
Проектирование БД для домашней библиотеки
Содержание:

ВВЕДЕНИЕ
Актуальность темы курсовой работы подтверждает тот факт, что сейчас умение обрабатывать информацию является ключевым навыком во всех сферах, не только в сфере информационных технологий. Разрабатывается все больше ПО для сбора, хранения и обработки информации. В том числе довольно новое, но очень популярное направление Big Data, которое применяется во многих отраслях современной инфраструктуры. Язык структурированных запросов (далее SQL – Structured Query Language) предоставляет пользователям очень простой и в то же время очень эффективный способ обработки данных. Помимо этого, SQL широко используется и в прикладном программировании, что дает возможность работать с ним и обычным пользователям, даже не прибегая к синтаксису самого языка.
В первую очередь, SQL предназначен для работы и управления реляционными базами данных. Далее мы рассмотрим их особенности и специфику работы. Важно отметить, что SQL является интегрируемым языком широкого пользования, что предоставляет пользователям возможность использовать его в ряде посторонних приложениях. Функциональность языка не изменяется вне зависимости от используемого ПО, устройства или базы данных.
Среди основных СУБД мы можем отметить таких «гигантов» в сфере IT технологий, как Microsoft (Microsoft SQL Server Management Studio, или SSMS), Oracle (Oracle SQL Developer), MySQL AB и Sun Microsystems (MySQL) и т.д.
Предметом исследования курсовой работы является «Проектирование БД для домашней библиотеки», объектом – «Базы данных».
Целью курсовой работы является изучение возможностей использования SQL даже для домашнего ежедневного использования. Являясь поклонником библиотек, книг и имея в наличии достаточное их количество, полученная в ходе исследоования и разработки БД может быть использована локально.
В рамках выполнения цели, необходимо будет решить следующие задачи:
1) определить основные понятия: база данных, система управления базами данных (далее – СУБД), классификация СУБД, основные возможности языка SQL;
3) проведение сравнительного анализа разных видов СУБД;
2) выявить преимущества и недостатки реляционной модели данных;
4) рассмотреть синтаксис языка SQL;
5) разработать структуру и подготовить скрипты для создания БД для домашней библиотеки.
Синтаксис скриптов будет использоваться для SSMS.
1 Глава. Аналитическая часть.
1.1 Описание предметной области. Постановка задачи
Еще совсем недавно использование Excel в качестве основного инструмента регистрации и обработки информации было обычным делом и даже крупные компании делились опытом и «фишками» использования Excel для ведения данных о сотрудниках, расчета заработной платы, премий, продаж, сведениях о клиентах и т.д. Сейчас же многие переходят на базы данных (далее – БД) и различные программы, использующие SQL как основной инструмент работы с БД. Что же это меняет? Почему использование Excel перестало быть таким популярным?
Первое преимущество использования SQL это, конечно же, возможность работы с БД несколькими пользователями одновременно, без риска «затереть» данные друг друга.
Оперативность работы. Ни для кого не секрет, что при значительном объеме данных, скорость работы Excel падает в несколько раз. А так же при использовании более сложного функционала, форм или макросов, скорость обработки функций так же падает. При работе с БД через прикладные программы (в основном использующих клиент-серверную архитектуру) запросы уже оптимизированы, и потеря скорости незначительна для конечного пользователя.
Простота. Конечно же, Excel – превосходный инструмент. Но, чтобы использовать все его возможности и оптимально работать с данными, необходимо иметь специфичные знания. Это превращает конечных пользователей в программистов, заставляя их разбираться с тонкостями работы макросов, вместо работы с данными. Прикладные программы же изначально создавались для удобства использования конечными пользователями без технических знаний. Это позволяет значительно сэкономить человеческий ресурс.
Это основные, но далеко не все преимущества перехода на прикладные программы с Excel. Конечно же, в некоторых случаях использование Excel остается конкурентным вариантом. И, при наличии соответствующих специалистов, Excel может полностью заменить прикладные программы, работающие с БД.
База данных – это организованный (упорядоченный) набор структурированной информации или данных, которые хранятся в электронном виде в компьютерной системе. Обычно, БД управляется с помощью системы управления базой данных.
Итак, перед нами стоит задача создать удобный инструмент для ведения домашней библиотеки с использованием СУБД. Для этого нам нужно будет:
- Придумать и настроить интерфейс для ввода данных;
- Создать структуру БД;
- Настроить БД;
- Определить список результатов (отчетов), которые мы хотим получать.
В качестве источника данных могут быть использованы следующие опции:
- Веб-интерфейс для записи данных в библиотеку;
- Загрузка данных из Excel с помощью стандартного фукционала СУБД;
- Ручной ввод в БД с помощью скриптов.
Есть и другие способы заполнения БД, но я предлагаю сконцентрироваться на этих трех, как на основных способах реализации поставленной задачи. Конечно, последние два пункта – это скорее привилегии администратора, либо начальная загрузка данных в БД, нежели ежедневное обновление информации. Наиболее удобным для постоянного использования является первый способ – веб-интерфейс. Там же можно будет настроить получение тех или иных отчетов.
Что же может понадобиться пользователю такой БД? Какие отчеты и результаты он бы хотел видеть на выборке? Предлагаю определить основные характеристики, которые будут описаны для книг:
- Автор;
- Название;
- Жанр и поджанр;
- Язык, на котором написана книга;
- Основной цвет обложки;
- Факт прочтения.
Соответственно, в качестве результата может быть отчет, отфильтрованный по одному или нескольким полям характеристик. И, в качестве стандартного отчета – все книги в библиотеке, которые еще не были прочитаны.
Т.к. библиотекой пользуюсь я одна – создавать многопользовательскую версию БД я не вижу смысла. Все действия будут выполняться одним единственным пользователем, он же – администратор БД.
Задачей курсовой работы является: создание удобного инструмента для ведения настроенной базы данных для домашней бибилиотеки и с возможностью выгружать необходимые отчеты из БД.
1.2.Выбор средств / методологии проектирования. Выбор СУБД
Система управления базами данных (далее СУБД) – это комплекс программных инструментов и средств, которые необходимы для создания структуры новой БД, ее редактирования, наполнения и отображения информации. СУБД могут быть классифицированы различными способами: по модели данных, по организации данных, по способу доступа к данным (Рисунок 1).

Рисунок 1 – Классификация СУБД
Классификация СУБД в соответствии с моделью данных. По данной классификации всего выделяют 5 типов СУБД. Рассмотрим их особенности:
- Иерархическая модель данных (Рисунок 2). Представляет собой набор элементов данных, расположенные в порядке подчинения. В иерархической структуре: каждый узел на более низком уровне должен быть связан только с одним узлом на более высоком уровне; корневой узел должен быть только один и он не должен подчиняться никакому другому узлу; до каждого узла существует только один путь от корневого.
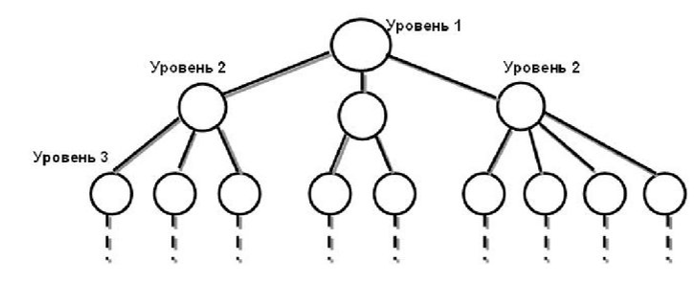
Рисунок 2 – Иерархическая модель данных
Примером Иерархической модели данных может служить модель населенных пунктов планеты Земля, где на первом (корневом) узле будет находиться планета Земля, далее континенты (Евразия, Африка, Южная Америка и т.д.), далее страны (Россия, Англия, Китай и т.д.), и, наконец, населенные пункты (Лондон, Москва, Санкт-Петербург, Париж и т.д.).
- Сетевая модель данных (Рисунок 3). Внешне похожа на иерархическую модель, но, в отличии от нее каждый узел может быть связан с любым узлом.

Рисунок 3 – Сетевая модель данных
Наглядным примером сетевой модели данных может служить список учеников школы, распределенных по дополнительным занятиям. На первом уровне будет находиться школа, далее классы (пока что никакого различия с иерархической структурой не наблюдается), на третьем уровне – ученики и на четвертом дополнительные занятия. На последних двух уровнях как раз яркий пример сетевой модели данных, так как ученики из разных классов могут заниматься в одном и том же кружке и, в свою очередь, каждый ученик может заниматься в нескольких кружках одновременно. Плюс каждый кружок проводит один из преподавателей, курирующих определенный класс, поэтому так же наблюдается связь четвертого и второго уровней структуры.
- Реляционная модель данных (Рисунок 4). Организована в виде двумерных таблиц. Каждая из таблиц в свою очередь является двумерным массивом. Таблицы должны соответствовать правилам: каждый из столбцов таблицы однородный по типу данных; каждый столбец имеет уникальное имя для этой таблицы; порядок строк и столбцов в таблице произвольный; каждая строчка (запись) имеет уникальный идентификатор для этой таблицы.

Рисунок 4 – Реляционная модель данных
Область применения реляционных таблиц очень широка. Для данной курсовой работы будет актуален пример списка сотрудников на предприятии (Рисунок 5). Для крупных предприятий характерно использование набора ID в полях описания сотрудника и последующее обращение к соответствующей таблице для определения значения этого ID. Допустим у нас имеется предприятие «Фирма». В базе данных Фирмы существует список физических лиц, в котором имеются все данные по людям, которые когда-либо так или иначе работали на предприятии. Далее имеется список работников – каждые прием и увольнение сотрудника. В этой таблице мы видим ссылку на ID из таблицы физических лиц, но так же имеется свой уникальный ID для каждого работника, т.к. одно и то же физ. лицо может быть принят и уволен несколько раз. Далее мы видим таблицу со списком назначений – в ней отражены все перемещения и изменения для каждого работника. В этой таблице так же записаны ID физ. лица и работника, но и свой уникальный ID присутствует. В столбце с должностью записывается ID должности, значение которой может быть извлечено из соответствующей таблицы должностей.
Набор таблиц и полей в подобной БД может варьироваться в зависимости от области применения и необходимости предприятия.

Рисунок 5 – Пример реляционной модели данных
- Объектно-ориентированная модель данных. Согласно определению, это БД, в которой данные формируются в виде объектов, атрибутов, методов и классов этих объектов. Каждый объект такой БД имеет свой уникальный идентификатор. Объекту присущи состояние и поведение. Состояние объекта характеризуется набором его атрибутов. Поведением объекта называется набор методов, управляющих его состоянием. Множество объектов с одинаковыми атрибутами и методами объединяются в классы объектов. Класс имеет свойство наследование – то есть создание нового класса, на основе уже существующего. При этом вновь созданный класс (подкласс) наследует все свойства родительского класса (суперкласс), но к ним приобретает свои дополнительные атрибуты и методы. Зачастую в прикладном программировании используются именно такие модели данных, так как с ними проще всего взаимодействовать на программном уровне. Проще всего представить объектно-ориентированную модель на примере (Рисунок 6). Рассмотрим ту же БД для предприятия «Фирма», но уже в объектно-ориентированной модели.

Рисунок 6 – Пример объектно-ориентированной БД
- Объектно-реляционная модель данных (Рисунок 7). Подобные базы данных совмещают в себе объектно-ориентированную модель по качеству хранящихся данных и реляционный подход к структуре хранения.
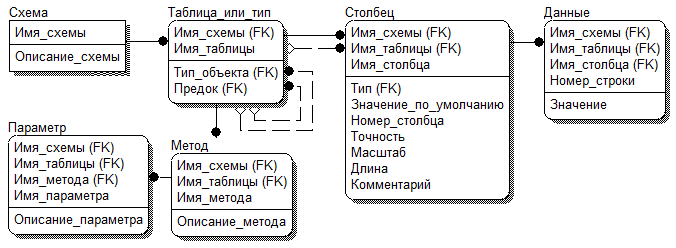
Рисунок 7 – Объектно-реляционная модель данных
Далее рассмотрим классификацию СУБД по организации данных. В такой классификации выделяют два типа СУБД.
- Локальная – БД называется локальной, если все ее части находятся на одном компьютере. Преимущество такой модели в ее независимости от сетевых процессов, т.к. все операции управления производятся на одном ПК. Но главный недостаток очевиден – редактирование БД происходит независимо на каждом ПК и, в случае работы в ней нескольких пользователей, сложно собрать и актуализировать все БД.
- Распределенная – БД называется распределенной, если ее части размещаются на двух или более устройствах. Это наиболее удобный вариант БД для многопользовательских систем. Так же, к плюсам подобного устройства БД можно отнести то, что части БД могут храниться на устройствах различного вида и с разными ОС.
По способу доступа к данным мы выделяем три основных вида организации СУБД.
- Файл-серверная архитектура – специфика данной архитектуры заключается в том, что пользователю передаются файлы из БД, но обрабатываются они уже на ПК пользователя. Из минусов такой системы сразу можно отметить, что на сеть дается дополнительная нагрузка в связи с излишними данными, передаваемыми пользователю, что негативно сказывается в случае большого объема объектов, хранящихся на сервере. Однако, эта структура отличается своей простотой, поэтому ее все еще можно встретить на некоторых небольших предприятиях.
- Клиент-серверная архитектура позволяет избежать тех проблем, которые преподносит файл-серверная архитектура. В подобной СУБД большая часть обработки данных происходит на машине сервера, а значит машина пользователя получает уже нужное количество данных, что позволяет снизить нагрузку на сеть, в отличие от предыдущего вида СУБД.
- Встраиваемая архитектура удобна, если БД используется только на одной машине. В этом случае СУБД встроена (тесно связана) с прикладной программой, обращающейся к ней. При этом сама БД находится на той же машине. Конечно, подобная структура не подойдет для средних или крупных предприятий, где администрирование производится несколькими людьми.
SQL (Structure Query Language) является языком программирования, который применяется для организации взаимодействия пользователя с реляционной базой данных. SQL работает по следующей схеме: запрос, написанный программистом на языке SQL обращается к некой СУБД, которая в свою очередь извлекает необходимую информацию из БД.
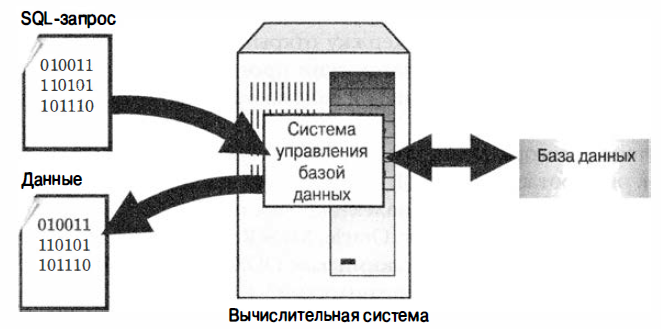
Рисунок 8 – Схема работы SQL
Несмотря на довольно простой принцип действия, сейчас можно говорить, что SQL предназначен не только для выборки данных, хотя это и является его основной функцией, но этот язык предлагает пользователю гораздо больше возможностей:
- Структура и организация запрашиваемых данных;
- Выборка данных;
- Обработка данных (добавление, изменение, удаление);
- Управление доступом к данным;
- Организация совместного использования БД;
- Обеспечение целостности данных.
Все эти возможности реализуются с помощью операторов SQL, либо встроенных функций СУБД. Рассмотрим основные операторы языка SQL.
Для удобства дальнейшей работы предлагаю воспользоваться примером БД, структура которой представлена в Приложении 1.
Запросы в языке SQL имеют примерно одинаковую структуру:
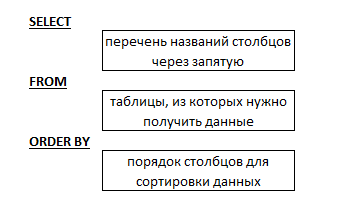
Рисунок 9 - Структура SQL запросов
Конечно, чем сложнее выборка данных, тем сложнее структура, больше подзапросов и массивнее объем обрабатываемых данных. Так же могут добавляться блоки условий и группировки данных, но основная структура практически всегда сохраняется в представленном виде.
Итак, все запросы на выборку данных в языке SQL начинаются с оператора SELECT. Следом за ним можно встретить следующие варианты:
- «TOP(n)» – где n – это количество строк. С помощью этого оператора мы можем вывести фиксированное количество строк. Используется совместно с перечнем столбцов.
- «pid, name, last_name» – перечень названий столбцов (через запятую), которые необходимо вывести в итоговой таблице.
- «*» - оператор, обозначающий все столбцы. Может использоваться как совместно с перечнем столбцов, так и индивидуально.
Далее, после определения набора столбцов следует оператор FROM. Здесь описываются таблицы, из которых необходимо получить данные. Чаще всего здесь используются операторы INNER/LEFT/RIGHT/FULL JOIN для объединения нескольких таблиц.
В случае необходимости, добавляется оператор условия WHERE, либо, если используются агрегирующие функции, HAVING. Здесь мы можем «отфильтровать» данные по нужным нам параметрам.
И заключительные операторы GROUP BY и ORDER BY. GROUP BY позволяет объединить строки с одинаковыми значениями в определенных столбцах (при этом, должны быть выбраны все столбцы, которые перечислены в операторе SELECT). Оператор ORDER BY позволяет сортировать данные в итоговой таблице, используется совместно с asc – по возрастанию, или desc – по убыванию.
Например, нам нужно из нашей БД выбрать фамилию, имя, город (в котором находится офис сотрудника) и должность сотрудников, с годом рождения с 1990 по 2000 включительно. Запрос будет выглядеть следующим образом:

Рисунок 10 - Пример запроса
Далее разберем операторы, позволяющие управлять данными в БД.
|
INSERT |
позволяет добавить одну или несколько строк с данными в существующую таблицу. |
|
DELETE |
позволяет удалить одну или несколько строк из существующей таблицы в БД. |
|
CREATE |
позволяет создать элемент БД (таблицу, хранимую процедуру, функцию). |
|
DROP |
позволяет удалить элемент БД (таблицу, хранимую процедуру, функцию). |
|
UPDATE |
позволяет изменить уже существующие данные в существующей таблице. |
Примеры использования:

Рисунок 11 - Примеры использования операторов
В данных примерах рассмотрены самые простые запросы, которые можно построить с помощью языка SQL. Но в жизни запросы гораздо сложнее и затрагивают большее количество данных. Данные могут не только выводиться при определенных условиях, но могут подвергаться более глубокому анализу. Поэтому SQL завоевал большое количество пользователей.
В рамках данной курсовой работы мы будем использовать MS SQL для проектирования БД домашней библиотеки. Учитывая структуру будущей БД, будет логичным выбором использование объектно-реляционной структуры БД.
1.3. Проектирование логической структуры базы данных
Ранее мы уже определили основные характеристики, или атрибуты, которыми должна обладать книга. Для удобства использования и экономии места в БД мы будем использовать реляционную модель, которая позволит избежать дублирующих значений.
Прежде чем приступить непосредственно к созданию БД, нужно продумать архитектуру будущей базы. Структурировать таблицы и данные.
Преследуя финальную цель – иметь удобную и понятную БД для домашней библиотеки – необходимо создать таблицу, в которой мы будем хранить данные о книгах – books (Рисунок 12).

Рисунок 12 – Таблица books
В качестве столбцов таблицы мы добавляем:
- Id – уникальный идентификатор книги, внешний ключ;
- Name – название книги, тип данных varchar;
- Auth – информация об авторе, ссылка на таблицу со списком авторов;
- Genre – жанр книги, ссылка на таблицу со списком жанров;
- Subgenre – поджанр книги, ссылка на таблицу со списком поджанров;
- Lang – язык, на которой написана книга, ссылка на таблицу со списком языков;
- Color – цвет обложки книги, ссылка на таблицу со списком цветов;
- Pos – расположение книги, ссылка на таблицу со списком шкафов и полок;
- Read – была книга прочитана или нет;
- Comment – поле для комментария.
Теперь создаем таблицу с авторами – authors (Рисунок 13).

Рисунок 13 – Таблица authors
- Id – уникальный идентификатор автора, внешний ключ;
- Last_name – фамилия автора;
- Name – имя автора;
- F_name – отчество автора (если имеется);
- Birthday – дата рождения автора;
- D_day – дата смерти (если имеется);
- S_bio – краткая биография;
- Native – родной язык автора.
Таблица со списком жанров и поджанров – genres (Рисунок 14).

Рисунок 14 – Таблица genres
- Id – уникальный идентификатор жанра/поджанра, внешний ключ;
- Name – название жанра/поджанра;
- Type – разделение на жанр/поджанр;
- Parent_id – ссылка на родительский жанр у поджанров.
Таблица с перечнем языков – languages (Рисунок 15).

Рисунок 15 – Таблица languages
- Id – уникальный идентификатор языка, внешний ключ;
- Name – название языка на этом языке;
- Name_en – название языка на английском.
Таблица с цветами – colors (Рисунок 16).

Рисунок 16 – Таблица colors
- Id – уникальный идентификатор цвета, внешний ключ;
- Name – название цвета.
Таблица с определением места книги – position (Рисунок 17).

Рисунок 17 – таблица position
- Id – уникальный идентификатор позиции, внешний ключ;
- Cabinet – id шкафа;
- Shelf – id полки
Таблица со всеми шкафами и полками – storage (Рисунок 18).

Рисунок 18 – таблица storage
- Id – уникальный идентификатор шкафа/полки, внешний ключ;
- Type – разделение на шкафы и полки;
- Parent_id – ссылка на родительский шкаф у полок;
- Desk – описание (местонахождение шкафа и тд).
Полная структура БД представлена в Приложении 2.
1.4. Проектирование физической структуры базы данных
После завершения построения логической модели БД, перейдем непосредственно к созданию физической модели БД.
На локальном сервере (MS Server 2019) создаем новую БД с названием library (Рисунок 19).

Рисунок 19 – Создание БД library
Далее создаем все таблицы, описанные выше и устанавливаем связи. Проверяем схему получившейся БД. Скрипты создания таблиц и создания связей, а так же схема БД приведены в Приложении 3.
ПРОЕКТИРОВАНИЕ БД ДЛЯ ДОМАШНЕЙ БИБЛИОТЕКИ
Инструкции по работе с базой данных
Как мы определили раньше, для организации ввода и вывода информации самым удобным решением будет создание локального сайта. Для удобной работой с БД удобным и простым решением будет создание сайта на языке PHP с использованием HTML для отрисовки интерфейса сайта. Так как сайт создается исключительно для локального использования, создавать сложную графику для сайта будет нерелевантным. Поэтому, используем самую простую табличную форму HTML (Рисунок 20).

Рисунок 20 – Внешний вид домашней страницы
Для создания новых записей или редактирования существующих создан раздел «Администрирование». При нажатии на заголовок раскрываются доступные опции (Рисунок 21).

Рисунок 21 – Раздел «Администрирование»
Разберем пример добавления автора. При клике на соответствующую кнопку «Добавить автора» раскрывается форма для ввода данных на отдельной странице (Рисунок 22). Форма организована с помощью HTML тега <form>, метод GET позволяет передать данные из формы в соответствующие переменные и с помощью PHP (драйвер SQL для PHP, семейство функций sqlsrv) записать эти данные в БД. В случае наличия связей между таблицами реализованы выпадающие списки с возможными вариантами (Рисунок 22).
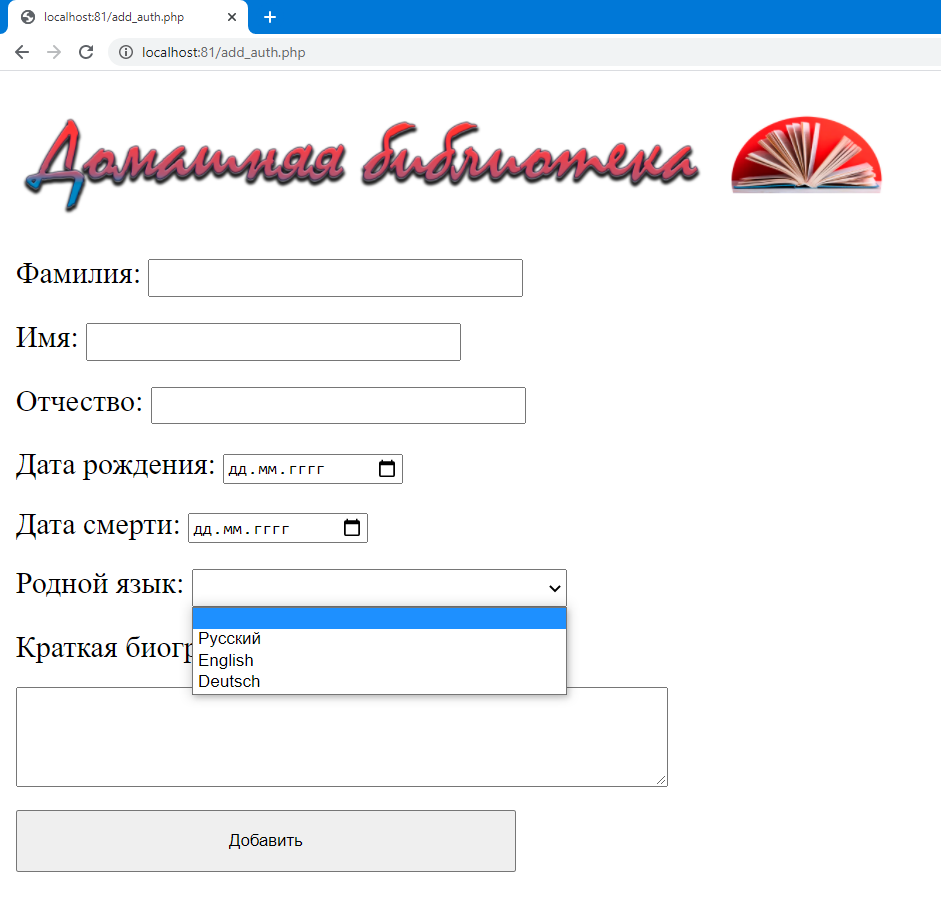
Рисунок 22 – Форма добавления нового автора.
После ввода данных идет обработка данных с помощью вспомогательной страницы, которая не отображается пользователю, а переадресовывает сразу на стартовую страницу. Попробуем создать нового автора. На данный момент в БД записаны некоторые данные (Рисунок 23).

Рисунок 23 – Данные в таблице authors
Попробуем добавить нового автора – Наталью Мазуркевич. Вводим все известные данные о ней (Рисунок 24).

Рисунок 24 – Заполненная форма
Нажимаем кнопку «Добавить». Мы вновь оказываемся на стартовой странице. Проверяем в БД, что информация успешно записана (Рисунок 25).

Рисунок 25 – Данные в БД после добавления нового автора через сайт
Добавление новой книги организовано слегка сложнее. Ввод данных идет поэтапно, с помощью нескольких страниц. Это связано с тем, что существуют зависимые списки (жанр и поджанр, полки и шкафы), которые возможно реализовать только посредством javascript, что усложнит процесс разработки сайта и сделает его менее выгодным по затраченному времени.
Аналогичным образом можно изменить или добавить любые записи в БД, предусмотрено редактирование всех данных через интерфейс по аналогичной схеме. Запись новых данных происходит с помощью php-запроса:
$sql="insert into books ( name, auth) values('".$_SESSION['bookname']."', ".$_SESSION['auth_id'].")";
$result=sqlsrv_query($on_link, $sql);
Аналогично происходит обновление данных:
$sql="update books set [comment]=(select case when '".$_SESSION['comment']."'<>'' then '".$_SESSION['comment']."' else(select [comment] from books where id=".$_SESSION['book_id'].") end) where id=".$_SESSION['book_id'];
$result=sqlsrv_query($on_link, $sql);
Разработка интерфейса и реализация проекта
Какие же отчеты могут понадобиться пользователю? Конечно же выгрузка со всеми книгами в библиотеке и с указанием всех их характеристик. Далее, задаваясь вопросом, что бы почитать, можно пользоваться отдельной выгрузкой с непрочитанными книгами. И, чтобы порекомендовать книги друзьям, можно получить выгрузку с уже прочитанными книгами. И последний отчет – пользовательский, где пользователь сам отмечает какую информацию из таблиц он желает получить. Список отчетов так же находится на стартовой странице и разворачивается нажатием на заголовок (Рисунок 26).

Рисунок 26 – Список доступных отчетов
Выгрузка отчетов реализована с помощью запуска Job’а, который отрабатывает инструкции в PowerShell и грузит соответствующий файл отчета в папку на сервере. Далее, бразер переадресовывает страницу на этот файл, и файл появляется в загрузках.
Обработка данных осуществляется с помощью созданных View на каждый отчет. Так, для отчета со всеми книгами и характеристиками используется view с кодом создания, представленном в Приложении 4. Скрипт для PowerShell, в свою очередь, выглядит следующим образом:
sqlcmd -S . -d library -E -s',' -W -Q "SELECT * FROM view_rep_books"> \...\extracts\report_books.csv
Структура стандартных отчетов приведена ниже на рисунках 27-29.
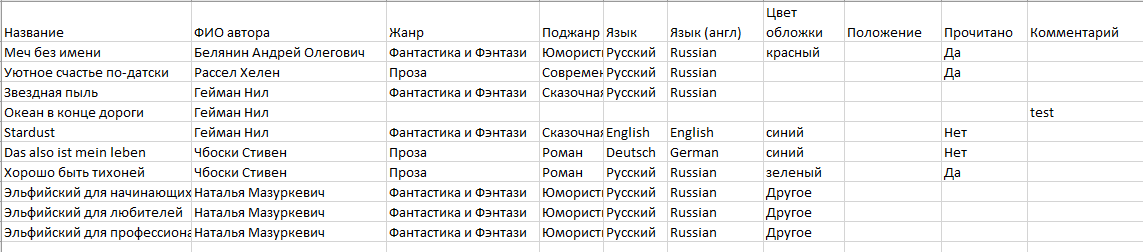
Рисунок 27 - Структура отчета "Все книги"

Рисунок 28 - Структура отчета "Непрочитанные книги"
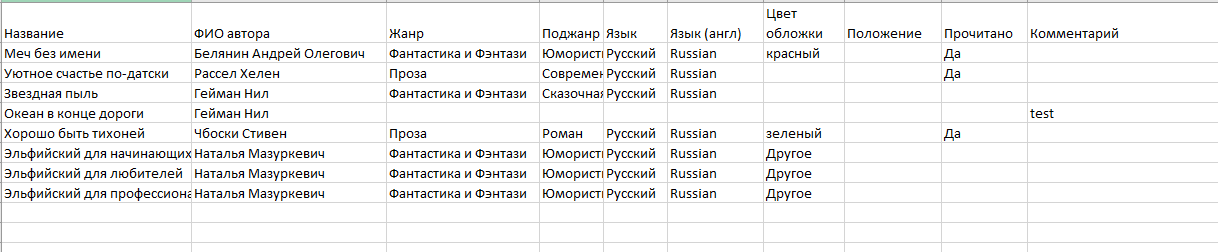
Рисунок 29 - Структура отчета "Прочитанные книги"
На странице пользовательского отчета необходимо отметить чекбоксы полей, которые необходимо включить в отчет (Рисунок 30). После этого, с помощью языка php идет объединение этих чекбоксов в запрос к базе, в результате которого выгружается отчет.

Рисунок 30 - Страница пользовательского отчета
Оценка экономической эффективности проекта
Для определения целесообразности реализуемого проекта необходимо рассмотреть затраты времени на создание БД и сайта и сопоставить их со временем, которое этот проект позволяет сэкономить. Ниже приведена таблица затрат времени.
|
№ |
Действие |
Затраты |
|
1 |
Установка и настройка MS SQL Server и сопутствующих приложений |
3 часа |
|
2 |
Создание базы данных, создание таблиц и связей |
1,5 часа |
|
3 |
Отрисовка графики (лого сайта) |
1 час |
|
4 |
Настройки php и драйверов для SQL |
2 часа |
|
5 |
Создание сайта |
5 часов |
|
6 |
Заполнение сайта исходными данными |
1,5 часа |
Получается, что всего на настройку сайта потребовалось 14 часов. В среднем, мне необходимо найти 3-4 книги в месяц, а так же просто просмотреть книги 5-7 раз в месяц. На поиск книги я трачу 5 минут, на просмотр всех книг 10-15 минут. Т.е. 4*5+7*15=125 минут в месяц. Сейчас же, чтобы найти книгу мне понадобится 1 минута, и 3 минуты на просмотр всех книг. 4*1+7*3=25. Значит в среднем я экономлю около 100 минут в месяц. За год я сэкономлю 1200 минут, а это 20 часов, что уже превышает время, потраченное мной на разработку БД и сайта.
ЗАКЛЮЧЕНИЕ
В рамках данной курсовой работы была изучена теория, определены основные понятия и технологии распределенной обработки данных. Проведена классификация БД и СУБД по различным признакам.
Был проведен анализ основных моделей БД, в результате которого была выбрана реляционная модель построения баз данных для дальнейшего использования.
Так же были рассмотрены особенности построения языка структурированных запросов SQL, который является информационно-логическим языком, предназначенным для описания, изменения и извлечения данных, хранимых в реляционных базах данных. Использование синтаксиса языка SQL сводится, к формированию всевозможных выборок строк и совершению операций над всеми записями, входящими в набор.
Наличие стандартов и набора тестов для определения совместимости конкретной реализации SQL к общепринятому стандарту заметно способствует унификации языка. При этом программист имеет возможность "подсказывать" СУБД при формировании запроса, какие лучше использовать индексы и в каком порядке.
Так же был рассмотрен практический пример использования SQL в прикладном программировании на основании разработки веб - приложения, для которого была разработана и описана реляционная база данных, созданы SQL запросы по работе с базой данных и описан интерфейс.
В процессе выполнения курсовой работы решены следующие задачи:
1) раскрыты сущность понятий база данных, системы управления базами данных путем изучения классификации баз данных и СУБД по степени распределенности, по технологии хранения данных, по содержимому, по моделям построения;
3) проведен сравнительный анализ разных видов СУБД;
4) рассмотрен основной синтаксис языка SQL;
5) разработана и реализована база данных а так же web-приложение для управления данными в БД.
Учитывая, что все поставленные задачи курсовой работы решены, можно утверждать, что цель курсовой работы достигнута.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. Новиков Б., Домбровская Г. Настройка приложений баз данных. – BHV, 2011. – С.22
2. Боуман Дж.С., Эмерсон С.Л., Дарновски М. Практическое руководство по SQL. – Вильямс, 2011. – С.56-90
3. Фейт С. TCP/IP. Архитектура, протоколы и реализация (включая IP версии 6 и IP Security) – Питер, 2011. С.
4. Дейт К. Введение в системы баз данных, 8-е издание. – Вильямс, 2006. – С.725
5. Дейт К. SQL и реляционная теория. Как грамотно писать код на SQL. – Символ-Плюс, 2010. – С.123
6. 102Дунаев В.В. Базы данных. Язык SQL. – СПб. : БХВ-Петербург, 2010. – С.88
7. Дейт К., Дарвен Х. Основы будущих систем баз данных. Третий манифест. – Янус-К, 2011. – С. 196
8. Дж. Кастаньетто, Х.Рават, С.Шуман, К.Сколло, Д.Велиаф «Профессиональное РНР программирование». – Пер. с англ. – СПб: Символ-Плюс, 2010. – С.76
10. Иванова Г.С. – «Основы программирования» Учебник для вузов. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2010. – С.156
12. Кренке Д. Теория и практика построения баз данных. – Питер, 2010. – С.206
13. Мирошниченко Г. Реляционные базы данных. Практические приемы оптимальных решений. – СПб. : БХВ-Петербург, 2011. – С.199
14. Астахова И.Ф., Толстобров А.П., Мельников В.М. SQL в примерах и задачах. – Мн.: Новое знание, 2011. – С.4
15. Советов Б.Я., Цехановский В.В., Чертовской В.Д. Базы данных. Теория и практика.– Высшая школа, 2010. – С.49
16. Скотт В. Эмблер, Прамодкумар Дж. Садаладж Рефакторинг баз данных. Эволюционное проектирование. – Вильямс, 2010. – C.36
17. Тоу Д. Настройка SQL. Для профессионалов. – Питер, 2011. – С.103
18. Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс. - Вильямс, 2010. – С.125
19. MySQL. Библиотека профессионала – Киев: Диалектика, 2012 – С.170-179
20. PHP/MySQL для начинающих – Кудиц-образ, 2010 – С.44-108
21. Теория и практика построения баз данных: Д. Крёнке. – Питер, 2011. – С.223-250
22. Базы данных. «Проектирование, реализация и сопровождение», Томас Конном, Королинг Берг – 2010. – С.102
28. Шкарина Л. Язык SQL: учебный курс. – СПб.: Питер, 2001 – С.23-96
29. https://www.php.net/manual/ru/funcref.php - Справочник функций, PHP
30. http://htmlbook.ru/ - Справочник по HTML и CSS
31. https://ru.wikipedia.org/wiki/База_данных – открытая библиотека Wikipedia, статья «Базы данных»
32. https://www.oracle.com/ru/ - официальный сайт Oracle в России, статьи по БД и СУБД.
33. https://site-do.ru/ - открытые уроки по SQL, БД и PHP
ПРИЛОЖЕНИЕ 1 – Структура тестовой БД.

|
pid |
name |
last_name |
birthday |
address |
|
1 |
Александр |
Иванов |
01.06.1995 |
Москва |
|
2 |
Светлана |
Сидорова |
20.02.1976 |
Самара |
|
3 |
Мария |
Крайнова |
30.04.1992 |
Оренбург |
|
4 |
Алиса |
Селезнева |
01.05.2001 |
Киев |
|
5 |
Игорь |
Верник |
05.06.1989 |
Минск |
|
6 |
Алексей |
Сидоров |
04.03.1996 |
Оренбург |
|
7 |
Илья |
Горный |
02.01.2002 |
Екатеринбург |
|
8 |
Марина |
Клюкова |
05.02.1998 |
Тамбов |
|
9 |
Светлана |
Смелая |
04.05.1995 |
Самара |
|
10 |
Олег |
Павлов |
01.06.2002 |
Москва |
|
11 |
Ольга |
Павлова |
06.08.1965 |
Киев |
|
12 |
Оксана |
Кротова |
07.04.1974 |
Москва |
|
13 |
Ксения |
Ветрова |
04.09.1980 |
Санкт-Петербург |
|
pid |
emp_id |
assign |
offid |
salid |
manager |
hire_date |
|
6 |
1 |
Директор |
1 |
6 |
NULL |
01.05.2010 |
|
5 |
2 |
Ассистент |
2 |
2 |
1 |
05.06.2010 |
|
2 |
3 |
Менеджер по продажам |
4 |
3 |
6 |
01.05.2010 |
|
9 |
4 |
Программист |
3 |
1 |
7 |
01.05.2010 |
|
7 |
5 |
Специалист поддержки |
1 |
7 |
6 |
05.06.2010 |
|
4 |
6 |
Директор офиса |
2 |
5 |
1 |
15.06.2010 |
|
11 |
7 |
Директор офиса |
4 |
5 |
1 |
15.06.2010 |
|
8 |
8 |
Переводчик |
1 |
8 |
6 |
25.10.2011 |
|
13 |
9 |
Юрист |
3 |
9 |
1 |
01.05.2010 |
|
1 |
10 |
Менеджер по продажам |
1 |
3 |
6 |
05.06.2010 |
|
12 |
11 |
Специалист отдела кадров |
4 |
10 |
1 |
01.05.2010 |
|
10 |
12 |
Бухгалтер |
1 |
11 |
13 |
05.06.2010 |
|
3 |
13 |
Старший бухгалтер |
2 |
4 |
7 |
01.05.2010 |
|
offid |
address |
city |
name |
|
1 |
Москва, Верхний проезд, 1Б |
Москва |
Центр |
|
2 |
Самара, ул. Ленинградская, 34А |
Самара |
Орг |
|
3 |
Киев, ул. Большая, 1, оф 314. |
Киев |
Укр |
|
4 |
Москва, Садовое кольцо, 217, оф. 54 |
Москва |
Мск-2 |
|
salid |
curr |
salary |
tax |
|
1 |
UAH |
10000,00 |
10,00 |
|
2 |
RUB |
45000,00 |
13,00 |
|
3 |
RUB |
70000,00 |
13,00 |
|
4 |
RUB |
349002,00 |
26,00 |
|
5 |
RUB |
245213,00 |
13,00 |
|
6 |
RUB |
4123522,00 |
13,00 |
|
7 |
RUB |
23215,00 |
13,00 |
|
8 |
RUB |
24356,00 |
13,00 |
|
9 |
UAH |
12459,00 |
10,00 |
|
10 |
RUB |
213953,00 |
26,00 |
|
11 |
RUB |
243514,00 |
13,00 |
ПРИЛОЖЕНИЕ 2 – Логическая структура БД для домашней библиотеки.

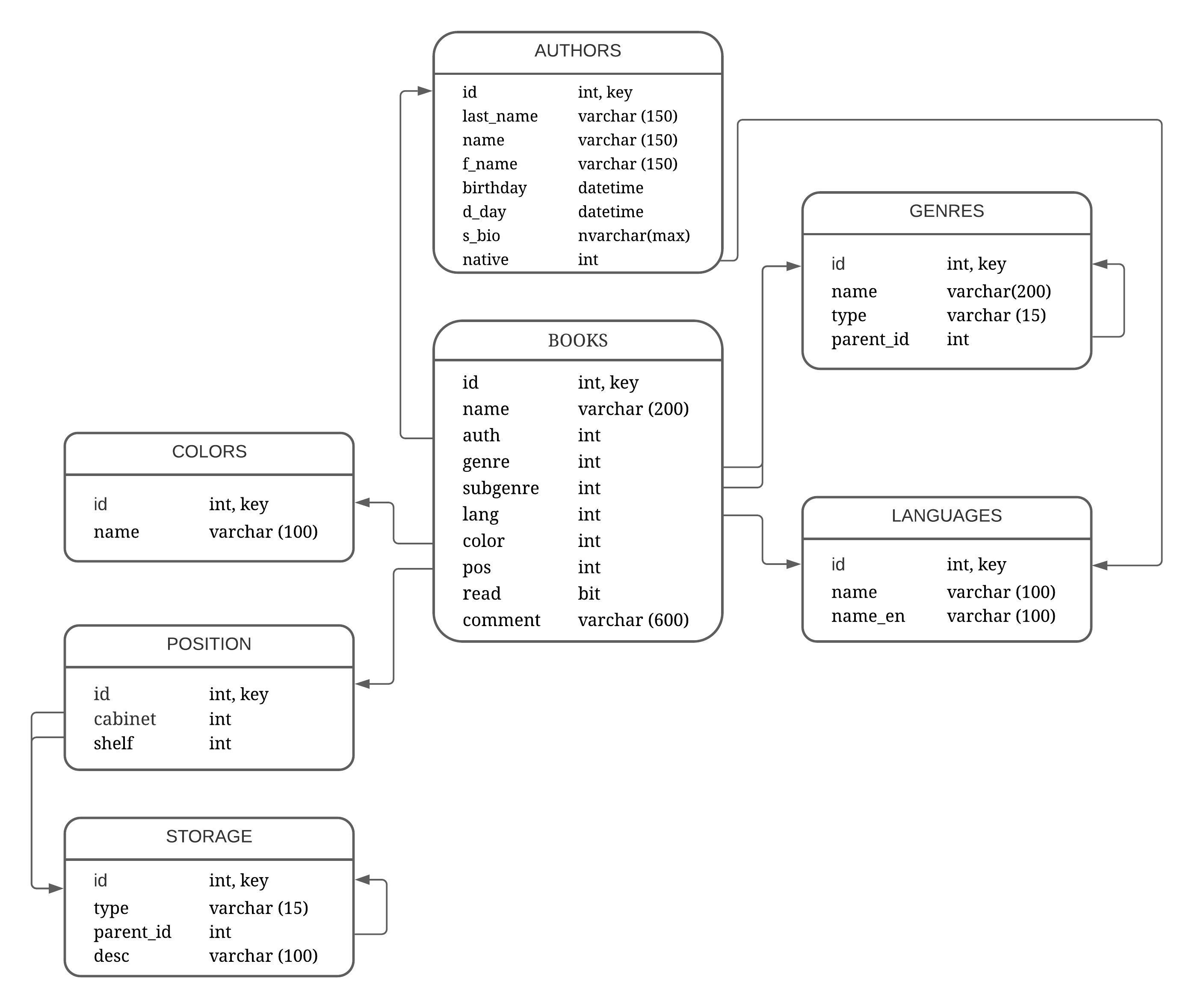
ПРИЛОЖЕНИЕ 3 – Скрипты создания таблиц и связей в БД library.



ПРИЛОЖЕНИЕ 4 – скрипт создания View для отчета со всеми книгами
create view view_rep_books
AS
select b.name as book, a.last_name+' '+a.name+' '+a.f_name as auth,
g.name as genre, g1.name as subgenre, l.name as lang, l.name_en as lang_eng, c.name as color, 'шкаф: '+cab.[desc]+', полка: '+sh.[desc] as position,
case [read] when 0 then 'Нет'
when 1 then 'Да'
end as readed,
b.comment
from books b
left join authors a on b.auth=a.id
left join colors c on b.color=c.id
left join genres g on b.genre=g.id
left join genres g1 on b.subgenre=g1.id
left join languages l on b.lang=l.id
left join position p on b.pos=p.id
left join storage cab on p.cabinet=cab.id
left join storage sh on p.shelf=sh.id
GO

- Труд, кадры и оплата труда в энергетике. Тенденции модификации заработной платы в современных условиях
- Методы принятия управленческих решений
- Организация энергетического обеспечения предприятия
- Организация энергетического хозяйства на предприятии
- Топливно-энергетический комплекс в составе национальной экономики (Роль ТЭК РФ в регулировании экономики)
- Топливно-энергетический комплекс в составе национальной экономики
- Генри Форд и массовое производство (Управление как наука)
- Художественно-конструкторский проект малой формы с простой формой
- Современная система мотивации персонала в организациях
- Проектирование информационной системы по управлению персоналом
- Традиционные организационные структуры (Системы управления предприятием, их формы и принципы)
- Производственные мощности в энергетике