
Понятие надежности программного средства
Содержание:

Основные понятия
Надежность программного обеспечения - способность программного продукта безотказно выполнять определенные функции при заданных условиях в течение заданного периода времени с достаточно большой вероятностью.
Степень надежности характеризуется вероятностью работы программного продукта без отказа в течение определенного периода времени.
Существует 4 основные составляющие функциональной надежности
программных систем:
- безотказность - свойство программы выполнять свои функции во время эксплуатации;
- работоспособность - свойство программы корректно работать весь заданный период эксплуатации;
- безопасность - свойство программы быть не опасной для людей и окружающих систем;
- защищенность - свойство программы противостоять случайным или умышленным вторжениям в нее.
Модель анализа надежности программных средств

-
- Факторы, влияющие на надежность ПО
К числу основных факторов, влияющих на надежность ПО отнесены:
- взаимодействие ПО с внешней. Этот фактор вносит наименьший вклад в надежность ПО при современном уровне надежности аппаратуры, ОС и компиляторов;
- взаимодействие с человеком (разработчиком и пользователем);
- организация ПО (проектирование, постановка задачи и способы их достижения и реализации) и качество его разработки. Этот фактор вносит наибольший вклад в надежность;
- тестирование.
- Ошибки ПО
В борьбе со сложностью ПО используются две концепции:
Иерархическая структура. Иерархия позволяет разбить систему по уровням понимания (абстракции, управления). Концепция уровней позволяет анализировать систему, скрывая несущественные для данного уровня детали реализации других уровней. Иерархия позволяет понимать, проектировать и описывать сложные системы.
Независимость. В соответствии с этой концепцией, для минимизации сложности, необходимо максимально усилить независимость элементов системы. Это означает такую декомпозицию системы, чтобы её высокочастотная динамика была заключена в отдельных компонентах, а межкомпонентные взаимодействия (связи) описывали только низкочастотную динамику системы.
Методы обнаружения ошибок, которые базируются на введении в ПО системы различных видов избыточности:
Временная избыточность. Использование части производительности ЭВМ для контроля исполнения и восстановления работоспособности ПО после сбоя.
Информационная избыточность. Дублирование части данных информационной системы для обеспечения надёжности и контроля достоверности данных.
Программная избыточность включает в себя: взаимное недоверие - компоненты системы проектируются, исходя из предположения, что другие компоненты и исходные данные содержат ошибки, и должны пытаться их обнаружить; немедленное обнаружение и регистрацию ошибок; выполнение одинаковых функций разными модулями системы и сопоставление результатов обработки; контроль и восстановление данных с использованием других видов избыточности.
Задача обеспечения ПО устойчивости к ошибкам направлены на применение методов минимизации ущерба, вызванного появлением ошибок, и включают в себя:
- обработку сбоев аппаратуры;
- повторное выполнение операций;
- динамическое изменение конфигурации;
- сокращенное обслуживание в случае отказа отдельных функций системы;
- копирование и восстановление данных;
- изоляцию ошибок.
Дается 4 группы принципов обеспечения надежности:
- предупреждение ошибок;
- обнаружение ошибок;
- исправление ошибок;
- обеспечение устойчивости к ошибкам.
Действия, направленные на минимизацию ошибок и сбоев:
- предотвращение ошибок за счет структурного программирования;
- сокрытие информации или дозированный доступ к данным со стороны программных средств и объектов в объектно-ориентированном программировании;
- отладка;
- устойчивость к сбоям;
- обработка исключительных ситуаций (перехват ошибок, например, деление на ноль) и локализация ошибок и сбоев;
- восстановление программы после сбоя.
В соответствии с ГОСТ 19.004-80 различают следующие виды работ, направленные на устранение ошибок в ПО: проверка, отладка и испытание программы.
Чем интенсивнее использование программного изделия (ПИ), тем быстрее выявляются в нем ошибки.
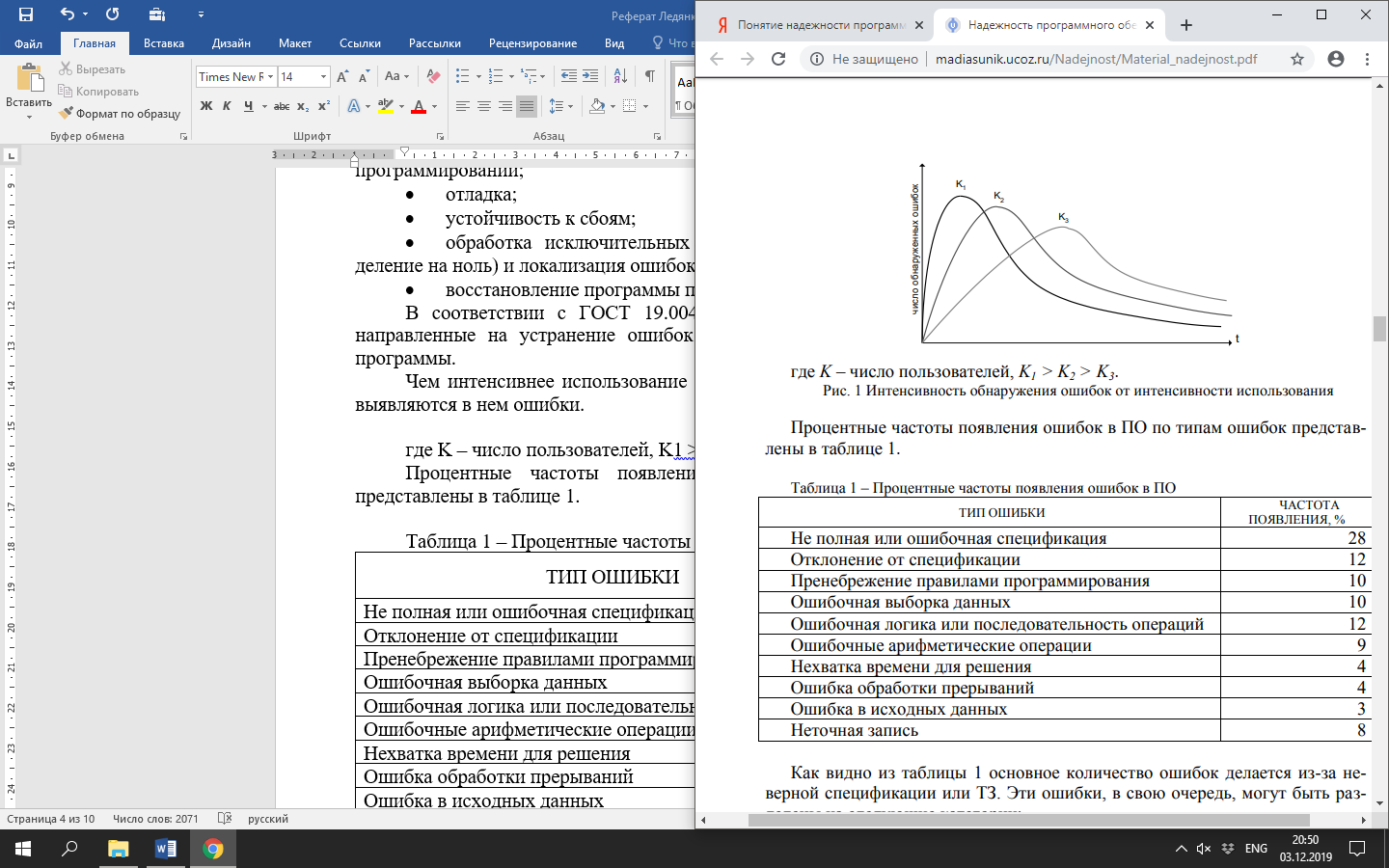
Рисунок 1 Интенсивность обнаружения ошибок от интенсивности использования
где K – число пользователей, K1 > K2 > K3.
Процентные частоты появления ошибок в ПО по типам ошибок представлены в таблице 1.
Таблица 1 – Процентные частоты появления ошибок в ПО
|
ТИП ОШИБКИ |
ЧАСТОТА ПОЯВЛЕНИЯ, % |
|
Не полная или ошибочная спецификация |
28 |
|
Отклонение от спецификации |
12 |
|
Пренебрежение правилами программирования |
10 |
|
Ошибочная выборка данных |
10 |
|
Ошибочная логика или последовательность операций |
12 |
|
Ошибочные арифметические операции |
9 |
|
Нехватка времени для решения |
4 |
|
Ошибка обработки прерываний |
4 |
|
Ошибка в исходных данных |
3 |
|
Неточная запись |
8 |
Как видно из таблицы 1 основное количество ошибок делается из-за неверной спецификации или ТЗ. Эти ошибки, в свою очередь, могут быть разделены на следующие категории:
Таблица 2 – Категории ошибок в ПО
|
ПРИЧИНА ОШИБКИ |
ЧАСТОТА ПОЯВЛЕНИЯ, % |
|
Ошибки в числовых значениях |
12 |
|
Недостаточные требования к точности |
4 |
|
Ошибочные символы или знаки |
2 |
|
Ошибки оформления |
15 |
|
Неправильное описание или требование к аппаратуре |
2 |
|
Исходные данные для разработки неполные, неточные или ошибочные |
52 |
|
Двусмысленность требований |
13 |
Из этих таблиц, кстати, следует, на что нужно обращать особое внимание при проведении валидации и верификации ПО (верификация отвечает на вопрос, правильно ли и качественно ли создана программа, а валидация (или аттестация) - на вопрос правильно ли работает программа).
Средства и способы повышения надёжности ПО
На основании методов обнаружения ошибок были разработаны следующие средства повышения надёжности ПО.
Средства, использующие временную избыточность: авторизация доступа пользователей к системе, анализ доступных пользователю ресурсов, выделение ресурсов согласно ролям и уровням подготовки пользователей, разграничение прав доступа пользователей к отдельным задачам, функциям управления, записям и полям баз данных.
Средства обеспечения надёжности, использующие информационную избыточность: ссылочная целостность баз данных обеспечивается за счёт системы внутренних уникальных ключей для всех информационных записей системы, открытая система кодирования, позволяющая пользователю в любой момент изменять коды любых объектов классификации, обеспечивает стыковку системы классификации АИС делопроизводство с ПО других разработчиков, механизмы проверки значений контрольных сумм записей системы, обеспечивают выявление всех несанкционированных модификаций (ошибок, сбоев) информации.
Способы обеспечения и повышения надежности ПО:
- усовершенствование технологии программирования (например, формальное описание этапов программирования при помощи языка UML);
- выбор алгоритмов, не чувствительных к различного рода нарушениям
- вычислительного процесса (использование алгоритмической избыточности);
- резервирование программ - N-версионное программирование;
- верификация и валидация программ с последующей коррекцией.
- Проблемы исследования надежности ПО
К основным проблемам исследований надежности ПО относятся:
- прежде всего - разработка методов оценки и прогнозирования надежности ПО;
- определение основных факторов, влияющих на надежность ПО;
- разработка методов, обеспечивающих достижение заданного уровня надежности ПО;
- совершенствование методов повышения надежности ПО в процессе проектирования и эксплуатации.
- Тестирование ПО
Важным этапом жизненного цикла ПО, определяющим качество и надёжность системы, является тестирование. Тестирование - процесс выполнения программ с намерением найти ошибки и включает в себя следующие этапы:
- автономное тестирование;
- тестирование сопряжений;
- тестирование функций;
- комплексное тестирование;
- тестирование полноты и корректности документации;
- тестирование конфигураций.
Надежность ПО повышается также с помощью применения различных методов тестирования. Полное тестирование ПО невозможно. Обычно применяют следующие виды тестирования:
- тестирование ветвей;
- математическое доказательство правильности алгоритма решения задачи;
- символическое тестирование, еще называется статическим тестированием. Удобно при локализации ошибки, проявление которой выявлено при конкретном узком или строго заданном диапазоне входных значений;
- динамическое тестирование (с помощью динамически генерируемых входных данных), что удобно при быстром тестировании во всем широком диапазоне входных параметров;
- тестирование путей выполнения программы;
- функциональное тестирование;
- проверки по времени выполнения программы;
- проверка по использованию ресурсов и стрессовое тестирование.
Модели надежности ПО
Все модели надежности можно классифицировать по тому, какой из перечисленных процессов они поддерживают (предсказывающие, прогнозные, измеряющие и т.д.). Нужно отметить, что модели надёжности, которые в качестве исходной информации используют данные об интервалах между отказами, можно отнести и к измеряющим, и к оценивающим в равной степени. Некоторые модели, основанные на информации, полученной в ходе тестирования ПО, дают возможность делать прогнозы поведения ПО в процессе эксплуатации.
Аналитические модели дают возможность рассчитывать количественные показатели надежности, основываясь на данных о поведении программы в процессе тестирования (измеряющие и оценивающие модели).
Эмпирические модели базируются на анализе структурных особенностей программ. Они рассматривают зависимость показателей надёжности от числа межмодульных связей, количества циклов в модулях и т.д. Часто эмпирические модели не дают конечных результатов показателей надёжности, однако они включены в классификационную схему, так как развитие этих моделей позволяет выявлять взаимосвязь между сложностью АСОД и его надежностью. Эти модели можно использовать на этапе проектирования ПО, когда осуществляется разбивка на модули и известна его структура.
Аналитические модели представлены двумя группами: динамические модели и статические. В динамических поведение ПС (появление отказов) рассматривается во времени. В статических моделях появление отказов не связывают со временем, а учитывают только зависимость количества ошибок от числа тестовых прогонов (по области ошибок) или зависимость количества ошибок от характеристики входных данных (по области данных).
Для использования динамических моделей необходимо иметь данные о появлении отказов во времени. Если фиксируются интервалы каждого отказа, то получается непрерывная картина появления отказов во времени (группа динамических моделей с непрерывным временем). С другой стороны, может фиксироваться только число отказов за произвольный интервал времени.
Динамические модели надежности
Модель Шумана
Исходными данными для модели Шумана, которая относится к динамическим моделям дискретного времени, собираются в процессе тестирования АСОД в течение фиксированных или случайных временных интервалов.
Каждый интервал - это стадия, на котором выполняется последовательность тестов и фиксируется некоторое число ошибок.
Модель Шумана может быть использована при определенном образе организованной процедуре тестирования. Использование модели Шумана предполагает, что тестирование поводиться в несколько этапов. Каждый этап представляет собой выполнение на полном комплексе разработанных тестовых данных. Выявление ошибки регистрируется, но не исправляются. По завершении этапа на основе собранных данных о поведении ПО на очередном этапе тестирования может быть использована модель Шумана для расчета количественных показателей надежности. При использовании модели Шумана предполагается, что исходное количество ошибок в программе постоянно, и в процессе тестирования может уменьшаться по мере того, как ошибки выявляются и исправляются.
Достоинство этой модели заключается в том, что можно исправлять ошибки, внося изменения в текст программы в ходе тестирования, не разбивая процесс на этапы, чтобы удовлетворить требованию постоянства числа машинных инструкции.
Модель La Padula
По этой модели выполнение последовательности тестов производиться в m этапов. Каждый этап заканчивается внесением изменений (исправлений) в ПП. Возрастающая функция надёжности базируется на числе ошибок, обнаруженных в ходе каждого тестового прогона.
Преимущество данной модели заключается в том, что она является прогнозной и, основываясь на данных, полученных в ходе тестирования, дает возможность предсказать вероятность безотказной работы программы на последующих этапах её выполнения.
Статические модели надежности
Статические модели принципиально отличаются от динамических прежде всего тем, что в них не учитывается время появления ошибок в процессе тестирования и не используется никаких предположений о поведении функции риска. Эти модели строятся на твердом статическом фундаменте.
Модель Миллса
Использование этой модели предполагает необходимость перед началом тестирования искусственно вносить в программу некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества ошибок, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как естественные, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования.
Тестируя программу в течение некоторого времени, собирается статистика об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные.
Соотношение:
дает возможность оценить N – первоначальное количество ошибок в программе. В данном соотношении, которое называется формулой Миллса, S –количество искусственно внесенных ошибок, n – число найденных собственных ошибок, V – число обнаруженных к моменту оценки искусственных ошибок.
Вторая часть модели связанна с проверкой гипотезы от N. Предположим, что в программе имеется К собственных ошибок, и внесем в нее еще S ошибок. В процессе тестирования были обнаружены все S внесенных ошибок и n собственных ошибок.
Тогда по формуле Миллса мы предполагаем, что первоначально в программе было N = n ошибок. Вероятность, с которой можно высказать такое предположение, возможно рассчитать по следующему соотношению:
Таким образом, величина С является мерой доверия к модели и показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель
ошибок: первое предсказывает возможное первоначально имевшихся в программе ошибок, а второе используется для установления доверительного
уровня прогноза. Однако формула (5.2) для расчета C не может быть в случае, когда не обнаружены все искусственно рассеяние ошибки. Для этого
случая, когда оценка надежности производиться до момента обнаружения
всех S рассеянных ошибок, величина C рассчитывается по модифицируемой
формуле
где числитель и знаменатель формулы при n <= K являются биноминальными коэффициентами вида
Если при тех же исходных условиях оценка надежности производится в момент, когда обнаружены 8 из 10 искусственных ошибок, то вероятность того, что в программе не было ошибок, увеличивается до 0.73. В действительности модель Миллса можно использовать для оценки N после каждой найденной ошибки. Предлагается во время всего периода тестирования отмечать на графике число найденных ошибок и текущее значение для N. Достоинством модели является простота применения математического аппарата, наглядность и возможность использования в процессе тестирования.
Однако она не лишена и ряда недостатков, самые существенные из которых – это необходимость внесения искусственных ошибок (этот процесс плохо формализуется) и достаточно вольное допущения величины K, которое основывается исключительно на интуиции и опыте человека, проводящего оценку, т.е. допускается большое влияние субъективного фактора.
Модель Липова
Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа тестов. Если сделать то же предположение, что и модель Миллса, т.е. что собственные и искусственные ошибки имеют равную вероятность быть найденными, то вероятность обнаружения n собственных и V внесенных ошибок равна:
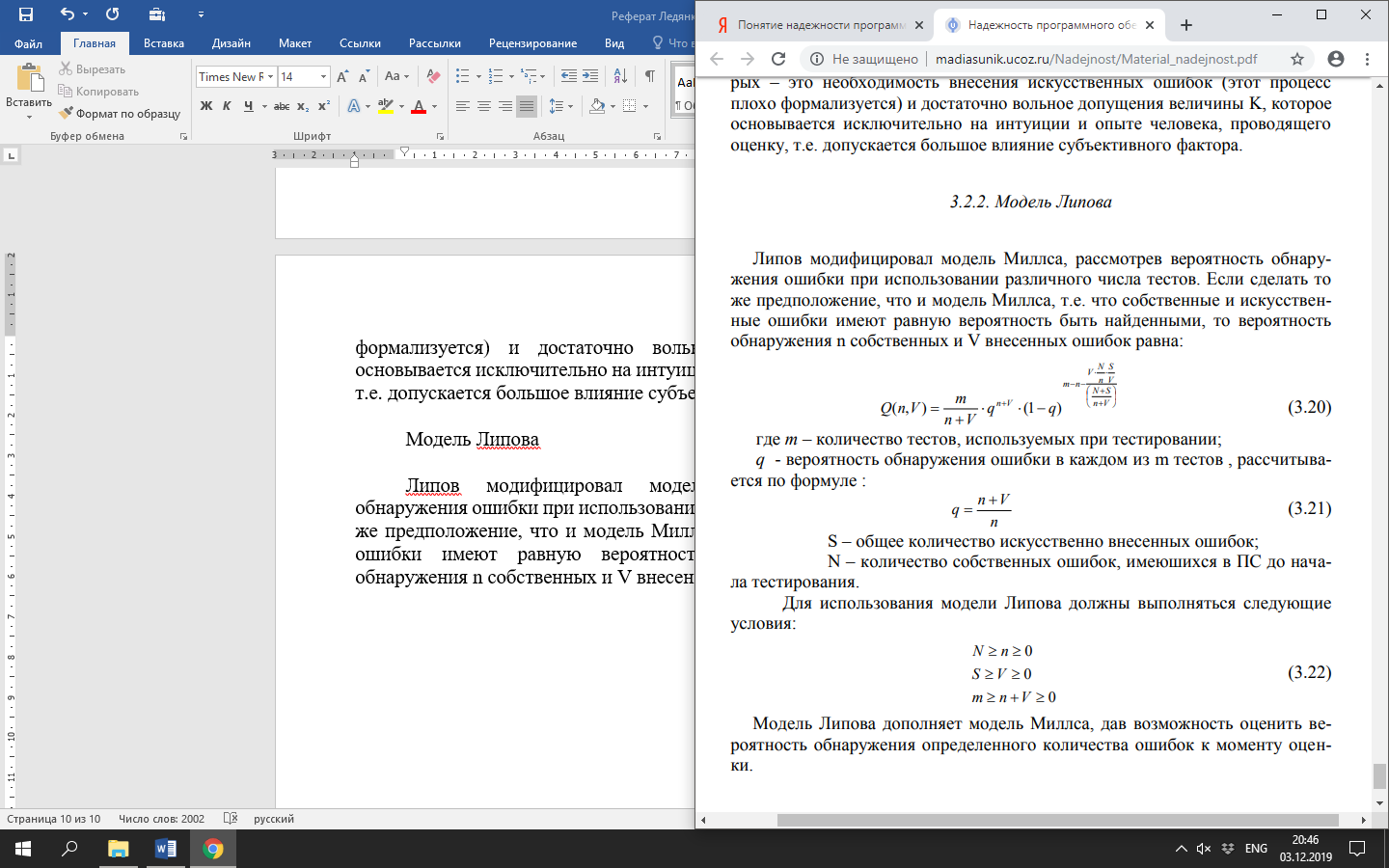
где m – количество тестов, используемых при тестировании;
q - вероятность обнаружения ошибки в каждом из m тестов, рассчитывается по формуле:
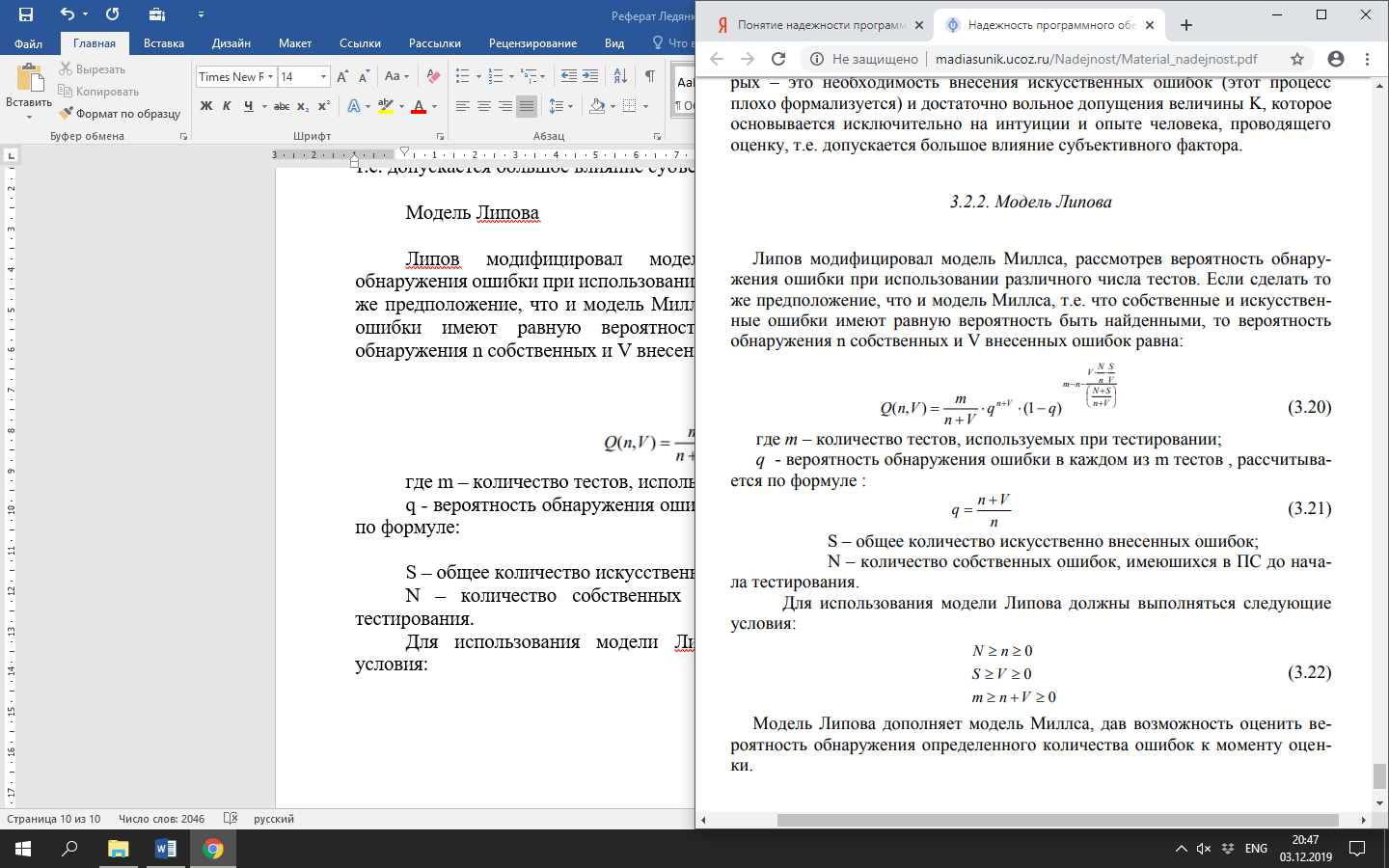
S – общее количество искусственно внесенных ошибок;
N – количество собственных ошибок, имеюшихся в ПС до начала тестирования.
Для использования модели Липова должны выполняться следующие условия:
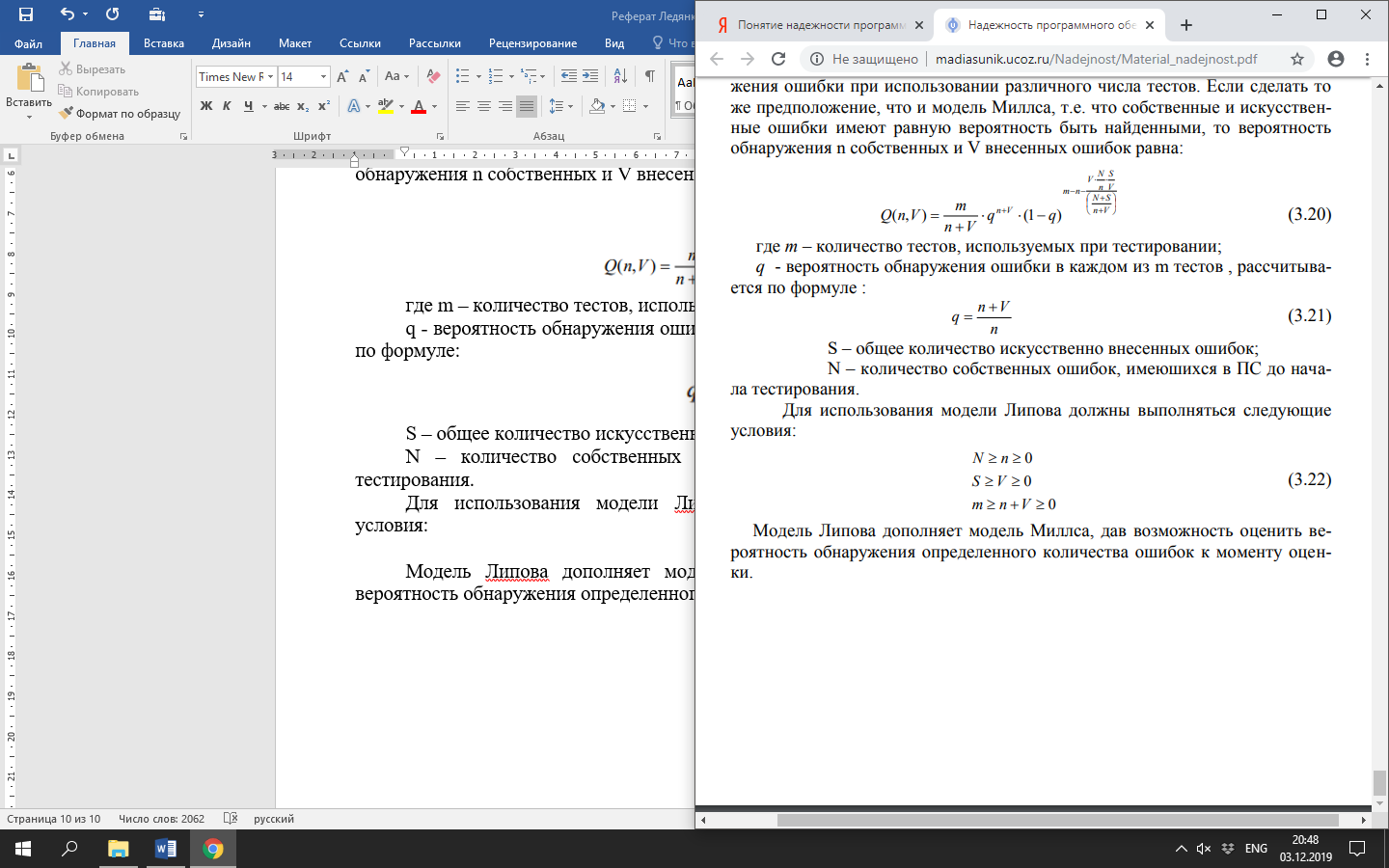
Модель Липова дополняет модель Миллса, дав возможность оценить вероятность обнаружения определенного количества ошибок к моменту оценки.

- Управление развитием организации
- Системы коллективной (групповой) работы
- Системы коллективной (групповой) работы (ИС)
- Информационн ая система управления взаимоотношениями с клиентами – CRM
- Описание и основные возможности мультимедиа технологий
- Мультимедиа технологии
- Общие характеристики скриптовых языков. Язык Python
- Правовые акты управления: понятие, функции и формы
- Применение OLAP-технологий в бизнесе
- Место и роль в мировой экономике Индии
- Макроэкономика и бизнес
- Архитектура ANSI-SPARC