
Технологии распознавания текста
Содержание:

Введение
Распознавание текста — это механический или электронный перевод различных текста в последовательность кодов, которые используются для представления в текстовом редакторе. Это широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учета в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тесту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения. Так же – это способность компьютера получать и интерпретировать интеллектуальный рукописный ввод. Распознавание текста может производиться «оффлайновым» методом из уже написанного на бумаге текста или «онлайновым» методом считыванием движений кончика ручки, к примеру по поверхности специального компьютерного экрана.
Оффлайновый вид распознавания успешно применяется в сферах деятельности, где необходимо обрабатывать большое количество рукописных документов, к примеру, в страховых компаниях. Качество распознавания можно повысить, используя структурированные документы (формы). Кроме того, можно улучшить качество, уменьшив диапазон возможных вводимых символов. Оффлайновое распознавание считается более сложным по сравнению с онлайновым.
Точное распознавание латинских символов в печатном тексте в настоящее время возможно только если доступны чёткие изображения, такие как сканированные печатные документы. Точность при такой постановке задачи превышает 99%, абсолютная точность может быть достигнута только путем последующего редактирования человеком. Проблемы распознавания рукописного «печатного» и стандартного рукописного текста, а также печатных текстов других форматов (особенно с очень большим числом символов) в настоящее время являются предметом активных исследований.
Актуальность
Широко исследуемой проблемой является распознавание рукописного текста. На данный момент достигнутая точность даже ниже, чем для рукописного «печатного» текста. Более высокие показатели могут быть достигнуты только с использованием контекстной и грамматической информации. Например, в процессе распознания искать целые слова в словаре легче, чем пытаться проанализировать отдельные символы из текста. Знание грамматики языка может также помочь определить, является ли слово глаголом или существительным. Формы отдельных рукописных символов иногда могут не содержать достаточно информации, чтобы точно (более 98 %) распознать весь рукописный текст.
Методы автоматического распознавания образов и их реализация в системах оптического чтения текстов (OCR-системах – Optical Character Recognition) – одна из самых плодотворных технологий ИИ.
В приведенной трактовке OCR понимается как автоматическое распознавание с помощью специальных программ изображений символов печатного или рукописного текста (например, введенного в компьютер с помощью сканера) и преобразование его в формат, пригодный для обработки текстовыми процессорами, редакторами текстов и т. д.
История создания.
В 1929 году Густав Таушек получил патент на метод оптического распознавания текста в Германии, после чего за ним последовал Гендель, получив патент на свой метод в США в 1933. В 1935 году Таушек также получил патент США на свой метод. Машина Таушека представляла собой механическое устройство, которое использовало шаблоны и фотодетектор.
В 1950 году Дэвид Х. Шепард, криптоаналитик из агентства безопасности вооружённых сил Соединённых Штатов, проанализировав задачу преобразования печатных сообщений в машинный язык для обработки компьютером, построил машину, решающую данную задачу. После того как он получил патент США, он сообщил об этом в «Вашингтон Дэйли Ньюз» (27 апреля 1951) и в «Нью-Йорк Таймс» (26 декабря 1953). Затем Шепард основал компанию, разрабатывающую интеллектуальные машины, которая вскоре выпустила первые в мире коммерческие системы оптического распознавания символов.
Первая коммерческая система была установлена на «Ридерс Дайджест» в 1955 году. Вторая система была продана компании «Стэндарт Ойл» для чтения кредитных карт для работы с чеками. Другие системы, поставляемые компанией Шепарда, были проданы в конце 1950-х годов, в том числе сканер страниц для национальных воздушных сил США, предназначенный для чтения и передачи по телетайпу машинописных сообщений. IBM позже получила лицензию на использование патентов Шепарда.
Примерно в 1965 году «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений. Для печати на документах барабанным принтером «Ар-Си-Эй» был использован специальный шрифт OCR-A. Машина для чтения документов работала непосредственно с компьютером RCA 301 (один из первых массивных компьютеров). Скорость работы машины была 1500 документов в минуту: она проверяла каждый документ, исключая те, которые она не смогла обработать правильно.
Почтовая служба Соединённых Штатов с 1965 года для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым. В Европе первой организацией, использующей машины с оптическим распознаванием текста, был британский почтамт. Почта Канады использует системы оптического распознавания символов с 1971 года. На первом этапе в центре сортировки системы оптического распознавания символов считывают имя и адрес получателя и печатают на конверте штрих-код. Он наносится специальными чернилами, которые отчётливо видимы в ультрафиолетовом свете. Это делается, чтобы избежать путаницы с полем адреса, заполненным человеком, которое может быть в любом месте на конверте.
В 1974 году Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом. Курцвейл считал, что лучшее применение этой технологии — создание машины чтения для слепых, которая позволила бы слепым людям иметь компьютер, умеющий читать текст вслух. Данное устройство требовало изобретения сразу двух технологий — ПЗС планшетного сканера и синтезатора, преобразующего текст в речь. Конечный продукт был представлен 13 января 1976 во время пресс-конференции, возглавляемой Курцвейлом и руководителями национальной федерации слепых.
В 1978 году компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов. Два года спустя Курцвейл продал свою компанию корпорации «Ксерокс», которая были заинтересована в дальнейшей коммерциализации систем распознавания текста. «Курцвейл Компьютер Продактс» стала дочерней компанией «Ксерокс», известной как «Скансофт».
Анализ подходов к проектированию систем оптического чтения текстов
Сокращение OCR иногда расшифровывают как Optical Character Reader. В этом случае под OCR понимают устройство оптического распознавания символов или автоматического чтения текста (см. Рисунок 1). В настоящее время такие устройства при промышленном использовании обрабатывают до 100 тыс. документов в сутки. Промышленное использование предполагает ввод документов хорошего и среднего качества. Это соответствует задачам обработки бланков переписи населения, налоговых деклараций и т. п.
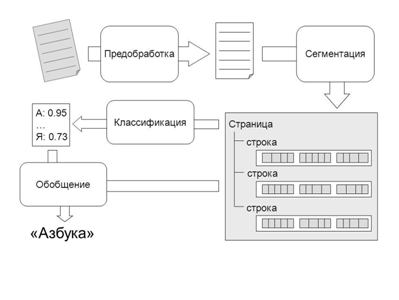
Рисунок 1 – Струтура OCR систем
Одной из таких систем является Cognitive Forms фирмы Cognitive Technologies, которая предназначена для массового ввода структурированных документов (например, налоговых деклараций, бухгалтерских форм, платежных документов и т. д.).
Эта OCR-система представляет собой программный комплекс для массового ввода документов, имеющих стандартизованные формы. Его модули, установленные на компьютерах локальной вычислительной сети, способны взаимодействовать друг с другом, образуя конвейер обработки данных, производительность которого может составлять более 10 тыс. страниц в сутки.
Технология ввода документов в стандартизованных формах включает две стадии: подготовительную и основную. На первой стадии создаются шаблоны документов, которые планируется вводить. Шаблон описывает свойства документа и входящих в него элементов данных: структуру документа, размер страниц, состав элементов данных, размеры и расположение соответствующих им полей, типы данных, форматы их представления, наборы допустимых значений и др. Шаблон может быть построен на основе графического представления документа. Для создания и редактирования шаблонов предназначено средство Cognitive Forms Designer. Основная стадия состоит из шести этапов.
Первый. Сканирование. Перевод бумажных документов в цифровое графическое представление. Управление данным процессом обеспечивают модуль пакетного сканирования Cognitive Forms ScanPack и модуль постраничного сканирования Cognitive Forms AutoScan.
Второй. Сортировка и комплектация. Документ может состоять из нескольких страниц, ассоциируемых с разными шаблонами. На этом этапе выполняется группирование полученных ранее графических образов страниц в наборы, соответствующие документам. Указанная задача решается в автоматическом режиме модулем Cognitive Forms Processor, который осуществляет:
- предварительную обработку графического представления и выделение графических примитивов (границ полей, строк текста и др.);
- выбор наиболее релевантного шаблона документа;
- выделение и распознавание элементов данных, значимых с точки зрения оценивания комплектности документа;
- контроль комплектности на основе соответствия последовательности типов страниц структуре, указанной в шаблоне.
Третий. Корректировка результатов сортировки. Этот этап выполняет оператор, к которому поступают некомплектные документы. Он выясняет причины возникших проблем и устраняет их.
Четвертый. Распознавание основной информации. Процесс реализуется модулем Cognitive Forms Processor. Графические представления страниц и распознанные значения элементов данных записываются в БД системы. Для повышения точности распознавания осуществляется логический контроль и контекстный анализ получаемых результатов.
Пятый. Верификация результатов распознавания. Документы, содержащие элементы данных, которые не распознаны либо распознаны не однозначно (например, из-за низкого качества документа или нарушения правил его заполнения), направляются оператору. Для верификации и корректировки результатов распознавания служит модуль Cognitive Forms Editor.
Шестой. Экспорт распознанных документов для передачи внешним приложениям.
Проанализировав уже разработанные системы можно сделать вывод, что каждая из этих систем имеет свои недостатки. Например, система FineReader показала отличные результаты на рукописных текстах с отдельно написанными символами, однако в текстах со словами, написанными слитно, было допущено большое количество ошибок.
В OCR-системе Cognitive Forms также существуют некоторые недостатки. Например, она плохо работает с неструктурированным текстом, так как предназначена для работы текстом, который записан в формы, специализированные документы и т.п.
Отметим следующие особенности предметной области, существенные с точки зрения OCR-систем:
- шрифтовое и размерное разнообразие символов;
- искажения в изображениях символов (разрывы образов символов, например, при увеличении изображения; слипание соседних символов и др.);
- перекосы при сканировании;
- посторонние включения в изображениях;
- большое разнообразие классов символов, которые могут быть распознаны только при наличии дополнительной контекстной информации.
Автоматическое чтение печатных и рукописных текстов является частным случаем автоматического визуального восприятия сложных изображений. Многочисленные исследования показали, что для полного решения этой задачи необходимо интеллектуальное распознавание, т. е. «распознавание с пониманием». Однако в настоящее время в технически реализуемых OCR-системах рассматриваемая проблема значительно упрощена и сведена к задаче классификации по признакам простых объектов. Эта задача описывается хорошо разработанным математическим аппаратом пороговых отделителей – разделяющими плоскостями.
В лучших OCR-системах используется технология распознавания, свойственная человеку. У человека распознавание образа является многоступенчатым.
Выделяются три принципа, на которых основаны все OCR-системы.
Принцип целостности образа: в исследуемом объекте всегда есть значимые части, между которыми существуют отношения. Результаты локальных операций с частями образа интерпретируются только совместно в процессе интерпретации целостных фрагментов и всего образа в целом.
Принцип целенаправленности: распознавание является целенаправленным процессом выдвижения и проверки гипотез (поиска того, что ожидается от объекта).
Принцип адаптивности: распознающая система должна быть способна к самообучению.
Графический образ символа на выходе сканера имеет вид шейпа, представляющего собой матрицу из точек, которую можно редактировать поэлементно. На рисунке приведен пример шейпа буквы «л» или «п» (см. Рисунок 2). Он ближе к букве «л», но без контекстной обработки утверждать это со 100%-ной уверенностью нельзя

Рисунок 2 – Пример шейпа
При контекстной обработке для распознавания «сомнительного» шейпа привлекается информация о результатах распознавания соседних элементов текста. В простейшем случае контекстом служит слово.
Информация об отдельном слове не всегда достаточна для принятия решения. Например, в слове «сто*» в позиции звездочки может располагаться как «л», так и «п». В таких случаях анализируемый контекст включает предложение или несколько предложений (фрагмент текста). Реализация соответствующих механизмов связана с решением проблемы понимания текста на естественном языке.
Виды классификаторов
Ранее мы определили, что система распознавания реализуется как классификатор. Существуют три типа классификаторов:
- шаблонные (растровые);
- признаковые;
- структурные.
В классификаторе первого типа с помощью критерия сравнения определяется, какой из шаблонов выбрать из базы (см. Рисунок 3). Самый простой критерий – минимум точек, отличающих шаблон от исследуемого изображения.
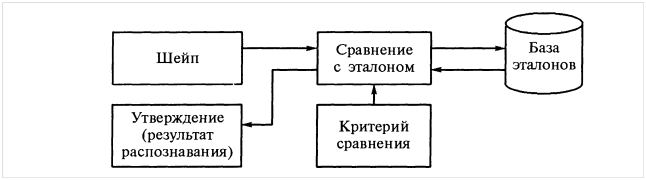
Рисунок 3 – Шаблонный классификатор
Наиболее распространены признаковые классификаторы. Анализ в них проводится только по набору чисел или признаков, вычисляемых по изображению. Таким образом, происходит распознавание не самого символа, а набора его признаков, т. е. производных данных от исследуемого символа. Это неизбежно вызывает некоторую потерю информации.
Структурные классификаторы переводят шейп символа в его топологическое представление, отражающее информацию о взаимном расположении структурных элементов символа. Эти данные могут быть представлены в графовой форме. Такой способ обеспечивает инвариантность относительно типов и размеров шрифтов. Недостатками являются трудность распознавания дефектных символов и медленная работа.
В современных OCR-системах обычно используются все три типа классификаторов, но основным является структурный. Для ускорения и повышения качества распознавания применяются растровый и признаковый классификаторы.
Также применяется так называемый структурно-пятенный эталон и его фонтанное (от англ. font – шрифт) представление. Оно имеет вид набора пятен с попарными отношениями между ними. Подобную структуру можно сравнить со множеством шаров, нанизанных на резиновые шнуры, которые можно растягивать (см. Рисунок 4). Данное представление нечувствительно к различным начертаниям и дефектам символов.

Рисунок 4 – Структурно-пятенный эталон.
Алгоритм основан на сочетании шаблонного и структурного методов распознавания образов. При анализе образца выделяются ключевые точки объекта – так называемые «пятна».
В качестве пятен, например, могут выступать:
- концы линий;
- узлы, где сходятся несколько линий;
- места изломов линий;
- места пересечения линий;
- крайние точки.
После выделения «пятен» определяются связи между ними – отрезок, дуга. Таким образом, итоговое описание представляет собой граф, который и служит объектом поиска в библиотеке «структурно-пятенных эталонов».
При поиске устанавливается соответствие между ключевыми точками образца и эталона, после чего определяется степень деформации связей, необходимая чтобы привести искомый объект к сравниваемому эталонному образцу. Меньшая степень необходимой деформации предполагает большую вероятность правильного распознавания символа.
Методы оптимизации распознавания
Для повышения качества распознавания применяются различные методы предобработки изображений с текстом, например шумоподавление. Источниками шумов на изображении могут быть:
- аналоговый шум:
- грязь, пыль;
- царапины;
- цифровой шум:
- тепловой шум матрицы;
- шум переноса заряда;
- шум квантования АЦП.
При цифровой обработке изображений применяется пространственное шумоподавление. Выделяют следующие методы:
- адаптивная фильтрация – линейное усреднение пикселей по соседним;
- медианная фильтрация;
- математическая морфология;
- размытие по Гауссу;
- методы на основе дискретного вейвлет-преобразования;
- метод главных компонент;
- анизотропная диффузия;
- фильтры Винера;
После распознавания может выполняться дополнительная коррекция, позволяющая увеличить качество распознавания спорных символов (то есть символов у которых есть несколько кандидатов с приблизительно одинаковой оценкой степени соответствия нескольким эталонам) на основе:
- анализа буквосочетаний, характерных для языка;
- словаря языка;
- грамматического анализа;
- и других методов.
Вывод
Автоматическое зрительное восприятие на сегодняшний день не достигает совершенства человеческого восприятия текста. Главная причина этого заключается в неумении строить достаточно полные и семантически выразительные компьютерные модели предметной области.
Проанализировав существующие методы распознавания текстов, можно сделать вывод, что лучше всего использовать метод структурно-пятенного шаблона, так как он объединяет в себе достоинства многих методов и благодаря этому является достаточно гибким чтобы применить его при распознавании рукописного текста.
Список литературы
- Абраменко А. Принципы распознавания / А. Абраменко – K:.Компьютер–пресс, 1997 – 123 с.
- Research Library – статья по искусственному интеллекту.
- Шамис А.Л. Принципы интеллектуализации автоматического распознавания / А.Л. Шамис – K:.2000 – 312 с.
- StatSoft – сайт, посвященный нейронным сетям.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознавани / М. Шлезингер, В. Главач – М.:2004 – 112 c.
- Гаврилов Г.П. Логический подход к искусственному интеллекту / Г.П. Гаврилов – М.: Мир, 1998 – 256 с.
- Кучуганов А.В. , Лапинская Г.В. Распознавание рукописных текстов / А.В. Кучуганов, Г.В. Лапинская – Ижевск:.Мир, 2006 – 514 с.
- Шлезингер М., Главач В. Структурное распознавание / М. Шлезингер , В. Главач – Киев: Наукова думка, 2006 – 300 с.

- Функциональные возможности СЭД
- Защита информации в процессах управления контентом (Направление подготовки: Разработка, сопровождение и обеспечение безопасности информационных систем)
- Структура аппарата районного суда
- Структура аппарата Верховного суда РФ
- Время менять мир. История отечественного тайм-менеджмента
- Особенности договора розничной купли-продажи
- Денежная эмиссия и ее формы
- История мозаики
- Германия с древнейших времен до 9 века
- Применение дополненной реальности в учебном процессе (по дисциплине «Цифровая трансформация в менеджменте»)
- 3D принтеры в медицине (Дисциплина «Аппаратное обеспечение вычислительных систем»)
- Проблема «утечки мозгов» и способы привлечения и удержания квалифицированных специалистов