
Нейронные сети (По дисциплине: Информационные технологии в юридической деятельности)
Содержание:

Введение
Искусственные нейронные сети (ИНС) – вид математических моделей, которые сроятся по принципу организации и функционирования их биологических аналогов сетей нервных клеток (нейронов) мозга. В основе их построения лежит идея о том, что нейроны можно моделировать довольно простыми автоматами (называемыми искусственными нейронами), а все сложность мозга, гибкость его функционирования и другие важнейшие качества определяются связами между нейронами.
История ИНС начинается с 1943 года, когда У. Маккалок и У. Питтс предложили первую модель нейрона и сформулировали основные положения теории функционирования человеческого мозга. С тех пор теория прошла довольно большой путь, а что касается практики, то годовой объем продаж на рынке ИНС в 1997 году составлял 2 млрд долларов с ежегодным приростом в 50%.
Устройство нейронных сетей. Искусственным нейроном называется простой элемент, сначала вычисляющий взвешенную сумму V входных величин Хi:
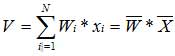
Здесь N - размерность пространства входных сигналов. Затем полученная сумма сравнивается с пороговой величиной W0, вслед за чем вступает в действие нелинейная функция активации f. Коэффициенты {Wi} во взвешенной сумме обычно называют синоптическими коэффициентами или весами. Саму же взвешенную сумму V мы будем называть потенциалом нейрона i. Выходной сигнал тогда имеет вид f(V). Величину порогового барьера можно рассматривать как еще один весовой коэффициент при постоянном входном сигнале. В этом случае мы говорим о расширенном входном пространстве: нейрон с N-мерным входом имеет N+1 весовой коэффициент. Если ввести в уравнение пороговую величину W0, то оно перепишется так:
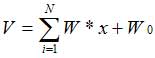
В зависимости от способа преобразования сигнала и характера активации возникают различные виды нейронных структур. Существуют детерминированные нейроны, когда активизирующая функция однозначно вычисляет выход по входу, и вероятностные нейроны, состояние которых в момент t есть случайная функция потенциала и состояния в момент t-1. Далее речь пойдёт о детерминированных нейронах.
Основная часть
Функции активации. В искусственных нейронах могут быть различные функции активации, но и в используемых программах, и в известной литературе указаны только следующие виды функций:
- Линейная: выходной сигнал нейрона равен его потенциалу
- Пороговая: нейрон выбирает решение из двух вариантов: активен /неактивен
- Много пороговая: выходной сигнал может принимать одно из q значений, определяемых (q-1) порогом внутри предельных значений
- Сигмовидная: рассматриваются два вида сигмовидных функций:
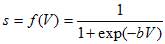 с выходными значениями в промежутке [0,1] и
с выходными значениями в промежутке [0,1] и
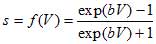 с выходными значениями в промежутке [-1,1]. Коэффициент b определяет крутизну сигмоида. Поскольку сигмоидная функция является гладким отображением (-?,?) на (-1,1), то крутизну можно учесть через величины весов и порогов, и без ограничения общности можно полагать ее равной единице.
с выходными значениями в промежутке [-1,1]. Коэффициент b определяет крутизну сигмоида. Поскольку сигмоидная функция является гладким отображением (-?,?) на (-1,1), то крутизну можно учесть через величины весов и порогов, и без ограничения общности можно полагать ее равной единице.
Типы архитектур нейросетей. Из точек на плоскости и соединений между ними можно построить множество графических фигур, называемых графами. Если каждую точку представить себе как один нейрон, а соединения между точками - как дендриты и синапсы, то мы получим нейронную сеть. Но не всякое соединение нейронов будет работоспособно или вообще целесообразно. Поэтому на сегодняшний день существует только несколько работающих и реализованных программно архитектур нейросетей. Я только вкратце опишу их устройство и классы решаемых ими задач. Сеть прямого распространения По архитектуре связей нейросети могут быть сгруппированы в два класса: сети прямого распространения, в которых связи не имеют петель, и сети рекуррентного типа, в которых возможны обратные связи.
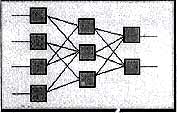
Сети прямого распространения подразделяются на однослойные перцепротроны (сети) и многослойные перцептроны (сети). Название перцептрона для нейросетей придумал американский нейрофизиолог Ф. Розенблатт, придумавший в 1957 году первый нейропроцессорный элемент (НПЭ), то есть нейросеть. Он же доказал сходимость области решений для персептрона при его обучении. Сразу после этого началось бурное исследование в этой области и был создан самый первый нейрокомпьютер Mark I. Многослойные сети отличаются тем, что между входными и выходными данными располагаются несколько так называемых скрытых слоев нейронов, добавляющих больше нелинейных связей в модель. Рассмотрим устройство простейшей многослойной нейросети.
Любая нейронная сеть состоит из входного слоя и выходного слоя. Соответственно подаются независимые и зависимые переменные. Входные данные преобразуются нейронами сети и сравниваются с выходом. Если отклонение больше заданного, то специальным образом изменяются веса связей нейронов между собой и пороговые значения, нейронов. Снова происходит процесс вычислений выходного значения и его сравнение с эталоном. Если отклонения меньше заданной погрешности, то процесс обучения прекращается. Помимо входного и выходного слоев в многослойной сети существуют так называемые скрытые слои. Они представляют собой нейроны, которые не имеют непосредственных входов исходных данных, а связаны только с выходами входного слоя и с входом выходного слоя. Таким образом, скрытые слои дополнительно преобразуют информацию и добавляют нелинейности в модели.
Если однослойная нейросеть очень хорошо справляется с задачами классификации, так как выходной слой нейронов сравнивает полученные от предыдущего слоя значения с порогом и выдает значение либо ноль, то есть меньше порогового значения, либо единицу - больше порогового (для случая пороговой внутренней функции нейрона), и не способен решать большинство практических задач (что было доказано Минским и Пейпертом), то многослойный перцептрон с сигмоидными решающими функциями способен аппроксимировать любую функциональную зависимость (это было доказано в виде теоремы). Но при этом не известно ни нужное число слоев, ни нужное количество скрытых нейронов, ни необходимое для обучения сети время. Эти проблемы до сих пор стоят перед исследователями и разработчиками нейросетей.
Класс рекуррентных нейросетей гораздо обширнее, да и сами сети сложнее по своему устройству. Поведение рекуррентных сетей описывается дифференциальными или разностными уравнениями, как правило, первого порядка. Это гораздо расширяет области применения нейросетей и способы их обучения. Сеть организована так, что каждый нейрон получает входную информацию от других нейронов, возможно, и от самого себя, и от окружающей среды. Этот тип сетей имеет важное значение, так как с их помощью можно моделировать нелинейные динамические системы. Среди рекуррентных сетей можно выделить сети Хопфилда и сети Кохонена. С помощью сетей Хопфилда можно обрабатывать неупорядоченные (рукописные буквы), упорядоченные во времени (временные ряды) или пространстве (графики) образцы. Рекуррентная нейросеть простейшего вида была введена Хопфилдом и построена она из N нейронов, связанных каждый с каждым кроме самого себя, причем все нейроны являются выходными. Нейросеть Хопфилда можно использовать в качестве ассоциативной памяти.
Сеть Кохонена еще называют "самоорганизующейся картой признаков". Сеть такого типа рассчитана на самостоятельное обучение. Во время обучения сообщать ей правильные ответы необязательно. В процессе обучения на вход сети подаются различные образцы. Сеть улавливает особенности их структуры и разделяет образцы на кластеры, а уже обученная сеть относит каждый вновь поступающий пример к одному из кластеров, руководствуясь некоторым критерием "близости". Сеть состоит из одного входного и одного выходного слоя. Количество элементов в выходном слое непосредственно определяет, сколько различных кластеров сеть сможет распознать. Каждый из выходных элементов получает на вход весь входной вектор. Как и во всякой нейронной сети, каждой связи приписан некоторый синоптический вес. В большинстве случаев каждый выходной элемент соединен также со своими соседями. Эти внутрисловные связи играют важную роль в процессе обучения, так как корректировка весов происходит только в окрестности того элемента, который наилучшим образом откликается на очередной вход. Выходные элементы соревнуются между собой за право вступить в действи и "получить урок". Выигрывает тот из них, чей вектор весов окажется ближе всех к входному вектору.
Обучение многослойной сети. Главное отличие и преимущество нейросетей перед классическими средствами прогнозирования и классификации заключается в их способности к обучению. Так что же такое обучение нейросетей? На этапе обучения происходит вычисление синоптических коэффициентов в процессе решения нейронной сетью задач, в которых нужный ответ определяется не по правилам, а с помощью примеров, сгруппированных в обучающие множества. Так что нейросеть на этапе обучения сама играет роль эксперта в процессе подготовки данных для построения экспертной системы. Предполагается, что правила находятся в структуре обучающих данных. Для обучения нейронной сети требуются обучающие данные. Они должны отвечать свойствам представительности и случайности или последовательности. Все зависит от класса решаемой задачи. Такие данные представляют собой ряды примеров с указанием для каждого из них значением выходного параметра, которое было бы желательно получить. Действия, которые при этом происходят, можно назвать контролируемым обучением: "учитель" подает на вход сети вектор исходных данных, а на выходной узел сообщает желаемое значение результата вычислений.
Контролируемое обучение нейросети можно рассматривать как решение оптимизационной задачи. Ее целью является минимизация функции ошибок Е на данном множестве примеров путем выбора значений весов W. Достижение минимума называется сходимостью процесса обучения. Именно возможность этого и доказал Розенблатт. Поскольку ошибка зависит от весов нелинейно, получить решение в аналитической форме невозможно, и поиск глобального минимума осуществляется посредством итерационного процесса так называемого обучающего алгоритма. Разработано уже более сотни разных обучающих алгоритмов, отличающихся друг от друга стратегией оптимизации и критерием ошибок. Обычно в качестве меры погрешности берется средняя квадратичная ошибка (СКО):
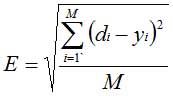 где М - число примеров в обучающем множестве. Минимизация величины Е осуществляется с помощью градиентных методов. Изменение весов происходит в направлении, обратном к направлению наибольшей крутизны для функции:
где М - число примеров в обучающем множестве. Минимизация величины Е осуществляется с помощью градиентных методов. Изменение весов происходит в направлении, обратном к направлению наибольшей крутизны для функции:
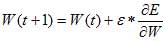
Обратное распространение ошибки. Одним из самых распространенных алгоритмов обучения нейросетей прямого распространения является алгоритм обратного распространения ошибки (Back Propagation, BP). Этот алгоритм был переоткрыт и популяризован в 1986 г. Румельхартом и МакКлелландом из группы по изучению параллельных распределенных процессов в Массачусетском технологическом институте. Здесь я хочу подробно изложить математическую суть алгоритма, так как очень часто в литературе ссылаются на какой-то факт или теорему, но никто не приводит его доказательства или источника. Честно говоря, то же самое относится к теореме об отображении нейросетью любой функциональной зависимости, на которой основываются все попытки применить нейросети к моделированию реальных процессов. Приведём алгоритм работы нейросети Итак, это алгоритм градиентного спуска, минимизирующий суммарную квадратичную ошибку:
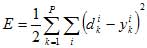
Здесь индекс i пробегает все выходы многослойной сети. Основная идея ВР состоит в том, чтобы вычислять чувствительность ошибки сети к изменениям весов. Для этого нужно вычислить частные производные от ошибки по весам. Пусть обучающее множество состоит из Р. образцов, входы которого где ? - длина шага в направлении, обратном к градиенту обозначены через {xik} Вычисление частных производных осуществляется по правилу цепи: вес входа i-гo нейрона, идущего от j-гo нейрона, пересчитывается по формуле:
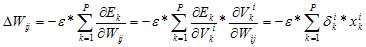
Если рассмотреть отдельно k-тый образец, то соответствующее изменение весов равно:
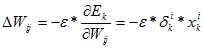
Множитель вычисляется через аналогичные множители из последующего слоя, и ошибка, таким образом, передается в обратном направлении. Для выходных элементов получим:
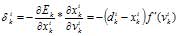
Для скрытых элементов множитель определяется так:
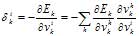 где индекс h пробегает номера всех нейронов, на которые воздействует i-ый нейрон.
где индекс h пробегает номера всех нейронов, на которые воздействует i-ый нейрон.
Заключение
Из теоремы об отображении практически любой функции с помощью многослойной нейросети следует, что обучаемая нами нейронная сеть в принципе способна сама подстроиться под любые данные с целью минимизации суммарной квадратичной ошибки. Чтобы этого не происходило, при обучении нейросетей используют следующий способ проверки сети. Для этого обучающую выборку еще перед началом обучения разбивают случайным образом на две подвыборки: обучающую и тестовую. Обучающую выборку используют собственно для процесса обучения, при этом изменяются веса нейронов. А тестовую используют в процессе обучения для проверки на ней суммарной квадратичной ошибки, но при этом не происходит изменение весов. Если нейросеть показывает улучшение аппроксимации и на обучающей, и на тестовой выборках, то обучение сети происходит в правильном направлении. Иначе может снижаться ошибка на обучающей выборке, но происходит ее увеличение на тестовой. Последнее означает, что сеть "переобучилась" и уже не может быть использована для прогнозирования или классификации. В этом случае немного изменяются веса нейронов, чтобы вывести сеть из окрестности локального минимума ошибки.
Литература
- С. Короткий, "Нейронные сети: Алгоритм обратного распространения". СПб, 2002, 328 с.
- С. Короткий,"Нейронные сети: Основные положения. СПб, 2002. 357 с.
- Фролов А.А., Муравьев И.П. Нейронные модели ассоциативной памяти. М.: Наука, 2004, 160 с.
- Фролов А.А., Муравьев И.П. Информационные характеристики нейронных сетей. М.: Наука, 2005, 160 с.

- Природа коррупции как социальное явление
- Память, процессы и виды памяти
- Тенденции развития современных конституций
- Основные институты общей части уголовного права зарубежных стран
- Формирование эффективного финансового рынка (Финансовые рынки выполняют ряд важных функций)
- Торговля: сущность, функции, место на потребительском рынке и роль в экономике России (Дисциплин «Торговое дело»)
- Теория и методика гимнастики. Понятие и место в системе физического воспитания.
- Темперамент. Виды темперамента
- 3адачи, формы и методы контроля обучения - по дисциплине Психология
- Место и роль экономики в Италии
- Концепции современного естествознания (Наука как высшая форма знания, теоретического и эмпирического знания.)
- Теория и методика подвижных игр (Значение подвижных игр в воспитании детей.)