
Технологии Больших данных (BigData) (Самое простое определение)
Содержание:

Самое простое определение
Из названия можно предположить, что термин `большие данные` относится просто к управлению и анализу больших объемов данных. Согласно отчету McKinsey Institute `Большие данные: новый рубеж для инноваций, конкуренции и производительности` (Big data: The next frontier for innovation, competition and productivity), термин `большие данные` относится к наборам данных, размер которых превосходит возможности типичных баз данных (БД) по занесению, хранению, управлению и анализу информации. И мировые репозитарии данных, безусловно, продолжают расти. В представленном в середине 2011 г. отчете аналитической компании IDC `Исследование цифровой вселенной` (Digital Universe Study), подготовку которого спонсировала компания EMC, предсказывалось, что общий мировой объем созданных и реплицированных данных в 2011-м может составить около 1,8 зеттабайта (1,8 трлн. гигабайт) — примерно в 9 раз больше того, что было создано в 2006-м.
Более сложное определение
Тем не менее `большие данные` предполагают нечто большее, чем просто анализ огромных объемов информации. Проблема не в том, что организации создают огромные объемы данных, а в том, что бóльшая их часть представлена в формате, плохо соответствующем традиционному структурированному формату БД, — это веб-журналы, видеозаписи, текстовые документы, машинный код или, например, геопространственные данные. Всё это хранится во множестве разнообразных хранилищ, иногда даже за пределами организации. В результате корпорации могут иметь доступ к огромному объему своих данных и не иметь необходимых инструментов, чтобы установить взаимосвязи между этими данными и сделать на их основе значимые выводы. Добавьте сюда то обстоятельство, что данные сейчас обновляются все чаще и чаще, и вы получите ситуацию, в которой традиционные методы анализа информации не могут угнаться за огромными объемами постоянно обновляемых данных, что в итоге и открывает дорогу технологиям больших данных.
Наилучшее определение
В сущности понятие больших данных подразумевает работу с информацией огромного объема и разнообразного состава, весьма часто обновляемой и находящейся в разных источниках в целях увеличения эффективности работы, создания новых продуктов и повышения конкурентоспособности. Консалтинговая компания Forrester дает краткую формулировку: `Большие данные объединяют техники и технологии, которые извлекают смысл из данных на экстремальном пределе практичности`.
Почему данные стали большими
Источников больших данных в современном мире великое множество. В их качестве могут выступать непрерывно поступающие данные с измерительных устройств, события от радиочастотных идентификаторов, потоки сообщений из социальных сетей, метеорологические данные, данные дистанционного зондирования земли, потоки данных о местонахождении абонентов сетей сотовой связи, устройств аудио- и видеорегистрации. Собственно, массовое распространение перечисленных выше технологий и принципиально новых моделей использования различно рода устройств и интернет-сервисов послужило отправной точкой для проникновения больших данных едва ли не во все сферы деятельности человека. В первую очередь, научно-исследовательскую деятельность, коммерческий сектор и государственное управление.
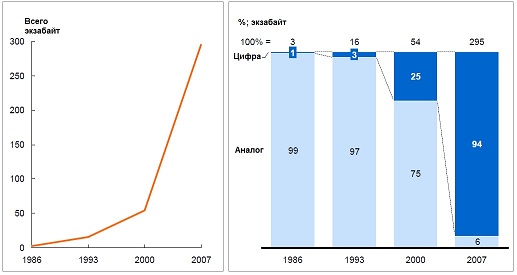
Рост объемов данных (слева) на фоне вытеснения аналоговых средств хранения (справа). Источник: Hilbert and López, `The world’s technological capacity to store, communicate, and compute information, Science, 2011Global/
Несколько занимательных и показательных фактов:
- В 2010 году корпорации мира накопили 7 экзабайтов данных, на наших домашних ПК и ноутбуках хранится 6 экзабайтов информации.
- Всю музыку мира можно разместить на диске стоимостью 600 долл.
- В 2010 году в сетях операторов мобильной связи обслуживалось 5 млрд телефонов.
- Каждый месяц в сети Facebook выкладывается в открытый доступ 30 млрд новых источников информации.
- Ежегодно объемы хранимой информации вырастают на 40%, в то время как глобальные затраты на ИТ растут всего на 5%.
- По состоянию на апрель 2011 года в библиотеке Конгресса США хранилось 235 терабайт данных.
- Американские компании в 15 из 17 отраслей экономики располагают большими объемами данных, чем библиотека Конгресса США.
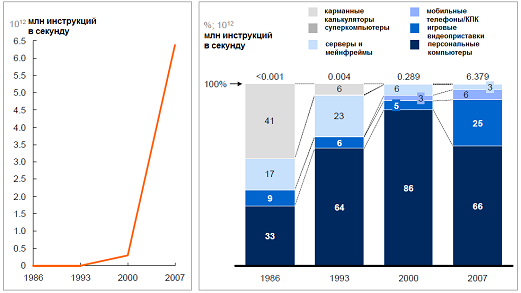
Рост вычислительной мощности компьютерной техники (слева) на фоне трансформации парадигмы работы с данными (справа). Источник: Hilbert and López, `The world’s technological capacity to store, communicate, and compute information, Science, 2011Global
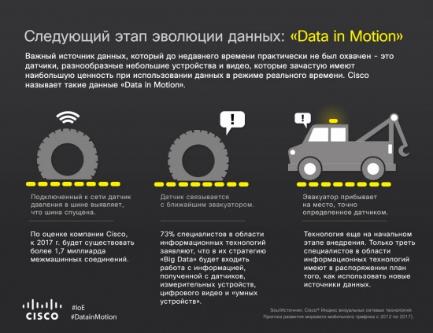
К примеру, датчики, установленные на авиадвигателе, генерируют около 10 Тб за полчаса. Примерно такие же потоки характерны для буровых установок и нефтеперерабатывающих комплексов. Только один сервис коротких сообщений Twitter, несмотря на ограничение длины сообщения в 140 символов, генерирует поток 8 Тб/сут. Если все подобные данные накапливать для дальнейшей обработки, то их суммарный объем будет измеряться десятками и сотнями петабайт. Дополнительные сложности проистекают из вариативности данных: их состав и структура подвержены постоянным изменениям при запуске новых сервисов, установке усовершенствованных сенсоров или развертывании новых маркетинговых кампаний.
Откуда данные поступают
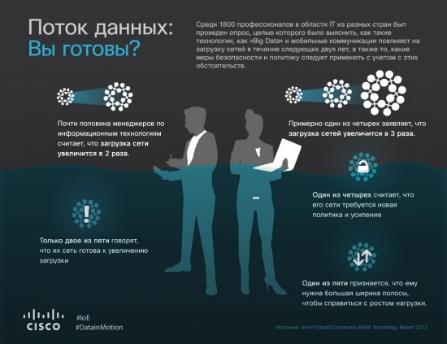
Компании собирают и используют данные самых разных типов, как структурированные, так и неструктурированные. Вот из каких источников получают данные участники опроса (Cisco Connected World Technology Report):
- 74 процента собирают текущие данные;
- 55 процентов собирают исторические данные;
- 48 процентов снимают данные с мониторов и датчиков;
- 40 процентов пользуются данными в реальном времени, а затем стирают их. Чаще всего данные в реальном времени используются в Индии (62 процента), США (60 процентов) и Аргентине (58 процентов);
- 32 процента опрошенных собирают неструктурированные данные – например, видео. В этой области лидирует Китай: там неструктурированные данные собирают 56 процентов опрошенных.
Методики анализа больших данных
Существует множество разнообразных методик анализа массивов данных, в основе которых лежит инструментарий, заимствованный из статистики и информатики (например, машинное обучение). Список не претендует на полноту, однако в нем отражены наиболее востребованные в различных отраслях подходы. При этом следует понимать, что исследователи продолжают работать над созданием новых методик и совершенствованием существующих. Кроме того, некоторые из перечисленных них методик вовсе не обязательно применимы исключительно к большим данным и могут с успехом использоваться для меньших по объему массивов (например, A/B-тестирование, регрессионный анализ). Безусловно, чем более объемный и диверсифицируемый массив подвергается анализу, тем более точные и релевантные данные удается получить на выходе.
A/B testing. Методика, в которой контрольная выборка поочередно сравнивается с другими. Тем самым удается выявить оптимальную комбинацию показателей для достижения, например, наилучшей ответной реакции потребителей на маркетинговое предложение. Большие данные позволяют провести огромное количество итераций и таким образом получить статистически достоверный результат.
Association rule learning. Набор методик для выявления взаимосвязей, т.е. ассоциативных правил, между переменными величинами в больших массивах данных. Используется в data mining.
Classification. Набор методик, которые позволяет предсказать поведение потребителей в определенном сегменте рынка (принятие решений о покупке, отток, объем потребления и проч.). Используется в data mining.
Cluster analysis. Статистический метод классификации объектов по группам за счет выявления наперед не известных общих признаков. Используется в data mining.
Crowdsourcing. Методика сбора данных из большого количества источников.
Data fusion and data integration. Набор методик, который позволяет анализировать комментарии пользователей социальных сетей и сопоставлять с результатами продаж в режиме реального времени.
Data mining. Набор методик, который позволяет определить наиболее восприимчивые для продвигаемого продукта или услуги категории потребителей, выявить особенности наиболее успешных работников, предсказать поведенческую модель потребителей.
Ensemble learning. В этом методе задействуется множество предикативных моделей за счет чего повышается качество сделанных прогнозов.
Genetic algorithms. В этой методике возможные решения представляют в виде `хромосом`, которые могут комбинироваться и мутировать. Как и в процессе естественной эволюции, выживает наиболее приспособленная особь.
Machine learning. Направление в информатике (исторически за ним закрепилось название `искусственный интеллект`), которое преследует цель создания алгоритмов самообучения на основе анализа эмпирических данных.
Natural language processing (NLP). Набор заимствованных из информатики и лингвистики методик распознавания естественного языка человека.
Network analysis. Набор методик анализа связей между узлами в сетях. Применительно к социальным сетям позволяет анализировать взаимосвязи между отдельными пользователями, компаниями, сообществами и т.п.
Optimization. Набор численных методов для редизайна сложных систем и процессов для улучшения одного или нескольких показателей. Помогает в принятии стратегических решений, например, состава выводимой на рынок продуктовой линейки, проведении инвестиционного анализа и проч.
Pattern recognition. Набор методик с элементами самообучения для предсказания поведенческой модели потребителей.
Predictive modeling. Набор методик, которые позволяют создать математическую модель наперед заданного вероятного сценария развития событий. Например, анализ базы данных CRM-системы на предмет возможных условий, которые подтолкнут абоненты сменить провайдера.
Regression. Набор статистических методов для выявления закономерности между изменением зависимой переменной и одной или несколькими независимыми. Часто применяется для прогнозирования и предсказаний. Используется в data mining.
Sentiment analysis. В основе методик оценки настроений потребителей лежат технологии распознавания естественного языка человека. Они позволяют вычленить из общего информационного потока сообщения, связанные с интересующим предметом (например, потребительским продуктом). Далее оценить полярность суждения (позитивное или негативное), степень эмоциональности и проч.
Signal processing. Заимствованный из радиотехники набор методик, который преследует цель распознавания сигнала на фоне шума и его дальнейшего анализа.
Spatial analysis. Набор отчасти заимствованных из статистики методик анализа пространственных данных – топологии местности, географических координат, геометрии объектов. Источником больших данных в этом случае часто выступают геоинформационные системы (ГИС).
Statistics. Наука о сборе, организации и интерпретации данных, включая разработку опросников и проведение экспериментов. Статистические методы часто применяются для оценочных суждений о взаимосвязях между теми или иными событиями.
Supervised learning. Набор основанных на технологиях машинного обучения методик, которые позволяют выявить функциональные взаимосвязи в анализируемых массивах данных.
Simulation. Моделирование поведения сложных систем часто используется для прогнозирования, предсказания и проработки различных сценариев при планировании.
Time series analysis. Набор заимствованных из статистики и цифровой обработки сигналов методов анализа повторяющихся с течением времени последовательностей данных. Одни из очевидных применений – отслеживание рынка ценных бумаг или заболеваемости пациентов.
Unsupervised learning. Набор основанных на технологиях машинного обучения методик, которые позволяют выявить скрытые функциональные взаимосвязи в анализируемых массивах данных. Имеет общие черты с Cluster Analysis.
Visualization. Методы графического представления результатов анализа больших данных в виде диаграмм или анимированных изображений для упрощения интерпретации облегчения понимания полученных результатов.
Аналитический инструментарий
Некоторые из перечисленных в предыдущем подразделе подходов или определенную их совокупность позволяют реализовать на практике аналитические движки для работы с большими данными. Из свободных или относительно недорогих открытых систем анализа Big Data можно порекомендовать:
- 1010data;
- Apache Chukwa;
- Apache Hadoop;
- Apache Hive;
- Apache Pig!;
- Jaspersoft;
- LexisNexis Risk Solutions HPCC Systems;
- MapReduce;
- Revolution Analytics (на базе языка R для мат.статистики).
Особый интерес в этом списке представляет Apache Hadoop – ПО с открытым кодом, которое за последние пять лет испытано в качестве анализатора данных большинством трекеров акций. Как только Yahoo открыла код Hadoop сообществу с открытым кодом, в ИТ-индустрии незамедлительно появилось целое направление по созданию продуктов на базе Hadoop. В настоящее время практически все современные средства анализа больших данных предоставляют средства интеграции с Hadoop. Их разработчиками выступают как стартапы, так и общеизвестные мировые компании.
Визуализация
Наглядное представление результатов анализа больших данных имеет принципиальное значение для их интерпретации. Не секрет, что восприятие человека ограничено, и ученые продолжают вести исследования в области совершенствования современных методов представления данных в виде изображений, диаграмм или анимаций. Казалось бы, ничего нового здесь придумать уже невозможно, но на самом деле это не так. В качестве иллюстрации приводим несколько прогрессивных методов визуализации, относительно недавно получивших распространение.
- Облако тегов
Каждому элементу в облаке тега присваивается определенный весовой коэффициент, который коррелирует с размером шрифта. В случае анализа текста величина весового коэффициента напрямую зависит от частоты употребления (цитирования) определенного слова или словосочетания. Позволяет читателю в сжатые сроки получить представление о ключевых моментах сколько угодно большого текста или набора текстов.

- Кластерграмма
Метод визуализации, использующийся при кластерном анализе. Показывает как отдельные элементы множества данных соотносятся с кластерами по мере изменения их количества. Выбор оптимального количества кластеров – важная составляющая кластерного анализа.
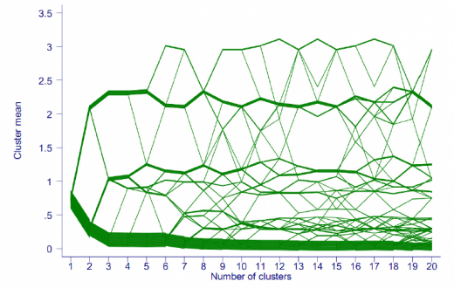
-
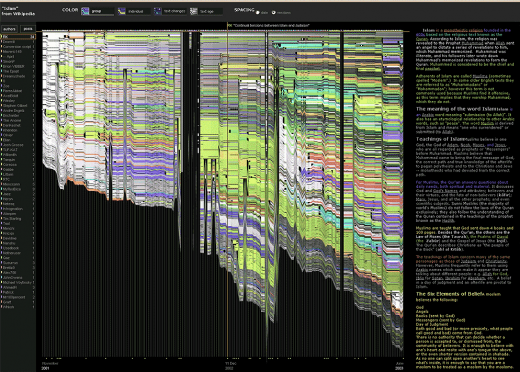
Исторический поток
Помогает следить за эволюцией документа, над созданием которого работает одновременно большое количество авторов. В частности, это типичная ситуация для сервисов wiki и сайта tadviser в том числе. По горизонтальной оси откладывается время, по вертикальной – вклад каждого из соавторов, т.е. объем введенного текста. Каждому уникальному автору присваивается определенный цвет на диаграмме. Приведенная диаграмма – результат анализа для слова «ислам» в Википедии. Хорошо видно, как возрастала активность авторов с течением времени.
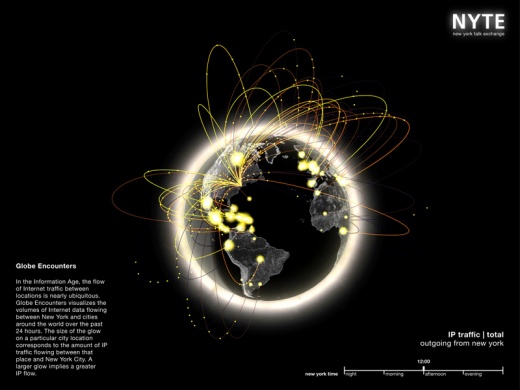
- Пространственный поток
Эта диаграмма позволяет отслеживать пространственное распределение информации. Приведенная в качестве примера диаграмма построена с помощью сервиса New York Talk Exchange. Она визуализирует интенсивность обмена IP-трафиком между Нью-Йорком и другими городами мира. Чем ярче линия – тем больше данных передается за единицу времени. Таким легко, не составляет труда выделить регионы, наиболее близкие к Нью-Йорку в контексте информационного обмена.
Проблема больших данных в различных отраслях
big data информация данные
Технологии Big Data успешно реализуются в различных индустриях, на инфографике отражены главенствующие потребители: банки, телеком, ритейл, энергетика, медицина и управление городской инфраструктурой. Интересно, что при всем разнообразии задач вендорские решения в сфере Big Data пока не приобрели ярко выраженной отраслевой направленности. Рынок находится не просто на стадии активного формирования, а в самом начале этой стадии.
Несмотря на малый срок существования сектора Big Data, уже есть оценки эффективного использования этих технологий, основанные на реальных примерах. Один из самых высоких показателей относится к энергетике – по оценкам аналитиков, аналитические технологии Big Data способны на 99% повысить точность распределения мощностей генераторов. А здравоохранение США, благодаря Big Data, может сэкономить до $300 млрд.

Рассмотрим использование Big Data в электронной коммерции.
В любой отрасли — туризм, финансы, спорт или розничная торговля — сегодня трудно представить бизнес без присутствия в Интернете в том или ином виде. Всемирная паутина дала возможность достучаться до каждого, а значит, расширить свою клиентскую базу стало просто как никогда. Но как собирать и где хранить информацию о клиентах? Как быстро и эффективно использовать большие объемы данных для принятия решений?
Что может дать Big Data
Информация о клиенте — вот за что не жалко отдать обе половины царства. И Big Data дает ответы на многие животрепещущие вопросы о заказчике: что он купил и что хотел бы купить, что ему понравилось, а что нет, когда он совершал покупки, как расплатился. И даже больше: персональные данные (адрес, пол, возраст), интересы (какие сайты посетил, кто в друзьях), активность (когда выходит в Интернет, что там ищет, какие отзывы оставляет) и многое другое.
Анализ такой информации — это шанс понять, нравится ли бренд покупателям. Готовы они покупать еще и еще или их следует немного «подтолкнуть» скидками и другими бонусами? Ответы на эти вопросы помогут создать идеального клиента. Того, который всегда готов купить товар по любой цене, активен в сообществах в социальных сетях, заинтересован в развитии бренда и рассказывает всем о понравившейся продукции.
К 2014 году каналов воздействия на клиента стало так много, что приходится использовать инструменты для их объединения. В туризме, например, давно существуют платформы, которые охватывают все аспекты организации путешествий: от планирования до заказа поездок. Туристы могут выбрать места в самолете, отель, достопримечательности, которые стоит посетить, и многое другое — все это в одном месте. Удобно, правда? Самое интересное, что и не только для пользователей. Такой подход делает весь процесс простым и эффективным также для всех остальных участников турбизнеса: авиакомпаний, отелей, туроператоров и т. д.
Однако с технической точки зрения это все — огромный объем информации. Обработка такого количества данных одновременно была невозможной еще несколько лет назад. Но на 2014 год нет никакой проблемы в том, чтобы предоставить клиенту персонализированный сервис на основе данных о его предпочтениях. И подать все в виде понятного и простого интерфейса, с которым даже ребенок справится.
Что в этом полезного?
Вот несколько примеров того, как можно получить конкурентные преимущества, используя Big Data:
- Персонализация — анализируя информацию о клиенте можно предложить решения, разработанные для конкретного пользователя. Получая конкурентное преимущество в глазах клиента и не тратясь при этом на улучшение качества продукта.
- Динамическое ценообразование — анализ данных о рынке позволит установить самую привлекательную цену для конкретного клиента. Иногда получить доверие в будущем гораздо важнее и выгодней, чем максимальная прибыль прямо сейчас.
- Обслуживание клиентов — Big Data поможет создать у заказчика чувство собственной значимости. Он сможет убедиться, что продавцу не все равно. Ведь покупатель получит именно то, что хочет.
- Трекинг — возможность уведомлять клиентов о том, где их заказ, в каком состоянии и когда он дойдет до них.
- Прогнозный анализ — с Big Data становится возможным предугадывать события до того, как они произойдут, и делать необходимые приготовления или изменения.
Помимо всего прочего Big Data сейчас используют еще и для воздействия на клиентов на эмоциональном уровне. Клиенту дают понять, что он особенный, создавая тем самым между ним и брендом определенную связь. Это в прямом смысле слова культивирует лояльность.
Хорошим примером такого подхода может служить приложение, разработанное для бренда одежды Free People, которое обеспечило компании рост продаж на 38%. Приложение позволяет пользователям обсудить последние коллекции, поделиться своими фото в новых нарядах в Pinterest и Instagram, голосовать за самые лучшие снимки. Такое естественное взаимодействие очень эффективно. Без сомнения, это отличный вариант монетизации накопленных данных, и мы еще не раз сможем увидеть как ритейлеры и социальные платформы помогают друг другу достучаться до клиента.
Информационная перегрузка — это выгодно?
Все уже привыкли к тому, что найти хоть какую-нибудь действительно полезную информацию очень сложно. В блогах, социальных сетях люди всегда рады прочитать что-нибудь интересное. И именно благодаря инструментам Big Data теперь есть возможность предложить пользователю именно те факты, которые были отобранные специально для него на основе данных о предыдущих заказах, поисковых запросах, «лайках» в соцсетях и т. д.
Возьмем, к примеру, бизнес, связанный со спортом и фитнесом. Эта отрасль очень быстро развивается. Во многом благодаря успеху приложений, объединивших теорию и практику здорового образа жизни.
Будущее e-commerce — это объединение персональных целей (скинуть пару кило) с теорией (изучить новый курс тренировок) и коммерцией (купить новые кроссовки и тренажеры). Идеальное приложение не только даст общие рекомендации по тренировочным программам. Оно позволит пользователю заказать нужные спорттовары или другие продукты прямо здесь и сейчас. А продавец, основываясь на данных из таких приложений, сможет предложить клиенту персональные скидки, членство в клубе, программы лояльности и многое другое.
Хорошо это или плохо, но обслуживать клиентов, основываясь на их личных предпочтениях, сегодня можно только с помощью Big Data. Большие корпорации нанимают целые команды разработчиков, которые изучают их бизнес и создают уникальные приложения. Представители малого и среднего бизнеса используют более общие готовые решения. Но у всех цель одна — дать клиенту то, что он хочет, помогая тем самым e-commerce расти, развиваться и процветать.
Размещено на Allbest.ru

- Понятие, цели, задачи и значение оценки бизнеса (ИДЕНТИФИКАЦИЯ ОБЪЕКТА ОЦЕНКИ В СООТВЕТСТВИИ С ТРЕБОВАНИЯМИ НОРМАТИВНЫХ ДОКУМЕНТОВ )
- Статус адвоката. Порядок его приобретения».
- Понятие, цели, задачи и значение оценки бизнеса (Цели, задачи оценки стоимости бизнеса)
- Инновационные проекты (Особенности инновационного проекта)
- Что такое web-камера, IP-камера и какова технология их использования?
- Становление и развитие науки уголовно-исполнительного права: генезис ее предмета.
- Людология и её роль при изучении интерфейса в видеоиграх
- Обзор моделей корпоративного управления за рубежом и их сравнительная характеристика (Японская модель корпоративного управления)
- Групповая политика. Применение объектов групповой политики
- ИСПОЛНЕНИЕ И ОТБЫВАНИЕ УГОЛОВНОГО НАКАЗАНИЯ В ВИДЕ ЛИШЕНИЯ СВОБОДЫ НА ОПРЕДЕЛЕННЫЙ СРОК В ИСПРАВИТЕЛЬНЫХ КОЛОНИЯХ ОСОБОГО РЕЖИМА
- Hospitality Trends: The Latest Trends in The Hospitality Industry
- Договор поставки