
Технология клиент-сервер (динамика создания и изменения клиент-серверной технологии)
Содержание:

Введение
В данный момент мы видим активный рост и стремительное преобразование компьютерных систем. Еще полвека назад компьютеры были громоздкие и дорогостоящие. Ни одна другая отрасль не развивается так стремительно, как область компьютерных технологий. Появление компьютерных сетей с высокой скоростью позволило объединять и обмениваться информацией несколько сотен компьютеров одновременно менее чем за секунду. В каждой крупной и маленькой организации собираются компьютерные сети, где используется высокоскоростная сеть большое количество компьютеров. Все это формирует сеть, которую так же называют распределенная система. Например, самая популярная распределенная система это интернет. При построении любой системы требуется глубокий анализ и точная проработка архитектуры, а так же знания и данные. Так же и при построении архитектуры информационной системы очень важно сформировать правильную ее архитектуру. В настоящее время, очень часто применяют технологию клиент-сервер для построения таких систем.
Целью курсовой работы является посмотреть динамику создания и изменения клиент-серверной технологии, изучить основные термины и методики.
Этапами решения задачи можно обозначить историю создания технологии, анализ технологии с точки зрения распределенной системы, какие задачи стоят при ее формировании. А так же рассмотрим применение архитектуры клиент-сервер для баз данных.
Основной источник для написания данной курсовой работы выбран классический учебник Э. Таненбаума и М. Ван Стеена «Распределенные системы, принципы и парадигмы», а так же некоторые интернет ресурсы и научные статьи, которые можно увидеть по тексту курсовой работы, в виде сносок в конце страницы.
Глава 1. История развития архитектуры ВС
Первые автоматизированные системы организационного управления появились в промышленности еще в 70 годы.
Компьютеризация промышленных предприятий у нас проделала огромный путь прежде, чем появилась архитектура клиент-сервер. Аппаратной базой самых первых АСУП являлись ламповые и полупроводниковые ЭВМ “Урал”, “Минск”, БЭСМ. В 80 годы аппаратной основой систем управления стали ЭВМ серии ЕС, мини-ЭВМ VAX и СМ. В 90 годы основой компьютеризации управления стали персональные ЭВМ и их локальные сети. [1,43]
Каждому этапу развития автоматизированных систем управления предприятию соответствовали своя господствующая архитектура приложений, свои технологии. Первой появилась централизованная архитектура, зачем архитектура локальных ПЭВМ, а потом и архитектура файл-сервер. Все варианты построения информационных приложений в той или иной степени до сих пор активно используются на практике. Поскольку все эти технологии не прошлое, а настоящее компьютеризации в промышленности, прежде чем перейти к архитектуре клиент-сервер, давайте рассмотрим их чуть подробнее. [2]
1.1 Централизованная архитектура приложений
Исторически первыми появились компьютерные системы с централизованной архитектурой приложений. [3] При использовании этой архитектуры все программное обеспечение автоматизированной системы выполняется централизованно на одном компьютере, выполняющем одновременно много задач и поддерживающем большое количество пользователей. На этом компьютере полностью осуществляется процесс ввода/ вывода информации, а также ее прикладная обработка. В качестве центрального компьютера для такой системы может применяться либо большая ЭВМ (называемая также майнфреймом) либо так называемая мини-ЭВМ. К подобному комплексу подключаются периферийные устройства для ввода/вывода информации от каждого пользователя. [1,56]
Вначале единственным способом общения пользователя с подобной техникой являлся так называемый пакетный режим - ввод информации осуществлялся, к примеру, с помощью пачки перфокарт. Обработав полученное задание, машина выдавала распечатку результатов работы.
Во второй половине 70 появились устройства для диалогового взаимодействия с компьютером - терминалы. Однако, они не выполняли никаких функций, кроме вывода символов, полученных от компьютера на дисплей и передачи введенных с клавиатуры символов в компьютер. Поэтому подобное устройство получило название “dumb terminal” - дословно “тупой терминал”. [4, 156]
Чаще всего у нас в подобных системах на предприятиях (на Западе это встречается заметно реже) взаимодействие между сотрудниками предприятия и ЭВМ осуществлялось не напрямую, а через операторов ЭВМ, которые получали исходную информацию в бумажном виде, заносили ее в компьютер, а затем передавали пользователям результаты работы программы виде распечаток. Естественно, что подобный цикл обработки информации требовал многочисленного обслуживающего персонала, занимал длительное время, порождал большое число ошибок и был очень негибким и весьма дорогостоящим. Кроме того, работа в централизованной архитектуре требовала специализированных знаний. А это создавало дополнительный барьер между управленцем и системой автоматизации и усложняло процесс ее адаптации к нуждам пользователей. [2,99]
Поэтому с помощью подобных систем было целесообразно автоматизировать только отдельные процессы в управлении предприятием с очень высокой трудоемкостью ручной обработки информации. К ним относились, как правило, задачи бухгалтерии, не слишком требовательные к оперативности обработки, с очень большим объемом рутинных вычислений и подготовки выходных форм. Сюда могли входить расчет заработной платы, бухгалтерский учет материальных ценностей, отгруженной продукции. Пользователи могли также осуществлять ввод информации и получение результатов обработки самостоятельно, с использованием алфавитно-цифровых терминалов. В таком варианте централизованные системы существуют и успешно функционируют до сих пор. [3]
В крупных зарубежных компаниях на майнфреймах до сих пор ведется значительная часть задач, связанных с компьютеризацией управления, прежде всего учетных. В СССР же подобные системы никогда не были широко распространены из-за малого количества и низкой надежности отечественных больших ЭВМ. Успешно работающих по сей день отечественных систем с централизованной архитектурой вообще единицы. Самая крупная из них, это всем известная глобальная система “Экспресс” для продажи железнодорожных билетов через кассы. [5,89]
Есть две главные причины того что системы на больших ЭВМ эксплуатируются до сих пор, несмотря на большие затраты на специализированную аппаратуру и информационные каналы для поддержания надежной связи между каждым терминалом и компьютером.
Во-первых, централизованная архитектура при необходимом качестве аппаратуры и программного обеспечения очень надежна (осщбенно в плане целостности данных). Абсолютная производительность майнфреймов не уступает самым большим комплексам в архитектуре клиент-сервер. Большая ЭВМ достаточной мощности может обеспечивать устойчивую работу огромного количества пользователей одновременно. Работоспособность подобных систем проверена многолетним опытом работы. Тот же “Экспресс” одновременно обслуживает тысячи пользователей, расположенных по всей России. Доведение любой новой системы до такого же уровня потребует не один год. [1,29]
Во-вторых, затраты на замену подобной системы, включая прямые затраты - на замену аппаратуры и программного обеспечения и непрямые затраты - на переподготовку пользователей, перестройку инфраструктуры и изменение технологии обработки информации составляют сумму, огромную даже для крупной западной компании. Исходный текст таких систем составляет сотни тысяч и даже миллионы строк, причем эти строки писались в течение десятилетий. [3]
Для разработки приложений в подобных системах часто используется язык COBOL (Common Business Oriented Language , Язык общего назначения, ориентированный на бизнес). Этот язык был разработан по заказу Пентагона еще в начале 60, и был изначально предназначен для решения информационных задач, связанных с коммерческой деятельности. В течение двух десятков лет на Западе (прежде всего, в США) он являлся основным инструментом разработки систем управления производством. На нем было разработано множество информационных систем для крупных компаний, которые эксплуатируются и поныне. Поэтому в Америке программисты на COBOL'е - до сих пор одни из самых дефицитных и высокооплачиваемых специалистов по информационным технологиям. [5]
Справедливости ради, стоит заметить, что использование больших ЭВМ само по себе еще не обязательно означает использование устаревшего программного обеспечения для разработки. С одной стороны, многие системы, используемые в приложениях клиент-сервер, существуют и для централизованных платформ. Например, самая известная и распространенная у нас система управления базами данных масштаба предприятия - Oracle изначально появилась для мини-ЭВМ и майнфреймов. Программное обеспечение для этих платформ до сих пор занимают очень значительную долю среди общего числа эксплуатирующихся систем компании Oracle. [2]
С другой стороны, по мере распространения архитектуры клиент-сервер появились возможности для ее интеграции с централизованной архитектуры. Сейчас большинство фирм, выпускающих большие ЭВМ, стали предлагать решения, позволяющие использовать их в качестве серверов в архитектуре клиент-сервер. Подобные гетерогенные (разнородные) комплексы позволяют, во-первых, совместно эксплуатировать централизованные приложения и системы клиент-сервер, а во-вторых, соединяют преимущества распределенной архитектуры с надежностью майнфреймов. [1]
1.2 Персональные ЭВМ - локальные задачи
Следующим значительным этапом развития компьютеризации организационного управления стали персональные ЭВМ. Появившись на Западе в начале, а у нас в конце 80-ых, этот инструмент привел к революционному расширению сферы компьютеризации управления. Компьютер из дорогостоящего и сложного в эксплуатации устройства, применяющегося в промышленности крайне редко, для решения отдельных задач, превратился в массовый инструмент для автоматизации повседневных задач конторской деятельности. [1]
По своему определению, персональный компьютер предназначен для автоматизации решения задач конкретного сотрудника. При этом между работником и инструментом автоматизации не стоит никаких посредников, а это сильно облегчает использование компьютера в текущей работе. Пользовательский интерфейс (способ взаимодействия с пользователем) для ПЭВМ намного удобней, богаче и, что самое главное, проще в освоении, чем интерфейс любой централизованной системы. [3]
Еще одним важным преимуществом персональной ЭВМ является то, что приемы взаимодействия с различным программным обеспечением однотипны или уж в любом случае похожи. Как правило, каждая их прикладных систем, разработанных в централизованной архитектуре, обладает своим уникальным интерфейсом. В то же время, при освоении новой программы для ПЭВМ можно использовать, по меньшей мере, часть знаний, полученных ранее при работе с другим программным обеспечением.
ПЭВМ можно освоить самостоятельно (или почти самостоятельно), и он всегда находится под рукой, непосредственно на рабочем месте. Поэтому персональные компьютере и у нас, и на Западе, стали повсеместно применяться прежде всего для решения пользователями своих собственных, локальных задач. Наиболее активно используемыми приложениями стали электронные таблицы и текстовые редакторы. [3]
Не будет преувеличением сказать, что эти приложения используются на ПЭВМ, а том числе и в промышленности, больше всех остальных, вместе взятых. [5]
Компьютеризация подготовки документов, несомненно, снимает с конкретных исполнителей большой объем рутинной работы, создает у них понимание возможностей применения ПЭВМ как полезного и очень удобного инструмента автоматизации управления. Однако, при этом рано или поздно выясняется, что само по себе появление у сотрудников персональных ЭВМ, даже в большом количестве, еще не приводит к заметным качественным изменениям в управлении. Особенно сильно это заметно на средних и больших предприятиях. [1]
Этому есть несколько объективных причин. Одна из них в том, что настольные приложения, такие как Word и Excel, не предназначены для работы с большим объемом структурированной информации, в них достаточно трудно отображать сложные взаимосвязи между данными. Поэтому персональный компьютер может очень быстро превратиться в хранилище большого количества слабо связанных между собой разрозненных документов. При этом в них может содержаться огромное количество информации, но быстро найти нужные данные, а уж тем более, получить полную картину на основе этой информации зачастую не способен даже ее хозяин.
К тому же, хранение информации в виде отдельных, не связанных друг с другом документов, может привести к появлению противоречий между ними. Например, отсутствуют надежные способы гарантировать, что итоговая сумма в одном документе соответствует расшифровке этой же суммы в другом. [2]
Конечно, для решения этой проблемы можно использовать еще один класс настольных приложений. Это специализированные системы управления базами данных для персональных ЭВМ, так называемые “настольные” СУБД. Они лучше приспособлены для работы с большими объемами структурированной информации, ее поиска, сортировки, осуществления выборок, подготовки отчетов. [4]
Еще одна проблема рассматриваемой архитектуры состоит в том, что наличие большого числа не связанных между собой ПЭВМ на отдельных рабочих местах часто вызывает такой же локальный взгляд на автоматизацию. На каждом рабочем месте решаются узкие задачи компьютеризации деятельности конкретного исполнителя. При этом часто не учитывается даже необходимость информационного взаимодействия между рабочими местами, не говоря уже о компьютеризации задач в рамках единой автоматизированной системы управления производством. [5]
Автоматизированная система управления, построенная с использованием локальных ПЭВМ, не слишком эффективно использует вычислительные ресурсы. Персональный компьютер по своей архитектуре напоминает маленький отдельно стоящий майнфрейм. Все операции полностью выполняются на одном отдельно взятом компьютере, отсутствует какое-либо разделение ресурсов между ПЭВМ. При увеличении объемов информации, обрабатываемой в системе, для того, чтобы поддерживать приемлемую производительность, приходится наращивать мощность компьютера, причем если возрастает нагрузка на несколько ПЭВМ, то необходимо модернизировать каждый из них по отдельности, а это значительные затраты.
Можно, конечно, использовать персональные компьютеры для автоматизации локальных задач, для которых достаточно отдельного рабочего места. Однако, большинство задач не являются изолированными друг от друга, поскольку в системе управления предприятием всегда существует тесные связи между отдельными звеньями, горизонтальные и вертикальные. Каждый сотрудник обменивается той или иной информацией с сотрудниками своего подразделения, с другими подразделениями, с руководством и с подчиненными. [5]
При наличии изолированных друг от друга ПЭВМ, обмен данными между ними либо будет осуществляться в бумажном виде, либо на дискетах. Оба этих варианта не слишком удобны - первый вариант приведет к повторному вводу информации в компьютер. Второй, как мы уже отмечали, неудобен и неэффективен. [1]
По мере увеличения числа ПЭВМ и повышения квалификации пользователей, на предприятии все сильней осознается потребность в быстром, надежном и удобном способе оперативного обмена большими объемами данных между компьютерами, а главное, между пользователями. Это позволил бы, как минимум, передавать информацию между отдельными рабочими местами, а как максимум,решать задачи более высокого уровня, объединяя отдельные автоматизированные места в интегрированные комплексы. И, естественно, спрос породил предложение - были созданы локальные вычислительные сети и архитектура файл-сервер. [1]
Локальные вычислительные сети и архитектура файл-сервер
Локальные вычислительные сети (ЛВС) предназначены для объединения отдельных вычислительных устройств. Они включают в себя ту или иную среду (чаще всего, проводную), обеспечивающую высокую скорость передачи данных, приемопередающие устройства, осуществляющие связь между компьютером и средой, а также набор протоколов, определяющих порядок взаимодействия в сети.
Расстояние между устройствами в локальных сетях, как правило, составляет десятки-сотни метров, то есть, эти технологии применяются в пределах одного здания. ЛВС обеспечивают высокую скорость информационного обмена, но само понятие “высокой скорости” сильно изменилось. Если в начале девяностых высокой считалась скорость в 1 мегабит в секунду, то сейчас обычным считается 100 мегабит в секунду, а на подходе и 1000 мегабит/с (1 гигабит/с), что в тысячу раз больше. [1]
Чаще всего, когда в организации появляется хотя бы несколько компьютеров, возникает потребность наладить оперативный обмен информацией между ними. Поэтому вскоре после появления персональных компьютеров для их объединения были созданы локальные вычислительные сети. [5]
Этому способствовали два фактора. Во-первых, количество ПЭВМ во многих организациях и на предприятиях стало значительным, и задача высокопроизводительного оперативного обмена информацией между рабочими стала особенно актуальной. [3]
Вторым немаловажным фактором стало постоянное снижение стоимости оборудования для сетей. Это привело к тому, что создание локальной сети перестало быть непозволительной роскошью, которая была по карману не только самым богатым организациям. Вообще, развитие сетевых технологий с одновременным снижением стоимости шло ошеломляющими темпами. [4]
Наиболее легкий, дешевый и простой вариант использования программных технологий соединения компьютеров при помощи ЛВС — это одноранговая сеть. В такой сети все компьютеры равноправны друг с другом. Каждый компьютер при этом может делать свои ресурсы доступными для остальных. В качестве таких ресурсов выступают прежде всего дисковое пространство и печатающие устройства. При этом не предполагается наличие специализированного компьютера - сервера, выделенного исключительно для совместного использования.
Одноранговая сеть позволяет решить проблемы передачи файлов между отдельными персональными компьютерами, а также разделения дефицитных ресурсов между несколькими пользователями. Однако, она не может быть использована для создания приложений, в которых необходим одновременный доступ к данным с нескольких ПЭВМ. Кроме того, надежность и производительность подобной сети крайне ограничена. [2]
Развитие информационных систем потребовало создания аппаратных и программных технологий для одновременного доступа к ресурсам большого числа пользователей. Для решения этой проблемы была предложена и успешно реализована, архитектура файл-сервер. На определенном этапе компьютеризации предприятия эта архитектура соответствует потребностям управления и позволяет создавать приложения, выполняющие задачи масштаба отдела. [5]
1.3 Архитектура файл-сервер
Предполагает наличие трех основных компонент: файлового сервера, файлового клиента и набора локальной сети для общения между ними.
Файловый сервер - это комплекс аппаратных и программных средств, обеспечивающий совместный доступ к файловым ресурсам (а также к принтерам) через локальную сеть многим пользователям одновременно. Как правило, при построении файлового сервера используется специализированная аппаратура (с большим объемом оперативной памяти, быстродействующими и более надежными внешними устройствами). Файловый сервер функционирует под управлением специализированного программного обеспечения - сетевой операционной системы. В качестве стандарта де-факто на промышленных предприятиях применяется серверная операционная система Netware фирмы Novell. [2]
Файловый клиент - это набор программного обеспечения, обеспечивающий доступ к файловым ресурсам сервера (или серверов) с персонального компьютера. Клиент устанавливается на каждом рабочем месте, с которого должен осуществляться доступ к серверу. Как правило, доступ к ресурсам осуществляется прозрачно для прикладных программ, то есть для пользователя они представляются аналогичными локальным ресурсам его персонального компьютера.
И наконец, для нормального функционирования файл-серверных приложений, естественно, необходима собственно локальная сеть, соединяющая между собой клиент и сервер. Работоспособность файл-серверного приложения напрямую зависит от надежности и производительности локальной сети. [4]
Как следует из самого термина файл-сервер, весь обмен между клиентскими рабочими местами и сервером осуществляется на уровне файлов. Типовые команды, которые передаются серверу в этой архитектуре - это открыть файл, прочитать определенное число байт их файла, записать в файл определенное число байт, закрыть файл. При этом сервер не обладает никакой информацией о содержимом файлов, поэтому всю обработку данных производит клиент. Это негативно на производительность системы. [1]
Использование архитектуры файл-сервер для любого предприятия является большим шагом вперед по сравнению с отдельными локальными ПЭВМ. Прежде всего, файл-сервер дает саму принципиальную возможность создания многопользовательских приложений, в которых доступ к одним и тем же данным осуществляется одновременно более чем с одного рабочего места. Во-вторых, поскольку улучшение сервера повышает производительность работы с любого клиентского места, эта архитектура более эффективна с точки зрения модернизации системы. Как правило, файл-сервер обладает специальными средствами, повышающими надежность хранения данных на сервере и уменьшающими вероятность потери информации после программного или аппаратного сбоя. И наконец, в архитектуре файл-сервер повышается безопасность системы, поскольку, как правило, сервер позволяет предоставлять различный уровень доступа к системе для разных пользователей. Как правило, при подключении клиента к серверу запрашивается имя и пароль, в зависимости от этого предоставляется соответствующий набор доступных ресурсов. [2]
Стоит заметить, что, поскольку в архитектуре файл-сервер впервые появляются клиент и сервер, то, строго говоря, в ней тоже используются клиент-серверные технологии, если брать самое широкое значение этого термина ( об этом мы будем говорить чуть позже). Однако, из-за того, что взаимодействие клиента и сервера осуществляется на слишком низком уровне - уровне файлов, в информационных приложениях, созданных в этой архитектуре, вся обработка данных ведется на клиенте. Для создания файл-серверных приложений, как правило, используются те же инструменты, что и для создания локальных приложений. [5]
На определенном этапе развития информационной системы предприятия архитектура файл-сервер является наиболее естественной. Она позволяет создать на предприятии автоматизированные комплексы масштаба отдела. Эти комплексы состоят из рабочих мест. Данные задач хранятся на сервере, как набор файлов, к которым осуществляется доступ со всех рабочих мест отдела. В архитектуре файл-сервер можно частично автоматизировать и обмен данными между различными отделами посредством передачи файлов. [2]
Однако, архитектура файл-сервер обладает целым рядом принципиальных ограничений. Это ограничения по числу одновременно работающих приложений с их ростом резко возрастает нагрузка на сеть. Это потенциальные проблемы с сохранностью данных при одновременном внесении изменений с разных мест. Это ограничения по сложности операций по обработке данных, поскольку вся она осуществляется на клиенте. Это, наконец, принципиальная невозможность гарантировать со стороны сервера целостность информации в базе данных, поскольку их обработка осуществляется каждым клиентом по отдельности.
На определенном этапе развития информационной системы предприятия все эти ограничения становятся принципиально важными. Как правило, этот скачок происходит при переходе к решению в рамках автоматизированной системы задач масштаба предприятия. При этом встает задача перехода к архитектуре клиент-сервер. [3]
1.4 Архитектура клиент-сервер
Подробно о том, что такое технологии и архитектура клиент-сервер, и почему они способны помочь при росте информационных систем на предприятии, мы поговорим ниже. Здесь же мы кратко опишем принципиальные архитектурные различия этой системы с файл-серверной, которая на сегодняшний день наиболее распространена в промышленности.
Как и для файл-серверной архитектуры, составными компонентами клиент-серверной архитектуры являются сервер, клиентские места и сетевая инфраструктура. Однако, в отличие от предыдущего случая, сервер здесь является уже не сервером файлов, а сервером баз данных или даже сервером приложений. Таким образом, на сервер ложится не просто хранение файлов, а поддержание базы данных в целостном состоянии или, в случае сервера приложений, даже выполнение той или иной части прикладной задачи. Естественно, что требования к серверу при этом могут возрастать в разы. [1]
С другой стороны, то, что сервер обладает информацией о характере хранимой базы данных, позволяет намного увеличить эффективность обработки. Поэтому для многих задач автоматизации нагрузка на сервер за счет более оптимального выполнения операций над данными по сравнению с аналогичными файл-серверными приложениями может даже уменьшиться. [2]
Соответственно, общение между клиентом и сервером происходит не на уровне файлов, а на уровне обмена запросами. Клиент передает серверу высокоуровневые запросы на получение той или иной информации либо на ее изменение, а сервер возвращает клиенту результаты выполнения запросов. При этом, в отличие от файл-серверной архитектуры, доступ к данным не является прозрачным для пользовательской программы. Поэтому, технология разработки таких приложений принципиально отлична от локальных и файл-серверных систем. [2]
На современном этапе сетевое обеспечение для архитектуры клиент-сервер аналогично файл-серверной. Клиент-серверные системы могут строиться с использованием тех же сетевых технологий и на той же сетевой инфраструктуре. Более того, как правило, на предприятии мирно сосуществуют обе эти архитектуры. Это вызвано двумя основными причинами. Во-первых, что на любом предприятии много задач, связанных с хранением и обменом документами, которые представляют собой отдельные файлы, а для них архитектура файл-сервер оптимальна. Во-вторых, файл-серверные задачи в том или ином объеме почти всегда сохраняются в том или ином объеме и эксплуатируются наряду с создаваемыми клиент-серверными приложениями. [4]
С точки зрения сетевого взаимодействия принципиально новым в приложениях клиент-сервер является возможность перехода к использованию глобальной сети. Скорость обмена в такой сети может быть на порядок ниже, а расстояния между рабочими местами могут достигать километров и даже десятков километров. Это осуществимо, поскольку в приложениях клиент-сервер объем передаваемой информации может быть радикально сокращен за счет использования высокоуровневых запросов к данным. [4]
Но главным изменение, которое может быть осуществлено промышленным предприятием при переходе к клиент-серверной архитектуре — это качественный скачок в масштабах задач, решаемых при компьютеризации, в том, насколько комплексно автоматизируется управление производством, в уровне целостности и достоверности данных, хранимых в информационной системе. [1]
Следует отметить, что появление клиент-серверных приложений на предприятии - процесс трудный и часто болезненный. Причем, помимо решения технических и финансовых проблем, при этом переходе очень важно осуществить изменение самого уровня управления, что влечет за собой огромную организационную работу. [3]
Вывод: В настоящее время мы наблюдаем активное развитие архитектуры вычислительных систем, на разных этапах существовали: централизованная архитектура приложений, персональные ЭВМ, файл-сервер и архитектура клиент-сервер [5]
Глава 2. Модель клиент-сервер как распределенная система
Распределенная система — это набор независимых компьютеров, представляющийся их пользователям единой объединенной системой. В этом определении оговариваются два момента. Первый относится к аппаратуре: все машины автономны. Второй касается программного обеспечения: пользователи думают, что имеют дело с единой системой. Важны оба момента. [1]
2.1 Определение и задачи распределенных систем
Распределенные системы должны также относительно легко поддаваться расширению, или масштабированию. Эта характеристика является прямым следствием наличия независимых компьютеров, но в то же время не указывает, каким образом эти компьютеры на самом деле объединяются в единую систему. Распределенные системы обычно существуют постоянно, однако некоторые их части могут временно выходить из строя. Пользователи и приложения не должны уведомляться о том, что эти части заменены или починены или что добавлены новые части для поддержки дополнительных пользователей или приложений. Для того чтобы поддержать представление различных компьютеров и сетей в виде единой системы, организация распределенных систем часто включает в себя дополнительный уровень программного обеспечения, находящийся между верхним уровнем, на котором находятся пользователи и приложения, и нижним уровнем, состоящим из операционных систем. [2]
В качестве примера рассмотрим сеть рабочих станций в университете или отделе компании. Вдобавок к персональной рабочей станции каждого из пользователей имеется пул процессоров машинного зала, не назначенных заранее ни одному из пользователей, но динамически выделяемых им при необходимости. Эта распределенная система может обладать единой файловой системой, в которой все файлы одинаково доступны со всех машин с использованием постоянного пути доступа. Кроме того, когда пользователь набирает команду, система может найти наилучшее место для выполнения запрашиваемого действия, возможно, на собственной рабочей станции пользователя, возможно, на простаивающей рабочей станции, принадлежащей кому-то другому, а может быть, и на одном из свободных процессоров машинного зала. [2] Если система в целом выглядит и ведет себя как классическая однопроцессорная система с разделением времени (то есть многопользовательская), она считается распределенной системой. В качестве второго примера рассмотрим работу информационной системы, которая поддерживает автоматическую обработку заказов. Обычно подобные системы используются сотрудниками нескольких отделов, возможно в разных местах. [1]
Так, сотрудники отдела продаж могут быть разбросаны по обширному региону или даже по всей стране. Заказы передаются с переносных компьютеров, соединяемых с системой при помощи телефонной сети, а возможно, и при помощи сотовых телефонов. Приходящие заказы автоматически передаются в отдел планирования, превращаясь там во внутренние заказы на поставку, которые поступают в отдел доставки, и в заявки на оплату, поступающие в бухгалтерию. Система автоматически пересылает эти документы имеющимся на месте сотрудникам, отвечающим за их обработку. Пользователи остаются в полном неведении о том, как заказы на самом деле курсируют внутри системы, для них все это представляется так, будто вся работа происходит в централизованной базе данных. [1]
Основная задача распределенных систем — облегчить пользователям доступ к удаленным ресурсам и обеспечить их совместное использование, регулируя этот процесс. Ресурсы могут быть виртуальными, однако традиционно они включают в себя принтеры, компьютеры, устройства хранения данных, файлы и данные. Web-страницы и сети также входят в этот список. Существует множество причин для совместного использования ресурсов. Одна из очевидных — это экономичность. Например, гораздо дешевле разрешить совместную работу с принтером нескольких пользователей, чем покупать и обслуживать отдельный принтер для каждого пользователя. Точно так же имеет смысл совместно использовать дорогие ресурсы, такие как суперкомпьютеры или высокопроизводительные хранилища данных. [1]
Однако по мере роста числа подключений и степени совместного использования ресурсов все более и более важными становятся вопросы безопасности. В современной практике системы имеют слабую защиту от подслушивания или вторжения по линиям связи. Пароли и другая особо важная информация часто пересылаются по сетям открытым текстом (то есть незашифрованными) или хранятся на серверах, надежность которых не подтверждена ничем, кроме нашей веры. Здесь имеется еще очень много возможностей для улучшения. Так, например, в настоящее время для заказа товаров необходимо просто сообщить номер своей кредитной карты. Редко требуется подтверждение того, что покупатель действительно владеет этой картой. В будущем заказ товара таким образом будет возможен только в том случае, если вы сможете физически подтвердить факт обладания этой картой при помощи считывателя карт. [1]
Другая проблема безопасности состоит в том, что прослеживание коммуникаций позволяет построить профиль предпочтений конкретного пользователя. Подобное отслеживание серьезно нарушает права личности, особенно если производится без уведомления пользователя. Связанная с этим проблема состоит в том, что рост подключений ведет к росту нежелательного общения, такого как получаемые по электронной почте бессмысленные письма, так называемый спам. Единственное, что мы можем сделать в этом случае, это защитить себя, используя специальные информационные фильтры, которые сортируют входящие сообщения на основании их содержимого. [2]
2.1.2 Единая компьютерная система
Как мы увидим, репликация имеет важное значение в распределенных системах. Так, ресурсы могут быть реплицированы для их лучшей доступности или повышения их производительности путем помещения копии неподалеку от того места, из которого к ней осуществляется доступ. Прозрачность репликации позволяет скрыть тот факт, что существует несколько копий ресурса. Для скрытия факта репликации от пользователей необходимо, чтобы все реплики имели одно и то же имя. Соответственно, система, которая поддерживает прозрачность репликаций должна поддерживать и прозрачность местоположения, поскольку иначе невозможно будет обращаться к репликам без указания их истинного местоположения. Мы часто упоминаем, что главная цель распределенных систем — обеспечить совместное использование ресурсов. [3]
Во многих случаях совместное использование ресурсов достигается посредством кооперации, например в случае коммутаций. Однако существует множество примеров настоящего совместного использования ресурсов. Например, два независимых пользователя могут сохранять свои файлы на одном файловом сервере или работать с одной и той же таблицей в совместно используемой базе данных. Следует отметить, что в таких случаях ни один из пользователей не имеет никакого понятия о том, что тот же ресурс задействован другим пользователем. Это явление называется прозрачностью параллельного доступа. [1]
Отметим, что подобный параллельный доступ к совместно используемому ресурсу сохраняет этот ресурс в непротиворечивом состоянии. Непротиворечивость может быть обеспечена механизмом блокР1ровок, когда пользователи, каждый по очереди, получают исключительные права на запрашиваемый ресурс. Более изощренный вариант — использование транзакций, однако, как мы увидим в следующих главах, механизм транзакций в распределенных системах труднореализуем. Популярное альтернативное определение распределенных систем, принадлежащее Leslie Lamport, выглядит так: «Вы понимаете, что у вас есть эта штука, поскольку при поломке компьютера вам никогда не предлагают приостановить работу». Это определение указывает еще на одну важную сторону распределенных систем: прозрачность отказов. Прозрачность отказов означает, что пользователя никогда не уведомляют о том, что ресурс (о котором он мог никогда и не слышать) не в состоянии правильно работать и что система далее восстановилась после этого повреждения. Маскировка сбоев — это одна из сложнейших проблем в распределенных системах и столь же необходимая их часть. Основная трудность состоит в маскировке проблем, возникающих в связи с невозможностью отличить неработоспособные ресурсы от ресурсов с очень медленным доступом. Так, контактируя с перегруженным web-сервером, браузер выжидает положенное время, а затем сообщает о недоступности страницы. При этом пользователь не должен думать, что сервер и правда не работает. [4]
Последний тип прозрачности, который обычно ассоциируется с распределенными системами, — это прозрачность сохранности маскирующая реальную или виртуальную сохранность ресурсов. Так, например, многие объектно-ориентированные базы данных предоставляют возможность непосредственного вызова методов для сохраненных объектов. За сценой в этот момент происходит следующее: сервер баз данных сначала копирует состояние объекта с диска в оперативную память, затем выполняет операцию и, наконец, записывает состояние на устройство длительного хранения. Пользователь, однако, остается в неведении о том, что сервер перемещает данные между оперативной памятью и диском. Сохранность играет важную роль в распределенных системах, однако не менее важна она и для обычных (не распределенных) систем. [5]
Хотя прозрачность распределения в общем желательна для всякой распределенной системы, существуют ситуации, когда попытки полностью скрыть от пользователя всякое распределение не слишком разумны. Это относится, например, к требованию присылать вам свежую электронную газету до 7 утра по местному времени, особенно если вы находитесь на другом конце света и живете в другом часовом поясе. Иначе ваша утренняя газета окажется совсем не той утренней газетой, которую вы ожидаете. [1]
Практика показывает, что при использовании компьютерных сетей на это реально требуется несколько сотен миллисекунд. Скорость передачи сигнала ограничивается не столько скоростью света, сколько скоростью работы промежуточных переключателей. Кроме того, существует равновесие между высокой степенью прозрачности и производительностью системы. Так, например, многие приложения, предназначенные для Интернета, многократно пытаются установить контакт с сервером, пока, наконец, не откажутся от этой затеи. Соответственно, попытки замаскировать сбой на промежуточном сервере, вместо того чтобы попытаться работать через другой сервер, замедляют всю систему. В данном случае было бы эффективнее как можно быстрее прекратить эти попытки или по крайней мере позволить пользователю прервать попытки установления контакта. Еще один пример: мы нуждаемся в том, чтобы реплики, находящиеся на разных континентах, были в любой момент гарантированно идентичны. Другими словами, если одна копия изменилась, изменения должны распространиться на все системы до того, как они выполнят какую-либо операцию. Понятно, что одиночная операция обновления может в этом случае занимать до нескольких секунд и вряд ли возможно проделать ее незаметно для пользователей. [3]
Открытая распределенная система — это система, предлагающая службы, вызов которых требует стандартные синтаксис и семантику. В компьютерных сетях формат, содержимое и смысл посылаемых и принимаемых сообщений подчиняются типовым правилам. Эти правила формализованы в протоколах. В распределенных системах службы обычно определяются через интерфейсы, которые часто описываются при помощи языка определения интерфейсов. Наиболее сложно точно определить то, что делает эта служба, то есть семантику интерфейсов. [4]
На практике подобные спецификации задаются неформально, посредством естественного языка. Будучи правильно описанным, определение интерфейса допускает возможность совместной работы произвольного процесса, нуждающегося в таком интерфейсе, с другим произвольным процессом, предоставляющим этот интерфейс. Определение интерфейса также позволяет двум независимым группам создать абсолютно разные реализации этого интерфейса для двух различных распределенных систем, которые будут работать абсолютно одинаково. [2]
Правильное определение самодостаточно и нейтрально. «Самодостаточно» означает, что в нем имеется все необходимое для реализации интерфейса. Однако многие определения интерфейсов сделаны самодостаточными не до конца, поскольку разработчикам необходимо включать в них специфические детали реализации. Важно отметить, что спецификация не определяет внешний вид реализации, она должна быть нейтральной. Самодостаточность и нейтральность необходимы для обеспечения переносимости и способности к взаимодействию. [5]
Способность к взаимодействию характеризует, насколько две реализации систем или компонентов от разных производителей в состоянии совместно работать, полагаясь только на то, что службы каждой из них соответствуют общему стандарту. Следующая важная характеристика открытых распределенных систем — это гибкость. Под гибкостью мы понимаем легкость конфигурирования системы, состоящей из различных компонентов, возможно от разных производителе. Не должны вызывать затруднений добавление к системе новых компонентов или замена существующих, при этом прочие компоненты, с которыми не производилось никаких действий, должны оставаться неизменными. [4]
В построении гибких открытых распределенных систем решающим фактором оказывается организация этих систем в виде наборов относительно небольших и легко заменяемых или адаптируемых компонентов. Это предполагает необходимость определения не только интерфейсов верхнего уровня, с которыми работают пользователи и приложения, но также PI интерфейсов внутренних модулей системы и описания взаимодействия этих модулей. Этот подход относительно молод. Множество старых и современных систем создавались цельными так, что компоненты одной гигантской программы разделялись только логически. В случае использования этого подхода независимая замена или адаптация компонентов, не затрагивающая систему в целом, была почти невозможна. Монолитные системы вообще стремятся скорее к закрытости, чем к открытости. Необходимость изменения в распределенных системах часто связана с тем, что компонент не оптимальным образом соответствует нуждам конкретного пользователя или приложения. [2]
Браузеры обычно позволяют пользователям адаптировать правила кэширования под их нужды путем определения размера кэша, а также того, должен ли документ проверяться на соответствие постоянно или только один раз за сеанс. Однако пользователь не может воздействовать на другие параметры, такие как длительность сохранения документа в кэше или очередность удаления документов из кэша при его переполнении. Также невозможно создавать правила на основе содержимого документа. [1]
Так, например, пользователь может пожелать кэшировать железнодорожные расписания, которые редко изменяются, но никогда — информацию о пробках на улицах города. Нам необходимо отделить правила от механизма. В случае кэширования в Web, например, браузер в идеале должен предоставлять только возможности для сохранения документов в кэше и одновременно давать пользователям возможность решать, какие документы и насколько долго там хранить. На практике это может быть реализовано предоставлением большого списка параметров, значения которых пользователь сможет (динамически) задавать. Еще лучше, если пользователь получит возможность сам устанавливать правила в виде подключаемых к браузеру компонентов. Разумеется, браузер должен понимать интерфейс этих компонентов, поскольку ему нужно будет, используя этот интерфейс, вызывать процедуры, содержащиеся в компонентах. [5]
В больших распределенных системах гигантское число сообщений необходимо направлять по множеству каналов. Теоретически для вычисления оптимального пути необходимо получить полную информацию о загруженности всех машин и линий и по алгоритмам из теории графов вычислить все оптимальные маршруты. Эта информация затем должна быть передана по системе для улучшения маршрутизации. Проблема состоит в том, что сбор и транспортировка всей информации туда- сюда — не слишком хорошая идея, поскольку сообщения, несущие эту информацию, могут перегрузить часть сети. Фактически следует избегать любого алгоритма, который требует передачи информации, собираемой со всей сети, на одну из ее машин для обработки с последующей раздачей результатов. Использовать следует только децентрализованные алгоритмы. Первые три свойства поясняют то, о чем мы только что говорили. Последнее, вероятно, менее очевидно, но не менее важно. Алгоритмы должны принимать во внимание отсутствие полной синхронизации таймеров. Чем больше система, тем большим будет и рассогласование. [1]
Одна из основных причин сложности масштабирования существующих распределенных систем, разработанных для локальных сетей, состоит в том, что в их основе лежит принцип синхронной связи. В этом виде связи запрашивающий службу агент, которого принято называть клиентом, блокируется до получения ответа. Этот подход обычно успешно работает в локальных сетях, когда связь между двумя машинами продолжается максимум сотни микросекунд. Однако в глобальных системах мы должны принять во внимание тот факт, что связь между процессами может продолжаться сотни миллисекунд, то есть на три порядка дольше. Построение интерактивных приложений с использованием синхронной связи в глобальных системах требует большой осторожности (и немалого терпения). Другая проблема, препятствующая географическому масштабированию, состоит в том, что связь в глобальных сетях фактически всегда организуется от точки к точке и потому ненадежна. В противоположность глобальным, локальные сети обычно дают высоконадежную связь, основанную на широковещательный рассылке, что делает разработку распределенных систем для них значительно проще. Для примера рассмотрим проблему локализации службы. В локальной сети система просто рассылает сообщение всем машинам, опрашивая их на предмет предоставления нужной службы. Машины, предоставляющие службу, отвечают на это сообщение, указывая в ответном сообщении свои сетевые адреса. Невозможно представить себе подобную схему определения местоположения в глобальной сети. Вместо этого необходимо обеспечить специальные места для расположения служб, которые может потребоваться масштабировать на весь мир и обеспечить их мощностью для обслуживания миллионов пользователей. [2]
Сокрытие времени ожидания связи применяется в случае географического масштабирования. Основная идея проста: постараться по возможности избежать ожидания ответа на запрос от удаленного сервера. Например, если была запрошена служба удаленной машины, альтернативой ожиданию ответа от сервера будет осуществление на запрашивающей стороне других возможных действий. В сущности, это означает разработку запрашивающего приложения в расчете на использование исключительно асинхронной связи. Когда будет получен ответ, приложение прервет свою работу и вызовет специальный обработчик для завершения отправленного ранее запроса. [3]
Асинхронная связь часто используется в системах пакетной обработки и параллельных приложениях, в которых во время ожидания одной задачей завершения связи предполагается выполнение других более или менее независимых задач. Для осуществления запроса может быть запущен новый управляющий поток выполнения. Хотя он будет блокирован на время ожидания ответа, другие потоки процесса продолжат свое выполнение. Однако многие приложения не в состоянии эффективно использовать асинхронную связь. Например, когда в интерактивном приложении пользователь посылает запрос, он обычно не в состоянии делать ничего более умного, чем просто ждать ответа. В этих случаях наилучшим решением будет сократить необходимый объем взаимодействия, например, переместив часть вычислений, обычно выполняемых на сервере, на клиента, процесс которого запрашивает службу. Стандартный случай применения этого подхода — доступ к базам данных с использованием форм. [1]
Вывод: распределенная система — это совокупность, компьютеров, которые независимы друг от друга и являющихся одной соединенной системой. основными задачами распределенной системы являются, доступность, прозрачность, открытость, масштабируемость.
Глава 3. Применение архитектуры клиент-сервер для БД
Вычислительная модель «клиент–сервер» исходно связана с парадигмой открытых систем, которая появилась в 90-х и быстро эволюционировала. Сам термин «клиент–сервер» изначально применялся к архитектуре программного обеспечения, которое описывало распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели назывался клиентом, а другой — сервером. Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов. [2]
Ранее приложение (пользовательская программа) не разделялось на части, оно выполнялось некоторым монолитным блоком. Но возникла идея более рационального использования ресурсов сети. Действительно, при монолитном исполнении используются ресурсы только одного компьютера, а остальные компьютеры в сети рассматриваются как терминалы. Но теперь, в отличие от периода main-фреймов, все компьютеры в сети обладают собственными ресурсами, и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их ресурсы. [1]
Как и в промышленности, в области вычислительной техники возникает древняя как мир идея распределения обязанностей, разделения труда. Конвейеры Форда сделали в свое время прорыв в автомобильной промышленности, показав наивысшую производительность труда именно из-за того, что весь процесс сборки был разбит на мелкие и максимально простые операции и каждый рабочий специализировался на выполнении только одной операции, но эту операцию он выполнял максимально быстро и качественно. [5]
Конечно, в вычислительной технике нельзя было напрямую использовать технологию автомобильного или любого другого механического производства, но идею использовать было возможно. Однако для воплощения идеи необходимо было разработать модель разбиения единого монолитного приложения на отдельные части и определить принципы взаимосвязи между этими частями.
3.1 Основной принцип для БД
Основной принцип технологии «клиент–сервер» применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу:
- функции ввода и отображения данных — презентационная логика (Presentation Logic);
- прикладные функции, определяющие основные алгоритмы решения задач приложения — бизнес-логика, или логика собственно приложения (Business Logic);
- функции обработки данных внутри приложения (Database Logic);
- функции управления информационными ресурсами (Database Manager System);
- служебные функции, играющие роль связок между функциями первых четырех групп. [4]
Презентационная логика (Presentation Logic) как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, к этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация. Поэтому основными задачами презентационной логики являются:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатие клавиш клавиатуры.
Некоторые возможности для организации презентационной логики приложений предоставляет знако-ориентированный пользовательский интерфейс, задаваемый моделями CICS (Customer Control Information System) и IMS/DC фирмы IBM и моделью TSO (Time Sharing Option) для централизованной main-фреймовой архитектуры. Модель GUI — графического пользовательского интерфейса поддерживается в операционных средах Microsoft’s Windows, Windows NT, в OS/2 Presentation Manager, X-Windows и OSF/Motif. [5]
Бизнес-логика, или логика собственно приложений (Business processing Logic), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием раз личных языков программирования, таких как C, C++, Cobol, SmallTalk, VisualBasic.
Логика обработки данных (Data manipulation Logic) — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД (DBMS). Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL. Обычно операторы языка SQL встраиваются в языки 3-го или 4-го поколения (3GL, 4GL), которые используются для написания кода приложения. [3]
Процессор управления данными (Database Manager System Processing) — это собственно СУБД, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
В централизованной архитектуре (Host-based processing) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой про граммы.
3.2 Модели распределений задач
В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений:
- распределенная презентация (Distribution presentation, DP);
- удаленная презентация (Remote Presentation, RP);
- распределенная бизнес-логика (Remote business logic, RBL);
- распределенное управление данными (Distributed data management, DDM);
- удаленное управление данными (Remote data management, RDA).
Эта условная классификация показывает, как могут быть распределены отдельные задачи между серверным и клиентскими процессами. В этой классификации отсутствует реализация удаленной бизнес-логики. Действительно, считается, что она не может быть удалена сама по себе полностью. Считается, что она может быть распределена между разными процессами, которые в общем-то могут выполняться на разных платформах, но должны корректно кооперироваться (взаимодействовать) друг с другом. [1]
3.3 Двухуровневые модели
Двухуровневая модель фактически является результатом распределения пяти указанных функций между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере. В чистом виде почти никакая модель не существует, однако рассмотрим наиболее характерные особенности каждой двухуровневой модели. [2]
3.3.1 Модель удаленного управления данными. Модель файлового сервера
Модель удаленного управления данными также называется моделью файлового сервера (File Server, FS). В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиенте. []
Распределение функций в этой модели представлено на Рисунке 1.
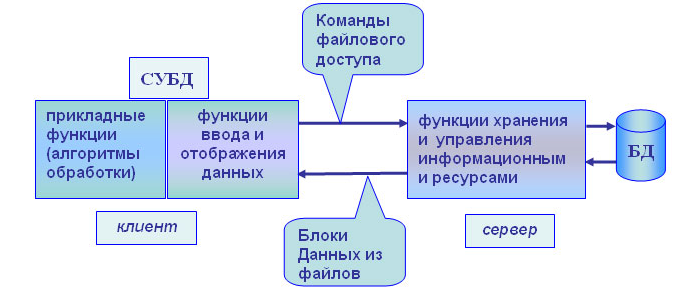 Рисунок 1. Двухуровневая модель
Рисунок 1. Двухуровневая модель
В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база метаданных, находится на клиенте. [3]
Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на клиенте. [2]
Каков алгоритм выполнения запроса клиента?
Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответа на запрос, то принимается решение о перекачке следующего блока информации и т. д. [1]
Недостатки этой модели:
- высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению;
- узкий спектр операций манипулирования с данными, который определяется только файловыми командами;
- отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
3.3.2 Модель удаленного доступа к данным
В модели удаленного доступа (Remote Data Access, RDA) база данных хранится на сервере. На сервере же находится ядро СУБД. На клиенте располагается презентационная логика и бизнес-логика приложения. [2] Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на Рисунке 2.
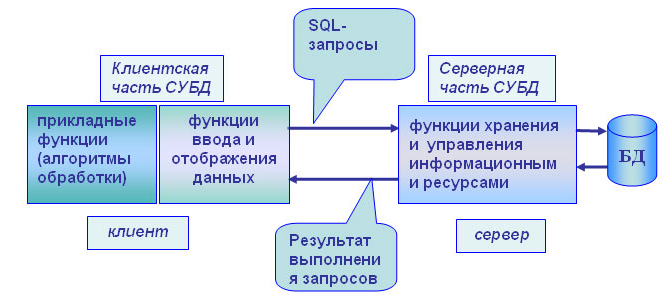 Рисунок 2. Модель удаленного доступа
Рисунок 2. Модель удаленного доступа
Преимущества данной модели:
- перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД, сведя к минимуму общее число процессов в операционной системе;
- сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций (это становится возможным, если отказаться от терминалов, не располагающих ресурсами, и заменить их компьютерами, выполняющими роль клиентских станций, которые обладают собственными локальными вычислительными ресурсами);
- резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, релевантные запросу, а не блоки файлов, как в FS-модели. [1]
Основное достоинство RDA-модели — унификация интерфейса «клиент–сервер», стандартом при общении приложения- клиента и сервера становится язык SQL. [5]
Недостатки данной модели:
- все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть;
- так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения — это вызывает излишнее дублирование кода приложений;
- сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте. Действительно, например, если нам необходимо выполнять контроль страховых запасов товаров на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаление товара со склада, должно выполнять проверку на объем остатка, и в случае, если он меньше страхового запаса, формировать соответствующую заявку на поставку требуемого товара. Это усложняет клиентское приложение, с одной стороны, а с другой — может вызвать необоснованный заказ дополнительных товаров несколькими приложениями. [4]
3.3.3 Модель сервера баз данных
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия:
- Необходимо, чтобы БД в каждый момент отражала текущее состояние предметной области, которое определяется не только собственно данными, но и связями между объектами данных, т. е. данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми.
- БД должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Например, завод может нормально работать только в том случае, если на складе имеется некоторый достаточный запас (страховой запас) деталей определенной номенклатуры: деталь может быть запущена в производство только в том случае, если на складе имеется в наличии достаточно материала для ее изготовления, и т. д. [1]
- Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них: например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры; при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара. [3]
- Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи.
- Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, т. е. такие, которые определены в DDL (data definition language) — языке описания данных, который является частью SQL. Однако в реальных предметных областях у нас действуют данные, которые несут в себе еще и семантическую составляющую, например координаты объектов или единицы различных метрик, так, рабочая неделя в отличие от реальной имеет сразу после пятницы понедельник. [1]
Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры. Модель сервера баз данных представлена на рисунке 3.
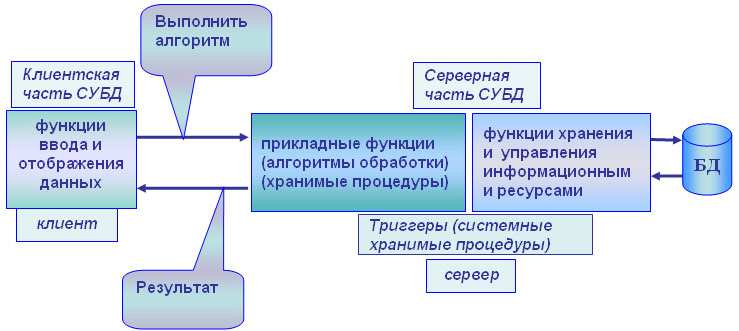 Рисунок 3. Пример сервера базы данных
Рисунок 3. Пример сервера базы данных
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается. [2]
Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД. [1]
Термин «триггер» взят из электроники и семантически очень точно характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры. [1]
Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. [5]
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так называемый встроенный SQL. Встроенный SQL мы рассмотрим далее.
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции:
- осуществляет мониторинг событий, связанных с описанными триггерами;
- обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
- обеспечивает исполнение внутренней программы каждого триггера;
- запускает хранимые процедуры по запросам пользователей;
- запускает хранимые процедуры из триггеров;
- возвращает требуемые данные клиенту;
- обеспечивает все функции СУБД: доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД.
Если мы переложили на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом» в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом». [4]
Для разгрузки сервера была предложена трехуровневая модель.
3.3.4 Модель сервера приложений
Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Архитектура трехуровневой модели приведена на рисунке 4. Этот промежуточный уровень содержит один или несколько серверов приложений. [1]
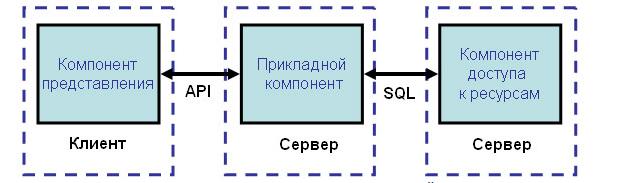 Рисунок 4. 3-уровневая архитектура
Рисунок 4. 3-уровневая архитектура
В этой модели компоненты приложения делятся между тремя исполнителями:
- Клиент обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, расположенной на компьютере-клиенте. Клиент исполняет коммуникационные функции front-end части приложения, которые обеспечивают клиенту доступ в локальную или глобальную сеть. Кроме того, реализация взаимодействия между клиентом и сервером может включать в себя управление распределенными транзакциями, что соответствует тем случаям, когда клиент также является клиентом менеджера распределенных транзакций. [5]
- Серверы приложений составляют новый промежуточный уровень архитектуры. Они спроектированы как исполнения общих незагружаемых функций для клиентов. Серверы приложений поддерживают функции клиентов как частей взаимодействующих рабочих групп, поддерживают сетевую доменную операционную среду, хранят и исполняют наиболее общие правила бизнес-логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов, особенно в распределенных транзакциях.
- Серверы баз данных в этой модели занимаются исключительно функциями СУБД: обеспечивают функции создания и ведения БД, поддерживают целостность реляционной БД, обеспечивают функции хранилищ данных (warehouse services). Кроме того, на них возлагаются функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и поддержки устаревших (унаследованных) приложений (legacy application). [4]
Отметим, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных, которые относятся к области OLAP-приложений (On-line analytical processing). В этой модели большая часть бизнес-логики клиента изолирована от возможностей встроенного SQL, реализованного в конкретной СУБД, и может быть выполнена на стандартных языках программирования, таких как C, C++, SmallTalk, Cobol. Это повышает переносимость системы, ее масштабируемость.
Функции промежуточных серверов могут быть в этой модели распределены в рамках глобальных транзакций путем поддержки XA-протокола (X/Open transaction interface protocol), который поддерживается большинством поставщиков СУБД. [2]
3.3.5 Архитектура серверов баз данных
В период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия процессов типа «клиент» и процессов типа «сервер». В современных же СУБД он является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом.
Рассмотрим эволюцию типов организации подобных механизмов. В основном этот механизм определяется структурой реализации серверных процессов, и часто называется архитектурой сервера баз данных. [3]
Первоначально, как мы уже отмечали, существовала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Это можно назвать нулевым этапом развития серверов БД (рисунок 5а).
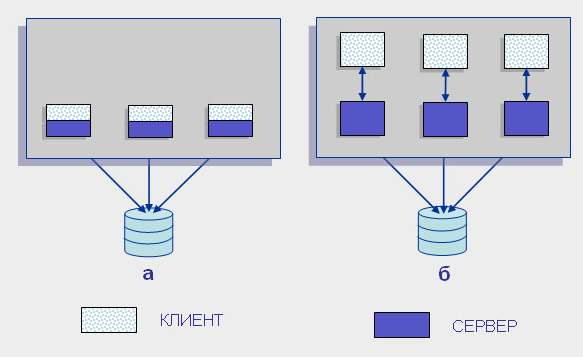 Рисунок 5. Развитие серверов БД
Рисунок 5. Развитие серверов БД
Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один к одному» (рисунок 5б), т. е. сервер обслуживал запросы только одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверных процессов.
Логически каждый клиент связан с сервером отдельной нитью (thread), или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной (multi-threaded). Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей.
Кроме того, возможность взаимодействия с одним сервером многих клиентов позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один к одному» будет создано 100 копий процессов СУБД для 100 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один серверный процесс. [2]
Однако такое решение имеет свои недостатки. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три. В некоторых системах эта проблема решается вводом промежуточного диспетчера. Подобная архитектура называется архитектурой виртуального сервера (virtual server) (рисунок 6).
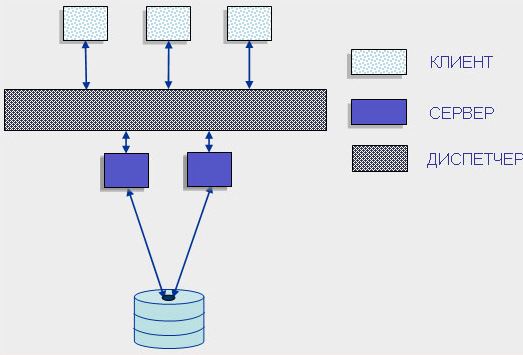 рисунок 6. Виртуальный сервер
рисунок 6. Виртуальный сервер
В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к актуальным серверам. В этом случае нет ограничений на использование многопроцессорных платформ. Количество актуальных серверов может быть согласовано с количеством процессоров в системе. [2]
Однако и эта архитектура не лишена недостатков, потому что здесь в систему добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки актуальных серверов (load balancing) и ограничивает возможности управления взаимодействием «клиент–сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу; во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов. [1]
Подобная организация взаимодействия «клиент–сервер» может рассматриваться как аналог банка, где имеется несколько окон кассиров, и специальный банковский служащий — администратор зала (диспетчер) направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако стоит лишь появиться посетителям с высшим приоритетом, которые должны обслуживаться в специальном окне, как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией. [4]
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основания говорить о многопотоковой архитектуре с несколькими серверами, представленной на рисунке 7.
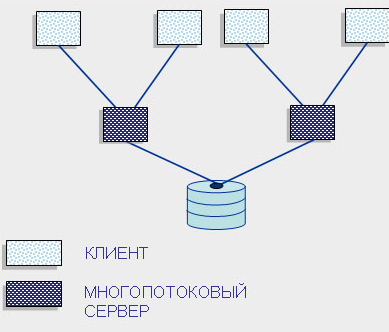 Рисунок 7. Многопотоковая архитектура
Рисунок 7. Многопотоковая архитектура
Она также может быть названа многонитиевой мультисерверной архитектурой. Эта архитектура связана с распараллеливанием выполнения одного пользовательского запроса несколькими серверными процессами. [3]
Существует несколько возможностей распараллеливания выполнения запроса. В этом случае пользовательский запрос разбивается на ряд подзапросов, которые могут выполняться параллельно, а результаты их выполнения потом объединяются в общий результат выполнения запроса. Тогда для обеспечения оперативности выполнения запросов их подзапросы могут быть направлены отдельным серверным процессам, а потом полученные результаты объединены в общий результат. В данном случае серверные процессы не являются независимыми процессами, такими, как рассматривались ранее. Эти серверные процессы принято называть нитями (treads), и управление нитями множества запросов пользователей требует дополнительных расходов от СУБД, однако при оперативной обработке информации в хранилищах данных такой подход наиболее перспективен. [2]
Вывод: таким образом, существует большой выбор способов организации архитектуры клиент-сервер системы для баз данных. Необходимо тщательно анализировать и учитывать плюсы и минусы каждой из архитектур.
Заключение
Активно развитие компьютерных наук и сети привело к большому количеству информации и способов реализации различных систем. Так полвека назад появилось понятие распределенные системы и стала часто использоваться технология клиент-сервер.
Эта технология применима к различным системах, но в рамках данного предмета мы рассмотрели 3 части.
Первая глава история архитектуры информационных систем показывает развитие архитектуры в целом, что предшествовало и что привело к формированию данной технологии.
Вторая глава, это распределенные системы, определения и задачи, так как клиент-серверная технология является архитектурой распределенной системы.
В заключительной практической части построили схемы различных типов архитектур клиент-серверной организации систем баз данных. Там мы рассмотрели различные уровни организации, а так же плюсы и минусы каждого паттерна.
Основные выводы которые можно сделать по данной курсовой работе:
- В настоящее время мы наблюдаем активное развитие архитектуры вычислительных систем, на разных этапах существовали: централизованная архитектура приложений, персональные ЭВМ, файл-сервер и архитектура клиент-сервер
- распределенная система — это совокупность, компьютеров, которые независимы друг от друга и являющихся одной соединенной системой. основными задачами распределенной системы являются, доступность, прозрачность, открытость, масштабируемость.
- существует большой выбор способов организации архитектуры клиент-сервер системы для баз данных. Необходимо тщательно анализировать и учитывать плюсы и минусы каждой из архитектур.
Библиография
- Таненбаум Э. Распределенные системы, принципы и парадигмы / Э. Таненбаум — Спб.: Питер, 2003. - 877 с.
- Гома Х. UML. Проектирование систем реального времени, параллельных и распределенных приложений / Х. Гома — ДМК Пресс, 2016. - 700 с.
- Габалин А. Вопросы оптимизации структуры распределенных систем обработки информации / А. Габалин — Издательский дом Университета "Университет" , 2007. - 300 с.
- Виноградов В. Информационно-вычислительные системы. Распределенные модульные системы автоматизации / В. Виноградов — Энергоатомиздат, 1986. - 385 с.
- Бежитский С. Распределенные системы обработки информации и управления / С. Бежитский — Энергоатомиздат, 2012. - 140 с.

- Применение объектно-ориентированного подхода при проектировании информационной системы (Используя принципы ООП)
- Профессиональная деформация
- Разработка регламента выполнения процесса "Совершенствование существующих продуктов"
- Операции, производимые с данными (данные и сообщения)
- Исключительные (имущественные) права на товарный знак ООО «O’STIN»
- Оценка стоимости ценных бумаг
- Теория государства и права как наука и учебная дисциплина
- Налоговая система РФ и проблемы её совершенствования
- Понятие и признаки государства
- Понятие и виды наследования (Основания и порядок наследования)
- Выбор стиля руководства в организации
- Выбор стиля руководства в организации (Классификация стилей руководства )