
Оперативный и интеллектуальный анализ данных
Содержание:

Введение
В настоящее время существует большое количество данных.Они представляются как необработанный материал предоставляемый, поставщиками данных и используемый потребителями для формирования информации . Данные бесконечны, и бывают как существенные так и незначащие. Чтобы понять с какими именно данными пользователь должен работать ему приходиться проделывать огромную работу, но со временем человечество изобретает все более упрощенные способы сбора и обработки данных. Так была разработана Data Mining.
Data Mining представляет собой процесс обнаружения в сырых данных ранее неизвестных, практически полезных и доступных знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Задачи, решаемые методами Data Mining, принято разделять на описательные (англ. descriptive) и предсказательные (англ. predictive).
В описательных задачах самое главное — это дать наглядное описание имеющихся скрытых закономерностей, в то время как в предсказательных задачах на первом плане стоит вопрос о предсказании для тех случаев, для которых данных ещё нет.
К описательным задачам относятся:
- поиск ассоциативных правил или паттернов (образцов);
- группировка объектов, кластерный анализ;
- построение регрессионной модели.
К предсказательным задачам относятся:
- классификация объектов (для заранее заданных классов);
- регрессионный анализ, анализ временных рядов.
С помощью интеллектуального анализа даных можно отыскивать действительно очень ценную информацию.
Data mining и искусственный интеллект:
Знания, добываемые методами Data mining принято представлять в виде моделей. В качестве таких моделей выступают:
- ассоциативные правила;
- деревья решений;
- кластеры;
- математические функции.
Интеллектуальный анализ данных представляет большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе. В основе методов Data mining лежат математические методы обработки данных, включая и статистические методы. В промышленных решениях, нередко, такие методы непосредственно включаются в пакеты Data mining.
Цели и задачи работы. Получение практических навыков применения современных информационных технологий, предназначенных для интеллектуального анализа данных, направленных на исследования целостного представления об анализе и интерпретации экспериментальных и статистических данных, как о процессе поиска, так и применения скрытых в них закономерностей.
Анализ данных.
Анализ данных — широкое понятие. Сегодня существуют десятки его определений.
В самом общем смысле анализ данных — это исследования, связанные с обсчетом
многомерной системы данных, имеющей множество параметров. В процессе анализа данных исследователь производит совокупность действий с целью формирования определенных представлений о характере явления, описываемого этими данными. Как правило, для анализа данных используются различные математические методы.
Анализ данных нельзя рассматривать только как обработку информации после
ее сбора. Анализ данных — это прежде всего средство проверки гипотез и решения задач исследователя.
Известное противоречие между ограниченными познавательными способностями
человека и бесконечностью Вселенной заставляет нас использовать модели и моделирование, тем самым упрощая изучение интересующих объектов, явлений и систем.
Слово «модель» (лат. modelium) означает «мера», «способ», «сходство с какой-
то вещью».
Построение моделей — универсальный способ изучения окружающего мира, позволяющий обнаруживать зависимости, прогнозировать, разбивать на группы и решать множество других задач. Основная цель моделирования в том, что модель должна достаточно хорошо отображать функционирование моделируемой системы.
Оперативный анализ данных.
Оперативный анализ данных - технология хранения и обработки многомерных данных, позволяющая получать сложные аналитические отчёты в реальном времени.
В основе технологии лежит представление данных в виде многомерных кубов, где измерениями являются категории, а в ячейках внутри куба содержатся факты и агрегаты.
Автором идеи OLAP является Эдгар Кодд, который сформулировал 12 правил, определивших эту технологию:
1)Многомерный концептуальный взгляд на данные (Multidimensional conceptual view).
2) Прозрачность для пользователя (Transparency).
3) Доступность разнородных источников данных (Accessibility).
4) Постоянство характеристик производительности при увеличении числа измерений (Consistent reporting performance).
5) Клиент-серверная архитектура (Client server architecture).
6) Общность измерений по структуре и возможностям обработки (Generic Dimensionality).
7) Обработка разреженных матриц (Dynamic sparse matrix handling).
8) Наличие многопользовательской среды (Multi-user support).
9) Операции с любым числом измерениями (Unrestricted cross-dimensional operations).
10) Интуитивное манипулирование данными (Intuitive data manipulation).
11) Гибкое формирование отчётности (Flexible reporting).
12) Неограниченное число измерений и уровней агрегирования данных (Unlimited Dimensions and aggregation levels).
В настоящее время список из этих 12 правил расширили до 18 главных правил, а всего их около 300.
Место OLAP в информационной структуре предприятие.
Термин "OLAP" неразрывно связан с термином "хранилище данных" (Data Warehouse).
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например, статистических отчетов.
Задача хранилища - предоставить "сырье" для анализа в одном месте и в простой, понятной структуре.
Есть и еще одна причина, оправдывающая появление отдельного хранилища - сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Под хранилищем можно понимать не обязательно гигантское скопление данных - главное, чтобы оно было удобно для анализа.
Централизация и удобное структурирование - это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного - гибкости. Их нельзя "покрутить", "развернуть" или "свернуть", чтобы получить желаемое представление данных. Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище.
Оперативная аналитическая обработка данных.
В основе концепции OLAP лежит принцип многомерного представления данных. В 1993 году E. F. Codd рассмотрел недостатки реляционной модели, в первую очередь, указав на невозможность "объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом", и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
По Кодду, многомерное концептуальное представление данных (multi-dimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных.
Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению.
Так, измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения "предприятие - подразделение - отдел - служащий". Измерение Время может даже включать два направления консолидации - "год - квартал - месяц - день" и "неделя - день", поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений.
Операция спуска (drilling down) соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема (rolling up) означает движение от низших уровней к высшим.
Требования к средствам оперативной аналитической обработки.
Многомерный подход возник практически одновременно и параллельно с реляционным. Однако, только начиная с середины девяностых годов, а точнее с
1993 г., интерес к МСУБД начал приобретать всеобщий характер. Именно в этом году появилась новая программная статья одного из основоположников реляционного подхода Э. Кодда, в которой он сформулировал 12 основных требований к средствам реализации OLAP
табл. 1
|
1. |
Многомерное представление данных |
Средства должны поддерживать многомерный на концептуальном уровне взгляд на данные. |
|
2. |
Прозрачность |
Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда они берутся. |
|
3. |
Доступность |
Средства должны сами выбирать и связываться с наилучшим для формирования ответа на данный запрос источником данных. Средства должны обеспечивать автоматическое отображение их собственной логической схемы в различные гетерогенные источники данных. |
|
4. |
Согласованная производительность |
Производительность практически не должна зависеть от количества Измерений в запросе. |
|
5. |
Поддержка архитектуры клиент-сервер |
Средства должны работать в архитектуре клиент-сервер. |
|
6. |
Равноправность всех измерений |
Ни одно из измерений не должно быть базовым, все они должны быть равноправными (симметричными). |
|
7. |
Динамическая обработка разреженных матриц |
Неопределенные значения должны храниться и обрабатываться наиболее эффективным способом. |
|
8. |
Поддержка многопользовательского режима работы с данными |
Средства должны обеспечивать возможность работать более чем одному пользователю. |
|
9. |
Поддержка операций на основе различных измерений |
Все многомерные операции (например Агрегация) должны единообразно и согласованно применяться к любому числу любых измерений. |
|
10. |
Простота манипулирования данными |
Средства должны иметь максимально удобный, естественный и комфортный пользовательский интерфейс. |
|
11. |
Развитые средства представления данных |
Средства должны поддерживать различные способы визуализации (представления) данных. |
|
12. |
Неограниченное число измерений и уровней агрегации данных |
Не должно быть ограничений на число поддерживаемых Измерений. |
Интеллектуальный анализ данных
интеллектуальный анализ данных (ИАД) обычно определяют, как метод поддержки принятия решений, основанный на анализе зависимостей между данными. В рамках такой общей формулировки обычный анализ отчетов, построенных по базе данных, также может рассматриваться как разновидность ИАД. Чтобы перейти к рассмотрению более продвинутых технологий ИАД, посмотрим, как можно автоматизировать поиск зависимостей между данными.
Целью интеллектуального анализа данных (англ. Datamining, другие варианты перевода - "добыча данных", "раскопка данных") является обнаружение неявных закономерностей в наборах данных. Как научное направление он стал активно развиваться в 90-х годах XXвека, что было вызвано широким распространением технологий автоматизированной обработки информации и накоплением в компьютерных системах больших объемов данных [1, с. 12]. И хотя существующие технологии позволяли, например, быстро найти в базе данных нужную информацию, этого во многих случаях было уже недостаточно. Возникла потребность поиска взаимосвязей между отдельными событиями среди больших объемов данных, для чего понадобились методы математической статистики, теории баз данных, теории искусственного интеллекта и ряда других областей.
Классическим считается определение, данное одним из основателей направления Григорием Пясецким-Шапиро [1,с.2]: DataMining - исследование и обнаружение "машиной" (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации.
Учитывая разнообразие форм представления данных, используемых алгоритмов и сфер применения, интеллектуальный анализ данных может проводиться с помощью программных продуктов следующих классов:
· специализированных "коробочных" программных продуктов для интеллектуального анализа;
· математических пакетов;
· электронных таблиц (и различного рода надстроек над ними);
· средств, интегрированных в системы управления базами данных (СУБД);
· других программных продуктов.
В качестве примера можно привести СУБД MicrosoftSQLServer и входящие в ее состав службы AnalysisServices, обеспечивающие пользователей средствами аналитической обработки данных в режиме on-line (OLAP)и интеллектуального анализа данных, которые впервые появились в MSSQLServer 2000.
Не только Microsoft, но и другие ведущие разработчики СУБД имеют в своем арсенале средства интеллектуального анализа данных.
В ходе проведения интеллектуального анализа данных проводится исследование множества объектов (или вариантов). В большинстве случаев его можно представить в виде таблицы, каждая строка которой соответствует одному из вариантов, а в столбцах содержатся значения параметров, его характеризующих. Зависимая переменная - параметр, значение которого рассматриваем как зависящее от других параметров (независимых переменных). Собственно, эту зависимость и необходимо определить, используя методы интеллектуального анализа данных.
Инструменты интеллектуального анализа данных.
Интеллектуальный анализ данных ― это не только используемые инструменты или программное обеспечение баз данных. Интеллектуальный анализ данных можно выполнить с относительно скромными системами баз данных и простыми инструментами, включая создание своих собственных, или с использованием готовых пакетов программного обеспечения. Сложный интеллектуальный анализ данных опирается на прошлый опыт и алгоритмы, определенные с помощью существующего программного обеспечения и пакетов, причем с различными методами ассоциируются разные специализированные инструменты.
Например, IBM SPSS®, который уходит корнями в статистический анализ и опросы, позволяет строить эффективные прогностические модели по прошлым тенденциям и давать точные прогнозы. IBM InfoSphere® Warehouse обеспечивает в одном пакете поиск источников данных, предварительную обработку и интеллектуальный анализ, позволяя извлекать информацию из исходной базы прямо в итоговый отчет.
В последнее время стала возможна работа с очень большими наборами данных и кластерная/крупномасштабная обработка данных, что позволяет делать еще более сложные обобщения результатов интеллектуального анализа данных по группам и сопоставлениям данных. Сегодня доступен совершенно новый спектр инструментов и систем, включая комбинированные системы хранения и обработки данных.
Можно анализировать самые разные наборы данных, включая традиционные базы данных SQL, необработанные текстовые данные, наборы "ключ/значение" и документальные базы. Кластерные базы данных, такие как Hadoop, Cassandra, CouchDB и Couchbase Server, хранят и предоставляют доступ к данным такими способами, которые не соответствуют традиционной табличной структуре.
В частности, более гибкий формат хранения базы документов придает обработке информации новую направленность и усложняет ее. Базы данных SQL строго регламентируют структуру и жестко придерживаются схемы, что упрощает запросы к ним и анализ данных с известными форматом и структурой.
Документальные базы данных, которые соответствуют стандартной структуре типа JSON, или файлы с некоторой машиночитаемой структурой тоже легко обрабатывать, хотя дело может осложняться разнообразной и переменчивой структурой. Например, в Hadoop, который обрабатывает совершенно "сырые" данные, может быть трудно выявить и извлечь информацию до начала ее обработки и сопоставления.
Процесс применения интеллектуальных технологий.
По сути, интеллектуальный анализ данных — это обработка информации и выявление в ней моделей и тенденций, которые помогают принимать решения. Принципы интеллектуального анализа данных известны в течение многих лет, но с появлением больших данных они получили еще более широкое распространение.
Большие данные привели к взрывному росту популярности более широких методов интеллектуального анализа данных, отчасти потому, что информации стало гораздо больше, и она по самой своей природе и содержанию становится более разнообразной и обширной. При работе с большими наборами данных уже недостаточно относительно простой и прямолинейной статистики. Имея 30 или 40 миллионов подробных записей о покупках, недостаточно знать, что два миллиона из них сделаны в одном и том же месте. Чтобы лучше удовлетворить потребности покупателей, необходимо понять, принадлежат ли эти два миллиона к определенной возрастной группе, и знать их средний заработок.
Эти бизнес-требования привели от простого поиска и статистического анализа данных к более сложному интеллектуальному анализу данных. Для решения бизнес-задач требуется такой анализ данных, который позволяет построить модель для описания информации и в конечном итоге приводит к созданию результирующего отчета. Этот процесс иллюстрирует рисунок 1.
Рисунок 1. Схема процесса
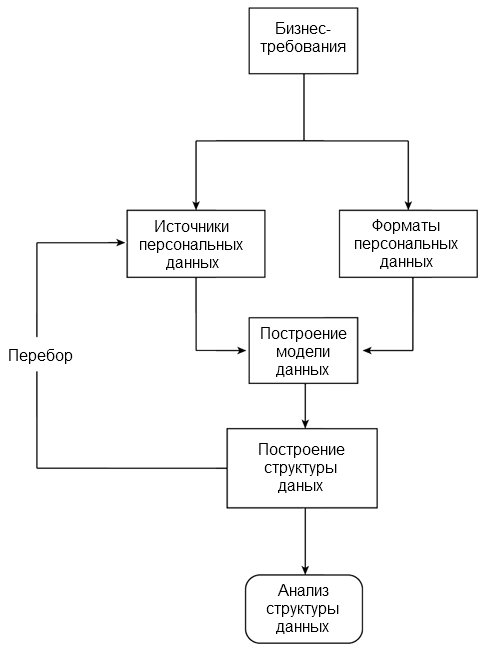
Процесс анализа данных, поиска и построения модели часто является итеративным, так как нужно разыскать и выявить различные сведения, которые можно извлечь. Необходимо также понимать, как связать, преобразовать и объединить их с другими данными для получения результата. После обнаружения новых элементов и аспектов данных подход к выявлению источников и форматов данных с последующим сопоставлением этой информации с заданным результатом может измениться.
Аспекты проблемы анализа, классификация методов
Аспекты проблемы анализа. Вся проблема аналитической подготовки принятия решений имеет три аспекта:
•сбор и хранение необходимой для принятия решений информации;
•собственно анализ, в том числе оперативный и интеллектуальный;
•подготовка результатов оперативного и интеллектуального анализа для эффективного их восприятия потребителями и принятия на её основе адекватных решений.
Аспект, касающийся сбора и хранения информации с сопутствующей доработкой, оформился в концепцию информационных хранилищ ( Data Warehouse ).
В связи с большим объёмом и сложностью аспект проблемы собственно анализа имеет два направления — оперативный анализ данных (информации), широко распространена англоязычная аббревиатура названия — On — Line Analytical Processing — OLAP. Основной задачей оперативного или OLAP -анализа является быстрое (в пределах секунд) извлечение необходимой аналитику или ЛПР для обоснования или принятия решения информации.
Интеллектуальный анализ информации – имеет также широко распространённое в русской специальной литературе англоязычное название Data mining. Предназначен для фундаментального исследования проблем в той или иной предметной области. Требования по времени менее жёстки, но используются более сложные методики. Ставятся, как правило, задачи и получают результаты стратегического значения.
Жёстких границ между OLAP и интеллектуальным анализом нет, но при решении сложных задач приходится использовать весьма мощные специальные программные средства или, как говорят, инструменты.
Классификация методов анализа. Существует большое количество методов анализа, которые делятся на группы по различным признакам.
Рассмотрим систему признаков, характеризующих методы анализа. Их можно сгруппировать:
По целям — это:
— оценка состояния и результатов деятельности предприятия;
— постоянный контроль рациональности ведения хозяйственной деятельности, выявление резервов для обеспечения выполнения поставленных задач;
— прогнозирование хода внутренних процессов на предприятии и внешних факторов, влияющих на его деятельность.
По временному фактору анализ разделяют на:
— использующий прошлую информацию, отражённую в документации и на различных носителях и содержащуюся в информационной системе — анализ фактов;
— на базе как прошлой, так и обращённой в будущее, то есть прогнозной информации — анализ событий и отклонений;
— анализ будущей информации — по существу оценка бюджетов и планов, их альтернатив.
По масштабности решаемых или обслуживаемых задач:
— стратегический, сюда можно отнести оценку эффективности целей, долгосрочные прогнозы, исторические оценки процессов и явлений и т.д.;
— оперативный — это оценка текущего состояния, выявление узких мест и отклонений;
— система раннего предупреждения.
По предметным областям:
— в маркетинге;
— производственной или основной деятельности;
— в логистике;
— обеспечении ресурсами;
— финансовой;
— в сфере инвестиций и инноваций.
По методам различают:
— сравнительный по подразделениям, предприятиям, регионам, временным периодам и т.д.;
— анализ отклонений;
— функционально-стоимостный;
— анализ цепочки создания стоимости и конкурентный анализ по Портеру;
— анализполейбизнеса (Profit Impact of Market Strategies — PIMS);
— бенчмаркинг (Beanchmarking );
— интеллектуальный анализ (Data mining).
Типы многомерных OLAP систем.
В рамках OLAP -технологий на основе того, что многомерное представление данных может быть организовано как средствами реляционных СУБД, так многомерных специализированных средств, различают три типа многомерных OLAP -систем:
— многомерный (Multidimensional) OLAP- MOLAP
-реляционный (Relation) OLAP — ROLAP
-смешанныйилигибридный ( Hibrid ) OLAP — HOLAP
Выше по существу изложены существо и различия между многомерной и реляционной моделью OLAP -систем. Сущность смешанной OLAP -системы заключается в возможности использования многомерного и реляционного подхода в зависимости от ситуации: размерности информационных массивов, их структуры, частности обращений к тем или иным записям, вида запросов и т.д.
Рассмотрим подробнее достоинства и недостатки приведённых разновидностей OLAP -систем.
Многомерные OLAP -системы
В многомерных СУБД данные организованы не в виде реляционных таблиц, а упорядоченных многомерных массивов или гиперкубов, когда все хранимые данные должны иметь одинаковую размерность, что означает необходимость образовывать максимально полный базис измерений. Данные могут быть организованы в виде поли кубов, в этом варианте значения каждого показателя хранятся с собственным набором измерений, обработка данных производится собственным инструментом системы.
Достоинствами MOLAP являются:
— более быстрое, чем при ROLAP получение ответов на запросы -затрачиваемое время на один-два порядка меньше;
— из-за ограничений SQL затрудняется реализация многих встроенных функций.
К ограничениям MOLAP относятся:
— сравнительно небольшие размеры баз данных — предел десятки Гигабайт;
— за счёт деморализации и предварительной агрегации многомерные массивы используют в 2,5-100 раз больше памяти, чем исходные данные;
— отсутствуют стандарты на интерфейс и средства манипулирования данными;
— имеются ограничения при загрузке данных.
Реляционные OLAP -системы
В настоящее время в массовых средствах, обеспечивающих аналитическую работу, преобладает использование инструментов на основе реляционного подхода.
Достоинствами ROLAP- систем являются:
— возможность оперативного анализа непосредственно содержащихся в хранилище данных, так как большинство исходных баз данных реляционного типа;
— при переменной размерности задачи выигрывают ROLAP, так как не требуется физическая реорганизация базы данных;
— ROLAP — системы могут использовать менее мощные клиентские станции и серверы, причём на серверы ложится основная нагрузка по обработке сложных SQL -запросов;
— уровень защиты информации и разграничения прав доступа в реляционных СУБД несравненно выше, чем в многомерных.
Недостатком ROLAP — систем является меньшая производительность, необходимость тщательной проработки схем базы данных, специальная настройка индексов, анализ статистики запросов и учёт выводов анализа при доработках схем баз данных, что приводит к значительным дополнительным трудозатратам.
Выполнение же этих условий позволяет при использовании ROLAP -систем добиться схожих с MOLAP -системами показателей в отношении времени доступа и даже превзойти в экономии памяти.
Гибридные OLAP -системы
Представляют собой сочетание инструментов, реализующих реляционную и многомерную модель данных. При таком подходе используются достоинства первых двух подходов и компенсируются их недостатки. В наиболее развитых программных продуктах такого назначения реализован именно этот принцип.
Использование гибридной архитектуры в OLAP -системах — это наиболее приемлемый путь решения проблем в применении программных инструментальных средств в многомерном анализе.

- Стандарты текстовой информации в ИС (текстовые редакторы)
- Технологии больших данных (Big Data)
- Реорганизация общества и его ликвидация: краткая характеристика и этапы процедур (Понятие и виды ликвидации)
- Отличительные особенности англо-американской модели корпоративного управления: ее преимущества и недостатки (Англо-американская модель корпоративного управления)
- Защитные механизмы OC Windows 8.1
- Активные и интерактивные технологии обучения
- Language and Literacy.
- KPI в контексте BPM
- Системы оперативного анализа данных OLAP
- Средства аутентификации по отпечаткам пальцев (Биометрические системы аутентификации.)
- Технологии больших данных (Big Data) (Большие данные.)
- Анимация и видео