
Методы кодирования данных (Основные типы данных и их кодирование)
Содержание:

Введение
Актуальность. Изначально, вычислительная техника возникла и использоваласть как средство для автоматизации всевозможных вычислений, По мере развития, компьютеры научились обрабатывать текстовые данные, представлявшие в начале лишь небольшие пояснения к вычислениям, но, со временем, преобразовавшиеся в большие массивы текстовых данных. Стремление эффективно и качественно оформить текстовые данные вызвало у людей желание дополнить их графическими данными в виде рисунков и графиков. Данные в виде чисел, текста и графики образовали необходимый набор, достаточный для решения большинства задач, выполняемых на компьютере. Однако, рост технологий и быстродействия компьютеров, позволил добавить к этому набору обработку звуковых и видеоданных, возникла необходимость в их передаче с одного компьютера на другой с использованием различных каналов передачи. Все это обусловило развитие методов представления и кодирования различных видов данных в компьютере.
Целью данного исследования яволяется рассмотрение методов кодирования данных для их представления в компьютере.
Объект исследования - данные в компьютере.
Предмет исследования – методы кодирования данных для их представления в компьютере.
Для выполнения данного исследования необходимо выполнить следующие задачи:
- рассмотреть основные типы данных в компьютере и их структуры;
- рассмотреть современные мотоды кодирования данных;
- изучить способы кодирования и декодирования данных при их передаче.
Методологической основой исследования стали научные труды отечественных и зарубежных ученых в области кодирования и передачи данных. В качестве методов исследования применялись общие и частные методы, включая теории по организации каналов передачи данных, современным методам кодирования и представления информации.
Глава 1. Понятия и сущность кодирования данных
1.1 Основные типы данных и их кодирование
Для автоматизации работы с данными очень важно унифицировать их формы представления. Для этого используются различные приемы кодирования.
Данные считаются закодированными, в случае если они представлены в виде набора цифр, которые называются кодами. Любая компьютерная система обрабатывает данные в закодированном виде, причем для построения кодов используется двоичная система счисления.
Рассмотрим методы кодирования цифровых, текстовых, графических и звуковых данных.
Τᴀᴋᴎᴍ ᴏбᴩᴀᴈᴏᴍ, десятичное число 375,125(10) в двоично-десятичном коде будет выглядеть следующим образом: 001101110101.000100100101.
В дальнейшем эти двоично-десятичные коды по специальной программе переводятся в двоичную систему счисления.
Для кодирования символьных данных существуют две международные системы:
- Восьмиразрядная система ASCII (AMERICAN STANDARD CODE FOR INFORMATIONAL INTERCHANGE – американский стандартный код информационного обмена).
- Шестнадцати разрядная система кодирования UNICODE
Восьмиразрядная система ASCII осуществляет кодирование в пределах одного байта и позволяет получить 256 кодовых комбинаций (28=256).
Существует специальная кодовая таблица для кодирования символьных данных, которая имеет 16 строк и 16 столбцов
Тип данных - фундаментальное понятие языка программирования. Тип данных определяет, что именно представляют собой данные, как они хранятся в памяти, какие операции с ними можно выполнять.
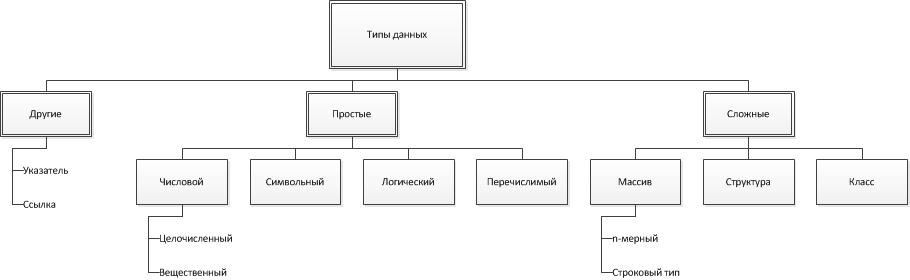
Рисунок 1 Классификация типов данных
Изначально, типы данных делятся на простые и составные. Простой - это тип данных, объекты (переменные или постоянные) которого не имеют доступной программисту внутренней структуры. Для объектов составного типа данных, в противовес простому, программист может работать с элементами внутренней его структуры.[1]
Числовой тип данных разработан для хранения естественно чисел. Символьный - для хранения одного символа. Логический тип имеет два значения: истина и ложь. Перечислимый тип может хранить только те значения, которые прямо указаны в его описании.
Для простых типов данных определяются границы диапазона и количество байт, занимаемых ими в памяти компьютера.
В большинстве языков программирования, простые типы жестко связаны с их представлением в памяти компьютера. Компьютер хранит данные в виде последовательности битов, каждый из которых может иметь значение 0 и 1. Фрагмент данных в памяти может выглядеть следующим образом 00011011011100010110010000111011 ...
Данные на битовом уровне (в памяти) не имеют ни структуры, ни смысла. Как интерпретировать данные, как целочисленное число, или вещественное, или символ, зависит от того, какой тип имеют данные, представленные в этой и последующих ячейках памяти.
Выделяют знаковые и беззнаковые. Как видно из названия, знаковые предназначены для хранения как положительных, так и отрицательных значений, нуль, а беззнаковые - чисел, не меньше нуля.[2]
Беззнаковые типы данных, в отличии от соответствующих знаковых, имеют в два раза больший диапазон. Это из-за их машинного представления. В знаковых типах первый бит указывает на знак числа: 1 - отрицательное, 0 - положительное.
Исходя из машинного представления целого числа, в ячейке памяти из n бит может хранится 2n для беззнаковых, и 2n-1 для знаковых типов.
Рассмотрим теперь конкретные целочисленные типы в трёх языках.
- C#
- C++
- Java
Таблица 1
Числа вещественного типа данных
|
Тип |
Разрядность в битах |
Диапазон чисел |
|
byte |
8 |
0 - 255 |
|
sbyte |
8 |
-128 - 127 |
|
short |
16 |
-32 768 - 32 767 |
|
ushort |
16 |
0 - 65 535 |
|
int |
32 |
-2 147 483 648 - 2 147 483 647 |
|
uint |
32 |
0 - 4 294 967 295 |
|
long |
64 |
-9 223 372 036 854 775 808 - 9 223 372 036 854 775 807 |
|
ulong |
64 |
0 - 18 446 744 073 709 551 615 |
Плавающая запятая — форма представления действительных чисел, в которой число хранится в форме мантиссы и показателя степени. В случае языков программирования, любое число может быть представлено в следующем виде
(1)
N=M∗10p
где N — записываемое число;
M — мантисса;
p (целое) — порядок.
Например: 14441544=1,4441544*107; 0,0004785=4,785*10-4.
Компьютер же на экран выведет следующие числа:
1,4441544E+7; 4,785E-4
Следовательно, в отведенной памяти хранится мантисса и порядок записываемого числа. Рассмотрим, например, типа данных, который хранится в 8 байтах или 64 битах. В данном случае, мантисса составляет 53 бита: 1 для знака числа и 52 для её значения; порядок 10 битов: 1 бит для знака и 10 для значения. Мы можем в данном случае говорить о диапазоне точности, то есть насколько малое и насколько большое число может хранить данный тип данных: 4,94×10−324 до 1.79×10308. Но, поскольку, память компьютера не безразмерна, да и далеко не всегда нужно, храниться несколько первых разрядов мантиссы, которые называются значащими.[3]
Вывод: вещественные типы данных, в отличии от целочисленных, характеризуются диапазоном точности и количеством значащих разрядов.
Рассмотрим конкретные типы данных в наших трёх языках.
- C#
- C++
- Java
Таблица 2
Типы данных
|
Тип |
Разрядность в битах |
Количество значащих цифр |
Диапазон точности |
|
float |
32 |
7 |
от 1,5*10-45 до 3,4*1038 |
|
double |
64 |
15 |
от 4,9*10-324 до 1,7*10308 |
|
decimal |
128 |
28 |
от 1,0*10-28 до 7,9*1028 |
Тип decimal создан специально для операций высокой точности, в частности финансовых операций. Он не реализован как примитивный тип, поэтому его частое использование может повлиять на производительность вычислений.
Символьный тип данных
Значение переменной этого типа данных представляет собой один символ. В действительности, это есть целое число. В зависимости от кодировки, это число превращается в некий символ. Данные типы данных характеризуются лишь размером выделяемой под них памяти.
- C#
- C++
- Java
Таблица 3
Символьный тип данных
|
Тип |
Разрядность в битах |
|
char |
16 |
Логический тип данных
Это тип данных, значения которых могут быть: true (правда) или false (ложь). Логическому типу данных соответствуют в С# и C++ тип bool, в Java - boolean.
Перечислимый тип данных
Во внутреннем представлении, это целочисленный тип данных, только здесь пользователь вместо числе использует заранее определенные строковые значения. Чтобы прочувствовать эту концепцию, приведем пример на языке С++ (в С# и Java аналогично)
enum Forms {shape, sphere, cylinder, polygon};
Теперь переменные перечислимого типа Forms могут принимать лишь значения, определенные в примере кода. Это очень удобно, ведь мы уже оперируем не с числами, а с некими смысловыми значениями, замечу лишь, что для компьютера эти значения всё-равно являются целыми числами.
Массив
Далее перейдем к сложным типам данных. Первый из них - это массив. Массив - это набор однотипных переменных, расположенных в памяти непосредственно друг за другом, доступ к которым осуществляется по индексу. Индекс массива — целое число, указывающее на конкретный элемент массива.[4]
Каждый массив характеризуется типом данных его элементов, который может быть как простым, так и сложным, то есть любым.
В языках программирования нельзя оперировать всем массивом, работают с конкретным элементом. Чтобы доступиться до него в трёх рассматриваемых нами языках используют оператор "[]".
array[0]
Индекс имеет тип данных чаще всего int.
Структура
Ранее были рассмотрены встроенные типы данных. Теперь мы переходим к пользовательским типам данных. Структура - конструкция, позволяющая содержать в себе набор переменных различных типов.
Структуры реализованы в языке программирования, чтобы собрать некие близки по смыслу вещи воедино.
Например, есть колесо автомобиля. У колеса есть диаметр, толщина, шина. Шина в свою очередь является структурой, у которой есть свои параметры: материал, марка, чем заполнена. Естественно, для каждого параметра можно создать свою переменную или константу, у нас появится большое количество переменных, которые, чтобы понять к чему они относятся, нужно в именах общую часть выделять. Имена будут нести лишнюю смысловую нагрузку. Получается запутанная история. А так мы определяем две структуры, а затем параметры в них.
struct Tyre
{
Material material;
int mark;
};
struct Wheel
{
double diameter;
double thickness;
Tyre tyre;
}
Класс
Еще одним пользовательским типом данных является класс. Класс умеет всё, что и структура, но кроме параметров, у него есть и методы, и поддерживает большое количество вещей, связанных с объектно-ориентированным программированием.
1.2 Основные структуры данных
Структуры данных являются важной частью разработки программного обеспечения и одной из наиболее распространенных тем для вопросов на собеседованиях с разработчиками. Хорошая новость в том, что они в основном являются просто специализированными форматами для организации и хранения данных. Из этой статьи вы узнаете о 10 наиболее распространенных структурах данных.[5] Также сюда добавлены видеоролики (на английском языке) по каждой из структур, и код их реализации на JS. А чтобы вы немного попрактиковались, я добавил сюда задачи из бесплатной учебной программы freeCodeCamp.
Обратите внимание, что некоторые из этих структур данных включают временную сложность в нотации Big O. Это не относится ко всем из них, поскольку временная сложность иногда основана на реализации. Если вы хотите узнать больше о нотации Big O, посмотрите видео от Briana Marie.
Несмотря на то, что для каждой структуры я привожу код реализации на JavaScript, вам вероятно, никогда не придется делать этого самостоятельно, только если вы не будете использовать низкоуровневый язык вроде С. JavaScript (как и большинство языков высокого уровня) имеет встроенные реализации многих из этих структур данных.[6]
Тем не менее, знание того, как реализовать эти структуры данных, даст вам огромное преимущество в поиске работы и может пригодиться, когда вы попытаетесь написать высокопроизводительный код.
Связные списки
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки.
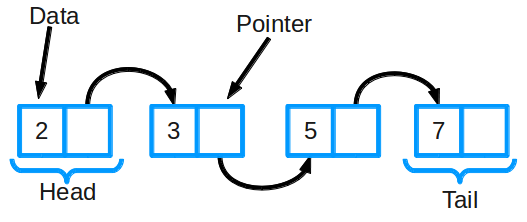
Рисунок 2 Связные списки
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности.
Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке.
Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
Стеки
Стек — это базовая структура данных, в которой вы можете только вставлять или удалять элементы в начале стека.[7] Он напоминает стопку книг. Если вы хотите взглянуть на книгу в середине стека, вы сначала должны взять книги, лежащие сверху.
Стек считается LIFO (Last In First Out) — это означает, что последний элемент, который добавлен в стек, — это первый элемент, который из него выходит.

Рисунок 3 Стеки
Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (называемый «push»), удаление элемента из стека (называемое «pop») и отображение содержимого стека (иногда называемого «pip»).
Очереди
Вы можете думать об этой структуре, как об очереди людей в продуктовом магазине. Стоящий первым будет обслужен первым. Также как очередь.

Рисунок 4 Очереди
Если рассматривать очередь с точки доступа к данным, то она является FIFO (First In First Out). Это означает, что после добавления нового элемента все элементы, которые были добавлены до этого, должны быть удалены до того, как новый элемент будет удален.
В очереди есть только две основные операции: enqueue и dequeue. Enqueue означает вставить элемент в конец очереди, а dequeue означает удаление переднего элемента.
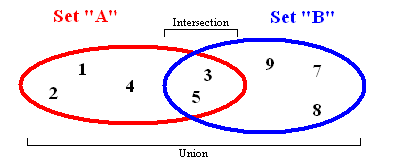
Рисунок 5 Множества
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно.
- Union (Объединение). Объединяет все элементы из двух разных множеств и возвращает результат, как новый набор (без дубликатов).
- Intersection (Пересечение). Если заданы два множества, эта функция вернет другое множество, содержащее элементы, которые имеются и в первом и во втором множестве.
- Difference (Разница). Вернет список элементов, которые находятся в одном множестве, но НЕ повторяются в другом.
- Subset(Подмножество) — возвращает булево значение, показывающее, содержит ли одно множество все элементы другого множества.
Map
Map — это структура данных, которая хранит данные в парах ключ / значение, где каждый ключ уникален. Map иногда называется ассоциативным массивом или словарем. Она часто используется для быстрого поиска данных.
Map’ы позволяют сделать следующее:
- Добавление пары в коллекцию
- Удаление пары из коллекции
- Изменение существующей пары
- Поиск значения, связанного с определенным ключом
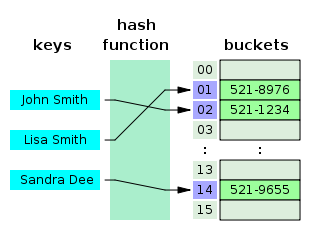
Рисунок 6 Хэш-таблицы
Хэш-таблица — это структура данных, реализующая интерфейс map, который позволяет хранить пары ключ / значение. Она использует хеш-функцию для вычисления индекса в массиве, по которым можно найти желаемое значение.
Хеш-функция обычно принимает строку и возвращает числовое значение. Хеш-функция всегда должна возвращать одинаковое число для одного и того же ввода. Когда два ввода хешируются с одним и тем же цифровым выходом, это коллизия. Суть в том, чтобы их было как можно меньше. Поэтому, когда вы вводите пару ключ / значение в хеш-таблице, ключ проходит через хеш-функцию и превращается в число.[8]
Это числовое значение затем используется в качестве фактического ключа, в котором значение хранится. Когда вы снова попытаетесь получить доступ к тому же ключу, хеширующая функция обработает ключ и вернет тот же числовой результат. Затем число будет использовано для поиска связанного значения. Это обеспечивает очень эффективное время поиска O (1) в среднем.
1.3 Способы кодирования данных
Одна и та же информация может представляться в нескольких формах. Основные способы кодирования позволяют это сделать в современном мире. После появления компьютерных технологий появилась необходимость кодирования любого типа информации, с которыми работает человек. Но решать задачу такого типа начали еще задолго до появления компьютеров.
1 способ. Двоичное кодирование. Одним из самых популярных и распространенных методов представления информации считается именно двоичное кодирование. В работе с вычислительными машинами, роботами и станками с числовым программным управлением чаще всего кодируют информацию в форме слов двоичного алфавита.
2 способ. Стенография. Этот способ относят к методам кодирования текстовой информации при помощи специальных знаков. Этот способ самый быстрый при записи устной речи. Навыками стенографии владеют только некоторые специально обученные люди, которым и дали название стенографисты. Такие люди успевают записать текст синхронно с речью человека, который выступает.
3 способ. Синхронизация. В процессе работы с цифровой информацией особенное значение получает синхронизация. В момент считывания либо записи информации немаловажным остается точное определение времени каждой смены знака. Если синхронизации нет, то период смены знака может определяться неправильно. В итоге этого неизбежной будет потеря или искажение данных.
В процессе работы с цифровой информацией особенное значение получает синхронизация. В момент считывания либо записи информации немаловажным остается точное определение времени каждой смены знака. Если синхронизации нет, то период смены знака может определяться неправильно. В итоге этого неизбежной будет потеря или искажение данных. 4 способ. Run Length Limited — RLL. На сегодняшний день одни из самых популярных методов является кодирование информации с ограничением длины поля записи. Благодаря этому способу на диске можно разместить в полтора раза больше данных, нежели в процессе записи по методу MFM. Используя этот метод происходит кодирование не отдельного бита, а целой группы.
5 способ. Таблицы перекодировки. Таблицей перекодировки считается та, которая содержит перечень кодируемых символов, упорядоченный специальным образом. Соответственно с этим и происходит преобразование символа в его двоичный код и обратно. 6 способ.
Глава 2. Осуществление кодирования данных
2.1 Передача информации в компьютерных сетях
Протоколы, предназначенные для маршрутизации в мобильной беспроводной сети, подразделяются на три основные категории. Это проактивные, реактивные и гибридные протоколы маршрутизации. В каждой категории существуют несколько протоколов: Реактивные протоколы маршрутизации начинают создавать маршруты только по требованию. Протокол маршрутизации будет пытаться установить маршрут в том случае, когда какой-либо узел захочет установить связь с другим узлом к которому он не имеет маршрута. Этот тип протоколов обычно основывается на заполнении сети сообщениями типа Route Request (RREQ) и Route Reply (REPL).[9]
При помощи со общений Route Request маршрут определяется от источника к необходимому узлу (цель), и как только необходимый узел получает RREQ сообщение, он отправляет REPL сообщения для подтверждения того, что маршрут установлен. Этот тип протоколов как правило эффективен в сетях с одинаковыми характеристиками и параметрами. Он обычно уменьшает количество прыжков выбранного маршрута.
Однако в больших сетях с множественными характеристиками количество хапов не такой важный показатель как пропускная способность в построенном маршруте.
Примеры реактивных протоколов маршрутизации: AODV (Ad hoc OnDemand Distance Vector Routing Protocol) DSR (Dynamic Source Routing Protocol) ACOR (Admission Control enabled On demand Routing Protocol) ABR (Associative Based Routing Protocol). Проактивные протоколы маршрутизации MANET также называют таблично-ориентированными протоколами, которые активно определяют уровень состояния сети.
Благодаря регулярному обмену в сетевой топологии пакетами между узлами в сети, каждый узел знает абсолютную топологию (картину) сети. Благодаря этому при выборе маршрута существует минимальная задержка. Это особенно важно для срочного трафика. Когда информация о маршруте быстро становится неверной, генерируется большое количество короткоживущих маршрутов в существующей топологии сети, которые не используются пока они действительны.
Таким образом, в результате повышения мобильности, существует недостаток, выраженный в увеличении объема трафика, генерирующегося при построении ненужных маршрутов. Особенно это заметно при значительном увеличении размера сети. Часть общего трафика управления, который состоит из актуальных практических данных, уменьшается.[10] Наконец, если узлы передают данные нечасто, то большая часть маршрутной информации рассматривается как избыточная.
Узлы, однако, продолжают тратить энергию для обновления этой неиспользуемой информации в своих маршрутных таблицах, что ведет к бессмысленной тракте энергии, а энергосбережение является важной частью в проектировании MANET.
Таким образом, проактивные протоколы маршрутизации лучше работают в сетях с низкой мобильностью или в сетях с часто генерируемым трафиком. Примеры проактивных протоколов маршрутизации: OLSR (Optimized Link State Routing Protocol) FSR (Fisheye State Routing Protocol) DSDV (Destination Sequenced Distance Vector Routing Protocol). CGSR (ClusterHead Gateway Switch Routing Protocol).
В силу того, что проактивные и реактивные протоколы маршрутизации работают хорошо в противоположных сценариях, гибридные протоколы маршрутизации объединили в себе методы обоих типов. Он используется для нахождения баланса между обоими типами протоколов.
Примеры гибридных протоколов маршрутизации: TORA (Temporallyordered Routing Algorithm Protocol) HSR (Hierarchical State Routing Protocol) ARPAM (Adhoc Routing Protocol for Aeronautical Mobile AdHoc Networks) OORP (OrderOne Routing Protocol) качестве средства имитационного моделирования использовался сете вой симулятор OPNET (Optimized Network Engineering Tool) Modeler вер сии 14.0. Это наиболее широко используемый коммерческий симулятор, работающий под операционной системой Microsoft Windows и включающий в себя реализацию исследуемых нами протоколов маршрутизации.[11]
Данный программный продукт не только поддерживает MANET маршрутизацию, но и также предоставляет параллельное ядро для поддержки увеличения стабильности и мобильности в сети. Функции интенсивного анализа OPNET обеспечивают лучшие условия для сравнения, вычисления и координации выходных данных. В рамках Opnet Modeler пользователи могут использовать графическую среду для того, чтобы создать, выполнить и проанализировать событийное моделирование сетей связи.
Он представляет собой удобный программный продукт, который может быть использован при решении большого числа задач, к которым, например, относятся формирование и про ведение проверки в протоколе связи, проведение анализа по взаимодействиям протоколов, оптимизация и планирование сети. Кроме того, есть возможности для осуществления на основе этого пакета проверки правильности соответствующих аналитических моделей, и описаний протоколов.
Основываясь на так называемом редакторе проекта, можно создавать палитру для сетевых объектов, которой пользователи могут присваивать разные способы соединения узлов и связи, которые могут иметь весьма сложный вид. Проведение автоматизированного порождения сетевых топологий кольца, звезды, случайной сети, кроме того, может быть поддержано и зарезервировано на основе утилит для импортируемых сетевых топологий по разным форматам.
Генерацию случайного трафика можно автоматически сгенерировать из алгоритмов, которые указаны пользователями, а также импортировать на базе имеющихся в стандартной комплектации пакетов форматов реальных трафиков. Проведение анализа результатов моделирования можно осуществить, а генерацию графов и анимации трафика можно сделать автоматически.[12] Среди возможных плюсов при формировании модели сети на основе программного обеспечения следует отметить то, что уровень гибкости, который обеспечивается с привлечением ядра моделирования, тот же, что и для моделирования, которое создано с нуля, но с использованием объектного построения среды.
Пользователь может намного быстрее производить разработку, усовершенствование и делать модели для многократного использования. Существует несколько сред редактора по одной для каждого из видов объектов. Для организации объектов можно отметить иерархическую структуру, для сетевых объектов (моделей) есть связи по набору узлов и объектов связи, при этом есть связи объектов узлов по набору объектов, типам модулей очерёдности, модулям процессоров, передатчику и приемнику.
В версии ПО для моделирования радиоканалов содержатся модели антенн радиопередатчика, антенн приемника, объекты узла, которые перемещаются (включая спутники). Логикой поведения процессоров и модуля очередности управляет модель процесса, которая может создаваться пользователем и изменяться в пределах редакторов процессов.
В редакторах процессов пользователи могут определять модели процессов через комбинации алгоритмов работы конечных автоматов (finitestate machine FSM) и операторов языков программирования C/C++. Проведение вызова событий модели процессов при моделировании управляется на основе возбуждения прерывания, а каждое из прерываний соответствует событиям, которые должны быть обработаны в рамках модели процессов.
2.2 Взаимосвязь данных и информации
В 2017 г. не склонные к риску предприятия наконец освоили облака — а мы и не заметили, пишет на портале TechTarget старший аналитик и консультант Taneja Group Майк Мэтчетт. Незаметно произойдет и переход к новым технологиям хранения данных в 2018 г.
Порой большие изменения подкрадываются очень тихо. Особенно если речь идет о будущем технологий хранения данных. Мэтчетт предлагает обратить внимание на следующие тренды:
Контейнеры появились благодаря давнему желанию найти удачный способ упаковки приложений. В этом году управление контейнерами корпоративного класса достигнет уровня зрелости управления виртуальными машинами, не утратив тех преимуществ, которыми обладают контейнеры по сравнению с виртуальными машинами.[13] Чисто программные (software-defined) ресурсы, такие как хранение, будут предоставляться главным образом в виде контейнеров.
В сочетании с динамическими операционными API-интерфейсами эти ресурсы составят очень гибкие программируемые инфраструктуры. Такой подход позволит производителям упаковывать приложения вместе с необходимой для них инфраструктурой в модули, которые можно развернуть где угодно, создавая даже такие облака, какие создают ЦОДы. Возможность развернуть ЦОД по запросу будет широко использоваться, например, при восстановлении после катастроф. Все говорят об искусственном интеллекте, а в действительности это машинное обучение постепенно проникает во все поры управления ИТ.
Следует абстрагироваться от шумихи и определить, где и как осторожно применяемое МО может принести существенную пользу. Концептуально МО в основном представляет собой развитую форму распознавания образов. Так что подумайте, где автоматическая идентификация сложных образов сэкономит время и силы. Все более широкая доступность алгоритмов МО породит новые процессы управления хранением.[14] Такие процессы смогут обучаться, корректировать операции и настройки для оптимизации нагрузки, быстро выявлять и устранять коренные причины аномалий, взаимодействовать с инфраструктурой хранения и управлять большими данными с целью минимизации затрат.
Менеджмент как сервис (Management as a Service, MaaS) применительно к хранению данных набирает популярность. Во-первых, любой массив хранения автоматически информирует службу технической поддержки о возникающих проблемах, анализирует управление и оптимизирует производительность. В 2018-м интервал между предоставлением сервисов удаленного управления быстро сократится с одного дня до пяти минут.
Большинство компаний будет управлять своими гибридными архитектурами с помощью облачных сервисов MaaS, и многие начнут отказываться от обременительного использования управляющего ПО на своей площадке. Не только крупные, но даже мелкие производители быстро создают MaaS-версии своих продуктов. Например, осенью прошлого года VMware выпустила несколько облачных управляющих сервисов, которые, в сущности, представляют собой онлайновые версии знакомых онпремис-возможностей.
Возросло количество массивов хранения, имеющих облачные аналоги, которые можно легко воспроизвести и использовать при возникновении сбоев. Вот лишь некоторые примеры: HPE Cloud Volumes (Nimble); IBM Spectrum Virtualize и облачное хранение Oracle, использующее ZFS Storage Appliance. Не следует требовать, чтобы при хранении в облаке для надежности гибридных операций использовалась та же или сходная операционная система, что и при локальном хранении.[15] В конце концов, главное достоинство публичного облака состоит в том, что конечный пользователь не должен беспокоиться, а в большинстве случаев даже знать, является инфраструктурный сервис физической машиной, виртуальным образом, временным контейнерным сервисом или чем-то еще.
Правда, для оптимизации сложных распределенных операций, связанных с хранением, может использоваться много патентованных технологий, таких как удаленная репликация данных, синхронизация моментальных снимков, управление метаданными и их индексирование, применение глобальной политики. Для операций гибридного хранения попросту нет стандартов. Даже пользующийся широкой поддержкой API-интерфейс хранения объектов AWS Simple Storage Service в действительности не является стандартом. По поводу облачного хранения разгорятся войны: организации будут шокированы, когда поймут, что им приходится платить как производителю системы хранения за ее облачный вариант, так облачному сервис-провайдеру за платформу.
Несмотря на шумиху, протокол Non-Volatile Memory Express (NVMe) не вызовет потрясений в области хранения, если судить по тому, что говорилось на VMworld и других конференциях осенью прошлого года. Да, он может дать прирост производительности при решении тех важнейших задач, которым сколько ни дай, все мало. Но он не окажет влияния на будущее хранения данных, даже отдаленно напоминающего эффект флэш-памяти NAND. Тем не менее, в 2018 г. в большинстве массивов хранения, вероятно, появится поддержка NVMe, что лишит некоторых производителей их преимуществ.
С другой стороны, вскоре после 2018 г. следует ожидать появления вычислительных архитектур, целенаправленно построенных на основе высокоскоростных энергонезависимых устройств хранения (Storage-Class Memory, SCM). Первые варианты SCM, которые выпустила Intel, установленные на картах PCIe с доступом по протоколу NVMe (3D XPoint), дали значительное повышение производительности. Но еще более быстрые виды SCM в сочетании с модулями динамической памяти RAM вызовут гораздо более сильное потрясение.[16]
2.3 Кодирование и декодирование данных
Как мы можем видеть, главной особенностью нашей современной жизни является информатизация общества и всех сфер его деятельности. Информационные ресурсы, сегодня, стали намного важнее, чем материальная составляющая либо энергетические возможности. Каждый день мы то и дело сталкиваемся с различными информационными потоками, без которых уже невозможно представить существование человечества. Информационные ресурсы, которые представляют собою массивы данных, как правило, крупных размеров, могут использоваться различными способами, как отдельными людьми, так и целыми предприятиями. Однако, большая часть современных организаций не могут качественно заниматься своей деятельностью без возможности защиты своей информации, ее надежного и удобного хранения, а также, быстрой передачи данных.
В результате использования обществом автоматизированных систем, образовалось немалое количество проблем, как у пользователей, так и у разработчиков. Основной из них является проблема информационной безопасности. Ее влияние велико, поэтому оставлять ее в бесконтрольном состоянии нельзя. Она требует постоянного сосредоточения, решения проблем и поиска новых путей совершенствования существующих методов. Особенно ввиду того, что практически вся современная информация может легко преобразоваться в машиночитаемую форму. А это значит, ее можно легко исказить, скопировать, либо уничтожить. Что, весьма, нежелательно. В совокупности с этим, развитие информационных технологий, присущее нашей современности, способствует распространению негативных явлений, таких как несанкционированный доступ к секретной информации, промышленный шпионаж.
Подобные действия представляют собой серьезную опасность для современных организаций. Поэтому вопросы защиты информации, на сегодняшний день, имеют большую актуальность. Спрос на хороших специалистов в этой области растет ежедневно. Информационная безопасность является довольно многогранной и существенной проблемой, которая требует серьезного подхода и использования надежных способов защиты информации от различного рода посягательств. С этой целью в стране разрабатываются различные государственные программы, развивается нормативно-правовая база. [1, 8]
Однако, помимо этого, для успешной работы с объемами информации, она должна иметь надлежащий вид, который обеспечит достоверность, компактность и удобство. [5, 64] Поэтому, сегодня, на практике применяются особые технологии, которые способны кодировать информацию, тем самым не только способствуя качественному ее использованию, а и предотвращая свободный доступ к ней, что, несомненно, повышает уровень безопасности. Интересно, что история кодирования информации началась несколько веков назад.
В 1792 году был создан первый телеграф Шаппа, который мог передавать оптическую информацию, используя таблицу кодов, где буквам соответствовали разные фигуры. После, революцию в сферу кодирования и декодирования привнес телеграф Морзе в 1837 году. Создатель предложил использовать для преобразования сообщений всего три символа: тире, точка, пауза. Также, запоминающимися изобретениями стали радиоприемник А. Попова, передающий данные беспроводным путем, и телеграф Бодо, который решал проблему неравномерности кода и сложность декодирования. Далее следовало создание электронно-вычислительных машин (ЭВМ). [2, 56]
Решающим фактором в разработке систем управления информацией был факт того, что для ее получения, передачи, хранения, используются именно ЭВМ. Чтобы эти машины могли успешно считывать данные, информация должна быть преобразована в символы, которые будут понятны для них. Что и было сделано. Таким образом, на данный момент, по каналам связи передаются очень большие объемы информации в виде кода, который преобразовывается специальными программами.
Существуют и обычные способы сбора данных, которые соответствуют всем стандартам, но, тем не менее, они являются несовершенными. Поэтому в современных системах передачи информации успешно применяются способы кодирования и декодирования. Рассмотрим эти понятия. Особым и неотъемлемым элементом обработки информации является кодирование, которое можно охарактеризовать как процесс составления кода, имеющего вид набора символов либо сокращений, соответствующих определенным элементам.
Код — это совокупность знаков, каждый из которых имеет соответствие с другими составляющими. Иногда данный термин заменяется понятием «шифр». Основные задачи кодирования состоят в обеспечении экономичности, компактности, надежности, а также, в соответствии скорости передачи данных пропускной способности канала.
Цель кодирования состоит в стремлении изменить информацию в другую форму, более компактную, такую, которую можно будет использовать при передаче и обработке информации. Данный способ обеспечивает присутствие таких элементов, как метод поиска, сортировка информации и ее упорядочивание, что, по сути, представляет собой принципиальную схему обработки информации, где процесс кодирования является частью операции ввода данных, имеющих вид входных кодов, которые образуются после декодирования. Говоря о декодировании, мы можем отметить, что эта операция обратна кодированию. Декодировщик превращает код в привычную для человека форму. В более широком смысле, декодирование — это процесс восстановления и придания смысла полученным сигналам.
С помощью декодирования можно найти какой-либо объект, а также выяснить его характеристики и особенности по заданному ранее коду. Однако, прежде чем будет происходить операция декодирования, для нее должны быть созданы определенные и достаточные условия. Во-первых, несомненно, это — однозначность, во-вторых, наличие декодирующего автомата, как обычного, так и самонастраивающегося, с помощью которого можно устранять влияние сбоя во входной последовательности.
Таким образом, расшифровка информации может осуществляться лишь при наличии необходимых технических средств. Осуществление процесса кодирования, как известно, происходит автоматически либо вручную. В последнем случае запись кода производится в виде символов, согласно каталогу кодов. Далее, информация отправляется в вычислительный центр, где кодируется оператором. Автоматическое кодирование осуществляется при помощи специального автомата, который читает язык человека, и, при помощи словаря, кодирует его в машинный код. Этот новый вид, в который преображается информация, гораздо короче и, поэтому, удобней для ее поиска и обработки. Очевидно, что для успешного осуществления всех процессов, в памяти ЭВМ должен храниться словарь, содержащий соответствия всем элементам языка.
С его помощью машина способна сама кодировать и декодировать информацию. [8, 58] В данной области существует такое понятие, как ключевой код, который используется тогда, когда нужно найти подробную информацию о чем-либо. Он более короткий, чем обычно. С его помощью, в памяти машины осуществляется поиск по массиву данных, хранящихся в ней. Особенностью такого массива является то, что он един для всех решаемых задач. Делить его на подсистемы нецелесообразно, так как это увеличит время обработки информации. Ключевой код может иметь вид, как регистрационного номера, так и обозначать основные признаки продукции. Коды для кодирования данных, бывают разными. Каждый из них отличается своим алгоритмом работы.
К примеру, код, который имеет прямое соответствие предметам — прямой; код, предоставляющий лишь адрес, по которому содержится информация — адресный. Последний используется, как правило, когда нужно найти большие объемы данных. Известно, что за единицу количества информации принимается 1 бит, или один двоичный разряд (0 или 1). Сегодня, для кодирования одного символа используется 8 бит. Все символы, буквы и цифры имеют вид групп двоичных разрядов. Такой процесс кодирования называется двоичным. Он используется в смартфонах, ноутбуках, компьютерах. Также, существует байт, или группа битов, обрабатывающаяся компьютером единовременно; машинное слово, объем которого может быть от 16 до 64 двоичных разрядов, в зависимости от вида ЭВМ.
Страница также является массивом информации. Она, как известно, содержит 1024 машинных слова. 16 и более страниц обычно находятся в одном блоке памяти. [8, 74] Ввиду большого количества информации об объектах, где каждый из них определяется кодом адреса, в состав которого входят номера слов, блоков, страниц, применяется метод классификации. Данное понятие представляет собой условное деление множества на классы, подклассы, согласно заданным признакам, и следуя правилам.
Кодирование информации двоичным способом является самым распространенным, при помощи которого работают все вычислительные системы. Лишь при наличии напряжения и тока в компьютере могут происходить сверхбыстрые вычисления, где высокое напряжение отвечает за единицы, а за нули — низкое. После, данные считываются, обрабатываются и выводятся на экран. Перевести понятный нам язык в десятичный можно при помощи специальных таблиц конверсии. Например, фраза «Life is good» будет иметь следующий вид:
«1101100110100111001101100101100000110100111100111000001100111110111111011111100100».
Чтобы расшифровать данную последовательность, необходимо бинарный код разделить на части, состоящие из семи отделений. «1101100» — буква L, «1101001» — буква I, «1100110» — буква F, «1100101» — буква E, и так далее до конца фразы. Это довольно легко. Хотелось бы отметить, что в теории кодирования встречается также и троичная, четвертая, шестнадцатеричная и многие другие системы исчисления. Последняя, как правило, применяется в языках программирования низкого уровня, например, в ассемблере. Благодаря ей, центральный процессор быстро выполняет команды. Также, она может использоваться в создании разнообразной программной документации.
Помимо цифр и букв, кодируются и символы. Данный этап обязателен в работе любого устройства. Кодирование осуществляется именно в момент работы программы с определенным текстом. С этой целью были созданы определенные стандарты, которые успешно используются на практике. Это — Юникод, являющийся самым популярным стандартом кодирования, ASCII, UTF-8, которые также широко распространены. Иногда, информацию нужно не просто закодировать, а зашифровать, то есть, скрыть содержимое. Шифрованием называется кодирование информации с целью ее сокрытия, чтобы ограничить к ней доступ для тех лиц, кому не положено ею пользоваться.
Структурно шифрование содержит в себе алгоритм, то есть двоичную математическую последовательность, и ключ, что является бинарной последовательностью. Обратный процесс шифрования — это дешифрование, или превращение информации в первоначальный вид. Данный метод обработки данных довольно активно используется в банковской системе, в облачных хранилищах, в операционных системах, в социальных сетях и мессенджерах. Сегодня, он является наиболее популярными способом защиты информации. Кстати, этот метод может использоваться не только по назначению, а также, для установления подлинности, и множества других задач. [4, 52] Еще одним способом кодирования является стеганография.
Он скрывает не только информацию, а и сам факт о том, что она существует. Такое кодирование осуществляется с помощью встраивания сообщения в картинки, музыку, видео. Произвести декодирование стенографической информации можно только специальными программами, или взломав ее. Комплексное использование стенографии и шифрования существенно повышает сложность обнаружения и раскрытия данных. В зависимости от способов кодирования, применяемые математические модели кодов могут быть различны. Наиболее часто они имеют вид кодовых матриц; кодовых деревьев; многочленов; а также, геометрических фигур.
В сфере информационных технологий кодирование осуществляется всегда, когда данные вводятся в систему. Пользователь может делать что угодно — печатать текст, создавать папки, отдельные файлы, копировать информацию. В любом случае, в итоге, все это преобразуется в набор единиц и нолей. Когда данную информацию необходимо отобразить на экране, система обрабатывает ее при помощи декодирования, и выводит данные. Эти операции осуществляются мгновенно. [4, 118]
В истории кодирования информации насчитывается большое число практических примеров. Один из наиболее интересных — шифровальная машина Энигма, которая использовалась нацистами во Второй Мировой.
Шифр ее был очень сложен. Сама машина представляла собой клавиатуру в сочетании с несколькими колесами. Варианты декодирования каждый день менялись — то, какой будет буква, зависело от конфигурации колес. Только вариантов их расположения было более ста триллионов возможных комбинаций. Взлом машины представлял собой достаточно сложный и долгий процесс. Однако, наработки, накопившиеся за то время, стали прообразом современных компьютеров. Действительно, информационное кодирование, с целью передачи данных, применяется на практике уже достаточно давно. Причин тому масса, но главными, на сегодняшний день, являются такие, как оснащение банковской сферы информационными технологиями, использование социальных сетей, осуществление онлайн-покупок.
Поэтому, с целью сохранения конфиденциальности, защиты данных от несанкционированного доступа, осуществляется кодирование любым удобным способом. Поддержание информационной безопасности — важная функция современного государства. В данной области проводится большая работа по выработке стандартов и методологии защиты данных. Суть политики безопасности состоит в предотвращении несанкционированного доступа, искажения, раскрытия, уничтожения информации. Для противостояния преступлениям применяется большое количество мер со стороны закона, проводятся мероприятия по обеспечению сохранности данных. [7, 154]
Также, мы можем наблюдать практические способы предупреждения правонарушений в самой системе. Это, конечно же, кодирование информации, которое помимо защиты данных, способствует более удобному их использованию, упрощает процесс обработки и хранения, а декодирование — возвращает их в первоначальный вид. [3, 208] Наиболее популярным способом кодирования является криптография, или шифрование, а также, использование устройств, ограничивающих доступ к объектам и данным. Например, биометрические системы.
Угрозы роста преступности в информационной сфере невозможно предсказать. Однако, за этот год наибольшую популярность приобрело развитие модели преступления «как услуги». То есть, на интернет-рынке действуют определенные сообщества либо отдельные лица, которые предоставляют пакеты криминальных услуг по низкой стоимости. В результате чего, совершается множество хакерских атак. Что несет большой риск для соблюдения конфиденциальности и целостности информации. Тем не менее, за последние годы область информационной безопасности стала значительно расти. В ее структуре появилось большое количество разнообразных специализаций. Это и компьютерная криминалистика, и защита программного обеспечения, безопасность сетей и связанной инфраструктуры и многое другое.
Профессионалы в данной области пользуются большой популярностью на рынке труда. Современное общество старается обеспечивать безопасность информационным ресурсам. Однако, это не всегда удается. Наверное, как бы информация не кодировалась, всегда найдется тот, кто сможет подобрать к ней ключ. Поэтому, данное исследование хотелось бы закончить словами Юджина Х. Спаффорда: «По-настоящему безопасной можно считать лишь ту систему, которая выключена, замурована в бетонный корпус, заперта в помещении со свинцовыми стенами и охраняется вооруженным караулом, — но и в этом случае сомнения не оставляют меня».
Заключение
В данной курсовой работе было проведено исследования современных методов кодирования и представления данных в компьютерах и каналах передачи данных.
В ходе проведения исследования выявлено, что:
- современные вычислительные системы оперируют самыми разнообразными данными, которые в зависимости от используемых форматов и применяемых к ним комманд, могут быть представлены в различных форматах;
- в вычислительных системах для хранения, обработки и передачи данных используются системы кодирования для хранения, обработки и передачи данных;
- существуют разнообразные способы и методы кодирования данных и зависят от поставленной задачи;
- формы для представления данных оределяются форматами (типами) данных.
Таким образом, поставленная цель рассмотрения и изучения методов кодирования и представления данных в вычислительных системах достигнута.
В ходе выполнения решены следующие задачи:
- рассмотрены основные типы данных в компьютере и их структуры;
- рассмотрены современные мотоды кодирования данных;
- изучены способы кодирования и декодирования данных при их передаче.
Список использованной литературы
- Администрирование баз данных Oracle в операционной системе UNIX. - М.: СПб: ЦКТиП Газпром, 2018. - 300 c.
- Антенны и фидеры. Передача информации по каналам связи. Контроль и измерения в технике связи / ред. С.В. Бородич. - М.: НИИР, 2017. - 100 c.
- Баззел, Р.Д. Информация и риск в маркетинге / Р.Д. Баззел, Д.Ф. Кокс, Р.В. Браун. - М.: Финстатинформ, 2017. - 708 c.
- Богнер, Р. Введение в цифровую фильтрацию / Р. Богнер, А. Константинидис. - М.: [не указано], 2015. - 283 c.
- Воскобойников, Я.С. Журналист и информация. Профессиональный опыт западной прессы / Я.С. Воскобойников, В.К. Юрьев. - М.: РИА-Новости, 2016. - 208 c.
- Глушаков, С.В. Базы данных / С.В. Глушаков, Д.В. Ломотько. - М.: Харьков: Фолио, 2018. - 504 c.
- Грешилов, А. А. Некорректные задачи цифровой обработки информации и сигналов / А.А. Грешилов. - М.: Университетская книга, Логос, 2012. - 360 c.
- Гурский, Ю. Photoshop CS2 и цифровое фото. Лучшие трюки и эффекты / Ю. Гурский, М. Бондаренко, С. Бондаренко. - М.: СПб: Питер, 2016. - 208 c.
- Джойнсон Используйте все возможности вашей цифровой камеры / Джойнсон, Саймон. - М.: АСТ, 2013. - 160 c.
- Долуханов, М.П. Введение в теорию передачи информации по электрическим каналам связи / М.П. Долуханов. - М.: Книга по Требованию, 2012. - 129 c.
- Дядюнов, А. Н. Адаптивные системы сбора и передачи аналоговой информации / А.Н. Дядюнов, Ю.А. Онищенко, А.И. Сенин. - М.: Машиностроение, 2017. - 288 c.
- Иванов, Ю.П. Исследование вопросов сопряжения цифровых систем передачи телефонных сигналов и сигналов звукового вещания на сети связи / Ю.П. Иванов. - Л.: ЛЭИС им. проф. М.А. Бонч-Бруевича, 2016. - 726 c.
- Информация президиума правления всероссийского театрального общества (январь-апрель 1980 г.). - М.: Всероссийское театральное общество, 2014. - 656 c.
- Йенсен Общество мечты. Как грядущий сдвиг от информации к воображению преобразит ваш бизнес / Йенсен, Ролф. - М.: СПб: Стокгольмская школа экономики в Санкт-Петербурге, 2017. - 272 c.
- Кадомцев, Б.Б. Динамика и информация / Б.Б. Кадомцев. - М.: [не указано], 2013. - 328 c.
- Ким, Д. 40 лучших приемов цифровой фотографии / Д. Ким. - М.: NT Press, 2012. - 224 c.
- Косик, О. В. Голоса из России. Очерки истории сбора и передачи за границу информации о положении Церкви в СССР. 1920-е — начало 1930-х годов / О.В. Косик. - М.: Православный Свято-Тихоновский гуманитарный университет, 2017. - 312 c.
- Курилова, А. В. Ввод и обработка цифровой информации. Практикум. Учебное пособие / А.В. Курилова, В.О. Оганесян. - Москва: РГГУ, 2013. - 160 c.
- Миллсап Oracle. Оптимизация производительности / Миллсап, Хольт Кэри; Джефф. - М.: СПб: Символ-Плюс, 2018. - 464 c.
- Рихтер, С. Г. Кодирование и передача речи в цифровых системах подвижной радиосвязи / С.Г. Рихтер. - М.: Горячая линия - Телеком, 2016. - 304 c.
- Семенов, А. С. Интегральная оптика для систем передачи и обработки информации / А.С. Семенов, В.Л. Смирнов, А.В. Шмалько. - М.: Радио и связь, 2014. - 224 c.
- Спивак, М. Восхитительный AMS-TeX: руководство по комфортному изготовлению научных публикаций в пакете AMS-TeX / М. Спивак. - М.: [не указано], 2013. - 890 c.
- Хазен, А.М. Введение меры информации в аксиоматическую базу механики / А.М. Хазен. - М.: [не указано], 2017. - 809 c.
- Холево, А.С. Введение в квантовую теорию информации / А.С. Холево. - М.: [не указано], 2016. - 128 c.
- Хуанг, Т.С.ред. Быстрые алгоритмы в цифровой обработке изображений. Преобразования и медианные фильтры / Т.С.ред. Хуанг. - М.: [не указано], 2013. - 177 c.
- Экслер, А.Б. Архиваторы. Программы для хранения и обработки информации в сжатом виде / А.Б. Экслер. - М.: МП Алекс, 2013. - 150 c.
- Ярыгина, И.З. Информация в банковской деятельности. (на примере мирового опыта) / И.З. Ярыгина. - М.: Консалтбанкир, 2014. - 104 c.
-
Администрирование баз данных Oracle в операционной системе UNIX. - М.: СПб: ЦКТиП Газпром, 2018. - 300 c. ↑
-
Курилова, А. В. Ввод и обработка цифровой информации. Практикум. Учебное пособие / А.В. Курилова, В.О. Оганесян. - Москва: РГГУ, 2013. - 160 c. ↑
-
Воскобойников, Я.С. Журналист и информация. Профессиональный опыт западной прессы / Я.С. Воскобойников, В.К. Юрьев. - М.: РИА-Новости, 2016. - 208 c. ↑
-
Антенны и фидеры. Передача информации по каналам связи. Контроль и измерения в технике связи / ред. С.В. Бородич. - М.: НИИР, 2017. - 100 c. ↑
-
Дядюнов, А. Н. Адаптивные системы сбора и передачи аналоговой информации / А.Н. Дядюнов, Ю.А. Онищенко, А.И. Сенин. - М.: Машиностроение, 2017. - 288 c. ↑
-
Джойнсон Используйте все возможности вашей цифровой камеры / Джойнсон, Саймон. - М.: АСТ, 2013. - 160 c. ↑
-
Баззел, Р.Д. Информация и риск в маркетинге / Р.Д. Баззел, Д.Ф. Кокс, Р.В. Браун. - М.: Финстатинформ, 2017. - 708 c. ↑
-
Богнер, Р. Введение в цифровую фильтрацию / Р. Богнер, А. Константинидис. - М.: [не указано], 2015. - 283 c. ↑
-
Хазен, А.М. Введение меры информации в аксиоматическую базу механики / А.М. Хазен. - М.: [не указано], 2017. - 809 c. ↑
-
Рихтер, С. Г. Кодирование и передача речи в цифровых системах подвижной радиосвязи / С.Г. Рихтер. - М.: Горячая линия - Телеком, 2016. - 304 c. ↑
-
Миллсап Oracle. Оптимизация производительности / Миллсап, Хольт Кэри; Джефф. - М.: СПб: Символ-Плюс, 2018. - 464 c. ↑
-
Йенсен Общество мечты. Как грядущий сдвиг от информации к воображению преобразит ваш бизнес / Йенсен, Ролф. - М.: СПб: Стокгольмская школа экономики в Санкт-Петербурге, 2017. - 272 c. ↑
-
Иванов, Ю.П. Исследование вопросов сопряжения цифровых систем передачи телефонных сигналов и сигналов звукового вещания на сети связи / Ю.П. Иванов. - Л.: ЛЭИС им. проф. М.А. Бонч-Бруевича, 2016. - 726 c. ↑
-
Гурский, Ю. Photoshop CS2 и цифровое фото. Лучшие трюки и эффекты / Ю. Гурский, М. Бондаренко, С. Бондаренко. - М.: СПб: Питер, 2016. - 208 c. ↑
-
Информация президиума правления всероссийского театрального общества (январь-апрель 1980 г.). - М.: Всероссийское театральное общество, 2014. - 656 c. ↑
-
Глушаков, С.В. Базы данных / С.В. Глушаков, Д.В. Ломотько. - М.: Харьков: Фолио, 2018. - 504 c. ↑

- Баланс и отчетность (Бухгалтерская отчетность организации и классификация)
- Организация бухгалтерского учета на предприятии (Цели и задачи бухгалтерского учета)
- Бухгалтерская отчетность организации: порядок ее составления и анализ (анализ показателей бухгалтерской отчетности АО «Хлеб»)
- Процесс монополизации рынка в теории и на практике (Виды монополий)
- Определения бухгалтерского учета в различных источниках и их анализ
- История развития малого бизнеса в России
- Создание и функционирование маркетинговой службы в организации
- Виды юридических лиц (Понятие, признаки и виды юридических лиц)
- Разработка сайта кинотеатра (Описание предметной области)
- Автоматизация обработки обращений в службу технической поддержки ФГУП РСВО
- Торговое предприятие (Краткий анализ предметной области, характеристика предприятия и его деятельности)
- Понятие и сущность местного самоуправления