «сегменты», которые передаются по физическим линиям связи [8].
|
Уровни модели OSI |
Уровни стека TCP/IP |
Протоколы TCP/IP |
Представление пакета |
|
Прикладной |
Прикладной |
HTTP, FTP, SMTP |
Поток байтов приложения |
|
Представления |
|||
|
Сеансовый |
|||
|
Транспортный |
Транспортный |
TCP, UDP |
Сегмент TCP (заголовок и данные) |
|
Сетевой |
Межсетевого взаимодействия |
IP, ICMP, ARP, RIP |
Дейтаграмма IP |
|
Канальный |
Сетевых интерфейсов (доступа) |
Ethernet, FDDI, PPP |
Сетевой пакет |
|
Физический |
Рисунок 3 – Уровни модели OSI (примеры протоколов и представление данных в соответствии с уровнями стека протоколов TCP/IP)
Каждый из уровней модели ISO/OSI выполняет свои функции:
1. Физический – передача и прием электрических сигналов.
2. Канальный – управление каналом связи и доступом к среде передачи данных.
3. Сетевой – определение оптимальных маршрутов передачи данных.
4. Транспортный – контроль целостности и правильности данных в процессе передачи и приема данных.
5. Сеансовый – создание, сопровождение и поддержание сеанса связи.
6. Уровень представления – кодирование и шифрование данных с помощью требуемых алгоритмов.
7. Прикладной – взаимодействие с клиентскими программами.
Сетевая модель OSI и стек протоколов TCP/IP выступают в качестве платформы взаимодействия клиентов и серверов в распределенных системах.
1.3 Взаимодействие процессов клиента и сервера
Процессы распределенных систем делятся на две группы. Серверы – процессы, реализующие некоторую службу, например, службу файловой системы или базы данных. Клиенты – процессы, запрашивающие службы у серверов путем посылки запроса и последующего ожидания ответа от сервера.
Взаимодействие клиента и сервера обозначают как режим работы типа «запрос-ответ».
Клиент
Сервер
Запрос
Ответ
Служба провайдера
Ожидание результата
Время
Рисунок 4 – Обобщенное взаимодействие между клиентом и сервером
Если базовая сеть надежна, то взаимодействие между клиентом и сервером может быть реализовано посредством простого протокола, не требующего установления соединения. Клиент, запрашивая службу, представляет запрос в форме сообщения с указанием службы, которой он желает воспользоваться, и необходимых для этого исходных данных. Сообщение передается серверу. Сервер постоянно ожидает входящего сообщения, получив его, обрабатывает, упаковывает результат в ответное сообщение и отправляет его клиенту. Использование простого протокола дает выигрыш в эффективности.
Пока сообщения не начнут пропадать или повреждаться можно успешно применять протокол типа запрос-ответ. Создать протокол, устойчивый к случайным сбоям связи – сложная задача. Единственное, что возможно сделать – предоставить возможность клиенту повторно отправить запрос, на который не был получен ответ. Проблема в том, что клиент не может определить, действительно ли сообщение было потеряно или произошла ошибка произошла при передаче ответа. Если ответ потерян, повторная отправка запроса требует повторного выполнения операции на сервере, которая требует вычислительных затрат. У этой проблемы нет одного решения.
В качестве альтернативы в клиент-серверных системах используется надежный протокол с установкой соединения. Решение в связи с низкой производительностью не слишком хорошо подходит для локальных сетей, но отлично работает в глобальных системах, для которых отсутствие надежности характерная черта сетевых соединений. Практически все прикладные протоколы Интернет основаны на надежных соединениях по протоколу TCP/IP (transmission control protocol/internet protocol). Когда клиент запрашивает службу, до посылки запроса серверу он должен установить с ним соединение. Сервер обычно использует для посылки ответа то же самое соединение, после чего оно разрывается. Проблема в том, что установка и разрыв соединения ресурсоемкие операции, особенно если сообщения с запросом и ответом невелики. Альтернативные решения объединяют операции управления соединением и передачи данных.
Понятие клиента, запрашивающего службы сервера, помогает понять сложность распределенных систем и управлять ей [16].
1.4 Варианты архитектуры клиент-серверных приложений
Архитектура «клиент-сервер» определяет модель взаимодействия компьютеров в вычислительной сети. Обычно один компьютер (сервер) располагает информационно-вычислительными и аппаратными ресурсами, такими как накопители данных, процессоры, базы данных и различные сервисы. Другие компьютеры (клиенты) пользуются этими ресурсами.
Конкретный сервер характеризуется видом ресурса, которым он владеет или ролью. Если ресурсом являются базы данных, то говорят, что сервер выполняет роль сервера баз данных. Если ресурс накопитель информации, то говорят о файловом сервере. Если ресурс – обработка электронной почты, то говорят о почтовом сервере.
Ключевой принцип технологии «клиент-сервер» состоит в разделении функций приложения на три группы или логические компоненты:
1. Компонент ввода и представления данных.
2. Прикладной компонент, поддерживающий функции, необходимые для выполнения действий предметной области.
3. Компонент доступа к информационным ресурсам или менеджер ресурсов, поддерживающий глобальные функции хранения и управления данными.
Различия в реализации приложений в рамках технологии «клиент-сервер» определяются тем, какие механизмы используются для реализации функций всех трех групп и как логические компоненты распределяются между компьютерами в сети.
Выделяются три подхода или модели реализации технологии «клиент-сервер» в приложениях: доступ к удаленным данным, сервер баз данных, сервер приложений [6].
1. Доступа к удаленным данным (RDA, remote data access). Реализация представления данных и прикладного компонента совмещены и выполнятся на компьютере-клиенте, который поддерживает функции ввода и отображения данных, так и чисто прикладные функции.
Доступ к ресурсам может выполняться с помощью языка запросов типа SQL (в случае баз данных) или вызовами функций специальных библиотек (в случае наличия интерфейса API). Запросы направляются по сети удаленному компьютеру, который работает с запросами и возвращает клиенту ответ.
КЛИЕНТ
СЕРВЕР
Компонент представления
Прикладной компонент
Компонент доступа к ресурсам
Ресурс
Запрос
Ответ
Рисунок 5 – Архитектура приложений «клиент-сервер» (модель толстого клиента для доступа к данным, RDA)
Говоря о таком виде архитектуры «клиент-сервер» обычно имеют модель, называемую «толстым клиентом».
2. Сервера базы данных (DBS, database server). Процесс, выполняемый на компьютере-клиенте, ограничивается функциями представления, а собственно прикладные функции реализованы в хранимых (резидентных) процедурах базы данных.
КЛИЕНТ
СЕРВЕР
Компонент представления
Компонент доступа к БД
БД
Вызов
Ответ
Прикладной компонент SQL
Рисунок 6 – Архитектура приложений «клиент-сервер» (модель системы для доступа к данным и сервисам, DBS)
Процедуры находятся непосредственно в базе данных и выполняются на компьютере-сервере, где функционирует ядро системы. В этом случае понятие ресурса сужено до конкретной базы данных. На практике часто используются смешанные модели, когда некоторые функции поддерживаются процедурами, а часть сложных функций реализуются в прикладной программе компьютера-клиента.
3. Сервера приложений (Application Server, AS).
Процесс компьютера-клиента обычно выполняет функции ввода и вывода данных. Прикладные функции выполняются группой процессов (серверов приложений), функционирующих на удаленном компьютере. Доступ к ресурсам, необходимым для решения прикладных задач, выполняется, как и в модели RDA. Из прикладных компонентов доступны ресурсы типа баз данных, файлы, очереди и т.д. Серверы приложений обычно выполняются на компьютере, где функционирует менеджер ресурсов.
КЛИЕНТ
СЕРВЕР
Компонент представления
Вызов
Ответ
Прикладной компонент SQL
СЕРВЕР
Вызов
Ответ
Доступ к ресурсам
БД
Рисунок 7 – Архитектура приложений «клиент-сервер» (модель системы сервера приложений, AS)
Модель «клиент-сервер», когда подавляющее большинство прикладных программ и сервисов расположено на стороне сервера, называется «тонким клиентом».
Модели RDA и DBS модели реализуют двухзвенную схему разделения функций, а модель сервера приложений AS реализует классическую трехзвенную схему разделения функций, когда прикладной компонент выделен как важнейший.
Для передачи данных используются различные способы, например, выделенный канал (наибольшая безопасность и надежность передачи данных, система взаимодействует с одним партнером) или ячеистая сеть (система взаимодействует с несколькими партнерами).
Клиент-серверный принцип применим и к взаимодействию программных процессов, а не только к узлам сети. Если один из процессов выполняет функции, предоставляя набор услуг, то такой процесс именуют сервером. Технология «клиент-сервер» дает представление о том, как должна быть организована современная распределенная информационная система. В каждом конкретном случае технологическое решение должно основываться на конкретных предметных областях и соответствующих прикладных платформах [2].
2. Организация и распределение клиентов и серверов
2.1 Типовые варианты организации архитектуры клиент-сервер
Простейшая физическая организация на компьютерах приложений в модели клиент-сервер предполагает наличие двух типов машин:
1. Клиентские машины, на которых имеются программы, реализующие только пользовательский интерфейс или его часть.
2. Серверы, реализующие все остальное, т.е. уровни обработки и данных.
Проблема подобной организации в том, что система не является распределенной: все происходит на сервере, а клиент представляет собой не что иное, как терминал.
Существует также множество других вариантов в распределенных системах, например, многозвенные архитектуры. Один из подходов к организации клиентов и серверов – это распределение программ, находящихся на уровне приложений по различным машинам [17].
Рассмотрим разделение на два типа машин: на клиенты и на серверы, что приведет нас к физически двухзвенной архитектуре. Один из возможных вариантов организации – поместить на клиентскую сторону только терминальную часть пользовательского интерфейса (вариант а), позволив приложению удаленно контролировать представление данных.
Альтернативой будет передача клиенту всей работы с пользовательским интерфейсом (вариант б). В обоих случаях происходит отделение от приложения графически внешнего интерфейса, связанный с остальной частью приложения на сервере посредством специфичного протокола. В модели интерфейс делает только то, что необходимо для предоставления интерфейса приложения.
Разработчика также могут перенести во внешний интерфейс часть приложения (вариант в). Примером может быть вариант, когда приложение создает форму непосредственно перед ее заполнением. Внешний интерфейс затем проверяет правильность и полноту заполнения формы и при необходимости взаимодействует с пользователем. Другим примером организации системы по образцу, представленному в варианте в, может служить текстовый процессор, в котором базовые функции редактирования осуществляются на стороне клиента с локально кэшируемыми или находящимися в памяти данными, а специальная обработка, т.к. проверка орфографии или грамматики, выполняется на стороне сервера.
|
КЛИЕНТСКАЯ МАШИНА |
||||
|
Пользовательский интерфейс |
Пользовательский интерфейс |
Пользовательский интерфейс |
Пользовательский интерфейс |
Пользовательский интерфейс |
|
Приложение |
Приложение |
Приложение |
||
|
Пользовательский интерфейс |
База данных |
|||
|
Приложение |
Приложение |
Приложение |
||
|
База данных |
База данных |
База данных |
База данных |
База данных |
|
СЕРВЕРНАЯ МАШИНА |
||||
|
Вариант а |
Вариант б |
Вариант в |
Вариант г |
Вариант д |
Рисунок 8 – Варианты организации архитектуры клиент-сервер
Во многих системах клиент-сервер популярна организация, представленная в варианте г. Эти типы организации применяются в том случае, когда клиентская машина соединена сетью с распределенной файловой системой или базой данных. Большая часть приложения работает на клиентской машине, а все операции с файлами или базой данных передаются на сервер.
Вариант д отражает ситуацию, когда часть данных содержится на локальном диске клиента, например, при работе в Интернет клиент может постепенно создать на локальном диске кэш наиболее часто просматриваемых веб-сайтов.
Следует отметить, что иногда серверу требуется работать в качестве клиента, т.е. обращаться к услугам другого сервера предоставляя собственные сервисы. Такая ситуация приводит к физически трехзвенной архитектуре. Программы, составляющие часть уровня обработки, выносятся на отдельный сервер, но дополнительно могут частично находиться и на машинах клиентов и серверов. Типичный пример – обработка транзакций.
2.2 Современные варианты организации архитектуры клиент-сервер
В современных архитектурах распределение на клиенты и серверы происходит способами, известными как вертикальное и горизонтальное распределение.
Особенностью вертикального распределения является то, что оно достигается размещением логически различных компонентов на разных машинах. Понятие связано с концепцией вертикального разбиения в распределенных реляционных базах данных, где под термином понимается разбиение по столбцам таблиц для их хранения на различных машинах. Вертикальное распределение – один из способов организации приложений клиент-сервер.
При горизонтальном распределении сервер может содержать физически разделенные части логически однородного модуля, причем работа с каждой из частей может происходить независимо. Это делается для выравнивания загрузки. В качестве примера горизонтального распределения можно рассмотреть веб-сервер, реплицированный на несколько машин локальной сети [20].
На каждом из серверов содержится один и тот же набор веб-страниц, и всякий раз, когда одна из страниц обновляется, ее копии незамедлительно рассылаются на все серверы. Сервер, которому будет передан приходящий запрос, выбирается по циклическому алгоритму (англоязычный термин round-robin). Форма горизонтального распределения весьма успешно используется для выравнивания нагрузки на серверы популярных веб-сайтов. Таким образом могут быть распределены и клиенты. Для несложного приложения, предназначенного для коллективной работы сервера вообще могут отсутствовать. В этом случае говорят об одноранговом распределении (англоязычный термин peer-to-peer). Например, пользователь хочет связаться с другим пользователем, оба должны запустить одно приложение, чтобы начать сеанс. Третий клиент может общаться с одним из них или обоими, для чего ему нужно запустить аналогичную программу.
ИНТЕРНЕТ
Линии связи
Очередь запросов к веб-серверу
Встреча и обработка входящих запросов
Запросы, обрабатываемые по принципу карусели (циклический алгоритм round robin)
Реплицированные веб-серверы, каждый из которых содержит одни и те же веб-страницы
Рисунок 9 – Пример горизонтального распределения служб веб-сервера
В практике можно встретить множество других вариантов организации распределенных систем, в частности существуют системы, распределенные одновременно и по вертикали, и по горизонтали.
2.3 Разделение клиент-серверных приложений на уровни
Одина из главных проблем клиент-серверной модели связана с точным разделением приложения на части. Обычно четкого различия нет, т.е. сервер распределенной базы данных может постоянно выступать клиентом, передающим запросы на различные файловые серверы, отвечающие за реализацию таблиц конкретной базы данных. В этом случае сервер баз данных выполняет только функции обработки запросов. Однако рассматривая множество приложений типа клиент-сервер, предназначенных для организации совместного доступа пользователей к базам данных рекомендуется разделять их на три уровня:
1. Уровень пользовательского интерфейса. Обычно реализуется на клиентах, включает программы и содержит функционал, необходимый для непосредственного взаимодействия пользователя с приложением. Сложность программ, входящих в пользовательский интерфейс различна. Простейший вариант интерфейса поддерживает символьный (консольный) вариант. Обычно на клиентских машинах имеется графический интерфейс с меню и множеством управляющих элементов, поддерживающих работу с мышью и клавиатурой. Современные интерфейсы значительно функциональны.
2. Уровень обработки. Уровень обычно содержит приложения. Исходя из этого многие приложения модели клиент-сервер построены из трех частей: части, которая занимается взаимодействием с пользователем, части, которая отвечает за работу с базой данных или файловой системой, и части, реализующей основной функционал. Последняя часть логически располагается на промежуточном уровне обработки. На уровне обработки трудно выделить общие закономерности.
В качестве примера выделения уровня обработки в клиент-серверном приложении можно рассмотреть поисковую машину сети Интернет.
Интерфейс поисковой системы достаточно прост: пользователь вводит строку, состоящую из ключевых слов, и получает страницу результатов поиска со списком заголовков веб-страниц. Результат формируется из огромной базы просмотренных и проиндексированных страниц. Ядром поисковой машины является программа, трансформирующая введенную пользователем строку в один или несколько запросов к базе данных. Затем система помещает результаты запроса в список и преобразует этот список в набор веб-страниц. В рамках модели клиент-сервер часть, которая отвечает за выборку информации, обычно находится на уровне обработки.
3. Уровень данных. Уровень в модели клиент-сервер обычно содержит собственно данные, с которыми происходит работа, а точнее приложения, обрабатывающие эти данные.
Ключевым свойством уровня данных является требование сохранности. Требование сохранности означает, что если приложение не работает, данные должны сохраняться в определенном месте в расчете на дальнейшее использование. В простейшем варианте уровень данных реализуется файловой системой, но чаще для его реализации задействуется база данных.
|
Пользовательский интерфейс |
УРОВЕНЬ ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА |
|||
|
Выражение с ключевыми словами (поисковый запрос пользователя) |
HTML-страница результатов поиска поисковой системы (список заголовков сайтов) |
УРОВЕНЬ ОБРАБОТКИ ДАННЫХ |
||
|
Генератор (фильтр) запросов к базе данных |
Генератор HTML-страниц |
Упорядоченный список заголовков страниц |
||
|
Запросы к базе данных |
Компонент упорядочивания (ранжирования) списков веб-страниц |
|||
|
Заголовки веб-страниц с метаинформацией |
||||
|
База данных проиндексированных веб-страниц поисковой системы |
УРОВЕНЬ ДАННЫХ |
|||
Рисунок 10 – Трехуровневая организация клиент-серверного приложения на примере поисковой системы
В модели клиент-сервер уровень данных обычно находится на стороне сервера. Кроме простого хранения данных уровень обычно отвечает за поддержание целостности хранимых данных для различных приложений. Уровень данных зачастую организуется в форме реляционной базы данных. Ключевым здесь является независимость данных. Данные организуются независимо от приложений так, чтобы изменения в организации данных не влияли на приложения, а приложения не оказывали влияния на организацию данных. Использование реляционных баз данных в модели клиент-сервер помогает отделить уровень обработки от уровня данных, но существует обширный класс приложений, для которых реляционные базы данных не являются лучшим выбором. Примерами таких приложений могут служить те, которые работают со сложными типами данных, т.е. данные которые проще моделировать в понятиях объектов, а не отношений. Примеры сложных типов могут служить простые наборы прямоугольников и проекты самолетов в случае систем автоматизированного проектирования. Мультимедиа системам значительно проще работать с видео- и аудиопотоками, используя специфичные для них операции, чем с моделями этих потоков в виде реляционных таблиц. В случае, когда операции с данными проще выразить в понятиях работы с объектами, имеет смысл реализовать уровень данных средствами объектно-ориентированных баз данных. Таким образом, часть функциональных возможностей, которые приходились на уровень обработки переходят в таком случае на уровень данных [17].
3. Программная модель клиента и сервера
3.1 Исходный код определений клиента и сервера
В качестве упрощенного примера рассмотрим описание клиента и файлового сервера на языке Си. Клиент и сервер должны совместно использовать определения, включаемые в тексты программ клиента и сервера директивой #include <header.h>, которые собраны в файле под названием header.h [4], [5].
Файл header.h, используемый клиентом и сервером.
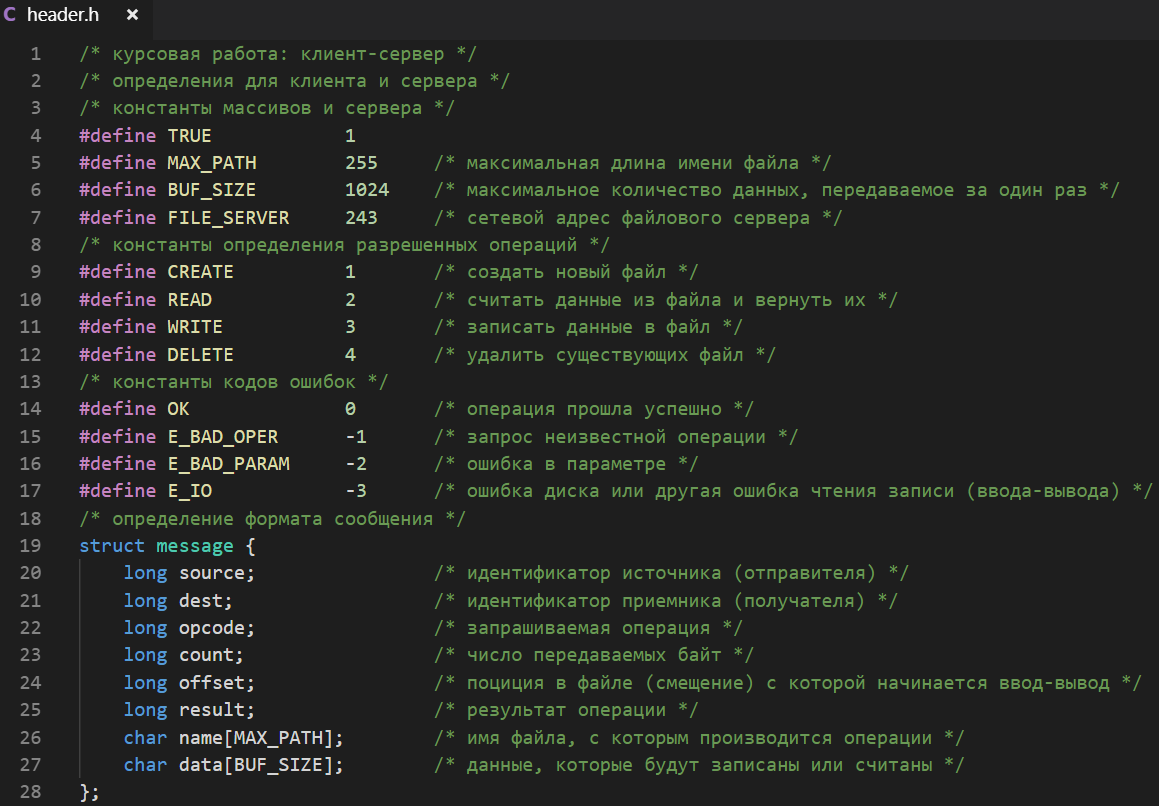
Рисунок 11 – Упрощенный исходный код файла определений header.h
Константы МАХ_РАТН и BUF_SIZE определяют размер двух массивов, используемых в сообщении. Константа MAX_PATH определяет число символов, которое может содержаться в имени файла, т.е. в строке с путем типа /home/user/documents/kursovaya.t. Константа BUF_SIZE задает размер блока данных, который может быть прочитан или записан за одну операцию путем установки размера буфера.
Константа FILE_SERVER задает сетевой адрес файлового сервера, на который клиенты могут посылать сообщения.
Вторая группа констант задает номера операций, которые необходимы для того, чтобы клиент и сервер знали, какой код представляет чтение, запись и т.д. Каждый ответ содержит код результата. Если операция завершена успешно, код результата обычно содержит полезную информацию, например, реальное число считанных байт. Если нет необходимости возвращать значение (например, при создании файла), используется значение ОК. Если операция завершилась ошибкой, код результата E_BAD_OPER, E_BAD_PARAM, E_IO сообщает причину.
Важная часть – определения формата сообщения. В примере это структура с восемью полями. Формат используется во всех запросах клиентов к серверу и ответах сервера клиенту. Поля source и dest определяют отправителя и получателя. Поле opcode – одна из ранее определенных операций: создание, чтение, запись или удаление. Поля count и offset служат для передачи параметров. Поле result в запросах от клиента к серверу не используется, а при ответах сервера клиенту содержит значение результата. В конце структуры два массива. Массив name содержит имя файла к которому клиент обращается. Массив data содержит данные, возвращаемые сервером при чтении или передаваемые на сервер при записи.
3.2 Исходный код сервера
Программа сервера содержит основной цикл, который начинается вызовом receive в ответ на сообщение с запросом. Первый параметр определяет отправителя запроса – его адрес, а второй указывает на буфер сообщений, идентифицируя, где должно быть сохранено пришедшее сообщение. Процедура receive блокирует сервер, пока не будет получено сообщение. Когда сообщение приходит, сервер продолжает работу и определяет тип кода операции. Для каждого кода операции вызывается своя процедура. Входящее сообщение и буфер для исходящих сообщений заданы в параметрах. Процедура проверяет входящее сообщение в параметре m1 и строит исходящее в параметре m2. Процедура возвращает значение функции, которое передается через поле result. После посылки ответа сервер возвращается к началу цикла, выполняет вызов receive и ожидает следующего сообщения.
/* курсовая работа: клиент-сервер */
/* код сервера */
#include <header.h>
void main(void) {
struct message m1, m2; /* входящее и исходящее сообщения */
int r; /* код результата */
while (TRUE) { /* сервер работает непрерывно */
receive(FILE_SERVER, &m1); /* блок ожидания сообщения */
switch(mi.opcode) { /* в зависимости от типа запроса */
case CREATE: r = do_create(&m1, &m2); break;
case READ: r = do_read(&m1, &m2); break;
case WRITE: r = do_write(&m1, &m2); break;
case DELETE: r = do_delete(&m1, &m2); break;
default: r = E_BAD_OPER;
}
m2.result = r; /* вернуть результат клиенту */
send(mi.source, &m2); /* послать ответ */
}
}
Рисунок 12 – Упрощенный исходный код файлового сервера
3.3 Исходный код клиента
Программа клиента реализует копирование файлов с использованием сервера. Тело процедуры содержит цикл чтения блока из исходного файла и записи его в файл-приемник. Цикл повторяется до тех пор, пока исходный файл не будет полностью скопирован, что определяется по коду возврата операции чтения – должен быть ноль или отрицательное число [17].
Первая часть цикла состоит из создания сообщения для операции чтения и пересылки его на сервер.
После получения ответа запускается вторая часть цикла, в ходе выполнения которой полученные данные посылаются обратно на сервер для записи в файл-приемник.
/* курсовая работа: клиент-сервер */
/* код клиента */
#include <header.h>
/* процедура копирования файла через сервер */
int copy(char *src, char *dst) {
struct message m1; /* буфер сообщения */
long position; /* текущая позиция в файле */
long client = 110; /* адрес клиента */
initialize(); /* инициализация, подготовка к выполнению */
position = 0; /* инициализация начального значения позиции */
/* начало цикла с постусловием (тело цикла выполняется минимум один раз) */
do {
m1.opcode = READ; /* операция чтения */
m1.offset = position; /* текущая позиция в файле */
m1.count = BUF_SIZE; /* сколько байт прочитать */
strcpy(&m1, name, src); /* скопировать имя читаемого файла */
send(FILE_SERVER, &m1); /* послать сообщение на файловый сервер */
receive(client, &m1); /* блок ожидания ответа */
m1.opcode = WRITE; /* записать полученные данные в файл-приемник, операция записи */
m1.offset = position; /* текущая позиция в файле */
m1.count = m1.result; /* сколько байт записать */
strcpy(&m1, name, clst); /* скопировать имя записываемого файла */
send(FILE_SERVER, &m1); /* послать сообщение на файловый сервер */
receive(client, &m1); /* блок ожидания ответа */
position += m1.result; /* в m1.result содержится количество записанных байт */
} while(m1.result > 0); /* повторять до окончания */
/* вернуть OK или код ошибки */
return(m1.result >= 0 ? OK : m1.result);
}
Рисунок 13 – Упрощенный исходный код клиента, который использует файловый сервер для копирования файлов
В коде отсутствуют детали, такие как отсутствие кода процедур do_xxxх, которые выполняют работу, отсутствует обработка ошибок.
ЗАКЛЮЧЕНИЕ
Взаимодействие происходит между процессами и мы рассмотрели роль различных типов процессов в распределенных системах. Концепция процесса появилась в операционных системах. Для однопользовательских операционных систем наиболее важными вопросами являются управление процессами и их планирование. При переходе к распределенным системам появляются другие важные вопросы, например, эффективная организация клиент-серверных систем с многопоточными технологиями. Хотя процессы являются строительными блоками распределенных систем, практика показывает, что дробления на процессы, предоставляемого операционными системами, на базе которых строятся распределенные системы, недостаточно. Вместо этого оказывается, что наличие более тонкого дробления в форме нескольких потоков выполнения. Основной вклад потоков выполнения в работе распределенных систем заключается в том, что они позволяют создавать клиенты и серверы так, что взаимодействие и локальная обработка выполняются параллельно.
Модель клиент-сервер крайне важна для распределенных систем. В работе рассмотрены основные типы организации клиентов и серверов, вопросы построения серверов. Серьезной проблемой, особенно в глобальных системах, является перенос процессов между различными машинами.
Чтобы добиться высокой степени прозрачности распределения, распределенные системы, работающие в глобальных сетях, могут нуждаться в маскировке больших задержек сообщений, курсирующих между процессами. Цикл задержки в глобальных сетях легко может достигать порядка сотен миллисекунд, а временами и секунд. Традиционный способ скрыть задержки связи – инициировав взаимодействие, немедленно перейти к другой работе. Типичным примером применения этой методики являются браузеры. Во многих случаях веб-документ, содержащийся в файле формата HTML, содержит, кроме текста, набор изображений, видео, код CSS и JavaScript и т.п. Для получения элементов веб-страницы браузер открывает соединение TCP/IP, читает поступающие данные и преобразует их в компоненты визуального представления. Установка соединения, как и чтение данных, представляет собой блокирующие операции. При работе с медленными коммуникациями ощущаются неудобства. Браузер обычно сначала получает страницу HTML-кода, а затем показывает ее. Для того чтобы по возможности скрыть задержки связи, некоторые браузеры начинают показывать данные по мере их получения. Когда текст с механизмами прокрутки становится доступным пользователю, браузер продолжает получение остальных файлов, необходимых для правильного отображения страницы, таких как картинки. По мере поступления они отображаются на экране. Таким образом, для того чтобы увидеть страницу, пользователь не должен дожидаться получения всех ее компонентов. В результате видно, что браузер выполняет несколько задач одновременно.
При получении основного файла HTML, активизируются отдельные потоки выполнения, отвечающие за дозагрузку других частей страницы. Каждый из потоков выполнения создает отдельное соединение с сервером и получает от него данные. Установление соединения и чтение данных с сервера может быть запрограммировано с использованием стандартных (блокирующих) системных вызовов. Это предполагает, что блокирующие вызовы не в состоянии приостановить основной процесс.
Использование многопоточных браузеров, которые в состоянии открывать несколько соединений с одним сервером, дает также и другой выигрыш. Если этот сервер сильно загружен или медленный, то пользователю практически не удастся добиться повышения производительности по сравнению с последовательным получением файлов. Однако во многих случаях веб-серверы могут быть реплицированы на несколько машин, при этом каждый из серверов будет содержать одинаковый набор документов. При поступлении запроса на веб-страницу запрос передается одному из серверов, обычно с использованием алгоритма циклического обслуживания или другого алгоритма выравнивания нагрузки.
Практика показывает, что многопоточность не только существенно упрощает код сервера, но и делает гораздо проще разработку тех серверов, в которых для достижения высокой производительности требуется параллельное выполнение нескольких приложений. В число таковых входят и мультипроцессорные системы. Даже сейчас, когда мультипроцессорные компьютеры активно выпускаются в виде рабочих станций общего назначения, использование для параллельной обработки многопоточности не потеряло своей актуальности. Чтобы ощутить достоинства потоков выполнения для написания кода серверов в работе была рассмотрена организация файлового сервера, который периодически оказывается блокированным ожиданием. Файловый сервер обычно ожидает входящего запроса на операции с файлами, после чего обрабатывает полученный запрос и возвращает ответ.
После проверки запроса сервер выбирает (то есть блокирует) находящийся в состоянии ожидания рабочий поток выполнения и передает запрос ему.
Возможна организация распределенных приложений в понятиях клиентов и серверов. Клиентский процесс обычно реализует пользовательский интерфейс, который может варьироваться от простого вывода информации до расширенных интерфейсов, способных поддерживать составные документы. Клиентское программное обеспечение, кроме того, способно поддерживать прозрачность рас деления, скрывая детали, касающиеся связи с серверами, текущего местоположения серверов и репликации серверов. Кроме того, программное обеспечение клиента способно частично скрыть возникающие сбои и процессы восстановления после сбоев. Серверы часто сложнее клиентов, но тем не менее при их построении применяется относительно немного архитектурных моделей. Так, например, серверы могут быть итеративными или параллельными, реализовывать одну или несколько служб, сохранять информацию о состоянии или не сохранять. Остальные архитектурные особенности касаются адресации служб и механизмов прерывания серверов после прихода запроса на обслуживание и возможно в ходе его выполнения.
Текущая практика показывает, что, возможно, лучшим средством справиться с гетерогенностью являются виртуальные машины, которые эффективно скрывают гетерогенность с помощью интерпретируемого кода.
Результатом выполнения работы стала программная модель клиент-серверного приложения общего назначения на языке Си. В ходе работы проведен анализ аппаратных и программных компонентов распределенных систем (серверов и рабочих станций, сетевого оборудования, операционных систем и сетевых приложений), взаимодействия процессов клиента и сервера по схеме «запрос-ответ». Приведено сравнение сетевой модели OSI с уровнями стека протоколов TCP/IP, а именно соответствие семи уровней модели OSI с четырьмя уровнями стека протоколов TCP/IP. Рассмотрены варианты организации архитектуры клиент-сервер: в частности, горизонтальное и вертикальное распределения (пример циклического обслуживания клиентов веб-сервера). Таким образом тщательно рассмотрены понятия сервера и клиента, характеристики технологии клиент-сервер, варианты архитектуры, что соответствует выбранной теме курсовой работы.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Бройдо В.Л. Вычислительные системы, сети и телекоммуникации. – СПб.:Питер. 2011. – 560с.
- Васильев Р., Стратегическое управление информационными системами, Тираж, 2017, 512с.
- Глазырина, И. Б. Введение в программирование [Электронный ресурс] : рабочий учебник / И. Б. Глазырина. – 2011. – www.lib.muh.ru.
- Глазырина, И. Б. Модульное программирование [Электронный ресурс] : рабочий учебник / И. Б. Глазырина. – 2011. – www.lib.muh.ru.
- Калинин, Е. И. Основы операционных систем [Электронный ресурс] : рабочий учебник / Е. И. Калинин. – 2010. – www.lib.muh.ru.
- Кандаурова Н., Вычислительные системы, сети и телекоммуникации, Флинта, 2016, 415с.
- Кузин А.В. Компьютерные сети. – М.: Форум-Инфра-М. 2011. – 192 с.
- Куроуз Д., Компьютерные сети. Нисходящий подход, Эксмо, 2016, 912с.
- Линн С., Администрирование Microsoft Windows Server 2012. – СПб.: Питер, 2014. – 304 с.: ил. – (Серия «Бестселлеры O’Reilly»).
- Олифер В., Олифер Н., Компьютерные сети. Принципы, технологии, протоколы, 5-е издание. – СПб.: Питер, 2016, 992с.
- Олифер В., Олифер Н. Сетевые операционные системы. – СПб.: Питер, 2009. – 669с.
- Рыбальченко М., Архитектура информационных систем, Юрайт, 2016, 92с.
- Сервер информационных технологий, www.citforum.ru.
- Сообщество в индустрии высоких технологий, www.habrahabr.ru.
- Смирнова Е.В. Построение коммутируемых компьютерных сетей: учебное пособие. – СПб.: Питер. 2012. – 237с.
- Таненбаум Э., Компьютерные сети, 5-е издание. – СПб.: Питер, 2016, 960с.
- Таненбаум Э., Распределенные системы. Принципы и парадигмы. – СПб.: Питер. 2003. – 877с.
- Шаньгин В.Ф. Информационная безопасность и защита информации: Учебное пособие / В.Ф. Шаньгин. – ил. – (Профессиональное образование). 2017.
- Шевченко, П. Н. Управление процессами [Электронный ресурс] : рабочий учебник / П. Н. Шевченко. – 2011. – www.lib.muh.ru.
- Чекмарев Ю., Вычислительные системы, сети и телекоммуникации, ДМК Пресс, 2016, 312с.
- Электронный журнал «Информатика и системы управления», www.ics.khstu.ru.

- Основы программирования на языке HTML. Алгоритм практической работы
- Сущность мотивации персонала и основные теории мотивации
- Анализ системы мотивации и стимулирования персонала в ООО «Янковая и К»
- Модель клиент-сервер (Определение сервера и клиента)
- Применение объектно-ориентированного подхода при проектировании информационной системы(Сущность объектно-ориентированного программирования)
- .Сущность и виды юридического позитивизма
- .Концепции государственного аппарата в управлении государством
- Современные политические режимы (Политический режим)
- Основные функции в системе менеджмента (Понятие менеджмента, состав основных категорий)
- Экономическое содержание и сущность механизмов принятия решения о выборе услуги
- Грамматическая функция суффиксальной морфемы.
- Классификация стилей руководства