
Динамические структуры данных. Списки (Основные понятия)
Содержание:

ВВЕДЕНИЕ
Компьютерные программы представляют собой определенные формулировки алгоритмов, основой которых является определенное представление различных структур данных. По определению Н. Вирта, создателя языка Паскаль:
Программа = Алгоритм + Структуры данных.
Другими словами, можно сказать, что программы представляют собой конкретные формулировки абстрактных алгоритмов, основанные на конкретных представлениях данных [8].
Алгоритмы представляют собой объекты систематического исследования специальной науки – теории алгоритмов, которая находится на стыке двух других наук - математики и информатики.
Сам термин «алгоритм» произошел от латинской формы записи имени великого математика IX в. аль-Хорезми - «Algorithmi». Именно он первым сформулировал правила выполнения арифметических действий. Изначально алгоритмом называли только правила выполнения четырех арифметических действий над многозначными числами.
В настоящее время люди постоянно сталкиваются с решением различных практических задач: приготовление супа, проезд в общественном транспорте, решение квадратного уравнения, поиск слова в словаре и т. д. При этом человек выполняет заранее продуманные (им или кем-то еще) предписания: какие действия и в какой последовательности должны быть выполнены. Эта последовательность действий может рассматриваться как алгоритм решения соответствующей задачи [4].
С точки зрения компьютера программа – это не только алгоритм, но и еще некоторый набор данных, которые необходимо обрабатывать в рамках алгоритма.
Актуальность рассматриваемой темы очевидна - структуры данных являются необходимыми компонентами любой компьютерной программы или программного комплекса. Следовательно, знание теории структур данных и, в частности, методов представления данных на различных уровнях, а также возможных операций над этими структурами, необходимо для глубокого изучения и уяснения таких разделов, как автоматизированные системы управления, компиляторы языков программирования, операционные системы, а также системы программного имитационного моделирования, управления базами данных, искусственного интеллекта и т.д. [13]
Объект исследования данной работы - структуры хранения данных в языках программирования высокого уровня, с помощью которых и реализуются программы.
Предмет исследования – динамические структуры данных, при помощи которых можно организовывать данные в списки.
Цель работы: раскрыть выбранную темы, а также реализовать списковые структуры данных на языке программирования высокого уровня.
Для достижения поставленной цели необходимо решить ряд задач:
- проанализировать литературу по выбранной теме;
- определить основные понятия;
- определить виды структур;
- привести примеры динамических структур данных;
- разработать приложение, демонстрирующее работу с динамическим списком.
При написании работы в качестве опорных источников использовались: Е.А. Кумагина – «Введение в структуры данных» и А.А. Ключарев – «Структуры и алгоритмы обработки данных».
1. СТРУКТУРЫ ДАННЫХ
1.1. Основные понятия
Алгоритмом принято называть точное предписание, определяющее вычислительный процесс, который за конечное число итераций приводит к искомому результату [1].
Современные компьютеры не только считывают и реализуют всевозможные алгоритмы, но и хранят при этом значительный объем информации, с которой необходимо быстро обращаться. Эта информация является абстракцией некоторого фрагмента реального мира и включает в свой состав некоторое множество данных, относящихся к какой-либо проблеме.
Независимо от сложности и содержания все данные в компьютере представляются в виде последовательности двоичных разрядов – битов. Такие данные слабо структурированы. Кроме того, подобное представление данных очень неудобно для человека. Более крупные и содержательные блоки данных называются структурами данных [16].
Структура данных представляет собой множество элементов данных и связей, установленных между ними. Это определение охватывает все возможные подходы к структуризации данных, однако, в каждой конкретной задаче выбор структуры данных определяется ее условием.
1.2. Классификация
Классификация структур данных приведена на рисунке 1 [6].
Понятие «физическая структура данных» характеризует способ физического размещен данных в памяти компьютера. Синонимы данного термина:
- структура хранения;
- внутренняя структура;
- структура памяти.
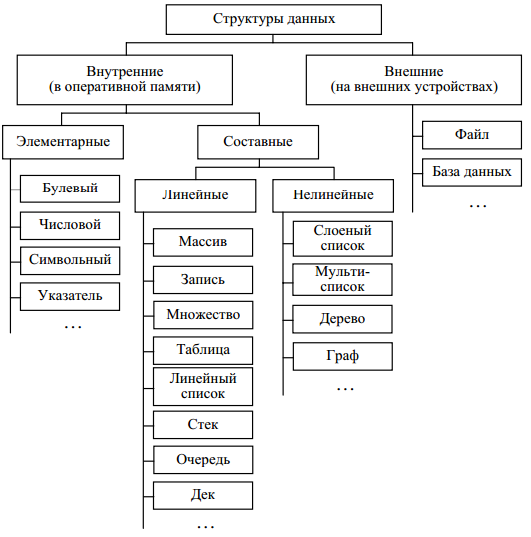
Рисунок 1 – Классификация структур данных
Абстрактная (логическая) логическая структура – структура данных без учета ее представления в памяти компьютера. В общем случае логическая и физическая структуры отличаются. Степень данного отличия определяется самой структурой и особенностями той среды, где она должна быть отражена. Данный факт является причиной существования особых процедур, осуществляющих отображение логической структуры данных в физическую, и наоборот. Эти процедуры обеспечивают доступ к физическим структурам и выполнение над ними различных операций, каждая из которых рассматривается применительно к физической или логической структуре данных. Кроме того, в зависимости от размещения физических структур, а следовательно, и доступа к ним, принято различать внешние (хранящиеся на внешних устройствах) и внутренние (расположенные в оперативной памяти) структуры данных.
Внутренние структуры данных бывают двух видов:
- элементарные (простые) – такие структуры данных, которые не могут быть разделены на составные части, большие, чем биты. С точки зрения компьютерного представления важно отметить, что каждая конкретная машинная архитектура с конкретной системой программирования всегда однозначно определяет размер элементарных данных и способ их размещения в памяти. С логической точки зрения элементарные данные – это неделимые единицы;
- составные (сложные) – такие структуры данных, которые состоят из элементарных или составных структур. Эти структуры определяются программистами при помощи специальных средств, предоставляемых языками программирования. Характерным признаком составной структуры является упорядоченность ее элементов. По этому признаку структуры делятся на линейные и нелинейные [5].
С точки зрения языков программирования, структуры данных неразрывно связаны с типами данных. Все данные, константы и переменные, а также значения функций и выражений определяются типами данных.
Тип данных определяет:
- структуру хранения данных – выделение памяти, способ представления данных, методы доступа;
- область допустимых значений;
- набор допустимых операций, применимых к данным [7].
Еще одним важным признаком структуры данных является ее изменчивость – изменение количества элементов и связей между ними. По признаку изменчивости структуры бывают статические (неизменяемые) и динамические. Использование статических переменных требует больших затрат памяти, которые, зачастую не оправданы. Динамические структуры позволяют использовать память именно тогда, когда она нужна, освобождая ее по завершению операций. Именно о динамических структурах пойдет речь дальше.
Динамические структуры данных – списки, стеки, очереди, деревья – способны изменять свои размеры в процессе исполнения программы. Каждый элемент любой динамической структуры представляет собой запись, которая хранит, как минимум два поля:
- поле данных;
- поле типа указатель, хранящее адрес следующей ячейки для связи ячеек между собой.
К динамическим структурам относят:
- односвязные (однонаправленные списки);
- двусвязные (двунаправленные списки);
- циклические списки;
- стек;
- дек;
- очередь;
- бинарные деревья [19].
Таким образом, в данной главе рассмотрены структуры данных, приведена их классификация по нескольким признакам.
2. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
2.1 Связный список
Если в рамках программы требуется хранить неупорядоченное множество элементов, число которых заранее известно, в таких случаях применяются массивы данных. Однако если количество элементов постоянно меняется, то в таких случаях для хранения используются динамические структуры [2].
По типу связности списки бывают следующих видов:
- односвязные;
- двусвязные;
- XOR-связные;
- кольцевые.
В односвязном списке полем связки является поле «next», указывающее на следующий элемент списка (поле содержит адрес следующего элемента). Такой элемент называется ссылочным и определяет ссылочный тип списка. Эти списки также называются однонаправленными. Двусвязные списки используют еще дно поле – «prev», указывающее на предыдущий элемент списка.
Если элемент списка не связан ни с каким другим элементов, в поле указателя хранится значение NULL.
Указатель на первый элемент списка - особый элемент, называемый головой списка («head»).
Структура односвязного линейного списка приведена на рисунке 2.
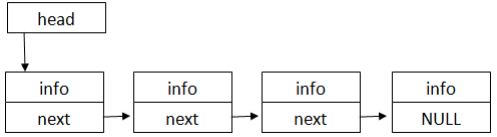
Рисунок 2 – Структура односвязного линейного списка
Структура односвязного кольцевого списка приведена на рисунке 3.
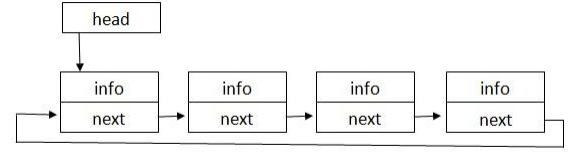
Рисунок 3 – Структура односвязного кольцевого списка
Структура двусвязного линейного списка приведена на рисунке 4.
XOR-связный список представляет собой структуру данных, похожую на обычный двусвязный список. Основное отличие заключается в том, что в каждом элементе хранится только один адрес – результат выполнения операции XOR (исключающее или, сложение по модулю два) над адресами предыдущего и следующего элементов списка (см. рисунок 5).
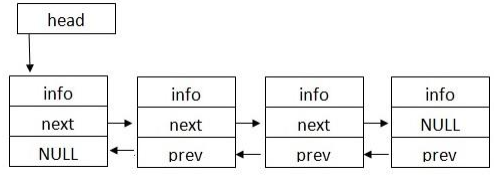
Рисунок 4 - Структура двусвязного линейного списка
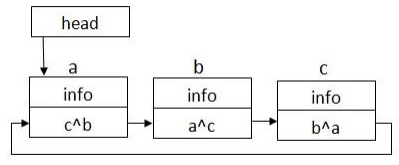
Рисунок 5 – Структура XOR списка
При инициализации XOR списка необходимо создавать два пустых элемента - текущий и предыдущий, чтобы при добавлении первого элемента вычислить его адрес [12].
Для добавления элемента в односвязный линейный список необходимо выполнить ряд шагов:
- создать новый элемент списка;
- определить место вставки;
- включить элемент в список.
Самый простой вариант добавления элемента – в начало списка. В данном случае «next» нового элемента ссылается на существующий элемент головы, после чего указатель головы списка переносится на вновь созданный элемент (см. рисунок 6).
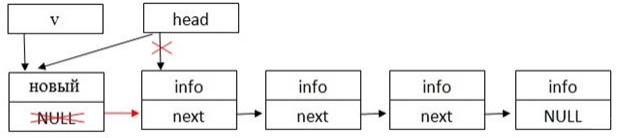
Рисунок 6 – Добавление элемента в начало списка
Второй вариант – добавление элемента в конец списка. В этом случае необходимо просмотреть весь список, найти его последний элемент и изменить ссылку со значения NULL на вновь созданный элемент. При этом ссылка «next» нового элемента будет равна NULL (см. рисунок 7).
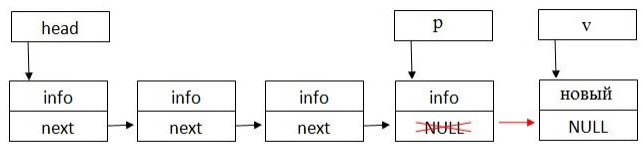
Рисунок 7 – Добавление элемента в конец списка
Схема добавления элемента в середину списка приведена на рисунке 8. Данный алгоритм предполагает выполнение следующих шагов:
- поле «next» нового элемента сослать на элемент, перед которым реализуется вставка;
- поле «next» элемента, после которого реализуется вставка, сослать на вновь созданный элемент [18].
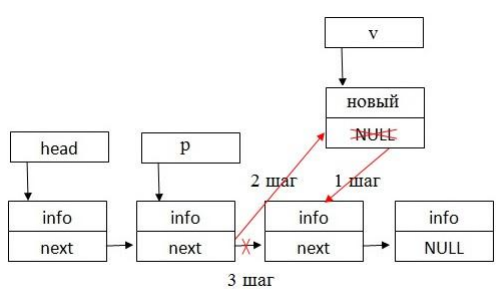
Рисунок 8 – Добавление элемента в середину списка
Операция удаления элементов также представляет собой последовательность нескольких шагов:
- найти элемент для удаления;
- переставить указатель;
- удалить элемент.
Схема удаления элемента из середины списка приведена на рисунке 9.
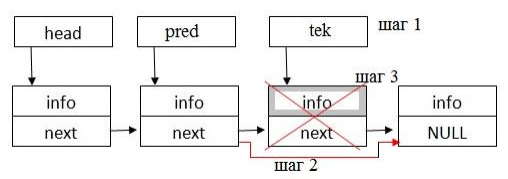
Рисунок 9 – Удаление элемента из середины списка
Схема удаления элемента из головы списка приведена на рисунке 10 [10].
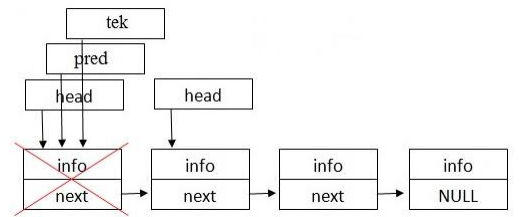
Рисунок 10 – Удаление элемента из головы списка
2.2. Стеки и очереди
Стеком называется структура данных, в которой новый элемент всегда помещается в начало списка, и при чтении также берется из начала, реализуя алгоритм LIFO (Last In – Firs Out).
Схема представления стека приведено на рисунке 11.
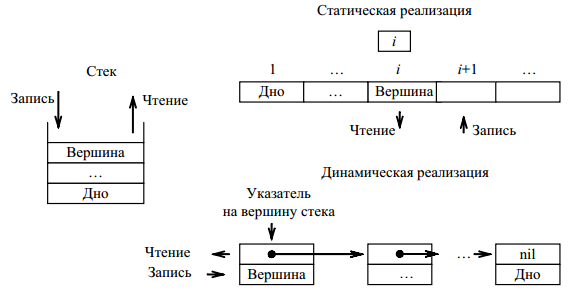
Рисунок 11 – Стек
В основе стека лежит динамический список. С учетом того, что работа всегда ведется только с головным элементом, исчезает необходимость просмотра элементов стека.
Очередь – это структура данных, представляющая собой последовательность элементов, образованная в порядке их поступления. Данный вид структуры реализует алгоритм FIFO (First In – First Out).
Частный случай очереди – дек (двусторонняя очередь). Схема реализации очереди представлена на рисунке 12.
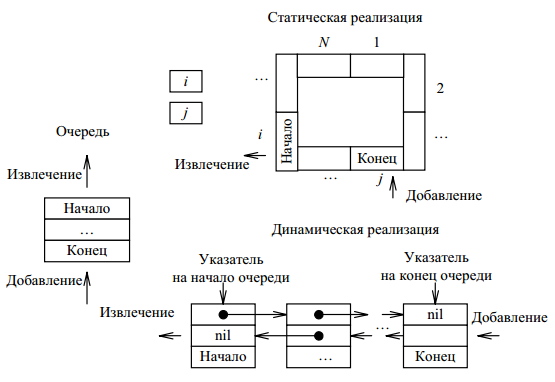
Рисунок 12 – Очередь
Очередь также реализуется на базе линейного списка. Важно учесть, что работа здесь ведется как с началом, так и с концом очередь, следовательно, необходимо хранить два указателя – на голову и на хвост списка [9].
2.3. Деревья
Ссылки могут использоваться не только для представления линейных списков, возможны и другие способы – например, структуры, состоящие из записей, связанных между собой системой ссылок. При этом каждая запись может содержать ссылки на несколько других записей. Подобное представление называется ориентированным графом [3].
Дерево – частный случай графа. Дерево обладает следующими свойствами:
- подструктуры, связанные с некоторым узлом, не связаны между собой;
- существует единственный узел, называемый корнем дерева;
- из корня, путем просмотра конечного числа ребер, можно достичь любого узла дерева.
Схема представления дерева приведена на рисунке 13.
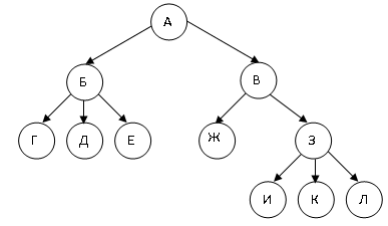
Рисунок 13 – Дерево
Здесь узел А – это корень дерева. Узлы Г, Д, Е, И, К, Л – листья дерева (терминальные узлы).
Частным случаем дерева, которое наиболее часто используется в программировании, является двоичное (бинарное) дерево. Каждый узел такого дерева имеет не более двух узлов-отростков (см. рисунок 14) [20].
Бинарное дерево называется полным, если присутствуют все листья одного уровня, и каждая внутренняя вершина имеет непустые правое и левое поддеревья. Дерево называется сбалансированным тогда и только тогда, когда высоты двух поддеревьев каждой из его вершин отличаются не более чем на единицу.
Существует несколько способов обхода дерева (просмотра всех его элементов):
- обход в глубину – посетить корень дерева, обойти левое поддерево, обойти правое поддерево;
- обход в ширину – данный метод основан на использовании очереди. Алгоритм обхода:
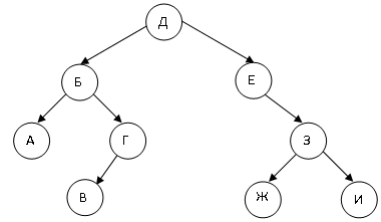
Рисунок 14 – Двоичное дерево
-
- изъять из очереди очередную вершину. Поместить в очередь ее дочерние вершины по порядку;
- если очередь пуста – конец обхода, иначе перейти к п.1 [11].
Таким образом, в рамках данной главы рассмотрены динамические структуры данных. Приведена их классификация по нескольким признакам. Отдельное внимание уделяется динамическим структурам данных – спискам и деревьям.
3. ПРАКТИЧЕСКАЯ ЧАСТЬ
3.1. Линейный односвязный список
Класс линейного односвязного списка должен содержать в себе указатель на первый элемент списка. В качестве элемента списка необходимо использовать структуру из двух полей:
- значение элемента списка;
- указатель на следующий элемент списка.
Таким образом, в разрабатываемом классе содержится всего один элемент – указатель на голову списка, а также необходимо предусмотреть методы:
- конструктор;
- деструктор;
- добавление элемента в начало списка;
- добавление элемента в конец списка;
- удаление из списка последнего элемента;
- поиск элемента по значению;
- вывод содержимого списка на экран.
Элемент структуры описывается следующим образом:
public: struct Node //описание узла - элемента списка
{
int value; //значение
struct Node *next; //ссылка на следующий элемент
} *head;
В данной записи head – это и есть указатель на первый элемент списка.
Методы класса:
- Spisok() – конструктор без параметров;
- Spisok(int val) – конструктор с параметром;
- ~Spisok() – деструктор;
- void AddAtBegin(int val) – добавление элемента в начало списка;
- void AddAtEnd(int val) – добавление элемента в конец списка;
- void Delete() – удаление из списка последнего элемента;
- int Search(int val) – поиск элемента по значению;
- void Show() – вывод содержимого списка на экран.
Блок-схемы методов представлены на рисунках 15-21.
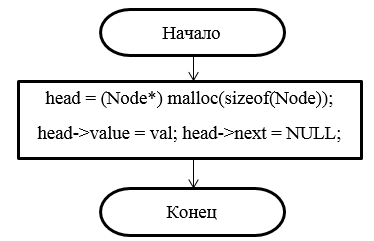
Рисунок 15 – Блок-схема конструктора
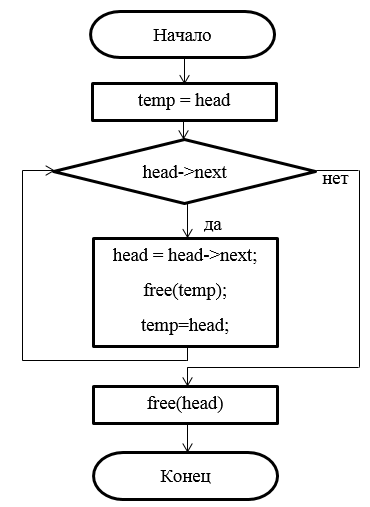
Рисунок 16 – Блок-схема деструктора
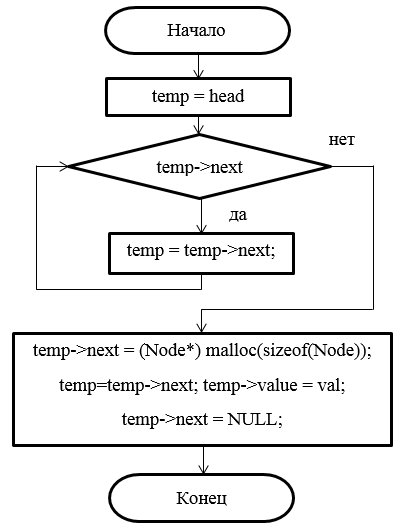
Рисунок 17 - Блок-схема метода добавления элемента в конец списка
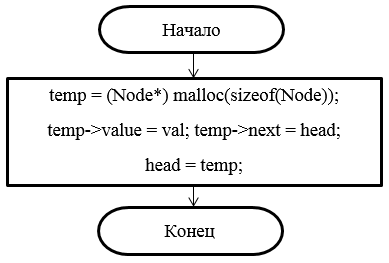
Рисунок 18 - Блок-схема метода добавления элемента в начало списка
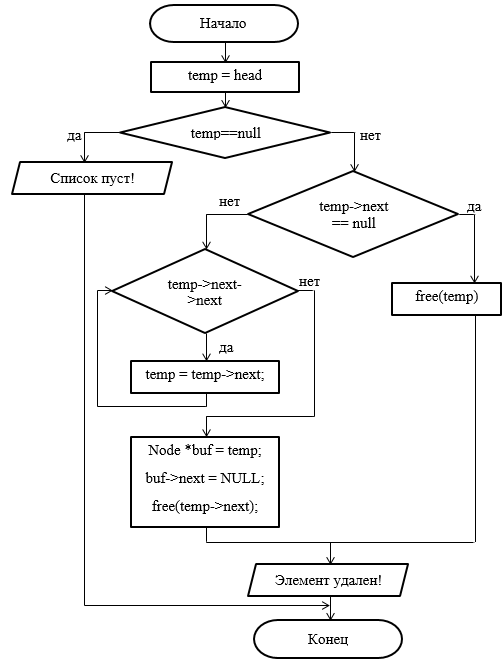
Рисунок 19 - Блок-схема метода удаления элемента из конца списка
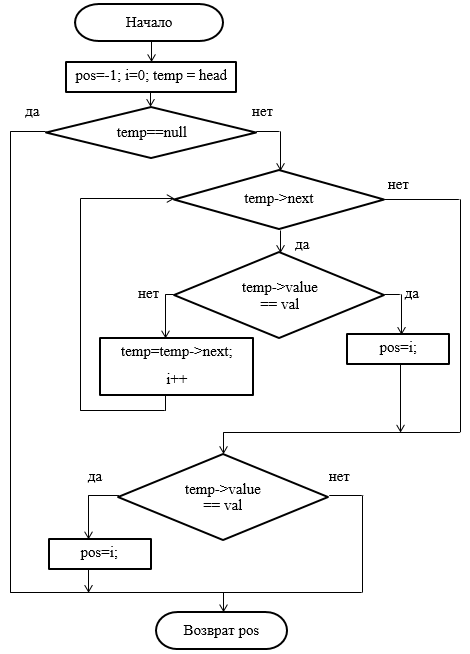
Рисунок 20 - Блок-схема метода поиска элемента по значению
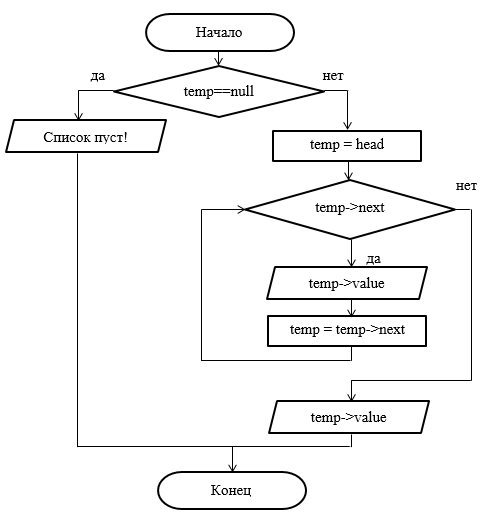
Рисунок 21 - Блок-схема метода вывода списка на экран
Для тестирования методов класса было создано приложение, исходный код которого надохится в приложении 1. Результаты тестирования программы представлены на рисунках 22-36.
Рисунок 22 – Окно запуска приложения
Рисунок 23 – Попытка просмотра пустого списка
Рисунок 24 – Попытка удаления из пустого списка
Рисунок 25 – Добавление элемента в начало списка
Рисунок 26 – Результат добавления элемента в начало списка
Рисунок 27 – Просмотр содержимого списка
Рисунок 28 – Добавление элемента в конец списка
Рисунок 29 – Результат добавления элемента в конец списка
Рисунок 30 – Просмотр содержимого списка
Рисунок 31 – Удаление последнего элемента
Рисунок 32 – Просмотр содержимого списка после удаления
Рисунок 33 – Поиск отсутствующего элемента
Рисунок 34 – Результат поиска отсутствующего элемента

Рисунок 35 – Поиск существующего элемента
Рисунок 36 – Результат поиска существующего элемента
3.2. Циклический двусвязный список
Класс циклического двусвязного списка должен содержать в себе указатель на первый элемент списка. В качестве элемента списка необходимо использовать структуру из трех полей:
- значение элемента списка;
- указатель на следующий элемент списка;
- указатель на предыдущий элемент списка.
Таким образом, в разрабатываемом классе содержится всего один элемент – указатель на голову списка, а также необходимо предусмотреть методы:
- конструктор;
- деструктор;
- добавление элемента в начало списка;
- добавление элемента в конец списка;
- удаление из списка последнего элемента;
- поиск элемента по значению;
- вывод содержимого списка на экран.
Элемент структуры описывается следующим образом:
public: struct Node //описание узла - элемента списка
{
int value; //значение
struct Node *next; //ссылка на следующий элемент
struct Node *back; //ссылка на предыдущий элемент
} *head;
В данной записи head – это и есть указатель на первый элемент списка.
Методы класса:
- Spisok() – конструктор без параметров;
- Spisok(int val) – конструктор с параметром;
- ~Spisok() – деструктор;
- void AddAtBegin(int val) – добавление элемента в начало списка;
- void AddAtEnd(int val) – добавление элемента в конец списка;
- void Delete() – удаление из списка последнего элемента;
- int Search(int val) – поиск элемента по значению;
- void Show() – вывод содержимого списка на экран.
Блок-схемы данных методов представлены на рисунках 37-
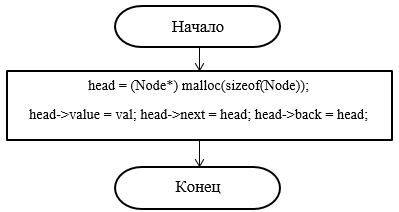
Рисунок 37 – Блок-схема конструктора
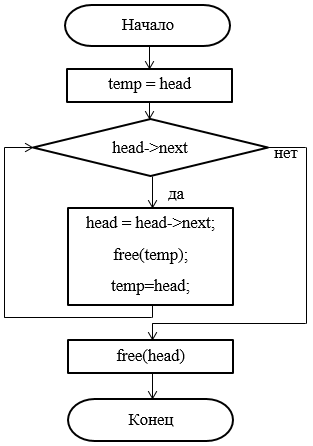
Рисунок 38 – Блок-схема деструктора
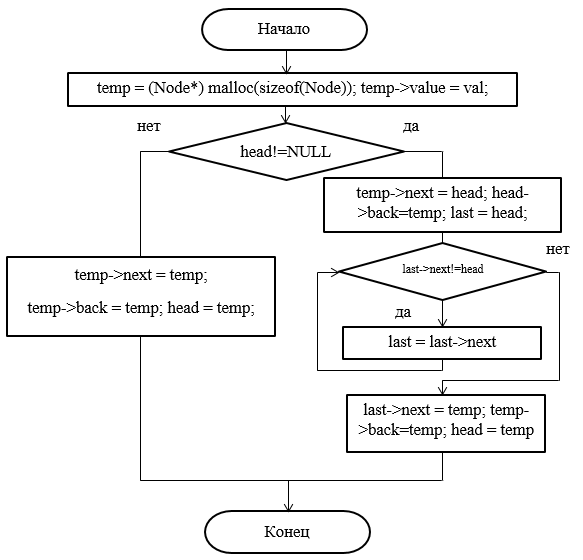
Рисунок 39 – Блок-схема метода добавления элемента в начало списка
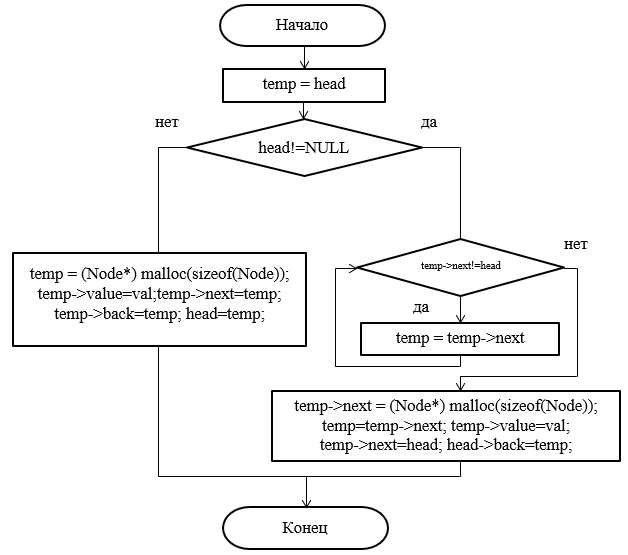
Рисунок 40 – Блок-схема метода добавления элемента в конец списка
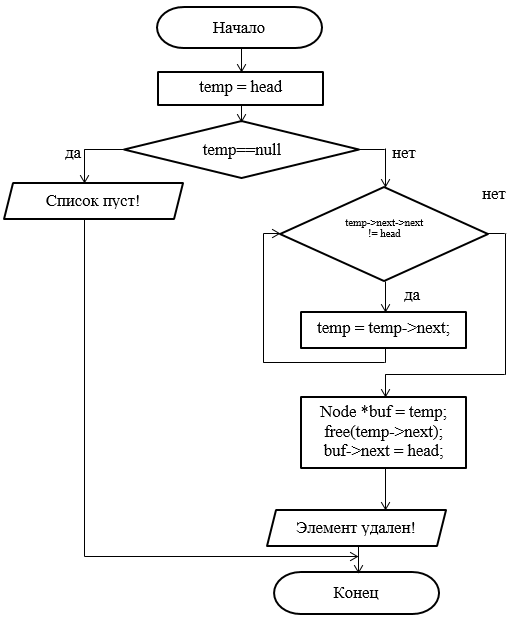
Рисунок 41 – Блок-схема метода удаления элемента из конца списка
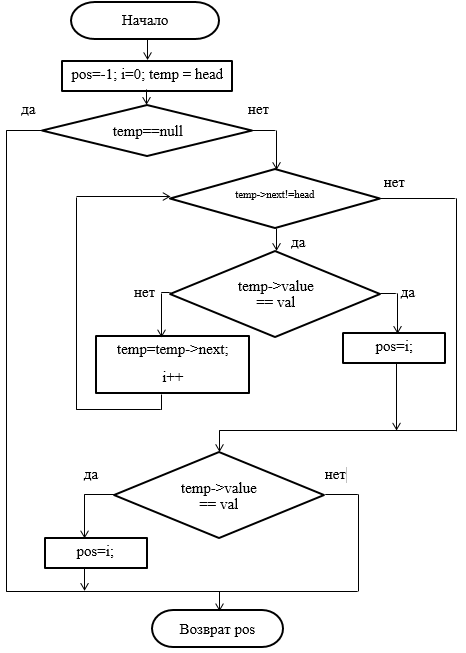
Рисунок 42 – Блок-схема метода поиска элемента по значению
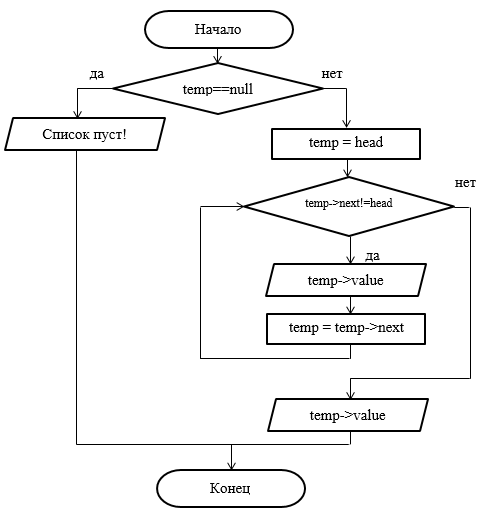
Рисунок 43 – Блок-схема метода вывода списка на экран
Для тестирования методов класса было создано приложение, исходный код которого надохится в приложении 2. Результаты тестирования программы представлены на рисунках 44-58.
Рисунок 44 – Окно запуска приложения
Рисунок 45 – Попытка просмотра пустого списка
Рисунок 46 – Попытка удаления из пустого списка
Рисунок 47 – Добавление элемента в начало списка
Рисунок 48 – Результат добавления элемента в начало списка
Рисунок 49 – Просмотр содержимого списка
Рисунок 50 – Добавление элемента в конец списка
Рисунок 51 – Результат добавления элемента в конец списка
Рисунок 52 – Просмотр содержимого списка
Рисунок 53 – Удаление последнего элемента
Рисунок 54 – Просмотр содержимого списка после удаления
Рисунок 55 – Поиск отсутствующего элемента
Рисунок 56 – Результат поиска отсутствующего элемента
Рисунок 57 – Поиск существующего элемента
Рисунок 58 – Результат поиска существующего элемента
Таким образом, в рамках практической части было разработано приложение, демонстрирующее работу с линейным односвязным и циклическим двусвязным списками.
ЗАКЛЮЧЕНИЕ
В рамках данной работы была рассмотрена тема «Динамические структуры данных. Списки».
Первая глава работы носит теоретический характер. В ней описываются общие понятия, приводится классификация структур данных, а также рассматриваются динамические структуры.
Структура данных представляет собой множество элементов данных и связей, установленных между ними.
Понятие «физическая структура данных» характеризует способ физического размещен данных в памяти компьютера.
Абстрактная (логическая) логическая структура – структура данных без учета ее представления в памяти компьютера.
Динамические структуры данных – структуры, обладающие свойством изменчивости.
К динамическим структурам относят:
- односвязные (однонаправленные списки);
- двусвязные (двунаправленные списки);
- циклические списки;
- стек;
- дек;
- очередь;
- бинарные деревья.
В рамках практической части разработаны класс линейного односвязного и циклического двусвязного списков на языке программирования высокого уровня С++, а также приложения, демонстрирующие работу с этими классами.
Основные функции, реализуемые в приложениях:
- вывод содержимого списка на экран;
- добавление элемента в начало списка;
- добавление элемента в конец списка;
- удаление последнего элемента списка;
- поиск элемента по значению;
- выход из программы.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Алексеев А.Ю. Динамические структуры данных: Учебно-методическое пособие / А.Ю. Алексеев, С.А. Ивановский, Д.В. Куликов – Петропавловск-Камчатский: КамчатГТУ, 2014. – 68 с.
- Блинов И.Н. Java. Методы программирования: уч.-мет. пособие / И.Н. Блинов, В.С. Романчик. – Минск : издательство «Четыре четверти», 2013. – 896 с.
- Бузыкова Ю.С. Языки и технологии программирования – Хабаровск : Изд-во Тихоокеан. гос. ун-та, 2014. – 44 с.
- Давыдова Н.А. Программирование / Н.А. Давыдова, Е.В. Боровская. – М.: БИНОМ, 2015. – 241 с.
- Далека В.Д. Модели и структуры данных. Учебное пособие. Харьков: ХГПУ, 2013. – 241 с.
- Кадырова Г.Р. Основы алгоритмизации и программирования – Ульяновск : УлГТУ, 2014. – 95 с.
- Ключарев А.А. Структуры и алгоритмы обработки данных / А.А. Ключарев, В.А. Матьяш, С.В. Щекин. – СПб.: Изд-во СПбГУАП, 2013. – 172 с.
- Конова Е.А. Структуры данных. Программирование на языке С и С++ / Е.А. Конова, Г.А. Поллак, А.М. Ткачев. – Челябинск: Изд-во ЮУрГУ, 2014. – 106 с.
- Кузниченко М.А. Динамические структуры данных: учебное пособие – Орск: Издательство ОГТИ, 2014. – 102 с.
- Кумагина Е.А. Введение в структуры данных / Е.А. Кумагина, Н.Н. Чернышова. – Нижний Новгород: Изд-во ННГУ, 2016. – 36 с.
- Латухина Е.А. Структуры данных и алгоритмы. – Архангельск: ИПЦ САФУ, 2013. – 42 с.
- Мясников Е.В. Списки и деревья / Е.В. Мясников, А.Б. Попов. – Самара: Изд-во СГАУ им. С.П. Королева, 2015. – 24 с.
- Назаренко П.А. Алгоритмы и структуры данных: учебное пособие. Самара: ПГУТИ, 2015. – 196 с.Третьяков Ю.А. Динамические структуры данных. – М.: Изд-во МГУ, 2012. – 24 с.
- Обухович Т.М. Программирование. Паскаль: Учебное пособие для студентов направления «Информатика и вычислительная техника» / Рубцовский индустриальный институт. – Рубцовск, 2015. – 73 с.
- Орлов С.А. Теория и практика языков программирования – СПб.: Питер, 2013. – 668 с
- Полетаев И.А. Программирования на языке высокого уровня Паскаль – Издательство ППИ, 2015. – 159 с.
- Прата С. Язык программирования С – М.: Издательский дом «Вильямс», 2013. – 960 с.
- Серикова Н.В. Практическое руководство к лабораторному практикуму «Динамические структуры данных». Минск, 2012. – 62 с.
- Фофанов О.Б. Алгоритмы и структуры данных. – Томск: Изд-во Томского политехнического университета, 2014. – 126 с.
- Чулюков В.А. методы разработки программ (алгоритмы и структуры данных). – Воронеж: Изд-во ВГУ, 2014. – 154 с.
ПРИЛОЖЕНИЯ
Линейный односвязный список
Spisok.h
#pragma once
class Spisok
{
public: struct Node //описание узла - элемента списка
{
int value; //значение
struct Node *next; //ссылка на следующий элемент
} *head;
//конструктор
Spisok(int val);
Spisok();
//деструктор
~Spisok();
//добавление в начало
void AddAtBegin(int val);
//добавление в конец
void AddAtEnd(int val);
//удаление из конца
void Delete();
//очистка списка
void Drop();
//поиск по значению
int Search(int val);
//вывод на экран
void Show();
};
Spisok.cpp
#include <stdlib.h>
#include <stdio.h>
#include "Spisok.h"
Spisok::Spisok()
{
}
Spisok::Spisok(int val)
{
head = (Node*)malloc(sizeof(Node)); //выделяем память под элемент
head->value = val; //сохраняем значение
head->next = NULL; //обнуляем ссылку на следующий элемент
}
Spisok::~Spisok()
{
Node *temp = head;
while (head->next)
{
head = head->next;
free(temp);
temp = head;
}
free(head);
}
void Spisok::AddAtBegin(int val)
{
Node *temp = (Node*)malloc(sizeof(Node)); //выделяем память
temp->value = val; //сохраняем значение
temp->next = head; //следующий элемент - бывший первый
head = temp; //переносим указатель первого элемента
}
void Spisok::AddAtEnd(int val)
{
Node *temp = head;
while (temp->next) //просматриваем список до конца
temp = temp->next;
temp->next = (Node*)malloc(sizeof(Node)); //выделяем память под новый элемент
temp = temp->next;
temp->value = val; //сохраняем значение
temp->next = NULL; //ссылка на следующий элемент = NULL т.к. добавление в конец
}
void Spisok::Delete()
{
Node *temp = head;
if (temp == NULL)
printf("List is empty!\n");
else
{
if (temp->next == NULL)
{
free(temp);
head = NULL;
}
else
{
while (temp->next->next)
temp = temp->next;
Node *buf = temp;
buf->next = NULL;
free(temp->next);
}
printf("Last element has been deleted!\n");
}
}
void Spisok::Drop()
{
Node *temp = head;
if (temp == NULL)
printf("List is empty!\n");
else
{
if (temp->next == NULL)
{
free(temp);
head = NULL;
}
else
{
while (temp->next->next)
{
Node *buf = temp;
temp = temp->next;
free(buf);
}
head = NULL;
}
printf("List was dropped!\n");
}
}
int Spisok::Search(int val)
{
Node *temp;
int pos = -1;
int i = 0;
temp = head;
if (temp == NULL) return pos;
while (temp->next) //просмотр всего списка
{
if (temp->value == val) //если значение найдено
{
pos = i; //сохраняем номер позиции
break;
}
else //если нет
{
temp = temp->next; //переходим к следующему элементу
i++;
}
}
if (temp->value == val) pos = i; //проверка последнего элемента
return pos; //возвращаем номер позиции или -1, если элемент не найден
}
void Spisok::Show() //функция вывода массива на экран
{
Node *temp;
system("cls"); //очистка экрана
if (head == NULL) //проверка - если список пуст
printf("List is empty!\n");
else
{
temp = head;
printf("List:\n");
while (temp->next != NULL) //просматриваем весь список
{
printf("%d ", temp->value); //выводим очередной элемент
temp = temp->next;
}
printf("%d\n", temp->value); //выводим последний элемент
}
system("pause"); //задержка экрана
}
main.cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include "Spisok.h"
int Menu() //функция показа меню
{
int choice;
system("cls");
printf("Menu\n");
printf("1. Show list\n");
printf("2. Add element at begin\n");
printf("3. Add element at end\n");
printf("4. Remove last element\n");
printf("5. Search element\n");
printf("6. Drop list\n");
printf("0. Exit\n");
printf("--------------------------------------------\n");
printf("Your choice: ");
scanf("%d", &choice); //осуществление выбора
return choice; //возврат выбранного значения
}
int getVal()
{
int val;
system("cls");
printf("Enter value: ");
scanf("%d", &val);
return val;
}
int main(int argc, char** argv) {
Spisok p;
p.head = NULL;
int n;
int choice = Menu();
while (choice != 0)
{
switch (choice)
{
case 1:
p.Show();
break;
case 2:
p.AddAtBegin(getVal());
system("cls");
printf("Element has been added!\n");
system("pause");
break;
case 3:
p.AddAtEnd(getVal());
system("cls");
printf("Element has been added!\n");
system("pause");
break;
case 4:
system("cls");
p.Delete();
system("pause");
break;
case 5:
n = p.Search(getVal());
system("cls");
if (n == -1) printf("No such element!\n");
else printf("Position = %d\n", n + 1);
system("pause");
break;
case 6:
system("cls");
p.Drop();
system("pause");
break;
default:
printf("Error!\nPress any key to continue...");
break;
}
choice = Menu();
}
return 1;
}
Циклический двусвязный список
Spisok.h
#pragma once
class Spisok
{
public: struct Node //описание узла - элемента списка
{
int value; //значение
struct Node *next; //ссылка на следующий элемент
struct Node *back; //ссылка на предыдущий элемент
} *head;
//конструктор
Spisok(int val);
Spisok();
//деструктор
~Spisok();
//добавление в начало
void AddAtBegin(int val);
//добавление в конец
void AddAtEnd(int val);
//удаление из конца
void Delete();
//поиск по значению
int Search(int val);
//вывод на экран
void Show();
};
Spisok.cpp
#include <stdlib.h>
#include <stdio.h>
#include "Spisok.h"
Spisok::Spisok()
{
}
Spisok::Spisok(int val)
{
head = (Node*)malloc(sizeof(Node)); //выделяем память под элемент
head->value = val; //сохраняем значение
head->next = head; //зацикливаем список по прямой ссылке
head->back = head; //зацикливаемсписок по обратной ссылке
}
Spisok::~Spisok()
{
Node *temp = head;
while (head->next)
{
head = head->next;
free(temp);
temp = head;
}
free(head);
}
void Spisok::AddAtBegin(int val)
{
Node *temp = (Node*)malloc(sizeof(Node)); //выделяем память
temp->value = val; //сохраняем значение
if (head != NULL)
{
temp->next = head;
head->back = temp;
Node *last = head; //ищем последний элемент
while (last->next != head)
last = last->next;
last->next = temp;
temp->back = last;
head = temp; //переносим указатель первого элемента
}
else
{
temp->next = temp;
temp->back = temp;
head = temp;
}
}
void Spisok::AddAtEnd(int val)
{
Node *temp = head;
if (head != NULL)
{
while (temp->next != head) //просматриваем список до конца
temp = temp->next;
temp->next = (Node*)malloc(sizeof(Node)); //выделяем память под новый элемент
temp = temp->next;
temp->value = val; //сохраняем значение
temp->next = head; //ссылка на следующий элемент = голове списка т.к. добавление в конец
head->back = temp;
}
else
{
Node *temp = (Node*)malloc(sizeof(Node)); //выделяем память
temp->value = val; //сохраняем значение
temp->next = temp;
temp->back = temp;
head = temp;
}
}
void Spisok::Delete()
{
Node *temp = head;
if (temp == NULL)
printf("List is empty!\n");
else
{
while (temp->next->next != head)
temp = temp->next;
Node *buf = temp;
free(temp->next);
buf->next = head;
printf("Last element has been deleted!\n");
}
}
int Spisok::Search(int val)
{
Node *temp;
int pos = -1;
int i = 0;
temp = head;
if (temp == NULL) return pos;
while (temp->next != head) //просмотр всего списка
{
if (temp->value == val) //если значение найдено
{
pos = i; //сохраняем номер позиции
break;
}
else //если нет
{
temp = temp->next; //переходим к следующему элементу
i++;
}
}
if (temp->value == val) pos = i; //проверка последнего элемента
return pos; //возвращаем номер позиции или -1, если элемент не найден
}
void Spisok::Show() //функция вывода массива на экран
{
Node *temp;
system("cls"); //очистка экрана
if (head == NULL) //проверка - если список пуст
printf("List is empty!\n");
else
{
temp = head;
printf("List:\n");
while (temp->next != head) //просматриваем весь список
{
printf("%d ", temp->value); //выводим очередной элемент
temp = temp->next;
}
printf("%d\n", temp->value); //выводим последний элемент
}
system("pause"); //задержка экрана
}
main.cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include "Spisok.h"
int Menu() //функция показа меню
{
int choice;
system("cls");
printf("Menu\n");
printf("1. Show list\n");
printf("2. Add element at begin\n");
printf("3. Add element at end\n");
printf("4. Remove last element\n");
printf("5. Search element\n");
printf("0. Exit\n");
printf("--------------------------------------------\n");
printf("Your choice: ");
scanf("%d", &choice); //осуществление выбора
return choice; //возврат выбранного значения
}
int getVal()
{
int val;
system("cls");
printf("Enter value: ");
scanf("%d", &val);
return val;
}
int main(int argc, char** argv) {
Spisok p;
p.head = NULL;
int n;
int choice = Menu();
while (choice != 0)
{
switch (choice)
{
case 1:
p.Show();
break;
case 2:
p.AddAtBegin(getVal());
system("cls");
printf("Element has been added!\n");
system("pause");
break;
case 3:
p.AddAtEnd(getVal());
system("cls");
printf("Element has been added!\n");
system("pause");
break;
case 4:
system("cls");
p.Delete();
system("pause");
break;
case 5:
n = p.Search(getVal());
system("cls");
if (n == -1) printf("No such element!\n");
else printf("Position = %d\n", n + 1);
system("pause");
break;
default:
printf("Error!\nPress any key to continue...");
break;
}
choice = Menu();
}
return 1;
}

- Состав правонарушения (Понятие состава правонарушения. Виды и принципы юридической ответственности)
- Страхование и его роль на финансовом рынке (Сущность и понятие страхования на финансовом рынке)
- Основные функции в системе менеджмента (Организация как функция менеджмента, принципы проектирования системы организационного управления)
- Аппарат государственной власти
- «Распределение и использование прибыли как источник экономического роста предприятий»
- Формы правления в прошлом и настоящем
- «Юридическая ответственность.»
- Модель «управленческой решетки» как инструмент для лидерства в организации (Модель и способы использования стилей управления Блейка и Моутона)
- Менеджмент человеческих ресурсов
- Роль в мотивации в поведении организации
- Сетевые операционные системы (Основные понятия)
- Применение объектно-ориентированного подхода при проектировании информационной системы (Понятие и классификация)