
Языки гипертекстовой разметки (Технологии хранения данных)
Содержание:

ВВЕДЕНИЕ
В современном высокотехнологичном мире информация является важнейшим ресурсом развития общества и рассматривается учеными в качестве одной из основ мироздания наравне с веществом и энергией.
Информационные процессы, к которым относят процессы получения, обобщения, систематизации, использования, передачи и хранения информации, играют первостепенную роль в жизни человеческого общества. С течением времени эта роль постепенно усиливается. Процесс проникновения информации во все сферы производства и общественной жизни называется информатизацией общества.
Информационному развитию способствует научно-технический прогресс, который также постоянно ускоряется.
К середине двадцатого века человечество накопило столь огромное количество информации, что люди уже не успевали ее обрабатывать. Специалисты заговорили об информационном взрыве. Именно в такой непростой момент у человека появился универсальный помощник для обработки информации – компьютер.
Изобретение компьютера вывело информационные процессы на новый уровень. Компьютеры выполняют обработку информации с невероятной скоростью, многократно превышающей возможности человека. К тому же компьютер под управлением грамотно составленной программы не допустит ошибок, которые неизбежны в случае работы человека.
Развитие компьютерной техники и сопутствующих технологий происходит очень высокими темпами. Постоянно появляются новые устройства и новое программное обеспечение. Компьютерные устройства и информационные услуги становятся все более доступными для людей во всем мире, умные устройства и интернет вещей заполняют жилища человека.
В связи с таким активным развитием IT-технологий информационные системы разрослись до очень больших размеров. Технологически и архитектурно оказалось правильным распределить эти системы на несколько уровней, разделенных как физически, так и программно. Такому положению дел способствовало в том числе появление персональных компьютеров.
Развитие локальных вычислительных сетей и повсеместное активное использование глобальной компьютерной сети Интернет сделало использование распределенных систем обработки информации стандартом де факто.
В настоящее время для представления информации в сети Интернет разработано семейство языков гипертекстовой разметки. Эти языки не являются языками программирования, их назначение состоит в формировании web-страниц в соответствии с целями их разработки для удобного восприятия пользователями.
Актуальность курсовой работы состоит в том, что любой современный человек должен знать, как устроены страницы в Интернет.
Объектом исследования курсовой работы являются распределенные системы обработки информации.
Предметом исследования курсовой работы являются языки гипертекстовой разметки.
Цель курсовой работы – изучение языков гипертекстовой разметки.
Задачи курсовой работы:
- изучить архитектуру и типы распределенных систем;
- исследовать особенности архитектуры клиент-сервер;
- сделать обзор различных языков гипертекстовой разметки и их назначение;
- освоить на теоретическом уровне и изучить на практическом уровне основы языка разметки гипертекста HTML;
- сделать выводы по результатам выполнения курсовой работы.
1 ХРАНИЛИЩЕ ДАННЫХ
1.1 Информация. Информационные процессы
Информация есть основное неопределяемое понятие информатики.
Под информацией понимают сведения об окружающем мире, процессах и явлениях, в нем происходящих, и их взаимосвязях.
С информацией связаны такие понятия, как:
- источник информации – объект или субъект, от которого исходит информация;
- приемник информации – объект или субъект, получающий информацию;
- канал связи – система технических средств и среда распространения сигналов для односторонней передачи данных.
Процесс передачи информации представлен на рисунке 1.

Рисунок 1 – Процесс получения и передачи информации
Информация характеризуется совокупностью свойств, основными из которых являются:
- ценность информации (показатель качества информации) - определяется важностью задач, которые может решить информационный субъект с помощью ее использования;
- достоверность информации - информация считается достоверной, если она отражает истинное положение дел. С течением времени ранее достоверная информация может утратить свою достоверность. Это связано со способностью информации устаревать;
- полнота информации - отвечает за то, насколько полно отражены в информации свойства информационного объекта;
- точность информации определяется степенью близости к реальному состоянию объекта, процесса, явления;
- актуальность информации - способностью отвечать задачам, решаемым в текущий момент;
- понятность информации – возможность усвоить содержание полученных знаний и синтезировать представление об информационном объекте;
- доступность информации - возможность получения свободного доступа к источнику информации. [4]
Свойства информации обобщены на рисунке 2.
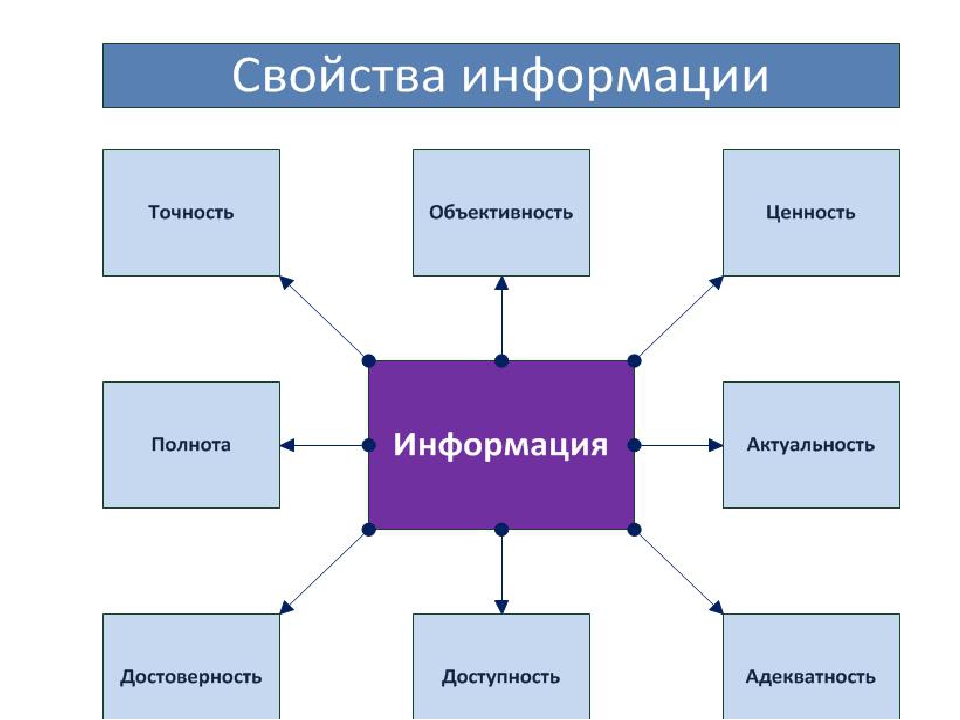
Рисунок 2 – Свойства информации
Большое значение для современного человека имеют информационные процессы.
Информационными процессами называют процессы
- получения;
- создания;
- сбора;
- обработки;
- накопления;
- хранения;
- поиска;
- распространения;
- представления;
- использования информации и другие процессы, связанные с информацией (рисунок 3).

Рисунок 3 – Информационные процессы
1.2 Информационное развитие общества
Можно утверждать, что развитие человеческого общества – это история накопления информации и развитие технологий осуществления информационных процессов.[13]
Процесс накопления информации постоянно ускоряется. Динамика роста цифровой информации представлена на рисунке 4.

Рисунок 4 - Динамика роста цифровой информации
Накопление информации влекло за собой развитие новых технологий их хранения, обработки и защиты. Такое развитие не было гладким процессом. В определенные моменты времени случались критические моменты, когда накапливалось такое количество информации, что справиться с ней имеющимися на тот момент средствами не представлялось возможным. Возникала насущная необходимость в появлении новых, современных, принципиально иных технологий.[19]
Такие моменты специалисты называют информационными революциями.
В настоящее время выделяют четыре основные информационные революции за всю историю развития человеческого общества.[16]+
Первая информационная революция связывается с с изобретением письменности. Появление письменности позволило обеспечить не только сохранность накопленных человечеством знаний, но и усилить компоненты достоверности этих знаний, сформировать условия для их существенно более широкого, чем ранее, распространения.
Вторую информационную революцию связывают с изобретением книгопечатания. Эта революция началась в эпоху возрождения. Именно книгопечатание исследователи считают одной из первых эффективных информационных технологий.
Высшей точкой эволюции второй информационной революции считают появление печатных средств массовой информации: газет, журналов, рекламных объявлений, информационных справочных изданий.
Начало третьей информационной революции относят к девятнадцатому веку. В этот период и позже были изобретены и получили широкое повсеместное распространение такие новейшие средства информационной коммуникации, как радио, телефон и телевидение.
Четвертая информационная революция ведет свой отсчет с пятидесятых годов двадцатого века – со времени изобретения и постепенного массового распространения компьютерной техники. В этот период средства цифровой вычислительной техники начали активно использоваться в социальной практике. Использование этих средств для переработки научной, экономической и социальной информации принципиальным образом изменило возможности человека по активизации и эффективному использованию информационных ресурсов.
Изобретение электронно-вычислительных машин привело к активному росту новых информационных технологий, особенно ориентированных на использование возможностей современной вычислительной техники и, в первую очередь, возможностей персональных компьютеров.
Кроме того, с получением впервые за всю историю развития цивилизации человек получил высокоэффективное средство для усиления своей интеллектуальной деятельности.
Периодичность информационных революций представлена на рисунке 5.

Рисунок 5 – Информационные революции
1.3 Технологии хранения данных
Стремительное развитие микропроцессорной техники и информационных технологий, наблюдаемые в последние несколько десятилетий, привели к тому, что большая и наиболее важная доля информации, относящейся к различным сферам деятельности предприятий или организаций, сегодня размещается в электронном виде в системах хранения данных.
Постфактум данные являются наиболее значимым активом любого бизнеса, любой компании. Данные обеспечивают успешность работы предприятия, возможность своевременного принятия эффективного и адекватного решения. Соответственно, постоянно растет значение разумного применения современных технологий хранения данных, обеспечивающих оперативность доступа к бизнес-информации, защиту и надёжность её хранения.[5]
Имеются убедительные примеры того, как потеря данных может привести к потере всего бизнеса. Наглядным свидетельством тому служат результаты исследований известной аналитической компании IDC, в соответствии с которыми только 10% американских компаний, полностью потерявших свои данные в результате неправильного отношения к технологиям их хранения, смогли реанимировать свой бизнес, и только 4% из этих компаний остались на рынке в течение следующих 3 лет.
Это означает, что продуманное и ответственное отношение к способам и технологии данных является залогом успешности любого современного предприятия.
С момента появления первых электронно-вычислительных машин и появления устройств внешней памяти прошло более семидесяти лет. За этот период разнообразие и возможности устройств хранения информации и их характеристики существенно расширились.
В настоящее время весьма широкое распространение получила следующая трехуровневая структура построения корпоративной системы хранения данных.
Первый уровень.
Системы и устройства с произвольным доступом для активно используемых данных (накопители на жёстких дисках, дисковые системы хранения и RAID-массивы). Для таких систем характерны малое время доступа и максимально высокий уровень частоты обращения и удельной стоимости хранения.
Второй уровень.
Системы и устройства с обеспечением произвольного доступа для нерегулярно употребляемых данных (CD/MO/DVD-устройства и библиотеки). Эти системы находятся в промежуточном положении по скорости доступа, емкости и частоте обращения.
Третий уровень.
Системы и устройства с последовательным доступом применяются с целью долговременного хранения данных (ленточные накопители, автозагрузчики и библиотеки). Обращение к ним осуществляется весьма редко. Такие системы являются самыми медленными системами хранения первого и второго уровней, имеют наибольшую емкостью и наименьшую удельную стоимость хранения.[10]
В целом технология уровневого хранения информации представлена на рисунке 6.

Рисунок 6 – Системы хранения данных
На основании представленных данных можно сделать однозначный вывод о возрастании роли информационных процессов в жизни общества, важности развития технологий хранения данных и необходимости совершенствования и оптимизации автоматизированных информационных систем.
2 ХРАНИЛИЩЕ ДАННЫХ
2.1 Концепция систем хранения данных
В предыдущем разделе была показана роль грамотной организации хранения данных, забота об сохранности и безопасности.
Информационная технология складирования данных – Data warehousing - была сформулирована специалистами компании IBM. Окончательные формулировки были определены и уточнены Б. Инмоном и Р. Кимбаллом в девяностых годах двадцатого века как метод решения информационно-аналитических задач в области принятия и поддержки решений.
Концепция складирования данных появилась как отдельный раздел практических технологий на границе технологии создания баз данных, компьютерного анализа данных и систем поддержки принятия решений - DSS. Концепция складирования данных не является абсолютом, она получает свое развитие и эволюцию. Она находит свое применение для широкого класса задач и приложений в бизнесе, науке и современных технологиях. [7]
Основной предпосылкой разработки концепции складирования данных послужила возникшая потребность администрацией множества компаний и бизнес - организаций в анализе имеющихся очень больших электронных массивов данных.
Упрощенная принципиальная схема функционирования организации и роль и место анализа непрерывным потоком поступающей информации представлена на рисунке 7.

Рисунок 7 – Организация информационных потоков на предприятии
В процессе выполнения производственных процессов и административно-хозяйственной деятельности компании, организации и предприятия накопили огромные объемы данных.
Эти данные накоплены как на традиционных бумажных носителях, так и на современных цифровых носителях в цифровой форме.
Такие наборы данных, накопленные годами коллекции информации, несут в себе огромный потенциал и широкие возможности по извлечению свежей и современной аналитической информации, на основе которой возможно и необходимо строить стратегию действий и развития организации, выявлять тенденции развития рынка, находить новые решения, обусловливающие успешное развитие в условиях конкурентной борьбы. Для множества предприятий осуществление такого анализа является обязательной частью их ежедневной деятельности, другие организации только приступают к активному использованию такого анализа.
Системы, базирующиеся на фундаменте информационной технологии складирования данных, характеризуются рядом важных особенностей, выделяющих их как новый класс информационных систем. [1]
К указанным особенностям специалисты относят следующие факторы:
- предметная ориентация системы;
- интегрированность хранимых в системе данных, собранных из различных источников;
- инвариантность данных во времени;
- относительно высокая стабильность данных;
- необходимость поиска компромисса в избыточности данных.[14]
Особенности систем складирования данных представлены на рисунке 8.

Рисунок 8 – Особенности складирования данных
2.2 Хранилище данных
Хранилище данных - Data warehousing - это зона складирования накапливаемых в системе данных, а также информационный источник для обоснованного принятия эффективных решений и развития задач анализа данных. Обычно в хранилище данных хранятся очень большие объемы информации. [3]
Упрощенная схема постулирует, что хранилище данных управляет данными, собранными как из операционных систем компании – On Line Transactions Processing – так и из источников, находящихся на внешних источниках данных, длительное время хранящихся в системе.
Одной из главных целей формирования и использования систем складирования данных является их ориентация на анализ накопленных данных. Структурирование данных в хранилищах данных должно быть реализовано таким образом, чтобы собранные и проанализированные данные эффективно использовались в аналитических приложениях – Analytical Applications.
Проблемы анализа собранных данных ставились и решались и до появления концепции складирования данных. Как результат в распоряжении аналитиков появился обширный набор пакетов программных продуктов для анализа и систематизации данных с целью принятия эффективных решений.
Основным отличием применения концепции складирования данных является структуризация, систематизация, классификация, фильтрация и другие направления обработки значительных по объему массивов электронной информации в форме, пригодной и удобной для анализа, визуализации результатов анализа и производства корпоративной отчетности.
История появления хранилищ данных ведет свою историю от концепции баз данных в качестве метода представления и накопления информации в электронном виде. Эта концепция сформировалась к середине шестидесятых годов прошлого века.
Первая система управления базами данных была разработана в 1969 году.
В 1970 году была предложена реляционная модель данных и на ее основе начали активно реализовываться популярные и сегодня реляционные системы управления базами данных. В рамках реляционного подхода с унифицированных позиций были решены многие задачи операционной (транзакционной) обработки данных.
Интенсивное накопление электронных информационных массивов информации различных институтов и организаций начало набирать активные обороты с середины восьмидесятых годов прошлого века.
Приводятся примеры о том, что в начале девяностых годов двадцатого века только в области химических дисциплин было зарегистрировано более 7000 библиографических, фактографических и смешанных баз данных.
В это время появилось определенное понимание того, что сбор данных в электронном виде – не самоцель, накопленные информационные массивы должны приносить пользу и могут быть использованы для эффективного анализа данных и быть полезны.
Первым, кто осознал этот факт, были менеджеры в области бизнеса и масштабного производства товаров и услуг. Накопленная информация несет в себе «информационный снимок» хронологии ее ситуации на рынке. Анализ развития административно-хозяйственной активности компании дает возможность значительно увеличить эффективность управления деятельностью, адекватно и наилучшим образом организовать взаимоотношения с клиентами, производство и сбыт товаров и услуг, минимизировать расходы.
Сегодня задачи анализа накопленных данных возложены на компьютерные информационные системы.[9]
Технологии баз данных и автоматизированных информационных систем активно используются для осуществления функции сбора и хранения данных, учета материальных и информационных объектов, поиска информации. В то же время аналитические возможности таких систем ограничены, поэтому разработка специальных технологий и приложений для управления анализом накопленных актуальны.
Предпосылки разработки хранилищ данных представлены на рисунке 9.

Рисунок 9 – Причины появления систем складирования данных
Созданию как централизованных, так и распределенных хранилищ данных, способствовали различные факторы современного развития общества и технологий.
Среди них:
- структурные изменения бизнеса;
- изменение требований пользователей;
- стандартизация программных продуктов обслуживания бизнеса;
- активное развитие технологий.[12]
Обобщенно основные факторы, катализирующие процесс создания и развития концепции систем складирования данных и хранилищ данных, представлены на рисунке 10.

Рисунок 10 - Основные факторы активизации разработки концепции хранилищ данных
Главная позиция концепции складирования данных заключается в том, что к данным, хранимым с целью анализа, наиболее эффективный доступ может быть обеспечен исключительно при условии выделения их из операционной (транзакционной) системы и помещения их в независимую систему складирования данных.
Такой подход сложился исторически. Ограниченность ресурсов аппаратного обеспечения и требование сохранности информации требовали создания резервных архивов данных на внешних магнитных носителях вне такой системы.
Специалисты указывают определенные причины необходимости разделения данных систем складирования данных и систем операционной обработки данных:
- отличия целевых требований к системам складирования данных и OLTP-системам (Online Transaction Processing - транзакционная система — обработка транзакций в реальном времени);
- необходимость накапливать информацию в хранилищах данных из многочисленных информационных источников. Это означает, что в случае, если данные создаются в самой OLTP-системе, то для системы складирования данных в подавляющем большинстве случаев информация генерируется вне ее;
- информация, попадая в хранилище данных, остается в исключительном большинстве случаев неизменной;
- информация в хранилище данных сохраняется в течение длительного времени.[2]
Схема разделения данных для анализа и оперативной обработки представлена на рисунке 11.

Рисунок 11 - Схема разделения данных для анализа и оперативной обработки
В настоящее время существует большое разнообразие распределенных хранилищ данных, разработанных для различных отраслей производства и с разными целями.
2.3 Классификация хранилищ данных
В качестве классических архитектур систем складирования данных специалисты выделяют следующие:
- системы с глобальным хранилищами данных;
- системы с независимыми киосками данных;
- системы с интегрированными киосками данных;
- системы, разработанные на основе комбинации из вышеуказанных архитектур.
Глобальным хранилищем данных – Global data warehouse- называется хранилище данных, в котором хранятся и поддерживаются все данные предприятия или их подавляющая часть.[20]
Такое хранилище является наиболее полно интегрированным хранилищем данных с большой степенью активности доступа к консолидированной информации и использованием его всеми отделениями предприятия или его администрацией в пределах базовых направлений деятельности предприятия.
Глобальное хранение данных проектируется и конструируется на базе нужд аналитической информационной поддержки предприятия в целом. Оно можно рассматриваться в качестве как общего репозитория для информации, обеспечивающей принятие эффективных решений для ведения бизнеса.
В физическом плане глобальное хранилище данных не обязательно должно быть реализовано в виде централизованного хранилища. Понятие «глобальное» применяется для демонстрации масштаба применения и организации доступа к данным в рамках всего предприятия.
Два основных архитектурных решения для глобальных хранилищ данных представлены на рисунке 12.

Рисунок 12 – Архитектурные решения для распределенного хранилища данных
2.4 Типовые технологические решения организации хранилищ данных
На практике используется несколько способов реализации хранилищ данных в рамках концепции и типовой архитектуры. [17]
Виртуальное хранилище данных.
Доступ к информации в режиме реального времени обеспечивается архитектурой посредством прикладного программного обеспечения промежуточного слоя. Базой данного решения выступает репозиторий метаданных. Репозиторий метаданных определяет источники информации, процедуры их начальной обработки, а также форматы представления информации итоговому клиенту.
В качестве недостатков такого решения отмечают интенсивный сетевой трафик с вытекающими снижением производительности несущей системы и угрозами нарушения целостности данных в результате ошибочных действий пользователей хранилищ данных.
Киоски данных.
Архитектурное решение в виде киосков данных является облегченной вариацией хранилища данных тематической направленности. Различают киоски данных, связанные с интегрированным хранилищами данных или несвязанные (автономные).
Глобальное хранилище данных.
Архитектура определяет единственный источник интегрированной информации предприятия.
Хранилища данных с многоуровневой архитектурой (наиболее распространена трехзвенная), (корпоративные хранилища данных).
Данная архитектура представлена на рисунке 13.

Рисунок 13 – Многоуровневая архитектура хранилищ данных
В архитектуре технологически реализованы три уровня:
- первый уровень реализует корпоративное хранилище данных предприятия;
- второй уровень поддерживает связанные киоски данных тематической направленности на базе многомерной системы управления базами данных;
- третий уровень – это реализация клиентских приложений пользователей с размещенными на них средствами информационного анализа.
Встроенные (комбинированные) хранилища данных.
Архитектура комбинированных хранилищ данных позиционирует собой хранилища данных, которые органически встраиваются в виртуальное предприятие или применяются в роли элемента аналитической поддержки в информационном воплощении бизнес-функций.
Корпоративная информационная фабрика.
Такая архитектура представляет собой эволюцию архитектуры корпоративного хранилища данных. Развитие заключается в скоординированном извлечении информации из источников данных и помещение ее в реляционную базу данных, нормализованную до третьей нормальной формы. Также предполагается заполнение дополнительных репозиториев презентационных данных.
Хранилище данных с архитектурой шины данных.
Данная архитектура хранилища данных представляет собой виртуальную коллекцию витрин данных, имеющих собственную архитектуру типа «звезда».
Объединенное (федеративное) хранилище данных.
В рамках объединенной архитектуры хранилище данных формируется из набора экземпляров хранилищ данных, которые действуют на полуавтономной базе и обычно организационно или территориально разнесены. Тем не менее, имеются основания для рассмотрения и управления этими наборами в качестве одного большого хранилища данных.
2.5 Облачные хранилище данных
Современным подходом децентрализованного и надежного хранения данных являются облачные хранилища информации.
Появлению такой услуги как облачное хранилище данных начале нового века способствовали два фактора.
Первый заключается в том, что ряд компаний – разработчиков программного обеспечения представили на рынке наборы Web-приложений для работы с документами. К таким приложениям в качестве дополнительного бесплатного бонуса предлагались файловые хранилища, с достаточно большой информационной емкостью.
Практика показала, что эти хранилища начали активно осваиваться пользователями для хранения совершенно различной информации, не ограниченной офисными форматами данных.
Вторая предпосылка развития облачных сервисов и хранилищ состоит в том, что примерно в то же время обострилась конкуренция за рынок между электронными почтовыми сервисами. В результате как один из результатов конкурентной борьбы появились новые услуги, в том числе и предоставление онлайн – хранилищ информации.
Облачное хранилище данных представляет собой модель онлайн -хранилища, в котором информация сохраняется на большом количестве распределенных в сети интернет компьютерных серверах, предлагаемых для эксплуатации пользователям.
Отличие этой модели от хранения данных на собственных выделенных серверах отличается от услуг облачных хранилищ тем, что количество или какая-либо внутренняя структура серверов клиенту не видна. Он воспринимает данные как единый большой виртуальный сервер, хотя на самом деле физически серверы обычно располагаются удаленно, иногда на разных континентах.
Основной принцип и задача виртуализации хранилища данных — с одной стороны, скрыть от пользователя все внутренние процессы обустройства хранилища, с другой стороны - задать каждому хранилищу единый конкурентный функционал.[6]
Схема корпоративного облачного хранилища представлена на рисунке 14.
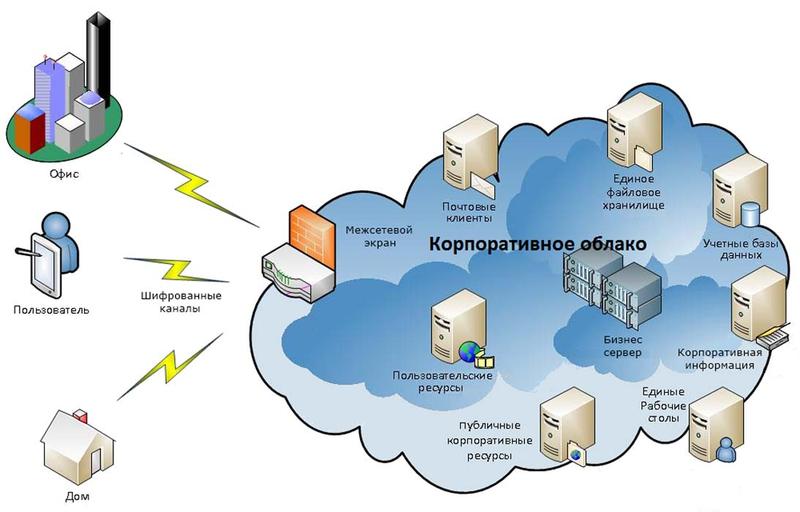
Рисунок 14 – Схема корпоративного облачного хранилища данных
Изучение вопроса позволяет прийти к выводу, что современным подходом к хранению и использованию информации являются распределенные хранилища данных.
3 ЯЗЫКИ РАЗМЕТКИ ГИПЕРТЕКСТА
3.1 Проект распределенной гипертекстовой системы
В 1989 году Тим Бернерс-Ли (рисунок 15) представил на рассмотрение администрации международного центра высоких энергий (CERN) проект распределенной гипертекстовой системы.

Рисунок 15 - Тим Бернерс-Ли – основатель «всемирной паутины»
Автор назвал свою систему World Wide Web (WWW), Всемирная паутина. Изначально идея разработки гипертекстовой навигационной системы заключалась в том, чтобы с ее помощью объединить все множество информационных ресурсов CERN в общую автоматизированную информационную систему.
Технология оказалась настолько удачной, что стала толчком к развитию одной из самых популярных в мире глобальных вычислительных систем – системе, которую сегодня называют Интернет.
Признание технологии WWW обусловлено двумя базовыми факторами:
- простота;
- применение протоколов межсетевого обмена семейства TCP/IP, (Transmission Control Protocol, протокол управления передачей/Internet Protocol, протокол Internet).
Эти два основных подхода и составляют основу глобальной вычислительной сети Интернет.[18]
С появлением и развитием всемирной компьютерной сети Интернет любой пользователь может проявить себя в качестве как создателей, так и читателей информационных материалов, опубликованных во всемирной паутине.
Сама популярность Интернет во многом обязана появлением WWW, которая является первой сетевой технологией, которая предложила пользователю простой современный интерфейс для доступа к самым разным сетевым ресурсам. Простота и удобство применения привели к увеличению количества пользователей Интернет, а также привлекли внимание коммерческих структур.
С тех пор процесс увеличения количества пользователей сети принял лавинообразный характер, таковым он является и в настоящее время Статистика роста пользователей Интернет в России представлена на рисунке 16.

Рисунок 16 – Рост количества пользователей Интернет в России
3.2 Разметка гипертекста
Язык разметки гипертекста Hyper Text Markup Language, иначе говоря - HTML является основным языком создания web-страниц.
На начальном этапе использования технология была чрезвычайно проста, и это имело аргументированное основание. Изначально специалистами было выдвинуто предположение, что при разработке различных элементов технологии (языка гипертекстовой разметки HTML, спецификации разработки прикладного программного обеспечения CGI, протокола обмена гипертекстовой информацией HTTP), что квалификация авторов информационных ресурсов и их оснащенность средствами вычислительной техники будут минимальными.
Язык гипертекстовой разметки HTML разработал Тим Бернерс - Ли Основой послужил стандарт языка разметки печатных документов Standard Generalized Markup Language - SGML - стандартный обобщенный язык разметки.
SGML является метаязыком, позволяющим определять язык разметки для документов.
Изначально этот язык создавался для совместного использования машинно-читаемых документов в крупных правительственных и аэрокосмических проектах. Его активно использовали в издательской и сфере печатной. Но повсеместному распространению SGML для повседневного использования препятствовала его сложность.
Основные части документа SGML:
- SGML-декларация служит для определения символов и ограничителей, которые могут быть использованы в приложении;
- DTD – Document Type Definition Document – компонент, определяющий синтаксис конструкций разметки. Этот компонент может включать дополнительные определения (например, символьные ссылки-мнемоники;
- спецификация семантики также имеет отношение к разметке, она описывает ограничения синтаксиса, которые нельзя выразить внутри DTD;
- содержимое SGML-документа – оно должно состоять как минимум по из корневого элемента. [11]
Пример синтаксиса SGML представлен на рисунке 17.

Рисунок 17 – Типичный синтаксис SGML
Язык SGML стандартизован международной организацией по стандартизации ISO в 1986 году.
Язык HTML базируется на синтаксисе SGML. Формальное описание синтаксиса HTML в терминах SGML было написано Дэниелом В. Конноли.
Разработчики HTML решили следующие задачи:
- предоставление дизайнерам гипертекстовых баз данных простого средства создания документов;
- доведение мощности средства до адекватного уровня отображения имевшихся на тот момент представления об интерфейсе пользователя гипертекстовых баз данных.
Простота языка HTML достигнута за счет использования теговой модели описания документа, которая имеет широкое применение в системах подготовки документов для печати (к примеру, язык разметки научных документов TeX).
Язык НТМL предоставляет пользователю возможность выполнять разметку электронного документа, который выводится на монитор с полиграфическим уровнем оформления. Язык разметки гипертекста НТМL позволяет в результирующем документе отображать самые разнообразные метки, иллюстрации, аудио- и видеофрагменты. В составе языка имеются развитые средства для формирования многоуровневых заголовков, выделений текстовых фрагментов различными способами, использования нумерованных и маркированных списков, таблиц и других возможностей.
Удачным решением разработчиков HTML, является выбором в качестве основы обычных текстовых файлов:
- текстовый файл может быть создан в произвольном текстовом редакторе, в среде любой операционной системы, на любой аппаратной платформе в среде какой угодно операционной системы;
- на момент создания HTML уже действовал американский стандарт разработки сетевых информационных систем, использующий в качестве единицы хранения обычный текстовый файл в кодировке, соответствующей соответствует ASCII.
Современная гипертекстовая база данных согласно концепции WWW представляет собой совокупность текстовых файлов, размеченных на языке HTML. При этом HTML-разметка определяет форму представления информации и структуру связей между отдельными файлами и иными информационными ресурсами (гипертекстовые ссылки).
Гипертекстовые ссылки устанавливают связь между различными текстовыми документами, а также документами, которые содержат графику, видео и текст. Появление возможности отображения и переходов между документами, содержащими разные виды информации, способствовало возникновению нового понятия — гипермедиа.
Функции интерпретатора языка разметки гипертекста HTML в WWW разделены между web-сервером гипертекстовой базы данных и интерфейсом пользователя, то есть отвечают архитектуре «клиент – сервер».
К настоящему времени разработано и стандартизировано несколько версий языка разметки гипертекста HTML (рисунок 18). Подготовкой и распространением документации на описание новых версий HTML занимается международная организация World Wide Web Consortium (W3C).

Рисунок 18 – Версии HTML
Каждая последующая версия языка получала развитие в виде новых возможностей по сравнению с предыдущей.
Современная версия HTML 5 отличается более строгой типизацией и валидацией кода (новые элементы форм), вводит новые семантические элементы (группировка контента, врезка, подпись к иллюстрации, «подвал» страницы, растровый холст) и предоставляет широкие возможности для создания анимированных элементов. Управление сценариями просмотра страниц сайтов применяют языки программирования – Java, JavaScript, JavaScript, VBScript, а также множество самых разных фреймворков.
На базе языка SGML основан еще один язык разметки - XML (Extensible Markup Language) - расширяемый язык разметки. Этот язык появился как развитие языка HTML по мере его усложнения. Язык XML относят к новому поколению языков разметки.
Принципиальное отличие XML от HTML состоит в том, что в XML отсутствуют предопределенные теги, разработчик имеет все возможности для создания собственных тегов.[8]
Языки гипертекстовой разметки продолжают развиваться в соответствии с тенденциями и потребностями информационного развития человечества. Эволюция языков разметки гипертекста представлена на рисунке 19.

Рисунок 19 - Эволюция языков разметки гипертекста
3.3 Основы языка HTML
Язык разметки гипертекста является основным языком формирования страниц сайтов.
HTML является описательным языком разметки документов, в нем используются теги - указатели разметки. Теговая модель описывает документ как набор контейнеров, каждый из которых открывается и закрывается тегами
Иначе говоря, документ НТМL является обычным АSСII - файлом, с добавленными в него управляющими тегами языка HTML.
Теги НТМL преимущественно интуитивно понятны и просты, так как образованы при помощи соответствующих слов английского языка, известных сокращений и обозначений.
Структура типичного HTML-документа представлена на рисунке 20.

Рисунок 20 - Структура типичного HTML-документа
В настоящее время при создании сайта принято разводить:
- разметку страницы и ее содержание – за них отвечает язык HTML;
- оформление страницы – оно обычно оформляется при помощи каскадных таблиц стилей CSS;
- динамику – она создается как при помощи специальных возможностей HTML, так и за счет использования языка сценариев JavaScript, так и других языков программирования.
Каждый HTML-тег является объектом в соответствии с объектной моделью документа – Docement Object Model. Вложенные теги при этом являются потомками родительского элемента. Текст, расположеный внутри тега, также является объектом. [15]
Пример объектной модели HTML-документа представлен на рисунке 21.
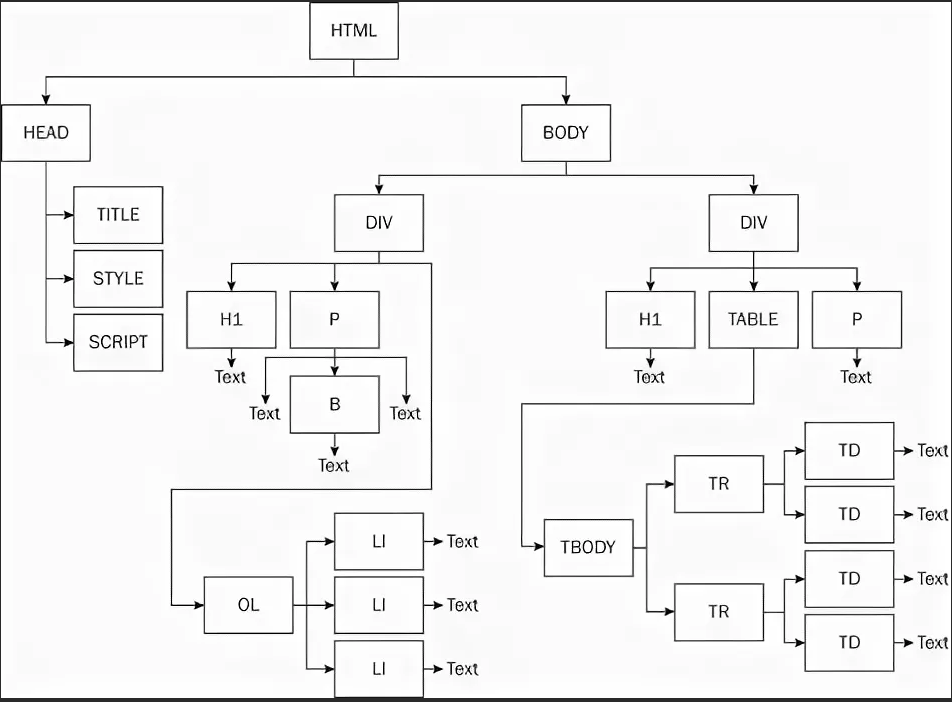
Рисунок 21 - Объектная модель HTML-документа
3.4 Примеры использования HTML
Язык разметки гипертекста HTML позволяет использовать в документе разные виды информации и разнообразные объекты. В сочетании с использованием стилей и небольших скриптов на языке программирования JavaScript можно создать интересные фрагменты страниц, даже если уровень владения этими инструментами – начальный.
В языке программирования HTML предусмотрено 6 уровней заголовков. Они описываются тегами
<H1>…</H1> - заголовок первого уровня
…
<H6>…</H6> - заголовок шестого уровня
Пример HTML - документа, использующего теги заголовков:
<html>
<body>
<style>
body{color:white;background-color:black;}
h1{color:red;}
h2{color:yellow;}
</style>
<h1>Это заголовок 1</h1>
<h2>Это заголовок 2</h2>
Это просто текст.
<h1>Это еще один заголовок 1</h1>
<h2>Это еще один заголовок 2</h2>
Это опять просто текст.
</body>
</html>
В контейнере <style>…</style> размещены описания стилей, отвечающие за цвет фона и цвет заголовков. Отображение документа в браузере представлено на рисунке 22.

Рисунок 22 – Заголовки в HTML-документе
Списки в HTML являются удобной формой представления данных. Язык HTML поддерживает нумерованные списки и ненумерованные (маркированные) списки.
Пример HTML – документа с использованием списков:
<html>
<head>
<title>Списки</title>
</head>
<body>Mapкированный список</body>
<ul type="square" title="Ненумерованный список">
<li>лиса
<li>волк
<li>кабан
</ul>
<br>Нумерованный список
<ol type="I" title="Нумерованный список">
<li>Иванов П.И.
<li>Маркина Е.Ю.
<li>Лебедев Н.А.
</ol>
</html>
Отображение документа со списками в браузере представлено на рисунке 23.

Рисунок 23 – Списки в HTML
Таблицы в HTML применяются таблицы как метод группировки отображения данных, а раньше активно использовали и для форматирования web-страниц.
Каждая таблица в HTML состоит из множества ячеек, которые располагаются в строках. А уже все эти строки и образуют целую таблицу. Для обозначение таблицы применяется парный тег <table> и </ table >.
Таблицы состоят из строк и ячеек. Для того чтобы создать простейшую таблицу, используются еще два тега: это парные теги <tr> и </tr> которые используются для создания строк, и парные теги, <td> и </td> отвечающие за создание ячеек.
Пример использования таблиц:
<html>
<head>
<title>
Сложная таблица
</title>
</head>
<body>
<h1 align="center" >Объединение ячеек</h1>
<table style="width: 450px; height: 250px;" border="1" align="center" bgcolor="#FFFFFF" bordercolor="#006699">
<tr>
<td colspan="2" align="center">Объединение столбцов Атрибут "<strong>colspan</strong>"</td>
<td rowspan="2">Объединение строк Атрибут "<strong>rowspan</strong>"</td>
</tr>
<tr>
<td >Маленькая ячейка</td>
<td >Еще одна<br> маленькая ячейка</td>
</tr>
</table>
</body>
</html>
Отображение документа с таблицей в браузере представлено на рисунке 24.

Рисунок 24 – Таблица сложной структуры
Внедрение в HTML-документ небольшого скрипта на языке программирования JavaScript позволяет пользователю в нижеследующем примере выбрать тот или и6ной рисунок для отображения.
<html>
<head>
<title>Изменение картинки при выборе из списка</title>
</head>
<script language="JavaScript">
pictures = new Array()
for(i=0;i<3;i++)
{
pictures[i] = new Image()
if(i==0) pictures[i].src = "1.jpg"
if(i==1) pictures[i].src = "2.jpg"
if(i==2) pictures[i].src = "3.jpg"
}
function l_image()
{
document.images[0].src = pictures[document.form1.item.selectedIndex].src
}
</SCRIPT>
</head>
<body>
<center><TABLE COLS=2 WIDTH="100%" >
<TR>
<th>
<form name=form1>
<select name=item onChange=l_image()>
<option>рисунок 1
<option>рисунок 2
<option selected>рисунок 3
</select>
</form>
</th>
</tr>
<tr>
<th ALIGN=CENTER VALIGN=CENTER>
<IMG SRC="1.jpg" NAME="tool"></th>
</TR>
</TABLE>
</center>
</body>
</html>
Отображение документа в браузере в зависимости от выбора пользователя представлено на рисунках 25 - 27.

Рисунок 25 – Выбран рисунок 1

Рисунок 26 - Выбран рисунок 2

Рисунок 27 - Выбран рисунок 3
По итогам раздела можно сделать вывод о том, что для создания простейшего сайта достаточно изучить несложный язык разметки гипертекста HTML. Для разработки профессионального сайта необходимо кроме языка HTML также уметь описывать стили (CSS), знать несколько языков описания сценариев и изучить фреймворки, реализующие отдельные полезные функции. Если разработчик сайта не является профессиональным программистом, он может использовать для формирования современного сайта готовую платформу (CMS или конструктор). Но знать как основу и понимать HTML полезно и даже обязательно.
ЗАКЛЮЧЕНИЕ
Выполнение курсовой работы посвящено изучению языков гипертекстовой разметки. Эти языки используются для создания и фиксации структуры текстовых документов. В современном мире эти языки являются базой для разработки web-страниц, составляющих основу глобальной сети Интернет.
В работе представлено понятие информации, информационных процессов, рассмотрены технологии организации хранения данных. Наибольшее внимание уделено в первой главе архитектуре распределенных хранилищ данных. Представлены обзорно облачные технологии и облачные хранилища информации.
Во второй главе курсовой работы исследованы языки разметки гипертекста – SGML, HTML, XML. Представлена эволюция языков гипертекстовой разметки, описано их назначение, показана структура документов. Особое внимание уделено изучению основ языка разметки гипертекста HTML как основному языку для разметки web-страниц. Подробно изучена стандартная структура HTML-документа, представлена классическая DOM-модель HTML-документа.
В практической части изучены отдельные теги языка HTML, например, описывающие заголовки разного уровня, таблицы, нумерованные и маркированные списки, отображение картинок. В некоторых примерах показано также использование внутренних CSS стилей и простых сценариев, разработанных на языке программирования JavaScript.
По итогам выполнения курсовой работы можно сделать вывод о доступности изучения языка HTML, о простоте его использования – простой текстовый файл можно создать в простейшем текстовом редакторе, и при правильном описании сайт будет отображен в браузере. Понимание этого языка требуется каждому современному специалисту.
СПИСОК ЛИТЕРАТУРЫ
- Брэгг Р. Безопасность сетей: полное руководство. - М.: Эком, 2015. - 348 c.
- Варфоломеев В.И. Программные средства офисного назначения. Практикум. - М.:МГУК, 2018. – 178 с.
- Васильков Ю.В. Компьютерные технологии вычислений в математическом планировании. - М.: Финансы и статистика, 2015. - 256 c.
- Дакетт Д. HTML и CSS. Разработка и дизайн веб-сайтов / Джон Дакетт. - М.: Эксмо, 2015. - 480 c.
- Дебольт, В. HTML и CSS. Совместное использование / Дебольт, Вирджиния. - М.: НТ Пресс, 2016. - 512 c.
- Дронов В. HTML 5, CSS 3 и Web 2.0. Разработка современных Web-сайтов / В. Дронов. - М.: БХВ-Петербург, 2017. - 351 c.
- Калашников В.И. Электроника и микропроцессорная техника: Учебник для студ. учреждений высш. проф. обр. - М.: ИЦ Академия, 2016. - 368 c.
- Квинт И.А. Создаем сайты с помощью HTML, XHTML и CSS / Игорь Квинт. - М.: Питер, 2014. - 448 c.
- Кузин А.В. Микропроцессорная техника. - М.: ИЦ Академия, 2015. - 304 c.
- Лазаро И.К. Полный справочник по HTML, CSS и JavaScript / Лазаро Исси Коэн, Джозеф Исси Коэн. - М.: ЭКОМ Паблишерз, 2016. - 943 c.
- Леонтьев В.П. Новейшая энциклопедия персонального компьютера. - М.: Олма-пресс, 2017. – 549 с.
- Мельников П.П. Компьютерные технологии в экономике. - М.: КноРус, 2018. - 224 c.
- Мержевич В.Н. HTML и CSS на примерах / Влад Мержевич. - М.: "БХВ-Петербург", 2016. - 448 c.
- Могилев А.В. Информатика: Учебное пособие для вузов. - М.: ИД Академия, 2015. – 347 с.
- Никсон Р. Создаем динамические веб-сайты с помощью PHP, MySQL, JavaScript, CSS и HTML5 / Р. Никсон. - Москва: Мир, 2016. - 688 c.
- Новиков Ю.В. Основы микропроцессорной техники. - М.: БИНОМ. Лаборатория знаний, 2018. - 357 c.
- Онокой Л.С. Компьютерные технологии в науке и образовании: Учебное пособие. - М.: ИД ФОРУМ, ИНФРА-М, 2017. - 224 c.
- Прохоренок Н.А. HTML, JavaScript, PHP и MySQL. Джентльменский набор Web-мастера / Н.А. Прохоренок, В.А. Дронов. - Москва: РГГУ, 2015. - 768 c.
- Фримен Э. Изучаем HTML, XHTML и CSS / Элизабет Фримен, Эрик Фримен. - М.: Питер, 2016. - 720 c.
- Шварц М.А. Сети и ЭВМ. Анализ и проектирование.- М.: Радио и связь, 2013. - 336 c.

- Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы (Проектирование экономических информационных систем)
- Налоги с физических лиц и их экономическое значение (Теоретические основы исчисления и взимания НДФЛ)
- Нотариат и его роль в защите гражданских прав и охраняемых законом интересов
- Управление поведением в конфликтных ситуациях
- Методы сбора и обработки первичной маркетинговой информации
- Роль мотивации в поведении организации
- Разработка регламента выполнения процесса «Управление информационными ресурсами
- Языки гипертекстовой разметки
- Опыт промышленной политики в разных странах(Теоретические аспекты формирования промышленной политики государства)
- Оборотные активы предприятия
- Особенности функционального состояния человека в экстремальных видах деятельности (Экстремальная деятельность)
- Психофизиология. Невербальные проявления эмоциональных состояний человека