
Технология «клиент-сервер» (Понятие технологии «клиент-сервер»)
Содержание:

Введение
Актуальность выполнения данной работы обусловлена тем, что область применения информационных систем постоянно расширяется, а сами они становятся все более и более сложными. Некоторые системы вырастают и усложняются настолько, что приобретают глобальный характер, и от их правильного и надежного функционирования начинает зависеть деятельность десятков или даже сотен тысяч людей.
В силу своей глобальности (нужно обеспечить доступ к системе из территориально разнесенных между собой точек), а также в силу ряда других причин такие системы часто имеют очень сложную архитектуру, предполагающую их функционирование в виде набора компонентов, каждый из которых выполняется на отдельном узле. Поскольку число таких систем постоянно возрастает, требования, предъявляемые к ним, достаточно серьезны. Сложность проектирования и разработки таких систем высока, а методы и средства, применяемые при реализации таких проектов, отличны от принятых при разработке монолитных систем.
Повсеместный переход на технологию «клиент-сервер» помогает решить много старых проблем, но при этом создал много новых. Одной из основных трудностей было и остается определение границы между функционалом клиента и сервера. Часто решение о переносе части задач на сервер пагубно сказывается на общей производительности системы, и наоборот, перенос части нагрузки на клиента может привести к потере централизации.
По мере роста популярности систем «клиент-сервер» набирала силу и технология ООП, которая предлагала перейти к системной архитектуре с тремя слоями: слой представления отводится пользовательскому интерфейсу, слой предметной области предназначен для описания основных функций приложения, необходимых для достижения поставленной перед ним цели, а третий слой представляет источник данных.
Объект исследования – интернет-технологии.
Предмет исследования – технология «клиент-сервер»
Целью данной работы является изучение технологии «клиент-сервер».
В соответствии с целью была определена необходимость постановки и решения следующих задач:
– дать понятие технологии «клиент-сервер»;
– описать модели взаимодействия «клиент-сервер»;
– описать архитектуру «клиент-сервер»;
– дать характеристику современным технологиям «клиент-сервер»;
– описать практику использования технологий «клиент-сервер».
1. Технология «клиент-сервер»
1.1. Понятие технологии «клиент-сервер»
«Клиент–сервер» представляет собой вычислительную или сетевую архитектуру, в которой задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми клиентами [3, с. 19]. Фактически клиент и сервер – это специальное программное обеспечение.
Поскольку одна программа-сервер может выполнять запросы от множества программ-клиентов, её размещают на специально выделенной вычислительной машине, настроенной особым образом, как правило, совместно с другими программами-серверами, поэтому производительность этой машины должна быть высокой. Из-за особой роли такой машины в сети, специфики её оборудования и программного обеспечения, её также называют сервером, а машины, выполняющие клиентские программы, соответственно, клиентами.
Как правило, компьютеры и прикладные программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами, другие имеют возможность обращаться к этим ресурсам. Компьютер, управляющий ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных, вычислительный сервер). Клиент и сервер какого-либо ресурса могут находиться как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
Основной принцип технологии «клиент-сервер» заключается в разделении функций приложения на три группы:
– ввод и непосредственное отображение данных (взаимодействие с пользователем);
– прикладные функции, которые являются характерными для данной предметной области;
– функции управления оперативными ресурсами вычислительной системы.
Поэтому, в любом прикладном программном приложении выделяются следующие компоненты:
– компонент представления данных;
– прикладной компонент;
– компонент управления ресурсом.
Связь между компонентами осуществляется по определенным правилам, которые называют «протокол взаимодействия».
1.2. Модели взаимодействия «клиент-сервер»
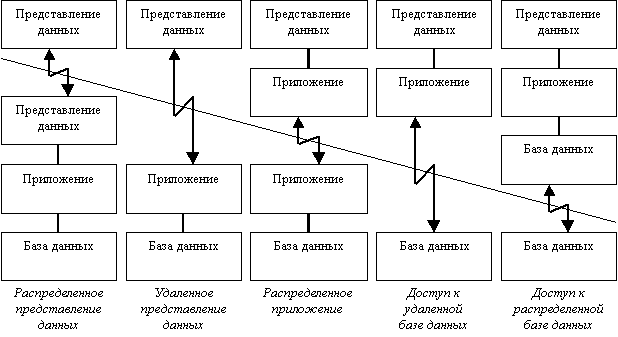
Компанией Gartner Group, специализирующейся в области исследования информационных технологий, предложена следующая классификация двухзвенных моделей взаимодействия клиент-сервер (двухзвенными эти модели называются потому, что три компонента приложения различным образом распределяются между двумя узлами), Приложение А.
Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только «картинка», сформированная на центральном компьютере [8, с. 86].
Затем, с появлением персональных компьютеров (ПК) и локальных сетей, были реализованы модели доступа к удаленной базе данных. Некоторое время базовой для сетей ПК была архитектура файлового сервера. При этом один из компьютеров является файловым сервером, на клиентах выполняются приложения, в которых совмещены компонент представления и прикладной компонент (система управления базами данных и прикладная программа) [16, с. 250].
Протокол обмена при этом представляет набор низкоуровневых вызовов операций файловой системы. Такая архитектура, реализуемая, как правило, с помощью персональных систем управления базами данных, имеет очевидные недостатки - высокий сетевой трафик и отсутствие унифицированного доступа к ресурсам.
С появлением первых специализированных серверов баз данных появилась возможность другой реализации модели доступа к удаленной базе данных. В этом случае ядро СУБД функционирует на сервере, протокол обмена обеспечивается с помощью языка SQL. Такой подход по сравнению с файловым сервером ведет к уменьшению загрузки сети и унификации интерфейса «клиент-сервер» [13, с. 74]. Однако, сетевой трафик остается достаточно высоким, кроме того, по-прежнему невозможно удовлетворительное администрирование приложений, поскольку в одной программе совмещаются различные функции.
Позже была разработана концепция активного сервера, который использовал механизм хранимых процедур. Это позволило часть прикладного компонента перенести на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же персональном компьютере, что и SQL-сервер [21, с. 369].
Преимущества такого подхода: возможно централизованное администрирование прикладных функций, значительно снижается сетевой трафик (т.к. передаются не структурированные SQL-запросы, а вызовы хранимых процедур). Недостаток - ограниченность специализированных средств разработки хранимых процедур по сравнению с языками общего назначения (C и Pascal).
В последнее время также наблюдается тенденция ко все большему использованию модели распределенного приложения. Характерной чертой таких приложений является логическое разделение приложения на две и более частей, каждая из которых может выполняться на отдельном компьютере. Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате. На практике сейчас обычно используются смешанный подход:
– простейшие прикладные функции выполняются хранимыми процедурами на сервере;
– более сложные реализуются на клиенте непосредственно в прикладной программе [24, с. 54].
Сейчас ряд поставщиков коммерческих систем управления базами данных объявило о планах реализации механизмов выполнения хранимых процедур с использованием языка программирования Java. Это соответствует концепции «тонкого клиента», функцией которого остается только непосредственное отображение данных (модель удаленного представления данных).
1.3. Архитектура «клиент-сервер»
Архитектура клиент-сервер определяет лишь общие принципы непосредственного взаимодействия между компьютерами, детали взаимодействия определяют различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
Существует два вида архитектуры взаимодействия клиент-сервер: первый получил название двухзвенная архитектура клиент-серверного взаимодействия, второй – многоуровневая архитектура клиент-сервер (иногда его называют трехуровневая архитектура или трехзвенная архитектура, но это частный случай).
Принцип работы двухуровневой архитектуры взаимодействия клиент-сервер заключается в том, что обработка запроса происходит на одной машине без использования сторонних ресурсов. Двухзвенная архитектура предъявляет жесткие требования к производительности сервера, но в тоже время является очень надежной. Двухуровневую модель взаимодействия клиент-сервер вы можете увидеть на рис. 1.
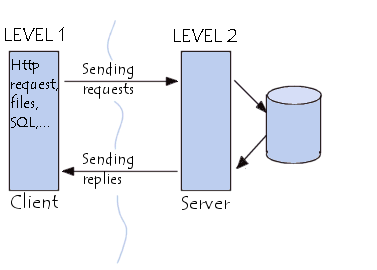
Рис. 1. Двухуровневая модель взаимодействия клиент-сервер
Здесь четко видно, что есть клиент (1-ый уровень), который позволяет человеку сделать запрос, и есть сервер, который обрабатывает запрос клиента.
Если говорить про многоуровневую архитектуру взаимодействия клиент-сервер, то в качестве примера можно привести любую современную систему управления базами данных (за исключением, библиотеки SQLite, которая в принципе не использует концепцию клиент-сервер) [4, с. 89].
Суть многоуровневой архитектуры заключается в том, что запрос клиента обрабатывается сразу несколькими серверами. Такой подход позволяет значительно снизить нагрузку на сервер из-за того, что происходит распределение операций, но в то же самое время данный подход не такой надежный, как двухзвенная архитектура. На рис. 2 можно увидеть пример многоуровневой архитектуры клиент-сервер.
Если посмотреть на данную архитектуру с позиции сайта. То первый уровень можно считать браузером, с помощью которого посетитель заходит на сайт, второй уровень – это связка Apache + PHP, а третий уровень – это база данных. Преимуществом модели взаимодействия клиент-сервер является то, что программный код клиентского приложения и серверного разделен.
Если говорить про локальные компьютерные сети, то к преимуществам архитектуры клиент-сервер можно отнести пониженные требования к машинам клиентов, так как большая часть вычислительных операций будет производиться на сервере, а также архитектура клиент-сервер довольно гибкая и позволяет администратору сделать локальную сеть более защищенной.
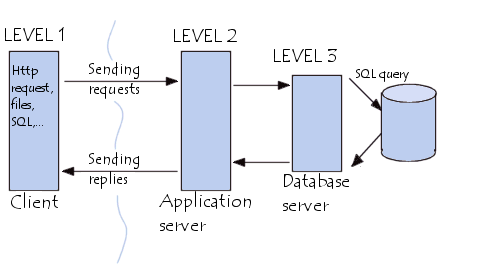
Рис. 2. Многоуровневая архитектура взаимодействия клиент-сервер
Типичный пример трехуровневой модели клиент-сервер. Если говорить в контексте систем управления базами данных, то первый уровень – это клиент, который позволяет нам писать различные структурированные SQL запросы к базе данных. Второй уровень – это движок системы управления базами данных, который интерпретирует запросы и реализует взаимодействие между клиентом и файловой системой, а третий уровень – это хранилище данных [2, с. 415].
К недостаткам модели взаимодействия клиент-сервер можно отнести то, что стоимость серверного оборудования значительно выше клиентского. Сервер должен обслуживать специально обученный и подготовленный человек [5, с. 190]. Если в локальной сети не будет работать сервер, то и клиенты не смогут работать. В качестве заключения нам стоит явно акцентировать внимание на том, что архитектура клиент-сервер не делит машины на только клиент или только сервер, а скорее позволяет распределить нагрузку и разделить функционал между клиентской частью и серверной.
2. Современные технологии «клиент-сервер»
2.1. Технологии обработки страниц на web-сайте
В последнее время все больше организаций сталкиваются с проблемой улучшения своей управляемости: улучшение контроля и ускорение бизнес-процессов, улучшение возможности их отслеживания и возможности получение метрик, характеризующих качество исполнения бизнес-процессов. Единственным способом реализации подобных задач является внедрение технологий, основанных на WEB-сайте с активными серверными страницами, выполняющие вышеуказанные функции. Однако в настоящее время попытка решения задачи внедрения таких технологий наталкивается на существенные сложности, которые связаны с эффективным выбором необходимой технологии обработки управленческой информации.
Существует два способа создания активного сервера Web на базе Microsoft Internet Information Server – с использованием программ расширения CGI или ISAPI или при помощи активных серверных страниц ASP.
Первый способ предполагает составление сложных программ на языке программирования C++ или типа Perl. Программы по расширению сервера Web являются обычными приложениями, которые исполняются на сервере Web. Они могут выполнять обращение к БД таким же образом, как и стандартные автономные приложения [6, с. 470].
Главным недостатком данного способа обработки информации является сложность ее реализации и отладки программ по расширению сервера Web, что существенно снижает эффективность процессов по разработке больших и сложных программных проектов. Особенно тяжело сопровождать динамически меняющиеся проекты.
Использование активных серверных страниц ASP, является значительно проще, хотя позволяют решать тот же самый комплекс задач, что и программное расширение сервера Web. Активные серверные страницы ASP являются текстовыми файлами с конструкциями языка HTML и необходимыми сценариями, которые были составлены на языках программирования, как JScript и VB Script [10, с. 185].
Возможности по составлению серверных приложений с использованием высокоуровневых языков сценариев и технологий компонентов COM существенно позволяет упростить процесс создания сложных программных приложений Web. При этом от разработчиков не требуется полного понимания особенностей программирования на уровне интерфейсов ОС или прикладных интерфейсов БД. Все разработки ведутся в терминах интерфейсов и свойств высокоуровневых компонент COM.
Сценарии, расположенные в страницах ASP, могут быть клиентскими и серверными. Серверные сценарии можно выделить специальным образом и могут быть исполнены на сервере, в то время как клиентские сценарии работают на ПК пользователя.
Результатом работы серверных сценариев ASP является динамически сформированный текст документа HTML, который отсылается пользователю. Данный текст загружается в окно браузера. Если созданный документ HTML будет содержать клиентские сценарии, они будут выполнены браузером [12, с. 260].
Технология ASP предполагает широкое использование серверных сценариев и объектов СОМ для создания динамических web-серверов. Средствами технологии ASP можно легко создавать интерактивные web-страницы, выполнять обработку данных введенных пользователем через формы, обращаться к базам данных.
Наиболее интересными и полезными качествами, которыми обладает технология ASP, можно считать:
– наличие удобного способа соединения серверных сценариев и HTML;
– наличие скриптового подхода, который упрощает процессы разработки и поддержки за счет того, что файл с исходным кодом ASP одновременно является его исполняемым файлом;
– поддержка концепции «Session» – переменные для всех пользовательских соединений, как решение проблем с протоколом HTTP;
– возможности организации распределенной архитектуры на основе инфраструктуры COM, DCOM, COM+. Дополнительные возможности, предоставляемые технологией MTS – контекст объектов, пул и т.д.;
– наличие удобного набора объектов-утилит: Server, Application, Request, Response, Session, ObjectContext [9, с. 120].
В тоже время, пользователь не может каким-либо образом получить содержимое страницы ASP, так как web-сервер отправляет ему не саму страницу, а результат ее интерпретации, таким образом, логика работы страницы скрыта от пользователей.
2.2. Реализация бизнес-задач на web-сайте с активными серверными страницами
Идеология разработки современных web-приложений заключается в инкапсуляции бизнес-логики в отдельные компоненты, которые разработаны по средствам технологии COM. Технология ASP является связующим звеном между этими компонентами и интерфейсом веб-приложения.
Active Server Pages представляет собой среду программирования, обеспечивающую возможности по комбинированию HTML, скриптов, и компонент для разработки динамических web-приложений. Обеспечивает необходимые возможности по встраиванию в web-страницы скриптов, позволяет логичным образом выполнить объединение оформления с данными которые были получены из разнообразных источников, например, из баз данных.
Реализация бизнес-задач на web-сайте с активными серверными страницами представляет собой специализированный физический процесс, посредством которого выполняется передача информации в пространстве. Данный процесс можно охарактеризовать наличием следующих компонентов: использование среды передачи информации; использование определенного носителя информации; наличие приёмника информации; наличие источника информации [11, с. 104].
Обработка ключевых бизнес-задач на web-сайте с активными серверными страницами может быть представлена в виде следующей схемы, рис. 3.
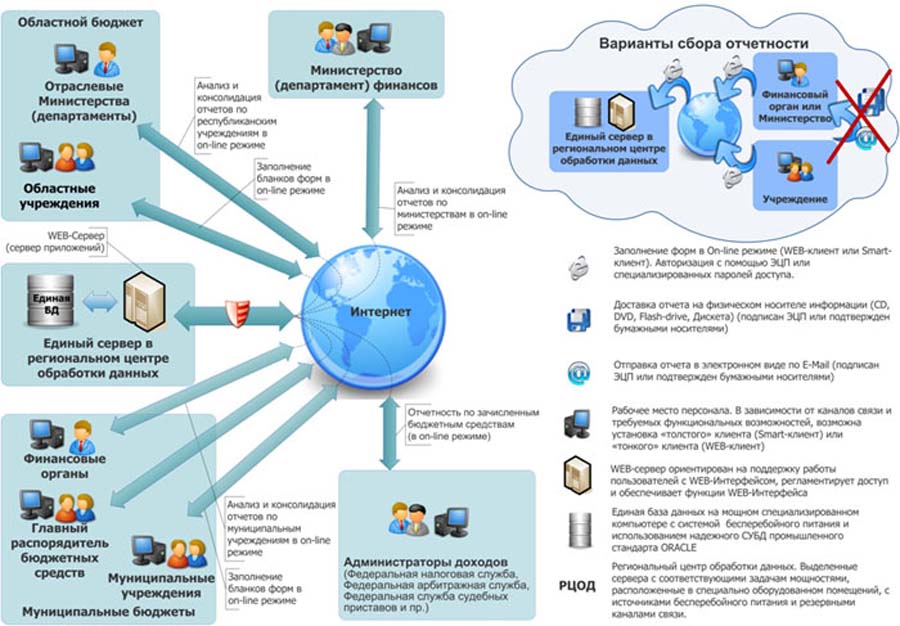
Рис. 3. Обработка бизнес-задач на web-сайте
В структуре операций информационного обмена на определенном web-сайте с использованием активных серверных страниц можно выделить следующее:
– операции по сбору данных используемые для накопления информации по обеспечению полноты информации для последующего принятия управленческих решений;
– операции по формализации оперативных данных используются для приведения данных, которые поступают из различных источников, к одинаковой форме, для сопоставления между собой для повышения уровня их доступности;
– фильтрация данных позволяет отсеивать не нужные данные; при этом необходимо уменьшить уровень шума, адекватность и достоверность данных возрастают;
– сортировка оперативных данных представляет собой упорядочение данных по определенным признакам для удобства дальнейшего использования; что позволить повысить доступность и обработку информации;
– архивация данных представляет собой определенную организацию хранения данных в удобной форме; данная организация данных необходима для снижения затрат по хранению данных и повышения эффективности их использования;
– защита данных представляет собой определенный комплекс мер, которые направлены на предотвращение утраты, воспроизведения и модификацию данных;
– транспортировка оперативных данных представляет собой прием и непосредственную передачу данных между участниками информационных процессов [15, с. 95].
Система информационного обмена на web-сайте с активными серверными страницами может быть предназначена для одного пользователя или для группы пользователей. В последнем случае нужно обеспечить условия, при которых информационный обмен между пользователями производится параллельно.
Информационный обмен на web-сайте с активными серверными страницами обеспечивает взаимодействие потребителей-поставщиков информации. Решение всякой проблемы в общем случае может включать такие этапы:
– выполнение поиска необходимой информации. Данный этап характеризуется обработкой информации в информационной системе или взаимодействии с ней;
– выполнение интерпретации сообщений. Данный этап характеризуется адаптацией сообщений - извлечение из полученных сообщений необходимой информации, которая необходима для решения поставленных задач. Второй этап заканчивается созданием информационного обеспечения решаемой задачи;
– решение задачи можно описать как использование web-сайта с активными серверными страницами, а также использование собственных знаний и опыта, при приложении определенных усилий, потребитель может создать новую информацию;
– создание сообщений выражается в процессе взаимодействия пользователя с web-сайтом по средствам использования технологий активных серверных страниц;
– распространение сообщений. Создатели сообщений вступают в активное взаимодействие с системой коммуникации, затрачивая определенные усилия по вводу новой информации в один из доступных каналов коммуникации [17, с. 650].
Типовая схема информационного обмена на web-сайте с активными серверными страницами представлена на рис. 4.
Управление информационным обменом на макроуровне может быть разделено на три типа задач, соответствующих данным каналам, которые можно описать следующим образом:
– организация работ и взаимодействия соисполнителей при выполнении работ;
– маркетинг – поиск заказчиков;
– управление документальными потоками – распространение информации в документальной форме по каналам на web-сайте с активными серверными страницами [19, с. 35].
Рис. 4. Типовая схема информационного обмена на web-сайте с активными серверными страницами
Обобщенными информационными системами в рассматриваемом случае могут являться:
– информационно-аналитические подразделения организаций;
– информационные службы или институты информации;
– специалисты-аналитики или информаторы;
– мировые информационные системы и сети информационного обмена.
2.3. Сетевые системы управления базами данных
Сетевая система управления базами данных представляет собой систему управления базами данных, которая поддерживает сетевую организацию: любая запись, которая называется записью старшего уровня, может включать данные, относящиеся к набору других записей, которые называются записями подчиненного уровня базы данных.
Основными понятиями сетевой модели базы данных в рамках системы управления базами данных являются: элемент (узел); уровень; связь.
Узел представляет собой определенную совокупность специальных атрибутов данных, которые используются для описания некоторого объекта базы данных системы управления базами данных. В рамках сетевой структуры каждый отдельный элемент базы данных может быть связан с любым другим элементом базы данных.
Сетевые базы данных, которые управляются при помощи системы управления базами данных подобны иерархическим, за исключением того, что в них имеются специальные указатели в обоих направлениях, которые позволяют соединить родственную информацию.
Несмотря на то, что данная модель позволяет решить некоторые проблемы, которые связаны с иерархической моделью организации баз данных, выполнение достаточно простых запросов остается сложным процессом. Средства системы управления базами данных позволяют достаточно просто разрабатывать пользовательские запросы и другие операции по манипулированию данными базы данных [23, с. 216].
Можно выделить примерный набор выполняемых операций для эффективного манипулирования оперативными данными базы данных по средствам использования специализированных сетевых систем управления базами данных:
– возможности оперативного поиска необходимой записи в представленном наборе однотипных записей пользовательских данных базы данных;
– возможности перехода от конкретного предка к первому потомку при помощи использования специализированных средств системы управления базами данных;
– возможности непосредственного перехода от потомка к предку по некоторой связи;
– возможности перехода к следующему потомку в некоторой связи вычислительной обработки;
– возможности создания новой записи базы данных;
– возможности уничтожения записей базы данных;
– возможности модифицирования записей базы данных;
– возможности включения в связь базы данных;
– возможности исключения данных из связи базы данных;
– возможности изменения связей базы данных [26, с. 42].
Имеется вспомогательная возможность потребовать для конкретного типа используемой связи отсутствие возможных потомков, которые не участвуют ни в одном экземпляре этого типа установленной связи (как это делается в рамках иерархической модели организации базы данных системы управления базами данных).
В рамках сетевых систем управления базами данных легко могут быть реализованы и иерархические даталогические модели и сетевые. Сетевые системы управления базами данных поддерживают сложные соотношения между типами данных, что позволяет сделать их пригодными в различных программных приложениях. Таким образом, к основным преимуществам использования сетевых систем управления базами данных можно отнести следующие:
– обработка больших объемов информации (наличие возможностей построения на базе такого рода систем управления базами данных «хранилищ данных»);
– поддержка аналитической обработки данных системы управления базами данных;
– эффективная реализация обработки данных по показателям затрат памяти и оперативности [1, с. 230].
Недостатком для пользователей сетевых систем управления базами данных является то, что они ограничены специальными связями, определенными для них разработчиками баз данных приложений. Подобно иерархическим, сетевые системы управления базами данных предполагают разработку баз данных приложений опытными программистами и системными аналитиками.
Также к недостаткам сетевой модели данных относится высокая сложность и жесткость схемы баз данных, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в базах данных обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями.
К сетевым функциям систем управления базами данных можно отнести следующие.
Возможности непосредственного управления данными во внешней памяти.
Функция управления данными во внешней памяти включает поддержку необходимых структур внешней памяти как для организации эффективного хранения оперативных данных, которые непосредственно входят в определенную базу данных информационной системы, так и для обеспечения базовых служебных целей, например, для повышения скорости доступа к оперативным данным базы данных. В некоторых системах управления базами данных представлены возможности файловых систем, в других работа выполняется вплоть до уровня различного рода устройств внешней памяти.
В современных и достаточно развитых системах управления базами данных пользователи могут даже не знать, использует ли данная система управления базами данных собственную файловую систему, и если использует, то как она в ней организовывает свои оперативные файлы и доступ к ним. В частности, в системе управления базами данных поддерживается собственная система именования объектов базы данных для более эффективного управления ими и организации доступа к оперативным данным.
Возможности управления буферами оперативной памяти.
Сетевые системы управления базами данных в большинстве случаев работают с базами данных достаточно большого размера; по крайней мере, непосредственный размер базы данных может быть значительно больше доступного объема оперативной памяти вычислительной системы [7, с. 850].
Практически единственным способом реального увеличения фактической скорости обработки оперативных данных базы данных является использование технологии буферизации обрабатываемых данных в оперативной памяти вычислительной системы. При этом, даже если операционной системой будет производиться общесистемная буферизация, этого будет недостаточно для целей системы. Поэтому в разных системах управления базами данных есть поддержка собственного набора специализированных буферов оперативной памяти с использованием собственной дисциплиной замены буферов.
Возможности управления транзакциями.
Транзакция представляет собой специальную последовательность операций над базой данных, которые рассматриваются системой управления базами данных в виде единого целого. Либо определенная транзакция будет успешно выполнена и система будет фиксировать произведенные изменения в пользовательской базе данных, посредством использования данной транзакции, во внешней памяти вычислительной системы, либо ни одно из этих изменений никак не отразится на базовом состоянии базы данных.
Понятие транзакции является необходимым для поддержки логической целостности используемой базы. Все транзакции начинаются при целостном состоянии определенной пользовательской базы и оставляет данное состояние целостным после своего непосредственного завершения, что позволяет сделать достаточно удобным использование механизма транзакции как некоторой единицы активности пользователей по отношению к обрабатываемой базе данных информационного пространства. При соответствующем управлении выполняющимися транзакциями в параллельном виде со стороны определенной системы все пользователи могут ощущать себя единственными пользователями системы, но при этом быть разделены на потоки, отдельные информационные единицы.
Возможности ведения журнализации.
Одним из базовых требований к системе управления базами данных является высокая надежность хранения оперативных данных во внешней памяти вычислительной системы. Под надежностью хранения оперативных данных можно понимать то, что система должна быть в состоянии восстановить последнее согласованное состояние своей базы данных после любого возможного программного или аппаратного сбоя [14, с. 410].
Обычно рассматриваются несколько возможных видов аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы вычислительной системы, и жесткие сбои, которые характеризуются достаточно высокой потерей оперативной информации, которая представлена на носителях во внешней памяти вычислительной системы. Примерами программных сбоев могут быть: аварийное завершение системы или аварийное завершение, в результате чего некоторые транзакции остаются незавершенными. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия транзакции.
MongoDB (от англ. humongous - огромный) представляет собой документоориентированную систему управления базами данных с открытыми исходными кодами, и не требует описания схем таблиц. Данную систему управления базами данных можно классифицировать как NoSQL, которая использует JSON-подобные документы и специальную схему базы данных.
СУБД MongoDB разработана на базе использования средств объектно-ориентированного языка программирования C++, в связи с чем она может быть достаточно легко портирована на самые различные технологические платформы. MongoDB можно развернуть на следующих платформах Linux, MacOS, Windows, Solaris. Можно также выполнить загрузку исходного кода и самостоятельно выполнить компиляцию MongoDB, но в тоже время рекомендуется использовать исключительно библиотеки, закачиваемые с официального сайта [18, с. 87].
Сконструированные пользовательские запросы могут быть использованы для возвращения конкретных полей определенного оперативного документа и пользовательские JavaScript-функции. СУБД MongoDB поддерживает широкий поиск на базе использования регулярных выражений. Также, в СУБД MongoDB можно выполнить настройку пользовательских запросов на возвращение случайных наборов результатов взаимодействия с базой данных. В MongoDB имеется специализированный механизм поддержки индексов, позволяющий эффективно обрабатывать записи базы данных.
MongoDB может достаточно эффективно работать с набором реплик. Набор реплик включает несколько копий данных. Каждый новый экземпляр такого рода набора реплик может в необходимый момент времени выступить в роли вспомогательной или основной реплики. Все операции чтения и записи по умолчанию выполняются с базовой репликой. Вспомогательные реплики поддерживаются в актуальном состоянии копии обрабатываемых данных [20, с. 110]. Если основная реплика даст сбой, набор реплик будет проводить выбор, какую именно из реплик нужно будет сделать основной. Второстепенные реплики могут быть использованы для выполнения операций чтения.
MongoDB может быть масштабирована в горизонтальном виде используя технологию шардинга. Пользователи MongoDB могут выбрать необходимый ключ шарда, который будет определять, как именно обрабатываемые данные в коллекции базы данных будут распределяться. Данные могут быть разделены на специальные диапазоны и распределены по шардам.
СУБД MongoDB может быть использована в качестве специализированного файлового хранилища с наличием возможностей балансировкой нагрузки и организации репликации обрабатываемых пользовательских данных.
Данная функция, которая называется Grid File System, предоставляется совместно с установленным набором драйверов MongoDB. СУБД MongoDB может предложить разработчикам специализированные функции для работы с сетевыми файлами и их реквизитным содержимым. Технологию GridFS можно использовать в плагинах для lighttpd и NGINX. GridFS позволяет разделить файл на составные части и хранить каждую отдельную часть как уникальный документ [22, с. 163].
В фреймворках для выполнения операций агрегации данных существует аналог SQL-инструкции GROUP BY. Операторы такого рода агрегации могут быть связанными в специальный конвейер как это выполнено в UNIX-конвейерах. В фреймворках так же имеется специальный оператор $lookup, который может быть использован для выполнения операций связки обрабатываемых документов в процессе выгрузке и выполнения статистических операций, например, среднеквадратическое отклонение.
JavaScript можно использовать в конструированных пользовательских запросах, пользовательских функциях аггрегации (например в MapReduce) и может быть отправлен пользовательской базе для непосредственного исполнения.
СУБД MongoDB поддерживает специальные коллекции, которые имеют фиксированный размер. Такого рода коллекции позволяют сохранить порядок вставки и по достижении указанного размера будут вести себя как кольцевой буфер.
В MongoDB реализован новый подход к организации баз данных, в которой не используются таблицы, схемы, запросы SQL, внешне ключи и многие другие вещи, которые являются присущими только объектно-реляционным базам данных.
В большинстве случаев выполнение хранения оперативных данных выполняется по средствам использования базах данных реляционного типа, к которым можно отнести MS SQL, MySQL, Oracle, PostgresSQL. И при этом, не является столь важным, подходят ли определенные реляционные базы данных для выполнения операций хранения данного типа данных или не подходят.
В отличие от технологий реляционных баз данных СУБД MongoDB предлагает использование документоориентированной модели данных, за счет чего она может работать намного быстрее, обладает более эффективной масштабируемостью, ее легче использовать в практической деятельности в рамках определенной предметной области.
3. Практика использования технологий «клиент-сервер»
3.1. Система «Банк-Клиент»
Система «Банк-Клиент» – программный комплекс, позволяющий клиенту совершать операции по счету, обмениваться документами и информацией с банком без посещения офиса кредитной организации. Обмен информации происходит через телефон и компьютер.
Удобная система «Банк-Клиент» способна избавить представителей организации от поездок в банк практически полностью.
Целесообразность использования системы дистанционного доступа к счету определяется, как правило, количеством операций организации. Удаленный доступ к счету – дополнительная услуга банка, которая оплачивается отдельно.
Преимущества системы «Банк-Клиент»:
– удобство. Для совершения платежей не нужно идти в банк – достаточно сформировать платежный документ в системе;
– снижение вероятности операционных ошибок – не нужно заполнять платежные поручения вручную, что позволяет избежать механических ошибок;
– система поддерживает полный спектр банковских документов и реализована с учетом всех требований Национального банка;
– гарантированный уровень безопасности (используются сертифицированные криптографические средства);
– гибкое управление правами клиентов и их сотрудников.
Функциональные возможности системы «Банк-Клиент»:
– работа с документами в национальной валюте (платежные поручения в национальной валюте);
– работа с документами в иностранной валюте (платежные поручения в иностранной валюте, заявления на покупку/продажу/конверсию иностранной валюты);
– контроль за кредитными договорами;
– контроль и операции по депозитным договорам;
– формирование и отправка зарплатных ведомостей;
– работа с корпоративными картами;
– формирование выписок по счетам.
Технологии дистанционного банковского обслуживания можно классифицировать по типам информационных систем, которые используются для поддержки банковских операций:
– система «Клиент-Банк» (remote banking, PC-banking, direct banking, home banking);
– интернет-Клиент (Online banking, тонкий клиент; Интернет-банкинг (Internet banking), WEB-banking);
– система «Банк-Клиент»;
– система «Телефон-Банк» (Телефонный банкинг (phone-banking), телебанкинг, SMS-banking);
– использование с обслуживанием банкоматов (ATM-banking) и устройств, связанных с банковским самообслуживанием [25, с. 88].
Рассмотрим более подробно особенности информационной системы «Банк-Клиент».
Классический тип системы «Банк-Клиент», который часто называют «толстый клиент». Данный тип системы предполагает, что на компьютере пользователей будет установлена отдельная программа-клиент. Программа-клиент обеспечивает хранение на персональном компьютере всех своих оперативных данных, к которым относятся платёжные документы и различные выписки по счетам. Программа-клиент может выполнять соединение с банком по разным каналам связи, например, по средствам сети Интернет.
Преимущество использование систем «Банк-клиент» заключается в том, что клиенту для выполнения работы с клиентской составляющей системы не нужно постоянное подключение к специализированной банковской части системы дистанционного банковского обслуживания. Также, таких систем является их широкий внутренний функционал по обеспечению ролей пользователей.
В частности, это является очень актуальным для поддержки работы юридических лиц. Базы данных данного вида систем, в большинстве случаев, могут быть установлены на полноценные системы управления базами данных, что в процессе организации с большим документооборотом обеспечивает возможности удобного резервирования текущей базы данных, а также обеспечивает полноценную работу с сетевой версией без наличия потерь в скорости выполнения обработки платежных документов клиента. Состав типовой конфигурации системы «Банк-Клиент» представлен на рис. 5.
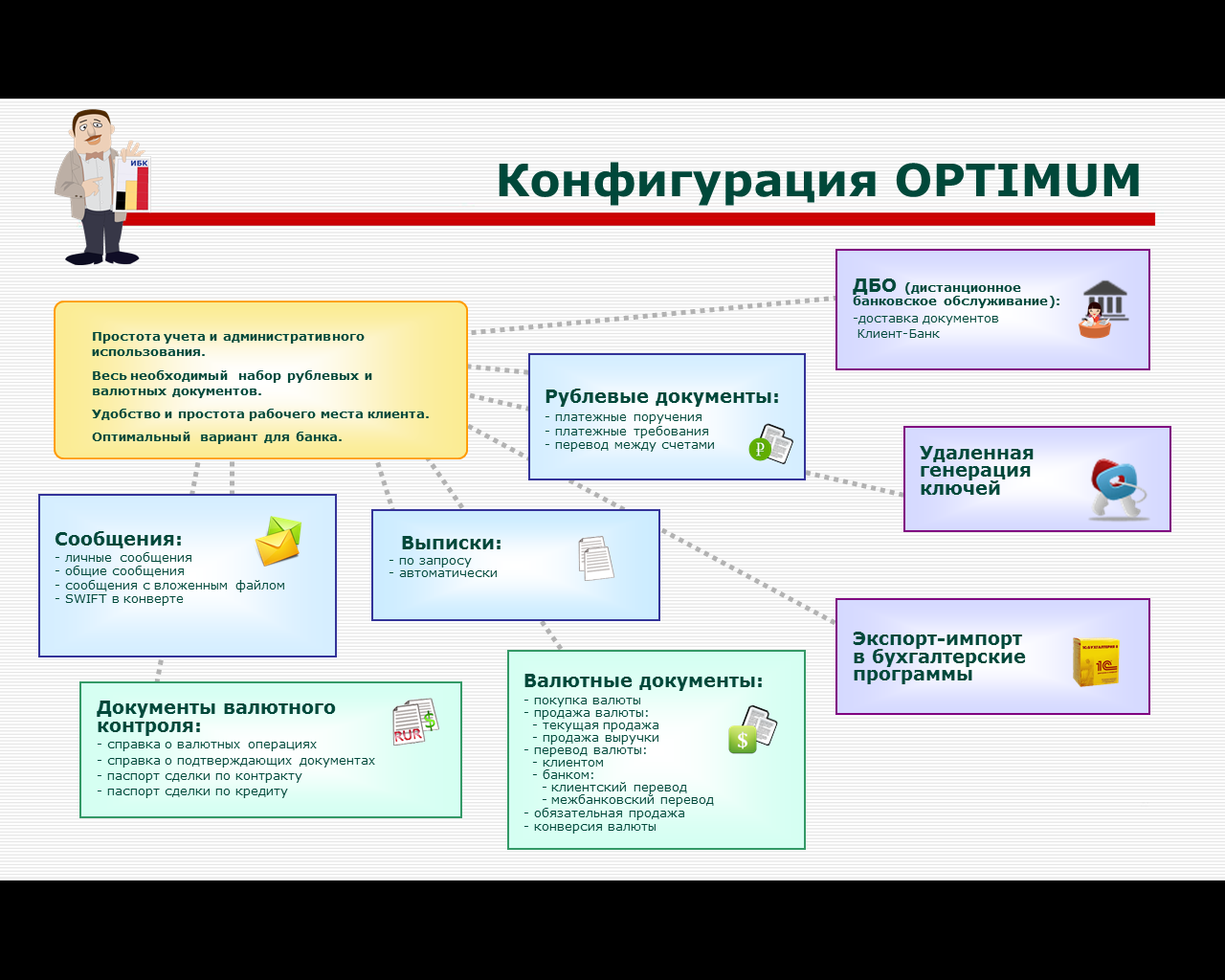
Рис. 5. Состав типовой конфигурации системы «Банк-Клиент»
В настоящее время стремительными темпами происходит внедрение систем электронного документооборота в различных предприятиях всех уровней. В соответствии с этим можно ожидать, что система «Банк-Клиент» в ближайшем будущем передаст часть своих сегодняшних функций внутренним средствам автоматизации предприятия. Как следствие этого существенно упростится экранный интерфейс.
Фактически система превратится в универсальную станцию внешнего документооборота, или EDI-станцию. Ее основными задачами станут следующие:
– обеспечение маршрутизации документов между групп пользователей и приложениями, обеспечение использования необходимых средств аутентификации и криптозащиты;
– обеспечения непосредственного взаимодействия с используемыми внутренними и внешними автоматизированными системами обработки информации;
– обеспечение комплекса возможностей обработки документов различного типа;
– обеспечение непосредственного взаимодействия с разными транспортными системами телекоммуникаций, в том числе, с системами off-line и on-line.
– обеспечение взаимодействия с разными транспортными вычислительными системами телекоммуникаций, в том числе, с системами off-line и on-line, рис. 6.
В настоящее время система «Банк-Клиент» превращается в необходимый вид сервиса, который каждый серьезный банк должен обеспечить своим клиентам. В условиях повсеместного перехода от бумажного к электронному документообороту, наличие данной системы зачастую может определить выбор клиентом банка.
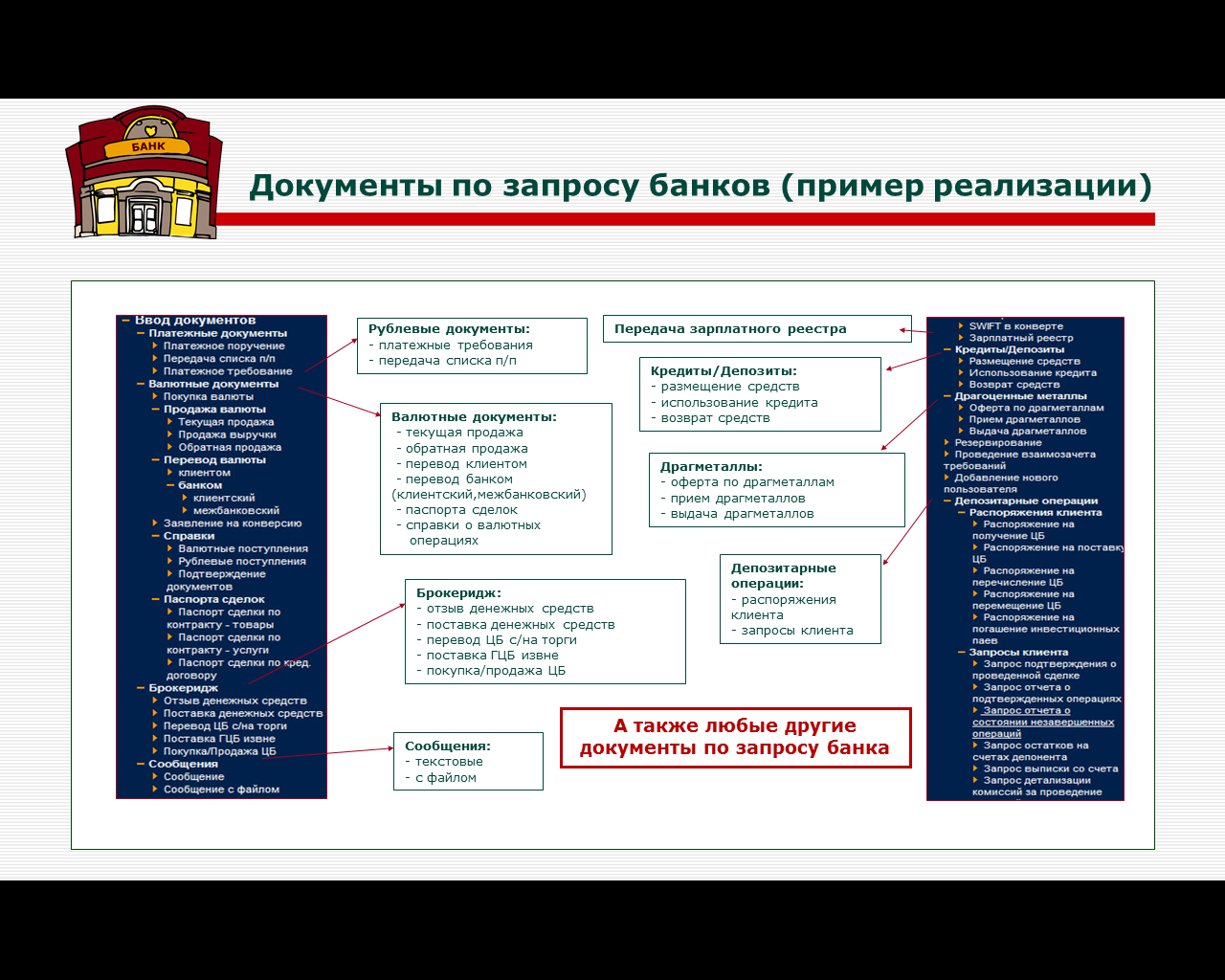
Рис. 6. Обработка документов в системе «Банк-Клиент»
Кроме того, при удачной реализации информационная система «Банк-Клиент» может быть использован банком для выполнения организации документооборота со всеми своими партнерами - любыми физическими и юридическими лицами.
3.2. Программный комплекс «ИНИСТ Банк-Клиент»
Компания «ИНИСТ» занимается разработкой систем «Банк-Клиент» с 1992 года. Программный комплекс «ИНИСТ Банк-Клиент» использует передовые технологии и богатый опыт эксплуатации системы российскими банками.
Система «ИНИСТ Банк-Клиент» позволяет клиентам получать информацию и управлять своими счетами в банке, используя специализированное рабочее место под Windows («Толстый клиент») или стандартный Интернет-браузер («Тонкий клиент»), а также осуществлять доступ к информации посредством телефонного банкинга и SMS сервисов, рис. 7.
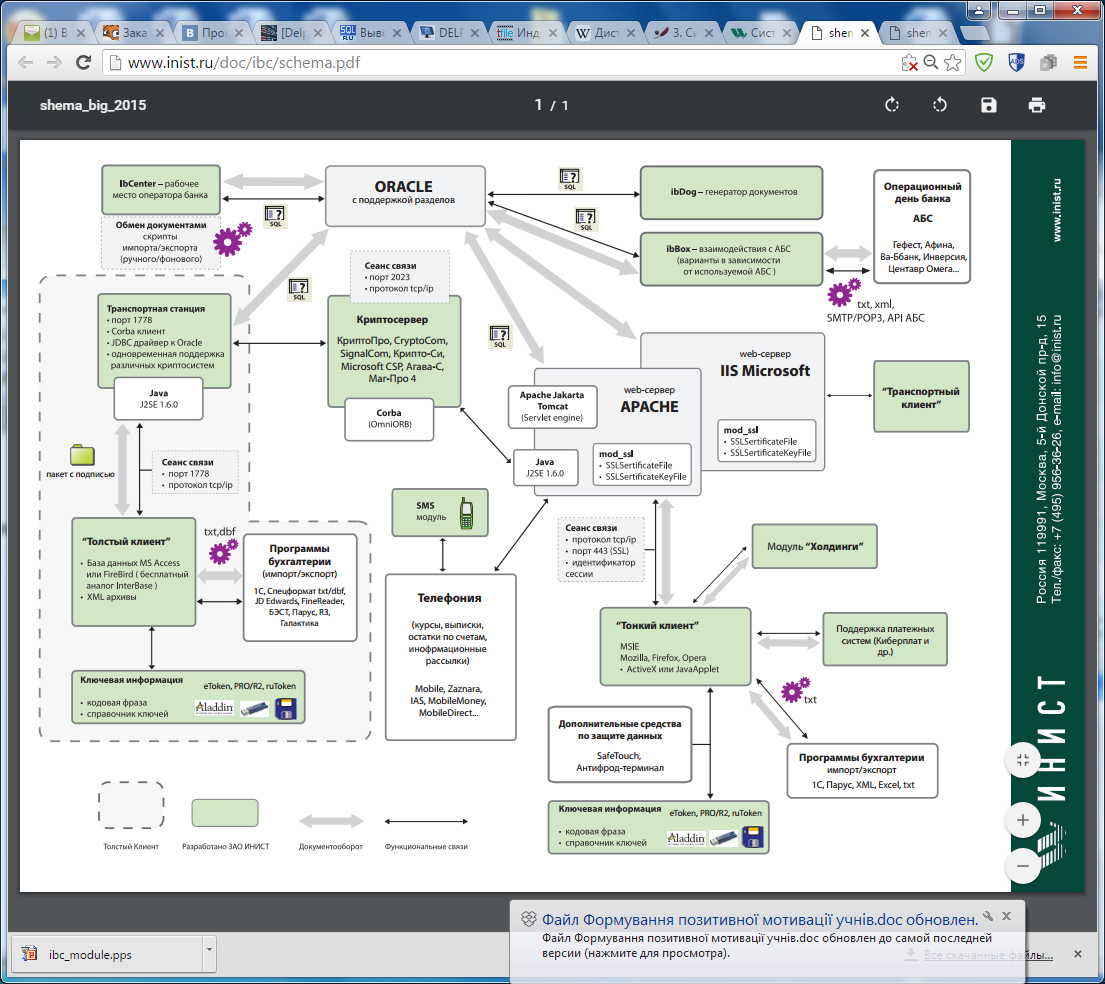
Рис. 7. Структурная схема работы программного комплекса
«ИНИСТ Банк-Клиент»
Основными достоинствами программного комплекса «ИНИСТ Банк-Клиент» являются:
– возможности развития системы и расширение ее возможностей;
– наличие простого и понятного интерфейса;
– полная совместимость со сторонними банковскими продуктами;
– возможности по настройке меню групп пользователей системы;
– соответствие протоколов системы с изменениями в законодательстве;
– наличие возможностей по работе с любыми каналами связи;
– возможности по работе неограниченного числа филиалов банка через главный центр системы «ИНИСТ Банк-Клиент»;
– возможности расширения информационной безопасности, параллельное и одновременное использование специальных ФСБ криптосистем;
– возможности кроссбраузерной совместимости;
– возможности настройки индивидуального дизайна системы [27, с. 413].
Базовые функции системы «ИНИСТ Банк-Клиент»:
– возможности по обслуживанию организаций и физических лиц;
– возможности по поддержке разнообразных криптобиблиотек;
– возможности по поддержке разнообразных форматов документов;
– наличие интерфейсов к разным АБС;
– возможности обмена данных с системами клиентов.
Система «ИНИСТ Банк-Клиент» реализована на основе архитектуры клиент-сервер, что обеспечивает высокую эффективность работы системы с надежность хранения данных и высокую защиту данных.
Дизайн системы «ИНИСТ Банк-Клиент» включает:
– наличие возможностей по выбору вариантов дизайна;
– наличие возможностей по замене цветов в оформления;
– наличие возможностей по разработке индивидуального дизайна;
– наличие возможностей по оформлению в стиле сайта банка.
Интерфейс системы «ИНИСТ Банк-Клиент» представлен на рис. 8.
Безопасность передачи информации и целостность доставляемых данных в системе «ИНИСТ Банк-Клиент» обеспечивается использованием современных разработок, к которым относятся:
Безопасность в системе «ИНИСТ Банк-Клиент» включает следующие компоненты:
– наличие защищенного SSL-соединения;
– использование электронного аналога собственной подписи обрабатываемых данных;
– возможности одновременной и параллельной работы с несколькими криптосистемами;
– использование ключевой регистрации;
– использование генератора одноразовых паролей;
– использование виртуальной клавиатуры.

Рис. 8. Интерфейс системы «ИНИСТ Банк-Клиент»
В настоящее время систему «ИНИСТ Банк-Клиент» используют более 20 банков и их филиалов, среди которых: Банк Российский Капитал; Юг-Инвестбанк, Краснодар; Нордеа Банк; Коммерческий банк ДельтаКредит; Росбанк; Банк «Национальный Клиринговый Центр».
Заключение
В процессе выполнения данной работы были получены следующие результаты. Установлено, что «клиент–сервер» – вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми клиентами. Основной принцип технологии «клиент-сервер» заключается в разделении функций приложения на три группы: ввод и отображение данных; прикладные функции, характерные для данной предметной области; функции управления ресурсами.
Архитектура клиент-сервер определяет лишь общие принципы взаимодействия между компьютерами, детали взаимодействия определяют различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол. Существует два вида архитектуры взаимодействия клиент-сервер: первый получил название двухзвенная архитектура клиент-серверного взаимодействия, второй – многоуровневая архитектура клиент-сервер.
Описаны современные технологии «клиент-сервер», одна из которых является технологии обработки страниц на web-сайте. Технология ASP предполагает широкое использование серверных сценариев и объектов СОМ для создания динамических web-серверов. Средствами технологии ASP можно легко создавать интерактивные web-страницы, выполнять обработку данных введенных пользователем через формы, обращаться к базам данных.
В структуре операций информационного обмена на web-сайте с активными серверными страницами можно выделить следующее: операции по сбору данных; операции по формализации данных; фильтрация данных; сортировка данных; архивация данных; защита данных; транспортировка данных.
В качестве практической реализации технологии «клиент-сервер» можно воспользоваться средствами сетевой системы управления базами данных. Сетевая СУБД представляет собой систему управления базами данных, которая поддерживает сетевую организацию: любая запись, которая называется записью старшего уровня, может включать данные, относящиеся к набору других записей, которые называются записями подчиненного уровня базы данных.
К сетевым функциям систем управления базами данных можно отнести следующие: возможности непосредственного управления данными во внешней памяти; возможности управления буферами оперативной памяти; возможности управления транзакциями; возможности ведения журнализации.
MongoDB представляет собой документоориентированную систему управления базами данных с открытыми исходными кодами, и не требует описания схем таблиц. Данную систему управления базами данных можно классифицировать как NoSQL, которая использует JSON-подобные документы и специальную схему базы данных.
Также, были описаны программные продукты, в основе которых заложена технология «клиент-сервер». Система «Клиент-Банк» – программный комплекс, позволяющий клиенту совершать операции по счету, обмениваться документами и информацией с банком без посещения офиса кредитной организации по средствам глобальной сети Internet.
Список использованной литературы
- Блюмин А.М. Информационные ресурсы: Учебное пособие для бакалавров / А.М. Блюмин, Н.А. Феоктистов. – 3-е изд., перераб. и доп. – М.: Издательско-торговая корпорация «Дашков и Ко», 2015 – 384 с.
- Валитов Ш.М. Современные системные технологии в отраслях экономики: Учебное пособие / Ш.М. Валитов, Ю.И. Азимов, В.А. Павлова. - М.: Проспект, 2016. – 504 c.
- Венделева М.А. Информационные технологии в управлении.: Учебное пособие для бакалавров / М.А. Венделева, Ю.В. Вертакова. - Люберцы: Юрайт, 2016. – 462 c.
- Гаврилов М.В. Информатика и информационные технологии: Учебник / М.В. Гаврилов, В.А. Климов. - Люберцы: Юрайт, 2016. – 383 c.
- Грошев А.С. Информационные технологии: лабораторный практикум / А. С. Грошев. – 2-е изд. – М.-Берлин: Директ-Медиа, 2015. – 285 с.
- Грошев А.С., Закляков П. В. Информатика: учеб. для вузов – 3-е изд., перераб. и доп. – М.: ДМК Пресс, 2015. – 588 с.
- Грофф, Джеймс Р., Вайнберг, Пол Н., Оппелъ, Эндрю Дж. SQL: полное руководство, 3-е изд.: Пер. с англ. - М.: ООО «И.Д. Вильямс», 2015. – 960 с.
- Дарков А.В. Информационные технологии: теоретические основы: Учебное пособие / А.В. Дарков, Н.Н. Шапошников. - СПб.: Лань, 2016. – 448 c.
- Ерохин В.В. Безопасность информационных систем: учеб пособие / В.В. Ерохин, Д.А. Погонышева, И.Г. Степченко. - М.: Флинта, 2016. – 184 c.
- Жданов С.А. Информационные системы: учебник / С.А. Жданов, М.Л. Соболева, А.С. Алфимова. - М.: Прометей, 2015. – 302 с.
- Замятина О.М. Вычислительные системы, сети и телекоммуникации. моделирование сетей.: Учебное пособие для магистратуры / О.М. Замятина. - Люберцы: Юрайт, 2016. – 159 c.
- Информационные системы и технологии: Научное издание. / Под ред. Ю.Ф. Тельнова. - М.: ЮНИТИ, 2016. – 303 c.
- Информационные технологии: Учебное пособие / Л.Г. Гагарина, Я.О. Теплова, Е.Л. Румянцева и др.; Под ред. Л.Г. Гагариной - М.: ИД ФОРУМ: НИЦ ИНФРА-М, 2015. – 320 c.
- Колисниченко Д.Н. PHP и MySQL. Разработка веб-приложений. Профессиональное программирование / Д.Н. Колисниченко. - СПб.: BHV, 2015. – 592 c.
- Корпоративные информационные системы управления: учебник / под ред. Н.М. Абдикеева, О.В. Китовой. - М.: ИНФРА-М, 2014. – 563 с.
- Косиненко Н.С. Информационные системы и технологии в экономике: Учебное пособие для бакалавров / Н.С. Косиненко, И.Г. Фризен. - М.: Дашков и К, 2015. – 304 c.
- Кренке Д. Теория и Практика построения баз данных / Д. Кренке. - М.: СПб: Питер; Издание 9-е, 2017. – 858 c.
- Кучинский В.Ф. Сетевые технологии обработки информации: учеб. пособие. – СПб: Университет ИТМО, 2015. – 115 с.
- Лапшина С.Н. Информационные технологии в менеджменте: учебное пособие / С. Н. Лапшина, Н. И. Тебайкина. – Екатеринбург: Изд-во Урал. ун-та, 2014. – 84 с.
- Лукин В.Н. Введение в проектирование баз данных / В.Н. Лукин. - М.: Вузовская книга, 2015. – 144 c.
- Олифер В., Олифер Н. Компьютерные сети (принципы, технологии, протоколы). - СПб.: Питер, 5-е изд., 2016. – 992 с.
- Основные положения информационной безопасности: Учебное пособие/В.Я.Ищейнов, М.В.Мецатунян - М.: Форум, НИЦ ИНФРА-М, 2015. – 208 c.
- Советов Б.Я. Информационные технологии: теоретические основы: Учебное пособие / Б.Я. Советов, В.В. Цехановский. - СПб.: Лань, 2016. – 448 c.
- Таланов В. М., Федосин С. А. Проектирование информационных систем и баз данных. Учеб. пособие. Изд.3. Переработанное и дополненное – Саранск: Изд-во СВМО, 2013. – 72 c.
- Хаббард Дж. Автоматизированное проектирование баз данных / Дж. Хаббард. - М.: Мир, 2015. – 296 c.
- Цуриков А.Н. Компьютерные системы и сети: учеб. пособие / А.Н. Цуриков; ФГБОУ ВО РГУПС. – Ростов н/Д, 2016. – 64 с.
- Ясенев В.Н. Информационные системы и технологии в экономике: учебное пособие / В.Н. Ясенев. - 3-е изд., перераб. и доп. - М.: Юнити-Дана, 2015. – 560 с.
Приложения
Приложение А
Классификация двухзвенных моделей взаимодействия клиент-сервер

- Информация в материальном мире ( Понятие информации)
- Применение процессного подхода для оптимизации бизнес-процессов (Бизнес-процессы компании)
- Умысел и его виды
- Современные политические режимы. (Основы понятия государственно-правового режима)
- Политический государственный режим, личность в и авторитарном государстве
- Эффективность менеджмента организации (ОЦЕНКА ЭФФЕКТИВНОСТИ СИСТЕМЫ МЕНЕДЖМЕНТА ООО «АГЕНТ»)
- Особенности налоговой политики в Российской Федерации (Предложения совершенствованию налоговой РФ)
- Управление поведением в конфликтных ситуациях (Причины возникновения конфликтов в коллективе, их классификация)
- Организационная культура и ее роль в современных организациях (Рекомендации по совершенствованию корпоративной культуры)
- Корпоративная культура в организации (История организации и её культура)
- Корпоративная культура в организации (Технологии формирования корпоративной культуры)
- Роль мотивации в поведении организации (Разработка мероприятий по совершенствованию системы нематериального стимулирования персонала ресторана Bao Mochi)