
Технология построения распределенных информационных систем
Содержание:

ВВЕДЕНИЕ
Автоматизированные системы позволяют хранить и оперативно обрабатывать большие объемы информации. Использование автоматизации рутинных процессов позволяет сократить время выполнения операций, повысить достоверность информации, уменьшить временные и трудовые затраты сотрудников компании на выполнение однотипных операций и формирования отчетной документации.
Темой данной курсовой работы является изучение технологии построения распределенных информационных систем.
Целью курсовой работы является изучение теоретических основ разработки информационных систем, изучение особенностей технологий информационных систем, а также обзор современных технологий разработки систем: COM и CORBA.
Задачи, которые необходимо решить для достижения поставленной цели:
- рассмотреть основные понятия, классификацию и структуру информационных систем;
- рассмотреть понятие жизненного цикла информационной системы;
- исследовать возможности основных технологий и методов проектирования информационных систем.
- рассмотреть основные технологии распределенной обработки информации;
- рассмотреть современные технологии разработки распределенных информационных систем.
Курсовая работа состоит из введения, трех разделов, заключения, списка используемых источников.
В первом разделе рассмотрены основные понятия, классификации и структура автоматизированных информационных систем. Дано определение жизненного цикла информационной систем, рассмотрены различные виды жизненного цикла. Также рассмотрены основные методы разработки информационных систем: MSF, CDM, RUP.
Во второй главе работы рассмотрены основные технологии распределенной обработки информации: технология файл-сервер, клиент-сервер, многоуровневая архитектура и Интернет/Интранет технология.
Третья глава работы посвящена современным технологиям разработки информационных систем. Рассмотрены особенности технологии COM и CORBA.
В заключении сделаны выводы по результатам выполнения курсовой работы и полученных знаний.
В процессе работы над курсовым проектом были изучены нормативные документы по теме исследования: ГОСТ 34.003-90, ГОСТ 34.601-90, ГОСТ Р ИСО/МЭК 12207–02, ОРММ ИСЖТ 5.03–00 и другие.
Значительная часть теоретического материала была использована из научных трудов такие авторов как: Грекул В.И., Денищенко Г.Н., Исаев Г.А., Коротков Э.М., Криницкий Н.А.
В процессе работы были использованы также и современные образовательные Интернет-ресурсы: intuit.ru, rsdn.ru, interface.ru.
ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ РАЗРАБОТКИ И ИСПОЛЬЗОВАНИЯ АВТОМАТИЗИРОВАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
Основные понятия, классификация и структура АИС
В настоящее время информация стала важнейшим ресурсом, а информационные системы используются практически во всех сферах деятельности.
Применение современных информационных технологий позволяет автоматизировать основную рутинную работу в любой организации, начиная от складского учета и заканчивая управления сложными агрегатами на производстве.
Благодаря огромному разнообразию задач, решаемых с помощью информационных систем, появилось огромное количество разновидностей систем со своим набором правил обработки информации.
Рассмотрим основные понятия автоматизированных информационных систем.
В научном труде Братищенко В.В. указано, что наиболее важным является понятие «система», означающее совокупность множества элементов, которые находятся в заранее определенных отношения друг с другом при соблюдении условий непротиворечивости и целостности. При этом все элементы системы представляют собой единое целое, но в некоторых случаях могут быть заменены или исключены без риска нарушения функционирования системы в целом [8].
Согласно ГОСТ 34.003-90 «Автоматизация – это совокупность действий или мероприятий, которые позволяют минимизировать участие человека в автоматизируемом процессе» [1]. В рассматриваемом контексте автоматизация подразумевает применение технических средств и информационных технологий для решения поставленных задач.
На рисунке 1.1 представлен список основных задач автоматизации [16].
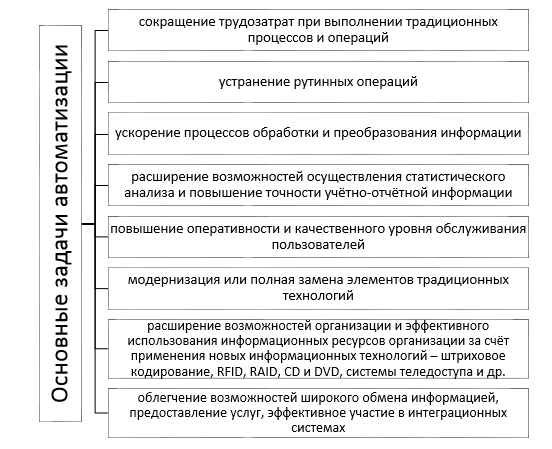
Рисунок 1.1 – Основные задачи автоматизации
Автоматизированная система (ГОСТ 34.003.90) - это система, состоящая из совокупности структурных элементов предприятия и набора средств для автоматизации определенного вида деятельности сотрудников предприятия [1].
Компонентом автоматизированной системы является один из видов его обеспечения: информационное, программное или техническое, обеспечивающее выполнение определенной задачи автоматизированной системы [2].
По характеру представления и логической организации информации различают несколько видов информационных системы [10]:
-
-
-
- фактографические – хранение данных организовано в виде набора экземпляров одного или нескольких типов объектов, каждый экземпляр данного набора описывает некоторое событие или факт. Каждый тип объекта включает в себя набор реквизитов, достаточно полно описывающих все характеристики экземпляра предметной области;
- документированные – хранение данных организовано в виде неструктурированных документов. В некоторых системах реализована возможность задания иерархии подчиненности документов;
- геоинформационные – хранение данных организовано в виде отдельных объектов с заранее сформированном набором реквизитов, объекты привязаны к электронной карте, которая представляет собой топографически компонент.
-
-
На рисунке 1.2 представлена классификация информационных систем (ИС) по функциональному признаку [10, 24].

Рисунок 1.2 - Классификация ИС по функциональному признаку
На рисунке 1.3 представлена классификация ИС в зависимости от функционального признака с учетом уровней управления и квалификации персонала. Классификация была представлена автором Орловым С.А. в своей работе [23].
По уровням управления ИС разделяют на [23]:
-
-
-
- системы оперативного уровня;
- системы специалистов;
- системы тактического уровня;
- стратегические системы.
-
-
ИС оперативного уровня позволяют автоматизировать деятельность специалистов-исполнителей: ведение учета сделок и их движения, учет и формирование счетов, поступление товаров на склад и являются связующим звеном между компанией и внешней средой. Задачи и входные данные систем оперативного уровня структурированы и запрограммированы в соответствии с определенным алгоритмом, если ИС не выполняет своих функций на должном уровне, то компания не получает информацию из внешней среды, либо система не выдает информацию по запросу [20, 23].
|
|

Рисунок 1.3 – Классификация ИС в зависимости от функционального признака с учетом уровней управления и квалификации персонала
ИС специалистов предназначены для автоматизации работы специалистов узкого профиля. Как правило, такие системы предназначены для обработки бумажных документов, оформления документов и отчетов и т.д. [26].
ИС специалистов можно разделить на две подгруппы: системы офисной автоматизации и обработки знаний [26].
ИС офисной автоматизации являются неотъемлемой часть работы офисных работников любого уровня: секретарь, бухгалтер и т.д. Основной целью таких систем является обработка данных, сокращение трудовых и временных затрат сотрудников, повышение эффективности их труда за счет автоматизации рутинных операций работы с данными: составление расписаний, учет документации, обработка текста, ведение календаря, общение по электронной почте и т.д. [26].
ИС обработки знаний используются в своей работе юристы, научные работники, проектировщики и т.д. То есть все специалисты, которые создают новые технологии, знания или продукт. К данной категории можно отнести информационные системы по проектированию сооружений, сложной обработке видео и изображений и т.д. [26].
ИС тактического уровня предназначены для ведения статистической и аналитической обработки информации. Например, сравнение данных за разные промежутки времени, формирование отчетов за выбранный период, получение архивных данных и т.д. [26].
В данной категории ИС можно выделить [15]:
- системы поддержки принятия решений – имеют в своем составе мощные аналитические алгоритмы прогнозирования событий. Такие системы используют сотрудники компаний, в обязанности которых входит обоснование принятых решений и выявление зависимостей в событиях и данных: аналитики, менеджеры и т.д.;
- управленческие ИС – предназначены для специалистов управленческого звена. Такие системы хранят и накапливают информацию о текущих процессах в компании.
Также существует классификация по степени автоматизации, сфере применения и характеру информации (рисунок 1.4) [13].
Ручные информационные системы не используют современных технических средств обработки информации. Например, работа сотрудников в компании, в которой не используются компьютеры.
Автоматически информационные системы работают без участия человека.
Автоматизированные информационные системы (АИС) предполагают наличие человека в цепочке управления, но главная роль возложена на компьютер [15].

Рисунок 1.4 - Классификация по степени автоматизации, сфере применения и характеру информации
Структура АИС должна обеспечивать бесперебойное выполнение всех ее функций и качественное взаимодействие всех ее элементов.
АИС состоит из двух частей [2]:
- обеспечивающая часть – совокупность всех видов обеспечения информационной системы для работы ее функциональной части;
- функциональная часть – обеспечивает выполнение функций информационной системы. Причем функциональная часть не может работать без наличия обеспечивающей части.
На рисунке 1.5 представлена структура АИС [22].
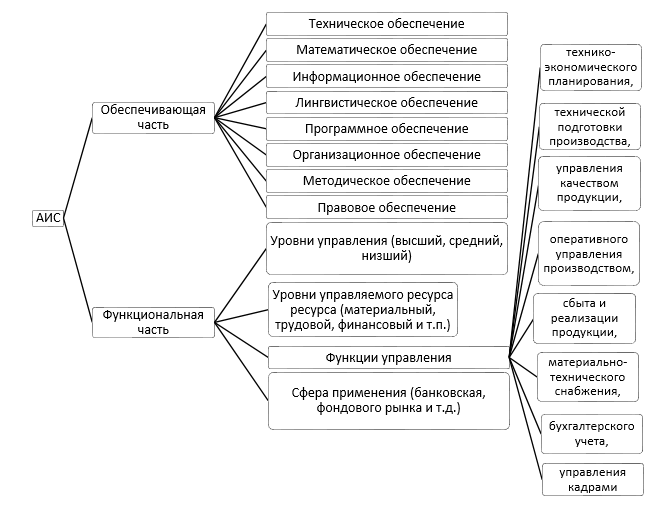
Рисунок 1.5 - Структура АИС
Жизненный цикл и модели жизненного цикла АИС
Согласно ГОСТ Р ИСО/МЭК 12207–02 – «Жизненный цикл информационной системы» – это период создания и использования ИС, который начинается на этапе возникновения потребности в ИС и заканчивается на этапе ее полного выхода из эксплуатации [3].
На рисунке 1.6 представлены стадии жизненного цикла любой ИС [4, 5].
На стадии анализа требований происходит анализ предметной области, сбор информации для определения будущей функциональности информационной системы, проводится анализ документов и материалов о деятельности объекта исследования [16].
Рисунок 1.6 – Стадии жизненного цикла
На стадии проектирования происходит выбор проектных решений по всем видам обеспечения будущей автоматизированной системы, также проводится описание компонент информационной системы и составление технического задания на разработку информационной системы согласно ГОСТ 34 или ГОСТ 19 [19]. После составления технического задания составляются алгоритмы работы системы, создается структура базы данных, оформляется документация по разработке информационной системы и выбор средств разработки.
На этапе разработки информационной системы происходит установка и настройка программного обеспечения информационной системы, кодирование алгоритмов работы программы, внесение корректив в структуру базы данных, реализация визуального интерфейса. Разрабатываются инструкции для пользователя, программиста и системного администратора [27].
На следующем этапе проводится тестирование разработанной информационной системы и ее отладка [27].
На этапе ввода в эксплуатацию выполняется ввод технических и программных средств, обучение и сертификация персонала, опытная эксплуатация, а также подписание акта приемки-сдачи работ [27].
На этапе сопровождения вносятся коррективы в работу информационной системы по результатам ее опытной эксплуатации и замечаний пользователей [27].
Для большинства современных компьютерных систем срок жизни информационной системы составляет около двух-трех лет. Но существуют и сложные системы, жизнь которых длится и 20, и 30 лет. Это зависит от решаемых задач каждой системы и ее необходимости.
Последовательность прохождения представленных стадий жизненного цикла зависит от конкретной модели жизненного цикла.
Различают три модели жизненного цикла информационной системы [28]:
-
-
-
- каскадная модель;
- итерационная модель;
- спиральная модель.
-
-
Каскадная модель жизненного цикла информационной системы предлагает, что переход на следующие этапы происходит только после полного выполнения работ на предыдущем этапе. Данная модель является классической для большинства прикладных информационных систем [5].
На рисунке 1.7 представлена схема каскадной модели жизненного цикла информационной системы [5].

Рисунок 1.7 - Схема каскадной модели жизненного цикла информационной системы
Каскадная модель отлично работает только в том случае, если на этапе разработки требований к информационной системе были полно, точно и правильно сформулированы все требования, чтобы дать возможность разработчику реализовать их как можно лучше. Но данная схема может быть полезна только для не очень сложных систем, которые хорошо поддаются алгоритмизации [16].
Достоинства каскадной модели жизненного цикла ИС [5, 16]:
1) на каждой стадии разработки информационной системы формируется законченный набор проектной документации, которая отличается полнотой и согласованностью;
2) последовательно выполняемые этапы работы позволяют более точно прогнозировать сроки завершения каждого этапа и затраты на каждом этапе.
Основные недостатки каскадной модели жизненного цикла:
1) запаздывание в получении реальных результатов по качеству разрабатываемой системы;
2) возможность согласования результатов с пользователями только в заранее запланированных точках после прохождения определенного этапа.
Таким образом, согласование полученных результатов с пользователями на промежуточных этапах невозможно, а это значительно ухудшает полученный результат в конечном итоге. Ожидания разработчика и пользователя могут полностью не соответствовать друг другу.
Следующая модель жизненного цикла – итерационная модель, которая по сути является разновидностью каскадной модели, но на каждом этапе присутствует обратная связь [5].
На рисунке 1.8 представлена схема итерационной модели жизненного цикла.

Рисунок 1.8 - Схема итерационной модели жизненного цикла
Часто на этапе реализации системы возникает ситуация, что запланированная на первом этапе функция является нереализуемой или неэффективном. В этом случае происходит возврат на несколько стадий назад и внесение изменений в техническое задание и код системы [5].
Стремление на начальном этапе формализовать все требования к информационной системе является нереализуемым при наличии в задаче более 3-5 функций, поэтому возможность отката на предыдущий этап крайне важно [16].
Но частота возврата на предыдущие этапы не должна превышать заранее оговоренной частоты, так как при наличии огромного количества возвратов на лицо плохая формализация задачи и необходимо пересмотреть техническое задание с нуля либо перепоручить это другой команде специалистов для получения другой точки зрения на систему в целом [3].
Достоинства итерационной модели - поэтапные корректировки, которые обеспечивают меньшую трудоемкость по сравнению с каскадной. Однако время жизни каждого из этапов рассчитывается на весь период разработки.
Существует еще одна модель жизненного цикла – спиральная модель жизненного цикла [5].

Рисунок 1.9 - Схема спиральная модели жизненного цикла
Особенностью спиральной модели жизненного цикла информационной системы является упор на начальные этапы: анализ требований и проектирование информационной системы [5].
Модель представляет собой итерационный процесс, где каждый цикл (итерация) на выходе выдает очередную версию проекта. От итерации к итерации информационная система совершенствуется. При этом каждый виток спирали соответствует поэтапной модели создания информационной системы. Таким образом, на каждом этапе конкретизируется и углубляется логика и функциональность системы вплоть до ее полной реализации согласно техническому заданию [16].
На рисунке 1.10 представлен список преимуществ и недостатков спиральной модели жизненного цикла [4]. Для разработки сложных информационных систем и программных комплексов следует использовать спиральную модель жизненного цикла. Для разработки информационных системы среднего масштаба подходит итерационная модель жизненного цикла.
Стандарты жизненного цикла информационной системы [27]:
- ГОСТ 34.601-90;
- ISO/IEC 12207:1995.
Специфические (отраслевые) подходы к разработке программного обеспечения реализованы в концепциях жизненного цикла, в основе которых лежат требования ИСО 12207 [28]:
- Rapid Application Development (RAD) – стадии анализ и планирование требований, проектирование, реализация, внедрение;
- Custom Development Method (методика Oracle);
- Rational Unified Process (RUP) – рациональный унифицированный процесс (IBM);
- Microsoft Solutions Framework (MSF). Включает 4 фазы: анализ, проектирование, разработка, стабилизация, предполагает использование объектно-ориентированного моделирования (Microsoft).

Рисунок 1.10 - Преимущества и недостатки спиральной модели жизненного цикла
. Проектирование и основные технологии разработки АИС
Методы проектирования информационных систем включают в себя использование программных и аппаратных средств, которые в совокупности образуют инструментальные средства программирования автоматизированных информационных систем.
На рисунке 1.11 представлены три составляющие технологии проектирования информационной системы [29].

Рисунок 1.11 - Три составляющие технологии проектирования ИС
Методы проектирования принято классифицировать по различным признакам. На рисунке 1.12 представлена полная классификация методов проектирования [15, 21].

Рисунок 1.12 - Классификация методов проектирования ИС
Проектирование информационных систем предполагает использование различных средств проектирования [21]:
- нормативные и правовые документы;
- системы классификации и кодирования информации;
- системы проектной документации;
- модели информационной системы и их составные части;
- методики анализа и принятия проектных решений;
- программные средства.
На рисунке 1.13 представлены иерархия технологий проектирования.
Каноническое проектирование информационной системы характеризует особенности ручной технологии проектирования без использования инструментальных средств. Каноническое проектирование применяется для небольших локальных информационных систем, проектируемых по каскадной модели жизненного цикла [21].
Индустриальное проектирования включает в себя автоматизированное и типовое проектирование [23].
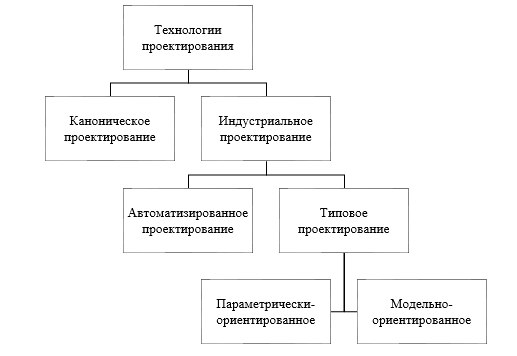
Рисунок 1.13 – Иерархия технологий проектирования ИС
К автоматизированному проектированию относятся CASE-технологии – совокупность методов анализа, проектирования, разработки и сопровождения ИС [6].
Целью CASE-технологий является отделение процесса проектирования информационной системы от ее кодирования и последующей разработки [6].
С помощью CASE-средств на этапе проектирования информационной системы строятся ER-модели, IDEF0, IDEF3, DFD [6].
Типовое проектирование включает в себя параметрически-ориентированное проектирование и модульное проектирование и предполагает создание системы из готовых составных частей.
Параметрически-ориентированное проектирование заключается в выборе составных элементов, наиболее подходящих объекту управления по своим параметрам.
Модельно-ориентированное проектирование заключается в адаптации состава и характеристик типовой информационной системы в соответствии с моделью объекта автоматизации.
В настоящее время существуют несколько современных технологий проектирования информационных систем [18]:
- Rational Unified Process (RUP);
- Custom Development Method (CDM);
- Microsoft Solutions Framework (MSF).
На рисунке 1.14 представлены основные этапы разработки по технологии RUP [18].

Рисунок 1.14 - Основные этапы разработки по технологии RUP
В основе технологии RUP лежит итерационная модель жизненного цикла. Управление проектом проводится на основе ключевых функциональных требований заказчика. Все силы разработчиков направлены на выполнение всех требований заказчика в конечной версии программы. По мере необходимости вносятся коррективы в техническое задание в соответствии с замечаниями и требованиями. Разработка проекта в руках архитекторов [20].
На начальной стадии формируется основной список требований и характеристик будущей системы, составляется типовой план-проект, выбираются один или несколько прототипов системы.
На стадии уточнения происходит конкретизация технического задания и окончательный выбор прототипа [20].
На стадии конструирования получен готовый программный продукт, набор сопроводительной документации. После внедрения системы подписывается акт приемки-сдачи [20].
Основные этапы разработки по технологии CDM представлены на рисунке 1.15 [21].

Рисунок 1.15 - Основные этапы разработки по технологии CDM
Методика Oracle CDM предназначена для управления и руководство проектом внедрения разработки и внедрения ИС масштаба предприятия [21].
Данный метод разработан специально для ускорения процесса внедрения системы на предприятии. Подход CDM включает в себя заранее подготовленный набор работ и шаблонов в соответствии с требованиями заказчика.
Методика CDM охватывает весь жизненный цикл проекта.
В состав методики CDM входят и другие методики [24]:
-
- PJM (Project Management Method) – управление проектом;
- AIM (Application Implementation Method) – внедрение прикладного ПО;
- BPR (Business Process Reengineering) – реинжиниринг бизнес-процессов;
- OCM (Organizational Change Management) – управление изменениями.
Технология Microsoft Solutions Framework (MSF) включает в себя набор принципов, моделей и правил, направленных быструю и качественную разработку программного обеспечения [21].
В состав MSF входят несколько моделей: модель процессов, управления проектом и рисками, модель проектной группы и управления подготовкой.
На рисунке 1.16 представлена схема основных этапов методологии MSF [16].

Рисунок 1.16 - Основные этапы разработки по технологии MSF
Методология MSF основана на спиральной модели жизненного цикла.
Основными задачами, описываемыми в технологии MSF, являются [23]:
1) Выбор или создание прототипа системы;
2) Разработка компонентов системы;
3) Объединение компонентов в единую целостную систему;
4) Реализация всех функций.
В качестве основных результатов работы методологии можно выделить:
- исходный код системы и исполняемые файлы;
- сценарии настройки и развертывания системы;
- спецификация готового продукта;
- сценарии тестирования системы.
Выводы
В первой главе работы рассмотрены основные понятия информационных систем, рассмотрена классификация систем по различным признакам. Рассмотрены основные структурные элементы информационных систем. Также рассмотрены основные понятия и модели жизненного цикла информационных систем. Представлено описание различных методов проектирования информационных систем: MSF, CDM, RUP. Все рассмотренные технологии разработки программного обеспечения позволяют организовать работу коллектива разработчиков от 5 и до 1000 человек. В каждой методологии определены роли и задачи для каждого участника разработки.
ГЛАВА 2. ОСНОВНЫЕ ТЕХНОЛОГИИ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ИНФОРМАЦИИ
2.1. Технология файл-сервер
Под распределенной обработкой данных понимают обработку приложений несколькими территориально распределенными компьютерами [12]. Технология «файл-сервер» основана на таких понятия как «файл-сервер» и «клиент».
Файл-сервер — это персональный компьютер, который обеспечивает хранение данных и выдачу их по требования клиента в виде файлов [9].
Клиентом может быть задача, рабочая станция или пользователь компьютерной сети. Клиент формирует запрос о выполнении процедур, чтения или записи в файл, который посылается на файл-сервер [9].
Сервер включает жесткий диск большой емкости, на котором хранится база данных файлов, доступ к которой могут иметь несколько клиентов одновременно. Сервер выполняет обработку и выборку данных для передачи клиенту, а клиент принимает данные и отображает их в удобном для пользователя виде на экране, либо выводит на печать.
Для работы информационной системы, организованной по технологии «файл-сервер» необходимо наличие сетевой операционной системы, которая обеспечивает работу клиента и сервера.
Первая часть находится на файловом сервере, а вторая устанавливается на всех клиентах (персональных компьютерах).
Вторая часть часто называется «оболочкой» и обеспечивает взаимодействие между сервером и программами рабочей станции.
Файловый сервер сам по себе используется только как хранилище файлов. Обработку запросов выполняет серверная часть системы.
На рисунке 2.1 представлена принципиальная схема работы информационной системы по технологии «файл-сервер» [13].

Рисунок 2.1 - Структура информационной системы с файл-сервером
На рисунке 2.2 представлена схема обработки запроса одного пользователя.

Рисунок 2.2 - Схема обработки запроса одного пользователя
При одновременном запросе нескольких пользователей схема будет выглядеть, как показано на рисунке 2.3.

Рисунок 2.3 - Схема обработки запроса нескольких пользователей
Недостатки технологии файл-сервер [9, 13]:
1) большая нагрузка на сеть и высокие требования к ее пропускной способности, чтобы обеспечить оптимальную скорость работы системы в целом. Также практически невозможно организовать приемлемую одновременную работу нескольких пользователей;
2) обработка данных происходит на компьютере пользователей, это требует увеличения мощности аппаратного обеспечения каждого пользователя и, как правило, ведет к значительным затратам при сомнительном увеличении производительности компьютеров сотрудников компании;
3) практически невозможно разграничить доступ к данным, так как для получения данных даже из одного поля, пользователю будет направлен целый файл, который может содержать информацию, которая является защищаемой.
Технология «файл-сервер» в настоящее время все еще используется, обычно для автоматизации небольших предприятий.
2.2. Технология клиент-сервер
Использование технологии «клиент-сервер» позволяет устранить недостатки технологии «файл-сервер».
Сервер базы данных расположен на компьютере-сервере и выполняет основной объем обработки данных. Клиентское приложение создает запросы в виде SQL-запросов. Серверное приложение получает по запросу данные из базы данных и передает их клиентскому приложению [18].
При такой схеме организации обмена данными в разы сокращается объем передаваемых данных по сети.
Большинство информационных системы разрабатывается по двухуровневой технологии «клиент-сервер».
На рисунке 2.4 представлена структура информационной системы по технологии «клиент-сервер» [23].
На компьютерах клиентов устанавливается программное обеспечение клиента, которое формирует запросы и отображает результаты пользователю.
Сетевое программное обеспечение передает данные между клиентом и серверов в двух направлениях [11].
Кроме того, в рамках технологии «клиент-сервер» сервер используется не только как хранилище программ и данных, но и как вычислительная среда.

Рисунок 2.4 - Структура информационной системы по технологии «клиент-сервер»
На рисунке 2.5 представлен пример обработки запроса одного пользователя.

Рисунок 2.5 - Пример обработки запроса одного пользователя
На рисунке 2.6 представлен пример обработки запроса нескольких пользователей, обращающихся к данным одновременно.

Рисунок 2.6 - Пример обработки запроса одновременно нескольких пользователей
Как видно из представленного примера технология «клиент-сервер» позволяет работать с данными одновременно несколькими пользователями без потери производительности и блокировки данных.
В мощных клиент - серверных СУБД существуют дополнительные механизмы, позволяющие увеличить производительности системы, снизить нагрузку на сеть, например, хранимые процедуры, которые выполняют пред-или постобработку данных на стороне сервера, исключая необходимость многоразовой обмены данными между клиентом и сервером [11].
Таким образом, по сравнению с технологией «файл-сервер» очевидны следующие преимущества технологии «клиент-сервер» [18, 23]:
1) по сети передается только те данные, которые были запрошены на стороне сервера, следовательно, требования к пропускной способности сети уменьшаются;
2) доступ к данным возможен одновременно несколькими пользователями без блокировки на чтение;
3) обработка данных происходит на сервере, следовательно, рабочие станции не должны обладать мощными параметрами, достаточно одного мощного сервера, что определяет экономичность данной технологии;
3) Доступ пользователя возможен только к тем данным, которые им могут быть получены в соответствии с правами и выделенными ролями.
2.3. Многоуровневая архитектура
Многоуровневая архитектура - архитектурная модель программного комплекса, предполагающая наличие в нём трёх компонентов: клиента, сервера приложений (к которому подключено клиентское приложение) и сервера баз данных (с которым работает сервер приложений) [17].
Структура информационной системы с многоуровневой архитектурой представлена на рисунке 2.7.
Многоуровневая архитектура включает в себя три уровня иерархии [17]:
1) Клиент;
2) Сервер приложений;
3) Сервер базы данных.
Серверу приложений передана бизнес-логика реализации функций системы, которая в технологии двухзвенного «клиент-сервера» располагалась на стороне клиента [20].

Рисунок 2.7 - Структура информационной системы с многоуровневой архитектурой
Передача функциональность на сторону сервера приложений позволяет еще больше освободить клиентскую часть систем, тем самым, снизив требования к производительности рабочих станций. В связи с этим клиентскую часть называют «тонким клиентом» [20].
Кроме того, отделение бизнес-логики позволяет упросить модернизацию ПО, так как достаточно исправить логику только в одном месте всей системы.
Достоинства многоуровневой технологии [17, 20]:
- возможность масштабируемости системы;
- возможность настройки системы благодаря изолированию уровней и бизнес-логики;
- высокий уровень безопасности данных;
- высокий уровень надежности системы;
- низкие требования пропускной способности канала связи;
- низкие требования к аппаратным характеристикам клиентских станцией, вплоть до простого смартфона.
К недостаткам многоуровневой архитектуры относятся:
- увеличение сложность реализации приложений;
- более сложное развертывание и администрирование системы;
- высокие требования к производительности сервера;
- высокие требования к пропускной способности канала связи между сервером базы данных и серверами приложений.
2.4. Интернет / Интранет - технология
Использование Интернет / Интранет технологий при создании информационных ресурсов и построении информационных систем различного назначения в ближайшее время станет доминирующим в мировом информационном пространстве по следующим причинам [29].
В основе Интернет / Интранет технологии построения информационных систем лежит способ организации доступа к данным через WWW-сервис сети Интернет [21, 29].
Основной принцип Интернет / Интранет технологии заключается в разделении вычислительных ресурсов как между многочисленными серверами, расположенными в различных концах сети, так и между серверами и клиентами (компьютер, на котором работает конечный пользователь) (рисунок 2.8) [22].

Рисунок 2.8 – Интернет / Интранет технология
Для реализации такой возможности используются [15]:
- HTTP-SQL (формирование SQL запросов к БД с WWW сервера);
- АPI (организация динамических приложений на стороне сервера);
- Java (JDBC - организация динамических приложений на стороне клиента) интерфейсов для формирования запросов пользователя к базам данных или к другим информационным источникам на получение и обработку информации.
Информационная система, разработанная на основе клиент - серверных Интернет / Интранет технологий, включает следующие серверные компоненты, представленные на рисунке 2.9 [16].

Рисунок 2.9 – Компоненты Интернет / Интранет технологии
Взаимодействие WWW сервера с базами данных может быть организовано двумя способами: через сервер транзакций или API интерфейс.
На рисунках 2.10-2.11 представлена связь сервера с базой данных через API интерфейс [18].
В качестве СУБД для реализации рассматриваемой технологии часто используют сетевые СУБД [10]:
- Informix;
- Oracle;
- MS SQL.
Для несетевых СУБД HTTP-SQL или TS (сервер транзакций) должны работать на одной машине, на которой работает используемая вами СУБД.

Рисунок 2.10 – Взаимодействие через API интерфейс – вариант 1
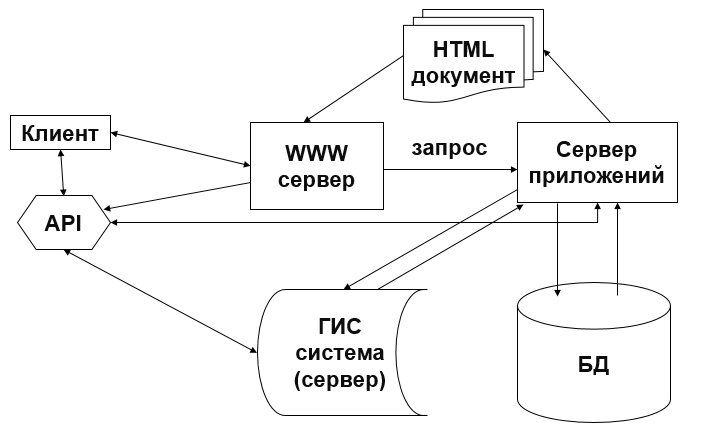
Рисунок 2.11 – Взаимодействие через API интерфейс – вариант 2
На рисунке 2.12 представлен список преимуществ Интернет / Интранет технологий [16].
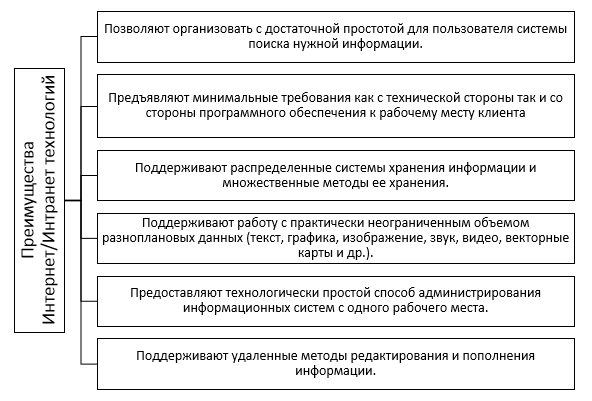
Рисунок 2.12 - Список преимуществ Интернет / Интранет технологий
В настоящее время технология распределенной обработки информации на основе Интернет/Интранет становится все более популярной в связи с информатизацией общества и массирования использования сети Интернет.
Выводы
В данной главе работы рассмотрены основные технологии распределенной обработки информации:
- файл-сервер;
- клиент-сервер;
- многоуровневая архитектура;
- Интернет/Интранет технология.
ГЛАВА 3. СОВРЕМЕННЫЕ ТЕХНОЛОГИИ РАЗРАБОТКИ ИНФОРМАЦИОННЫХ СИСТЕМЫ
Технология COM
COM (Component Object Model) - это метод разработки программных компонентов, небольших двоичных исполняемых файлов, которые предоставляют необходимые сервисы приложениям, операционным системам и другим компонентам. Другими словами, COM определяет стандартный механизм, с помощью которого одна часть программного обеспечения предоставляет свои сервисы другой независимо от способа их реализации [25].
COM - это не язык программирования, а подход (спецификация) к созданию программ, обеспечивающий взаимодействие программ любых типов. Компоненты COM объединяются друг с другом для создания приложений или систем компонентов. Компоненты можно менять во время выполнения, без перекомпиляции или перекомпоновки приложения. COM - это основа, на которой построены такие технологии Microsoft, как ActiveX, DirectX и OLE [30].
Технологии, основанные на COM представлены на рисунке 3.1 [31].

Рисунок 3.1 - Технологии, основанные на COM
Таким образом, ключевое слово при использовании COM - компонент. К компонентам обычно предъявляются следующие требования [31]:
1. Компонент должен скрывать используемый язык программирования.
2. Компоненты должны распространяться в двоичной форме. Их необходимо поставлять уже скомпилированными, скомпонованными и готовыми к использованию.
3. Должна быть возможность модернизировать компоненты, не затрагивая уже существующих пользователей. Новые версии компонента должны работать как со старыми, так и с новыми клиентами.
4. Компоненты должны перемещаться по сети. Необходимо, чтобы компонент и использующая его программа могли выполняться внутри одного процесса, в разных процессах и на разных машинах.
Преимущества использования компонентов
COM обеспечивает создание распределенных модульных систем в архитектуре «клиент-сервер». COM имеет следующие преимущества по сравнению с традиционной архитектурой программных систем[25]:
1. COM предоставляет стандартный набор функций для доступа к провайдеру сервиса (COM-серверу), получения информации о предоставляемых им сервисах и вызова требуемого сервиса. В качестве COM-сервера может выступать операционная система или приложение.
2. COM использует объектно-ориентированные концепции для обеспечения модульности при построении сложных распределенных систем, а также для повторного использования готовых компонентов и их разработки с сохранением совместимости с предыдущими версиями.
3. COM реализует модель вычислений "клиент-сервер", что обеспечивает преимущества распределенной обработки данных.
4. COM обеспечивает вызов сервисов в сетевом окружении, независимо от расположения COM-сервера.
Использование программных компонентов, разработанных на основе технологии COM, значительно расширяет возможности разработчиков приложений, конечных пользователей и предприятий [30]:
1. Разработчики приложений могут повысить эффективность своей работы за счет создания легко масштабируемых систем на базе готовых компонентов, а также получают возможность встраивать компоненты собственной разработки в существующие системы.
2. Конечные пользователи получают широкий выбор готовых стандартизированных программных компонентов, которые они могут использовать в своих системах.
3. Предприятия также могут использовать преимущества компонентного подхода, так как доступность готовых программных компонентов общего назначения позволяет сконцентрироваться на разработке компонентов, специфичных для сферы бизнеса данного предприятия. Компонентная архитектура также позволяет создавать интерфейсы к существующим корпоративным системам и предоставлять объектно-ориентированный доступ к их данным.
Кроме очевидных способности приложения эволюционировать с течением времени, удобства и гибкости при модернизации существующих приложений, создание программ из компонентов имеет другие достоинства [25, 33].
Адаптация приложений. Пользователи часто хотят подстроить приложения к своим нуждам. Конечные пользователи предпочитают, чтобы приложение работало так, как они привыкли. Компонентные архитектуры хорошо приспособлены для адаптации, так как любой компонент можно заменить другим, более соответствующим потребностям пользователя.
Библиотеки компонентов. Одна из самых многообещающих сторон внедрения компонентной архитектуры - быстрая разработка приложений. Компоненты, помещенные в библиотеку, можно использовать как детали вашего нового приложения.
Распределенные компоненты. С возрастанием производительности и общего значения сетей потребность в приложениях, состоящих из разбросанных по разным местам кусков, будет только повышаться. Компонентная архитектура помогает упростить процесс разработки подобных распределенных приложений. Создать из обычного приложения распределенное легче, если это обычное приложение состоит из компонентов.
СОМ и объектно-ориентированный подход [30]:
- СОМ является объектно-ориентированной технологией, но она отличается от других объектно-ориентированных технологий:
- СОМ-объект поддерживает более одного интерфейса
- Класс в СОМ понимается как описание конкретной реализации набора интерфейсов
- СОМ-объекты поддерживают только наследование интерфейса, т.е. потомок должен самостоятельно определить код методов родителя.
Понятие OLE и ActiveX
OLE (Object Linking and Embedding) - технология создания составных документов связыванием и внедрением. Документ сервера может быть либо связан, либо внедрен в документ контейнера. Методы создания составных документов: копирование и вставка через буфер обмена либо метод drag-and-drop [25].
Контейнер составных документов должен поддерживать интерфейсы: IOleClientSite (позволяет серверу обращаться к своему контейнеру) и IAdviseSink (сервер использует для того, чтобы информировать контейнер о том, что происходит с ним) [31].
ActiveX - технология создания приложений на основе СОМ. Спецификация управляющих элементов ActiveX определяет четыре основных аспекта их функционирования: обеспечение пользовательского интерфейса, обеспечение вызова методов управляющего элемента контейнером, посылка событий контейнеру, получение информации о свойствах среды контейнера и обеспечение доступа к свойствам управляющего элемента и их модификации [31].
Технология CORBA
CORBA — технологический стандарт написания распределённых приложений, продвигаемый консорциумом (рабочей группой) OMG и соответствующая ему информационная технология [7].
Технология CORBA создана для поддержки разработки и развёртывания сложных объектно-ориентированных прикладных систем [14].
CORBA является механизмом в программном обеспечении для осуществления интеграции изолированных систем, которое даёт возможность программам, написанным на разных языках программирования, работающим в разных узлах сети, взаимодействовать друг с другом так же просто, как если бы они находились в адресном пространстве одного процесса [14].
Спецификация CORBA предписывает объединение программного кода в объект, который должен содержать информацию о функциональности кода и интерфейсах доступа. Готовые объекты могут вызываться из других программ (или объектов спецификации CORBA), расположенных в сети [14].
Спецификация CORBA использует язык описания интерфейсов (OMG IDL) для определения интерфейсов взаимодействия объектов с внешним миром, она описывает правила отображения из IDL в язык, используемый разработчиком CORBA-объекта [14].
Стандартизованы отображения для Ада, Си, C++, Lisp, Smalltalk, Java, Кобол, Object Pascal, ПЛ/1 и Python. Также существуют нестандартные отображения на языки Perl, Visual Basic, Ruby и Tcl, реализованные средствами ORB, написанными для этих языков.
Архитектура CORBA основана на трех ключевых блоках [32]:
1. OMG Interface Definition Language (IDL) – язык описания интерфейсов.
2. Object Request Broker (ORB) – брокер объектных запросов.
3. Internet Inter-ORB Protocol (IIOP) – стандартный протокол обмена данными для CORBA, реализованный на базе TCP/IP.
На рисунке 3.2 представлено взаимодействие объектов в архитектуре CORBA [32].

Рисунок 3.2 - Взаимодействие объектов в архитектуре CORBA
Основу CORBA составляет объектный брокер запросов (Object Request Broker). ORB управляет взаимодействием объектов в распределенной сетевой среде. IIOP (Internet Inter-ORB Protocol) — это специальный протокол взаимодействия между ORB [14].
В адресном пространстве клиента функционирует специальный объект, называемый заглушкой (stub). Поучив запрос от клиента, он упаковывает параметры запроса в специальный формат и передает его серверу, а точнее скелету [14].
Скелет (skeleton) — объект, работающий в адресном пространстве сервера. Получив запрос от клиента, он распаковывает его и передает серверу. Также скелет преобразует ответы сервера и передает их клиенту (заглушке) [7].
Технология работы CORBA-приложения заключается в следующем [7]:
1. Формируется «заглушка» (Stub), которая представляет собой откомпилированное IDL-описание интерфейса клиентской части.
2. Формируется «скелет» (Skeleton) - откомпилированное IDL-описание интерфейса серверного объекта.
3. Выполняется реализация серверного объекта (Object Implementation) и клиентской части к нему (Client).
4. Для каждого экземпляра CORBA-объекта формируется своя уникальная объектная ссылка.
5. Клиент, применяя объектную ссылку, передает ORB данные о том, какой именно экземпляр объекта должен быть задействован. При этом клиент действует так, как будто оперирует напрямую с экземпляром объекта, однако в действительности происходит обращение к методам заглушки, которая затем и передает через ORB запрос на выполнение и код скелета серверного объекта.
Для описываемой схемы взаимодействия частей приложения характерны следующие черты [32]:
1. Клиент с самого начала знает о типе исполняемого объекта, поскольку как клиентская заглушка, так и скелет серверного объекта, генерируются из одного и того же IDL-описания.
2. ORB клиента и ORB серверного объекта базируются на общем протоколе IIOP.
Помимо удалённых объектов в CORBA 3.0 определено понятие объект по значению. Код методов таких объектов по умолчанию выполняется локально. Если объект по значению был получен с удалённой стороны, то необходимый код должен либо быть заранее известен обеим сторонам, либо быть динамически загружен. Чтобы это было возможно, запись, определяющая такой объект, содержит поле Code Base — список URL, откуда может быть загружен код [14].
У объекта по значению могут также быть и удалённые методы, поля, которые передаются вместе с самим объектом. Поля, в свою очередь также могут быть такими объектами, формируя таким образом списки, деревья или произвольные графы. Объекты по значению могут иметь иерархию классов, включая абстрактные и множественное наследование [7].
Компонентная модель CORBA (CCM) — недавнее дополнение к семейству определений CORBA [32].
CCM была введена начиная с CORBA 3.0 и описывает стандартный каркас приложения для компонент CORBA. CCM построено под сильным влиянием Enterprise JavaBeans (EJB) и фактически является его независимым от языка расширением. CCM предоставляет абстракцию сущностей, которые могут предоставлять и получать сервисы через чётко определённые именованные интерфейсы, порты [33].
Модель CCM предоставляет контейнер компонентов, в котором могут поставляться программные компоненты. Контейнер предоставляет набор служб, которые может использовать компонент. Эти службы включают (но не ограничены) службу уведомления, авторизации, персистентности и управления транзакциями. Это наиболее часто используемые распределённым приложением службы. Перенося реализацию этих сервисов от необходимости реализации самим приложением в функциональность контейнера приложения, можно значительно снизить сложность реализации собственно компонентов [33].
Выводы
В третьей главе работы рассмотрены технологии разработки информационной системы: COM и CORBA. Несмотря на внешнюю похожесть, что вызвано общностью решаемых задач, между COM и CORBA, пожалуй, больше различий, чем сходства. В большинстве случаев либо нецелесообразно использовать CORBA (для небольших и простых проектов под Windows просто по причине относительно высоких затрат на приобретение программного обеспечения, лицензий и пр.), либо практически невозможно использовать COM (для сложных, масштабируемых, высоконадежных проектов или просто при работе в гетерогенных средах, а не только в Windows). Windows-приложения, ориентированные на взаимодействие с Microsoft Office, всегда будут использовать COM; проекты с использованием Java и любых Java-технологий (кроме Microsoft J++).
ЗАКЛЮЧЕНИЕ
В настоящей курсовой работе была изучена технология построения распределенных информационных систем.
Для более полного раскрытия темы курсовой работы, первоначально были рассмотрены теоретические основы разработки информационных систем. Рассмотрена структура и классификация информационных систем по различным признакам. Рассмотрены также основные модели жизненного цикла информационных систем: каскадная, спиральная, итерационная. Проведена характеристика современных методов и технологий проектирования информационных систем. В частности, дана краткая характеристика таких технологий как: MSF, CDM и RUP. Рассмотрены особенности их работы. В результате проведенного исследования получены знания, которое будут использованы при проектировании информационных систем.
Вторая глава курсовой работы посвящена технологиям распределенной обработки информации. Дана характеристика и примеры работы технологий файл-сервер, клиент-сервер, многоуровневой архитектуры и Интернет/Интранет технологии. Полученные знания будут необходимы в дальнейшем обучении и при разработке распределенных информационных систем. С моей точки зрения наиболее распространенной является технология клиент-сервер.
Третья глава работы посвящена изучению технологий разработки распределенных информационных систем: СORBA и COM. После изучения особенностей данных технологий, я сделал однозначный вывод о том, что более понятной и интересной для меня является технология COM. В будущем планирую использовать данную технологию при разработке информационных систем.
В результате выполнения курсовой работы я получил не только теоретические знания в области технологии разработки распределенных информационных систем, но и получил опыт работы с большим количеством источников литературы, систематизации и обобщения полученных знаний.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- ГОСТ 34.003-90 Информационная технология. Комплекс стандартов на автоматизированные системы. Термины и определения
- ГОСТ 34.601-90 Информационная технология. Комплекс стандартов на автоматизированные системы. Автоматизированные системы. Стадии создания
- ГОСТ Р ИСО/МЭК 12207–02. Информационная технология. Процессы жизненного цикла программных средств.
- ГОСТ Р ИСО/МЭК 15271–02. Руководство по ИСО/МЭК 12207 (процессы жизненного цикла программных средств).
- ОРММ ИСЖТ 5.03–00. Процессы жизненного цикла ИС и программных средств – М.: ВНИИАС МПС России, 2000. – 48 с.
- Александров, Д.В. Инструментальные средства информационного менеджмента. CASE-технологии и распределенные информационные системы: Учебное пособие / Д.В. Александров. - М.: ФиС, 2011. - 224 c.
- Ахтырченко К. В. Применение технологии CORBA при построении распределенных информационных систем. - М.: ИНТЕР, 2014. - 528 c.
- Братищенко В.В. Проектирование информационных систем. — Иркутск: Изд-во БГУЭП, 2014. — 84 с.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2013. - 528 c.
- Грекул В.И., Денищенко Г.Н., Коровкина Н.Л. Проектирование информационных систем. — М.: Интернет-университет информационных технологий - ИНТУИТ.ру, 2011.
- Дэвид А. Марка, Клемент МакГоуэн. Методология структурного анализа и проектирования. /Пер. с англ. – М.: Метатехнология, 2011, 240 с.
- Елманова Н. Распределенные вычисления и технологии Inprise. М.: ИНФРА - М, 2012. – 398 с.
- Исаев Г.А., Проектирование информационных систем. Учебное пособие, М.- Омега-Л, 2015. – 432 с.
- Калиниченко Л.А., Когаловский М.Р. Стандарты OMG: Язык определения интерфейсов IDL в архитектуре CORBA. — М.: «Вильямс», 2012. — 480 с.
- Коротков Э.М. Создание информационных систем: учебник. - 2-е изд. – М.: ИНФРА - М, 2012. – 398 с.
- Колтунова Е. Требования к информационной системе и модели жизненного цикла. - СПб.: Питер, 2013. - 179 c.
- Коржов В.А. Многоуровневые системы клиент-сервер. – СПб. : Питер, 2002. – 464 с.
- Криницкий, Н.А. Автоматизированные информационные системы / Н.А. Криницкий, Г.А. Миронов, Г.Д. Фролов. - М.: Наука, 2016. - 100 c.
- Лысенко М.А. Методики анализа и проектирования жизненного цикла информационных систем. - М.: МГТУ им. Баумана, 2011. - 342 c.
- Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2013. - 176 c.
- Назаров С.В. Компьютерные технологии обработки информации. – М.: Финансы и статистика, 2012. – 290 с.
- Норенков, И.П. Автоматизированные информационные системы: Учебное пособие / И.П. Норенков. - М.: МГТУ им. Баумана, 2011. - 342 c.
- Орлов, С.А. Технологии разработки программного обеспечения: учеб. / С.А. Орлов. – СПб. : Питер, 2002. – 464 с.
- Олейник, П.П. Корпоративные информационные системы: Учебник для вузов. Стандарт третьего поколения / П.П. Олейник. - СПб.: Питер, 2012. - 176 c.
- Роберт Дж. Оберг. Технология COM+. Основы и программирование = Understanding and Programming COM+: A Practical Guide to Windows 2000 First Edition. — М.: «Вильямс», 2013. — С. 480.
- Федотова Е.Л. Информационные технологии и системы: Учебное пособие. - М.: ИД. «Форум»: ИНФРА - М. 2013. - 352с.
- Стадии жизненного цикла ПО / Интуит. URL: www.intuit.ru/studies/courses/3735/977/lecture/14671?page=5 (дата обращения 28.04.2017)
- Жизненный цикл информационной системы, статья / Интуит. URL: www.intuit.ru/studies/courses/2195/55/lecture/1620 (дата обращения 29.04.2017)
- Курс лекций по дисциплине «информационные системы» / Научный институт. URL: http://www.tspu.tula.ru/ivt/old_site/umr/is/l2.htm (дата обращения 29.04.2017)
- Основные понятия технологии COM / Научный институт. URL: http://techn.sstu.ru/kafedri/%D0%BF%D0%BE%D0%B4%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F/1/MetMat/murashev/com/lec/ (дата обращения 01.05.2017)
- Введение в COM / RSDN. URL: http://rsdn.org/article/com/introcom.xml (дата обращения 01.05.2017)
- Курс лекций: «Технология CORBA» / Интуит. URL: http://www.intuit.ru/studies/courses/571/427/lecture/9705 (дата обращения 01.05.2017)
- Сравнение COM и CORBA / Интерфейс. URL: http://www.interface.ru/fset.asp?Url=/borland/corbacom.htm (дата обращения 01.05.2017)

- Языки гипертекстовой разметки (конкретные реализации языков гипертекстовой разметки)
- Основы программирования на языке HTML (практические аспекты программирования на языке HTML)
- Мотивация и управленческая деятельность
- Коммерческие риски и способы их уменьшения (на примере ООО «МФ Банк»)
- Основные защитные механизмы ОС семейства Unix
- Основы программирования на языке QBasic (примеры реализации программ)
- Коммерческие риски и способы их уменьшения
- Распределенная технология обработки информации (свойства систем распределённой обработки информации)
- Устройство персонального компьютера (структура и архитектура ПК)
- Франчайзинг как особый вид вертикальных ограничений (на примере компании «TOM FARR»)
- Анализ денежных средств предприятия (на примере ООО «Партнер»)
- Процессор персонального компьютера. Назначение, функции, классификация процессора (современные процессоры)