
"Технология построения распределенных информационных систем"
Содержание:

ВВЕДЕНИЕ
Актуальность данной темы курсовой работы состоит в том, что в мировой экономике происходят процесса глобализации и информационной интеграции. Они затронули и нашу страну, которая в силу географического положения и размеров вынуждена применять распределенные информационные системы (ИС). Распределенные ИС обеспечивают работу с данными, расположенными на разных серверах, различных аппаратно-программных платформах и хранящимися в различных форматах. Они легко расширяются, основаны на открытых стандартах и протоколах, обеспечивают интеграцию своих ресурсов с другими ИС, предоставляют пользователям простые интерфейсы.
В мире существует громадное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты. Проблема состоит в том, что при их создании не учитывались требования несовместимости. Эти компоненты не понимают один другого, они не могут работать совместно. Желательно иметь механизм или набор механизмов, которые позволят сделать такие независимо разработанные информационно-вычислительные ресурсы совместимыми.
В данной работе рассмотрены основные сведения о распределенной информационной системе: описаны предпосылки ее развития, средства работы с данными, введено понятие распределенной базы данных, а также ее типов и основных принципов. В третьей главе представлены примеры распределенных информационных систем, такие как: - Informix On-Line фирмы Informix Software;- Ingres Intelligent Database фирмы Ingres Corp;- Oracle (version 7) фирмы Oracle Corp;- Sybase System 10 фирмы Sybase Inc.
Целью исследования является изучение определения и задач распределенных систем.
Для реализации поставленной цели необходимо выполнить ряд задач:
- Изучение предпосылки создания и определение распределительных систем;
- Рассмотрение средства работы с распределенными данными;
- Изучение задач распределительных систем;
- Рассмотрение аппаратных средств распределенных систем;
- Рассмотрение программных средств распределенных систем;
- Изучение примеров распределенных систем и т.д.
При написании данной работы были использованы современные научные и учебные источники.
Глава 1 Понятие распределенных информационных систем
1.1 Предпосылки создания и определение распределительных систем
До 80-х годов прошлого века компьютерные системы были большими и дорогими. Соответственно большинство организаций имели в лучшем случае несколько компьютеров, работающих как правило независимо друг-от-друга.
С середины 80-х ситуация начала меняться, чему способствовали два фактора:
- появление первых микропроцессоров и соответственно основанных на них компьютеров;
- появление высокоскоростных компьютерных сетей.
Локальные сети (Local Area Network, LAN) соединяют сотни компьютеров, находящихся в здании. В результате компьютеры могут обмениваться данными на очень больших скоростях (100 Mbit/s, 1 Gbit/s, бывает больше, но редко).
Глобальные сети (Wide Area Network, WAN) позволяют компьютерам по всему миру обмениваться информацией между собой. Скорости, как правило, ниже чем в LAN.[1]
В результате на сегодняшний день достаточно легко можно собрать компьютерную систему состоящую из множества компьютеров соединенных высокоскоростной сетью которая обычно называется компьютерной сетью или распределенной системой (distributed system) в отличие от централизованных (sentralized system) или однопроцессорных (single-processor system) систем.
В вольной трактовке распределенную систему можно определить как набор независимых компьютеров, предоставляющейся их пользователю в виде единой обьединенной системы.
В этом определении следует выделить два момента:
- Аппаратура - все компьютеры автономны;
- Программное обеспечение - пользователь думает, что имеет дело с единой системой.
К важнейшим характеристикам распределенных систем следует отнести следующие:
- От пользователя скрыты различия между компьютерами и способы связи между ними;
- Способ, при помощи которого пользователи и приложения единообразно работают в такой системе;
- Распределенные системы должны относительно легко поддаваться расширению (масштабирование);
- Пользователи и приложения не должны зависеть от того, что часть системы может временно выйти из строя.
Для поддержания представления различных компьютеров и сетей в виде единой системы распределенные системы часто включают в себы дополнительный уровень ПО, находящийся между верхним уровнем (на котором работают пользователи и приложения) и нижним уровнем (на котором находятся операционные системы). Такая система обычно называется системой промежуточного уровня (middleware).
Некоторые примеры распределенных систем:
- Сеть рабочих станций в университетской лаборатории. Эта распределенная система может обладать единой файловой системой, в которой все файлы одинаково доступны для всех машин с использованием постоянного пути доступа.
- Система автоматической обработки заказов. Обычно подобные системы используются сотрудниками различных отделов, возможно находящимися в разных местах. Заказы передаются с мобильных терминалов (ноутбуки, КПК, телефоны). Приходящие заказы автоматически пересылаются в отдел планирования преобразуясь там во внутренние заказы на поставку которые поступают в отдел доставки и в заявки на оплату поступающие в бухгалтерию. Пользователи остаются в неведении о том, как заказы курсируют внутри системы, для них все представляется так, будто вся работа происходит в централизованной базе данных.
- Всемирная Паутина (World Wide Web, WWW) предоставляет простую, целостную и единообразную модель распределенных документов. Публикация документа очень проста - вы должны только задать ему имя в виде унифицированного указателя ресурса (Unified Resource Locator, URL), которое ссылается локальный файл с содержимым документа. В идеале, если-бы WWW предоставлялась пользователям гигантской системой документооборота, она могла-бы считаться истинно распределенной системой. На практике это не так, так-как пользователи осознают, что документы находятся в разных местах и распределены по различным серверам.[2]
C самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность информации.
Но поскольку информационные системы требуют сложных структур данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной создания различных систем управления.
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных, например, хранение информации в нескольких файлах. Таким образом, все это способствовало созданию распределенных информационных систем.[3]
Фактически, если информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна иметь некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных.
В мире существует громадное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты.
Обычно, распределенной считают такую систему, в которой функционирует более одного сервера БД. Это применяется для уменьшения нагрузки на сервер и обеспечения работы территориально удаленных подразделений. Различная сложность создания, модификации, сопровождения, интеграции с другими системами позволяют разделить ИС на классы малых, средних и крупных распределенных систем.
Малые ИС имеют небольшой жизненный цикл (ЖЦ), ориентацию на массовое использование, невысокую цену, невозможность модификации без участия разработчиков, использующие в основном настольные системы управления базами данных (СУБД), однородное аппаратно-программное обеспечение, не имеющие средств обеспечения безопасности. Крупные корпоративные ИС, системы федерального уровня и другие имеют длительный жизненный цикл, миграцию унаследованных систем, разнообразие аппаратно-программного обеспечения, масштабность и сложность решаемых задач, пересечение множества предметных областей, аналитическую обработку данных, территориальную распределенность компонент.[4]
К функциям таких ИС следует отнести, прежде всего, работу с распределенными данными, расположенными на разных физических серверах, различных аппаратно-программных платформах и хранящихся в различных внутренних форматах. В этом случае система должна предоставлять полную информацию о себе и всех своих ресурсах, легко расширяться, быть основана на открытых стандартах и протоколах, обеспечивать возможность интегрировать свои ресурсы с ресурсами других ИС.
Для пользователей система должна обеспечивать различные уровни привилегий для пользователей и предоставлять простые интерфейсы доступа к информации. Данные из разнородных систем обычно объединяются в логические группы, к которой и адресуются запросы. Абстрактная система запросов предполагает, что система оперирует не конкретным синтаксисом запросов, а его логической сутью на основе абстрактных атрибутов.
При построении распределенных ИС, как правило, используются две базовые архитектуры: Клиент/сервер и Internet Intranet.
Корпоративные ИС, построенные по архитектуре Клиент/сервер, предоставляют клиентам широкий спектр приложений и инструментов разработки, которые ориентированы на максимальное использование вычислительных возможностей клиентских рабочих мест.
Ресурсы сервера используются в основном для хранения и обмена документами, а также для выхода во внешнюю среду. Данная архитектура позволяет лучше защитить серверную часть приложений, при этом, предоставляя возможность приложениям либо непосредственно адресоваться к другим серверным приложениям, либо маршрутизировать запросы к ним.
Однако, частые обращения клиента к серверу снижают производительность работы сети. Приходится решать вопросы безопасной работы в сети, так как приложения и данные распределены между различными клиентами. Распределенный характер построения системы обусловливает сложность ее настройки и сопровождения
В основе ИС на базе Internet Intranet лежит принцип "открытой архитектуры". ПО ИС реализуется в виде аплетов или сервлетов (программ на языке JAVA) или в виде cgi модулей (программ на Perl или С). ИС данной архитектуры включает Web-yinh\, реализованные при помощи технологий CORBA Enterprise JavaBeans, ActiveX 1X'ОМ, многоуровневые приложения на основе Java и XML, .Net-концепция с XML, в которой обмен между различными серверами (хранилищами данных, бизнес-приложениями, серверами для мобильных клиентов и другое) производится при помощи нейтрального к любой архитектуре XML.
Под распределенной информационной базой понимается неограниченное количество баз данных, дистанционно отдаленных друг от друга и имеющих ряд общих характеристик:
- функционирующих по единым правилам, определенным централизованно для всех баз данных, входящих в распределенную информационную базу;
- обмен данными осуществляется по правилам, также определенным централизованно.
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
-необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
- необходимость введения централизованного изменения структуры и правил работы баз данных для работы всех дистанционно отдаленных подразделений (филиалов) и юридических лиц (с невозможностью изменения определенных правил непосредственно в отдаленном подразделении);
- необходимость ограничения и осуществления контроля изменения данных в дистанционно отдаленных подразделениях компании (филиалах).
1.2 Средства работы с распределенными данными
При выборе распределенной ИС в первую очередь следует обратить внимание на то, какие операционные системы и сетевые протоколы она поддерживает. Однако не менее важным является и то, какие методы распределения данных в ней реализованы.
1) Фрагментация и дублирование
Один из способов распределенного хранения таблиц - это фрагментация. Таблица может быть расщеплена на части, которые будут помещены в разные узлы. Другой способ распределения данных - это дублирование (репликация). Можно создать дубли всей БД или ее частей и разместить эти дубли в узлах. Оба метода позволяют хранить данные именно в том узле, где они наиболее часто используются.[5] Это сводит к минимуму затраты на передачу данных по сети и уменьшает использование процессоров и прочих ресурсов остальных узлов. При такой архитектуре БД приложения передача данных по сети выполняется достаточно редко.
2) Словари данных и директории
После того, как данные распределены по разным узлам сети, важно найти и использовать эти данные. Для того, чтобы найти данные и преобразовать их в нужный формат, используются глобальные словари данных и директории. В словаре хранится информация о данных, их использовании, правах доступа к данным, а также о приложениях. Директории данных используются для того, чтобы определить, где хранятся данные и как их извлечь. Словари и директории могут быть глобальными и локальными
3) Двухфазная фиксация изменений
Методы распределения данных конечно очень важны, однако сердцем современных распределенных СУБД является протокол двухфазной фиксации изменений. Этот протокол управляет выполнением транзакций, изменяющих данные нескольких узлов. Основная идея двухфазной фиксации заключается в следующем: недопустима ситуация при которой транзакция, изменяющая данные в нескольких узлах, выполняется в одних узлах и не выполняется в других узлах. Транзакция должна быть либо успешно выполнена во всех узлах, либо не выполнена ни в одном узле.
4) Обеспечение целостности
Важной характеристикой распределенной ИС является то, как она обеспечивает поддержку ссылочной целостности между данными таблицы-мастера и данными связанных с ней таблиц. Рассмотрим пример ссылочной целостности. Предположим в распределенной БД имеются три таблицы:
- таблица, содержащая информацию о детях сотрудников;
- таблица, содержащая информацию о зарплатах сотрудников за год;
- таблица, содержащая информацию о темах, выполненных сотрудником.
Все эти таблицы содержат столбец "ФИО сотрудника". Правила обеспечения ссылочной целостности требуют, чтобы при изменении значений столбца "ФИО сотрудника" в одной таблице, автоматически выполнялась корректировка значений этого столбца в других таблицах. Для обеспечения ссылочной целостности используются 2 различных метода - триггеры и декларативные ограничения целостности стандарта ANSI.
1.3 Задачи распределенных систем
Рассмотрим четыре важнейшие задачи, решение которых делает построение распределенных систем осмысленным.
Задача 1. Доступ пользователей к ресурсам
Основная задача распределенной системы - облегчить пользователям доступ к удаленным ресурсам и обеспечить их совместное использование, регулируя этот процесс. Традиционно ресурсы включают в себя: принтеры, компьютеры, устройства хранения данных, файлы и данные. Одна из очевидных причин совместного использования ресурсов - экономичность. Другая очевидная причина - облегчение кооперации и обмена информацией.
Так, широкое использование сети интернет привело к появлению концепции виртуального офиса, когда географически удаленные друг от друга группы сотрудников работают вместе при помощи систем групповой работы (groupware) - программ для совместного редактирования документов, проведения презентаций и т.д.[6]
Стоит заметить, что по мере роста степени совместного использования ресурсов все более и более важными становятся вопросы безопасности.
Задача 2. Прозрачность
Сокрытие того факта, что процессы и ресурсы физически распределены по множеству компьютеров - важная задача распределенных систем. Распределенные системы, которые представляются пользователям и приложениям в виде единой компьютерной системы называют прозрачными (transparent).
Концепция прозрачности применима к различным аспектам функционирования распределенных систем:
- Доступ (access transparency). Скрывается разница в представлении данных и доступа к ресурсам. Например, при передаче целого числа с компьютера на базе процессора Intel x86 на компьютер на базе процессора Sun SPARC следует учитывать, что на Intel используется Little Endian представление целых чисел, а на SPARC - Big Endian.
- Местоположение (location transparency). Скрывается местоположение ресурса. Важную роль в реализации прозрачности местоположения имеет именование. Например URL http://www.yandex.ru/index.html не содержит никакой информации о реальном местоположении сервера Яндекса.
- Перенос (migration transparency). Скрывается факт переноса ресурса в другое место. Т.е. смена местоположения ресурса не влияет на доступ к нему.
- Смена местоположения (relocation transparency). Скрывается факт перемещения ресурса в другое место в процессе обработки. В качестве примера - мобильные пользователи, работающие с беспроводным переносным компьютером и не отключающиеся от сети при переходе с места на место.
- Репликация (replication transparency). Скрывается факт репликации ресурса, т.е. существования нескольких копий ресурса. Для скрытия факта репликации необходимо, чтобы все реплики (копии) имели одно и то-же имя. Соответственно система, которая поддерживает прозрачность репликации должна поддерживать и прозрачность местоположения.
- Параллельный доступ (concurrency transparency). Скрывает факт возможного совместного использования ресурса несколькими пользователями одновременно. Такой параллельный доступ к совместно используемому ресурсу сохраняет этот ресурс в непротиворечивом состоянии. Для обеспечения непротиворечивости может быть использован механизм блокировок или механизм транзакций (хотя реализация механизма транзакций - очень непростая задача в рамках распределенной системы)
- Отказ (failure transparency). Скрывается факт выхода из строя и восстановления ресурса. Лэсли Лампорт: "Вы понимаете, что у вас есть эта штука, поскольку при поломке компьютера вам никогда не предлагают приостановить работу". Основная трудность состоит в сложности отличить неработоспособный ресурс от ресурса с очень медленным доступом.
- Сохранность (persistence transparency). Скрывается, хранится программный ресурс на диске или находится в оперативной памяти. Например, многие объектно-ориентированные базы данных предоставляют возможность непосредственного вызова методов для сохранных объектов. Сервер БД при этом копирует состояние объекта в оперативную память, вызывает метод объекта запрошенный пользователем и сохраняет новое состояние объекта на диск. Пользователь об этой цепочке ничего не знает.
Несмотря на то, что прозрачность в общем желательна для любой распределенной системы, существуют ситуации когда попытки скрыть от пользователя всякую распределенность не слишком разумны. Существует паритет между высокой степенью прозрачности и производительностью системы. Таким образом можно сказать, что достижение прозрачности - это разумная цель при проектировании и разработке распределенных систем, но она не должна рассматриваться в отрыве от других характеристик системы.
Задача 3. Открытость
Открытая распределенная система (open distributed system) - это система, предполагающая службы, вызов которых осуществляется с использованием стандартизированного синтаксиса и семантики.
В распределенных системах службы обычно определяются через интерфейсы, которые описываются некоторым образом, например в помощью специального языка определения интерфейсов (Interface Definition Language, IDL). Описание интерфейсов касается в основном синтаксиса служб, семантика-же должна быть описана отдельно, чаще всего средствами естественного языка (в виде документов-спецификаций и комментариев).
Будучи правильно описанным определение интерфейса допускает возможность совместной работы произвольного процесса, нуждающегося в таком интерфейсе, с другим произвольным процессом, реализующим этот интерфейс.
Способность к взаимодействию (interoperability) характеризует насколько две реализации системы в состоянии совместно работать, полагаясь только на то, что службы каждой из них соответствуют общему стандарту.
Переносимость (portability) характеризует то, насколько приложение, разработанное для распределенной системы A может без изменений выполняться в распределенной системе B.
Гибкость (flexibility) характеризует легкость конфигурирования системы, состоящей из различных компонентов, возможно от разных производителей. Добавление к системе новых компонентов или замена существующих не должно вызывать затруднений. Гибкость == расширяемость.
В построении гибких открытых распределенных систем решающим фактором оказывается организация этих систем в виде наборов относительно небольших и легко заменяемых или адаптируемых компонентов. Это предполагает не только описание интерфейсов верхнего уровня, но также и интерфейсов внутренних модулей приложения и описания взаимодействия этих модулей.
Задача 4. Масштабируемость
Масштабируемость системы может измеряться по трем различным показателям:
- Система может быть масштабируемой по отношению к ее размеру, что означает легкость подключения к ней дополнительных пользователей и ресурсов.
- Система может быть масштабируемой географически, т.е. пользователи и ресурсы могут быть разнесены в пространстве.
- Система может быть масштабируемой в административном смысле, т.е. быть проста в управлении при работе во множестве административно-независимых организаций.
Рассмотрим масштабирование по размеру. При необходимости увеличить число пользователей или ресурсов могут возникнуть ограничения, связанные с централизацией служб, данных и алгоритмов.
Например:
|
Концепция |
Пример |
|
Централизованные службы |
Один сервер на всех пользователей |
|
Централизованные данные |
Единый телефонный справочник |
|
Централизованные алгоритмы |
Организация маршрутизации на основе полной информации |
Иногда использование единственного сервера является неизбежным, например, при обеспечении работы с конфиденциальной информацией.
Централизация данных также вредна, как и централизация служб. Сложно представить себе, например, систему DNS, построенную на основе единственного суперсервера, хранящего все записи.
Централизация алгоритмов - это тоже очень неудачная идея. Основная проблема в том, что попытка собрать всю необходимую для работы алгоритма информацию со всей сети на одном узле приведет к тому, что сеть будет перегружена служебным трафиком и нормальное функционирование системы станет невозможно. Соответственно в распределенных системах следует использовать децентрализованные алгоритмы, которые обладают рядом свойств, отличающих их от централизованных алгоритмов:
- ни одна из машин не обладает полной информацией о состоянии системы;
- машины принимают решения на основе локальной информации;
- сбой в работе одной машины не нарушает работу алгоритма;
- не требуется предположение о существовании единого времени.
Первые три свойства более-менее понятны, последнее-же возможно требует некоторого уточнения. Любой алгоритм, начинающийся со слов "Ровно в 12:00:00 все машины делают ..." работать не будет, поскольку невозможно синхронизировать все часы на свете.
NOTE: Google Spanner http://research.google.com/archive/spanner.html . Один из компонентов системы - атомные часы в каждом сервере.
У географической масштабируемости - свои сложности. Одна из основных проблем масштабирования распределенных систем, разработанных для локальных сетей, на глобальные сети - то, что в их основе лежит принцип синхронной связи. Т.е. процесс, выполняющий запрос, блокируется до получения ответа. Другое важное отличие организации глобальных коммуникаций от локальных - существенно меньшая надежность глобальных сетей с точки зрения передачи отдельно-взятого блока данных.
Также следует принимать во внимание вопрос обеспечения масштабирования распределенной системы на множество административно-независимых областей. Основная проблема, которую надо при этом решить - состоит в конфликтах правил, относящихся к использованию ресурсов (и плате за них), управлению и безопасности. Здесь можно выделить два типа проверок безопасности: злонамеренные атаки из новой области на системы и атака на ресурсы области из самой распределенной системы.
Существуют три основные технологии масштабирования:
- сокрытие времени ожидания связи;
- распределение;
- репликация.
Сокрытие времени ожидания применяется в случае географического масштабирования. Идея - постараться по возможности избежать ожидания ответа от удаленного сервера. Т.е. нужно разрабатывать приложения в расчете на использование только асинхронной связи. Когда будет получает ответ, приложение прервет свою работу и вызовет специальный обработчик для завершения отправленного ранее запроса. В случае, если использование асинхронной связи слишком сложно либо не соответствует паттерну использования приложения - можно пойти другим путем - уменьшить объем необходимого взаимодействия, например, перенести часть логики с сервера на клиент.
Распределение предполагает разбиение компонентов на мелкие части и последующее разнесение этих частей по системе. Хороший пример - DNS.
Репликация компонентов распределенной системы не только повышает доступность, но и помогает выровнять загрузку компонентов, что ведет к повышению производительности. Особая форма репликации - кэширование. Основное различие - кэширование происходит на стороне потребителя ресурса, а репликация - на стороне системы предоставляющей ресурс.
У репликации и кэширования есть один подводный камень: поскольку есть множество копий ресурса, модификация одной из них делает ее отличной от остальных - возникает проблема непротиворечивости данных (consistency).
Глава 2 Средства распределенных систем
2.1 Аппаратные средства распределенных систем
Системы, построенные из набора независимых компьютеров можно подразделить на две большие группы:
- мультипроцессоры - компьютеры используют память совместно, т.е. все процессоры системы имеют единое адресное пространство;
- мультикомпьютеры - каждый компьютер использует только свою память, у каждого процессора свое собственное адресное пространство.
Каждая из этих категорий может быть подразделена на дополнительные под-категории на основе архитектуры соединяющей их сети:
- шинная - присутствует одиночная сеть, плата, шина, кабель или другая среда, соединяющая все машины между собой;
- коммутируемая - нет единой магистрали, сообщения передаются по каналам с принятием явного решения о коммутации с конкретным выходным каналом.
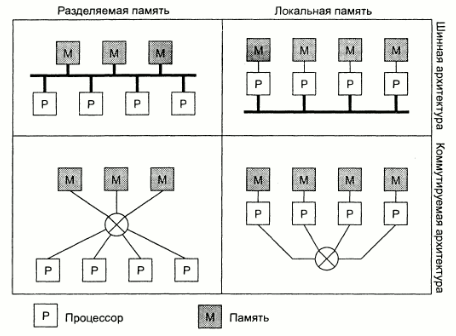
Рис. 1.
Мультикомпьютерные системы также можно подразделить на гомогенные и гетерогенные. Для гомогенных систем характерна одна соединяющая компьютеры сеть и одинаковы все процессоры (и как правило одинаков объем памяти доступной каждому процессору). Гетерогенные-же могут содержать в своем составе целую гамму различных аппаратных решений.
Мультипроцессорные системы
Типичная архитектура, используемая в мультипроцессорных системах - шинная. Характерная особенность - все процессоры имеют прямой доступ к общей памяти. Когда процессор А записывает слово в память, а процессор В микросекундой позже считывает слово из памяти, процессор В получает в точности информацию, записанную туда процессором А. Память, обладающая таким поведением называется согласованной (coherent). Проблема такой схемы в том, что уже при наличии 4-5 процессоров шина данных оказывается сильно перегруженной и общая производительность системы резко падает. Решением этой проблемы является размещение между процессором и шиной высокоскоростной кэш-памяти.
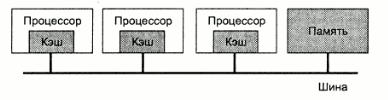
Рис.2
Если запрашиваемые данные находятся в кэше, то не произойдет обращения к шине. Если размер кэш-памяти достаточно велик, вероятность успеха (коэффициент кеш-попаданий, hit rate) велика и трафик на шине снижается, позволяя включить в систему большее количество процессоров.
Однако очевидно, что введение кэша порождает проблему несогласованности памяти. Изменение данных в памяти одним процессором должно каким-то образом синхронизироваться с кэшем всех процессоров.
Шинная архитектура накладывает ограничение на количество процессоров в системе. Ориентировочно 256 процессоров - реальный потолок таких систем, не смотря на использование кэша.
Один из вариантов решения проблемы этого ограничения шинной архитектуры - разделение общей памяти на модули и связь их с процессорами с помощью коммутирующей решетки (crossbar switch). С ее помощи каждый процессор может быть связан с каждым модулем памяти.
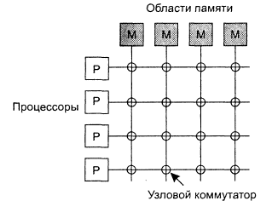
Рис.3
Достоинство узловых коммутаторов также и в том, что к памяти могут одновременно получить доступ несколько процессоров (естественно не любые комбинации допустимы).
Недостаток данного подхода в том, что при N процессорах и M модулей памяти потребуется NxM узлов решетки. Соответственно при росте количества процессоров/блоков памяти опять возникает проблема физической реализуемости системы. Один их вариантов решения данной проблемы - коммутирующая омега-сеть, например такая:
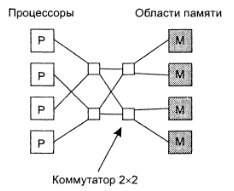
Рис.4
Еще один способ уменьшения затрат на коммутацию - переход к иерархическим системам. В таких системах с каждым процессором ассоциируется некоторая область памяти, к которой данный процессор получает максимально быстрый доступ. Доступ-же к памяти, ассоциированной с другими процессорами происходит существенно медленнее. Термин - NUMA (Non-Uniform Memory Access):
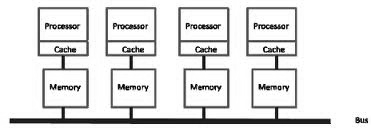
Рис.5
Гомогенные мультикомпьютерные системы
Построить мультикомпьютерную систему относительно несложно. Главная проблема при этом - обеспечение взаимодействия процессоров между собой.
В гомогенных мультикомпьютерных системах как-правило узлы системы монтируются в большой стойке и соединяются единой высокоскоростной сетью (топология сети может быть как шинной, так и на основе коммутатора).
Как и в случае мультипроцессоров с шинной архитектурой, мультикомпьютеры с шинной архитектурой имеют ограниченную масштабируемость.
В коммутируемых мультикомпьютерах сообщения, передаваемые от процессора к процессору маршрутизируются в соединительной сети. Существует множество топологий, например квадратные решетки и гиперкубы:
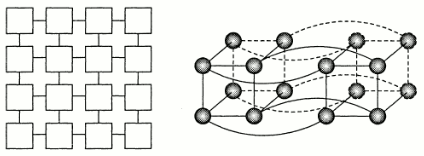
Рис.6
Коммутируемые мультикомпьютерные системы могут быть очень разнообразны. На одном конце спектра лежат процессоры с массовым параллелизмом (Massively Parallel Processors, MPP) - гигантские суперкомпьютеры содержащие сотни тысяч процессоров и использующие специально-разработанные сверх-высокоскоростные сети. На другом конце спектра обнаруживаются кластеры рабочих станций (Clusters of Workstations, COW), основу которых составляют стандартные персональные компьютеры соединенные посредством коммерческих коммуникационных компонент.
Гетерогенные мультикомпьютерные системы
Данный тип систем является самым распространенным в современном парке распределенных систем. Компьютеры, входящие в состав системы могут быть крайне разнообразны. Также неоднородной может быть и соединяющая их сеть. Часто гетерогенные системы строятся на основе уже существующих сетей и каналов передачи данных.[7]
В отличие от мультипроцессоров и гомогенных мультикомпьютеров многие крупномасштабные мультикомпьютерные системы нуждаются в глобальном подходе. Это означает, что приложение не может расчитывать на то, что ему всегда будет доступна определенная производительность или определенные службы. В связи с этим создание приложений для гетерогенных мультикомпьютерных систем требует использования специального програмного обеспечения, обеспечивающего нужный уровень проздачности для разработчика приложений.
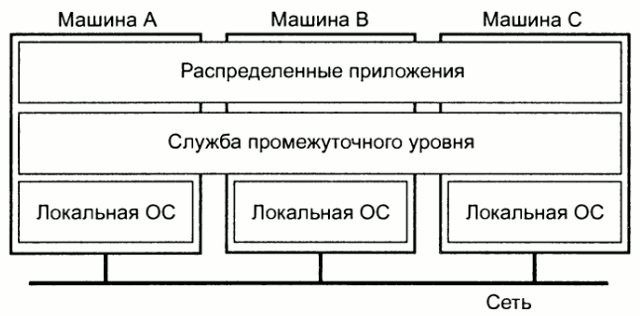
2.2 Программные средства распределенных систем
Программно распределенные системы очень похожи на традиционные операционные системы. Прежде всего они работают как менеджеры ресурсов существующего аппаратного обеспечения, помогающие множеству пользователей и процессов совместно исползховать процессоры, память, перефирийные устройства, сеть и данные всех видов. Во-вторых распределенная системы скрывает сложность и гетерогенную природу аппаратного обеспечения на базе которого она построена, предоставляя виртуальную машину для выполнения приложений.
Операционные системы для распределенных компьютеров можно подразделить на:
- сильно связанные - операционная система старается работать с единым глобальным представлением ресурсов, которыми она управляет;
- слабо связанные - представляются как набор операционных систем, каждая из которых работает на своем компьютере, которые, однако функционируют совместно, делая собственные службы доступными другим.
Сильно-связанные операционные системы обычно называют распределенными операционными системами и чаще всего используют для управления мультипроцессорами или гомогенными мультикомпьютерами.
Слабосвязанные операционные системы в свою очередь называют сетевыми операционными системами и используют для управления гетерогенными мультикомпьютерами. Как правило в купе с сетевой операционной системой частью распределенной системыв являются системы промужеточного уровня (middleware).
Распределенные операционные системы
Существует два типа распределенных операционных систем:
- мультипроцессорная операционная система - управляет ресурсами мультипроцессора;
- мультикомпьютерная операционная система - разрабатывается для гомогенных мультикомпьютеров.
Операционные системы для однопроцессорных компьютеров
Традиционно операционные системы строились для управления компьютерами с одним процессором. Основной задачей таких операционных систем была организация легкого доступа пользователей и призожений к разделяемым устройствам - процессору, памяти, дискам и перефирийным устройствам. Для приложения это выглядит так, словно эти ресурсы находатся в его полном распоряжении. В этом смысле говорят, что операционная система реализует виртуальную машину предоставляя приложениям средства многозадачности. Важно тут то, что приложения как-бы отделены друг от друга - например приложения A не может изменить данные приложения B просто обратившись в ту область памяти, где эти данные хранятся. Также важно то, что приложения могут использовать предоставленные их ресурсы только так, как это предписано операционной системой. Например приложениям обычно запрещено копировать данные напрямую в сетевой интерфейс - нужно использовать специальный API операционной системы.
Следовательно операционная система должна полностью контролировать распределение и использование аппаратных ресурсов. Поэтому большинство процессоров поддерживают как минимум 2 режима работы:
- режим ядра (kernel mode) - доступны для выполнения все инструкции процессора, доступна вся имеющаяся память и регистры;
- пользовательский режим (user mode) - доступ к регистрам и памяти ограничен, запрещены к исполнению некоторые инструкции процессора.
На время выполнения кода операционной системы процессор переключается в режим ядра. Единственный способ перейти из пользовательского режима в режим ядра - сделать системный вызов - одну из базовых служб предоставляемых операционной системой, полностью контролируемую ей.
Типичной ситауцией является то, что практически весь код операционной системы выполняется в режиме ядра, т.е. операционная система (вернее ядро операционной системы) представляет собой большую монолитную программу, выполняющуюся в едином адресном пространстве. Замена или адаптция компонентов системы в таком случае без перезакрузки системы является затруднительной.
Другой вариант - организация операционной системы в виде двух частей:
- набор модулей для управления аппаратным обеспечением, которые могут выполняться на пользовательском уровне (по крайней мере большая часть их кода);
- микроядро, содержащее исключительно код для установки регистров устройств, переключения процессора с процесса на процесс, работы с блоком управления памятью и перехвата аппаратных прерываний. Также в нем обычно содержится код, преобразующий вызовы соответствующих модулей пользовательского уровня в системные вызовы и возвращающий результаты.
Схема организации операционной системы на основе микроядра приведена ниже:
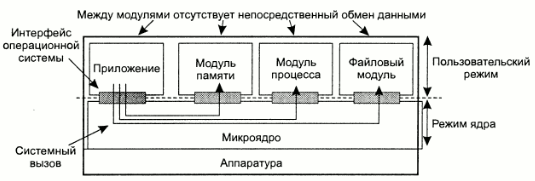
Рис.7
TODO: Достоинства и недостатки микрояденных систем.
Примеры микроядерных операционных систем:
- AIX
- Mac OS X (Mach 3.0)
- OpenVMS
- Minix
Мультипроцессорные операционные системы
Логичным развитием однопроцессорных операционных систем является возможность поддержки нескольких процессоров имеющих доступ к совместно используемой памяти. С концептуальной точки зрения данное расширение функциональности не сложно. Однако многие классические однопроцессорные операционные системы разработаны как монолитные программы с одним потоком управления. Адаптация подобных систем под мультипроцессорные зачастую означает повторное проектирование и реализацию всего ядра. Современные ОС как правило изначально разрабатываюся с учетом возможности работы в многопроцессорных системах.
В многопроцессорных операционных системах, как впрочем и в мультизадачных однопроцессорных, ставится задача обеспечения взаимодействия между приложениями, для чего используются специальные конструкции: семафоры и мониторы.
Семафор может быть представлен как целое число, поддерживающее две операции - инкремент и декремент. При этом операция декремента на семафоре, имеющем нулевое значение блокируется до того момента, пока не произойдет инкремент этого семафора (как правило другим процессом). Операции над семафорами являются атомарными, т.е. во время операции над семафором ни один другой процесс не может получить доступ к этому семафору.
Монитор представляет собой конструкцию языка программирования, напоминяющую обьект в обьектно-ориентированных языках. Монитор содержит переменные и процедуры, причем доступ к процедурам может осуществляться только путем вызова соответствующих процедур. И в каждый момент времени выполнение процедуры доступно только одному процессу, т.е. если один процесс выполняет какую-либо процедуру монитора, то второй процесс будет заблокирован при попытке вызова процедуры монитора (той-же самой или другой) до тех пор, пока первый процесс не закончит выполнение процедуры. Реализация мониторов чаще всего строится на базе специальных семафоров, которые могут принимать значения 0 или 1. Такие семафоры носят название мьютекс (mutex, mutual exclusion) и с ними ассоциируются две операции - lock и unlock. Также мониторы применяются для организации такого примитива синхронизации как условные переменные - специальные переменные с двумя доступными операциями: wait (ждать события) и signal (породить событие).
Мультикомпьютерные операционные системы
Мультикомпьютерные операционные системы обладают гораздо более разнообразной структурой и значительно сложнее, чем мультипроцессорные. Единственно возможным видом связи между компонентами системы является передача сообщений (нет общей памяти). Типичная организация мультикомпьютерной операционной системы представлена на рисунке:
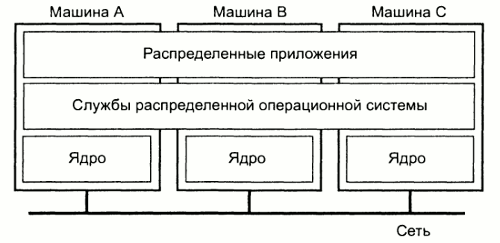
Рис.8
Каждый узел имеет свое ядро, которое управляет локальными ресурсами. Кроме того, каждый узел имеет отдельный компонент для межпроцессорного взаимодействия, то-есть в данном случае посилки сообщений на другие узлы и прием вообщений от них.
Поверх каждого локального ядра лежит уровень программного обеспечения общего назначения, реализхующий операционную систему в виде виртуальной машины, поддерживающей параллельную работу над различными задачами.
Мультикомпьютерные системы могут предоставлять приложениям средства совместного использования памяти, а могут и не предоставлять, ограничиваясь средствами передачи сообщений.
Системы с распределенной разделяемой памятью
Существует большое число разработок, направленных на решение вопроса эмуляции совместно используемой памяти на мультикомпьютерных системах. Один из распространненных подходов - задействовать виртуальную память каждого отдельного узла для поддержки общего виртуального адресного пространства - распределенная разделяемая память (Distributed Shared Memory, DSM) со страничной организацией.
В системе с DSM адресное пространство разделено на страницы (типичный размер - 4 Кб, 8Кб), распределеные по всем узлам системы. Когда процессор адресуется к памяти, которая не является локальной, происходит прерывание, операционная система перемещает страницу в локальную память и перезапускает выполнение инструкции, вызвавшей прерывание.
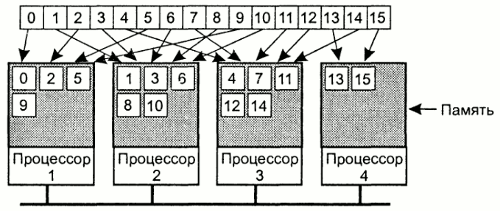
Рис.9
Одно из улучшений данного подхода состоит в том, чтобы реплицировать на все узлы те страницы памяти, которые не изменяются (содержат код программы, значения констант и т.д.)
Возможна также репликация и не закрытых от записи страниц, до тех пор, пока не происходит запись никакой разницы между репликацией страниц доступных только для чтения и страниц доступных для записи нет. Однако, как только какая-то страница изменяется, все остальные ее копи должны обьявляться невалидными, иначе будет нарушена целостность данных в системе.
Также при построении DSM систем важно правильно выбрать размер страниц памяти, используемых системой. Затраты на передачу страницы по сети в первую очередь определяюся затратами на подготовку к передаче, а не размером страницы. Таким образом можно повысить производительность увеличив размер страницы. олднако при этом увеличивается вероятность того, что страница памяти будет содержать данные двух различных процессов, выпорлняющихся на разных узлах. В результате операционная система будет вынуждена постоянни пересылать эту страницу он узла к узлу:
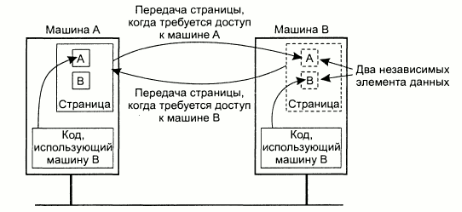
Рис.10
2.3 Распределенные базы данных
Распределённые базы данных (РБД) — совокупность логически взаимосвязанных баз данных, распределённых в компьютерной сети.
РБД состоит из набора узлов, связанных коммуникационной сетью, в которой:
а) каждый узел — это полноценная СУБД сама по себе;
б) узлы взаимодействуют между собой таким образом, что пользователь любого из них может получить доступ к любым данным в сети так, как будто они находятся на его собственном узле.
Каждый узел сам по себе является системой базы данных. Любой пользователь может выполнить операции над данными на своём локальном узле точно так же, как если бы этот узел вовсе не входил в распределённую систему. Распределённую систему баз данных можно рассматривать как партнёрство между отдельными локальными СУБД на отдельных локальных узлах.
Фундаментальный принцип создания распределённых баз данных («правило 0»): Для пользователя распределённая система должна выглядеть так же, как нераспределённая система.
Фундаментальный принцип имеет следствием определённые дополнительные правила или цели. Таких целей всего двенадцать:
1.Локальная независимость. Узлы в распределённой системе должны быть независимы, или автономны. Локальная независимость означает, что все операции на узле контролируются этим узлом.
2.Отсутствие опоры на центральный узел. Локальная независимость предполагает, что все узлы в распределённой системе должны рассматриваться как равные. Поэтому не должно быть никаких обращений к «центральному» или «главному» узлу с целью получения некоторого централизованного сервиса.
3.Непрерывное функционирование. Распределённые системы должны предоставлять более высокую степень надёжности и доступности.
4.Независимость от расположения. Пользователи не должны знать, где именно данные хранятся физически и должны поступать так, как если бы все данные хранились на их собственном локальном узле.
5.Независимость от фрагментации. Система поддерживает независимость от фрагментации, если данная переменная-отношение может быть разделена на части или фрагменты при организации её физического хранения. В этом случае данные могут храниться в том месте, где они чаще всего используются, что позволяет достичь локализации большинства операций и уменьшения сетевого трафика.
6.Независимость от репликации. Система поддерживает репликацию данных, если данная хранимая переменная-отношение — или в общем случае данный фрагмент данной хранимой переменной-отношения — может быть представлена несколькими отдельными копиями или репликами, которые хранятся на нескольких отдельных узлах.
7.Обработка распределённых запросов. Суть в том, что для запроса может потребоваться обращение к нескольким узлам. В такой системе может быть много возможных способов пересылки данных, позволяющих выполнить рассматриваемый запрос.
8.Управление распределёнными транзакциями. Существует 2 главных аспекта управления транзакциями: управление восстановлением и управление параллельностью обработки. Что касается управления восстановлением, то чтобы обеспечить атомарность транзакции в распределённой среде, система должна гарантировать, что все множество относящихся к данной транзакции агентов (агент — процесс, который выполняется для данной транзакции на отдельном узле) или зафиксировало свои результаты, или выполнило откат. Что касается управления параллельностью, то оно в большинстве распределённых систем базируется на механизме блокирования, точно так, как и в нераспределённых системах.
9.Аппаратная независимость. Желательно иметь возможность запускать одну и ту же СУБД на различных аппаратных платформах и, более того, добиться, чтобы различные машины участвовали в работе распределённой системы как равноправные партнёры.
10.Независимость от операционной системы. Возможность функционирования СУБД под различными операционными системами.
11.Независимость от сети. Возможность поддерживать много принципиально различных узлов, отличающихся оборудованием и операционными системами, а также ряд типов различных коммуникационных сетей.
12.Независимость от типа СУБД. Необходимо, чтобы экземпляры СУБД на различных узлах все вместе поддерживали один и тот же интерфейс, и совсем необязательно, чтобы это были копии одной и той же версии СУБД [6].
Основная задача систем управления распределенными базами данных состоит в обеспечении средства интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе данных.
Возможны однородные и неоднородные распределенные базы данных. В однородном случае каждая локальная база данных управляется одной и той же СУБД. В неоднородной системе локальные базы данных могут относиться даже к разным моделям данных.
Помимо вышеназванных типов распределенных баз данных можно выделить следующие:
1) Распределённые Базы Данных
2) Мультибазы данных с глобальной схемой. Система Мультибаз данных - это распределённая система, которая служит внешним интерфейсом для доступа ко множеству локальных СУБД или структурируется, как глобальный уровень над локальными СУБД.
3) Федеративные базы данных. В отличие от мультибаз не располагают глобальной схемой, к которой обращаются все приложения. Вместо этого поддерживается локальная схема импорта-экспорта данных. На каждом узле поддерживается частичная глобальная схема, описывающая информацию тех удалённых источников, данные с которых необходимы для функционирования.
4) Мультибазы с общим языком доступа - распределённые среды управления с технологией "клиент-сервер"
5) Интероперабельные системы - это системы, в которых сами приложения, выполняемые в среде той или иной СУБД, ответственны за интерфейсы между различными средами приложения, независимо от того, являются они однородными или неоднородными. Системы ориентированы главным образом на обмен данными. Дальнейшее развитие этих систем является объектно-ориентированные БД.
Когда у предприятия есть удаленные филиалы, возникает необходимость в синхронизации данных между ними и главным офисом. Естественно, что в основной базе предприятия должны отображаться любые изменения касательно филиалов. Такую синхронизацию можно осуществлять при помощи механизмов распределенной базы данных.
В главном офисе создаются начальные образы базы (для каждого филиала - свой образ) и передаются в филиалы, где их загружают. При этом задаются настройки обмена, по которым будет происходить синхронизация между каждой из периферийных (подчиненных) баз и главной базой.
Структура предприятия может быть такова, что у филиалов, подчиненных главному офису, могут быть свои удаленные подразделения. Тогда для них производят процедуру аналогичную той, что была совершена при настройке филиалов, подчиненных напрямую главной базе. [8]
Таким образом, можно подытожить, что в распределенной базе формируются древообразные связи. Например, на предприятии главному офису подчинено два филиала, причем у первого филиала есть два удаленных подразделения, а у второго - три подразделения. Получается, что основной базе подчинено две периферийных базы. Первой периферийной базе, в свою очередь, подчинено еще две базы, а второй периферийной - три. Связи в такой распределенной базе представлены на рис. 11.
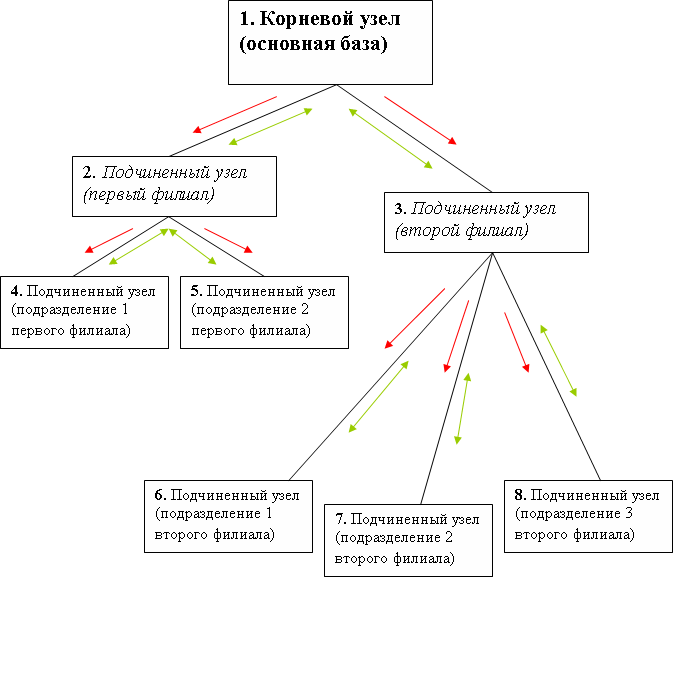
Рис.11. Принцип работы БД
Узел 1 является корневым для всей распределенной базы и главным узлом для подчиненных ему второму и третьему. Второй узел является главным узлом для подчиненных ему четвертому и пятому. Третий узел будет главным для подчиненных ему шестому, седьмому и восьмому.
Любой узел распределенной базы данных (УРБД) "видит" только узлы, напрямую связанные с ним. С такими узлами он и осуществляет обмен данными.
Внесение изменений в данные информационной базы возможно в любом узле УРБД, причем изменения данных передаются между любыми связанными узлами. На схеме направления, по которым передаются изменения данных, обозначены зелеными стрелочками (по ним из любого узла УРБД за определенное количество шагов можно попасть в любой другой узел, отсюда следует, что при внесении изменений в данные любого узла эти изменения постепенно перенесутся во все остальные).
Внесение изменений в конфигурацию информационной базы возможно только в одном (корневом) узле УРБД, причем изменения конфигурации передаются от главного узла к подчиненным. На схеме направления, по которым передаются изменения конфигурации, обозначены красными стрелочками.
Теперь рассмотрим, каким образом осуществляется обмен данными между узлами УРБД. При внесении изменений в данные информационной базы программа запоминает, что было изменено и каким образом. Для любого узла раз в определенный промежуток времени запускается обработка (вручную либо автоматически), которая формирует специальные сообщения, в каких в формате XML отображена информация о том, были ли изменения (если были, то какие), и отправляет их в определенные каталоги по локальной сети либо по FTP, или же на определенные адреса электронной почты.
Также обработка проверяет, появились ли в этом каталоге либо электронном ящике аналогичные сообщения от других узлов, связанных напрямую с этим узлом, адресованные ему. Если появились, то загрузит сообщения, а следовательно, и изменения в данных. Инфраструктура сообщений поддерживает нумерацию сообщений, и позволяет получать подтверждения от узла-получателя о приеме сообщений. Такое подтверждение содержится в каждом сообщении, приходящем от узла-получателя в виде номера последнего принятого сообщения.
Если узел-приемник еще не успел загрузить сообщение из каталога обмена, узел-источник не будет выкладывать, а тем более формировать файл сообщений в каталог обмена по этому узлу. Подразумевается, что после успешной загрузки, файл удаляется из каталога обмена. Это позволяет не осуществлять лишние операции при обмене и не загружать канал лишний раз.
При изменении конфигурации базы информация об изменениях распространяется в сообщениях обмена вместе с изменениями данных.
Обмен данными между базами производится следующим образом:
1) В базе-источнике система определяет список изменённых объектов за время, прошедшее с предыдущего сеанса выгрузки данных.
2) По данному списку система формирует XML-пакет, который передается в базу-приемник.
Для того чтобы сформировать пакет система обращается к измененным объектам базы данных. При обращении система блокирует данные объекты.
3) XML-пакет передается в базу-приемник.
В базе-приемнике XML-пакет разворачивается и изменения, содержащиеся в нем, вносятся в базу.
Все изменения записываются в рамках одной транзакции, при этом все измененные объекты блокируются.
2.4 Примеры распределенных систем
Сегодня практически все крупнейшие производители систем управления базами данных предлагают решения в области управления распределенными ресурсами. Однако все эти решения поддерживают ограниченные функции построения неоднородных распределенных систем.
Среди многочисленных прототипов и научно-исследовательских систем следует упомянуть систему SDD-1, созданную в конце 70-х начале 80-х годов в научно-исследовательском отделении фирмы Computer Corporation of America; систему R*, которая является распределенной версией системы System R и создана в начале 80-х годов фирмой IBM; а также систему Distributed INGRES, которая является распределенной версией системы INGRES и создана также в начале 80-х годов в Калифорнийском университете в Беркли. [9]
Что касается коммерческих продуктов, то в настоящее время в большинстве реляционных систем предусмотрены разные виды поддержки использования распределенных баз данных с разной степенью функциональности. Среди таких систем наиболее известны система INGRES/STAR отделения Ingres Division фирмы The ASK Group Inc., система ORACLE фирмы Oracle Corporation, а также модуль распределенной работы системы DB2 фирмы IBM.
Сегодня многие фирмы - разработчики СУБД заявляют о том, что они поддерживают работу с распределенными БД, однако при ближайшем рассмотрении в большинстве случаев эти заявления оказываются несколько преувеличенными. Специалисты в области СУБД считают, что только несколько пакетов СУБД позволяют в некоторой степени реализовать распределенную базу данных.
В работе дано следующее определение распределенной БД: "Распределенная БД - это множество физических баз данных, которые выглядят для пользователя как одна логическая БД". К сожалению, на сегодняшний день ни одна СУБД полностью не реализует это определение. Наиболее близко к его реализации подошли следующие СУБД:
- Informix On-Line фирмы Informix Software;
- Ingres Intelligent Database фирмы Ingres Corp;
- Oracle (version 7) фирмы Oracle Corp;
- Sybase System 10 фирмы Sybase Inc.
Хотя ни одна из этих 4 СУБД полностью не реализует все функции распределенной СУБД, однако каждая из них реализует или в скором времени будет реализовывать поддержку работы с распределенной БД.
Наиболее полно функции распределенной СУБД реализованы в СУБД Ingres и Oracle. Коротко рассмотрим возможности этих пакетов.
СУБД Ingres работает на множестве UNIX-платформ, на платформах DEC VMS, Hewlett-Packard MPE, DOS, Microsoft Windows 3.1, OS/2, Macintosh. Она также работает со многими сетевыми протоколами, включая Open System Interconnection Transport Class 4. Ingres имеет средства для доступа к данным СУБД DB2, Rdb, Allbase. Основные функции распределенной СУБД обеспечиваются дополнительной компонентой Ingres/Star. Она поддерживает оптимизацию распределенных запросов, позволяет читать и обновлять в рамках одной транзакции данные разных узлов, обеспечивает возможность удалять записи одновременно в нескольких узлах.
СУБД Informix-Online разработана для среды UNIX, но может также работать под Novell. Informix-Online имеет оптимизатор запросов и реализует те же функции работы с распределенной БД, что и Ingres, однако у Informix более жесткие требования к ресурсам компьютера, в частности ему требуется больше оперативной памяти.
СУБД System 10 фирмы Sybase в настоящее время находится в состоянии разработки. Она должна работать на UNIX-платформах, на платформах OS/2, Window NT, NetWare. System 10 будет работать с несколькими сетевыми протоколами и поддерживать связь с СУБД DB2, Oracle 7, Informix-Online, Rdb. System 10 будет иметь оптимизатор распределенных запросов, она позволит читать и обновлять данные нескольких узлов. Функции работы с распределенной БД будут реализованы с помощью дополнительной компоненты Replication Server.
В 7 версии СУБД Oracle реализовано множество функций для работы с распределенной БД. Среди них следует выделить оптимизатор распределенных запросов и средство чтения и обновления данных нескольких узлов в рамках одной транзакции. Oracle v 7 работает на более чем 80 вычислительных платформах, поддерживает большинство существующих коммерческих сетевых протоколов и может обмениваться данными с СУБД DB2, SQL/DS, Tandem Computers, NonStop SQL, Rdb, HP TurboImage. Разрабатываются шлюзы еще к 18 СУБД.
В Oracle словарь данных хранится также, как остальные данные, поэтому его таблицы могут быть распределены по узлам сети. Все операции с распределенной БД "прозрачны" для пользователей и разработчиков. В области обновления распределенной БД Oracle обогнал всех своих конкурентов. Пользователи Oracle могут с помощью компоненты SQL*Net "прозрачно" работать с данными (не обязательно данными Oracle), размещающимися на различных типах компьютеров и в различных узлах сети. Высокопроизводительное средство "прозрачного" обновления распределенной БД реализовано на основе оригинально выполненного двухфазного протокола фиксации изменений.[10]
Все 4 рассмотренные СУБД поддерживают локальную автономию узлов. Это означает, что администратор БД может рассматривать локальную БД конкретного узла как самостоятельную БД. Все СУБД поддерживают ANSI стандарт языка SQL - ANSI SQL-89 и расширение этого стандарта. Запросы к БД формулируются на языке SQL. Дополнительно к непроцедурному языку SQL Oracle поддерживает свой собственный процедурный язык PL/SQL, а Sybase поддерживает свой язык Transact-SQL.
Все 4 СУБД обеспечивают "прозрачный" механизм запроса, обновления и просмотра данных, размещенных в нескольких узлах. Уже отмечалось, что все 4 СУБД могут обмениваться данными с другими СУБД. Однако только двухфазный протокол фиксации Oracle 7 позволяет выполнять распределенные обновления данных в разных СУБД. Проблема заключается в том, что двухфазные протоколы фиксации изменений разных СУБД плохо совместимы между собой.
Все 4 пакета обеспечивают выполнение локальной и глобальной блокировки данных. Однако они реализуют эту блокировку на различных уровнях. Так Oracle по умолчанию реализует блокировку на уровне записи, а остальные СУБД - на уровне страницы или таблицы. Механизм блокировок позволяет предотвратить изменение данных, которые в это время контролируются другими пользователями. Тем самым обеспечивается целостность и непротиворечивость данных. Блокировка на уровне записи позволяет одновременно обновлять соседние записи одной и той же таблицы. Это резко снижает время ожидания, ускоряет обработку данных и уменьшает вероятность возникновения взаимоблокировок.
Все фирмы-разработчики распределенных СУБД намерены в будущем поддерживать архитектуру распределенной базы данных фирмы IBM (Distributed Relational Database Architecture). Правда хотя IBM уже давно объявила о начале работ по реализации этой архитектуры, она до сих пор не закончена. Это очевидно связано с очень высокой сложностью реализации объявленной архитектуры.
ЗАКЛЮЧЕНИЕ
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
- необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
- необходимость введения централизованного изменения структуры и правил работы баз данных для работы всех дистанционно отдаленных подразделений (филиалов) и юридических лиц (с невозможностью изменения определенных правил непосредственно в отдаленном подразделении);
- необходимость ограничения и осуществления контроля изменения данных в дистанционно отдаленных подразделениях компании (филиалах).
Основная задача систем управления распределенными базами данных состоит в обеспечении средства интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе данных.
Таким образом, распределенные информационные системы являются неотъемлемой частью современной информационной системы. При этом должны обеспечиваться: простота использования системы; возможности автономного функционирования при нарушениях связности сети или при административных потребностях; высокая степень эффективности.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Александров, Д.В. Инструментальные средства информационного менеджмента. CASE-технологии и распределенные информационные системы: Учебное пособие / Д.В. Александров. - М.: ФиС, 2015. - 224 c.
- Алиев, В.С. Информационные технологии и системы финансового менеджмента: Учебное пособие / В.С. оглы Алиев. - М.: Форум, ИНФРА-М, 2015. - 320 c.
- Амириди, Ю.В. Информационные системы в экономике. Управление эффективностью банковского бизнеса: Учебное пособие / Ю.В. Амириди, Е.Р. Кочанова, О.А. Морозова . - М.: КноРус, 2015. - 174 c.
- Балдин, К.В Информационные системы в экономике: Учебник / К.В Балдин, В.Б. Уткин. - М.: Дашков и К, 2015. - 395 c.
- Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2013. - 112 c.
- Бодров, О.А. Предметно-ориентированные экономические информационные системы: Учебник для вузов. / О.А. Бодров, Р.Е. Медведев. - М.: ГЛТ , 2013. - 244 c.
- Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2015. - 283 c.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2015. - 528 c.
- Вдовин, В.М. Предметно-ориентированные экономические информационные системы: Учебное пособие / В.М. Вдовин, Л.Е. Суркова и др. - М.: Дашков и К, 2016. - 388 c.
- Гвоздева, В.А. Информатика, автоматизированные информационные технологии и системы: Учебник / В.А. Гвоздева. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013. - 544 c.
- Гобарева, Я.Л. Банковские информационные системы и технологии. Ч. 1. Технология банковского учета / Я.Л. Гобарева, Е.Р Кочанова. - М.: Финансы и статистика, 2015. - 384 c.
- Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: БИНОМ. ЛЗ, 2012. - 292 c.
- Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: Бином, 2015. - 292 c.
- Горбенко, А.О. Информационные системы в экономике: Учебное пособие / А.О. Горбенко. - М.: БИНОМ. Лаборатория знаний, 2014. - 292 c.
- Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2015. - 176 c.
- Данелян, Т.Я. Экономические информационные системы (ЭИС) предприятий и организаций: Монография. / Т.Я. Данелян. - М.: ЮНИТИ, 2015. - 284 c.
- Дворкович, В.П. Цифровые видеоинформационные системы (теория и практика) / В.П. Дворкович, А.В. Дворкович. - М.: Техносфера, 2012. - 1008 c.
- Емельянов, С.В. Информационные технологии и вычислительные системы: вычислительные системы. математическое моделирование. прикладные аспекты информатики / С.В. Емельянов. - М.: Ленанд, 2015. - 96 c.
- Енджейчик, И. Предметно-ориентированные экономические информационные системы: Учебник / И. Енджейчик. - М.: Финансы и статистика, 2007. - 224 c.
- Ермолин, Н.П. Информационные системы в экономике. Практикум / Н.П. Ермолин. - М.: КноРус, 2012. - 256 c.
Приложение 1
-
Емельянов, С.В. Информационные технологии и вычислительные системы: вычислительные системы. математическое моделирование. прикладные аспекты информатики / С.В. Емельянов. - М.: Ленанд, 2015. - 96 c ↑
-
Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2015. - 176 c. ↑
-
Вдовин, В.М. Предметно-ориентированные экономические информационные системы: Учебное пособие / В.М. Вдовин, Л.Е. Суркова и др. - М.: Дашков и К, 2016. - 388 c ↑
-
Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2015. - 283 c. ↑
-
Бодров, О.А. Предметно-ориентированные экономические информационные системы: Учебник для вузов. / О.А. Бодров, Р.Е. Медведев. - М.: ГЛТ , 2013. - 244 c. ↑
-
Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2013. - 112 c. ↑
-
Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: БИНОМ. ЛЗ, 2012. - 292 c. ↑
-
Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2013. - 112 c. ↑
-
Дворкович, В.П. Цифровые видеоинформационные системы (теория и практика) / В.П. Дворкович, А.В. Дворкович. - М.: Техносфера, 2012. - 1008 c. ↑
-
Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2015. - 176 c. ↑

- Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы (SADT-методология)
- Применение процессного подхода для оптимизации бизнес-процессов (процессный подход к реинжинирингу бизнес процессов)
- Контроль и надзор за субъектами осуществляющими оперативно-розыскную деятельность (формы контроля и надзора за ОРД)
- Правовое регулирование банкротства в России (общая характеристика индивидуального предпринимательства в России)
- Применение объектно-ориентированного подхода при проектировании информационной системы (ОАО «РЖД» )
- Человеческий фактор в управлении организацией (Значение и сущность)
- Финансовый анализ бухгалтерского баланса предприятия (основы анализа бухгалтерской отчетности)
- Особенности и функции коммуникационного менеджмента в формировании корпоративной культуры
- «Проектирование базы данных учёта реализации продукта»
- Эволюция научных взглядов на мотивацию персонала
- Субъекты малого предпринимательства (общие положения о субъектах малого предпринимательства)
- Правовые основы организации нотариата (общие положения правовых основ организации нотариата )