
Нейронная Сеть
Содержание:

Как работает нейронная сеть: алгоритмы, обучение, функции активации и потери
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
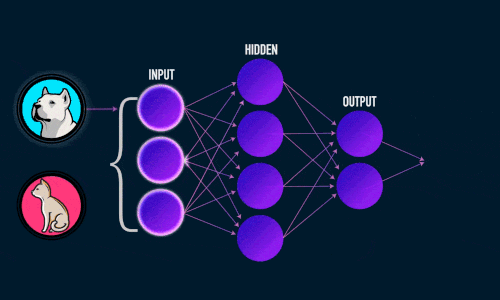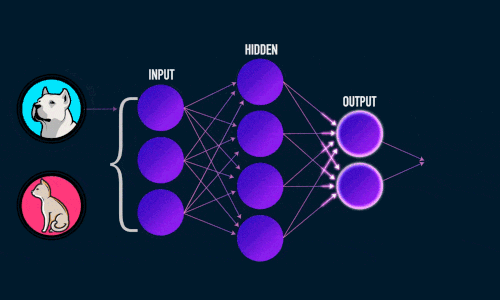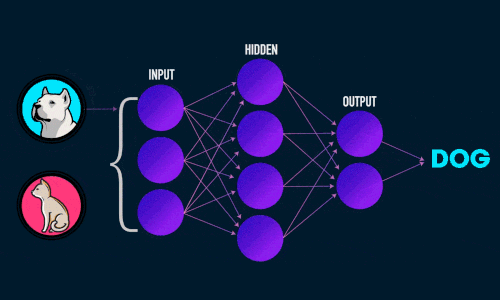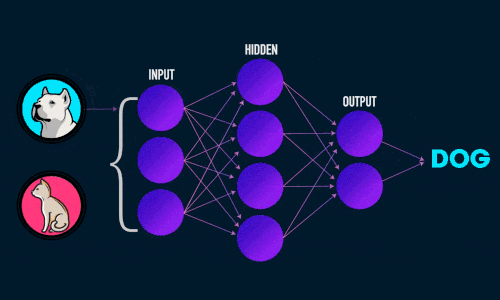
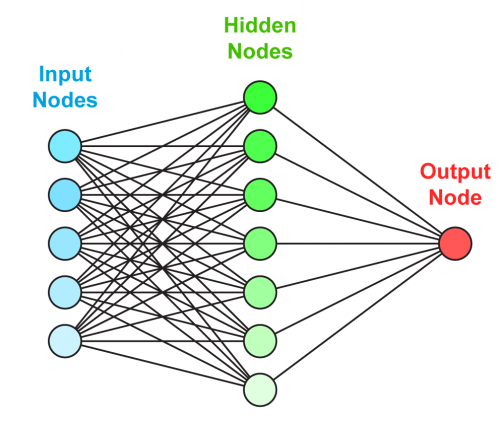
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
Обучение нейросетей происходит в два этапа:
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
Прямое распространение ошибки
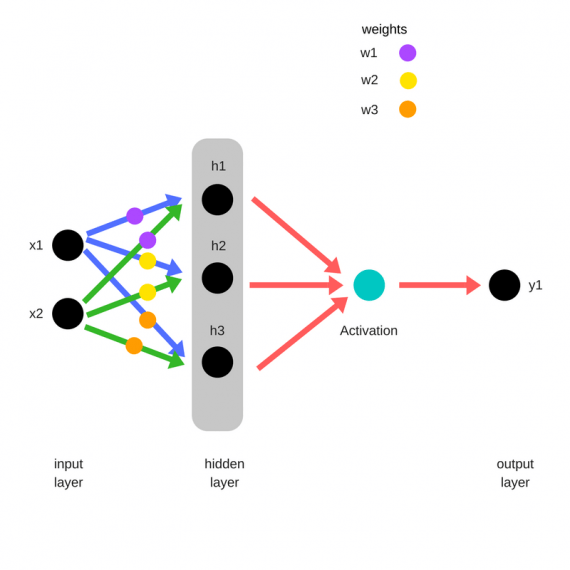
Прямое распространение
Зададим начальные веса случайным образом:
- w1
- w2
- w3
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение
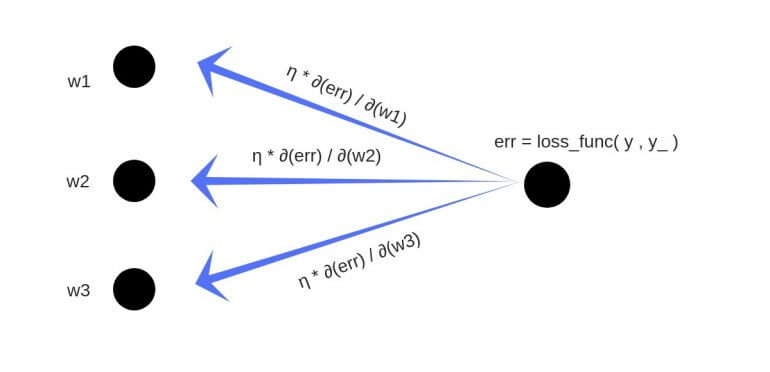
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
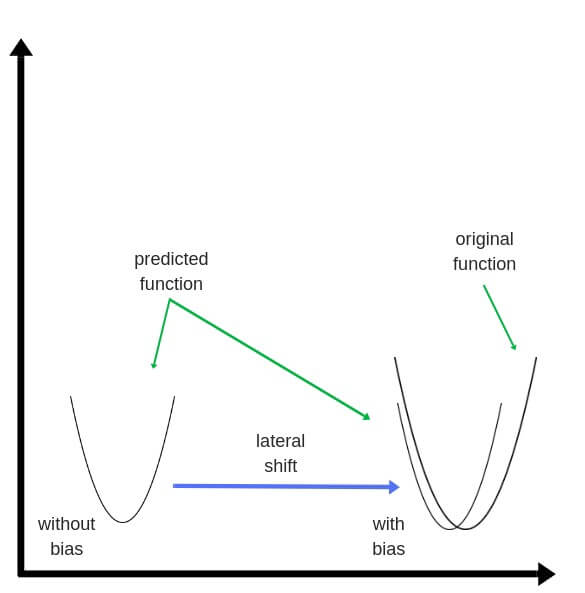
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
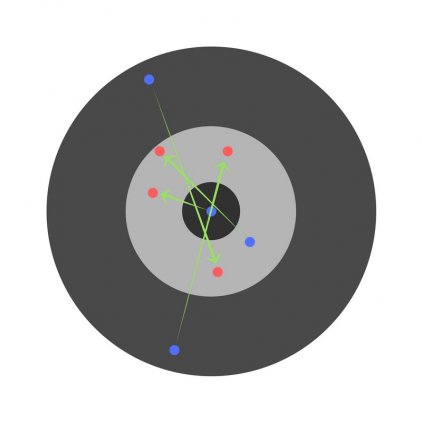
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
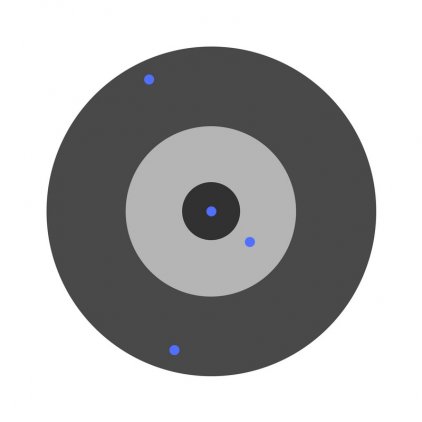
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
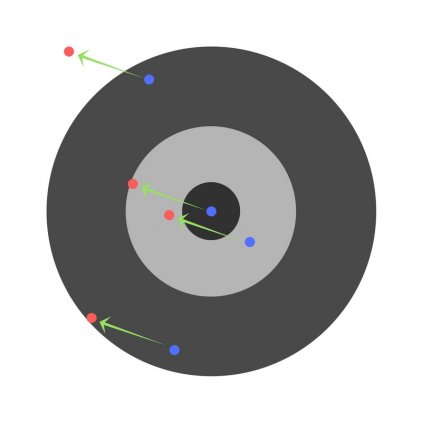
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
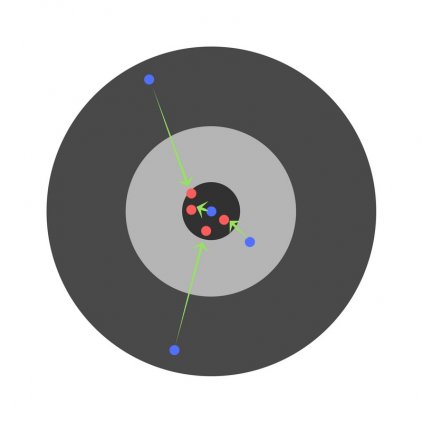
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
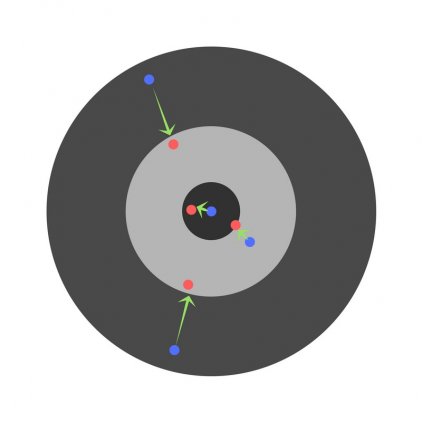
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
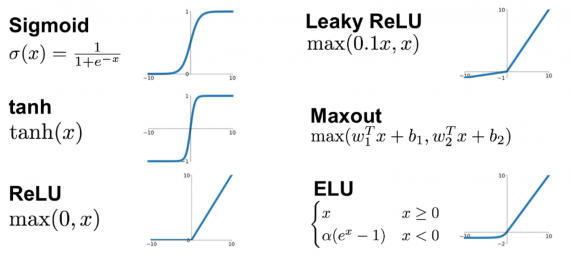
Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
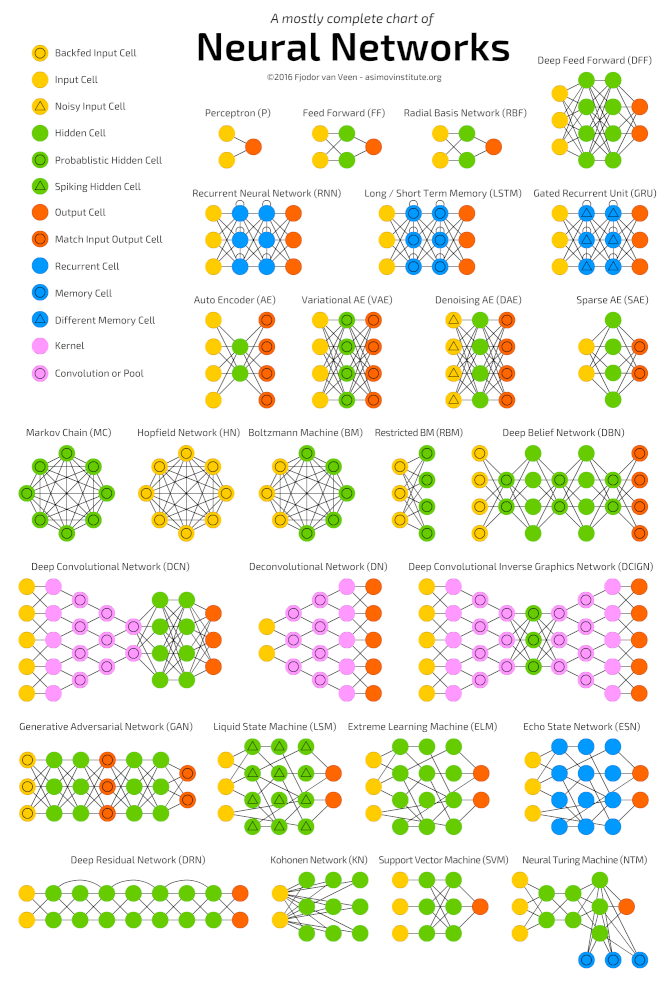
Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:
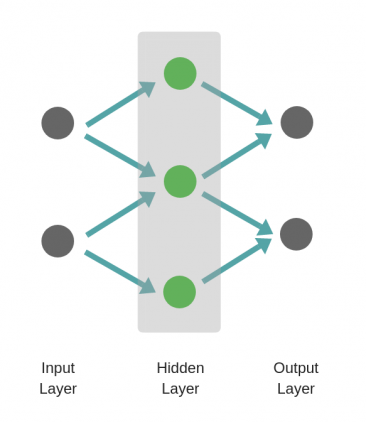
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
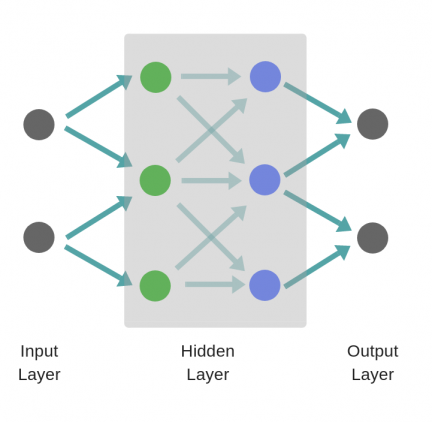
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
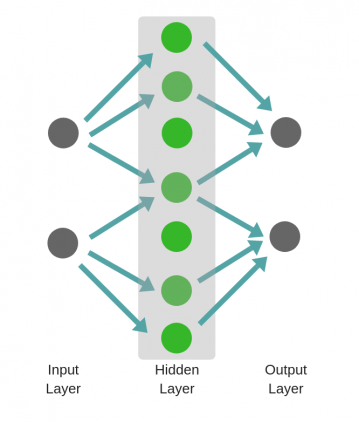
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Пример:
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
Но
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
Действительно,
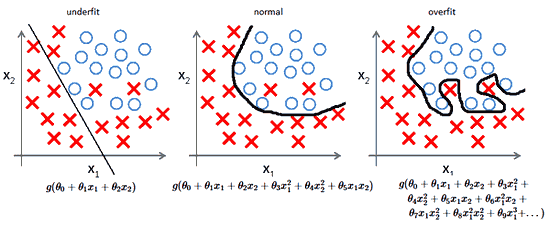
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Нейронной̆ сетью является определенная последовательность нейронов, которые соединяются между собой̆ с помощью синапсов. Идея программирования нейронных сетей̆ с помощью подобной структуры заимствована напрямую из биологии, благодаря чему, электронные вычислительные машины обретают возможности осуществления не только обработки, запоминания разной̆ информации, но и ее воспроизведения из собственной̆ памяти.
Первоочередными направлениями применения нейронных сетей являются те, где для решения конкретных задач необходимо осуществлять сложные аналитическиӗ вычисления: распределение данных по параметрам – классификация, распознавание, предсказывание вариантов развития различных событий.
Наиболее эффективным способом построения моделей, создаваемых при помощи нейронных сетей является их реализация при помощи теории графов. Вычислительные графики составляются из вершин – нейронов, которые соединены между со- бой ребрами синапсами. При этом каждый нейрон обладает таким параметром, как валентность, вес.
Основной единицей нейронной сети, получающей̆ информацию, производящеӗ над ней̆ вычисления и передающиӗ ее далее является нейрон. Существует три типа нейронов: входной̆, скрытый̆ и выходной̆, которые поочередно получают,
обрабатывают информацию и генерируют результат. При этом каждый̆ нейрон в сети обладает двумя главными параметрами: входными и выходными данными. Так данные передаются от нейрона к нейрону поочередно обрабатываясь каждым, после чего суммарная информация нормализуется при помощи функцией активации. Функция активации – это способ нормализации входных данных.
Синапс – связь между нейронами. Он обладает особенным параметром – весом. Вес нейрона равен количеству нейронов, которые передают ему информацию. Для последующих нейронов доминирующей̆ будет являться информация, полученная от нейрона с наибольшим весом. С помощью данного подхода получаемая на входе информация обрабатывается и преобразуется в результат.
Наиболее эффективным способом построения моделей, создаваемых при помощи нейронных сетей̆ является их реализация при помощи теории графов. Вычислительные графики составляются из вершин – нейронов, которые соединены между со- бой ребрами – синапсами. При этом каждый нейрон обладает таким параметром, как валентность – вес.
На данный̆ момент большинство сфер жизни общества претерпевают изменения по причине внедрения различных современных информационных технологий, которые позволяют автоматизировать многие процессы и уменьшить затраты и издержки. Исключением не является и область юриспруденции. На данный момент множество
профессиональных обязанностей̆, которые ранее выполнялись при помощи рядовых юристов упрощены с помощью применения информационных технологий. Так были значительно упрощены и об- легчены процессы поиска, обработки и анализа требуемой информации, а также оперативного обмена и передачи различных сведений.
Также одним из крайне перспективных направлений применения информационных технологий являются информационно-консультационные системы, обеспечивающие пользователя воз- мощностью оперативного поиска и выявления различного рода связей между подозреваемыми или же событиями. Ярчайшими примерами подобных систем являются такие АИС, как «Спрут», «Квадрат» и «Сейф».
«Спрут» является ЮАИС, позволяющей̆ на основе анализа данных выявлять ранее скрытые цепочки фактов и событий, связывающих исполнителей̆ и заказчиков правонарушений. «Квадрат» оптимизирует процесс аналитики, проводимой рядовыми следователями с целью выявления связей между местом, в котором было свершено преступление и проживающими на данной̆ территории преступниками. А юридическая автоматизированная система «Сейф» позволяет раскрывать дела, связанные с расследованием различного рода хищений денежных средств из хранилищ, основываясь на анализе почерка свершенного преступления.
Автоматизированные информационные системы являются одним из самых заурядных примеров применения ИТ в юриспруденции. На данный̆ момент АИС повсеместно внедрены в сферах судопроизводства, государственного управления, экспертной и правоохранительной деятельности. Наиболее яркими примерами служат автоматизированные информационные системы АГИПС и АДИС, применяемые в случае необходимости проведения электронного доказывания для мероприятий розыскного характера, АГИПС «Сова» и ГИС «Зеркало», обеспечивающие возможность проведения экспертиз для судебной̆ системы.
В отдельных случаях судьи могут принять к сведению при инкриминировании улики, полученные при помощи регистрирующих приборов: видеокамер, которые устанавливаются на улицах возле дорог, банкоматов и т.п., авто регистраторов, расположенных в транспортных средствах. Любая информация, которая может быть получена из подобных банков данных используется в качестве доказательств.
В связи с высокими темпами развития технического прогресса: совершенствования средств и методов противодействия преступности, стало необходимым принятие Федерального закона No 143- ФЗ от 01.07.2010 г., который позволил, в случае необходимости, извлекать информацию о соединениях между абонентами и (или) абонентскими устройствами. Так с помощью информационных технологий автоматизировались процессы получения сведений как о дате, времени, продолжительности соединений между абонентами и абонентскими устройствами, номерах абонентов, других данных,
позволяющих идентифицировать абонентов, так и сведений о номерах и месте расположения приемопередающих базовых станций.
В программировании существует несколько основных направлений: алгоритмическое, логическое и др. Несмотря на то, что наиболее распространенным является алгоритмическое программирование, логическое направление является крайне эффективным при решении узкого набора задач.
Наука, которая занимается изучением истинности значений высказываний, называется логикой̆ высказываний. Данный раздел математики и логики занимается непосредственным исследованием логической̆ формы сложных высказываний, которые основываются с помощью элементарных вы- сказываний посредством применения различных логических операций. Высказыванием называются предложения, характеризующиеся наличием одного из двух состояний: ложного или истинного.
Применение логики высказываний в программировании осуществляется в формате объявления логических переменных с последующим присвоением им ложного или истинного значения. Подобные метод позволяет не только упрощать логические высказывания, но и выявлять противоречия посредством применения законов алгебры логики. Основными операциями данной̆ алгебры являются конъюнкция, дизъюнкция, инверсия, импликация, следование и эквиваленция.
Все логические программы имеют минимальный комплект элементов. Собственно, таковыми являются формальный язык, список правил построения выражений, правила перехода, описание начального выражения и аналитическая машина. Формальный язык – это специальное средство, применение которого осуществляется для описания конкретной̆ ситуации. Помимо списка или же правил построения корректных выражений необходимы данные, используемые в терминах рассматриваемого формального языка. Также в данных терминах определяются и выражаются правила перехода от первичного легального выражения к вторичному. Аналитической̆ машиной̆ является программа, которая анализирует выражения с целью построения пути от начального состояния в конечное, что является решением задачи. Наиболее известным примером применения логических программ являются шахматы.
Любая правовая норма состоит из трех частей, отвечающих на свои вопросы. Гипотеза сообщает об обстоятельствах, при которых требуется пользоваться нормой, диспозиция указывает на закрепляемое правило поведения, и санкция конкретизирует какие, именно, меры будут применены в случае нарушения нормы и наступления юридической ответственности.
В настоящее время проблема противоречий в законодательстве, или иначе говоря правовых коллизий, является крайне острой и актуальной. Это обусловлено тем, что законодательство является динамичной, а не статичной структурой, постоянно изменяющееся и подстраивающейся под притязания на новые правовые состояния. Существует целый ряд процессов, которые объективно являются причинами возникновения противоречий, напри- мер, такие, как низкое качество нормативных актов, различные конфликты интересов, падение роли за- конов и возрастание роли локального нормотворчества, а также возникновение теневого права.
Наиболее подходящим средством для поиска и предотвращения правовых противоречий являются нейронные сети с применением алгебры логики высказываний. С их использованием появится возможность полного анализа санкций, применяемых во всех правовых нормах, на предмет наличия коллизий, с последующим сегментированием полученных результатов по видам права.
Особую значимость и важность проблемы предупреждения противоречий крайне сложно переоценить. Такие механизмы и технологии как нейронные сети, несомненно, найдут свою нишу в юриспруденции в качестве метода по аналитике и прогнозированию правовых противоречий в законодательстве.
Источники:
https://habr.com/ru/post/312450/
https://wiki.loginom.ru/articles/neural-network.html
https://cyberleninka.ru/article/n/vozmozhnosti-primeneniya-neyronnyh-setey-v-yurisprudentsii/viewer

- Власть и лидерство: сущность и значение
- «Агностицизм»
- Мировые религии
- Использование современных переплетных материалов в книжной многополосной продукции
- Метрология, полиграфическая деятельность
- Основы стандартизации, сертификации и метрологии. (Основы метрологии)
- Архимед - основатель теоретической гидростатики
- Миссия и цели организации (Миссия организации.)
- Автоматизация судопроизводства
- Proxy сервер
- Proxy сервер (Инфокоммуникационные системы в сети).
- Мифология в астрономии