
Стандарты текстовой информации в ИС (Основные понятия представления текстовой информации в ИС.)
Содержание:

Основные понятия представления текстовой информации в ИС.
Рассмотрение данного вопроса правильней было бы начать с определения «Информационной системы».
Информационная система (ИС) — это система, предназначенная для ведения информационной модели, чаще всего — какой-либо области человеческой деятельности.
Эта система должна обеспечивать средства для протекания информационных процессов:
- Хранение;
- Передача;
- Преобразование информации.
Различают 3 класса информационных систем по степени их автоматизации:
Ручные информационные системы - характеризуются отсутствием современных технических средств переработки информации и выполнением всех операций
человеком. Например, о деятельности менеджера в фирме, где отсутствуют компьютеры, можно говорить, что он работает с ручной ИС.
Автоматизированные информационные системы (АИС) - наиболее популярный класс ИС. Предполагают участие в процессе обработки информации и человека, и
технических средств, причем главная роль отводится компьютеру.
Автоматические информационные системы — выполняют все операции по переработке информации без участия человека, различные роботы. Примером автоматических информационных систем являются многие поисковые системы сети
Интернет, например Google, Rambler, Yandex, где сбор информации о сайтах осуществляется автоматически поисковым роботом (crawler) и человеческий фактор не влияет на ранжирование результатов поиска.
Обычно под термином ИС понимают именно Автоматизированные информационные системы (АИС).
Обработка текстовой информации.
Существует множество методов обработки информации, но в большинстве случаев они сводятся к обработке текстовых и числовых данных.
Текстовая информация может возникать из различных источников и иметь различную степень сложности по форме представления. В зависимости от формы представления для обработки текстовых сообщений используют разнообразные информационные технологии. Чаще всего в качестве инструментального средства обработки текстовой электронной информации применяют текстовые редакторы или процессоры. Они представляют программный продукт, обеспечивающий пользователя специальными средствами, предназначенными для создания, обработки и хранения текстовой информации. Текстовые редакторы и процессоры используются для составления, редактирования и обработки различных видов информации. Отличие текстовых редакторов от процессоров заключается в том, что редакторы, как правило, предназначены для работы только с текстами, а процессоры позволяют использовать и другие виды информации.
Редакторы, предназначенные для подготовки текстов условно можно разделить на обычные (подготовка писем и других простых документов) и сложные (оформление документов с разными шрифтами, включающие графики, рисунки и др.). Редакторы, используемые для автоматизированной работы с текстом, можно разделить на несколько типов: простейшие, интегрированные, гипертекстовые редакторы, распознаватели текстов, редакторы научных текстов, издательские системы.
В простейших редакторах-форматерах (например, “Блокнот”) для внутреннего представления текста дополнительные коды не используются, тексты же обычно формируются на основе знаков кодовой таблицы ASCII.
Текстовые процессоры представляют систему подготовки текстов (Word Processor). Наибольшей популярностью среди них пользуется программа MS Word. Технология обработки текстовой информации с помощью таких программ обычно включает следующие этапы:
1) создание файла для хранения текстовой информации;
2) ввод и (или) копирование текстовой информации в компьютер;
3) сохранение текста, представленного в электронной форме;
4) открытие файла, хранящего текстовую информацию;
5) редактирование электронной текстовой информации;
6) форматирование текста, хранящегося в электронной форме;
7) создание текстовых файлов на основе встроенных в текстовый редактор стилей оформления;
8) автоматическое формирование оглавления к тексту и алфавитного справочника;
9) автоматическая проверка орфографии и грамматики;
10) встраивание в текст различных элементов и объектов;
11) объединение документов;
12) печать текста.
К основным операциям редактирования относят: добавление; удаление; перемещение; копирование фрагмента текста, а также поиска и контекстной замены. Если создаваемый текст представляет многостраничный документ, то можно применять форматирование страниц или разделов. При этом в тексте появятся такие структурные элементы, как: закладки, сноски, перекрестные ссылки и колонтитулы.
Большинство текстовых процессоров поддерживает концепцию составного документа – контейнера, включающего различные объекты. Она позволяет вставлять в текст документа рисунки, таблицы, графические изображения, подготовленные в других программных средах. Используемая при этом технология связи и внедрения объектов называется OLE (Object Linking and Embedding – связь и внедрение объектов).
Для автоматизации выполнения часто повторяемых действий в текстовых процессорах используют макрокоманды. Самый простой макрос – записанная последовательность нажатия клавиш, перемещений и щелчков мышью. Она может воспроизводиться, как магнитофонная запись. Её можно обработать и изменить, добавив стандартные макрокоманды.
Перенос текстов из одного текстового редактора в другой осуществляется программой-конвертером. Она создаёт выходной файл в соответствующем формате. Обычно программы текстовой обработки имеют встроенные модули конвертирования популярных файловых форматов.
Разновидностью текстовых процессоров являются настольные издательские системы. В них можно готовить материалы по правилам полиграфии. Программы настольных издательских систем (например, Publishing, PageMaker) являются инструментом верстальщика, дизайнера, технического редактора. С их помощью можно легко менять форматы и нумерацию страниц, размер отступов, комбинировать различными шрифтами и т.п. В большей степени они предназначены для издания полиграфической продукции.
Международные стандарты кодов символов и их представление в современных ИС, языках программирования и программных платформах.
Кодировки ASCII, ANSI, КОI8 и некоторые другие.
Поскольку текст изначально дискретен — он состоит из отдельных символов, — для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов, его составляющих. При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые таблицы символов, в которых каждому коду символа ставится в соответствие изображение символа.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Существует много различных кодировок. В большинстве из них символы кодируются восьмибитовыми (или однобайтными) числами. В одном байте можно записать 256 различных целых чисел. Этого достаточно для кодирования всех букв русского и латинского алфавитов, арабских цифр, знаков препинания и некоторых других необходимых символов.
Для наглядности кодируемые символы располагаются в таблице. Таблица разбита на 16 строк и 16 столбцов. Каждая строка и каждый столбец имеют четырехразрядные двоичные номера от 0000 до 1111 (или шестнадцатеричные от 0 до F). Код символа составляется из номеров столбца и строки, на пересечении которых он находится. Этим двоичным числам соответствуют десятичные числа от 0 до 255.
До появления операционной системы Windows основной являлась кодовая таблица символов ASCII (American Standard Code for Information Interchange - американский стандартный код обмена информацией).
Разработана она была в 1960-х годах в США и применялась для любых видов передачи информации, в том числе и некомпьютерных (телеграф, факсимильная связь и т. д.).
Первая половина таблицы ASCII (коды от 0 до 127) содержит знаки препинания, цифры, символы латинского алфавита, математические знаки и является общепринятой. Коды от 128 до 255 называются расширенными и используются для национальных алфавитов и символов псевдографики.
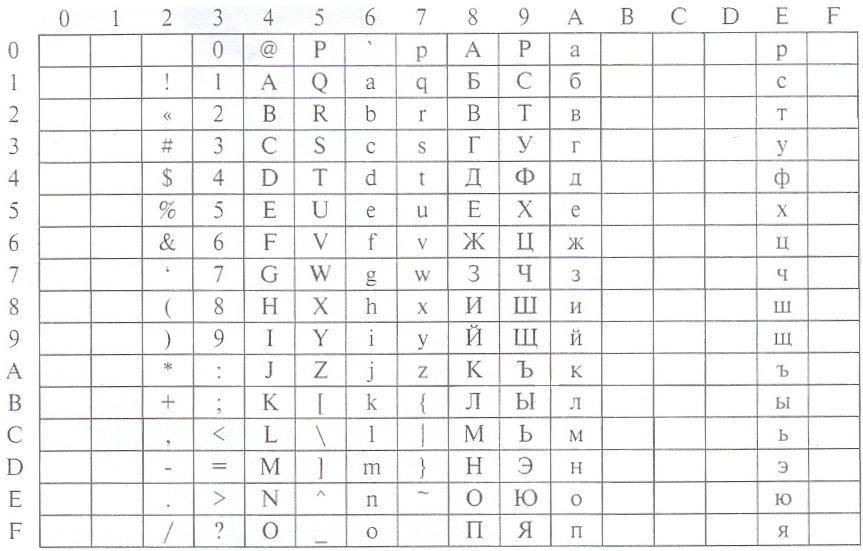
В таблице ASCII отсутствуют символы кириллицы. Для представления кириллицы в DOS была разработана кодовая страница СР-866, построенная на основе ASCII. Символы с кодами от 0 до 127 в этой таблице такие же, как в кодировке ASCII, а символы кириллицы расположены на тех позициях, где в таблице ASCII находятся относительно редко используемые символы национальных алфавитов и греческие буквы. Ниже приведен фрагмент этой таблицы []. Символам кириллицы здесь соответствуют десятичные коды от 128 до 175 и от 224 до 239.
С появлением графической среды Windows ASCII морально устарела, в частности, ненужными стали псевдографические символы. Фирмой Мiсrosоft была разработана новая кодовая таблица ANSI. Для представления кириллицы в Windows на основе кодировки ANSI построена кодовая страница СР-12565. Символам кириллицы здесь соответствуют шестнадцатеричные коды от С0 до FF, или в десятичной системе счисления от 192 до 255.
В середине семидесятых годов специалистами одного из советских НИИ был разработан новый стандарт, предназначенный для представления символов русского языка в электронной форме. Сейчас эта кодировка известна под наименованием КОI8 (код обмена информации восьмибитовый). Став базовой кодировкой для только что появившихся тогда в нашей стране русифицированных UNIХ - совместимых операционных систем, KOI8 была принята Госстандартом СССР в качестве базовой спецификации для обмена электронными документами на русском языке, в силу чего данной кодировке было присвоено соответствие стандарту ГОСТ 19768-74.
После ликвидации Советского Союза этот стандарт претерпел некоторые изменения, разделившись на две отдельные спецификации: KOI8-R применяется в настоящее время для представления символов русского языка, KOI8-U – украинского.
Кодировка КОI8 также используется в качестве принятого в Российском Интернете «формата по умолчанию» при пересылке сообщений электронной почты.
Стандарт MicroSoft/IBM code page 866 (альтернативная кодировка DOS) служит базовой кодировкой в операционных системах MS-DOS и OS/2, и потому в настоящее время медленно, но верно утрачивает свои позиции, ибо даже сам разработчик и производитель DOS компания Мiсrоsоft отказалась от дальнейшей поддержки этой линии операционных платформ. Тем не менее, кодировка жива и по сей день, прежде всего благодаря той части пользователей, которые не намерены пока расставаться с браузерами, работающими в среде MS – DOS.
Компания MicroSoft, создавая программное обеспечение для работы в Интернете, как водится, пошла своим путем, предложив стандарт Мiсrоsоft code page 1251 (Windows-1251), получивший чрезвычайно широкое распространение благодаря необыкновенной популярности операционной системы Мiсrоsоft Windows и http - сервера IIS (Internet 1nformation Server), входящего в комплект поставки Windows NT/2000. Именно поэтому и Windows – 1251, и KOI8 - R входят в тот минимально допустимый набор кодировок, которые должна обязательно поддерживать любая мало-мальски уважающая себя веб - страница.
Кодировка ISO – 8859-5 была разработана Международной организацией по стандартизации (International Standards Organization, ISO) с единственной целью: унифицировать представление символов национальных алфавитов в электронной форме. Именно поэтому ISO предложила целый набор кодировок серии 8859, каждая из которых описывала свой набор знаков: существует соответствующая кодировка ISO для арабского языка (ISO-8859-6), иврита (ISO-8859-8), латиницы (ISO-8859-1) и других языков мира. В силу различных причин русский вариант кодировки ISO не получил широкого распространения, однако все же изредка встречается в Интернете и потому поддерживается рядом русскоязычных серверов.
Кодировка Macintosh СР (МАС) ориентирована на персональные компьютеры Apple Macintosh, оснащенные операционной системой MacOS. Из-за высокой стоимости Аррlе - совместимые компьютеры не стали в России популярными, однако они весьма широко используются на Западе и иногда эксплуатируются на крупных отечественных предприятиях.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы любых языков мира. Этот стандарт используется в качестве основной кодировки в операционной системе Microsoft Windows ХР.
Стандарт кодирования символов Unicode.
Unicode (Юникод или Уникод, англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. «Unicode Consortium»), объединяющей крупнейшие IT-корпорации. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены коды от U+0400 до U+052F.
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах.
UNIX-образные операционные системы, в том числе, Linux, BSD, Mac OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от восьмибитного представления символов в пользу шестнадцатибитного. Сейчас большинство языков программирования поддерживают строки Unicode, хотя их представление может различаться в зависимости от реализации.
Стандарт Юникод поддерживает языки как с направлением написания слева - направо (англ. Left – to - right, LTR) так и с написанием справа - налево (англ. Right – to - eft, RTL), как иврит и арабский язык. Кроме того, Юникод поддерживает комбинированные тексты, содержащие одновременно RTL и LTR фразы. Данная возможность называется двунаправленность (англ. bidirectional, Bidir). Простые реализации Юникода могут не иметь поддержки двунаправленности.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов;
- цифры;
- знаки пунктуации;
- специальные знаки (математические, технические, идеограммы и пр.);
- разделители.
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные надстрочные или подстрочные элементы, представляются в виде последовательности кодов, составленной по определённым правилам (декомпозированный вариант) или единого символа (композированный вариант).
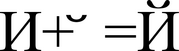
Представление символа «Й» (U+0419) в виде базового символа «И» (U+0418) и комбинируемого символа « » (U+0306).
» (U+0306).
Графические символы в Юникод подразделяются на протяжённые и непротяжённые (бесширинные). Непротяженные символы при отображении не занимают места в строке. К ним относятся ударения, диакритические знаки и т. п. При кодировании в Юникоде, как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми, а непротяжённые — комбинируемыми, потому что они не могут встречаться самостоятельно. Например, символ «á» будет представлен как последовательность базового символа «a» (U+0061) и комбинируемого символа «´» (U+0301) или как отдельный символ «á» (U+00C1).
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
В Юникоде зарезервировано 1 114 112 (= 220 + 216) позиций символов, из которых сейчас используется около 90000. Первые 256 знакомест совпадают с кодовой таблицей ISO 8859-1 (Latin-1).
Хоть формы записи UTF-8 и UTF-32 позволяют кодировать до 231 (2 147 483 648) кодовых позиций, принято решение использовать лишь 220+216 (1 114 112) для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — на сегодняшний день используется чуть больше 96 000 кодовых позиций.
Кодовое пространство разделено на 17 «плоскостей» по 65536 (= 216) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей. Плоскости 16 и 17 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» или «U+yyyyyyyy», где xxxx и yyyyyyyy — шестнадцатеричная запись номера символа. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Базовая многоязыковая плоскость.
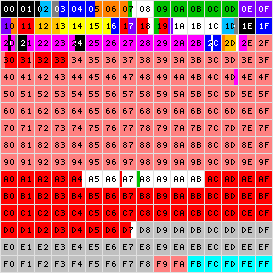
Базовая плоскость UNICODE:
|
Чёрный |
— расширенный латинский алфавит; |
|
Голубой |
— лингвистические символы международного фонетического алфавита IPA; |
|
Синий |
— другие европейские алфавиты; |
|
Оранжевый |
— письменности Ближнего Востока; |
|
Светло-оранжевый |
— письменности Африки; |
|
Зелёный |
— письменности Южной Азии; |
|
Фиолетовый |
— письменности Юго-восточной Азии; |
|
Красный |
— письменности Восточной Азии; |
|
Розовый |
— унифицированные китайско-японско-корейские символы; |
|
Жёлтый |
— письменности аборигенов Северной Америки; |
|
Пурпурный |
— символы; |
|
Тёмно-серый |
— диакритики; |
|
Светло-серый |
— суррогатные пары UTF-16 и области для частного использования; |
|
Сине-зелёный |
— другие знаки; |
|
Белый |
— не используется. |
Плоскость 0 (Основная многоязыковая плоскость, англ. Basic Multilanguage Plane, BMP) содержит символы практически для всех современных письменностей и большое число специальных символов. Большая часть таблицы занята китайско – японско - корейскими иероглифами.
Плоскость 1 (дополнительная многоязыковая плоскость, англ. Supplementary Multilingual Plane, SMP) отведена, в первую очередь, для исторических письменностей, но также включает музыкальные и математические символы.
Некоторые регионы Unicode выделены для частного использования и экспериментов.
Частная область включает:
- Регион в Базовой плоскости U+E000…U+F8FF
- Расширенные плоскости 15 (U+F0000…U+FFFFF) и 16 (U+100000…U+10FFFF).
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы — а эта работа ведётся постоянно, поскольку изначально система Юникод была представлена в ISO в недоработанном виде — выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
- 1.1 (соответствует стандарту ISO/IEC 10646—1:1993),
- 2.0, 2.1 (тот же стандарт ISO/IEC 10646—1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2),
- 3.0 (стандарт ISO/IEC 10646—1:2000).
- 3.2 (стандарт 2002 года)
- 4.0 (стандарт 2003)
- 4.01 (стандарт 2004)
- 4.1 (стандарт 2005)
- 5.0 (стандарт 2006)
Для примера можно рассмотреть символы, представленные в основной плоскости в версии Unicode 4.1.
В Unicode 4.1 в основной плоскости представлены следующие символы:
- Базовый латинский алфавит (0000—007F)
- Дополнительные символы Latin-1 (0080—00FF)
- Расширенный латинский алфавит-A (0100—017F)
- Расширенный латинский алфавит-B (0180—024F)
- Международный фонетический алфавит (IPA) Extensions (0250—02AF)
- Пробельные символы (02B0—02FF)
- диакритические символы (0300—036F)
- Греческий и коптский алфавиты (0370—03FF)
- Кириллица (0400—04FF)
- Дополнительные символы кириллицы (0500—052F)
- Армянский алфавит (0530—058F)
- Еврейский алфавит (0590—05FF)
- Арабский алфавит (0600—06FF)
- Сирийский алфавит (0700—074F)
- Дополнительные символы арабского алфавита (0750—077F)
- Thaana (0780—07BF)
- Индийские письменности:
- Деванагари (0900—097F)
- Бенгали (0980—09FF)
- Gurmukhi (0A00—0A7F)
- Gujarati (0A80—0AFF)
- Oriya (0B00—0B7F)
- Tamil (0B80—0BFF)
- Telugu (0C00—0C7F)
- Kannada (0C80—0CFF)
- Malayalam (0D00—0D7F)
- Sinhala (0D80—0DFF)
- Тайский алфавит (0E00—0E7F)
- Лаосская письменность (0E80—0EFF)
- Тибетская письменность (0F00—0FFF)
- Бирманский алфавит (1000—109F)
- Грузинский алфавит (10A0—10FF)
- Отдельные буквы (Jamo) хангыль (1100—11FF)
- Амхарский язык (1200—137F)
- Ethiopic Supplement (1380—139F)
- Язык чероки (13A0—13FF)
- Unified Canadian Aboriginal Syllabics (1400—167F)
- Ogham (1680—169F)
- Рунный алфавит (16A0—16FF)
- Филиппинские письменности:
- Tagalog (1700—171F)
- Hanunoo (1720—173F)
- Buhid (1740—175F)
- Tagbanwa (1760—177F)
- Кхмерский алфавит (1780—17FF)
- Монгольский алфавит (1800—18AF)
- Limbu (1900—194F)
- Tai Le (1950—197F)
- New Tai Lue (1980—19DF)
- Khmer Symbols (19E0—19FF)
- Buginese (1A00—1A1F)
- Фонетические расширения (1D00—1D7F)
- Дополнительные фонетичестие расширения (1D80—1DBF)
- Дополнительные диакритические знаки (1DC0—1DFF)
- Latin Extended Additional (1E00—1EFF)
- Расширенный греческий алфавит (1F00—1FFF)
- Символы:
- Пунктуация (2000—206F)
- Надстрочные и подстрочные знаки (2070—209F)
- Символы валют (20A0—20CF)
- Combining Diacritical Marks for Symbols (20D0—20FF)
- Letterlike Symbols (2100—214F)
- Number Forms (2150—218F)
- Стрелки (2190—21FF)
- Математические операторы (2200—22FF)
- Прочие технические символы (2300—23FF)
- Control Pictures (2400—243F)
- Optical Character Recognition (2440—245F)
- Enclosed Alphanumerics (2460—24FF)
- Символы для рисования рамок (2500—257F)
- Block Elements (2580—259F)
- Геометрические фигуры (25A0—25FF)
- Прочие символы (2600—26FF)
- Dingbats (2700—27BF)
- Miscellaneous Mathematical Symbols-A (27C0—27EF)
- Supplemental Arrows-A (27F0—27FF)
- Азбука Брайля (2800—28FF)
- Supplemental Arrows-B (2900—297F)
- Miscellaneous Mathematical Symbols-B (2980—29FF)
- Supplemental Mathematical Operators (2A00—2AFF)
- Miscellaneous Symbols and Arrows (2B00—2BFF)
- Глаголица (2C00—2C5F)
- Коптский алфавит (2C80—2CFF)
- Georgian Supplement (2D00—2D2F)
- Tifinagh (2D30—2D7F)
- Ethiopic Extended (2D80—2DDF)
- Supplemental Punctuation (2E00—2E7F)
- CJK Radicals Supplement (2E80—2EFF)
- Kangxi Radicals (2F00—2FDF)
- Ideographic Description Characters (2FF0—2FFF)
- CJK Symbols and Punctuation (3000—303F)
- Хирагана (3040—309F)
- Катакана (30A0—30FF)
- Чжуинь (Бопомофо) (3100—312F)
- Хангыль Compatibility Jamo (3130—318F)
- Kanbun (3190—319F)
- Расширение Бопомофо (31A0—31BF)
- CJK Strokes (31C0—31EF)
- Katakana Phonetic Extensions (31F0—31FF)
- Enclosed CJK Letters and Months (3200—32FF)
- CJK Compatibility (3300—33FF)
- CJK Unified Ideographs Extension A (3400—4DBF)
- Yijing Hexagram Symbols (4DC0—4DFF)
- CJK Unified Ideographs (4E00—9FFF)
- Yi Syllables (A000—A48F)
- Yi Radicals (A490—A4CF)
- Modifier Tone Letters (A700—A71F)
- Syloti Nagri (A800—A82F)
- Слоги хангыль (AC00—D7AF)
- Верхняя часть суррогатных пар (D800—DB7F)
- Верхняя часть суррогатных пар для частного использования (DB80—DBFF)
- Нижняя часть суррогатных пар (DC00—DFFF)
- Область для частного использования (E000—F8FF)
- CJK Compatibility Ideographs (F900—FAFF)
- Alphabetic Presentation Forms (FB00—FB4F)
- Arabic Presentation Forms-A (FB50—FDFF)
- Variation Selectors (FE00—FE0F)
- Vertical Forms (FE10—FE1F)
- Combining Half Marks (FE20—FE2F)
- CJK Compatibility Forms (FE30—FE4F)
- Small Form Variants (FE50—FE6F)
- Arabic Presentation Forms-B (FE70—FEFF)
- Halfwidth and Fullwidth Forms (FF00—FFEF)
- Специальные символы (FFF0—FFFF)
Некоторые письменности будут добавлены в следующей версии Unicode. Эти письменности и предложенные диапазоны перечислены далее:
- N'Ko ( Mandekan) (07C0—07FF)
- Balinese (1B00—1B7F)
- Lepcha ( Rong) (1C00—1C4F)
- Latin Extended-C (2C60—2C7F)
- Santali (Ol Cemet' / Ol Chiki) (2DE0—2DFF)
- Vai (A500—A61F)
- Latin Extended-D (A720—A7FF)
- Phags-pa (A840—A87F)
- Saurashtra (AB00—AB5F)
Но, как ни грустно это признавать, любая изобретённая человеком система, Unicode не свободен от недостатков.
Недостатки стандарта кодирования символов Unicode.
- Многие системы письма всё ещё не представлены в Юникоде. Например, письменность церковнославянского языка содержит много дополнительных графических элементов (такие как титлы и надстрочные буквы). Они не могут быть должным образом представлены в системе Юникод, хотя отдельные элементы для этого имеются. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, пока в принципе не предусмотрено.
- Тексты на китайском, корейском и японском языке имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Данная возможность не отражена в Юникоде (впрочем, она и не должна быть отражена, поскольку это относится к форматированию текста, а не к кодированию символов).
- В стандартах Юникода не было зафиксировано, когда вводится отдельная кодовая позиция для готового (Precomposed) символа, а когда его необходимо набирать из базового и диакритического. Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде отдельных символов, хотя могут быть представлены и набором базового символа плюс диакритика (Decomposed): Е+¨ (U+0415 U+0308), И+
 (U+0418 U+0306). В то же время, множество символов из языков с алфавитами на основе кириллицы не имеют precomposed форм.
(U+0418 U+0306). В то же время, множество символов из языков с алфавитами на основе кириллицы не имеют precomposed форм. - Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханджа), но при этом в Юникоде обозначаться одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды. Часто возникают накладки, когда, например, японский текст выглядит «по-китайски». Аналогично, русский и сербский языки используют разное начертание курсивных букв n и m (в сербском они выглядят как и и ш). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
- Файлы с текстом в Юникоде занимают больше места в памяти, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков алфавит которых укладывается в ASCII). Однако с увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной.
- Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки BOM и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
ISO/IEC 10646.
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO) началось в 1991 году. В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним, Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате, значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. Universal Multiple-Octet Coded Character Set). Как уже упоминалось, UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Список используемой литературы.
1. В. Холмогоров. – «Основы веб - мастерства. Учебный курс.» 3-е издание.
Изд. «Питер». – С.-Петербург., 2013 год. (стр. 27,28). [7]
2. И.В. Миссинг, Ю.Д. Романова, В.И. Шестаков. – «Информатика и информационные технологии». – Изд. «Эксмо» - Москва, 2005. (стр.28, 29).[7]
3. http://fontproblem.narod.ru/index.html?http://fontproblem.narod.ru/unicode.htm#Un_4Un_4 (с этого сайта была взята некоторая информация про кодировку символов «Unicode»).[10][19][20]
4. О. Ефимова, В. Морозов, Н. Угринович. – «Курс компьютерной технологии с основами информатики». – Изд. «АСТ», - Москва, 2003. (стр. 203, 204). [3]
5. Т. Пратт, М. Зелковиц. – «Языки программирования. Разработка и реализация. 4-е издание». – Изд. «Питер», - С. – Петербург, 2012 год.
(стр. 545). [52]
6. Г.С. Гохберг, А.В. Зафиевский, А.А. Короткин. – «Информационные технологии», - Изд. «ACADEMA», - Москва, 2004. (стр. 124). [52]
7. http://ru.wikipedia.org – главная страница Википедии.
http://ru.wikipedia.org/wiki/%D0%93%D0%B8%D0%BF%D0%B5%D1%80%D1%82%D0%B5%D0%BA%D1%81%D1%82 [52]
http://letopisi.ru/index.php/%d0%93%d0%b8%d0%bf%d0%b5%d1%80%d1%82%d0%b5%d0%ba%d1%81%d1%82 – ссылки на использованный из Википедии материал на тему «Гипертекст». [53]
8. http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0#.D0.98.D1.81.D1.82.D0.BE.D1.87.D0.BD.D0.B8.D0.BA.D0.B8_.D0.B8.D0.BD.D1.84.D0.BE.D1.80.D0.BC.D0.B0.D1.86.D0.B8.D0.B8 – материал из Википедии. [3]
9. http://urist.fatal.ru/Book/Glava5/Glava5.htm [3]
10. http://inftis.narod.ru/it/5-6/n6.htm [3]
11. http://fontproblem.narod.ru/index.html?http://fontproblem.narod.ru/crosref/shrift_format.htm [41]
12. http://fontproblem.narod.ru/index.html?http://fontproblem.narod.ru/srift.htm#Zas [22]
13. http://fontproblem.narod.ru/index.html?http://fontproblem.narod.ru/crosref/aticles/Times.htm#Times_1Times_1 [34]
14. http://ifont.ru/n1-28.html [29]
Оглавление.
Основные понятия представления текстовой информации в ИС. 3
Обработка текстовой информации. 3
Кодировки ASCII, ANSI, КОI8 и некоторые другие. 7
Стандарт кодирования символов Unicode. 10
Недостатки стандарта кодирования символов Unicode. 19
Шрифты и особенности работы с ними в ИС. 22
Общие характеристики шрифтов. 22
Некоторый набор терминов, которые необходимо знать при работе со шрифтами. 24
Список используемой литературы. 25

- правление проектами
- Виды проектного анализа (Понятие и классификация инвестиционных проектов)
- Формы налогообложения, применимые для Обществ с ограниченной ответственностью, и особенности их применения..
- Методы проведения урока с применением информационных технологий и ресурсов Интернет
- Методы и средства дистанционного обучения (Информационные технологии в обучении физической культуре)
- Судейство спортивного соревнования по баскетболу
- Жилищный фонд (ПОНЯТИЕ ЖИЛИЩНОГО ФОНДА)
- Принципы налогового права (Общие принципы налогового права характерные для финансового права в целом.)
- Система источников права интеллектуальной собственности
- Договоры страхования (Участники договора страхования)
- Технологии работы с ГТ и ММ ИТ.
- Проблемы и перспективы развития малого бизнеса