
Откуда берутся Большие Данные
Содержание:

Введение
В реферате мы рассмотрим несколько вводных моментов про большие данные:
- Что такое Big Data и откуда берётся;
- Что анализируют в качестве больших данных;
- Каким основным принципам следуют все средства и парадигмы работы с большими данными;
- Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года.
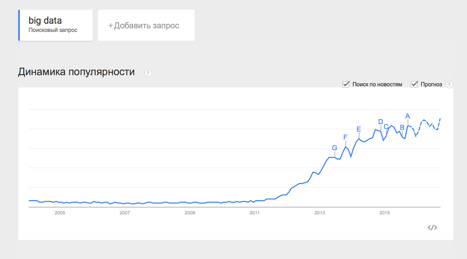
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле?
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин. Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой:
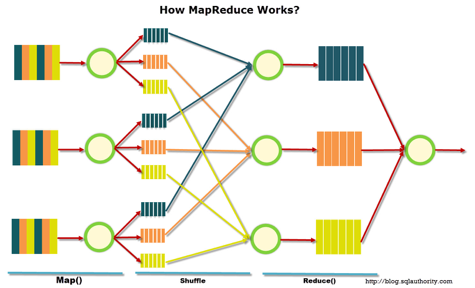
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Откуда берутся большие данные?
1. Большие данные покупают
Ещё в 2014 году американская компания, брокер в области отелей, авиабилетов, проката автомобилей Priceline объявила, что планирует заключить сделку с приложением Open Table на $2,6 млрд, выкупив права на сервис, чтобы узнать своих клиентов получше с помощью обработки данных.
По итогам 2015 года генеральный директор компании Priceline Group Даррен Хьюстон в своем интервью поделился успехами и перспективами Оpen Table, включая расширение проекта в странах персидского залива и Ближнего Востока.
Только в 2015 году Priceline извлек из 55 миллиардных валовых заказов более $9 млрд выручки только купленных компаний. Что лишний раз подтверждает стратегическую нацеленность Priceline.
2. Большие данные добывают
Группа компаний SMB, эксперт в области аналитики и бизнес-консалтинга, занимается инерцией рыночных трендов в сфере малого и среднего бизнеса. По данным группы компании 57% малого бизнеса используют анализ и обработку больших данных для увеличения показателей и роста бизнеса.
Среди таких видов предпринимательства оказалось немало HoReCa сегмента. Бары и рестораны используют обработку данных для составления портрета своих клиентов и фокус групп, их любимые блюда и напитки. Также на основе полученных данных формируются программы лояльности для посетителей.
3. Большие данные собирают самостоятельно
Компания Venga, разработчик в области хранения и обработки данных сумела сформировать четкий портрет аудитории своих клиентов и увеличить вероятность их повторного визита в заведение. И всё это с помощью анализа данных POS-терминала, полученных от резервирования столов через отдельный сервис.
Данные с POS-систем, маркетинга, бухгалтерского учета, инвентаризации и системы планирования являются основой для создания больших данных. Но ключевой особенностью больших данных должно быть огромное количество информации, география данных, и их выдержанность.
Недавно компания удостоилась премии Timmy Awards как «Лучший IT-стратап проект» по улучшению бизнеса. А также за заслуги в выстраивании эффективной CRM системы, способствующей улучшению обратной связи и взаимодействия с клиентом и анализа больших данных.
Что анализируют в качестве больших данных?
В итоге большие данные не перестают находить всё новые резервуары. А крупные компании всё чаще задумываются о создании своих каналов получения и анализа необходимой информации.
Так примерно выглядит взаимосвязь данных, в результате сбора которых можно получить большие, но относительно неглубокие данные.

Таким образом, большие данные начинаются с обработки комбинированной информации различных форматов структурированного и неструктурированного характера (от ежемесячных бухгалтерских учетов, заканчивая показателями данных, полученных с камер наблюдения).
При наличии всех возможных источников, big data не ограничивается ничем в своей выборке. Получается, чем больше доступных данных, тем точнее показатели и модели вычислений становятся.
Области применения
Задачи по работе с Big Data сегодня решают крупные IT-вендоры. Как правило, они поставляют целые стеки решений, позволяющих заказчику не только собирать и хранить, но и обрабатывать данные.
Например, крупнейший мировой интернет-аукцион eBay ежедневно анализирует миллиард транзакций, поисковые запросы покупателей, поведение покупателей и продавцов и даже профили из соцсетей. В результате такого анализа подбираются оптимальные пары покупатель-продавец, которые выдаются в рекомендациях в первую очередь. Общий объем собираемых eBay данных — 50 петабайт. Решение для eBay реализовано на платформе SAP HANA, которая обеспечивает интеграцию с инфраструктурой аукциона. В нем также используется решение по прогнозной аналитике - SAP Predictive Analytics для анализа всех процессов и рекомендаций по их улучшению.
Интересный пример применения Big Data реализован в CSX Corporation в США. Транспортная сеть компании насчитывает 21 тысячу миль железнодорожных путей, обслуживающих несколько крупнейших городов США. Специальные алгоритмы обрабатывают более 48 тысяч транспортных комбинаций, а также 1,7 тысячи макроэкономических показателей для оценки долгосрочного влияния рыночных условий. Кроме того, CSX анализирует краткосрочные факторы: данные об обслуживании клиентов, цены, и соответствие временным интервалам — для того, чтобы понять причины любого роста или спада производительности.
Ритейл, телеком, банки, компании аэрокосмической отрасли и даже футбольные клубы используют Big Data для улучшения своей работы. Подробнее об этом эксперты рынка расскажут на SAP Forum 13 апреля в «Крокус Экспо» в Москве. В форуме примут участие 4 тысячи представителей компаний из ключевых отраслей экономики. Участники смогут лично познакомиться с 60 реализованными сценариями цифровой трансформации бизнес-моделей и 50 интерактивными бизнес-технологиями в действии.
Заключение
Мы рассмотрели несколько вводных моментов про большие данные:
- Что такое Big Data и откуда берётся;
- Каким основным принципам следуют все средства и парадигмы работы с большими данными;
- ·Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена;
- Что анализируют в качестве больших данных.
Список используемой литературы
- Введение в статистическое обучение с примерами на языке R, 2016г, 400стр, Trevor Hastie, Роберт Тибширани, Гарет Джеймс, Даниела Уиттон
Все лгут. Поисковики, Big Data и Интернет знают о вас всё, 2017, Cет Cтивенс-Давидовиц
Анализ больших наборов данных, 2014, Джеффри Д. Ульман
- Маркетинг на основе баз данных, 2008, 448стр, Артур М. Хьюз
- Черняк Леонид, Большие Данные - новая теория и практика/ Открытые системы. СУБД. - М.: Открытые системы, 2011
- Интернет ресурс, https://rb.ru/opinion/dayte-dannye/
- Интернет ресурс, https://secretmag.ru/business/methods/gde-rabotayut-bolshie-dannye.htm

- «Время строит аэропланы». История отечественного тайм-менеджмента. (Первый этап – 20-е годы 20 века.)
- Слово о законе и благодати (Первая часть)
- Обзор и функциональные возможности ECM «Documentum» (Возможности EMC Documentum)
- ИСПОЛНЕНИЕ И ОТБЫВАНИЕ НАКАЗАНИЯ В ВИДЕ ЛИШЕНИЯ СВОБОДЫ НА ОПРЕДЕЛЕННЫЙ СРОК В ИСПРАВИТЕЛЬНОЙ КОЛОНИИ СТРОГОГО РЕЖИМА
- ИСПОЛНЕНИЕ И ОТБЫВАНИЕ НАКАЗАНИЯ В ВИДЕ ЛИШЕНИЯ СВОБОДЫ НА ОПРЕДЕЛЕННЫЙ СРОК В ИСПРАВИТЕЛЬНОЙ КОЛОНИИ СТРОГОГО РЕЖИМА (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ НАКАЗАНИЯ В ВИДЕ ЛИШЕНИЯ СВОБОДЫ)
- ЗАЩИТА ПО НАЗНАЧЕНИЮ КАК КОНСТИТУЦИОННАЯ ГАРАНТИЯ (Основная часть)
- Слово о законе и благодати
- Исторический аспект становления и развития корпораций в России (Становление и развитие корпораций в России )
- Акционерные общества как разновидность корпораций (ОБЩИЕ ПОЛОЖЕНИЯ)
- Акционерные общества как разновидность корпораций
- Сравнительный анализ комплексных программных средств обеспечения сетевой безопасности
- Источники международного частного права (Понятие источников международного права)