
Технология «клиент-сервер» (Модель клиент-сервер)
Содержание:

ВВЕДЕНИЕ
Как правило, компьютеры и программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами (файловая система, процессор, принтер, база данных и т.д.), другие имеют возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных, вычислительный сервер...). Клиент и сервер какого-либо ресурса могут находится как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
Основной принцип технологии "клиент-сервер" заключается в разделении функций приложения на три группы:
- ввод и отображение данных (взаимодействие с пользователем);
- прикладные функции, характерные для данной предметной области;
- функции управления ресурсами (файловой системой, базой даных и т.д.)
Поэтому, в любом приложении выделяются следующие компоненты:
- компонент представления данных
- прикладной компонент
- компонент управления ресурсом
Связь между компонентами осуществляется по определенным правилам, которые называют "протокол взаимодействия".
Технология «клиент-сервер» пришла на смену централизованной схеме управления вычислительным процессом на мейнфреймах еще в 80-х годах прошлого века. Благодаря высокой живучести и надежности вычислительной системы, легкости масштабирования, возможности одновременной работы пользователя с несколькими приложениями, высокой оперативности обработки информации, обеспечению пользователя высококачественным интерфейсом и другим возможностям эта весьма перспективная и далеко не исчерпавшая себя технология получила свое дальнейшее развитие.
Со временем малофункциональную модель файлового сервера для локальных сетей (FS) заменили появившиеся одна за одной модели структуры «Клиент- сервер» (RDA, DBS и AS).
Заняв нишу баз данных, технология «Клиент – сервер» стала основной технологией глобальной сети Internet. Далее, в результате перенесения идей сети Internet в среду корпоративных систем, появилась технология Intranet. В отличие от технологии «Клиент-сервер» эта технология ориентирована не на данные, а на информацию в ее окончательно готовом к потреблению виде. Вычислительные системы, построенные на основе Intеrnet, имеют в своем составе центральные серверы информации и распределенные компоненты представления информации конечному пользователю (программы-навигаторы, или браузеры). Взаимодействие между клиентом и сервером в Intеrnet происходит при помощи web – технологий.[1]
На сегодняшний день технология «Клиент-сервер» получает все большее распространение, однако сама по себе она не предлагает универсальных рецептов. Она лишь дает общее представление о том, как должна быть организована современная распределенная информационная система. В то же время реализации этой технологии в конкретных программных продуктах и даже в видах программного обеспечения различаются весьма существенно.
ГЛАВА 1. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1.1. Основные понятия серверов
Сервер (от англ. server обслуживающий). В зависимости от предназначения существует несколько определений понятия сервер.
1. Сервер (сеть) — логический или физический узел сети обслуживающий запросы к одному адресу и/или доменному имени (смежным доменным именам) состоящий из одного или системы аппаратных серверов на котором выполняются один или система серверных программ
2. Сервер (программное обеспечение) — программное обеспечение принимающее запросы от клиентов (в архитектуре клиент-сервер).
3. Сервер (аппаратное обеспечение) — компьютер (или специальное компьютерное оборудование) выделенный и/или специализированный для выполнения определенных сервисных функций.
4. Сервер в информационных технологиях — программный компонент вычислительной системы выполняющий сервисные функции по запросу клиента предоставляя ему доступ к определённым ресурсам.[2]
Взаимосвязь понятий. Серверное приложение (сервер) запускается на компьютере так же называемом "сервер" при этом при рассмотрении топологии сети такой узел называют "сервером". В общем случае может быть так что серверное приложение запущено на обычной рабочей станции или серверное приложение, запущенное на серверном компьютере в рамках рассматриваемой топологии выступает в роли клиента (т.е. не является сервером с точки зрения сетевой топологии).
В зависимости от того, в какой мере человек владеет навыками работы на компьютере и какие операции собирается выполнять на нем, он выбирает подходящий для себя компьютер. Например, для офисного компьютера важно, чтобы он был не очень дорогим и мог работать с типовыми офисными приложениями. Для семьи, где дети любят компьютерные игры, а взрослые – фильмы, желательно выбрать компьютер, который будет достаточно мощным, и способным воспроизводить разные медиа-данные. Однако, с любым персональным компьютером работает один пользователь.
Иное дело – сервер. Сервер - компьютер, на который установлено специальное программное обеспечение. Именно оно дает возможность оказывать услуги другим устройствам, подключенным к серверу, - сразу нескольким компьютерам, принтерам, факсам и т.д. Устройства, подключенные к серверу, называют клиентами.
Наличие сервера позволяет предприятию выполнять более масштабные задачи, нежели это возможно при использовании обычного компьютера.
Именно от качества сервера зависит успешность работы всей сети предприятия и возможность выполнения тех целей и задач, которые стоят перед ним. В зависимости от задач компании и нужно выбирать сервер.[3]
Самая главная характеристика сервера – это его производительность, которая зависит от нескольких параметров:
- во-первых, от типа и производительности процессоров;
- во-вторых, от объема и типа оперативной памяти;
- в-третьих, от производительности дисковой подсистемы.
Например, чем больше процессоров составляют начинку сервера и чем больше ядер в каждом из них, тем больше мощность всей сети. В принципе, выбирая конфигурацию сервера, нужно обязательно предусмотреть возможность расширения его через некоторое время, если возникнет потребность. Для этого нужно позаботиться о наличии процессоров, памяти и пр. устройств, совместимых с уже имеющимися.
Вторая важная характеристика сервера – его управляемость. Имеется ввиду, что должны быть обеспечены такие функции, как удаленные мониторинг и диагностика. Т.е. желательно, чтобы сервером можно было управлять на расстоянии: включать и перезагружать, диагностировать и исправлять неполадки даже в выключенном состоянии (при условии, что он подключен к электрической сети).[4]
Первые две характеристики – производительность и управляемость – в значительной мере влияют на надежность сервера, что подразумевает не только физическую его надежность и качественную сборку, но и программную, которая состоит в стабильной работе всех программ.
Кроме перечисленного, следует обратить внимание на масштабируемость сервера, что позволяет значительно увеличить его мощность в плане производимых операционной системой вычислительных операций. Иными словами, масштабируемость означает, что система имеет способность увеличивать мощность в случае увеличения рабочей нагрузки без снижения таких показателей, как надежность и отказоустойчивость.
1.2. Модель клиент-сервер
Клиент-серверная система характеризуется наличием двух взаимодействующих самостоятельных процессов - клиента и сервера которые в общем случае могут выполняться на разных компьютерах обмениваясь данными по сети.
Процессы, реализующие некоторую службу, например службу файловой системы или базы данных называются серверами (servers). Процессы, запрашивающие службы у серверов путем посылки запроса и последующего ожидания ответа от сервера называются клиентами (clients) .[5]
По такой схеме могут быть построены системы обработки данных на основе СУБД почтовые и другие системы. Мы будем говорить о базах данных и системах на их основе. И здесь удобнее будет не просто рассматривать клиент-серверную архитектуру, а сравнить ее с другой - файл-серверной.
В файл-серверной системе данные хранятся на файловом сервере (например ,Novell NetWare или Windows NT Server) а их обработка осуществляется на рабочих станциях на которых, как правило,функционирует одна из так называемых "настольных СУБД" - Access FoxPro Paradox и т.п..[6]
Приложение на рабочей станции "отвечает за все" - за формирование пользовательского интерфейса логическую обработку данных и за непосредственное манипулирование данными. Файловый сервер предоставляет услуги только самого низкого уровня - открытие закрытие и модификацию файлов. Обратите внимание – файлов, а не базы данных. Система управления базами данных расположена на рабочей станции.
Таким образом, непосредственным манипулированием данными занимается несколько независимых и несогласованных между собой процессов.[7] Кроме того для осуществления любой обработки (поиск модификация суммирование и т.п.) все данные необходимо передать по сети с сервера на рабочую станцию (см. рис. Сравнение файл-серверной и клиент-серверной моделей)
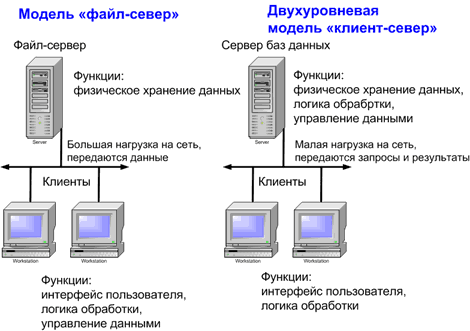
Рис 1. Сравнение файл-серверной и клиент-серверной моделей
В клиент-серверной системе функционируют (как минимум) два приложения - клиент и сервер, делящие между собой те функции, которые в файл-серверной архитектуре целиком выполняет приложение на рабочей станции. Хранением и непосредственным манипулированием данными занимается сервер баз данных, в качестве которого может выступать Microsoft SQL Server Oracle Sybase и т.п..[8]
Формированием пользовательского интерфейса занимается клиент для построения которого можно использовать целый ряд специальных инструментов а также большинство настольных СУБД. Логика обработки данных может выполняться как на клиенте, так и на сервере. Клиент посылает на сервер запросы сформулированные, как правило, на языке SQL. Сервер обрабатывает эти запросы и передает клиенту результат (разумеется, клиентов может быть много)[9].
Таким образом, непосредственным манипулированием данными занимается один процесс. При этом обработка данных происходит там же, где данные хранятся - на сервере что исключает необходимость передачи больших объемов данных по сети.[10]
Что дает архитектура клиент-сервер?
Посмотрим на данную архитектуру с точки зрения потребностей бизнеса. Какие же качества привносит клиент-сервер в информационную систему?
Надежность - сервер баз данных осуществляет модификацию данных на основе механизма транзакций который придает любой совокупности операций объявленных как транзакция следующие свойства:
Атомарность - при любых обстоятельствах будут либо выполнены все операции транзакции либо не выполнена ни одна; целостность данных при завершении транзакции;
Независимость - транзакции инициированные разными пользователями не вмешиваются в дела друг друга;
Устойчивость к сбоям - после завершения транзакции ее результаты уже не пропадут. Механизм транзакций, поддерживаемый сервером баз данных, намного более эффективен чем аналогичный механизм в настольных СУБД т.к. сервер централизованно контролирует работу транзакций. Кроме того, в файл-серверной системе сбой на любой из рабочих станций может привести к потере данных и их недоступности для других рабочих станций, в то время как в клиент-серверной системе сбой на клиенте практически никогда не сказывается на целостности данных и их доступности для других клиентов.
Масштабируемость - способность системы адаптироваться к росту количества пользователей и объема базы данных при адекватном повышении производительности аппаратной платформы без замены программного обеспечения.[11]
Общеизвестно, что возможности настольных СУБД серьезно ограничены - это пять-семь пользователей и 30-50 Мб соответственно. Цифры разумеется представляют собой некие средние значения в конкретных случаях они могут отклоняться как в ту так и в другую сторону. Что наиболее существенно эти барьеры нельзя преодолеть за счет наращивания возможностей аппаратуры.
Системы же на основе серверов баз данных могут поддерживать тысячи пользователей и сотни ГБ информации - дайте им только соответствующую аппаратную платформу.
Безопасность - сервер баз данных предоставляет мощные средства защиты данных от несанкционированного доступа невозможные в настольных СУБД. При этом права доступа администрируются очень гибко - до уровня полей таблиц. Кроме того можно вообще запретить прямое обращение к таблицам осуществляя взаимодействие пользователя с данными через промежуточные объекты - представления и хранимые процедуры. Так что администратор может быть уверен - никакой слишком умный пользователь не прочитает то что ему читать неположено.
Гибкость - в приложении работающем с данными можно выделить три логических слоя:
-пользовательского интерфейса;
-правил логической обработки (бизнес-правил);
-управления данными (не следует только путать логические слои с физическими уровнями, о которых речь пойдет ниже).[12]
Как уже говорилось, в файл-серверной архитектуре все три слоя реализуются в одном монолитном приложении, функционирующем на рабочей станции. Поэтому изменения в любом из слоев приводят однозначно к модификации приложения и последующему обновлению его версий на рабочих станциях.[13]
В двухуровневом клиент-серверном приложении показанном на рисунке выше, как правило, все функции по формированию пользовательского интерфейса реализуются на клиенте все функции по управлению данными - на сервере а вот бизнес-правила можно реализовать как на сервере используя механизмы программирования сервера (хранимые процедуры триггеры представления и т.п.) так и на клиенте.[14]
В трехуровневом приложении появляется третий промежуточный уровень реализующий бизнес-правила которые являются наиболее часто изменяемыми компонентами приложения (см. рис. Трехуровневая модель клиент-серверного приложения)
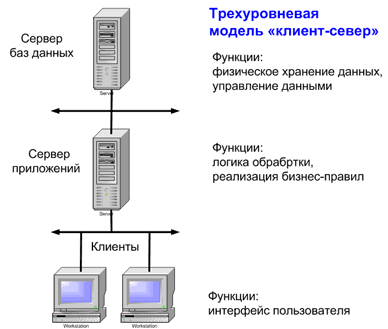
Рис 2. Трехуровневая модель клиент-серверного приложения
Наличие не одного, а нескольких уровней позволяет гибко и с минимальными затратами адаптировать приложение к изменяющимся требованиям бизнеса.[15]
Попробуем все вышеизложенное проиллюстрировать на маленьком примере. Предположим в некоей организации изменились правила расчета заработной платы (бизнес-правила) и требуется обновить соответствующее программное обеспечение.
1) В файл-серверной системе мы "просто" вносим изменения в приложение и обновляем его версии на рабочих станциях. Но это "просто" влечет за собой максимальные трудозатраты.
2) В двухуровневой клиент-серверной системе если алгоритм расчета зарплаты реализован на сервере в виде правила расчета зарплаты его выполняет сервер бизнес-правил выполненный например в виде OLE-сервера и мы обновим один из его объектов ничего не меняя ни в клиентском приложении ни на сервере баз данных.[16]
1.3. Классификация стандартных серверов
Как правило, каждый сервер обслуживает один (или несколько схожих) протоколов и серверы можно классифицировать по типу услуг которые они предоставляют.
Универсальные серверы — особый вид серверной программы не предоставляющий никаких услуг самостоятельно. Вместо этого универсальные серверы предоставляют серверам услуг упрощенный интерфейс к ресурсам межпроцессного взаимодействия и/или унифицированный доступ клиентов к различным услугам. Существуют несколько видов таких серверов:
- inetd от англ. internet super-server daemon демон сервисов IP — стандартное средство UNIX-систем — программа позволяющая писать серверы TCP/IP (и сетевых протоколов других семейств) работающие с клиентом через перенаправленные inetd потоки стандартного ввода и вывода (stdin и stdout).
- RPC от англ. Remote Procedure Call удаленный вызов процедур — система интеграции серверов в виде процедур доступных для вызова удаленным пользователем через унифицированный интерфейс.[17] Интерфейс изобретенный Sun Microsystems для своей операционной системы (SunOS Solaris; Unix-система) в настоящее время используетстся как в большинстве Unix-систем так и в Windows.
Прикладные клиент-серверные технологии Windows:
- (D-)COM (англ. (Distributed) Component Object Model — модель составных объектов) и др. — Позволяет одним программам выполнять операции над объектами данных используя процедуры других программ. Изначально данная технология предназначена для их «внедрения и связывания объектов» - OLE англ. Object Linking and Embedding) но в общем позволяет писать широкий спектр различных прикладных серверов. COM работает только в пределах одного компьютера DCOM доступна удаленно через RPC.
- Active-X — Расширение COM и DCOM для создания мультимедиа-приложений.[18]
Универсальные серверы часто используются для написания всевозможных информационных серверов серверов которым не нужна какая-то специфическая работа с сетью серверов не имеющих никаких задач кроме обслуживания клиентов. Например, в роли серверов для inetd могут выступать обычные консольные программы и скрипты.
Большинство внутренних и сетевых специфических серверов Windows работают через универсальные серверы (RPC (D-)COM).
Сетевые службы обеспечивают функционирование сети например серверы DHCP и BOOTP обеспечивают стартовую инициализацию серверов и рабочих станций DNS — трансляцию имен в адреса и наоборот.[19]
Серверы туннелирования (например различные VPN-серверы) и прокси-серверы обеспечивают связь с сетью недоступной роутингом.
Серверы AAA и Radius обеспечивают в сети единую аутентификацию авторизацию и ведение логов доступа.
Информационные службы. К информационным службам можно отнести как простейшие серверы сообщающие информацию о хосте (time daytime motd) пользователях (finger ident) так и серверы для мониторинга например SNMP. Большинство информационных служб работают через универсальные серверы.[20]
Особым видом информационных служб являются серверы синхронизации времени — NTP кроме информировании клиента о точном времени NTP-сервер периодически опрашивает несколько других серверов на предмет коррекции собственного времени. Кроме коррекции времени анализируется и корректируется скорость хода системных часов. Коррекция времени осуществляется ускорением или замедлением хода системных часов (в зависимости от направления коррекции) чтобы избежать проблем возможных при простой перестановке времени.
Файл-серверы представляют собой серверы для обеспечения доступа к файлам на диске сервера.
Прежде всего, это серверы передачи файлов по заказу по протоколам FTP TFTP SFTP и HTTP. Протокол HTTP ориентирован на передачу текстовых файлов но серверы могут отдавать в качестве запрошенных файлов и произвольные данные например динамически созданные веб-страницы картинки музыку и т. п.
Другие серверы позволяют монтировать дисковые разделы сервера в дисковое пространство клиента и полноценно работать с файлами на них. Это позволяют серверы протоколов NFS и SMB. Серверы NFS и SMB работают через интерфейс RPC.[21]
Недостатки файл-серверной системы:
• Очень большая нагрузка на сеть повышенные требования к пропускной способности. На практике это делает практически невозможной одновременную работу большого числа пользователей с большими объемами данных.[22]
• Обработка данных осуществляется на компьютере пользователей. Это влечет повышенные требования к аппаратному обеспечению каждого пользователя. Чем больше пользователей тем больше денег придется потратить на оснащение их компьютеров.
• Блокировка данных при редактировании одним пользователем делает невозможной работу с этими данными других пользователей.
• Безопасность. Для обеспечения возможности работы с такой системой Вам будет необходимо дать каждому пользователю полный доступ к целому файлу в котором его может интересовать только одно поле
Серверы доступа к данным обслуживают базу данных и отдают данные по запросам. Один из самых простых серверов подобного типа — LDAP (англ. Lightweight Directory Access Protocol — облегчённый протокол доступа к спискам).
Для доступа к серверам баз данных единого протокола не существует однако все серверы баз данных объединяет использование единых правил формирования запросов — язык SQL (англ. Structured Query Language — язык структурированных запросов).
Службы обмена сообщениями позволяют пользователю передавать и получать сообщения (обычно — текстовые).
В первую очередь, это серверы электронной почты, работающие по протоколу SMTP. SMTP-сервер принимает сообщение и доставляет его в локальный почтовый ящик пользователя или на другой SMTP-сервер (сервер назначения или промежуточный). На многопользовательских компьютерах пользователи работают с почтой прямо на терминале (или веб-интерфейсе). Для работы с почтой на персональном компьютере почта забирается из почтового ящика через серверы, работающие по протоколам POP3 или IMAP.[23]
Для организации конференций существует серверы новостей, работающие по протоколу NNTP.
Для обмена сообщениями в реальном времени существуют серверы чатов. Стандартный чат-сервер работает по протоколу IRC — распределенный чат для интернета. Существует большое количество других чат-протоколов, например ICQ или Jabber.
Серверы удаленного доступа.
Серверы удаленного доступа через соответствующую клиентскую программу обеспечивают пользователя консольным доступом к удаленной системе.
Для обеспечения доступа к командной строке служат серверы telnet RSH SSH.
Графический интерфейс для Unix-систем — X Window System имеет встроенный сервер удаленного доступа, так как с такой возможностью разрабатывался изначально. Иногда возможность удаленного доступа к интерфейсу Х-Window неправильно называют «X-Server» (этим термином в X-Window называется видеодрайвер).[24]
Стандартный сервер удаленного доступа к графическому интерфейсу Microsoft Windows называется терминальный сервер.
Некоторую разновидность управления (точнее мониторинга и конфигурирования) также предоставляет протокол SNMP. Компьютер или аппаратное устройство для этого должно иметь SNMP-сервер.
Игровые серверы служат для одновременной игры нескольких пользователей в единой игровой ситуации. Некоторые игры имеют сервер в основной поставке и позволяют запускать его в невыделенном режиме (то есть позволяют играть на машине, на которой запущен сервер).
Серверные решения — операционные системы и/или пакеты программ оптимизированные под выполнение компьютером функций сервера и/или содержащие в своем составе комплект программ для реализации типичного сервисов.
Примером серверных решений можно привести Unix-системы изначально предназначенные для реализации серверной инфраструктуры или серверные модификации платформы Microsoft Windows.[25]
Также необходимо выделить пакеты серверов и сопутствующих программ (например, комплект веб-сервер/PHP/MySQL для быстрой развертки хостинга) для установки под Windows (для Unix свойственна модульная или «пакетная» установка каждого компонента, поэтому такие решения редки).
В интегрированных серверных решениях установка всех компонентов выполняется единовременно все компоненты в той или иной мере тесно интегрированы и предварительно настроены друг на друга.
Однако в этом случае замена одного из серверов или вторичных приложений (если их возможности не удовлетворяют потребностям) может представлять проблему.
Серверные решения служат для упрощения организации базовой ИТ-инфраструктуры компаний то есть для оперативного построения полноценной сети в компании в том числе и «с нуля». Компоновка отдельных серверных приложений в решение подразумевает что решение предназначено для выполнения большинства типовых задач; при этом значительно снижается сложность развертывания и общая стоимость владения ИТ-инфраструктурой построенной на таких решениях.[26]
Прокси-сервер (от англ. proxy — «представитель уполномоченный») служба в компьютерных сетях позволяющая клиентам выполнять косвенные запросы к другим сетевым службам. Сначала клиент подключается к прокси-серверу и запрашивает какой-либо ресурс (например e-mail) расположенный на другом сервере. Затем прокси-сервер либо подключается к указанному серверу и получает ресурс у него либо возвращает ресурс из собственного кеша (в случаях, если прокси имеет свой кеш). В некоторых случаях запрос клиента или ответ сервера может быть изменён прокси-сервером в определённых целях. Также прокси-сервер позволяет защищать клиентский компьютер от некоторых сетевых атак.[27]
Глава 2. Технология "клиент-сервер"
Технология «клиент-сервер» пришла на смену централизованной схеме управления вычислительным процессом на мейнфреймах еще в 80-х годах прошлого века. Благодаря высокой живучести и надежности вычислительной системы, легкости масштабирования, возможности одновременной работы пользователя с несколькими приложениями, высокой оперативности обработки информации, обеспечению пользователя высококачественным интерфейсом и другим возможностям эта весьма перспективная и далеко не исчерпавшая себя технология получила свое дальнейшее развитие. [28]
Со временем малофункциональную модель файлового сервера для локальных сетей (FS) заменили появившиеся одна за одной модели структуры «Клиент- сервер» (RDA, DBS и AS).
Заняв нишу баз данных, технология «Клиент – сервер» стала основной технологией глобальной сети Internet. Далее, в результате перенесения идей сети Internet в среду корпоративных систем, появилась технология Intranet. В отличие от технологии «Клиент-сервер» эта технология ориентирована не на данные, а на информацию в ее окончательно готовом к потреблению виде. Вычислительные системы, построенные на основе Intranet, имеют в своем составе центральные серверы информации и распределенные компоненты представления информации конечному пользователю (программы-навигаторы, или браузеры). Взаимодействие между клиентом и сервером в Intеrnet происходит при помощи web – технологий.[29]
На сегодняшний день технология «Клиент-сервер» получает все большее распространение, однако сама по себе она не предлагает универсальных рецептов. Она лишь дает общее представление о том, как должна быть организована современная распределенная информационная система. В то же время реализации этой технологии в конкретных программных продуктах и даже в видах программного обеспечения различаются весьма существенно. [30]
2.1 Классическая двухуровневая архитектура «Клиент – сервер»
Ключевым отличием архитектуры клиент-сервер от архитектуры файл-сервер является абстрагирование от внутреннего представления данных (физической схемы данных). При такой архитектуре клиентские программы манипулируют данными на уровне логической схемы. Для реализации архитектуры клиент-сервер обычно используют многопользовательские СУБД, например, Oracle или Microsoft SQL Server.
Клиент-серверная информационная система состоит из трех основных компонент: программное обеспечение сервера; программное обеспечение конечного пользователя; промежуточное программное обеспечение (рис.3). Программное обеспечение сервера, кроме управления базами данных обеспечивает обслуживание клиентов.[31]
|
|
|
Рисунок 3. – Структура клиент-серверной ИС |
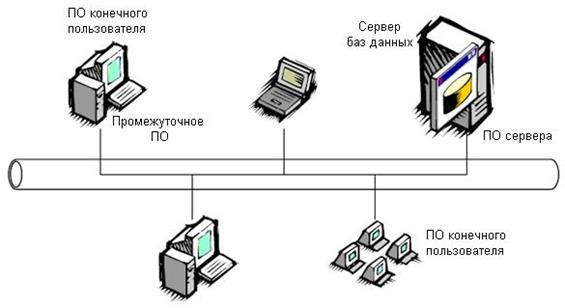
В таких СУБД предусмотрены механизмы блокировки и элементы управления многопользовательским доступом, которые обеспечивают защиту данных от рисков, присущих параллельному доступу. Кроме этого, серверу баз данных приходится защищать данные от несанкционированного доступа, оптимизировать запросы к базе данных, обеспечивать целостность данных и контроль завершение транзакций. В клиент-серверной организации клиенты могут быть достаточно "тонкими", а сервер должен быть "толстым" настолько, чтобы удовлетворять потребности всех клиентов. [32]К программному обеспечению конечного пользователя относятся средства разработки прикладных программ и генераторы отчетов, в том числе электронные таблицы и текстовые процессоры. С помощью этого программного обеспечения пользователи устанавливают связь с сервером, формируют запросы, которые автоматически генерируются в запросы на языке SQL и отправляются на сервер.[33] Сервер принимает и обрабатывает запросы, а затем передает полученные результаты клиентам. Промежуточное программное обеспечение ― часть системы клиент-сервер, которая связывает программное обеспечение конечного пользователя с сервером.[34]
Использование архитектуры клиент-сервер позволило создавать надежные (в смысле целостности данных) многопользовательские ИС с централизованной базой данных, независимые от аппаратной (а часто и программной) части сервера БД и поддерживающие графический интерфейс пользователя на клиентских станциях, связанных локальной сетью. Причем издержки на разработку приложений существенно сокращались.[35]
Такая архитектура имеет два уровня, характерной особенностью которой является то, что клиентские программы работает с данными через запросы к серверному ПО, а базовые функции приложения разделены между клиентом и сервером (рис.4).
|
|
|
Рис. 4.– Модель сервера СУБД двухуровневой ИС |
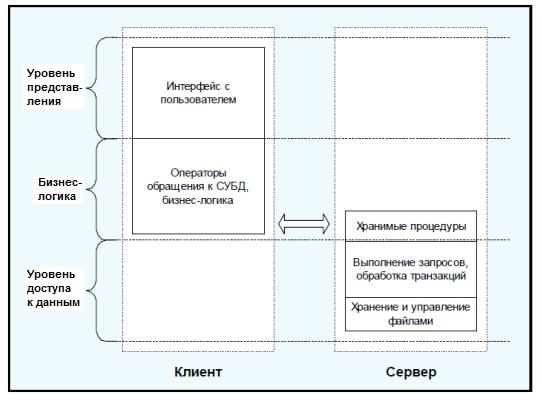
К достоинствам этой архитектуры относятся:
· полная поддержка многопользовательской работы;
· обеспечение целостности данных.
Двухуровневую архитектуру целесообразно использовать на предприятиях с количеством пользователей несколько десятков, поскольку операционная система сервера при обслуживании большого количества клиентов слишком перегружается управлением многочисленными соединениями с сервером.[36]
Недостатками двухуровневой клиент-серверной архитектуры являются:
· Бизнес логика приложений осталась в клиентском ПО. При любом изменении алгоритмов, надо обновлять пользовательское ПО на каждом клиенте.
· Высокие требования к пропускной способности коммуникационных каналов с сервером, что препятствует использование клиентских станций иначе как в локальной сети.
· Слабая защита данных от взлома, в особенности от недобросовестных пользователей системы.
· Высокая сложность администрирования и настройки рабочих мест пользователей системы.
· Необходимость использовать мощные ПК на клиентских местах.
· Высокая сложность разработки системы из-за необходимости выполнять бизнес-логику и обеспечивать пользовательский интерфейс в одной программе.[37]
Большинство недостатков 2-х уровневой (классической) архитектуры клиент-сервер проистекают от использования клиентской станции в качестве исполнителя бизнес-логики ИС.[38]
Поэтому очевидным шагом дальнейшей эволюции архитектур ИС явилась идея "тонкого клиента", то есть разбиения алгоритмов обработки данных на части связанные с выполнением бизнес-функций и связанные с отображением информации в удобном для человека представлении. При этом на клиентской машине оставляют лишь вторую часть, связанную с первичной проверкой и отображением информации, перенося всю реальную функциональность системы на серверную часть.
Обычно компоненты сети не равноправны: у одних есть доступ к ресурсам (например, принтер, процессор, система управления базой данных (СУБД), файловая система и так далее), другие имеют возможность обращаться к этим ресурсам.
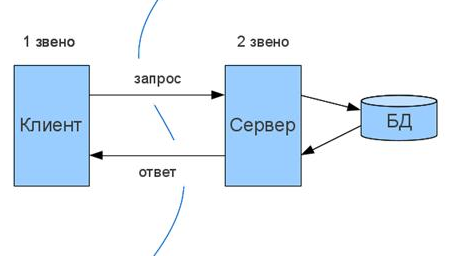
Технология «Клиент – сервер» - это архитектура программного комплекса, в которой происходит распределение прикладной программы по двум логически различным компонентам (клиент и сервер), взаимодействующим по схеме «запрос-ответ» и решающим свои определенные задачи.(Приложение 1)
Компьютер (или программа), управляющий и/или владеющий каким-либо ресурсом, называют сервером этого ресурса.
Компьютер (или программа), запрашивающий и пользующийся каким-либо ресурсом, называют клиентом этого ресурса.[39]
Клиент и сервер могут находиться как на одном компьютере (ПК), так и на разных ПК в сети. Также может возникать такая ситуация, когда некоторый программный блок будет одновременно выполнять функции сервера по отношению к одному блоку и клиента по отношению к другому.[40]
Основной принцип технологии «Клиент-сервер» заключается в разделении функций приложения как минимум на три группы:
- модули интерфейса с пользователем;
Также эту группу называют логикой представления. Через эту группу пользователи взаимодействуют с приложением. Независимо от конкретных характеристик логики представления (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и информационной системой.
- модули хранения данных;
Эту группу также называют бизнес-логикой. Бизнес-логика определяет, для чего конкретно предназначено приложение (например, прикладные функции, характерные для данной предметной области). Разделение приложения по границам между программами обеспечивает естественную основу для распределения приложения на нескольких компьютерах.
- модули обработки данных (функции управления ресурсами);
Эту группу также называют логикой доступа к данным или алгоритмами доступа к данным. Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или СУБД.[41] При помощи модулей обработки данных организуется специфический для приложения интерфейс к СУБД.
При помощи интерфейса приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных).[42]
Каждая из этих групп может быть реализована независимо от двух других. Например, не изменяя программ, используемых для хранения и обработки данных, можно изменить интерфейс с пользователем таким образом, что одни и те же данные будут отображаться в виде таблиц, графиков или гистограмм. Очень простые приложения часто способны собрать все три части в единственную программу, и подобное разделение соответствует функциональным границам.
В соответствии с разделением функций в любом приложении выделяются следующие компоненты:
- компонент представления данных;
- прикладной компонент;
- компонент управления ресурсом.
В классической архитектуре клиент-сервер приходится распределять три основные части приложения по двум физическим модулям. Обычно прикладной компонент располагается на сервере (например, сервере базы данных), компонент представления данных - на стороне клиента, а компонент управления ресурсом распределяется между клиентской и серверной частями. В этом заключается основной недостаток классической двухуровневой архитектуры.[43]
В двухзвенной архитектуре при разбиении алгоритмов обработки данных разработчики должны иметь полную информацию о последних изменениях, внесенных в систему, и понимать эти изменения, что создает большие сложности при разработке клиент-серверных систем, их установке и сопровождении, поскольку необходимо тратить значительные усилия на координацию действий разных групп специалистов. В действиях разработчиков часто возникают противоречия, а это тормозит развитие системы и вынуждает изменять уже готовые и проверенные элементы.[44]
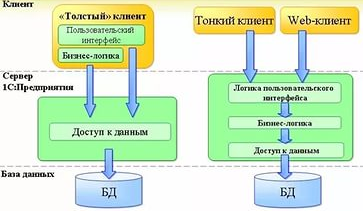
Чтобы избежать несогласованности различных элементов архитектуры были созданы две модификации двухзвенной архитектуры «Клиент – сервер»: «Толстый клиент» («Тонкий сервер») и «Тонкий клиент» («Толстый сервер»).
В данных архитектурах разработчики попытались выполнять обработку данных на одной из двух физических частей - либо на стороне клиента («Толстый клиент»), либо на сервере («Тонкий клиент).
Каждый подход имеет свои недостатки. В первом случае неоправданно перегружается сеть, потому что по ней передаются необработанные, а значит, избыточные данные. Кроме того, усложняется поддержка системы и ее изменение, так как замена алгоритма вычислений или исправление ошибки требует одновременной полной замены всех интерфейсных программ, а иначе могут возникнуть ошибки или несогласованность данных. Если же вся обработка информации выполняется на сервере, то возникает проблема описания встроенных процедур и их отладки. Систему с обработкой информации на сервере абсолютно невозможно перенести на другую платформу (ОС), что является серьезным недостатком.[45]
Если все-таки разрабатывается двухуровневая классическая архитектура «Клиент – сервер», то необходимо помнить следующее:
архитектура «Толстый сервер» аналогична архитектуре «Тонкий клиент» (Приложение 2);
Передача запроса от клиента на сервер, обработка запроса сервером и передача результата клиенту. При этом архитектуры имеют следующие недостатки:
- усложняется реализация, так как языки типа SQL не приспособлены для разработки подобного ПО и нет хороших средств отладки;
- производительность программ, написанных на языках типа SQL, значительно ниже, чем созданных на других языках, что имеет важное значение для сложных систем;
- программы, написанные на СУБД-языках, обычно работают недостаточно надежно; ошибка в них может привести к выходу из строя всего сервера баз данных;
- получившиеся таким образом программы полностью непереносимы на другие системы и платформы. [46]
Обработка запроса происходит на стороне клиента, то есть происходит передача клиенту всех необработанных данных с сервера. При этом архитектуры имеют следующие недостатки:
- усложняется обновление ПО, поскольку его замену нужно производить одновременно по всей системе;
- усложняется распределение полномочий, так как разграничение доступа происходит не по действиям, а по таблицам;
перегружается сеть вследствие передачи по ней необработанных данных;
- слабая защита данных, поскольку сложно правильно распределить полномочия.
Для решения перечисленных проблем используются многоуровневые (три и более уровней) архитектуры «Клиент-сервер».
2.2 Трехуровневая модель «клиент- сервер»
С середины 90-х годов прошлого века признание специалистов получила трехзвенная архитектура «Клиент – сервер», которая разделила информационную систему по функциональным возможностям на три отдельных компонента: логика представления, бизнес-логика и логика доступа к данным. В отличие от двухзвенной архитектуры в трехзвенной появляется дополнительное звено - сервер приложений, который предназначен для осуществления бизнес-логики, при этом полностью разгружается клиент, который направляет запросы промежуточному программному обеспечению, и максимально используются все возможности серверов. [47]
В трехуровневой архитектуре клиент обычно не перегружен функциями обработки данных, а выполняет свою основную роль системы представления информации, поступающей с сервера приложений. Такой интерфейс можно реализовать с помощью стандартных средств Web-технологии - браузера, CGI и Java. Это уменьшает объем данных, передаваемых между клиентом и сервером приложений, что позволяет подключать клиентские компьютеры даже по медленным линиям типа телефонных каналов. Кроме того, клиентская часть может быть настолько простой, что в большинстве случаев ее реализуют с помощью универсального браузера. Но если менять ее все-таки придется, то эту процедуру можно осуществить быстро и безболезненно.[48]
Существует несколько категорий продуктов промежуточного слоя:
- Message orientated – яркие представители MQseries и JMS;
- Object Broker – яркие представители CORBA и DCOM;
- Component based – яркие представители.NET и EJB.
Использование сервера приложений дает больше возможностей, например, уменьшается нагрузка на клиентские компьютеры, потому что сервер приложений распределяет нагрузку и обеспечивает защиту от сбоев. Так как бизнес-логика хранится на сервере приложений, то при каких-либо изменениях в отчетности или расчетах клиентские программы никоим образом не затрагиваются. [49]
Существует несколько серверов приложений от таких знаменитых компаний как Sun Microsystem, Borland, IBM, Oracle и каждый из них отличается набором предоставляемых сервисов (производительность в данном случае учитывать не будем). Эти сервисы облегчают программирование и развертывание приложений масштаба предприятия. Обычно сервер приложений предоставляет следующие сервисы:
- WEB Server – чаще всего включают в поставку самый популярный и мощный Apache;
- WEB Container – позволяет выполнять JSP и сервлеты. Для Apache таким сервисом является Tomcat;
- CORBA Agent – может предоставлять распределенную директорию для хранения CORBA объектов;
- Messaging Service – брокер сообщений;
- Transaction Service – уже из названия понятно, что это сервис транзакций;
- JDBC – драйвера для подключения к базам данных, ведь именно серверу приложений придется общаться с базами данных и ему нужно уметь подключаться к используемой в вашей компании базе;
- Java Mail – данный сервис может предоставлять сервис к SMTP;
- JMS (Java Messaging Service) – обработка синхронных и асинхронных сообщений;
- RMI (Remote Method Invocation) - вызов удаленных процедур.
Многоуровневые клиент-серверные системы достаточно легко можно перевести на Web-технологию - для этого достаточно заменить клиентскую часть универсальным или специализированным браузером, а сервер приложений дополнить Web-сервером и небольшими программами вызова процедур сервера. Для разработки этих программ можно использовать как Common Gateway Interface (CGI), так и более современную технологию Java.[50]
В трехуровневой системе в качестве каналов связи между сервером приложений и СУБД можно использовать более скоростные линии, которые потребуют минимальных затрат, так как сервера обычно находятся в одном помещении (серверной) и не будет перегружать сеть из-за передачи большого количества информации.
Из всего вышесказанного можно сделать вывод, что двухуровневая архитектура сильно уступает многоуровневой архитектуре, поэтому в настоящее время используется только многоуровневая архитектура «Клиент – сервер», в которой различают три модификации - RDA, DBS и AS. [51]
На верхнем уровне абстрагирования взаимодействия клиента и сервера достаточно четко можно выделить следующие компоненты:
-презентационная логика (Presentation Layer - PL), предназначенная для работы с данными пользователя;
-бизнес-логика (Business Layer - BL), предназначенная для проверки правильности данных, поддержки ссылочной целостности;
-логика доступа к ресурсам (Access Layer - AL), предназначенная для хранения данных;
Таким образом, можно прийти к нескольким моделям клиент-серверного взаимодействия:
1. "Толстый" клиент. (fat client)
Сервер БД Пользовательский интерфейс
Данные Бизнес-логика
Пользовательский интерфейс
Бизнес-логика
Наиболее часто встречающийся вариант реализации архитектуры клиент-сервер в уже внедренных и активно используемых системах. Такая модель подразумевает объединение в клиентском приложении как PL, так и BL, таким образом обеспечивается полная децентрализация управления бизнес-логикой. [52]Однако в случае необходимости выполнения каких-либо изменений в клиентском приложении придется менять исходный код. Серверная часть, при описанном подходе, представляет собой сервер баз данных, реализующий AL. К описанной модели часто применяют аббревиатуру RDA - Remote Data Access.
2. "Тонкий" клиент. (thin client)
Бизнес- Логика Пользовательский интерфейс
Данные
Пользовательский интерфейс
Модель, начинающая активно использоваться в корпоративной среде в связи с распространением Internet-технологий и, в первую очередь, Web-браузеров. В этом случае клиентское приложение обеспечивает реализацию PL, поэтому клиент может довольствоваться довольно скромной аппаратной платформой, а сервер объединяет BL и AL. [53]Максимальная загрузка сервера предусматривает выполнение бизнес-логики только с помощью хранимых процедур сервера (Хранимые процедуры - откомпилированные SQL-инструкции, хранящиеся на сервере). Это позволяет максимально централизовать контроль над данными и легко изменять правила работы сразу для целого предприятия. С другой стороны, незначительная корректировка правил, касающаяся только части пользователей, потребует длительной процедуры согласования. В этом случае невозможно реализовать какие-то исключения из общих правил для некоторых пользователей или приложений. В принципе, это хорошо и является залогом безопасности и целостности данных.[54]
3. Сервер бизнес-логики. (трехуровневая архитектура)
Промежуточный сервер
Пользовательский
Бизнес-логика интерфейс
второго уровня
Сервер БД
Пользовательский
Бизнес-логика интерфейс
сервера
Данные
Модель с физически выделенным в отдельное приложение блоком BL, таким образом получаем трехуровневую архитектуру “клиент-сервер”. На сервере БД может функционировать “универсальная” часть бизнес-логики (правила на уровне предприятия или группы связанных приложений). Такая схема позволяет поддерживать тонких клиентов на пользовательских компьютерах и в то же время разгрузить сервер БД от чрезмерной загрузки при сохранении гибкой системы работы с бизнес-правилами. В качестве промежуточного сервера может использоваться второй SQL-сервер, но чаще рациональней задействовать персональную СУБД, которая менее требовательна к аппаратным ресурсам и может обеспечить удобные средства построения и поддержки бизнес-логики.[55]
2.3 Различные модели технологии «Клиент – сервер»
Самой первой базовой технологией для локальных сетей являлась модель файлового сервера (FS). В свое время данная технология была очень среди отечественных разработчиков, использовавших такие системы, как FoxPro, Clipper, Clarion, Paradox и так далее.[56]
В модели FS функции всех трех компонентов (компонент представления, прикладной компонент и компонент доступа к ресурсам) совмещены в одном коде, который выполняется на компьютере-сервере (хосте). Компьютер-клиент в данной архитектуре вообще отсутствует, а ввод и отображение данных производятся через терминал или компьютер в режиме эмуляции терминала. Приложения обычно разрабатываются на языке четвертого поколения (4GL). Один из компьютеров в сети считается файловым сервером и предоставляет другим компьютерам услуги по обработке файлов. Он работает под управлением сетевых ОС и играет роль компонента доступа к информационным ресурсам. На других ПК в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент.[57]
Технология взаимодействия клиента и сервера следующая: запрос направляется на файловый сервер, который передает СУБД, размещенной на компьютере-клиенте, требуемый блок данных. Вся обработка осуществляется на терминале.
Протокол обмена представляет собой набор вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
Преимуществами данной технологии являются:
- простота разработки приложений;
- удобство администрирования и обновления ПО из-за компактного расположения всех компонентов на одном компьютере;
- низкая стоимость оборудования рабочих мест (терминалы или дешевые компьютеры с невысокими характеристиками в режиме эмуляции терминала всегда дешевле полноценных ПК).[58]
Но достоинства FS – модели перекрывают ее недостатки:
- большая загрузка сети;
Несмотря на небольшой объем данных, пересылаемых по сети, время отклика является критичным, так как каждый символ, введенный пользователем на терминале, должен быть передан на сервер, обработан приложением и возвращен обратно для вывода на экран терминала. Помимо этого существует проблема распределения нагрузки между несколькими компьютерами. [59]
- дорогостоящее аппаратное обеспечение сервера, так как все пользователи разделяют его ресурсы;
- отсутствие графического интерфейса.
Благодаря решению проблем, присущих технологии «Файл – сервер» появилась более прогрессивная технология, получившая название «Клиент – сервер».
Для современных СУБД архитектура «клиент-сервер» стала фактически стандартом. Если предполагается, что проектируемая сетевая технология будет иметь архитектуру «клиент-сервер», то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер, то есть часть функций приложений будет реализована в программе-клиенте, другая - в программе-сервере.
Различия в реализации приложений в рамках технологии «Клиент-сервер» определяются четырьмя факторами:
- какие виды программного обеспечения в логических компонентах;
какие механизмы программного обеспечения используются для реализации функций логических компонентов;
как логические компоненты распределяются компьютерами в сети
- какие механизмы используются для связи компонент между собой. [60]
Исходя из этого, выделяются три подхода, каждый из которых реализован в соответствующей модели технологии «Клиент – сервер»:
- модель доступа к удаленным данным (Remote Date Access - RDA);
- модель сервера базы данных (DateBase Server - DBS);
- модель сервера приложений (Application Server - AS).
Рассмотрим функции и характеристики различных моделей технологии «Клиент-сервер».
Модель доступа к удаленным данным (RDA) – сетевая архитектура технологии «Клиент – сервер», при которой коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Доступ к информационным ресурсам обеспечивается при помощи непроцедурного языка (например ,SQL – запросов для баз данных) или вызовами функций специальной библиотеки (если имеется специальный интерфейс прикладного программирования - API).[61]
Запросы к информационным ресурсам направляются по сети удаленному компьютеру, который обрабатывает и выполняет их, возвращая клиенту блоки данных.
Основным преимуществом RDA-модели является широкий выбор инструментальных средств разработки приложений, обеспечивающих быстрое создание desktop-приложений, работающих с SQL-ориентированными СУБД. Обычно инструментальные средства поддерживают графический интерфейс пользователя с ОС, а также средства автоматической генерации кода, в которых смешаны прикладные функции и функции представления.[62]
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, например, если речь идет о базах данных), либо вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования - API). [63]
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия, и возвращает клиенту результат, оформленный как блок данных (рис.3). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль - обслуживание запросов и обработка данных. В Разделе 2 будет показано, что такое распределение обязанностей между клиентами и сервером базы данных не догма - сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Прежде всего, перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД, сводя к минимуму общее число процессов операционной системы. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций.[64] Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на ввод-вывод (как в системах с файловым сервером), а запросы на языке SQL, их объем существенно меньше.
Основное достоинство RDA-модели - унификация интерфейса "клиент-сервер" в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обоим. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором уже шла речь . Поэтому целесообразно использовать его не только в качестве средства доступа к данным, но и стандарта общения клиента и сервера. [65]
Такое общение можно сравнить с беседой нескольких человек, когда один отвечает на вопросы остальных (вопросы задаются одновременно). Причем делает это он так быстро, что время ожидания ответа приближается к нулю. Высокая скорость общения достигается прежде всего благодаря четкой формулировке вопроса, когда спрашивающему и отвечающему не нужно дополнительных консультаций по сути вопроса. Беседующие обмениваются несколькими короткими однозначными фразами, им ничего не нужно уточнять.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные).[66]
Наряду с RDA-моделью все большую популярность приобретает перспективная DBS-модель (рис. 4). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур - средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД. Более подробно о хранимых процедурах рассказано в п. 2.3.[67]
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, то есть ядро СУБД. Достоинства DBS-модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам модели можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими как C или Pascal. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур. [68]
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель). Так или иначе,современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей либо их разумное сочетание.[69]
При этом RDA-модель имеет ряд ограничений.
Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Приложение является нераспределенным, и вся его логика локализована на компьютере-клиенте, поэтому взаимодействие его с сервером посредством SQL-запросов приводит к передаче по сети данных большого объема, возможно, избыточных. Как только число клиентов возрастает, сеть становится узким местом, ограничивая быстродействие всей информационной системы.
Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно. Если различные по своей природе функции (функции представления и чисто прикладные функции) смешаны в одной и той же программе, написанной на языке четвертого поколения (4GL), то при необходимости изменения прикладных функций приходится переписывать всю программу целиком.
В – третьих, при коллективной работе над проектом, обычно каждому разработчику поручается реализация отдельных прикладных функций, что делает невозможным контроль за их взаимной непротиворечивостью. Каждому из разработчиков приходится программировать интерфейс с пользователем, что ставит под вопрос единый стиль интерфейса и его целостность. Сложность обновления программного обеспечения возникает еще и потому, что замену ПО необходимо производить одновременно на всех компьютерах-клиентах. [70]
В – четвертых, из-за невозможности реализации разграничения доступа по функциям только на стороне сервера, а только на стороне клиента, возникает низкий уровень безопасности. При этом разграничение выполняется только по таблицам базы данных, что снижает защищенность.
Несмотря на широкое распространение, RDA-модель уступает место более технологичной DBS-модели.[71]
Модель сервера баз данных (DBS) - сетевая архитектура технологии «Клиент – сервер», основу которой составляет механизм хранимых процедур, реализующий прикладные функции. В DBS – модели понятие информационного ресурса сужено до базы данных из-за того же механизма хранимых процедур, который реализован в СУБД, да и то не во всех.
В DBS-модели приложение является распределенным. Компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент (реализующий бизнес-функции) оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Хранимые процедуры также называют компилируемыми резидентными процедурами или процедурами базы данных.
Преимущества DBS-модели перед RDA-моделью очевидны: это и возможность централизованного администрирования различных функций, и снижение трафика сети из-за того, что вместо SQL-запросов по сети передаются вызовы хранимых процедур, и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. Однако есть и недостатки. [72]
Во-первых, разнообразные процедурные расширения SQL, используемые для написания хранимых процедур, не являются языками программирования в полном смысле слова. Они встроены в конкретные СУБД и имеют ограниченные возможности. Следовательно, система, в которой прикладной компонент реализован при помощи хранимых процедур, не является мобильной относительно СУБД. В большинстве СУБД отсутствуют возможности отладки и тестирования хранимых процедур, что может привести не просто к сбою, а к полной неработоспособности всей базы данных.
Во-вторых, в DBS-модели не предусмотрены разнообразные варианты взаимодействия клиента и сервера, необходимые для децентрализация приложений, например хранимые очереди, асинхронные вызовы и другие.
В-третьих, DBS-модель не обеспечивает требуемой эффективности использования вычислительных ресурсов. Ограничения в ядре СУБД не позволяют в полной мере организовать эффективный баланс загрузки, миграцию процедур на другие компьютеры-серверы БД и реализовать другие полезные функции, например запросы с приоритетом. [73]
На практике чаще используется разумный синтез RDA- и DBS-моделей для построения многопользовательских информационных систем: поддержка целостности базы данных и некоторых простейших прикладные функции хранимых процедур (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель).
Все недостатки DBS - модели учтены в AS-модели, которая в наибольшей степени отражает сильные стороны технологии «клиент-сервер».
Модель сервера приложений (AS) - сетевая архитектура технологии «Клиент – сервер», представляющая собой процесс, выполняемый на компьютере-клиенте и отвечающий за интерфейс с пользователем (ввод и отображение данных). Основным элементом данной модели является прикладной компонент, называющийся сервером приложения, функционирующий на удаленном компьютере (или нескольких компьютерах). Сервер приложений реализован как группа прикладных функций, оформленных в виде сервисов (служб).[74] Каждый сервис предоставляет некоторые услуги всем программам, которые желают и могут ими воспользоваться.
Серверов приложений может быть несколько, и каждый их них предоставляет определенный набор услуг. Любая программа, которая пользуется ими, рассматривается как клиент приложения.
Детали реализации прикладных функций в сервере приложений полностью скрыты от клиента приложения. Клиент, которым может быть стандартный браузер, обращается с запросом к конкретной службе, при этом серверы приложений обезличены и служат для создания графического интерфейса с пользователем, что позволяет эффективно управлять балансом загрузки. Запросы, поступающие от клиента, выстраиваются в очередь к AS-процессу, который извлекает и передает их для обработки службе в соответствии с приоритетами. [75]
Так как данные «спрятаны» за сервером приложений, в котором обычно встроена проверка полномочий клиента, в СУБД обеспечивается высокий уровень защиты данных.
Доступ к информационным ресурсам, необходимым для решения прикладных задач, обеспечивается как и в RDA-модели менеджером ресурсов (например, SQL-сервер). Из прикладных компонентов доступны такие ресурсы как, базы данных, очереди, почтовые службы и другие. Серверы приложений выполняются, как правило, на том же компьютере, где функционирует менеджер ресурсов, что избавляет от необходимости направления SQL-запросов по сети и повышает производительность системы, Также серверы приложений могут выполняться и на других компьютерах. [76]
AS-модель является универсальной системой, в которой может быть сколько угодно уровней, взаимодействующих между собой. Четкое разграничение логических компонентов, возможность баланса загрузки между несколькими серверами, и рациональный выбор программных средств для их реализации обеспечивают модели такой уровень гибкости, защиты данных и открытости, который пока недостижим в RDA- и DBS-моделях. В AS-модели возможна работа по медленным линиям связи, что значительно снижает трафик между клиентом и сервером приложений. Исходя из выше сказанного, именно AS-модель является фундаментом для мониторов обработки транзакций. [77]
Изучив все модели технологии «Клиент – сервер», можно сделать следующий вывод: RDA- и DBS-модели имеют в основе двухзвенную схему разделения функций. В RDA-модели прикладные функции отданы клиенту, в DBS-модели их реализация осуществляется через ядро СУБД. В RDA-модели прикладной компонент сливается с компонентом представления, в DBS-модели интегрируется в компонент доступа к ресурсам.
В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, имеющий стандартизированные интерфейсы с двумя другими компонентами.
Результаты анализа моделей технологий «Файловый сервер» и «Клиент – сервер» представлены в таблице 1.[78]
Несмотря на свое названия технология «Клиент –сервер» также является системой распределенных вычислений. В данном случае распределенные вычисления рассматриваются как архитектура «Клиент – сервер» с участием нескольких серверов. Применительно к распределенной обработке термин «сервер» означает просто программу, отвечающую на запросы и выполняющую необходимые действия по запросу клиента. Поскольку распределенные вычисления - это один из видов систем «Клиент – сервер», то пользователи получают такие же преимущества, например, увеличение общей пропускной способности и возможность многозадачной работы. Кроме того, интеграция дискретных сетевых компонентов и обеспечение их функционирования как единого целого способствует увеличению эффективности и снижению издержек. [79]
Так как обработка осуществляется в любом месте сети, распределенные вычисления в архитектуре «Клиент–сервер» гарантируют эффективное масштабирование. Чтобы добиться баланса между клиентом и сервером, компонент приложения должен выполняться на сервере только в том случае, когда централизованная обработка более эффективна. Если логика программы, взаимодействующей с централизованными данными, сосредоточена на той же машине, что и данные, их необязательно передавать по сети, поэтому требования к сетевой среде могут быть снижены.
Таким образом, если предстоит работа с небольшими информационными системами, не требующими графического интерфейса с пользователем, можно выбрать FS - модель. Проблему графического интерфейса легко решает RDA-модель. DBS-модель является хорошим вариантом для СУБД. AS-модель является лучшим вариантом для создания больших информационных систем, а также в случае использования низкоскоростных каналов связи.[80]
ЗАКЛЮЧЕНИЕ
В заключение можно сделать следующие выводы.
На сегодняшний день развитие информационных технологий - создание единых сетей предприятий и корпораций, объединяющих удаленные компьютеры и локальные сети, часто использующие разные платформы, в единую информационную систему. Т.е. необходимо объединить пользователей компьютеров в единое информационное пространство и предоставить им совместный доступ к ресурсам. Однако здесь возникает множество трудностей, связанных с решением задачи по организации каналов связи кабель Internet не протянешь по городу, а тем более до другого конца планеты. При построении корпоративных сетей иногда используются телефонные каналы, но связь по таким коммутируемым линиям ненадежна, аренда выделенных линий связи дорога, а эффективность такого канала невысокая.
Самым оптимальным вариантом является использование уже существующих глобальных сетей передачи данных общего пользования, чтобы коммуникационный протокол в корпоративной сети совпадал с принятым в существующих глобальных сетях. Наиболее рациональным выбором здесь следует считать протокол Х.25. Данный протокол позволяет работать даже на низкокачественных линиях связи, так как разрабатывался он для подключения удаленных терминалов к большим ЭВМ и соответственно включает в себя мощные средства коррекции ошибок, освобождая от этой работы пользователя.[81]
Таким образом, при большом числе компьютеров, (десятки, сотни и даже
тысячи) предприятия чаще всего полагаются на сети модели «клиент-
сервер».
Упрощенно можно считать, что в такой сети отдельный компьютер
подключается к одному или нескольким мощным компьютерам, которые
называются серверами.
Сервер – это компьютер, или выполняющаяся на нём программа, которая
предоставляет клиентам доступ к общим ресурсам и управляет этими
ресурсами.
Клиент – пользователь (получатель) услуг и/или ресурсов, которые
предоставляет сервер.
В серверных сетях серверы оснащены процессорами и сетевой
операционной системой.
Роль серверов состоит в обеспечение централизованной защиты и управлении трафиком, а так же в предоставление клиентам ресурсов: информации, приложений и доступа к устройствам совместного пользования (например, к принтерам). В клиент – серверной среде в роли клиентов выступают настольные ПК (именно ПК, а не неинтеллектуальные терминалы!) под управлением операционной системы типа Windows 95 или Windows NT Workstation. Как правило, клиент использует собственные вычислительные мощности для обработки информации, полученной от сервера, но полагается на сервер в части предоставления необходимых данных и приложений. Такое распределение ролей в обработке информации носит название клиентской (front - end) и серверной (back - end) обработки.
Таким образом, любая компьютерная сеть, по сути, является сетью клиент-сервер. Пользователь, подключивший свой компьютер к Интернет, будет иметь дело с сетью клиент-сервер и даже если компьютер не имеет выхода в сеть его программное обеспечение да и сам он ,скорее всего, организованы по схеме клиент-сервер.[82]
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Дрога А. А., Жукова П. Н., Копонев Д. Н., Лукьянов Д. Б., Прокопенко А. Н. Информатика и математика. - Минск, 2015.
2. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.
3. Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.
4. Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015.
5. А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014.
6.Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.
7. Мельников В. Защита информации в компьютерных системах. - М.: Финансы и статистика, Электронинформ, 2014.
8. Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015.
9. Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.
10. Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.
11. Саймон А.П. Стратегические технологии баз данных. Пер. с англ./Под ред. и с предисл. М.Р.Когаловского. – М.: Финансы и статистика, 2015.
ПРИЛОЖЕНИЯ
ПРИЛОЖЕНИЕ 1
Архитектура «клиент-сервер»
ПРИЛОЖЕНИЕ 2
Архитектура «тонкий клиент»
-
Дрога А. А., Жукова П. Н., Копонев Д. Н., Лукьянов Д. Б., Прокопенко А. Н. Информатика и математика. - Минск, 2015.- С.12-15. ↑
-
А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014. – С.16-18. ↑
-
Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015.-С.8-11. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.-С. 78-81. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.- С.47-49. ↑
-
А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014.- С.79-82. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.- С.49-51. ↑
-
Саймон А.П. Стратегические технологии баз данных. Пер. с англ./Под ред. и с предисл. М.Р.Когаловского. – М.: Финансы и статистика, 2015.-С. 36-38. ↑
-
А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014.- С.16-18. ↑
-
Саймон А.П. Стратегические технологии баз данных. Пер. с англ./Под ред. и с предисл. М.Р.Когаловского. – М.: Финансы и статистика, 2015.- С.38-41 ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.62-64. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.64-65. ↑
-
Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015.- С.51-53. ↑
-
Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015.-С.53-55. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.- С.19-21. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.-С.21-24. ↑
-
Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015.- С.55-58. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.- С.72-74. ↑
-
Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015.-С.58-60. ↑
-
Дрога А. А., Жукова П. Н., Копонев Д. Н., Лукьянов Д. Б., Прокопенко А. Н. Информатика и математика. - Минск, 2015.- С.98-101. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.- С.69-72. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.- С.36-39. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.- С.29-30. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.- С.39-41. ↑
-
А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014.- С.72-73. ↑
-
Мельников В. Защита информации в компьютерных системах. - М.: Финансы и статистика, Электронинформ, 2014.- С. 44-46. ↑
-
Мельников В. Защита информации в компьютерных системах. - М.: Финансы и статистика, Электронинформ, 2014. – С.46-48. ↑
-
Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015.- С.61-62. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.14-15 ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.58-60. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.15-17. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.-С.17-19. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.60-62. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.-С.62-65. ↑
-
. Саймон А.П. Стратегические технологии баз данных. Пер. с англ./Под ред. и с предисл. М.Р.Когаловского. – М.: Финансы и статистика, 2015.- С.71-73. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.19-21. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.- С.58-59. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015 – С.60-63. ↑
-
Дрога А. А., Жукова П. Н., Копонев Д. Н., Лукьянов Д. Б., Прокопенко А. Н. Информатика и математика. - Минск, 2015.- С.32-35. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.- С.63-66. ↑
-
А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014.- С.11-15. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015. – С. 91-93. ↑
-
Мельников В. Защита информации в компьютерных системах. - М.: Финансы и статистика, Электронинформ, 2014 . – С.47-50. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015. – С.93-96. ↑
-
Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015.- С.42-44. ↑
-
Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015.- С.44-47. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.71-73. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.86-87. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.87-89. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.89-91. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.-С.80-82. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014. –С.82-84. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014. – С.84-87. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.101-103. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.103-106. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.- С.84-87. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.- С.87-89. ↑
-
Дрога А. А., Жукова П. Н., Копонев Д. Н., Лукьянов Д. Б., Прокопенко А. Н. Информатика и математика. - Минск, 2015. – С.12-16. ↑
-
Дрога А. А., Жукова П. Н., Копонев Д. Н., Лукьянов Д. Б., Прокопенко А. Н. Информатика и математика. - Минск, 2015.- С.16-18. ↑
-
Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015. – С.76-78. ↑
-
Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование -- М.: «Вильямс», 2015. – С.78-81. ↑
-
Мельников В. Защита информации в компьютерных системах. - М.: Финансы и статистика, Электронинформ, 2014. – С.39-41. ↑
-
А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2014.- С.19-21. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.49-51. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.51-53. ↑
-
Саймон А.П. Стратегические технологии баз данных. Пер. с англ./Под ред. и с предисл. М.Р.Когаловского. – М.: Финансы и статистика, 2015.- С.98-101. ↑
-
Саймон А.П. Стратегические технологии баз данных. Пер. с англ./Под ред. и с предисл. М.Р.Когаловского. – М.: Финансы и статистика, 2015.- С.101-104. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.121-124. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.124-126. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.- С.65-67. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.- С.67-69. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015.- С.17-19. ↑
-
Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика -- 3-е изд. -- М.: «Вильямс», 2015. – С.19-22. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.- С.59-61. ↑
-
Кузнецов С. Д. Основы баз данных. -- 1-е изд. -- М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2015.- С.61-64. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.78-82. ↑
-
Альперович М. Еще раз об архитектуре "клиент-сервер".//Компьютер-Информ,-№2,- 2014.- С.82-85. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.111-113. ↑
-
Альперович М. Построение распределенных информационных систем на базе Microsoft SQLServer.//Компьютер-Информ,-№4,-2016.- С.113-114. ↑
-
Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015.- С.71-74. ↑
-
Ладыженский Г.М. Системы управления базами данных - коротко о главном.//СУБД,-№2, 3, 4,-2015. – С.82-84. ↑
-
Титоренко Г.А. Информационные технологии управления. М., Юнити: 2015.- С.39-41. ↑

- Особенности управления региональным рынком труда (Сущность, структура и механизм функционирования рынка труда)
- Управление поведением в конфликтных ситуациях (Определение, виды и типы конфликтов в организации)
- Игра как метод воспитания (Игра: понятие, характеристика, функции)
- Игра как метод воспитания (Теория происхождения игры)
- Принципы и основания наследования»
- Влияние кадровой стратегии на работу коллектива
- Логистический подход к управлению запасами (Понятие, сущность и виды производственных запасов)
- Мультипроцессоры (Некоторые этапы из истории освоения массового параллелизма)
- Разработка регламента выполнения процесса «Планирование налоговой стратегии
- Особенности государственного управления регионом в современных условиях
- Основы нотариального сообщества: федеральная нотариальная палата, нотариальная палата субъекта РФ (Система субъектов нотариальной деятельности)
- Нотариальные действия (Понятие и виды нотариального производства)