
Технология "клиент-сервер"
Содержание:

Введение
Актуальность выполнения данной работы обусловлена тем, что характерной чертой нашего времени являются интенсивно развивающиеся процессы информатизации практически во всех сферах человеческой деятельности. Они привели к формированию новой инфраструктуры, которая связана с новым типом общественных отношений, с новой реальностью, с совершенно новыми информационными технологиями различных видов деятельности.
Информационные технологии становятся важнейшим инструментом научно-технического и социально-экономического развития общества, играя существенную роль в ускорении процессов получения, распространения и последующего использования новых знаний. Влияя на качество интеллектуальных ресурсов социума, информационные технологии повышают уровень и качество самой жизни человека.
Информационно-коммуникационные технологии включают в свой состав специализированные характеристики следующих понятий: система; информационная система; автоматизированная система. Определение перечисленных понятий позволяет более точно подобрать необходимые компоненты информационно-коммуникационной составляющей человеческой жизнедеятельности.
Несмотря на кажущуюся простоту процесса автоматизации, не так-то легко можно получить эффективное программное решение, кроме того, определенные трудности представляет постоянное изменение комплекса требований предъявляемых к учету обрабатываемой оперативной информации, постоянно увеличивающаяся потребность в быстро адаптируемых к новым изменчивым условиям прикладных программных комплексах. Автоматизация по средствам практического использования прототипного программирования позволяет получить многофункциональный продукт за достаточно короткое время.
Объект исследования – интернет-технологии.
Предмет исследования – технология «клиент-сервер»
Целью данной работы является изучение технологии «клиент-сервер».
В соответствии с целью была определена необходимость постановки и решения следующих задач:
– дать понятие технологии «клиент-сервер»;
– описать модели взаимодействия «клиент-сервер»;
– описать архитектуру «клиент-сервер»;
– дать характеристику современным технологиям «клиент-сервер»;
– описать практику использования технологий «клиент-сервер».
Глава 1. Технология «клиент-сервер»
1.1. Описание технологии «клиент-сервер»
«Клиент–сервер» (англ. client–server) представляет собой вычислительную или сетевую архитектуру, в которой задания или сетевая нагрузка распределяется между активными поставщиками услуг, которые называются серверами, и заказчиками услуг, называемыми клиентами. Фактически клиент и сервер представляет собой прикладное программное обеспечение. Обычно эти прикладные программы располагаются на разных вычислительных машинах и взаимодействуют между собой по средствам использования средств вычислительной сети с использованием сетевых протоколов, но в тоже время они могут быть расположены также и на одной машине [3].
Программы-серверы ожидают от клиентских прикладных программ запросы и предоставляют им свои вычислительные ресурсы в виде некоторых данных или в виде сервисных функций. В связи с тем, что одна программа-сервер может выполнять запросы от нескольких прикладных программ-клиентов, её размещают на специально выделенной вычислительной машине, которая настраивается особым образом, как правило, совместно с другими прикладными программами-серверами, поэтому производительность такой машины должна быть достаточно высокой [14].
Из-за особой роли такой машины в вычислительной сети, специфики её оборудования и прикладного программного обеспечения, её также называют сервером, а машины, которые выполняют клиентские прикладные программы, соответственно, клиентами [7].
Клиент и сервер взаимодействую друг с другом в сети Интернет или в любой другой компьютерной сети при помощи различных сетевых протоколов, например, IP протокол, HTTP протокол, FTP и другие. Протоколов на самом деле очень много и каждый протокол позволяет оказывать ту или иную услугу.
Например, при помощи HTTP протокола браузер отправляет специальное HTTP сообщение, в котором указано какую информацию и в каком виде он хочет получить от сервера, сервер, получив такое сообщение, отсылает браузеру в ответ похожее по структуре сообщение (или несколько сообщений), в котором содержится нужная информация, обычно это HTML документ [1].
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier) в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы, но ими могут быть логические объекты или что-то абстрактное. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. (в частности, для этого используется HTTP-заголовок). Именно благодаря возможности указания способа кодирования сообщения, клиент и сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
HTTP – протокол прикладного уровня; аналогичными ему являются FTP и SMTP. Обмен сообщениями идёт по обыкновенной схеме «запрос-ответ». Для идентификации ресурсов HTTP использует глобальные URI. В отличие от многих других протоколов, HTTP не сохраняет своего состояния [10]. Это означает отсутствие сохранения промежуточного состояния между парами «запрос-ответ». Компоненты, использующие HTTP, могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами (например, «куки» на стороне клиента, «сессии» на стороне сервера). Браузер, посылающий запросы, может отслеживать задержки ответов. Сервер может хранить IP-адреса и заголовки запросов последних клиентов. Однако сам протокол не осведомлён о предыдущих запросах и ответах, в нём не предусмотрена внутренняя поддержка состояния, к нему не предъявляются такие требования.
Многие сетевые протоколы построены на архитектуре клиент-сервер, поэтому в их основе обычно лежат одинаковые или схожие принципы взаимодействия, а разницу можно увидеть лишь в деталях, которые обусловлены особенностями и спецификой области, для которой разрабатывался тот или иной сетевой протокол [5].
Архитектура клиент-сервер определяет лишь общие принципы взаимодействия между компьютерами, детали взаимодействия определяют различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что нужно. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
1.2. Двухзвенная архитектура
В любой сети (даже одноранговой), построенной на современных сетевых технологиях, присутствуют элементы клиент-серверного взаимодействия, чаще всего на основе двухзвенной архитектуры. Двухзвенной (two-tier, 2-tier) она называется из-за необходимости распределения трех базовых компонентов между двумя узлами (клиентом и сервером) [19].
Двухзвенная архитектура используется в клиент-серверных системах, где вычислительный сервер отвечает на клиентские запросы напрямую и в полном объеме, при этом используя только собственные вычислительные ресурсы [2].
Т.е. сервер не вызывает сторонние сетевые прикладные программные приложения и не обращается к сторонним вычислительным ресурсам для выполнения какой-либо части пользовательского структурированного запроса.
В классической ситуации (когда роль клиента выполняет браузер) для того, чтобы пользователь увидел графический интерфейс приложения в окне браузера, последний должен обработать полученный ответ веб-сервера, в котором будет содержаться информация, реализованная с применением HTML, CSS, JS (самые используемые технологии). Именно эти технологии «дают понять» браузеру, как именно необходимо «отрисовать» все, что он получил в ответе [16].
Веб-сервер – это сервер, принимающий HTTP-запросы от клиентов и выдающий им HTTP-ответы. Веб-сервером называют как прикладное программное обеспечение, выполняющее функции веб-сервера, так и непосредственно компьютер, на котором это программное обеспечение работает.
Наиболее распространенными видами программного обеспечения веб-серверов являются Apache, IIS и NGINX. На веб-сервере функционирует тестируемое приложение, которое может быть реализовано с применением самых разнообразных языков программирования: PHP; Python; Ruby; Java; Perl и пр.
База данных фактически не является частью веб-сервера, но большинство приложений просто не могут выполнять все возложенные на них функции без нее, так как именно в базе данных хранится вся динамическая информация приложения [21].
В настоящее время намечается тенденция возврата к тому, с чего начиналась клиент-серверная архитектура – к централизации вычислений на основе использования модели терминал-сервера. В современной реинкарнации терминалы отличаются от своих алфавитно-цифровых предков тем, что имея минимум программных и аппаратных средств, представляют мультимедийные возможности (в т.ч. графический пользовательский интерфейс) [4].
Работу терминалов обеспечивает высокопроизводительный сервер, куда вынесено все, вплоть до виртуальных драйверов устройств, включая драйверы видеоподсистемы.
Если говорить про многоуровневую архитектуру взаимодействия клиент-сервер, то в качестве примера можно привести любую современную СУБД (за исключением, наверное, библиотеки SQLite, которая в принципе не использует концепцию клиент-сервер).
Несколько процессов или потоков могут одновременно без каких-либо проблем читать данные из одной базы. Запись в базу можно осуществить только в том случае, если никаких других запросов в данный момент не обслуживается; в противном случае попытка записи оканчивается неудачей, и в программу возвращается код ошибки [12]. Другим вариантом развития событий является автоматическое повторение попыток записи в течение заданного интервала времени.
Старые версии SQLite были спроектированы без каких-либо ограничений, единственным условием было то, чтобы база данных умещалась в памяти, в которой все вычисления производились при помощи 32-разрядных целых чисел. Это создавало определённые проблемы. Из-за того, что верхние пределы не были определены и соответственно должным образом протестированы, часто обнаруживались ошибки при использовании SQLite в достаточно экстремальных условиях [17]. Поэтому в новых версиях SQLite были введены пределы, которые теперь проверяются вместе с общим набором тестов.
Сама библиотека SQLite написана на C; существует большое количество привязок к другим языкам программирования, в том числе Apple Swift, Delphi, C++, Java, C#, VB.NET, Python, Perl, Node.js, PHP, PureBasic, Tcl (средства для работы с Tcl включены в комплект поставки SQLite), Ruby, Haskell, Scheme, Smalltalk, Lua и Parser, а также ко многим другим [11].
Простота и удобство встраивания SQLite привели к тому, что библиотека используется в браузерах, музыкальных плеерах и многих других программах.
В частности, SQLite используется в:
– Adobe Integrated Runtime – среда для запуска приложений (частично);
– Gears;
– Autoit;
– Фреймворк Qt [8].
Суть многоуровневой архитектуры заключается в том, что запрос клиента обрабатывается сразу несколькими серверами. Такой подход позволяет значительно снизить нагрузку на сервер из-за того, что происходит распределение операций, но в то же самое время данный подход не такой надежный, как двухзвенная архитектура.
1.3. Трехзвенная архитектура
Еще одна тенденция в клиент-серверных технологиях связана со все большим использованием распределенных вычислений. Они реализуются на основе модели сервера приложений, где сетевое приложение разделено на две и более частей, каждая из которых может выполняться на отдельном компьютере.
Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате. В этом случае двухзвенная клиент-серверная архитектура становится трехзвенной (three-tier, 3-tier) [6].
N-уровневая архитектура приложения предоставляет модель, по которой разработчики могут создавать гибкие и повторно-используемые приложения. Разделяя приложение на уровни абстракции, разработчики приобретают возможность внесения изменений в какой-то определённый слой, вместо того, чтобы перерабатывать всё приложение целиком. Трёхуровневая архитектура обычно состоит из уровня представления, уровня бизнес-логики и уровня хранения данных.
Хотя понятия слоя и уровня зачастую используются как взаимозаменяемые, многие сходятся во мнении, что между ними всё-таки есть различие. Различие заключается в том, что слой — это механизм логического структурирования компонентов, из которых состоит программное решение, в то время как уровень – это механизм физического структурирования инфраструктуры системы [15]. Трёхслойное решение легко может быть развёрнуто на единственном уровне, таком как персональная рабочая станция.
Двухзвенная архитектура является намного проще, в отличие от трехзвенной, так как все получаемые запросы обслуживаются одним вычислительным сервером, но именно из-за этого она будет менее надежной и предъявляет повышенные требования к вычислительной производительности используемого сервера [13].
Трехзвенная архитектура сложнее, но благодаря тому, что функции распределены между серверами второго и третьего уровня, эта архитектура представляет:
– высокую степень гибкости и масштабируемости;
– высокую безопасность;
– высокую производительность (т.к. задачи распределены между серверами) [27].
Преимуществом модели взаимодействия клиент-сервер является то, что программный код клиентского приложения и серверного разделен. Если мы говорим про локальные компьютерные сети, то к преимуществам архитектуры клиент-сервер можно отнести пониженные требования к машинам клиентов, так как большая часть вычислительных операций будет производиться на сервере, а также архитектура клиент-сервер довольно гибкая и позволяет администратору сделать локальную сеть более защищенной.
К недостаткам модели взаимодействия клиент-сервер можно отнести то, что стоимость серверного оборудования значительно выше клиентского. Сервер должен обслуживать специально обученный и подготовленный человек. Если в локальной сети ложится сервер, то и клиенты не смогут работать [18].
В качестве заключения стоит явно акцентировать внимание на том, что архитектура клиент-сервер не делит машины на только клиент или только сервер, а скорее позволяет распределить нагрузку и разделить функционал между клиентской частью и серверной.
Таким образом, была представлена характеристика технологии «клиент-сервер», которая представляет собой вычислительную или сетевую архитектуру, в которой задания или сетевая нагрузка распределяется между активными поставщиками услуг, которые называются серверами, и заказчиками услуг, называемыми клиентами. Были описаны достоинства и недостатки технологии клиент-сервер [9].
Также, была описана двухзвенная архитектура, которая используется в клиент-серверных системах, где вычислительный сервер отвечает на клиентские запросы напрямую и в полном объеме, при этом используя только собственные вычислительные ресурсы. Трехзвенная архитектура связана с все большим использованием распределенных вычислений. Они реализуются на основе модели сервера приложений, где сетевое приложение разделено на две и более частей, каждая из которых может выполняться на отдельном компьютере.
Глава 2. Распределенные системы обработки информации
2.1. Описание распределенных систем обработки информации
Распределенная система обработки информации представляет собой систему, которая охватывает несколько взаимодействующих компьютеров; система взаимодействующих независимых автоматизированных информационных систем.
В распределенных системах обработки информации основополагающим обстоятельством становится невозможность одной системы получить полностью достоверную информацию о состоянии другой системы на заданный момент времени и невозможность контролировать полностью ее поведение [25].
Практическая реализация распределенной системы обработки информации охватывает несколько независимых организаций и приводит в итоге к непосредственному созданию определенной распределенной вычислительной системы при реализации автоматизированного обмена информацией между ними.
Примером распределенной вычислительной системы, может быть информационное взаимодействие между туроператором, гостиницей, авиакомпанией и консульством на базе специализированного программного обеспечения.
Перечислим основные требования к участникам распределенной системы обработки информации:
– распределенные системы могут быть созданы для конкретного предприятия с последующим доступом к другим системам и организации информационного взаимодействия;
– каждая информационная система, являющаяся частью распределенной системы, имеет определенную логику работы, которая не всегда ясна участникам этого взаимодействия и выступает в виде «черного ящика»;
– обмен информацией между участниками распределенной системы использует средства локальных сетей и возможности глобальной сети Интернет;
– все участники распределенной системы имеют свои базы данных или банк данных, в которых хранят состояние своей модели некоторой предметной области;
– невозможность получить достоверное состояние другой вычислительной системы;
– вычислительные системы могут выдавать упрощенную или измененную информацию другим участникам распределенной вычислительной системы [22].
Распределенная система может иметь общую цель, например, решение большой вычислительной задачи; в этом случае пользователь видит коллекцию автономных процессоров, как единое целое.
Кроме того, каждый отдельный персональный компьютер может иметь свой собственный пользователь с индивидуальными информационными потребностями, а цель распределенной системы заключается в координации использования общих ресурсов или предоставлении услуг связи пользователей.
Другие типичные свойства распределенных систем включают в себя следующее:
– система должна терпеть определенные неудачи в отдельных компьютерах;
– структура системы (топологии сети, задержки в сети, число компьютеров) не известно заранее, то система может состоять из различных видов компьютеров и сетевых каналов, и система может изменяться во время выполнения распределенной программы;
– каждый компьютер имеет только ограниченное, неполное представление о системе. Каждый компьютер может знать только одну часть входного сигнала.
Распределенная обработка оперативных данных имеет следующие преимущества:
– возможность увеличения числа удаленных взаимодействующих пользователей, выполняющих функции сбора, обработки, хранения и передачи информации;
– снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз на разных персональных компьютерах;
– обеспечение доступа пользователей к вычислительным ресурсам ЛВС;
– обеспечение операций обмена данными между удаленными пользователями [20].
При распределенной обработке производится работа с базой данных, т.е. представление данных, их обработка. При этом работа с базой на логическом уровне осуществляется на компьютере клиента, а поддержание базы в актуальном состоянии – на сервере.
Параллельные вычисления можно рассматривать как частную тесно связанную форму распределенных вычислений и распределенные вычисления можно рассматривать как слабосвязанные виде параллельных вычислений. Тем не менее, можно классифицировать примерно параллельные системы, как «параллельно» или «распределенным» с использованием следующих критериев:
– в параллельных вычислениях, все используемые процессоры могут иметь необходимый доступ к общей памяти для обмена информации между процессорами;
– в распределенных вычислениях, каждый процессор имеет свою собственную память (распределенная память). Обмен информации осуществляется путем передачи сообщений между процессорами.
2.2. Возможности распределенных систем обработки информации
В современных сетевых информационных технологиях всё чаще используют распределённую обработку данных. Она позволяет повысить эффективность удовлетворения информационных потребностей пользователей, обеспечить гибкость и оперативность принимаемых им решений и др.
Под распределённой обработкой данных понимают обработку приложений несколькими территориально разделенными ЭВМ. Распределенная обработка данных (Distributed Data Processing, DDP) - это методика выполнения прикладных программ группой систем.
При этом пользователь получает возможность работать с сетевыми службами и прикладными процессами, расположенными в нескольких взаимосвязанных абонентских системах. Распределённая обработка данных позволяет повысить эффективность удовлетворения информационных потребностей пользователей, обеспечивает гибкость и оперативность принимаемых ими решений. Функции распределённой среды включают службы:
– каталогов, позволяющие клиентам находить серверы;
– удаленного вызова процедур;
– обслуживания файлов;
– безопасности данных;
– времени, синхронизирующие часы в абонентских системах.
Информационные системы, связанные с обработкой больших объемов информации, используют для хранения информации базы и банки данных. При этом в прикладных программных приложениях, связанных с обработкой данных, собственно управление базой данных может выполняться централизованно.
Параллельный доступ к одной базе данных нескольких пользователей, в том случае если база данных расположена на одной конкретной машине, соответствует режиму распределенного доступа к централизованной базы данных. Такие системы называются системами распределенной обработки данных.
Приведем пример распределенной системы архитектуры SСАDА-пакета PcVue ориентированной на создание систем диспетчерского контроля и управления различного масштаба, начиная от автономных операторских мест и кончая распределенными автоматизированными системами управления, в которых задействованы сразу несколько рабочих станций, объединенных в сеть [24].
Архитектура клиент-сервер и обмен данными между станциями являются базисными для PcVue. Как результат этого, данная система является гибким решением для диспетчеризации в области автоматизированных систем управления.
Достигая промышленных стандартов надежности и производительности, это решение удовлетворяет запросы как приложений для простых одиночных станций, так и клиент-серверных приложений с возможностями избыточности и безопасности.
При использовании PcVue в сетевом многостанционном приложении используется база данных с поддержкой удаленного доступа. Переход от автономной конфигурации к распределенной архитектуре в сети Еthеrnеt TСР/IР с избыточными серверами данных столь же прост, как и регистрация в сети.
Используя встроенную поддержку избыточности, PcVue позволяет гарантировать непрерывность сбора данных в случае отказа отдельных системных компонент.
Каждый отдельный компонент и каждая станция в конфигурации имеют признак состояния достоверности, который позволяет упростить диспетчеризацию работоспособности системы в режиме реального времени [23].
Вычислительная система РсVuе включает специализированный набор Wеb-услуг для облегчения создания Wеb-портала и интеграции с другими приложениями предприятия. Этот сервис поддерживает системы MЕS (Mаnufасturing Еxесution Systеm), СMMS (Сomрutеrisеd Mаintеnаnсе Mаnаgеmеnt System), SСM (Suррly Сhаin Mаnаgеmеnt) и ЕRР (Еntеrрrisе Rеsourсе Planning).
PcVue поддерживает оперативную обработку данных в корпоративной базе данных Miсrosoft SQL Sеrvеr 2005 и поставляется совместно с изделием SQL Sеrvеr 2005 Еxрrеss Еdition. В совокупности с прикладным программным компонентом WеbVuе PcVue предлагает комплексное решение для «тонкого» клиента, которое является постоянно доступным из обычного Wеb-браузера через глобальную сеть Internet или вычислительную сеть интернет.
Вычислительный сервер WеbVuе полностью интегрируется со всеми специализированными средствами и мерами безопасности системы межсетевой защиты предприятия.
В отличие от обычного персонального компьютера, работающего под управлением операционной системы Windows, Linux или другой операционной системы, «тонкий» клиент WеbVuе не нуждается ни в каком дополнительном локальном прикладном программном приложении, кроме стандартного Wеb-браузера, для обеспечения доступа к мнемосхемам, данным реального времени и историческим данным PcVue [26].
Станция Wеb-сервера РсVuе использует специализированную технологию Miсrosoft IIS для управления комплексной безопасностью совместно с межсетевой защитой предприятия. Полностью поддерживается управление правами пользователя и процессами аутентификации.
Можно удаленно подтверждать тревоги, просматривать графики трендов и реализовывать удаленные команды без разработки новых мнемосхем.
Таким образом, была раскрыта сущность распределенных систем обработки информации. Распределенная система обработки информации представляет собой систему, которая охватывает несколько взаимодействующих компьютеров; система взаимодействующих независимых автоматизированных информационных систем.
Глава 3. Программная разработка
3.1. Разработка базы данных
Федеральное агентство по государственной поддержке деятельности агропромышленного комплекса находится в ведении Министерства сельского хозяйства Российской Федерации и работает по государственному заданию, в состав которого входит выполнение работ, оказание услуг в сфере агропромышленного комплекса в целях обеспечения реализации предусмотренных законодательством Российской Федерации полномочий Министерства сельского хозяйства Российской Федерации по осуществлению государственной поддержки по следующим направлениям: сельскохозяйственное страхование, агрокредитование, реализация инвестиционных проектов и осуществление капитальных вложений в сфере агропромышленного производства.
Анализ организационной структуры и деятельности организации позволил выявить наиболее важные участки автоматизации. Так, было установлено, что в первую очередь необходимо провести работы по автоматизации отдела агрострахования по предоставлению субсидий. Это позволит достичь высоких показателей эффективности, как подразделения, так и организации в целом.
В результате разработки должны быть достигнуты следующие показатели: организация учета информации, основанная на применении системы управления базами данных; разработка пользовательского интерфейса для работы с системой, обеспечивающего интуитивно-понятные процедуры вызова основных функций системы и быстрый доступ к базе данных; надежное хранение информационных массивов, реализованное посредством обеспечения целостности данных; сокращение времени на проведение основных операций персоналом компании, что, безусловно, должно повлечь за собой качественные улучшения в деятельности компании.
Оперативной информацией является изменяемая оперативная информация для каждого отдельного случая ее практического использования. Входными являются такие справочники и документы:
– справочник «Организация»;
– справочник «Заказчик»;
– справочник «Федеральный округ»;
– справочник «Субъект РФ»;
– справочник «Цель заявки»;
– справочник «Сотрудник»;
– справочник «Должность»;
– документ «Целевая программа»;
– документ «Заявка».
Даталогическая модель базы данных информационной системы представлена на рис. 1.
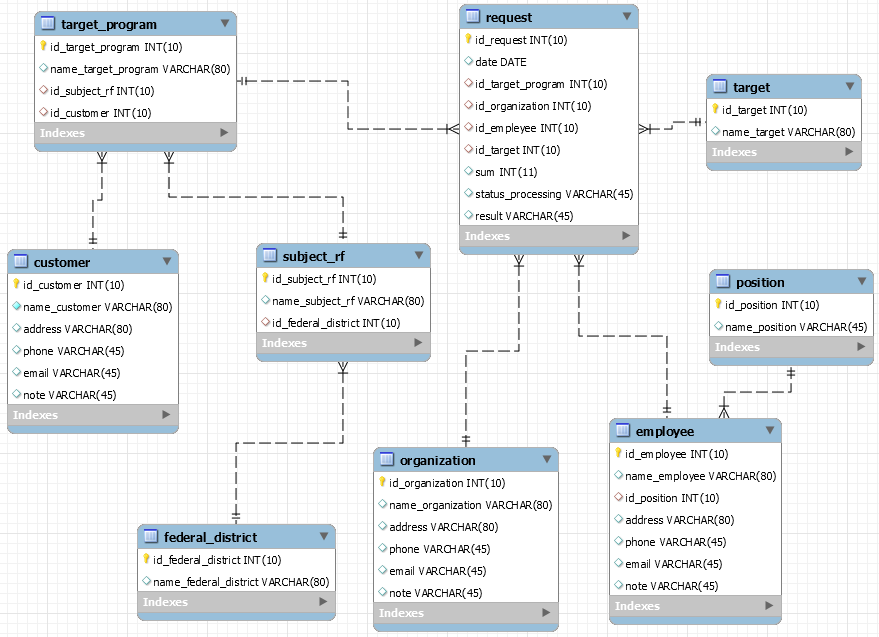
Рис. 1. Даталогическая модель
Таким образом, были представлены основные сведения о используемых реквизитах таблиц базы данных разрабатываемой информационной системы обработки оперативной информации компании. Представленные реквизиты позволяют в полной мере реализовать необходимый функционал разрабатываемой информационной системы.
3.2. Порядок работы с системой
Работа с информационной системой начинается путем запуска исполняемого файла program.exe. Далее пользователю нужно ввести логин и пароль, на основании которого будет предоставлен определенный доступ; соответственно, для оператора (login: operator, password: operator) будут доступны возможности работы с документами, справочниками и отчетами, для администратора (login: admin, password: admin) будут доступны возможности работы с документами и отчетами. Интерфейсная форма входа в систему представлена на рис. 2.
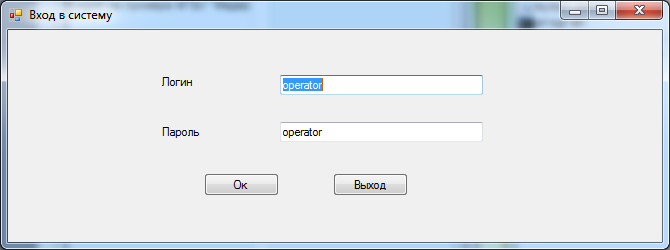
Рис. 2. Интерфейсная форма входа в систему
Интерфейс главной пользовательской формы включает пользовательское меню, содержащее следующие пункты верхнего уровня:
– справочники;
– документы;
– отчеты;
– выход, рис. 3.
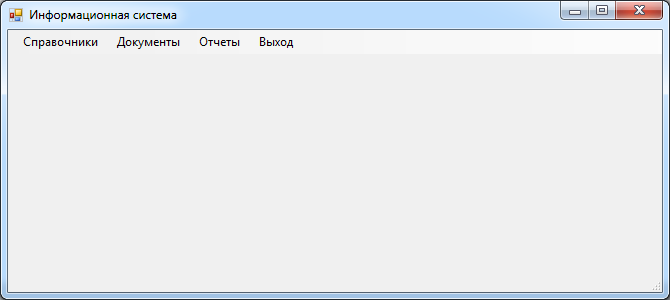
Рис. 3. Интерфейс главной формы
Первый пункт главного меню информационной системы «Справочники» включает такие справочники:
– организация;
– заказчик;
– федеральный округ;
– субъект РФ;
– цель заявки
– сотрудник;
– должность.
Ввод и редактирование данных о организации можно выполнить при помощи использования справочника «Организация», пользовательская форма которого представлена на рис. 4.
Форма является основным объектом информационной системы, на ней будут располагаться другие информационные объекты доступа к базе данных. Каждая форма в период выполнения информационной системы соответствует отдельному окну.
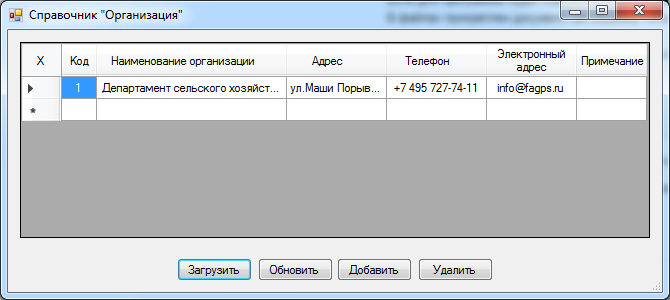
Рис. 4. Пользовательская форма «Организация»
Ввод и редактирование данных о заказчиках организации можно выполнить при помощи использования справочника «Заказчик», пользовательская форма которого представлена на рис. 5.

Рис. 5. Пользовательская форма «Заказчик»
Ввод и редактирование данных о федеральных округах можно выполнить при помощи справочника «Федеральный округ», пользовательская форма которого представлена на рис. 6.
Рис. 6. Пользовательская форма «Федеральный округ»
Ввод и редактирование данных о субъектах РФ можно выполнить при помощи справочника «Субъект РФ», пользовательская форма которого представлена на рис. 7.
Рис. 7. Пользовательская форма «Субъект РФ»
Ввод и редактирование данных о целях заявок можно выполнить при помощи справочника «Цель заявки», пользовательская форма которого представлена на рис. 8.
Рис. 8. Пользовательская форма «Цель заявки»
Ввод и редактирование данных о сотрудниках организации можно выполнить при помощи справочника «Сотрудник», пользовательская форма которого представлена на рис. 9.
Рис. 9. Пользовательская форма «Сотрудник»
Ввод и редактирование данных о должностях сотрудников можно выполнить при помощи практического использования справочника «Должность», пользовательская форма которого представлена на рис. 10.
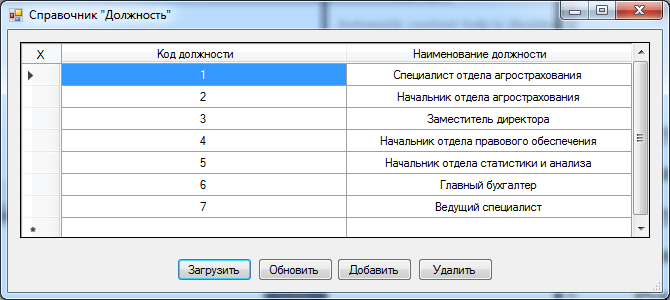
Рис. 10. Пользовательская форма «Должность»
Второй пункт главного меню информационной системы «Документы» включает такие документы: целевая программа; заявка.
Ввод и непосредственное редактирование оперативных данных о целевых программах можно выполнить при помощи практического использования документа «Целевая программа», пользовательская форма которого представлена на следующем рис. 11.
Ввод и редактирование оперативных данных о заявках можно выполнить при помощи практического использования документа «Заявка», пользовательская форма которого представлена на следующем рис. 12.
Третий пункт главного меню информационной системы «Отчеты» включает следующие запросы и отчеты:
– заявки на дату;
– информация о заказчике;
– информация о целевых программах.
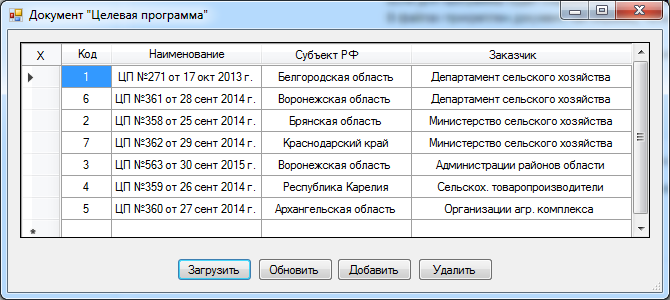
Рис. 11. Пользовательская форма «Целевая программа»

Рис. 12. Пользовательская форма «Заявка»
Первый запрос предоставляет пользователю информационной системы возможности просмотра оперативных данных о заявках клиентов организации на определенную дату. Для поиска оперативной информации о заявках нужно указать интересующую дату, после чего будет выведена информация о соответствующих заявках. Интерфейсная форма запроса «Заявки на дату» представлена на рис. 13.
Интерфейсная форма запроса «Информация о заказчике» представлена на рис. 14.
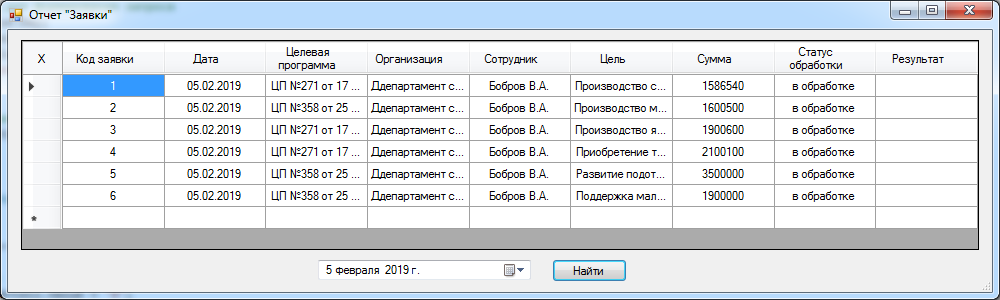
Рис. 13. Пользовательская форма «Заявки на дату»
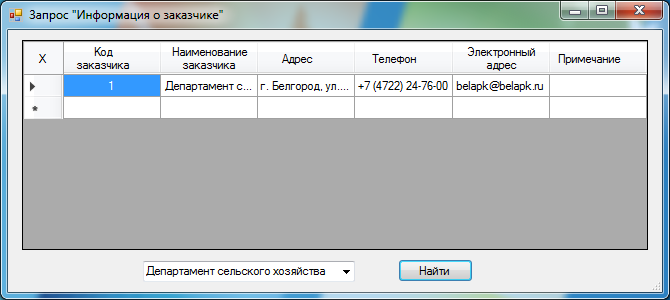
Рис. 14. Пользовательская форма «Информация о заказчике»
Таким образом, описанные объекты информационной системы отражают технологию работы с ней. Накопленная оперативная информация в базе данных информационной системы может быть использована для дальнейшей обработки средствами корпоративного web-сайта в виде представления информации о целевых программах, информации о заказчиках, заявках.
Заключение
При выполнении курсовой работы было установлено, что технология «клиент–сервер» представляет собой вычислительную или сетевую архитектуру, в которой задания или сетевая нагрузка распределяется между поставщиками некоторых услуг, которые называются серверами, и заказчиками услуг (клиентами). Ключевым принципом технологии «клиент-сервер» реализуется через разделение функций прикладного программного приложения на несколько группы: ввод и отображение оперативных данных; прикладные функции, которые характерны для определенной предметной области; функции управления вычислительными ресурсами.
Архитектура «клиент-сервер» позволяет определить базовые принципы непосредственного взаимодействия между персональными компьютерами, детали непосредственного взаимодействия определяют разные протоколы. Данная концепция говорит о том, что необходимо разделять машины в вычислительной сети на клиентские, которым всегда что-то нужно и на серверные, которые дают то, что необходимо.
При этом взаимодействие всегда начинает клиент, а правила, по которым выполняется непосредственное взаимодействие описывает используемый протокол. Существует два вида архитектуры взаимодействия клиент-сервер: первый это двухзвенная архитектура клиент-серверного взаимодействия, второй – многоуровневая архитектура клиент-сервер.
Описаны современные технологии «клиент-сервер», одна из которых является технологии обработки страниц на web-сайте. Технология ASP предполагает широкое использование серверных сценариев и объектов СОМ для создания динамических web-серверов. Средствами технологии ASP можно легко создавать интерактивные web-страницы, выполнять обработку данных введенных пользователем через формы, обращаться к базам данных.
Разработанная база данных информационной системы включает следующие таблицы: организация; заказчик; федеральный округ; субъект РФ; цель заявки; сотрудник; должность; целевая программа; заявка. На основании перечисленного перечня таблиц были разработаны соответствующие формы, запросы и отчеты.
Аналитические возможности разработанной информационной системы включают реализацию следующие запросов: заявки на дату; информация о заказчике; информация о целевых программах.
Дальнейшим развитием информационной системы лежит в расширении функциональных возможностей.
Список использованной литературы
- Архитектура и проектирование программных систем : монография / С.В. Назаров. – 2-е изд., перераб. и доп. – М. : ИНФРА-М, 2018. – 374 с.
- Архитектура ЭВМ и вычислительные системы : учебник / В.В. Степина. – М.: КУРС: ИНФРА-М, 2018. – 384 с.
- Блюмин А.М. Информационные ресурсы: Учебное пособие для бакалавров / А.М. Блюмин, Н.А. Феоктистов. – 3-е изд., перераб. и доп. – М.: Издательско-торговая корпорация «Дашков и Ко», 2015 – 384 с.
- Валитов Ш.М. Современные системные технологии в отраслях экономики: Учебное пособие / Ш.М. Валитов, Ю.И. Азимов, В.А. Павлова. - М.: Проспект, 2016. – 504 c.
- Венделева М.А. Информационные технологии в управлении.: Учебное пособие для бакалавров / М.А. Венделева, Ю.В. Вертакова. - Люберцы: Юрайт, 2016. – 462 c.
- Гаврилов М.В. Информатика и информационные технологии: Учебник / М.В. Гаврилов, В.А. Климов. - Люберцы: Юрайт, 2016. – 383 c.
- Грошев А.С. Информационные технологии : лабораторный практикум / А. С. Грошев. – 2-е изд. – М.-Берлин: Директ-Медиа, 2015. – 285 с.
- Грошев А.С., Закляков П. В. Информатика: учеб. для вузов – 3-е изд., перераб. и доп. – М.: ДМК Пресс, 2015. – 588 с.
- Грофф, Джеймс Р., Вайнберг, Пол Н., Оппелъ, Эндрю Дж. SQL: полное руководство, 3-е изд.: Пер. с англ. - М.: ООО «И.Д. Вильямс», 2015. – 960 с.
- Дарков А.В. Информационные технологии: теоретические основы: Учебное пособие / А.В. Дарков, Н.Н. Шапошников. - СПб.: Лань, 2016. – 448 c.
- Ерохин В.В. Безопасность информационных систем: учеб пособие / В.В. Ерохин, Д.А. Погонышева, И.Г. Степченко. - М.: Флинта, 2016. – 184 c.
- Жданов С.А. Информационные системы: учебник / С.А. Жданов, М.Л. Соболева, А.С. Алфимова. - М.: Прометей, 2015. – 302 с.
- Замятина О.М. Вычислительные системы, сети и телекоммуникации. моделирование сетей.: Учебное пособие для магистратуры / О.М. Замятина. - Люберцы: Юрайт, 2016. – 159 c.
- Информатика: программные средства персонального компьютера : учеб. пособие / В.Н. Яшин. – М. : ИНФРА-М, 2018. – 236 с.
- Информатика : учебник / И.И. Сергеева, А.А. Музалевская, Н.В. Тарасова. – 2-е изд., перераб. и доп. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 384 с.
- Информатика (курс лекций) : учеб. пособие / В.Т. Безручко. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 432 с.
- Информатика и информационно-коммуникационные технологии (ИКТ) : учеб. пособие / Н.Г. Плотникова. – М. : РИОР : ИНФРА-М, 2018. – 124 с.
- Информационные системы и технологии: Научное издание. / Под ред. Ю.Ф. Тельнова. - М.: ЮНИТИ, 2016. – 303 c.
- Информационные технологии: Учебное пособие / Л.Г. Гагарина, Я.О. Теплова, Е.Л. Румянцева и др.; Под ред. Л.Г. Гагариной - М.: ИД ФОРУМ: НИЦ ИНФРА-М, 2015. – 320 c.
- Информационные технологии в профессиональной деятельности : учеб. пособие / Е.Л. Федотова. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 367 с.
- Колисниченко Д.Н. PHP и MySQL. Разработка веб-приложений. Профессиональное программирование / Д.Н. Колисниченко. - СПб.: BHV, 2015. – 592 c.
- Корпоративные информационные системы управления : учебник / под ред. Н.М. Абдикеева, О.В. Китовой. - М. : ИНФРА-М, 2014. – 563 с.
- Кучинский В.Ф. Сетевые технологии обработки информации: учеб. пособие. – СПб: Университет ИТМО, 2015. – 115 с.
- Лапшина С.Н. Информационные технологии в менеджменте : учебное пособие / С. Н. Лапшина, Н. И. Тебайкина. – Екатеринбург : Изд-во Урал. ун-та, 2014. – 84 с.
- Олифер В., Олифер Н. Компьютерные сети (принципы, технологии, протоколы). - СПб.: Питер, 5-е изд., 2016. – 992 с.
- Таланов В. М., Федосин С. А. Проектирование информационных систем и баз данных. Учеб. пособие. Изд.3. Переработанное и дополненное – Саранск: Изд-во СВМО, 2013. – 72 c.
- Хаббард Дж. Автоматизированное проектирование баз данных / Дж. Хаббард. - М.: Мир, 2015. – 296 c.

- Информация в материальном мире(Теоретические основы анализа понятия «информация» и ее места в материальном мире)
- Разработка регламента выполнения процесса «Управление персоналом»
- Анализ внешней и внутренней среды организации
- Организация общественной власти в первобытном обществе
- Налоговые правонарушения (Общие вопросы налоговых правонарушений)
- Налоговые правонарушения
- Управление поведением в конфликтных ситуациях
- Роль мотивации в поведении организации
- Основные функции в системе менеджмента
- Организация маркетинга на предприятии (теоретические аспекты)
- Коммерческая деятельность оптового торгового предприятия и ее совершенствование (на примере конкретной организации)
- Руководство, стили руководства